
url
stringlengths 58
61
| repository_url
stringclasses 1
value | labels_url
stringlengths 72
75
| comments_url
stringlengths 67
70
| events_url
stringlengths 65
68
| html_url
stringlengths 46
51
| id
int64 599M
1.79B
| node_id
stringlengths 18
32
| number
int64 1
6.01k
| title
stringlengths 1
290
| user
dict | labels
list | state
stringclasses 2
values | locked
bool 1
class | assignee
dict | assignees
list | comments
sequence | created_at
int64 1,587B
1,689B
| updated_at
int64 1,588B
1,689B
| closed_at
int64 1,587B
1,689B
⌀ | author_association
stringclasses 3
values | active_lock_reason
null | body
stringlengths 0
228k
⌀ | reactions
dict | timeline_url
stringlengths 67
70
| performed_via_github_app
null | state_reason
stringclasses 3
values | draft
float64 0
1
⌀ | pull_request
dict | is_pull_request
bool 2
classes |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
https://api.github.com/repos/huggingface/datasets/issues/5487 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5487/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5487/comments | https://api.github.com/repos/huggingface/datasets/issues/5487/events | https://github.com/huggingface/datasets/issues/5487 | 1,564,480,121 | I_kwDODunzps5dQBJ5 | 5,487 | Incorrect filepath for dill module | {
"login": "avivbrokman",
"id": 35349273,
"node_id": "MDQ6VXNlcjM1MzQ5Mjcz",
"avatar_url": "https://avatars.githubusercontent.com/u/35349273?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/avivbrokman",
"html_url": "https://github.com/avivbrokman",
"followers_url": "https://api.github.com/users/avivbrokman/followers",
"following_url": "https://api.github.com/users/avivbrokman/following{/other_user}",
"gists_url": "https://api.github.com/users/avivbrokman/gists{/gist_id}",
"starred_url": "https://api.github.com/users/avivbrokman/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/avivbrokman/subscriptions",
"organizations_url": "https://api.github.com/users/avivbrokman/orgs",
"repos_url": "https://api.github.com/users/avivbrokman/repos",
"events_url": "https://api.github.com/users/avivbrokman/events{/privacy}",
"received_events_url": "https://api.github.com/users/avivbrokman/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Hi! The correct path is still `dill._dill.XXXX` in the latest release. What do you get when you run `python -c \"import dill; print(dill.__version__)\"` in your environment?",
"`0.3.6` I feel like that's bad news, because it's probably not the issue.\r\n\r\nMy mistake, about the wrong path guess. I think I didn't notice that the first `dill` in the path isn't supposed to be included in the path specification in python.\r\n<img width=\"146\" alt=\"Screen Shot 2023-01-31 at 12 58 32 PM\" src=\"https://user-images.githubusercontent.com/35349273/215844209-74af6a8f-9bff-4c75-9495-44c658c8e9f7.png\">\r\n",
"Hi, @avivbrokman, this issue you report appeared only with old versions of dill. See:\r\n- #288\r\n\r\nAre you sure you are in the right Python environment?\r\n- Please note that Jupyter (where I guess you get the error) may have multiple execution backends (IPython kernels) that might be different from the Python environment your are using to get the dill version\r\n - Have you run `import dill; print(dill.__version__)` in the same Jupyter/IPython that you were using when you got the error while executing `import datasets`?",
"I'm using spyder, and I am still getting `0.3.6` for `dill`, so unfortunately #288 isn't applicable, I think. However, I found something odd that I believe is a clue: \r\n\r\n```\r\nimport inspect\r\nimport dill\r\n\r\ninspect.getfile(dill)\r\n>>> '/Users/avivbrokman/opt/anaconda3/lib/python3.9/site-packages/dill/__init__.py'\r\n```\r\n\r\nI checked out the directory, and there is no `dill` subdirectory within '/Users/avivbrokman/opt/anaconda3/lib/python3.9/site-packages/dill`, as there should be. Rather, `_dill.py` is in '/Users/avivbrokman/opt/anaconda3/lib/python3.9/site-packages/dill` itself. \r\n\r\n If I run `pip install dill` or `pip install --upgrade dill`, I get the message `Requirement already satisfied: dill in ./opt/anaconda3/lib/python3.9/site-packages (0.3.6)`. If I run `conda upgrade dill`, I get the message `Solving environment: failed with repodata from current_repodata.json, will retry with next repodata source.` a couple of times, followed by\r\n\r\n```\r\nSolving environment: failed\r\nSolving environment: / \r\nFound conflicts! Looking for incompatible packages.\r\n```\r\n\r\nAnd then terminal proceeds to list conflicts between different packages I have.\r\n\r\nThis is all very strange to me because I recently uninstalled and reinstalled `anaconda`.\r\n",
"As I said above, I guess this is not a problem with `datasets`. I think you have different Python environments: one with the new dill version (the one you get while using pip) and other with the old dill version (the one where you get the AttributeError).\r\n\r\nYou should update `dill` in the Python environment you are using within spyder.\r\n\r\nPlease note that the `_dill` module is present in the `dill` package since their 2.8.0 version."
] | 1,675,177,268,000 | 1,677,255,516,000 | 1,677,255,516,000 | NONE | null | ### Describe the bug
I installed the `datasets` package and when I try to `import` it, I get the following error:
```
Traceback (most recent call last):
File "/var/folders/jt/zw5g74ln6tqfdzsl8tx378j00000gn/T/ipykernel_3805/3458380017.py", line 1, in <module>
import datasets
File "/Users/avivbrokman/opt/anaconda3/lib/python3.9/site-packages/datasets/__init__.py", line 43, in <module>
from .arrow_dataset import Dataset
File "/Users/avivbrokman/opt/anaconda3/lib/python3.9/site-packages/datasets/arrow_dataset.py", line 66, in <module>
from .arrow_writer import ArrowWriter, OptimizedTypedSequence
File "/Users/avivbrokman/opt/anaconda3/lib/python3.9/site-packages/datasets/arrow_writer.py", line 27, in <module>
from .features import Features, Image, Value
File "/Users/avivbrokman/opt/anaconda3/lib/python3.9/site-packages/datasets/features/__init__.py", line 17, in <module>
from .audio import Audio
File "/Users/avivbrokman/opt/anaconda3/lib/python3.9/site-packages/datasets/features/audio.py", line 12, in <module>
from ..download.streaming_download_manager import xopen
File "/Users/avivbrokman/opt/anaconda3/lib/python3.9/site-packages/datasets/download/__init__.py", line 9, in <module>
from .download_manager import DownloadManager, DownloadMode
File "/Users/avivbrokman/opt/anaconda3/lib/python3.9/site-packages/datasets/download/download_manager.py", line 36, in <module>
from ..utils.py_utils import NestedDataStructure, map_nested, size_str
File "/Users/avivbrokman/opt/anaconda3/lib/python3.9/site-packages/datasets/utils/py_utils.py", line 602, in <module>
class Pickler(dill.Pickler):
File "/Users/avivbrokman/opt/anaconda3/lib/python3.9/site-packages/datasets/utils/py_utils.py", line 605, in Pickler
dispatch = dill._dill.MetaCatchingDict(dill.Pickler.dispatch.copy())
AttributeError: module 'dill' has no attribute '_dill'
```
Looking at the github source code for dill, it appears that `datasets` has a bug or is not compatible with the latest `dill`. Specifically, rather than `dill._dill.XXXX` it should be `dill.dill._dill.XXXX`. But given the popularity of `datasets` I feel confused about me being the first person to have this issue, so it makes me wonder if I'm misdiagnosing the issue.
### Steps to reproduce the bug
Install `dill` and `datasets` packages and then `import datasets`
### Expected behavior
I expect `datasets` to import.
### Environment info
- `datasets` version: 2.9.0
- Platform: macOS-10.16-x86_64-i386-64bit
- Python version: 3.9.13
- PyArrow version: 11.0.0
- Pandas version: 1.4.4 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5487/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5487/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5486 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5486/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5486/comments | https://api.github.com/repos/huggingface/datasets/issues/5486/events | https://github.com/huggingface/datasets/issues/5486 | 1,564,059,749 | I_kwDODunzps5dOahl | 5,486 | Adding `sep` to TextConfig | {
"login": "omar-araboghli",
"id": 29576434,
"node_id": "MDQ6VXNlcjI5NTc2NDM0",
"avatar_url": "https://avatars.githubusercontent.com/u/29576434?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/omar-araboghli",
"html_url": "https://github.com/omar-araboghli",
"followers_url": "https://api.github.com/users/omar-araboghli/followers",
"following_url": "https://api.github.com/users/omar-araboghli/following{/other_user}",
"gists_url": "https://api.github.com/users/omar-araboghli/gists{/gist_id}",
"starred_url": "https://api.github.com/users/omar-araboghli/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/omar-araboghli/subscriptions",
"organizations_url": "https://api.github.com/users/omar-araboghli/orgs",
"repos_url": "https://api.github.com/users/omar-araboghli/repos",
"events_url": "https://api.github.com/users/omar-araboghli/events{/privacy}",
"received_events_url": "https://api.github.com/users/omar-araboghli/received_events",
"type": "User",
"site_admin": false
} | [] | open | false | null | [] | [
"Hi @omar-araboghli, thanks for your proposal.\r\n\r\nHave you tried to use \"csv\" loader instead of \"text\"? That already has a `sep` argument.",
"Hi @albertvillanova, thanks for the quick response!\r\n\r\nIndeed, I have been trying to use `csv` instead of `text`. However I am still not able to define range of rows as one sequence, that is achievable with passing `sample_by='paragraph'` to the `TextConfig`\r\n\r\nFor instance, the below code\r\n\r\n```python\r\nimport datasets\r\n\r\ndataset = datasets.load_dataset(\r\n path='csv',\r\n data_files={'train': TRAINING_SET_PATH},\r\n sep='\\t',\r\n header=None,\r\n column_names=['tokens', 'pos_tags', 'chunk_tags', 'ner_tags']\r\n)\r\n```\r\n\r\nleads to \r\n\r\n```python\r\ndataset\r\n>>> DatasetDict({\r\n train: Dataset({\r\n features: ['tokens', 'pos_tags', 'chunk_tags', 'ner_tags'],\r\n num_rows: 62543\r\n })\r\n})\r\n\r\ndataset['train'][0]\r\n>>> {'tokens': 'Distribution',\r\n 'pos_tags': 'NN',\r\n 'chunk_tags': 'O',\r\n 'ner_tags': 'O'\r\n}\r\n```\r\nIs there a way to deal with multiple csv rows as one dataset instance, where each column is a sequence of those rows ?"
] | 1,675,161,593,000 | 1,675,176,618,000 | null | NONE | null | I have a local a `.txt` file that follows the `CONLL2003` format which I need to load using `load_script`. However, by using `sample_by='line'`, one can only split the dataset into lines without splitting each line into columns. Would it be reasonable to add a `sep` argument in combination with `sample_by='paragraph'` to parse a paragraph into an array for each column ? If so, I am happy to contribute!
## Environment
* `python 3.8.10`
* `datasets 2.9.0`
## Snippet of `train.txt`
```txt
Distribution NN O O
and NN O O
dynamics NN O O
of NN O O
electron NN O B-RP
complexes NN O I-RP
in NN O O
cyanobacterial NN O B-R
membranes NN O I-R
The NN O O
occurrence NN O O
of NN O O
prostaglandin NN O B-R
F2α NN O I-R
in NN O O
Pharbitis NN O B-R
seedlings NN O I-R
grown NN O O
under NN O O
short NN O B-P
days NN O I-P
or NN O I-P
days NN O I-P
```
## Current Behaviour
```python
# defining 4 features ['tokens', 'pos_tags', 'chunk_tags', 'ner_tags'] here would fail with `ValueError: Length of names (4) does not match length of arrays (1)`
dataset = datasets.load_dataset(path='text', features=features, data_files={'train': 'train.txt'}, sample_by='line')
dataset['train']['tokens'][0]
>>> 'Distribution\tNN\tO\tO'
```
## Expected Behaviour / Suggestion
```python
# suppose we defined 4 features ['tokens', 'pos_tags', 'chunk_tags', 'ner_tags']
dataset = datasets.load_dataset(path='text', features=features, data_files={'train': 'train.txt'}, sample_by='paragraph', sep='\t')
dataset['train']['tokens'][0]
>>> ['Distribution', 'and', 'dynamics', ... ]
dataset['train']['ner_tags'][0]
>>> ['O', 'O', 'O', ... ]
``` | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5486/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5486/timeline | null | null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5485 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5485/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5485/comments | https://api.github.com/repos/huggingface/datasets/issues/5485/events | https://github.com/huggingface/datasets/pull/5485 | 1,563,002,829 | PR_kwDODunzps5I2ER2 | 5,485 | Add section in tutorial for IterableDataset | {
"login": "stevhliu",
"id": 59462357,
"node_id": "MDQ6VXNlcjU5NDYyMzU3",
"avatar_url": "https://avatars.githubusercontent.com/u/59462357?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/stevhliu",
"html_url": "https://github.com/stevhliu",
"followers_url": "https://api.github.com/users/stevhliu/followers",
"following_url": "https://api.github.com/users/stevhliu/following{/other_user}",
"gists_url": "https://api.github.com/users/stevhliu/gists{/gist_id}",
"starred_url": "https://api.github.com/users/stevhliu/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/stevhliu/subscriptions",
"organizations_url": "https://api.github.com/users/stevhliu/orgs",
"repos_url": "https://api.github.com/users/stevhliu/repos",
"events_url": "https://api.github.com/users/stevhliu/events{/privacy}",
"received_events_url": "https://api.github.com/users/stevhliu/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008492 / 0.011353 (-0.002861) | 0.004717 / 0.011008 (-0.006292) | 0.101111 / 0.038508 (0.062602) | 0.029129 / 0.023109 (0.006019) | 0.307564 / 0.275898 (0.031666) | 0.367038 / 0.323480 (0.043558) | 0.007105 / 0.007986 (-0.000881) | 0.003622 / 0.004328 (-0.000706) | 0.078370 / 0.004250 (0.074120) | 0.036960 / 0.037052 (-0.000093) | 0.315612 / 0.258489 (0.057123) | 0.353601 / 0.293841 (0.059760) | 0.032900 / 0.128546 (-0.095647) | 0.011405 / 0.075646 (-0.064241) | 0.322331 / 0.419271 (-0.096940) | 0.040823 / 0.043533 (-0.002710) | 0.306734 / 0.255139 (0.051595) | 0.328155 / 0.283200 (0.044955) | 0.087169 / 0.141683 (-0.054514) | 1.460543 / 1.452155 (0.008389) | 1.498094 / 1.492716 (0.005378) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.011863 / 0.018006 (-0.006143) | 0.416315 / 0.000490 (0.415826) | 0.003463 / 0.000200 (0.003263) | 0.000075 / 0.000054 (0.000020) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.023219 / 0.037411 (-0.014192) | 0.096469 / 0.014526 (0.081943) | 0.105960 / 0.176557 (-0.070596) | 0.148993 / 0.737135 (-0.588142) | 0.108112 / 0.296338 (-0.188226) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.415662 / 0.215209 (0.200453) | 4.155111 / 2.077655 (2.077456) | 1.834943 / 1.504120 (0.330823) | 1.622752 / 1.541195 (0.081557) | 1.701630 / 1.468490 (0.233140) | 0.690596 / 4.584777 (-3.894181) | 3.399385 / 3.745712 (-0.346327) | 3.140521 / 5.269862 (-2.129341) | 1.609152 / 4.565676 (-2.956524) | 0.082132 / 0.424275 (-0.342143) | 0.012343 / 0.007607 (0.004735) | 0.532715 / 0.226044 (0.306670) | 5.323032 / 2.268929 (3.054104) | 2.326625 / 55.444624 (-53.118000) | 1.944263 / 6.876477 (-4.932213) | 1.994015 / 2.142072 (-0.148058) | 0.813805 / 4.805227 (-3.991422) | 0.149233 / 6.500664 (-6.351431) | 0.065318 / 0.075469 (-0.010151) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.212441 / 1.841788 (-0.629347) | 13.979069 / 8.074308 (5.904761) | 14.003998 / 10.191392 (3.812606) | 0.146956 / 0.680424 (-0.533468) | 0.028564 / 0.534201 (-0.505637) | 0.392370 / 0.579283 (-0.186913) | 0.399695 / 0.434364 (-0.034669) | 0.473481 / 0.540337 (-0.066856) | 0.562625 / 1.386936 (-0.824311) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006821 / 0.011353 (-0.004532) | 0.004570 / 0.011008 (-0.006438) | 0.076217 / 0.038508 (0.037709) | 0.028888 / 0.023109 (0.005779) | 0.345431 / 0.275898 (0.069533) | 0.389246 / 0.323480 (0.065766) | 0.005939 / 0.007986 (-0.002046) | 0.003356 / 0.004328 (-0.000973) | 0.075880 / 0.004250 (0.071629) | 0.041427 / 0.037052 (0.004374) | 0.344481 / 0.258489 (0.085992) | 0.398508 / 0.293841 (0.104667) | 0.031801 / 0.128546 (-0.096745) | 0.011763 / 0.075646 (-0.063884) | 0.085600 / 0.419271 (-0.333672) | 0.042656 / 0.043533 (-0.000876) | 0.345893 / 0.255139 (0.090754) | 0.376910 / 0.283200 (0.093711) | 0.092451 / 0.141683 (-0.049232) | 1.461222 / 1.452155 (0.009068) | 1.555822 / 1.492716 (0.063106) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.235781 / 0.018006 (0.217774) | 0.418485 / 0.000490 (0.417995) | 0.005560 / 0.000200 (0.005360) | 0.000078 / 0.000054 (0.000023) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.025410 / 0.037411 (-0.012001) | 0.103780 / 0.014526 (0.089254) | 0.110183 / 0.176557 (-0.066374) | 0.151097 / 0.737135 (-0.586039) | 0.112539 / 0.296338 (-0.183799) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.436686 / 0.215209 (0.221477) | 4.341594 / 2.077655 (2.263940) | 2.062309 / 1.504120 (0.558190) | 1.857461 / 1.541195 (0.316267) | 1.947204 / 1.468490 (0.478713) | 0.699641 / 4.584777 (-3.885136) | 3.406983 / 3.745712 (-0.338729) | 3.294705 / 5.269862 (-1.975157) | 1.360582 / 4.565676 (-3.205095) | 0.083025 / 0.424275 (-0.341250) | 0.012461 / 0.007607 (0.004854) | 0.537767 / 0.226044 (0.311722) | 5.393316 / 2.268929 (3.124387) | 2.516692 / 55.444624 (-52.927932) | 2.163987 / 6.876477 (-4.712490) | 2.220480 / 2.142072 (0.078408) | 0.810648 / 4.805227 (-3.994579) | 0.151820 / 6.500664 (-6.348844) | 0.068080 / 0.075469 (-0.007389) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.279382 / 1.841788 (-0.562405) | 13.989947 / 8.074308 (5.915638) | 14.039229 / 10.191392 (3.847836) | 0.141071 / 0.680424 (-0.539352) | 0.017118 / 0.534201 (-0.517083) | 0.381558 / 0.579283 (-0.197725) | 0.390407 / 0.434364 (-0.043957) | 0.440920 / 0.540337 (-0.099418) | 0.525478 / 1.386936 (-0.861458) |\n\n</details>\n</details>\n\n\n"
] | 1,675,104,184,000 | 1,675,275,338,000 | 1,675,274,926,000 | MEMBER | null | Introduces an `IterableDataset` and how to access it in the tutorial section. It also adds a brief next step section at the end to provide a path for users who want more explanation and a path for users who want something more practical and learn how to preprocess these dataset types. It'll complement the awesome new doc introduced in:
- #5410 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5485/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5485/timeline | null | null | 0 | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5485",
"html_url": "https://github.com/huggingface/datasets/pull/5485",
"diff_url": "https://github.com/huggingface/datasets/pull/5485.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5485.patch",
"merged_at": "2023-02-01T18:08:46"
} | true |
https://api.github.com/repos/huggingface/datasets/issues/5484 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5484/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5484/comments | https://api.github.com/repos/huggingface/datasets/issues/5484/events | https://github.com/huggingface/datasets/pull/5484 | 1,562,877,070 | PR_kwDODunzps5I1oaq | 5,484 | Update docs for `nyu_depth_v2` dataset | {
"login": "awsaf49",
"id": 36858976,
"node_id": "MDQ6VXNlcjM2ODU4OTc2",
"avatar_url": "https://avatars.githubusercontent.com/u/36858976?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/awsaf49",
"html_url": "https://github.com/awsaf49",
"followers_url": "https://api.github.com/users/awsaf49/followers",
"following_url": "https://api.github.com/users/awsaf49/following{/other_user}",
"gists_url": "https://api.github.com/users/awsaf49/gists{/gist_id}",
"starred_url": "https://api.github.com/users/awsaf49/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/awsaf49/subscriptions",
"organizations_url": "https://api.github.com/users/awsaf49/orgs",
"repos_url": "https://api.github.com/users/awsaf49/repos",
"events_url": "https://api.github.com/users/awsaf49/events{/privacy}",
"received_events_url": "https://api.github.com/users/awsaf49/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"I think I need to create another PR on https://huggingface.co/datasets/huggingface/documentation-images/tree/main/datasets for hosting the images there?",
"_The documentation is not available anymore as the PR was closed or merged._",
"Thanks for the update @awsaf49 !",
"> Thanks a lot for the updates!\r\n> \r\n> Just some minor things remain and the we should be good to ship this 🚀\r\n\r\n@sayakpaul I have updated the minor things. Please approve the workflows",
"I think this PR is good to go..\r\n@sayakpaul @lhoestq ",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.009064 / 0.011353 (-0.002289) | 0.005262 / 0.011008 (-0.005746) | 0.099608 / 0.038508 (0.061100) | 0.035015 / 0.023109 (0.011906) | 0.296501 / 0.275898 (0.020602) | 0.353619 / 0.323480 (0.030139) | 0.007903 / 0.007986 (-0.000083) | 0.004093 / 0.004328 (-0.000235) | 0.075260 / 0.004250 (0.071009) | 0.043142 / 0.037052 (0.006089) | 0.307755 / 0.258489 (0.049266) | 0.336340 / 0.293841 (0.042499) | 0.038596 / 0.128546 (-0.089950) | 0.011861 / 0.075646 (-0.063786) | 0.334226 / 0.419271 (-0.085045) | 0.051472 / 0.043533 (0.007940) | 0.298539 / 0.255139 (0.043400) | 0.316856 / 0.283200 (0.033656) | 0.108620 / 0.141683 (-0.033063) | 1.434901 / 1.452155 (-0.017254) | 1.468368 / 1.492716 (-0.024348) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.208402 / 0.018006 (0.190395) | 0.445799 / 0.000490 (0.445309) | 0.003704 / 0.000200 (0.003504) | 0.000084 / 0.000054 (0.000030) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.025435 / 0.037411 (-0.011976) | 0.105874 / 0.014526 (0.091348) | 0.115652 / 0.176557 (-0.060905) | 0.150872 / 0.737135 (-0.586263) | 0.121705 / 0.296338 (-0.174633) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.397816 / 0.215209 (0.182607) | 3.977766 / 2.077655 (1.900111) | 1.850848 / 1.504120 (0.346728) | 1.686062 / 1.541195 (0.144867) | 1.786277 / 1.468490 (0.317787) | 0.696250 / 4.584777 (-3.888527) | 3.785255 / 3.745712 (0.039543) | 3.355013 / 5.269862 (-1.914849) | 1.818232 / 4.565676 (-2.747444) | 0.085408 / 0.424275 (-0.338867) | 0.012567 / 0.007607 (0.004960) | 0.524185 / 0.226044 (0.298140) | 5.061975 / 2.268929 (2.793047) | 2.299866 / 55.444624 (-53.144758) | 1.966709 / 6.876477 (-4.909768) | 2.018760 / 2.142072 (-0.123313) | 0.841341 / 4.805227 (-3.963886) | 0.166374 / 6.500664 (-6.334290) | 0.061854 / 0.075469 (-0.013615) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.221666 / 1.841788 (-0.620122) | 14.373194 / 8.074308 (6.298886) | 14.253614 / 10.191392 (4.062222) | 0.172979 / 0.680424 (-0.507445) | 0.029176 / 0.534201 (-0.505025) | 0.447399 / 0.579283 (-0.131884) | 0.443663 / 0.434364 (0.009299) | 0.537071 / 0.540337 (-0.003267) | 0.640539 / 1.386936 (-0.746397) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.007019 / 0.011353 (-0.004334) | 0.005091 / 0.011008 (-0.005917) | 0.074588 / 0.038508 (0.036080) | 0.032391 / 0.023109 (0.009282) | 0.340548 / 0.275898 (0.064650) | 0.367159 / 0.323480 (0.043679) | 0.005594 / 0.007986 (-0.002392) | 0.004003 / 0.004328 (-0.000325) | 0.073946 / 0.004250 (0.069695) | 0.045921 / 0.037052 (0.008868) | 0.340245 / 0.258489 (0.081756) | 0.397958 / 0.293841 (0.104117) | 0.036539 / 0.128546 (-0.092007) | 0.012258 / 0.075646 (-0.063388) | 0.087406 / 0.419271 (-0.331865) | 0.049276 / 0.043533 (0.005743) | 0.345235 / 0.255139 (0.090096) | 0.361250 / 0.283200 (0.078050) | 0.100757 / 0.141683 (-0.040926) | 1.464644 / 1.452155 (0.012489) | 1.545852 / 1.492716 (0.053136) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.222952 / 0.018006 (0.204945) | 0.434607 / 0.000490 (0.434117) | 0.000438 / 0.000200 (0.000238) | 0.000060 / 0.000054 (0.000006) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.028834 / 0.037411 (-0.008577) | 0.107523 / 0.014526 (0.092997) | 0.122077 / 0.176557 (-0.054479) | 0.156574 / 0.737135 (-0.580561) | 0.122917 / 0.296338 (-0.173421) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.417292 / 0.215209 (0.202083) | 4.165980 / 2.077655 (2.088325) | 1.996731 / 1.504120 (0.492611) | 1.802946 / 1.541195 (0.261751) | 1.878456 / 1.468490 (0.409966) | 0.711035 / 4.584777 (-3.873742) | 3.847357 / 3.745712 (0.101644) | 2.088354 / 5.269862 (-3.181508) | 1.344763 / 4.565676 (-3.220913) | 0.086356 / 0.424275 (-0.337919) | 0.012530 / 0.007607 (0.004923) | 0.511693 / 0.226044 (0.285648) | 5.126093 / 2.268929 (2.857165) | 2.490023 / 55.444624 (-52.954602) | 2.180274 / 6.876477 (-4.696202) | 2.221511 / 2.142072 (0.079438) | 0.836348 / 4.805227 (-3.968879) | 0.169554 / 6.500664 (-6.331110) | 0.064555 / 0.075469 (-0.010914) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.293466 / 1.841788 (-0.548321) | 14.785700 / 8.074308 (6.711392) | 13.858493 / 10.191392 (3.667101) | 0.161777 / 0.680424 (-0.518646) | 0.017794 / 0.534201 (-0.516407) | 0.426286 / 0.579283 (-0.152997) | 0.422517 / 0.434364 (-0.011847) | 0.530777 / 0.540337 (-0.009560) | 0.634822 / 1.386936 (-0.752114) |\n\n</details>\n</details>\n\n\n"
] | 1,675,100,228,000 | 1,679,568,072,000 | 1,675,606,504,000 | CONTRIBUTOR | null | This PR will fix the issue mentioned in #5461.
cc: @sayakpaul @lhoestq
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5484/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5484/timeline | null | null | 0 | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5484",
"html_url": "https://github.com/huggingface/datasets/pull/5484",
"diff_url": "https://github.com/huggingface/datasets/pull/5484.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5484.patch",
"merged_at": "2023-02-05T14:15:04"
} | true |
https://api.github.com/repos/huggingface/datasets/issues/5483 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5483/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5483/comments | https://api.github.com/repos/huggingface/datasets/issues/5483/events | https://github.com/huggingface/datasets/issues/5483 | 1,560,894,690 | I_kwDODunzps5dCVzi | 5,483 | Unable to upload dataset | {
"login": "yuvalkirstain",
"id": 57996478,
"node_id": "MDQ6VXNlcjU3OTk2NDc4",
"avatar_url": "https://avatars.githubusercontent.com/u/57996478?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/yuvalkirstain",
"html_url": "https://github.com/yuvalkirstain",
"followers_url": "https://api.github.com/users/yuvalkirstain/followers",
"following_url": "https://api.github.com/users/yuvalkirstain/following{/other_user}",
"gists_url": "https://api.github.com/users/yuvalkirstain/gists{/gist_id}",
"starred_url": "https://api.github.com/users/yuvalkirstain/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/yuvalkirstain/subscriptions",
"organizations_url": "https://api.github.com/users/yuvalkirstain/orgs",
"repos_url": "https://api.github.com/users/yuvalkirstain/repos",
"events_url": "https://api.github.com/users/yuvalkirstain/events{/privacy}",
"received_events_url": "https://api.github.com/users/yuvalkirstain/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Seems to work now, perhaps it was something internal with our university's network."
] | 1,674,919,106,000 | 1,674,979,789,000 | 1,674,979,789,000 | NONE | null | ### Describe the bug
Uploading a simple dataset ends with an exception
### Steps to reproduce the bug
I created a new conda env with python 3.10, pip installed datasets and:
```python
>>> from datasets import load_dataset, load_from_disk, Dataset
>>> d = Dataset.from_dict({"text": ["hello"] * 2})
>>> d.push_to_hub("ttt111")
/home/olab/kirstain/anaconda3/envs/datasets/lib/python3.10/site-packages/huggingface_hub/utils/_hf_folder.py:92: UserWarning: A token has been found in `/a/home/cc/students/cs/kirstain/.huggingface/token`. This is the old path where tokens were stored. The new location is `/home/olab/kirstain/.cache/huggingface/token` which is configurable using `HF_HOME` environment variable. Your token has been copied to this new location. You can now safely delete the old token file manually or use `huggingface-cli logout`.
warnings.warn(
Creating parquet from Arrow format: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1/1 [00:00<00:00, 279.94ba/s]
Upload 1 LFS files: 0%| | 0/1 [00:02<?, ?it/s]
Pushing dataset shards to the dataset hub: 0%| | 0/1 [00:04<?, ?it/s]
Traceback (most recent call last):
File "/home/olab/kirstain/anaconda3/envs/datasets/lib/python3.10/site-packages/huggingface_hub/utils/_errors.py", line 264, in hf_raise_for_status
response.raise_for_status()
File "/home/olab/kirstain/anaconda3/envs/datasets/lib/python3.10/site-packages/requests/models.py", line 1021, in raise_for_status
raise HTTPError(http_error_msg, response=self)
requests.exceptions.HTTPError: 403 Client Error: Forbidden for url: https://s3.us-east-1.amazonaws.com/lfs.huggingface.co/repos/cf/0c/cf0c5ab8a3f729e5f57a8b79a36ecea64a31126f13218591c27ed9a1c7bd9b41/ece885a4bb6bbc8c1bb51b45542b805283d74590f72cd4c45d3ba76628570386?X-Amz-Algorithm=AWS4-HMAC-SHA256&X-Amz-Content-Sha256=UNSIGNED-PAYLOAD&X-Amz-Credential=AKIA4N7VTDGO27GPWFUO%2F20230128%2Fus-east-1%2Fs3%2Faws4_request&X-Amz-Date=20230128T151640Z&X-Amz-Expires=900&X-Amz-Signature=89e78e9a9d70add7ed93d453334f4f93c6f29d889d46750a1f2da04af73978db&X-Amz-SignedHeaders=host&x-amz-storage-class=INTELLIGENT_TIERING&x-id=PutObject
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "/home/olab/kirstain/anaconda3/envs/datasets/lib/python3.10/site-packages/huggingface_hub/_commit_api.py", line 334, in _inner_upload_lfs_object
return _upload_lfs_object(
File "/home/olab/kirstain/anaconda3/envs/datasets/lib/python3.10/site-packages/huggingface_hub/_commit_api.py", line 391, in _upload_lfs_object
lfs_upload(
File "/home/olab/kirstain/anaconda3/envs/datasets/lib/python3.10/site-packages/huggingface_hub/lfs.py", line 273, in lfs_upload
_upload_single_part(
File "/home/olab/kirstain/anaconda3/envs/datasets/lib/python3.10/site-packages/huggingface_hub/lfs.py", line 305, in _upload_single_part
hf_raise_for_status(upload_res)
File "/home/olab/kirstain/anaconda3/envs/datasets/lib/python3.10/site-packages/huggingface_hub/utils/_errors.py", line 318, in hf_raise_for_status
raise HfHubHTTPError(str(e), response=response) from e
huggingface_hub.utils._errors.HfHubHTTPError: 403 Client Error: Forbidden for url: https://s3.us-east-1.amazonaws.com/lfs.huggingface.co/repos/cf/0c/cf0c5ab8a3f729e5f57a8b79a36ecea64a31126f13218591c27ed9a1c7bd9b41/ece885a4bb6bbc8c1bb51b45542b805283d74590f72cd4c45d3ba76628570386?X-Amz-Algorithm=AWS4-HMAC-SHA256&X-Amz-Content-Sha256=UNSIGNED-PAYLOAD&X-Amz-Credential=AKIA4N7VTDGO27GPWFUO%2F20230128%2Fus-east-1%2Fs3%2Faws4_request&X-Amz-Date=20230128T151640Z&X-Amz-Expires=900&X-Amz-Signature=89e78e9a9d70add7ed93d453334f4f93c6f29d889d46750a1f2da04af73978db&X-Amz-SignedHeaders=host&x-amz-storage-class=INTELLIGENT_TIERING&x-id=PutObject
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/home/olab/kirstain/anaconda3/envs/datasets/lib/python3.10/site-packages/datasets/arrow_dataset.py", line 4909, in push_to_hub
repo_id, split, uploaded_size, dataset_nbytes, repo_files, deleted_size = self._push_parquet_shards_to_hub(
File "/home/olab/kirstain/anaconda3/envs/datasets/lib/python3.10/site-packages/datasets/arrow_dataset.py", line 4804, in _push_parquet_shards_to_hub
_retry(
File "/home/olab/kirstain/anaconda3/envs/datasets/lib/python3.10/site-packages/datasets/utils/file_utils.py", line 281, in _retry
return func(*func_args, **func_kwargs)
File "/home/olab/kirstain/anaconda3/envs/datasets/lib/python3.10/site-packages/huggingface_hub/utils/_validators.py", line 124, in _inner_fn
return fn(*args, **kwargs)
File "/home/olab/kirstain/anaconda3/envs/datasets/lib/python3.10/site-packages/huggingface_hub/hf_api.py", line 2537, in upload_file
commit_info = self.create_commit(
File "/home/olab/kirstain/anaconda3/envs/datasets/lib/python3.10/site-packages/huggingface_hub/utils/_validators.py", line 124, in _inner_fn
return fn(*args, **kwargs)
File "/home/olab/kirstain/anaconda3/envs/datasets/lib/python3.10/site-packages/huggingface_hub/hf_api.py", line 2346, in create_commit
upload_lfs_files(
File "/home/olab/kirstain/anaconda3/envs/datasets/lib/python3.10/site-packages/huggingface_hub/utils/_validators.py", line 124, in _inner_fn
return fn(*args, **kwargs)
File "/home/olab/kirstain/anaconda3/envs/datasets/lib/python3.10/site-packages/huggingface_hub/_commit_api.py", line 346, in upload_lfs_files
thread_map(
File "/home/olab/kirstain/anaconda3/envs/datasets/lib/python3.10/site-packages/tqdm/contrib/concurrent.py", line 94, in thread_map
return _executor_map(ThreadPoolExecutor, fn, *iterables, **tqdm_kwargs)
File "/home/olab/kirstain/anaconda3/envs/datasets/lib/python3.10/site-packages/tqdm/contrib/concurrent.py", line 76, in _executor_map
return list(tqdm_class(ex.map(fn, *iterables, **map_args), **kwargs))
File "/home/olab/kirstain/anaconda3/envs/datasets/lib/python3.10/site-packages/tqdm/std.py", line 1195, in __iter__
for obj in iterable:
File "/home/olab/kirstain/anaconda3/envs/datasets/lib/python3.10/concurrent/futures/_base.py", line 621, in result_iterator
yield _result_or_cancel(fs.pop())
File "/home/olab/kirstain/anaconda3/envs/datasets/lib/python3.10/concurrent/futures/_base.py", line 319, in _result_or_cancel
return fut.result(timeout)
File "/home/olab/kirstain/anaconda3/envs/datasets/lib/python3.10/concurrent/futures/_base.py", line 458, in result
return self.__get_result()
File "/home/olab/kirstain/anaconda3/envs/datasets/lib/python3.10/concurrent/futures/_base.py", line 403, in __get_result
raise self._exception
File "/home/olab/kirstain/anaconda3/envs/datasets/lib/python3.10/concurrent/futures/thread.py", line 58, in run
result = self.fn(*self.args, **self.kwargs)
File "/home/olab/kirstain/anaconda3/envs/datasets/lib/python3.10/site-packages/huggingface_hub/_commit_api.py", line 338, in _inner_upload_lfs_object
raise RuntimeError(
RuntimeError: Error while uploading 'data/train-00000-of-00001-6df93048e66df326.parquet' to the Hub.
```
### Expected behavior
The dataset should be uploaded without any exceptions
### Environment info
- `datasets` version: 2.9.0
- Platform: Linux-4.15.0-65-generic-x86_64-with-glibc2.27
- Python version: 3.10.9
- PyArrow version: 11.0.0
- Pandas version: 1.5.3
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5483/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5483/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5482 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5482/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5482/comments | https://api.github.com/repos/huggingface/datasets/issues/5482/events | https://github.com/huggingface/datasets/issues/5482 | 1,560,853,137 | I_kwDODunzps5dCLqR | 5,482 | Reload features from Parquet metadata | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892871,
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement",
"name": "enhancement",
"color": "a2eeef",
"default": true,
"description": "New feature or request"
},
{
"id": 3761482852,
"node_id": "LA_kwDODunzps7gM6xk",
"url": "https://api.github.com/repos/huggingface/datasets/labels/good%20second%20issue",
"name": "good second issue",
"color": "BDE59C",
"default": false,
"description": "Issues a bit more difficult than \"Good First\" issues"
}
] | closed | false | {
"login": "MFreidank",
"id": 6368040,
"node_id": "MDQ6VXNlcjYzNjgwNDA=",
"avatar_url": "https://avatars.githubusercontent.com/u/6368040?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/MFreidank",
"html_url": "https://github.com/MFreidank",
"followers_url": "https://api.github.com/users/MFreidank/followers",
"following_url": "https://api.github.com/users/MFreidank/following{/other_user}",
"gists_url": "https://api.github.com/users/MFreidank/gists{/gist_id}",
"starred_url": "https://api.github.com/users/MFreidank/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/MFreidank/subscriptions",
"organizations_url": "https://api.github.com/users/MFreidank/orgs",
"repos_url": "https://api.github.com/users/MFreidank/repos",
"events_url": "https://api.github.com/users/MFreidank/events{/privacy}",
"received_events_url": "https://api.github.com/users/MFreidank/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "MFreidank",
"id": 6368040,
"node_id": "MDQ6VXNlcjYzNjgwNDA=",
"avatar_url": "https://avatars.githubusercontent.com/u/6368040?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/MFreidank",
"html_url": "https://github.com/MFreidank",
"followers_url": "https://api.github.com/users/MFreidank/followers",
"following_url": "https://api.github.com/users/MFreidank/following{/other_user}",
"gists_url": "https://api.github.com/users/MFreidank/gists{/gist_id}",
"starred_url": "https://api.github.com/users/MFreidank/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/MFreidank/subscriptions",
"organizations_url": "https://api.github.com/users/MFreidank/orgs",
"repos_url": "https://api.github.com/users/MFreidank/repos",
"events_url": "https://api.github.com/users/MFreidank/events{/privacy}",
"received_events_url": "https://api.github.com/users/MFreidank/received_events",
"type": "User",
"site_admin": false
}
] | [
"I'd be happy to have a look, if nobody else has started working on this yet @lhoestq. \r\n\r\nIt seems to me that for the `arrow` format features are currently attached as metadata [in `datasets.arrow_writer`](https://github.com/huggingface/datasets/blob/5f810b7011a8a4ab077a1847c024d2d9e267b065/src/datasets/arrow_writer.py#L412) and retrieved from the metadata at `load_dataset` time using [`datasets.features.features.from_arrow_schema`](https://github.com/huggingface/datasets/blob/5f810b7011a8a4ab077a1847c024d2d9e267b065/src/datasets/features/features.py#L1602). \r\n\r\nThis will need to be replicated for `parquet` via calls to [this api](https://arrow.apache.org/docs/python/generated/pyarrow.parquet.write_metadata.html) from `io.parquet.ParquetWriter` and `io.parquet.ParquetReader` [respectively](https://github.com/huggingface/datasets/blob/5f810b7011a8a4ab077a1847c024d2d9e267b065/src/datasets/io/parquet.py#L104).\r\n\r\nAny other important considerations?\r\n",
"Thanks @MFreidank ! That's correct :)\r\n\r\nReading the metadata to infer the features can be ideally done in the `parquet.py` file in `packaged_builder` when a parquet file is read. You can cast the arrow table to the schema you get from the features.arrow_schema",
"#self-assign"
] | 1,674,911,551,000 | 1,676,217,422,000 | 1,676,217,422,000 | MEMBER | null | The idea would be to allow this :
```python
ds.to_parquet("my_dataset/ds.parquet")
reloaded = load_dataset("my_dataset")
assert ds.features == reloaded.features
```
And it should also work with Image and Audio types (right now they're reloaded as a dict type)
This can be implemented by storing and reading the feature types in the parquet metadata, as we do for arrow files. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5482/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5482/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5481 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5481/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5481/comments | https://api.github.com/repos/huggingface/datasets/issues/5481/events | https://github.com/huggingface/datasets/issues/5481 | 1,560,468,195 | I_kwDODunzps5dAtrj | 5,481 | Load a cached dataset as iterable | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892871,
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement",
"name": "enhancement",
"color": "a2eeef",
"default": true,
"description": "New feature or request"
},
{
"id": 3761482852,
"node_id": "LA_kwDODunzps7gM6xk",
"url": "https://api.github.com/repos/huggingface/datasets/labels/good%20second%20issue",
"name": "good second issue",
"color": "BDE59C",
"default": false,
"description": "Issues a bit more difficult than \"Good First\" issues"
}
] | open | false | null | [] | [
"Can I work on this issue? I am pretty new to this.",
"Hi ! Sure :) you can comment `#self-assign` to assign yourself to this issue.\r\n\r\nI can give you some pointers to get started:\r\n\r\n`load_dataset` works roughly this way:\r\n1. it instantiate a dataset builder using `load_dataset_builder()`\r\n2. the builder download and prepare the dataset as Arrow files in the cache using `download_and_prepare()`\r\n3. the builder returns a Dataset object with `as_dataset()`\r\n\r\nOne way to approach this would be to implement `as_iterable_dataset()` in `builder.py`.\r\n\r\nAnd similarly to `as_dataset()`, you can use the `ArrowReader`. It has a `get_file_instructions()` method that can be helpful. It gives you the files to read as list of dictionaries with those keys: `filename`, `skip` and `take`.\r\n\r\nThe `skip` and `take` arguments are used in case the user wants to load a subset of the dataset, e.g.\r\n```python\r\nload_dataset(..., split=\"train[:10]\")\r\n```\r\n\r\nLet me know if you have questions or if I can help :)",
"This use-case is a bit specific, and `load_dataset` already has enough parameters (plus, `streaming=True` also returns an iterable dataset, so we would have to explain the difference), so I think it would be better to add `IterableDataset.from_file` to the API (more flexible and aligned with the goal from https://github.com/huggingface/datasets/issues/3444) instead.",
"> This use-case is a bit specific\r\n\r\nThis allows to use `datasets` for large scale training where map-style datasets are too slow and use too much memory in PyTorch. So I would still consider adding it.\r\n\r\nAlternatively we could add this feature one level bellow:\r\n```python\r\nbuilder = load_dataset_builder(...)\r\nbuilder.download_and_prepare()\r\nids = builder.as_iterable_dataset()\r\n```",
"Yes, I see how this can be useful. Still, I think `Dataset.to_iterable` + `IterableDataset.from_file` would be much cleaner in terms of the API design (and more flexible since `load_dataset` can only access the \"initial\" (unprocessed) version of a dataset).\r\n\r\nAnd since it can be tricky to manually find the \"initial\" version of a dataset in the cache, maybe `load_dataset` could return an iterable dataset streamed from the cache if `streaming=True` and the cache is up-to-date. ",
"> This allows to use datasets for large scale training where map-style datasets are too slow and use too much memory in PyTorch.\r\n\r\nI second that. e.g. In my last experiment Oscar-en uses 16GB RSS RAM per process and when using multiple processes the host quickly runs out cpu memory. ",
">And since it can be tricky to manually find the \"initial\" version of a dataset in the cache, maybe load_dataset could return an iterable dataset streamed from the cache if streaming=True and the cache is up-to-date.\r\n\r\nThis is exactly the need on JeanZay (HPC) - I have the dataset cache ready, but the compute node is offline, so making streaming work off a local cache would address that need.\r\n\r\nIf you will have a working POC I can be the tester. ",
"> Yes, I see how this can be useful. Still, I think Dataset.to_iterable + IterableDataset.from_file would be much cleaner in terms of the API design (and more flexible since load_dataset can only access the \"initial\" (unprocessed) version of a dataset).\r\n\r\nI like `IterableDataset.from_file` as well. On the other hand `Dataset.to_iterable` first requires to load a Dataset object, which can take time depending on your hardware and your dataset size (sometimes 1h+).\r\n\r\n> And since it can be tricky to manually find the \"initial\" version of a dataset in the cache, maybe load_dataset could return an iterable dataset streamed from the cache if streaming=True and the cache is up-to-date.\r\n\r\nThat would definitely do the job. I was suggesting a different parameter just to make explicit the difference between\r\n- streaming from the raw data\r\n- streaming from the local cache\r\n\r\nBut I'd be fine with streaming from cache is the cache is up-to-date since it's always faster. We could log a message as usual to make it explicit that the cache is used",
"> I was suggesting a different parameter just to make explicit the difference between\r\n\r\nMosaicML's `streaming` library does the same (tries to stream from the local cache if possible), so logging a message should be explicit enough :).",
"Ok ! Sounds good then :)",
"Hi Both! It has been a while since my first issue so I am gonna go for this one ! #self-assign",
"#self-assign",
"I like idea of `IterableDataset.from_file`. ",
"https://github.com/huggingface/datasets/pull/5821 should be helpful to implement `IterableDataset.from_file`, since it defines a new ArrowExamplesIterable that takes an Arrow tables generator function (e.g. from a file) and can be used in an IterableDataset",
"@lhoestq I have just started working on this issue. ",
"@lhoestq Thank you for taking over.",
"So what's recommanded usage of `IterableDataset.from_file` and `load_dataset`? How about I have multiple arrow files and `load_dataset` is often convenient to handle that.",
"If you have multiple Arrow files you can load them using\r\n\r\n```python\r\nfrom datasets import load_dataset\r\n\r\ndata_files = {\"train\": [\"path/to/0.arrow\", \"path/to/1.arrow\", ..., \"path/to/n.arrow\"]}\r\n\r\nds = load_dataset(\"arrow\", data_files=data_files, streaming=True)\r\n```\r\n\r\nThis is equivalent to calling `IterableDataset.from_file` and `concatenate_datasets`."
] | 1,674,855,831,000 | 1,687,776,533,000 | null | MEMBER | null | The idea would be to allow something like
```python
ds = load_dataset("c4", "en", as_iterable=True)
```
To be used to train models. It would load an IterableDataset from the cached Arrow files.
Cc @stas00
Edit : from the discussions we may load from cache when streaming=True | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5481/reactions",
"total_count": 4,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 4,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5481/timeline | null | null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5480 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5480/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5480/comments | https://api.github.com/repos/huggingface/datasets/issues/5480/events | https://github.com/huggingface/datasets/pull/5480 | 1,560,364,866 | PR_kwDODunzps5ItY2y | 5,480 | Select columns of Dataset or DatasetDict | {
"login": "daskol",
"id": 9336514,
"node_id": "MDQ6VXNlcjkzMzY1MTQ=",
"avatar_url": "https://avatars.githubusercontent.com/u/9336514?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/daskol",
"html_url": "https://github.com/daskol",
"followers_url": "https://api.github.com/users/daskol/followers",
"following_url": "https://api.github.com/users/daskol/following{/other_user}",
"gists_url": "https://api.github.com/users/daskol/gists{/gist_id}",
"starred_url": "https://api.github.com/users/daskol/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/daskol/subscriptions",
"organizations_url": "https://api.github.com/users/daskol/orgs",
"repos_url": "https://api.github.com/users/daskol/repos",
"events_url": "https://api.github.com/users/daskol/events{/privacy}",
"received_events_url": "https://api.github.com/users/daskol/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.009963 / 0.011353 (-0.001390) | 0.005512 / 0.011008 (-0.005496) | 0.100495 / 0.038508 (0.061987) | 0.039929 / 0.023109 (0.016820) | 0.299749 / 0.275898 (0.023850) | 0.372330 / 0.323480 (0.048850) | 0.008689 / 0.007986 (0.000703) | 0.004334 / 0.004328 (0.000006) | 0.076469 / 0.004250 (0.072218) | 0.048091 / 0.037052 (0.011039) | 0.303884 / 0.258489 (0.045395) | 0.352747 / 0.293841 (0.058906) | 0.038941 / 0.128546 (-0.089605) | 0.012541 / 0.075646 (-0.063105) | 0.334227 / 0.419271 (-0.085044) | 0.048802 / 0.043533 (0.005269) | 0.295800 / 0.255139 (0.040661) | 0.316222 / 0.283200 (0.033022) | 0.108246 / 0.141683 (-0.033437) | 1.452735 / 1.452155 (0.000580) | 1.466293 / 1.492716 (-0.026423) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.010497 / 0.018006 (-0.007510) | 0.507427 / 0.000490 (0.506937) | 0.003054 / 0.000200 (0.002854) | 0.000084 / 0.000054 (0.000030) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.029529 / 0.037411 (-0.007883) | 0.114151 / 0.014526 (0.099625) | 0.120599 / 0.176557 (-0.055957) | 0.161881 / 0.737135 (-0.575255) | 0.127669 / 0.296338 (-0.168669) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.399631 / 0.215209 (0.184421) | 3.992997 / 2.077655 (1.915343) | 1.803770 / 1.504120 (0.299650) | 1.612301 / 1.541195 (0.071106) | 1.717846 / 1.468490 (0.249356) | 0.706753 / 4.584777 (-3.878024) | 3.798224 / 3.745712 (0.052512) | 2.169733 / 5.269862 (-3.100128) | 1.358264 / 4.565676 (-3.207413) | 0.086828 / 0.424275 (-0.337447) | 0.012606 / 0.007607 (0.004999) | 0.512085 / 0.226044 (0.286041) | 5.101491 / 2.268929 (2.832563) | 2.285688 / 55.444624 (-53.158936) | 1.955160 / 6.876477 (-4.921317) | 2.045887 / 2.142072 (-0.096186) | 0.878836 / 4.805227 (-3.926392) | 0.166483 / 6.500664 (-6.334181) | 0.062656 / 0.075469 (-0.012814) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.215152 / 1.841788 (-0.626636) | 15.436187 / 8.074308 (7.361879) | 14.489951 / 10.191392 (4.298559) | 0.199019 / 0.680424 (-0.481404) | 0.029148 / 0.534201 (-0.505053) | 0.440309 / 0.579283 (-0.138974) | 0.452041 / 0.434364 (0.017677) | 0.527102 / 0.540337 (-0.013236) | 0.634302 / 1.386936 (-0.752634) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.007814 / 0.011353 (-0.003539) | 0.005582 / 0.011008 (-0.005427) | 0.075466 / 0.038508 (0.036958) | 0.034421 / 0.023109 (0.011312) | 0.342345 / 0.275898 (0.066447) | 0.389943 / 0.323480 (0.066463) | 0.006346 / 0.007986 (-0.001639) | 0.004442 / 0.004328 (0.000113) | 0.074440 / 0.004250 (0.070190) | 0.056383 / 0.037052 (0.019331) | 0.340293 / 0.258489 (0.081804) | 0.394416 / 0.293841 (0.100575) | 0.037217 / 0.128546 (-0.091330) | 0.012597 / 0.075646 (-0.063050) | 0.087005 / 0.419271 (-0.332267) | 0.051626 / 0.043533 (0.008094) | 0.336690 / 0.255139 (0.081551) | 0.369143 / 0.283200 (0.085943) | 0.110764 / 0.141683 (-0.030919) | 1.459003 / 1.452155 (0.006849) | 1.557333 / 1.492716 (0.064617) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.319596 / 0.018006 (0.301590) | 0.514697 / 0.000490 (0.514207) | 0.005286 / 0.000200 (0.005086) | 0.000086 / 0.000054 (0.000032) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.032579 / 0.037411 (-0.004832) | 0.111094 / 0.014526 (0.096568) | 0.127827 / 0.176557 (-0.048730) | 0.169967 / 0.737135 (-0.567168) | 0.133149 / 0.296338 (-0.163189) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.424637 / 0.215209 (0.209428) | 4.217889 / 2.077655 (2.140235) | 2.044844 / 1.504120 (0.540724) | 1.863513 / 1.541195 (0.322319) | 1.975674 / 1.468490 (0.507184) | 0.695493 / 4.584777 (-3.889284) | 3.815562 / 3.745712 (0.069850) | 3.534427 / 5.269862 (-1.735435) | 1.684874 / 4.565676 (-2.880802) | 0.085560 / 0.424275 (-0.338715) | 0.012439 / 0.007607 (0.004832) | 0.541231 / 0.226044 (0.315187) | 5.287166 / 2.268929 (3.018237) | 2.596622 / 55.444624 (-52.848002) | 2.315913 / 6.876477 (-4.560564) | 2.418454 / 2.142072 (0.276381) | 0.838947 / 4.805227 (-3.966281) | 0.168149 / 6.500664 (-6.332515) | 0.066439 / 0.075469 (-0.009030) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.264814 / 1.841788 (-0.576974) | 15.861324 / 8.074308 (7.787016) | 14.352515 / 10.191392 (4.161123) | 0.167032 / 0.680424 (-0.513391) | 0.017766 / 0.534201 (-0.516435) | 0.421821 / 0.579283 (-0.157462) | 0.426657 / 0.434364 (-0.007707) | 0.526742 / 0.540337 (-0.013595) | 0.623851 / 1.386936 (-0.763085) |\n\n</details>\n</details>\n\n\n"
] | 1,674,849,976,000 | 1,676,286,613,000 | 1,676,282,375,000 | CONTRIBUTOR | null | Close #5474 and #5468. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5480/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5480/timeline | null | null | 0 | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5480",
"html_url": "https://github.com/huggingface/datasets/pull/5480",
"diff_url": "https://github.com/huggingface/datasets/pull/5480.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5480.patch",
"merged_at": "2023-02-13T09:59:35"
} | true |
https://api.github.com/repos/huggingface/datasets/issues/5479 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5479/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5479/comments | https://api.github.com/repos/huggingface/datasets/issues/5479/events | https://github.com/huggingface/datasets/issues/5479 | 1,560,357,590 | I_kwDODunzps5dASrW | 5,479 | audiofolder works on local env, but creates empty dataset in a remote one, what dependencies could I be missing/outdated | {
"login": "jcho19",
"id": 107211437,
"node_id": "U_kgDOBmPqrQ",
"avatar_url": "https://avatars.githubusercontent.com/u/107211437?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/jcho19",
"html_url": "https://github.com/jcho19",
"followers_url": "https://api.github.com/users/jcho19/followers",
"following_url": "https://api.github.com/users/jcho19/following{/other_user}",
"gists_url": "https://api.github.com/users/jcho19/gists{/gist_id}",
"starred_url": "https://api.github.com/users/jcho19/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jcho19/subscriptions",
"organizations_url": "https://api.github.com/users/jcho19/orgs",
"repos_url": "https://api.github.com/users/jcho19/repos",
"events_url": "https://api.github.com/users/jcho19/events{/privacy}",
"received_events_url": "https://api.github.com/users/jcho19/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [] | 1,674,849,682,000 | 1,674,969,794,000 | 1,674,969,794,000 | NONE | null | ### Describe the bug
I'm using a custom audio dataset (400+ audio files) in the correct format for audiofolder. Although loading the dataset with audiofolder works in one local setup, it doesn't in a remote one (it just creates an empty dataset). I have both ffmpeg and libndfile installed on both computers, what could be missing/need to be updated in the one that doesn't work? On the remote env, libsndfile is 1.0.28 and ffmpeg is 4.2.1.
from datasets import load_dataset
ds = load_dataset("audiofolder", data_dir="...")
Here is the output (should be generating 400+ rows):
Downloading and preparing dataset audiofolder/default to ...
Downloading data files: 0%| | 0/2 [00:00<?, ?it/s]
Downloading data files: 0it [00:00, ?it/s]
Extracting data files: 0it [00:00, ?it/s]
Generating train split: 0 examples [00:00, ? examples/s]
Dataset audiofolder downloaded and prepared to ... Subsequent calls will reuse this data.
0%| | 0/1 [00:00<?, ?it/s]
DatasetDict({
train: Dataset({
features: ['audio', 'transcription'],
num_rows: 1
})
})
Here is my pip environment in the one that doesn't work (uses torch 1.11.a0 from shared env):
Package Version
------------------- -------------------
aiofiles 22.1.0
aiohttp 3.8.3
aiosignal 1.3.1
altair 4.2.1
anyio 3.6.2
appdirs 1.4.4
argcomplete 2.0.0
argon2-cffi 20.1.0
astunparse 1.6.3
async-timeout 4.0.2
attrs 21.2.0
audioread 3.0.0
backcall 0.2.0
bleach 4.0.0
certifi 2021.10.8
cffi 1.14.6
charset-normalizer 2.0.12
click 8.1.3
contourpy 1.0.7
cycler 0.11.0
datasets 2.9.0
debugpy 1.4.1
decorator 5.0.9
defusedxml 0.7.1
dill 0.3.6
distlib 0.3.4
entrypoints 0.3
evaluate 0.4.0
expecttest 0.1.3
fastapi 0.89.1
ffmpy 0.3.0
filelock 3.6.0
fonttools 4.38.0
frozenlist 1.3.3
fsspec 2023.1.0
future 0.18.2
gradio 3.16.2
h11 0.14.0
httpcore 0.16.3
httpx 0.23.3
huggingface-hub 0.12.0
idna 3.3
ipykernel 6.2.0
ipython 7.26.0
ipython-genutils 0.2.0
ipywidgets 7.6.3
jedi 0.18.0
Jinja2 3.0.1
jiwer 2.5.1
joblib 1.2.0
jsonschema 3.2.0
jupyter 1.0.0
jupyter-client 6.1.12
jupyter-console 6.4.0
jupyter-core 4.7.1
jupyterlab-pygments 0.1.2
jupyterlab-widgets 1.0.0
kiwisolver 1.4.4
Levenshtein 0.20.2
librosa 0.9.2
linkify-it-py 1.0.3
llvmlite 0.39.1
markdown-it-py 2.1.0
MarkupSafe 2.0.1
matplotlib 3.6.3
matplotlib-inline 0.1.2
mdit-py-plugins 0.3.3
mdurl 0.1.2
mistune 0.8.4
multidict 6.0.4
multiprocess 0.70.14
nbclient 0.5.4
nbconvert 6.1.0
nbformat 5.1.3
nest-asyncio 1.5.1
notebook 6.4.3
numba 0.56.4
numpy 1.20.3
orjson 3.8.5
packaging 21.0
pandas 1.5.3
pandocfilters 1.4.3
parso 0.8.2
pexpect 4.8.0
pickleshare 0.7.5
Pillow 9.4.0
pip 22.3.1
pipx 1.1.0
platformdirs 2.5.2
pooch 1.6.0
prometheus-client 0.11.0
prompt-toolkit 3.0.19
psutil 5.9.0
ptyprocess 0.7.0
pyarrow 10.0.1
pycparser 2.20
pycryptodome 3.16.0
pydantic 1.10.4
pydub 0.25.1
Pygments 2.10.0
pyparsing 2.4.7
pyrsistent 0.18.0
python-dateutil 2.8.2
python-multipart 0.0.5
pytz 2022.7.1
PyYAML 6.0
pyzmq 22.2.1
qtconsole 5.1.1
QtPy 1.10.0
rapidfuzz 2.13.7
regex 2022.10.31
requests 2.27.1
resampy 0.4.2
responses 0.18.0
rfc3986 1.5.0
scikit-learn 1.2.1
scipy 1.6.3
Send2Trash 1.8.0
setuptools 65.5.1
shiboken6 6.3.1
shiboken6-generator 6.3.1
six 1.16.0
sniffio 1.3.0
soundfile 0.11.0
starlette 0.22.0
terminado 0.11.0
testpath 0.5.0
threadpoolctl 3.1.0
tokenizers 0.13.2
toolz 0.12.0
torch 1.11.0a0+gitunknown
tornado 6.1
tqdm 4.64.1
traitlets 5.0.5
transformers 4.27.0.dev0
types-dataclasses 0.6.4
typing_extensions 4.1.1
uc-micro-py 1.0.1
urllib3 1.26.9
userpath 1.8.0
uvicorn 0.20.0
virtualenv 20.14.1
wcwidth 0.2.5
webencodings 0.5.1
websockets 10.4
wheel 0.37.1
widgetsnbextension 3.5.1
xxhash 3.2.0
yarl 1.8.2
### Steps to reproduce the bug
Create a pip environment with the packages listed above (make sure ffmpeg and libsndfile is installed with same versions listed above).
Create a custom audio dataset and load it in with load_dataset("audiofolder", ...)
### Expected behavior
load_dataset should create a dataset with 400+ rows.
### Environment info
- `datasets` version: 2.9.0
- Platform: Linux-3.10.0-1160.80.1.el7.x86_64-x86_64-with-glibc2.17
- Python version: 3.9.0
- PyArrow version: 10.0.1
- Pandas version: 1.5.3 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5479/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5479/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5478 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5478/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5478/comments | https://api.github.com/repos/huggingface/datasets/issues/5478/events | https://github.com/huggingface/datasets/pull/5478 | 1,560,357,583 | PR_kwDODunzps5ItXQG | 5,478 | Tip for recomputing metadata | {
"login": "stevhliu",
"id": 59462357,
"node_id": "MDQ6VXNlcjU5NDYyMzU3",
"avatar_url": "https://avatars.githubusercontent.com/u/59462357?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/stevhliu",
"html_url": "https://github.com/stevhliu",
"followers_url": "https://api.github.com/users/stevhliu/followers",
"following_url": "https://api.github.com/users/stevhliu/following{/other_user}",
"gists_url": "https://api.github.com/users/stevhliu/gists{/gist_id}",
"starred_url": "https://api.github.com/users/stevhliu/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/stevhliu/subscriptions",
"organizations_url": "https://api.github.com/users/stevhliu/orgs",
"repos_url": "https://api.github.com/users/stevhliu/repos",
"events_url": "https://api.github.com/users/stevhliu/events{/privacy}",
"received_events_url": "https://api.github.com/users/stevhliu/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008167 / 0.011353 (-0.003186) | 0.004404 / 0.011008 (-0.006605) | 0.100462 / 0.038508 (0.061954) | 0.028835 / 0.023109 (0.005726) | 0.326759 / 0.275898 (0.050861) | 0.355150 / 0.323480 (0.031670) | 0.007200 / 0.007986 (-0.000786) | 0.003293 / 0.004328 (-0.001035) | 0.078006 / 0.004250 (0.073756) | 0.033298 / 0.037052 (-0.003754) | 0.307119 / 0.258489 (0.048630) | 0.337689 / 0.293841 (0.043848) | 0.033016 / 0.128546 (-0.095530) | 0.011383 / 0.075646 (-0.064263) | 0.321989 / 0.419271 (-0.097283) | 0.039793 / 0.043533 (-0.003740) | 0.295388 / 0.255139 (0.040249) | 0.322694 / 0.283200 (0.039494) | 0.082989 / 0.141683 (-0.058694) | 1.496701 / 1.452155 (0.044546) | 1.548861 / 1.492716 (0.056145) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.176587 / 0.018006 (0.158580) | 0.397660 / 0.000490 (0.397170) | 0.001063 / 0.000200 (0.000863) | 0.000070 / 0.000054 (0.000015) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.022386 / 0.037411 (-0.015025) | 0.096380 / 0.014526 (0.081854) | 0.103032 / 0.176557 (-0.073525) | 0.135050 / 0.737135 (-0.602086) | 0.105941 / 0.296338 (-0.190397) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.430989 / 0.215209 (0.215780) | 4.310309 / 2.077655 (2.232654) | 2.142596 / 1.504120 (0.638477) | 1.952043 / 1.541195 (0.410848) | 1.817803 / 1.468490 (0.349312) | 0.690026 / 4.584777 (-3.894751) | 3.315413 / 3.745712 (-0.430299) | 3.370336 / 5.269862 (-1.899525) | 1.668707 / 4.565676 (-2.896970) | 0.081860 / 0.424275 (-0.342415) | 0.012493 / 0.007607 (0.004886) | 0.527779 / 0.226044 (0.301735) | 5.318732 / 2.268929 (3.049804) | 2.467029 / 55.444624 (-52.977596) | 2.247171 / 6.876477 (-4.629306) | 2.270825 / 2.142072 (0.128752) | 0.802288 / 4.805227 (-4.002939) | 0.148895 / 6.500664 (-6.351770) | 0.064967 / 0.075469 (-0.010503) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.259304 / 1.841788 (-0.582484) | 13.662441 / 8.074308 (5.588133) | 14.074662 / 10.191392 (3.883270) | 0.152907 / 0.680424 (-0.527516) | 0.028340 / 0.534201 (-0.505861) | 0.397356 / 0.579283 (-0.181927) | 0.392600 / 0.434364 (-0.041764) | 0.467935 / 0.540337 (-0.072402) | 0.539890 / 1.386936 (-0.847046) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006156 / 0.011353 (-0.005197) | 0.004371 / 0.011008 (-0.006637) | 0.076391 / 0.038508 (0.037883) | 0.026455 / 0.023109 (0.003346) | 0.339816 / 0.275898 (0.063917) | 0.370032 / 0.323480 (0.046552) | 0.004614 / 0.007986 (-0.003372) | 0.003200 / 0.004328 (-0.001129) | 0.075408 / 0.004250 (0.071157) | 0.034100 / 0.037052 (-0.002953) | 0.341232 / 0.258489 (0.082743) | 0.380290 / 0.293841 (0.086449) | 0.031021 / 0.128546 (-0.097525) | 0.011562 / 0.075646 (-0.064084) | 0.085564 / 0.419271 (-0.333708) | 0.041431 / 0.043533 (-0.002102) | 0.359570 / 0.255139 (0.104431) | 0.366919 / 0.283200 (0.083719) | 0.088242 / 0.141683 (-0.053441) | 1.460703 / 1.452155 (0.008548) | 1.534351 / 1.492716 (0.041635) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.225703 / 0.018006 (0.207697) | 0.395014 / 0.000490 (0.394524) | 0.000385 / 0.000200 (0.000185) | 0.000060 / 0.000054 (0.000006) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.023975 / 0.037411 (-0.013436) | 0.098658 / 0.014526 (0.084132) | 0.105043 / 0.176557 (-0.071513) | 0.139988 / 0.737135 (-0.597148) | 0.106854 / 0.296338 (-0.189484) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.442454 / 0.215209 (0.227245) | 4.430860 / 2.077655 (2.353205) | 2.084823 / 1.504120 (0.580704) | 1.870421 / 1.541195 (0.329226) | 1.901618 / 1.468490 (0.433128) | 0.699214 / 4.584777 (-3.885563) | 3.336911 / 3.745712 (-0.408801) | 1.856479 / 5.269862 (-3.413383) | 1.166496 / 4.565676 (-3.399180) | 0.083189 / 0.424275 (-0.341086) | 0.012293 / 0.007607 (0.004686) | 0.543147 / 0.226044 (0.317102) | 5.452030 / 2.268929 (3.183101) | 2.506689 / 55.444624 (-52.937936) | 2.168186 / 6.876477 (-4.708291) | 2.172277 / 2.142072 (0.030205) | 0.813554 / 4.805227 (-3.991673) | 0.152074 / 6.500664 (-6.348590) | 0.066891 / 0.075469 (-0.008579) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.278635 / 1.841788 (-0.563153) | 13.690232 / 8.074308 (5.615924) | 13.403201 / 10.191392 (3.211809) | 0.128171 / 0.680424 (-0.552253) | 0.016687 / 0.534201 (-0.517514) | 0.378645 / 0.579283 (-0.200638) | 0.382922 / 0.434364 (-0.051442) | 0.467483 / 0.540337 (-0.072854) | 0.559026 / 1.386936 (-0.827910) |\n\n</details>\n</details>\n\n\n"
] | 1,674,849,682,000 | 1,675,106,541,000 | 1,675,106,126,000 | MEMBER | null | From this [feedback](https://discuss.huggingface.co/t/nonmatchingsplitssizeserror/30033) on the forum, thought I'd include a tip for recomputing the metadata numbers if it is your own dataset. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5478/reactions",
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 1,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5478/timeline | null | null | 0 | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5478",
"html_url": "https://github.com/huggingface/datasets/pull/5478",
"diff_url": "https://github.com/huggingface/datasets/pull/5478.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5478.patch",
"merged_at": "2023-01-30T19:15:26"
} | true |
https://api.github.com/repos/huggingface/datasets/issues/5477 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5477/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5477/comments | https://api.github.com/repos/huggingface/datasets/issues/5477/events | https://github.com/huggingface/datasets/issues/5477 | 1,559,909,892 | I_kwDODunzps5c-lYE | 5,477 | Unpin sqlalchemy once issue is fixed | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [] | open | false | null | [] | [
"@albertvillanova It looks like that issue has been fixed so I made a PR to unpin sqlalchemy! ",
"The source issue:\r\n- https://github.com/pandas-dev/pandas/issues/40686\r\n\r\nhas been fixed:\r\n- https://github.com/pandas-dev/pandas/pull/48576\r\n\r\nThe fix was released yesterday (2023-04-03) only in `pandas-2.0.0`:\r\n- https://github.com/pandas-dev/pandas/releases/tag/v2.0.0\r\n\r\nbut it will not be back-ported to `pandas-1`:\r\n- https://github.com/pandas-dev/pandas/pull/48576#issuecomment-1466467159\r\n\r\nAlso note that `pandas-2.0.0` dropped support for Python 3.7:\r\n- https://github.com/pandas-dev/pandas/issues/41678\r\n- https://github.com/pandas-dev/pandas/pull/41989\r\n\r\nTherefore, we cannot unpin `sqlalchemy` until we drop support for Python 3.7 (these Python users cannot use `pandas-2`)."
] | 1,674,831,715,000 | 1,680,595,603,000 | null | MEMBER | null | Once the source issue is fixed:
- pandas-dev/pandas#51015
we should revert the pin introduced in:
- #5476 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5477/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5477/timeline | null | null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5476 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5476/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5476/comments | https://api.github.com/repos/huggingface/datasets/issues/5476/events | https://github.com/huggingface/datasets/pull/5476 | 1,559,594,684 | PR_kwDODunzps5IqwC_ | 5,476 | Pin sqlalchemy | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.012442 / 0.011353 (0.001089) | 0.006274 / 0.011008 (-0.004734) | 0.128249 / 0.038508 (0.089741) | 0.040117 / 0.023109 (0.017008) | 0.383725 / 0.275898 (0.107827) | 0.510494 / 0.323480 (0.187014) | 0.009037 / 0.007986 (0.001051) | 0.008256 / 0.004328 (0.003927) | 0.105329 / 0.004250 (0.101079) | 0.046909 / 0.037052 (0.009857) | 0.401980 / 0.258489 (0.143491) | 0.461332 / 0.293841 (0.167491) | 0.065629 / 0.128546 (-0.062917) | 0.020043 / 0.075646 (-0.055604) | 0.453773 / 0.419271 (0.034501) | 0.063456 / 0.043533 (0.019923) | 0.384458 / 0.255139 (0.129319) | 0.449699 / 0.283200 (0.166499) | 0.118197 / 0.141683 (-0.023486) | 1.915080 / 1.452155 (0.462925) | 1.957132 / 1.492716 (0.464416) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.209657 / 0.018006 (0.191651) | 0.592478 / 0.000490 (0.591988) | 0.004137 / 0.000200 (0.003937) | 0.000124 / 0.000054 (0.000069) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.029607 / 0.037411 (-0.007804) | 0.129559 / 0.014526 (0.115033) | 0.148326 / 0.176557 (-0.028231) | 0.190506 / 0.737135 (-0.546629) | 0.143177 / 0.296338 (-0.153162) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.626166 / 0.215209 (0.410957) | 6.612680 / 2.077655 (4.535026) | 2.432354 / 1.504120 (0.928234) | 2.051482 / 1.541195 (0.510287) | 2.055822 / 1.468490 (0.587332) | 1.210099 / 4.584777 (-3.374678) | 5.498117 / 3.745712 (1.752405) | 3.054838 / 5.269862 (-2.215024) | 2.182875 / 4.565676 (-2.382802) | 0.144518 / 0.424275 (-0.279757) | 0.014132 / 0.007607 (0.006525) | 0.801805 / 0.226044 (0.575761) | 7.911235 / 2.268929 (5.642307) | 3.372762 / 55.444624 (-52.071862) | 2.517266 / 6.876477 (-4.359210) | 2.515329 / 2.142072 (0.373256) | 1.501731 / 4.805227 (-3.303497) | 0.252569 / 6.500664 (-6.248096) | 0.080987 / 0.075469 (0.005518) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.709880 / 1.841788 (-0.131907) | 18.640340 / 8.074308 (10.566032) | 23.560908 / 10.191392 (13.369516) | 0.265680 / 0.680424 (-0.414744) | 0.046438 / 0.534201 (-0.487763) | 0.571973 / 0.579283 (-0.007310) | 0.642425 / 0.434364 (0.208061) | 0.698167 / 0.540337 (0.157830) | 0.842132 / 1.386936 (-0.544804) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.009268 / 0.011353 (-0.002085) | 0.006052 / 0.011008 (-0.004956) | 0.133448 / 0.038508 (0.094939) | 0.034417 / 0.023109 (0.011308) | 0.435573 / 0.275898 (0.159675) | 0.479642 / 0.323480 (0.156162) | 0.008016 / 0.007986 (0.000030) | 0.006616 / 0.004328 (0.002288) | 0.106256 / 0.004250 (0.102005) | 0.048995 / 0.037052 (0.011942) | 0.450056 / 0.258489 (0.191567) | 0.511027 / 0.293841 (0.217187) | 0.052928 / 0.128546 (-0.075618) | 0.020824 / 0.075646 (-0.054822) | 0.450105 / 0.419271 (0.030834) | 0.062729 / 0.043533 (0.019196) | 0.438887 / 0.255139 (0.183748) | 0.468732 / 0.283200 (0.185532) | 0.116101 / 0.141683 (-0.025582) | 1.909689 / 1.452155 (0.457534) | 2.042007 / 1.492716 (0.549291) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.198265 / 0.018006 (0.180259) | 0.541799 / 0.000490 (0.541309) | 0.003938 / 0.000200 (0.003738) | 0.000116 / 0.000054 (0.000062) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.035933 / 0.037411 (-0.001478) | 0.130754 / 0.014526 (0.116229) | 0.146143 / 0.176557 (-0.030414) | 0.202042 / 0.737135 (-0.535094) | 0.155648 / 0.296338 (-0.140691) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.691123 / 0.215209 (0.475914) | 6.708370 / 2.077655 (4.630715) | 2.957120 / 1.504120 (1.453000) | 2.558350 / 1.541195 (1.017155) | 2.611271 / 1.468490 (1.142781) | 1.327355 / 4.584777 (-3.257422) | 5.755975 / 3.745712 (2.010263) | 3.295556 / 5.269862 (-1.974305) | 2.159831 / 4.565676 (-2.405845) | 0.161409 / 0.424275 (-0.262866) | 0.015470 / 0.007607 (0.007863) | 0.840611 / 0.226044 (0.614567) | 8.550064 / 2.268929 (6.281136) | 3.832013 / 55.444624 (-51.612612) | 3.032909 / 6.876477 (-3.843568) | 3.155651 / 2.142072 (1.013578) | 1.612486 / 4.805227 (-3.192741) | 0.273789 / 6.500664 (-6.226875) | 0.085618 / 0.075469 (0.010149) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.808376 / 1.841788 (-0.033412) | 18.267614 / 8.074308 (10.193306) | 21.047679 / 10.191392 (10.856286) | 0.259089 / 0.680424 (-0.421335) | 0.029211 / 0.534201 (-0.504990) | 0.556303 / 0.579283 (-0.022980) | 0.625264 / 0.434364 (0.190900) | 0.680814 / 0.540337 (0.140476) | 0.810146 / 1.386936 (-0.576790) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008779 / 0.011353 (-0.002574) | 0.004644 / 0.011008 (-0.006364) | 0.099814 / 0.038508 (0.061306) | 0.029830 / 0.023109 (0.006721) | 0.299159 / 0.275898 (0.023261) | 0.354815 / 0.323480 (0.031335) | 0.006968 / 0.007986 (-0.001018) | 0.003521 / 0.004328 (-0.000808) | 0.077687 / 0.004250 (0.073437) | 0.035019 / 0.037052 (-0.002034) | 0.309548 / 0.258489 (0.051059) | 0.345228 / 0.293841 (0.051387) | 0.033644 / 0.128546 (-0.094902) | 0.011564 / 0.075646 (-0.064083) | 0.321835 / 0.419271 (-0.097437) | 0.041798 / 0.043533 (-0.001735) | 0.298190 / 0.255139 (0.043051) | 0.328874 / 0.283200 (0.045674) | 0.088175 / 0.141683 (-0.053508) | 1.481755 / 1.452155 (0.029600) | 1.503085 / 1.492716 (0.010369) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.170930 / 0.018006 (0.152924) | 0.422155 / 0.000490 (0.421666) | 0.001708 / 0.000200 (0.001509) | 0.000083 / 0.000054 (0.000028) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.022588 / 0.037411 (-0.014824) | 0.095775 / 0.014526 (0.081249) | 0.103939 / 0.176557 (-0.072618) | 0.138441 / 0.737135 (-0.598694) | 0.107896 / 0.296338 (-0.188442) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.418243 / 0.215209 (0.203034) | 4.171432 / 2.077655 (2.093777) | 1.906029 / 1.504120 (0.401909) | 1.698174 / 1.541195 (0.156979) | 1.748339 / 1.468490 (0.279849) | 0.691026 / 4.584777 (-3.893751) | 3.393354 / 3.745712 (-0.352358) | 2.722412 / 5.269862 (-2.547450) | 1.462439 / 4.565676 (-3.103238) | 0.084713 / 0.424275 (-0.339562) | 0.012131 / 0.007607 (0.004524) | 0.522153 / 0.226044 (0.296109) | 5.197916 / 2.268929 (2.928988) | 2.314270 / 55.444624 (-53.130354) | 1.986599 / 6.876477 (-4.889878) | 2.012757 / 2.142072 (-0.129315) | 0.802540 / 4.805227 (-4.002687) | 0.148673 / 6.500664 (-6.351991) | 0.065924 / 0.075469 (-0.009545) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.263790 / 1.841788 (-0.577998) | 13.874784 / 8.074308 (5.800476) | 13.842276 / 10.191392 (3.650884) | 0.149002 / 0.680424 (-0.531422) | 0.028550 / 0.534201 (-0.505651) | 0.396913 / 0.579283 (-0.182370) | 0.401543 / 0.434364 (-0.032821) | 0.473754 / 0.540337 (-0.066583) | 0.560455 / 1.386936 (-0.826481) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006724 / 0.011353 (-0.004629) | 0.004507 / 0.011008 (-0.006502) | 0.098447 / 0.038508 (0.059939) | 0.027888 / 0.023109 (0.004779) | 0.428956 / 0.275898 (0.153058) | 0.451557 / 0.323480 (0.128077) | 0.005056 / 0.007986 (-0.002929) | 0.003363 / 0.004328 (-0.000965) | 0.075990 / 0.004250 (0.071740) | 0.038688 / 0.037052 (0.001635) | 0.421550 / 0.258489 (0.163061) | 0.459480 / 0.293841 (0.165639) | 0.031408 / 0.128546 (-0.097138) | 0.011559 / 0.075646 (-0.064088) | 0.320054 / 0.419271 (-0.099217) | 0.041917 / 0.043533 (-0.001616) | 0.420878 / 0.255139 (0.165739) | 0.444813 / 0.283200 (0.161613) | 0.090409 / 0.141683 (-0.051274) | 1.490058 / 1.452155 (0.037904) | 1.645206 / 1.492716 (0.152489) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.221105 / 0.018006 (0.203099) | 0.407537 / 0.000490 (0.407047) | 0.000410 / 0.000200 (0.000210) | 0.000059 / 0.000054 (0.000004) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.024658 / 0.037411 (-0.012754) | 0.099230 / 0.014526 (0.084705) | 0.107788 / 0.176557 (-0.068769) | 0.143040 / 0.737135 (-0.594096) | 0.109440 / 0.296338 (-0.186899) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.453303 / 0.215209 (0.238094) | 4.520376 / 2.077655 (2.442722) | 2.133909 / 1.504120 (0.629789) | 1.926996 / 1.541195 (0.385801) | 2.019870 / 1.468490 (0.551380) | 0.707423 / 4.584777 (-3.877354) | 3.391903 / 3.745712 (-0.353809) | 1.860661 / 5.269862 (-3.409201) | 1.159940 / 4.565676 (-3.405736) | 0.083773 / 0.424275 (-0.340502) | 0.012228 / 0.007607 (0.004621) | 0.554666 / 0.226044 (0.328622) | 5.567564 / 2.268929 (3.298636) | 2.636718 / 55.444624 (-52.807907) | 2.240215 / 6.876477 (-4.636262) | 2.218951 / 2.142072 (0.076879) | 0.817167 / 4.805227 (-3.988060) | 0.151633 / 6.500664 (-6.349032) | 0.066515 / 0.075469 (-0.008954) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.296665 / 1.841788 (-0.545123) | 13.997898 / 8.074308 (5.923590) | 13.286607 / 10.191392 (3.095215) | 0.148906 / 0.680424 (-0.531518) | 0.016600 / 0.534201 (-0.517601) | 0.377459 / 0.579283 (-0.201824) | 0.379938 / 0.434364 (-0.054426) | 0.461628 / 0.540337 (-0.078709) | 0.550592 / 1.386936 (-0.836344) |\n\n</details>\n</details>\n\n\n"
] | 1,674,818,798,000 | 1,674,821,211,000 | 1,674,820,668,000 | MEMBER | null | since sqlalchemy update to 2.0.0 the CI started to fail: https://github.com/huggingface/datasets/actions/runs/4023742457/jobs/6914976514
the error comes from pandas: https://github.com/pandas-dev/pandas/issues/51015 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5476/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5476/timeline | null | null | 0 | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5476",
"html_url": "https://github.com/huggingface/datasets/pull/5476",
"diff_url": "https://github.com/huggingface/datasets/pull/5476.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5476.patch",
"merged_at": "2023-01-27T11:57:48"
} | true |
https://api.github.com/repos/huggingface/datasets/issues/5475 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5475/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5475/comments | https://api.github.com/repos/huggingface/datasets/issues/5475/events | https://github.com/huggingface/datasets/issues/5475 | 1,559,030,149 | I_kwDODunzps5c7OmF | 5,475 | Dataset scan time is much slower than using native arrow | {
"login": "jonny-cyberhaven",
"id": 121845112,
"node_id": "U_kgDOB0M1eA",
"avatar_url": "https://avatars.githubusercontent.com/u/121845112?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/jonny-cyberhaven",
"html_url": "https://github.com/jonny-cyberhaven",
"followers_url": "https://api.github.com/users/jonny-cyberhaven/followers",
"following_url": "https://api.github.com/users/jonny-cyberhaven/following{/other_user}",
"gists_url": "https://api.github.com/users/jonny-cyberhaven/gists{/gist_id}",
"starred_url": "https://api.github.com/users/jonny-cyberhaven/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jonny-cyberhaven/subscriptions",
"organizations_url": "https://api.github.com/users/jonny-cyberhaven/orgs",
"repos_url": "https://api.github.com/users/jonny-cyberhaven/repos",
"events_url": "https://api.github.com/users/jonny-cyberhaven/events{/privacy}",
"received_events_url": "https://api.github.com/users/jonny-cyberhaven/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Hi ! In your code you only iterate on the Arrow buffers - you don't actually load the data as python objects. For a fair comparison, you can modify your code using:\r\n```diff\r\n- for _ in range(0, len(table), bsz):\r\n- _ = {k:table[k][_ : _ + bsz] for k in cols}\r\n+ for _ in range(0, len(table), bsz):\r\n+ _ = {k:table[k][_ : _ + bsz].to_pylist() for k in cols}\r\n```\r\n\r\nI re-ran your code and got a speed ratio of 1.00x and 1.02x",
"Ah I see, datasets is implicitly making this conversion. Thanks for pointing that out!\r\n\r\nIf it's not too much, I would also suggest updating some of your docs with the same `.to_pylist()` conversion in the code snippet that follows [here](https://huggingface.co/course/chapter5/4?fw=pt#:~:text=let%E2%80%99s%20run%20a%20little%20speed%20test%20by%20iterating%20over%20all%20the%20elements%20in%20the%20PubMed%20Abstracts%20dataset%3A).",
"This code snippet shows `datasets` code that reads the Arrow data as python objects already, there is no need to add to_pylist. Or were you thinking about something else ?"
] | 1,674,783,145,000 | 1,675,095,431,000 | 1,675,095,431,000 | CONTRIBUTOR | null | ### Describe the bug
I'm basically running the same scanning experiment from the tutorials https://huggingface.co/course/chapter5/4?fw=pt except now I'm comparing to a native pyarrow version.
I'm finding that the native pyarrow approach is much faster (2 orders of magnitude). Is there something I'm missing that explains this phenomenon?
### Steps to reproduce the bug
https://colab.research.google.com/drive/11EtHDaGAf1DKCpvYnAPJUW-LFfAcDzHY?usp=sharing
### Expected behavior
I expect scan times to be on par with using pyarrow directly.
### Environment info
standard colab environment | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5475/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5475/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5474 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5474/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5474/comments | https://api.github.com/repos/huggingface/datasets/issues/5474/events | https://github.com/huggingface/datasets/issues/5474 | 1,558,827,155 | I_kwDODunzps5c6dCT | 5,474 | Column project operation on `datasets.Dataset` | {
"login": "daskol",
"id": 9336514,
"node_id": "MDQ6VXNlcjkzMzY1MTQ=",
"avatar_url": "https://avatars.githubusercontent.com/u/9336514?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/daskol",
"html_url": "https://github.com/daskol",
"followers_url": "https://api.github.com/users/daskol/followers",
"following_url": "https://api.github.com/users/daskol/following{/other_user}",
"gists_url": "https://api.github.com/users/daskol/gists{/gist_id}",
"starred_url": "https://api.github.com/users/daskol/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/daskol/subscriptions",
"organizations_url": "https://api.github.com/users/daskol/orgs",
"repos_url": "https://api.github.com/users/daskol/repos",
"events_url": "https://api.github.com/users/daskol/events{/privacy}",
"received_events_url": "https://api.github.com/users/daskol/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892865,
"node_id": "MDU6TGFiZWwxOTM1ODkyODY1",
"url": "https://api.github.com/repos/huggingface/datasets/labels/duplicate",
"name": "duplicate",
"color": "cfd3d7",
"default": true,
"description": "This issue or pull request already exists"
},
{
"id": 1935892871,
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement",
"name": "enhancement",
"color": "a2eeef",
"default": true,
"description": "New feature or request"
}
] | closed | false | null | [] | [
"Hi ! This would be a nice addition indeed :) This sounds like a duplicate of https://github.com/huggingface/datasets/issues/5468\r\n\r\n> Not sure. Some of my PRs are still open and some do not have any discussions.\r\n\r\nSorry to hear that, feel free to ping me on those PRs"
] | 1,674,769,673,000 | 1,676,282,377,000 | 1,676,282,377,000 | CONTRIBUTOR | null | ### Feature request
There is no operation to select a subset of columns of original dataset. Expected API follows.
```python
a = Dataset.from_dict({
'int': [0, 1, 2]
'char': ['a', 'b', 'c'],
'none': [None] * 3,
})
b = a.project('int', 'char') # usually, .select()
print(a.column_names) # stdout: ['int', 'char', 'none']
print(b.column_names) # stdout: ['int', 'char']
```
Method project can easily accept not only column names (as a `str)` but univariant function applied to corresponding column as an example. Or keyword arguments can be used in order to rename columns in advance (see `pandas`, `pyspark`, `pyarrow`, and SQL)..
### Motivation
Projection is a typical operation in every data processing library. And it is a basic block of a well-known data manipulation language like SQL. Without this operation `datasets.Dataset` interface is not complete.
