
CCMUSIC Evaluated Benchmark
Collection
The 6 datasets published in our paper
•
6 items
•
Updated
•
8
The original dataset is created by [1], with no evaluation provided. The original CTIS dataset contains recordings from 287 varieties of Chinese traditional instruments, reformed Chinese musical instruments, and instruments from ethnic minority groups. Notably, some of these instruments are rarely encountered by the majority of the Chinese populace. The dataset was later utilized by [2] for Chinese instrument recognition, where only 78 instruments—approximately one-third of the total instrument classes—were used.
We begin by performing data cleaning to remove recordings without specific instrument labels. Additionally, recordings that are not instrumental sounds, such as interview recordings, are removed to enhance usability. The filtered dataset contains recordings of 209 types of Chinese traditional musical instruments. Compared to the original 287 instrument types, 78 were removed. Among the remaining instruments, seven have two variants each, and one instrument, Yangqin, has four variants. We treat variants as separate classes, thus 219 labels are included at last.
In the original dataset, the Chinese character label for each instrument was represented by the folder name housing its audio files. During integration, we add Chinese pinyin label to make the dataset more accessible to researchers who are not familiar in Chinese. Then, we've reorganized the data into a dictionary with five columns, which includes: audio with a sampling rate of 44,100 Hz, pre-processed mel spectrogram, numerical label, instrument name in Chinese, and instrument name in Chinese pinyin. The provision of mel spectrograms primarily serves to enhance the visualization of the audio in the viewer. For the remaining datasets, these mel spectrograms will also be included in the integrated data structure. The total data number is 4,956, with a duration of 32.63 hours. The average duration of the recordings is 23.7 seconds.
We have constructed the default subset of the current integrated version of the dataset. Building on the default subset, we applied silence removal with a threshold of top_db=40 to the audio files, converting them into mel, CQT, and chroma spectrograms. The audio was then segmented into 2-second clips, with segments shorter than 2 seconds padded using circular padding. This process resulted in the construction of the eval subset for dataset evaluation experiments.
 |
 |
|---|---|
| Fig. 1 | Fig. 2 |
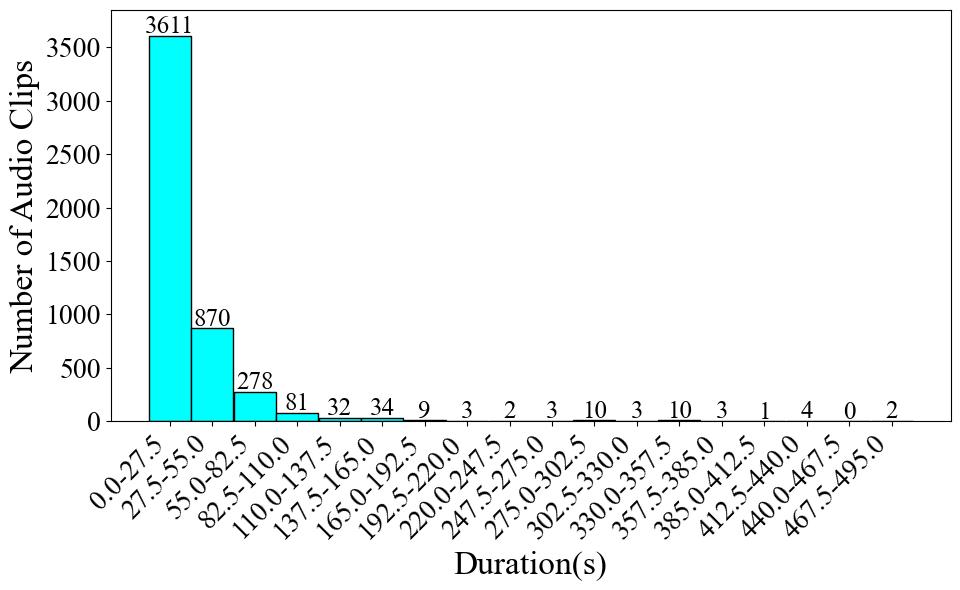
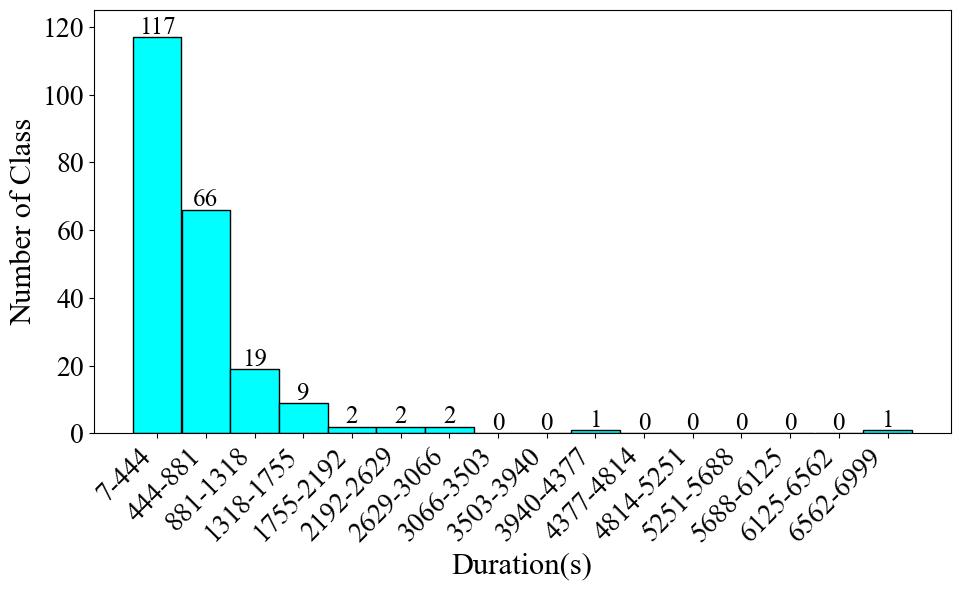
Due to the large number of categories in this dataset, we are unable to provide the audio duration per category and the proportion of audio clips by category, as we have done for other datasets. Instead, we provide a chart showing the distribution of the number of audio clips across different durations, as shown in Fig. 1. Along with a chart, displayed in Fig. 2, showing the instrument categories distribution across various durations. From Fig. 1, 4,277 clips (86%) are concentrated in the 0-45 second range, with a steep drop in the number of samples in longer durations. For the longest duration interval (450-495 seconds), the corresponding category is Konghou only. In Fig. 2, the audio duration of 211 instrument categories is less than 1755 seconds. While 8 classes have audio duration longer than this. The single instrument that possesses the longest audio duration is Zhongruan. This indicates that there is only a slight class imbalance problem for this dataset.
