
You need to agree to share your contact information to access this dataset
This repository is publicly accessible, but you have to accept the conditions to access its files and content.
Accessing the full TabLib dataset requires permission from Approximate Labs. To request access, please provide the following details and Approximate Labs will process your request as soon as possible.
Log in or Sign Up to review the conditions and access this dataset content.
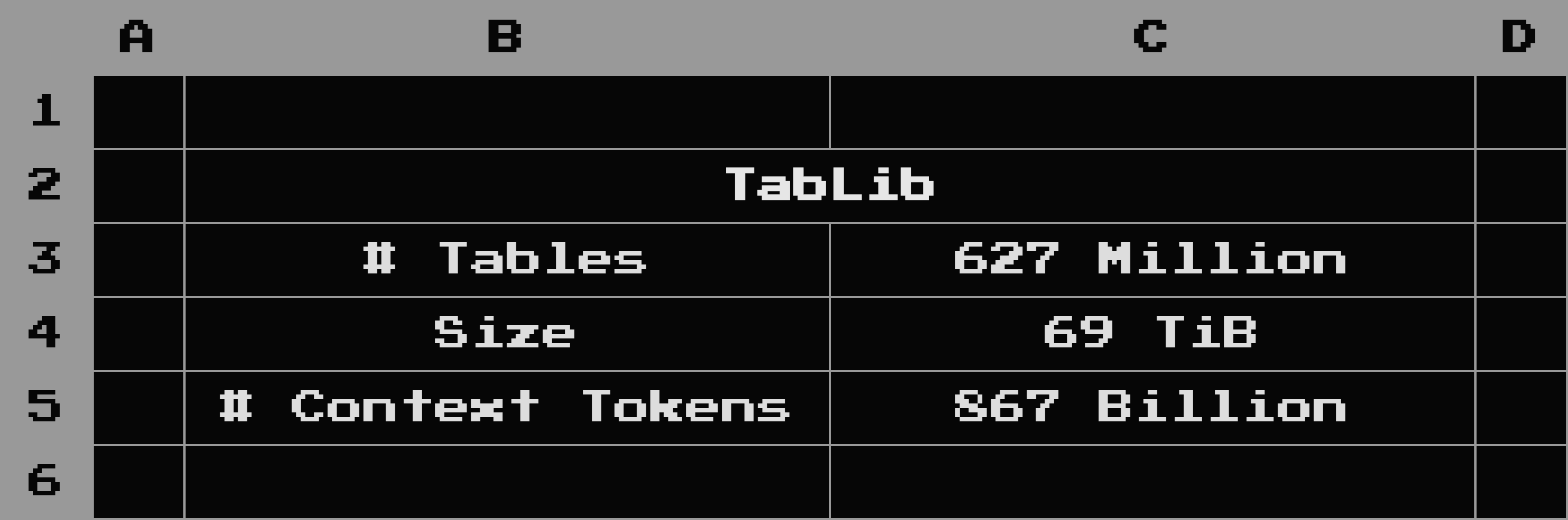
TabLib
A minimally-preprocessed dataset of 627M tables (69 TiB) extracted from HTML, PDF, CSV, TSV, Excel, and SQLite files from GitHub and Common Crawl.
This includes 867B tokens of "context metadata": each table includes provenance information and table context such as filename, text before/after, HTML metadata, etc.
A smaller 0.1% sample of this dataset can be found here.
For more information, read the paper & announcement blog.
Dataset Details
Sources
- GitHub: nearly all public GitHub repositories
- Common Crawl: the
CC-MAIN-2023-23crawl
Reading Tables
Tables are stored as serialized Arrow bytes in the arrow_bytes column. To read these, you will need to deserialize the bytes:
import datasets
import pyarrow as pa
# load a single file of the dataset
ds = datasets.load_dataset(
'approximatelabs/tablib-v1-full',
data_files='tablib/job=github_000005/batch=000001/part=000001/manifest.parquet',
token='...',
)
df = ds['train'].to_pandas()
tables = [pa.RecordBatchStreamReader(b).read_all() for b in df['arrow_bytes']]
Licensing
This dataset is intended for research use only.
For specific licensing information, refer to the license of the specific datum being used.
Contact
If you have any questions, comments, or concerns about licensing, pii, etc. please contact using this form.
Approximate Labs
TabLib is a project from Approximate Labs. Find us on Twitter, Github, Linkedin, and Discord.
Citations
If you use TabLib for any of your research, please cite the TabLib paper:
@misc{eggert2023tablib,
title={TabLib: A Dataset of 627M Tables with Context},
author={Gus Eggert and Kevin Huo and Mike Biven and Justin Waugh},
year={2023},
eprint={2310.07875},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
- Downloads last month
- 129