### Your contribution
Not sure. Some of my PRs are still open and some do not have any discussions. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5474/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5474/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5473 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5473/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5473/comments | https://api.github.com/repos/huggingface/datasets/issues/5473/events | https://github.com/huggingface/datasets/pull/5473 | 1,558,668,197 | PR_kwDODunzps5Inm9h | 5,473 | Set dev version | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008959 / 0.011353 (-0.002394) | 0.004549 / 0.011008 (-0.006460) | 0.102012 / 0.038508 (0.063504) | 0.030122 / 0.023109 (0.007013) | 0.303731 / 0.275898 (0.027833) | 0.344418 / 0.323480 (0.020938) | 0.007199 / 0.007986 (-0.000787) | 0.003415 / 0.004328 (-0.000913) | 0.079784 / 0.004250 (0.075534) | 0.034894 / 0.037052 (-0.002158) | 0.304739 / 0.258489 (0.046250) | 0.359457 / 0.293841 (0.065616) | 0.034194 / 0.128546 (-0.094352) | 0.011348 / 0.075646 (-0.064298) | 0.324340 / 0.419271 (-0.094931) | 0.041071 / 0.043533 (-0.002461) | 0.304437 / 0.255139 (0.049298) | 0.335517 / 0.283200 (0.052317) | 0.087787 / 0.141683 (-0.053895) | 1.467293 / 1.452155 (0.015138) | 1.543529 / 1.492716 (0.050813) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.187654 / 0.018006 (0.169648) | 0.426558 / 0.000490 (0.426068) | 0.003585 / 0.000200 (0.003385) | 0.000076 / 0.000054 (0.000022) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.023410 / 0.037411 (-0.014001) | 0.097065 / 0.014526 (0.082539) | 0.105358 / 0.176557 (-0.071198) | 0.140941 / 0.737135 (-0.596195) | 0.109484 / 0.296338 (-0.186855) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.420334 / 0.215209 (0.205125) | 4.223235 / 2.077655 (2.145581) | 1.866213 / 1.504120 (0.362093) | 1.673829 / 1.541195 (0.132634) | 1.757828 / 1.468490 (0.289337) | 0.702203 / 4.584777 (-3.882574) | 3.426192 / 3.745712 (-0.319521) | 1.950392 / 5.269862 (-3.319470) | 1.286139 / 4.565676 (-3.279538) | 0.082858 / 0.424275 (-0.341417) | 0.012587 / 0.007607 (0.004980) | 0.531920 / 0.226044 (0.305876) | 5.344425 / 2.268929 (3.075497) | 2.337875 / 55.444624 (-53.106749) | 1.967713 / 6.876477 (-4.908764) | 2.022075 / 2.142072 (-0.119997) | 0.829267 / 4.805227 (-3.975961) | 0.151712 / 6.500664 (-6.348952) | 0.066617 / 0.075469 (-0.008852) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.251867 / 1.841788 (-0.589921) | 13.861756 / 8.074308 (5.787448) | 14.236309 / 10.191392 (4.044917) | 0.138215 / 0.680424 (-0.542209) | 0.028600 / 0.534201 (-0.505601) | 0.395890 / 0.579283 (-0.183393) | 0.403971 / 0.434364 (-0.030393) | 0.479033 / 0.540337 (-0.061305) | 0.564019 / 1.386936 (-0.822917) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006845 / 0.011353 (-0.004508) | 0.004544 / 0.011008 (-0.006464) | 0.098719 / 0.038508 (0.060211) | 0.029082 / 0.023109 (0.005973) | 0.426011 / 0.275898 (0.150113) | 0.447185 / 0.323480 (0.123705) | 0.005203 / 0.007986 (-0.002783) | 0.004790 / 0.004328 (0.000462) | 0.076446 / 0.004250 (0.072196) | 0.040649 / 0.037052 (0.003596) | 0.414810 / 0.258489 (0.156321) | 0.452082 / 0.293841 (0.158241) | 0.031842 / 0.128546 (-0.096704) | 0.011575 / 0.075646 (-0.064071) | 0.320710 / 0.419271 (-0.098561) | 0.044994 / 0.043533 (0.001461) | 0.415645 / 0.255139 (0.160506) | 0.435235 / 0.283200 (0.152035) | 0.091756 / 0.141683 (-0.049927) | 1.493900 / 1.452155 (0.041746) | 1.592353 / 1.492716 (0.099637) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.264710 / 0.018006 (0.246703) | 0.410553 / 0.000490 (0.410064) | 0.024497 / 0.000200 (0.024297) | 0.000232 / 0.000054 (0.000178) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.024452 / 0.037411 (-0.012959) | 0.102673 / 0.014526 (0.088147) | 0.107787 / 0.176557 (-0.068770) | 0.147368 / 0.737135 (-0.589767) | 0.112127 / 0.296338 (-0.184211) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.471294 / 0.215209 (0.256085) | 4.711638 / 2.077655 (2.633983) | 2.436819 / 1.504120 (0.932699) | 2.238540 / 1.541195 (0.697345) | 2.334134 / 1.468490 (0.865644) | 0.697668 / 4.584777 (-3.887108) | 3.414332 / 3.745712 (-0.331380) | 2.783248 / 5.269862 (-2.486614) | 1.529599 / 4.565676 (-3.036078) | 0.082626 / 0.424275 (-0.341649) | 0.012385 / 0.007607 (0.004778) | 0.580486 / 0.226044 (0.354441) | 5.837914 / 2.268929 (3.568986) | 2.915129 / 55.444624 (-52.529495) | 2.606254 / 6.876477 (-4.270223) | 2.659031 / 2.142072 (0.516958) | 0.810431 / 4.805227 (-3.994796) | 0.151666 / 6.500664 (-6.348998) | 0.066873 / 0.075469 (-0.008596) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.259933 / 1.841788 (-0.581855) | 14.052388 / 8.074308 (5.978080) | 13.356141 / 10.191392 (3.164749) | 0.138416 / 0.680424 (-0.542008) | 0.016582 / 0.534201 (-0.517619) | 0.378110 / 0.579283 (-0.201173) | 0.385089 / 0.434364 (-0.049275) | 0.465299 / 0.540337 (-0.075038) | 0.559780 / 1.386936 (-0.827156) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.011945 / 0.011353 (0.000592) | 0.006128 / 0.011008 (-0.004880) | 0.128926 / 0.038508 (0.090418) | 0.037708 / 0.023109 (0.014599) | 0.373449 / 0.275898 (0.097551) | 0.423567 / 0.323480 (0.100088) | 0.009848 / 0.007986 (0.001863) | 0.006097 / 0.004328 (0.001769) | 0.098275 / 0.004250 (0.094024) | 0.043199 / 0.037052 (0.006147) | 0.376848 / 0.258489 (0.118359) | 0.441819 / 0.293841 (0.147978) | 0.055094 / 0.128546 (-0.073453) | 0.019704 / 0.075646 (-0.055942) | 0.422746 / 0.419271 (0.003474) | 0.061764 / 0.043533 (0.018231) | 0.381056 / 0.255139 (0.125917) | 0.419343 / 0.283200 (0.136144) | 0.116720 / 0.141683 (-0.024963) | 1.763913 / 1.452155 (0.311759) | 1.872306 / 1.492716 (0.379589) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.198651 / 0.018006 (0.180645) | 0.560565 / 0.000490 (0.560075) | 0.004269 / 0.000200 (0.004069) | 0.000114 / 0.000054 (0.000059) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.027307 / 0.037411 (-0.010104) | 0.128276 / 0.014526 (0.113750) | 0.129015 / 0.176557 (-0.047542) | 0.167269 / 0.737135 (-0.569866) | 0.143955 / 0.296338 (-0.152384) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.564954 / 0.215209 (0.349745) | 5.810570 / 2.077655 (3.732916) | 2.456382 / 1.504120 (0.952262) | 2.115809 / 1.541195 (0.574614) | 2.097363 / 1.468490 (0.628873) | 1.189712 / 4.584777 (-3.395065) | 5.318287 / 3.745712 (1.572575) | 2.965763 / 5.269862 (-2.304099) | 2.177958 / 4.565676 (-2.387719) | 0.144135 / 0.424275 (-0.280140) | 0.014348 / 0.007607 (0.006741) | 0.781715 / 0.226044 (0.555670) | 7.688349 / 2.268929 (5.419421) | 3.189260 / 55.444624 (-52.255365) | 2.552340 / 6.876477 (-4.324137) | 2.559312 / 2.142072 (0.417240) | 1.490755 / 4.805227 (-3.314473) | 0.257908 / 6.500664 (-6.242756) | 0.082016 / 0.075469 (0.006547) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.565735 / 1.841788 (-0.276053) | 17.660338 / 8.074308 (9.586030) | 19.493573 / 10.191392 (9.302181) | 0.241310 / 0.680424 (-0.439114) | 0.043485 / 0.534201 (-0.490716) | 0.557397 / 0.579283 (-0.021886) | 0.624385 / 0.434364 (0.190021) | 0.634601 / 0.540337 (0.094264) | 0.743140 / 1.386936 (-0.643796) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.010134 / 0.011353 (-0.001219) | 0.005858 / 0.011008 (-0.005150) | 0.128741 / 0.038508 (0.090232) | 0.036769 / 0.023109 (0.013660) | 0.470894 / 0.275898 (0.194996) | 0.524302 / 0.323480 (0.200822) | 0.006830 / 0.007986 (-0.001156) | 0.006166 / 0.004328 (0.001838) | 0.094875 / 0.004250 (0.090625) | 0.051201 / 0.037052 (0.014148) | 0.493992 / 0.258489 (0.235503) | 0.510540 / 0.293841 (0.216699) | 0.056354 / 0.128546 (-0.072192) | 0.020512 / 0.075646 (-0.055134) | 0.417809 / 0.419271 (-0.001463) | 0.061941 / 0.043533 (0.018408) | 0.498883 / 0.255139 (0.243744) | 0.480762 / 0.283200 (0.197563) | 0.110753 / 0.141683 (-0.030930) | 1.914096 / 1.452155 (0.461941) | 1.941338 / 1.492716 (0.448622) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.237955 / 0.018006 (0.219949) | 0.518136 / 0.000490 (0.517647) | 0.000475 / 0.000200 (0.000275) | 0.000095 / 0.000054 (0.000040) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.032947 / 0.037411 (-0.004465) | 0.127857 / 0.014526 (0.113331) | 0.133911 / 0.176557 (-0.042646) | 0.188406 / 0.737135 (-0.548729) | 0.143939 / 0.296338 (-0.152400) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.787553 / 0.215209 (0.572344) | 6.976572 / 2.077655 (4.898918) | 2.897964 / 1.504120 (1.393844) | 2.545906 / 1.541195 (1.004711) | 2.622111 / 1.468490 (1.153620) | 1.278283 / 4.584777 (-3.306494) | 5.650447 / 3.745712 (1.904734) | 4.955835 / 5.269862 (-0.314027) | 2.767946 / 4.565676 (-1.797731) | 0.149385 / 0.424275 (-0.274890) | 0.014340 / 0.007607 (0.006733) | 0.861774 / 0.226044 (0.635730) | 8.660985 / 2.268929 (6.392057) | 3.685611 / 55.444624 (-51.759014) | 2.963087 / 6.876477 (-3.913390) | 3.020746 / 2.142072 (0.878673) | 1.538908 / 4.805227 (-3.266319) | 0.285875 / 6.500664 (-6.214789) | 0.080337 / 0.075469 (0.004867) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.575155 / 1.841788 (-0.266633) | 17.548946 / 8.074308 (9.474638) | 19.954104 / 10.191392 (9.762712) | 0.242025 / 0.680424 (-0.438398) | 0.025586 / 0.534201 (-0.508615) | 0.515676 / 0.579283 (-0.063607) | 0.607035 / 0.434364 (0.172671) | 0.633597 / 0.540337 (0.093259) | 0.744577 / 1.386936 (-0.642359) |\n\n</details>\n</details>\n\n\n"
] | 1,674,761,684,000 | 1,674,762,454,000 | 1,674,761,910,000 | MEMBER | null | null | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5473/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5473/timeline | null | null | 0 | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5473",
"html_url": "https://github.com/huggingface/datasets/pull/5473",
"diff_url": "https://github.com/huggingface/datasets/pull/5473.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5473.patch",
"merged_at": "2023-01-26T19:38:30"
} | true |
https://api.github.com/repos/huggingface/datasets/issues/5472 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5472/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5472/comments | https://api.github.com/repos/huggingface/datasets/issues/5472/events | https://github.com/huggingface/datasets/pull/5472 | 1,558,662,251 | PR_kwDODunzps5Inlp8 | 5,472 | Release: 2.9.0 | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008578 / 0.011353 (-0.002775) | 0.004535 / 0.011008 (-0.006473) | 0.100694 / 0.038508 (0.062186) | 0.029570 / 0.023109 (0.006460) | 0.296384 / 0.275898 (0.020486) | 0.354405 / 0.323480 (0.030925) | 0.006962 / 0.007986 (-0.001024) | 0.003405 / 0.004328 (-0.000924) | 0.077275 / 0.004250 (0.073025) | 0.036623 / 0.037052 (-0.000429) | 0.309844 / 0.258489 (0.051355) | 0.340343 / 0.293841 (0.046502) | 0.033626 / 0.128546 (-0.094920) | 0.011433 / 0.075646 (-0.064214) | 0.322659 / 0.419271 (-0.096612) | 0.040509 / 0.043533 (-0.003024) | 0.294002 / 0.255139 (0.038863) | 0.323259 / 0.283200 (0.040059) | 0.088023 / 0.141683 (-0.053660) | 1.462039 / 1.452155 (0.009885) | 1.495401 / 1.492716 (0.002684) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.218614 / 0.018006 (0.200608) | 0.482359 / 0.000490 (0.481869) | 0.001216 / 0.000200 (0.001016) | 0.000081 / 0.000054 (0.000027) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.023167 / 0.037411 (-0.014245) | 0.098468 / 0.014526 (0.083942) | 0.108273 / 0.176557 (-0.068284) | 0.139991 / 0.737135 (-0.597144) | 0.109032 / 0.296338 (-0.187307) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.421526 / 0.215209 (0.206317) | 4.216808 / 2.077655 (2.139153) | 1.860550 / 1.504120 (0.356431) | 1.654518 / 1.541195 (0.113323) | 1.699064 / 1.468490 (0.230574) | 0.691489 / 4.584777 (-3.893287) | 3.401885 / 3.745712 (-0.343827) | 2.792860 / 5.269862 (-2.477001) | 1.516269 / 4.565676 (-3.049408) | 0.081627 / 0.424275 (-0.342648) | 0.012556 / 0.007607 (0.004949) | 0.531535 / 0.226044 (0.305491) | 5.320752 / 2.268929 (3.051823) | 2.314502 / 55.444624 (-53.130123) | 1.967118 / 6.876477 (-4.909359) | 2.008252 / 2.142072 (-0.133821) | 0.809730 / 4.805227 (-3.995497) | 0.148112 / 6.500664 (-6.352552) | 0.064821 / 0.075469 (-0.010648) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.269754 / 1.841788 (-0.572033) | 13.884200 / 8.074308 (5.809892) | 13.914390 / 10.191392 (3.722998) | 0.150176 / 0.680424 (-0.530248) | 0.028463 / 0.534201 (-0.505738) | 0.398723 / 0.579283 (-0.180561) | 0.400433 / 0.434364 (-0.033931) | 0.485169 / 0.540337 (-0.055169) | 0.565995 / 1.386936 (-0.820941) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006479 / 0.011353 (-0.004874) | 0.004504 / 0.011008 (-0.006504) | 0.097905 / 0.038508 (0.059397) | 0.027140 / 0.023109 (0.004031) | 0.408742 / 0.275898 (0.132844) | 0.448707 / 0.323480 (0.125228) | 0.004819 / 0.007986 (-0.003166) | 0.004761 / 0.004328 (0.000433) | 0.075456 / 0.004250 (0.071205) | 0.036282 / 0.037052 (-0.000771) | 0.405961 / 0.258489 (0.147472) | 0.449411 / 0.293841 (0.155570) | 0.031159 / 0.128546 (-0.097387) | 0.011693 / 0.075646 (-0.063954) | 0.321124 / 0.419271 (-0.098147) | 0.041369 / 0.043533 (-0.002164) | 0.408070 / 0.255139 (0.152931) | 0.428704 / 0.283200 (0.145504) | 0.086839 / 0.141683 (-0.054844) | 1.477772 / 1.452155 (0.025617) | 1.555913 / 1.492716 (0.063197) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.239494 / 0.018006 (0.221488) | 0.410785 / 0.000490 (0.410295) | 0.000989 / 0.000200 (0.000789) | 0.000072 / 0.000054 (0.000017) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.023805 / 0.037411 (-0.013607) | 0.097904 / 0.014526 (0.083378) | 0.106437 / 0.176557 (-0.070120) | 0.140555 / 0.737135 (-0.596580) | 0.107169 / 0.296338 (-0.189170) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.470233 / 0.215209 (0.255024) | 4.700451 / 2.077655 (2.622797) | 2.391712 / 1.504120 (0.887592) | 2.191125 / 1.541195 (0.649930) | 2.268924 / 1.468490 (0.800434) | 0.692421 / 4.584777 (-3.892356) | 3.387117 / 3.745712 (-0.358595) | 1.881731 / 5.269862 (-3.388130) | 1.155759 / 4.565676 (-3.409917) | 0.082040 / 0.424275 (-0.342236) | 0.012687 / 0.007607 (0.005080) | 0.567556 / 0.226044 (0.341511) | 5.701408 / 2.268929 (3.432480) | 2.864368 / 55.444624 (-52.580256) | 2.512073 / 6.876477 (-4.364404) | 2.546078 / 2.142072 (0.404005) | 0.795939 / 4.805227 (-4.009288) | 0.150078 / 6.500664 (-6.350586) | 0.067644 / 0.075469 (-0.007825) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.281681 / 1.841788 (-0.560107) | 13.967107 / 8.074308 (5.892799) | 13.293648 / 10.191392 (3.102256) | 0.128027 / 0.680424 (-0.552397) | 0.016791 / 0.534201 (-0.517410) | 0.379400 / 0.579283 (-0.199884) | 0.386847 / 0.434364 (-0.047517) | 0.469859 / 0.540337 (-0.070478) | 0.564203 / 1.386936 (-0.822733) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008701 / 0.011353 (-0.002652) | 0.004564 / 0.011008 (-0.006444) | 0.100578 / 0.038508 (0.062070) | 0.029209 / 0.023109 (0.006100) | 0.315308 / 0.275898 (0.039410) | 0.381022 / 0.323480 (0.057542) | 0.007152 / 0.007986 (-0.000834) | 0.003511 / 0.004328 (-0.000817) | 0.078361 / 0.004250 (0.074110) | 0.035394 / 0.037052 (-0.001658) | 0.331076 / 0.258489 (0.072586) | 0.366613 / 0.293841 (0.072772) | 0.033466 / 0.128546 (-0.095080) | 0.011521 / 0.075646 (-0.064126) | 0.322178 / 0.419271 (-0.097093) | 0.040891 / 0.043533 (-0.002641) | 0.320418 / 0.255139 (0.065279) | 0.345199 / 0.283200 (0.062000) | 0.087906 / 0.141683 (-0.053777) | 1.476801 / 1.452155 (0.024646) | 1.497738 / 1.492716 (0.005022) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.178094 / 0.018006 (0.160087) | 0.408317 / 0.000490 (0.407827) | 0.001825 / 0.000200 (0.001625) | 0.000067 / 0.000054 (0.000012) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.022402 / 0.037411 (-0.015010) | 0.097104 / 0.014526 (0.082578) | 0.105361 / 0.176557 (-0.071196) | 0.139728 / 0.737135 (-0.597407) | 0.109613 / 0.296338 (-0.186725) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.418245 / 0.215209 (0.203036) | 4.155655 / 2.077655 (2.078000) | 1.865892 / 1.504120 (0.361772) | 1.659003 / 1.541195 (0.117809) | 1.725649 / 1.468490 (0.257159) | 0.688733 / 4.584777 (-3.896044) | 3.323529 / 3.745712 (-0.422184) | 1.867807 / 5.269862 (-3.402054) | 1.157740 / 4.565676 (-3.407936) | 0.081947 / 0.424275 (-0.342329) | 0.012471 / 0.007607 (0.004864) | 0.529333 / 0.226044 (0.303288) | 5.284898 / 2.268929 (3.015970) | 2.321741 / 55.444624 (-53.122883) | 1.975683 / 6.876477 (-4.900794) | 2.029691 / 2.142072 (-0.112381) | 0.810212 / 4.805227 (-3.995015) | 0.148185 / 6.500664 (-6.352479) | 0.064594 / 0.075469 (-0.010875) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.183391 / 1.841788 (-0.658396) | 13.574760 / 8.074308 (5.500452) | 14.215015 / 10.191392 (4.023623) | 0.150776 / 0.680424 (-0.529648) | 0.029058 / 0.534201 (-0.505143) | 0.404071 / 0.579283 (-0.175212) | 0.401289 / 0.434364 (-0.033075) | 0.490946 / 0.540337 (-0.049392) | 0.582292 / 1.386936 (-0.804644) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006695 / 0.011353 (-0.004658) | 0.004499 / 0.011008 (-0.006510) | 0.097633 / 0.038508 (0.059125) | 0.027606 / 0.023109 (0.004496) | 0.413191 / 0.275898 (0.137293) | 0.441896 / 0.323480 (0.118416) | 0.005703 / 0.007986 (-0.002283) | 0.004608 / 0.004328 (0.000280) | 0.074392 / 0.004250 (0.070141) | 0.037966 / 0.037052 (0.000913) | 0.410736 / 0.258489 (0.152247) | 0.448581 / 0.293841 (0.154740) | 0.031594 / 0.128546 (-0.096952) | 0.011597 / 0.075646 (-0.064049) | 0.319632 / 0.419271 (-0.099639) | 0.041189 / 0.043533 (-0.002343) | 0.407120 / 0.255139 (0.151981) | 0.433416 / 0.283200 (0.150216) | 0.089932 / 0.141683 (-0.051751) | 1.453919 / 1.452155 (0.001764) | 1.545892 / 1.492716 (0.053176) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.224302 / 0.018006 (0.206296) | 0.415519 / 0.000490 (0.415029) | 0.000407 / 0.000200 (0.000207) | 0.000060 / 0.000054 (0.000006) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.024104 / 0.037411 (-0.013307) | 0.098202 / 0.014526 (0.083676) | 0.106416 / 0.176557 (-0.070140) | 0.141090 / 0.737135 (-0.596045) | 0.110188 / 0.296338 (-0.186150) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.478252 / 0.215209 (0.263043) | 4.739684 / 2.077655 (2.662029) | 2.419040 / 1.504120 (0.914920) | 2.217705 / 1.541195 (0.676510) | 2.303288 / 1.468490 (0.834798) | 0.696682 / 4.584777 (-3.888095) | 3.401962 / 3.745712 (-0.343750) | 1.886015 / 5.269862 (-3.383846) | 1.175084 / 4.565676 (-3.390592) | 0.083064 / 0.424275 (-0.341211) | 0.012613 / 0.007607 (0.005006) | 0.579105 / 0.226044 (0.353060) | 5.792119 / 2.268929 (3.523191) | 2.889778 / 55.444624 (-52.554846) | 2.537438 / 6.876477 (-4.339039) | 2.574814 / 2.142072 (0.432741) | 0.803438 / 4.805227 (-4.001789) | 0.151912 / 6.500664 (-6.348752) | 0.068291 / 0.075469 (-0.007178) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.286002 / 1.841788 (-0.555786) | 14.179443 / 8.074308 (6.105135) | 13.443939 / 10.191392 (3.252547) | 0.152427 / 0.680424 (-0.527996) | 0.017248 / 0.534201 (-0.516953) | 0.378734 / 0.579283 (-0.200549) | 0.382276 / 0.434364 (-0.052087) | 0.465323 / 0.540337 (-0.075014) | 0.556454 / 1.386936 (-0.830482) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008675 / 0.011353 (-0.002678) | 0.004537 / 0.011008 (-0.006471) | 0.100179 / 0.038508 (0.061671) | 0.029307 / 0.023109 (0.006198) | 0.294687 / 0.275898 (0.018789) | 0.356868 / 0.323480 (0.033388) | 0.006992 / 0.007986 (-0.000994) | 0.003380 / 0.004328 (-0.000949) | 0.076961 / 0.004250 (0.072710) | 0.036047 / 0.037052 (-0.001005) | 0.308037 / 0.258489 (0.049548) | 0.341089 / 0.293841 (0.047248) | 0.033416 / 0.128546 (-0.095131) | 0.011534 / 0.075646 (-0.064112) | 0.322976 / 0.419271 (-0.096296) | 0.040894 / 0.043533 (-0.002639) | 0.296501 / 0.255139 (0.041362) | 0.324605 / 0.283200 (0.041405) | 0.086713 / 0.141683 (-0.054970) | 1.502784 / 1.452155 (0.050630) | 1.535013 / 1.492716 (0.042297) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.186647 / 0.018006 (0.168641) | 0.411003 / 0.000490 (0.410514) | 0.003594 / 0.000200 (0.003394) | 0.000074 / 0.000054 (0.000020) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.023704 / 0.037411 (-0.013707) | 0.096154 / 0.014526 (0.081629) | 0.103671 / 0.176557 (-0.072885) | 0.138878 / 0.737135 (-0.598258) | 0.106947 / 0.296338 (-0.189391) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.417180 / 0.215209 (0.201970) | 4.149579 / 2.077655 (2.071925) | 1.865763 / 1.504120 (0.361643) | 1.669722 / 1.541195 (0.128527) | 1.722345 / 1.468490 (0.253855) | 0.695910 / 4.584777 (-3.888867) | 3.342266 / 3.745712 (-0.403446) | 1.884568 / 5.269862 (-3.385294) | 1.265013 / 4.565676 (-3.300664) | 0.081836 / 0.424275 (-0.342439) | 0.012371 / 0.007607 (0.004764) | 0.522997 / 0.226044 (0.296953) | 5.225434 / 2.268929 (2.956506) | 2.304701 / 55.444624 (-53.139924) | 1.949067 / 6.876477 (-4.927410) | 2.016347 / 2.142072 (-0.125725) | 0.809850 / 4.805227 (-3.995377) | 0.148396 / 6.500664 (-6.352268) | 0.063340 / 0.075469 (-0.012129) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.224621 / 1.841788 (-0.617167) | 13.814223 / 8.074308 (5.739915) | 13.879728 / 10.191392 (3.688336) | 0.149530 / 0.680424 (-0.530894) | 0.028439 / 0.534201 (-0.505762) | 0.392726 / 0.579283 (-0.186557) | 0.396894 / 0.434364 (-0.037469) | 0.474395 / 0.540337 (-0.065943) | 0.569090 / 1.386936 (-0.817847) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006483 / 0.011353 (-0.004870) | 0.004527 / 0.011008 (-0.006481) | 0.098038 / 0.038508 (0.059530) | 0.027239 / 0.023109 (0.004130) | 0.441773 / 0.275898 (0.165875) | 0.471448 / 0.323480 (0.147968) | 0.005034 / 0.007986 (-0.002951) | 0.004732 / 0.004328 (0.000403) | 0.075036 / 0.004250 (0.070785) | 0.036711 / 0.037052 (-0.000341) | 0.442634 / 0.258489 (0.184145) | 0.476479 / 0.293841 (0.182638) | 0.031303 / 0.128546 (-0.097243) | 0.011642 / 0.075646 (-0.064005) | 0.320750 / 0.419271 (-0.098521) | 0.048698 / 0.043533 (0.005165) | 0.441205 / 0.255139 (0.186066) | 0.464845 / 0.283200 (0.181645) | 0.092716 / 0.141683 (-0.048967) | 1.510028 / 1.452155 (0.057874) | 1.574065 / 1.492716 (0.081349) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.220756 / 0.018006 (0.202750) | 0.393971 / 0.000490 (0.393482) | 0.002506 / 0.000200 (0.002306) | 0.000073 / 0.000054 (0.000018) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.024455 / 0.037411 (-0.012956) | 0.100164 / 0.014526 (0.085638) | 0.108053 / 0.176557 (-0.068504) | 0.142973 / 0.737135 (-0.594163) | 0.110108 / 0.296338 (-0.186231) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.473639 / 0.215209 (0.258430) | 4.737521 / 2.077655 (2.659866) | 2.466208 / 1.504120 (0.962088) | 2.272608 / 1.541195 (0.731413) | 2.349255 / 1.468490 (0.880764) | 0.699928 / 4.584777 (-3.884849) | 3.348443 / 3.745712 (-0.397269) | 2.604611 / 5.269862 (-2.665250) | 1.543080 / 4.565676 (-3.022597) | 0.082627 / 0.424275 (-0.341648) | 0.012251 / 0.007607 (0.004644) | 0.569949 / 0.226044 (0.343905) | 5.732316 / 2.268929 (3.463388) | 2.913541 / 55.444624 (-52.531084) | 2.560584 / 6.876477 (-4.315892) | 2.615192 / 2.142072 (0.473120) | 0.803822 / 4.805227 (-4.001406) | 0.150821 / 6.500664 (-6.349843) | 0.067128 / 0.075469 (-0.008341) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.272278 / 1.841788 (-0.569510) | 13.783339 / 8.074308 (5.709030) | 13.243601 / 10.191392 (3.052209) | 0.136421 / 0.680424 (-0.544003) | 0.016565 / 0.534201 (-0.517636) | 0.381102 / 0.579283 (-0.198181) | 0.386166 / 0.434364 (-0.048197) | 0.474249 / 0.540337 (-0.066089) | 0.566826 / 1.386936 (-0.820110) |\n\n</details>\n</details>\n\n\n"
] | 1,674,761,382,000 | 1,674,762,044,000 | 1,674,761,580,000 | MEMBER | null | null | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5472/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5472/timeline | null | null | 0 | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5472",
"html_url": "https://github.com/huggingface/datasets/pull/5472",
"diff_url": "https://github.com/huggingface/datasets/pull/5472.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5472.patch",
"merged_at": "2023-01-26T19:33:00"
} | true |
https://api.github.com/repos/huggingface/datasets/issues/5471 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5471/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5471/comments | https://api.github.com/repos/huggingface/datasets/issues/5471/events | https://github.com/huggingface/datasets/pull/5471 | 1,558,557,545 | PR_kwDODunzps5InPA7 | 5,471 | Add num_test_batches option | {
"login": "amyeroberts",
"id": 22614925,
"node_id": "MDQ6VXNlcjIyNjE0OTI1",
"avatar_url": "https://avatars.githubusercontent.com/u/22614925?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/amyeroberts",
"html_url": "https://github.com/amyeroberts",
"followers_url": "https://api.github.com/users/amyeroberts/followers",
"following_url": "https://api.github.com/users/amyeroberts/following{/other_user}",
"gists_url": "https://api.github.com/users/amyeroberts/gists{/gist_id}",
"starred_url": "https://api.github.com/users/amyeroberts/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/amyeroberts/subscriptions",
"organizations_url": "https://api.github.com/users/amyeroberts/orgs",
"repos_url": "https://api.github.com/users/amyeroberts/repos",
"events_url": "https://api.github.com/users/amyeroberts/events{/privacy}",
"received_events_url": "https://api.github.com/users/amyeroberts/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"_The documentation is not available anymore as the PR was closed or merged._",
"I thought this issue was resolved in my parallel `to_tf_dataset` PR! I changed the default `num_test_batches` in `_get_output_signature` to 20 and used a test batch size of 1 to maximize variance to detect shorter samples. I think it's still okay to have this PR, though - but I'd use the new value of 20 as the default!",
"@Rocketknight1 You're right - I didn't have the most recent changes to the default values. Updated now to 20! I still think it would be good to have it configurable from the `to_tf_dataset` call so the user has the option to either make it more robust if many samples are needed, or faster if only one is needed. That, and I selfishly want it for faster tests. ",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.010441 / 0.011353 (-0.000912) | 0.005605 / 0.011008 (-0.005404) | 0.115712 / 0.038508 (0.077204) | 0.040907 / 0.023109 (0.017797) | 0.357673 / 0.275898 (0.081775) | 0.415427 / 0.323480 (0.091947) | 0.008827 / 0.007986 (0.000842) | 0.006069 / 0.004328 (0.001740) | 0.088985 / 0.004250 (0.084735) | 0.048461 / 0.037052 (0.011409) | 0.362065 / 0.258489 (0.103576) | 0.393643 / 0.293841 (0.099802) | 0.043844 / 0.128546 (-0.084703) | 0.013757 / 0.075646 (-0.061889) | 0.390993 / 0.419271 (-0.028278) | 0.053612 / 0.043533 (0.010079) | 0.348688 / 0.255139 (0.093549) | 0.377818 / 0.283200 (0.094619) | 0.115762 / 0.141683 (-0.025920) | 1.751826 / 1.452155 (0.299672) | 1.773326 / 1.492716 (0.280609) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.220668 / 0.018006 (0.202662) | 0.536830 / 0.000490 (0.536340) | 0.000467 / 0.000200 (0.000267) | 0.000069 / 0.000054 (0.000015) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.031500 / 0.037411 (-0.005911) | 0.125796 / 0.014526 (0.111270) | 0.137539 / 0.176557 (-0.039017) | 0.184651 / 0.737135 (-0.552484) | 0.145707 / 0.296338 (-0.150632) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.465876 / 0.215209 (0.250667) | 4.637711 / 2.077655 (2.560056) | 2.132335 / 1.504120 (0.628215) | 1.862593 / 1.541195 (0.321398) | 1.961701 / 1.468490 (0.493211) | 0.800551 / 4.584777 (-3.784226) | 4.453321 / 3.745712 (0.707608) | 4.291030 / 5.269862 (-0.978832) | 2.256685 / 4.565676 (-2.308991) | 0.097787 / 0.424275 (-0.326488) | 0.014116 / 0.007607 (0.006509) | 0.593395 / 0.226044 (0.367351) | 5.885774 / 2.268929 (3.616845) | 2.666224 / 55.444624 (-52.778400) | 2.276673 / 6.876477 (-4.599803) | 2.358190 / 2.142072 (0.216117) | 0.981398 / 4.805227 (-3.823829) | 0.196997 / 6.500664 (-6.303668) | 0.077020 / 0.075469 (0.001550) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.365646 / 1.841788 (-0.476142) | 17.418157 / 8.074308 (9.343849) | 15.838749 / 10.191392 (5.647357) | 0.172749 / 0.680424 (-0.507675) | 0.033711 / 0.534201 (-0.500490) | 0.513306 / 0.579283 (-0.065978) | 0.503201 / 0.434364 (0.068837) | 0.608954 / 0.540337 (0.068616) | 0.734697 / 1.386936 (-0.652239) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008749 / 0.011353 (-0.002604) | 0.005738 / 0.011008 (-0.005270) | 0.084946 / 0.038508 (0.046438) | 0.040386 / 0.023109 (0.017277) | 0.398698 / 0.275898 (0.122800) | 0.435843 / 0.323480 (0.112363) | 0.006812 / 0.007986 (-0.001174) | 0.004567 / 0.004328 (0.000239) | 0.085857 / 0.004250 (0.081607) | 0.054791 / 0.037052 (0.017738) | 0.400381 / 0.258489 (0.141892) | 0.460313 / 0.293841 (0.166472) | 0.042299 / 0.128546 (-0.086247) | 0.014128 / 0.075646 (-0.061519) | 0.100497 / 0.419271 (-0.318775) | 0.058356 / 0.043533 (0.014823) | 0.399774 / 0.255139 (0.144635) | 0.428210 / 0.283200 (0.145011) | 0.122084 / 0.141683 (-0.019598) | 1.683519 / 1.452155 (0.231365) | 1.798024 / 1.492716 (0.305307) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.255058 / 0.018006 (0.237051) | 0.488831 / 0.000490 (0.488342) | 0.008349 / 0.000200 (0.008149) | 0.000183 / 0.000054 (0.000129) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.034870 / 0.037411 (-0.002541) | 0.131818 / 0.014526 (0.117292) | 0.143607 / 0.176557 (-0.032949) | 0.197413 / 0.737135 (-0.539722) | 0.148970 / 0.296338 (-0.147368) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.492831 / 0.215209 (0.277622) | 4.963085 / 2.077655 (2.885430) | 2.367803 / 1.504120 (0.863683) | 2.145535 / 1.541195 (0.604340) | 2.289452 / 1.468490 (0.820962) | 0.812691 / 4.584777 (-3.772086) | 4.554068 / 3.745712 (0.808356) | 2.377126 / 5.269862 (-2.892735) | 1.537243 / 4.565676 (-3.028433) | 0.099742 / 0.424275 (-0.324534) | 0.014757 / 0.007607 (0.007149) | 0.628714 / 0.226044 (0.402670) | 6.240197 / 2.268929 (3.971268) | 2.961929 / 55.444624 (-52.482696) | 2.533436 / 6.876477 (-4.343040) | 2.642619 / 2.142072 (0.500547) | 0.976002 / 4.805227 (-3.829225) | 0.197912 / 6.500664 (-6.302752) | 0.078767 / 0.075469 (0.003297) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.522863 / 1.841788 (-0.318925) | 18.210504 / 8.074308 (10.136196) | 15.664172 / 10.191392 (5.472780) | 0.178510 / 0.680424 (-0.501914) | 0.020852 / 0.534201 (-0.513349) | 0.501757 / 0.579283 (-0.077526) | 0.496542 / 0.434364 (0.062178) | 0.624958 / 0.540337 (0.084620) | 0.746960 / 1.386936 (-0.639976) |\n\n</details>\n</details>\n\n\n"
] | 1,674,756,580,000 | 1,674,843,405,000 | 1,674,842,916,000 | CONTRIBUTOR | null | `to_tf_dataset` calls can be very costly because of the number of test batches drawn during `_get_output_signature`. The test batches are draw in order to estimate the shapes when creating the tensorflow dataset. This is necessary when the shapes can be irregular, but not in cases when the tensor shapes are the same across all samples. This PR adds an option to change the number of batches drawn, so the user can speed this conversion up.
Running the following, and modifying `num_test_batches`
```
import time
from datasets import load_dataset
from transformers import DefaultDataCollator
data_collator = DefaultDataCollator()
dataset = load_dataset("beans")
dataset = dataset["train"].with_format("np")
start = time.time()
dataset = dataset.to_tf_dataset(
columns=["image"],
label_cols=["label"],
batch_size=8,
collate_fn=data_collator,
num_test_batches=NUM_TEST_BATCHES,
)
end = time.time()
print(end - start)
```
NUM_TEST_BATCHES=200: 0.8197s
NUM_TEST_BATCHES=50: 0.3070s
NUM_TEST_BATCHES=2: 0.1417s
NUM_TEST_BATCHES=1: 0.1352s | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5471/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5471/timeline | null | null | 0 | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5471",
"html_url": "https://github.com/huggingface/datasets/pull/5471",
"diff_url": "https://github.com/huggingface/datasets/pull/5471.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5471.patch",
"merged_at": "2023-01-27T18:08:36"
} | true |
https://api.github.com/repos/huggingface/datasets/issues/5470 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5470/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5470/comments | https://api.github.com/repos/huggingface/datasets/issues/5470/events | https://github.com/huggingface/datasets/pull/5470 | 1,558,542,611 | PR_kwDODunzps5InLw9 | 5,470 | Update dataset card creation | {
"login": "stevhliu",
"id": 59462357,
"node_id": "MDQ6VXNlcjU5NDYyMzU3",
"avatar_url": "https://avatars.githubusercontent.com/u/59462357?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/stevhliu",
"html_url": "https://github.com/stevhliu",
"followers_url": "https://api.github.com/users/stevhliu/followers",
"following_url": "https://api.github.com/users/stevhliu/following{/other_user}",
"gists_url": "https://api.github.com/users/stevhliu/gists{/gist_id}",
"starred_url": "https://api.github.com/users/stevhliu/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/stevhliu/subscriptions",
"organizations_url": "https://api.github.com/users/stevhliu/orgs",
"repos_url": "https://api.github.com/users/stevhliu/repos",
"events_url": "https://api.github.com/users/stevhliu/events{/privacy}",
"received_events_url": "https://api.github.com/users/stevhliu/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"_The documentation is not available anymore as the PR was closed or merged._",
"The CI failure is unrelated to your PR - feel free to merge :)",
"Haha thanks, you read my mind :)",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008332 / 0.011353 (-0.003021) | 0.004556 / 0.011008 (-0.006452) | 0.102239 / 0.038508 (0.063731) | 0.029332 / 0.023109 (0.006222) | 0.296189 / 0.275898 (0.020291) | 0.355746 / 0.323480 (0.032266) | 0.007705 / 0.007986 (-0.000281) | 0.003488 / 0.004328 (-0.000840) | 0.079142 / 0.004250 (0.074891) | 0.034980 / 0.037052 (-0.002073) | 0.307460 / 0.258489 (0.048971) | 0.345944 / 0.293841 (0.052103) | 0.033815 / 0.128546 (-0.094731) | 0.011603 / 0.075646 (-0.064044) | 0.322097 / 0.419271 (-0.097175) | 0.043753 / 0.043533 (0.000220) | 0.296706 / 0.255139 (0.041567) | 0.323195 / 0.283200 (0.039996) | 0.092295 / 0.141683 (-0.049388) | 1.542556 / 1.452155 (0.090401) | 1.571896 / 1.492716 (0.079180) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.191075 / 0.018006 (0.173069) | 0.407394 / 0.000490 (0.406905) | 0.002033 / 0.000200 (0.001833) | 0.000073 / 0.000054 (0.000018) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.023175 / 0.037411 (-0.014236) | 0.094774 / 0.014526 (0.080248) | 0.105782 / 0.176557 (-0.070775) | 0.146608 / 0.737135 (-0.590528) | 0.107519 / 0.296338 (-0.188819) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.421516 / 0.215209 (0.206306) | 4.201091 / 2.077655 (2.123436) | 1.880285 / 1.504120 (0.376165) | 1.676333 / 1.541195 (0.135139) | 1.734301 / 1.468490 (0.265811) | 0.688504 / 4.584777 (-3.896273) | 3.370289 / 3.745712 (-0.375423) | 3.127661 / 5.269862 (-2.142201) | 1.562570 / 4.565676 (-3.003106) | 0.081687 / 0.424275 (-0.342588) | 0.012334 / 0.007607 (0.004727) | 0.524125 / 0.226044 (0.298080) | 5.245595 / 2.268929 (2.976667) | 2.332622 / 55.444624 (-53.112002) | 1.973212 / 6.876477 (-4.903265) | 2.006507 / 2.142072 (-0.135565) | 0.807126 / 4.805227 (-3.998101) | 0.148254 / 6.500664 (-6.352411) | 0.064240 / 0.075469 (-0.011229) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.206880 / 1.841788 (-0.634907) | 13.854877 / 8.074308 (5.780569) | 13.806772 / 10.191392 (3.615380) | 0.144380 / 0.680424 (-0.536044) | 0.028492 / 0.534201 (-0.505709) | 0.393854 / 0.579283 (-0.185429) | 0.402210 / 0.434364 (-0.032154) | 0.462138 / 0.540337 (-0.078199) | 0.537480 / 1.386936 (-0.849456) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006692 / 0.011353 (-0.004661) | 0.004529 / 0.011008 (-0.006479) | 0.077925 / 0.038508 (0.039417) | 0.027824 / 0.023109 (0.004715) | 0.342288 / 0.275898 (0.066390) | 0.375071 / 0.323480 (0.051591) | 0.004889 / 0.007986 (-0.003097) | 0.003353 / 0.004328 (-0.000975) | 0.076198 / 0.004250 (0.071947) | 0.037797 / 0.037052 (0.000744) | 0.347834 / 0.258489 (0.089345) | 0.384200 / 0.293841 (0.090359) | 0.032184 / 0.128546 (-0.096362) | 0.011674 / 0.075646 (-0.063972) | 0.086242 / 0.419271 (-0.333029) | 0.044465 / 0.043533 (0.000932) | 0.341712 / 0.255139 (0.086573) | 0.366908 / 0.283200 (0.083709) | 0.091526 / 0.141683 (-0.050156) | 1.495798 / 1.452155 (0.043643) | 1.571700 / 1.492716 (0.078984) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.221962 / 0.018006 (0.203955) | 0.393095 / 0.000490 (0.392605) | 0.000385 / 0.000200 (0.000185) | 0.000074 / 0.000054 (0.000020) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.024365 / 0.037411 (-0.013046) | 0.099278 / 0.014526 (0.084753) | 0.105940 / 0.176557 (-0.070617) | 0.141334 / 0.737135 (-0.595802) | 0.110898 / 0.296338 (-0.185440) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.446150 / 0.215209 (0.230941) | 4.471441 / 2.077655 (2.393786) | 2.124864 / 1.504120 (0.620744) | 1.909950 / 1.541195 (0.368755) | 1.970085 / 1.468490 (0.501595) | 0.706711 / 4.584777 (-3.878066) | 3.380336 / 3.745712 (-0.365376) | 1.866106 / 5.269862 (-3.403756) | 1.160657 / 4.565676 (-3.405019) | 0.082786 / 0.424275 (-0.341489) | 0.012470 / 0.007607 (0.004862) | 0.537620 / 0.226044 (0.311575) | 5.390588 / 2.268929 (3.121659) | 2.539137 / 55.444624 (-52.905488) | 2.191867 / 6.876477 (-4.684610) | 2.236212 / 2.142072 (0.094139) | 0.810756 / 4.805227 (-3.994471) | 0.150933 / 6.500664 (-6.349731) | 0.066141 / 0.075469 (-0.009328) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.271595 / 1.841788 (-0.570193) | 13.840013 / 8.074308 (5.765705) | 13.334443 / 10.191392 (3.143051) | 0.150096 / 0.680424 (-0.530328) | 0.016919 / 0.534201 (-0.517282) | 0.375534 / 0.579283 (-0.203749) | 0.387203 / 0.434364 (-0.047161) | 0.463500 / 0.540337 (-0.076838) | 0.553496 / 1.386936 (-0.833440) |\n\n</details>\n</details>\n\n\n"
] | 1,674,755,871,000 | 1,674,836,820,000 | 1,674,836,410,000 | MEMBER | null | Encourages users to create a dataset card on the Hub directly with the new metadata ui + import dataset card template instead of telling users to manually create and upload one. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5470/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5470/timeline | null | null | 0 | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5470",
"html_url": "https://github.com/huggingface/datasets/pull/5470",
"diff_url": "https://github.com/huggingface/datasets/pull/5470.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5470.patch",
"merged_at": "2023-01-27T16:20:10"
} | true |
https://api.github.com/repos/huggingface/datasets/issues/5469 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5469/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5469/comments | https://api.github.com/repos/huggingface/datasets/issues/5469/events | https://github.com/huggingface/datasets/pull/5469 | 1,558,346,906 | PR_kwDODunzps5Imhk2 | 5,469 | Remove deprecated `shard_size` arg from `.push_to_hub()` | {
"login": "polinaeterna",
"id": 16348744,
"node_id": "MDQ6VXNlcjE2MzQ4NzQ0",
"avatar_url": "https://avatars.githubusercontent.com/u/16348744?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/polinaeterna",
"html_url": "https://github.com/polinaeterna",
"followers_url": "https://api.github.com/users/polinaeterna/followers",
"following_url": "https://api.github.com/users/polinaeterna/following{/other_user}",
"gists_url": "https://api.github.com/users/polinaeterna/gists{/gist_id}",
"starred_url": "https://api.github.com/users/polinaeterna/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/polinaeterna/subscriptions",
"organizations_url": "https://api.github.com/users/polinaeterna/orgs",
"repos_url": "https://api.github.com/users/polinaeterna/repos",
"events_url": "https://api.github.com/users/polinaeterna/events{/privacy}",
"received_events_url": "https://api.github.com/users/polinaeterna/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008272 / 0.011353 (-0.003081) | 0.004494 / 0.011008 (-0.006515) | 0.100764 / 0.038508 (0.062256) | 0.028741 / 0.023109 (0.005632) | 0.309020 / 0.275898 (0.033122) | 0.354184 / 0.323480 (0.030704) | 0.007455 / 0.007986 (-0.000531) | 0.003377 / 0.004328 (-0.000951) | 0.078472 / 0.004250 (0.074222) | 0.034719 / 0.037052 (-0.002333) | 0.312787 / 0.258489 (0.054298) | 0.342878 / 0.293841 (0.049037) | 0.033326 / 0.128546 (-0.095221) | 0.011519 / 0.075646 (-0.064127) | 0.323556 / 0.419271 (-0.095716) | 0.039929 / 0.043533 (-0.003604) | 0.304627 / 0.255139 (0.049488) | 0.322876 / 0.283200 (0.039677) | 0.086410 / 0.141683 (-0.055273) | 1.502607 / 1.452155 (0.050453) | 1.577953 / 1.492716 (0.085237) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.192861 / 0.018006 (0.174855) | 0.406008 / 0.000490 (0.405519) | 0.001075 / 0.000200 (0.000875) | 0.000071 / 0.000054 (0.000016) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.023351 / 0.037411 (-0.014060) | 0.096086 / 0.014526 (0.081561) | 0.104641 / 0.176557 (-0.071915) | 0.141940 / 0.737135 (-0.595195) | 0.109266 / 0.296338 (-0.187073) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.416496 / 0.215209 (0.201287) | 4.161581 / 2.077655 (2.083926) | 1.815357 / 1.504120 (0.311238) | 1.609536 / 1.541195 (0.068341) | 1.654105 / 1.468490 (0.185615) | 0.693947 / 4.584777 (-3.890830) | 3.349029 / 3.745712 (-0.396683) | 1.883968 / 5.269862 (-3.385893) | 1.287988 / 4.565676 (-3.277688) | 0.081765 / 0.424275 (-0.342511) | 0.012373 / 0.007607 (0.004766) | 0.517186 / 0.226044 (0.291142) | 5.200892 / 2.268929 (2.931964) | 2.247414 / 55.444624 (-53.197211) | 1.910601 / 6.876477 (-4.965876) | 1.965407 / 2.142072 (-0.176666) | 0.814386 / 4.805227 (-3.990841) | 0.149295 / 6.500664 (-6.351369) | 0.064667 / 0.075469 (-0.010802) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.247258 / 1.841788 (-0.594530) | 13.837355 / 8.074308 (5.763047) | 13.850454 / 10.191392 (3.659062) | 0.136078 / 0.680424 (-0.544346) | 0.028322 / 0.534201 (-0.505878) | 0.391394 / 0.579283 (-0.187889) | 0.407494 / 0.434364 (-0.026870) | 0.473784 / 0.540337 (-0.066554) | 0.562953 / 1.386936 (-0.823983) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006559 / 0.011353 (-0.004794) | 0.004546 / 0.011008 (-0.006462) | 0.099527 / 0.038508 (0.061019) | 0.027428 / 0.023109 (0.004319) | 0.344276 / 0.275898 (0.068377) | 0.377897 / 0.323480 (0.054417) | 0.004913 / 0.007986 (-0.003072) | 0.003338 / 0.004328 (-0.000990) | 0.077589 / 0.004250 (0.073339) | 0.038819 / 0.037052 (0.001766) | 0.343165 / 0.258489 (0.084676) | 0.386228 / 0.293841 (0.092387) | 0.031753 / 0.128546 (-0.096794) | 0.011756 / 0.075646 (-0.063890) | 0.322537 / 0.419271 (-0.096735) | 0.049865 / 0.043533 (0.006332) | 0.340493 / 0.255139 (0.085354) | 0.372179 / 0.283200 (0.088980) | 0.099669 / 0.141683 (-0.042013) | 1.487841 / 1.452155 (0.035686) | 1.527400 / 1.492716 (0.034683) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.180782 / 0.018006 (0.162776) | 0.393494 / 0.000490 (0.393004) | 0.003004 / 0.000200 (0.002804) | 0.000076 / 0.000054 (0.000022) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.024997 / 0.037411 (-0.012415) | 0.098232 / 0.014526 (0.083707) | 0.107869 / 0.176557 (-0.068688) | 0.141042 / 0.737135 (-0.596093) | 0.109551 / 0.296338 (-0.186787) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.477115 / 0.215209 (0.261906) | 4.783928 / 2.077655 (2.706273) | 2.435725 / 1.504120 (0.931605) | 2.233111 / 1.541195 (0.691916) | 2.341097 / 1.468490 (0.872607) | 0.694304 / 4.584777 (-3.890473) | 3.345687 / 3.745712 (-0.400025) | 1.886932 / 5.269862 (-3.382929) | 1.155585 / 4.565676 (-3.410092) | 0.082867 / 0.424275 (-0.341408) | 0.012420 / 0.007607 (0.004813) | 0.576575 / 0.226044 (0.350530) | 5.777691 / 2.268929 (3.508762) | 2.882219 / 55.444624 (-52.562405) | 2.543613 / 6.876477 (-4.332864) | 2.578939 / 2.142072 (0.436866) | 0.803143 / 4.805227 (-4.002084) | 0.151929 / 6.500664 (-6.348735) | 0.067777 / 0.075469 (-0.007693) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.282711 / 1.841788 (-0.559077) | 13.942771 / 8.074308 (5.868463) | 13.376206 / 10.191392 (3.184814) | 0.152916 / 0.680424 (-0.527508) | 0.016619 / 0.534201 (-0.517582) | 0.375141 / 0.579283 (-0.204142) | 0.381660 / 0.434364 (-0.052704) | 0.465090 / 0.540337 (-0.075247) | 0.555068 / 1.386936 (-0.831868) |\n\n</details>\n</details>\n\n\n"
] | 1,674,747,656,000 | 1,674,754,671,000 | 1,674,754,259,000 | CONTRIBUTOR | null | The docstrings say that it was supposed to be deprecated since version 2.4.0, can we remove it? | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5469/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5469/timeline | null | null | 0 | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5469",
"html_url": "https://github.com/huggingface/datasets/pull/5469",
"diff_url": "https://github.com/huggingface/datasets/pull/5469.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5469.patch",
"merged_at": "2023-01-26T17:30:59"
} | true |
https://api.github.com/repos/huggingface/datasets/issues/5468 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5468/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5468/comments | https://api.github.com/repos/huggingface/datasets/issues/5468/events | https://github.com/huggingface/datasets/issues/5468 | 1,558,066,625 | I_kwDODunzps5c3jXB | 5,468 | Allow opposite of remove_columns on Dataset and DatasetDict | {
"login": "hollance",
"id": 346853,
"node_id": "MDQ6VXNlcjM0Njg1Mw==",
"avatar_url": "https://avatars.githubusercontent.com/u/346853?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/hollance",
"html_url": "https://github.com/hollance",
"followers_url": "https://api.github.com/users/hollance/followers",
"following_url": "https://api.github.com/users/hollance/following{/other_user}",
"gists_url": "https://api.github.com/users/hollance/gists{/gist_id}",
"starred_url": "https://api.github.com/users/hollance/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/hollance/subscriptions",
"organizations_url": "https://api.github.com/users/hollance/orgs",
"repos_url": "https://api.github.com/users/hollance/repos",
"events_url": "https://api.github.com/users/hollance/events{/privacy}",
"received_events_url": "https://api.github.com/users/hollance/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892871,
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement",
"name": "enhancement",
"color": "a2eeef",
"default": true,
"description": "New feature or request"
},
{
"id": 1935892877,
"node_id": "MDU6TGFiZWwxOTM1ODkyODc3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/good%20first%20issue",
"name": "good first issue",
"color": "7057ff",
"default": true,
"description": "Good for newcomers"
}
] | closed | false | null | [] | [
"Hi! I agree it would be nice to have a method like that. Instead of `keep_columns`, we can name it `select_columns` to be more aligned with PyArrow's naming convention (`pa.Table.select`).",
"Hi, I am a newbie to open source and would like to contribute. @mariosasko can I take up this issue ?",
"Hey, I also want to work on this issue I am a newbie to open source. ",
"This sounds related to https://github.com/huggingface/datasets/issues/5474\r\n\r\nI'm fine with `select_columns`, or we could also override `select` to also accept a list of columns maybe ?",
"@lhoestq, I am planning to add a member function to the dataset class to perform the selection operation. Do you think its the right way to proceed? or there is a better option ?",
"Unless @mariosasko thinks otherwise, I think it can go in `Dataset.select()` :)\r\nThough some parameters like keep_in_memory, indices_cache_file_name or writer_batch_size wouldn't when selecting columns, so we would need to update the docstring as well",
"If someone wants to give it a shot, feel free to comment `#self-assign` and it will assign the issue to you.\r\n\r\nFeel free to ping us here if you have questions or if we can help :)",
"I would rather have this functionality as a separate method. IMO it's always better to be explicit than to have an API where a single method can do different/uncorrelated things (somewhat reminds me of Pandas, and there is probably a good reason why PyArrow is more rigid in this aspect).",
"In the end I also think it would be nice to have it as a separate method, this way we can also have it for `IterableDataset` (which can't have `select` for indices)"
] | 1,674,736,089,000 | 1,676,282,378,000 | 1,676,282,378,000 | NONE | null | ### Feature request
In this blog post https://huggingface.co/blog/audio-datasets, I noticed the following code:
```python
COLUMNS_TO_KEEP = ["text", "audio"]
all_columns = gigaspeech["train"].column_names
columns_to_remove = set(all_columns) - set(COLUMNS_TO_KEEP)
gigaspeech = gigaspeech.remove_columns(columns_to_remove)
```
This kind of thing happens a lot when you don't need to keep all columns from the dataset. It would be more convenient (and less error prone) if you could just write:
```python
gigaspeech = gigaspeech.keep_columns(["text", "audio"])
```
Internally, `keep_columns` could still call `remove_columns`, but it expresses more clearly what the user's intent is.
### Motivation
Less code to write for the user of the dataset.
### Your contribution
- | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5468/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5468/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5467 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5467/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5467/comments | https://api.github.com/repos/huggingface/datasets/issues/5467/events | https://github.com/huggingface/datasets/pull/5467 | 1,557,898,273 | PR_kwDODunzps5IlAlk | 5,467 | Fix conda command in readme | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"ah didn't read well - it's all good",
"or maybe it isn't ? `-c huggingface -c conda-forge` installs from HF or from conda-forge ?",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.010196 / 0.011353 (-0.001157) | 0.005531 / 0.011008 (-0.005477) | 0.104601 / 0.038508 (0.066093) | 0.041322 / 0.023109 (0.018213) | 0.302080 / 0.275898 (0.026182) | 0.396579 / 0.323480 (0.073099) | 0.008874 / 0.007986 (0.000888) | 0.004482 / 0.004328 (0.000153) | 0.077487 / 0.004250 (0.073236) | 0.051113 / 0.037052 (0.014061) | 0.321850 / 0.258489 (0.063361) | 0.354946 / 0.293841 (0.061105) | 0.039822 / 0.128546 (-0.088724) | 0.012622 / 0.075646 (-0.063024) | 0.337898 / 0.419271 (-0.081374) | 0.048372 / 0.043533 (0.004839) | 0.299646 / 0.255139 (0.044507) | 0.321113 / 0.283200 (0.037914) | 0.114780 / 0.141683 (-0.026903) | 1.475750 / 1.452155 (0.023595) | 1.496307 / 1.492716 (0.003590) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.311443 / 0.018006 (0.293437) | 0.567268 / 0.000490 (0.566778) | 0.006149 / 0.000200 (0.005950) | 0.000089 / 0.000054 (0.000035) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.029407 / 0.037411 (-0.008004) | 0.118611 / 0.014526 (0.104085) | 0.122247 / 0.176557 (-0.054309) | 0.164770 / 0.737135 (-0.572365) | 0.128561 / 0.296338 (-0.167778) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.399185 / 0.215209 (0.183976) | 3.972995 / 2.077655 (1.895340) | 1.764638 / 1.504120 (0.260518) | 1.574058 / 1.541195 (0.032863) | 1.741695 / 1.468490 (0.273205) | 0.705664 / 4.584777 (-3.879113) | 3.915399 / 3.745712 (0.169686) | 2.310154 / 5.269862 (-2.959707) | 1.554067 / 4.565676 (-3.011610) | 0.087133 / 0.424275 (-0.337142) | 0.012393 / 0.007607 (0.004786) | 0.510758 / 0.226044 (0.284713) | 5.114906 / 2.268929 (2.845977) | 2.304473 / 55.444624 (-53.140152) | 1.960768 / 6.876477 (-4.915709) | 2.092263 / 2.142072 (-0.049810) | 0.867973 / 4.805227 (-3.937255) | 0.170000 / 6.500664 (-6.330664) | 0.068358 / 0.075469 (-0.007111) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.211022 / 1.841788 (-0.630765) | 16.777269 / 8.074308 (8.702961) | 15.272659 / 10.191392 (5.081267) | 0.182149 / 0.680424 (-0.498274) | 0.029577 / 0.534201 (-0.504624) | 0.446590 / 0.579283 (-0.132693) | 0.454724 / 0.434364 (0.020360) | 0.541938 / 0.540337 (0.001601) | 0.640886 / 1.386936 (-0.746050) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008441 / 0.011353 (-0.002912) | 0.006105 / 0.011008 (-0.004904) | 0.100349 / 0.038508 (0.061841) | 0.040675 / 0.023109 (0.017565) | 0.381775 / 0.275898 (0.105877) | 0.425246 / 0.323480 (0.101767) | 0.007197 / 0.007986 (-0.000789) | 0.004972 / 0.004328 (0.000644) | 0.075346 / 0.004250 (0.071096) | 0.065339 / 0.037052 (0.028286) | 0.379340 / 0.258489 (0.120851) | 0.435646 / 0.293841 (0.141805) | 0.038891 / 0.128546 (-0.089656) | 0.013079 / 0.075646 (-0.062568) | 0.339273 / 0.419271 (-0.079999) | 0.057478 / 0.043533 (0.013945) | 0.373516 / 0.255139 (0.118377) | 0.402388 / 0.283200 (0.119189) | 0.123145 / 0.141683 (-0.018538) | 1.503765 / 1.452155 (0.051610) | 1.609797 / 1.492716 (0.117081) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.420354 / 0.018006 (0.402348) | 0.589272 / 0.000490 (0.588782) | 0.045861 / 0.000200 (0.045662) | 0.000527 / 0.000054 (0.000473) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.033918 / 0.037411 (-0.003493) | 0.128041 / 0.014526 (0.113515) | 0.130274 / 0.176557 (-0.046283) | 0.180605 / 0.737135 (-0.556530) | 0.136377 / 0.296338 (-0.159962) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.440343 / 0.215209 (0.225133) | 4.390264 / 2.077655 (2.312610) | 2.218738 / 1.504120 (0.714618) | 2.052399 / 1.541195 (0.511204) | 2.231912 / 1.468490 (0.763422) | 0.716805 / 4.584777 (-3.867972) | 3.909277 / 3.745712 (0.163565) | 2.302121 / 5.269862 (-2.967740) | 1.419454 / 4.565676 (-3.146222) | 0.088067 / 0.424275 (-0.336208) | 0.012994 / 0.007607 (0.005387) | 0.548267 / 0.226044 (0.322223) | 5.462973 / 2.268929 (3.194044) | 2.768414 / 55.444624 (-52.676210) | 2.489320 / 6.876477 (-4.387157) | 2.569546 / 2.142072 (0.427474) | 0.853135 / 4.805227 (-3.952092) | 0.170618 / 6.500664 (-6.330046) | 0.069908 / 0.075469 (-0.005562) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.304726 / 1.841788 (-0.537062) | 17.335977 / 8.074308 (9.261669) | 15.088319 / 10.191392 (4.896927) | 0.190893 / 0.680424 (-0.489531) | 0.018133 / 0.534201 (-0.516068) | 0.429324 / 0.579283 (-0.149959) | 0.439212 / 0.434364 (0.004848) | 0.545312 / 0.540337 (0.004975) | 0.663972 / 1.386936 (-0.722964) |\n\n</details>\n</details>\n\n\n",
"_The documentation is not available anymore as the PR was closed or merged._"
] | 1,674,727,381,000 | 1,674,757,936,000 | 1,674,757,777,000 | MEMBER | null | The [conda forge channel](https://anaconda.org/conda-forge/datasets) is lagging behind (as of right now, only 2.7.1 is available), we should recommend using the [Hugging face channel](https://anaconda.org/HuggingFace/datasets) that we are maintaining
```
conda install -c huggingface datasets
``` | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5467/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5467/timeline | null | null | 0 | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5467",
"html_url": "https://github.com/huggingface/datasets/pull/5467",
"diff_url": "https://github.com/huggingface/datasets/pull/5467.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5467.patch",
"merged_at": null
} | true |
https://api.github.com/repos/huggingface/datasets/issues/5466 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5466/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5466/comments | https://api.github.com/repos/huggingface/datasets/issues/5466/events | https://github.com/huggingface/datasets/pull/5466 | 1,557,584,845 | PR_kwDODunzps5Ij-z1 | 5,466 | remove pathlib.Path with URIs | {
"login": "jonny-cyberhaven",
"id": 121845112,
"node_id": "U_kgDOB0M1eA",
"avatar_url": "https://avatars.githubusercontent.com/u/121845112?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/jonny-cyberhaven",
"html_url": "https://github.com/jonny-cyberhaven",
"followers_url": "https://api.github.com/users/jonny-cyberhaven/followers",
"following_url": "https://api.github.com/users/jonny-cyberhaven/following{/other_user}",
"gists_url": "https://api.github.com/users/jonny-cyberhaven/gists{/gist_id}",
"starred_url": "https://api.github.com/users/jonny-cyberhaven/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jonny-cyberhaven/subscriptions",
"organizations_url": "https://api.github.com/users/jonny-cyberhaven/orgs",
"repos_url": "https://api.github.com/users/jonny-cyberhaven/repos",
"events_url": "https://api.github.com/users/jonny-cyberhaven/events{/privacy}",
"received_events_url": "https://api.github.com/users/jonny-cyberhaven/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Thanks !\r\n`os.path.join` will use a backslash `\\` on windows which will also fail. You can use this instead in `load_from_disk`:\r\n```python\r\nfrom .filesystems import is_remote_filesystem\r\n\r\nis_local = not is_remote_filesystem(fs)\r\npath_join = os.path.join if is_local else posixpath.join\r\n```",
"Thank you ! I did a minor change to not have to define a new function and I ran the CI. If it's green we can merge :)",
"_The documentation is not available anymore as the PR was closed or merged._",
"> \r\n\r\n\r\n\r\n> Thank you ! I did a minor change to not have to define a new function and I ran the CI. If it's green we can merge :)\r\n\r\nlol it's a battle of +1 imports or +1 functions. LGTM, I was editing fast and swapped which branch gets os vs Path. Should be ok now 🤙",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.012043 / 0.011353 (0.000690) | 0.006585 / 0.011008 (-0.004423) | 0.149007 / 0.038508 (0.110499) | 0.039514 / 0.023109 (0.016405) | 0.403893 / 0.275898 (0.127995) | 0.431252 / 0.323480 (0.107772) | 0.009218 / 0.007986 (0.001233) | 0.006108 / 0.004328 (0.001779) | 0.114666 / 0.004250 (0.110416) | 0.044962 / 0.037052 (0.007910) | 0.411592 / 0.258489 (0.153103) | 0.461561 / 0.293841 (0.167721) | 0.059958 / 0.128546 (-0.068589) | 0.029047 / 0.075646 (-0.046599) | 0.456000 / 0.419271 (0.036728) | 0.060744 / 0.043533 (0.017211) | 0.415816 / 0.255139 (0.160677) | 0.430488 / 0.283200 (0.147289) | 0.122477 / 0.141683 (-0.019205) | 1.862910 / 1.452155 (0.410755) | 1.974698 / 1.492716 (0.481981) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.257230 / 0.018006 (0.239224) | 0.606854 / 0.000490 (0.606364) | 0.006175 / 0.000200 (0.005975) | 0.000099 / 0.000054 (0.000044) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.030533 / 0.037411 (-0.006879) | 0.130702 / 0.014526 (0.116177) | 0.143781 / 0.176557 (-0.032775) | 0.183272 / 0.737135 (-0.553863) | 0.151267 / 0.296338 (-0.145071) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.637422 / 0.215209 (0.422213) | 6.503535 / 2.077655 (4.425880) | 2.630387 / 1.504120 (1.126267) | 2.281180 / 1.541195 (0.739985) | 2.354341 / 1.468490 (0.885851) | 1.306497 / 4.584777 (-3.278280) | 5.837184 / 3.745712 (2.091472) | 3.257198 / 5.269862 (-2.012663) | 2.050681 / 4.565676 (-2.514995) | 0.146415 / 0.424275 (-0.277860) | 0.015386 / 0.007607 (0.007779) | 0.790146 / 0.226044 (0.564102) | 8.056137 / 2.268929 (5.787209) | 3.383566 / 55.444624 (-52.061059) | 2.707620 / 6.876477 (-4.168856) | 2.714857 / 2.142072 (0.572785) | 1.520847 / 4.805227 (-3.284380) | 0.266028 / 6.500664 (-6.234636) | 0.091422 / 0.075469 (0.015953) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.656148 / 1.841788 (-0.185640) | 18.833393 / 8.074308 (10.759085) | 21.360824 / 10.191392 (11.169432) | 0.227608 / 0.680424 (-0.452816) | 0.049018 / 0.534201 (-0.485183) | 0.593418 / 0.579283 (0.014135) | 0.656690 / 0.434364 (0.222326) | 0.709171 / 0.540337 (0.168833) | 0.828226 / 1.386936 (-0.558710) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.010112 / 0.011353 (-0.001241) | 0.006761 / 0.011008 (-0.004247) | 0.146723 / 0.038508 (0.108215) | 0.038451 / 0.023109 (0.015342) | 0.524267 / 0.275898 (0.248369) | 0.609484 / 0.323480 (0.286004) | 0.008502 / 0.007986 (0.000516) | 0.006964 / 0.004328 (0.002635) | 0.111396 / 0.004250 (0.107146) | 0.056839 / 0.037052 (0.019787) | 0.514649 / 0.258489 (0.256160) | 0.604212 / 0.293841 (0.310372) | 0.061410 / 0.128546 (-0.067137) | 0.020396 / 0.075646 (-0.055250) | 0.505026 / 0.419271 (0.085754) | 0.067280 / 0.043533 (0.023747) | 0.522249 / 0.255139 (0.267110) | 0.559484 / 0.283200 (0.276284) | 0.120943 / 0.141683 (-0.020740) | 2.124323 / 1.452155 (0.672169) | 2.153397 / 1.492716 (0.660681) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.216614 / 0.018006 (0.198608) | 0.594181 / 0.000490 (0.593692) | 0.004079 / 0.000200 (0.003879) | 0.000117 / 0.000054 (0.000063) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.036925 / 0.037411 (-0.000486) | 0.131322 / 0.014526 (0.116797) | 0.148542 / 0.176557 (-0.028015) | 0.196045 / 0.737135 (-0.541090) | 0.156867 / 0.296338 (-0.139472) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.669722 / 0.215209 (0.454513) | 6.858856 / 2.077655 (4.781202) | 3.093969 / 1.504120 (1.589849) | 2.667385 / 1.541195 (1.126190) | 2.797192 / 1.468490 (1.328702) | 1.334759 / 4.584777 (-3.250018) | 6.024861 / 3.745712 (2.279149) | 3.257779 / 5.269862 (-2.012083) | 2.202816 / 4.565676 (-2.362860) | 0.147617 / 0.424275 (-0.276658) | 0.015451 / 0.007607 (0.007844) | 0.887015 / 0.226044 (0.660970) | 8.371288 / 2.268929 (6.102360) | 3.807451 / 55.444624 (-51.637173) | 3.079483 / 6.876477 (-3.796994) | 3.103321 / 2.142072 (0.961249) | 1.520272 / 4.805227 (-3.284955) | 0.273079 / 6.500664 (-6.227585) | 0.088613 / 0.075469 (0.013143) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.818913 / 1.841788 (-0.022875) | 19.274269 / 8.074308 (11.199960) | 19.871784 / 10.191392 (9.680392) | 0.250388 / 0.680424 (-0.430036) | 0.030562 / 0.534201 (-0.503638) | 0.560566 / 0.579283 (-0.018717) | 0.664701 / 0.434364 (0.230337) | 0.714513 / 0.540337 (0.174176) | 0.827227 / 1.386936 (-0.559710) |\n\n</details>\n</details>\n\n\n"
] | 1,674,703,545,000 | 1,674,752,937,000 | 1,674,752,351,000 | CONTRIBUTOR | null | Pathlib will convert "//" to "/" which causes retry errors when downloading from cloud storage | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5466/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5466/timeline | null | null | 0 | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5466",
"html_url": "https://github.com/huggingface/datasets/pull/5466",
"diff_url": "https://github.com/huggingface/datasets/pull/5466.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5466.patch",
"merged_at": "2023-01-26T16:59:11"
} | true |
https://api.github.com/repos/huggingface/datasets/issues/5465 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5465/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5465/comments | https://api.github.com/repos/huggingface/datasets/issues/5465/events | https://github.com/huggingface/datasets/issues/5465 | 1,557,510,618 | I_kwDODunzps5c1bna | 5,465 | audiofolder creates empty dataset even though the dataset passed in follows the correct structure | {
"login": "jcho19",
"id": 107211437,
"node_id": "U_kgDOBmPqrQ",
"avatar_url": "https://avatars.githubusercontent.com/u/107211437?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/jcho19",
"html_url": "https://github.com/jcho19",
"followers_url": "https://api.github.com/users/jcho19/followers",
"following_url": "https://api.github.com/users/jcho19/following{/other_user}",
"gists_url": "https://api.github.com/users/jcho19/gists{/gist_id}",
"starred_url": "https://api.github.com/users/jcho19/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jcho19/subscriptions",
"organizations_url": "https://api.github.com/users/jcho19/orgs",
"repos_url": "https://api.github.com/users/jcho19/repos",
"events_url": "https://api.github.com/users/jcho19/events{/privacy}",
"received_events_url": "https://api.github.com/users/jcho19/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [] | 1,674,697,545,000 | 1,674,722,925,000 | 1,674,722,925,000 | NONE | null | ### Describe the bug
The structure of my dataset folder called "my_dataset" is : data metadata.csv
The data folder consists of all mp3 files and metadata.csv consist of file locations like 'data/...mp3 and transcriptions. There's 400+ mp3 files and corresponding transcriptions for my dataset.
When I run the following:
ds = load_dataset("audiofolder", data_dir="my_dataset")
I get:
Using custom data configuration default-...
Downloading and preparing dataset audiofolder/default to /...
Downloading data files: 0%| | 0/2 [00:00<?, ?it/s]
Downloading data files: 0it [00:00, ?it/s]
Extracting data files: 0it [00:00, ?it/s]
Generating train split: 0 examples [00:00, ? examples/s]
Dataset audiofolder downloaded and prepared to /.... Subsequent calls will reuse this data.
0%| | 0/1 [00:00<?, ?it/s]
DatasetDict({
train: Dataset({
features: ['audio', 'transcription'],
num_rows: 1
})
})
### Steps to reproduce the bug
Create a dataset folder called 'my_dataset' with a subfolder called 'data' that has mp3 files. Also, create metadata.csv that has file locations like 'data/...mp3' and their corresponding transcription.
Run:
ds = load_dataset("audiofolder", data_dir="my_dataset")
### Expected behavior
It should generate a dataset with numerous rows.
### Environment info
Run on Jupyter notebook | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5465/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5465/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5464 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5464/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5464/comments | https://api.github.com/repos/huggingface/datasets/issues/5464/events | https://github.com/huggingface/datasets/issues/5464 | 1,557,462,104 | I_kwDODunzps5c1PxY | 5,464 | NonMatchingChecksumError for hendrycks_test | {
"login": "sarahwie",
"id": 8027676,
"node_id": "MDQ6VXNlcjgwMjc2NzY=",
"avatar_url": "https://avatars.githubusercontent.com/u/8027676?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sarahwie",
"html_url": "https://github.com/sarahwie",
"followers_url": "https://api.github.com/users/sarahwie/followers",
"following_url": "https://api.github.com/users/sarahwie/following{/other_user}",
"gists_url": "https://api.github.com/users/sarahwie/gists{/gist_id}",
"starred_url": "https://api.github.com/users/sarahwie/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sarahwie/subscriptions",
"organizations_url": "https://api.github.com/users/sarahwie/orgs",
"repos_url": "https://api.github.com/users/sarahwie/repos",
"events_url": "https://api.github.com/users/sarahwie/events{/privacy}",
"received_events_url": "https://api.github.com/users/sarahwie/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Thanks for reporting, @sarahwie.\r\n\r\nPlease note this issue was already fixed in `datasets` 2.6.0 version:\r\n- #5040\r\n\r\nIf you update your `datasets` version, you will be able to load the dataset:\r\n```\r\npip install -U datasets\r\n```",
"Oops, missed that I needed to upgrade. Thanks!"
] | 1,674,693,803,000 | 1,674,798,271,000 | 1,674,718,918,000 | NONE | null | ### Describe the bug
The checksum of the file has likely changed on the remote host.
### Steps to reproduce the bug
`dataset = nlp.load_dataset("hendrycks_test", "anatomy")`
### Expected behavior
no error thrown
### Environment info
- `datasets` version: 2.2.1
- Platform: macOS-13.1-arm64-arm-64bit
- Python version: 3.9.13
- PyArrow version: 9.0.0
- Pandas version: 1.5.1 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5464/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5464/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5463 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5463/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5463/comments | https://api.github.com/repos/huggingface/datasets/issues/5463/events | https://github.com/huggingface/datasets/pull/5463 | 1,557,021,041 | PR_kwDODunzps5IiGWb | 5,463 | Imagefolder docs: mention support of CSV and ZIP | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.009559 / 0.011353 (-0.001794) | 0.006425 / 0.011008 (-0.004583) | 0.112951 / 0.038508 (0.074443) | 0.030835 / 0.023109 (0.007725) | 0.313846 / 0.275898 (0.037948) | 0.352780 / 0.323480 (0.029301) | 0.007740 / 0.007986 (-0.000246) | 0.006843 / 0.004328 (0.002515) | 0.082632 / 0.004250 (0.078382) | 0.039704 / 0.037052 (0.002652) | 0.328526 / 0.258489 (0.070037) | 0.369162 / 0.293841 (0.075321) | 0.047603 / 0.128546 (-0.080943) | 0.015834 / 0.075646 (-0.059812) | 0.385912 / 0.419271 (-0.033360) | 0.053838 / 0.043533 (0.010306) | 0.325778 / 0.255139 (0.070639) | 0.361863 / 0.283200 (0.078663) | 0.097388 / 0.141683 (-0.044295) | 1.510132 / 1.452155 (0.057978) | 1.555980 / 1.492716 (0.063264) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.210792 / 0.018006 (0.192786) | 0.507270 / 0.000490 (0.506780) | 0.002383 / 0.000200 (0.002183) | 0.000095 / 0.000054 (0.000041) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.023057 / 0.037411 (-0.014355) | 0.103471 / 0.014526 (0.088945) | 0.111671 / 0.176557 (-0.064885) | 0.145665 / 0.737135 (-0.591470) | 0.131447 / 0.296338 (-0.164891) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.502979 / 0.215209 (0.287770) | 5.111471 / 2.077655 (3.033816) | 2.093604 / 1.504120 (0.589484) | 1.761342 / 1.541195 (0.220148) | 1.919485 / 1.468490 (0.450995) | 1.065672 / 4.584777 (-3.519105) | 5.109746 / 3.745712 (1.364034) | 4.694027 / 5.269862 (-0.575835) | 2.438401 / 4.565676 (-2.127275) | 0.133579 / 0.424275 (-0.290696) | 0.012355 / 0.007607 (0.004748) | 0.669077 / 0.226044 (0.443033) | 6.533905 / 2.268929 (4.264976) | 2.698832 / 55.444624 (-52.745792) | 2.146377 / 6.876477 (-4.730100) | 2.220563 / 2.142072 (0.078491) | 1.287855 / 4.805227 (-3.517372) | 0.238221 / 6.500664 (-6.262443) | 0.071426 / 0.075469 (-0.004043) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.332659 / 1.841788 (-0.509129) | 15.610100 / 8.074308 (7.535791) | 16.691117 / 10.191392 (6.499725) | 0.226338 / 0.680424 (-0.454086) | 0.039964 / 0.534201 (-0.494237) | 0.462911 / 0.579283 (-0.116372) | 0.575923 / 0.434364 (0.141560) | 0.592583 / 0.540337 (0.052245) | 0.658552 / 1.386936 (-0.728384) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008388 / 0.011353 (-0.002965) | 0.005360 / 0.011008 (-0.005648) | 0.104574 / 0.038508 (0.066066) | 0.030109 / 0.023109 (0.007000) | 0.389294 / 0.275898 (0.113396) | 0.424813 / 0.323480 (0.101333) | 0.006629 / 0.007986 (-0.001356) | 0.005222 / 0.004328 (0.000893) | 0.080157 / 0.004250 (0.075907) | 0.045811 / 0.037052 (0.008759) | 0.398708 / 0.258489 (0.140219) | 0.429449 / 0.293841 (0.135608) | 0.052242 / 0.128546 (-0.076304) | 0.017439 / 0.075646 (-0.058207) | 0.362678 / 0.419271 (-0.056593) | 0.054151 / 0.043533 (0.010618) | 0.387932 / 0.255139 (0.132793) | 0.410544 / 0.283200 (0.127344) | 0.101210 / 0.141683 (-0.040473) | 1.486496 / 1.452155 (0.034341) | 1.576404 / 1.492716 (0.083687) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.259468 / 0.018006 (0.241461) | 0.521661 / 0.000490 (0.521172) | 0.000456 / 0.000200 (0.000256) | 0.000078 / 0.000054 (0.000024) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.027045 / 0.037411 (-0.010366) | 0.107615 / 0.014526 (0.093089) | 0.133228 / 0.176557 (-0.043329) | 0.156807 / 0.737135 (-0.580328) | 0.125226 / 0.296338 (-0.171113) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.528804 / 0.215209 (0.313595) | 5.516402 / 2.077655 (3.438748) | 2.387531 / 1.504120 (0.883412) | 2.084734 / 1.541195 (0.543539) | 2.091894 / 1.468490 (0.623404) | 1.089761 / 4.584777 (-3.495016) | 5.093067 / 3.745712 (1.347355) | 2.670349 / 5.269862 (-2.599512) | 1.784723 / 4.565676 (-2.780953) | 0.125528 / 0.424275 (-0.298747) | 0.013702 / 0.007607 (0.006095) | 0.667755 / 0.226044 (0.441710) | 6.653900 / 2.268929 (4.384972) | 3.006058 / 55.444624 (-52.438567) | 2.512919 / 6.876477 (-4.363558) | 2.546824 / 2.142072 (0.404751) | 1.269008 / 4.805227 (-3.536219) | 0.234388 / 6.500664 (-6.266276) | 0.065675 / 0.075469 (-0.009795) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.372222 / 1.841788 (-0.469566) | 15.565156 / 8.074308 (7.490848) | 16.800666 / 10.191392 (6.609274) | 0.220656 / 0.680424 (-0.459768) | 0.023690 / 0.534201 (-0.510511) | 0.450049 / 0.579283 (-0.129234) | 0.580433 / 0.434364 (0.146069) | 0.558899 / 0.540337 (0.018561) | 0.676799 / 1.386936 (-0.710137) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.009440 / 0.011353 (-0.001913) | 0.005159 / 0.011008 (-0.005849) | 0.099152 / 0.038508 (0.060644) | 0.035939 / 0.023109 (0.012830) | 0.300968 / 0.275898 (0.025070) | 0.365676 / 0.323480 (0.042196) | 0.008220 / 0.007986 (0.000235) | 0.004071 / 0.004328 (-0.000257) | 0.075216 / 0.004250 (0.070965) | 0.042173 / 0.037052 (0.005121) | 0.315055 / 0.258489 (0.056566) | 0.338287 / 0.293841 (0.044446) | 0.037789 / 0.128546 (-0.090758) | 0.011856 / 0.075646 (-0.063791) | 0.332975 / 0.419271 (-0.086297) | 0.047087 / 0.043533 (0.003554) | 0.295107 / 0.255139 (0.039968) | 0.315416 / 0.283200 (0.032217) | 0.102273 / 0.141683 (-0.039410) | 1.464908 / 1.452155 (0.012754) | 1.500281 / 1.492716 (0.007565) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.208522 / 0.018006 (0.190516) | 0.446576 / 0.000490 (0.446086) | 0.005766 / 0.000200 (0.005566) | 0.000084 / 0.000054 (0.000029) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.027924 / 0.037411 (-0.009487) | 0.111296 / 0.014526 (0.096771) | 0.119055 / 0.176557 (-0.057502) | 0.157755 / 0.737135 (-0.579381) | 0.125539 / 0.296338 (-0.170799) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.395683 / 0.215209 (0.180474) | 3.962696 / 2.077655 (1.885042) | 1.789511 / 1.504120 (0.285391) | 1.591541 / 1.541195 (0.050346) | 1.661276 / 1.468490 (0.192786) | 0.693524 / 4.584777 (-3.891253) | 3.836526 / 3.745712 (0.090813) | 2.187284 / 5.269862 (-3.082578) | 1.521420 / 4.565676 (-3.044257) | 0.084370 / 0.424275 (-0.339905) | 0.012083 / 0.007607 (0.004476) | 0.498017 / 0.226044 (0.271972) | 4.982356 / 2.268929 (2.713428) | 2.235881 / 55.444624 (-53.208743) | 1.912067 / 6.876477 (-4.964410) | 2.052172 / 2.142072 (-0.089900) | 0.836232 / 4.805227 (-3.968995) | 0.165234 / 6.500664 (-6.335431) | 0.062933 / 0.075469 (-0.012536) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.197785 / 1.841788 (-0.644003) | 15.233655 / 8.074308 (7.159347) | 14.254450 / 10.191392 (4.063058) | 0.169149 / 0.680424 (-0.511274) | 0.028794 / 0.534201 (-0.505407) | 0.437214 / 0.579283 (-0.142069) | 0.434836 / 0.434364 (0.000472) | 0.531594 / 0.540337 (-0.008744) | 0.626266 / 1.386936 (-0.760670) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.007394 / 0.011353 (-0.003959) | 0.005305 / 0.011008 (-0.005703) | 0.098888 / 0.038508 (0.060380) | 0.033069 / 0.023109 (0.009959) | 0.388427 / 0.275898 (0.112529) | 0.415216 / 0.323480 (0.091736) | 0.005610 / 0.007986 (-0.002375) | 0.004922 / 0.004328 (0.000593) | 0.073694 / 0.004250 (0.069443) | 0.047368 / 0.037052 (0.010315) | 0.379604 / 0.258489 (0.121115) | 0.424876 / 0.293841 (0.131035) | 0.039471 / 0.128546 (-0.089075) | 0.012219 / 0.075646 (-0.063427) | 0.345925 / 0.419271 (-0.073346) | 0.048981 / 0.043533 (0.005448) | 0.379303 / 0.255139 (0.124164) | 0.404682 / 0.283200 (0.121483) | 0.103932 / 0.141683 (-0.037751) | 1.490852 / 1.452155 (0.038697) | 1.578900 / 1.492716 (0.086183) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.201393 / 0.018006 (0.183387) | 0.452484 / 0.000490 (0.451994) | 0.005627 / 0.000200 (0.005428) | 0.000129 / 0.000054 (0.000075) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.029317 / 0.037411 (-0.008094) | 0.114904 / 0.014526 (0.100378) | 0.126678 / 0.176557 (-0.049878) | 0.178315 / 0.737135 (-0.558820) | 0.131603 / 0.296338 (-0.164736) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.459830 / 0.215209 (0.244621) | 4.595358 / 2.077655 (2.517703) | 2.383582 / 1.504120 (0.879462) | 2.181945 / 1.541195 (0.640750) | 2.309517 / 1.468490 (0.841027) | 0.704803 / 4.584777 (-3.879974) | 3.820411 / 3.745712 (0.074698) | 4.872173 / 5.269862 (-0.397689) | 2.266090 / 4.565676 (-2.299586) | 0.085805 / 0.424275 (-0.338470) | 0.012488 / 0.007607 (0.004881) | 0.557500 / 0.226044 (0.331456) | 5.570830 / 2.268929 (3.301901) | 2.836202 / 55.444624 (-52.608422) | 2.530534 / 6.876477 (-4.345943) | 2.599792 / 2.142072 (0.457720) | 0.843852 / 4.805227 (-3.961376) | 0.169427 / 6.500664 (-6.331237) | 0.065521 / 0.075469 (-0.009948) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.246014 / 1.841788 (-0.595774) | 15.455336 / 8.074308 (7.381028) | 13.559111 / 10.191392 (3.367719) | 0.169131 / 0.680424 (-0.511293) | 0.017812 / 0.534201 (-0.516389) | 0.421161 / 0.579283 (-0.158122) | 0.458286 / 0.434364 (0.023922) | 0.534692 / 0.540337 (-0.005645) | 0.639299 / 1.386936 (-0.747637) |\n\n</details>\n</details>\n\n\n"
] | 1,674,667,441,000 | 1,674,671,615,000 | 1,674,671,175,000 | MEMBER | null | null | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5463/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5463/timeline | null | null | 0 | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5463",
"html_url": "https://github.com/huggingface/datasets/pull/5463",
"diff_url": "https://github.com/huggingface/datasets/pull/5463.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5463.patch",
"merged_at": "2023-01-25T18:26:15"
} | true |
https://api.github.com/repos/huggingface/datasets/issues/5462 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5462/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5462/comments | https://api.github.com/repos/huggingface/datasets/issues/5462/events | https://github.com/huggingface/datasets/pull/5462 | 1,556,572,144 | PR_kwDODunzps5Iglqu | 5,462 | Concatenate on axis=1 with misaligned blocks | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008860 / 0.011353 (-0.002493) | 0.004564 / 0.011008 (-0.006444) | 0.101556 / 0.038508 (0.063048) | 0.030000 / 0.023109 (0.006891) | 0.304404 / 0.275898 (0.028506) | 0.366247 / 0.323480 (0.042767) | 0.007182 / 0.007986 (-0.000804) | 0.003583 / 0.004328 (-0.000746) | 0.079665 / 0.004250 (0.075415) | 0.036529 / 0.037052 (-0.000523) | 0.310998 / 0.258489 (0.052509) | 0.346954 / 0.293841 (0.053113) | 0.034098 / 0.128546 (-0.094448) | 0.011576 / 0.075646 (-0.064070) | 0.320448 / 0.419271 (-0.098824) | 0.043328 / 0.043533 (-0.000205) | 0.307317 / 0.255139 (0.052178) | 0.325071 / 0.283200 (0.041871) | 0.096406 / 0.141683 (-0.045277) | 1.540331 / 1.452155 (0.088176) | 1.589533 / 1.492716 (0.096817) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.011034 / 0.018006 (-0.006972) | 0.422066 / 0.000490 (0.421577) | 0.002409 / 0.000200 (0.002209) | 0.000071 / 0.000054 (0.000017) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.023703 / 0.037411 (-0.013708) | 0.099935 / 0.014526 (0.085409) | 0.105966 / 0.176557 (-0.070591) | 0.142259 / 0.737135 (-0.594876) | 0.109327 / 0.296338 (-0.187011) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.418381 / 0.215209 (0.203172) | 4.177564 / 2.077655 (2.099909) | 1.880196 / 1.504120 (0.376076) | 1.669169 / 1.541195 (0.127974) | 1.725989 / 1.468490 (0.257499) | 0.689384 / 4.584777 (-3.895393) | 3.380963 / 3.745712 (-0.364749) | 1.884192 / 5.269862 (-3.385670) | 1.162409 / 4.565676 (-3.403268) | 0.082045 / 0.424275 (-0.342230) | 0.012575 / 0.007607 (0.004968) | 0.525824 / 0.226044 (0.299779) | 5.272574 / 2.268929 (3.003646) | 2.283492 / 55.444624 (-53.161132) | 1.947390 / 6.876477 (-4.929087) | 2.013790 / 2.142072 (-0.128283) | 0.806280 / 4.805227 (-3.998948) | 0.149267 / 6.500664 (-6.351397) | 0.066967 / 0.075469 (-0.008502) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.216511 / 1.841788 (-0.625277) | 13.869829 / 8.074308 (5.795521) | 14.189967 / 10.191392 (3.998575) | 0.148716 / 0.680424 (-0.531708) | 0.028324 / 0.534201 (-0.505877) | 0.390856 / 0.579283 (-0.188427) | 0.404389 / 0.434364 (-0.029975) | 0.456050 / 0.540337 (-0.084287) | 0.544139 / 1.386936 (-0.842797) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006727 / 0.011353 (-0.004626) | 0.004515 / 0.011008 (-0.006494) | 0.098791 / 0.038508 (0.060283) | 0.027596 / 0.023109 (0.004487) | 0.439066 / 0.275898 (0.163168) | 0.480555 / 0.323480 (0.157076) | 0.005066 / 0.007986 (-0.002920) | 0.004669 / 0.004328 (0.000341) | 0.075334 / 0.004250 (0.071084) | 0.039779 / 0.037052 (0.002726) | 0.439860 / 0.258489 (0.181371) | 0.480787 / 0.293841 (0.186946) | 0.031550 / 0.128546 (-0.096996) | 0.011668 / 0.075646 (-0.063978) | 0.317348 / 0.419271 (-0.101923) | 0.041312 / 0.043533 (-0.002220) | 0.442934 / 0.255139 (0.187795) | 0.463677 / 0.283200 (0.180478) | 0.090066 / 0.141683 (-0.051617) | 1.544152 / 1.452155 (0.091998) | 1.584455 / 1.492716 (0.091738) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.224284 / 0.018006 (0.206278) | 0.406982 / 0.000490 (0.406492) | 0.000427 / 0.000200 (0.000227) | 0.000061 / 0.000054 (0.000006) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.024914 / 0.037411 (-0.012497) | 0.102608 / 0.014526 (0.088082) | 0.106931 / 0.176557 (-0.069626) | 0.140828 / 0.737135 (-0.596308) | 0.112015 / 0.296338 (-0.184324) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.471078 / 0.215209 (0.255869) | 4.705742 / 2.077655 (2.628088) | 2.437442 / 1.504120 (0.933322) | 2.242768 / 1.541195 (0.701573) | 2.302158 / 1.468490 (0.833668) | 0.697314 / 4.584777 (-3.887462) | 3.357730 / 3.745712 (-0.387982) | 1.913306 / 5.269862 (-3.356556) | 1.173879 / 4.565676 (-3.391798) | 0.083257 / 0.424275 (-0.341018) | 0.012480 / 0.007607 (0.004873) | 0.573407 / 0.226044 (0.347362) | 5.728650 / 2.268929 (3.459721) | 2.868863 / 55.444624 (-52.575761) | 2.548640 / 6.876477 (-4.327837) | 2.596622 / 2.142072 (0.454549) | 0.805563 / 4.805227 (-3.999664) | 0.150860 / 6.500664 (-6.349804) | 0.068344 / 0.075469 (-0.007125) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.300368 / 1.841788 (-0.541420) | 13.920451 / 8.074308 (5.846143) | 14.222430 / 10.191392 (4.031038) | 0.152497 / 0.680424 (-0.527927) | 0.017415 / 0.534201 (-0.516786) | 0.378827 / 0.579283 (-0.200456) | 0.384165 / 0.434364 (-0.050199) | 0.439364 / 0.540337 (-0.100973) | 0.525710 / 1.386936 (-0.861226) |\n\n</details>\n</details>\n\n\n",
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008482 / 0.011353 (-0.002871) | 0.004405 / 0.011008 (-0.006604) | 0.099662 / 0.038508 (0.061154) | 0.029062 / 0.023109 (0.005953) | 0.298329 / 0.275898 (0.022431) | 0.332837 / 0.323480 (0.009357) | 0.006760 / 0.007986 (-0.001225) | 0.003290 / 0.004328 (-0.001039) | 0.077659 / 0.004250 (0.073409) | 0.034745 / 0.037052 (-0.002307) | 0.303134 / 0.258489 (0.044644) | 0.346402 / 0.293841 (0.052561) | 0.033511 / 0.128546 (-0.095035) | 0.011464 / 0.075646 (-0.064183) | 0.322932 / 0.419271 (-0.096340) | 0.040697 / 0.043533 (-0.002836) | 0.301951 / 0.255139 (0.046812) | 0.328961 / 0.283200 (0.045761) | 0.084802 / 0.141683 (-0.056881) | 1.506247 / 1.452155 (0.054092) | 1.547631 / 1.492716 (0.054915) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.190370 / 0.018006 (0.172363) | 0.405786 / 0.000490 (0.405297) | 0.002196 / 0.000200 (0.001997) | 0.000072 / 0.000054 (0.000018) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.022958 / 0.037411 (-0.014453) | 0.095736 / 0.014526 (0.081210) | 0.103684 / 0.176557 (-0.072872) | 0.138200 / 0.737135 (-0.598936) | 0.105618 / 0.296338 (-0.190721) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.415239 / 0.215209 (0.200030) | 4.147223 / 2.077655 (2.069569) | 1.850322 / 1.504120 (0.346202) | 1.662815 / 1.541195 (0.121620) | 1.671563 / 1.468490 (0.203073) | 0.693806 / 4.584777 (-3.890971) | 3.352938 / 3.745712 (-0.392774) | 1.849257 / 5.269862 (-3.420604) | 1.161603 / 4.565676 (-3.404074) | 0.081884 / 0.424275 (-0.342391) | 0.012726 / 0.007607 (0.005119) | 0.521105 / 0.226044 (0.295061) | 5.231910 / 2.268929 (2.962981) | 2.306073 / 55.444624 (-53.138551) | 1.950449 / 6.876477 (-4.926028) | 1.988433 / 2.142072 (-0.153640) | 0.811168 / 4.805227 (-3.994059) | 0.149960 / 6.500664 (-6.350704) | 0.064845 / 0.075469 (-0.010624) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.221487 / 1.841788 (-0.620301) | 13.756534 / 8.074308 (5.682226) | 13.825369 / 10.191392 (3.633977) | 0.155641 / 0.680424 (-0.524783) | 0.028444 / 0.534201 (-0.505757) | 0.390364 / 0.579283 (-0.188919) | 0.397592 / 0.434364 (-0.036772) | 0.455905 / 0.540337 (-0.084433) | 0.534606 / 1.386936 (-0.852330) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006281 / 0.011353 (-0.005071) | 0.004533 / 0.011008 (-0.006475) | 0.098328 / 0.038508 (0.059820) | 0.026998 / 0.023109 (0.003889) | 0.424814 / 0.275898 (0.148915) | 0.457653 / 0.323480 (0.134173) | 0.004617 / 0.007986 (-0.003368) | 0.003320 / 0.004328 (-0.001009) | 0.075884 / 0.004250 (0.071634) | 0.035865 / 0.037052 (-0.001187) | 0.431674 / 0.258489 (0.173185) | 0.468286 / 0.293841 (0.174445) | 0.031915 / 0.128546 (-0.096631) | 0.011680 / 0.075646 (-0.063967) | 0.319575 / 0.419271 (-0.099696) | 0.047792 / 0.043533 (0.004259) | 0.428191 / 0.255139 (0.173052) | 0.445657 / 0.283200 (0.162458) | 0.090464 / 0.141683 (-0.051218) | 1.465480 / 1.452155 (0.013326) | 1.548985 / 1.492716 (0.056268) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.185671 / 0.018006 (0.167664) | 0.399274 / 0.000490 (0.398784) | 0.002822 / 0.000200 (0.002622) | 0.000083 / 0.000054 (0.000028) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.025934 / 0.037411 (-0.011477) | 0.099480 / 0.014526 (0.084954) | 0.110264 / 0.176557 (-0.066293) | 0.140558 / 0.737135 (-0.596577) | 0.110832 / 0.296338 (-0.185507) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.473491 / 0.215209 (0.258282) | 4.722507 / 2.077655 (2.644852) | 2.456242 / 1.504120 (0.952122) | 2.255999 / 1.541195 (0.714804) | 2.300816 / 1.468490 (0.832326) | 0.698226 / 4.584777 (-3.886551) | 3.397296 / 3.745712 (-0.348416) | 2.741674 / 5.269862 (-2.528187) | 1.462103 / 4.565676 (-3.103573) | 0.082736 / 0.424275 (-0.341539) | 0.012183 / 0.007607 (0.004576) | 0.580144 / 0.226044 (0.354099) | 5.794351 / 2.268929 (3.525422) | 2.881201 / 55.444624 (-52.563423) | 2.544384 / 6.876477 (-4.332093) | 2.555227 / 2.142072 (0.413154) | 0.805849 / 4.805227 (-3.999378) | 0.151822 / 6.500664 (-6.348842) | 0.067477 / 0.075469 (-0.007992) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.300224 / 1.841788 (-0.541564) | 13.595361 / 8.074308 (5.521053) | 13.967622 / 10.191392 (3.776230) | 0.129222 / 0.680424 (-0.551202) | 0.016939 / 0.534201 (-0.517262) | 0.375190 / 0.579283 (-0.204094) | 0.383511 / 0.434364 (-0.050853) | 0.437179 / 0.540337 (-0.103158) | 0.525674 / 1.386936 (-0.861262) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.012364 / 0.011353 (0.001011) | 0.006098 / 0.011008 (-0.004911) | 0.158908 / 0.038508 (0.120400) | 0.039798 / 0.023109 (0.016689) | 0.383786 / 0.275898 (0.107888) | 0.533961 / 0.323480 (0.210481) | 0.012079 / 0.007986 (0.004094) | 0.006483 / 0.004328 (0.002155) | 0.109660 / 0.004250 (0.105410) | 0.048391 / 0.037052 (0.011339) | 0.447426 / 0.258489 (0.188937) | 0.477292 / 0.293841 (0.183451) | 0.066492 / 0.128546 (-0.062054) | 0.021155 / 0.075646 (-0.054492) | 0.474473 / 0.419271 (0.055202) | 0.063520 / 0.043533 (0.019987) | 0.444941 / 0.255139 (0.189802) | 0.450675 / 0.283200 (0.167475) | 0.129236 / 0.141683 (-0.012447) | 2.009362 / 1.452155 (0.557207) | 1.912067 / 1.492716 (0.419350) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.260384 / 0.018006 (0.242378) | 0.577654 / 0.000490 (0.577165) | 0.004977 / 0.000200 (0.004777) | 0.000110 / 0.000054 (0.000056) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.028101 / 0.037411 (-0.009310) | 0.161680 / 0.014526 (0.147154) | 0.146107 / 0.176557 (-0.030450) | 0.173878 / 0.737135 (-0.563257) | 0.186149 / 0.296338 (-0.110190) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.689835 / 0.215209 (0.474626) | 6.775888 / 2.077655 (4.698234) | 2.885499 / 1.504120 (1.381379) | 2.486855 / 1.541195 (0.945660) | 2.540831 / 1.468490 (1.072341) | 1.328135 / 4.584777 (-3.256642) | 5.964983 / 3.745712 (2.219271) | 3.400713 / 5.269862 (-1.869149) | 2.423257 / 4.565676 (-2.142419) | 0.129767 / 0.424275 (-0.294508) | 0.017936 / 0.007607 (0.010328) | 0.909284 / 0.226044 (0.683239) | 8.778791 / 2.268929 (6.509863) | 3.890757 / 55.444624 (-51.553867) | 3.072116 / 6.876477 (-3.804360) | 3.085390 / 2.142072 (0.943318) | 1.571710 / 4.805227 (-3.233517) | 0.279290 / 6.500664 (-6.221374) | 0.087775 / 0.075469 (0.012306) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.751223 / 1.841788 (-0.090564) | 20.313135 / 8.074308 (12.238827) | 22.793800 / 10.191392 (12.602408) | 0.296052 / 0.680424 (-0.384372) | 0.053420 / 0.534201 (-0.480781) | 0.600626 / 0.579283 (0.021343) | 0.634505 / 0.434364 (0.200142) | 0.724000 / 0.540337 (0.183663) | 0.869283 / 1.386936 (-0.517653) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.014876 / 0.011353 (0.003523) | 0.008113 / 0.011008 (-0.002895) | 0.177038 / 0.038508 (0.138530) | 0.050825 / 0.023109 (0.027716) | 0.473989 / 0.275898 (0.198091) | 0.601058 / 0.323480 (0.277578) | 0.007536 / 0.007986 (-0.000450) | 0.006761 / 0.004328 (0.002432) | 0.105260 / 0.004250 (0.101010) | 0.073960 / 0.037052 (0.036908) | 0.447711 / 0.258489 (0.189222) | 0.609998 / 0.293841 (0.316157) | 0.061280 / 0.128546 (-0.067267) | 0.019370 / 0.075646 (-0.056276) | 0.510466 / 0.419271 (0.091194) | 0.062695 / 0.043533 (0.019162) | 0.436778 / 0.255139 (0.181639) | 0.489916 / 0.283200 (0.206717) | 0.137305 / 0.141683 (-0.004378) | 1.801554 / 1.452155 (0.349399) | 2.082409 / 1.492716 (0.589692) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.291304 / 0.018006 (0.273298) | 0.599041 / 0.000490 (0.598551) | 0.008017 / 0.000200 (0.007817) | 0.000127 / 0.000054 (0.000072) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.031243 / 0.037411 (-0.006169) | 0.139689 / 0.014526 (0.125163) | 0.138678 / 0.176557 (-0.037878) | 0.180458 / 0.737135 (-0.556677) | 0.149753 / 0.296338 (-0.146585) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.699692 / 0.215209 (0.484482) | 7.273327 / 2.077655 (5.195672) | 3.222650 / 1.504120 (1.718530) | 2.679424 / 1.541195 (1.138229) | 2.842378 / 1.468490 (1.373888) | 1.394633 / 4.584777 (-3.190143) | 6.379970 / 3.745712 (2.634258) | 5.944663 / 5.269862 (0.674801) | 3.105214 / 4.565676 (-1.460462) | 0.138790 / 0.424275 (-0.285485) | 0.014211 / 0.007607 (0.006604) | 0.815275 / 0.226044 (0.589230) | 8.549334 / 2.268929 (6.280405) | 3.754795 / 55.444624 (-51.689829) | 3.125222 / 6.876477 (-3.751255) | 3.269639 / 2.142072 (1.127566) | 1.464187 / 4.805227 (-3.341040) | 0.314557 / 6.500664 (-6.186107) | 0.107354 / 0.075469 (0.031885) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.480793 / 1.841788 (-0.360995) | 16.770328 / 8.074308 (8.696019) | 18.054861 / 10.191392 (7.863469) | 0.198257 / 0.680424 (-0.482167) | 0.026493 / 0.534201 (-0.507708) | 0.489701 / 0.579283 (-0.089582) | 0.540890 / 0.434364 (0.106526) | 0.566675 / 0.540337 (0.026337) | 0.661918 / 1.386936 (-0.725018) |\n\n</details>\n</details>\n\n\n"
] | 1,674,650,002,000 | 1,674,725,820,000 | 1,674,725,239,000 | MEMBER | null | Allow to concatenate on axis 1 two tables made of misaligned blocks.