| Statistical items | Values |
|---|---|
| Total count | 4956 |
| Total duration(s) | 117482.75025085056 |
| Mean duration(s) | 23.705155417847124 |
| Min duration(s) | 0.27639583333333334 |
| Max duration(s) | 494.2522902494331 |
| Instrument types | 209 |
| Label Numbers | 219 |
| Eval subset total | 43054 |
| Class with the longest audio duartion | 中阮 |
| Class in the longest audio duartion interval | 箜篌 |
| audio | mel | label (200+class) | cname (string) |
| .wav, 44100Hz | .jpg, 44100Hz | C0090/ C0091/ ... T0323 |
大笒/ 高音横笛/ ... 都它尔 |
git clone [email protected]:datasets/ccmusic-database/CTIS
cd CTIS
During the integration, we first performed data cleaning to remove recordings with no specific instrument labels. The filtered dataset comprises recordings of 200 types of Chinese traditional musical instruments, totaling 3,974 audio clips. On average, there are approximately 20 audio clips per instrument. The data structure of the integrated dataset consists of three columns: an audio column containing audio files in .wav format, all sampled at a uniform rate of 22,050 Hz, a label column with 200 categories corresponding to the Chinese pinyin of the instrument names, and an additional column for the Chinese instrument names. This integrated dataset can be utilized for tasks such as Chinese instrument recognition or instrument acoustic analysis.
MIR, audio classification
Chinese, English
from datasets import load_dataset
dataset = load_dataset("ccmusic-database/CTIS", split="train")
for item in dataset:
print(item)
from modelscope.msdatasets import MsDataset
ds = MsDataset.load("ccmusic-database/CTIS", subset_name="eval")
for item in ds["train"]:
print(item)
for item in ds["validation"]:
print(item)
for item in ds["test"]:
print(item)
.zip(.wav), .csv
Up to 287 kinds of Chinese traditional musical instruments, improved Chinese musical instruments and Chinese ethnic musical instruments
instruments, percussion
Lack of a dataset for Chinese traditional musical instruments
Zhaorui Liu, Monan Zhou
Students from CCMUSIC
Building a high-quality musical sound database requires consideration on every aspect of the criteria in terms of the recording environment, performer, sample content, annotation standard and quality of recording and performing.
Students from CCMUSIC
Advancing the Digitization Process of Traditional Chinese Instruments
Only for Traditional Chinese Instruments
Sample imbalance
Zijin Li
[1] Liang, Xiaojing et al. “Constructing a Multimedia Chinese Musical Instrument Database.” Lecture Notes in Electrical Engineering (2019): n. pag.
[2] Li, R., & Zhang, Q. (2022). Audio recognition of Chinese traditional instruments based on machine learning. Cogn. Comput. Syst., 4, 108-115.
[3] https://huggingface.co/ccmusic-database/CTIS
[4] Li Z, Liang X, Liu J, et al. DCMI: A Database of Chinese Musical Instruments[J].
@dataset{zhaorui_liu_2021_5676893,
author = {Monan Zhou, Shenyang Xu, Zhaorui Liu, Zhaowen Wang, Feng Yu, Wei Li and Baoqiang Han},
title = {CCMusic: an Open and Diverse Database for Chinese Music Information Retrieval Research},
month = {mar},
year = {2024},
publisher = {HuggingFace},
version = {1.2},
url = {https://huggingface.co/ccmusic-database}
}
Provide a dataset for Chinese Traditional Instrument Sounds