For example if the first table has 2 row blocks of 3 rows each, and the second table has 3 row blocks or 2 rows each.
To do that, I slice the row blocks to re-align the blocks.
Fix https://github.com/huggingface/datasets/issues/5413 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5462/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5462/timeline | null | null | 0 | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5462",
"html_url": "https://github.com/huggingface/datasets/pull/5462",
"diff_url": "https://github.com/huggingface/datasets/pull/5462.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5462.patch",
"merged_at": "2023-01-26T09:27:19"
} | true |
https://api.github.com/repos/huggingface/datasets/issues/5461 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5461/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5461/comments | https://api.github.com/repos/huggingface/datasets/issues/5461/events | https://github.com/huggingface/datasets/issues/5461 | 1,555,532,719 | I_kwDODunzps5ct4uv | 5,461 | Discrepancy in `nyu_depth_v2` dataset | {
"login": "awsaf49",
"id": 36858976,
"node_id": "MDQ6VXNlcjM2ODU4OTc2",
"avatar_url": "https://avatars.githubusercontent.com/u/36858976?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/awsaf49",
"html_url": "https://github.com/awsaf49",
"followers_url": "https://api.github.com/users/awsaf49/followers",
"following_url": "https://api.github.com/users/awsaf49/following{/other_user}",
"gists_url": "https://api.github.com/users/awsaf49/gists{/gist_id}",
"starred_url": "https://api.github.com/users/awsaf49/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/awsaf49/subscriptions",
"organizations_url": "https://api.github.com/users/awsaf49/orgs",
"repos_url": "https://api.github.com/users/awsaf49/repos",
"events_url": "https://api.github.com/users/awsaf49/events{/privacy}",
"received_events_url": "https://api.github.com/users/awsaf49/received_events",
"type": "User",
"site_admin": false
} | [] | open | false | null | [] | [
"Ccing @dwofk (the author of `fast-depth`). \r\n\r\nThanks, @awsaf49 for reporting this. I believe this is because the NYU Depth V2 shipped from `fast-depth` is already preprocessed. \r\n\r\nIf you think it might be better to have the NYU Depth V2 dataset from BTS [here](https://huggingface.co/datasets/sayakpaul/nyu_depth_v2) feel free to open a PR, I am happy to provide guidance :) ",
"Good catch ! Ideally it would be nice to have the datasets in the raw form, this way users can choose whatever processing they want to apply",
"> Ccing @dwofk (the author of `fast-depth`).\r\n> \r\n> Thanks, @awsaf49 for reporting this. I believe this is because the NYU Depth V2 shipped from `fast-depth` is already preprocessed.\r\n> \r\n> If you think it might be better to have the NYU Depth V2 dataset from BTS [here](https://huggingface.co/datasets/sayakpaul/nyu_depth_v2) feel free to open a PR, I am happy to provide guidance :)\r\n\r\n@sayakpaul I would love to create a PR on this. As this will be my first PR here, some guidance would be helpful.\r\n\r\nNeed a bit of advice on the dataset, there are three publicly available datasets. Which one should I consider for PR?\r\n1. [BTS](https://github.com/cleinc/bts): Containst train/test: 36K/654 data, dtype = `uint16` hence more precise\r\n2. [DenseDepth](https://github.com/ialhashim/DenseDepth) It contains train/test: 50K/654 data, dtype = `uint8` hence less precise\r\n3. [Official](https://cs.nyu.edu/~silberman/datasets/nyu_depth_v2.html#raw_parts): Size is big 400GB+, requires **MatLab** code for fixing **projection** and **sync**, DataType: `pgm` and `dump` hence can't be used directly.\r\n\r\ncc: @lhoestq\r\n\r\n",
"I think BTS. Repositories like https://github.com/vinvino02/GLPDepth usually use BTS. Also, just for clarity, the PR will be to https://huggingface.co/datasets/sayakpaul/nyu_depth_v2. Once we have worked it out, we can update the following things:\r\n\r\n* https://github.com/huggingface/blog/pull/718\r\n* https://huggingface.co/docs/datasets/main/en/depth_estimation\r\n\r\nDon't worry about it if it seems overwhelming. We will work it out together :) \r\n\r\n@lhoestq what do you think? ",
"@sayakpaul If I get this right I have to,\r\n1. Create a PR on https://huggingface.co/datasets/sayakpaul/nyu_depth_v2\r\n2. Create a PR on https://github.com/huggingface/blog\r\n3. Create a PR on https://github.com/huggingface/datasets to update https://github.com/huggingface/datasets/blob/main/docs/source/depth_estimation.mdx",
"The last two are low-hanging fruits. Don't worry about them. ",
"Yup opening a PR to use BTS on https://huggingface.co/datasets/sayakpaul/nyu_depth_v2 sounds good :) Thanks for the help !",
"Finally, I have found the origin of the **discretized depth map**. When I first loaded the datasets from HF I noticed it was 30GB but in DenseDepth data is only 4GB with dtype=uint8. This means data from fast-depth (before loading to HF) must have high precision. So when I tried to dig deeper by directly loading depth_map from `h5py`, I found depth_map from `h5py` came with `float32`. But when the data is processed in HF with `datasets.Image()` it was directly converted to `uint8` from `float32` hence the **discretized** depth map.\r\nhttps://github.com/huggingface/datasets/blob/c78559cacbb0ca6e0bc8bfc313cc0359f8c23ead/src/datasets/features/image.py#L91-L93\r\n\r\n## Solutions:\r\n\r\n#### 1. Array2D\r\nUse `Array2D` feature with `float32` for depth_map \r\n\r\n* Code:\r\n```py\r\nFeatures({'depth_map': Array2D(shape=(480, 640), dtype='float32')})\r\n```\r\n* Pros:\r\nNo precision loss.\r\n\r\n* Cons:\r\nAs depth_map is saved as Array I think it can't be visuzlied in [hf.co/dataset](https://huggingface.co/datasets/sayakpaul/nyu_depth_v2) page like segmentation mask.\r\n\r\n#### 2. Uint16\r\nUse `uint16` as dtype for Image in `_h5_loader` for saving depth maps and accept `uint16` dtype in `datasets.Image()` feature.\r\n\r\n* Code\r\n```py\r\ndepth = np.array(h5f[\"depth\"])\r\ndepth /= 10.0 # [0, max_depth] -> [0, 1]\r\ndepth *= (2**16 -1) # transform from [0, 1] -> [0, 2^16 - 1]\r\ndepth = depth.astype('uint16')\r\n```\r\n* Pros:\r\n * We can visualize depth map in hf.co/datasets page like segmentation mask.\r\n * No need for post-processing.\r\n\r\n* Cons:\r\n * We need to make two change\r\n * Modify `_h5_loader` in https://huggingface.co/datasets/sayakpaul/nyu_depth_v2 to convert depth_map from `float32` to `uint16`.\r\n * Make sure `datasets.Image()` converts `np.ndarray` to `uint16` checking max value\r\n * Precision loss due to `float32` to `uint16`\r\n * Post-processing required for depth_map to transform from `[0, 2^16 - 1]` to `[0, max_depth]` before feeding them to model.",
"Thanks so much for digging into this. \r\n\r\nSince the second solution entails changes to core datatypes in `datasets`, I think it's better to go with the first solution. \r\n\r\n@lhoestq WDYT?",
"@sayakpaul Yes, Solution 1 requires minimal change and provides no precision loss. But I think support for `uint16` image would be a great addition as many datasets come with `uint16` image. For example [UW-Madison GI Tract Image Segmentation](https://www.kaggle.com/competitions/uw-madison-gi-tract-image-segmentation) dataset, here the image itself comes with `uint16` dtype rather than mask. So, saving `uint16` image with `uint8` will result in precision loss.\r\n\r\nPerhaps we can adapt solution 1 for this issue and Add support for `uint16` image separately?",
"Using Array2D makes it not practical to use to train a model - in `transformers` we expect an image type.\r\n\r\nThere is a pull request to support more precision than uint8 in Image() here: https://github.com/huggingface/datasets/pull/5365/files\r\n\r\nwe can probably merge it today and do a release right away",
"Fantastic, @lhoestq! \r\n\r\n@awsaf49 then let's wait for the PR to get merged and then take the next steps? ",
"Sure",
"The PR adds support for uint16 which is ok for BTS if I understand correctly, would it be ok for you ?",
"If the main issue with the current version of NYU we have on the Hub is related to the precision loss stemming from `Image()`, I'd prefer if `Image()` supported float32 as well. ",
"I also prefer `float32` as it offers more precision. But I'm not sure if we'll be able to visualize image with `float32` precision.",
"We could have a separate loading for the float32 one using Array2D, but I feel like it's less convenient to use due to the amount of disk space and because it's not an Image() type. That's why I think uint16 is a better solution for users",
"A bit confused here, If https://github.com/huggingface/datasets/pull/5365 gets merged won't this issue will be resolved automatically?",
"Yes in theory :)",
"actually float32 also seems to work in this PR (it just doesn't work for multi-channel)",
"In that case, a new PR isn't necessary, right?",
"Yep. I just tested from the PR and it works:\r\n```python\r\n>>> train_dataset = load_dataset(\"sayakpaul/nyu_depth_v2\", split=\"train\", streaming=True) \r\nDownloading readme: 100%|██████████████████| 8.71k/8.71k [00:00<00:00, 3.60MB/s]\r\n>>> next(iter(train_dataset))\r\n{'image': <PIL.PngImagePlugin.PngImageFile image mode=RGB size=640x480 at 0x1382ED7F0>,\r\n 'depth_map': <PIL.TiffImagePlugin.TiffImageFile image mode=F size=640x480 at 0x1382EDF28>}\r\n>>> x = next(iter(train_dataset))\r\n>>> np.asarray(x[\"depth_map\"]) \r\narray([[0. , 0. , 0. , ..., 0. , 0. ,\r\n 0. ],\r\n [0. , 0. , 0. , ..., 0. , 0. ,\r\n 0. ],\r\n [0. , 0. , 0. , ..., 0. , 0. ,\r\n 0. ],\r\n ...,\r\n [0. , 2.2861192, 2.2861192, ..., 2.234162 , 2.234162 ,\r\n 0. ],\r\n [0. , 2.2861192, 2.2861192, ..., 2.234162 , 2.234162 ,\r\n 0. ],\r\n [0. , 2.2861192, 2.2861192, ..., 2.234162 , 2.234162 ,\r\n 0. ]], dtype=float32)\r\n```",
"Great! the case is closed! This issue has been solved and I have to say, it was quite the thrill ride. I felt like Sherlock Holmes, solving a mystery and finding the bug🕵️♂️. But in all seriousness, it was a pleasure working on this issue and I'm glad we could get to the bottom of it.\r\n\r\nOn another note, should I consider closing the issue? I think we still need to make updates on https://github.com/huggingface/blog and https://github.com/huggingface/datasets/blob/main/docs/source/depth_estimation.mdx",
"Haha thanks Mr Holmes :p\r\n\r\nmaybe let's close this issue when we're done updating the blog post and the documentation",
"@awsaf49 thank you for your hard work! \r\n\r\nI am a little unsure why the other links need to be updated, though. They all rely on datasets internally. ",
"I think depth_map still shows discretized version. It would be nice to have corrected one.\r\n<img src=\"https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/datasets/depth_est_target_viz.png\" width = 300>",
"Also, I think we need to make some changes in the code to visualize depth_map as it is `float32` . `plot.imshow()` supports either [0, 1] + float32 or [0. 255] + uint8",
"Oh yes! Do you want to start with the fixes? Please feel free to say no but I wanted to make sure your contributions are reflected properly in our doc and the blog :)",
"Yes I think that would be nice :)",
"I'll make the changes tomorrow. I hope it's okay..."
] | 1,674,587,746,000 | 1,675,716,720,000 | null | CONTRIBUTOR | null | ### Describe the bug
I think there is a discrepancy between depth map of `nyu_depth_v2` dataset [here](https://huggingface.co/docs/datasets/main/en/depth_estimation) and actual depth map. Depth values somehow got **discretized/clipped** resulting in depth maps that are different from actual ones. Here is a side-by-side comparison,

I tried to find the origin of this issue but sadly as I mentioned in tensorflow/datasets/issues/4674, the download link from `fast-depth` doesn't work anymore hence couldn't verify if the error originated there or during porting data from there to HF.
Hi @sayakpaul, as you worked on huggingface/datasets/issues/5255, if you still have access to that data could you please share the data or perhaps checkout this issue?
### Steps to reproduce the bug
This [notebook](https://colab.research.google.com/drive/1K3ZU8XUPRDOYD38MQS9nreQXJYitlKSW?usp=sharing#scrollTo=UEW7QSh0jf0i) from @sayakpaul could be used to generate depth maps and actual ground truths could be checked from this [dataset](https://www.kaggle.com/datasets/awsaf49/nyuv2-bts-dataset) from BTS repo.
> Note: BTS dataset has only 36K data compared to the train-test 50K. They sampled the data as adjacent frames look quite the same
### Expected behavior
Expected depth maps should be smooth rather than discrete/clipped.
### Environment info
- `datasets` version: 2.8.1.dev0
- Platform: Linux-5.10.147+-x86_64-with-glibc2.29
- Python version: 3.8.10
- PyArrow version: 9.0.0
- Pandas version: 1.3.5 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5461/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5461/timeline | null | null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5460 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5460/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5460/comments | https://api.github.com/repos/huggingface/datasets/issues/5460/events | https://github.com/huggingface/datasets/pull/5460 | 1,555,387,532 | PR_kwDODunzps5Icn9C | 5,460 | Document that removing all the columns returns an empty document and the num_row is lost | {
"login": "thomasw21",
"id": 24695242,
"node_id": "MDQ6VXNlcjI0Njk1MjQy",
"avatar_url": "https://avatars.githubusercontent.com/u/24695242?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/thomasw21",
"html_url": "https://github.com/thomasw21",
"followers_url": "https://api.github.com/users/thomasw21/followers",
"following_url": "https://api.github.com/users/thomasw21/following{/other_user}",
"gists_url": "https://api.github.com/users/thomasw21/gists{/gist_id}",
"starred_url": "https://api.github.com/users/thomasw21/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/thomasw21/subscriptions",
"organizations_url": "https://api.github.com/users/thomasw21/orgs",
"repos_url": "https://api.github.com/users/thomasw21/repos",
"events_url": "https://api.github.com/users/thomasw21/events{/privacy}",
"received_events_url": "https://api.github.com/users/thomasw21/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.011812 / 0.011353 (0.000459) | 0.006878 / 0.011008 (-0.004130) | 0.128720 / 0.038508 (0.090212) | 0.038506 / 0.023109 (0.015397) | 0.359670 / 0.275898 (0.083772) | 0.422908 / 0.323480 (0.099428) | 0.010115 / 0.007986 (0.002129) | 0.004332 / 0.004328 (0.000004) | 0.096281 / 0.004250 (0.092031) | 0.048850 / 0.037052 (0.011798) | 0.373795 / 0.258489 (0.115306) | 0.414643 / 0.293841 (0.120802) | 0.057568 / 0.128546 (-0.070978) | 0.024135 / 0.075646 (-0.051512) | 0.411764 / 0.419271 (-0.007507) | 0.060167 / 0.043533 (0.016634) | 0.367119 / 0.255139 (0.111980) | 0.391813 / 0.283200 (0.108613) | 0.112125 / 0.141683 (-0.029558) | 1.869560 / 1.452155 (0.417406) | 1.845649 / 1.492716 (0.352932) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.211449 / 0.018006 (0.193443) | 0.522453 / 0.000490 (0.521963) | 0.003984 / 0.000200 (0.003784) | 0.000096 / 0.000054 (0.000042) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.026015 / 0.037411 (-0.011397) | 0.117747 / 0.014526 (0.103221) | 0.125037 / 0.176557 (-0.051520) | 0.168351 / 0.737135 (-0.568785) | 0.132390 / 0.296338 (-0.163949) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.605653 / 0.215209 (0.390444) | 5.883452 / 2.077655 (3.805798) | 2.367052 / 1.504120 (0.862932) | 2.137671 / 1.541195 (0.596476) | 2.042370 / 1.468490 (0.573880) | 1.168442 / 4.584777 (-3.416335) | 5.205236 / 3.745712 (1.459524) | 2.992514 / 5.269862 (-2.277348) | 2.191829 / 4.565676 (-2.373847) | 0.137702 / 0.424275 (-0.286574) | 0.015898 / 0.007607 (0.008291) | 0.783987 / 0.226044 (0.557942) | 7.768965 / 2.268929 (5.500036) | 3.249149 / 55.444624 (-52.195476) | 2.530687 / 6.876477 (-4.345790) | 2.675212 / 2.142072 (0.533140) | 1.482804 / 4.805227 (-3.322423) | 0.276845 / 6.500664 (-6.223819) | 0.080597 / 0.075469 (0.005128) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.519086 / 1.841788 (-0.322701) | 17.394093 / 8.074308 (9.319785) | 19.613554 / 10.191392 (9.422162) | 0.253291 / 0.680424 (-0.427133) | 0.047746 / 0.534201 (-0.486455) | 0.547114 / 0.579283 (-0.032170) | 0.623873 / 0.434364 (0.189509) | 0.631924 / 0.540337 (0.091586) | 0.744390 / 1.386936 (-0.642546) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.009229 / 0.011353 (-0.002124) | 0.006206 / 0.011008 (-0.004802) | 0.121866 / 0.038508 (0.083357) | 0.033629 / 0.023109 (0.010519) | 0.435172 / 0.275898 (0.159274) | 0.472093 / 0.323480 (0.148613) | 0.006946 / 0.007986 (-0.001039) | 0.004848 / 0.004328 (0.000519) | 0.097289 / 0.004250 (0.093038) | 0.046982 / 0.037052 (0.009930) | 0.447365 / 0.258489 (0.188876) | 0.491213 / 0.293841 (0.197372) | 0.055486 / 0.128546 (-0.073060) | 0.019788 / 0.075646 (-0.055858) | 0.399830 / 0.419271 (-0.019441) | 0.058943 / 0.043533 (0.015411) | 0.447658 / 0.255139 (0.192519) | 0.465752 / 0.283200 (0.182552) | 0.110441 / 0.141683 (-0.031242) | 1.773155 / 1.452155 (0.321001) | 1.899370 / 1.492716 (0.406653) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.191188 / 0.018006 (0.173181) | 0.523721 / 0.000490 (0.523232) | 0.004008 / 0.000200 (0.003808) | 0.000126 / 0.000054 (0.000072) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.032579 / 0.037411 (-0.004833) | 0.120870 / 0.014526 (0.106344) | 0.154991 / 0.176557 (-0.021565) | 0.175450 / 0.737135 (-0.561685) | 0.136526 / 0.296338 (-0.159813) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.627262 / 0.215209 (0.412052) | 6.457989 / 2.077655 (4.380334) | 2.935188 / 1.504120 (1.431068) | 2.558705 / 1.541195 (1.017510) | 2.669455 / 1.468490 (1.200965) | 1.228791 / 4.584777 (-3.355985) | 5.621262 / 3.745712 (1.875549) | 3.181775 / 5.269862 (-2.088086) | 2.115116 / 4.565676 (-2.450560) | 0.159348 / 0.424275 (-0.264927) | 0.013598 / 0.007607 (0.005991) | 0.834732 / 0.226044 (0.608687) | 8.051097 / 2.268929 (5.782168) | 3.761681 / 55.444624 (-51.682943) | 2.898158 / 6.876477 (-3.978319) | 2.936289 / 2.142072 (0.794217) | 1.476307 / 4.805227 (-3.328920) | 0.269845 / 6.500664 (-6.230819) | 0.087225 / 0.075469 (0.011756) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.632522 / 1.841788 (-0.209266) | 17.615297 / 8.074308 (9.540989) | 20.501172 / 10.191392 (10.309780) | 0.248845 / 0.680424 (-0.431579) | 0.024852 / 0.534201 (-0.509349) | 0.498957 / 0.579283 (-0.080326) | 0.588566 / 0.434364 (0.154202) | 0.611051 / 0.540337 (0.070714) | 0.726321 / 1.386936 (-0.660615) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008920 / 0.011353 (-0.002433) | 0.004666 / 0.011008 (-0.006342) | 0.098584 / 0.038508 (0.060076) | 0.030213 / 0.023109 (0.007103) | 0.298180 / 0.275898 (0.022282) | 0.358932 / 0.323480 (0.035452) | 0.007182 / 0.007986 (-0.000804) | 0.005430 / 0.004328 (0.001102) | 0.077962 / 0.004250 (0.073712) | 0.038516 / 0.037052 (0.001463) | 0.308840 / 0.258489 (0.050351) | 0.343678 / 0.293841 (0.049837) | 0.033701 / 0.128546 (-0.094845) | 0.011460 / 0.075646 (-0.064186) | 0.319809 / 0.419271 (-0.099462) | 0.040731 / 0.043533 (-0.002802) | 0.299772 / 0.255139 (0.044633) | 0.324292 / 0.283200 (0.041092) | 0.087755 / 0.141683 (-0.053928) | 1.493077 / 1.452155 (0.040922) | 1.527462 / 1.492716 (0.034746) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.187927 / 0.018006 (0.169921) | 0.412785 / 0.000490 (0.412296) | 0.003235 / 0.000200 (0.003035) | 0.000080 / 0.000054 (0.000026) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.023313 / 0.037411 (-0.014098) | 0.095663 / 0.014526 (0.081137) | 0.105094 / 0.176557 (-0.071463) | 0.140389 / 0.737135 (-0.596746) | 0.108477 / 0.296338 (-0.187861) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.410680 / 0.215209 (0.195471) | 4.109287 / 2.077655 (2.031632) | 1.833214 / 1.504120 (0.329094) | 1.622837 / 1.541195 (0.081642) | 1.679899 / 1.468490 (0.211409) | 0.686920 / 4.584777 (-3.897857) | 3.463267 / 3.745712 (-0.282445) | 1.867035 / 5.269862 (-3.402826) | 1.150631 / 4.565676 (-3.415046) | 0.081209 / 0.424275 (-0.343066) | 0.012384 / 0.007607 (0.004777) | 0.521070 / 0.226044 (0.295026) | 5.208829 / 2.268929 (2.939900) | 2.289032 / 55.444624 (-53.155592) | 1.942976 / 6.876477 (-4.933501) | 1.990660 / 2.142072 (-0.151413) | 0.802976 / 4.805227 (-4.002252) | 0.148199 / 6.500664 (-6.352465) | 0.064644 / 0.075469 (-0.010825) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.277029 / 1.841788 (-0.564759) | 13.915489 / 8.074308 (5.841181) | 14.035486 / 10.191392 (3.844094) | 0.138205 / 0.680424 (-0.542219) | 0.028968 / 0.534201 (-0.505232) | 0.394275 / 0.579283 (-0.185008) | 0.399967 / 0.434364 (-0.034397) | 0.460595 / 0.540337 (-0.079742) | 0.537625 / 1.386936 (-0.849311) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006485 / 0.011353 (-0.004868) | 0.004534 / 0.011008 (-0.006474) | 0.097742 / 0.038508 (0.059234) | 0.027231 / 0.023109 (0.004122) | 0.431321 / 0.275898 (0.155423) | 0.469212 / 0.323480 (0.145732) | 0.004894 / 0.007986 (-0.003092) | 0.004147 / 0.004328 (-0.000181) | 0.073650 / 0.004250 (0.069400) | 0.037052 / 0.037052 (-0.000000) | 0.434196 / 0.258489 (0.175707) | 0.480539 / 0.293841 (0.186698) | 0.031923 / 0.128546 (-0.096623) | 0.011522 / 0.075646 (-0.064124) | 0.317062 / 0.419271 (-0.102209) | 0.041124 / 0.043533 (-0.002409) | 0.432013 / 0.255139 (0.176874) | 0.456760 / 0.283200 (0.173560) | 0.089757 / 0.141683 (-0.051925) | 1.497752 / 1.452155 (0.045597) | 1.585342 / 1.492716 (0.092626) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.227784 / 0.018006 (0.209778) | 0.404570 / 0.000490 (0.404080) | 0.000556 / 0.000200 (0.000356) | 0.000065 / 0.000054 (0.000011) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.025201 / 0.037411 (-0.012210) | 0.099348 / 0.014526 (0.084822) | 0.114984 / 0.176557 (-0.061573) | 0.147039 / 0.737135 (-0.590097) | 0.109727 / 0.296338 (-0.186611) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.468415 / 0.215209 (0.253206) | 4.692228 / 2.077655 (2.614573) | 2.403382 / 1.504120 (0.899262) | 2.196026 / 1.541195 (0.654832) | 2.234736 / 1.468490 (0.766246) | 0.703011 / 4.584777 (-3.881766) | 3.451513 / 3.745712 (-0.294199) | 2.596811 / 5.269862 (-2.673051) | 1.544079 / 4.565676 (-3.021598) | 0.083153 / 0.424275 (-0.341123) | 0.012605 / 0.007607 (0.004998) | 0.570265 / 0.226044 (0.344220) | 5.735996 / 2.268929 (3.467067) | 2.865336 / 55.444624 (-52.579288) | 2.508340 / 6.876477 (-4.368137) | 2.547144 / 2.142072 (0.405072) | 0.813018 / 4.805227 (-3.992210) | 0.150327 / 6.500664 (-6.350337) | 0.065837 / 0.075469 (-0.009632) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.268941 / 1.841788 (-0.572847) | 13.835698 / 8.074308 (5.761390) | 13.992726 / 10.191392 (3.801334) | 0.127751 / 0.680424 (-0.552673) | 0.016673 / 0.534201 (-0.517528) | 0.381921 / 0.579283 (-0.197362) | 0.390688 / 0.434364 (-0.043676) | 0.446234 / 0.540337 (-0.094103) | 0.532631 / 1.386936 (-0.854305) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008486 / 0.011353 (-0.002867) | 0.004573 / 0.011008 (-0.006435) | 0.100096 / 0.038508 (0.061588) | 0.029449 / 0.023109 (0.006340) | 0.298384 / 0.275898 (0.022486) | 0.361886 / 0.323480 (0.038406) | 0.006813 / 0.007986 (-0.001173) | 0.003394 / 0.004328 (-0.000935) | 0.077563 / 0.004250 (0.073312) | 0.035605 / 0.037052 (-0.001447) | 0.306864 / 0.258489 (0.048375) | 0.346438 / 0.293841 (0.052597) | 0.033156 / 0.128546 (-0.095390) | 0.011567 / 0.075646 (-0.064079) | 0.322189 / 0.419271 (-0.097083) | 0.040161 / 0.043533 (-0.003372) | 0.299329 / 0.255139 (0.044190) | 0.326375 / 0.283200 (0.043175) | 0.086572 / 0.141683 (-0.055111) | 1.502473 / 1.452155 (0.050319) | 1.528539 / 1.492716 (0.035823) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.008502 / 0.018006 (-0.009505) | 0.411045 / 0.000490 (0.410555) | 0.003179 / 0.000200 (0.002980) | 0.000073 / 0.000054 (0.000018) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.023177 / 0.037411 (-0.014234) | 0.096948 / 0.014526 (0.082422) | 0.104068 / 0.176557 (-0.072489) | 0.138739 / 0.737135 (-0.598396) | 0.108241 / 0.296338 (-0.188097) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.411156 / 0.215209 (0.195947) | 4.092992 / 2.077655 (2.015337) | 1.841903 / 1.504120 (0.337783) | 1.637449 / 1.541195 (0.096254) | 1.670968 / 1.468490 (0.202478) | 0.697301 / 4.584777 (-3.887476) | 3.354717 / 3.745712 (-0.390995) | 1.851518 / 5.269862 (-3.418344) | 1.160367 / 4.565676 (-3.405309) | 0.082613 / 0.424275 (-0.341662) | 0.012477 / 0.007607 (0.004870) | 0.524839 / 0.226044 (0.298795) | 5.264173 / 2.268929 (2.995245) | 2.294530 / 55.444624 (-53.150094) | 1.933233 / 6.876477 (-4.943244) | 1.968959 / 2.142072 (-0.173113) | 0.817104 / 4.805227 (-3.988123) | 0.149072 / 6.500664 (-6.351592) | 0.064911 / 0.075469 (-0.010558) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.222215 / 1.841788 (-0.619573) | 13.607545 / 8.074308 (5.533237) | 13.990230 / 10.191392 (3.798838) | 0.150855 / 0.680424 (-0.529568) | 0.028844 / 0.534201 (-0.505357) | 0.396169 / 0.579283 (-0.183114) | 0.406957 / 0.434364 (-0.027407) | 0.464069 / 0.540337 (-0.076268) | 0.554027 / 1.386936 (-0.832909) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006296 / 0.011353 (-0.005057) | 0.004563 / 0.011008 (-0.006445) | 0.097719 / 0.038508 (0.059211) | 0.027106 / 0.023109 (0.003996) | 0.409333 / 0.275898 (0.133435) | 0.445397 / 0.323480 (0.121917) | 0.004906 / 0.007986 (-0.003080) | 0.003316 / 0.004328 (-0.001012) | 0.075363 / 0.004250 (0.071112) | 0.039366 / 0.037052 (0.002314) | 0.412710 / 0.258489 (0.154221) | 0.451789 / 0.293841 (0.157948) | 0.031810 / 0.128546 (-0.096736) | 0.011681 / 0.075646 (-0.063965) | 0.318484 / 0.419271 (-0.100788) | 0.046741 / 0.043533 (0.003208) | 0.411631 / 0.255139 (0.156492) | 0.435274 / 0.283200 (0.152074) | 0.092366 / 0.141683 (-0.049317) | 1.492243 / 1.452155 (0.040089) | 1.617603 / 1.492716 (0.124887) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.217376 / 0.018006 (0.199369) | 0.400940 / 0.000490 (0.400450) | 0.003700 / 0.000200 (0.003500) | 0.000075 / 0.000054 (0.000021) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.023733 / 0.037411 (-0.013678) | 0.098553 / 0.014526 (0.084027) | 0.105790 / 0.176557 (-0.070767) | 0.139537 / 0.737135 (-0.597598) | 0.109862 / 0.296338 (-0.186477) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.476562 / 0.215209 (0.261353) | 4.773469 / 2.077655 (2.695814) | 2.447302 / 1.504120 (0.943182) | 2.240596 / 1.541195 (0.699401) | 2.271370 / 1.468490 (0.802880) | 0.698913 / 4.584777 (-3.885864) | 3.345648 / 3.745712 (-0.400064) | 1.845008 / 5.269862 (-3.424854) | 1.163213 / 4.565676 (-3.402464) | 0.082456 / 0.424275 (-0.341819) | 0.012315 / 0.007607 (0.004708) | 0.575881 / 0.226044 (0.349836) | 5.769575 / 2.268929 (3.500647) | 2.909759 / 55.444624 (-52.534865) | 2.580259 / 6.876477 (-4.296218) | 2.590473 / 2.142072 (0.448401) | 0.802765 / 4.805227 (-4.002462) | 0.151514 / 6.500664 (-6.349150) | 0.067718 / 0.075469 (-0.007751) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.293014 / 1.841788 (-0.548773) | 13.934072 / 8.074308 (5.859763) | 13.538760 / 10.191392 (3.347368) | 0.126490 / 0.680424 (-0.553934) | 0.016653 / 0.534201 (-0.517548) | 0.381220 / 0.579283 (-0.198064) | 0.387571 / 0.434364 (-0.046793) | 0.444674 / 0.540337 (-0.095663) | 0.550802 / 1.386936 (-0.836134) |\n\n</details>\n</details>\n\n\n"
] | 1,674,581,618,000 | 1,674,663,070,000 | 1,674,662,643,000 | MEMBER | null | null | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5460/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5460/timeline | null | null | 0 | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5460",
"html_url": "https://github.com/huggingface/datasets/pull/5460",
"diff_url": "https://github.com/huggingface/datasets/pull/5460.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5460.patch",
"merged_at": "2023-01-25T16:04:03"
} | true |
https://api.github.com/repos/huggingface/datasets/issues/5459 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5459/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5459/comments | https://api.github.com/repos/huggingface/datasets/issues/5459/events | https://github.com/huggingface/datasets/pull/5459 | 1,555,367,504 | PR_kwDODunzps5Icjwe | 5,459 | Disable aiohttp requoting of redirection URL | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"_The documentation is not available anymore as the PR was closed or merged._",
"Comment by @lhoestq:\r\n> Do you think we need this in `datasets` if it's fixed on the moon landing side ? In the aiohttp doc they consider those symbols as \"non-safe\" ",
"The lib `requests` does not perform that requote on redirect URLs.",
"Indeed, the `requests` library does perform a requoting, but this does not unquote `%27`:\r\n```python\r\nIn [1]: from requests.utils import requote_uri\r\n\r\nIn [2]: url = \"https://netloc/path?param=param%27%27value\"\r\n\r\nIn [3]: url\r\nOut[3]: 'https://netloc/path?param=param%27%27value'\r\n\r\nIn [4]: requote_uri(url)\r\nOut[4]: 'https://netloc/path?param=param%27%27value'\r\n```\r\n\r\nHowever, the `aiohttp` library uses `yarl.ULR` and this does unquote `%27`:\r\n```python\r\nIn [5]: from yarl import URL\r\n\r\nIn [6]: url\r\nOut[6]: 'https://netloc/path?param=param%27%27value'\r\n\r\nIn [7]: str(URL(url))\r\nOut[7]: \"https://netloc/path?param=param''value\"\r\n```\r\n\r\nIf we pass `requote_redirect_url=False` to `aiohttp`, then it passes `encoded=True` to `yarl.ULR`: https://github.com/aio-libs/aiohttp/blob/4635161ee8e7ad321cca46e01ce5bfeb1ad8bf26/aiohttp/client.py#L578-L580\r\n```python\r\nparsed_url = URL(\r\n r_url, encoded=not self._requote_redirect_url\r\n)\r\n```\r\nwhich does not unquote `%27`:\r\n```python\r\nIn [8]: url\r\nOut[8]: 'https://netloc/path?param=param%27%27value'\r\n\r\nIn [9]: str(URL(url, encoded=True))\r\nOut[9]: 'https://netloc/path?param=param%27%27value'\r\n```",
"See the issues we opened in the respective libraries:\r\n- aiohttp\r\n - aio-libs/aiohttp#7183\r\n- requests\r\n - psf/requests#6341",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.012399 / 0.011353 (0.001047) | 0.006388 / 0.011008 (-0.004620) | 0.134173 / 0.038508 (0.095665) | 0.037059 / 0.023109 (0.013949) | 0.420697 / 0.275898 (0.144799) | 0.473981 / 0.323480 (0.150502) | 0.009857 / 0.007986 (0.001871) | 0.004791 / 0.004328 (0.000463) | 0.106886 / 0.004250 (0.102636) | 0.044871 / 0.037052 (0.007818) | 0.429843 / 0.258489 (0.171354) | 0.461569 / 0.293841 (0.167728) | 0.057285 / 0.128546 (-0.071261) | 0.018809 / 0.075646 (-0.056837) | 0.432613 / 0.419271 (0.013342) | 0.058086 / 0.043533 (0.014553) | 0.413064 / 0.255139 (0.157925) | 0.444407 / 0.283200 (0.161207) | 0.119102 / 0.141683 (-0.022581) | 1.875954 / 1.452155 (0.423799) | 1.916392 / 1.492716 (0.423676) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.267489 / 0.018006 (0.249483) | 0.567554 / 0.000490 (0.567064) | 0.005901 / 0.000200 (0.005701) | 0.000134 / 0.000054 (0.000079) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.031248 / 0.037411 (-0.006164) | 0.123014 / 0.014526 (0.108489) | 0.140001 / 0.176557 (-0.036556) | 0.191476 / 0.737135 (-0.545659) | 0.141687 / 0.296338 (-0.154652) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.637481 / 0.215209 (0.422272) | 6.255969 / 2.077655 (4.178314) | 2.559811 / 1.504120 (1.055691) | 2.118154 / 1.541195 (0.576960) | 2.079487 / 1.468490 (0.610997) | 1.201079 / 4.584777 (-3.383698) | 5.592625 / 3.745712 (1.846913) | 5.143344 / 5.269862 (-0.126517) | 2.764716 / 4.565676 (-1.800960) | 0.142539 / 0.424275 (-0.281736) | 0.015541 / 0.007607 (0.007934) | 0.771407 / 0.226044 (0.545363) | 7.631657 / 2.268929 (5.362728) | 3.279684 / 55.444624 (-52.164940) | 2.587566 / 6.876477 (-4.288911) | 2.624622 / 2.142072 (0.482549) | 1.427878 / 4.805227 (-3.377350) | 0.257759 / 6.500664 (-6.242906) | 0.078616 / 0.075469 (0.003147) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.609305 / 1.841788 (-0.232483) | 18.258792 / 8.074308 (10.184484) | 20.345242 / 10.191392 (10.153850) | 0.267366 / 0.680424 (-0.413058) | 0.047035 / 0.534201 (-0.487166) | 0.568881 / 0.579283 (-0.010402) | 0.662763 / 0.434364 (0.228399) | 0.668927 / 0.540337 (0.128590) | 0.755766 / 1.386936 (-0.631170) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.010017 / 0.011353 (-0.001336) | 0.006816 / 0.011008 (-0.004192) | 0.105038 / 0.038508 (0.066529) | 0.038689 / 0.023109 (0.015580) | 0.482113 / 0.275898 (0.206215) | 0.540072 / 0.323480 (0.216592) | 0.007738 / 0.007986 (-0.000248) | 0.005134 / 0.004328 (0.000806) | 0.102203 / 0.004250 (0.097953) | 0.054080 / 0.037052 (0.017028) | 0.501057 / 0.258489 (0.242568) | 0.567186 / 0.293841 (0.273345) | 0.060330 / 0.128546 (-0.068217) | 0.020059 / 0.075646 (-0.055587) | 0.123102 / 0.419271 (-0.296170) | 0.063426 / 0.043533 (0.019893) | 0.494171 / 0.255139 (0.239032) | 0.538238 / 0.283200 (0.255039) | 0.119613 / 0.141683 (-0.022069) | 1.853728 / 1.452155 (0.401574) | 1.984621 / 1.492716 (0.491904) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.282511 / 0.018006 (0.264505) | 0.563190 / 0.000490 (0.562700) | 0.000465 / 0.000200 (0.000265) | 0.000086 / 0.000054 (0.000032) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.029267 / 0.037411 (-0.008144) | 0.135618 / 0.014526 (0.121093) | 0.146286 / 0.176557 (-0.030271) | 0.188570 / 0.737135 (-0.548565) | 0.155839 / 0.296338 (-0.140499) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.671660 / 0.215209 (0.456451) | 6.718775 / 2.077655 (4.641120) | 3.004601 / 1.504120 (1.500481) | 2.640504 / 1.541195 (1.099309) | 2.666788 / 1.468490 (1.198298) | 1.242655 / 4.584777 (-3.342122) | 5.780119 / 3.745712 (2.034407) | 3.247935 / 5.269862 (-2.021927) | 2.114007 / 4.565676 (-2.451669) | 0.147546 / 0.424275 (-0.276729) | 0.014408 / 0.007607 (0.006801) | 0.824407 / 0.226044 (0.598362) | 8.278185 / 2.268929 (6.009257) | 3.733463 / 55.444624 (-51.711161) | 2.976732 / 6.876477 (-3.899745) | 3.132758 / 2.142072 (0.990686) | 1.446095 / 4.805227 (-3.359132) | 0.258628 / 6.500664 (-6.242036) | 0.085513 / 0.075469 (0.010043) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.702681 / 1.841788 (-0.139106) | 18.725123 / 8.074308 (10.650815) | 19.622808 / 10.191392 (9.431416) | 0.215845 / 0.680424 (-0.464579) | 0.029246 / 0.534201 (-0.504955) | 0.554819 / 0.579283 (-0.024464) | 0.630926 / 0.434364 (0.196562) | 0.637663 / 0.540337 (0.097325) | 0.837948 / 1.386936 (-0.548988) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008540 / 0.011353 (-0.002813) | 0.004538 / 0.011008 (-0.006470) | 0.101507 / 0.038508 (0.062999) | 0.029751 / 0.023109 (0.006641) | 0.292608 / 0.275898 (0.016710) | 0.354734 / 0.323480 (0.031254) | 0.007430 / 0.007986 (-0.000556) | 0.003365 / 0.004328 (-0.000964) | 0.078703 / 0.004250 (0.074452) | 0.034858 / 0.037052 (-0.002194) | 0.303518 / 0.258489 (0.045029) | 0.336523 / 0.293841 (0.042682) | 0.033741 / 0.128546 (-0.094805) | 0.011460 / 0.075646 (-0.064186) | 0.319551 / 0.419271 (-0.099721) | 0.041102 / 0.043533 (-0.002431) | 0.295914 / 0.255139 (0.040775) | 0.322142 / 0.283200 (0.038943) | 0.084694 / 0.141683 (-0.056989) | 1.481308 / 1.452155 (0.029153) | 1.530271 / 1.492716 (0.037554) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.180516 / 0.018006 (0.162510) | 0.405741 / 0.000490 (0.405251) | 0.002806 / 0.000200 (0.002606) | 0.000072 / 0.000054 (0.000018) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.023359 / 0.037411 (-0.014052) | 0.096950 / 0.014526 (0.082424) | 0.103991 / 0.176557 (-0.072566) | 0.143700 / 0.737135 (-0.593435) | 0.106764 / 0.296338 (-0.189575) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.416966 / 0.215209 (0.201757) | 4.145601 / 2.077655 (2.067946) | 1.838258 / 1.504120 (0.334139) | 1.629396 / 1.541195 (0.088201) | 1.649707 / 1.468490 (0.181217) | 0.689624 / 4.584777 (-3.895153) | 3.414584 / 3.745712 (-0.331129) | 1.874295 / 5.269862 (-3.395566) | 1.251930 / 4.565676 (-3.313746) | 0.081782 / 0.424275 (-0.342493) | 0.012868 / 0.007607 (0.005261) | 0.523904 / 0.226044 (0.297859) | 5.251032 / 2.268929 (2.982104) | 2.301549 / 55.444624 (-53.143075) | 1.942110 / 6.876477 (-4.934367) | 2.023014 / 2.142072 (-0.119058) | 0.816492 / 4.805227 (-3.988736) | 0.150107 / 6.500664 (-6.350558) | 0.065118 / 0.075469 (-0.010351) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.226433 / 1.841788 (-0.615355) | 13.852569 / 8.074308 (5.778261) | 13.862779 / 10.191392 (3.671387) | 0.146361 / 0.680424 (-0.534062) | 0.028652 / 0.534201 (-0.505549) | 0.398251 / 0.579283 (-0.181032) | 0.403590 / 0.434364 (-0.030774) | 0.492184 / 0.540337 (-0.048154) | 0.581040 / 1.386936 (-0.805896) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006859 / 0.011353 (-0.004494) | 0.004632 / 0.011008 (-0.006376) | 0.076653 / 0.038508 (0.038145) | 0.027865 / 0.023109 (0.004755) | 0.354472 / 0.275898 (0.078573) | 0.385462 / 0.323480 (0.061982) | 0.005125 / 0.007986 (-0.002861) | 0.003420 / 0.004328 (-0.000909) | 0.076018 / 0.004250 (0.071768) | 0.040197 / 0.037052 (0.003144) | 0.353675 / 0.258489 (0.095186) | 0.394911 / 0.293841 (0.101070) | 0.032909 / 0.128546 (-0.095637) | 0.011713 / 0.075646 (-0.063933) | 0.085921 / 0.419271 (-0.333350) | 0.044462 / 0.043533 (0.000929) | 0.349997 / 0.255139 (0.094858) | 0.375207 / 0.283200 (0.092008) | 0.091288 / 0.141683 (-0.050394) | 1.536515 / 1.452155 (0.084361) | 1.581878 / 1.492716 (0.089162) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.273284 / 0.018006 (0.255277) | 0.424457 / 0.000490 (0.423967) | 0.044659 / 0.000200 (0.044459) | 0.000247 / 0.000054 (0.000192) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.025473 / 0.037411 (-0.011938) | 0.100014 / 0.014526 (0.085488) | 0.108551 / 0.176557 (-0.068006) | 0.147913 / 0.737135 (-0.589223) | 0.112729 / 0.296338 (-0.183610) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.448162 / 0.215209 (0.232953) | 4.472701 / 2.077655 (2.395046) | 2.078384 / 1.504120 (0.574264) | 1.861292 / 1.541195 (0.320097) | 1.920482 / 1.468490 (0.451991) | 0.706968 / 4.584777 (-3.877809) | 3.433109 / 3.745712 (-0.312603) | 1.898684 / 5.269862 (-3.371178) | 1.174375 / 4.565676 (-3.391302) | 0.083666 / 0.424275 (-0.340609) | 0.012388 / 0.007607 (0.004781) | 0.546011 / 0.226044 (0.319966) | 5.487514 / 2.268929 (3.218585) | 2.534124 / 55.444624 (-52.910500) | 2.168441 / 6.876477 (-4.708036) | 2.203458 / 2.142072 (0.061386) | 0.813333 / 4.805227 (-3.991894) | 0.153169 / 6.500664 (-6.347495) | 0.067151 / 0.075469 (-0.008318) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.277815 / 1.841788 (-0.563972) | 13.920545 / 8.074308 (5.846237) | 13.473801 / 10.191392 (3.282409) | 0.129035 / 0.680424 (-0.551389) | 0.016737 / 0.534201 (-0.517464) | 0.388413 / 0.579283 (-0.190870) | 0.388785 / 0.434364 (-0.045579) | 0.481735 / 0.540337 (-0.058602) | 0.576390 / 1.386936 (-0.810546) |\n\n</details>\n</details>\n\n\n"
] | 1,674,580,739,000 | 1,675,241,133,000 | 1,675,154,274,000 | MEMBER | null | The library `aiohttp` performs a requoting of redirection URLs that unquotes the single quotation mark character: `%27` => `'`
This is a problem for our Hugging Face Hub, which requires exact URL from location header.
Specifically, in the query component of the URL (`https://netloc/path?query`), the value for `response-content-disposition` contains `%27`:
```
response-content-disposition=attachment%3B+filename*%3DUTF-8%27%27sample.jsonl.gz%3B+filename%3D%22sample.jsonl.gz%22%3B
```
and after the requoting, the `%27` characters get unquoted to `'`:
```
response-content-disposition=attachment%3B+filename*%3DUTF-8''sample.jsonl.gz%3B+filename%3D%22sample.jsonl.gz%22%3B
```
This PR disables the `aiohttp` requoting of redirection URLs. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5459/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5459/timeline | null | null | 0 | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5459",
"html_url": "https://github.com/huggingface/datasets/pull/5459",
"diff_url": "https://github.com/huggingface/datasets/pull/5459.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5459.patch",
"merged_at": "2023-01-31T08:37:54"
} | true |
https://api.github.com/repos/huggingface/datasets/issues/5458 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5458/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5458/comments | https://api.github.com/repos/huggingface/datasets/issues/5458/events | https://github.com/huggingface/datasets/issues/5458 | 1,555,054,737 | I_kwDODunzps5csECR | 5,458 | slice split while streaming | {
"login": "SvenDS9",
"id": 122370631,
"node_id": "U_kgDOB0s6Rw",
"avatar_url": "https://avatars.githubusercontent.com/u/122370631?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/SvenDS9",
"html_url": "https://github.com/SvenDS9",
"followers_url": "https://api.github.com/users/SvenDS9/followers",
"following_url": "https://api.github.com/users/SvenDS9/following{/other_user}",
"gists_url": "https://api.github.com/users/SvenDS9/gists{/gist_id}",
"starred_url": "https://api.github.com/users/SvenDS9/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/SvenDS9/subscriptions",
"organizations_url": "https://api.github.com/users/SvenDS9/orgs",
"repos_url": "https://api.github.com/users/SvenDS9/repos",
"events_url": "https://api.github.com/users/SvenDS9/events{/privacy}",
"received_events_url": "https://api.github.com/users/SvenDS9/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Hi! Yes, that's correct. When `streaming` is `True`, only split names can be specified as `split`, and for slicing, you have to use `.skip`/`.take` instead.\r\n\r\nE.g. \r\n`load_dataset(\"lhoestq/demo1\",revision=None, streaming=True, split=\"train[:3]\")`\r\n\r\nrewritten with `.skip`/`.take`:\r\n`load_dataset(\"lhoestq/demo1\",revision=None, streaming=True, split=\"train\").take(3)`\r\n\r\n\r\n",
"Thank you for your quick response!"
] | 1,674,569,297,000 | 1,674,573,107,000 | 1,674,573,107,000 | NONE | null | ### Describe the bug
When using the `load_dataset` function with streaming set to True, slicing splits is apparently not supported.
Did I miss this in the documentation?
### Steps to reproduce the bug
`load_dataset("lhoestq/demo1",revision=None, streaming=True, split="train[:3]")`
causes ValueError: Bad split: train[:3]. Available splits: ['train', 'test'] in builder.py, line 1213, in as_streaming_dataset
### Expected behavior
The first 3 entries of the dataset as a stream
### Environment info
- `datasets` version: 2.8.0
- Platform: Windows-10-10.0.19045-SP0
- Python version: 3.10.9
- PyArrow version: 10.0.1
- Pandas version: 1.5.2
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5458/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5458/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5457 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5457/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5457/comments | https://api.github.com/repos/huggingface/datasets/issues/5457/events | https://github.com/huggingface/datasets/issues/5457 | 1,554,171,264 | I_kwDODunzps5cosWA | 5,457 | prebuilt dataset relies on `downloads/extracted` | {
"login": "stas00",
"id": 10676103,
"node_id": "MDQ6VXNlcjEwNjc2MTAz",
"avatar_url": "https://avatars.githubusercontent.com/u/10676103?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/stas00",
"html_url": "https://github.com/stas00",
"followers_url": "https://api.github.com/users/stas00/followers",
"following_url": "https://api.github.com/users/stas00/following{/other_user}",
"gists_url": "https://api.github.com/users/stas00/gists{/gist_id}",
"starred_url": "https://api.github.com/users/stas00/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/stas00/subscriptions",
"organizations_url": "https://api.github.com/users/stas00/orgs",
"repos_url": "https://api.github.com/users/stas00/repos",
"events_url": "https://api.github.com/users/stas00/events{/privacy}",
"received_events_url": "https://api.github.com/users/stas00/received_events",
"type": "User",
"site_admin": false
} | [] | open | false | null | [] | [
"Hi! \r\n\r\nThis issue is due to our audio/image datasets not being self-contained. This allows us to save disk space (files are written only once) but also leads to the issues like this one. We plan to make all our datasets self-contained in Datasets 3.0.\r\n\r\nIn the meantime, you can run the following map to ensure your dataset is self-contained:\r\n```python\r\nfrom datasets.table import embed_table_storage\r\n# load_dataset ...\r\ndset = dset.with_format(\"arrow\")\r\ndset.map(embed_table_storage, batched=True)\r\ndset = dset.with_format(\"python\")\r\n```\r\n",
"Understood. Thank you, Mario.\r\n\r\nPerhaps the solution could be very simple - move the extracted files into the directory of the cached dataset? Which would make it self-contained already and won't require waiting for a new major release. Unless I'm missing some back-compat nuance.\r\n\r\nBut regardless if X relies on Y - it could check if Y is still there when loading X. so not checking full consistency but just the top-level directory it relies on."
] | 1,674,526,172,000 | 1,674,584,050,000 | null | MEMBER | null | ### Describe the bug
I pre-built the dataset:
```
python -c 'import sys; from datasets import load_dataset; ds=load_dataset(sys.argv[1])' HuggingFaceM4/general-pmd-synthetic-testing
```
and it can be used just fine.
now I wipe out `downloads/extracted` and it no longer works.
```
rm -r ~/.cache/huggingface/datasets/downloads
```
That is I can still load it:
```
python -c 'import sys; from datasets import load_dataset; ds=load_dataset(sys.argv[1])' HuggingFaceM4/general-pmd-synthetic-testing
No config specified, defaulting to: general-pmd-synthetic-testing/100.unique
Found cached dataset general-pmd-synthetic-testing (/home/stas/.cache/huggingface/datasets/HuggingFaceM4___general-pmd-synthetic-testing/100.unique/1.1.1/86bc445e3e48cb5ef79de109eb4e54ff85b318cd55c3835c4ee8f86eae33d9d2)
```
but if I try to use it:
```
E stderr: Traceback (most recent call last):
E stderr: File "/mnt/nvme0/code/huggingface/m4-master-6/m4/training/main.py", line 116, in <module>
E stderr: train_loader, val_loader = get_dataloaders(
E stderr: File "/mnt/nvme0/code/huggingface/m4-master-6/m4/training/dataset.py", line 170, in get_dataloaders
E stderr: train_loader = get_dataloader_from_config(
E stderr: File "/mnt/nvme0/code/huggingface/m4-master-6/m4/training/dataset.py", line 443, in get_dataloader_from_config
E stderr: dataloader = get_dataloader(
E stderr: File "/mnt/nvme0/code/huggingface/m4-master-6/m4/training/dataset.py", line 264, in get_dataloader
E stderr: is_pmd = "meta" in hf_dataset[0] and "source" in hf_dataset[0]
E stderr: File "/mnt/nvme0/code/huggingface/datasets-master/src/datasets/arrow_dataset.py", line 2601, in __getitem__
E stderr: return self._getitem(
E stderr: File "/mnt/nvme0/code/huggingface/datasets-master/src/datasets/arrow_dataset.py", line 2586, in _getitem
E stderr: formatted_output = format_table(
E stderr: File "/mnt/nvme0/code/huggingface/datasets-master/src/datasets/formatting/formatting.py", line 634, in format_table
E stderr: return formatter(pa_table, query_type=query_type)
E stderr: File "/mnt/nvme0/code/huggingface/datasets-master/src/datasets/formatting/formatting.py", line 406, in __call__
E stderr: return self.format_row(pa_table)
E stderr: File "/mnt/nvme0/code/huggingface/datasets-master/src/datasets/formatting/formatting.py", line 442, in format_row
E stderr: row = self.python_features_decoder.decode_row(row)
E stderr: File "/mnt/nvme0/code/huggingface/datasets-master/src/datasets/formatting/formatting.py", line 225, in decode_row
E stderr: return self.features.decode_example(row) if self.features else row
E stderr: File "/mnt/nvme0/code/huggingface/datasets-master/src/datasets/features/features.py", line 1846, in decode_example
E stderr: return {
E stderr: File "/mnt/nvme0/code/huggingface/datasets-master/src/datasets/features/features.py", line 1847, in <dictcomp>
E stderr: column_name: decode_nested_example(feature, value, token_per_repo_id=token_per_repo_id)
E stderr: File "/mnt/nvme0/code/huggingface/datasets-master/src/datasets/features/features.py", line 1304, in decode_nested_example
E stderr: return decode_nested_example([schema.feature], obj)
E stderr: File "/mnt/nvme0/code/huggingface/datasets-master/src/datasets/features/features.py", line 1296, in decode_nested_example
E stderr: if decode_nested_example(sub_schema, first_elmt) != first_elmt:
E stderr: File "/mnt/nvme0/code/huggingface/datasets-master/src/datasets/features/features.py", line 1309, in decode_nested_example
E stderr: return schema.decode_example(obj, token_per_repo_id=token_per_repo_id)
E stderr: File "/mnt/nvme0/code/huggingface/datasets-master/src/datasets/features/image.py", line 144, in decode_example
E stderr: image = PIL.Image.open(path)
E stderr: File "/home/stas/anaconda3/envs/py38-pt113/lib/python3.8/site-packages/PIL/Image.py", line 3092, in open
E stderr: fp = builtins.open(filename, "rb")
E stderr: FileNotFoundError: [Errno 2] No such file or directory: '/mnt/nvme0/code/data/cache/huggingface/datasets/downloads/extracted/134227b9b94c4eccf19b205bf3021d4492d0227b9be6c2ddb6bf517d8d55a8cb/data/101/images_01.jpg'
```
Only if I wipe out the cached dir and rebuild then it starts working as `download/extracted` is back again with extracted files.
```
rm -r ~/.cache/huggingface/datasets/HuggingFaceM4___general-pmd-synthetic-testing
python -c 'import sys; from datasets import load_dataset; ds=load_dataset(sys.argv[1])' HuggingFaceM4/general-pmd-synthetic-testing
```
I think there are 2 issues here:
1. why does it still rely on extracted files after `arrow` files were printed - did I do something incorrectly when creating this dataset?
2. why doesn't the dataset know that it has been gutted and loads just fine? If it has a dependency on `download/extracted` then `load_dataset` should check if it's there and fail or force rebuilding. I am sure this could be a very expensive operation, so probably really solving #1 will not require this check. and this second item is probably an overkill. Other than perhaps if it had an optional `check_consistency` flag to do that.
### Environment info
datasets@main | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5457/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5457/timeline | null | null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5456 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5456/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5456/comments | https://api.github.com/repos/huggingface/datasets/issues/5456/events | https://github.com/huggingface/datasets/pull/5456 | 1,553,905,148 | PR_kwDODunzps5IXq92 | 5,456 | feat: tqdm for `to_parquet` | {
"login": "zanussbaum",
"id": 33707069,
"node_id": "MDQ6VXNlcjMzNzA3MDY5",
"avatar_url": "https://avatars.githubusercontent.com/u/33707069?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/zanussbaum",
"html_url": "https://github.com/zanussbaum",
"followers_url": "https://api.github.com/users/zanussbaum/followers",
"following_url": "https://api.github.com/users/zanussbaum/following{/other_user}",
"gists_url": "https://api.github.com/users/zanussbaum/gists{/gist_id}",
"starred_url": "https://api.github.com/users/zanussbaum/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/zanussbaum/subscriptions",
"organizations_url": "https://api.github.com/users/zanussbaum/orgs",
"repos_url": "https://api.github.com/users/zanussbaum/repos",
"events_url": "https://api.github.com/users/zanussbaum/events{/privacy}",
"received_events_url": "https://api.github.com/users/zanussbaum/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.012395 / 0.011353 (0.001042) | 0.006466 / 0.011008 (-0.004542) | 0.127605 / 0.038508 (0.089097) | 0.044929 / 0.023109 (0.021820) | 0.399856 / 0.275898 (0.123958) | 0.491341 / 0.323480 (0.167861) | 0.009193 / 0.007986 (0.001207) | 0.005419 / 0.004328 (0.001090) | 0.100577 / 0.004250 (0.096327) | 0.045338 / 0.037052 (0.008286) | 0.409970 / 0.258489 (0.151481) | 0.452941 / 0.293841 (0.159100) | 0.054350 / 0.128546 (-0.074197) | 0.019069 / 0.075646 (-0.056578) | 0.427036 / 0.419271 (0.007765) | 0.073616 / 0.043533 (0.030083) | 0.395384 / 0.255139 (0.140245) | 0.442381 / 0.283200 (0.159181) | 0.123185 / 0.141683 (-0.018498) | 1.797640 / 1.452155 (0.345485) | 1.888860 / 1.492716 (0.396143) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.211041 / 0.018006 (0.193035) | 0.539350 / 0.000490 (0.538860) | 0.001683 / 0.000200 (0.001483) | 0.000118 / 0.000054 (0.000064) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.031699 / 0.037411 (-0.005712) | 0.132696 / 0.014526 (0.118170) | 0.133710 / 0.176557 (-0.042846) | 0.190074 / 0.737135 (-0.547061) | 0.142919 / 0.296338 (-0.153420) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.643521 / 0.215209 (0.428312) | 6.137350 / 2.077655 (4.059695) | 2.463894 / 1.504120 (0.959774) | 2.120043 / 1.541195 (0.578848) | 2.121898 / 1.468490 (0.653408) | 1.287319 / 4.584777 (-3.297458) | 5.517864 / 3.745712 (1.772151) | 5.070820 / 5.269862 (-0.199042) | 2.948967 / 4.565676 (-1.616710) | 0.175861 / 0.424275 (-0.248415) | 0.015292 / 0.007607 (0.007685) | 0.843195 / 0.226044 (0.617150) | 7.884275 / 2.268929 (5.615347) | 3.182821 / 55.444624 (-52.261803) | 2.576093 / 6.876477 (-4.300384) | 2.537160 / 2.142072 (0.395088) | 1.510029 / 4.805227 (-3.295198) | 0.249404 / 6.500664 (-6.251260) | 0.080434 / 0.075469 (0.004965) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.618695 / 1.841788 (-0.223093) | 18.879207 / 8.074308 (10.804899) | 21.075272 / 10.191392 (10.883880) | 0.260781 / 0.680424 (-0.419643) | 0.046387 / 0.534201 (-0.487813) | 0.570709 / 0.579283 (-0.008574) | 0.619050 / 0.434364 (0.184686) | 0.642295 / 0.540337 (0.101958) | 0.780070 / 1.386936 (-0.606866) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.010418 / 0.011353 (-0.000935) | 0.006104 / 0.011008 (-0.004905) | 0.133609 / 0.038508 (0.095101) | 0.035101 / 0.023109 (0.011992) | 0.471931 / 0.275898 (0.196033) | 0.504498 / 0.323480 (0.181018) | 0.007388 / 0.007986 (-0.000598) | 0.004852 / 0.004328 (0.000523) | 0.094535 / 0.004250 (0.090284) | 0.056832 / 0.037052 (0.019779) | 0.470513 / 0.258489 (0.212024) | 0.531285 / 0.293841 (0.237444) | 0.058271 / 0.128546 (-0.070276) | 0.020523 / 0.075646 (-0.055123) | 0.437398 / 0.419271 (0.018126) | 0.065390 / 0.043533 (0.021857) | 0.503702 / 0.255139 (0.248563) | 0.515876 / 0.283200 (0.232677) | 0.118615 / 0.141683 (-0.023068) | 1.865380 / 1.452155 (0.413225) | 1.990316 / 1.492716 (0.497600) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.246772 / 0.018006 (0.228766) | 0.560607 / 0.000490 (0.560118) | 0.005675 / 0.000200 (0.005475) | 0.000142 / 0.000054 (0.000088) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.034692 / 0.037411 (-0.002719) | 0.174016 / 0.014526 (0.159490) | 0.179838 / 0.176557 (0.003282) | 0.217118 / 0.737135 (-0.520018) | 0.184811 / 0.296338 (-0.111527) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.675970 / 0.215209 (0.460760) | 6.787039 / 2.077655 (4.709384) | 2.932619 / 1.504120 (1.428499) | 2.545076 / 1.541195 (1.003882) | 2.566705 / 1.468490 (1.098215) | 1.287365 / 4.584777 (-3.297412) | 5.468441 / 3.745712 (1.722729) | 5.227726 / 5.269862 (-0.042136) | 2.868970 / 4.565676 (-1.696706) | 0.153535 / 0.424275 (-0.270740) | 0.020087 / 0.007607 (0.012480) | 0.860562 / 0.226044 (0.634518) | 8.656109 / 2.268929 (6.387180) | 3.749424 / 55.444624 (-51.695200) | 3.011337 / 6.876477 (-3.865139) | 3.119045 / 2.142072 (0.976973) | 1.562174 / 4.805227 (-3.243053) | 0.279161 / 6.500664 (-6.221504) | 0.084905 / 0.075469 (0.009436) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.638684 / 1.841788 (-0.203104) | 18.834760 / 8.074308 (10.760452) | 21.554310 / 10.191392 (11.362918) | 0.274518 / 0.680424 (-0.405906) | 0.030343 / 0.534201 (-0.503858) | 0.539094 / 0.579283 (-0.040189) | 0.627258 / 0.434364 (0.192895) | 0.624638 / 0.540337 (0.084301) | 0.742776 / 1.386936 (-0.644160) |\n\n</details>\n</details>\n\n\n"
] | 1,674,511,538,000 | 1,674,559,607,000 | 1,674,559,032,000 | CONTRIBUTOR | null | As described in #5418
I noticed also that the `to_json` function supports multi-workers whereas `to_parquet`, is that not possible/not needed with Parquet or something that hasn't been implemented yet? | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5456/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5456/timeline | null | null | 0 | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5456",
"html_url": "https://github.com/huggingface/datasets/pull/5456",
"diff_url": "https://github.com/huggingface/datasets/pull/5456.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5456.patch",
"merged_at": "2023-01-24T11:17:12"
} | true |
https://api.github.com/repos/huggingface/datasets/issues/5455 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5455/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5455/comments | https://api.github.com/repos/huggingface/datasets/issues/5455/events | https://github.com/huggingface/datasets/pull/5455 | 1,553,040,080 | PR_kwDODunzps5IUvAZ | 5,455 | Single TQDM bar in multi-proc map | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008372 / 0.011353 (-0.002981) | 0.004658 / 0.011008 (-0.006350) | 0.102005 / 0.038508 (0.063497) | 0.029030 / 0.023109 (0.005920) | 0.296968 / 0.275898 (0.021070) | 0.364898 / 0.323480 (0.041418) | 0.006899 / 0.007986 (-0.001087) | 0.003410 / 0.004328 (-0.000919) | 0.079705 / 0.004250 (0.075455) | 0.034265 / 0.037052 (-0.002787) | 0.305695 / 0.258489 (0.047206) | 0.343275 / 0.293841 (0.049434) | 0.033783 / 0.128546 (-0.094763) | 0.011604 / 0.075646 (-0.064042) | 0.322577 / 0.419271 (-0.096694) | 0.040540 / 0.043533 (-0.002993) | 0.299176 / 0.255139 (0.044037) | 0.333157 / 0.283200 (0.049957) | 0.087460 / 0.141683 (-0.054223) | 1.494392 / 1.452155 (0.042237) | 1.539580 / 1.492716 (0.046863) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.176206 / 0.018006 (0.158200) | 0.413702 / 0.000490 (0.413212) | 0.002625 / 0.000200 (0.002425) | 0.000071 / 0.000054 (0.000017) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.023886 / 0.037411 (-0.013525) | 0.099758 / 0.014526 (0.085232) | 0.104349 / 0.176557 (-0.072208) | 0.147138 / 0.737135 (-0.589998) | 0.108682 / 0.296338 (-0.187657) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.411957 / 0.215209 (0.196748) | 4.110004 / 2.077655 (2.032349) | 1.820951 / 1.504120 (0.316831) | 1.629726 / 1.541195 (0.088532) | 1.672573 / 1.468490 (0.204083) | 0.686627 / 4.584777 (-3.898150) | 3.382665 / 3.745712 (-0.363047) | 2.875908 / 5.269862 (-2.393954) | 1.475331 / 4.565676 (-3.090345) | 0.081353 / 0.424275 (-0.342922) | 0.012521 / 0.007607 (0.004914) | 0.516226 / 0.226044 (0.290182) | 5.157658 / 2.268929 (2.888729) | 2.302012 / 55.444624 (-53.142612) | 1.950831 / 6.876477 (-4.925646) | 1.962081 / 2.142072 (-0.179992) | 0.800007 / 4.805227 (-4.005221) | 0.148462 / 6.500664 (-6.352202) | 0.064448 / 0.075469 (-0.011021) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.227977 / 1.841788 (-0.613810) | 13.776087 / 8.074308 (5.701779) | 13.749825 / 10.191392 (3.558433) | 0.137034 / 0.680424 (-0.543390) | 0.028461 / 0.534201 (-0.505740) | 0.392335 / 0.579283 (-0.186948) | 0.397404 / 0.434364 (-0.036960) | 0.450831 / 0.540337 (-0.089507) | 0.533716 / 1.386936 (-0.853220) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006883 / 0.011353 (-0.004470) | 0.004625 / 0.011008 (-0.006383) | 0.099039 / 0.038508 (0.060531) | 0.028068 / 0.023109 (0.004958) | 0.419988 / 0.275898 (0.144090) | 0.449543 / 0.323480 (0.126063) | 0.005232 / 0.007986 (-0.002753) | 0.003527 / 0.004328 (-0.000801) | 0.076308 / 0.004250 (0.072057) | 0.040523 / 0.037052 (0.003471) | 0.420165 / 0.258489 (0.161676) | 0.463220 / 0.293841 (0.169379) | 0.032368 / 0.128546 (-0.096178) | 0.011784 / 0.075646 (-0.063863) | 0.320675 / 0.419271 (-0.098597) | 0.041861 / 0.043533 (-0.001672) | 0.424903 / 0.255139 (0.169764) | 0.443528 / 0.283200 (0.160328) | 0.090869 / 0.141683 (-0.050814) | 1.504757 / 1.452155 (0.052602) | 1.557824 / 1.492716 (0.065108) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.224020 / 0.018006 (0.206014) | 0.404090 / 0.000490 (0.403601) | 0.000403 / 0.000200 (0.000203) | 0.000058 / 0.000054 (0.000004) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.024556 / 0.037411 (-0.012855) | 0.101280 / 0.014526 (0.086754) | 0.108017 / 0.176557 (-0.068540) | 0.146679 / 0.737135 (-0.590456) | 0.111468 / 0.296338 (-0.184870) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.478955 / 0.215209 (0.263746) | 4.769628 / 2.077655 (2.691973) | 2.473238 / 1.504120 (0.969118) | 2.263588 / 1.541195 (0.722393) | 2.285425 / 1.468490 (0.816935) | 0.699051 / 4.584777 (-3.885726) | 3.390495 / 3.745712 (-0.355217) | 1.858569 / 5.269862 (-3.411293) | 1.162081 / 4.565676 (-3.403596) | 0.083294 / 0.424275 (-0.340981) | 0.012410 / 0.007607 (0.004803) | 0.580786 / 0.226044 (0.354741) | 5.866868 / 2.268929 (3.597940) | 2.944358 / 55.444624 (-52.500266) | 2.596241 / 6.876477 (-4.280235) | 2.664464 / 2.142072 (0.522392) | 0.806751 / 4.805227 (-3.998476) | 0.152389 / 6.500664 (-6.348275) | 0.066945 / 0.075469 (-0.008524) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.290545 / 1.841788 (-0.551243) | 14.005727 / 8.074308 (5.931419) | 14.478951 / 10.191392 (4.287559) | 0.127488 / 0.680424 (-0.552935) | 0.016929 / 0.534201 (-0.517272) | 0.378380 / 0.579283 (-0.200904) | 0.387499 / 0.434364 (-0.046865) | 0.440816 / 0.540337 (-0.099522) | 0.525794 / 1.386936 (-0.861142) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008704 / 0.011353 (-0.002649) | 0.004474 / 0.011008 (-0.006534) | 0.101720 / 0.038508 (0.063212) | 0.030426 / 0.023109 (0.007317) | 0.298944 / 0.275898 (0.023046) | 0.371491 / 0.323480 (0.048011) | 0.007042 / 0.007986 (-0.000944) | 0.003479 / 0.004328 (-0.000850) | 0.078086 / 0.004250 (0.073835) | 0.037014 / 0.037052 (-0.000038) | 0.312964 / 0.258489 (0.054475) | 0.351251 / 0.293841 (0.057410) | 0.033286 / 0.128546 (-0.095260) | 0.011468 / 0.075646 (-0.064179) | 0.321784 / 0.419271 (-0.097488) | 0.040700 / 0.043533 (-0.002832) | 0.303799 / 0.255139 (0.048660) | 0.336982 / 0.283200 (0.053782) | 0.089448 / 0.141683 (-0.052235) | 1.462430 / 1.452155 (0.010275) | 1.524448 / 1.492716 (0.031732) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.178390 / 0.018006 (0.160384) | 0.402474 / 0.000490 (0.401984) | 0.002697 / 0.000200 (0.002497) | 0.000078 / 0.000054 (0.000023) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.022679 / 0.037411 (-0.014733) | 0.097759 / 0.014526 (0.083234) | 0.105102 / 0.176557 (-0.071454) | 0.140720 / 0.737135 (-0.596415) | 0.109119 / 0.296338 (-0.187219) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.414153 / 0.215209 (0.198944) | 4.131799 / 2.077655 (2.054144) | 1.852325 / 1.504120 (0.348205) | 1.646955 / 1.541195 (0.105760) | 1.662880 / 1.468490 (0.194390) | 0.693823 / 4.584777 (-3.890954) | 3.378843 / 3.745712 (-0.366869) | 1.861324 / 5.269862 (-3.408538) | 1.156916 / 4.565676 (-3.408761) | 0.082385 / 0.424275 (-0.341890) | 0.012166 / 0.007607 (0.004559) | 0.528690 / 0.226044 (0.302646) | 5.286388 / 2.268929 (3.017459) | 2.319941 / 55.444624 (-53.124684) | 1.959462 / 6.876477 (-4.917014) | 1.995102 / 2.142072 (-0.146970) | 0.817158 / 4.805227 (-3.988069) | 0.149479 / 6.500664 (-6.351185) | 0.065668 / 0.075469 (-0.009801) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.240228 / 1.841788 (-0.601560) | 13.770357 / 8.074308 (5.696048) | 13.940638 / 10.191392 (3.749246) | 0.152589 / 0.680424 (-0.527835) | 0.028498 / 0.534201 (-0.505703) | 0.392579 / 0.579283 (-0.186704) | 0.402843 / 0.434364 (-0.031521) | 0.455429 / 0.540337 (-0.084909) | 0.541090 / 1.386936 (-0.845846) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006692 / 0.011353 (-0.004661) | 0.004514 / 0.011008 (-0.006495) | 0.097058 / 0.038508 (0.058550) | 0.027780 / 0.023109 (0.004671) | 0.415806 / 0.275898 (0.139908) | 0.443079 / 0.323480 (0.119599) | 0.005181 / 0.007986 (-0.002805) | 0.003408 / 0.004328 (-0.000921) | 0.075263 / 0.004250 (0.071013) | 0.038169 / 0.037052 (0.001116) | 0.417292 / 0.258489 (0.158803) | 0.461875 / 0.293841 (0.168034) | 0.032280 / 0.128546 (-0.096266) | 0.011571 / 0.075646 (-0.064075) | 0.319091 / 0.419271 (-0.100181) | 0.048295 / 0.043533 (0.004762) | 0.423619 / 0.255139 (0.168480) | 0.435064 / 0.283200 (0.151864) | 0.094869 / 0.141683 (-0.046814) | 1.523000 / 1.452155 (0.070846) | 1.583097 / 1.492716 (0.090381) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.214326 / 0.018006 (0.196320) | 0.391623 / 0.000490 (0.391134) | 0.004602 / 0.000200 (0.004403) | 0.000078 / 0.000054 (0.000024) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.024306 / 0.037411 (-0.013106) | 0.101178 / 0.014526 (0.086652) | 0.108504 / 0.176557 (-0.068053) | 0.144114 / 0.737135 (-0.593022) | 0.111088 / 0.296338 (-0.185250) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.472573 / 0.215209 (0.257364) | 4.748929 / 2.077655 (2.671274) | 2.441602 / 1.504120 (0.937482) | 2.238841 / 1.541195 (0.697647) | 2.303303 / 1.468490 (0.834813) | 0.696618 / 4.584777 (-3.888159) | 3.373867 / 3.745712 (-0.371845) | 2.809009 / 5.269862 (-2.460852) | 1.337240 / 4.565676 (-3.228437) | 0.082682 / 0.424275 (-0.341593) | 0.012834 / 0.007607 (0.005227) | 0.569686 / 0.226044 (0.343642) | 5.723407 / 2.268929 (3.454478) | 2.882944 / 55.444624 (-52.561680) | 2.543530 / 6.876477 (-4.332947) | 2.581856 / 2.142072 (0.439784) | 0.802353 / 4.805227 (-4.002874) | 0.149947 / 6.500664 (-6.350717) | 0.065865 / 0.075469 (-0.009604) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.282146 / 1.841788 (-0.559642) | 13.831344 / 8.074308 (5.757036) | 14.081550 / 10.191392 (3.890157) | 0.141735 / 0.680424 (-0.538689) | 0.016677 / 0.534201 (-0.517524) | 0.378967 / 0.579283 (-0.200316) | 0.383775 / 0.434364 (-0.050589) | 0.432892 / 0.540337 (-0.107446) | 0.518042 / 1.386936 (-0.868894) |\n\n</details>\n</details>\n\n\n",
"Omg I love this ! cc @TevenLeScao @thomasw21 this will save your terminals from infinite streams of progress bars",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008680 / 0.011353 (-0.002673) | 0.004597 / 0.011008 (-0.006411) | 0.101154 / 0.038508 (0.062646) | 0.029831 / 0.023109 (0.006722) | 0.300619 / 0.275898 (0.024721) | 0.358259 / 0.323480 (0.034779) | 0.007284 / 0.007986 (-0.000701) | 0.003511 / 0.004328 (-0.000817) | 0.078805 / 0.004250 (0.074555) | 0.037192 / 0.037052 (0.000140) | 0.307241 / 0.258489 (0.048752) | 0.354648 / 0.293841 (0.060807) | 0.033696 / 0.128546 (-0.094851) | 0.011660 / 0.075646 (-0.063986) | 0.324266 / 0.419271 (-0.095006) | 0.043393 / 0.043533 (-0.000140) | 0.297503 / 0.255139 (0.042364) | 0.326037 / 0.283200 (0.042838) | 0.091165 / 0.141683 (-0.050517) | 1.479970 / 1.452155 (0.027816) | 1.508507 / 1.492716 (0.015791) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.179995 / 0.018006 (0.161989) | 0.464282 / 0.000490 (0.463793) | 0.003953 / 0.000200 (0.003753) | 0.000077 / 0.000054 (0.000023) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.022696 / 0.037411 (-0.014715) | 0.099510 / 0.014526 (0.084984) | 0.103741 / 0.176557 (-0.072816) | 0.137837 / 0.737135 (-0.599299) | 0.108776 / 0.296338 (-0.187563) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.417034 / 0.215209 (0.201825) | 4.183479 / 2.077655 (2.105824) | 1.855329 / 1.504120 (0.351209) | 1.660675 / 1.541195 (0.119481) | 1.723936 / 1.468490 (0.255446) | 0.687815 / 4.584777 (-3.896962) | 3.331280 / 3.745712 (-0.414432) | 2.821430 / 5.269862 (-2.448432) | 1.542394 / 4.565676 (-3.023283) | 0.081665 / 0.424275 (-0.342610) | 0.012483 / 0.007607 (0.004875) | 0.524758 / 0.226044 (0.298713) | 5.277285 / 2.268929 (3.008357) | 2.278067 / 55.444624 (-53.166557) | 1.923232 / 6.876477 (-4.953245) | 1.978645 / 2.142072 (-0.163428) | 0.806225 / 4.805227 (-3.999002) | 0.147568 / 6.500664 (-6.353096) | 0.064206 / 0.075469 (-0.011263) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.175079 / 1.841788 (-0.666708) | 13.677443 / 8.074308 (5.603135) | 14.064103 / 10.191392 (3.872711) | 0.167462 / 0.680424 (-0.512962) | 0.028677 / 0.534201 (-0.505524) | 0.399090 / 0.579283 (-0.180193) | 0.398930 / 0.434364 (-0.035433) | 0.461604 / 0.540337 (-0.078733) | 0.540978 / 1.386936 (-0.845958) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006846 / 0.011353 (-0.004507) | 0.004452 / 0.011008 (-0.006556) | 0.076169 / 0.038508 (0.037661) | 0.028290 / 0.023109 (0.005181) | 0.341105 / 0.275898 (0.065207) | 0.381465 / 0.323480 (0.057986) | 0.005038 / 0.007986 (-0.002948) | 0.003298 / 0.004328 (-0.001031) | 0.075794 / 0.004250 (0.071544) | 0.039225 / 0.037052 (0.002173) | 0.342995 / 0.258489 (0.084506) | 0.384878 / 0.293841 (0.091037) | 0.031766 / 0.128546 (-0.096780) | 0.011597 / 0.075646 (-0.064049) | 0.084849 / 0.419271 (-0.334423) | 0.041795 / 0.043533 (-0.001737) | 0.341770 / 0.255139 (0.086631) | 0.383142 / 0.283200 (0.099942) | 0.088854 / 0.141683 (-0.052829) | 1.465116 / 1.452155 (0.012961) | 1.566888 / 1.492716 (0.074171) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.225129 / 0.018006 (0.207123) | 0.394290 / 0.000490 (0.393801) | 0.000397 / 0.000200 (0.000197) | 0.000060 / 0.000054 (0.000006) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.025492 / 0.037411 (-0.011919) | 0.100494 / 0.014526 (0.085968) | 0.110587 / 0.176557 (-0.065969) | 0.142715 / 0.737135 (-0.594420) | 0.110962 / 0.296338 (-0.185376) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.437240 / 0.215209 (0.222031) | 4.379191 / 2.077655 (2.301536) | 2.055059 / 1.504120 (0.550939) | 1.844643 / 1.541195 (0.303448) | 1.914678 / 1.468490 (0.446188) | 0.695607 / 4.584777 (-3.889170) | 3.353845 / 3.745712 (-0.391867) | 1.837403 / 5.269862 (-3.432459) | 1.155518 / 4.565676 (-3.410158) | 0.082753 / 0.424275 (-0.341523) | 0.012812 / 0.007607 (0.005205) | 0.537304 / 0.226044 (0.311260) | 5.387425 / 2.268929 (3.118497) | 2.506986 / 55.444624 (-52.937638) | 2.159031 / 6.876477 (-4.717445) | 2.187844 / 2.142072 (0.045772) | 0.796880 / 4.805227 (-4.008347) | 0.151850 / 6.500664 (-6.348815) | 0.067577 / 0.075469 (-0.007892) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.257779 / 1.841788 (-0.584009) | 13.968842 / 8.074308 (5.894534) | 13.544220 / 10.191392 (3.352828) | 0.149962 / 0.680424 (-0.530462) | 0.016875 / 0.534201 (-0.517326) | 0.394714 / 0.579283 (-0.184570) | 0.387845 / 0.434364 (-0.046519) | 0.481674 / 0.540337 (-0.058664) | 0.569820 / 1.386936 (-0.817116) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.009745 / 0.011353 (-0.001607) | 0.005307 / 0.011008 (-0.005702) | 0.104230 / 0.038508 (0.065722) | 0.039745 / 0.023109 (0.016635) | 0.306102 / 0.275898 (0.030204) | 0.384390 / 0.323480 (0.060910) | 0.008265 / 0.007986 (0.000279) | 0.005516 / 0.004328 (0.001187) | 0.076023 / 0.004250 (0.071772) | 0.048266 / 0.037052 (0.011213) | 0.315380 / 0.258489 (0.056891) | 0.365735 / 0.293841 (0.071895) | 0.038222 / 0.128546 (-0.090324) | 0.012397 / 0.075646 (-0.063249) | 0.348964 / 0.419271 (-0.070307) | 0.047668 / 0.043533 (0.004135) | 0.301037 / 0.255139 (0.045898) | 0.322982 / 0.283200 (0.039783) | 0.109307 / 0.141683 (-0.032376) | 1.420777 / 1.452155 (-0.031378) | 1.468290 / 1.492716 (-0.024426) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.262386 / 0.018006 (0.244380) | 0.557151 / 0.000490 (0.556661) | 0.000352 / 0.000200 (0.000152) | 0.000062 / 0.000054 (0.000007) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.029508 / 0.037411 (-0.007903) | 0.113960 / 0.014526 (0.099434) | 0.123176 / 0.176557 (-0.053381) | 0.161928 / 0.737135 (-0.575207) | 0.129196 / 0.296338 (-0.167142) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.407051 / 0.215209 (0.191842) | 4.072550 / 2.077655 (1.994895) | 1.899809 / 1.504120 (0.395689) | 1.751981 / 1.541195 (0.210786) | 1.841361 / 1.468490 (0.372871) | 0.713908 / 4.584777 (-3.870869) | 3.703339 / 3.745712 (-0.042373) | 2.091283 / 5.269862 (-3.178578) | 1.323810 / 4.565676 (-3.241866) | 0.084691 / 0.424275 (-0.339584) | 0.012685 / 0.007607 (0.005078) | 0.511301 / 0.226044 (0.285257) | 5.109741 / 2.268929 (2.840813) | 2.315073 / 55.444624 (-53.129551) | 2.012746 / 6.876477 (-4.863731) | 2.160074 / 2.142072 (0.018002) | 0.853025 / 4.805227 (-3.952202) | 0.165301 / 6.500664 (-6.335363) | 0.062244 / 0.075469 (-0.013225) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.219727 / 1.841788 (-0.622061) | 15.319675 / 8.074308 (7.245367) | 13.100883 / 10.191392 (2.909491) | 0.173451 / 0.680424 (-0.506973) | 0.029173 / 0.534201 (-0.505028) | 0.440162 / 0.579283 (-0.139122) | 0.429771 / 0.434364 (-0.004593) | 0.518689 / 0.540337 (-0.021648) | 0.608590 / 1.386936 (-0.778346) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.007839 / 0.011353 (-0.003514) | 0.005409 / 0.011008 (-0.005599) | 0.076468 / 0.038508 (0.037960) | 0.036568 / 0.023109 (0.013459) | 0.337568 / 0.275898 (0.061670) | 0.379353 / 0.323480 (0.055873) | 0.006208 / 0.007986 (-0.001778) | 0.005971 / 0.004328 (0.001643) | 0.073765 / 0.004250 (0.069514) | 0.056609 / 0.037052 (0.019556) | 0.344578 / 0.258489 (0.086089) | 0.405249 / 0.293841 (0.111408) | 0.037652 / 0.128546 (-0.090894) | 0.012549 / 0.075646 (-0.063097) | 0.087086 / 0.419271 (-0.332186) | 0.056669 / 0.043533 (0.013136) | 0.334121 / 0.255139 (0.078983) | 0.354582 / 0.283200 (0.071383) | 0.113293 / 0.141683 (-0.028390) | 1.437327 / 1.452155 (-0.014828) | 1.574400 / 1.492716 (0.081684) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.325235 / 0.018006 (0.307229) | 0.535405 / 0.000490 (0.534915) | 0.014119 / 0.000200 (0.013919) | 0.000278 / 0.000054 (0.000224) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.030826 / 0.037411 (-0.006585) | 0.114077 / 0.014526 (0.099552) | 0.128799 / 0.176557 (-0.047758) | 0.172164 / 0.737135 (-0.564971) | 0.133665 / 0.296338 (-0.162673) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.430898 / 0.215209 (0.215689) | 4.285507 / 2.077655 (2.207853) | 2.089767 / 1.504120 (0.585647) | 1.899457 / 1.541195 (0.358262) | 2.042875 / 1.468490 (0.574385) | 0.690575 / 4.584777 (-3.894202) | 3.815905 / 3.745712 (0.070192) | 3.371085 / 5.269862 (-1.898776) | 1.865748 / 4.565676 (-2.699929) | 0.086678 / 0.424275 (-0.337597) | 0.013172 / 0.007607 (0.005565) | 0.552038 / 0.226044 (0.325994) | 5.275093 / 2.268929 (3.006165) | 2.561102 / 55.444624 (-52.883522) | 2.224235 / 6.876477 (-4.652242) | 2.330315 / 2.142072 (0.188243) | 0.845163 / 4.805227 (-3.960064) | 0.170675 / 6.500664 (-6.329989) | 0.068446 / 0.075469 (-0.007023) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.261213 / 1.841788 (-0.580575) | 15.354959 / 8.074308 (7.280651) | 15.034302 / 10.191392 (4.842910) | 0.146704 / 0.680424 (-0.533720) | 0.017986 / 0.534201 (-0.516215) | 0.425978 / 0.579283 (-0.153305) | 0.421806 / 0.434364 (-0.012558) | 0.494844 / 0.540337 (-0.045493) | 0.587870 / 1.386936 (-0.799066) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.012765 / 0.011353 (0.001412) | 0.006429 / 0.011008 (-0.004579) | 0.133669 / 0.038508 (0.095161) | 0.041420 / 0.023109 (0.018311) | 0.419990 / 0.275898 (0.144092) | 0.505218 / 0.323480 (0.181738) | 0.010189 / 0.007986 (0.002204) | 0.005134 / 0.004328 (0.000805) | 0.100890 / 0.004250 (0.096640) | 0.045639 / 0.037052 (0.008587) | 0.440593 / 0.258489 (0.182103) | 0.476966 / 0.293841 (0.183125) | 0.059270 / 0.128546 (-0.069276) | 0.018625 / 0.075646 (-0.057021) | 0.444957 / 0.419271 (0.025686) | 0.060669 / 0.043533 (0.017136) | 0.415373 / 0.255139 (0.160234) | 0.461810 / 0.283200 (0.178610) | 0.116119 / 0.141683 (-0.025564) | 1.873691 / 1.452155 (0.421536) | 1.939891 / 1.492716 (0.447175) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.259529 / 0.018006 (0.241523) | 0.587213 / 0.000490 (0.586723) | 0.003729 / 0.000200 (0.003529) | 0.000115 / 0.000054 (0.000060) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.032064 / 0.037411 (-0.005347) | 0.140228 / 0.014526 (0.125702) | 0.147139 / 0.176557 (-0.029417) | 0.193731 / 0.737135 (-0.543405) | 0.162126 / 0.296338 (-0.134213) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.639262 / 0.215209 (0.424053) | 6.496491 / 2.077655 (4.418836) | 2.602044 / 1.504120 (1.097924) | 2.245891 / 1.541195 (0.704696) | 2.301321 / 1.468490 (0.832831) | 1.234088 / 4.584777 (-3.350689) | 5.883315 / 3.745712 (2.137603) | 3.166902 / 5.269862 (-2.102959) | 2.258279 / 4.565676 (-2.307398) | 0.146203 / 0.424275 (-0.278072) | 0.015490 / 0.007607 (0.007883) | 0.800188 / 0.226044 (0.574144) | 8.150866 / 2.268929 (5.881938) | 3.419508 / 55.444624 (-52.025117) | 2.712174 / 6.876477 (-4.164302) | 2.805059 / 2.142072 (0.662987) | 1.421047 / 4.805227 (-3.384180) | 0.254274 / 6.500664 (-6.246390) | 0.083886 / 0.075469 (0.008417) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.651962 / 1.841788 (-0.189826) | 19.453202 / 8.074308 (11.378894) | 24.643881 / 10.191392 (14.452489) | 0.263612 / 0.680424 (-0.416812) | 0.046913 / 0.534201 (-0.487288) | 0.579861 / 0.579283 (0.000578) | 0.695137 / 0.434364 (0.260773) | 0.705479 / 0.540337 (0.165142) | 0.806073 / 1.386936 (-0.580863) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.010384 / 0.011353 (-0.000969) | 0.007460 / 0.011008 (-0.003548) | 0.107830 / 0.038508 (0.069322) | 0.036792 / 0.023109 (0.013682) | 0.469585 / 0.275898 (0.193687) | 0.521278 / 0.323480 (0.197798) | 0.007472 / 0.007986 (-0.000513) | 0.007774 / 0.004328 (0.003446) | 0.105405 / 0.004250 (0.101154) | 0.053732 / 0.037052 (0.016680) | 0.486299 / 0.258489 (0.227810) | 0.537067 / 0.293841 (0.243226) | 0.053378 / 0.128546 (-0.075168) | 0.022018 / 0.075646 (-0.053628) | 0.127765 / 0.419271 (-0.291507) | 0.063844 / 0.043533 (0.020311) | 0.479724 / 0.255139 (0.224585) | 0.511243 / 0.283200 (0.228043) | 0.123223 / 0.141683 (-0.018460) | 1.934167 / 1.452155 (0.482013) | 2.003168 / 1.492716 (0.510451) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.227670 / 0.018006 (0.209664) | 0.609125 / 0.000490 (0.608635) | 0.004408 / 0.000200 (0.004208) | 0.000147 / 0.000054 (0.000092) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.035905 / 0.037411 (-0.001506) | 0.142207 / 0.014526 (0.127681) | 0.154749 / 0.176557 (-0.021808) | 0.216191 / 0.737135 (-0.520944) | 0.156577 / 0.296338 (-0.139761) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.665085 / 0.215209 (0.449876) | 6.510923 / 2.077655 (4.433269) | 2.902438 / 1.504120 (1.398318) | 2.561427 / 1.541195 (1.020232) | 2.669556 / 1.468490 (1.201066) | 1.190340 / 4.584777 (-3.394437) | 5.933066 / 3.745712 (2.187354) | 5.627784 / 5.269862 (0.357922) | 2.971922 / 4.565676 (-1.593755) | 0.140884 / 0.424275 (-0.283391) | 0.015382 / 0.007607 (0.007775) | 0.810441 / 0.226044 (0.584396) | 8.255538 / 2.268929 (5.986609) | 3.819014 / 55.444624 (-51.625611) | 3.222479 / 6.876477 (-3.653998) | 3.181700 / 2.142072 (1.039627) | 1.483403 / 4.805227 (-3.321824) | 0.262726 / 6.500664 (-6.237939) | 0.090252 / 0.075469 (0.014783) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.748566 / 1.841788 (-0.093222) | 19.566894 / 8.074308 (11.492586) | 24.382155 / 10.191392 (14.190763) | 0.260118 / 0.680424 (-0.420305) | 0.028725 / 0.534201 (-0.505476) | 0.564875 / 0.579283 (-0.014408) | 0.666708 / 0.434364 (0.232344) | 0.691165 / 0.540337 (0.150827) | 0.837061 / 1.386936 (-0.549875) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.010098 / 0.011353 (-0.001255) | 0.005797 / 0.011008 (-0.005211) | 0.111262 / 0.038508 (0.072754) | 0.039687 / 0.023109 (0.016578) | 0.331081 / 0.275898 (0.055183) | 0.395878 / 0.323480 (0.072398) | 0.009244 / 0.007986 (0.001259) | 0.004498 / 0.004328 (0.000170) | 0.086129 / 0.004250 (0.081879) | 0.046662 / 0.037052 (0.009610) | 0.361926 / 0.258489 (0.103437) | 0.386155 / 0.293841 (0.092314) | 0.043657 / 0.128546 (-0.084889) | 0.013545 / 0.075646 (-0.062101) | 0.383735 / 0.419271 (-0.035537) | 0.055727 / 0.043533 (0.012194) | 0.355356 / 0.255139 (0.100217) | 0.358749 / 0.283200 (0.075550) | 0.123219 / 0.141683 (-0.018463) | 1.707982 / 1.452155 (0.255828) | 1.773342 / 1.492716 (0.280626) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.238902 / 0.018006 (0.220896) | 0.495525 / 0.000490 (0.495036) | 0.001742 / 0.000200 (0.001542) | 0.000096 / 0.000054 (0.000041) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.031276 / 0.037411 (-0.006135) | 0.124286 / 0.014526 (0.109760) | 0.136236 / 0.176557 (-0.040321) | 0.180257 / 0.737135 (-0.556879) | 0.141047 / 0.296338 (-0.155292) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.465075 / 0.215209 (0.249865) | 4.543997 / 2.077655 (2.466342) | 2.036632 / 1.504120 (0.532512) | 1.820356 / 1.541195 (0.279161) | 1.860692 / 1.468490 (0.392202) | 0.807549 / 4.584777 (-3.777227) | 4.400369 / 3.745712 (0.654657) | 2.423372 / 5.269862 (-2.846490) | 1.741338 / 4.565676 (-2.824339) | 0.099457 / 0.424275 (-0.324818) | 0.014464 / 0.007607 (0.006857) | 0.599442 / 0.226044 (0.373398) | 5.867798 / 2.268929 (3.598870) | 2.641859 / 55.444624 (-52.802766) | 2.294246 / 6.876477 (-4.582231) | 2.329639 / 2.142072 (0.187567) | 0.981897 / 4.805227 (-3.823331) | 0.189278 / 6.500664 (-6.311386) | 0.071868 / 0.075469 (-0.003601) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.471800 / 1.841788 (-0.369988) | 17.149150 / 8.074308 (9.074841) | 15.818942 / 10.191392 (5.627550) | 0.174760 / 0.680424 (-0.505664) | 0.033507 / 0.534201 (-0.500694) | 0.511055 / 0.579283 (-0.068228) | 0.517107 / 0.434364 (0.082743) | 0.650813 / 0.540337 (0.110476) | 0.752515 / 1.386936 (-0.634421) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008651 / 0.011353 (-0.002702) | 0.005935 / 0.011008 (-0.005073) | 0.088589 / 0.038508 (0.050081) | 0.038796 / 0.023109 (0.015687) | 0.415430 / 0.275898 (0.139532) | 0.443693 / 0.323480 (0.120213) | 0.006631 / 0.007986 (-0.001354) | 0.004638 / 0.004328 (0.000309) | 0.085779 / 0.004250 (0.081529) | 0.053994 / 0.037052 (0.016942) | 0.408349 / 0.258489 (0.149860) | 0.475441 / 0.293841 (0.181600) | 0.042792 / 0.128546 (-0.085754) | 0.013938 / 0.075646 (-0.061709) | 0.102173 / 0.419271 (-0.317098) | 0.057940 / 0.043533 (0.014407) | 0.408967 / 0.255139 (0.153828) | 0.422741 / 0.283200 (0.139541) | 0.121844 / 0.141683 (-0.019839) | 1.772779 / 1.452155 (0.320625) | 1.837706 / 1.492716 (0.344989) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.228896 / 0.018006 (0.210890) | 0.497964 / 0.000490 (0.497475) | 0.004402 / 0.000200 (0.004202) | 0.000112 / 0.000054 (0.000057) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.035626 / 0.037411 (-0.001786) | 0.132021 / 0.014526 (0.117495) | 0.145599 / 0.176557 (-0.030957) | 0.192317 / 0.737135 (-0.544818) | 0.150165 / 0.296338 (-0.146174) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.500216 / 0.215209 (0.285007) | 5.002916 / 2.077655 (2.925262) | 2.502439 / 1.504120 (0.998319) | 2.353019 / 1.541195 (0.811825) | 2.485082 / 1.468490 (1.016592) | 0.827694 / 4.584777 (-3.757083) | 4.569319 / 3.745712 (0.823607) | 3.739820 / 5.269862 (-1.530042) | 2.097857 / 4.565676 (-2.467819) | 0.098636 / 0.424275 (-0.325639) | 0.014608 / 0.007607 (0.007001) | 0.604411 / 0.226044 (0.378366) | 6.131702 / 2.268929 (3.862774) | 3.043988 / 55.444624 (-52.400637) | 2.642427 / 6.876477 (-4.234050) | 2.687223 / 2.142072 (0.545151) | 0.968808 / 4.805227 (-3.836419) | 0.193876 / 6.500664 (-6.306788) | 0.076931 / 0.075469 (0.001462) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.511820 / 1.841788 (-0.329968) | 17.971574 / 8.074308 (9.897265) | 16.512738 / 10.191392 (6.321346) | 0.223702 / 0.680424 (-0.456722) | 0.020191 / 0.534201 (-0.514010) | 0.511045 / 0.579283 (-0.068238) | 0.499813 / 0.434364 (0.065449) | 0.642147 / 0.540337 (0.101810) | 0.756029 / 1.386936 (-0.630907) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008909 / 0.011353 (-0.002444) | 0.005096 / 0.011008 (-0.005912) | 0.098568 / 0.038508 (0.060060) | 0.034548 / 0.023109 (0.011438) | 0.294762 / 0.275898 (0.018864) | 0.366093 / 0.323480 (0.042613) | 0.007476 / 0.007986 (-0.000510) | 0.003982 / 0.004328 (-0.000347) | 0.075975 / 0.004250 (0.071725) | 0.040499 / 0.037052 (0.003446) | 0.315050 / 0.258489 (0.056561) | 0.351273 / 0.293841 (0.057433) | 0.038327 / 0.128546 (-0.090219) | 0.011943 / 0.075646 (-0.063703) | 0.332148 / 0.419271 (-0.087124) | 0.047648 / 0.043533 (0.004115) | 0.295817 / 0.255139 (0.040678) | 0.322704 / 0.283200 (0.039504) | 0.100830 / 0.141683 (-0.040853) | 1.422162 / 1.452155 (-0.029993) | 1.468972 / 1.492716 (-0.023744) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.201164 / 0.018006 (0.183158) | 0.435425 / 0.000490 (0.434935) | 0.001576 / 0.000200 (0.001376) | 0.000218 / 0.000054 (0.000163) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.026667 / 0.037411 (-0.010744) | 0.106161 / 0.014526 (0.091636) | 0.115836 / 0.176557 (-0.060720) | 0.151511 / 0.737135 (-0.585624) | 0.122248 / 0.296338 (-0.174091) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.395974 / 0.215209 (0.180765) | 3.952958 / 2.077655 (1.875303) | 1.772111 / 1.504120 (0.267991) | 1.581370 / 1.541195 (0.040175) | 1.602811 / 1.468490 (0.134321) | 0.694072 / 4.584777 (-3.890705) | 3.640238 / 3.745712 (-0.105474) | 2.028865 / 5.269862 (-3.240997) | 1.419182 / 4.565676 (-3.146495) | 0.084078 / 0.424275 (-0.340197) | 0.012248 / 0.007607 (0.004641) | 0.499768 / 0.226044 (0.273723) | 4.997449 / 2.268929 (2.728521) | 2.280711 / 55.444624 (-53.163913) | 1.971701 / 6.876477 (-4.904776) | 1.983248 / 2.142072 (-0.158824) | 0.831030 / 4.805227 (-3.974198) | 0.163008 / 6.500664 (-6.337656) | 0.061887 / 0.075469 (-0.013582) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.191744 / 1.841788 (-0.650043) | 14.424546 / 8.074308 (6.350238) | 14.530127 / 10.191392 (4.338735) | 0.165793 / 0.680424 (-0.514631) | 0.029099 / 0.534201 (-0.505102) | 0.447830 / 0.579283 (-0.131453) | 0.441036 / 0.434364 (0.006672) | 0.554697 / 0.540337 (0.014360) | 0.668854 / 1.386936 (-0.718082) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006825 / 0.011353 (-0.004528) | 0.004998 / 0.011008 (-0.006010) | 0.074197 / 0.038508 (0.035689) | 0.032381 / 0.023109 (0.009272) | 0.335745 / 0.275898 (0.059847) | 0.360474 / 0.323480 (0.036994) | 0.005420 / 0.007986 (-0.002566) | 0.005121 / 0.004328 (0.000792) | 0.074980 / 0.004250 (0.070730) | 0.046392 / 0.037052 (0.009340) | 0.338693 / 0.258489 (0.080204) | 0.383679 / 0.293841 (0.089838) | 0.035380 / 0.128546 (-0.093166) | 0.012197 / 0.075646 (-0.063449) | 0.085738 / 0.419271 (-0.333533) | 0.049990 / 0.043533 (0.006458) | 0.342640 / 0.255139 (0.087501) | 0.355139 / 0.283200 (0.071939) | 0.102992 / 0.141683 (-0.038690) | 1.451900 / 1.452155 (-0.000254) | 1.550919 / 1.492716 (0.058202) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.223241 / 0.018006 (0.205235) | 0.436954 / 0.000490 (0.436464) | 0.003319 / 0.000200 (0.003120) | 0.000088 / 0.000054 (0.000034) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.028042 / 0.037411 (-0.009370) | 0.106079 / 0.014526 (0.091554) | 0.122713 / 0.176557 (-0.053843) | 0.156543 / 0.737135 (-0.580593) | 0.122424 / 0.296338 (-0.173914) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.439482 / 0.215209 (0.224273) | 4.283112 / 2.077655 (2.205457) | 2.139705 / 1.504120 (0.635585) | 1.940898 / 1.541195 (0.399703) | 2.003906 / 1.468490 (0.535416) | 0.703269 / 4.584777 (-3.881508) | 3.780391 / 3.745712 (0.034679) | 2.079963 / 5.269862 (-3.189898) | 1.330669 / 4.565676 (-3.235007) | 0.086582 / 0.424275 (-0.337693) | 0.012497 / 0.007607 (0.004890) | 0.519329 / 0.226044 (0.293284) | 5.218117 / 2.268929 (2.949189) | 2.635982 / 55.444624 (-52.808643) | 2.301111 / 6.876477 (-4.575366) | 2.341312 / 2.142072 (0.199239) | 0.840157 / 4.805227 (-3.965070) | 0.166174 / 6.500664 (-6.334490) | 0.062890 / 0.075469 (-0.012579) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.257672 / 1.841788 (-0.584116) | 14.983374 / 8.074308 (6.909066) | 14.284441 / 10.191392 (4.093049) | 0.176077 / 0.680424 (-0.504347) | 0.017544 / 0.534201 (-0.516657) | 0.429619 / 0.579283 (-0.149664) | 0.426371 / 0.434364 (-0.007993) | 0.534832 / 0.540337 (-0.005506) | 0.643322 / 1.386936 (-0.743614) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.010622 / 0.011353 (-0.000731) | 0.005856 / 0.011008 (-0.005152) | 0.108608 / 0.038508 (0.070100) | 0.039868 / 0.023109 (0.016759) | 0.327853 / 0.275898 (0.051955) | 0.396721 / 0.323480 (0.073241) | 0.008916 / 0.007986 (0.000930) | 0.004590 / 0.004328 (0.000261) | 0.085020 / 0.004250 (0.080770) | 0.046608 / 0.037052 (0.009555) | 0.356369 / 0.258489 (0.097880) | 0.391142 / 0.293841 (0.097301) | 0.040579 / 0.128546 (-0.087967) | 0.012249 / 0.075646 (-0.063397) | 0.387740 / 0.419271 (-0.031532) | 0.057794 / 0.043533 (0.014262) | 0.335763 / 0.255139 (0.080624) | 0.369847 / 0.283200 (0.086647) | 0.121276 / 0.141683 (-0.020407) | 1.605406 / 1.452155 (0.153251) | 1.709524 / 1.492716 (0.216808) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.226688 / 0.018006 (0.208681) | 0.493320 / 0.000490 (0.492831) | 0.002825 / 0.000200 (0.002626) | 0.000088 / 0.000054 (0.000033) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.031874 / 0.037411 (-0.005538) | 0.117365 / 0.014526 (0.102840) | 0.127697 / 0.176557 (-0.048859) | 0.175589 / 0.737135 (-0.561546) | 0.137731 / 0.296338 (-0.158608) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.472563 / 0.215209 (0.257354) | 4.744383 / 2.077655 (2.666728) | 2.152015 / 1.504120 (0.647895) | 1.925398 / 1.541195 (0.384203) | 2.054613 / 1.468490 (0.586123) | 0.821703 / 4.584777 (-3.763074) | 4.468177 / 3.745712 (0.722465) | 4.687682 / 5.269862 (-0.582179) | 2.379674 / 4.565676 (-2.186003) | 0.101325 / 0.424275 (-0.322950) | 0.014891 / 0.007607 (0.007284) | 0.593161 / 0.226044 (0.367117) | 5.641670 / 2.268929 (3.372741) | 2.460206 / 55.444624 (-52.984419) | 2.131148 / 6.876477 (-4.745329) | 2.351067 / 2.142072 (0.208994) | 0.997634 / 4.805227 (-3.807593) | 0.195338 / 6.500664 (-6.305326) | 0.075540 / 0.075469 (0.000071) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.411585 / 1.841788 (-0.430203) | 17.055689 / 8.074308 (8.981381) | 16.544028 / 10.191392 (6.352636) | 0.180840 / 0.680424 (-0.499584) | 0.034549 / 0.534201 (-0.499652) | 0.510256 / 0.579283 (-0.069027) | 0.525632 / 0.434364 (0.091268) | 0.601206 / 0.540337 (0.060868) | 0.668468 / 1.386936 (-0.718469) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008989 / 0.011353 (-0.002364) | 0.006065 / 0.011008 (-0.004943) | 0.088294 / 0.038508 (0.049786) | 0.040404 / 0.023109 (0.017295) | 0.405622 / 0.275898 (0.129724) | 0.454519 / 0.323480 (0.131039) | 0.006919 / 0.007986 (-0.001067) | 0.004545 / 0.004328 (0.000217) | 0.087023 / 0.004250 (0.082772) | 0.055962 / 0.037052 (0.018910) | 0.400942 / 0.258489 (0.142453) | 0.490670 / 0.293841 (0.196829) | 0.044086 / 0.128546 (-0.084461) | 0.014485 / 0.075646 (-0.061162) | 0.103333 / 0.419271 (-0.315938) | 0.059663 / 0.043533 (0.016130) | 0.404944 / 0.255139 (0.149805) | 0.425763 / 0.283200 (0.142563) | 0.123989 / 0.141683 (-0.017694) | 1.777244 / 1.452155 (0.325089) | 1.879884 / 1.492716 (0.387167) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.226440 / 0.018006 (0.208434) | 0.492688 / 0.000490 (0.492198) | 0.004691 / 0.000200 (0.004491) | 0.000110 / 0.000054 (0.000055) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.035123 / 0.037411 (-0.002288) | 0.134288 / 0.014526 (0.119762) | 0.145542 / 0.176557 (-0.031015) | 0.195372 / 0.737135 (-0.541764) | 0.152551 / 0.296338 (-0.143787) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.468615 / 0.215209 (0.253406) | 4.813363 / 2.077655 (2.735708) | 2.333606 / 1.504120 (0.829486) | 2.107344 / 1.541195 (0.566149) | 2.109109 / 1.468490 (0.640619) | 0.783779 / 4.584777 (-3.800998) | 4.521448 / 3.745712 (0.775736) | 2.290532 / 5.269862 (-2.979329) | 1.553488 / 4.565676 (-3.012189) | 0.088786 / 0.424275 (-0.335489) | 0.013091 / 0.007607 (0.005484) | 0.567165 / 0.226044 (0.341120) | 5.974315 / 2.268929 (3.705386) | 2.815018 / 55.444624 (-52.629606) | 2.488954 / 6.876477 (-4.387522) | 2.461849 / 2.142072 (0.319776) | 0.934487 / 4.805227 (-3.870740) | 0.190209 / 6.500664 (-6.310455) | 0.074811 / 0.075469 (-0.000658) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.513476 / 1.841788 (-0.328311) | 17.902599 / 8.074308 (9.828291) | 14.308027 / 10.191392 (4.116635) | 0.201992 / 0.680424 (-0.478432) | 0.018678 / 0.534201 (-0.515523) | 0.454707 / 0.579283 (-0.124576) | 0.470643 / 0.434364 (0.036279) | 0.612534 / 0.540337 (0.072197) | 0.685773 / 1.386936 (-0.701163) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.009385 / 0.011353 (-0.001968) | 0.005220 / 0.011008 (-0.005788) | 0.098722 / 0.038508 (0.060214) | 0.035382 / 0.023109 (0.012273) | 0.297114 / 0.275898 (0.021216) | 0.371443 / 0.323480 (0.047963) | 0.008070 / 0.007986 (0.000084) | 0.004204 / 0.004328 (-0.000125) | 0.075621 / 0.004250 (0.071370) | 0.046015 / 0.037052 (0.008963) | 0.304569 / 0.258489 (0.046080) | 0.345598 / 0.293841 (0.051757) | 0.037946 / 0.128546 (-0.090600) | 0.011972 / 0.075646 (-0.063674) | 0.331993 / 0.419271 (-0.087279) | 0.047250 / 0.043533 (0.003717) | 0.296588 / 0.255139 (0.041449) | 0.316070 / 0.283200 (0.032870) | 0.108211 / 0.141683 (-0.033472) | 1.447619 / 1.452155 (-0.004535) | 1.481243 / 1.492716 (-0.011473) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.274860 / 0.018006 (0.256854) | 0.503139 / 0.000490 (0.502649) | 0.003598 / 0.000200 (0.003398) | 0.000081 / 0.000054 (0.000027) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.026752 / 0.037411 (-0.010660) | 0.109008 / 0.014526 (0.094482) | 0.119109 / 0.176557 (-0.057448) | 0.158462 / 0.737135 (-0.578673) | 0.126171 / 0.296338 (-0.170168) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.396396 / 0.215209 (0.181187) | 3.963055 / 2.077655 (1.885400) | 1.796308 / 1.504120 (0.292188) | 1.600565 / 1.541195 (0.059370) | 1.742409 / 1.468490 (0.273919) | 0.690942 / 4.584777 (-3.893835) | 3.713343 / 3.745712 (-0.032369) | 2.066804 / 5.269862 (-3.203058) | 1.292946 / 4.565676 (-3.272730) | 0.084344 / 0.424275 (-0.339931) | 0.012473 / 0.007607 (0.004865) | 0.513109 / 0.226044 (0.287065) | 5.175141 / 2.268929 (2.906213) | 2.266559 / 55.444624 (-53.178066) | 1.935737 / 6.876477 (-4.940740) | 2.028911 / 2.142072 (-0.113161) | 0.831191 / 4.805227 (-3.974036) | 0.163155 / 6.500664 (-6.337509) | 0.063414 / 0.075469 (-0.012055) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.195429 / 1.841788 (-0.646358) | 15.257933 / 8.074308 (7.183625) | 14.358815 / 10.191392 (4.167423) | 0.152677 / 0.680424 (-0.527747) | 0.028890 / 0.534201 (-0.505311) | 0.455342 / 0.579283 (-0.123941) | 0.442602 / 0.434364 (0.008238) | 0.526833 / 0.540337 (-0.013505) | 0.618296 / 1.386936 (-0.768640) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.007613 / 0.011353 (-0.003740) | 0.005515 / 0.011008 (-0.005493) | 0.073759 / 0.038508 (0.035251) | 0.033944 / 0.023109 (0.010835) | 0.347764 / 0.275898 (0.071866) | 0.371143 / 0.323480 (0.047664) | 0.005997 / 0.007986 (-0.001988) | 0.004322 / 0.004328 (-0.000006) | 0.073002 / 0.004250 (0.068751) | 0.053051 / 0.037052 (0.015999) | 0.340345 / 0.258489 (0.081856) | 0.383761 / 0.293841 (0.089920) | 0.037734 / 0.128546 (-0.090813) | 0.012815 / 0.075646 (-0.062831) | 0.086998 / 0.419271 (-0.332273) | 0.050165 / 0.043533 (0.006632) | 0.343864 / 0.255139 (0.088725) | 0.356734 / 0.283200 (0.073534) | 0.108955 / 0.141683 (-0.032728) | 1.464558 / 1.452155 (0.012403) | 1.560084 / 1.492716 (0.067368) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.327885 / 0.018006 (0.309878) | 0.515515 / 0.000490 (0.515025) | 0.000439 / 0.000200 (0.000239) | 0.000059 / 0.000054 (0.000004) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.030741 / 0.037411 (-0.006670) | 0.107634 / 0.014526 (0.093108) | 0.127121 / 0.176557 (-0.049436) | 0.164044 / 0.737135 (-0.573092) | 0.129097 / 0.296338 (-0.167242) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.435690 / 0.215209 (0.220481) | 4.350705 / 2.077655 (2.273050) | 2.199597 / 1.504120 (0.695477) | 2.022715 / 1.541195 (0.481521) | 2.265907 / 1.468490 (0.797417) | 0.695817 / 4.584777 (-3.888960) | 3.795207 / 3.745712 (0.049494) | 3.061587 / 5.269862 (-2.208274) | 1.872213 / 4.565676 (-2.693463) | 0.085265 / 0.424275 (-0.339010) | 0.012243 / 0.007607 (0.004636) | 0.547209 / 0.226044 (0.321164) | 5.383626 / 2.268929 (3.114698) | 2.707439 / 55.444624 (-52.737185) | 2.393773 / 6.876477 (-4.482703) | 2.481385 / 2.142072 (0.339312) | 0.826169 / 4.805227 (-3.979059) | 0.166643 / 6.500664 (-6.334021) | 0.065817 / 0.075469 (-0.009652) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.274469 / 1.841788 (-0.567318) | 15.565025 / 8.074308 (7.490717) | 14.254192 / 10.191392 (4.062800) | 0.166785 / 0.680424 (-0.513639) | 0.017830 / 0.534201 (-0.516371) | 0.430406 / 0.579283 (-0.148877) | 0.435655 / 0.434364 (0.001292) | 0.530605 / 0.540337 (-0.009732) | 0.636355 / 1.386936 (-0.750581) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008466 / 0.011353 (-0.002887) | 0.004679 / 0.011008 (-0.006329) | 0.100534 / 0.038508 (0.062025) | 0.029513 / 0.023109 (0.006403) | 0.302866 / 0.275898 (0.026968) | 0.352816 / 0.323480 (0.029336) | 0.006912 / 0.007986 (-0.001074) | 0.003513 / 0.004328 (-0.000815) | 0.078625 / 0.004250 (0.074375) | 0.036725 / 0.037052 (-0.000327) | 0.312135 / 0.258489 (0.053646) | 0.344579 / 0.293841 (0.050738) | 0.033870 / 0.128546 (-0.094677) | 0.011563 / 0.075646 (-0.064083) | 0.318982 / 0.419271 (-0.100290) | 0.043002 / 0.043533 (-0.000531) | 0.301956 / 0.255139 (0.046817) | 0.330798 / 0.283200 (0.047599) | 0.091755 / 0.141683 (-0.049927) | 1.458577 / 1.452155 (0.006422) | 1.532642 / 1.492716 (0.039926) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.194853 / 0.018006 (0.176847) | 0.396844 / 0.000490 (0.396354) | 0.004401 / 0.000200 (0.004201) | 0.000076 / 0.000054 (0.000022) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.022971 / 0.037411 (-0.014441) | 0.096595 / 0.014526 (0.082069) | 0.106104 / 0.176557 (-0.070452) | 0.144815 / 0.737135 (-0.592320) | 0.110036 / 0.296338 (-0.186303) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.415025 / 0.215209 (0.199816) | 4.138136 / 2.077655 (2.060481) | 1.861253 / 1.504120 (0.357133) | 1.653420 / 1.541195 (0.112226) | 1.703784 / 1.468490 (0.235294) | 0.698261 / 4.584777 (-3.886516) | 3.357240 / 3.745712 (-0.388472) | 3.025790 / 5.269862 (-2.244072) | 1.637191 / 4.565676 (-2.928485) | 0.085620 / 0.424275 (-0.338655) | 0.012454 / 0.007607 (0.004846) | 0.524708 / 0.226044 (0.298663) | 5.269234 / 2.268929 (3.000306) | 2.290612 / 55.444624 (-53.154012) | 1.936107 / 6.876477 (-4.940370) | 1.968216 / 2.142072 (-0.173856) | 0.810438 / 4.805227 (-3.994789) | 0.154133 / 6.500664 (-6.346531) | 0.064978 / 0.075469 (-0.010491) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.231782 / 1.841788 (-0.610006) | 13.545573 / 8.074308 (5.471264) | 14.558765 / 10.191392 (4.367373) | 0.140763 / 0.680424 (-0.539661) | 0.029259 / 0.534201 (-0.504942) | 0.407776 / 0.579283 (-0.171507) | 0.410244 / 0.434364 (-0.024120) | 0.477313 / 0.540337 (-0.063024) | 0.551465 / 1.386936 (-0.835471) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006272 / 0.011353 (-0.005081) | 0.004397 / 0.011008 (-0.006611) | 0.077496 / 0.038508 (0.038988) | 0.026946 / 0.023109 (0.003837) | 0.342992 / 0.275898 (0.067094) | 0.374407 / 0.323480 (0.050927) | 0.004849 / 0.007986 (-0.003136) | 0.004549 / 0.004328 (0.000220) | 0.076439 / 0.004250 (0.072189) | 0.035829 / 0.037052 (-0.001224) | 0.343483 / 0.258489 (0.084994) | 0.385581 / 0.293841 (0.091740) | 0.031745 / 0.128546 (-0.096801) | 0.011617 / 0.075646 (-0.064030) | 0.087207 / 0.419271 (-0.332064) | 0.042252 / 0.043533 (-0.001281) | 0.343223 / 0.255139 (0.088084) | 0.368707 / 0.283200 (0.085508) | 0.093259 / 0.141683 (-0.048424) | 1.506904 / 1.452155 (0.054750) | 1.567583 / 1.492716 (0.074867) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.158962 / 0.018006 (0.140955) | 0.395982 / 0.000490 (0.395492) | 0.003604 / 0.000200 (0.003404) | 0.000078 / 0.000054 (0.000023) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.025003 / 0.037411 (-0.012408) | 0.101176 / 0.014526 (0.086650) | 0.104494 / 0.176557 (-0.072062) | 0.140414 / 0.737135 (-0.596722) | 0.108398 / 0.296338 (-0.187941) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.436849 / 0.215209 (0.221640) | 4.369428 / 2.077655 (2.291774) | 2.070613 / 1.504120 (0.566493) | 1.867511 / 1.541195 (0.326317) | 1.866589 / 1.468490 (0.398099) | 0.700036 / 4.584777 (-3.884741) | 3.407513 / 3.745712 (-0.338199) | 3.022409 / 5.269862 (-2.247453) | 1.581423 / 4.565676 (-2.984253) | 0.083425 / 0.424275 (-0.340850) | 0.012380 / 0.007607 (0.004773) | 0.535087 / 0.226044 (0.309043) | 5.374814 / 2.268929 (3.105886) | 2.504841 / 55.444624 (-52.939784) | 2.166484 / 6.876477 (-4.709993) | 2.166363 / 2.142072 (0.024291) | 0.803692 / 4.805227 (-4.001535) | 0.150873 / 6.500664 (-6.349791) | 0.066253 / 0.075469 (-0.009216) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.291256 / 1.841788 (-0.550532) | 13.827843 / 8.074308 (5.753535) | 13.839334 / 10.191392 (3.647942) | 0.153530 / 0.680424 (-0.526894) | 0.016896 / 0.534201 (-0.517305) | 0.379937 / 0.579283 (-0.199346) | 0.396241 / 0.434364 (-0.038123) | 0.461808 / 0.540337 (-0.078530) | 0.553023 / 1.386936 (-0.833913) |\n\n</details>\n</details>\n\n\n"
] | 1,674,478,180,000 | 1,676,319,814,000 | 1,676,319,398,000 | CONTRIBUTOR | null | Use the "shard generator approach with periodic progress updates" (used in `save_to_disk` and multi-proc `load_dataset`) in `Dataset.map` to enable having a single TQDM progress bar in the multi-proc mode.
Closes https://github.com/huggingface/datasets/issues/771, closes https://github.com/huggingface/datasets/issues/3177
TODO:
- [x] cleaner refactor of the `_map_single` decorators now that they also have to wrap generator functions (decorate `map` instead of `map_single` with the `transmit_` decorators and predict the shards' fingerprint in `map`) | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5455/reactions",
"total_count": 2,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 1,
"rocket": 1,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5455/timeline | null | null | 0 | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5455",
"html_url": "https://github.com/huggingface/datasets/pull/5455",
"diff_url": "https://github.com/huggingface/datasets/pull/5455.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5455.patch",
"merged_at": "2023-02-13T20:16:38"
} | true |
https://api.github.com/repos/huggingface/datasets/issues/5454 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5454/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5454/comments | https://api.github.com/repos/huggingface/datasets/issues/5454/events | https://github.com/huggingface/datasets/issues/5454 | 1,552,890,419 | I_kwDODunzps5cjzoz | 5,454 | Save and resume the state of a DataLoader | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892871,
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement",
"name": "enhancement",
"color": "a2eeef",
"default": true,
"description": "New feature or request"
},
{
"id": 2067400324,
"node_id": "MDU6TGFiZWwyMDY3NDAwMzI0",
"url": "https://api.github.com/repos/huggingface/datasets/labels/generic%20discussion",
"name": "generic discussion",
"color": "c5def5",
"default": false,
"description": "Generic discussion on the library"
}
] | open | false | null | [] | [
"Something that'd be nice to have is \"manual update of state\". One of the learning from training LLMs is the ability to skip some batches whenever we notice huge spike might be handy.",
"Your outline spec is very sound and clear, @lhoestq - thank you!\r\n\r\n@thomasw21, indeed that would be a wonderful extra feature. In Megatron-Deepspeed we manually drained the dataloader for the range we wanted. I wasn't very satisfied with the way we did it, since its behavior would change if you were to do multiple range skips. I think it should remember all the ranges it skipped and not just skip the last range - since otherwise the data is inconsistent (but we probably should discuss this in a separate issue not to derail this much bigger one)."
] | 1,674,471,534,000 | 1,674,524,748,000 | null | MEMBER | null | It would be nice when using `datasets` with a PyTorch DataLoader to be able to resume a training from a DataLoader state (e.g. to resume a training that crashed)
What I have in mind (but lmk if you have other ideas or comments):
For map-style datasets, this requires to have a PyTorch Sampler state that can be saved and reloaded per node and worker.
For iterable datasets, this requires to save the state of the dataset iterator, which includes:
- the current shard idx and row position in the current shard
- the epoch number
- the rng state
- the shuffle buffer
Right now you can already resume the data loading of an iterable dataset by using `IterableDataset.skip` but it takes a lot of time because it re-iterates on all the past data until it reaches the resuming point.
cc @stas00 @sgugger | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5454/reactions",
"total_count": 2,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 2,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5454/timeline | null | null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5453 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5453/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5453/comments | https://api.github.com/repos/huggingface/datasets/issues/5453/events | https://github.com/huggingface/datasets/pull/5453 | 1,552,727,425 | PR_kwDODunzps5ITraa | 5,453 | Fix base directory while extracting insecure TAR files | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008215 / 0.011353 (-0.003138) | 0.004510 / 0.011008 (-0.006498) | 0.099270 / 0.038508 (0.060761) | 0.028682 / 0.023109 (0.005573) | 0.332726 / 0.275898 (0.056827) | 0.371025 / 0.323480 (0.047545) | 0.006665 / 0.007986 (-0.001320) | 0.003329 / 0.004328 (-0.001000) | 0.078509 / 0.004250 (0.074259) | 0.032388 / 0.037052 (-0.004664) | 0.348540 / 0.258489 (0.090051) | 0.382212 / 0.293841 (0.088371) | 0.033307 / 0.128546 (-0.095239) | 0.011642 / 0.075646 (-0.064004) | 0.322573 / 0.419271 (-0.096699) | 0.041297 / 0.043533 (-0.002236) | 0.322710 / 0.255139 (0.067571) | 0.361593 / 0.283200 (0.078394) | 0.082276 / 0.141683 (-0.059407) | 1.481932 / 1.452155 (0.029777) | 1.531677 / 1.492716 (0.038961) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.194964 / 0.018006 (0.176958) | 0.406002 / 0.000490 (0.405512) | 0.001015 / 0.000200 (0.000815) | 0.000075 / 0.000054 (0.000021) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.023317 / 0.037411 (-0.014095) | 0.097231 / 0.014526 (0.082705) | 0.103898 / 0.176557 (-0.072659) | 0.139864 / 0.737135 (-0.597271) | 0.106785 / 0.296338 (-0.189554) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.419036 / 0.215209 (0.203827) | 4.193985 / 2.077655 (2.116330) | 1.879069 / 1.504120 (0.374949) | 1.675384 / 1.541195 (0.134190) | 1.696225 / 1.468490 (0.227735) | 0.695257 / 4.584777 (-3.889520) | 3.437971 / 3.745712 (-0.307741) | 2.656037 / 5.269862 (-2.613824) | 1.463320 / 4.565676 (-3.102356) | 0.082575 / 0.424275 (-0.341700) | 0.012593 / 0.007607 (0.004986) | 0.526643 / 0.226044 (0.300599) | 5.278366 / 2.268929 (3.009437) | 2.288106 / 55.444624 (-53.156518) | 1.954875 / 6.876477 (-4.921602) | 1.950641 / 2.142072 (-0.191431) | 0.808289 / 4.805227 (-3.996938) | 0.148790 / 6.500664 (-6.351875) | 0.064775 / 0.075469 (-0.010694) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.215219 / 1.841788 (-0.626569) | 13.551467 / 8.074308 (5.477159) | 13.841547 / 10.191392 (3.650155) | 0.153610 / 0.680424 (-0.526814) | 0.028308 / 0.534201 (-0.505893) | 0.397087 / 0.579283 (-0.182196) | 0.401724 / 0.434364 (-0.032640) | 0.458042 / 0.540337 (-0.082296) | 0.544955 / 1.386936 (-0.841981) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006321 / 0.011353 (-0.005032) | 0.004336 / 0.011008 (-0.006673) | 0.097196 / 0.038508 (0.058688) | 0.026933 / 0.023109 (0.003824) | 0.416520 / 0.275898 (0.140622) | 0.450703 / 0.323480 (0.127223) | 0.004831 / 0.007986 (-0.003155) | 0.003252 / 0.004328 (-0.001076) | 0.074981 / 0.004250 (0.070730) | 0.036136 / 0.037052 (-0.000917) | 0.423166 / 0.258489 (0.164677) | 0.460936 / 0.293841 (0.167095) | 0.031859 / 0.128546 (-0.096687) | 0.011500 / 0.075646 (-0.064146) | 0.318197 / 0.419271 (-0.101074) | 0.041472 / 0.043533 (-0.002061) | 0.419227 / 0.255139 (0.164088) | 0.444712 / 0.283200 (0.161512) | 0.088841 / 0.141683 (-0.052841) | 1.497237 / 1.452155 (0.045083) | 1.572111 / 1.492716 (0.079395) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.239261 / 0.018006 (0.221255) | 0.400358 / 0.000490 (0.399868) | 0.003460 / 0.000200 (0.003261) | 0.000078 / 0.000054 (0.000024) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.024016 / 0.037411 (-0.013395) | 0.098414 / 0.014526 (0.083888) | 0.107220 / 0.176557 (-0.069337) | 0.143538 / 0.737135 (-0.593598) | 0.108607 / 0.296338 (-0.187731) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.473896 / 0.215209 (0.258687) | 4.740386 / 2.077655 (2.662731) | 2.458046 / 1.504120 (0.953926) | 2.260895 / 1.541195 (0.719700) | 2.280218 / 1.468490 (0.811728) | 0.694843 / 4.584777 (-3.889934) | 3.349795 / 3.745712 (-0.395917) | 1.846970 / 5.269862 (-3.422892) | 1.151481 / 4.565676 (-3.414195) | 0.082054 / 0.424275 (-0.342221) | 0.012664 / 0.007607 (0.005057) | 0.573400 / 0.226044 (0.347355) | 5.750648 / 2.268929 (3.481720) | 2.904257 / 55.444624 (-52.540367) | 2.555181 / 6.876477 (-4.321295) | 2.595830 / 2.142072 (0.453758) | 0.799580 / 4.805227 (-4.005647) | 0.151088 / 6.500664 (-6.349576) | 0.066639 / 0.075469 (-0.008831) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.251413 / 1.841788 (-0.590375) | 13.743368 / 8.074308 (5.669060) | 13.808729 / 10.191392 (3.617337) | 0.144765 / 0.680424 (-0.535659) | 0.016606 / 0.534201 (-0.517594) | 0.376503 / 0.579283 (-0.202780) | 0.381510 / 0.434364 (-0.052854) | 0.440295 / 0.540337 (-0.100043) | 0.524248 / 1.386936 (-0.862688) |\n\n</details>\n</details>\n\n\n",
"Thanks a lot, @albertvillanova - I validated that your fix solves the original problem!"
] | 1,674,464,260,000 | 1,674,524,060,000 | 1,674,468,642,000 | MEMBER | null | This PR fixes the extraction of insecure TAR files by changing the base path against which TAR members are compared:
- from: "."
- to: `output_path`
This PR also adds tests for extracting insecure TAR files.
Related to:
- #5441
- #5452
@stas00 please note this PR addresses just one of the issues you pointed out: the use of the cwd by the extractor. The other issues (actionable error messages, raise instead of log error) should be addressed in other PRs. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5453/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5453/timeline | null | null | 0 | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5453",
"html_url": "https://github.com/huggingface/datasets/pull/5453",
"diff_url": "https://github.com/huggingface/datasets/pull/5453.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5453.patch",
"merged_at": "2023-01-23T10:10:42"
} | true |
https://api.github.com/repos/huggingface/datasets/issues/5452 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5452/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5452/comments | https://api.github.com/repos/huggingface/datasets/issues/5452/events | https://github.com/huggingface/datasets/pull/5452 | 1,552,655,939 | PR_kwDODunzps5ITcA3 | 5,452 | Swap log messages for symbolic/hard links in tar extractor | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.011848 / 0.011353 (0.000495) | 0.006988 / 0.011008 (-0.004020) | 0.138078 / 0.038508 (0.099570) | 0.040310 / 0.023109 (0.017201) | 0.411857 / 0.275898 (0.135959) | 0.509496 / 0.323480 (0.186016) | 0.010695 / 0.007986 (0.002709) | 0.005275 / 0.004328 (0.000946) | 0.107157 / 0.004250 (0.102907) | 0.050987 / 0.037052 (0.013935) | 0.432387 / 0.258489 (0.173898) | 0.495136 / 0.293841 (0.201295) | 0.055273 / 0.128546 (-0.073273) | 0.019573 / 0.075646 (-0.056074) | 0.460356 / 0.419271 (0.041084) | 0.060916 / 0.043533 (0.017383) | 0.426140 / 0.255139 (0.171002) | 0.430461 / 0.283200 (0.147261) | 0.124569 / 0.141683 (-0.017114) | 1.989404 / 1.452155 (0.537250) | 1.942052 / 1.492716 (0.449335) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.287233 / 0.018006 (0.269227) | 0.606056 / 0.000490 (0.605566) | 0.004435 / 0.000200 (0.004235) | 0.000144 / 0.000054 (0.000090) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.032353 / 0.037411 (-0.005058) | 0.124237 / 0.014526 (0.109711) | 0.143280 / 0.176557 (-0.033276) | 0.182081 / 0.737135 (-0.555055) | 0.148085 / 0.296338 (-0.148253) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.613550 / 0.215209 (0.398341) | 6.172421 / 2.077655 (4.094766) | 2.466018 / 1.504120 (0.961898) | 2.166433 / 1.541195 (0.625238) | 2.192511 / 1.468490 (0.724021) | 1.248777 / 4.584777 (-3.336000) | 5.746150 / 3.745712 (2.000438) | 3.097184 / 5.269862 (-2.172678) | 2.078176 / 4.565676 (-2.487501) | 0.144351 / 0.424275 (-0.279924) | 0.014830 / 0.007607 (0.007223) | 0.761699 / 0.226044 (0.535655) | 7.713201 / 2.268929 (5.444272) | 3.359647 / 55.444624 (-52.084977) | 2.652595 / 6.876477 (-4.223882) | 2.721952 / 2.142072 (0.579880) | 1.493036 / 4.805227 (-3.312192) | 0.252336 / 6.500664 (-6.248328) | 0.082906 / 0.075469 (0.007436) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.643887 / 1.841788 (-0.197901) | 18.762775 / 8.074308 (10.688466) | 22.003583 / 10.191392 (11.812191) | 0.256361 / 0.680424 (-0.424062) | 0.048048 / 0.534201 (-0.486153) | 0.601971 / 0.579283 (0.022688) | 0.712801 / 0.434364 (0.278438) | 0.684473 / 0.540337 (0.144136) | 0.802566 / 1.386936 (-0.584370) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.010410 / 0.011353 (-0.000943) | 0.006719 / 0.011008 (-0.004289) | 0.132862 / 0.038508 (0.094354) | 0.036973 / 0.023109 (0.013863) | 0.470925 / 0.275898 (0.195027) | 0.502864 / 0.323480 (0.179384) | 0.007447 / 0.007986 (-0.000539) | 0.005629 / 0.004328 (0.001301) | 0.091985 / 0.004250 (0.087734) | 0.057537 / 0.037052 (0.020485) | 0.458362 / 0.258489 (0.199873) | 0.518324 / 0.293841 (0.224483) | 0.056540 / 0.128546 (-0.072007) | 0.021266 / 0.075646 (-0.054380) | 0.448289 / 0.419271 (0.029018) | 0.064211 / 0.043533 (0.020678) | 0.492596 / 0.255139 (0.237457) | 0.495030 / 0.283200 (0.211830) | 0.121858 / 0.141683 (-0.019825) | 1.823821 / 1.452155 (0.371667) | 2.012165 / 1.492716 (0.519449) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.296252 / 0.018006 (0.278245) | 0.601688 / 0.000490 (0.601198) | 0.006369 / 0.000200 (0.006169) | 0.000107 / 0.000054 (0.000053) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.035821 / 0.037411 (-0.001590) | 0.132722 / 0.014526 (0.118196) | 0.141819 / 0.176557 (-0.034738) | 0.205115 / 0.737135 (-0.532020) | 0.148917 / 0.296338 (-0.147422) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.678207 / 0.215209 (0.462998) | 6.969918 / 2.077655 (4.892263) | 3.077831 / 1.504120 (1.573711) | 2.689296 / 1.541195 (1.148102) | 2.706462 / 1.468490 (1.237972) | 1.249125 / 4.584777 (-3.335652) | 5.793917 / 3.745712 (2.048205) | 3.137565 / 5.269862 (-2.132297) | 2.056880 / 4.565676 (-2.508796) | 0.151918 / 0.424275 (-0.272357) | 0.015029 / 0.007607 (0.007422) | 0.833975 / 0.226044 (0.607930) | 8.575649 / 2.268929 (6.306720) | 3.812115 / 55.444624 (-51.632509) | 3.124219 / 6.876477 (-3.752258) | 3.178645 / 2.142072 (1.036572) | 1.488260 / 4.805227 (-3.316967) | 0.268239 / 6.500664 (-6.232425) | 0.089463 / 0.075469 (0.013993) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.645461 / 1.841788 (-0.196327) | 19.074412 / 8.074308 (11.000104) | 21.626726 / 10.191392 (11.435334) | 0.210525 / 0.680424 (-0.469899) | 0.032166 / 0.534201 (-0.502035) | 0.555572 / 0.579283 (-0.023711) | 0.654667 / 0.434364 (0.220303) | 0.632471 / 0.540337 (0.092133) | 0.756510 / 1.386936 (-0.630426) |\n\n</details>\n</details>\n\n\n"
] | 1,674,460,418,000 | 1,674,466,855,000 | 1,674,462,677,000 | MEMBER | null | The log messages do not match their if-condition. This PR swaps them.
Found while investigating:
- #5441
CC: @lhoestq | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5452/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5452/timeline | null | null | 0 | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5452",
"html_url": "https://github.com/huggingface/datasets/pull/5452",
"diff_url": "https://github.com/huggingface/datasets/pull/5452.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5452.patch",
"merged_at": "2023-01-23T08:31:17"
} | true |
https://api.github.com/repos/huggingface/datasets/issues/5451 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5451/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5451/comments | https://api.github.com/repos/huggingface/datasets/issues/5451/events | https://github.com/huggingface/datasets/issues/5451 | 1,552,336,300 | I_kwDODunzps5chsWs | 5,451 | ImageFolder BadZipFile: Bad offset for central directory | {
"login": "hmartiro",
"id": 1524208,
"node_id": "MDQ6VXNlcjE1MjQyMDg=",
"avatar_url": "https://avatars.githubusercontent.com/u/1524208?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/hmartiro",
"html_url": "https://github.com/hmartiro",
"followers_url": "https://api.github.com/users/hmartiro/followers",
"following_url": "https://api.github.com/users/hmartiro/following{/other_user}",
"gists_url": "https://api.github.com/users/hmartiro/gists{/gist_id}",
"starred_url": "https://api.github.com/users/hmartiro/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/hmartiro/subscriptions",
"organizations_url": "https://api.github.com/users/hmartiro/orgs",
"repos_url": "https://api.github.com/users/hmartiro/repos",
"events_url": "https://api.github.com/users/hmartiro/events{/privacy}",
"received_events_url": "https://api.github.com/users/hmartiro/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Hi ! Could you share the full stack trace ? Which dataset did you try to load ?\r\n\r\nit may be related to https://github.com/huggingface/datasets/pull/5640",
"The `BadZipFile` error means the ZIP file is corrupted, so I'm closing this issue as it's not directly related to `datasets`.",
"For others that find this issue following a `BadZipFile` error, I had the same problem because I had a file in a folder dataset `my-image.target` and the datasets library was incorrectly determining that the (PNG) file was a zip archive. When it tried to extract the file, this error occurred. \r\n\r\nUpdating to `datasets==2.12.0` fixed the problem for me."
] | 1,674,431,412,000 | 1,684,838,148,000 | 1,676,046,696,000 | NONE | null | ### Describe the bug
I'm getting the following exception:
```
lib/python3.10/zipfile.py:1353 in _RealGetContents │
│ │
│ 1350 │ │ # self.start_dir: Position of start of central directory │
│ 1351 │ │ self.start_dir = offset_cd + concat │
│ 1352 │ │ if self.start_dir < 0: │
│ ❱ 1353 │ │ │ raise BadZipFile("Bad offset for central directory") │
│ 1354 │ │ fp.seek(self.start_dir, 0) │
│ 1355 │ │ data = fp.read(size_cd) │
│ 1356 │ │ fp = io.BytesIO(data) │
╰──────────────────────────────────────────────────────────────────────────────────────────────────╯
BadZipFile: Bad offset for central directory
Extracting data files: 35%|█████████████████▊ | 38572/110812 [00:10<00:20, 3576.26it/s]
```
### Steps to reproduce the bug
```
load_dataset(
args.dataset_name,
args.dataset_config_name,
cache_dir=args.cache_dir,
),
```
### Expected behavior
loads the dataset
### Environment info
datasets==2.8.0
Python 3.10.8
Linux 129-146-3-202 5.15.0-52-generic #58~20.04.1-Ubuntu SMP Thu Oct 13 13:09:46 UTC 2022 x86_64 x86_64 x86_64 GNU/Linux | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5451/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5451/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5450 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5450/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5450/comments | https://api.github.com/repos/huggingface/datasets/issues/5450/events | https://github.com/huggingface/datasets/issues/5450 | 1,551,109,365 | I_kwDODunzps5cdAz1 | 5,450 | to_tf_dataset with a TF collator causes bizarrely persistent slowdown | {
"login": "Rocketknight1",
"id": 12866554,
"node_id": "MDQ6VXNlcjEyODY2NTU0",
"avatar_url": "https://avatars.githubusercontent.com/u/12866554?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Rocketknight1",
"html_url": "https://github.com/Rocketknight1",
"followers_url": "https://api.github.com/users/Rocketknight1/followers",
"following_url": "https://api.github.com/users/Rocketknight1/following{/other_user}",
"gists_url": "https://api.github.com/users/Rocketknight1/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Rocketknight1/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Rocketknight1/subscriptions",
"organizations_url": "https://api.github.com/users/Rocketknight1/orgs",
"repos_url": "https://api.github.com/users/Rocketknight1/repos",
"events_url": "https://api.github.com/users/Rocketknight1/events{/privacy}",
"received_events_url": "https://api.github.com/users/Rocketknight1/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"wtf",
"Couldn't find what's causing this, this will need more investigation",
"A possible hint: The function it seems to be spending a lot of time in (when iterating over the original dataset) is `_get_mp` in the PIL JPEG decoder: \r\n\r\n",
"If \"mp\" is multiprocessing, this might suggest some kind of negative interaction between the JPEG decoder and TF's handling of processes/threads. Note that we haven't merged the parallel `to_tf_dataset` PR yet, so it's not caused by that PR!",
"Update: MP isn't multiprocessing at all, it's an internal PIL method for loading metadata from JPEG files. No idea why that would be a bottleneck, but I'll see if a Python profiler can't figure out where the time is actually being spent.",
"After further profiling, the slowdown is in the C methods for JPEG decoding that are included as part of PIL. Because Python profilers can't inspect inside that, I don't have any further information on which lines exactly are responsible for the slowdown or why.\r\n\r\nIn the meantime, I'm going to suggest switching from `return_tensors=\"tf\"` to `return_tensors=\"np\"` in most of our `transformers` code - this generally works better for pre-processing. Two relevant PRs are [here](https://github.com/huggingface/transformers/pull/21266) and [here](https://github.com/huggingface/notebooks/pull/308).",
"Closing this issue as we've done what we can with this one! "
] | 1,674,230,917,000 | 1,676,297,614,000 | 1,676,297,614,000 | MEMBER | null | ### Describe the bug
This will make more sense if you take a look at [a Colab notebook that reproduces this issue.](https://colab.research.google.com/drive/1rxyeciQFWJTI0WrZ5aojp4Ls1ut18fNH?usp=sharing)
Briefly, there are several datasets that, when you iterate over them with `to_tf_dataset` **and** a data collator that returns `tf` tensors, become very slow. We haven't been able to figure this one out - it can be intermittent, and we have no idea what could possibly cause it. The weirdest thing is that **the slowdown affects other attempts to access the underlying dataset**. If you try to iterate over the `tf.data.Dataset`, then interrupt execution, and then try to iterate over the original dataset, the original dataset is now also very slow! This is true even if the dataset format is not set to `tf` - the iteration is slow even though it's not calling TF at all!
There is a simple workaround for this - we can simply get our data collators to return `np` tensors. When we do this, the bug is never triggered and everything is fine. In general, `np` is preferred for this kind of preprocessing work anyway, when the preprocessing is not going to be compiled into a pure `tf.data` pipeline! However, the issue is fascinating, and the TF team were wondering if anyone in datasets (cc @lhoestq @mariosasko) might have an idea of what could cause this.
### Steps to reproduce the bug
Run the attached Colab.
### Expected behavior
The slowdown should go away, or at least not persist after we stop iterating over the `tf.data.Dataset`
### Environment info
The issue occurs on multiple versions of Python and TF, both on local machines and on Colab.
All testing was done using the latest versions of `transformers` and `datasets` from `main` | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5450/reactions",
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 1,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5450/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5449 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5449/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5449/comments | https://api.github.com/repos/huggingface/datasets/issues/5449/events | https://github.com/huggingface/datasets/pull/5449 | 1,550,801,453 | PR_kwDODunzps5INgD9 | 5,449 | Support fsspec 2023.1.0 in CI | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008227 / 0.011353 (-0.003126) | 0.004496 / 0.011008 (-0.006512) | 0.099319 / 0.038508 (0.060811) | 0.029929 / 0.023109 (0.006820) | 0.296686 / 0.275898 (0.020788) | 0.355372 / 0.323480 (0.031892) | 0.006864 / 0.007986 (-0.001122) | 0.003458 / 0.004328 (-0.000871) | 0.077234 / 0.004250 (0.072983) | 0.037072 / 0.037052 (0.000020) | 0.311675 / 0.258489 (0.053186) | 0.338965 / 0.293841 (0.045124) | 0.033562 / 0.128546 (-0.094985) | 0.011399 / 0.075646 (-0.064248) | 0.322406 / 0.419271 (-0.096865) | 0.043034 / 0.043533 (-0.000499) | 0.298083 / 0.255139 (0.042944) | 0.323661 / 0.283200 (0.040462) | 0.089380 / 0.141683 (-0.052303) | 1.479363 / 1.452155 (0.027208) | 1.518337 / 1.492716 (0.025620) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.177822 / 0.018006 (0.159816) | 0.400806 / 0.000490 (0.400317) | 0.002121 / 0.000200 (0.001921) | 0.000074 / 0.000054 (0.000019) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.021986 / 0.037411 (-0.015426) | 0.096749 / 0.014526 (0.082223) | 0.101443 / 0.176557 (-0.075113) | 0.137519 / 0.737135 (-0.599616) | 0.105558 / 0.296338 (-0.190780) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.418983 / 0.215209 (0.203774) | 4.189579 / 2.077655 (2.111924) | 1.877831 / 1.504120 (0.373711) | 1.666213 / 1.541195 (0.125019) | 1.680735 / 1.468490 (0.212245) | 0.693033 / 4.584777 (-3.891744) | 3.420553 / 3.745712 (-0.325160) | 1.819647 / 5.269862 (-3.450214) | 1.144934 / 4.565676 (-3.420743) | 0.082209 / 0.424275 (-0.342066) | 0.012433 / 0.007607 (0.004826) | 0.526781 / 0.226044 (0.300737) | 5.273689 / 2.268929 (3.004760) | 2.323468 / 55.444624 (-53.121156) | 1.960508 / 6.876477 (-4.915969) | 2.035338 / 2.142072 (-0.106735) | 0.812789 / 4.805227 (-3.992438) | 0.148429 / 6.500664 (-6.352235) | 0.064727 / 0.075469 (-0.010742) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.253218 / 1.841788 (-0.588569) | 13.303426 / 8.074308 (5.229118) | 13.651074 / 10.191392 (3.459682) | 0.135178 / 0.680424 (-0.545246) | 0.028483 / 0.534201 (-0.505717) | 0.393284 / 0.579283 (-0.185999) | 0.401957 / 0.434364 (-0.032407) | 0.457136 / 0.540337 (-0.083201) | 0.535835 / 1.386936 (-0.851101) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006335 / 0.011353 (-0.005017) | 0.004454 / 0.011008 (-0.006554) | 0.097565 / 0.038508 (0.059057) | 0.026917 / 0.023109 (0.003808) | 0.350779 / 0.275898 (0.074881) | 0.391979 / 0.323480 (0.068499) | 0.004648 / 0.007986 (-0.003337) | 0.003204 / 0.004328 (-0.001124) | 0.076987 / 0.004250 (0.072737) | 0.035257 / 0.037052 (-0.001796) | 0.347193 / 0.258489 (0.088704) | 0.391462 / 0.293841 (0.097621) | 0.031244 / 0.128546 (-0.097302) | 0.011460 / 0.075646 (-0.064186) | 0.321606 / 0.419271 (-0.097665) | 0.041218 / 0.043533 (-0.002315) | 0.341884 / 0.255139 (0.086745) | 0.374920 / 0.283200 (0.091720) | 0.086383 / 0.141683 (-0.055300) | 1.501750 / 1.452155 (0.049595) | 1.565060 / 1.492716 (0.072344) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.165447 / 0.018006 (0.147441) | 0.401885 / 0.000490 (0.401395) | 0.000975 / 0.000200 (0.000775) | 0.000070 / 0.000054 (0.000015) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.024494 / 0.037411 (-0.012917) | 0.097334 / 0.014526 (0.082808) | 0.105324 / 0.176557 (-0.071232) | 0.142430 / 0.737135 (-0.594705) | 0.107249 / 0.296338 (-0.189089) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.441632 / 0.215209 (0.226423) | 4.407729 / 2.077655 (2.330074) | 2.078167 / 1.504120 (0.574047) | 1.864210 / 1.541195 (0.323015) | 1.885948 / 1.468490 (0.417458) | 0.693974 / 4.584777 (-3.890803) | 3.386837 / 3.745712 (-0.358875) | 1.840291 / 5.269862 (-3.429571) | 1.150524 / 4.565676 (-3.415153) | 0.082240 / 0.424275 (-0.342035) | 0.012488 / 0.007607 (0.004881) | 0.537589 / 0.226044 (0.311545) | 5.404007 / 2.268929 (3.135078) | 2.537467 / 55.444624 (-52.907157) | 2.190775 / 6.876477 (-4.685702) | 2.224746 / 2.142072 (0.082674) | 0.799524 / 4.805227 (-4.005703) | 0.150639 / 6.500664 (-6.350025) | 0.066473 / 0.075469 (-0.008997) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.258559 / 1.841788 (-0.583228) | 13.773583 / 8.074308 (5.699275) | 13.964322 / 10.191392 (3.772930) | 0.156295 / 0.680424 (-0.524129) | 0.016824 / 0.534201 (-0.517377) | 0.377476 / 0.579283 (-0.201807) | 0.390163 / 0.434364 (-0.044201) | 0.442541 / 0.540337 (-0.097796) | 0.529404 / 1.386936 (-0.857532) |\n\n</details>\n</details>\n\n\n"
] | 1,674,219,197,000 | 1,674,221,570,000 | 1,674,221,163,000 | MEMBER | null | Support fsspec 2023.1.0 in CI.
In the 2023.1.0 fsspec release, they replaced the type of `fsspec.registry`:
- from `ReadOnlyRegistry`, with an attribute called `target`
- to `MappingProxyType`, without that attribute
Consequently, we need to change our `mock_fsspec` fixtures, that were using the `target` attribute.
Fix #5448. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5449/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5449/timeline | null | null | 0 | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5449",
"html_url": "https://github.com/huggingface/datasets/pull/5449",
"diff_url": "https://github.com/huggingface/datasets/pull/5449.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5449.patch",
"merged_at": "2023-01-20T13:26:03"
} | true |
https://api.github.com/repos/huggingface/datasets/issues/5448 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5448/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5448/comments | https://api.github.com/repos/huggingface/datasets/issues/5448/events | https://github.com/huggingface/datasets/issues/5448 | 1,550,618,514 | I_kwDODunzps5cbI-S | 5,448 | Support fsspec 2023.1.0 in CI | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892871,
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement",
"name": "enhancement",
"color": "a2eeef",
"default": true,
"description": "New feature or request"
}
] | closed | false | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
}
] | [] | 1,674,210,391,000 | 1,674,221,165,000 | 1,674,221,165,000 | MEMBER | null | Once we find out the root cause of:
- #5445
we should revert the temporary pin on fsspec introduced by:
- #5447 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5448/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5448/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5447 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5447/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5447/comments | https://api.github.com/repos/huggingface/datasets/issues/5447/events | https://github.com/huggingface/datasets/pull/5447 | 1,550,599,193 | PR_kwDODunzps5IM0Nu | 5,447 | Fix CI by temporarily pinning fsspec < 2023.1.0 | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.011875 / 0.011353 (0.000522) | 0.008188 / 0.011008 (-0.002821) | 0.131137 / 0.038508 (0.092629) | 0.038127 / 0.023109 (0.015018) | 0.383864 / 0.275898 (0.107966) | 0.458617 / 0.323480 (0.135137) | 0.010989 / 0.007986 (0.003003) | 0.004892 / 0.004328 (0.000563) | 0.101955 / 0.004250 (0.097704) | 0.045081 / 0.037052 (0.008029) | 0.409768 / 0.258489 (0.151279) | 0.446597 / 0.293841 (0.152756) | 0.058588 / 0.128546 (-0.069958) | 0.020872 / 0.075646 (-0.054774) | 0.432982 / 0.419271 (0.013711) | 0.075875 / 0.043533 (0.032342) | 0.380923 / 0.255139 (0.125784) | 0.432994 / 0.283200 (0.149795) | 0.122678 / 0.141683 (-0.019005) | 1.857865 / 1.452155 (0.405710) | 1.927801 / 1.492716 (0.435085) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.212941 / 0.018006 (0.194935) | 0.527977 / 0.000490 (0.527488) | 0.002996 / 0.000200 (0.002797) | 0.000105 / 0.000054 (0.000051) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.030046 / 0.037411 (-0.007366) | 0.126384 / 0.014526 (0.111858) | 0.138307 / 0.176557 (-0.038250) | 0.185338 / 0.737135 (-0.551797) | 0.144733 / 0.296338 (-0.151606) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.627096 / 0.215209 (0.411887) | 6.418014 / 2.077655 (4.340360) | 2.547675 / 1.504120 (1.043555) | 2.195552 / 1.541195 (0.654357) | 2.200377 / 1.468490 (0.731887) | 1.289935 / 4.584777 (-3.294842) | 5.670839 / 3.745712 (1.925127) | 5.252597 / 5.269862 (-0.017265) | 2.878470 / 4.565676 (-1.687207) | 0.143754 / 0.424275 (-0.280521) | 0.014814 / 0.007607 (0.007207) | 0.810073 / 0.226044 (0.584028) | 8.183757 / 2.268929 (5.914829) | 3.375525 / 55.444624 (-52.069099) | 2.594048 / 6.876477 (-4.282428) | 2.598095 / 2.142072 (0.456023) | 1.554493 / 4.805227 (-3.250734) | 0.263159 / 6.500664 (-6.237505) | 0.089822 / 0.075469 (0.014353) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.660847 / 1.841788 (-0.180941) | 18.434283 / 8.074308 (10.359975) | 21.764887 / 10.191392 (11.573495) | 0.264524 / 0.680424 (-0.415900) | 0.048519 / 0.534201 (-0.485682) | 0.587468 / 0.579283 (0.008185) | 0.634142 / 0.434364 (0.199778) | 0.675374 / 0.540337 (0.135037) | 0.777510 / 1.386936 (-0.609426) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.010021 / 0.011353 (-0.001332) | 0.006207 / 0.011008 (-0.004801) | 0.130490 / 0.038508 (0.091982) | 0.037957 / 0.023109 (0.014848) | 0.489381 / 0.275898 (0.213483) | 0.536522 / 0.323480 (0.213042) | 0.008611 / 0.007986 (0.000626) | 0.004894 / 0.004328 (0.000565) | 0.101617 / 0.004250 (0.097367) | 0.052629 / 0.037052 (0.015577) | 0.509211 / 0.258489 (0.250721) | 0.545023 / 0.293841 (0.251182) | 0.057468 / 0.128546 (-0.071078) | 0.023393 / 0.075646 (-0.052253) | 0.431408 / 0.419271 (0.012137) | 0.064967 / 0.043533 (0.021434) | 0.495261 / 0.255139 (0.240122) | 0.527098 / 0.283200 (0.243898) | 0.113172 / 0.141683 (-0.028511) | 1.937072 / 1.452155 (0.484918) | 2.048413 / 1.492716 (0.555697) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.245406 / 0.018006 (0.227399) | 0.526772 / 0.000490 (0.526283) | 0.004379 / 0.000200 (0.004179) | 0.000114 / 0.000054 (0.000060) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.031785 / 0.037411 (-0.005626) | 0.130949 / 0.014526 (0.116424) | 0.145660 / 0.176557 (-0.030896) | 0.186991 / 0.737135 (-0.550144) | 0.151000 / 0.296338 (-0.145338) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.708643 / 0.215209 (0.493434) | 7.179252 / 2.077655 (5.101597) | 3.143375 / 1.504120 (1.639255) | 2.714298 / 1.541195 (1.173103) | 2.773441 / 1.468490 (1.304951) | 1.312821 / 4.584777 (-3.271956) | 5.798396 / 3.745712 (2.052684) | 3.253215 / 5.269862 (-2.016646) | 2.147260 / 4.565676 (-2.418416) | 0.154673 / 0.424275 (-0.269602) | 0.014918 / 0.007607 (0.007311) | 0.860618 / 0.226044 (0.634573) | 8.774455 / 2.268929 (6.505527) | 3.925020 / 55.444624 (-51.519604) | 3.139361 / 6.876477 (-3.737115) | 3.208883 / 2.142072 (1.066810) | 1.547305 / 4.805227 (-3.257922) | 0.268814 / 6.500664 (-6.231850) | 0.084578 / 0.075469 (0.009109) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.694990 / 1.841788 (-0.146798) | 18.619183 / 8.074308 (10.544875) | 21.929886 / 10.191392 (11.738494) | 0.265763 / 0.680424 (-0.414661) | 0.028325 / 0.534201 (-0.505876) | 0.552910 / 0.579283 (-0.026373) | 0.616864 / 0.434364 (0.182500) | 0.637858 / 0.540337 (0.097521) | 0.744508 / 1.386936 (-0.642428) |\n\n</details>\n</details>\n\n\n"
] | 1,674,209,462,000 | 1,674,211,093,000 | 1,674,210,523,000 | MEMBER | null | Temporarily pin fsspec < 2023.1.0
Fix #5445. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5447/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5447/timeline | null | null | 0 | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5447",
"html_url": "https://github.com/huggingface/datasets/pull/5447",
"diff_url": "https://github.com/huggingface/datasets/pull/5447.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5447.patch",
"merged_at": "2023-01-20T10:28:43"
} | true |
https://api.github.com/repos/huggingface/datasets/issues/5446 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5446/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5446/comments | https://api.github.com/repos/huggingface/datasets/issues/5446/events | https://github.com/huggingface/datasets/pull/5446 | 1,550,591,588 | PR_kwDODunzps5IMyka | 5,446 | test v0.12.0.rc0 | {
"login": "Wauplin",
"id": 11801849,
"node_id": "MDQ6VXNlcjExODAxODQ5",
"avatar_url": "https://avatars.githubusercontent.com/u/11801849?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Wauplin",
"html_url": "https://github.com/Wauplin",
"followers_url": "https://api.github.com/users/Wauplin/followers",
"following_url": "https://api.github.com/users/Wauplin/following{/other_user}",
"gists_url": "https://api.github.com/users/Wauplin/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Wauplin/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Wauplin/subscriptions",
"organizations_url": "https://api.github.com/users/Wauplin/orgs",
"repos_url": "https://api.github.com/users/Wauplin/repos",
"events_url": "https://api.github.com/users/Wauplin/events{/privacy}",
"received_events_url": "https://api.github.com/users/Wauplin/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"_The documentation is not available anymore as the PR was closed or merged._",
"@Wauplin I was testing it in a dedicated branch without opening a PR: https://github.com/huggingface/datasets/commits/test-hfh-0.12.0rc0",
"Oops, sorry @albertvillanova. I thought for next time I'll start the CIs before pinging everyone.\r\nI'm closing this one.",
"@Wauplin in your Slack message, you asked people from every major dependent library to check that our CI work. That is why I am checking it... :)\r\n\r\nAlso, I think for this purpose it is better to test it in a dedicated branch, rather than opening and closing a PR.",
"Yes, yes I know. Completely my fault on this one"
] | 1,674,209,119,000 | 1,674,211,402,000 | 1,674,209,628,000 | CONTRIBUTOR | null | DO NOT MERGE.
Only to test the CI.
cc @lhoestq @albertvillanova | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5446/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5446/timeline | null | null | 0 | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5446",
"html_url": "https://github.com/huggingface/datasets/pull/5446",
"diff_url": "https://github.com/huggingface/datasets/pull/5446.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5446.patch",
"merged_at": null
} | true |
https://api.github.com/repos/huggingface/datasets/issues/5445 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5445/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5445/comments | https://api.github.com/repos/huggingface/datasets/issues/5445/events | https://github.com/huggingface/datasets/issues/5445 | 1,550,588,703 | I_kwDODunzps5cbBsf | 5,445 | CI tests are broken: AttributeError: 'mappingproxy' object has no attribute 'target' | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
}
] | [] | 1,674,208,990,000 | 1,674,210,524,000 | 1,674,210,524,000 | MEMBER | null | CI tests are broken, raising `AttributeError: 'mappingproxy' object has no attribute 'target'`. See: https://github.com/huggingface/datasets/actions/runs/3966497597/jobs/6797384185
```
...
ERROR tests/test_streaming_download_manager.py::TestxPath::test_xpath_rglob[mock://top_level-date=2019-10-0[1-4]/*-expected_paths4] - AttributeError: 'mappingproxy' object has no attribute 'target'
===== 2076 passed, 19 skipped, 15 warnings, 47 errors in 115.54s (0:01:55) =====
``` | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5445/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5445/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5444 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5444/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5444/comments | https://api.github.com/repos/huggingface/datasets/issues/5444/events | https://github.com/huggingface/datasets/issues/5444 | 1,550,185,071 | I_kwDODunzps5cZfJv | 5,444 | info messages logged as warnings | {
"login": "davidgilbertson",
"id": 4443482,
"node_id": "MDQ6VXNlcjQ0NDM0ODI=",
"avatar_url": "https://avatars.githubusercontent.com/u/4443482?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/davidgilbertson",
"html_url": "https://github.com/davidgilbertson",
"followers_url": "https://api.github.com/users/davidgilbertson/followers",
"following_url": "https://api.github.com/users/davidgilbertson/following{/other_user}",
"gists_url": "https://api.github.com/users/davidgilbertson/gists{/gist_id}",
"starred_url": "https://api.github.com/users/davidgilbertson/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/davidgilbertson/subscriptions",
"organizations_url": "https://api.github.com/users/davidgilbertson/orgs",
"repos_url": "https://api.github.com/users/davidgilbertson/repos",
"events_url": "https://api.github.com/users/davidgilbertson/events{/privacy}",
"received_events_url": "https://api.github.com/users/davidgilbertson/received_events",
"type": "User",
"site_admin": false
} | [] | open | false | null | [] | [
"Looks like a duplicate of https://github.com/huggingface/datasets/issues/1948. \r\n\r\nI also think these should be logged as INFO messages, but let's see what @lhoestq thinks.",
"It can be considered unexpected to see a `map` function return instantaneously. The warning is here to explain this case by mentioning that the cache was used. I don't expect first time users (only seeing warnings) to guess that the cache works this way",
"Oh, so it's intentional? Do all Hugging Face packages use `warning` when using cache?\r\nI guess feel free to close this issue then.",
"Yes it's intentional for `map`. For `load_dataset` it's also intentional but for a different reason: it shows where in the cache the dataset is located, in case the user wants to clear the cache.",
"OK I see. It's surprising to me that these are considered \"something unexpected happened\", the concept of cache is pretty common.\r\n\r\nHas a user every actually complained that they ran their code once, and it took a minute while the data downloaded, then ran their code again and it ran really fast (and completed successfully) but they were so baffled by the fact that it ran quickly, _and_ didn't set the log level to INFO, _and_ hadn't read the docs (or thought about it) to know that datasets are cached, that they logged an issue asking that this information be output as a warning every time they run their code?\r\n\r\nThat seems like a very niche scenario to cater for, given that the side effect is to flood the console with irrelevant warnings for every other user every other time they run a bit of `datasets` code. And the real world impact is that people TURN OFF warnings, which is a pretty bad habit to get into.\r\n\r\nAnyhoo, if there's no chance I'm going to change your mind, please close the issue :)",
"I see your point and I'm not closed to switching to INFO, but I think those logs are important to make the library less opaque. I also just checked `transformers` scripts and they default to INFO which is nice. However for colab users the default is still WARNING iirc, and it counts as one of the main env where `datasets` is used.\r\n\r\nWe also use progress bars a lot in `datasets`, that are shown if the logger is at the WARNING level. But we offer a function to disable the progress bars if necessary.",
"These kinds of messages are logged as INFO in Transformers, so we should probably be consistent with them"
] | 1,674,177,558,000 | 1,681,745,994,000 | null | NONE | null | ### Describe the bug
Code in `datasets` is using `logger.warning` when it should be using `logger.info`.
Some of these are probably a matter of opinion, but I think anything starting with `logger.warning(f"Loading chached` clearly falls into the info category.
Definitions from the Python docs for reference:
* INFO: Confirmation that things are working as expected.
* WARNING: An indication that something unexpected happened, or indicative of some problem in the near future (e.g. ‘disk space low’). The software is still working as expected.
In theory, a user should be able to resolve things such that there are no warnings.
### Steps to reproduce the bug
Load any dataset that's already cached.
### Expected behavior
No output when log level is at the default WARNING level.
### Environment info
- `datasets` version: 2.8.0
- Platform: Linux-5.10.102.1-microsoft-standard-WSL2-x86_64-with-glibc2.31
- Python version: 3.10.8
- PyArrow version: 9.0.0
- Pandas version: 1.5.2 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5444/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5444/timeline | null | null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5443 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5443/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5443/comments | https://api.github.com/repos/huggingface/datasets/issues/5443/events | https://github.com/huggingface/datasets/pull/5443 | 1,550,178,914 | PR_kwDODunzps5ILbk8 | 5,443 | Update share tutorial | {
"login": "stevhliu",
"id": 59462357,
"node_id": "MDQ6VXNlcjU5NDYyMzU3",
"avatar_url": "https://avatars.githubusercontent.com/u/59462357?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/stevhliu",
"html_url": "https://github.com/stevhliu",
"followers_url": "https://api.github.com/users/stevhliu/followers",
"following_url": "https://api.github.com/users/stevhliu/following{/other_user}",
"gists_url": "https://api.github.com/users/stevhliu/gists{/gist_id}",
"starred_url": "https://api.github.com/users/stevhliu/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/stevhliu/subscriptions",
"organizations_url": "https://api.github.com/users/stevhliu/orgs",
"repos_url": "https://api.github.com/users/stevhliu/repos",
"events_url": "https://api.github.com/users/stevhliu/events{/privacy}",
"received_events_url": "https://api.github.com/users/stevhliu/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.009885 / 0.011353 (-0.001468) | 0.005338 / 0.011008 (-0.005670) | 0.099967 / 0.038508 (0.061459) | 0.036860 / 0.023109 (0.013751) | 0.295283 / 0.275898 (0.019385) | 0.369504 / 0.323480 (0.046024) | 0.008267 / 0.007986 (0.000281) | 0.004375 / 0.004328 (0.000046) | 0.076294 / 0.004250 (0.072043) | 0.047058 / 0.037052 (0.010006) | 0.314463 / 0.258489 (0.055974) | 0.348125 / 0.293841 (0.054284) | 0.038334 / 0.128546 (-0.090213) | 0.012102 / 0.075646 (-0.063544) | 0.333049 / 0.419271 (-0.086223) | 0.050727 / 0.043533 (0.007195) | 0.299244 / 0.255139 (0.044105) | 0.318210 / 0.283200 (0.035010) | 0.112609 / 0.141683 (-0.029074) | 1.450377 / 1.452155 (-0.001778) | 1.485177 / 1.492716 (-0.007539) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.287083 / 0.018006 (0.269077) | 0.564268 / 0.000490 (0.563778) | 0.003578 / 0.000200 (0.003378) | 0.000093 / 0.000054 (0.000039) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.026755 / 0.037411 (-0.010657) | 0.105857 / 0.014526 (0.091331) | 0.118291 / 0.176557 (-0.058266) | 0.155735 / 0.737135 (-0.581401) | 0.122527 / 0.296338 (-0.173812) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.396992 / 0.215209 (0.181783) | 3.958562 / 2.077655 (1.880908) | 1.781570 / 1.504120 (0.277451) | 1.617743 / 1.541195 (0.076549) | 1.753504 / 1.468490 (0.285013) | 0.681509 / 4.584777 (-3.903268) | 3.816910 / 3.745712 (0.071198) | 2.087359 / 5.269862 (-3.182503) | 1.328380 / 4.565676 (-3.237297) | 0.083542 / 0.424275 (-0.340733) | 0.012081 / 0.007607 (0.004473) | 0.505127 / 0.226044 (0.279082) | 5.075136 / 2.268929 (2.806208) | 2.259871 / 55.444624 (-53.184753) | 1.944302 / 6.876477 (-4.932175) | 2.102624 / 2.142072 (-0.039449) | 0.819779 / 4.805227 (-3.985448) | 0.165584 / 6.500664 (-6.335080) | 0.061774 / 0.075469 (-0.013695) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.208258 / 1.841788 (-0.633530) | 14.841635 / 8.074308 (6.767327) | 14.484515 / 10.191392 (4.293123) | 0.156464 / 0.680424 (-0.523959) | 0.028839 / 0.534201 (-0.505362) | 0.440860 / 0.579283 (-0.138423) | 0.433892 / 0.434364 (-0.000472) | 0.515339 / 0.540337 (-0.024998) | 0.608838 / 1.386936 (-0.778098) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.007548 / 0.011353 (-0.003804) | 0.005464 / 0.011008 (-0.005544) | 0.096987 / 0.038508 (0.058479) | 0.034472 / 0.023109 (0.011363) | 0.391249 / 0.275898 (0.115351) | 0.432779 / 0.323480 (0.109299) | 0.006170 / 0.007986 (-0.001816) | 0.004316 / 0.004328 (-0.000013) | 0.074184 / 0.004250 (0.069934) | 0.054254 / 0.037052 (0.017202) | 0.397947 / 0.258489 (0.139458) | 0.451253 / 0.293841 (0.157412) | 0.037098 / 0.128546 (-0.091449) | 0.012649 / 0.075646 (-0.062997) | 0.333533 / 0.419271 (-0.085739) | 0.050247 / 0.043533 (0.006714) | 0.390446 / 0.255139 (0.135307) | 0.410547 / 0.283200 (0.127347) | 0.110888 / 0.141683 (-0.030795) | 1.452160 / 1.452155 (0.000006) | 1.596331 / 1.492716 (0.103615) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.256061 / 0.018006 (0.238055) | 0.552674 / 0.000490 (0.552184) | 0.003362 / 0.000200 (0.003162) | 0.000095 / 0.000054 (0.000040) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.030199 / 0.037411 (-0.007213) | 0.110288 / 0.014526 (0.095762) | 0.127412 / 0.176557 (-0.049145) | 0.165428 / 0.737135 (-0.571707) | 0.131658 / 0.296338 (-0.164680) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.441946 / 0.215209 (0.226737) | 4.414209 / 2.077655 (2.336555) | 2.284530 / 1.504120 (0.780410) | 2.110752 / 1.541195 (0.569557) | 2.210751 / 1.468490 (0.742260) | 0.698829 / 4.584777 (-3.885948) | 3.819044 / 3.745712 (0.073332) | 3.274021 / 5.269862 (-1.995840) | 1.781284 / 4.565676 (-2.784393) | 0.085264 / 0.424275 (-0.339011) | 0.012360 / 0.007607 (0.004753) | 0.553519 / 0.226044 (0.327475) | 5.466395 / 2.268929 (3.197467) | 2.825839 / 55.444624 (-52.618786) | 2.439451 / 6.876477 (-4.437026) | 2.582534 / 2.142072 (0.440462) | 0.841644 / 4.805227 (-3.963583) | 0.172288 / 6.500664 (-6.328376) | 0.067215 / 0.075469 (-0.008254) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.283623 / 1.841788 (-0.558165) | 15.753163 / 8.074308 (7.678855) | 14.983263 / 10.191392 (4.791871) | 0.187584 / 0.680424 (-0.492840) | 0.017999 / 0.534201 (-0.516202) | 0.427157 / 0.579283 (-0.152126) | 0.435456 / 0.434364 (0.001092) | 0.496800 / 0.540337 (-0.043537) | 0.592557 / 1.386936 (-0.794379) |\n\n</details>\n</details>\n\n\n"
] | 1,674,176,954,000 | 1,674,229,485,000 | 1,674,229,050,000 | MEMBER | null | Based on feedback from discussion #5423, this PR updates the sharing tutorial with a mention of writing your own dataset loading script to support more advanced dataset creation options like multiple configs.
I'll open a separate PR to update the *Create a Dataset card* with the new Hub metadata UI update 😄 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5443/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5443/timeline | null | null | 0 | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5443",
"html_url": "https://github.com/huggingface/datasets/pull/5443",
"diff_url": "https://github.com/huggingface/datasets/pull/5443.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5443.patch",
"merged_at": "2023-01-20T15:37:30"
} | true |
https://api.github.com/repos/huggingface/datasets/issues/5442 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5442/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5442/comments | https://api.github.com/repos/huggingface/datasets/issues/5442/events | https://github.com/huggingface/datasets/issues/5442 | 1,550,084,450 | I_kwDODunzps5cZGli | 5,442 | OneDrive Integrations with HF Datasets | {
"login": "Mohammed20201991",
"id": 59222637,
"node_id": "MDQ6VXNlcjU5MjIyNjM3",
"avatar_url": "https://avatars.githubusercontent.com/u/59222637?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Mohammed20201991",
"html_url": "https://github.com/Mohammed20201991",
"followers_url": "https://api.github.com/users/Mohammed20201991/followers",
"following_url": "https://api.github.com/users/Mohammed20201991/following{/other_user}",
"gists_url": "https://api.github.com/users/Mohammed20201991/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Mohammed20201991/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Mohammed20201991/subscriptions",
"organizations_url": "https://api.github.com/users/Mohammed20201991/orgs",
"repos_url": "https://api.github.com/users/Mohammed20201991/repos",
"events_url": "https://api.github.com/users/Mohammed20201991/events{/privacy}",
"received_events_url": "https://api.github.com/users/Mohammed20201991/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892871,
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement",
"name": "enhancement",
"color": "a2eeef",
"default": true,
"description": "New feature or request"
}
] | closed | false | null | [] | [
"Hi! \r\n\r\nWe use [`fsspec`](https://github.com/fsspec/filesystem_spec) to integrate with storage providers. You can find more info (and the usage examples) in [our docs](https://huggingface.co/docs/datasets/v2.8.0/filesystems#download-and-prepare-a-dataset-into-a-cloud-storage).\r\n\r\n[`gdrivefs`](https://github.com/fsspec/gdrivefs) makes it possible to use Google Drive as a storage service in Datasets, but this is not the case for OneDrive, since its[ Python SDK](https://github.com/OneDrive/onedrive-sdk-python) is not integrated with `fsspec`. Can you please request the integration with `fsspec` in their repo to address this limitation?",
"I'm closing this issue as implementing a fsspec-compliant OneDrive filesystem is not our responsibility."
] | 1,674,169,928,000 | 1,677,255,471,000 | 1,677,255,471,000 | NONE | null | ### Feature request
First of all , I would like to thank all community who are developed DataSet storage and make it free available
How to integrate our Onedrive account or any other possible storage clouds (like google drive,...) with the **HF** datasets section.
For example, if I have **50GB** on my **Onedrive** account and I want to move between drive and Hugging face repo or vis versa
### Motivation
make the dataset section more flexible with other possible storage
like the integration between Google Collab and Google drive the storage
### Your contribution
Can be done using Hugging face CLI | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5442/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5442/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5441 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5441/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5441/comments | https://api.github.com/repos/huggingface/datasets/issues/5441/events | https://github.com/huggingface/datasets/pull/5441 | 1,548,417,594 | PR_kwDODunzps5IFeCW | 5,441 | resolving a weird tar extract issue | {
"login": "stas00",
"id": 10676103,
"node_id": "MDQ6VXNlcjEwNjc2MTAz",
"avatar_url": "https://avatars.githubusercontent.com/u/10676103?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/stas00",
"html_url": "https://github.com/stas00",
"followers_url": "https://api.github.com/users/stas00/followers",
"following_url": "https://api.github.com/users/stas00/following{/other_user}",
"gists_url": "https://api.github.com/users/stas00/gists{/gist_id}",
"starred_url": "https://api.github.com/users/stas00/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/stas00/subscriptions",
"organizations_url": "https://api.github.com/users/stas00/orgs",
"repos_url": "https://api.github.com/users/stas00/repos",
"events_url": "https://api.github.com/users/stas00/events{/privacy}",
"received_events_url": "https://api.github.com/users/stas00/received_events",
"type": "User",
"site_admin": false
} | [] | open | false | null | [] | [
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.011815 / 0.011353 (0.000463) | 0.006407 / 0.011008 (-0.004601) | 0.132937 / 0.038508 (0.094429) | 0.040634 / 0.023109 (0.017525) | 0.398049 / 0.275898 (0.122151) | 0.498207 / 0.323480 (0.174727) | 0.010111 / 0.007986 (0.002126) | 0.007282 / 0.004328 (0.002954) | 0.103661 / 0.004250 (0.099411) | 0.046223 / 0.037052 (0.009171) | 0.411490 / 0.258489 (0.153001) | 0.480973 / 0.293841 (0.187132) | 0.058397 / 0.128546 (-0.070149) | 0.019952 / 0.075646 (-0.055695) | 0.440734 / 0.419271 (0.021463) | 0.064585 / 0.043533 (0.021052) | 0.392556 / 0.255139 (0.137417) | 0.437842 / 0.283200 (0.154643) | 0.130684 / 0.141683 (-0.010999) | 1.910552 / 1.452155 (0.458397) | 1.984644 / 1.492716 (0.491927) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.264417 / 0.018006 (0.246411) | 0.676519 / 0.000490 (0.676030) | 0.003369 / 0.000200 (0.003169) | 0.000125 / 0.000054 (0.000071) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.034558 / 0.037411 (-0.002854) | 0.126561 / 0.014526 (0.112035) | 0.134478 / 0.176557 (-0.042079) | 0.202125 / 0.737135 (-0.535010) | 0.143273 / 0.296338 (-0.153066) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.618592 / 0.215209 (0.403383) | 6.224435 / 2.077655 (4.146780) | 2.636689 / 1.504120 (1.132569) | 2.243507 / 1.541195 (0.702313) | 2.312449 / 1.468490 (0.843959) | 1.188499 / 4.584777 (-3.396277) | 5.738347 / 3.745712 (1.992635) | 4.891933 / 5.269862 (-0.377929) | 2.697631 / 4.565676 (-1.868046) | 0.140200 / 0.424275 (-0.284076) | 0.015484 / 0.007607 (0.007877) | 0.781947 / 0.226044 (0.555903) | 7.946600 / 2.268929 (5.677671) | 3.365574 / 55.444624 (-52.079050) | 2.783443 / 6.876477 (-4.093034) | 2.738634 / 2.142072 (0.596561) | 1.487247 / 4.805227 (-3.317980) | 0.255681 / 6.500664 (-6.244983) | 0.084607 / 0.075469 (0.009138) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.717846 / 1.841788 (-0.123941) | 18.405566 / 8.074308 (10.331258) | 20.508578 / 10.191392 (10.317186) | 0.262364 / 0.680424 (-0.418060) | 0.050881 / 0.534201 (-0.483319) | 0.587516 / 0.579283 (0.008232) | 0.650900 / 0.434364 (0.216536) | 0.656168 / 0.540337 (0.115830) | 0.778876 / 1.386936 (-0.608061) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.010817 / 0.011353 (-0.000536) | 0.007338 / 0.011008 (-0.003670) | 0.131949 / 0.038508 (0.093441) | 0.037244 / 0.023109 (0.014135) | 0.565994 / 0.275898 (0.290096) | 0.567434 / 0.323480 (0.243954) | 0.007733 / 0.007986 (-0.000252) | 0.005216 / 0.004328 (0.000887) | 0.096578 / 0.004250 (0.092328) | 0.056001 / 0.037052 (0.018949) | 0.538209 / 0.258489 (0.279720) | 0.580385 / 0.293841 (0.286544) | 0.053654 / 0.128546 (-0.074892) | 0.019471 / 0.075646 (-0.056176) | 0.448781 / 0.419271 (0.029509) | 0.064774 / 0.043533 (0.021241) | 0.540222 / 0.255139 (0.285083) | 0.563058 / 0.283200 (0.279858) | 0.122716 / 0.141683 (-0.018967) | 1.839402 / 1.452155 (0.387247) | 1.915523 / 1.492716 (0.422806) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.310448 / 0.018006 (0.292442) | 0.603664 / 0.000490 (0.603175) | 0.004833 / 0.000200 (0.004633) | 0.000145 / 0.000054 (0.000090) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.032340 / 0.037411 (-0.005072) | 0.130115 / 0.014526 (0.115589) | 0.154192 / 0.176557 (-0.022364) | 0.200655 / 0.737135 (-0.536480) | 0.144961 / 0.296338 (-0.151377) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.671588 / 0.215209 (0.456379) | 6.691642 / 2.077655 (4.613988) | 2.915230 / 1.504120 (1.411110) | 2.573337 / 1.541195 (1.032143) | 2.578204 / 1.468490 (1.109714) | 1.249028 / 4.584777 (-3.335749) | 5.808539 / 3.745712 (2.062827) | 3.079317 / 5.269862 (-2.190545) | 2.033308 / 4.565676 (-2.532369) | 0.142411 / 0.424275 (-0.281864) | 0.015525 / 0.007607 (0.007918) | 0.800389 / 0.226044 (0.574345) | 8.228236 / 2.268929 (5.959308) | 3.660207 / 55.444624 (-51.784417) | 3.021033 / 6.876477 (-3.855444) | 3.088335 / 2.142072 (0.946263) | 1.380137 / 4.805227 (-3.425091) | 0.252065 / 6.500664 (-6.248599) | 0.084302 / 0.075469 (0.008833) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.709429 / 1.841788 (-0.132359) | 18.358770 / 8.074308 (10.284462) | 21.109844 / 10.191392 (10.918452) | 0.231549 / 0.680424 (-0.448875) | 0.029251 / 0.534201 (-0.504950) | 0.560719 / 0.579283 (-0.018564) | 0.610125 / 0.434364 (0.175761) | 0.630015 / 0.540337 (0.089678) | 0.751656 / 1.386936 (-0.635280) |\n\n</details>\n</details>\n\n\n",
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_5441). All of your documentation changes will be reflected on that endpoint.",
"I think I managed to reproduce it:\r\n\r\n```\r\nrm -rf ~/.cache/huggingface/datasets/HuggingFaceM4___cm4-synthetic-testing\r\nmkdir -p /tmp/xxx/hf-data\r\nsudo ln -s /tmp/xxx /test\r\nmkdir -p /tmp/yyy\r\nln -sf /test/hf-data /tmp/yyy/data\r\ncd /tmp/yyy\r\npython -c 'import sys; from datasets import load_dataset; ds=load_dataset(sys.argv[1])' HuggingFaceM4/cm4-synthetic-testing\r\n```\r\n\r\nPlease note it includes a creation of a symlink from the `/` (so `sudo`) - may be there is a simpler way but I'm just trying to replicate the real setup. Of course please be careful - it's mostly under `/tmp` not to destroy anything if you try to run this.\r\n\r\nthis fails with:\r\n\r\n```\r\nNo config specified, defaulting to: cm4-synthetic-testing/100.unique\r\nDownloading and preparing dataset cm4-synthetic-testing/100.unique (download: 20.71 KiB, generated: 49.99 MiB, post-processed: Unknown size, total: 50.01 MiB) to /home/stas/.cache/huggingface/datasets/HuggingFaceM4___cm4-synthetic-testing/100.unique/1.1.1/2e33dcc086c7209b8ccff4b19e44f1d41b5be53262e7d793142b96c2e984602b...\r\nExtraction of data is blocked (illegal path: /tmp/yyy)\r\n[...]\r\nExtraction of data/115/texts_03.txt is blocked (illegal path: /tmp/yyy)\r\nGenerating 100.unique split: 0%| | 0/100 [00:00<?, ? examples/s]Generating 100-long unique records split\r\n\r\nTraceback (most recent call last):\r\n File \"/mnt/nvme0/code/huggingface/datasets-master/src/datasets/builder.py\", line 1571, in _prepare_split_single\r\n for key, record in generator:\r\n File \"/home/stas/.cache/huggingface/modules/datasets_modules/datasets/HuggingFaceM4--cm4-synthetic-testing/2e33dcc086c7209b8ccff4b19e44f1d41b5be53262e7d793142b96c2e984602b/cm4-synthetic-testing.py\", line 190, in _generate_examples\r\n raise ValueError(f\"can't find any data - check {data_path}\")\r\nValueError: can't find any data - check /home/stas/.cache/huggingface/datasets/downloads/extracted/134227b9b94c4eccf19b205bf3021d4492d0227b9be6c2ddb6bf517d8d55a8cb/data\r\n\r\nThe above exception was the direct cause of the following exception:\r\n\r\nTraceback (most recent call last):\r\n File \"<string>\", line 1, in <module>\r\n File \"/mnt/nvme0/code/huggingface/datasets-master/src/datasets/load.py\", line 1757, in load_dataset\r\n builder_instance.download_and_prepare(\r\n File \"/mnt/nvme0/code/huggingface/datasets-master/src/datasets/builder.py\", line 860, in download_and_prepare\r\n self._download_and_prepare(\r\n File \"/mnt/nvme0/code/huggingface/datasets-master/src/datasets/builder.py\", line 1612, in _download_and_prepare\r\n super()._download_and_prepare(\r\n File \"/mnt/nvme0/code/huggingface/datasets-master/src/datasets/builder.py\", line 953, in _download_and_prepare\r\n self._prepare_split(split_generator, **prepare_split_kwargs)\r\n File \"/mnt/nvme0/code/huggingface/datasets-master/src/datasets/builder.py\", line 1450, in _prepare_split\r\n for job_id, done, content in self._prepare_split_single(\r\n File \"/mnt/nvme0/code/huggingface/datasets-master/src/datasets/builder.py\", line 1607, in _prepare_split_single\r\n raise DatasetGenerationError(\"An error occurred while generating the dataset\") from e\r\ndatasets.builder.DatasetGenerationError: An error occurred while generating the dataset\r\n```\r\n\r\nnote that `illegal path: /tmp/yyy` is now with the mods of this PR.\r\n\r\n----------------------\r\n\r\nAlso I think the whole thing should have failed at the first `illegal path` and not continue running. But as it continued and gave:\r\n\r\n\r\n> ValueError: can't find any data - check /home/stas/.cache/huggingface/datasets/downloads/extracted/134227b9b94c4eccf19b205bf3021d4492d0227b9be6c2ddb6bf517d8d55a8cb/data\r\n\r\nwhat can a user do with that other than confirming that that dir is indeed empty, but no clue is given to why and it's far from obvious that one needs to scroll up and discover earlier issues. Most users won't do that.\r\n\r\n(my apologies for writing out so much - was trying to make the situation clear)",
"Thank you, Albert, for the explanation.\r\n\r\nTo summarize I think what's needed is:\r\n\r\n1. add a comment in the code to why this is done for someone being puzzled over the odd code\r\n2. and to use an actionable by the user error message\r\n3. perform an untrapped assert on that tar extract error and not continue, so that the user will not get a later misleading error that the folder is empty and is completely not actionable and it's is far from obvious that one needs to scroll up to find earlier errors, which were trapped.\r\n\r\nAfter reading the advisory I'm still not sure why `cwd` is used and not a designated `~/.cache/huggingface/datasets/downloads/extracted`, I can't see what difference does it make since I could `chdir` to the designated directory and it would be `cwd`. The security solution is trying to ensure that `/etc/passwd` won't get overriden. So why is the check done in `.` and not the real target base directory, since the extraction isn't done in the current working dir. By not using `.` you lower the chances that the user will have all sorts of local symlinks that could trigger the issue since `datasets` typically is the only one managing it's `~/.cache/huggingface/datasets` domain and 99.9% of the time the user won't manually create files in it.\r\n\r\nthank you!\r\n"
] | 1,674,094,641,000 | 1,674,233,362,000 | null | MEMBER | null | ok, every so often, I have been getting a strange failure on dataset install:
```
$ python -c 'import sys; from datasets import load_dataset; ds=load_dataset(sys.argv[1])' HuggingFaceM4/general-pmd-synthetic-testing
No config specified, defaulting to: general-pmd-synthetic-testing/100.unique
Downloading and preparing dataset general-pmd-synthetic-testing/100.unique (download: 3.21 KiB, generated: 16.01 MiB, post-processed: Unknown size, total: 16.02 MiB) to /home/stas/.cache/huggingface/datasets/HuggingFaceM4___general-pmd-synthetic-testing/100.unique/1.1.1/86bc445e3e48cb5ef79de109eb4e54ff85b318cd55c3835c4ee8f86eae33d9d2...
Extraction of data is blocked (illegal path)
Extraction of data/1 is blocked (illegal path)
Extraction of data/1/text.null is blocked (illegal path)
[...]
```
I had no idea what to do with that - what in the world does **illegal path** mean?
I started looking at the code in `TarExtractor` and added a debug print of `base` so that told me that there was a problem with the current directory - which was a clone of one of the hf repos.
This particular dataset extracts into a directory `data` and the current dir I was running the tests from already had `data` in it which was a symbolic link to another partition and somehow all that `badpath` code was blowing up there.
https://github.com/huggingface/datasets/blob/80eb8db74f49b7ee9c0f73a819c22177fabd61db/src/datasets/utils/extract.py#L113-L114
I tried hard to come up with a repro, but no matter what I tried it only fails in that particular clone directory that has a `data` symlink and not anywhere else.
In any case, in this PR I'm proposing to at least give a user a hint of what seems to be an issue.
I'm not at all happy with the info I got with this proposed change, but at least it gave me a hint that `TarExtractor` tries to extract into the current directory without any respect to pre-existing files. Say what?
https://github.com/huggingface/datasets/blob/80eb8db74f49b7ee9c0f73a819c22177fabd61db/src/datasets/utils/extract.py#L110
why won't it use the `datasets` designated directory for that? There would never be a problem if it were to do that.
I had to look at all those `resolved`, `badpath` calls and see what it did and why it failed, since it was far from obvious. It appeared like it resolved a symlink and compared it to the original path which of course wasn't matching.
So perhaps you have a better solution than what I proposed in this PR. I think that code line I quoted is the one that should be fixed instead.
But if you can't think of a better solution let's merge this at least so that the user will have a clue that the current dir is somehow involved.
p.s. I double checked that if I remove the pre-existing `data` symlink in the current dir I'm running the dataset install command from, the problem goes away too.
Thanks.
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5441/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5441/timeline | null | null | 0 | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5441",
"html_url": "https://github.com/huggingface/datasets/pull/5441",
"diff_url": "https://github.com/huggingface/datasets/pull/5441.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5441.patch",
"merged_at": null
} | true |
https://api.github.com/repos/huggingface/datasets/issues/5440 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5440/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5440/comments | https://api.github.com/repos/huggingface/datasets/issues/5440/events | https://github.com/huggingface/datasets/pull/5440 | 1,538,361,143 | PR_kwDODunzps5HpRbF | 5,440 | Fix documentation about batch samplers | {
"login": "thomasw21",
"id": 24695242,
"node_id": "MDQ6VXNlcjI0Njk1MjQy",
"avatar_url": "https://avatars.githubusercontent.com/u/24695242?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/thomasw21",
"html_url": "https://github.com/thomasw21",
"followers_url": "https://api.github.com/users/thomasw21/followers",
"following_url": "https://api.github.com/users/thomasw21/following{/other_user}",
"gists_url": "https://api.github.com/users/thomasw21/gists{/gist_id}",
"starred_url": "https://api.github.com/users/thomasw21/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/thomasw21/subscriptions",
"organizations_url": "https://api.github.com/users/thomasw21/orgs",
"repos_url": "https://api.github.com/users/thomasw21/repos",
"events_url": "https://api.github.com/users/thomasw21/events{/privacy}",
"received_events_url": "https://api.github.com/users/thomasw21/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008874 / 0.011353 (-0.002479) | 0.004685 / 0.011008 (-0.006323) | 0.101478 / 0.038508 (0.062970) | 0.031409 / 0.023109 (0.008300) | 0.305429 / 0.275898 (0.029531) | 0.371777 / 0.323480 (0.048297) | 0.007282 / 0.007986 (-0.000704) | 0.005545 / 0.004328 (0.001217) | 0.078583 / 0.004250 (0.074333) | 0.037171 / 0.037052 (0.000118) | 0.320186 / 0.258489 (0.061696) | 0.347881 / 0.293841 (0.054040) | 0.034005 / 0.128546 (-0.094541) | 0.011534 / 0.075646 (-0.064113) | 0.326079 / 0.419271 (-0.093193) | 0.040856 / 0.043533 (-0.002677) | 0.307327 / 0.255139 (0.052188) | 0.323521 / 0.283200 (0.040321) | 0.090407 / 0.141683 (-0.051276) | 1.481994 / 1.452155 (0.029840) | 1.490372 / 1.492716 (-0.002345) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.175161 / 0.018006 (0.157155) | 0.447009 / 0.000490 (0.446519) | 0.003570 / 0.000200 (0.003370) | 0.000072 / 0.000054 (0.000017) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.023868 / 0.037411 (-0.013543) | 0.100791 / 0.014526 (0.086265) | 0.108131 / 0.176557 (-0.068425) | 0.147993 / 0.737135 (-0.589142) | 0.111205 / 0.296338 (-0.185133) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.425369 / 0.215209 (0.210160) | 4.241694 / 2.077655 (2.164040) | 2.145403 / 1.504120 (0.641283) | 1.913517 / 1.541195 (0.372322) | 1.887307 / 1.468490 (0.418817) | 0.691615 / 4.584777 (-3.893162) | 3.402233 / 3.745712 (-0.343480) | 1.992532 / 5.269862 (-3.277330) | 1.322292 / 4.565676 (-3.243385) | 0.082862 / 0.424275 (-0.341413) | 0.012595 / 0.007607 (0.004988) | 0.528490 / 0.226044 (0.302445) | 5.313338 / 2.268929 (3.044409) | 2.645037 / 55.444624 (-52.799587) | 2.326279 / 6.876477 (-4.550198) | 2.396955 / 2.142072 (0.254883) | 0.819354 / 4.805227 (-3.985873) | 0.150889 / 6.500664 (-6.349775) | 0.066517 / 0.075469 (-0.008952) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.233673 / 1.841788 (-0.608114) | 14.563293 / 8.074308 (6.488985) | 14.317989 / 10.191392 (4.126597) | 0.150767 / 0.680424 (-0.529657) | 0.028972 / 0.534201 (-0.505229) | 0.400547 / 0.579283 (-0.178736) | 0.402267 / 0.434364 (-0.032097) | 0.459375 / 0.540337 (-0.080962) | 0.544419 / 1.386936 (-0.842517) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006817 / 0.011353 (-0.004536) | 0.004588 / 0.011008 (-0.006421) | 0.099224 / 0.038508 (0.060716) | 0.027730 / 0.023109 (0.004621) | 0.412310 / 0.275898 (0.136412) | 0.445731 / 0.323480 (0.122252) | 0.005197 / 0.007986 (-0.002788) | 0.003601 / 0.004328 (-0.000728) | 0.076200 / 0.004250 (0.071950) | 0.041813 / 0.037052 (0.004761) | 0.415282 / 0.258489 (0.156793) | 0.457182 / 0.293841 (0.163341) | 0.031920 / 0.128546 (-0.096626) | 0.011712 / 0.075646 (-0.063934) | 0.320859 / 0.419271 (-0.098412) | 0.041466 / 0.043533 (-0.002067) | 0.418156 / 0.255139 (0.163017) | 0.435501 / 0.283200 (0.152302) | 0.090727 / 0.141683 (-0.050955) | 1.484014 / 1.452155 (0.031859) | 1.568072 / 1.492716 (0.075356) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.263356 / 0.018006 (0.245350) | 0.410768 / 0.000490 (0.410278) | 0.015983 / 0.000200 (0.015783) | 0.000301 / 0.000054 (0.000246) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.024522 / 0.037411 (-0.012889) | 0.103986 / 0.014526 (0.089460) | 0.109253 / 0.176557 (-0.067303) | 0.142308 / 0.737135 (-0.594827) | 0.114037 / 0.296338 (-0.182302) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.452617 / 0.215209 (0.237407) | 4.505215 / 2.077655 (2.427560) | 2.185546 / 1.504120 (0.681426) | 1.995540 / 1.541195 (0.454345) | 1.962875 / 1.468490 (0.494385) | 0.690237 / 4.584777 (-3.894540) | 3.448311 / 3.745712 (-0.297401) | 1.901572 / 5.269862 (-3.368289) | 1.170832 / 4.565676 (-3.394844) | 0.082333 / 0.424275 (-0.341942) | 0.012569 / 0.007607 (0.004962) | 0.547822 / 0.226044 (0.321778) | 5.504180 / 2.268929 (3.235251) | 2.693981 / 55.444624 (-52.750644) | 2.320710 / 6.876477 (-4.555767) | 2.270508 / 2.142072 (0.128435) | 0.803145 / 4.805227 (-4.002083) | 0.152168 / 6.500664 (-6.348496) | 0.067408 / 0.075469 (-0.008061) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.260689 / 1.841788 (-0.581099) | 14.281112 / 8.074308 (6.206804) | 14.549742 / 10.191392 (4.358350) | 0.129337 / 0.680424 (-0.551087) | 0.017181 / 0.534201 (-0.517020) | 0.380473 / 0.579283 (-0.198810) | 0.387689 / 0.434364 (-0.046675) | 0.446734 / 0.540337 (-0.093603) | 0.532479 / 1.386936 (-0.854457) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008953 / 0.011353 (-0.002400) | 0.004917 / 0.011008 (-0.006091) | 0.098699 / 0.038508 (0.060191) | 0.034460 / 0.023109 (0.011351) | 0.294604 / 0.275898 (0.018706) | 0.322709 / 0.323480 (-0.000770) | 0.007780 / 0.007986 (-0.000206) | 0.004061 / 0.004328 (-0.000267) | 0.076134 / 0.004250 (0.071883) | 0.043786 / 0.037052 (0.006734) | 0.302155 / 0.258489 (0.043666) | 0.339779 / 0.293841 (0.045938) | 0.038305 / 0.128546 (-0.090241) | 0.012131 / 0.075646 (-0.063515) | 0.332656 / 0.419271 (-0.086615) | 0.048029 / 0.043533 (0.004496) | 0.303859 / 0.255139 (0.048720) | 0.315861 / 0.283200 (0.032662) | 0.100758 / 0.141683 (-0.040925) | 1.468072 / 1.452155 (0.015918) | 1.521325 / 1.492716 (0.028609) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.244975 / 0.018006 (0.226969) | 0.524392 / 0.000490 (0.523902) | 0.003720 / 0.000200 (0.003520) | 0.000087 / 0.000054 (0.000032) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.027704 / 0.037411 (-0.009707) | 0.109048 / 0.014526 (0.094522) | 0.118298 / 0.176557 (-0.058259) | 0.158748 / 0.737135 (-0.578388) | 0.125654 / 0.296338 (-0.170684) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.406973 / 0.215209 (0.191764) | 4.057502 / 2.077655 (1.979847) | 1.939847 / 1.504120 (0.435727) | 1.746457 / 1.541195 (0.205262) | 1.698866 / 1.468490 (0.230376) | 0.692884 / 4.584777 (-3.891893) | 3.736988 / 3.745712 (-0.008724) | 2.050122 / 5.269862 (-3.219740) | 1.299808 / 4.565676 (-3.265868) | 0.085285 / 0.424275 (-0.338990) | 0.012768 / 0.007607 (0.005161) | 0.510814 / 0.226044 (0.284770) | 5.105319 / 2.268929 (2.836391) | 2.304003 / 55.444624 (-53.140621) | 1.951123 / 6.876477 (-4.925354) | 1.998504 / 2.142072 (-0.143568) | 0.840235 / 4.805227 (-3.964993) | 0.164521 / 6.500664 (-6.336143) | 0.064215 / 0.075469 (-0.011254) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.272520 / 1.841788 (-0.569268) | 14.648110 / 8.074308 (6.573802) | 14.573754 / 10.191392 (4.382362) | 0.170053 / 0.680424 (-0.510371) | 0.029389 / 0.534201 (-0.504811) | 0.438924 / 0.579283 (-0.140359) | 0.433572 / 0.434364 (-0.000792) | 0.517702 / 0.540337 (-0.022635) | 0.600389 / 1.386936 (-0.786547) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.007362 / 0.011353 (-0.003991) | 0.005451 / 0.011008 (-0.005557) | 0.099336 / 0.038508 (0.060828) | 0.033284 / 0.023109 (0.010174) | 0.377143 / 0.275898 (0.101245) | 0.423724 / 0.323480 (0.100244) | 0.006194 / 0.007986 (-0.001792) | 0.004208 / 0.004328 (-0.000121) | 0.074473 / 0.004250 (0.070223) | 0.049874 / 0.037052 (0.012821) | 0.376012 / 0.258489 (0.117523) | 0.439942 / 0.293841 (0.146101) | 0.037860 / 0.128546 (-0.090686) | 0.012546 / 0.075646 (-0.063100) | 0.349123 / 0.419271 (-0.070148) | 0.048980 / 0.043533 (0.005447) | 0.391205 / 0.255139 (0.136066) | 0.396474 / 0.283200 (0.113274) | 0.105846 / 0.141683 (-0.035836) | 1.502475 / 1.452155 (0.050321) | 1.612303 / 1.492716 (0.119587) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.300815 / 0.018006 (0.282809) | 0.542171 / 0.000490 (0.541681) | 0.005465 / 0.000200 (0.005265) | 0.000094 / 0.000054 (0.000039) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.028904 / 0.037411 (-0.008508) | 0.110352 / 0.014526 (0.095827) | 0.123275 / 0.176557 (-0.053282) | 0.161958 / 0.737135 (-0.575178) | 0.133595 / 0.296338 (-0.162743) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.438724 / 0.215209 (0.223515) | 4.373633 / 2.077655 (2.295979) | 2.178981 / 1.504120 (0.674861) | 1.992442 / 1.541195 (0.451247) | 2.063149 / 1.468490 (0.594659) | 0.696688 / 4.584777 (-3.888089) | 3.849370 / 3.745712 (0.103658) | 3.509495 / 5.269862 (-1.760367) | 1.923320 / 4.565676 (-2.642356) | 0.085554 / 0.424275 (-0.338721) | 0.012510 / 0.007607 (0.004903) | 0.535953 / 0.226044 (0.309909) | 5.365684 / 2.268929 (3.096755) | 2.686902 / 55.444624 (-52.757723) | 2.330922 / 6.876477 (-4.545554) | 2.353445 / 2.142072 (0.211373) | 0.878336 / 4.805227 (-3.926891) | 0.167296 / 6.500664 (-6.333368) | 0.064564 / 0.075469 (-0.010905) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.244696 / 1.841788 (-0.597091) | 15.027981 / 8.074308 (6.953673) | 14.545797 / 10.191392 (4.354405) | 0.147229 / 0.680424 (-0.533194) | 0.018007 / 0.534201 (-0.516194) | 0.446196 / 0.579283 (-0.133087) | 0.437418 / 0.434364 (0.003054) | 0.510732 / 0.540337 (-0.029606) | 0.594814 / 1.386936 (-0.792122) |\n\n</details>\n</details>\n\n\n"
] | 1,674,061,467,000 | 1,674,064,649,000 | 1,674,064,204,000 | MEMBER | null | null | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5440/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5440/timeline | null | null | 0 | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5440",
"html_url": "https://github.com/huggingface/datasets/pull/5440",
"diff_url": "https://github.com/huggingface/datasets/pull/5440.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5440.patch",
"merged_at": "2023-01-18T17:50:04"
} | true |
https://api.github.com/repos/huggingface/datasets/issues/5439 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5439/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5439/comments | https://api.github.com/repos/huggingface/datasets/issues/5439/events | https://github.com/huggingface/datasets/issues/5439 | 1,537,973,564 | I_kwDODunzps5bq508 | 5,439 | [dataset request] Add Common Voice 12.0 | {
"login": "MohammedRakib",
"id": 31034499,
"node_id": "MDQ6VXNlcjMxMDM0NDk5",
"avatar_url": "https://avatars.githubusercontent.com/u/31034499?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/MohammedRakib",
"html_url": "https://github.com/MohammedRakib",
"followers_url": "https://api.github.com/users/MohammedRakib/followers",
"following_url": "https://api.github.com/users/MohammedRakib/following{/other_user}",
"gists_url": "https://api.github.com/users/MohammedRakib/gists{/gist_id}",
"starred_url": "https://api.github.com/users/MohammedRakib/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/MohammedRakib/subscriptions",
"organizations_url": "https://api.github.com/users/MohammedRakib/orgs",
"repos_url": "https://api.github.com/users/MohammedRakib/repos",
"events_url": "https://api.github.com/users/MohammedRakib/events{/privacy}",
"received_events_url": "https://api.github.com/users/MohammedRakib/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892871,
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement",
"name": "enhancement",
"color": "a2eeef",
"default": true,
"description": "New feature or request"
}
] | open | false | {
"login": "polinaeterna",
"id": 16348744,
"node_id": "MDQ6VXNlcjE2MzQ4NzQ0",
"avatar_url": "https://avatars.githubusercontent.com/u/16348744?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/polinaeterna",
"html_url": "https://github.com/polinaeterna",
"followers_url": "https://api.github.com/users/polinaeterna/followers",
"following_url": "https://api.github.com/users/polinaeterna/following{/other_user}",
"gists_url": "https://api.github.com/users/polinaeterna/gists{/gist_id}",
"starred_url": "https://api.github.com/users/polinaeterna/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/polinaeterna/subscriptions",
"organizations_url": "https://api.github.com/users/polinaeterna/orgs",
"repos_url": "https://api.github.com/users/polinaeterna/repos",
"events_url": "https://api.github.com/users/polinaeterna/events{/privacy}",
"received_events_url": "https://api.github.com/users/polinaeterna/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "polinaeterna",
"id": 16348744,
"node_id": "MDQ6VXNlcjE2MzQ4NzQ0",
"avatar_url": "https://avatars.githubusercontent.com/u/16348744?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/polinaeterna",
"html_url": "https://github.com/polinaeterna",
"followers_url": "https://api.github.com/users/polinaeterna/followers",
"following_url": "https://api.github.com/users/polinaeterna/following{/other_user}",
"gists_url": "https://api.github.com/users/polinaeterna/gists{/gist_id}",
"starred_url": "https://api.github.com/users/polinaeterna/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/polinaeterna/subscriptions",
"organizations_url": "https://api.github.com/users/polinaeterna/orgs",
"repos_url": "https://api.github.com/users/polinaeterna/repos",
"events_url": "https://api.github.com/users/polinaeterna/events{/privacy}",
"received_events_url": "https://api.github.com/users/polinaeterna/received_events",
"type": "User",
"site_admin": false
}
] | [
"@polinaeterna any tentative date on when the Common Voice 12.0 dataset will be added ?"
] | 1,674,047,225,000 | 1,674,671,933,000 | null | NONE | null | ### Feature request
Please add the common voice 12_0 datasets. Apart from English, a significant amount of audio-data has been added to the other minor-language datasets.
### Motivation
The dataset link:
https://commonvoice.mozilla.org/en/datasets
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5439/reactions",
"total_count": 2,
"+1": 2,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5439/timeline | null | null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5438 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5438/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5438/comments | https://api.github.com/repos/huggingface/datasets/issues/5438/events | https://github.com/huggingface/datasets/pull/5438 | 1,537,489,730 | PR_kwDODunzps5HmWA8 | 5,438 | Update actions/checkout in CD Conda release | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008470 / 0.011353 (-0.002883) | 0.004721 / 0.011008 (-0.006287) | 0.099024 / 0.038508 (0.060516) | 0.029831 / 0.023109 (0.006722) | 0.325887 / 0.275898 (0.049989) | 0.380753 / 0.323480 (0.057273) | 0.007101 / 0.007986 (-0.000885) | 0.004734 / 0.004328 (0.000406) | 0.077576 / 0.004250 (0.073326) | 0.037207 / 0.037052 (0.000154) | 0.320463 / 0.258489 (0.061974) | 0.369284 / 0.293841 (0.075443) | 0.033411 / 0.128546 (-0.095135) | 0.011610 / 0.075646 (-0.064037) | 0.321460 / 0.419271 (-0.097811) | 0.041315 / 0.043533 (-0.002217) | 0.349186 / 0.255139 (0.094047) | 0.384546 / 0.283200 (0.101347) | 0.088045 / 0.141683 (-0.053637) | 1.536341 / 1.452155 (0.084186) | 1.527806 / 1.492716 (0.035089) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.193435 / 0.018006 (0.175429) | 0.451732 / 0.000490 (0.451243) | 0.003165 / 0.000200 (0.002965) | 0.000082 / 0.000054 (0.000027) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.023203 / 0.037411 (-0.014208) | 0.096211 / 0.014526 (0.081685) | 0.105665 / 0.176557 (-0.070891) | 0.141074 / 0.737135 (-0.596061) | 0.108584 / 0.296338 (-0.187755) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.419041 / 0.215209 (0.203832) | 4.187915 / 2.077655 (2.110261) | 1.855336 / 1.504120 (0.351216) | 1.660046 / 1.541195 (0.118851) | 1.674646 / 1.468490 (0.206156) | 0.692257 / 4.584777 (-3.892520) | 3.466853 / 3.745712 (-0.278860) | 1.900925 / 5.269862 (-3.368936) | 1.294696 / 4.565676 (-3.270980) | 0.082792 / 0.424275 (-0.341483) | 0.012808 / 0.007607 (0.005201) | 0.529622 / 0.226044 (0.303578) | 5.337025 / 2.268929 (3.068096) | 2.326558 / 55.444624 (-53.118066) | 1.956256 / 6.876477 (-4.920221) | 2.035911 / 2.142072 (-0.106161) | 0.815824 / 4.805227 (-3.989403) | 0.148720 / 6.500664 (-6.351944) | 0.064226 / 0.075469 (-0.011243) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.231347 / 1.841788 (-0.610440) | 13.724596 / 8.074308 (5.650288) | 13.933878 / 10.191392 (3.742486) | 0.150913 / 0.680424 (-0.529511) | 0.028460 / 0.534201 (-0.505741) | 0.393564 / 0.579283 (-0.185719) | 0.407185 / 0.434364 (-0.027179) | 0.458250 / 0.540337 (-0.082087) | 0.547993 / 1.386936 (-0.838943) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006653 / 0.011353 (-0.004699) | 0.004615 / 0.011008 (-0.006393) | 0.098062 / 0.038508 (0.059554) | 0.027849 / 0.023109 (0.004740) | 0.409116 / 0.275898 (0.133218) | 0.448770 / 0.323480 (0.125290) | 0.004856 / 0.007986 (-0.003130) | 0.003427 / 0.004328 (-0.000901) | 0.075748 / 0.004250 (0.071498) | 0.037942 / 0.037052 (0.000889) | 0.410232 / 0.258489 (0.151743) | 0.457394 / 0.293841 (0.163553) | 0.031927 / 0.128546 (-0.096620) | 0.011618 / 0.075646 (-0.064028) | 0.321231 / 0.419271 (-0.098040) | 0.041416 / 0.043533 (-0.002117) | 0.413535 / 0.255139 (0.158396) | 0.438196 / 0.283200 (0.154997) | 0.089551 / 0.141683 (-0.052132) | 1.459298 / 1.452155 (0.007143) | 1.552594 / 1.492716 (0.059878) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.228186 / 0.018006 (0.210180) | 0.404393 / 0.000490 (0.403904) | 0.006944 / 0.000200 (0.006744) | 0.000081 / 0.000054 (0.000026) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.025167 / 0.037411 (-0.012244) | 0.101282 / 0.014526 (0.086756) | 0.107282 / 0.176557 (-0.069275) | 0.139797 / 0.737135 (-0.597339) | 0.110477 / 0.296338 (-0.185861) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.479121 / 0.215209 (0.263912) | 4.778210 / 2.077655 (2.700555) | 2.464687 / 1.504120 (0.960567) | 2.255312 / 1.541195 (0.714118) | 2.287348 / 1.468490 (0.818858) | 0.694769 / 4.584777 (-3.890008) | 3.460860 / 3.745712 (-0.284852) | 3.078881 / 5.269862 (-2.190980) | 1.297726 / 4.565676 (-3.267950) | 0.082699 / 0.424275 (-0.341576) | 0.012652 / 0.007607 (0.005045) | 0.583308 / 0.226044 (0.357263) | 5.839199 / 2.268929 (3.570271) | 2.893724 / 55.444624 (-52.550900) | 2.546503 / 6.876477 (-4.329974) | 2.559570 / 2.142072 (0.417498) | 0.802357 / 4.805227 (-4.002870) | 0.151890 / 6.500664 (-6.348774) | 0.068593 / 0.075469 (-0.006876) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.262421 / 1.841788 (-0.579367) | 13.771848 / 8.074308 (5.697540) | 14.046017 / 10.191392 (3.854625) | 0.140950 / 0.680424 (-0.539474) | 0.016839 / 0.534201 (-0.517362) | 0.378870 / 0.579283 (-0.200413) | 0.385908 / 0.434364 (-0.048456) | 0.438539 / 0.540337 (-0.101799) | 0.522761 / 1.386936 (-0.864175) |\n\n</details>\n</details>\n\n\n"
] | 1,674,024,795,000 | 1,674,049,791,000 | 1,674,049,369,000 | MEMBER | null | This PR updates the "checkout" GitHub Action to its latest version, as previous ones are deprecated: https://github.blog/changelog/2022-09-22-github-actions-all-actions-will-begin-running-on-node16-instead-of-node12/ | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5438/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5438/timeline | null | null | 0 | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5438",
"html_url": "https://github.com/huggingface/datasets/pull/5438",
"diff_url": "https://github.com/huggingface/datasets/pull/5438.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5438.patch",
"merged_at": "2023-01-18T13:42:48"
} | true |
https://api.github.com/repos/huggingface/datasets/issues/5437 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5437/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5437/comments | https://api.github.com/repos/huggingface/datasets/issues/5437/events | https://github.com/huggingface/datasets/issues/5437 | 1,536,837,144 | I_kwDODunzps5bmkYY | 5,437 | Can't load png dataset with 4 channel (RGBA) | {
"login": "WiNE-iNEFF",
"id": 41611046,
"node_id": "MDQ6VXNlcjQxNjExMDQ2",
"avatar_url": "https://avatars.githubusercontent.com/u/41611046?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/WiNE-iNEFF",
"html_url": "https://github.com/WiNE-iNEFF",
"followers_url": "https://api.github.com/users/WiNE-iNEFF/followers",
"following_url": "https://api.github.com/users/WiNE-iNEFF/following{/other_user}",
"gists_url": "https://api.github.com/users/WiNE-iNEFF/gists{/gist_id}",
"starred_url": "https://api.github.com/users/WiNE-iNEFF/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/WiNE-iNEFF/subscriptions",
"organizations_url": "https://api.github.com/users/WiNE-iNEFF/orgs",
"repos_url": "https://api.github.com/users/WiNE-iNEFF/repos",
"events_url": "https://api.github.com/users/WiNE-iNEFF/events{/privacy}",
"received_events_url": "https://api.github.com/users/WiNE-iNEFF/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Hi! Can you please share the directory structure of your image folder and the `load_dataset` call? We decode images with Pillow, and Pillow supports RGBA PNGs, so this shouldn't be a problem.\r\n\r\n",
"> Hi! Can you please share the directory structure of your image folder and the `load_dataset` call? We decode images with Pillow, and Pillow supports RGBA PNGs, so this shouldn't be a problem.\n> \n> \n\nI have only 1 folder that I use in the load_dataset function with the name \"IMGDATA\" and all my 9000 images are located in this folder.\n`\nfrom datasets import load_dataset\n\ndataset = load_dataset(\"IMGDATA\")\n`\nAt the same time, using another data set with images consisting of 3 RGB channels, everything works",
"Okay, I figured out what was wrong. When uploading my dataset via Google Drive, the images broke and Pillow couldn't open them. As a result, I solved the problem by downloading the ZIP archive"
] | 1,673,979,747,000 | 1,674,073,215,000 | 1,674,073,215,000 | NONE | null | I try to create dataset which contains about 9000 png images 64x64 in size, and they are all 4-channel (RGBA). When trying to use load_dataset() then a dataset is created from only 2 images. What exactly interferes I can not understand.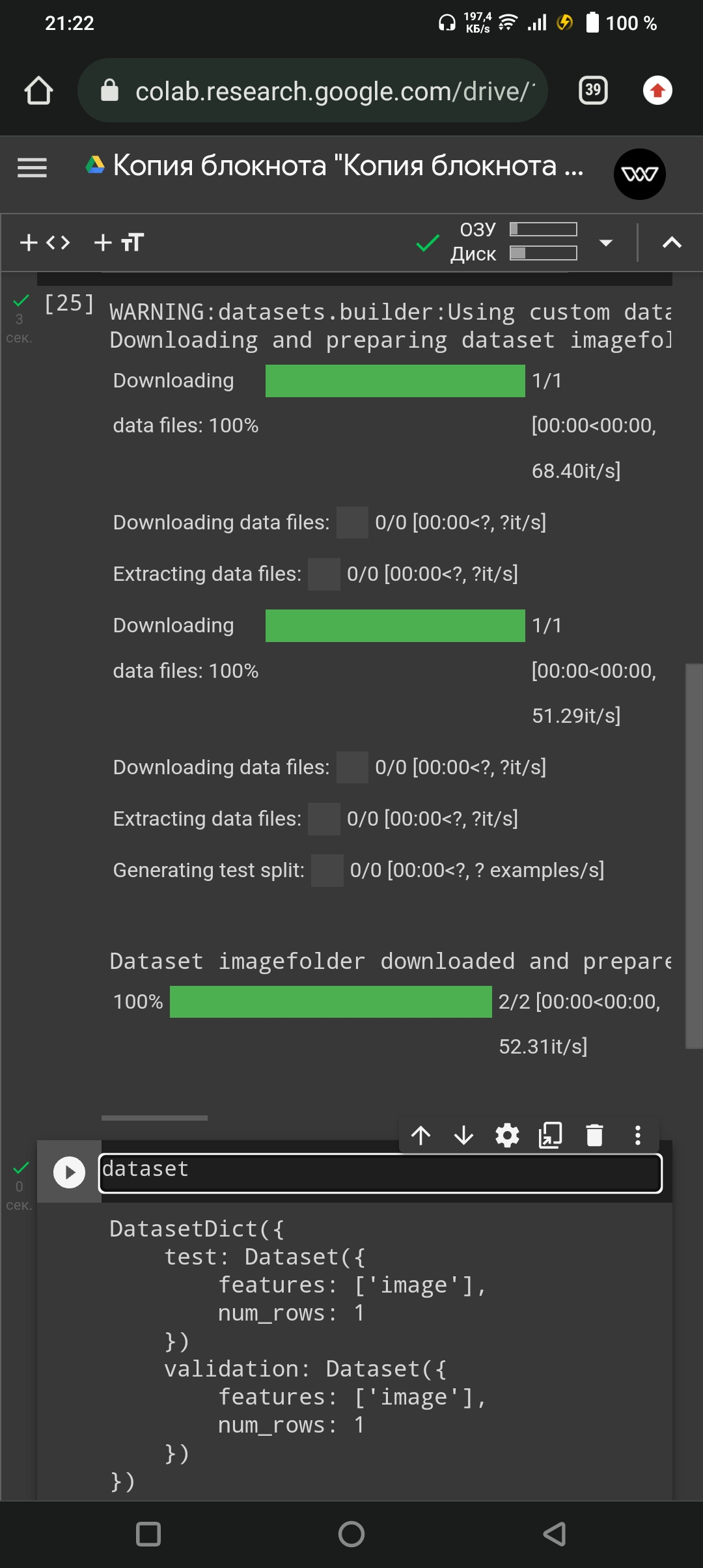 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5437/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5437/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5436 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5436/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5436/comments | https://api.github.com/repos/huggingface/datasets/issues/5436/events | https://github.com/huggingface/datasets/pull/5436 | 1,536,633,173 | PR_kwDODunzps5Hjh4v | 5,436 | Revert container image pin in CI benchmarks | {
"login": "0x2b3bfa0",
"id": 11387611,
"node_id": "MDQ6VXNlcjExMzg3NjEx",
"avatar_url": "https://avatars.githubusercontent.com/u/11387611?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/0x2b3bfa0",
"html_url": "https://github.com/0x2b3bfa0",
"followers_url": "https://api.github.com/users/0x2b3bfa0/followers",
"following_url": "https://api.github.com/users/0x2b3bfa0/following{/other_user}",
"gists_url": "https://api.github.com/users/0x2b3bfa0/gists{/gist_id}",
"starred_url": "https://api.github.com/users/0x2b3bfa0/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/0x2b3bfa0/subscriptions",
"organizations_url": "https://api.github.com/users/0x2b3bfa0/orgs",
"repos_url": "https://api.github.com/users/0x2b3bfa0/repos",
"events_url": "https://api.github.com/users/0x2b3bfa0/events{/privacy}",
"received_events_url": "https://api.github.com/users/0x2b3bfa0/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.013736 / 0.011353 (0.002383) | 0.006253 / 0.011008 (-0.004755) | 0.127076 / 0.038508 (0.088568) | 0.040997 / 0.023109 (0.017888) | 0.394744 / 0.275898 (0.118846) | 0.454285 / 0.323480 (0.130805) | 0.009864 / 0.007986 (0.001878) | 0.005093 / 0.004328 (0.000765) | 0.098714 / 0.004250 (0.094464) | 0.044308 / 0.037052 (0.007255) | 0.421951 / 0.258489 (0.163462) | 0.462280 / 0.293841 (0.168439) | 0.059979 / 0.128546 (-0.068567) | 0.020607 / 0.075646 (-0.055039) | 0.443593 / 0.419271 (0.024321) | 0.062332 / 0.043533 (0.018799) | 0.411335 / 0.255139 (0.156196) | 0.426524 / 0.283200 (0.143324) | 0.118233 / 0.141683 (-0.023450) | 1.877681 / 1.452155 (0.425527) | 1.865271 / 1.492716 (0.372555) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.234791 / 0.018006 (0.216784) | 0.557322 / 0.000490 (0.556833) | 0.000528 / 0.000200 (0.000328) | 0.000105 / 0.000054 (0.000051) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.030260 / 0.037411 (-0.007151) | 0.122594 / 0.014526 (0.108068) | 0.142142 / 0.176557 (-0.034414) | 0.197098 / 0.737135 (-0.540037) | 0.150978 / 0.296338 (-0.145360) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.622644 / 0.215209 (0.407435) | 6.320078 / 2.077655 (4.242423) | 2.552755 / 1.504120 (1.048635) | 2.188647 / 1.541195 (0.647453) | 2.226602 / 1.468490 (0.758112) | 1.288083 / 4.584777 (-3.296694) | 5.624143 / 3.745712 (1.878431) | 3.208382 / 5.269862 (-2.061480) | 2.115222 / 4.565676 (-2.450455) | 0.146420 / 0.424275 (-0.277856) | 0.014464 / 0.007607 (0.006857) | 0.816470 / 0.226044 (0.590425) | 7.984049 / 2.268929 (5.715120) | 3.364942 / 55.444624 (-52.079682) | 2.552306 / 6.876477 (-4.324171) | 2.664575 / 2.142072 (0.522503) | 1.556177 / 4.805227 (-3.249050) | 0.263389 / 6.500664 (-6.237275) | 0.076861 / 0.075469 (0.001391) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.553734 / 1.841788 (-0.288054) | 18.365029 / 8.074308 (10.290721) | 20.993993 / 10.191392 (10.802601) | 0.235642 / 0.680424 (-0.444782) | 0.047084 / 0.534201 (-0.487117) | 0.555610 / 0.579283 (-0.023673) | 0.659413 / 0.434364 (0.225049) | 0.639284 / 0.540337 (0.098947) | 0.756317 / 1.386936 (-0.630620) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.014709 / 0.011353 (0.003356) | 0.006673 / 0.011008 (-0.004335) | 0.133718 / 0.038508 (0.095210) | 0.035699 / 0.023109 (0.012590) | 0.459089 / 0.275898 (0.183191) | 0.538071 / 0.323480 (0.214591) | 0.007376 / 0.007986 (-0.000610) | 0.004688 / 0.004328 (0.000360) | 0.104909 / 0.004250 (0.100659) | 0.064942 / 0.037052 (0.027890) | 0.466158 / 0.258489 (0.207669) | 0.566100 / 0.293841 (0.272259) | 0.057368 / 0.128546 (-0.071178) | 0.021572 / 0.075646 (-0.054075) | 0.413826 / 0.419271 (-0.005446) | 0.079543 / 0.043533 (0.036010) | 0.493313 / 0.255139 (0.238174) | 0.517787 / 0.283200 (0.234587) | 0.119836 / 0.141683 (-0.021847) | 1.833956 / 1.452155 (0.381801) | 2.003288 / 1.492716 (0.510572) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.276013 / 0.018006 (0.258007) | 0.549194 / 0.000490 (0.548704) | 0.010939 / 0.000200 (0.010739) | 0.000129 / 0.000054 (0.000075) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.034983 / 0.037411 (-0.002428) | 0.131576 / 0.014526 (0.117050) | 0.140651 / 0.176557 (-0.035906) | 0.186455 / 0.737135 (-0.550681) | 0.146309 / 0.296338 (-0.150029) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.675973 / 0.215209 (0.460763) | 6.821862 / 2.077655 (4.744208) | 3.090307 / 1.504120 (1.586187) | 2.710679 / 1.541195 (1.169484) | 2.891577 / 1.468490 (1.423087) | 1.306160 / 4.584777 (-3.278617) | 5.629763 / 3.745712 (1.884051) | 4.662578 / 5.269862 (-0.607283) | 2.670195 / 4.565676 (-1.895482) | 0.153867 / 0.424275 (-0.270408) | 0.016028 / 0.007607 (0.008421) | 0.878702 / 0.226044 (0.652658) | 8.801612 / 2.268929 (6.532683) | 4.005520 / 55.444624 (-51.439104) | 3.124755 / 6.876477 (-3.751721) | 3.382132 / 2.142072 (1.240060) | 1.525951 / 4.805227 (-3.279277) | 0.263350 / 6.500664 (-6.237315) | 0.079285 / 0.075469 (0.003815) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.647591 / 1.841788 (-0.194197) | 18.281646 / 8.074308 (10.207338) | 21.072142 / 10.191392 (10.880750) | 0.232236 / 0.680424 (-0.448188) | 0.026126 / 0.534201 (-0.508075) | 0.546926 / 0.579283 (-0.032357) | 0.634496 / 0.434364 (0.200132) | 0.604345 / 0.540337 (0.064007) | 0.730159 / 1.386936 (-0.656777) |\n\n</details>\n</details>\n\n\n"
] | 1,673,971,190,000 | 1,674,032,749,000 | 1,674,023,346,000 | CONTRIBUTOR | null | Closes #5433, reverts #5432, and also:
* Uses [ghcr.io container images](https://cml.dev/doc/self-hosted-runners/#docker-images) for extra speed
* Updates `actions/checkout` to `v3` (note that `v2` is [deprecated](https://github.blog/changelog/2022-09-22-github-actions-all-actions-will-begin-running-on-node16-instead-of-node12/))
* Follows the new naming convention for environment variables introduced with [iterative/cml#1272](https://github.com/iterative/cml/pull/1272) | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5436/reactions",
"total_count": 3,
"+1": 3,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5436/timeline | null | null | 0 | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5436",
"html_url": "https://github.com/huggingface/datasets/pull/5436",
"diff_url": "https://github.com/huggingface/datasets/pull/5436.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5436.patch",
"merged_at": "2023-01-18T06:29:06"
} | true |
https://api.github.com/repos/huggingface/datasets/issues/5435 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5435/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5435/comments | https://api.github.com/repos/huggingface/datasets/issues/5435/events | https://github.com/huggingface/datasets/issues/5435 | 1,536,099,300 | I_kwDODunzps5bjwPk | 5,435 | Wrong statement in "Load a Dataset in Streaming mode" leads to data leakage | {
"login": "DanielYang59",
"id": 80093591,
"node_id": "MDQ6VXNlcjgwMDkzNTkx",
"avatar_url": "https://avatars.githubusercontent.com/u/80093591?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/DanielYang59",
"html_url": "https://github.com/DanielYang59",
"followers_url": "https://api.github.com/users/DanielYang59/followers",
"following_url": "https://api.github.com/users/DanielYang59/following{/other_user}",
"gists_url": "https://api.github.com/users/DanielYang59/gists{/gist_id}",
"starred_url": "https://api.github.com/users/DanielYang59/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/DanielYang59/subscriptions",
"organizations_url": "https://api.github.com/users/DanielYang59/orgs",
"repos_url": "https://api.github.com/users/DanielYang59/repos",
"events_url": "https://api.github.com/users/DanielYang59/events{/privacy}",
"received_events_url": "https://api.github.com/users/DanielYang59/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Just for your information, Tensorflow confirmed this issue [here.](https://github.com/tensorflow/tensorflow/issues/59279)",
"Thanks for reporting, @HaoyuYang59.\r\n\r\nPlease note that these are different \"dataset\" objects: our docs refer to Hugging Face `datasets.Dataset` and not to TensorFlow `tf.data.Dataset`.\r\n\r\nOur `datasets.Dataset.shuffle` method does not have a `reshuffle_each_iteration` argument. Therefore, I would say the statement in our docs is True because they refer to `datasets.Dataset.shuffle`, `datasets.Dataset.skip` and `datasets.Dataset.take`.\r\n\r\nI think this issue is restricted to TensorFlow dataset, and this would be addressed by them in the issue you opened in their repo: https://github.com/tensorflow/tensorflow/issues/59279",
"Also note that you are referring to an outdated documentation page: datasets 1.10.2 version\r\n\r\nCurrent datasets version is 2.8.0 and the corresponding documentation page is: https://huggingface.co/docs/datasets/stream#split-dataset",
"Hi @albertvillanova thanks for your reply and your explaination here. \r\n\r\nSorry for the confusion as I'm not actually a user of your repo and I just happen to find the thread by Google (and didn't read carefully).\r\n\r\nGreat to know that and you made everything very clear now.\r\n\r\nThanks for your time and sorry for the consusion.\r\n\r\nWishing you a wonderful time. \r\n\r\nRegards"
] | 1,673,949,856,000 | 1,674,122,163,000 | 1,674,122,163,000 | NONE | null | ### Describe the bug
In the [Split your dataset with take and skip](https://huggingface.co/docs/datasets/v1.10.2/dataset_streaming.html#split-your-dataset-with-take-and-skip), it states:
> Using take (or skip) prevents future calls to shuffle from shuffling the dataset shards order, otherwise the taken examples could come from other shards. In this case it only uses the shuffle buffer. Therefore it is advised to shuffle the dataset before splitting using take or skip. See more details in the [Shuffling the dataset: shuffle](https://huggingface.co/docs/datasets/v1.10.2/dataset_streaming.html#iterable-dataset-shuffling) section.`
>> \# You can also create splits from a shuffled dataset
>> train_dataset = shuffled_dataset.skip(1000)
>> eval_dataset = shuffled_dataset.take(1000)
Where the shuffled dataset comes from:
`shuffled_dataset = dataset.shuffle(buffer_size=10_000, seed=42)`
At least in Tensorflow 2.9/2.10/2.11, [docs](https://www.tensorflow.org/api_docs/python/tf/data/Dataset#shuffle) states the `reshuffle_each_iteration` argument is `True` by default. This means the dataset would be shuffled after each epoch, and as a result **the validation data would leak into training test**.
### Steps to reproduce the bug
N/A
### Expected behavior
The `reshuffle_each_iteration` argument should be set to `False`.
### Environment info
Tensorflow 2.9/2.10/2.11 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5435/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5435/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5434 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5434/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5434/comments | https://api.github.com/repos/huggingface/datasets/issues/5434/events | https://github.com/huggingface/datasets/issues/5434 | 1,536,090,042 | I_kwDODunzps5bjt-6 | 5,434 | sample_dataset module not found | {
"login": "nickums",
"id": 15816213,
"node_id": "MDQ6VXNlcjE1ODE2MjEz",
"avatar_url": "https://avatars.githubusercontent.com/u/15816213?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/nickums",
"html_url": "https://github.com/nickums",
"followers_url": "https://api.github.com/users/nickums/followers",
"following_url": "https://api.github.com/users/nickums/following{/other_user}",
"gists_url": "https://api.github.com/users/nickums/gists{/gist_id}",
"starred_url": "https://api.github.com/users/nickums/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/nickums/subscriptions",
"organizations_url": "https://api.github.com/users/nickums/orgs",
"repos_url": "https://api.github.com/users/nickums/repos",
"events_url": "https://api.github.com/users/nickums/events{/privacy}",
"received_events_url": "https://api.github.com/users/nickums/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Hi! Can you describe what the actual error is?",
"working on the setfit example script\r\n\r\n from setfit import SetFitModel, SetFitTrainer, sample_dataset\r\n\r\nImportError: cannot import name 'sample_dataset' from 'setfit' (C:\\Python\\Python38\\lib\\site-packages\\setfit\\__init__.py)\r\n\r\n apart from that, I also had to hack these loads to import thses modules:\r\n from datasets.load import load_dataset \r\n from datasets.arrow_dataset import Dataset\r\n from datasets.dataset_dict import DatasetDict",
"Hi! This issue is related to the [SetFit](https://github.com/huggingface/setfit) project, so can you please open it there?"
] | 1,673,949,474,000 | 1,674,136,332,000 | 1,674,114,911,000 | NONE | null | null | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5434/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5434/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5433 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5433/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5433/comments | https://api.github.com/repos/huggingface/datasets/issues/5433/events | https://github.com/huggingface/datasets/issues/5433 | 1,536,017,901 | I_kwDODunzps5bjcXt | 5,433 | Support latest Docker image in CI benchmarks | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892871,
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement",
"name": "enhancement",
"color": "a2eeef",
"default": true,
"description": "New feature or request"
}
] | closed | false | null | [] | [
"Sorry, it was us:[^1] https://github.com/iterative/cml/pull/1317 & https://github.com/iterative/cml/issues/1319#issuecomment-1385599559; should be fixed with [v0.18.17](https://github.com/iterative/cml/releases/tag/v0.18.17).\r\n\r\n[^1]: More or less, see https://github.com/yargs/yargs/issues/873.",
"Opened https://github.com/huggingface/datasets/pull/5436 unpinning again the container image.",
"Hi @0x2b3bfa0, thanks a lot for the investigation, the context about the the root cause and for fixing it!!\r\n\r\nWe are reviewing your PR to unpin the container image."
] | 1,673,946,368,000 | 1,674,023,348,000 | 1,674,023,348,000 | MEMBER | null | Once we find out the root cause of:
- #5431
we should revert the temporary pin on the Docker image version introduced by:
- #5432 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5433/reactions",
"total_count": 2,
"+1": 2,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5433/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5432 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5432/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5432/comments | https://api.github.com/repos/huggingface/datasets/issues/5432/events | https://github.com/huggingface/datasets/pull/5432 | 1,535,893,019 | PR_kwDODunzps5HhEA8 | 5,432 | Fix CI benchmarks by temporarily pinning Docker image version | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008519 / 0.011353 (-0.002834) | 0.004451 / 0.011008 (-0.006558) | 0.102401 / 0.038508 (0.063893) | 0.029779 / 0.023109 (0.006669) | 0.302654 / 0.275898 (0.026756) | 0.366002 / 0.323480 (0.042522) | 0.007044 / 0.007986 (-0.000942) | 0.003350 / 0.004328 (-0.000978) | 0.078213 / 0.004250 (0.073963) | 0.035208 / 0.037052 (-0.001844) | 0.312980 / 0.258489 (0.054491) | 0.344217 / 0.293841 (0.050376) | 0.033089 / 0.128546 (-0.095457) | 0.011443 / 0.075646 (-0.064203) | 0.353143 / 0.419271 (-0.066128) | 0.040851 / 0.043533 (-0.002682) | 0.304501 / 0.255139 (0.049362) | 0.329118 / 0.283200 (0.045918) | 0.087399 / 0.141683 (-0.054284) | 1.500200 / 1.452155 (0.048046) | 1.536176 / 1.492716 (0.043459) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.209626 / 0.018006 (0.191619) | 0.425551 / 0.000490 (0.425061) | 0.001168 / 0.000200 (0.000968) | 0.000069 / 0.000054 (0.000014) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.023664 / 0.037411 (-0.013748) | 0.096792 / 0.014526 (0.082266) | 0.105652 / 0.176557 (-0.070905) | 0.140796 / 0.737135 (-0.596340) | 0.109319 / 0.296338 (-0.187019) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.414802 / 0.215209 (0.199593) | 4.152619 / 2.077655 (2.074964) | 1.814403 / 1.504120 (0.310283) | 1.611392 / 1.541195 (0.070198) | 1.667350 / 1.468490 (0.198860) | 0.691855 / 4.584777 (-3.892922) | 3.406584 / 3.745712 (-0.339128) | 1.940332 / 5.269862 (-3.329530) | 1.279061 / 4.565676 (-3.286615) | 0.082938 / 0.424275 (-0.341337) | 0.012388 / 0.007607 (0.004781) | 0.521738 / 0.226044 (0.295693) | 5.233764 / 2.268929 (2.964835) | 2.306573 / 55.444624 (-53.138051) | 1.954631 / 6.876477 (-4.921845) | 2.048315 / 2.142072 (-0.093757) | 0.816921 / 4.805227 (-3.988306) | 0.150983 / 6.500664 (-6.349681) | 0.066628 / 0.075469 (-0.008842) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.235939 / 1.841788 (-0.605849) | 14.047114 / 8.074308 (5.972806) | 14.149842 / 10.191392 (3.958450) | 0.152836 / 0.680424 (-0.527588) | 0.028837 / 0.534201 (-0.505364) | 0.396232 / 0.579283 (-0.183051) | 0.409950 / 0.434364 (-0.024414) | 0.460296 / 0.540337 (-0.080041) | 0.556787 / 1.386936 (-0.830149) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006582 / 0.011353 (-0.004771) | 0.004491 / 0.011008 (-0.006518) | 0.100093 / 0.038508 (0.061585) | 0.026826 / 0.023109 (0.003717) | 0.413971 / 0.275898 (0.138073) | 0.445625 / 0.323480 (0.122145) | 0.004892 / 0.007986 (-0.003094) | 0.003295 / 0.004328 (-0.001034) | 0.077879 / 0.004250 (0.073628) | 0.039177 / 0.037052 (0.002125) | 0.353299 / 0.258489 (0.094810) | 0.406566 / 0.293841 (0.112725) | 0.031633 / 0.128546 (-0.096913) | 0.011517 / 0.075646 (-0.064130) | 0.320939 / 0.419271 (-0.098332) | 0.041487 / 0.043533 (-0.002046) | 0.353735 / 0.255139 (0.098596) | 0.434786 / 0.283200 (0.151586) | 0.087722 / 0.141683 (-0.053961) | 1.515134 / 1.452155 (0.062979) | 1.588908 / 1.492716 (0.096191) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.225312 / 0.018006 (0.207305) | 0.398324 / 0.000490 (0.397834) | 0.000453 / 0.000200 (0.000253) | 0.000064 / 0.000054 (0.000009) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.024645 / 0.037411 (-0.012766) | 0.099399 / 0.014526 (0.084873) | 0.107006 / 0.176557 (-0.069550) | 0.145090 / 0.737135 (-0.592045) | 0.110046 / 0.296338 (-0.186292) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.450573 / 0.215209 (0.235364) | 4.498030 / 2.077655 (2.420375) | 2.193164 / 1.504120 (0.689044) | 1.940103 / 1.541195 (0.398908) | 1.957137 / 1.468490 (0.488647) | 0.697599 / 4.584777 (-3.887178) | 3.465146 / 3.745712 (-0.280566) | 1.918209 / 5.269862 (-3.351653) | 1.183921 / 4.565676 (-3.381756) | 0.082540 / 0.424275 (-0.341735) | 0.012495 / 0.007607 (0.004888) | 0.549702 / 0.226044 (0.323658) | 5.526841 / 2.268929 (3.257912) | 2.658611 / 55.444624 (-52.786014) | 2.259542 / 6.876477 (-4.616935) | 2.310139 / 2.142072 (0.168066) | 0.810550 / 4.805227 (-3.994677) | 0.152369 / 6.500664 (-6.348295) | 0.066295 / 0.075469 (-0.009174) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.289240 / 1.841788 (-0.552547) | 14.032143 / 8.074308 (5.957834) | 13.973492 / 10.191392 (3.782100) | 0.140082 / 0.680424 (-0.540342) | 0.017113 / 0.534201 (-0.517088) | 0.386534 / 0.579283 (-0.192749) | 0.393723 / 0.434364 (-0.040641) | 0.448891 / 0.540337 (-0.091446) | 0.533085 / 1.386936 (-0.853851) |\n\n</details>\n</details>\n\n\n"
] | 1,673,939,731,000 | 1,673,945,902,000 | 1,673,945,477,000 | MEMBER | null | This PR fixes CI benchmarks, by temporarily pinning Docker image version, instead of "latest" tag.
It also updates deprecated `cml-send-comment` command and using `cml comment create` instead.
Fix #5431. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5432/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5432/timeline | null | null | 0 | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5432",
"html_url": "https://github.com/huggingface/datasets/pull/5432",
"diff_url": "https://github.com/huggingface/datasets/pull/5432.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5432.patch",
"merged_at": "2023-01-17T08:51:17"
} | true |
https://api.github.com/repos/huggingface/datasets/issues/5431 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5431/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5431/comments | https://api.github.com/repos/huggingface/datasets/issues/5431/events | https://github.com/huggingface/datasets/issues/5431 | 1,535,862,621 | I_kwDODunzps5bi2dd | 5,431 | CI benchmarks are broken: Unknown arguments: runnerPath, path | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 4296013012,
"node_id": "LA_kwDODunzps8AAAABAA_01A",
"url": "https://api.github.com/repos/huggingface/datasets/labels/maintenance",
"name": "maintenance",
"color": "d4c5f9",
"default": false,
"description": "Maintenance tasks"
}
] | closed | false | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
}
] | [] | 1,673,938,197,000 | 1,674,023,604,000 | 1,673,945,478,000 | MEMBER | null | Our CI benchmarks are broken, raising `Unknown arguments` error: https://github.com/huggingface/datasets/actions/runs/3932397079/jobs/6724905161
```
Unknown arguments: runnerPath, path
```
Stack trace:
```
100%|██████████| 500/500 [00:01<00:00, 338.98ba/s]
Updating lock file 'dvc.lock'
To track the changes with git, run:
git add dvc.lock
To enable auto staging, run:
dvc config core.autostage true
Use `dvc push` to send your updates to remote storage.
cml send-comment <markdown file>
Global Options:
--log Logging verbosity
[string] [choices: "error", "warn", "info", "debug"] [default: "info"]
--driver Git provider where the repository is hosted
[string] [choices: "github", "gitlab", "bitbucket"] [default: infer from the
environment]
--repo Repository URL or slug
[string] [default: infer from the environment]
--driver-token, --token CI driver personal/project access token (PAT)
[string] [default: infer from the environment]
--help Show help [boolean]
Options:
--target Comment type (`commit`, `pr`, `commit/f00bar`,
`pr/42`, `issue/1337`),default is automatic (`pr`
but fallback to `commit`). [string]
--watch Watch for changes and automatically update the
comment [boolean]
--publish Upload any local images found in the Markdown
report [boolean] [default: true]
--publish-url Self-hosted image server URL
[string] [default: "https://asset.cml.dev/"]
--publish-native, --native Uses driver's native capabilities to upload assets
instead of CML's storage; not available on GitHub
[boolean]
--watermark-title Hidden comment marker (used for targeting in
subsequent `cml comment update`); "{workflow}" &
"{run}" are auto-replaced [string] [default: ""]
Unknown arguments: runnerPath, path
Error: Process completed with exit code 1.
```
Issue reported to iterative/cml:
- iterative/cml#1319 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5431/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5431/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5430 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5430/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5430/comments | https://api.github.com/repos/huggingface/datasets/issues/5430/events | https://github.com/huggingface/datasets/issues/5430 | 1,535,856,503 | I_kwDODunzps5bi093 | 5,430 | Support Apache Beam >= 2.44.0 | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892871,
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement",
"name": "enhancement",
"color": "a2eeef",
"default": true,
"description": "New feature or request"
}
] | open | false | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
}
] | [
"Some of the shard files now have 0 number of rows.\r\n\r\nWe have opened an issue in the Apache Beam repo:\r\n- https://github.com/apache/beam/issues/25041"
] | 1,673,937,732,000 | 1,673,971,938,000 | null | MEMBER | null | Once we find out the root cause of:
- #5426
we should revert the temporary pin on apache-beam introduced by:
- #5429 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5430/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5430/timeline | null | null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5429 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5429/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5429/comments | https://api.github.com/repos/huggingface/datasets/issues/5429/events | https://github.com/huggingface/datasets/pull/5429 | 1,535,192,687 | PR_kwDODunzps5HeuyT | 5,429 | Fix CI by temporarily pinning apache-beam < 2.44.0 | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"_The documentation is not available anymore as the PR was closed or merged._"
] | 1,673,886,009,000 | 1,673,887,902,000 | 1,673,887,743,000 | MEMBER | null | Temporarily pin apache-beam < 2.44.0
Fix #5426. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5429/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5429/timeline | null | null | 0 | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5429",
"html_url": "https://github.com/huggingface/datasets/pull/5429",
"diff_url": "https://github.com/huggingface/datasets/pull/5429.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5429.patch",
"merged_at": "2023-01-16T16:49:03"
} | true |
https://api.github.com/repos/huggingface/datasets/issues/5428 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5428/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5428/comments | https://api.github.com/repos/huggingface/datasets/issues/5428/events | https://github.com/huggingface/datasets/issues/5428 | 1,535,166,139 | I_kwDODunzps5bgMa7 | 5,428 | Load/Save FAISS index using fsspec | {
"login": "Dref360",
"id": 8976546,
"node_id": "MDQ6VXNlcjg5NzY1NDY=",
"avatar_url": "https://avatars.githubusercontent.com/u/8976546?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Dref360",
"html_url": "https://github.com/Dref360",
"followers_url": "https://api.github.com/users/Dref360/followers",
"following_url": "https://api.github.com/users/Dref360/following{/other_user}",
"gists_url": "https://api.github.com/users/Dref360/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Dref360/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Dref360/subscriptions",
"organizations_url": "https://api.github.com/users/Dref360/orgs",
"repos_url": "https://api.github.com/users/Dref360/repos",
"events_url": "https://api.github.com/users/Dref360/events{/privacy}",
"received_events_url": "https://api.github.com/users/Dref360/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892871,
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement",
"name": "enhancement",
"color": "a2eeef",
"default": true,
"description": "New feature or request"
}
] | closed | false | null | [] | [
"Hi! Sure, feel free to submit a PR. Maybe if we want to be consistent with the existing API, it would be cleaner to directly add support for `fsspec` paths in `Dataset.load_faiss_index`/`Dataset.save_faiss_index` in the same manner as it was done in `Dataset.load_from_disk`/`Dataset.save_to_disk`.",
"That's a great idea! I'll do that instead. "
] | 1,673,885,292,000 | 1,679,930,302,000 | 1,679,930,302,000 | CONTRIBUTOR | null | ### Feature request
From what I understand `faiss` already support this [link](https://github.com/facebookresearch/faiss/wiki/Index-IO,-cloning-and-hyper-parameter-tuning#generic-io-support)
I would like to use a stream as input to `Dataset.load_faiss_index` and `Dataset.save_faiss_index`.
### Motivation
In my case, I'm saving faiss index in cloud storage and use `fsspec` to load them. It would be ideal if I could send the stream directly instead of copying the file locally (or mounting the bucket) and then load the index.
### Your contribution
I can submit the PR | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5428/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5428/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5427 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5427/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5427/comments | https://api.github.com/repos/huggingface/datasets/issues/5427/events | https://github.com/huggingface/datasets/issues/5427 | 1,535,162,889 | I_kwDODunzps5bgLoJ | 5,427 | Unable to download dataset id_clickbait | {
"login": "ilos-vigil",
"id": 45941585,
"node_id": "MDQ6VXNlcjQ1OTQxNTg1",
"avatar_url": "https://avatars.githubusercontent.com/u/45941585?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ilos-vigil",
"html_url": "https://github.com/ilos-vigil",
"followers_url": "https://api.github.com/users/ilos-vigil/followers",
"following_url": "https://api.github.com/users/ilos-vigil/following{/other_user}",
"gists_url": "https://api.github.com/users/ilos-vigil/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ilos-vigil/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ilos-vigil/subscriptions",
"organizations_url": "https://api.github.com/users/ilos-vigil/orgs",
"repos_url": "https://api.github.com/users/ilos-vigil/repos",
"events_url": "https://api.github.com/users/ilos-vigil/events{/privacy}",
"received_events_url": "https://api.github.com/users/ilos-vigil/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
}
] | [
"Thanks for reporting, @ilos-vigil.\r\n\r\nWe have transferred this issue to the corresponding dataset on the Hugging Face Hub: https://huggingface.co/datasets/id_clickbait/discussions/1 "
] | 1,673,885,136,000 | 1,674,035,488,000 | 1,674,033,919,000 | NONE | null | ### Describe the bug
I tried to download dataset `id_clickbait`, but receive this error message.
```
FileNotFoundError: Couldn't find file at https://md-datasets-cache-zipfiles-prod.s3.eu-west-1.amazonaws.com/k42j7x2kpn-1.zip
```
When i open the link using browser, i got this XML data.
```xml
<?xml version="1.0" encoding="UTF-8"?>
<Error><Code>NoSuchBucket</Code><Message>The specified bucket does not exist</Message><BucketName>md-datasets-cache-zipfiles-prod</BucketName><RequestId>NVRM6VEEQD69SD00</RequestId><HostId>W/SPDxLGvlCGi0OD6d7mSDvfOAUqLAfvs9nTX50BkJrjMny+X9Jnqp/Li2lG9eTUuT4MUkAA2jjTfCrCiUmu7A==</HostId></Error>
```
### Steps to reproduce the bug
Code snippet:
```
from datasets import load_dataset
load_dataset('id_clickbait', 'annotated')
load_dataset('id_clickbait', 'raw')
```
Link to Kaggle notebook: https://www.kaggle.com/code/ilosvigil/bug-check-on-id-clickbait-dataset
### Expected behavior
Successfully download and load `id_newspaper` dataset.
### Environment info
- `datasets` version: 2.8.0
- Platform: Linux-5.15.65+-x86_64-with-debian-bullseye-sid
- Python version: 3.7.12
- PyArrow version: 8.0.0
- Pandas version: 1.3.5 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5427/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5427/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5426 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5426/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5426/comments | https://api.github.com/repos/huggingface/datasets/issues/5426/events | https://github.com/huggingface/datasets/issues/5426 | 1,535,158,555 | I_kwDODunzps5bgKkb | 5,426 | CI tests are broken: SchemaInferenceError | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
}
] | [] | 1,673,884,927,000 | 1,685,688,032,000 | 1,673,887,744,000 | MEMBER | null | CI test (unit, ubuntu-latest, deps-minimum) is broken, raising a `SchemaInferenceError`: see https://github.com/huggingface/datasets/actions/runs/3930901593/jobs/6721492004
```
FAILED tests/test_beam.py::BeamBuilderTest::test_download_and_prepare_sharded - datasets.arrow_writer.SchemaInferenceError: Please pass `features` or at least one example when writing data
```
Stack trace:
```
______________ BeamBuilderTest.test_download_and_prepare_sharded _______________
[gw1] linux -- Python 3.7.15 /opt/hostedtoolcache/Python/3.7.15/x64/bin/python
self = <tests.test_beam.BeamBuilderTest testMethod=test_download_and_prepare_sharded>
@require_beam
def test_download_and_prepare_sharded(self):
import apache_beam as beam
original_write_parquet = beam.io.parquetio.WriteToParquet
expected_num_examples = len(get_test_dummy_examples())
with tempfile.TemporaryDirectory() as tmp_cache_dir:
builder = DummyBeamDataset(cache_dir=tmp_cache_dir, beam_runner="DirectRunner")
with patch("apache_beam.io.parquetio.WriteToParquet") as write_parquet_mock:
write_parquet_mock.side_effect = partial(original_write_parquet, num_shards=2)
> builder.download_and_prepare()
tests/test_beam.py:97:
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
/opt/hostedtoolcache/Python/3.7.15/x64/lib/python3.7/site-packages/datasets/builder.py:864: in download_and_prepare
**download_and_prepare_kwargs,
/opt/hostedtoolcache/Python/3.7.15/x64/lib/python3.7/site-packages/datasets/builder.py:1976: in _download_and_prepare
num_examples, num_bytes = beam_writer.finalize(metrics.query(m_filter))
/opt/hostedtoolcache/Python/3.7.15/x64/lib/python3.7/site-packages/datasets/arrow_writer.py:694: in finalize
shard_num_bytes, _ = parquet_to_arrow(source, destination)
/opt/hostedtoolcache/Python/3.7.15/x64/lib/python3.7/site-packages/datasets/arrow_writer.py:740: in parquet_to_arrow
num_bytes, num_examples = writer.finalize()
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
self = <datasets.arrow_writer.ArrowWriter object at 0x7f6dcbb3e810>
close_stream = True
def finalize(self, close_stream=True):
self.write_rows_on_file()
# In case current_examples < writer_batch_size, but user uses finalize()
if self._check_duplicates:
self.check_duplicate_keys()
# Re-intializing to empty list for next batch
self.hkey_record = []
self.write_examples_on_file()
# If schema is known, infer features even if no examples were written
if self.pa_writer is None and self.schema:
self._build_writer(self.schema)
if self.pa_writer is not None:
self.pa_writer.close()
self.pa_writer = None
if close_stream:
self.stream.close()
else:
if close_stream:
self.stream.close()
> raise SchemaInferenceError("Please pass `features` or at least one example when writing data")
E datasets.arrow_writer.SchemaInferenceError: Please pass `features` or at least one example when writing data
/opt/hostedtoolcache/Python/3.7.15/x64/lib/python3.7/site-packages/datasets/arrow_writer.py:593: SchemaInferenceError
``` | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5426/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5426/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5425 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5425/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5425/comments | https://api.github.com/repos/huggingface/datasets/issues/5425/events | https://github.com/huggingface/datasets/issues/5425 | 1,534,581,850 | I_kwDODunzps5bd9xa | 5,425 | Sort on multiple keys with datasets.Dataset.sort() | {
"login": "rocco-fortuna",
"id": 101344863,
"node_id": "U_kgDOBgpmXw",
"avatar_url": "https://avatars.githubusercontent.com/u/101344863?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/rocco-fortuna",
"html_url": "https://github.com/rocco-fortuna",
"followers_url": "https://api.github.com/users/rocco-fortuna/followers",
"following_url": "https://api.github.com/users/rocco-fortuna/following{/other_user}",
"gists_url": "https://api.github.com/users/rocco-fortuna/gists{/gist_id}",
"starred_url": "https://api.github.com/users/rocco-fortuna/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/rocco-fortuna/subscriptions",
"organizations_url": "https://api.github.com/users/rocco-fortuna/orgs",
"repos_url": "https://api.github.com/users/rocco-fortuna/repos",
"events_url": "https://api.github.com/users/rocco-fortuna/events{/privacy}",
"received_events_url": "https://api.github.com/users/rocco-fortuna/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892871,
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement",
"name": "enhancement",
"color": "a2eeef",
"default": true,
"description": "New feature or request"
},
{
"id": 1935892877,
"node_id": "MDU6TGFiZWwxOTM1ODkyODc3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/good%20first%20issue",
"name": "good first issue",
"color": "7057ff",
"default": true,
"description": "Good for newcomers"
}
] | closed | false | null | [] | [
"Hi! \r\n\r\n`Dataset.sort` calls `df.sort_values` internally, and `df.sort_values` brings all the \"sort\" columns in memory, so sorting on multiple keys could be very expensive. This makes me think that maybe we can replace `df.sort_values` with `pyarrow.compute.sort_indices` - the latter can also sort on multiple keys and currently loads the data into memory; however, there is a plan to eventually implement \"memory-map\" friendly kernels for the Arrow compute ops (using the Acero execution engine). \r\n\r\nSo to address this issue, you should replace `df.sort_values` with `pyarrow.compute.sort_indices` in `Dataset.sort` and adjust the signature of this function (deprecate the `kind` parameter, etc.).\r\n\r\nPS: Feel free to ping us if you need some additional help/pointers",
"@mariosasko If I understand the code right, using `pyarrow.compute.sort_indices` would also require changes to the `select` method if it is meant to sort multiple keys. That's because `select` only accepts 1D input for `indices`, not an iterable or similar which would be required for multiple keys unless you want some looping over selects. Doesn't seem that straight-forward but I might be missing something here... ",
"@MichlF No, it doesn't require modifying select because sorting on multiple keys also returns a 1D array.\r\n\r\nIt's easier to understand with an example:\r\n```python\r\n>>> import pyarrow as pa\r\n>>> import pyarrow.compute as pc\r\n>>> table = pa.table({\r\n... \"name\": [\"John\", \"Eve\", \"Peter\", \"John\"],\r\n... \"surname\": [\"Johnson\", \"Smith\", \"Smith\", \"Doe\"],\r\n... \"age\": [20, 40, 30, 50],\r\n... })\r\n>>> indices = pc.sort_indices(table, sort_keys=[(\"name\", \"ascending\"), (\"surname\", \"ascending\")])\r\n>>> print(indices)\r\n[\r\n 1,\r\n 3,\r\n 0,\r\n 2\r\n]\r\n```\r\n\r\n",
"Thanks for clarifying.\r\nI can prepare a PR to address this issue. This would be my first PR here so I have a few maybe silly questions but:\r\n- What is the preferred input type of `sort_keys` for the sort method? A sequence with name, order tuples like pyarrow's `sort_indices` requires?\r\n- What about backwards compatability: is it supposed to also accept the old way of calling sort() or should both `column` and `kind` be deprecated?\r\n- If `sort_keys` is provided in the same format as for pyarrow's `sort_indices` - i.e. along with order for each column -, `reverse` doesn't make much sense either and should be deprecated as well I assume.",
"I think we can have the following signature:\r\n```python\r\ndef sort(\r\n self,\r\n column_names: Union[str, Sequence[str]],\r\n reverse: Union[bool, Sequence[bool]] = False,\r\n kind=\"deprecated\",\r\n null_placement: str = \"last\",\r\n keep_in_memory: bool = False,\r\n load_from_cache_file: bool = True,\r\n indices_cache_file_name: Optional[str] = None,\r\n writer_batch_size: Optional[int] = 1000,\r\n new_fingerprint: Optional[str] = None,\r\n ) -> \"Dataset\":\r\n``` \r\n\r\nSo we should:\r\n* rename`column` to `column_names`. `column` is a positional argument, so it's OK to rename it (not marked as positional-only with \"/\", but still should be fine)\r\n* deprecate `kind`\r\n* keep `reverse` instead of introducing `sort_keys`, but we should allow passing a list of booleans that defines the sort order of each column from `column_names` to it (`reverse = False` would be equal to `[False] * len(column_names)` and `reverse = True` to `[True] * len(column_names)`)",
"I am pretty much done with the PR. Just one clarification: `Sequence` in `arrow_dataset.py` is a custom dataclass from `features.py` instead of the `type.hinting` class `Sequence` from Python. Do you suggest using that custom `Sequence` class somehow ? Otherwise signature currently reads instead:\r\n```Python\r\n def sort(\r\n self,\r\n column_names: Union[str, List[str]],\r\n reverse: Union[bool, List[bool]] = False,\r\n kind = \"deprecated\",\r\n null_placement: str = \"last\",\r\n keep_in_memory: bool = False,\r\n load_from_cache_file: bool = True,\r\n indices_cache_file_name: Optional[str] = None,\r\n writer_batch_size: Optional[int] = 1000,\r\n new_fingerprint: Optional[str] = None,\r\n )\r\n```\r\n\r\nAlso, to maintain backwards compatibility, I added conditionals for `null_placement`, because pyarrow's `null_placement` only accepts `at_start` and `at_end`, and not `last` and `first`.\r\nIf that is all good, I think I can open the PR.",
"I meant `typing.Sequence` (`datasets.Sequence` is a feature type). \r\n\r\nRegarding `null_placement`, I think we can support both `at_start` and `at_end`, and `last` and `first` (for backward compatibility; convert internally to `at_end` and `at_start` respectively).",
"> I meant typing.Sequence (datasets.Sequence is a feature type).\r\n\r\nSorry, I actually meant `typing.Sequence` and not `type.hinting`. However, the issue is still that `dataset.Sequence` is imported in `arrow_dataset.py` so I cannot import and use `typing.Sequence` for the `sort`'s signature without overwriting the `dataset.Sequence` import. The latter is used in the `align_labels_with_mapping` method so it's a necessary import for `arrow_dataset.py`. \r\nTo import `typing.Sequence` as something else than `Sequence` to avoid overwriting may only be confusing and doesn't seem good practice!? The other solution is to keep `List` type hinting as in the signature I posted in my previous post but this excludes other Sequence types and may cause problems further down the line.\r\nPlease advise,\r\nThanks for all the clarifications!",
"You can avoid the name collision by renaming `typing.Sequence` to `Sequence_` when importing:\r\n```python\r\nfrom typing import Sequence as Sequence_\r\n```",
"Resolved via #5502 "
] | 1,673,860,946,000 | 1,677,255,311,000 | 1,677,255,311,000 | NONE | null | ### Feature request
From discussion on forum: https://discuss.huggingface.co/t/datasets-dataset-sort-does-not-preserve-ordering/29065/1
`sort()` does not preserve ordering, and it does not support sorting on multiple columns, nor a key function.
The suggested solution:
> ... having something similar to pandas and be able to specify multiple columns for sorting. We’re already using pandas under the hood to do the sorting in datasets.
The suggested workaround:
> convert your dataset to pandas and use `df.sort_values()`
### Motivation
Preserved ordering when sorting is very handy when one needs to sort on multiple columns, A and B, so that e.g. whenever A is equal for two or more rows, B is kept sorted.
Having a parameter to do this in 🤗datasets would be cleaner than going through pandas and back, and it wouldn't add much complexity to the library.
Alternatives:
- the possibility to specify multiple keys to sort by with decreasing priority (suggested solution),
- the ability to provide a key function for sorting, so that one can manually specify the sorting criteria.
### Your contribution
I'll be happy to contribute by submitting a PR. Will get documented on `CONTRIBUTING.MD`.
Would love to get thoughts on this, if anyone has anything to add. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5425/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5425/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5424 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5424/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5424/comments | https://api.github.com/repos/huggingface/datasets/issues/5424/events | https://github.com/huggingface/datasets/issues/5424 | 1,534,394,756 | I_kwDODunzps5bdQGE | 5,424 | When applying `ReadInstruction` to custom load it's not DatasetDict but list of Dataset? | {
"login": "macabdul9",
"id": 25720695,
"node_id": "MDQ6VXNlcjI1NzIwNjk1",
"avatar_url": "https://avatars.githubusercontent.com/u/25720695?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/macabdul9",
"html_url": "https://github.com/macabdul9",
"followers_url": "https://api.github.com/users/macabdul9/followers",
"following_url": "https://api.github.com/users/macabdul9/following{/other_user}",
"gists_url": "https://api.github.com/users/macabdul9/gists{/gist_id}",
"starred_url": "https://api.github.com/users/macabdul9/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/macabdul9/subscriptions",
"organizations_url": "https://api.github.com/users/macabdul9/orgs",
"repos_url": "https://api.github.com/users/macabdul9/repos",
"events_url": "https://api.github.com/users/macabdul9/events{/privacy}",
"received_events_url": "https://api.github.com/users/macabdul9/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Hi! You can get a `DatasetDict` if you pass a dictionary with read instructions as follows:\r\n```python\r\ninstructions = [\r\n ReadInstruction(split_name=\"train\", from_=0, to=10, unit='%', rounding='closest'),\r\n ReadInstruction(split_name=\"dev\", from_=0, to=10, unit='%', rounding='closest'),\r\n ReadInstruction(split_name=\"test\", from_=0, to=5, unit='%', rounding='closest')\r\n]\r\n\r\ndataset = load_dataset('csv', data_dir=\"data/\", data_files={\"train\":\"train.tsv\", \"dev\":\"dev.tsv\", \"test\":\"test.tsv\"}, delimiter=\"\\t\", split={inst.split_name: inst for inst in instructions})\r\n```\r\n"
] | 1,673,852,068,000 | 1,677,255,540,000 | 1,677,255,540,000 | NONE | null | ### Describe the bug
I am loading datasets from custom `tsv` files stored locally and applying split instructions for each split. Although the ReadInstruction is being applied correctly and I was expecting it to be `DatasetDict` but instead it is a list of `Dataset`.
### Steps to reproduce the bug
Steps to reproduce the behaviour:
1. Import
`from datasets import load_dataset, ReadInstruction`
2. Instruction to load the dataset
```
instructions = [
ReadInstruction(split_name="train", from_=0, to=10, unit='%', rounding='closest'),
ReadInstruction(split_name="dev", from_=0, to=10, unit='%', rounding='closest'),
ReadInstruction(split_name="test", from_=0, to=5, unit='%', rounding='closest')
]
```
3. Load
`dataset = load_dataset('csv', data_dir="data/", data_files={"train":"train.tsv", "dev":"dev.tsv", "test":"test.tsv"}, delimiter="\t", split=instructions)`
### Expected behavior
**Current behaviour**
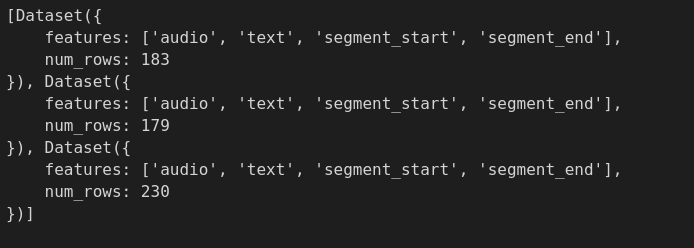
:
**Expected behaviour**
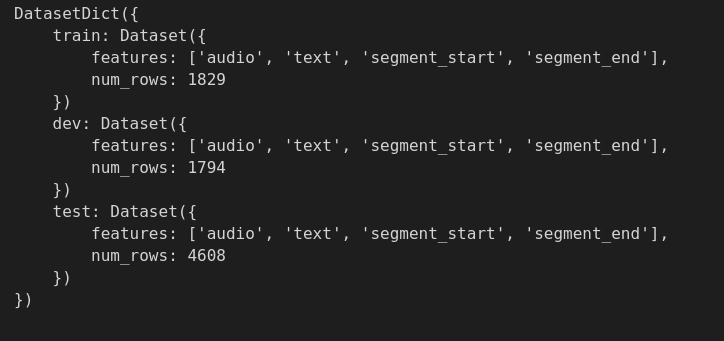
### Environment info
``datasets==2.8.0
``
`Python==3.8.5
`
`Platform - Ubuntu 20.04.4 LTS` | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5424/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5424/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5422 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5422/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5422/comments | https://api.github.com/repos/huggingface/datasets/issues/5422/events | https://github.com/huggingface/datasets/issues/5422 | 1,533,385,239 | I_kwDODunzps5bZZoX | 5,422 | Datasets load error for saved github issues | {
"login": "folterj",
"id": 7360564,
"node_id": "MDQ6VXNlcjczNjA1NjQ=",
"avatar_url": "https://avatars.githubusercontent.com/u/7360564?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/folterj",
"html_url": "https://github.com/folterj",
"followers_url": "https://api.github.com/users/folterj/followers",
"following_url": "https://api.github.com/users/folterj/following{/other_user}",
"gists_url": "https://api.github.com/users/folterj/gists{/gist_id}",
"starred_url": "https://api.github.com/users/folterj/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/folterj/subscriptions",
"organizations_url": "https://api.github.com/users/folterj/orgs",
"repos_url": "https://api.github.com/users/folterj/repos",
"events_url": "https://api.github.com/users/folterj/events{/privacy}",
"received_events_url": "https://api.github.com/users/folterj/received_events",
"type": "User",
"site_admin": false
} | [] | open | false | null | [] | [
"I can confirm that the error exists!\r\nI'm trying to read 3 parquet files locally:\r\n```python\r\nfrom datasets import load_dataset, Features, Value, ClassLabel\r\n\r\nreview_dataset = load_dataset(\r\n \"parquet\",\r\n data_files={\r\n \"train\": os.path.join(sentiment_analysis_data_path, \"train.parquet\"),\r\n \"validation\": os.path.join(sentiment_analysis_data_path, \"validation.parquet\"),\r\n \"test\": os.path.join(sentiment_analysis_data_path, \"test.parquet\"),\r\n },\r\n)\r\n```\r\n\r\nBut you can fix it, by specifying `features` for `load_dataset()` function like this:\r\n```python\r\nfrom datasets import load_dataset, Features, Value, ClassLabel\r\n\r\nfeatures = Features(\r\n {\r\n \"label\": ClassLabel(\r\n num_classes=3,\r\n names=[\"negative\", \"neutral\", \"positive\"],\r\n ),\r\n \"text\": Value(dtype=\"string\"),\r\n }\r\n)\r\n\r\nreview_dataset = load_dataset(\r\n \"parquet\",\r\n data_files={\r\n \"train\": os.path.join(sentiment_analysis_data_path, \"train.parquet\"),\r\n \"validation\": os.path.join(sentiment_analysis_data_path, \"validation.parquet\"),\r\n \"test\": os.path.join(sentiment_analysis_data_path, \"test.parquet\"),\r\n },\r\n features=features,\r\n)\r\n\r\nprint(review_dataset)\r\n```",
"@Extremesarova I think this is a different issue, but understand using features could be a work-around.\r\nIt seems the field `closed_at` is `null` in many cases.\r\n\r\nI've not found a way to specify only a single feature without (succesfully) specifiying the full and quite detailed set of expected features. Using this features set gives an error the column names don't match.\r\n`features = Features({'closed_at': Value(dtype='timestamp[s]', id=None)})`\r\n\r\n",
"Found this when searching for the same error, looks like based on #3965 it's just an issue with the data. I found that changing `df = pd.DataFrame.from_records(all_issues)` to `df = pd.DataFrame.from_records(all_issues).dropna(axis=1, how='all').drop(['milestone'], axis=1)` from the fetch_issues function fixed the issue. \r\nThe \"milestone\" column seemed to be problematic (only ~50 non null rows) and dropped any columns that were all null as well just in case.",
"I have this same issue. I saved a dataset to disk and now I can't load it.",
"Ok the solution was to use load_from_disk instead of load_dataset."
] | 1,673,717,378,000 | 1,683,314,708,000 | null | NONE | null | ### Describe the bug
Loading a previously downloaded & saved dataset as described in the HuggingFace course:
issues_dataset = load_dataset("json", data_files="issues/datasets-issues.jsonl", split="train")
Gives this error:
datasets.builder.DatasetGenerationError: An error occurred while generating the dataset
A work-around I found was to use streaming.
### Steps to reproduce the bug
Reproduce by executing the code provided:
https://huggingface.co/course/chapter5/5?fw=pt
From the heading:
'let’s create a function that can download all the issues from a GitHub repository'
### Expected behavior
No error
### Environment info
Datasets version 2.8.0. Note that version 2.6.1 gives the same error (related to null timestamp).
**[EDIT]**
This is the complete error trace confirming the issue is related to the timestamp (`Couldn't cast array of type timestamp[s] to null`)
```
Using custom data configuration default-950028611d2860c8
Downloading and preparing dataset json/default to [...]/.cache/huggingface/datasets/json/default-950028611d2860c8/0.0.0/0f7e3662623656454fcd2b650f34e886a7db4b9104504885bd462096cc7a9f51...
Downloading data files: 100%|██████████| 1/1 [00:00<?, ?it/s]
Extracting data files: 100%|██████████| 1/1 [00:00<00:00, 500.63it/s]
Generating train split: 2619 examples [00:00, 7155.72 examples/s]Traceback (most recent call last):
File "[...]\miniconda3\envs\HuggingFace\lib\site-packages\datasets\builder.py", line 1831, in _prepare_split_single
writer.write_table(table)
File "[...]\miniconda3\envs\HuggingFace\lib\site-packages\datasets\arrow_writer.py", line 567, in write_table
pa_table = table_cast(pa_table, self._schema)
File "[...]\miniconda3\envs\HuggingFace\lib\site-packages\datasets\table.py", line 2282, in table_cast
return cast_table_to_schema(table, schema)
File "[...]\miniconda3\envs\HuggingFace\lib\site-packages\datasets\table.py", line 2241, in cast_table_to_schema
arrays = [cast_array_to_feature(table[name], feature) for name, feature in features.items()]
File "[...]\miniconda3\envs\HuggingFace\lib\site-packages\datasets\table.py", line 2241, in <listcomp>
arrays = [cast_array_to_feature(table[name], feature) for name, feature in features.items()]
File "[...]\miniconda3\envs\HuggingFace\lib\site-packages\datasets\table.py", line 1807, in wrapper
return pa.chunked_array([func(chunk, *args, **kwargs) for chunk in array.chunks])
File "[...]\miniconda3\envs\HuggingFace\lib\site-packages\datasets\table.py", line 1807, in <listcomp>
return pa.chunked_array([func(chunk, *args, **kwargs) for chunk in array.chunks])
File "[...]\miniconda3\envs\HuggingFace\lib\site-packages\datasets\table.py", line 2035, in cast_array_to_feature
arrays = [_c(array.field(name), subfeature) for name, subfeature in feature.items()]
File "[...]\miniconda3\envs\HuggingFace\lib\site-packages\datasets\table.py", line 2035, in <listcomp>
arrays = [_c(array.field(name), subfeature) for name, subfeature in feature.items()]
File "[...]\miniconda3\envs\HuggingFace\lib\site-packages\datasets\table.py", line 1809, in wrapper
return func(array, *args, **kwargs)
File "[...]\miniconda3\envs\HuggingFace\lib\site-packages\datasets\table.py", line 2101, in cast_array_to_feature
return array_cast(array, feature(), allow_number_to_str=allow_number_to_str)
File "[...]\miniconda3\envs\HuggingFace\lib\site-packages\datasets\table.py", line 1809, in wrapper
return func(array, *args, **kwargs)
File "[...]\miniconda3\envs\HuggingFace\lib\site-packages\datasets\table.py", line 1990, in array_cast
raise TypeError(f"Couldn't cast array of type {array.type} to {pa_type}")
TypeError: Couldn't cast array of type timestamp[s] to null
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "C:\Program Files\JetBrains\PyCharm 2022.1.3\plugins\python\helpers\pydev\pydevconsole.py", line 364, in runcode
coro = func()
File "<input>", line 1, in <module>
File "C:\Program Files\JetBrains\PyCharm 2022.1.3\plugins\python\helpers\pydev\_pydev_bundle\pydev_umd.py", line 198, in runfile
pydev_imports.execfile(filename, global_vars, local_vars) # execute the script
File "C:\Program Files\JetBrains\PyCharm 2022.1.3\plugins\python\helpers\pydev\_pydev_imps\_pydev_execfile.py", line 18, in execfile
exec(compile(contents+"\n", file, 'exec'), glob, loc)
File "[...]\PycharmProjects\TransformersTesting\dataset_issues.py", line 20, in <module>
issues_dataset = load_dataset("json", data_files="issues/datasets-issues.jsonl", split="train")
File "[...]\miniconda3\envs\HuggingFace\lib\site-packages\datasets\load.py", line 1757, in load_dataset
builder_instance.download_and_prepare(
File "[...]\miniconda3\envs\HuggingFace\lib\site-packages\datasets\builder.py", line 860, in download_and_prepare
self._download_and_prepare(
File "[...]\miniconda3\envs\HuggingFace\lib\site-packages\datasets\builder.py", line 953, in _download_and_prepare
self._prepare_split(split_generator, **prepare_split_kwargs)
File "[...]\miniconda3\envs\HuggingFace\lib\site-packages\datasets\builder.py", line 1706, in _prepare_split
for job_id, done, content in self._prepare_split_single(
File "[...]\miniconda3\envs\HuggingFace\lib\site-packages\datasets\builder.py", line 1849, in _prepare_split_single
raise DatasetGenerationError("An error occurred while generating the dataset") from e
datasets.builder.DatasetGenerationError: An error occurred while generating the dataset
Generating train split: 2619 examples [00:19, 7155.72 examples/s]
``` | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5422/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5422/timeline | null | null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5421 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5421/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5421/comments | https://api.github.com/repos/huggingface/datasets/issues/5421/events | https://github.com/huggingface/datasets/issues/5421 | 1,532,278,307 | I_kwDODunzps5bVLYj | 5,421 | Support case-insensitive Hub dataset name in load_dataset | {
"login": "severo",
"id": 1676121,
"node_id": "MDQ6VXNlcjE2NzYxMjE=",
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/severo",
"html_url": "https://github.com/severo",
"followers_url": "https://api.github.com/users/severo/followers",
"following_url": "https://api.github.com/users/severo/following{/other_user}",
"gists_url": "https://api.github.com/users/severo/gists{/gist_id}",
"starred_url": "https://api.github.com/users/severo/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/severo/subscriptions",
"organizations_url": "https://api.github.com/users/severo/orgs",
"repos_url": "https://api.github.com/users/severo/repos",
"events_url": "https://api.github.com/users/severo/events{/privacy}",
"received_events_url": "https://api.github.com/users/severo/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892871,
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement",
"name": "enhancement",
"color": "a2eeef",
"default": true,
"description": "New feature or request"
}
] | closed | false | null | [] | [
"Closing as case-insensitivity should be only for URL redirection on the Hub. In the APIs, we will only support the canonical name (https://github.com/huggingface/moon-landing/pull/2399#issuecomment-1382085611)"
] | 1,673,615,227,000 | 1,673,640,752,000 | 1,673,640,752,000 | CONTRIBUTOR | null | ### Feature request
The dataset name on the Hub is case-insensitive (see https://github.com/huggingface/moon-landing/pull/2399, internal issue), i.e., https://huggingface.co/datasets/GLUE redirects to https://huggingface.co/datasets/glue.
Ideally, we could load the glue dataset using the following:
```
from datasets import load_dataset
load_dataset('GLUE', 'cola')
```
It breaks because the loading script `GLUE.py` does not exist (`glue.py` should be selected instead).
Minor additional comment: in other cases without a loading script, we can load the dataset, but the automatically generated config name depends on the casing:
- `load_dataset('severo/danish-wit')` generates the config name `severo--danish-wit-e6fda5b070deb133`, while
- `load_dataset('severo/danish-WIT')` generates the config name `severo--danish-WIT-e6fda5b070deb133`
### Motivation
To follow the same UX on the Hub and in the datasets library.
### Your contribution
... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5421/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5421/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5420 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5420/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5420/comments | https://api.github.com/repos/huggingface/datasets/issues/5420/events | https://github.com/huggingface/datasets/pull/5420 | 1,532,265,742 | PR_kwDODunzps5HVAhL | 5,420 | ci: 🎡 remove two obsolete issue templates | {
"login": "severo",
"id": 1676121,
"node_id": "MDQ6VXNlcjE2NzYxMjE=",
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/severo",
"html_url": "https://github.com/severo",
"followers_url": "https://api.github.com/users/severo/followers",
"following_url": "https://api.github.com/users/severo/following{/other_user}",
"gists_url": "https://api.github.com/users/severo/gists{/gist_id}",
"starred_url": "https://api.github.com/users/severo/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/severo/subscriptions",
"organizations_url": "https://api.github.com/users/severo/orgs",
"repos_url": "https://api.github.com/users/severo/repos",
"events_url": "https://api.github.com/users/severo/events{/privacy}",
"received_events_url": "https://api.github.com/users/severo/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008450 / 0.011353 (-0.002902) | 0.004478 / 0.011008 (-0.006530) | 0.100440 / 0.038508 (0.061931) | 0.029568 / 0.023109 (0.006459) | 0.296705 / 0.275898 (0.020807) | 0.354565 / 0.323480 (0.031085) | 0.006887 / 0.007986 (-0.001098) | 0.003415 / 0.004328 (-0.000914) | 0.078876 / 0.004250 (0.074626) | 0.034927 / 0.037052 (-0.002125) | 0.307695 / 0.258489 (0.049206) | 0.340917 / 0.293841 (0.047076) | 0.033630 / 0.128546 (-0.094916) | 0.011626 / 0.075646 (-0.064020) | 0.322644 / 0.419271 (-0.096627) | 0.040254 / 0.043533 (-0.003279) | 0.297419 / 0.255139 (0.042280) | 0.321584 / 0.283200 (0.038384) | 0.086202 / 0.141683 (-0.055481) | 1.465579 / 1.452155 (0.013425) | 1.521456 / 1.492716 (0.028740) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.200890 / 0.018006 (0.182884) | 0.410300 / 0.000490 (0.409811) | 0.001647 / 0.000200 (0.001447) | 0.000074 / 0.000054 (0.000020) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.022569 / 0.037411 (-0.014843) | 0.096062 / 0.014526 (0.081536) | 0.102474 / 0.176557 (-0.074082) | 0.138596 / 0.737135 (-0.598539) | 0.106262 / 0.296338 (-0.190077) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.415976 / 0.215209 (0.200766) | 4.144322 / 2.077655 (2.066667) | 1.871783 / 1.504120 (0.367663) | 1.669478 / 1.541195 (0.128283) | 1.718214 / 1.468490 (0.249724) | 0.687870 / 4.584777 (-3.896907) | 3.362084 / 3.745712 (-0.383628) | 1.844127 / 5.269862 (-3.425735) | 1.149611 / 4.565676 (-3.416066) | 0.081410 / 0.424275 (-0.342865) | 0.012278 / 0.007607 (0.004671) | 0.518245 / 0.226044 (0.292200) | 5.185164 / 2.268929 (2.916236) | 2.299029 / 55.444624 (-53.145595) | 1.960021 / 6.876477 (-4.916456) | 2.009751 / 2.142072 (-0.132322) | 0.803759 / 4.805227 (-4.001468) | 0.147340 / 6.500664 (-6.353324) | 0.063896 / 0.075469 (-0.011573) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.254142 / 1.841788 (-0.587646) | 13.799683 / 8.074308 (5.725375) | 13.940387 / 10.191392 (3.748995) | 0.151246 / 0.680424 (-0.529178) | 0.028709 / 0.534201 (-0.505491) | 0.391600 / 0.579283 (-0.187683) | 0.405750 / 0.434364 (-0.028614) | 0.455479 / 0.540337 (-0.084858) | 0.541022 / 1.386936 (-0.845914) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006462 / 0.011353 (-0.004891) | 0.004462 / 0.011008 (-0.006547) | 0.096588 / 0.038508 (0.058080) | 0.026931 / 0.023109 (0.003822) | 0.344595 / 0.275898 (0.068697) | 0.378743 / 0.323480 (0.055264) | 0.005672 / 0.007986 (-0.002314) | 0.003345 / 0.004328 (-0.000984) | 0.074363 / 0.004250 (0.070112) | 0.037300 / 0.037052 (0.000248) | 0.346895 / 0.258489 (0.088406) | 0.388585 / 0.293841 (0.094744) | 0.031459 / 0.128546 (-0.097088) | 0.011522 / 0.075646 (-0.064124) | 0.318507 / 0.419271 (-0.100764) | 0.041145 / 0.043533 (-0.002388) | 0.343866 / 0.255139 (0.088727) | 0.366490 / 0.283200 (0.083291) | 0.086793 / 0.141683 (-0.054890) | 1.483859 / 1.452155 (0.031704) | 1.574006 / 1.492716 (0.081290) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.220436 / 0.018006 (0.202430) | 0.402988 / 0.000490 (0.402498) | 0.000435 / 0.000200 (0.000235) | 0.000063 / 0.000054 (0.000009) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.024573 / 0.037411 (-0.012838) | 0.099190 / 0.014526 (0.084664) | 0.106796 / 0.176557 (-0.069761) | 0.142387 / 0.737135 (-0.594748) | 0.109991 / 0.296338 (-0.186347) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.473452 / 0.215209 (0.258243) | 4.749554 / 2.077655 (2.671899) | 2.433482 / 1.504120 (0.929362) | 2.224276 / 1.541195 (0.683082) | 2.261579 / 1.468490 (0.793088) | 0.699876 / 4.584777 (-3.884901) | 3.378366 / 3.745712 (-0.367346) | 1.835062 / 5.269862 (-3.434799) | 1.161249 / 4.565676 (-3.404427) | 0.082967 / 0.424275 (-0.341308) | 0.012745 / 0.007607 (0.005138) | 0.580006 / 0.226044 (0.353962) | 5.789868 / 2.268929 (3.520939) | 2.909496 / 55.444624 (-52.535128) | 2.539196 / 6.876477 (-4.337280) | 2.617737 / 2.142072 (0.475665) | 0.810320 / 4.805227 (-3.994907) | 0.152501 / 6.500664 (-6.348163) | 0.067201 / 0.075469 (-0.008268) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.257844 / 1.841788 (-0.583943) | 13.865295 / 8.074308 (5.790987) | 14.169073 / 10.191392 (3.977680) | 0.135655 / 0.680424 (-0.544769) | 0.016597 / 0.534201 (-0.517604) | 0.374915 / 0.579283 (-0.204368) | 0.382771 / 0.434364 (-0.051593) | 0.431934 / 0.540337 (-0.108403) | 0.524617 / 1.386936 (-0.862319) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008748 / 0.011353 (-0.002605) | 0.004489 / 0.011008 (-0.006519) | 0.100923 / 0.038508 (0.062415) | 0.031436 / 0.023109 (0.008326) | 0.306508 / 0.275898 (0.030610) | 0.365110 / 0.323480 (0.041630) | 0.007161 / 0.007986 (-0.000824) | 0.005489 / 0.004328 (0.001160) | 0.078909 / 0.004250 (0.074658) | 0.036097 / 0.037052 (-0.000955) | 0.307907 / 0.258489 (0.049418) | 0.370277 / 0.293841 (0.076436) | 0.034184 / 0.128546 (-0.094362) | 0.011613 / 0.075646 (-0.064033) | 0.322896 / 0.419271 (-0.096375) | 0.041829 / 0.043533 (-0.001704) | 0.299669 / 0.255139 (0.044530) | 0.322217 / 0.283200 (0.039017) | 0.087751 / 0.141683 (-0.053932) | 1.476277 / 1.452155 (0.024122) | 1.548196 / 1.492716 (0.055480) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.183002 / 0.018006 (0.164995) | 0.415627 / 0.000490 (0.415138) | 0.003272 / 0.000200 (0.003072) | 0.000070 / 0.000054 (0.000015) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.024881 / 0.037411 (-0.012531) | 0.103424 / 0.014526 (0.088898) | 0.106446 / 0.176557 (-0.070110) | 0.142806 / 0.737135 (-0.594330) | 0.110938 / 0.296338 (-0.185401) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.421669 / 0.215209 (0.206460) | 4.207457 / 2.077655 (2.129802) | 1.882176 / 1.504120 (0.378056) | 1.677609 / 1.541195 (0.136415) | 1.734065 / 1.468490 (0.265575) | 0.695915 / 4.584777 (-3.888862) | 3.416731 / 3.745712 (-0.328981) | 1.872575 / 5.269862 (-3.397286) | 1.163612 / 4.565676 (-3.402064) | 0.082710 / 0.424275 (-0.341565) | 0.012659 / 0.007607 (0.005052) | 0.528785 / 0.226044 (0.302741) | 5.305328 / 2.268929 (3.036399) | 2.299850 / 55.444624 (-53.144774) | 1.968137 / 6.876477 (-4.908339) | 2.028326 / 2.142072 (-0.113746) | 0.813157 / 4.805227 (-3.992070) | 0.149997 / 6.500664 (-6.350668) | 0.066739 / 0.075469 (-0.008730) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.206332 / 1.841788 (-0.635456) | 13.795510 / 8.074308 (5.721202) | 14.367695 / 10.191392 (4.176303) | 0.138106 / 0.680424 (-0.542318) | 0.028760 / 0.534201 (-0.505441) | 0.394822 / 0.579283 (-0.184461) | 0.403291 / 0.434364 (-0.031073) | 0.463273 / 0.540337 (-0.077065) | 0.540881 / 1.386936 (-0.846055) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006830 / 0.011353 (-0.004523) | 0.004606 / 0.011008 (-0.006402) | 0.097763 / 0.038508 (0.059255) | 0.027832 / 0.023109 (0.004723) | 0.422970 / 0.275898 (0.147072) | 0.460313 / 0.323480 (0.136833) | 0.005110 / 0.007986 (-0.002876) | 0.003428 / 0.004328 (-0.000901) | 0.075047 / 0.004250 (0.070797) | 0.038374 / 0.037052 (0.001322) | 0.422762 / 0.258489 (0.164273) | 0.469886 / 0.293841 (0.176045) | 0.032391 / 0.128546 (-0.096155) | 0.011804 / 0.075646 (-0.063843) | 0.320439 / 0.419271 (-0.098832) | 0.041939 / 0.043533 (-0.001594) | 0.422521 / 0.255139 (0.167382) | 0.446420 / 0.283200 (0.163220) | 0.090715 / 0.141683 (-0.050968) | 1.484578 / 1.452155 (0.032423) | 1.556154 / 1.492716 (0.063438) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.260735 / 0.018006 (0.242728) | 0.415586 / 0.000490 (0.415096) | 0.026960 / 0.000200 (0.026760) | 0.000296 / 0.000054 (0.000241) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.024926 / 0.037411 (-0.012486) | 0.099651 / 0.014526 (0.085125) | 0.107810 / 0.176557 (-0.068747) | 0.148685 / 0.737135 (-0.588451) | 0.112725 / 0.296338 (-0.183614) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.472669 / 0.215209 (0.257460) | 4.718827 / 2.077655 (2.641172) | 2.475583 / 1.504120 (0.971463) | 2.260862 / 1.541195 (0.719667) | 2.307820 / 1.468490 (0.839330) | 0.699464 / 4.584777 (-3.885313) | 3.376282 / 3.745712 (-0.369431) | 1.872650 / 5.269862 (-3.397211) | 1.176399 / 4.565676 (-3.389277) | 0.082854 / 0.424275 (-0.341421) | 0.012845 / 0.007607 (0.005237) | 0.582088 / 0.226044 (0.356044) | 5.861609 / 2.268929 (3.592681) | 2.930728 / 55.444624 (-52.513896) | 2.624310 / 6.876477 (-4.252167) | 2.762130 / 2.142072 (0.620058) | 0.811902 / 4.805227 (-3.993325) | 0.152516 / 6.500664 (-6.348149) | 0.067670 / 0.075469 (-0.007799) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.289790 / 1.841788 (-0.551997) | 14.267607 / 8.074308 (6.193299) | 14.120655 / 10.191392 (3.929263) | 0.128442 / 0.680424 (-0.551982) | 0.017079 / 0.534201 (-0.517121) | 0.381807 / 0.579283 (-0.197476) | 0.400546 / 0.434364 (-0.033818) | 0.447629 / 0.540337 (-0.092709) | 0.532006 / 1.386936 (-0.854930) |\n\n</details>\n</details>\n\n\n"
] | 1,673,614,723,000 | 1,673,616,960,000 | 1,673,616,541,000 | CONTRIBUTOR | null | add-dataset is not needed anymore since the "canonical" datasets are on the Hub. And dataset-viewer is managed within the datasets-server project.
See https://github.com/huggingface/datasets/issues/new/choose
<img width="1245" alt="Capture d’écran 2023-01-13 à 13 59 58" src="https://user-images.githubusercontent.com/1676121/212325813-2d4c30e2-343e-4aa2-8cce-b2b77f45628e.png">
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5420/reactions",
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 1,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5420/timeline | null | null | 0 | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5420",
"html_url": "https://github.com/huggingface/datasets/pull/5420",
"diff_url": "https://github.com/huggingface/datasets/pull/5420.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5420.patch",
"merged_at": "2023-01-13T13:29:01"
} | true |
https://api.github.com/repos/huggingface/datasets/issues/5419 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5419/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5419/comments | https://api.github.com/repos/huggingface/datasets/issues/5419/events | https://github.com/huggingface/datasets/issues/5419 | 1,531,999,850 | I_kwDODunzps5bUHZq | 5,419 | label_column='labels' in datasets.TextClassification and 'label' or 'label_ids' in transformers.DataColator | {
"login": "CreatixEA",
"id": 172385,
"node_id": "MDQ6VXNlcjE3MjM4NQ==",
"avatar_url": "https://avatars.githubusercontent.com/u/172385?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/CreatixEA",
"html_url": "https://github.com/CreatixEA",
"followers_url": "https://api.github.com/users/CreatixEA/followers",
"following_url": "https://api.github.com/users/CreatixEA/following{/other_user}",
"gists_url": "https://api.github.com/users/CreatixEA/gists{/gist_id}",
"starred_url": "https://api.github.com/users/CreatixEA/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/CreatixEA/subscriptions",
"organizations_url": "https://api.github.com/users/CreatixEA/orgs",
"repos_url": "https://api.github.com/users/CreatixEA/repos",
"events_url": "https://api.github.com/users/CreatixEA/events{/privacy}",
"received_events_url": "https://api.github.com/users/CreatixEA/received_events",
"type": "User",
"site_admin": false
} | [] | open | false | null | [] | [
"Hi! Thanks for pointing out this inconsistency. Changing the default value at this point is probably not worth it, considering we've started discussing the state of the task API internally - we will most likely deprecate the current one and replace it with a more robust solution that relies on the `train_eval_index` field stored in the YAML section of the dataset cards."
] | 1,673,602,807,000 | 1,674,143,211,000 | null | NONE | null | ### Describe the bug
When preparing a dataset for a task using `datasets.TextClassification`, the output feature is named `labels`. When preparing the trainer using the `transformers.DataCollator` the default column name is `label` if binary or `label_ids` if multi-class problem.
It is required to rename the column accordingly to the expected name : `label` or `label_ids`
### Steps to reproduce the bug
```python
from datasets import TextClassification, AutoTokenized, DataCollatorWithPadding
ds_prepared = my_dataset.prepare_for_task(TextClassification(text_column='TEXT', label_column='MY_LABEL_COLUMN_1_OR_0'))
print(ds_prepared)
tokenizer = AutoTokenizer.from_pretrained("distilbert-base-uncased")
ds_tokenized = ds_prepared.map(lambda x: tokenizer(x['text'], truncation=True), batched=True)
print(ds_tokenized)
data_collator = DataCollatorWithPadding(tokenizer=tokenizer, return_tensors="tf")
tf_data = model.prepare_tf_dataset(ds_tokenized, shuffle=True, batch_size=16, collate_fn=data_collator)
print(tf_data)
```
### Expected behavior
Without renaming the the column, the target column is not in the final tf_data since it is not in the column name expected by the data_collator.
To correct this, we have to rename the column:
```python
ds_prepared = my_dataset.prepare_for_task(TextClassification(text_column='TEXT', label_column='MY_LABEL_COLUMN_1_OR_0')).rename_column('labels', 'label')
```
### Environment info
- `datasets` version: 2.8.0
- Platform: Linux-5.15.79.1-microsoft-standard-WSL2-x86_64-with-glibc2.35
- Python version: 3.10.6
- PyArrow version: 10.0.1
- Pandas version: 1.5.2
- `transformers` version: 4.26.0.dev0
- Platform: Linux-5.15.79.1-microsoft-standard-WSL2-x86_64-with-glibc2.35
- Python version: 3.10.6
- Huggingface_hub version: 0.11.1
- PyTorch version (GPU?): not installed (NA)
- Tensorflow version (GPU?): 2.11.0 (True)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: <fill in>
- Using distributed or parallel set-up in script?: <fill in> | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5419/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5419/timeline | null | null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5418 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5418/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5418/comments | https://api.github.com/repos/huggingface/datasets/issues/5418/events | https://github.com/huggingface/datasets/issues/5418 | 1,530,111,184 | I_kwDODunzps5bM6TQ | 5,418 | Add ProgressBar for `to_parquet` | {
"login": "zanussbaum",
"id": 33707069,
"node_id": "MDQ6VXNlcjMzNzA3MDY5",
"avatar_url": "https://avatars.githubusercontent.com/u/33707069?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/zanussbaum",
"html_url": "https://github.com/zanussbaum",
"followers_url": "https://api.github.com/users/zanussbaum/followers",
"following_url": "https://api.github.com/users/zanussbaum/following{/other_user}",
"gists_url": "https://api.github.com/users/zanussbaum/gists{/gist_id}",
"starred_url": "https://api.github.com/users/zanussbaum/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/zanussbaum/subscriptions",
"organizations_url": "https://api.github.com/users/zanussbaum/orgs",
"repos_url": "https://api.github.com/users/zanussbaum/repos",
"events_url": "https://api.github.com/users/zanussbaum/events{/privacy}",
"received_events_url": "https://api.github.com/users/zanussbaum/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892871,
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement",
"name": "enhancement",
"color": "a2eeef",
"default": true,
"description": "New feature or request"
}
] | closed | false | {
"login": "zanussbaum",
"id": 33707069,
"node_id": "MDQ6VXNlcjMzNzA3MDY5",
"avatar_url": "https://avatars.githubusercontent.com/u/33707069?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/zanussbaum",
"html_url": "https://github.com/zanussbaum",
"followers_url": "https://api.github.com/users/zanussbaum/followers",
"following_url": "https://api.github.com/users/zanussbaum/following{/other_user}",
"gists_url": "https://api.github.com/users/zanussbaum/gists{/gist_id}",
"starred_url": "https://api.github.com/users/zanussbaum/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/zanussbaum/subscriptions",
"organizations_url": "https://api.github.com/users/zanussbaum/orgs",
"repos_url": "https://api.github.com/users/zanussbaum/repos",
"events_url": "https://api.github.com/users/zanussbaum/events{/privacy}",
"received_events_url": "https://api.github.com/users/zanussbaum/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "zanussbaum",
"id": 33707069,
"node_id": "MDQ6VXNlcjMzNzA3MDY5",
"avatar_url": "https://avatars.githubusercontent.com/u/33707069?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/zanussbaum",
"html_url": "https://github.com/zanussbaum",
"followers_url": "https://api.github.com/users/zanussbaum/followers",
"following_url": "https://api.github.com/users/zanussbaum/following{/other_user}",
"gists_url": "https://api.github.com/users/zanussbaum/gists{/gist_id}",
"starred_url": "https://api.github.com/users/zanussbaum/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/zanussbaum/subscriptions",
"organizations_url": "https://api.github.com/users/zanussbaum/orgs",
"repos_url": "https://api.github.com/users/zanussbaum/repos",
"events_url": "https://api.github.com/users/zanussbaum/events{/privacy}",
"received_events_url": "https://api.github.com/users/zanussbaum/received_events",
"type": "User",
"site_admin": false
}
] | [
"Thanks for your proposal, @zanussbaum. Yes, I agree that would definitely be a nice feature to have!",
"@albertvillanova I’m happy to make a quick PR for the feature! let me know ",
"That would be awesome ! You can comment `#self-assign` to assign you to this issue and open a PR :) Will be happy to review",
"Closing as this has been merged @lhoestq "
] | 1,673,499,980,000 | 1,674,584,304,000 | 1,674,584,304,000 | CONTRIBUTOR | null | ### Feature request
Add a progress bar for `Dataset.to_parquet`, similar to how `to_json` works.
### Motivation
It's a bit frustrating to not know how long a dataset will take to write to file and if it's stuck or not without a progress bar
### Your contribution
Sure I can help if needed | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5418/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5418/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5416 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5416/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5416/comments | https://api.github.com/repos/huggingface/datasets/issues/5416/events | https://github.com/huggingface/datasets/pull/5416 | 1,526,988,113 | PR_kwDODunzps5HDLmR | 5,416 | Fix RuntimeError: Sharding is ambiguous for this dataset | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"_The documentation is not available anymore as the PR was closed or merged._",
"By the way, do we know how many datasets are impacted by this issue?\r\n\r\nMaybe we should do a patch release with this fix.",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.009256 / 0.011353 (-0.002097) | 0.005033 / 0.011008 (-0.005975) | 0.099346 / 0.038508 (0.060838) | 0.035204 / 0.023109 (0.012095) | 0.303017 / 0.275898 (0.027119) | 0.335632 / 0.323480 (0.012152) | 0.007953 / 0.007986 (-0.000033) | 0.005806 / 0.004328 (0.001477) | 0.076121 / 0.004250 (0.071871) | 0.041164 / 0.037052 (0.004112) | 0.305536 / 0.258489 (0.047047) | 0.348452 / 0.293841 (0.054611) | 0.037704 / 0.128546 (-0.090842) | 0.011982 / 0.075646 (-0.063664) | 0.333264 / 0.419271 (-0.086008) | 0.047738 / 0.043533 (0.004205) | 0.310126 / 0.255139 (0.054987) | 0.318719 / 0.283200 (0.035519) | 0.098933 / 0.141683 (-0.042750) | 1.421058 / 1.452155 (-0.031096) | 1.554771 / 1.492716 (0.062054) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.258627 / 0.018006 (0.240620) | 0.450814 / 0.000490 (0.450324) | 0.011288 / 0.000200 (0.011088) | 0.000136 / 0.000054 (0.000081) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.027004 / 0.037411 (-0.010407) | 0.109067 / 0.014526 (0.094541) | 0.120401 / 0.176557 (-0.056155) | 0.158336 / 0.737135 (-0.578799) | 0.126244 / 0.296338 (-0.170094) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.401847 / 0.215209 (0.186638) | 4.006003 / 2.077655 (1.928348) | 1.806342 / 1.504120 (0.302223) | 1.619751 / 1.541195 (0.078556) | 1.709660 / 1.468490 (0.241170) | 0.692444 / 4.584777 (-3.892333) | 3.853691 / 3.745712 (0.107979) | 2.143910 / 5.269862 (-3.125951) | 1.471600 / 4.565676 (-3.094076) | 0.084589 / 0.424275 (-0.339686) | 0.012276 / 0.007607 (0.004669) | 0.506529 / 0.226044 (0.280485) | 5.028361 / 2.268929 (2.759432) | 2.277660 / 55.444624 (-53.166964) | 1.930365 / 6.876477 (-4.946112) | 1.965494 / 2.142072 (-0.176579) | 0.826752 / 4.805227 (-3.978475) | 0.165050 / 6.500664 (-6.335614) | 0.062702 / 0.075469 (-0.012767) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.234539 / 1.841788 (-0.607249) | 15.067401 / 8.074308 (6.993093) | 14.041920 / 10.191392 (3.850528) | 0.162590 / 0.680424 (-0.517834) | 0.028941 / 0.534201 (-0.505260) | 0.438518 / 0.579283 (-0.140765) | 0.443787 / 0.434364 (0.009423) | 0.516671 / 0.540337 (-0.023666) | 0.609036 / 1.386936 (-0.777900) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.007535 / 0.011353 (-0.003818) | 0.005283 / 0.011008 (-0.005725) | 0.097116 / 0.038508 (0.058608) | 0.033357 / 0.023109 (0.010247) | 0.383398 / 0.275898 (0.107500) | 0.425516 / 0.323480 (0.102037) | 0.006039 / 0.007986 (-0.001947) | 0.004074 / 0.004328 (-0.000255) | 0.073207 / 0.004250 (0.068956) | 0.052153 / 0.037052 (0.015101) | 0.386385 / 0.258489 (0.127896) | 0.429900 / 0.293841 (0.136059) | 0.038341 / 0.128546 (-0.090205) | 0.012417 / 0.075646 (-0.063230) | 0.333859 / 0.419271 (-0.085413) | 0.051157 / 0.043533 (0.007625) | 0.395022 / 0.255139 (0.139883) | 0.402462 / 0.283200 (0.119262) | 0.105207 / 0.141683 (-0.036475) | 1.510679 / 1.452155 (0.058524) | 1.584205 / 1.492716 (0.091489) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.225805 / 0.018006 (0.207799) | 0.452109 / 0.000490 (0.451619) | 0.000429 / 0.000200 (0.000229) | 0.000057 / 0.000054 (0.000002) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.029653 / 0.037411 (-0.007759) | 0.112609 / 0.014526 (0.098083) | 0.121828 / 0.176557 (-0.054728) | 0.159003 / 0.737135 (-0.578133) | 0.129306 / 0.296338 (-0.167033) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.453001 / 0.215209 (0.237792) | 4.514882 / 2.077655 (2.437228) | 2.277494 / 1.504120 (0.773374) | 2.073870 / 1.541195 (0.532675) | 2.153346 / 1.468490 (0.684856) | 0.698363 / 4.584777 (-3.886414) | 3.921763 / 3.745712 (0.176051) | 2.123133 / 5.269862 (-3.146729) | 1.347618 / 4.565676 (-3.218058) | 0.085654 / 0.424275 (-0.338621) | 0.012059 / 0.007607 (0.004452) | 0.568183 / 0.226044 (0.342139) | 5.720047 / 2.268929 (3.451119) | 2.777973 / 55.444624 (-52.666651) | 2.453426 / 6.876477 (-4.423051) | 2.523977 / 2.142072 (0.381905) | 0.841979 / 4.805227 (-3.963248) | 0.167958 / 6.500664 (-6.332706) | 0.064929 / 0.075469 (-0.010540) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.235297 / 1.841788 (-0.606491) | 15.883598 / 8.074308 (7.809290) | 14.395328 / 10.191392 (4.203936) | 0.162401 / 0.680424 (-0.518022) | 0.017806 / 0.534201 (-0.516394) | 0.423853 / 0.579283 (-0.155430) | 0.423266 / 0.434364 (-0.011098) | 0.490351 / 0.540337 (-0.049986) | 0.588116 / 1.386936 (-0.798820) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.010759 / 0.011353 (-0.000594) | 0.005748 / 0.011008 (-0.005260) | 0.119195 / 0.038508 (0.080687) | 0.033476 / 0.023109 (0.010367) | 0.364081 / 0.275898 (0.088183) | 0.422456 / 0.323480 (0.098976) | 0.009780 / 0.007986 (0.001795) | 0.006170 / 0.004328 (0.001841) | 0.093242 / 0.004250 (0.088991) | 0.041049 / 0.037052 (0.003997) | 0.372132 / 0.258489 (0.113643) | 0.442501 / 0.293841 (0.148660) | 0.054889 / 0.128546 (-0.073657) | 0.018302 / 0.075646 (-0.057345) | 0.378899 / 0.419271 (-0.040373) | 0.058455 / 0.043533 (0.014922) | 0.356141 / 0.255139 (0.101002) | 0.400866 / 0.283200 (0.117666) | 0.103384 / 0.141683 (-0.038299) | 1.629867 / 1.452155 (0.177713) | 1.693939 / 1.492716 (0.201222) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.240484 / 0.018006 (0.222478) | 0.509137 / 0.000490 (0.508648) | 0.000450 / 0.000200 (0.000250) | 0.000080 / 0.000054 (0.000026) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.025856 / 0.037411 (-0.011555) | 0.113214 / 0.014526 (0.098689) | 0.119420 / 0.176557 (-0.057136) | 0.158663 / 0.737135 (-0.578473) | 0.123542 / 0.296338 (-0.172797) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.555900 / 0.215209 (0.340691) | 5.580295 / 2.077655 (3.502640) | 2.216640 / 1.504120 (0.712520) | 1.904944 / 1.541195 (0.363749) | 1.865839 / 1.468490 (0.397349) | 1.158325 / 4.584777 (-3.426452) | 5.097420 / 3.745712 (1.351708) | 2.881775 / 5.269862 (-2.388087) | 2.068896 / 4.565676 (-2.496780) | 0.129028 / 0.424275 (-0.295247) | 0.014075 / 0.007607 (0.006468) | 0.698874 / 0.226044 (0.472830) | 7.131225 / 2.268929 (4.862296) | 2.901686 / 55.444624 (-52.542939) | 2.186146 / 6.876477 (-4.690330) | 2.251172 / 2.142072 (0.109100) | 1.342264 / 4.805227 (-3.462963) | 0.232045 / 6.500664 (-6.268619) | 0.073520 / 0.075469 (-0.001949) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.431314 / 1.841788 (-0.410474) | 16.313055 / 8.074308 (8.238747) | 18.451552 / 10.191392 (8.260160) | 0.232875 / 0.680424 (-0.447549) | 0.042170 / 0.534201 (-0.492031) | 0.495261 / 0.579283 (-0.084022) | 0.582901 / 0.434364 (0.148537) | 0.582049 / 0.540337 (0.041712) | 0.681122 / 1.386936 (-0.705814) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008131 / 0.011353 (-0.003222) | 0.006162 / 0.011008 (-0.004847) | 0.113721 / 0.038508 (0.075213) | 0.030797 / 0.023109 (0.007688) | 0.413108 / 0.275898 (0.137210) | 0.449968 / 0.323480 (0.126488) | 0.006126 / 0.007986 (-0.001860) | 0.004848 / 0.004328 (0.000519) | 0.085465 / 0.004250 (0.081214) | 0.045817 / 0.037052 (0.008764) | 0.419360 / 0.258489 (0.160871) | 0.489077 / 0.293841 (0.195236) | 0.050841 / 0.128546 (-0.077705) | 0.020646 / 0.075646 (-0.055000) | 0.379838 / 0.419271 (-0.039434) | 0.068897 / 0.043533 (0.025365) | 0.422182 / 0.255139 (0.167043) | 0.435529 / 0.283200 (0.152330) | 0.115299 / 0.141683 (-0.026384) | 1.655134 / 1.452155 (0.202979) | 1.835198 / 1.492716 (0.342481) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.207041 / 0.018006 (0.189034) | 0.491263 / 0.000490 (0.490773) | 0.003554 / 0.000200 (0.003354) | 0.000104 / 0.000054 (0.000050) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.030830 / 0.037411 (-0.006582) | 0.127003 / 0.014526 (0.112477) | 0.142901 / 0.176557 (-0.033656) | 0.177570 / 0.737135 (-0.559565) | 0.137758 / 0.296338 (-0.158580) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.632820 / 0.215209 (0.417611) | 6.215535 / 2.077655 (4.137880) | 2.615310 / 1.504120 (1.111190) | 2.261431 / 1.541195 (0.720236) | 2.220570 / 1.468490 (0.752080) | 1.215820 / 4.584777 (-3.368957) | 5.247680 / 3.745712 (1.501968) | 3.120054 / 5.269862 (-2.149807) | 1.950947 / 4.565676 (-2.614730) | 0.149980 / 0.424275 (-0.274295) | 0.015241 / 0.007607 (0.007634) | 0.879714 / 0.226044 (0.653670) | 7.941913 / 2.268929 (5.672984) | 3.512456 / 55.444624 (-51.932168) | 2.693833 / 6.876477 (-4.182644) | 2.772780 / 2.142072 (0.630708) | 1.459581 / 4.805227 (-3.345646) | 0.264820 / 6.500664 (-6.235844) | 0.076698 / 0.075469 (0.001228) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.437719 / 1.841788 (-0.404068) | 16.750309 / 8.074308 (8.676001) | 18.646776 / 10.191392 (8.455384) | 0.227858 / 0.680424 (-0.452566) | 0.024239 / 0.534201 (-0.509962) | 0.486172 / 0.579283 (-0.093111) | 0.574731 / 0.434364 (0.140367) | 0.557776 / 0.540337 (0.017439) | 0.672921 / 1.386936 (-0.714015) |\n\n</details>\n</details>\n\n\n"
] | 1,673,340,199,000 | 1,674,061,937,000 | 1,674,050,942,000 | MEMBER | null | This PR fixes the RuntimeError: Sharding is ambiguous for this dataset.
The error for ambiguous sharding will be raised only if num_proc > 1.
Fix #5415, fix #5414.
Fix https://huggingface.co/datasets/ami/discussions/3. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5416/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5416/timeline | null | null | 0 | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5416",
"html_url": "https://github.com/huggingface/datasets/pull/5416",
"diff_url": "https://github.com/huggingface/datasets/pull/5416.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5416.patch",
"merged_at": "2023-01-18T14:09:02"
} | true |
https://api.github.com/repos/huggingface/datasets/issues/5415 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5415/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5415/comments | https://api.github.com/repos/huggingface/datasets/issues/5415/events | https://github.com/huggingface/datasets/issues/5415 | 1,526,904,861 | I_kwDODunzps5bArgd | 5,415 | RuntimeError: Sharding is ambiguous for this dataset | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
}
] | [] | 1,673,336,171,000 | 1,674,050,944,000 | 1,674,050,943,000 | MEMBER | null | ### Describe the bug
When loading some datasets, a RuntimeError is raised.
For example, for "ami" dataset: https://huggingface.co/datasets/ami/discussions/3
```
.../huggingface/datasets/src/datasets/builder.py in _prepare_split(self, split_generator, check_duplicate_keys, file_format, num_proc, max_shard_size)
1415 fpath = path_join(self._output_dir, fname)
1416
-> 1417 num_input_shards = _number_of_shards_in_gen_kwargs(split_generator.gen_kwargs)
1418 if num_input_shards <= 1 and num_proc is not None:
1419 logger.warning(
.../huggingface/datasets/src/datasets/utils/sharding.py in _number_of_shards_in_gen_kwargs(gen_kwargs)
10 lists_lengths = {key: len(value) for key, value in gen_kwargs.items() if isinstance(value, list)}
11 if len(set(lists_lengths.values())) > 1:
---> 12 raise RuntimeError(
13 (
14 "Sharding is ambiguous for this dataset: "
RuntimeError: Sharding is ambiguous for this dataset: we found several data sources lists of different lengths, and we don't know over which list we should parallelize:
- key samples_paths has length 6
- key ids has length 7
- key verification_ids has length 6
To fix this, check the 'gen_kwargs' and make sure to use lists only for data sources, and use tuples otherwise. In the end there should only be one single list, or several lists with the same length.
```
This behavior was introduced when implementing multiprocessing by PR:
- #5107
### Steps to reproduce the bug
```python
ds = load_dataset("ami", "microphone-single", split="train", revision="2d7620bb7c3f1aab9f329615c3bdb598069d907a")
```
### Expected behavior
No error raised.
### Environment info
Since datasets 2.7.0 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5415/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5415/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5414 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5414/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5414/comments | https://api.github.com/repos/huggingface/datasets/issues/5414/events | https://github.com/huggingface/datasets/issues/5414 | 1,525,733,818 | I_kwDODunzps5a8Nm6 | 5,414 | Sharding error with Multilingual LibriSpeech | {
"login": "Nithin-Holla",
"id": 19574344,
"node_id": "MDQ6VXNlcjE5NTc0MzQ0",
"avatar_url": "https://avatars.githubusercontent.com/u/19574344?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Nithin-Holla",
"html_url": "https://github.com/Nithin-Holla",
"followers_url": "https://api.github.com/users/Nithin-Holla/followers",
"following_url": "https://api.github.com/users/Nithin-Holla/following{/other_user}",
"gists_url": "https://api.github.com/users/Nithin-Holla/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Nithin-Holla/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Nithin-Holla/subscriptions",
"organizations_url": "https://api.github.com/users/Nithin-Holla/orgs",
"repos_url": "https://api.github.com/users/Nithin-Holla/repos",
"events_url": "https://api.github.com/users/Nithin-Holla/events{/privacy}",
"received_events_url": "https://api.github.com/users/Nithin-Holla/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
}
] | [
"Thanks for reporting, @Nithin-Holla.\r\n\r\nThis is a known issue for multiple datasets and we are investigating it:\r\n- See e.g.: https://huggingface.co/datasets/ami/discussions/3",
"Main issue:\r\n- #5415",
"@albertvillanova Thanks! As a workaround for now, can I use the dataset in streaming mode?",
"Yes, @Nithin-Holla, in the meantime you can use this dataset in streaming mode."
] | 1,673,275,531,000 | 1,674,050,944,000 | 1,674,050,944,000 | NONE | null | ### Describe the bug
Loading the German Multilingual LibriSpeech dataset results in a RuntimeError regarding sharding with the following stacktrace:
```
Downloading and preparing dataset multilingual_librispeech/german to /home/nithin/datadrive/cache/huggingface/datasets/facebook___multilingual_librispeech/german/2.1.0/1904af50f57a5c370c9364cc337699cfe496d4e9edcae6648a96be23086362d0...
Downloading data files: 100%
3/3 [00:00<00:00, 107.23it/s]
Downloading data files: 100%
1/1 [00:00<00:00, 35.08it/s]
Downloading data files: 100%
6/6 [00:00<00:00, 303.36it/s]
Downloading data files: 100%
3/3 [00:00<00:00, 130.37it/s]
Downloading data files: 100%
1049/1049 [00:00<00:00, 4491.40it/s]
Downloading data files: 100%
37/37 [00:00<00:00, 1096.78it/s]
Downloading data files: 100%
40/40 [00:00<00:00, 1003.93it/s]
Extracting data files: 100%
3/3 [00:11<00:00, 2.62s/it]
Generating train split:
469942/0 [34:13<00:00, 273.21 examples/s]
Output exceeds the size limit. Open the full output data in a text editor
---------------------------------------------------------------------------
RuntimeError Traceback (most recent call last)
<ipython-input-14-74fa6d092bdc> in <module>
----> 1 mls = load_dataset(MLS_DATASET,
2 LANGUAGE,
3 cache_dir="~/datadrive/cache/huggingface/datasets",
4 ignore_verifications=True)
/anaconda/envs/py38_default/lib/python3.8/site-packages/datasets/load.py in load_dataset(path, name, data_dir, data_files, split, cache_dir, features, download_config, download_mode, ignore_verifications, keep_in_memory, save_infos, revision, use_auth_token, task, streaming, num_proc, **config_kwargs)
1755
1756 # Download and prepare data
-> 1757 builder_instance.download_and_prepare(
1758 download_config=download_config,
1759 download_mode=download_mode,
/anaconda/envs/py38_default/lib/python3.8/site-packages/datasets/builder.py in download_and_prepare(self, output_dir, download_config, download_mode, ignore_verifications, try_from_hf_gcs, dl_manager, base_path, use_auth_token, file_format, max_shard_size, num_proc, storage_options, **download_and_prepare_kwargs)
858 if num_proc is not None:
859 prepare_split_kwargs["num_proc"] = num_proc
--> 860 self._download_and_prepare(
861 dl_manager=dl_manager,
862 verify_infos=verify_infos,
/anaconda/envs/py38_default/lib/python3.8/site-packages/datasets/builder.py in _download_and_prepare(self, dl_manager, verify_infos, **prepare_splits_kwargs)
1609
1610 def _download_and_prepare(self, dl_manager, verify_infos, **prepare_splits_kwargs):
...
RuntimeError: Sharding is ambiguous for this dataset: we found several data sources lists of different lengths, and we don't know over which list we should parallelize:
- key audio_archives has length 1049
- key local_extracted_archive has length 1049
- key limited_ids_paths has length 1
To fix this, check the 'gen_kwargs' and make sure to use lists only for data sources, and use tuples otherwise. In the end there should only be one single list, or several lists with the same length.
```
### Steps to reproduce the bug
Here is the code to reproduce it:
```python
from datasets import load_dataset
MLS_DATASET = "facebook/multilingual_librispeech"
LANGUAGE = "german"
mls = load_dataset(MLS_DATASET,
LANGUAGE,
cache_dir="~/datadrive/cache/huggingface/datasets",
ignore_verifications=True)
```
### Expected behavior
The expected behaviour is that the dataset is successfully loaded.
### Environment info
- `datasets` version: 2.8.0
- Platform: Linux-5.4.0-1094-azure-x86_64-with-glibc2.10
- Python version: 3.8.8
- PyArrow version: 10.0.1
- Pandas version: 1.2.4 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5414/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5414/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5413 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5413/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5413/comments | https://api.github.com/repos/huggingface/datasets/issues/5413/events | https://github.com/huggingface/datasets/issues/5413 | 1,524,591,837 | I_kwDODunzps5a32zd | 5,413 | concatenate_datasets fails when two dataset with shards > 1 and unequal shard numbers | {
"login": "ZeguanXiao",
"id": 38279341,
"node_id": "MDQ6VXNlcjM4Mjc5MzQx",
"avatar_url": "https://avatars.githubusercontent.com/u/38279341?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ZeguanXiao",
"html_url": "https://github.com/ZeguanXiao",
"followers_url": "https://api.github.com/users/ZeguanXiao/followers",
"following_url": "https://api.github.com/users/ZeguanXiao/following{/other_user}",
"gists_url": "https://api.github.com/users/ZeguanXiao/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ZeguanXiao/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ZeguanXiao/subscriptions",
"organizations_url": "https://api.github.com/users/ZeguanXiao/orgs",
"repos_url": "https://api.github.com/users/ZeguanXiao/repos",
"events_url": "https://api.github.com/users/ZeguanXiao/events{/privacy}",
"received_events_url": "https://api.github.com/users/ZeguanXiao/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
}
] | [
"Hi ! Thanks for reporting :)\r\n\r\nI managed to reproduce the hub using\r\n```python\r\n\r\nfrom datasets import concatenate_datasets, Dataset, load_from_disk\r\n\r\nDataset.from_dict({\"a\": range(9)}).save_to_disk(\"tmp/ds1\")\r\nds1 = load_from_disk(\"tmp/ds1\")\r\nds1 = concatenate_datasets([ds1, ds1])\r\n\r\nDataset.from_dict({\"b\": range(6)}).save_to_disk(\"tmp/ds2\")\r\nds2 = load_from_disk(\"tmp/ds2\")\r\nds2 = concatenate_datasets([ds2, ds2, ds2])\r\n\r\nconcatenate_datasets([ds1, ds2], axis=1)\r\n```\r\nand I get\r\n```python\r\nTraceback (most recent call last): \r\n File \"test.py\", line 98, in <module>\r\n dds = concatenate_datasets([ds1, ds2], axis=1)\r\n File \"/Users/.../datasets/combine.py\", line 182, in concatenate_datasets\r\n return _concatenate_map_style_datasets(dsets, info=info, split=split, axis=axis)\r\n File \"/Users/.../datasets/arrow_dataset.py\", line 5499, in _concatenate_map_style_datasets\r\n table = concat_tables([dset._data for dset in dsets], axis=axis)\r\n File \"/Users/.../datasets/table.py\", line 1778, in concat_tables\r\n return ConcatenationTable.from_tables(tables, axis=axis)\r\n File \"/Users/.../datasets/table.py\", line 1483, in from_tables\r\n blocks = _extend_blocks(blocks, table_blocks, axis=axis)\r\n File \"/Users/.../datasets/table.py\", line 1477, in _extend_blocks\r\n result[i].extend(row_blocks)\r\nIndexError: list index out of range\r\n```\r\n\r\nIt appears to happen when the two datasets have a number of shards that is not the same"
] | 1,673,197,312,000 | 1,674,725,241,000 | 1,674,725,241,000 | NONE | null | ### Describe the bug
When using `concatenate_datasets([dataset1, dataset2], axis = 1)` to concatenate two datasets with shards > 1, it fails:
```
File "/home/xzg/anaconda3/envs/tri-transfer/lib/python3.9/site-packages/datasets/combine.py", line 182, in concatenate_datasets
return _concatenate_map_style_datasets(dsets, info=info, split=split, axis=axis)
File "/home/xzg/anaconda3/envs/tri-transfer/lib/python3.9/site-packages/datasets/arrow_dataset.py", line 5499, in _concatenate_map_style_datasets
table = concat_tables([dset._data for dset in dsets], axis=axis)
File "/home/xzg/anaconda3/envs/tri-transfer/lib/python3.9/site-packages/datasets/table.py", line 1778, in concat_tables
return ConcatenationTable.from_tables(tables, axis=axis)
File "/home/xzg/anaconda3/envs/tri-transfer/lib/python3.9/site-packages/datasets/table.py", line 1483, in from_tables
blocks = _extend_blocks(blocks, table_blocks, axis=axis)
File "/home/xzg/anaconda3/envs/tri-transfer/lib/python3.9/site-packages/datasets/table.py", line 1477, in _extend_blocks
result[i].extend(row_blocks)
IndexError: list index out of range
```
### Steps to reproduce the bug
dataset = concatenate_datasets([dataset1, dataset2], axis = 1)
### Expected behavior
The datasets are correctly concatenated.
### Environment info
datasets==2.8.0 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5413/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5413/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5412 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5412/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5412/comments | https://api.github.com/repos/huggingface/datasets/issues/5412/events | https://github.com/huggingface/datasets/issues/5412 | 1,524,250,269 | I_kwDODunzps5a2jad | 5,412 | load_dataset() cannot find dataset_info.json with multiple training runs in parallel | {
"login": "destigres",
"id": 7139344,
"node_id": "MDQ6VXNlcjcxMzkzNDQ=",
"avatar_url": "https://avatars.githubusercontent.com/u/7139344?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/destigres",
"html_url": "https://github.com/destigres",
"followers_url": "https://api.github.com/users/destigres/followers",
"following_url": "https://api.github.com/users/destigres/following{/other_user}",
"gists_url": "https://api.github.com/users/destigres/gists{/gist_id}",
"starred_url": "https://api.github.com/users/destigres/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/destigres/subscriptions",
"organizations_url": "https://api.github.com/users/destigres/orgs",
"repos_url": "https://api.github.com/users/destigres/repos",
"events_url": "https://api.github.com/users/destigres/events{/privacy}",
"received_events_url": "https://api.github.com/users/destigres/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Hi ! It fails because the dataset is already being prepared by your first run. I'd encourage you to prepare your dataset before using it for multiple trainings.\r\n\r\nYou can also specify another cache directory by passing `cache_dir=` to `load_dataset()`.",
"Thank you! What do you mean by prepare it beforehand? I am unclear how to conduct dataset preparation outside of using the `load_dataset` function.",
"You can have a separate script that does load_dataset + map + save_to_disk to save your prepared dataset somewhere. Then in your training script you can reload the dataset with load_from_disk",
"Thank you! I believe I was running additional map steps after loading, resulting in the cache conflict. "
] | 1,673,138,672,000 | 1,674,160,123,000 | 1,674,160,123,000 | NONE | null | ### Describe the bug
I have a custom local dataset in JSON form. I am trying to do multiple training runs in parallel. The first training run runs with no issue. However, when I start another run on another GPU, the following code throws this error.
If there is a workaround to ignore the cache I think that would solve my problem too.
I am using datasets version 2.8.0.
### Steps to reproduce the bug
1. Start training run of GPU 0 loading dataset from
```
load_dataset(
"json",
data_files=tr_dataset_path,
split=f"train",
download_mode="force_redownload",
)
```
2. While GPU 0 is training, start an identical run on GPU 1. GPU 1 will produce the following error:
```
Traceback (most recent call last):
File "/local-scratch1/data/mt/code/qq/train.py", line 198, in <module>
main()
File "/home/username/.local/lib/python3.8/site-packages/click/core.py", line 1130, in __call__
return self.main(*args, **kwargs)
File "/home/username/.local/lib/python3.8/site-packages/click/core.py", line 1055, in main
rv = self.invoke(ctx)
File "/home/username/.local/lib/python3.8/site-packages/click/core.py", line 1404, in invoke
return ctx.invoke(self.callback, **ctx.params)
File "/home/username/.local/lib/python3.8/site-packages/click/core.py", line 760, in invoke
return __callback(*args, **kwargs)
File "/local-scratch1/data/mt/code/qq/train.py", line 113, in main
load_dataset(
File "/home/username/miniconda3/envs/qq3/lib/python3.8/site-packages/datasets/load.py", line 1734, in load_dataset
builder_instance = load_dataset_builder(
File "/home/username/miniconda3/envs/qq3/lib/python3.8/site-packages/datasets/load.py", line 1518, in load_dataset_builder
builder_instance: DatasetBuilder = builder_cls(
File "/home/username/miniconda3/envs/qq3/lib/python3.8/site-packages/datasets/builder.py", line 366, in __init__
self.info = DatasetInfo.from_directory(self._cache_dir)
File "/home/username/miniconda3/envs/qq3/lib/python3.8/site-packages/datasets/info.py", line 313, in from_directory
with fs.open(path_join(dataset_info_dir, config.DATASET_INFO_FILENAME), "r", encoding="utf-8") as f:
File "/home/username/miniconda3/envs/qq3/lib/python3.8/site-packages/fsspec/spec.py", line 1094, in open
self.open(
File "/home/username/miniconda3/envs/qq3/lib/python3.8/site-packages/fsspec/spec.py", line 1106, in open
f = self._open(
File "/home/username/miniconda3/envs/qq3/lib/python3.8/site-packages/fsspec/implementations/local.py", line 175, in _open
return LocalFileOpener(path, mode, fs=self, **kwargs)
File "/home/username/miniconda3/envs/qq3/lib/python3.8/site-packages/fsspec/implementations/local.py", line 273, in __init__
self._open()
File "/home/username/miniconda3/envs/qq3/lib/python3.8/site-packages/fsspec/implementations/local.py", line 278, in _open
self.f = open(self.path, mode=self.mode)
FileNotFoundError: [Errno 2] No such file or directory: '/home/username/.cache/huggingface/datasets/json/default-43d06a4aedb25e6d/0.0.0/0f7e3662623656454fcd2b650f34e886a7db4b9104504885bd462096cc7a9f51/dataset_info.json'
```
### Expected behavior
Expected behavior: 2nd GPU training run should run the same as 1st GPU training run.
### Environment info
Copy-and-paste the text below in your GitHub issue.
- `datasets` version: 2.8.0
- Platform: Linux-5.4.0-120-generic-x86_64-with-glibc2.10
- Python version: 3.8.15
- PyArrow version: 9.0.0
- Pandas version: 1.5.2 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5412/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5412/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5411 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5411/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5411/comments | https://api.github.com/repos/huggingface/datasets/issues/5411/events | https://github.com/huggingface/datasets/pull/5411 | 1,523,297,786 | PR_kwDODunzps5G23-T | 5,411 | Update docs of S3 filesystem with async aiobotocore | {
"login": "maheshpec",
"id": 5677912,
"node_id": "MDQ6VXNlcjU2Nzc5MTI=",
"avatar_url": "https://avatars.githubusercontent.com/u/5677912?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/maheshpec",
"html_url": "https://github.com/maheshpec",
"followers_url": "https://api.github.com/users/maheshpec/followers",
"following_url": "https://api.github.com/users/maheshpec/following{/other_user}",
"gists_url": "https://api.github.com/users/maheshpec/gists{/gist_id}",
"starred_url": "https://api.github.com/users/maheshpec/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/maheshpec/subscriptions",
"organizations_url": "https://api.github.com/users/maheshpec/orgs",
"repos_url": "https://api.github.com/users/maheshpec/repos",
"events_url": "https://api.github.com/users/maheshpec/events{/privacy}",
"received_events_url": "https://api.github.com/users/maheshpec/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008587 / 0.011353 (-0.002766) | 0.004613 / 0.011008 (-0.006395) | 0.100446 / 0.038508 (0.061938) | 0.029606 / 0.023109 (0.006497) | 0.302102 / 0.275898 (0.026204) | 0.357364 / 0.323480 (0.033884) | 0.007031 / 0.007986 (-0.000954) | 0.003593 / 0.004328 (-0.000735) | 0.078110 / 0.004250 (0.073860) | 0.035495 / 0.037052 (-0.001557) | 0.312522 / 0.258489 (0.054033) | 0.349336 / 0.293841 (0.055495) | 0.033719 / 0.128546 (-0.094827) | 0.011449 / 0.075646 (-0.064197) | 0.321760 / 0.419271 (-0.097512) | 0.043697 / 0.043533 (0.000165) | 0.304476 / 0.255139 (0.049337) | 0.333126 / 0.283200 (0.049926) | 0.092756 / 0.141683 (-0.048927) | 1.506734 / 1.452155 (0.054579) | 1.547381 / 1.492716 (0.054664) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.178177 / 0.018006 (0.160171) | 0.427814 / 0.000490 (0.427324) | 0.002505 / 0.000200 (0.002305) | 0.000074 / 0.000054 (0.000020) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.023039 / 0.037411 (-0.014372) | 0.097113 / 0.014526 (0.082587) | 0.105014 / 0.176557 (-0.071543) | 0.141185 / 0.737135 (-0.595950) | 0.108843 / 0.296338 (-0.187495) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.424148 / 0.215209 (0.208939) | 4.247599 / 2.077655 (2.169944) | 2.130720 / 1.504120 (0.626600) | 1.916349 / 1.541195 (0.375154) | 1.831515 / 1.468490 (0.363025) | 0.688301 / 4.584777 (-3.896476) | 3.381749 / 3.745712 (-0.363963) | 2.900045 / 5.269862 (-2.369817) | 1.576248 / 4.565676 (-2.989428) | 0.082354 / 0.424275 (-0.341921) | 0.012200 / 0.007607 (0.004593) | 0.525753 / 0.226044 (0.299709) | 5.277672 / 2.268929 (3.008743) | 2.603870 / 55.444624 (-52.840754) | 2.296203 / 6.876477 (-4.580273) | 2.308014 / 2.142072 (0.165942) | 0.809056 / 4.805227 (-3.996171) | 0.148122 / 6.500664 (-6.352542) | 0.066097 / 0.075469 (-0.009372) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.214059 / 1.841788 (-0.627728) | 13.671332 / 8.074308 (5.597024) | 13.694554 / 10.191392 (3.503162) | 0.151454 / 0.680424 (-0.528970) | 0.028514 / 0.534201 (-0.505687) | 0.391480 / 0.579283 (-0.187804) | 0.404499 / 0.434364 (-0.029865) | 0.458111 / 0.540337 (-0.082226) | 0.539454 / 1.386936 (-0.847482) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006795 / 0.011353 (-0.004558) | 0.004463 / 0.011008 (-0.006545) | 0.099542 / 0.038508 (0.061034) | 0.027588 / 0.023109 (0.004479) | 0.423023 / 0.275898 (0.147125) | 0.458459 / 0.323480 (0.134979) | 0.004981 / 0.007986 (-0.003005) | 0.003321 / 0.004328 (-0.001008) | 0.075727 / 0.004250 (0.071477) | 0.040541 / 0.037052 (0.003489) | 0.423724 / 0.258489 (0.165235) | 0.468334 / 0.293841 (0.174493) | 0.031732 / 0.128546 (-0.096814) | 0.011478 / 0.075646 (-0.064168) | 0.319807 / 0.419271 (-0.099465) | 0.041215 / 0.043533 (-0.002318) | 0.423060 / 0.255139 (0.167921) | 0.446157 / 0.283200 (0.162957) | 0.088884 / 0.141683 (-0.052799) | 1.553404 / 1.452155 (0.101250) | 1.607797 / 1.492716 (0.115080) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.208314 / 0.018006 (0.190307) | 0.411627 / 0.000490 (0.411137) | 0.002416 / 0.000200 (0.002216) | 0.000078 / 0.000054 (0.000024) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.024641 / 0.037411 (-0.012770) | 0.101047 / 0.014526 (0.086521) | 0.108410 / 0.176557 (-0.068147) | 0.142860 / 0.737135 (-0.594276) | 0.112486 / 0.296338 (-0.183852) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.485520 / 0.215209 (0.270311) | 4.864009 / 2.077655 (2.786355) | 2.541865 / 1.504120 (1.037745) | 2.339569 / 1.541195 (0.798374) | 2.378258 / 1.468490 (0.909768) | 0.698000 / 4.584777 (-3.886777) | 3.343137 / 3.745712 (-0.402575) | 1.842264 / 5.269862 (-3.427597) | 1.154707 / 4.565676 (-3.410969) | 0.082826 / 0.424275 (-0.341449) | 0.012379 / 0.007607 (0.004772) | 0.583335 / 0.226044 (0.357291) | 5.885934 / 2.268929 (3.617006) | 2.997769 / 55.444624 (-52.446856) | 2.653681 / 6.876477 (-4.222796) | 2.761656 / 2.142072 (0.619583) | 0.799883 / 4.805227 (-4.005344) | 0.151398 / 6.500664 (-6.349266) | 0.067445 / 0.075469 (-0.008024) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.292009 / 1.841788 (-0.549779) | 13.976180 / 8.074308 (5.901872) | 14.219469 / 10.191392 (4.028077) | 0.127810 / 0.680424 (-0.552614) | 0.016919 / 0.534201 (-0.517282) | 0.376401 / 0.579283 (-0.202882) | 0.388563 / 0.434364 (-0.045801) | 0.444904 / 0.540337 (-0.095433) | 0.532290 / 1.386936 (-0.854646) |\n\n</details>\n</details>\n\n\n"
] | 1,673,047,157,000 | 1,674,040,739,000 | 1,674,040,324,000 | CONTRIBUTOR | null | [s3fs has migrated to all async calls](https://github.com/fsspec/s3fs/commit/0de2c6fb3d87c08ea694de96dca0d0834034f8bf).
Updating documentation to use `AioSession` while using s3fs for download manager as well as working with datasets | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5411/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5411/timeline | null | null | 0 | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5411",
"html_url": "https://github.com/huggingface/datasets/pull/5411",
"diff_url": "https://github.com/huggingface/datasets/pull/5411.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5411.patch",
"merged_at": "2023-01-18T11:12:04"
} | true |
https://api.github.com/repos/huggingface/datasets/issues/5410 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5410/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5410/comments | https://api.github.com/repos/huggingface/datasets/issues/5410/events | https://github.com/huggingface/datasets/pull/5410 | 1,521,168,032 | PR_kwDODunzps5GvnJH | 5,410 | Map-style Dataset to IterableDataset | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.009812 / 0.011353 (-0.001540) | 0.005290 / 0.011008 (-0.005719) | 0.099728 / 0.038508 (0.061220) | 0.036712 / 0.023109 (0.013602) | 0.305924 / 0.275898 (0.030026) | 0.349844 / 0.323480 (0.026365) | 0.008353 / 0.007986 (0.000368) | 0.004464 / 0.004328 (0.000135) | 0.075329 / 0.004250 (0.071079) | 0.046146 / 0.037052 (0.009094) | 0.304197 / 0.258489 (0.045708) | 0.354245 / 0.293841 (0.060404) | 0.039270 / 0.128546 (-0.089276) | 0.012496 / 0.075646 (-0.063151) | 0.334390 / 0.419271 (-0.084882) | 0.049428 / 0.043533 (0.005896) | 0.297318 / 0.255139 (0.042179) | 0.315646 / 0.283200 (0.032447) | 0.106746 / 0.141683 (-0.034937) | 1.443562 / 1.452155 (-0.008593) | 1.546022 / 1.492716 (0.053305) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.303419 / 0.018006 (0.285413) | 0.536971 / 0.000490 (0.536481) | 0.001335 / 0.000200 (0.001135) | 0.000088 / 0.000054 (0.000033) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.030484 / 0.037411 (-0.006927) | 0.110043 / 0.014526 (0.095518) | 0.125265 / 0.176557 (-0.051291) | 0.171410 / 0.737135 (-0.565725) | 0.128978 / 0.296338 (-0.167361) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.398354 / 0.215209 (0.183145) | 3.984180 / 2.077655 (1.906526) | 1.781134 / 1.504120 (0.277014) | 1.589656 / 1.541195 (0.048462) | 1.704192 / 1.468490 (0.235702) | 0.682271 / 4.584777 (-3.902506) | 3.731504 / 3.745712 (-0.014208) | 2.243520 / 5.269862 (-3.026342) | 1.511334 / 4.565676 (-3.054343) | 0.084243 / 0.424275 (-0.340032) | 0.012261 / 0.007607 (0.004654) | 0.507499 / 0.226044 (0.281454) | 5.066037 / 2.268929 (2.797109) | 2.246107 / 55.444624 (-53.198517) | 1.921032 / 6.876477 (-4.955444) | 2.144111 / 2.142072 (0.002039) | 0.845233 / 4.805227 (-3.959995) | 0.165392 / 6.500664 (-6.335272) | 0.064201 / 0.075469 (-0.011268) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.217649 / 1.841788 (-0.624138) | 15.890487 / 8.074308 (7.816179) | 14.772039 / 10.191392 (4.580647) | 0.192901 / 0.680424 (-0.487523) | 0.029119 / 0.534201 (-0.505082) | 0.442904 / 0.579283 (-0.136380) | 0.451035 / 0.434364 (0.016671) | 0.520788 / 0.540337 (-0.019550) | 0.623588 / 1.386936 (-0.763348) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.007452 / 0.011353 (-0.003901) | 0.005426 / 0.011008 (-0.005582) | 0.096488 / 0.038508 (0.057980) | 0.033575 / 0.023109 (0.010465) | 0.375688 / 0.275898 (0.099790) | 0.412393 / 0.323480 (0.088913) | 0.006050 / 0.007986 (-0.001936) | 0.004424 / 0.004328 (0.000095) | 0.073102 / 0.004250 (0.068852) | 0.052672 / 0.037052 (0.015620) | 0.379352 / 0.258489 (0.120862) | 0.436065 / 0.293841 (0.142224) | 0.036594 / 0.128546 (-0.091952) | 0.012380 / 0.075646 (-0.063266) | 0.332899 / 0.419271 (-0.086373) | 0.048859 / 0.043533 (0.005326) | 0.373215 / 0.255139 (0.118076) | 0.386990 / 0.283200 (0.103791) | 0.105166 / 0.141683 (-0.036517) | 1.490762 / 1.452155 (0.038607) | 1.611310 / 1.492716 (0.118593) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.333142 / 0.018006 (0.315136) | 0.537137 / 0.000490 (0.536647) | 0.000452 / 0.000200 (0.000252) | 0.000063 / 0.000054 (0.000009) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.030368 / 0.037411 (-0.007043) | 0.109608 / 0.014526 (0.095083) | 0.124220 / 0.176557 (-0.052336) | 0.162834 / 0.737135 (-0.574301) | 0.128037 / 0.296338 (-0.168302) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.440991 / 0.215209 (0.225782) | 4.400825 / 2.077655 (2.323170) | 2.158768 / 1.504120 (0.654648) | 1.968158 / 1.541195 (0.426963) | 2.085115 / 1.468490 (0.616625) | 0.710757 / 4.584777 (-3.874020) | 3.835441 / 3.745712 (0.089729) | 2.204118 / 5.269862 (-3.065744) | 1.378909 / 4.565676 (-3.186767) | 0.089149 / 0.424275 (-0.335126) | 0.013066 / 0.007607 (0.005459) | 0.539165 / 0.226044 (0.313121) | 5.414176 / 2.268929 (3.145248) | 2.677020 / 55.444624 (-52.767604) | 2.328334 / 6.876477 (-4.548143) | 2.518933 / 2.142072 (0.376860) | 0.840902 / 4.805227 (-3.964325) | 0.170365 / 6.500664 (-6.330299) | 0.063909 / 0.075469 (-0.011561) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.237205 / 1.841788 (-0.604583) | 15.678776 / 8.074308 (7.604468) | 14.118576 / 10.191392 (3.927184) | 0.167236 / 0.680424 (-0.513188) | 0.018177 / 0.534201 (-0.516024) | 0.426680 / 0.579283 (-0.152603) | 0.425126 / 0.434364 (-0.009238) | 0.501755 / 0.540337 (-0.038582) | 0.592754 / 1.386936 (-0.794182) |\n\n</details>\n</details>\n\n\n",
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008708 / 0.011353 (-0.002645) | 0.004462 / 0.011008 (-0.006546) | 0.100159 / 0.038508 (0.061651) | 0.029543 / 0.023109 (0.006434) | 0.304056 / 0.275898 (0.028158) | 0.367098 / 0.323480 (0.043618) | 0.007049 / 0.007986 (-0.000937) | 0.003294 / 0.004328 (-0.001034) | 0.076954 / 0.004250 (0.072703) | 0.036850 / 0.037052 (-0.000202) | 0.307556 / 0.258489 (0.049067) | 0.348327 / 0.293841 (0.054486) | 0.033520 / 0.128546 (-0.095026) | 0.011312 / 0.075646 (-0.064334) | 0.317588 / 0.419271 (-0.101684) | 0.040196 / 0.043533 (-0.003337) | 0.298330 / 0.255139 (0.043191) | 0.333821 / 0.283200 (0.050622) | 0.086584 / 0.141683 (-0.055099) | 1.480205 / 1.452155 (0.028050) | 1.520975 / 1.492716 (0.028259) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.186641 / 0.018006 (0.168635) | 0.414420 / 0.000490 (0.413930) | 0.003021 / 0.000200 (0.002821) | 0.000073 / 0.000054 (0.000018) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.022953 / 0.037411 (-0.014458) | 0.097338 / 0.014526 (0.082812) | 0.104985 / 0.176557 (-0.071572) | 0.139208 / 0.737135 (-0.597927) | 0.108031 / 0.296338 (-0.188307) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.417969 / 0.215209 (0.202759) | 4.173189 / 2.077655 (2.095534) | 1.862813 / 1.504120 (0.358693) | 1.653226 / 1.541195 (0.112031) | 1.725917 / 1.468490 (0.257426) | 0.701038 / 4.584777 (-3.883739) | 3.350500 / 3.745712 (-0.395213) | 1.913156 / 5.269862 (-3.356705) | 1.267597 / 4.565676 (-3.298079) | 0.082197 / 0.424275 (-0.342078) | 0.012499 / 0.007607 (0.004892) | 0.520173 / 0.226044 (0.294128) | 5.219981 / 2.268929 (2.951053) | 2.306029 / 55.444624 (-53.138595) | 1.948169 / 6.876477 (-4.928307) | 2.013160 / 2.142072 (-0.128912) | 0.813325 / 4.805227 (-3.991902) | 0.149729 / 6.500664 (-6.350935) | 0.065492 / 0.075469 (-0.009977) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.194163 / 1.841788 (-0.647625) | 13.739562 / 8.074308 (5.665254) | 13.881988 / 10.191392 (3.690596) | 0.138180 / 0.680424 (-0.542244) | 0.029031 / 0.534201 (-0.505170) | 0.387858 / 0.579283 (-0.191425) | 0.395171 / 0.434364 (-0.039193) | 0.446349 / 0.540337 (-0.093988) | 0.527073 / 1.386936 (-0.859863) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006504 / 0.011353 (-0.004849) | 0.004564 / 0.011008 (-0.006444) | 0.099108 / 0.038508 (0.060599) | 0.027420 / 0.023109 (0.004311) | 0.340712 / 0.275898 (0.064814) | 0.391613 / 0.323480 (0.068133) | 0.004977 / 0.007986 (-0.003009) | 0.003375 / 0.004328 (-0.000953) | 0.076403 / 0.004250 (0.072152) | 0.036650 / 0.037052 (-0.000402) | 0.341948 / 0.258489 (0.083459) | 0.392065 / 0.293841 (0.098224) | 0.031802 / 0.128546 (-0.096745) | 0.011659 / 0.075646 (-0.063987) | 0.320099 / 0.419271 (-0.099173) | 0.041615 / 0.043533 (-0.001918) | 0.342125 / 0.255139 (0.086986) | 0.372833 / 0.283200 (0.089633) | 0.089032 / 0.141683 (-0.052650) | 1.486691 / 1.452155 (0.034536) | 1.567326 / 1.492716 (0.074610) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.193123 / 0.018006 (0.175117) | 0.404062 / 0.000490 (0.403573) | 0.003460 / 0.000200 (0.003260) | 0.000079 / 0.000054 (0.000024) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.024565 / 0.037411 (-0.012846) | 0.098958 / 0.014526 (0.084432) | 0.108701 / 0.176557 (-0.067855) | 0.142567 / 0.737135 (-0.594569) | 0.111048 / 0.296338 (-0.185290) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.474549 / 0.215209 (0.259340) | 4.753776 / 2.077655 (2.676121) | 2.435528 / 1.504120 (0.931409) | 2.234491 / 1.541195 (0.693297) | 2.269474 / 1.468490 (0.800984) | 0.695636 / 4.584777 (-3.889141) | 3.367816 / 3.745712 (-0.377896) | 1.854828 / 5.269862 (-3.415034) | 1.159729 / 4.565676 (-3.405948) | 0.082267 / 0.424275 (-0.342008) | 0.012483 / 0.007607 (0.004876) | 0.578490 / 0.226044 (0.352446) | 5.814490 / 2.268929 (3.545561) | 2.893310 / 55.444624 (-52.551314) | 2.540555 / 6.876477 (-4.335922) | 2.573705 / 2.142072 (0.431633) | 0.800545 / 4.805227 (-4.004682) | 0.151306 / 6.500664 (-6.349358) | 0.067925 / 0.075469 (-0.007544) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.294645 / 1.841788 (-0.547142) | 13.641842 / 8.074308 (5.567534) | 14.015200 / 10.191392 (3.823808) | 0.128829 / 0.680424 (-0.551595) | 0.016870 / 0.534201 (-0.517331) | 0.389137 / 0.579283 (-0.190146) | 0.388384 / 0.434364 (-0.045980) | 0.447711 / 0.540337 (-0.092627) | 0.540637 / 1.386936 (-0.846299) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.012282 / 0.011353 (0.000929) | 0.006328 / 0.011008 (-0.004680) | 0.129666 / 0.038508 (0.091158) | 0.039403 / 0.023109 (0.016294) | 0.375464 / 0.275898 (0.099566) | 0.463167 / 0.323480 (0.139687) | 0.010329 / 0.007986 (0.002344) | 0.005111 / 0.004328 (0.000782) | 0.108727 / 0.004250 (0.104476) | 0.047156 / 0.037052 (0.010103) | 0.381869 / 0.258489 (0.123380) | 0.441936 / 0.293841 (0.148095) | 0.054750 / 0.128546 (-0.073796) | 0.019809 / 0.075646 (-0.055837) | 0.436389 / 0.419271 (0.017118) | 0.066585 / 0.043533 (0.023052) | 0.402108 / 0.255139 (0.146969) | 0.424571 / 0.283200 (0.141371) | 0.118326 / 0.141683 (-0.023357) | 1.870175 / 1.452155 (0.418020) | 1.878720 / 1.492716 (0.386004) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.012863 / 0.018006 (-0.005144) | 0.528670 / 0.000490 (0.528181) | 0.006057 / 0.000200 (0.005857) | 0.000124 / 0.000054 (0.000069) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.030091 / 0.037411 (-0.007320) | 0.136143 / 0.014526 (0.121618) | 0.148931 / 0.176557 (-0.027626) | 0.179578 / 0.737135 (-0.557558) | 0.144528 / 0.296338 (-0.151810) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.594080 / 0.215209 (0.378871) | 6.029101 / 2.077655 (3.951446) | 2.443084 / 1.504120 (0.938964) | 2.123949 / 1.541195 (0.582754) | 2.183021 / 1.468490 (0.714531) | 1.235453 / 4.584777 (-3.349324) | 5.585121 / 3.745712 (1.839408) | 3.208510 / 5.269862 (-2.061351) | 2.090334 / 4.565676 (-2.475342) | 0.150353 / 0.424275 (-0.273922) | 0.016787 / 0.007607 (0.009180) | 0.797561 / 0.226044 (0.571516) | 7.756291 / 2.268929 (5.487363) | 3.283638 / 55.444624 (-52.160986) | 2.527441 / 6.876477 (-4.349036) | 2.590765 / 2.142072 (0.448692) | 1.446818 / 4.805227 (-3.358409) | 0.250563 / 6.500664 (-6.250101) | 0.077919 / 0.075469 (0.002450) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.612022 / 1.841788 (-0.229765) | 18.363316 / 8.074308 (10.289008) | 22.578570 / 10.191392 (12.387178) | 0.232801 / 0.680424 (-0.447623) | 0.048232 / 0.534201 (-0.485969) | 0.549518 / 0.579283 (-0.029766) | 0.624663 / 0.434364 (0.190299) | 0.674745 / 0.540337 (0.134408) | 0.803489 / 1.386936 (-0.583447) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.009872 / 0.011353 (-0.001481) | 0.006593 / 0.011008 (-0.004415) | 0.139248 / 0.038508 (0.100740) | 0.035708 / 0.023109 (0.012598) | 0.551335 / 0.275898 (0.275437) | 0.544995 / 0.323480 (0.221515) | 0.007085 / 0.007986 (-0.000900) | 0.004742 / 0.004328 (0.000413) | 0.095823 / 0.004250 (0.091572) | 0.051674 / 0.037052 (0.014621) | 0.463405 / 0.258489 (0.204916) | 0.640392 / 0.293841 (0.346551) | 0.055242 / 0.128546 (-0.073304) | 0.022602 / 0.075646 (-0.053044) | 0.419171 / 0.419271 (-0.000100) | 0.062986 / 0.043533 (0.019453) | 0.503683 / 0.255139 (0.248544) | 0.568719 / 0.283200 (0.285519) | 0.113906 / 0.141683 (-0.027777) | 1.825248 / 1.452155 (0.373094) | 1.985667 / 1.492716 (0.492951) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.237478 / 0.018006 (0.219472) | 0.528861 / 0.000490 (0.528371) | 0.008507 / 0.000200 (0.008307) | 0.000158 / 0.000054 (0.000103) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.033536 / 0.037411 (-0.003875) | 0.144202 / 0.014526 (0.129677) | 0.139472 / 0.176557 (-0.037084) | 0.184540 / 0.737135 (-0.552596) | 0.147818 / 0.296338 (-0.148520) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.671654 / 0.215209 (0.456445) | 6.616368 / 2.077655 (4.538713) | 2.805634 / 1.504120 (1.301514) | 2.482890 / 1.541195 (0.941695) | 2.547686 / 1.468490 (1.079195) | 1.289169 / 4.584777 (-3.295608) | 5.551436 / 3.745712 (1.805724) | 5.228500 / 5.269862 (-0.041362) | 2.456706 / 4.565676 (-2.108970) | 0.148556 / 0.424275 (-0.275720) | 0.015290 / 0.007607 (0.007683) | 0.837090 / 0.226044 (0.611045) | 8.373561 / 2.268929 (6.104632) | 3.663910 / 55.444624 (-51.780714) | 2.927117 / 6.876477 (-3.949360) | 2.976785 / 2.142072 (0.834712) | 1.501618 / 4.805227 (-3.303609) | 0.263321 / 6.500664 (-6.237343) | 0.082644 / 0.075469 (0.007175) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.707419 / 1.841788 (-0.134368) | 18.371117 / 8.074308 (10.296809) | 22.015154 / 10.191392 (11.823762) | 0.232066 / 0.680424 (-0.448357) | 0.027149 / 0.534201 (-0.507052) | 0.544450 / 0.579283 (-0.034833) | 0.605134 / 0.434364 (0.170770) | 0.656063 / 0.540337 (0.115725) | 0.788121 / 1.386936 (-0.598815) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008952 / 0.011353 (-0.002401) | 0.005592 / 0.011008 (-0.005416) | 0.101138 / 0.038508 (0.062630) | 0.035573 / 0.023109 (0.012464) | 0.295959 / 0.275898 (0.020060) | 0.365347 / 0.323480 (0.041867) | 0.008136 / 0.007986 (0.000150) | 0.004479 / 0.004328 (0.000150) | 0.078806 / 0.004250 (0.074556) | 0.045180 / 0.037052 (0.008127) | 0.321687 / 0.258489 (0.063198) | 0.345874 / 0.293841 (0.052033) | 0.038720 / 0.128546 (-0.089826) | 0.012534 / 0.075646 (-0.063112) | 0.335571 / 0.419271 (-0.083700) | 0.049048 / 0.043533 (0.005515) | 0.294756 / 0.255139 (0.039617) | 0.327496 / 0.283200 (0.044296) | 0.109181 / 0.141683 (-0.032502) | 1.417068 / 1.452155 (-0.035087) | 1.455473 / 1.492716 (-0.037244) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.267774 / 0.018006 (0.249768) | 0.538546 / 0.000490 (0.538056) | 0.001755 / 0.000200 (0.001555) | 0.000090 / 0.000054 (0.000035) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.026839 / 0.037411 (-0.010572) | 0.105862 / 0.014526 (0.091336) | 0.118278 / 0.176557 (-0.058279) | 0.157926 / 0.737135 (-0.579209) | 0.124700 / 0.296338 (-0.171638) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.399060 / 0.215209 (0.183851) | 3.991409 / 2.077655 (1.913754) | 1.763569 / 1.504120 (0.259449) | 1.579602 / 1.541195 (0.038407) | 1.652928 / 1.468490 (0.184438) | 0.692962 / 4.584777 (-3.891815) | 3.784635 / 3.745712 (0.038922) | 3.249341 / 5.269862 (-2.020521) | 1.815711 / 4.565676 (-2.749966) | 0.084384 / 0.424275 (-0.339891) | 0.012546 / 0.007607 (0.004939) | 0.521397 / 0.226044 (0.295352) | 5.075824 / 2.268929 (2.806895) | 2.258353 / 55.444624 (-53.186272) | 1.925220 / 6.876477 (-4.951256) | 2.002821 / 2.142072 (-0.139252) | 0.830507 / 4.805227 (-3.974720) | 0.165845 / 6.500664 (-6.334819) | 0.063905 / 0.075469 (-0.011565) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.198726 / 1.841788 (-0.643061) | 14.804448 / 8.074308 (6.730139) | 12.855167 / 10.191392 (2.663775) | 0.167932 / 0.680424 (-0.512492) | 0.028643 / 0.534201 (-0.505558) | 0.441224 / 0.579283 (-0.138059) | 0.434924 / 0.434364 (0.000560) | 0.516188 / 0.540337 (-0.024150) | 0.605017 / 1.386936 (-0.781919) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.007031 / 0.011353 (-0.004322) | 0.005157 / 0.011008 (-0.005851) | 0.086943 / 0.038508 (0.048434) | 0.031377 / 0.023109 (0.008268) | 0.334810 / 0.275898 (0.058912) | 0.368590 / 0.323480 (0.045110) | 0.005973 / 0.007986 (-0.002013) | 0.004173 / 0.004328 (-0.000155) | 0.067033 / 0.004250 (0.062783) | 0.054070 / 0.037052 (0.017018) | 0.332232 / 0.258489 (0.073743) | 0.384982 / 0.293841 (0.091141) | 0.034023 / 0.128546 (-0.094524) | 0.011301 / 0.075646 (-0.064345) | 0.295644 / 0.419271 (-0.123628) | 0.045589 / 0.043533 (0.002056) | 0.330739 / 0.255139 (0.075600) | 0.352841 / 0.283200 (0.069642) | 0.104829 / 0.141683 (-0.036854) | 1.329360 / 1.452155 (-0.122794) | 1.437956 / 1.492716 (-0.054760) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.299187 / 0.018006 (0.281181) | 0.563407 / 0.000490 (0.562917) | 0.004179 / 0.000200 (0.003979) | 0.000114 / 0.000054 (0.000060) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.027405 / 0.037411 (-0.010006) | 0.097498 / 0.014526 (0.082972) | 0.114265 / 0.176557 (-0.062292) | 0.146823 / 0.737135 (-0.590313) | 0.117948 / 0.296338 (-0.178391) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.378756 / 0.215209 (0.163547) | 3.774804 / 2.077655 (1.697150) | 1.804149 / 1.504120 (0.300029) | 1.626312 / 1.541195 (0.085117) | 1.731111 / 1.468490 (0.262620) | 0.633493 / 4.584777 (-3.951284) | 3.488220 / 3.745712 (-0.257492) | 3.064710 / 5.269862 (-2.205151) | 1.690647 / 4.565676 (-2.875029) | 0.076093 / 0.424275 (-0.348182) | 0.010820 / 0.007607 (0.003213) | 0.465091 / 0.226044 (0.239046) | 4.676842 / 2.268929 (2.407913) | 2.297381 / 55.444624 (-53.147244) | 1.960355 / 6.876477 (-4.916122) | 1.983742 / 2.142072 (-0.158330) | 0.739525 / 4.805227 (-4.065702) | 0.152663 / 6.500664 (-6.348001) | 0.057316 / 0.075469 (-0.018153) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.104721 / 1.841788 (-0.737067) | 14.577171 / 8.074308 (6.502863) | 13.680402 / 10.191392 (3.489010) | 0.182234 / 0.680424 (-0.498190) | 0.018853 / 0.534201 (-0.515348) | 0.426194 / 0.579283 (-0.153089) | 0.429202 / 0.434364 (-0.005162) | 0.543125 / 0.540337 (0.002788) | 0.645887 / 1.386936 (-0.741049) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.010055 / 0.011353 (-0.001298) | 0.005576 / 0.011008 (-0.005432) | 0.100059 / 0.038508 (0.061551) | 0.038535 / 0.023109 (0.015425) | 0.297538 / 0.275898 (0.021640) | 0.368117 / 0.323480 (0.044637) | 0.008540 / 0.007986 (0.000555) | 0.004469 / 0.004328 (0.000141) | 0.075801 / 0.004250 (0.071551) | 0.046604 / 0.037052 (0.009552) | 0.307242 / 0.258489 (0.048753) | 0.343949 / 0.293841 (0.050108) | 0.039353 / 0.128546 (-0.089194) | 0.012446 / 0.075646 (-0.063200) | 0.334628 / 0.419271 (-0.084643) | 0.051628 / 0.043533 (0.008095) | 0.298726 / 0.255139 (0.043587) | 0.316010 / 0.283200 (0.032810) | 0.120564 / 0.141683 (-0.021119) | 1.459396 / 1.452155 (0.007241) | 1.493682 / 1.492716 (0.000965) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.011702 / 0.018006 (-0.006304) | 0.570261 / 0.000490 (0.569771) | 0.003760 / 0.000200 (0.003560) | 0.000091 / 0.000054 (0.000037) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.028806 / 0.037411 (-0.008605) | 0.112150 / 0.014526 (0.097625) | 0.123140 / 0.176557 (-0.053417) | 0.173055 / 0.737135 (-0.564080) | 0.130060 / 0.296338 (-0.166279) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.398216 / 0.215209 (0.183007) | 3.978677 / 2.077655 (1.901022) | 1.754229 / 1.504120 (0.250109) | 1.561892 / 1.541195 (0.020697) | 1.679138 / 1.468490 (0.210648) | 0.690254 / 4.584777 (-3.894523) | 3.817698 / 3.745712 (0.071986) | 2.177854 / 5.269862 (-3.092008) | 1.361860 / 4.565676 (-3.203816) | 0.084108 / 0.424275 (-0.340167) | 0.012640 / 0.007607 (0.005033) | 0.504385 / 0.226044 (0.278341) | 5.034103 / 2.268929 (2.765174) | 2.254032 / 55.444624 (-53.190593) | 1.910439 / 6.876477 (-4.966038) | 2.003515 / 2.142072 (-0.138558) | 0.839747 / 4.805227 (-3.965480) | 0.165654 / 6.500664 (-6.335010) | 0.063483 / 0.075469 (-0.011986) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.187521 / 1.841788 (-0.654267) | 15.381121 / 8.074308 (7.306812) | 14.579418 / 10.191392 (4.388026) | 0.199221 / 0.680424 (-0.481202) | 0.029335 / 0.534201 (-0.504866) | 0.443159 / 0.579283 (-0.136124) | 0.447772 / 0.434364 (0.013408) | 0.545071 / 0.540337 (0.004733) | 0.650494 / 1.386936 (-0.736442) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.007675 / 0.011353 (-0.003677) | 0.005364 / 0.011008 (-0.005644) | 0.097921 / 0.038508 (0.059413) | 0.033645 / 0.023109 (0.010536) | 0.404818 / 0.275898 (0.128920) | 0.429983 / 0.323480 (0.106503) | 0.006106 / 0.007986 (-0.001879) | 0.005281 / 0.004328 (0.000953) | 0.073762 / 0.004250 (0.069512) | 0.053065 / 0.037052 (0.016012) | 0.400657 / 0.258489 (0.142168) | 0.447743 / 0.293841 (0.153902) | 0.036782 / 0.128546 (-0.091765) | 0.012593 / 0.075646 (-0.063054) | 0.332825 / 0.419271 (-0.086446) | 0.049424 / 0.043533 (0.005891) | 0.400397 / 0.255139 (0.145258) | 0.414794 / 0.283200 (0.131594) | 0.106555 / 0.141683 (-0.035128) | 1.466917 / 1.452155 (0.014762) | 1.571351 / 1.492716 (0.078635) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.254337 / 0.018006 (0.236331) | 0.568360 / 0.000490 (0.567870) | 0.000445 / 0.000200 (0.000245) | 0.000059 / 0.000054 (0.000004) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.031044 / 0.037411 (-0.006367) | 0.112282 / 0.014526 (0.097756) | 0.127205 / 0.176557 (-0.049352) | 0.166551 / 0.737135 (-0.570584) | 0.130520 / 0.296338 (-0.165818) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.442906 / 0.215209 (0.227697) | 4.430218 / 2.077655 (2.352563) | 2.287251 / 1.504120 (0.783132) | 2.112345 / 1.541195 (0.571150) | 2.240952 / 1.468490 (0.772462) | 0.713800 / 4.584777 (-3.870977) | 3.884161 / 3.745712 (0.138449) | 2.166901 / 5.269862 (-3.102960) | 1.374490 / 4.565676 (-3.191187) | 0.087548 / 0.424275 (-0.336727) | 0.012369 / 0.007607 (0.004761) | 0.540783 / 0.226044 (0.314739) | 5.396187 / 2.268929 (3.127258) | 2.779636 / 55.444624 (-52.664988) | 2.434220 / 6.876477 (-4.442257) | 2.508180 / 2.142072 (0.366107) | 0.852470 / 4.805227 (-3.952757) | 0.171266 / 6.500664 (-6.329398) | 0.065463 / 0.075469 (-0.010006) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.241720 / 1.841788 (-0.600067) | 15.332568 / 8.074308 (7.258260) | 13.688723 / 10.191392 (3.497331) | 0.145150 / 0.680424 (-0.535273) | 0.017694 / 0.534201 (-0.516507) | 0.426078 / 0.579283 (-0.153205) | 0.441189 / 0.434364 (0.006825) | 0.540284 / 0.540337 (-0.000054) | 0.657548 / 1.386936 (-0.729388) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008604 / 0.011353 (-0.002749) | 0.004566 / 0.011008 (-0.006442) | 0.099607 / 0.038508 (0.061099) | 0.029628 / 0.023109 (0.006519) | 0.300481 / 0.275898 (0.024583) | 0.342596 / 0.323480 (0.019116) | 0.007003 / 0.007986 (-0.000982) | 0.003408 / 0.004328 (-0.000920) | 0.079076 / 0.004250 (0.074826) | 0.034104 / 0.037052 (-0.002948) | 0.303856 / 0.258489 (0.045367) | 0.348729 / 0.293841 (0.054888) | 0.033752 / 0.128546 (-0.094794) | 0.011497 / 0.075646 (-0.064149) | 0.321568 / 0.419271 (-0.097704) | 0.041472 / 0.043533 (-0.002061) | 0.303396 / 0.255139 (0.048257) | 0.331121 / 0.283200 (0.047921) | 0.086203 / 0.141683 (-0.055480) | 1.476995 / 1.452155 (0.024840) | 1.539428 / 1.492716 (0.046712) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.215810 / 0.018006 (0.197803) | 0.414292 / 0.000490 (0.413802) | 0.000388 / 0.000200 (0.000188) | 0.000058 / 0.000054 (0.000004) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.023441 / 0.037411 (-0.013970) | 0.098463 / 0.014526 (0.083938) | 0.105435 / 0.176557 (-0.071121) | 0.139736 / 0.737135 (-0.597399) | 0.109467 / 0.296338 (-0.186872) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.418244 / 0.215209 (0.203035) | 4.160693 / 2.077655 (2.083039) | 1.878895 / 1.504120 (0.374775) | 1.679338 / 1.541195 (0.138143) | 1.730384 / 1.468490 (0.261894) | 0.688603 / 4.584777 (-3.896174) | 3.393542 / 3.745712 (-0.352170) | 1.901337 / 5.269862 (-3.368525) | 1.447269 / 4.565676 (-3.118408) | 0.083003 / 0.424275 (-0.341272) | 0.012574 / 0.007607 (0.004967) | 0.526363 / 0.226044 (0.300318) | 5.275159 / 2.268929 (3.006230) | 2.323642 / 55.444624 (-53.120982) | 1.982929 / 6.876477 (-4.893548) | 2.014081 / 2.142072 (-0.127991) | 0.809466 / 4.805227 (-3.995761) | 0.149038 / 6.500664 (-6.351626) | 0.064394 / 0.075469 (-0.011075) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.207439 / 1.841788 (-0.634349) | 13.691048 / 8.074308 (5.616740) | 13.880965 / 10.191392 (3.689573) | 0.148553 / 0.680424 (-0.531871) | 0.028397 / 0.534201 (-0.505804) | 0.391818 / 0.579283 (-0.187465) | 0.407181 / 0.434364 (-0.027183) | 0.481163 / 0.540337 (-0.059175) | 0.570689 / 1.386936 (-0.816247) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006361 / 0.011353 (-0.004992) | 0.004520 / 0.011008 (-0.006488) | 0.097679 / 0.038508 (0.059171) | 0.027223 / 0.023109 (0.004113) | 0.407966 / 0.275898 (0.132068) | 0.439868 / 0.323480 (0.116388) | 0.004625 / 0.007986 (-0.003360) | 0.004039 / 0.004328 (-0.000289) | 0.074548 / 0.004250 (0.070298) | 0.034957 / 0.037052 (-0.002095) | 0.412762 / 0.258489 (0.154273) | 0.449716 / 0.293841 (0.155875) | 0.031272 / 0.128546 (-0.097274) | 0.011598 / 0.075646 (-0.064049) | 0.320922 / 0.419271 (-0.098349) | 0.041250 / 0.043533 (-0.002283) | 0.411439 / 0.255139 (0.156300) | 0.429722 / 0.283200 (0.146523) | 0.087161 / 0.141683 (-0.054522) | 1.512573 / 1.452155 (0.060418) | 1.569385 / 1.492716 (0.076668) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.222612 / 0.018006 (0.204606) | 0.409086 / 0.000490 (0.408596) | 0.004246 / 0.000200 (0.004046) | 0.000083 / 0.000054 (0.000028) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.024324 / 0.037411 (-0.013087) | 0.099055 / 0.014526 (0.084530) | 0.106809 / 0.176557 (-0.069748) | 0.141275 / 0.737135 (-0.595860) | 0.109426 / 0.296338 (-0.186913) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.469736 / 0.215209 (0.254527) | 4.686900 / 2.077655 (2.609246) | 2.413392 / 1.504120 (0.909272) | 2.217366 / 1.541195 (0.676171) | 2.266957 / 1.468490 (0.798467) | 0.698647 / 4.584777 (-3.886129) | 3.389317 / 3.745712 (-0.356395) | 1.862315 / 5.269862 (-3.407546) | 1.160931 / 4.565676 (-3.404746) | 0.082829 / 0.424275 (-0.341446) | 0.012627 / 0.007607 (0.005020) | 0.568027 / 0.226044 (0.341983) | 5.683220 / 2.268929 (3.414291) | 2.865701 / 55.444624 (-52.578924) | 2.522401 / 6.876477 (-4.354076) | 2.542395 / 2.142072 (0.400323) | 0.801224 / 4.805227 (-4.004003) | 0.149946 / 6.500664 (-6.350718) | 0.065447 / 0.075469 (-0.010023) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.283756 / 1.841788 (-0.558032) | 13.903662 / 8.074308 (5.829354) | 13.238389 / 10.191392 (3.046997) | 0.142304 / 0.680424 (-0.538120) | 0.016922 / 0.534201 (-0.517279) | 0.377797 / 0.579283 (-0.201487) | 0.382460 / 0.434364 (-0.051904) | 0.464645 / 0.540337 (-0.075692) | 0.556270 / 1.386936 (-0.830666) |\n\n</details>\n</details>\n\n\n",
"> I think this would be more of a Conceptual Guide doc since this is more explanatory and compares the differences between a Dataset and an IterableDataset\r\n\r\nsounds good to me !\r\n\r\n> There are definitely places in the docs where we can add a nice and link to this doc though to build up the user's understanding of this topic. For example, in the Know your dataset [tutorial](https://huggingface.co/docs/datasets/access), we only introduce the regular Dataset object and not the IterableDataset. We can add a section there for IterableDataset and then link to this doc that explains the difference between the two 🙂\r\n\r\ngood idea, thanks :)",
"I'll open a PR to add a section on `IterableDataset`'s in the tutorial, and once you're done editing this doc I can give it a final polish! 😄 ",
"I moved the doc page to conceptual guides and took your suggestions into account :)\r\n\r\nI think this is ready for final review now",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.009890 / 0.011353 (-0.001463) | 0.005156 / 0.011008 (-0.005852) | 0.099493 / 0.038508 (0.060984) | 0.036671 / 0.023109 (0.013562) | 0.304686 / 0.275898 (0.028788) | 0.339070 / 0.323480 (0.015590) | 0.008466 / 0.007986 (0.000481) | 0.005863 / 0.004328 (0.001534) | 0.075082 / 0.004250 (0.070832) | 0.045926 / 0.037052 (0.008874) | 0.303157 / 0.258489 (0.044668) | 0.363710 / 0.293841 (0.069870) | 0.038497 / 0.128546 (-0.090049) | 0.012063 / 0.075646 (-0.063583) | 0.334463 / 0.419271 (-0.084808) | 0.048161 / 0.043533 (0.004628) | 0.300431 / 0.255139 (0.045292) | 0.330344 / 0.283200 (0.047145) | 0.105509 / 0.141683 (-0.036174) | 1.475242 / 1.452155 (0.023087) | 1.550624 / 1.492716 (0.057908) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.245749 / 0.018006 (0.227743) | 0.575091 / 0.000490 (0.574601) | 0.001556 / 0.000200 (0.001357) | 0.000089 / 0.000054 (0.000035) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.030447 / 0.037411 (-0.006964) | 0.110982 / 0.014526 (0.096456) | 0.126760 / 0.176557 (-0.049797) | 0.173375 / 0.737135 (-0.563760) | 0.128799 / 0.296338 (-0.167539) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.392861 / 0.215209 (0.177651) | 3.911231 / 2.077655 (1.833576) | 1.757413 / 1.504120 (0.253293) | 1.563287 / 1.541195 (0.022093) | 1.658678 / 1.468490 (0.190188) | 0.677244 / 4.584777 (-3.907533) | 3.754917 / 3.745712 (0.009205) | 3.779417 / 5.269862 (-1.490444) | 1.993159 / 4.565676 (-2.572517) | 0.084425 / 0.424275 (-0.339850) | 0.012500 / 0.007607 (0.004893) | 0.501788 / 0.226044 (0.275743) | 5.003173 / 2.268929 (2.734244) | 2.273547 / 55.444624 (-53.171077) | 1.909766 / 6.876477 (-4.966711) | 1.968287 / 2.142072 (-0.173785) | 0.834895 / 4.805227 (-3.970332) | 0.165312 / 6.500664 (-6.335352) | 0.062202 / 0.075469 (-0.013267) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.203080 / 1.841788 (-0.638708) | 15.158284 / 8.074308 (7.083976) | 14.174484 / 10.191392 (3.983092) | 0.171540 / 0.680424 (-0.508883) | 0.028604 / 0.534201 (-0.505597) | 0.438379 / 0.579283 (-0.140904) | 0.429447 / 0.434364 (-0.004917) | 0.540979 / 0.540337 (0.000642) | 0.630322 / 1.386936 (-0.756614) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.007600 / 0.011353 (-0.003753) | 0.005400 / 0.011008 (-0.005608) | 0.097983 / 0.038508 (0.059475) | 0.033407 / 0.023109 (0.010297) | 0.384429 / 0.275898 (0.108531) | 0.415880 / 0.323480 (0.092400) | 0.006085 / 0.007986 (-0.001900) | 0.004330 / 0.004328 (0.000002) | 0.074654 / 0.004250 (0.070403) | 0.053076 / 0.037052 (0.016024) | 0.383958 / 0.258489 (0.125469) | 0.427289 / 0.293841 (0.133448) | 0.036710 / 0.128546 (-0.091836) | 0.012400 / 0.075646 (-0.063246) | 0.332712 / 0.419271 (-0.086560) | 0.058390 / 0.043533 (0.014857) | 0.377747 / 0.255139 (0.122608) | 0.398997 / 0.283200 (0.115798) | 0.117370 / 0.141683 (-0.024313) | 1.464211 / 1.452155 (0.012057) | 1.596465 / 1.492716 (0.103749) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.212989 / 0.018006 (0.194983) | 0.554968 / 0.000490 (0.554479) | 0.004305 / 0.000200 (0.004105) | 0.000116 / 0.000054 (0.000061) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.029167 / 0.037411 (-0.008244) | 0.109156 / 0.014526 (0.094631) | 0.122575 / 0.176557 (-0.053982) | 0.163058 / 0.737135 (-0.574077) | 0.127431 / 0.296338 (-0.168908) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.445395 / 0.215209 (0.230185) | 4.447534 / 2.077655 (2.369879) | 2.259186 / 1.504120 (0.755066) | 2.082956 / 1.541195 (0.541761) | 2.259126 / 1.468490 (0.790636) | 0.692271 / 4.584777 (-3.892506) | 3.795759 / 3.745712 (0.050047) | 3.603000 / 5.269862 (-1.666862) | 1.948556 / 4.565676 (-2.617120) | 0.084589 / 0.424275 (-0.339687) | 0.012751 / 0.007607 (0.005144) | 0.544783 / 0.226044 (0.318738) | 5.452278 / 2.268929 (3.183349) | 2.809467 / 55.444624 (-52.635157) | 2.479297 / 6.876477 (-4.397180) | 2.587756 / 2.142072 (0.445683) | 0.832258 / 4.805227 (-3.972970) | 0.167424 / 6.500664 (-6.333240) | 0.066064 / 0.075469 (-0.009405) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.262719 / 1.841788 (-0.579069) | 15.917869 / 8.074308 (7.843561) | 13.879301 / 10.191392 (3.687909) | 0.187712 / 0.680424 (-0.492712) | 0.018175 / 0.534201 (-0.516026) | 0.425840 / 0.579283 (-0.153443) | 0.426164 / 0.434364 (-0.008200) | 0.527465 / 0.540337 (-0.012872) | 0.629478 / 1.386936 (-0.757458) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.009064 / 0.011353 (-0.002289) | 0.004824 / 0.011008 (-0.006184) | 0.100869 / 0.038508 (0.062361) | 0.030803 / 0.023109 (0.007694) | 0.350880 / 0.275898 (0.074982) | 0.423816 / 0.323480 (0.100336) | 0.007581 / 0.007986 (-0.000405) | 0.003642 / 0.004328 (-0.000686) | 0.077682 / 0.004250 (0.073432) | 0.039856 / 0.037052 (0.002803) | 0.366097 / 0.258489 (0.107608) | 0.409226 / 0.293841 (0.115385) | 0.033698 / 0.128546 (-0.094848) | 0.011730 / 0.075646 (-0.063916) | 0.321683 / 0.419271 (-0.097588) | 0.041794 / 0.043533 (-0.001739) | 0.351175 / 0.255139 (0.096036) | 0.374328 / 0.283200 (0.091128) | 0.091833 / 0.141683 (-0.049850) | 1.507082 / 1.452155 (0.054927) | 1.543289 / 1.492716 (0.050572) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.010670 / 0.018006 (-0.007337) | 0.429674 / 0.000490 (0.429184) | 0.003246 / 0.000200 (0.003046) | 0.000081 / 0.000054 (0.000026) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.025015 / 0.037411 (-0.012397) | 0.102155 / 0.014526 (0.087629) | 0.107010 / 0.176557 (-0.069546) | 0.144265 / 0.737135 (-0.592870) | 0.110635 / 0.296338 (-0.185703) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.414211 / 0.215209 (0.199002) | 4.125582 / 2.077655 (2.047928) | 1.997856 / 1.504120 (0.493736) | 1.847676 / 1.541195 (0.306481) | 1.994100 / 1.468490 (0.525610) | 0.694975 / 4.584777 (-3.889802) | 3.373629 / 3.745712 (-0.372083) | 2.863255 / 5.269862 (-2.406606) | 1.565723 / 4.565676 (-2.999953) | 0.082539 / 0.424275 (-0.341736) | 0.012650 / 0.007607 (0.005043) | 0.522989 / 0.226044 (0.296945) | 5.205720 / 2.268929 (2.936792) | 2.352292 / 55.444624 (-53.092332) | 2.080467 / 6.876477 (-4.796010) | 2.231014 / 2.142072 (0.088942) | 0.811252 / 4.805227 (-3.993975) | 0.149171 / 6.500664 (-6.351493) | 0.065207 / 0.075469 (-0.010262) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.203137 / 1.841788 (-0.638651) | 14.244903 / 8.074308 (6.170595) | 14.454368 / 10.191392 (4.262976) | 0.139090 / 0.680424 (-0.541334) | 0.028738 / 0.534201 (-0.505463) | 0.396394 / 0.579283 (-0.182889) | 0.407207 / 0.434364 (-0.027156) | 0.478036 / 0.540337 (-0.062302) | 0.568488 / 1.386936 (-0.818448) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006878 / 0.011353 (-0.004475) | 0.004636 / 0.011008 (-0.006372) | 0.099118 / 0.038508 (0.060610) | 0.028076 / 0.023109 (0.004967) | 0.416097 / 0.275898 (0.140199) | 0.451722 / 0.323480 (0.128242) | 0.005364 / 0.007986 (-0.002622) | 0.003506 / 0.004328 (-0.000822) | 0.075791 / 0.004250 (0.071541) | 0.041373 / 0.037052 (0.004321) | 0.416358 / 0.258489 (0.157869) | 0.458440 / 0.293841 (0.164599) | 0.031870 / 0.128546 (-0.096676) | 0.011751 / 0.075646 (-0.063896) | 0.321748 / 0.419271 (-0.097524) | 0.041780 / 0.043533 (-0.001752) | 0.425037 / 0.255139 (0.169898) | 0.444169 / 0.283200 (0.160969) | 0.093145 / 0.141683 (-0.048538) | 1.472151 / 1.452155 (0.019996) | 1.542942 / 1.492716 (0.050226) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.224287 / 0.018006 (0.206281) | 0.415303 / 0.000490 (0.414813) | 0.003180 / 0.000200 (0.002980) | 0.000082 / 0.000054 (0.000027) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.026377 / 0.037411 (-0.011035) | 0.106222 / 0.014526 (0.091696) | 0.113873 / 0.176557 (-0.062684) | 0.143255 / 0.737135 (-0.593880) | 0.112642 / 0.296338 (-0.183697) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.444149 / 0.215209 (0.228940) | 4.421434 / 2.077655 (2.343779) | 2.082198 / 1.504120 (0.578078) | 1.879909 / 1.541195 (0.338715) | 1.968526 / 1.468490 (0.500036) | 0.697230 / 4.584777 (-3.887546) | 3.430800 / 3.745712 (-0.314912) | 1.893353 / 5.269862 (-3.376509) | 1.173271 / 4.565676 (-3.392406) | 0.082636 / 0.424275 (-0.341639) | 0.012357 / 0.007607 (0.004750) | 0.544008 / 0.226044 (0.317964) | 5.465472 / 2.268929 (3.196543) | 2.530017 / 55.444624 (-52.914608) | 2.178462 / 6.876477 (-4.698014) | 2.279570 / 2.142072 (0.137498) | 0.804890 / 4.805227 (-4.000337) | 0.152091 / 6.500664 (-6.348573) | 0.069442 / 0.075469 (-0.006027) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.256722 / 1.841788 (-0.585065) | 14.554131 / 8.074308 (6.479823) | 13.499913 / 10.191392 (3.308521) | 0.144350 / 0.680424 (-0.536074) | 0.016977 / 0.534201 (-0.517224) | 0.378836 / 0.579283 (-0.200447) | 0.392004 / 0.434364 (-0.042360) | 0.468423 / 0.540337 (-0.071914) | 0.584711 / 1.386936 (-0.802225) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008542 / 0.011353 (-0.002811) | 0.004552 / 0.011008 (-0.006456) | 0.100543 / 0.038508 (0.062035) | 0.029717 / 0.023109 (0.006608) | 0.301948 / 0.275898 (0.026050) | 0.360211 / 0.323480 (0.036731) | 0.006881 / 0.007986 (-0.001105) | 0.003433 / 0.004328 (-0.000896) | 0.077760 / 0.004250 (0.073510) | 0.037069 / 0.037052 (0.000017) | 0.314084 / 0.258489 (0.055595) | 0.347759 / 0.293841 (0.053918) | 0.033255 / 0.128546 (-0.095291) | 0.011487 / 0.075646 (-0.064160) | 0.323873 / 0.419271 (-0.095399) | 0.041203 / 0.043533 (-0.002330) | 0.298397 / 0.255139 (0.043258) | 0.327174 / 0.283200 (0.043974) | 0.088892 / 0.141683 (-0.052791) | 1.560114 / 1.452155 (0.107959) | 1.532475 / 1.492716 (0.039759) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.226080 / 0.018006 (0.208074) | 0.467492 / 0.000490 (0.467003) | 0.002198 / 0.000200 (0.001998) | 0.000074 / 0.000054 (0.000019) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.023627 / 0.037411 (-0.013784) | 0.096696 / 0.014526 (0.082170) | 0.106196 / 0.176557 (-0.070360) | 0.140496 / 0.737135 (-0.596639) | 0.108859 / 0.296338 (-0.187480) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.422335 / 0.215209 (0.207126) | 4.214879 / 2.077655 (2.137224) | 1.865866 / 1.504120 (0.361747) | 1.660914 / 1.541195 (0.119719) | 1.691869 / 1.468490 (0.223379) | 0.688164 / 4.584777 (-3.896613) | 3.432708 / 3.745712 (-0.313004) | 1.856852 / 5.269862 (-3.413010) | 1.243685 / 4.565676 (-3.321991) | 0.081552 / 0.424275 (-0.342723) | 0.012491 / 0.007607 (0.004884) | 0.524331 / 0.226044 (0.298287) | 5.255090 / 2.268929 (2.986162) | 2.269705 / 55.444624 (-53.174919) | 1.936722 / 6.876477 (-4.939755) | 2.018958 / 2.142072 (-0.123114) | 0.800658 / 4.805227 (-4.004569) | 0.148665 / 6.500664 (-6.351999) | 0.064210 / 0.075469 (-0.011259) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.235422 / 1.841788 (-0.606365) | 14.156755 / 8.074308 (6.082447) | 14.005916 / 10.191392 (3.814524) | 0.150983 / 0.680424 (-0.529441) | 0.028500 / 0.534201 (-0.505701) | 0.393013 / 0.579283 (-0.186270) | 0.408191 / 0.434364 (-0.026173) | 0.481017 / 0.540337 (-0.059320) | 0.581711 / 1.386936 (-0.805225) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006950 / 0.011353 (-0.004403) | 0.004575 / 0.011008 (-0.006434) | 0.076702 / 0.038508 (0.038194) | 0.028050 / 0.023109 (0.004941) | 0.342916 / 0.275898 (0.067018) | 0.378861 / 0.323480 (0.055381) | 0.005315 / 0.007986 (-0.002671) | 0.004822 / 0.004328 (0.000494) | 0.075560 / 0.004250 (0.071310) | 0.040441 / 0.037052 (0.003388) | 0.344284 / 0.258489 (0.085795) | 0.386519 / 0.293841 (0.092678) | 0.032122 / 0.128546 (-0.096424) | 0.011843 / 0.075646 (-0.063803) | 0.085798 / 0.419271 (-0.333473) | 0.043027 / 0.043533 (-0.000506) | 0.342910 / 0.255139 (0.087771) | 0.366618 / 0.283200 (0.083418) | 0.094766 / 0.141683 (-0.046917) | 1.492981 / 1.452155 (0.040827) | 1.566994 / 1.492716 (0.074278) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.166083 / 0.018006 (0.148076) | 0.409315 / 0.000490 (0.408826) | 0.003189 / 0.000200 (0.002989) | 0.000127 / 0.000054 (0.000072) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.024753 / 0.037411 (-0.012658) | 0.099112 / 0.014526 (0.084586) | 0.106668 / 0.176557 (-0.069889) | 0.142562 / 0.737135 (-0.594573) | 0.110648 / 0.296338 (-0.185690) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.452668 / 0.215209 (0.237459) | 4.501188 / 2.077655 (2.423534) | 2.086197 / 1.504120 (0.582077) | 1.873955 / 1.541195 (0.332761) | 1.935610 / 1.468490 (0.467120) | 0.708290 / 4.584777 (-3.876487) | 3.426986 / 3.745712 (-0.318726) | 2.805852 / 5.269862 (-2.464009) | 1.516918 / 4.565676 (-3.048759) | 0.084067 / 0.424275 (-0.340208) | 0.012776 / 0.007607 (0.005169) | 0.548853 / 0.226044 (0.322809) | 5.488198 / 2.268929 (3.219270) | 2.704464 / 55.444624 (-52.740161) | 2.377817 / 6.876477 (-4.498660) | 2.366152 / 2.142072 (0.224079) | 0.818192 / 4.805227 (-3.987035) | 0.152649 / 6.500664 (-6.348015) | 0.066914 / 0.075469 (-0.008555) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.273803 / 1.841788 (-0.567985) | 14.071633 / 8.074308 (5.997325) | 13.655586 / 10.191392 (3.464194) | 0.149471 / 0.680424 (-0.530953) | 0.016745 / 0.534201 (-0.517456) | 0.386850 / 0.579283 (-0.192434) | 0.393595 / 0.434364 (-0.040769) | 0.480396 / 0.540337 (-0.059942) | 0.573708 / 1.386936 (-0.813228) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008173 / 0.011353 (-0.003180) | 0.004461 / 0.011008 (-0.006547) | 0.100284 / 0.038508 (0.061776) | 0.028900 / 0.023109 (0.005791) | 0.293639 / 0.275898 (0.017741) | 0.359450 / 0.323480 (0.035971) | 0.007567 / 0.007986 (-0.000418) | 0.003434 / 0.004328 (-0.000894) | 0.077913 / 0.004250 (0.073663) | 0.036313 / 0.037052 (-0.000740) | 0.308484 / 0.258489 (0.049995) | 0.347575 / 0.293841 (0.053734) | 0.033367 / 0.128546 (-0.095179) | 0.011508 / 0.075646 (-0.064138) | 0.323490 / 0.419271 (-0.095782) | 0.042285 / 0.043533 (-0.001248) | 0.295696 / 0.255139 (0.040557) | 0.332475 / 0.283200 (0.049276) | 0.089980 / 0.141683 (-0.051703) | 1.461851 / 1.452155 (0.009697) | 1.493030 / 1.492716 (0.000314) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.191068 / 0.018006 (0.173062) | 0.396768 / 0.000490 (0.396278) | 0.002355 / 0.000200 (0.002155) | 0.000080 / 0.000054 (0.000025) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.023117 / 0.037411 (-0.014294) | 0.096155 / 0.014526 (0.081630) | 0.102424 / 0.176557 (-0.074132) | 0.142148 / 0.737135 (-0.594987) | 0.105954 / 0.296338 (-0.190384) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.421227 / 0.215209 (0.206018) | 4.200403 / 2.077655 (2.122748) | 1.899410 / 1.504120 (0.395290) | 1.684091 / 1.541195 (0.142896) | 1.698084 / 1.468490 (0.229594) | 0.696195 / 4.584777 (-3.888582) | 3.364116 / 3.745712 (-0.381596) | 1.899133 / 5.269862 (-3.370728) | 1.281405 / 4.565676 (-3.284272) | 0.082958 / 0.424275 (-0.341317) | 0.012433 / 0.007607 (0.004826) | 0.521856 / 0.226044 (0.295812) | 5.217626 / 2.268929 (2.948698) | 2.309228 / 55.444624 (-53.135396) | 1.956828 / 6.876477 (-4.919648) | 2.018964 / 2.142072 (-0.123108) | 0.816855 / 4.805227 (-3.988373) | 0.152867 / 6.500664 (-6.347798) | 0.064764 / 0.075469 (-0.010705) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.219020 / 1.841788 (-0.622768) | 13.509058 / 8.074308 (5.434750) | 13.637826 / 10.191392 (3.446434) | 0.156620 / 0.680424 (-0.523804) | 0.028518 / 0.534201 (-0.505683) | 0.399138 / 0.579283 (-0.180146) | 0.399931 / 0.434364 (-0.034433) | 0.482902 / 0.540337 (-0.057435) | 0.574089 / 1.386936 (-0.812847) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006232 / 0.011353 (-0.005121) | 0.004467 / 0.011008 (-0.006542) | 0.075494 / 0.038508 (0.036986) | 0.026891 / 0.023109 (0.003782) | 0.356603 / 0.275898 (0.080705) | 0.371977 / 0.323480 (0.048497) | 0.004709 / 0.007986 (-0.003276) | 0.003230 / 0.004328 (-0.001099) | 0.074338 / 0.004250 (0.070088) | 0.035588 / 0.037052 (-0.001464) | 0.349554 / 0.258489 (0.091065) | 0.389672 / 0.293841 (0.095831) | 0.031524 / 0.128546 (-0.097022) | 0.011493 / 0.075646 (-0.064153) | 0.084584 / 0.419271 (-0.334688) | 0.041945 / 0.043533 (-0.001588) | 0.341057 / 0.255139 (0.085918) | 0.367876 / 0.283200 (0.084677) | 0.090113 / 0.141683 (-0.051569) | 1.507104 / 1.452155 (0.054949) | 1.567810 / 1.492716 (0.075094) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.210939 / 0.018006 (0.192933) | 0.392600 / 0.000490 (0.392110) | 0.002188 / 0.000200 (0.001988) | 0.000073 / 0.000054 (0.000018) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.024294 / 0.037411 (-0.013118) | 0.100325 / 0.014526 (0.085799) | 0.104027 / 0.176557 (-0.072530) | 0.141189 / 0.737135 (-0.595947) | 0.107438 / 0.296338 (-0.188901) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.443314 / 0.215209 (0.228105) | 4.429612 / 2.077655 (2.351957) | 2.129275 / 1.504120 (0.625156) | 1.940016 / 1.541195 (0.398821) | 2.008975 / 1.468490 (0.540485) | 0.695434 / 4.584777 (-3.889343) | 3.355137 / 3.745712 (-0.390575) | 2.606262 / 5.269862 (-2.663600) | 1.451283 / 4.565676 (-3.114394) | 0.082875 / 0.424275 (-0.341400) | 0.012398 / 0.007607 (0.004791) | 0.544262 / 0.226044 (0.318218) | 5.450829 / 2.268929 (3.181900) | 2.582074 / 55.444624 (-52.862550) | 2.220037 / 6.876477 (-4.656439) | 2.232473 / 2.142072 (0.090401) | 0.802094 / 4.805227 (-4.003134) | 0.150188 / 6.500664 (-6.350476) | 0.066543 / 0.075469 (-0.008926) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.269098 / 1.841788 (-0.572690) | 13.764780 / 8.074308 (5.690472) | 13.461490 / 10.191392 (3.270098) | 0.143841 / 0.680424 (-0.536583) | 0.016687 / 0.534201 (-0.517514) | 0.388548 / 0.579283 (-0.190736) | 0.385229 / 0.434364 (-0.049135) | 0.478966 / 0.540337 (-0.061371) | 0.570355 / 1.386936 (-0.816581) |\n\n</details>\n</details>\n\n\n",
"I took your comments into account :)\r\n\r\n> Regarding the docs, I think it would be better to add this info as notes/tips/sections to the existing docs (Process/Stream; e.g. a tip under Dataset.shuffle that explains how to make this operation more performant by using to_iterable + shuffle, etc.) rather than introducing a new doc page.\r\n\r\nI added a paragraph in the Dataset.shuffle docstring, and a note in the Process doc page",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.010906 / 0.011353 (-0.000447) | 0.005995 / 0.011008 (-0.005014) | 0.120183 / 0.038508 (0.081675) | 0.042166 / 0.023109 (0.019057) | 0.350945 / 0.275898 (0.075046) | 0.433055 / 0.323480 (0.109575) | 0.009093 / 0.007986 (0.001107) | 0.004695 / 0.004328 (0.000366) | 0.090362 / 0.004250 (0.086112) | 0.051402 / 0.037052 (0.014350) | 0.368677 / 0.258489 (0.110188) | 0.410926 / 0.293841 (0.117086) | 0.044471 / 0.128546 (-0.084075) | 0.014051 / 0.075646 (-0.061595) | 0.397765 / 0.419271 (-0.021507) | 0.057227 / 0.043533 (0.013694) | 0.357587 / 0.255139 (0.102448) | 0.377470 / 0.283200 (0.094270) | 0.119482 / 0.141683 (-0.022201) | 1.719799 / 1.452155 (0.267645) | 1.758228 / 1.492716 (0.265511) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.224385 / 0.018006 (0.206379) | 0.505070 / 0.000490 (0.504580) | 0.004863 / 0.000200 (0.004663) | 0.000379 / 0.000054 (0.000324) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.030366 / 0.037411 (-0.007046) | 0.130481 / 0.014526 (0.115955) | 0.136429 / 0.176557 (-0.040128) | 0.182263 / 0.737135 (-0.554872) | 0.142871 / 0.296338 (-0.153468) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.467623 / 0.215209 (0.252414) | 4.665522 / 2.077655 (2.587868) | 2.130885 / 1.504120 (0.626766) | 1.903810 / 1.541195 (0.362615) | 2.019077 / 1.468490 (0.550587) | 0.820868 / 4.584777 (-3.763909) | 4.543118 / 3.745712 (0.797406) | 2.491541 / 5.269862 (-2.778321) | 1.585377 / 4.565676 (-2.980299) | 0.101850 / 0.424275 (-0.322426) | 0.014737 / 0.007607 (0.007129) | 0.597241 / 0.226044 (0.371197) | 5.938445 / 2.268929 (3.669516) | 2.695799 / 55.444624 (-52.748825) | 2.286890 / 6.876477 (-4.589587) | 2.363064 / 2.142072 (0.220991) | 0.986670 / 4.805227 (-3.818557) | 0.194407 / 6.500664 (-6.306257) | 0.074767 / 0.075469 (-0.000702) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.420630 / 1.841788 (-0.421158) | 17.537702 / 8.074308 (9.463394) | 16.521804 / 10.191392 (6.330412) | 0.173622 / 0.680424 (-0.506802) | 0.033944 / 0.534201 (-0.500257) | 0.520461 / 0.579283 (-0.058822) | 0.541283 / 0.434364 (0.106919) | 0.651906 / 0.540337 (0.111569) | 0.771724 / 1.386936 (-0.615212) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008448 / 0.011353 (-0.002905) | 0.005893 / 0.011008 (-0.005115) | 0.087995 / 0.038508 (0.049487) | 0.038602 / 0.023109 (0.015493) | 0.400048 / 0.275898 (0.124150) | 0.436998 / 0.323480 (0.113518) | 0.006414 / 0.007986 (-0.001572) | 0.004478 / 0.004328 (0.000149) | 0.086444 / 0.004250 (0.082194) | 0.056535 / 0.037052 (0.019483) | 0.402066 / 0.258489 (0.143577) | 0.458730 / 0.293841 (0.164889) | 0.041622 / 0.128546 (-0.086924) | 0.014014 / 0.075646 (-0.061632) | 0.101382 / 0.419271 (-0.317889) | 0.056986 / 0.043533 (0.013453) | 0.404527 / 0.255139 (0.149388) | 0.428105 / 0.283200 (0.144906) | 0.118321 / 0.141683 (-0.023361) | 1.716940 / 1.452155 (0.264785) | 1.834683 / 1.492716 (0.341967) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.252917 / 0.018006 (0.234910) | 0.485950 / 0.000490 (0.485461) | 0.000489 / 0.000200 (0.000289) | 0.000066 / 0.000054 (0.000011) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.035023 / 0.037411 (-0.002388) | 0.139055 / 0.014526 (0.124529) | 0.144165 / 0.176557 (-0.032392) | 0.189559 / 0.737135 (-0.547577) | 0.153213 / 0.296338 (-0.143126) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.505069 / 0.215209 (0.289860) | 5.024620 / 2.077655 (2.946965) | 2.429469 / 1.504120 (0.925349) | 2.186210 / 1.541195 (0.645015) | 2.275971 / 1.468490 (0.807481) | 0.829432 / 4.584777 (-3.755345) | 4.518600 / 3.745712 (0.772888) | 2.466418 / 5.269862 (-2.803443) | 1.558910 / 4.565676 (-3.006767) | 0.102017 / 0.424275 (-0.322258) | 0.015191 / 0.007607 (0.007584) | 0.619092 / 0.226044 (0.393048) | 6.241105 / 2.268929 (3.972176) | 3.044213 / 55.444624 (-52.400411) | 2.630194 / 6.876477 (-4.246282) | 2.723685 / 2.142072 (0.581613) | 0.994018 / 4.805227 (-3.811210) | 0.198722 / 6.500664 (-6.301942) | 0.075812 / 0.075469 (0.000343) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.545497 / 1.841788 (-0.296291) | 18.305250 / 8.074308 (10.230942) | 16.035275 / 10.191392 (5.843883) | 0.209339 / 0.680424 (-0.471085) | 0.020903 / 0.534201 (-0.513298) | 0.499909 / 0.579283 (-0.079374) | 0.488775 / 0.434364 (0.054411) | 0.581990 / 0.540337 (0.041653) | 0.697786 / 1.386936 (-0.689150) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.011706 / 0.011353 (0.000353) | 0.008406 / 0.011008 (-0.002602) | 0.130887 / 0.038508 (0.092379) | 0.037468 / 0.023109 (0.014359) | 0.385043 / 0.275898 (0.109145) | 0.458837 / 0.323480 (0.135357) | 0.013400 / 0.007986 (0.005414) | 0.004885 / 0.004328 (0.000557) | 0.107156 / 0.004250 (0.102905) | 0.046958 / 0.037052 (0.009906) | 0.419314 / 0.258489 (0.160825) | 0.456061 / 0.293841 (0.162220) | 0.058859 / 0.128546 (-0.069687) | 0.016682 / 0.075646 (-0.058965) | 0.428401 / 0.419271 (0.009129) | 0.062908 / 0.043533 (0.019376) | 0.370902 / 0.255139 (0.115763) | 0.433897 / 0.283200 (0.150697) | 0.125672 / 0.141683 (-0.016011) | 1.818279 / 1.452155 (0.366124) | 1.935767 / 1.492716 (0.443050) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.011928 / 0.018006 (-0.006078) | 0.591995 / 0.000490 (0.591506) | 0.008416 / 0.000200 (0.008216) | 0.000122 / 0.000054 (0.000067) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.029640 / 0.037411 (-0.007772) | 0.121044 / 0.014526 (0.106518) | 0.141840 / 0.176557 (-0.034716) | 0.195856 / 0.737135 (-0.541280) | 0.146460 / 0.296338 (-0.149879) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.591838 / 0.215209 (0.376629) | 5.817309 / 2.077655 (3.739654) | 2.411864 / 1.504120 (0.907744) | 2.098517 / 1.541195 (0.557323) | 2.214609 / 1.468490 (0.746119) | 1.217542 / 4.584777 (-3.367235) | 5.658394 / 3.745712 (1.912682) | 5.155807 / 5.269862 (-0.114055) | 2.797313 / 4.565676 (-1.768363) | 0.141309 / 0.424275 (-0.282967) | 0.014462 / 0.007607 (0.006855) | 0.772274 / 0.226044 (0.546230) | 7.547357 / 2.268929 (5.278429) | 3.150178 / 55.444624 (-52.294446) | 2.500130 / 6.876477 (-4.376347) | 2.572036 / 2.142072 (0.429964) | 1.434498 / 4.805227 (-3.370729) | 0.257355 / 6.500664 (-6.243309) | 0.087491 / 0.075469 (0.012022) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.483899 / 1.841788 (-0.357889) | 17.990741 / 8.074308 (9.916433) | 20.398965 / 10.191392 (10.207573) | 0.239529 / 0.680424 (-0.440895) | 0.046118 / 0.534201 (-0.488083) | 0.528349 / 0.579283 (-0.050934) | 0.614333 / 0.434364 (0.179969) | 0.653621 / 0.540337 (0.113284) | 0.794654 / 1.386936 (-0.592282) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008732 / 0.011353 (-0.002621) | 0.006432 / 0.011008 (-0.004576) | 0.090811 / 0.038508 (0.052303) | 0.030154 / 0.023109 (0.007045) | 0.407885 / 0.275898 (0.131987) | 0.452457 / 0.323480 (0.128977) | 0.006966 / 0.007986 (-0.001020) | 0.006449 / 0.004328 (0.002120) | 0.094439 / 0.004250 (0.090188) | 0.050628 / 0.037052 (0.013576) | 0.401815 / 0.258489 (0.143326) | 0.451814 / 0.293841 (0.157973) | 0.047456 / 0.128546 (-0.081090) | 0.019019 / 0.075646 (-0.056628) | 0.112941 / 0.419271 (-0.306331) | 0.057677 / 0.043533 (0.014145) | 0.406160 / 0.255139 (0.151021) | 0.434469 / 0.283200 (0.151269) | 0.110515 / 0.141683 (-0.031167) | 1.601393 / 1.452155 (0.149238) | 1.745581 / 1.492716 (0.252865) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.280264 / 0.018006 (0.262258) | 0.630074 / 0.000490 (0.629585) | 0.006900 / 0.000200 (0.006700) | 0.000112 / 0.000054 (0.000058) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.027338 / 0.037411 (-0.010073) | 0.114772 / 0.014526 (0.100246) | 0.130436 / 0.176557 (-0.046121) | 0.168990 / 0.737135 (-0.568145) | 0.135842 / 0.296338 (-0.160496) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.666739 / 0.215209 (0.451530) | 6.212953 / 2.077655 (4.135298) | 2.781716 / 1.504120 (1.277596) | 2.369975 / 1.541195 (0.828781) | 2.338807 / 1.468490 (0.870317) | 1.174138 / 4.584777 (-3.410639) | 5.420297 / 3.745712 (1.674585) | 4.972669 / 5.269862 (-0.297192) | 2.214294 / 4.565676 (-2.351382) | 0.135429 / 0.424275 (-0.288846) | 0.013877 / 0.007607 (0.006270) | 0.750805 / 0.226044 (0.524761) | 7.145429 / 2.268929 (4.876500) | 3.215081 / 55.444624 (-52.229544) | 2.598307 / 6.876477 (-4.278170) | 2.690479 / 2.142072 (0.548406) | 1.344673 / 4.805227 (-3.460554) | 0.241536 / 6.500664 (-6.259128) | 0.075544 / 0.075469 (0.000074) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.473595 / 1.841788 (-0.368192) | 17.372237 / 8.074308 (9.297929) | 18.586588 / 10.191392 (8.395196) | 0.209300 / 0.680424 (-0.471124) | 0.030878 / 0.534201 (-0.503323) | 0.509131 / 0.579283 (-0.070152) | 0.617884 / 0.434364 (0.183520) | 0.633721 / 0.540337 (0.093383) | 0.727624 / 1.386936 (-0.659312) |\n\n</details>\n</details>\n\n\n",
"Took your last comments into account !\r\n\r\n> so maybe a better title for it would be \"Optimize processing\" (or \"Working with datasets at scale\" as I mentioned earlier on Slack)\r\n\r\nI think the content would be slightly different, e.g. focus more on multiprocessing/sharding or what data formats to use. This can be a complementary page IMO\r\n\r\n> PS: I think it would be a good idea to add links to the Guide pages for better discoverability and to somewhat \"justify their presence in the docs\" (from the tutorial/how-to pages to the guides; some guides are not referenced at all)\r\n\r\nAdded a link in the how-to stream page. We may want to include it in the tutorial at one point at well - right now none of the tutorials mention streaming",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.009167 / 0.011353 (-0.002186) | 0.005345 / 0.011008 (-0.005663) | 0.098302 / 0.038508 (0.059794) | 0.035649 / 0.023109 (0.012540) | 0.295597 / 0.275898 (0.019699) | 0.358843 / 0.323480 (0.035364) | 0.008011 / 0.007986 (0.000025) | 0.004229 / 0.004328 (-0.000100) | 0.075123 / 0.004250 (0.070872) | 0.046098 / 0.037052 (0.009046) | 0.310581 / 0.258489 (0.052092) | 0.343230 / 0.293841 (0.049389) | 0.038318 / 0.128546 (-0.090229) | 0.011954 / 0.075646 (-0.063693) | 0.331056 / 0.419271 (-0.088216) | 0.052875 / 0.043533 (0.009342) | 0.302758 / 0.255139 (0.047619) | 0.340596 / 0.283200 (0.057396) | 0.113676 / 0.141683 (-0.028007) | 1.448272 / 1.452155 (-0.003883) | 1.498008 / 1.492716 (0.005291) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.240524 / 0.018006 (0.222518) | 0.555823 / 0.000490 (0.555333) | 0.003143 / 0.000200 (0.002943) | 0.000098 / 0.000054 (0.000044) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.027764 / 0.037411 (-0.009647) | 0.105006 / 0.014526 (0.090480) | 0.120550 / 0.176557 (-0.056007) | 0.167052 / 0.737135 (-0.570084) | 0.124521 / 0.296338 (-0.171818) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.401758 / 0.215209 (0.186549) | 3.989629 / 2.077655 (1.911974) | 1.767307 / 1.504120 (0.263187) | 1.579451 / 1.541195 (0.038257) | 1.637642 / 1.468490 (0.169152) | 0.702524 / 4.584777 (-3.882253) | 3.714326 / 3.745712 (-0.031386) | 2.131829 / 5.269862 (-3.138033) | 1.487410 / 4.565676 (-3.078267) | 0.084901 / 0.424275 (-0.339374) | 0.012292 / 0.007607 (0.004685) | 0.505211 / 0.226044 (0.279166) | 5.074479 / 2.268929 (2.805551) | 2.243068 / 55.444624 (-53.201556) | 1.880199 / 6.876477 (-4.996278) | 2.003757 / 2.142072 (-0.138315) | 0.870719 / 4.805227 (-3.934508) | 0.167626 / 6.500664 (-6.333039) | 0.062024 / 0.075469 (-0.013445) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.192969 / 1.841788 (-0.648819) | 14.830812 / 8.074308 (6.756504) | 14.331178 / 10.191392 (4.139786) | 0.199222 / 0.680424 (-0.481202) | 0.029292 / 0.534201 (-0.504909) | 0.440427 / 0.579283 (-0.138857) | 0.437893 / 0.434364 (0.003529) | 0.547155 / 0.540337 (0.006818) | 0.645255 / 1.386936 (-0.741681) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.007465 / 0.011353 (-0.003888) | 0.005386 / 0.011008 (-0.005622) | 0.073609 / 0.038508 (0.035100) | 0.033550 / 0.023109 (0.010440) | 0.341730 / 0.275898 (0.065832) | 0.371518 / 0.323480 (0.048038) | 0.005986 / 0.007986 (-0.001999) | 0.004264 / 0.004328 (-0.000065) | 0.073749 / 0.004250 (0.069498) | 0.051452 / 0.037052 (0.014399) | 0.347385 / 0.258489 (0.088896) | 0.392284 / 0.293841 (0.098444) | 0.036981 / 0.128546 (-0.091566) | 0.012431 / 0.075646 (-0.063216) | 0.086421 / 0.419271 (-0.332850) | 0.053014 / 0.043533 (0.009481) | 0.336660 / 0.255139 (0.081521) | 0.359155 / 0.283200 (0.075956) | 0.107666 / 0.141683 (-0.034017) | 1.424324 / 1.452155 (-0.027830) | 1.543027 / 1.492716 (0.050310) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.260862 / 0.018006 (0.242855) | 0.552057 / 0.000490 (0.551567) | 0.000449 / 0.000200 (0.000249) | 0.000059 / 0.000054 (0.000005) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.029184 / 0.037411 (-0.008227) | 0.108799 / 0.014526 (0.094274) | 0.125136 / 0.176557 (-0.051421) | 0.157436 / 0.737135 (-0.579699) | 0.126333 / 0.296338 (-0.170005) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.424054 / 0.215209 (0.208845) | 4.227847 / 2.077655 (2.150192) | 2.051102 / 1.504120 (0.546983) | 1.848651 / 1.541195 (0.307457) | 1.922728 / 1.468490 (0.454238) | 0.705903 / 4.584777 (-3.878874) | 3.800977 / 3.745712 (0.055265) | 2.099345 / 5.269862 (-3.170517) | 1.342919 / 4.565676 (-3.222757) | 0.086128 / 0.424275 (-0.338147) | 0.012539 / 0.007607 (0.004932) | 0.528767 / 0.226044 (0.302723) | 5.299989 / 2.268929 (3.031061) | 2.534280 / 55.444624 (-52.910345) | 2.229532 / 6.876477 (-4.646945) | 2.326704 / 2.142072 (0.184632) | 0.838533 / 4.805227 (-3.966694) | 0.168446 / 6.500664 (-6.332218) | 0.065158 / 0.075469 (-0.010311) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.250091 / 1.841788 (-0.591697) | 14.988651 / 8.074308 (6.914343) | 13.655103 / 10.191392 (3.463711) | 0.165079 / 0.680424 (-0.515345) | 0.017829 / 0.534201 (-0.516372) | 0.425903 / 0.579283 (-0.153381) | 0.419771 / 0.434364 (-0.014593) | 0.534309 / 0.540337 (-0.006028) | 0.635563 / 1.386936 (-0.751373) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.010569 / 0.011353 (-0.000784) | 0.005790 / 0.011008 (-0.005218) | 0.118626 / 0.038508 (0.080118) | 0.040455 / 0.023109 (0.017346) | 0.342309 / 0.275898 (0.066411) | 0.411828 / 0.323480 (0.088349) | 0.008824 / 0.007986 (0.000839) | 0.005426 / 0.004328 (0.001098) | 0.088740 / 0.004250 (0.084489) | 0.050042 / 0.037052 (0.012990) | 0.352350 / 0.258489 (0.093861) | 0.396030 / 0.293841 (0.102189) | 0.043385 / 0.128546 (-0.085162) | 0.013805 / 0.075646 (-0.061841) | 0.396489 / 0.419271 (-0.022783) | 0.055667 / 0.043533 (0.012135) | 0.336165 / 0.255139 (0.081026) | 0.372912 / 0.283200 (0.089713) | 0.115343 / 0.141683 (-0.026340) | 1.656412 / 1.452155 (0.204257) | 1.708993 / 1.492716 (0.216277) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.011650 / 0.018006 (-0.006357) | 0.444415 / 0.000490 (0.443926) | 0.003985 / 0.000200 (0.003785) | 0.000136 / 0.000054 (0.000082) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.031718 / 0.037411 (-0.005693) | 0.119640 / 0.014526 (0.105114) | 0.138519 / 0.176557 (-0.038037) | 0.188847 / 0.737135 (-0.548288) | 0.137891 / 0.296338 (-0.158448) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.447540 / 0.215209 (0.232331) | 4.577189 / 2.077655 (2.499534) | 2.106992 / 1.504120 (0.602872) | 1.889631 / 1.541195 (0.348436) | 1.972256 / 1.468490 (0.503766) | 0.778209 / 4.584777 (-3.806568) | 4.430279 / 3.745712 (0.684567) | 2.401226 / 5.269862 (-2.868636) | 1.481251 / 4.565676 (-3.084425) | 0.094244 / 0.424275 (-0.330031) | 0.013961 / 0.007607 (0.006354) | 0.570962 / 0.226044 (0.344917) | 5.809224 / 2.268929 (3.540295) | 2.663290 / 55.444624 (-52.781334) | 2.201228 / 6.876477 (-4.675249) | 2.319240 / 2.142072 (0.177168) | 0.938340 / 4.805227 (-3.866887) | 0.185546 / 6.500664 (-6.315118) | 0.069087 / 0.075469 (-0.006382) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.448597 / 1.841788 (-0.393191) | 17.188573 / 8.074308 (9.114265) | 16.197532 / 10.191392 (6.006140) | 0.194064 / 0.680424 (-0.486360) | 0.033694 / 0.534201 (-0.500507) | 0.507585 / 0.579283 (-0.071699) | 0.505470 / 0.434364 (0.071106) | 0.623270 / 0.540337 (0.082932) | 0.729964 / 1.386936 (-0.656972) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008529 / 0.011353 (-0.002824) | 0.005705 / 0.011008 (-0.005304) | 0.085594 / 0.038508 (0.047086) | 0.038377 / 0.023109 (0.015268) | 0.384221 / 0.275898 (0.108323) | 0.414678 / 0.323480 (0.091199) | 0.006195 / 0.007986 (-0.001791) | 0.004549 / 0.004328 (0.000221) | 0.082710 / 0.004250 (0.078460) | 0.054899 / 0.037052 (0.017847) | 0.404017 / 0.258489 (0.145528) | 0.450309 / 0.293841 (0.156468) | 0.040620 / 0.128546 (-0.087926) | 0.013774 / 0.075646 (-0.061872) | 0.099231 / 0.419271 (-0.320041) | 0.057183 / 0.043533 (0.013650) | 0.390806 / 0.255139 (0.135667) | 0.419334 / 0.283200 (0.136134) | 0.116449 / 0.141683 (-0.025234) | 1.709124 / 1.452155 (0.256969) | 1.812769 / 1.492716 (0.320052) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.225206 / 0.018006 (0.207199) | 0.440530 / 0.000490 (0.440040) | 0.002982 / 0.000200 (0.002782) | 0.000102 / 0.000054 (0.000048) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.032256 / 0.037411 (-0.005155) | 0.127086 / 0.014526 (0.112560) | 0.138133 / 0.176557 (-0.038424) | 0.176168 / 0.737135 (-0.560968) | 0.146072 / 0.296338 (-0.150267) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.474374 / 0.215209 (0.259165) | 4.785106 / 2.077655 (2.707452) | 2.319344 / 1.504120 (0.815225) | 2.075239 / 1.541195 (0.534045) | 2.179231 / 1.468490 (0.710741) | 0.832124 / 4.584777 (-3.752653) | 4.376302 / 3.745712 (0.630590) | 3.966837 / 5.269862 (-1.303024) | 1.820230 / 4.565676 (-2.745446) | 0.100692 / 0.424275 (-0.323583) | 0.014748 / 0.007607 (0.007141) | 0.568702 / 0.226044 (0.342657) | 5.771548 / 2.268929 (3.502619) | 2.747431 / 55.444624 (-52.697193) | 2.448482 / 6.876477 (-4.427994) | 2.497206 / 2.142072 (0.355133) | 0.960842 / 4.805227 (-3.844385) | 0.192855 / 6.500664 (-6.307809) | 0.072494 / 0.075469 (-0.002975) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.474542 / 1.841788 (-0.367245) | 17.344804 / 8.074308 (9.270496) | 15.336082 / 10.191392 (5.144690) | 0.200134 / 0.680424 (-0.480290) | 0.020728 / 0.534201 (-0.513473) | 0.488854 / 0.579283 (-0.090429) | 0.490781 / 0.434364 (0.056418) | 0.626288 / 0.540337 (0.085950) | 0.721130 / 1.386936 (-0.665806) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008542 / 0.011353 (-0.002811) | 0.004624 / 0.011008 (-0.006384) | 0.100749 / 0.038508 (0.062241) | 0.029587 / 0.023109 (0.006478) | 0.298680 / 0.275898 (0.022782) | 0.359659 / 0.323480 (0.036180) | 0.007001 / 0.007986 (-0.000984) | 0.003398 / 0.004328 (-0.000930) | 0.078654 / 0.004250 (0.074404) | 0.036440 / 0.037052 (-0.000612) | 0.313245 / 0.258489 (0.054756) | 0.342776 / 0.293841 (0.048936) | 0.033195 / 0.128546 (-0.095352) | 0.011500 / 0.075646 (-0.064146) | 0.323957 / 0.419271 (-0.095314) | 0.039878 / 0.043533 (-0.003655) | 0.298189 / 0.255139 (0.043050) | 0.325488 / 0.283200 (0.042289) | 0.087276 / 0.141683 (-0.054407) | 1.480846 / 1.452155 (0.028691) | 1.507016 / 1.492716 (0.014300) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.189570 / 0.018006 (0.171564) | 0.406407 / 0.000490 (0.405917) | 0.003062 / 0.000200 (0.002862) | 0.000073 / 0.000054 (0.000019) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.022865 / 0.037411 (-0.014546) | 0.096103 / 0.014526 (0.081578) | 0.106462 / 0.176557 (-0.070094) | 0.140888 / 0.737135 (-0.596247) | 0.108172 / 0.296338 (-0.188167) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.415951 / 0.215209 (0.200742) | 4.172187 / 2.077655 (2.094532) | 1.842210 / 1.504120 (0.338090) | 1.636997 / 1.541195 (0.095802) | 1.706078 / 1.468490 (0.237588) | 0.695825 / 4.584777 (-3.888952) | 3.337354 / 3.745712 (-0.408358) | 1.877880 / 5.269862 (-3.391982) | 1.153882 / 4.565676 (-3.411794) | 0.082923 / 0.424275 (-0.341352) | 0.012814 / 0.007607 (0.005207) | 0.521793 / 0.226044 (0.295748) | 5.275980 / 2.268929 (3.007051) | 2.279230 / 55.444624 (-53.165394) | 1.941777 / 6.876477 (-4.934700) | 1.981297 / 2.142072 (-0.160775) | 0.809669 / 4.805227 (-3.995558) | 0.148753 / 6.500664 (-6.351911) | 0.064909 / 0.075469 (-0.010560) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.226757 / 1.841788 (-0.615031) | 13.717354 / 8.074308 (5.643046) | 12.925885 / 10.191392 (2.734493) | 0.137926 / 0.680424 (-0.542498) | 0.028788 / 0.534201 (-0.505413) | 0.396654 / 0.579283 (-0.182630) | 0.401931 / 0.434364 (-0.032432) | 0.460515 / 0.540337 (-0.079823) | 0.537903 / 1.386936 (-0.849033) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006757 / 0.011353 (-0.004596) | 0.004474 / 0.011008 (-0.006534) | 0.076571 / 0.038508 (0.038063) | 0.027580 / 0.023109 (0.004471) | 0.348231 / 0.275898 (0.072333) | 0.398403 / 0.323480 (0.074923) | 0.005089 / 0.007986 (-0.002897) | 0.004676 / 0.004328 (0.000347) | 0.076444 / 0.004250 (0.072194) | 0.038508 / 0.037052 (0.001456) | 0.348515 / 0.258489 (0.090026) | 0.401456 / 0.293841 (0.107615) | 0.031630 / 0.128546 (-0.096916) | 0.011698 / 0.075646 (-0.063949) | 0.085805 / 0.419271 (-0.333467) | 0.041962 / 0.043533 (-0.001570) | 0.343415 / 0.255139 (0.088276) | 0.383001 / 0.283200 (0.099801) | 0.090231 / 0.141683 (-0.051452) | 1.488114 / 1.452155 (0.035960) | 1.569039 / 1.492716 (0.076323) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.261751 / 0.018006 (0.243745) | 0.411354 / 0.000490 (0.410865) | 0.015103 / 0.000200 (0.014903) | 0.000262 / 0.000054 (0.000208) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.025423 / 0.037411 (-0.011988) | 0.101334 / 0.014526 (0.086808) | 0.108835 / 0.176557 (-0.067722) | 0.143995 / 0.737135 (-0.593140) | 0.111751 / 0.296338 (-0.184588) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.446507 / 0.215209 (0.231298) | 4.461543 / 2.077655 (2.383888) | 2.104648 / 1.504120 (0.600528) | 1.895900 / 1.541195 (0.354706) | 1.985481 / 1.468490 (0.516991) | 0.699029 / 4.584777 (-3.885748) | 3.371064 / 3.745712 (-0.374648) | 1.883445 / 5.269862 (-3.386416) | 1.166150 / 4.565676 (-3.399527) | 0.082639 / 0.424275 (-0.341636) | 0.012605 / 0.007607 (0.004998) | 0.544860 / 0.226044 (0.318815) | 5.513223 / 2.268929 (3.244294) | 2.570661 / 55.444624 (-52.873963) | 2.206066 / 6.876477 (-4.670411) | 2.256346 / 2.142072 (0.114273) | 0.801142 / 4.805227 (-4.004085) | 0.150412 / 6.500664 (-6.350252) | 0.067742 / 0.075469 (-0.007727) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.303477 / 1.841788 (-0.538310) | 14.287767 / 8.074308 (6.213458) | 13.525563 / 10.191392 (3.334171) | 0.148202 / 0.680424 (-0.532222) | 0.016868 / 0.534201 (-0.517333) | 0.380729 / 0.579283 (-0.198555) | 0.388177 / 0.434364 (-0.046187) | 0.477410 / 0.540337 (-0.062927) | 0.569343 / 1.386936 (-0.817593) |\n\n</details>\n</details>\n\n\n",
"> PS: I think it would be a good idea to add links to the Guide pages for better discoverability and to somewhat \"justify their presence in the docs\" (from the tutorial/how-to pages to the guides; some guides are not referenced at all)\r\n\r\nJust merged #5485, which references this new doc! Will look for other pages in the docs where it'd make sense to add them :)"
] | 1,672,942,337,000 | 1,675,275,105,000 | 1,675,269,361,000 | MEMBER | null | Added `ds.to_iterable()` to get an iterable dataset from a map-style arrow dataset.
It also has a `num_shards` argument to split the dataset before converting to an iterable dataset. Sharding is important to enable efficient shuffling and parallel loading of iterable datasets.
TODO:
- [x] tests
- [x] docs
Fix https://github.com/huggingface/datasets/issues/5265 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5410/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5410/timeline | null | null | 0 | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5410",
"html_url": "https://github.com/huggingface/datasets/pull/5410",
"diff_url": "https://github.com/huggingface/datasets/pull/5410.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5410.patch",
"merged_at": "2023-02-01T16:36:01"
} | true |
https://api.github.com/repos/huggingface/datasets/issues/5409 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5409/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5409/comments | https://api.github.com/repos/huggingface/datasets/issues/5409/events | https://github.com/huggingface/datasets/pull/5409 | 1,520,374,219 | PR_kwDODunzps5Gs3nL | 5,409 | Fix deprecation warning when use_auth_token passed to download_and_prepare | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008627 / 0.011353 (-0.002726) | 0.004572 / 0.011008 (-0.006436) | 0.099653 / 0.038508 (0.061145) | 0.030010 / 0.023109 (0.006901) | 0.300492 / 0.275898 (0.024594) | 0.360443 / 0.323480 (0.036963) | 0.007125 / 0.007986 (-0.000860) | 0.003431 / 0.004328 (-0.000897) | 0.078103 / 0.004250 (0.073852) | 0.036884 / 0.037052 (-0.000168) | 0.312289 / 0.258489 (0.053800) | 0.345795 / 0.293841 (0.051954) | 0.034001 / 0.128546 (-0.094545) | 0.011405 / 0.075646 (-0.064242) | 0.321258 / 0.419271 (-0.098013) | 0.040591 / 0.043533 (-0.002942) | 0.301114 / 0.255139 (0.045975) | 0.337226 / 0.283200 (0.054027) | 0.088055 / 0.141683 (-0.053628) | 1.451892 / 1.452155 (-0.000263) | 1.494881 / 1.492716 (0.002164) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.186749 / 0.018006 (0.168743) | 0.414089 / 0.000490 (0.413600) | 0.002475 / 0.000200 (0.002275) | 0.000070 / 0.000054 (0.000015) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.022413 / 0.037411 (-0.014999) | 0.097547 / 0.014526 (0.083021) | 0.104196 / 0.176557 (-0.072361) | 0.139819 / 0.737135 (-0.597316) | 0.108345 / 0.296338 (-0.187994) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.424750 / 0.215209 (0.209541) | 4.261513 / 2.077655 (2.183859) | 2.150888 / 1.504120 (0.646768) | 1.935925 / 1.541195 (0.394730) | 1.867456 / 1.468490 (0.398966) | 0.694384 / 4.584777 (-3.890393) | 3.370539 / 3.745712 (-0.375173) | 1.886714 / 5.269862 (-3.383148) | 1.256542 / 4.565676 (-3.309135) | 0.082841 / 0.424275 (-0.341434) | 0.012344 / 0.007607 (0.004737) | 0.529801 / 0.226044 (0.303757) | 5.315438 / 2.268929 (3.046509) | 2.460517 / 55.444624 (-52.984107) | 2.261840 / 6.876477 (-4.614637) | 2.338710 / 2.142072 (0.196638) | 0.818433 / 4.805227 (-3.986794) | 0.150571 / 6.500664 (-6.350093) | 0.066524 / 0.075469 (-0.008945) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.253086 / 1.841788 (-0.588702) | 13.862614 / 8.074308 (5.788306) | 14.145149 / 10.191392 (3.953757) | 0.165867 / 0.680424 (-0.514557) | 0.029269 / 0.534201 (-0.504932) | 0.397579 / 0.579283 (-0.181704) | 0.401113 / 0.434364 (-0.033251) | 0.463269 / 0.540337 (-0.077068) | 0.551494 / 1.386936 (-0.835442) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006610 / 0.011353 (-0.004743) | 0.004583 / 0.011008 (-0.006425) | 0.096680 / 0.038508 (0.058172) | 0.027352 / 0.023109 (0.004242) | 0.409292 / 0.275898 (0.133394) | 0.445790 / 0.323480 (0.122310) | 0.004987 / 0.007986 (-0.002999) | 0.003462 / 0.004328 (-0.000866) | 0.074472 / 0.004250 (0.070221) | 0.037875 / 0.037052 (0.000822) | 0.411496 / 0.258489 (0.153007) | 0.454721 / 0.293841 (0.160880) | 0.031884 / 0.128546 (-0.096662) | 0.011682 / 0.075646 (-0.063964) | 0.318831 / 0.419271 (-0.100441) | 0.041781 / 0.043533 (-0.001752) | 0.411247 / 0.255139 (0.156108) | 0.436215 / 0.283200 (0.153016) | 0.090021 / 0.141683 (-0.051662) | 1.492385 / 1.452155 (0.040231) | 1.565182 / 1.492716 (0.072465) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.221263 / 0.018006 (0.203257) | 0.399074 / 0.000490 (0.398584) | 0.000405 / 0.000200 (0.000205) | 0.000058 / 0.000054 (0.000004) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.025139 / 0.037411 (-0.012272) | 0.097952 / 0.014526 (0.083426) | 0.106078 / 0.176557 (-0.070479) | 0.143231 / 0.737135 (-0.593904) | 0.109177 / 0.296338 (-0.187161) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.441668 / 0.215209 (0.226459) | 4.403247 / 2.077655 (2.325592) | 2.072749 / 1.504120 (0.568629) | 1.866248 / 1.541195 (0.325053) | 1.906418 / 1.468490 (0.437927) | 0.697234 / 4.584777 (-3.887543) | 3.412016 / 3.745712 (-0.333696) | 1.852572 / 5.269862 (-3.417289) | 1.168270 / 4.565676 (-3.397407) | 0.082132 / 0.424275 (-0.342144) | 0.013191 / 0.007607 (0.005584) | 0.548932 / 0.226044 (0.322888) | 5.503891 / 2.268929 (3.234962) | 2.539784 / 55.444624 (-52.904841) | 2.181292 / 6.876477 (-4.695184) | 2.242197 / 2.142072 (0.100125) | 0.804027 / 4.805227 (-4.001200) | 0.151649 / 6.500664 (-6.349015) | 0.067088 / 0.075469 (-0.008381) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.296267 / 1.841788 (-0.545520) | 13.986484 / 8.074308 (5.912176) | 13.440705 / 10.191392 (3.249313) | 0.140787 / 0.680424 (-0.539637) | 0.017132 / 0.534201 (-0.517069) | 0.381899 / 0.579283 (-0.197384) | 0.385535 / 0.434364 (-0.048829) | 0.439957 / 0.540337 (-0.100380) | 0.532980 / 1.386936 (-0.853956) |\n\n</details>\n</details>\n\n\n"
] | 1,672,909,858,000 | 1,673,003,176,000 | 1,673,002,753,000 | MEMBER | null | The `DatasetBuilder.download_and_prepare` argument `use_auth_token` was deprecated in:
- #5302
However, `use_auth_token` is still passed to `download_and_prepare` in our built-in `io` readers (csv, json, parquet,...).
This PR fixes it, so that no deprecation warning is raised.
Fix #5407. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5409/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5409/timeline | null | null | 0 | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5409",
"html_url": "https://github.com/huggingface/datasets/pull/5409",
"diff_url": "https://github.com/huggingface/datasets/pull/5409.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5409.patch",
"merged_at": "2023-01-06T10:59:13"
} | true |
https://api.github.com/repos/huggingface/datasets/issues/5408 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5408/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5408/comments | https://api.github.com/repos/huggingface/datasets/issues/5408/events | https://github.com/huggingface/datasets/issues/5408 | 1,519,890,752 | I_kwDODunzps5al7FA | 5,408 | dataset map function could not be hash properly | {
"login": "Tungway1990",
"id": 68179274,
"node_id": "MDQ6VXNlcjY4MTc5Mjc0",
"avatar_url": "https://avatars.githubusercontent.com/u/68179274?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Tungway1990",
"html_url": "https://github.com/Tungway1990",
"followers_url": "https://api.github.com/users/Tungway1990/followers",
"following_url": "https://api.github.com/users/Tungway1990/following{/other_user}",
"gists_url": "https://api.github.com/users/Tungway1990/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Tungway1990/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Tungway1990/subscriptions",
"organizations_url": "https://api.github.com/users/Tungway1990/orgs",
"repos_url": "https://api.github.com/users/Tungway1990/repos",
"events_url": "https://api.github.com/users/Tungway1990/events{/privacy}",
"received_events_url": "https://api.github.com/users/Tungway1990/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Hi ! On macos I tried with\r\n- py 3.9.11\r\n- datasets 2.8.0\r\n- transformers 4.25.1\r\n- dill 0.3.4\r\n\r\nand I was able to hash `prepare_dataset` correctly:\r\n```python\r\nfrom datasets.fingerprint import Hasher\r\nHasher.hash(prepare_dataset)\r\n```\r\n\r\nWhat version of transformers do you have ? Can you try to call `Hasher.hash` on the the tokenizer and the feature extractor to see which one can't be hashed ?",
"Thanks for your prompt reply.\r\n\r\nI update datasets version to 2.8.0 and the warning is gong."
] | 1,672,883,999,000 | 1,673,011,339,000 | 1,673,011,338,000 | NONE | null | ### Describe the bug
I follow the [blog post](https://huggingface.co/blog/fine-tune-whisper#building-a-demo) to finetune a Cantonese transcribe model.
When using map function to prepare dataset, following warning pop out:
`common_voice = common_voice.map(prepare_dataset,
remove_columns=common_voice.column_names["train"], num_proc=1)`
> Parameter 'function'=<function prepare_dataset at 0x000001D1D9D79A60> of the transform datasets.arrow_dataset.Dataset._map_single couldn't be hashed properly, a random hash was used instead. Make sure your transforms and parameters are serializable with pickle or dill for the dataset fingerprinting and caching to work. If you reuse this transform, the caching mechanism will consider it to be different from the previous calls and recompute everything. This warning is only showed once. Subsequent hashing failures won't be showed.
I read https://github.com/huggingface/datasets/issues/4521 and https://github.com/huggingface/datasets/issues/3178 but cannot solve the issue.
### Steps to reproduce the bug
```python
from datasets import load_dataset, DatasetDict
common_voice = DatasetDict()
common_voice["train"] = load_dataset("mozilla-foundation/common_voice_11_0", "zh-HK",
split="train+validation")
common_voice["test"] = load_dataset("mozilla-foundation/common_voice_11_0", "zh-HK",
split="test")
common_voice = common_voice.remove_columns(["accent", "age", "client_id", "down_votes", "gender", "locale", "path", "segment", "up_votes"])
from transformers import WhisperFeatureExtractor, WhisperTokenizer, WhisperProcessor
feature_extractor = WhisperFeatureExtractor.from_pretrained("openai/whisper-small")
tokenizer = WhisperTokenizer.from_pretrained("openai/whisper-small", language="chinese", task="transcribe")
processor = WhisperProcessor.from_pretrained("openai/whisper-small", language="chinese", task="transcribe")
from datasets import Audio
common_voice = common_voice.cast_column("audio", Audio(sampling_rate=16000))
def prepare_dataset(batch):
# load and resample audio data from 48 to 16kHz
audio = batch["audio"]
# compute log-Mel input features from input audio array
batch["input_features"] = feature_extractor(audio["array"],
sampling_rate=audio["sampling_rate"]).input_features[0]
# encode target text to label ids
batch["labels"] = tokenizer(batch["sentence"]).input_ids
return batch
common_voice = common_voice.map(prepare_dataset,
remove_columns=common_voice.column_names["train"], num_proc=1)
```
### Expected behavior
Should be no warning shown.
### Environment info
- `datasets` version: 2.7.0
- Platform: Windows-10-10.0.19045-SP0
- Python version: 3.9.12
- PyArrow version: 8.0.0
- Pandas version: 1.3.5
- dill version: 0.3.4
- multiprocess version: 0.70.12.2 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5408/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5408/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5407 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5407/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5407/comments | https://api.github.com/repos/huggingface/datasets/issues/5407/events | https://github.com/huggingface/datasets/issues/5407 | 1,519,797,345 | I_kwDODunzps5alkRh | 5,407 | Datasets.from_sql() generates deprecation warning | {
"login": "msummerfield",
"id": 21002157,
"node_id": "MDQ6VXNlcjIxMDAyMTU3",
"avatar_url": "https://avatars.githubusercontent.com/u/21002157?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/msummerfield",
"html_url": "https://github.com/msummerfield",
"followers_url": "https://api.github.com/users/msummerfield/followers",
"following_url": "https://api.github.com/users/msummerfield/following{/other_user}",
"gists_url": "https://api.github.com/users/msummerfield/gists{/gist_id}",
"starred_url": "https://api.github.com/users/msummerfield/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/msummerfield/subscriptions",
"organizations_url": "https://api.github.com/users/msummerfield/orgs",
"repos_url": "https://api.github.com/users/msummerfield/repos",
"events_url": "https://api.github.com/users/msummerfield/events{/privacy}",
"received_events_url": "https://api.github.com/users/msummerfield/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
}
] | [
"Thanks for reporting @msummerfield. We are fixing it."
] | 1,672,879,397,000 | 1,673,002,754,000 | 1,673,002,754,000 | NONE | null | ### Describe the bug
Calling `Datasets.from_sql()` generates a warning:
`.../site-packages/datasets/builder.py:712: FutureWarning: 'use_auth_token' was deprecated in version 2.7.1 and will be removed in 3.0.0. Pass 'use_auth_token' to the initializer/'load_dataset_builder' instead.`
### Steps to reproduce the bug
Any valid call to `Datasets.from_sql()` will produce the deprecation warning.
### Expected behavior
No warning.
The fix should be simply to remove the parameter `use_auth_token` from the call to `builder.download_and_prepare()` at line 43 of `io/sql.py` (it is set to `None` anyway, and is not needed).
### Environment info
- `datasets` version: 2.8.0
- Platform: Linux-4.15.0-169-generic-x86_64-with-glibc2.27
- Python version: 3.9.15
- PyArrow version: 10.0.1
- Pandas version: 1.5.2
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5407/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5407/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5406 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5406/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5406/comments | https://api.github.com/repos/huggingface/datasets/issues/5406/events | https://github.com/huggingface/datasets/issues/5406 | 1,519,140,544 | I_kwDODunzps5ajD7A | 5,406 | [2.6.1][2.7.0] Upgrade `datasets` to fix `TypeError: can only concatenate str (not "int") to str` | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
} | [] | open | false | null | [] | [
"I still get this error on 2.9.0\r\n<img width=\"1925\" alt=\"image\" src=\"https://user-images.githubusercontent.com/7208470/215597359-2f253c76-c472-4612-8099-d3a74d16eb29.png\">\r\n",
"Hi ! I just tested locally and or colab and it works fine for 2.9 on `sst2`.\r\n\r\nAlso the code that is shown in your stack trace is not present in the 2.9 source code - so I'm wondering how you installed `datasets` that could cause this ? (you can check by searching for `[0:{label_ids[-1] + 1}]` in the [2.9 codebase](https://github.dev/huggingface/datasets/tree/b5672a956d5de864e6f5550e493527d962d6ae55) - it doesn't find anything)\r\n\r\nAnyway you can try uninstalling `datasets` and install it again",
"For what it's worth, I've also gotten this error on 2.9.0, and I've tried uninstalling an reinstalling\r\n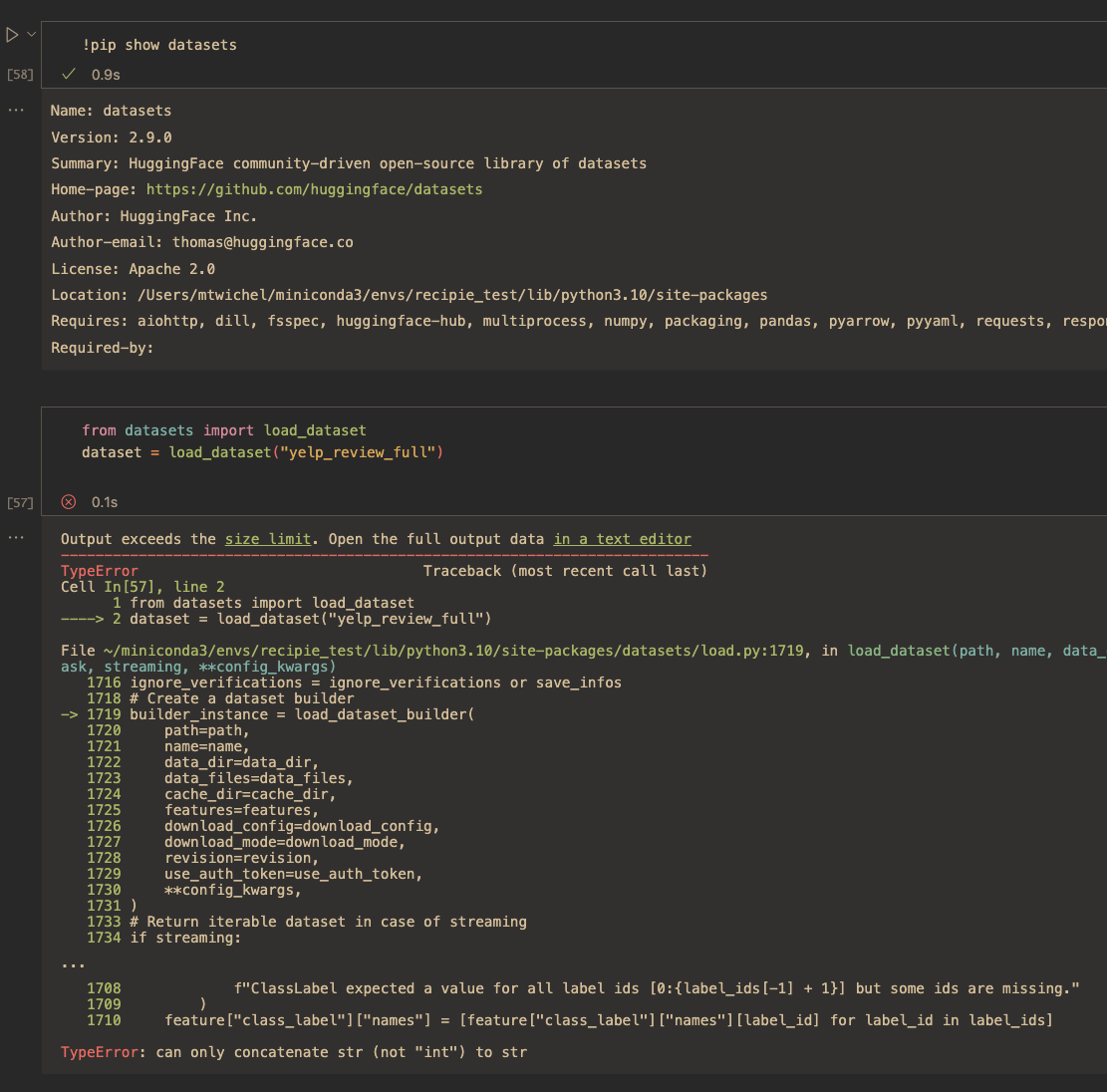\r\n\r\nI'm very new to this package (I was following this tutorial: https://huggingface.co/docs/transformers/training), so there's a good chance I was doing something wrong 😅 but thought I'd pass along the feedback",
"@ntrpnr @mtwichel Did you install `datasets` with conda ?\r\n\r\nI suspect that `datasets` 2.9 on conda still have this issue for some reason. When I install `datasets` with `pip` I don't have this error.",
"> @ntrpnr @mtwichel Did you install datasets with conda ?\r\n\r\nI did yeah, I wonder if that's the issue",
"I just checked on conda at https://anaconda.org/HuggingFace/datasets/files\r\n\r\nand everything looks fine, I got\r\n```python\r\n\r\nf\"ClassLabel expected a value for all label ids [0:{int(label_ids[-1]) + 1}] but some ids are missing.\"\r\n```\r\nas expected in features.py line 1760 (notice the \"int()\") to not have the TypeError.\r\n\r\nFrom where on conda did you install `datasets` ? You should use the `HuggingFace` official channel\r\n\r\nedit: the conda-forge one [here](https://anaconda.org/conda-forge/datasets/files) seems ok as well",
"Could you also try this in your notebook ? In case your python kernel doesn't match the `pip` environment in your shell\r\n```python\r\nimport datasets; datasets.__version__\r\n```\r\nand\r\n```\r\n!which python\r\n```\r\n```python\r\nimport sys; sys.executable\r\n```",
"Mmmm, just a potential clue:\r\n\r\nWhere are you running your Python code? Is it the Spyder IDE?\r\n\r\nI have recently seen some users reporting conflicting Python environments while using Spyder...\r\n\r\nMaybe related:\r\n- #5487",
"Other potential clue:\r\n- Had you already imported `datasets` before pip-updating it? You should first update datasets, before importing it. Otherwise, you need to restart the kernel after updating it.",
"I installed `datasets` with Conda using `conda install datasets` and got this issue.\r\n\r\nThen I tried to reinstall using\r\n`\r\nconda install -c huggingface -c conda-forge datasets\r\n`\r\nThe issue is now fixed.",
"I'm still getting this error on 2.13.0"
] | 1,672,845,004,000 | 1,687,373,138,000 | null | MEMBER | null | `datasets` 2.6.1 and 2.7.0 started to stop supporting datasets like IMDB, ConLL or MNIST datasets.
When loading a dataset using 2.6.1 or 2.7.0, you may this error when loading certain datasets:
```python
TypeError: can only concatenate str (not "int") to str
```
This is because we started to update the metadata of those datasets to a format that is not supported in 2.6.1 and 2.7.0
This change is required or those datasets won't be supported by the Hugging Face Hub.
Therefore if you encounter this error or if you're using `datasets` 2.6.1 or 2.7.0, we encourage you to update to a newer version.
For example, versions 2.6.2 and 2.7.1 patch this issue.
```python
pip install -U datasets
```
All the datasets affected are the ones with a ClassLabel feature type and YAML "dataset_info" metadata. More info [here](https://github.com/huggingface/datasets/issues/5275).
We apologize for the inconvenience. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5406/reactions",
"total_count": 10,
"+1": 10,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5406/timeline | null | null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5405 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5405/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5405/comments | https://api.github.com/repos/huggingface/datasets/issues/5405/events | https://github.com/huggingface/datasets/issues/5405 | 1,517,879,386 | I_kwDODunzps5aeQBa | 5,405 | size_in_bytes the same for all splits | {
"login": "Breakend",
"id": 1609857,
"node_id": "MDQ6VXNlcjE2MDk4NTc=",
"avatar_url": "https://avatars.githubusercontent.com/u/1609857?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Breakend",
"html_url": "https://github.com/Breakend",
"followers_url": "https://api.github.com/users/Breakend/followers",
"following_url": "https://api.github.com/users/Breakend/following{/other_user}",
"gists_url": "https://api.github.com/users/Breakend/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Breakend/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Breakend/subscriptions",
"organizations_url": "https://api.github.com/users/Breakend/orgs",
"repos_url": "https://api.github.com/users/Breakend/repos",
"events_url": "https://api.github.com/users/Breakend/events{/privacy}",
"received_events_url": "https://api.github.com/users/Breakend/received_events",
"type": "User",
"site_admin": false
} | [] | open | false | null | [] | [
"Hi @Breakend,\r\n\r\nIndeed, the attribute `size_in_bytes` refers to the size of the entire dataset configuration, for all splits (size of downloaded files + Arrow files), not the specific split.\r\nThis is also the case for `download_size` (downloaded files) and `dataset_size` (Arrow files).\r\n\r\nThe size of the Arrow files for a specific split can be accessed: e.g. size of the \"test\" split only\r\n```python\r\nds[\"train\"].info.splits[\"test\"].num_bytes\r\n```\r\n\r\nI agree this is confusing and maybe we should improve it."
] | 1,672,777,548,000 | 1,672,824,179,000 | null | NONE | null | ### Describe the bug
Hi, it looks like whenever you pull a dataset and get size_in_bytes, it returns the same size for all splits (and that size is the combined size of all splits). It seems like this shouldn't be the intended behavior since it is misleading. Here's an example:
```
>>> from datasets import load_dataset
>>> x = load_dataset("glue", "wnli")
Found cached dataset glue (/Users/breakend/.cache/huggingface/datasets/glue/wnli/1.0.0/dacbe3125aa31d7f70367a07a8a9e72a5a0bfeb5fc42e75c9db75b96da6053ad)
100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 3/3 [00:00<00:00, 1097.70it/s]
>>> x["train"].size_in_bytes
186159
>>> x["validation"].size_in_bytes
186159
>>> x["test"].size_in_bytes
186159
>>>
```
### Steps to reproduce the bug
```
>>> from datasets import load_dataset
>>> x = load_dataset("glue", "wnli")
>>> x["train"].size_in_bytes
186159
>>> x["validation"].size_in_bytes
186159
>>> x["test"].size_in_bytes
186159
```
### Expected behavior
The expected behavior is that it should return the separate sizes for all splits.
### Environment info
- `datasets` version: 2.7.1
- Platform: macOS-12.5-arm64-arm-64bit
- Python version: 3.10.8
- PyArrow version: 10.0.1
- Pandas version: 1.5.2 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5405/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5405/timeline | null | null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5404 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5404/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5404/comments | https://api.github.com/repos/huggingface/datasets/issues/5404/events | https://github.com/huggingface/datasets/issues/5404 | 1,517,566,331 | I_kwDODunzps5adDl7 | 5,404 | Better integration of BIG-bench | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892871,
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement",
"name": "enhancement",
"color": "a2eeef",
"default": true,
"description": "New feature or request"
}
] | open | false | null | [] | [
"Hi, I made my version : https://huggingface.co/datasets/tasksource/bigbench"
] | 1,672,760,277,000 | 1,675,974,626,000 | null | MEMBER | null | ### Feature request
Ideally, it would be nice to have a maintained PyPI package for `bigbench`.
### Motivation
We'd like to allow anyone to access, explore and use any task.
### Your contribution
@lhoestq has opened an issue in their repo:
- https://github.com/google/BIG-bench/issues/906 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5404/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5404/timeline | null | null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5403 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5403/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5403/comments | https://api.github.com/repos/huggingface/datasets/issues/5403/events | https://github.com/huggingface/datasets/pull/5403 | 1,517,466,492 | PR_kwDODunzps5Gi3d9 | 5,403 | Replace one letter import in docs | {
"login": "MKhalusova",
"id": 1065417,
"node_id": "MDQ6VXNlcjEwNjU0MTc=",
"avatar_url": "https://avatars.githubusercontent.com/u/1065417?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/MKhalusova",
"html_url": "https://github.com/MKhalusova",
"followers_url": "https://api.github.com/users/MKhalusova/followers",
"following_url": "https://api.github.com/users/MKhalusova/following{/other_user}",
"gists_url": "https://api.github.com/users/MKhalusova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/MKhalusova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/MKhalusova/subscriptions",
"organizations_url": "https://api.github.com/users/MKhalusova/orgs",
"repos_url": "https://api.github.com/users/MKhalusova/repos",
"events_url": "https://api.github.com/users/MKhalusova/events{/privacy}",
"received_events_url": "https://api.github.com/users/MKhalusova/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"_The documentation is not available anymore as the PR was closed or merged._",
"> Thanks for the docs fix for consistency.\r\n> \r\n> Again for consistency, it would be nice to make the same fix across all the docs, e.g.\r\n> \r\n> https://github.com/huggingface/datasets/blob/310cdddd1c43f9658de172b85b6509d07d5e31a1/docs/source/image_classification.mdx?plain=1#L41\r\n\r\nExcellent point!",
"@albertvillanova Should be all of them now :)",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008776 / 0.011353 (-0.002576) | 0.004534 / 0.011008 (-0.006474) | 0.101921 / 0.038508 (0.063413) | 0.029995 / 0.023109 (0.006886) | 0.307180 / 0.275898 (0.031282) | 0.371001 / 0.323480 (0.047521) | 0.007089 / 0.007986 (-0.000896) | 0.003474 / 0.004328 (-0.000855) | 0.079498 / 0.004250 (0.075248) | 0.036522 / 0.037052 (-0.000531) | 0.311729 / 0.258489 (0.053240) | 0.349861 / 0.293841 (0.056020) | 0.033815 / 0.128546 (-0.094731) | 0.011435 / 0.075646 (-0.064211) | 0.322924 / 0.419271 (-0.096347) | 0.040981 / 0.043533 (-0.002552) | 0.306174 / 0.255139 (0.051035) | 0.331979 / 0.283200 (0.048780) | 0.091293 / 0.141683 (-0.050389) | 1.480935 / 1.452155 (0.028780) | 1.522022 / 1.492716 (0.029306) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.195053 / 0.018006 (0.177047) | 0.424898 / 0.000490 (0.424408) | 0.003869 / 0.000200 (0.003669) | 0.000075 / 0.000054 (0.000021) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.024323 / 0.037411 (-0.013088) | 0.098061 / 0.014526 (0.083535) | 0.105770 / 0.176557 (-0.070787) | 0.145799 / 0.737135 (-0.591336) | 0.109109 / 0.296338 (-0.187230) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.420434 / 0.215209 (0.205225) | 4.194781 / 2.077655 (2.117126) | 2.030498 / 1.504120 (0.526378) | 1.885314 / 1.541195 (0.344120) | 1.996485 / 1.468490 (0.527995) | 0.708540 / 4.584777 (-3.876237) | 3.400694 / 3.745712 (-0.345018) | 2.888704 / 5.269862 (-2.381157) | 1.578100 / 4.565676 (-2.987577) | 0.082150 / 0.424275 (-0.342125) | 0.012277 / 0.007607 (0.004669) | 0.527312 / 0.226044 (0.301268) | 5.289566 / 2.268929 (3.020637) | 2.369997 / 55.444624 (-53.074628) | 2.040365 / 6.876477 (-4.836112) | 2.298857 / 2.142072 (0.156785) | 0.808446 / 4.805227 (-3.996781) | 0.149355 / 6.500664 (-6.351309) | 0.065993 / 0.075469 (-0.009477) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.231829 / 1.841788 (-0.609959) | 13.874762 / 8.074308 (5.800454) | 13.464379 / 10.191392 (3.272987) | 0.151105 / 0.680424 (-0.529319) | 0.028689 / 0.534201 (-0.505512) | 0.398720 / 0.579283 (-0.180564) | 0.402108 / 0.434364 (-0.032256) | 0.463426 / 0.540337 (-0.076912) | 0.541919 / 1.386936 (-0.845017) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006979 / 0.011353 (-0.004373) | 0.004723 / 0.011008 (-0.006285) | 0.099172 / 0.038508 (0.060664) | 0.027970 / 0.023109 (0.004861) | 0.415096 / 0.275898 (0.139198) | 0.455916 / 0.323480 (0.132437) | 0.005950 / 0.007986 (-0.002036) | 0.003423 / 0.004328 (-0.000906) | 0.075512 / 0.004250 (0.071262) | 0.040894 / 0.037052 (0.003842) | 0.419810 / 0.258489 (0.161321) | 0.461913 / 0.293841 (0.168072) | 0.033014 / 0.128546 (-0.095532) | 0.011613 / 0.075646 (-0.064033) | 0.320983 / 0.419271 (-0.098289) | 0.049902 / 0.043533 (0.006369) | 0.426378 / 0.255139 (0.171239) | 0.445594 / 0.283200 (0.162394) | 0.098978 / 0.141683 (-0.042705) | 1.485724 / 1.452155 (0.033570) | 1.563978 / 1.492716 (0.071262) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.232137 / 0.018006 (0.214131) | 0.432785 / 0.000490 (0.432296) | 0.006173 / 0.000200 (0.005973) | 0.000085 / 0.000054 (0.000031) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.024924 / 0.037411 (-0.012487) | 0.102878 / 0.014526 (0.088352) | 0.107976 / 0.176557 (-0.068581) | 0.143581 / 0.737135 (-0.593554) | 0.111644 / 0.296338 (-0.184694) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.490902 / 0.215209 (0.275693) | 4.914060 / 2.077655 (2.836405) | 2.569465 / 1.504120 (1.065345) | 2.346872 / 1.541195 (0.805677) | 2.412047 / 1.468490 (0.943557) | 0.704975 / 4.584777 (-3.879802) | 3.443669 / 3.745712 (-0.302043) | 3.172055 / 5.269862 (-2.097807) | 1.332152 / 4.565676 (-3.233525) | 0.083023 / 0.424275 (-0.341252) | 0.012699 / 0.007607 (0.005092) | 0.592511 / 0.226044 (0.366466) | 5.916376 / 2.268929 (3.647448) | 3.028472 / 55.444624 (-52.416152) | 2.691159 / 6.876477 (-4.185318) | 2.786132 / 2.142072 (0.644060) | 0.814045 / 4.805227 (-3.991182) | 0.156630 / 6.500664 (-6.344034) | 0.071330 / 0.075469 (-0.004139) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.277936 / 1.841788 (-0.563852) | 14.331367 / 8.074308 (6.257059) | 13.685694 / 10.191392 (3.494302) | 0.138915 / 0.680424 (-0.541509) | 0.016844 / 0.534201 (-0.517357) | 0.390307 / 0.579283 (-0.188976) | 0.385207 / 0.434364 (-0.049157) | 0.448128 / 0.540337 (-0.092210) | 0.532609 / 1.386936 (-0.854327) |\n\n</details>\n</details>\n\n\n"
] | 1,672,755,992,000 | 1,672,758,378,000 | 1,672,757,941,000 | CONTRIBUTOR | null | This PR updates a code example for consistency across the docs based on [feedback from this comment](https://github.com/huggingface/transformers/pull/20925/files/9fda31634d203a47d3212e4e8d43d3267faf9808#r1058769500):
"In terms of style we usually stay away from one-letter imports like this (even if the community uses them) as they are not always known by beginners and one letter is very undescriptive. Here it wouldn't change anything to use albumentations instead of A."
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5403/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5403/timeline | null | null | 0 | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5403",
"html_url": "https://github.com/huggingface/datasets/pull/5403",
"diff_url": "https://github.com/huggingface/datasets/pull/5403.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5403.patch",
"merged_at": "2023-01-03T14:59:01"
} | true |
https://api.github.com/repos/huggingface/datasets/issues/5402 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5402/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5402/comments | https://api.github.com/repos/huggingface/datasets/issues/5402/events | https://github.com/huggingface/datasets/issues/5402 | 1,517,409,429 | I_kwDODunzps5acdSV | 5,402 | Missing state.json when creating a cloud dataset using a dataset_builder | {
"login": "danielfleischer",
"id": 22022514,
"node_id": "MDQ6VXNlcjIyMDIyNTE0",
"avatar_url": "https://avatars.githubusercontent.com/u/22022514?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/danielfleischer",
"html_url": "https://github.com/danielfleischer",
"followers_url": "https://api.github.com/users/danielfleischer/followers",
"following_url": "https://api.github.com/users/danielfleischer/following{/other_user}",
"gists_url": "https://api.github.com/users/danielfleischer/gists{/gist_id}",
"starred_url": "https://api.github.com/users/danielfleischer/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/danielfleischer/subscriptions",
"organizations_url": "https://api.github.com/users/danielfleischer/orgs",
"repos_url": "https://api.github.com/users/danielfleischer/repos",
"events_url": "https://api.github.com/users/danielfleischer/events{/privacy}",
"received_events_url": "https://api.github.com/users/danielfleischer/received_events",
"type": "User",
"site_admin": false
} | [] | open | false | null | [] | [
"`load_from_disk` must be used on datasets saved using `save_to_disk`: they correspond to fully serialized datasets including their state.\r\n\r\nOn the other hand, `download_and_prepare` just downloads the raw data and convert them to arrow (or parquet if you want). We are working on allowing you to reload a dataset saved on S3 with `download_and_prepare` using `load_dataset` in #5281 \r\n\r\nFor now I'd encourage you to keep using `save_to_disk`",
"Thanks, I'll follow that issue. \r\n\r\nI was following the [cloud storage](https://huggingface.co/docs/datasets/filesystems) docs section and perhaps I'm missing some part of the flow; start with `load_dataset_builder` + `download_and_prepare`. You say I need an explicit `save_to_disk` but what object needs to be saved? the builder? is that related to the other issue?",
"Right now `load_dataset_builder` + `download_and_prepare` is to be used with tools like dask or spark, but `load_dataset` will support private cloud storage soon as well so you'll be able to reload the dataset with `datasets`.\r\n\r\nRight now the only function that can load a dataset from a cloud storage is `load_from_disk`, that must be used with a dataset serialized with `save_to_disk`."
] | 1,672,753,199,000 | 1,672,853,037,000 | null | NONE | null | ### Describe the bug
Using `load_dataset_builder` to create a builder, run `download_and_prepare` do upload it to S3. However when trying to load it, there are missing `state.json` files. Complete example:
```python
from aiobotocore.session import AioSession as Session
from datasets import load_from_disk, load_datase, load_dataset_builder
import s3fs
storage_options = {"session": Session()}
fs = s3fs.S3FileSystem(**storage_options)
output_dir = "s3://bucket/imdb"
builder = load_dataset_builder("imdb")
builder.download_and_prepare(output_dir, storage_options=storage_options)
load_from_disk(output_dir, fs=fs) # ERROR
# [Errno 2] No such file or directory: '/tmp/tmpy22yys8o/bucket/imdb/state.json'
```
As a comparison, if you use the non lazy `load_dataset`, it works and the S3 folder has different structure + state.json files. Example:
```python
from aiobotocore.session import AioSession as Session
from datasets import load_from_disk, load_dataset, load_dataset_builder
import s3fs
storage_options = {"session": Session()}
fs = s3fs.S3FileSystem(**storage_options)
output_dir = "s3://bucket/imdb"
dataset = load_dataset("imdb",)
dataset.save_to_disk(output_dir, fs=fs)
load_from_disk(output_dir, fs=fs) # WORKS
```
You still want the 1st option for the laziness and the parquet conversion. Thanks!
### Steps to reproduce the bug
```python
from aiobotocore.session import AioSession as Session
from datasets import load_from_disk, load_datase, load_dataset_builder
import s3fs
storage_options = {"session": Session()}
fs = s3fs.S3FileSystem(**storage_options)
output_dir = "s3://bucket/imdb"
builder = load_dataset_builder("imdb")
builder.download_and_prepare(output_dir, storage_options=storage_options)
load_from_disk(output_dir, fs=fs) # ERROR
# [Errno 2] No such file or directory: '/tmp/tmpy22yys8o/bucket/imdb/state.json'
```
BTW, you need the AioSession as s3fs is now based on aiobotocore, see https://github.com/fsspec/s3fs/issues/385.
### Expected behavior
Expected to be able to load the dataset from S3.
### Environment info
```
s3fs 2022.11.0
s3transfer 0.6.0
datasets 2.8.0
aiobotocore 2.4.2
boto3 1.24.59
botocore 1.27.59
```
python 3.7.15. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5402/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5402/timeline | null | null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5401 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5401/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5401/comments | https://api.github.com/repos/huggingface/datasets/issues/5401/events | https://github.com/huggingface/datasets/pull/5401 | 1,517,160,935 | PR_kwDODunzps5Gh1XQ | 5,401 | Support Dataset conversion from/to Spark | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [] | open | false | null | [] | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_5401). All of your documentation changes will be reflected on that endpoint.",
"Cool thanks !\r\n\r\nSpark DataFrame are usually quite big, and I believe here `from_spark` would load everything in the driver node's RAM, which is quite limiting. Same for `to_spark` which would load everything in the driver node's RAM before sending the data to the executor. Maybe we can mention this in the docstring ?\r\n\r\nTo transfer big datasets from/into the HF ecosystem using Spark maybe we can just make sure that `pyspark` can read/write to the HF Hub, and that `datasets` can read from HDFS/S3/etc.",
"Yes @lhoestq , consider this as a first integration of the Datasets library with Spark.\r\n- This PR implements the basic conversion between both.\r\n - And yes, we are using the Spark's `pandas` API (that uses `pyarrow` under the hood): everything is transferred to the driver.\r\n - Note that we are converting from/to a Datasets dataset: this is not distributed\r\n\r\nThe next step is to support the integration of the HF Hub with Spark, that I think should be done using `hffs`.",
"Thinking more about it I don't really see how those two methods help in practice, since one can already do `datasets` <-> pandas <-> spark and those two methods don't add value over this.\r\n\r\nHowever I think it can be good documentation to explain that it's possible to do it and it's super simple"
] | 1,672,739,860,000 | 1,672,928,493,000 | null | MEMBER | null | This PR implements Spark integration by supporting `Dataset` conversion from/to Spark `DataFrame`. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5401/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5401/timeline | null | null | 0 | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5401",
"html_url": "https://github.com/huggingface/datasets/pull/5401",
"diff_url": "https://github.com/huggingface/datasets/pull/5401.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5401.patch",
"merged_at": null
} | true |
https://api.github.com/repos/huggingface/datasets/issues/5400 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5400/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5400/comments | https://api.github.com/repos/huggingface/datasets/issues/5400/events | https://github.com/huggingface/datasets/pull/5400 | 1,517,032,972 | PR_kwDODunzps5GhaGI | 5,400 | Support streaming datasets with os.path.exists and Path.exists | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008638 / 0.011353 (-0.002715) | 0.004565 / 0.011008 (-0.006444) | 0.098984 / 0.038508 (0.060476) | 0.030118 / 0.023109 (0.007009) | 0.321779 / 0.275898 (0.045881) | 0.366905 / 0.323480 (0.043426) | 0.006931 / 0.007986 (-0.001055) | 0.004728 / 0.004328 (0.000399) | 0.078358 / 0.004250 (0.074108) | 0.037755 / 0.037052 (0.000702) | 0.312694 / 0.258489 (0.054205) | 0.351781 / 0.293841 (0.057940) | 0.033266 / 0.128546 (-0.095280) | 0.011397 / 0.075646 (-0.064250) | 0.323501 / 0.419271 (-0.095771) | 0.040779 / 0.043533 (-0.002754) | 0.303533 / 0.255139 (0.048394) | 0.340940 / 0.283200 (0.057740) | 0.088701 / 0.141683 (-0.052982) | 1.472058 / 1.452155 (0.019904) | 1.529535 / 1.492716 (0.036818) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.191803 / 0.018006 (0.173797) | 0.409773 / 0.000490 (0.409283) | 0.002704 / 0.000200 (0.002504) | 0.000217 / 0.000054 (0.000163) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.023520 / 0.037411 (-0.013891) | 0.096967 / 0.014526 (0.082441) | 0.107911 / 0.176557 (-0.068646) | 0.146425 / 0.737135 (-0.590710) | 0.109025 / 0.296338 (-0.187314) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.418565 / 0.215209 (0.203356) | 4.183429 / 2.077655 (2.105774) | 1.886534 / 1.504120 (0.382414) | 1.689015 / 1.541195 (0.147820) | 1.710757 / 1.468490 (0.242267) | 0.693211 / 4.584777 (-3.891566) | 3.380062 / 3.745712 (-0.365650) | 2.619910 / 5.269862 (-2.649952) | 1.457512 / 4.565676 (-3.108164) | 0.082421 / 0.424275 (-0.341854) | 0.012126 / 0.007607 (0.004519) | 0.525249 / 0.226044 (0.299205) | 5.244541 / 2.268929 (2.975613) | 2.305908 / 55.444624 (-53.138717) | 1.945298 / 6.876477 (-4.931178) | 2.015618 / 2.142072 (-0.126455) | 0.816746 / 4.805227 (-3.988481) | 0.148325 / 6.500664 (-6.352339) | 0.063939 / 0.075469 (-0.011530) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.255790 / 1.841788 (-0.585998) | 13.433219 / 8.074308 (5.358911) | 13.916957 / 10.191392 (3.725565) | 0.153468 / 0.680424 (-0.526956) | 0.028722 / 0.534201 (-0.505479) | 0.398245 / 0.579283 (-0.181038) | 0.399067 / 0.434364 (-0.035296) | 0.457525 / 0.540337 (-0.082812) | 0.542391 / 1.386936 (-0.844545) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006411 / 0.011353 (-0.004942) | 0.004552 / 0.011008 (-0.006456) | 0.098036 / 0.038508 (0.059527) | 0.026532 / 0.023109 (0.003422) | 0.412270 / 0.275898 (0.136372) | 0.442771 / 0.323480 (0.119291) | 0.004891 / 0.007986 (-0.003094) | 0.003488 / 0.004328 (-0.000841) | 0.075437 / 0.004250 (0.071186) | 0.036228 / 0.037052 (-0.000824) | 0.413246 / 0.258489 (0.154757) | 0.453546 / 0.293841 (0.159705) | 0.031054 / 0.128546 (-0.097492) | 0.011589 / 0.075646 (-0.064058) | 0.318477 / 0.419271 (-0.100794) | 0.041075 / 0.043533 (-0.002457) | 0.411182 / 0.255139 (0.156043) | 0.436991 / 0.283200 (0.153792) | 0.086563 / 0.141683 (-0.055120) | 1.511948 / 1.452155 (0.059793) | 1.570925 / 1.492716 (0.078208) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.200510 / 0.018006 (0.182504) | 0.403450 / 0.000490 (0.402960) | 0.000397 / 0.000200 (0.000197) | 0.000058 / 0.000054 (0.000003) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.023950 / 0.037411 (-0.013461) | 0.097334 / 0.014526 (0.082808) | 0.105228 / 0.176557 (-0.071328) | 0.137699 / 0.737135 (-0.599436) | 0.107063 / 0.296338 (-0.189275) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.474420 / 0.215209 (0.259211) | 4.748212 / 2.077655 (2.670557) | 2.407318 / 1.504120 (0.903198) | 2.198949 / 1.541195 (0.657755) | 2.220377 / 1.468490 (0.751887) | 0.704022 / 4.584777 (-3.880755) | 3.366128 / 3.745712 (-0.379584) | 1.839454 / 5.269862 (-3.430408) | 1.151183 / 4.565676 (-3.414493) | 0.082818 / 0.424275 (-0.341457) | 0.012765 / 0.007607 (0.005158) | 0.571913 / 0.226044 (0.345868) | 5.722544 / 2.268929 (3.453615) | 2.858279 / 55.444624 (-52.586346) | 2.513479 / 6.876477 (-4.362998) | 2.574227 / 2.142072 (0.432154) | 0.803282 / 4.805227 (-4.001945) | 0.150603 / 6.500664 (-6.350061) | 0.066594 / 0.075469 (-0.008875) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.301161 / 1.841788 (-0.540627) | 13.580745 / 8.074308 (5.506436) | 13.301551 / 10.191392 (3.110159) | 0.141424 / 0.680424 (-0.539000) | 0.016579 / 0.534201 (-0.517622) | 0.380726 / 0.579283 (-0.198557) | 0.383011 / 0.434364 (-0.051353) | 0.438717 / 0.540337 (-0.101620) | 0.527085 / 1.386936 (-0.859851) |\n\n</details>\n</details>\n\n\n"
] | 1,672,731,757,000 | 1,673,001,764,000 | 1,673,001,344,000 | MEMBER | null | Support streaming datasets with `os.path.exists` and `pathlib.Path.exists`. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5400/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5400/timeline | null | null | 0 | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5400",
"html_url": "https://github.com/huggingface/datasets/pull/5400",
"diff_url": "https://github.com/huggingface/datasets/pull/5400.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5400.patch",
"merged_at": "2023-01-06T10:35:44"
} | true |
https://api.github.com/repos/huggingface/datasets/issues/5399 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5399/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5399/comments | https://api.github.com/repos/huggingface/datasets/issues/5399/events | https://github.com/huggingface/datasets/issues/5399 | 1,515,548,427 | I_kwDODunzps5aVW8L | 5,399 | Got disconnected from remote data host. Retrying in 5sec [2/20] | {
"login": "alhuri",
"id": 46427957,
"node_id": "MDQ6VXNlcjQ2NDI3OTU3",
"avatar_url": "https://avatars.githubusercontent.com/u/46427957?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/alhuri",
"html_url": "https://github.com/alhuri",
"followers_url": "https://api.github.com/users/alhuri/followers",
"following_url": "https://api.github.com/users/alhuri/following{/other_user}",
"gists_url": "https://api.github.com/users/alhuri/gists{/gist_id}",
"starred_url": "https://api.github.com/users/alhuri/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/alhuri/subscriptions",
"organizations_url": "https://api.github.com/users/alhuri/orgs",
"repos_url": "https://api.github.com/users/alhuri/repos",
"events_url": "https://api.github.com/users/alhuri/events{/privacy}",
"received_events_url": "https://api.github.com/users/alhuri/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [] | 1,672,578,011,000 | 1,672,644,112,000 | 1,672,644,112,000 | NONE | null | ### Describe the bug
While trying to upload my image dataset of a CSV file type to huggingface by running the below code. The dataset consists of a little over 100k of image-caption pairs
### Steps to reproduce the bug
```
df = pd.read_csv('x.csv', encoding='utf-8-sig')
features = Features({
'link': Image(decode=True),
'caption': Value(dtype='string'),
})
#make sure u r logged in to HF
ds = Dataset.from_pandas(df, features=features)
ds.features
ds.push_to_hub("x/x")
```
I got the below error and It always stops at the same progress
```
100%|██████████| 4/4 [23:53<00:00, 358.48s/ba]
100%|██████████| 4/4 [24:37<00:00, 369.47s/ba]%|▍ | 1/22 [00:06<02:09, 6.16s/it]
100%|██████████| 4/4 [25:00<00:00, 375.15s/ba]%|▉ | 2/22 [25:54<2:36:15, 468.80s/it]
100%|██████████| 4/4 [24:53<00:00, 373.29s/ba]%|█▎ | 3/22 [51:01<4:07:07, 780.39s/it]
100%|██████████| 4/4 [24:01<00:00, 360.34s/ba]%|█▊ | 4/22 [1:17:00<5:04:07, 1013.74s/it]
100%|██████████| 4/4 [23:59<00:00, 359.91s/ba]%|██▎ | 5/22 [1:41:07<5:24:06, 1143.90s/it]
100%|██████████| 4/4 [24:16<00:00, 364.06s/ba]%|██▋ | 6/22 [2:05:14<5:29:15, 1234.74s/it]
100%|██████████| 4/4 [25:24<00:00, 381.10s/ba]%|███▏ | 7/22 [2:29:38<5:25:52, 1303.52s/it]
100%|██████████| 4/4 [25:24<00:00, 381.24s/ba]%|███▋ | 8/22 [2:56:02<5:23:46, 1387.58s/it]
100%|██████████| 4/4 [25:08<00:00, 377.23s/ba]%|████ | 9/22 [3:22:24<5:13:17, 1445.97s/it]
100%|██████████| 4/4 [24:11<00:00, 362.87s/ba]%|████▌ | 10/22 [3:48:24<4:56:02, 1480.19s/it]
100%|██████████| 4/4 [24:44<00:00, 371.11s/ba]%|█████ | 11/22 [4:12:42<4:30:10, 1473.66s/it]
100%|██████████| 4/4 [24:35<00:00, 368.81s/ba]%|█████▍ | 12/22 [4:37:34<4:06:29, 1478.98s/it]
100%|██████████| 4/4 [24:02<00:00, 360.67s/ba]%|█████▉ | 13/22 [5:03:24<3:45:04, 1500.45s/it]
100%|██████████| 4/4 [24:07<00:00, 361.78s/ba]%|██████▎ | 14/22 [5:27:33<3:17:59, 1484.97s/it]
100%|██████████| 4/4 [23:39<00:00, 354.85s/ba]%|██████▊ | 15/22 [5:51:48<2:52:10, 1475.82s/it]
Pushing dataset shards to the dataset hub: 73%|███████▎ | 16/22 [6:16:58<2:28:37, 1486.31s/it]Got disconnected from remote data host. Retrying in 5sec [1/20]
Got disconnected from remote data host. Retrying in 5sec [2/20]
Got disconnected from remote data host. Retrying in 5sec [3/20]
Got disconnected from remote data host. Retrying in 5sec [4/20]
Got disconnected from remote data host. Retrying in 5sec [5/20]
Got disconnected from remote data host. Retrying in 5sec [6/20]
Got disconnected from remote data host. Retrying in 5sec [7/20]
Got disconnected from remote data host. Retrying in 5sec [8/20]
Got disconnected from remote data host. Retrying in 5sec [9/20]
...
Got disconnected from remote data host. Retrying in 5sec [19/20]
Got disconnected from remote data host. Retrying in 5sec [20/20]
75%|███████▌ | 3/4 [24:47<08:15, 495.86s/ba]
Pushing dataset shards to the dataset hub: 73%|███████▎ | 16/22 [6:41:46<2:30:39, 1506.65s/it]
Output exceeds the size limit. Open the full output data in a text editor
---------------------------------------------------------------------------
ConnectionError Traceback (most recent call last)
<ipython-input-1-dbf8530779e9> in <module>
16 ds.features
```
### Expected behavior
I was trying to upload an image dataset and expected it to be fully uploaded
### Environment info
- `datasets` version: 2.8.0
- Platform: Windows-10-10.0.19041-SP0
- Python version: 3.7.9
- PyArrow version: 10.0.1
- Pandas version: 1.3.5 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5399/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5399/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5398 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5398/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5398/comments | https://api.github.com/repos/huggingface/datasets/issues/5398/events | https://github.com/huggingface/datasets/issues/5398 | 1,514,425,231 | I_kwDODunzps5aREuP | 5,398 | Unpin pydantic | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [] | 1,672,396,651,000 | 1,672,397,021,000 | 1,672,397,021,000 | MEMBER | null | Once `pydantic` fixes their issue in their 1.10.3 version, unpin it.
See issue:
- #5394
See temporary fix:
- #5395 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5398/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5398/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5397 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5397/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5397/comments | https://api.github.com/repos/huggingface/datasets/issues/5397/events | https://github.com/huggingface/datasets/pull/5397 | 1,514,412,246 | PR_kwDODunzps5GYirs | 5,397 | Unpin pydantic test dependency | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.012922 / 0.011353 (0.001569) | 0.006568 / 0.011008 (-0.004440) | 0.139567 / 0.038508 (0.101059) | 0.039362 / 0.023109 (0.016253) | 0.444238 / 0.275898 (0.168340) | 0.529102 / 0.323480 (0.205622) | 0.010275 / 0.007986 (0.002290) | 0.006134 / 0.004328 (0.001805) | 0.107506 / 0.004250 (0.103255) | 0.047948 / 0.037052 (0.010896) | 0.460469 / 0.258489 (0.201980) | 0.516817 / 0.293841 (0.222976) | 0.058637 / 0.128546 (-0.069909) | 0.019516 / 0.075646 (-0.056130) | 0.464111 / 0.419271 (0.044839) | 0.062140 / 0.043533 (0.018607) | 0.445004 / 0.255139 (0.189865) | 0.460117 / 0.283200 (0.176917) | 0.116591 / 0.141683 (-0.025092) | 1.936834 / 1.452155 (0.484680) | 1.941837 / 1.492716 (0.449120) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.284130 / 0.018006 (0.266124) | 0.588109 / 0.000490 (0.587619) | 0.004383 / 0.000200 (0.004183) | 0.000143 / 0.000054 (0.000089) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.032984 / 0.037411 (-0.004427) | 0.132811 / 0.014526 (0.118285) | 0.150932 / 0.176557 (-0.025625) | 0.203759 / 0.737135 (-0.533377) | 0.149612 / 0.296338 (-0.146726) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.677666 / 0.215209 (0.462457) | 6.627611 / 2.077655 (4.549956) | 2.679526 / 1.504120 (1.175406) | 2.272536 / 1.541195 (0.731342) | 2.371179 / 1.468490 (0.902689) | 1.205282 / 4.584777 (-3.379495) | 5.733537 / 3.745712 (1.987825) | 3.165279 / 5.269862 (-2.104583) | 2.287918 / 4.565676 (-2.277759) | 0.144581 / 0.424275 (-0.279695) | 0.016812 / 0.007607 (0.009205) | 0.841719 / 0.226044 (0.615675) | 8.379119 / 2.268929 (6.110191) | 3.507169 / 55.444624 (-51.937456) | 2.756666 / 6.876477 (-4.119811) | 2.814091 / 2.142072 (0.672018) | 1.495835 / 4.805227 (-3.309392) | 0.253651 / 6.500664 (-6.247013) | 0.081258 / 0.075469 (0.005789) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.651586 / 1.841788 (-0.190202) | 19.039628 / 8.074308 (10.965320) | 21.269814 / 10.191392 (11.078421) | 0.241024 / 0.680424 (-0.439400) | 0.047975 / 0.534201 (-0.486225) | 0.563727 / 0.579283 (-0.015556) | 0.666808 / 0.434364 (0.232445) | 0.661065 / 0.540337 (0.120728) | 0.762884 / 1.386936 (-0.624052) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.010141 / 0.011353 (-0.001212) | 0.006216 / 0.011008 (-0.004792) | 0.135491 / 0.038508 (0.096983) | 0.035439 / 0.023109 (0.012330) | 0.482789 / 0.275898 (0.206891) | 0.520673 / 0.323480 (0.197193) | 0.006358 / 0.007986 (-0.001627) | 0.005432 / 0.004328 (0.001104) | 0.094448 / 0.004250 (0.090197) | 0.048379 / 0.037052 (0.011326) | 0.509359 / 0.258489 (0.250870) | 0.539583 / 0.293841 (0.245742) | 0.054621 / 0.128546 (-0.073925) | 0.021382 / 0.075646 (-0.054265) | 0.435539 / 0.419271 (0.016267) | 0.060630 / 0.043533 (0.017097) | 0.469593 / 0.255139 (0.214454) | 0.507838 / 0.283200 (0.224639) | 0.112062 / 0.141683 (-0.029621) | 1.829694 / 1.452155 (0.377539) | 1.972266 / 1.492716 (0.479549) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.291669 / 0.018006 (0.273663) | 0.590104 / 0.000490 (0.589614) | 0.000661 / 0.000200 (0.000461) | 0.000082 / 0.000054 (0.000028) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.034933 / 0.037411 (-0.002479) | 0.134867 / 0.014526 (0.120341) | 0.138892 / 0.176557 (-0.037665) | 0.192619 / 0.737135 (-0.544516) | 0.153787 / 0.296338 (-0.142551) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.666762 / 0.215209 (0.451553) | 6.741736 / 2.077655 (4.664082) | 2.988712 / 1.504120 (1.484592) | 2.554823 / 1.541195 (1.013628) | 2.655651 / 1.468490 (1.187161) | 1.276603 / 4.584777 (-3.308174) | 5.827960 / 3.745712 (2.082247) | 5.046876 / 5.269862 (-0.222985) | 2.829775 / 4.565676 (-1.735902) | 0.151525 / 0.424275 (-0.272750) | 0.016504 / 0.007607 (0.008897) | 0.849749 / 0.226044 (0.623704) | 8.331675 / 2.268929 (6.062747) | 3.664529 / 55.444624 (-51.780096) | 2.976495 / 6.876477 (-3.899982) | 3.034737 / 2.142072 (0.892664) | 1.499036 / 4.805227 (-3.306191) | 0.261027 / 6.500664 (-6.239637) | 0.088306 / 0.075469 (0.012837) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.693506 / 1.841788 (-0.148282) | 18.939914 / 8.074308 (10.865605) | 20.685460 / 10.191392 (10.494068) | 0.218316 / 0.680424 (-0.462108) | 0.029010 / 0.534201 (-0.505191) | 0.565246 / 0.579283 (-0.014037) | 0.633573 / 0.434364 (0.199209) | 0.656895 / 0.540337 (0.116558) | 0.781975 / 1.386936 (-0.604961) |\n\n</details>\n</details>\n\n\n"
] | 1,672,395,729,000 | 1,672,397,591,000 | 1,672,397,020,000 | MEMBER | null | Once pydantic-1.10.3 has been yanked, we can unpin it: https://pypi.org/project/pydantic/1.10.3/
See reply by pydantic team https://github.com/pydantic/pydantic/issues/4885#issuecomment-1367819807
```
v1.10.3 has been yanked.
```
in response to spacy request: https://github.com/pydantic/pydantic/issues/4885#issuecomment-1367810049
```
On behalf of spacy-related packages: would it be possible for you to temporarily yank v1.10.3?
To address this and be compatible with v1.10.4, we'd have to release new versions of a whole series of packages and nearly everyone (including me) is currently on vacation. Even if v1.10.4 is released with a fix, pip would still back off to v1.10.3 for spacy, etc. because of its current pins for typing_extensions. If it could instead back off to v1.10.2, we'd have a bit more breathing room to make the updates on our end.
```
Close #5398.
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5397/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5397/timeline | null | null | 0 | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5397",
"html_url": "https://github.com/huggingface/datasets/pull/5397",
"diff_url": "https://github.com/huggingface/datasets/pull/5397.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5397.patch",
"merged_at": "2022-12-30T10:43:40"
} | true |
https://api.github.com/repos/huggingface/datasets/issues/5396 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5396/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5396/comments | https://api.github.com/repos/huggingface/datasets/issues/5396/events | https://github.com/huggingface/datasets/pull/5396 | 1,514,002,934 | PR_kwDODunzps5GXMhp | 5,396 | Fix checksum verification | {
"login": "daskol",
"id": 9336514,
"node_id": "MDQ6VXNlcjkzMzY1MTQ=",
"avatar_url": "https://avatars.githubusercontent.com/u/9336514?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/daskol",
"html_url": "https://github.com/daskol",
"followers_url": "https://api.github.com/users/daskol/followers",
"following_url": "https://api.github.com/users/daskol/following{/other_user}",
"gists_url": "https://api.github.com/users/daskol/gists{/gist_id}",
"starred_url": "https://api.github.com/users/daskol/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/daskol/subscriptions",
"organizations_url": "https://api.github.com/users/daskol/orgs",
"repos_url": "https://api.github.com/users/daskol/repos",
"events_url": "https://api.github.com/users/daskol/events{/privacy}",
"received_events_url": "https://api.github.com/users/daskol/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Hi ! If I'm not mistaken both `expected_checksums[url]` and `recorded_checksums[url]` are dictionaries with keys \"checksum\" and \"num_bytes\". So we need to check whether `expected_checksums[url] != recorded_checksums[url]` (or simply `expected_checksums[url][\"checksum\"] != recorded_checksums[url][\"checksum\"]`)\r\n\r\nBut in your fix you're checking `expected_checksums[url] != recorded_checksums[url]['checksum']`.\r\n\r\nSo I think it's fine to keep this as is",
"No, the issue is that there is comparison of sclar value and dictionary.",
"Acording to [`DatasetInfo`][1], we need specify a dictionary which maps a URL to a checksum as follows.\r\n\r\n```python\r\nCHECKSUMS = {\r\n URL: 'a5dc6bf63ea088ade6e98594bfa386f45211c38b2a3db3dd11b33bd530f3c481',\r\n}\r\n\r\nclass FancyDataset:\r\n def _info(self):\r\n return DatasetInfo(..., download_checksums=CHECKSUMS)\r\n```\r\n\r\nHowever, `load_dataset` fails with this checksum definition.\r\n\r\n[1]: https://github.com/huggingface/datasets/blob/main/src/datasets/info.py#L124-L125",
"I think it has to be formatted like this right now. Maybe the DatasetInfo doc is unclear and we can improve it\r\n```python\r\nCHECKSUMS = {\r\n URL: {\"checksum\": checksum, \"num_bytes\": num_bytes},\r\n}\r\n```",
"Right. I am not sure that this is a correct way to do it. People usually calculate sha256, md5, or whatever else but not size in bytes. Also, people use only some of checksum algorithms. This means that comparing dictionaries in `verify_checksums` is too strict (requires equality of all items) and raises compatibility issues in the future. Another issue is that a comparison of dictionaries assumes type constraints which imply type equality. \r\n\r\nSince almost noone uses checksums as far as I known, my PR suggests a minimal change to mitigate these issues except support of a specific checksum algorithm which is a separated feature and should be contributed in a separate PRs from my perspective.",
"Applying this change will break the verification code, since the `expected_checksums` is a dict with those two keys.",
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_5396). All of your documentation changes will be reflected on that endpoint."
] | 1,672,343,117,000 | 1,676,286,682,000 | 1,676,286,682,000 | CONTRIBUTOR | null | Expected checksum was verified against checksum dict (not checksum). | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5396/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5396/timeline | null | null | 0 | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5396",
"html_url": "https://github.com/huggingface/datasets/pull/5396",
"diff_url": "https://github.com/huggingface/datasets/pull/5396.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5396.patch",
"merged_at": null
} | true |
https://api.github.com/repos/huggingface/datasets/issues/5395 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5395/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5395/comments | https://api.github.com/repos/huggingface/datasets/issues/5395/events | https://github.com/huggingface/datasets/pull/5395 | 1,513,997,335 | PR_kwDODunzps5GXLUl | 5,395 | Temporarily pin pydantic test dependency | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.012220 / 0.011353 (0.000867) | 0.005943 / 0.011008 (-0.005065) | 0.128223 / 0.038508 (0.089715) | 0.037352 / 0.023109 (0.014242) | 0.397143 / 0.275898 (0.121245) | 0.483935 / 0.323480 (0.160455) | 0.010279 / 0.007986 (0.002293) | 0.004842 / 0.004328 (0.000513) | 0.101403 / 0.004250 (0.097153) | 0.042935 / 0.037052 (0.005883) | 0.421642 / 0.258489 (0.163153) | 0.456328 / 0.293841 (0.162487) | 0.065639 / 0.128546 (-0.062907) | 0.019820 / 0.075646 (-0.055826) | 0.426090 / 0.419271 (0.006818) | 0.069583 / 0.043533 (0.026051) | 0.402662 / 0.255139 (0.147523) | 0.428826 / 0.283200 (0.145626) | 0.116760 / 0.141683 (-0.024923) | 1.806216 / 1.452155 (0.354061) | 1.852629 / 1.492716 (0.359913) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.226555 / 0.018006 (0.208548) | 0.584693 / 0.000490 (0.584203) | 0.008612 / 0.000200 (0.008412) | 0.000205 / 0.000054 (0.000150) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.028393 / 0.037411 (-0.009018) | 0.123355 / 0.014526 (0.108829) | 0.134423 / 0.176557 (-0.042133) | 0.188536 / 0.737135 (-0.548600) | 0.141595 / 0.296338 (-0.154743) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.589359 / 0.215209 (0.374150) | 5.974655 / 2.077655 (3.897001) | 2.465580 / 1.504120 (0.961460) | 2.007618 / 1.541195 (0.466424) | 2.078788 / 1.468490 (0.610298) | 1.216646 / 4.584777 (-3.368131) | 5.217516 / 3.745712 (1.471804) | 3.107188 / 5.269862 (-2.162674) | 2.251641 / 4.565676 (-2.314036) | 0.138640 / 0.424275 (-0.285635) | 0.015046 / 0.007607 (0.007439) | 0.780092 / 0.226044 (0.554048) | 7.749564 / 2.268929 (5.480635) | 3.080708 / 55.444624 (-52.363917) | 2.393897 / 6.876477 (-4.482579) | 2.387738 / 2.142072 (0.245665) | 1.458844 / 4.805227 (-3.346384) | 0.252476 / 6.500664 (-6.248188) | 0.076594 / 0.075469 (0.001125) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.540868 / 1.841788 (-0.300919) | 17.295684 / 8.074308 (9.221376) | 19.669300 / 10.191392 (9.477908) | 0.250315 / 0.680424 (-0.430109) | 0.045068 / 0.534201 (-0.489133) | 0.538840 / 0.579283 (-0.040443) | 0.584443 / 0.434364 (0.150079) | 0.614476 / 0.540337 (0.074138) | 0.729928 / 1.386936 (-0.657008) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.009218 / 0.011353 (-0.002135) | 0.006261 / 0.011008 (-0.004747) | 0.125541 / 0.038508 (0.087033) | 0.034405 / 0.023109 (0.011296) | 0.468381 / 0.275898 (0.192483) | 0.503336 / 0.323480 (0.179856) | 0.006839 / 0.007986 (-0.001146) | 0.004724 / 0.004328 (0.000396) | 0.097875 / 0.004250 (0.093625) | 0.051278 / 0.037052 (0.014225) | 0.473323 / 0.258489 (0.214834) | 0.537392 / 0.293841 (0.243551) | 0.055588 / 0.128546 (-0.072958) | 0.021041 / 0.075646 (-0.054605) | 0.416952 / 0.419271 (-0.002320) | 0.070128 / 0.043533 (0.026595) | 0.465224 / 0.255139 (0.210085) | 0.504678 / 0.283200 (0.221478) | 0.112504 / 0.141683 (-0.029179) | 1.865865 / 1.452155 (0.413710) | 1.988296 / 1.492716 (0.495580) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.314170 / 0.018006 (0.296164) | 0.526726 / 0.000490 (0.526236) | 0.018691 / 0.000200 (0.018491) | 0.000128 / 0.000054 (0.000073) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.033772 / 0.037411 (-0.003639) | 0.124796 / 0.014526 (0.110270) | 0.134700 / 0.176557 (-0.041856) | 0.190595 / 0.737135 (-0.546541) | 0.143205 / 0.296338 (-0.153133) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.656708 / 0.215209 (0.441499) | 6.470503 / 2.077655 (4.392848) | 2.866430 / 1.504120 (1.362310) | 2.506846 / 1.541195 (0.965651) | 2.548669 / 1.468490 (1.080179) | 1.226695 / 4.584777 (-3.358082) | 5.117866 / 3.745712 (1.372153) | 3.032822 / 5.269862 (-2.237040) | 1.999152 / 4.565676 (-2.566524) | 0.142974 / 0.424275 (-0.281301) | 0.015011 / 0.007607 (0.007404) | 0.799729 / 0.226044 (0.573684) | 8.286313 / 2.268929 (6.017385) | 3.636482 / 55.444624 (-51.808142) | 2.888038 / 6.876477 (-3.988439) | 2.924982 / 2.142072 (0.782910) | 1.471996 / 4.805227 (-3.333231) | 0.257119 / 6.500664 (-6.243545) | 0.077294 / 0.075469 (0.001825) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.608290 / 1.841788 (-0.233497) | 17.599119 / 8.074308 (9.524811) | 18.917086 / 10.191392 (8.725694) | 0.236237 / 0.680424 (-0.444187) | 0.026061 / 0.534201 (-0.508140) | 0.527359 / 0.579283 (-0.051925) | 0.589176 / 0.434364 (0.154812) | 0.602310 / 0.540337 (0.061973) | 0.726756 / 1.386936 (-0.660180) |\n\n</details>\n</details>\n\n\n",
"Issue reported to `pydantic`: \r\n- https://github.com/pydantic/pydantic/issues/4885\r\n\r\nFixing PR at `pydantic`:\r\n- https://github.com/pydantic/pydantic/pull/4886"
] | 1,672,342,459,000 | 1,672,382,217,000 | 1,672,347,626,000 | MEMBER | null | Temporarily pin `pydantic` until a permanent solution is found.
Fix #5394. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5395/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5395/timeline | null | null | 0 | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5395",
"html_url": "https://github.com/huggingface/datasets/pull/5395",
"diff_url": "https://github.com/huggingface/datasets/pull/5395.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5395.patch",
"merged_at": "2022-12-29T21:00:26"
} | true |
https://api.github.com/repos/huggingface/datasets/issues/5394 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5394/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5394/comments | https://api.github.com/repos/huggingface/datasets/issues/5394/events | https://github.com/huggingface/datasets/issues/5394 | 1,513,976,229 | I_kwDODunzps5aPXGl | 5,394 | CI error: TypeError: dataclass_transform() got an unexpected keyword argument 'field_specifiers' | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
}
] | [
"I still getting the same error :\r\n\r\n`python -m spacy download fr_core_news_lg\r\n`.\r\n`import spacy`",
"@MFatnassi, this issue and the corresponding fix only affect our Continuous Integration testing environment.\r\n\r\nNote that `datasets` does not depend on `spacy`."
] | 1,672,340,324,000 | 1,672,396,851,000 | 1,672,347,627,000 | MEMBER | null | ### Describe the bug
While installing the dependencies, the CI raises a TypeError:
```
Traceback (most recent call last):
File "/opt/hostedtoolcache/Python/3.7.15/x64/lib/python3.7/runpy.py", line 183, in _run_module_as_main
mod_name, mod_spec, code = _get_module_details(mod_name, _Error)
File "/opt/hostedtoolcache/Python/3.7.15/x64/lib/python3.7/runpy.py", line 142, in _get_module_details
return _get_module_details(pkg_main_name, error)
File "/opt/hostedtoolcache/Python/3.7.15/x64/lib/python3.7/runpy.py", line 109, in _get_module_details
__import__(pkg_name)
File "/opt/hostedtoolcache/Python/3.7.15/x64/lib/python3.7/site-packages/spacy/__init__.py", line 6, in <module>
from .errors import setup_default_warnings
File "/opt/hostedtoolcache/Python/3.7.15/x64/lib/python3.7/site-packages/spacy/errors.py", line 2, in <module>
from .compat import Literal
File "/opt/hostedtoolcache/Python/3.7.15/x64/lib/python3.7/site-packages/spacy/compat.py", line 3, in <module>
from thinc.util import copy_array
File "/opt/hostedtoolcache/Python/3.7.15/x64/lib/python3.7/site-packages/thinc/__init__.py", line 5, in <module>
from .config import registry
File "/opt/hostedtoolcache/Python/3.7.15/x64/lib/python3.7/site-packages/thinc/config.py", line 2, in <module>
import confection
File "/opt/hostedtoolcache/Python/3.7.15/x64/lib/python3.7/site-packages/confection/__init__.py", line 10, in <module>
from pydantic import BaseModel, create_model, ValidationError, Extra
File "pydantic/__init__.py", line 2, in init pydantic.__init__
File "pydantic/dataclasses.py", line 46, in init pydantic.dataclasses
# | None | Attribute is set to None. |
File "pydantic/main.py", line 121, in init pydantic.main
TypeError: dataclass_transform() got an unexpected keyword argument 'field_specifiers'
```
See: https://github.com/huggingface/datasets/actions/runs/3793736481/jobs/6466356565
### Steps to reproduce the bug
```shell
pip install .[tests,metrics-tests]
python -m spacy download en_core_web_sm
```
### Expected behavior
No error.
### Environment info
See: https://github.com/huggingface/datasets/actions/runs/3793736481/jobs/6466356565 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5394/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5394/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5393 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5393/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5393/comments | https://api.github.com/repos/huggingface/datasets/issues/5393/events | https://github.com/huggingface/datasets/pull/5393 | 1,512,908,613 | PR_kwDODunzps5GTg0a | 5,393 | Finish deprecating the fs argument | {
"login": "dconathan",
"id": 15098095,
"node_id": "MDQ6VXNlcjE1MDk4MDk1",
"avatar_url": "https://avatars.githubusercontent.com/u/15098095?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/dconathan",
"html_url": "https://github.com/dconathan",
"followers_url": "https://api.github.com/users/dconathan/followers",
"following_url": "https://api.github.com/users/dconathan/following{/other_user}",
"gists_url": "https://api.github.com/users/dconathan/gists{/gist_id}",
"starred_url": "https://api.github.com/users/dconathan/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/dconathan/subscriptions",
"organizations_url": "https://api.github.com/users/dconathan/orgs",
"repos_url": "https://api.github.com/users/dconathan/repos",
"events_url": "https://api.github.com/users/dconathan/events{/privacy}",
"received_events_url": "https://api.github.com/users/dconathan/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"_The documentation is not available anymore as the PR was closed or merged._",
"> Thanks for the deprecation. Some minor suggested fixes below...\r\n> \r\n> Also note that the corresponding tests should be updated as well.\r\n\r\nThanks for the suggestions/typo fixes. I updated the failing test - passing locally now",
"Nice thanks !\r\n\r\nI believe you also need to update `_load_info` and `_save_info` in `builder.py` - they're still passing `fs=self._fs` instead of `storage_options=self._fs.storage_options`\r\n\r\nThis should remove the remaining warnings in the CI such as \r\n\r\n```python\r\ntests/test_builder.py::test_builder_with_filesystem_download_and_prepare_reload\r\ntests/test_load.py::test_load_dataset_local[False]\r\ntests/test_load.py::test_load_dataset_local[True]\r\ntests/test_load.py::test_load_dataset_zip_csv[csv_path-False]\r\ntests/test_load.py::test_load_dataset_then_move_then_reload\r\n /opt/hostedtoolcache/Python/3.7.15/x64/lib/python3.7/site-packages/datasets/info.py:344: FutureWarning: 'fs' was deprecated in favor of 'storage_options' in version 2.9.0 and will be removed in 3.0.0.\r\n You can remove this warning by passing 'storage_options=fs.storage_options' instead.\r\n```",
"re: docstring, I assume passing in `storage_options=s3.storage_options` is correct/necessary to pass the secrets?",
"what about \r\nhttps://github.com/huggingface/datasets/blob/5b793dd8c43bf6e85f165238becb3c64f6cd3ed0/src/datasets/filesystems/__init__.py#L43-L54\r\nleave as is? Is this function no longer necessary?",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008877 / 0.011353 (-0.002475) | 0.004725 / 0.011008 (-0.006283) | 0.100738 / 0.038508 (0.062230) | 0.030251 / 0.023109 (0.007141) | 0.301483 / 0.275898 (0.025585) | 0.374161 / 0.323480 (0.050681) | 0.007225 / 0.007986 (-0.000761) | 0.003654 / 0.004328 (-0.000674) | 0.078400 / 0.004250 (0.074149) | 0.035786 / 0.037052 (-0.001267) | 0.309744 / 0.258489 (0.051255) | 0.355834 / 0.293841 (0.061994) | 0.034344 / 0.128546 (-0.094202) | 0.011584 / 0.075646 (-0.064062) | 0.321462 / 0.419271 (-0.097810) | 0.041201 / 0.043533 (-0.002332) | 0.298808 / 0.255139 (0.043669) | 0.332626 / 0.283200 (0.049426) | 0.089131 / 0.141683 (-0.052552) | 1.477888 / 1.452155 (0.025734) | 1.530365 / 1.492716 (0.037649) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.191647 / 0.018006 (0.173640) | 0.424339 / 0.000490 (0.423849) | 0.002941 / 0.000200 (0.002741) | 0.000075 / 0.000054 (0.000020) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.023442 / 0.037411 (-0.013969) | 0.097264 / 0.014526 (0.082738) | 0.105655 / 0.176557 (-0.070901) | 0.145055 / 0.737135 (-0.592081) | 0.108750 / 0.296338 (-0.187588) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.422925 / 0.215209 (0.207716) | 4.216022 / 2.077655 (2.138367) | 1.876441 / 1.504120 (0.372322) | 1.665115 / 1.541195 (0.123920) | 1.711105 / 1.468490 (0.242615) | 0.701820 / 4.584777 (-3.882957) | 3.389319 / 3.745712 (-0.356393) | 1.909868 / 5.269862 (-3.359994) | 1.270482 / 4.565676 (-3.295195) | 0.083680 / 0.424275 (-0.340595) | 0.012347 / 0.007607 (0.004740) | 0.531076 / 0.226044 (0.305031) | 5.344045 / 2.268929 (3.075117) | 2.310897 / 55.444624 (-53.133728) | 1.971953 / 6.876477 (-4.904524) | 2.113748 / 2.142072 (-0.028325) | 0.823766 / 4.805227 (-3.981462) | 0.150864 / 6.500664 (-6.349800) | 0.066263 / 0.075469 (-0.009206) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.253190 / 1.841788 (-0.588598) | 13.757887 / 8.074308 (5.683579) | 13.888195 / 10.191392 (3.696803) | 0.137285 / 0.680424 (-0.543139) | 0.029151 / 0.534201 (-0.505050) | 0.387402 / 0.579283 (-0.191881) | 0.401673 / 0.434364 (-0.032691) | 0.450474 / 0.540337 (-0.089863) | 0.533757 / 1.386936 (-0.853179) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006919 / 0.011353 (-0.004434) | 0.004655 / 0.011008 (-0.006353) | 0.096946 / 0.038508 (0.058438) | 0.028697 / 0.023109 (0.005588) | 0.420020 / 0.275898 (0.144122) | 0.460193 / 0.323480 (0.136713) | 0.005189 / 0.007986 (-0.002796) | 0.003425 / 0.004328 (-0.000904) | 0.074900 / 0.004250 (0.070649) | 0.041844 / 0.037052 (0.004792) | 0.421538 / 0.258489 (0.163049) | 0.468497 / 0.293841 (0.174656) | 0.032573 / 0.128546 (-0.095973) | 0.011731 / 0.075646 (-0.063916) | 0.320221 / 0.419271 (-0.099050) | 0.042113 / 0.043533 (-0.001420) | 0.422757 / 0.255139 (0.167618) | 0.445372 / 0.283200 (0.162172) | 0.090300 / 0.141683 (-0.051383) | 1.458598 / 1.452155 (0.006443) | 1.550060 / 1.492716 (0.057344) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.235489 / 0.018006 (0.217483) | 0.418207 / 0.000490 (0.417718) | 0.002511 / 0.000200 (0.002311) | 0.000080 / 0.000054 (0.000025) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.025603 / 0.037411 (-0.011808) | 0.100237 / 0.014526 (0.085711) | 0.108617 / 0.176557 (-0.067939) | 0.148417 / 0.737135 (-0.588719) | 0.110163 / 0.296338 (-0.186176) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.474804 / 0.215209 (0.259595) | 4.745370 / 2.077655 (2.667715) | 2.417819 / 1.504120 (0.913699) | 2.209892 / 1.541195 (0.668697) | 2.263296 / 1.468490 (0.794806) | 0.695537 / 4.584777 (-3.889240) | 3.381028 / 3.745712 (-0.364684) | 2.952271 / 5.269862 (-2.317591) | 1.507041 / 4.565676 (-3.058636) | 0.083334 / 0.424275 (-0.340941) | 0.012554 / 0.007607 (0.004947) | 0.578861 / 0.226044 (0.352817) | 5.795241 / 2.268929 (3.526313) | 2.858544 / 55.444624 (-52.586080) | 2.516270 / 6.876477 (-4.360207) | 2.557350 / 2.142072 (0.415278) | 0.801799 / 4.805227 (-4.003428) | 0.151579 / 6.500664 (-6.349085) | 0.068765 / 0.075469 (-0.006704) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.279935 / 1.841788 (-0.561853) | 14.049065 / 8.074308 (5.974757) | 13.972703 / 10.191392 (3.781311) | 0.140551 / 0.680424 (-0.539873) | 0.016831 / 0.534201 (-0.517370) | 0.383886 / 0.579283 (-0.195397) | 0.385661 / 0.434364 (-0.048703) | 0.444525 / 0.540337 (-0.095813) | 0.532197 / 1.386936 (-0.854739) |\n\n</details>\n</details>\n\n\n"
] | 1,672,241,597,000 | 1,674,045,753,000 | 1,674,045,332,000 | CONTRIBUTOR | null | See #5385 for some discussion on this
The `fs=` arg was depcrecated from `Dataset.save_to_disk` and `Dataset.load_from_disk` in `2.8.0` (to be removed in `3.0.0`). There are a few other places where the `fs=` arg was still used (functions/methods in `datasets.info` and `datasets.load`). This PR adds a similar behavior, warnings and the `storage_options=` arg to these functions and methods.
One question: should the "deprecated" / "added" versions be `2.8.1` for the docs/warnings on these? Right now I'm going with "fs was deprecated in 2.8.0" but "storage_options= was added in 2.8.1" where appropriate.
@mariosasko | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5393/reactions",
"total_count": 2,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 2,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5393/timeline | null | null | 0 | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5393",
"html_url": "https://github.com/huggingface/datasets/pull/5393",
"diff_url": "https://github.com/huggingface/datasets/pull/5393.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5393.patch",
"merged_at": "2023-01-18T12:35:32"
} | true |
https://api.github.com/repos/huggingface/datasets/issues/5392 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5392/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5392/comments | https://api.github.com/repos/huggingface/datasets/issues/5392/events | https://github.com/huggingface/datasets/pull/5392 | 1,512,712,529 | PR_kwDODunzps5GS2DF | 5,392 | Fix Colab notebook link | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.011196 / 0.011353 (-0.000157) | 0.006039 / 0.011008 (-0.004969) | 0.122497 / 0.038508 (0.083989) | 0.043884 / 0.023109 (0.020774) | 0.372982 / 0.275898 (0.097084) | 0.444229 / 0.323480 (0.120749) | 0.009489 / 0.007986 (0.001503) | 0.004612 / 0.004328 (0.000284) | 0.093921 / 0.004250 (0.089670) | 0.052698 / 0.037052 (0.015646) | 0.372327 / 0.258489 (0.113838) | 0.426586 / 0.293841 (0.132745) | 0.046755 / 0.128546 (-0.081792) | 0.014848 / 0.075646 (-0.060799) | 0.410474 / 0.419271 (-0.008798) | 0.058206 / 0.043533 (0.014674) | 0.367051 / 0.255139 (0.111912) | 0.389950 / 0.283200 (0.106750) | 0.120857 / 0.141683 (-0.020826) | 1.795195 / 1.452155 (0.343040) | 1.823938 / 1.492716 (0.331222) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.215199 / 0.018006 (0.197192) | 0.482420 / 0.000490 (0.481930) | 0.001834 / 0.000200 (0.001634) | 0.000099 / 0.000054 (0.000044) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.034483 / 0.037411 (-0.002928) | 0.135503 / 0.014526 (0.120977) | 0.149991 / 0.176557 (-0.026565) | 0.198482 / 0.737135 (-0.538653) | 0.153556 / 0.296338 (-0.142783) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.504492 / 0.215209 (0.289283) | 4.950949 / 2.077655 (2.873294) | 2.251186 / 1.504120 (0.747067) | 2.049195 / 1.541195 (0.508000) | 2.123325 / 1.468490 (0.654835) | 0.865651 / 4.584777 (-3.719126) | 4.652297 / 3.745712 (0.906585) | 4.417260 / 5.269862 (-0.852602) | 2.362390 / 4.565676 (-2.203287) | 0.098845 / 0.424275 (-0.325430) | 0.014675 / 0.007607 (0.007068) | 0.608048 / 0.226044 (0.382003) | 6.063863 / 2.268929 (3.794935) | 2.753041 / 55.444624 (-52.691583) | 2.340961 / 6.876477 (-4.535516) | 2.511934 / 2.142072 (0.369862) | 0.989297 / 4.805227 (-3.815930) | 0.195770 / 6.500664 (-6.304894) | 0.076027 / 0.075469 (0.000558) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.479617 / 1.841788 (-0.362170) | 18.917860 / 8.074308 (10.843552) | 18.219594 / 10.191392 (8.028202) | 0.218494 / 0.680424 (-0.461930) | 0.037207 / 0.534201 (-0.496994) | 0.571543 / 0.579283 (-0.007741) | 0.527884 / 0.434364 (0.093520) | 0.658661 / 0.540337 (0.118324) | 0.755449 / 1.386936 (-0.631487) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008762 / 0.011353 (-0.002591) | 0.006019 / 0.011008 (-0.004989) | 0.118756 / 0.038508 (0.080248) | 0.039584 / 0.023109 (0.016474) | 0.400127 / 0.275898 (0.124229) | 0.468114 / 0.323480 (0.144634) | 0.006771 / 0.007986 (-0.001215) | 0.004689 / 0.004328 (0.000360) | 0.087274 / 0.004250 (0.083023) | 0.055548 / 0.037052 (0.018496) | 0.419901 / 0.258489 (0.161412) | 0.459516 / 0.293841 (0.165675) | 0.044197 / 0.128546 (-0.084349) | 0.014162 / 0.075646 (-0.061484) | 0.409634 / 0.419271 (-0.009638) | 0.058668 / 0.043533 (0.015135) | 0.404758 / 0.255139 (0.149619) | 0.431562 / 0.283200 (0.148363) | 0.122361 / 0.141683 (-0.019322) | 1.726597 / 1.452155 (0.274442) | 1.798977 / 1.492716 (0.306260) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.250831 / 0.018006 (0.232825) | 0.489811 / 0.000490 (0.489321) | 0.000490 / 0.000200 (0.000290) | 0.000071 / 0.000054 (0.000016) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.035666 / 0.037411 (-0.001745) | 0.134899 / 0.014526 (0.120374) | 0.153156 / 0.176557 (-0.023401) | 0.202409 / 0.737135 (-0.534726) | 0.157350 / 0.296338 (-0.138989) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.522464 / 0.215209 (0.307254) | 5.204449 / 2.077655 (3.126794) | 2.617410 / 1.504120 (1.113290) | 2.406246 / 1.541195 (0.865052) | 2.494487 / 1.468490 (1.025997) | 0.834923 / 4.584777 (-3.749854) | 4.794186 / 3.745712 (1.048474) | 2.617939 / 5.269862 (-2.651922) | 1.648310 / 4.565676 (-2.917367) | 0.109785 / 0.424275 (-0.314490) | 0.015217 / 0.007607 (0.007610) | 0.682970 / 0.226044 (0.456926) | 6.853894 / 2.268929 (4.584966) | 3.277150 / 55.444624 (-52.167475) | 2.832502 / 6.876477 (-4.043975) | 2.984874 / 2.142072 (0.842802) | 1.005307 / 4.805227 (-3.799921) | 0.200623 / 6.500664 (-6.300041) | 0.076852 / 0.075469 (0.001383) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.556656 / 1.841788 (-0.285131) | 19.088978 / 8.074308 (11.014669) | 16.946406 / 10.191392 (6.755014) | 0.204419 / 0.680424 (-0.476004) | 0.021456 / 0.534201 (-0.512745) | 0.523603 / 0.579283 (-0.055680) | 0.530067 / 0.434364 (0.095703) | 0.604058 / 0.540337 (0.063721) | 0.731531 / 1.386936 (-0.655405) |\n\n</details>\n</details>\n\n\n"
] | 1,672,227,893,000 | 1,672,760,174,000 | 1,672,759,651,000 | MEMBER | null | Fix notebook link to open in Colab. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5392/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5392/timeline | null | null | 0 | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5392",
"html_url": "https://github.com/huggingface/datasets/pull/5392",
"diff_url": "https://github.com/huggingface/datasets/pull/5392.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5392.patch",
"merged_at": "2023-01-03T15:27:31"
} | true |
https://api.github.com/repos/huggingface/datasets/issues/5391 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5391/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5391/comments | https://api.github.com/repos/huggingface/datasets/issues/5391/events | https://github.com/huggingface/datasets/issues/5391 | 1,510,350,400 | I_kwDODunzps5aBh5A | 5,391 | Whisper Event - RuntimeError: The size of tensor a (504) must match the size of tensor b (448) at non-singleton dimension 1 100% 1000/1000 [2:52:21<00:00, 10.34s/it] | {
"login": "catswithbats",
"id": 12885107,
"node_id": "MDQ6VXNlcjEyODg1MTA3",
"avatar_url": "https://avatars.githubusercontent.com/u/12885107?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/catswithbats",
"html_url": "https://github.com/catswithbats",
"followers_url": "https://api.github.com/users/catswithbats/followers",
"following_url": "https://api.github.com/users/catswithbats/following{/other_user}",
"gists_url": "https://api.github.com/users/catswithbats/gists{/gist_id}",
"starred_url": "https://api.github.com/users/catswithbats/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/catswithbats/subscriptions",
"organizations_url": "https://api.github.com/users/catswithbats/orgs",
"repos_url": "https://api.github.com/users/catswithbats/repos",
"events_url": "https://api.github.com/users/catswithbats/events{/privacy}",
"received_events_url": "https://api.github.com/users/catswithbats/received_events",
"type": "User",
"site_admin": false
} | [] | open | false | null | [] | [
"Hey @catswithbats! Super sorry for the late reply! This is happening because there is data with label length (504) that exceeds the model's max length (448). \r\n\r\nThere are two options here:\r\n1. Increase the model's `max_length` parameter: \r\n```python\r\nmodel.config.max_length = 512\r\n```\r\n2. Filter data with labels longer than max length: https://discuss.huggingface.co/t/open-to-the-community-whisper-fine-tuning-event/26681/21?u=sanchit-gandhi\r\n\r\nNote that the datasets repo is reserved for issues directly related to the HF datasets library. Issues related to custom fine-tuning implementations are more applicable to the HF Forum: https://discuss.huggingface.co. You're more likely to get a response by posting your issue in the most applicable place and boost the chance of someone sharing a working solution!",
"@sanchit-gandhi Thank you for all your work on this topic.\r\n\r\nI'm finding that changing the `max_length` value does not make this error go away."
] | 1,671,981,434,000 | 1,687,732,076,000 | null | NONE | null | Done in a VM with a GPU (Ubuntu) following the [Whisper Event - PYTHON](https://github.com/huggingface/community-events/tree/main/whisper-fine-tuning-event#python-script) instructions.
Attempted using [RuntimeError: he size of tensor a (504) must match the size of tensor b (448) at non-singleton dimension 1 100% 1000/1000 - WEB](https://discuss.huggingface.co/t/trainer-runtimeerror-the-size-of-tensor-a-462-must-match-the-size-of-tensor-b-448-at-non-singleton-dimension-1/26010/10 ) - another person experiencing the same issue. But could not resolve the issue with the google/fleurs data. __Not clear what can be modified in the PY code to resolve the input data size mismatch, as the training data is already very small__.
Tried posting on Discord, @sanchit-gandhi and @vaibhavs10. Was hoping that the event is over and some input/help is now available. [Hugging Face - whisper-small-amet](https://huggingface.co/drmeeseeks/whisper-small-amet).
The paper [Robust Speech Recognition via Large-Scale Weak Supervision](https://arxiv.org/abs/2212.04356) am_et is a low resource language (Table E), with the WER results ranging from 120-229, based on model size. (Whisper small WER=120.2).
# ---> Initial Training Output
/usr/local/lib/python3.8/dist-packages/transformers/optimization.py:306: FutureWarning: This implementation of AdamW is deprecated and will be removed in a future version. Use the PyTorch implementation torch.optim.AdamW instead, or set `no_deprecation_warning=True` to disable this warning
warnings.warn(
[INFO|trainer.py:1641] 2022-12-18 05:23:28,799 >> ***** Running training *****
[INFO|trainer.py:1642] 2022-12-18 05:23:28,799 >> Num examples = 446
[INFO|trainer.py:1643] 2022-12-18 05:23:28,799 >> Num Epochs = 72
[INFO|trainer.py:1644] 2022-12-18 05:23:28,799 >> Instantaneous batch size per device = 16
[INFO|trainer.py:1645] 2022-12-18 05:23:28,799 >> Total train batch size (w. parallel, distributed & accumulation) = 32
[INFO|trainer.py:1646] 2022-12-18 05:23:28,799 >> Gradient Accumulation steps = 2
[INFO|trainer.py:1647] 2022-12-18 05:23:28,800 >> Total optimization steps = 1000
[INFO|trainer.py:1648] 2022-12-18 05:23:28,801 >> Number of trainable parameters = 241734912
# ---> Error
14% 9/65 [07:07<48:34, 52.04s/it][INFO|configuration_utils.py:523] 2022-12-18 05:03:07,941 >> Generate config GenerationConfig {
"begin_suppress_tokens": [
220,
50257
],
"bos_token_id": 50257,
"decoder_start_token_id": 50258,
"eos_token_id": 50257,
"max_length": 448,
"pad_token_id": 50257,
"transformers_version": "4.26.0.dev0",
"use_cache": false
}
Traceback (most recent call last):
File "run_speech_recognition_seq2seq_streaming.py", line 629, in <module>
main()
File "run_speech_recognition_seq2seq_streaming.py", line 578, in main
train_result = trainer.train(resume_from_checkpoint=checkpoint)
File "/usr/local/lib/python3.8/dist-packages/transformers/trainer.py", line 1534, in train
return inner_training_loop(
File "/usr/local/lib/python3.8/dist-packages/transformers/trainer.py", line 1859, in _inner_training_loop
self._maybe_log_save_evaluate(tr_loss, model, trial, epoch, ignore_keys_for_eval)
File "/usr/local/lib/python3.8/dist-packages/transformers/trainer.py", line 2122, in _maybe_log_save_evaluate
metrics = self.evaluate(ignore_keys=ignore_keys_for_eval)
File "/usr/local/lib/python3.8/dist-packages/transformers/trainer_seq2seq.py", line 78, in evaluate
return super().evaluate(eval_dataset, ignore_keys=ignore_keys, metric_key_prefix=metric_key_prefix)
File "/usr/local/lib/python3.8/dist-packages/transformers/trainer.py", line 2818, in evaluate
output = eval_loop(
File "/usr/local/lib/python3.8/dist-packages/transformers/trainer.py", line 3000, in evaluation_loop
loss, logits, labels = self.prediction_step(model, inputs, prediction_loss_only, ignore_keys=ignore_keys)
File "/usr/local/lib/python3.8/dist-packages/transformers/trainer_seq2seq.py", line 213, in prediction_step
outputs = model(**inputs)
File "/usr/local/lib/python3.8/dist-packages/torch/nn/modules/module.py", line 1190, in _call_impl
return forward_call(*input, **kwargs)
File "/usr/local/lib/python3.8/dist-packages/transformers/models/whisper/modeling_whisper.py", line 1197, in forward
outputs = self.model(
File "/usr/local/lib/python3.8/dist-packages/torch/nn/modules/module.py", line 1190, in _call_impl
return forward_call(*input, **kwargs)
File "/usr/local/lib/python3.8/dist-packages/transformers/models/whisper/modeling_whisper.py", line 1066, in forward
decoder_outputs = self.decoder(
File "/usr/local/lib/python3.8/dist-packages/torch/nn/modules/module.py", line 1190, in _call_impl
return forward_call(*input, **kwargs)
File "/usr/local/lib/python3.8/dist-packages/transformers/models/whisper/modeling_whisper.py", line 873, in forward
hidden_states = inputs_embeds + positions
RuntimeError: The size of tensor a (504) must match the size of tensor b (448) at non-singleton dimension 1
100% 1000/1000 [2:52:21<00:00, 10.34s/it]
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5391/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5391/timeline | null | null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5390 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5390/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5390/comments | https://api.github.com/repos/huggingface/datasets/issues/5390/events | https://github.com/huggingface/datasets/issues/5390 | 1,509,357,553 | I_kwDODunzps5Z9vfx | 5,390 | Error when pushing to the CI hub | {
"login": "severo",
"id": 1676121,
"node_id": "MDQ6VXNlcjE2NzYxMjE=",
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/severo",
"html_url": "https://github.com/severo",
"followers_url": "https://api.github.com/users/severo/followers",
"following_url": "https://api.github.com/users/severo/following{/other_user}",
"gists_url": "https://api.github.com/users/severo/gists{/gist_id}",
"starred_url": "https://api.github.com/users/severo/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/severo/subscriptions",
"organizations_url": "https://api.github.com/users/severo/orgs",
"repos_url": "https://api.github.com/users/severo/repos",
"events_url": "https://api.github.com/users/severo/events{/privacy}",
"received_events_url": "https://api.github.com/users/severo/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Hmmm, git bisect tells me that the behavior is the same since https://github.com/huggingface/datasets/commit/67e65c90e9490810b89ee140da11fdd13c356c9c (3 Oct), i.e. https://github.com/huggingface/datasets/pull/4926",
"Maybe related to the discussions in https://github.com/huggingface/datasets/pull/5196",
"Maybe the current version of moonlanding in Hub CI is the issue.\r\n\r\nI relaunched tests that were working two days ago: now they are failing. https://github.com/huggingface/datasets-server/commit/746414449cae4b311733f8a76e5b3b4ca73b38a9 for example\r\n\r\ncc @huggingface/moon-landing ",
"Hi! I don't think this has anything to do with `datasets`. Hub CI seems to be the culprit - the identical failure can be found in [this](https://github.com/huggingface/datasets/pull/5389) PR (with unrelated changes) opened today.",
"OK! Thanks for looking at it. Closing then."
] | 1,671,802,597,000 | 1,671,827,342,000 | 1,671,827,342,000 | CONTRIBUTOR | null | ### Describe the bug
Note that it's a special case where the Hub URL is "https://hub-ci.huggingface.co", which does not appear if we do the same on the Hub (https://huggingface.co).
The call to `dataset.push_to_hub(` fails:
```
Pushing dataset shards to the dataset hub: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1/1 [00:01<00:00, 1.93s/it]
Traceback (most recent call last):
File "reproduce_hubci.py", line 16, in <module>
dataset.push_to_hub(repo_id=repo_id, private=False, token=USER_TOKEN, embed_external_files=True)
File "/home/slesage/hf/datasets/src/datasets/arrow_dataset.py", line 5025, in push_to_hub
HfApi(endpoint=config.HF_ENDPOINT).upload_file(
File "/home/slesage/.pyenv/versions/datasets/lib/python3.8/site-packages/huggingface_hub/hf_api.py", line 1346, in upload_file
raise err
File "/home/slesage/.pyenv/versions/datasets/lib/python3.8/site-packages/huggingface_hub/hf_api.py", line 1337, in upload_file
r.raise_for_status()
File "/home/slesage/.pyenv/versions/datasets/lib/python3.8/site-packages/requests/models.py", line 953, in raise_for_status
raise HTTPError(http_error_msg, response=self)
requests.exceptions.HTTPError: 400 Client Error: Bad Request for url: https://hub-ci.huggingface.co/api/datasets/__DUMMY_DATASETS_SERVER_USER__/bug-16718047265472/upload/main/README.md
```
### Steps to reproduce the bug
```python
# reproduce.py
from datasets import Dataset
import time
USER = "__DUMMY_DATASETS_SERVER_USER__"
USER_TOKEN = "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"
dataset = Dataset.from_dict({"a": [1, 2, 3]})
repo_id = f"{USER}/bug-{int(time.time() * 10e3)}"
dataset.push_to_hub(repo_id=repo_id, private=False, token=USER_TOKEN, embed_external_files=True)
```
```bash
$ HF_ENDPOINT="https://hub-ci.huggingface.co" python reproduce.py
```
### Expected behavior
No error and the dataset should be uploaded to the Hub with the README file (which generates the error).
### Environment info
- `datasets` version: 2.8.0
- Platform: Linux-5.15.0-1026-aws-x86_64-with-glibc2.35
- Python version: 3.9.15
- PyArrow version: 7.0.0
- Pandas version: 1.5.2
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5390/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5390/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5389 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5389/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5389/comments | https://api.github.com/repos/huggingface/datasets/issues/5389/events | https://github.com/huggingface/datasets/pull/5389 | 1,509,348,626 | PR_kwDODunzps5GHsOo | 5,389 | Fix link in `load_dataset` docstring | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008935 / 0.011353 (-0.002417) | 0.004582 / 0.011008 (-0.006426) | 0.100950 / 0.038508 (0.062442) | 0.030305 / 0.023109 (0.007196) | 0.299759 / 0.275898 (0.023861) | 0.378577 / 0.323480 (0.055097) | 0.007834 / 0.007986 (-0.000152) | 0.003399 / 0.004328 (-0.000930) | 0.078568 / 0.004250 (0.074318) | 0.037990 / 0.037052 (0.000938) | 0.313025 / 0.258489 (0.054536) | 0.359543 / 0.293841 (0.065702) | 0.033631 / 0.128546 (-0.094916) | 0.011681 / 0.075646 (-0.063966) | 0.324542 / 0.419271 (-0.094729) | 0.041014 / 0.043533 (-0.002519) | 0.302884 / 0.255139 (0.047745) | 0.337059 / 0.283200 (0.053859) | 0.089403 / 0.141683 (-0.052280) | 1.491262 / 1.452155 (0.039108) | 1.521626 / 1.492716 (0.028910) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.172627 / 0.018006 (0.154621) | 0.419406 / 0.000490 (0.418917) | 0.001974 / 0.000200 (0.001775) | 0.000070 / 0.000054 (0.000016) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.023598 / 0.037411 (-0.013814) | 0.098127 / 0.014526 (0.083601) | 0.105611 / 0.176557 (-0.070946) | 0.142612 / 0.737135 (-0.594523) | 0.121687 / 0.296338 (-0.174651) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.418512 / 0.215209 (0.203303) | 4.173099 / 2.077655 (2.095444) | 1.865900 / 1.504120 (0.361780) | 1.664053 / 1.541195 (0.122858) | 1.726289 / 1.468490 (0.257799) | 0.693214 / 4.584777 (-3.891563) | 3.499982 / 3.745712 (-0.245730) | 1.894278 / 5.269862 (-3.375583) | 1.178214 / 4.565676 (-3.387463) | 0.082391 / 0.424275 (-0.341884) | 0.012486 / 0.007607 (0.004878) | 0.532190 / 0.226044 (0.306145) | 5.286612 / 2.268929 (3.017684) | 2.316680 / 55.444624 (-53.127944) | 1.964020 / 6.876477 (-4.912457) | 2.016457 / 2.142072 (-0.125616) | 0.812290 / 4.805227 (-3.992937) | 0.149102 / 6.500664 (-6.351562) | 0.064215 / 0.075469 (-0.011254) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.281919 / 1.841788 (-0.559869) | 14.107509 / 8.074308 (6.033201) | 13.892369 / 10.191392 (3.700977) | 0.146164 / 0.680424 (-0.534260) | 0.028740 / 0.534201 (-0.505460) | 0.395218 / 0.579283 (-0.184066) | 0.406321 / 0.434364 (-0.028043) | 0.460880 / 0.540337 (-0.079458) | 0.545975 / 1.386936 (-0.840961) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006797 / 0.011353 (-0.004556) | 0.004522 / 0.011008 (-0.006486) | 0.098440 / 0.038508 (0.059932) | 0.027722 / 0.023109 (0.004613) | 0.423995 / 0.275898 (0.148097) | 0.456164 / 0.323480 (0.132684) | 0.005156 / 0.007986 (-0.002830) | 0.003439 / 0.004328 (-0.000889) | 0.075307 / 0.004250 (0.071057) | 0.039599 / 0.037052 (0.002547) | 0.423671 / 0.258489 (0.165181) | 0.463841 / 0.293841 (0.170001) | 0.032473 / 0.128546 (-0.096073) | 0.011674 / 0.075646 (-0.063972) | 0.320548 / 0.419271 (-0.098723) | 0.041618 / 0.043533 (-0.001915) | 0.426133 / 0.255139 (0.170994) | 0.443018 / 0.283200 (0.159819) | 0.091103 / 0.141683 (-0.050579) | 1.468758 / 1.452155 (0.016604) | 1.532695 / 1.492716 (0.039978) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.255314 / 0.018006 (0.237308) | 0.422982 / 0.000490 (0.422492) | 0.015405 / 0.000200 (0.015205) | 0.000103 / 0.000054 (0.000049) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.025260 / 0.037411 (-0.012152) | 0.102062 / 0.014526 (0.087537) | 0.108161 / 0.176557 (-0.068395) | 0.144205 / 0.737135 (-0.592930) | 0.111686 / 0.296338 (-0.184653) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.482633 / 0.215209 (0.267424) | 4.824777 / 2.077655 (2.747123) | 2.488626 / 1.504120 (0.984506) | 2.285410 / 1.541195 (0.744215) | 2.336793 / 1.468490 (0.868303) | 0.701894 / 4.584777 (-3.882883) | 3.506908 / 3.745712 (-0.238804) | 3.399789 / 5.269862 (-1.870072) | 1.536359 / 4.565676 (-3.029317) | 0.083621 / 0.424275 (-0.340655) | 0.012702 / 0.007607 (0.005094) | 0.581259 / 0.226044 (0.355215) | 5.829640 / 2.268929 (3.560711) | 2.932201 / 55.444624 (-52.512424) | 2.577175 / 6.876477 (-4.299301) | 2.621782 / 2.142072 (0.479710) | 0.812074 / 4.805227 (-3.993153) | 0.152840 / 6.500664 (-6.347824) | 0.067982 / 0.075469 (-0.007487) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.274915 / 1.841788 (-0.566873) | 14.345800 / 8.074308 (6.271492) | 14.242475 / 10.191392 (4.051083) | 0.143636 / 0.680424 (-0.536788) | 0.016824 / 0.534201 (-0.517377) | 0.376449 / 0.579283 (-0.202834) | 0.394219 / 0.434364 (-0.040145) | 0.435368 / 0.540337 (-0.104969) | 0.518393 / 1.386936 (-0.868544) |\n\n</details>\n</details>\n\n\n",
"I also fixed the rest of the links that point to the markdown files. \r\n\r\nPS: the CI failures are unrelated ",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008641 / 0.011353 (-0.002712) | 0.004560 / 0.011008 (-0.006448) | 0.100559 / 0.038508 (0.062051) | 0.029744 / 0.023109 (0.006635) | 0.300580 / 0.275898 (0.024682) | 0.359100 / 0.323480 (0.035620) | 0.007016 / 0.007986 (-0.000970) | 0.003393 / 0.004328 (-0.000936) | 0.078649 / 0.004250 (0.074399) | 0.038138 / 0.037052 (0.001086) | 0.307730 / 0.258489 (0.049241) | 0.347678 / 0.293841 (0.053837) | 0.033630 / 0.128546 (-0.094917) | 0.011452 / 0.075646 (-0.064194) | 0.320903 / 0.419271 (-0.098369) | 0.042659 / 0.043533 (-0.000874) | 0.298886 / 0.255139 (0.043747) | 0.324371 / 0.283200 (0.041171) | 0.092582 / 0.141683 (-0.049101) | 1.490017 / 1.452155 (0.037863) | 1.512825 / 1.492716 (0.020109) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.178965 / 0.018006 (0.160958) | 0.420001 / 0.000490 (0.419512) | 0.002686 / 0.000200 (0.002486) | 0.000071 / 0.000054 (0.000017) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.023568 / 0.037411 (-0.013843) | 0.097027 / 0.014526 (0.082502) | 0.104721 / 0.176557 (-0.071836) | 0.148757 / 0.737135 (-0.588378) | 0.110849 / 0.296338 (-0.185489) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.415034 / 0.215209 (0.199825) | 4.155249 / 2.077655 (2.077594) | 1.837027 / 1.504120 (0.332907) | 1.627754 / 1.541195 (0.086559) | 1.687958 / 1.468490 (0.219468) | 0.699542 / 4.584777 (-3.885235) | 3.376707 / 3.745712 (-0.369005) | 2.900778 / 5.269862 (-2.369083) | 1.556168 / 4.565676 (-3.009508) | 0.082438 / 0.424275 (-0.341837) | 0.012339 / 0.007607 (0.004732) | 0.524952 / 0.226044 (0.298907) | 5.269852 / 2.268929 (3.000924) | 2.278770 / 55.444624 (-53.165854) | 1.917987 / 6.876477 (-4.958490) | 1.955000 / 2.142072 (-0.187072) | 0.821169 / 4.805227 (-3.984058) | 0.149019 / 6.500664 (-6.351645) | 0.064604 / 0.075469 (-0.010865) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.199768 / 1.841788 (-0.642020) | 13.760897 / 8.074308 (5.686589) | 13.911550 / 10.191392 (3.720158) | 0.161727 / 0.680424 (-0.518697) | 0.028615 / 0.534201 (-0.505586) | 0.393917 / 0.579283 (-0.185366) | 0.392524 / 0.434364 (-0.041840) | 0.451763 / 0.540337 (-0.088574) | 0.536880 / 1.386936 (-0.850056) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006407 / 0.011353 (-0.004946) | 0.004420 / 0.011008 (-0.006588) | 0.097244 / 0.038508 (0.058736) | 0.027114 / 0.023109 (0.004005) | 0.412512 / 0.275898 (0.136614) | 0.448189 / 0.323480 (0.124709) | 0.005831 / 0.007986 (-0.002155) | 0.005423 / 0.004328 (0.001095) | 0.076051 / 0.004250 (0.071801) | 0.038828 / 0.037052 (0.001776) | 0.414586 / 0.258489 (0.156097) | 0.457196 / 0.293841 (0.163355) | 0.031615 / 0.128546 (-0.096931) | 0.011542 / 0.075646 (-0.064104) | 0.316967 / 0.419271 (-0.102304) | 0.041278 / 0.043533 (-0.002254) | 0.411371 / 0.255139 (0.156232) | 0.436376 / 0.283200 (0.153177) | 0.090212 / 0.141683 (-0.051471) | 1.461831 / 1.452155 (0.009677) | 1.606515 / 1.492716 (0.113799) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.221453 / 0.018006 (0.203447) | 0.404140 / 0.000490 (0.403650) | 0.000422 / 0.000200 (0.000222) | 0.000060 / 0.000054 (0.000005) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.024588 / 0.037411 (-0.012824) | 0.098604 / 0.014526 (0.084078) | 0.113682 / 0.176557 (-0.062874) | 0.141141 / 0.737135 (-0.595994) | 0.110069 / 0.296338 (-0.186270) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.477267 / 0.215209 (0.262058) | 4.775086 / 2.077655 (2.697431) | 2.445449 / 1.504120 (0.941329) | 2.242220 / 1.541195 (0.701025) | 2.303542 / 1.468490 (0.835051) | 0.693448 / 4.584777 (-3.891329) | 3.413319 / 3.745712 (-0.332393) | 3.052734 / 5.269862 (-2.217127) | 1.434075 / 4.565676 (-3.131602) | 0.082429 / 0.424275 (-0.341846) | 0.012594 / 0.007607 (0.004987) | 0.584259 / 0.226044 (0.358214) | 5.865098 / 2.268929 (3.596169) | 2.926301 / 55.444624 (-52.518324) | 2.572555 / 6.876477 (-4.303921) | 2.608584 / 2.142072 (0.466512) | 0.805029 / 4.805227 (-4.000198) | 0.151247 / 6.500664 (-6.349417) | 0.067142 / 0.075469 (-0.008327) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.285454 / 1.841788 (-0.556334) | 14.296425 / 8.074308 (6.222117) | 14.147278 / 10.191392 (3.955886) | 0.151698 / 0.680424 (-0.528726) | 0.016876 / 0.534201 (-0.517325) | 0.383302 / 0.579283 (-0.195981) | 0.388461 / 0.434364 (-0.045902) | 0.438286 / 0.540337 (-0.102051) | 0.525249 / 1.386936 (-0.861687) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008677 / 0.011353 (-0.002676) | 0.004863 / 0.011008 (-0.006145) | 0.096606 / 0.038508 (0.058098) | 0.034004 / 0.023109 (0.010895) | 0.296362 / 0.275898 (0.020464) | 0.323445 / 0.323480 (-0.000035) | 0.007341 / 0.007986 (-0.000644) | 0.005518 / 0.004328 (0.001189) | 0.073584 / 0.004250 (0.069334) | 0.041471 / 0.037052 (0.004419) | 0.302183 / 0.258489 (0.043694) | 0.339369 / 0.293841 (0.045528) | 0.037375 / 0.128546 (-0.091171) | 0.011827 / 0.075646 (-0.063819) | 0.330723 / 0.419271 (-0.088549) | 0.048751 / 0.043533 (0.005218) | 0.298370 / 0.255139 (0.043231) | 0.317781 / 0.283200 (0.034582) | 0.097488 / 0.141683 (-0.044195) | 1.456242 / 1.452155 (0.004088) | 1.530149 / 1.492716 (0.037433) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.207053 / 0.018006 (0.189046) | 0.438165 / 0.000490 (0.437675) | 0.001161 / 0.000200 (0.000961) | 0.000078 / 0.000054 (0.000024) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.025353 / 0.037411 (-0.012059) | 0.105536 / 0.014526 (0.091010) | 0.116122 / 0.176557 (-0.060434) | 0.151605 / 0.737135 (-0.585530) | 0.121777 / 0.296338 (-0.174561) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.402780 / 0.215209 (0.187571) | 4.017882 / 2.077655 (1.940227) | 1.813111 / 1.504120 (0.308991) | 1.620000 / 1.541195 (0.078805) | 1.649186 / 1.468490 (0.180696) | 0.687523 / 4.584777 (-3.897254) | 3.712595 / 3.745712 (-0.033117) | 2.038535 / 5.269862 (-3.231326) | 1.414794 / 4.565676 (-3.150882) | 0.083357 / 0.424275 (-0.340918) | 0.012032 / 0.007607 (0.004425) | 0.502899 / 0.226044 (0.276854) | 5.038914 / 2.268929 (2.769985) | 2.250476 / 55.444624 (-53.194148) | 1.919954 / 6.876477 (-4.956523) | 1.930928 / 2.142072 (-0.211144) | 0.826634 / 4.805227 (-3.978593) | 0.161599 / 6.500664 (-6.339066) | 0.061356 / 0.075469 (-0.014113) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.228998 / 1.841788 (-0.612790) | 14.587914 / 8.074308 (6.513606) | 14.237514 / 10.191392 (4.046122) | 0.190913 / 0.680424 (-0.489510) | 0.029104 / 0.534201 (-0.505097) | 0.436160 / 0.579283 (-0.143123) | 0.431464 / 0.434364 (-0.002900) | 0.511670 / 0.540337 (-0.028668) | 0.609046 / 1.386936 (-0.777890) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006980 / 0.011353 (-0.004373) | 0.005260 / 0.011008 (-0.005748) | 0.095288 / 0.038508 (0.056780) | 0.032465 / 0.023109 (0.009356) | 0.410799 / 0.275898 (0.134901) | 0.423814 / 0.323480 (0.100334) | 0.005533 / 0.007986 (-0.002452) | 0.005764 / 0.004328 (0.001436) | 0.070713 / 0.004250 (0.066462) | 0.048193 / 0.037052 (0.011141) | 0.405742 / 0.258489 (0.147253) | 0.458773 / 0.293841 (0.164932) | 0.036415 / 0.128546 (-0.092131) | 0.012192 / 0.075646 (-0.063454) | 0.330655 / 0.419271 (-0.088617) | 0.055945 / 0.043533 (0.012412) | 0.407497 / 0.255139 (0.152358) | 0.421496 / 0.283200 (0.138296) | 0.106285 / 0.141683 (-0.035398) | 1.459837 / 1.452155 (0.007683) | 1.573147 / 1.492716 (0.080431) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.205776 / 0.018006 (0.187770) | 0.441523 / 0.000490 (0.441033) | 0.003073 / 0.000200 (0.002873) | 0.000092 / 0.000054 (0.000037) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.029207 / 0.037411 (-0.008205) | 0.110295 / 0.014526 (0.095770) | 0.130233 / 0.176557 (-0.046324) | 0.157489 / 0.737135 (-0.579647) | 0.125374 / 0.296338 (-0.170965) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.440942 / 0.215209 (0.225733) | 4.389647 / 2.077655 (2.311992) | 2.234883 / 1.504120 (0.730763) | 2.029510 / 1.541195 (0.488315) | 2.082503 / 1.468490 (0.614013) | 0.698046 / 4.584777 (-3.886731) | 3.769127 / 3.745712 (0.023415) | 2.058511 / 5.269862 (-3.211351) | 1.324302 / 4.565676 (-3.241375) | 0.085695 / 0.424275 (-0.338580) | 0.012122 / 0.007607 (0.004515) | 0.552406 / 0.226044 (0.326362) | 5.527073 / 2.268929 (3.258145) | 2.711354 / 55.444624 (-52.733270) | 2.328848 / 6.876477 (-4.547629) | 2.340750 / 2.142072 (0.198678) | 0.846300 / 4.805227 (-3.958927) | 0.167465 / 6.500664 (-6.333199) | 0.063419 / 0.075469 (-0.012050) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.262452 / 1.841788 (-0.579336) | 15.043537 / 8.074308 (6.969229) | 14.212563 / 10.191392 (4.021171) | 0.170229 / 0.680424 (-0.510194) | 0.017696 / 0.534201 (-0.516505) | 0.423194 / 0.579283 (-0.156089) | 0.430908 / 0.434364 (-0.003456) | 0.491733 / 0.540337 (-0.048604) | 0.599267 / 1.386936 (-0.787669) |\n\n</details>\n</details>\n\n\n",
"Program enthusiastic "
] | 1,671,801,991,000 | 1,674,673,243,000 | 1,674,578,018,000 | CONTRIBUTOR | null | Fix https://github.com/huggingface/datasets/issues/5387, fix https://github.com/huggingface/datasets/issues/4566 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5389/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5389/timeline | null | null | 0 | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5389",
"html_url": "https://github.com/huggingface/datasets/pull/5389",
"diff_url": "https://github.com/huggingface/datasets/pull/5389.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5389.patch",
"merged_at": "2023-01-24T16:33:38"
} | true |
https://api.github.com/repos/huggingface/datasets/issues/5388 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5388/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5388/comments | https://api.github.com/repos/huggingface/datasets/issues/5388/events | https://github.com/huggingface/datasets/issues/5388 | 1,509,042,348 | I_kwDODunzps5Z8iis | 5,388 | Getting Value Error while loading a dataset.. | {
"login": "valmetisrinivas",
"id": 51160232,
"node_id": "MDQ6VXNlcjUxMTYwMjMy",
"avatar_url": "https://avatars.githubusercontent.com/u/51160232?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/valmetisrinivas",
"html_url": "https://github.com/valmetisrinivas",
"followers_url": "https://api.github.com/users/valmetisrinivas/followers",
"following_url": "https://api.github.com/users/valmetisrinivas/following{/other_user}",
"gists_url": "https://api.github.com/users/valmetisrinivas/gists{/gist_id}",
"starred_url": "https://api.github.com/users/valmetisrinivas/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/valmetisrinivas/subscriptions",
"organizations_url": "https://api.github.com/users/valmetisrinivas/orgs",
"repos_url": "https://api.github.com/users/valmetisrinivas/repos",
"events_url": "https://api.github.com/users/valmetisrinivas/events{/privacy}",
"received_events_url": "https://api.github.com/users/valmetisrinivas/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Hi! I can't reproduce this error locally (Mac) or in Colab. What version of `datasets` are you using?",
"Hi [mariosasko](https://github.com/mariosasko), the datasets version is '2.8.0'.",
"@valmetisrinivas you get that error because you imported `datasets` (and thus `fsspec`) before installing `zstandard`.\r\n\r\nPlease, restart your Colab runtime and execute the install commands before importing `datasets`:\r\n```python\r\n!pip install datasets\r\n!pip install zstandard\r\n\r\nfrom datasets import load_dataset\r\n\r\nds = load_dataset(\r\n \"json\",\r\n data_files=\"https://the-eye.eu/public/AI/pile_preliminary_components/FreeLaw_Opinions.jsonl.zst\",\r\n split=\"train\",\r\n streaming=True,\r\n)\r\nnext(iter(ds))\r\n```",
"> @valmetisrinivas you get that error because you imported `datasets` (and thus `fsspec`) before installing `zstandard`.\r\n> \r\n> Please, restart your Colab runtime and execute the install commands before importing `datasets`:\r\n> \r\n> ```python\r\n> !pip install datasets\r\n> !pip install zstandard\r\n> \r\n> from datasets import load_dataset\r\n> \r\n> ds = load_dataset(\r\n> \"json\",\r\n> data_files=\"https://the-eye.eu/public/AI/pile_preliminary_components/FreeLaw_Opinions.jsonl.zst\",\r\n> split=\"train\",\r\n> streaming=True,\r\n> )\r\n> next(iter(ds))\r\n> ```\r\n\r\nI guess that was the problem, importing datasets before the installation of zstandard. Thank you for the feedback. "
] | 1,671,783,403,000 | 1,672,302,993,000 | 1,672,163,949,000 | NONE | null | ### Describe the bug
I am trying to load a dataset using Hugging Face Datasets load_dataset method. I am getting the value error as show below. Can someone help with this? I am using Windows laptop and Google Colab notebook.
```
WARNING:datasets.builder:Using custom data configuration default-a1d9e8eaedd958cd
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
[<ipython-input-12-5b4fdcb8e6d5>](https://localhost:8080/#) in <module>
6 )
7
----> 8 next(iter(law_dataset_streamed))
17 frames
[/usr/local/lib/python3.8/dist-packages/fsspec/core.py](https://localhost:8080/#) in get_compression(urlpath, compression)
485 compression = infer_compression(urlpath)
486 if compression is not None and compression not in compr:
--> 487 raise ValueError("Compression type %s not supported" % compression)
488 return compression
489
ValueError: Compression type zstd not supported
```
### Steps to reproduce the bug
```
!pip install zstandard
from datasets import load_dataset
lds = load_dataset(
"json",
data_files="https://the-eye.eu/public/AI/pile_preliminary_components/FreeLaw_Opinions.jsonl.zst",
split="train",
streaming=True,
)
```
### Expected behavior
I expect an iterable object as the output 'lds' to be created.
### Environment info
Windows laptop with Google Colab notebook | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5388/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5388/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5387 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5387/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5387/comments | https://api.github.com/repos/huggingface/datasets/issues/5387/events | https://github.com/huggingface/datasets/issues/5387 | 1,508,740,177 | I_kwDODunzps5Z7YxR | 5,387 | Missing documentation page : improve-performance | {
"login": "astariul",
"id": 43774355,
"node_id": "MDQ6VXNlcjQzNzc0MzU1",
"avatar_url": "https://avatars.githubusercontent.com/u/43774355?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/astariul",
"html_url": "https://github.com/astariul",
"followers_url": "https://api.github.com/users/astariul/followers",
"following_url": "https://api.github.com/users/astariul/following{/other_user}",
"gists_url": "https://api.github.com/users/astariul/gists{/gist_id}",
"starred_url": "https://api.github.com/users/astariul/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/astariul/subscriptions",
"organizations_url": "https://api.github.com/users/astariul/orgs",
"repos_url": "https://api.github.com/users/astariul/repos",
"events_url": "https://api.github.com/users/astariul/events{/privacy}",
"received_events_url": "https://api.github.com/users/astariul/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Hi! Our documentation builder does not support links to sections, hence the bug. This is the link it should point to https://huggingface.co/docs/datasets/v2.8.0/en/cache#improve-performance."
] | 1,671,757,977,000 | 1,674,578,020,000 | 1,674,578,020,000 | NONE | null | ### Describe the bug
Trying to access https://huggingface.co/docs/datasets/v2.8.0/en/package_reference/cache#improve-performance, the page is missing.
The link is in here : https://huggingface.co/docs/datasets/v2.8.0/en/package_reference/loading_methods#datasets.load_dataset.keep_in_memory
### Steps to reproduce the bug
Access the page and see it's missing.
### Expected behavior
Not missing page
### Environment info
Doesn't matter | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5387/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5387/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5386 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5386/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5386/comments | https://api.github.com/repos/huggingface/datasets/issues/5386/events | https://github.com/huggingface/datasets/issues/5386 | 1,508,592,918 | I_kwDODunzps5Z600W | 5,386 | `max_shard_size` in `datasets.push_to_hub()` breaks with large files | {
"login": "salieri",
"id": 1086393,
"node_id": "MDQ6VXNlcjEwODYzOTM=",
"avatar_url": "https://avatars.githubusercontent.com/u/1086393?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/salieri",
"html_url": "https://github.com/salieri",
"followers_url": "https://api.github.com/users/salieri/followers",
"following_url": "https://api.github.com/users/salieri/following{/other_user}",
"gists_url": "https://api.github.com/users/salieri/gists{/gist_id}",
"starred_url": "https://api.github.com/users/salieri/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/salieri/subscriptions",
"organizations_url": "https://api.github.com/users/salieri/orgs",
"repos_url": "https://api.github.com/users/salieri/repos",
"events_url": "https://api.github.com/users/salieri/events{/privacy}",
"received_events_url": "https://api.github.com/users/salieri/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Hi! \r\n\r\nThis behavior stems from the fact that we don't always embed image bytes in the underlying arrow table, which can lead to bad size estimation (we use the first 1000 table rows to [estimate](https://github.com/huggingface/datasets/blob/9a7272cd4222383a5b932b0083a4cc173fda44e8/src/datasets/arrow_dataset.py#L4627) the external file size). We plan to address this in the next major release by always embedding external bytes. In the meantime, you can either shuffle the dataset with `.shuffle().flatten_indices()` to make the estimation more precise or embed the bytes in the table like so:\r\n```python\r\nfrom datasets.table import embed_table_storage\r\nformat = ds.format\r\nds = ds.with_format(\"arrow\")\r\nds = ds.map(embed_table_storage, batched=True)\r\nds = ds.with_format(**format)\r\n...\r\nds.push_to_hub(...)\r\n```",
"Embedding the bytes worked like charm. Thanks @mariosasko!"
] | 1,671,745,858,000 | 1,672,098,351,000 | 1,672,098,351,000 | NONE | null | ### Describe the bug
`max_shard_size` parameter for `datasets.push_to_hub()` works unreliably with large files, generating shard files that are way past the specified limit.
In my private dataset, which contains unprocessed images of all sizes (up to `~100MB` per file), I've encountered cases where `max_shard_size='100MB'` results in shard files that are `>2GB` in size. Setting `max_shard_size` to another value, such as `1GB` or `500MB` does not fix this problem.
**The real problem is this:** When the shard file size grows too big, the entire dataset breaks because of #4721 and ultimately https://issues.apache.org/jira/browse/ARROW-5030. Since `max_shard_size` does not let one accurately control the size of the shard files, it becomes very easy to build a large dataset without any warnings that it will be broken -- even when you think you are mitigating this problem by setting `max_shard_size`.
```
File " /path/to/sd-test-suite-v1/venv/lib/site-packages/datasets/builder.py", line 1763, in _prepare_split_single
for _, table in generator:
File " /path/to/sd-test-suite-v1/venv/lib/site-packages/datasets/packaged_modules/parquet/parquet.py", line 69, in _generate_tables
for batch_idx, record_batch in enumerate(
File "pyarrow/_parquet.pyx", line 1323, in iter_batches
File "pyarrow/error.pxi", line 121, in pyarrow.lib.check_status
pyarrow.lib.ArrowNotImplementedError: Nested data conversions not implemented for chunked array outputs
```
### Steps to reproduce the bug
1. Clone [example repo](https://github.com/salieri/hf-dataset-shard-size-bug)
2. Follow steps in [README.md](https://github.com/salieri/hf-dataset-shard-size-bug/blob/main/README.md)
3. After uploading the dataset, you will see that the shard file size varies between `30MB` and `200MB` -- way beyond the `max_shard_size='75MB'` limit (example: `train-00003-of-00131...` is `155MB` in [here](https://huggingface.co/datasets/slri/shard-size-test/tree/main/data))
(Note that this example repo does not generate shard files that are so large that they would trigger #4721)
### Expected behavior
The shard file size should remain below or equal to `max_shard_size`.
### Environment info
- `datasets` version: 2.8.0
- Platform: Linux-5.10.157-139.675.amzn2.aarch64-aarch64-with-glibc2.17
- Python version: 3.7.15
- PyArrow version: 10.0.1
- Pandas version: 1.3.5 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5386/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5386/timeline | null | completed | null | null | false |