
anchor
stringlengths 1
23.8k
| positive
stringlengths 1
23.8k
| negative
stringlengths 1
31k
| anchor_status
stringclasses 3
values |
|---|---|---|---|
## Inspiration
Recent mass shooting events are indicative of a rising, unfortunate trend in the United States. During a shooting, someone may be killed every 3 seconds on average, while it takes authorities an average of 10 minutes to arrive on a crime scene after a distress call. In addition, cameras and live closed circuit video monitoring are almost ubiquitous now, but are almost always used for post-crime analysis. Why not use them immediately? With the power of Google Cloud and other tools, we can use camera feed to immediately detect weapons real-time, identify a threat, send authorities a pinpointed location, and track the suspect - all in one fell swoop.
## What it does
At its core, our intelligent surveillance system takes in a live video feed and constantly watches for any sign of a gun or weapon. Once detected, the system immediately bounds the weapon, identifies the potential suspect with the weapon, and sends the authorities a snapshot of the scene and precise location information. In parallel, the suspect is matched against a database for any additional information that could be provided to the authorities.
## How we built it
The core of our project is distributed across the Google Cloud framework and AWS Rekognition. A camera (most commonly a CCTV) presents a live feed to a model, which is constantly looking for anything that looks like a gun using GCP's Vision API. Once detected, we bound the gun and nearby people and identify the shooter through a distance calculation. The backend captures all of this information and sends this to check against a cloud-hosted database of people. Then, our frontend pulls from the identified suspect in the database and presents all necessary information to authorities in a concise dashboard which employs the Maps API. As soon as a gun is drawn, the authorities see the location on a map, the gun holder's current scene, and if available, his background and physical characteristics. Then, AWS Rekognition uses face matching to run the threat against a database to present more detail.
## Challenges we ran into
There are some careful nuances to the idea that we had to account for in our project. For one, few models are pre-trained on weapons, so we experimented with training our own model in addition to using the Vision API. Additionally, identifying the weapon holder is a difficult task - sometimes the gun is not necessarily closest to the person holding it. This is offset by the fact that we send a scene snapshot to the authorities, and most gun attacks happen from a distance. Testing is also difficult, considering we do not have access to guns to hold in front of a camera.
## Accomplishments that we're proud of
A clever geometry-based algorithm to predict the person holding the gun. Minimized latency when running several processes at once. Clean integration with a database integrating in real-time.
## What we learned
It's easy to say we're shooting for MVP, but we need to be careful about managing expectations for what features should be part of the MVP and what features are extraneous.
## What's next for HawkCC
As with all machine learning based products, we would train a fresh model on our specific use case. Given the raw amount of CCTV footage out there, this is not a difficult task, but simply a time-consuming one. This would improve accuracy in 2 main respects - cleaner identification of weapons from a slightly top-down view, and better tracking of individuals within the frame. SMS alert integration is another feature that we could easily plug into the surveillance system as well, and further compound the reaction improvement time. | ## Inspiration
One of our teammate’s grandfathers suffers from diabetic retinopathy, which causes severe vision loss.
Looking on a broader scale, over 2.2 billion people suffer from near or distant vision impairment worldwide. After examining the issue closer, it can be confirmed that the issue disproportionately affects people over the age of 50 years old. We wanted to create a solution that would help them navigate the complex world independently.
## What it does
### Object Identification:
Utilizes advanced computer vision to identify and describe objects in the user's surroundings, providing real-time audio feedback.
### Facial Recognition:
It employs machine learning for facial recognition, enabling users to recognize and remember familiar faces, and fostering a deeper connection with their environment.
### Interactive Question Answering:
Acts as an on-demand information resource, allowing users to ask questions and receive accurate answers, covering a wide range of topics.
### Voice Commands:
Features a user-friendly voice command system accessible to all, facilitating seamless interaction with the AI assistant: Sierra.
## How we built it
* Python
* OpenCV
* GCP & Firebase
* Google Maps API, Google Pyttsx3, Google’s VERTEX AI Toolkit (removed later due to inefficiency)
## Challenges we ran into
* Slow response times with Google Products, resulting in some replacements of services (e.g. Pyttsx3 was replaced by a faster, offline nlp model from Vosk)
* Due to the hardware capabilities of our low-end laptops, there is some amount of lag and slowness in the software with average response times of 7-8 seconds.
* Due to strict security measures and product design, we faced a lack of flexibility in working with the Maps API. After working together with each other and viewing some tutorials, we learned how to integrate Google Maps into the dashboard
## Accomplishments that we're proud of
We are proud that by the end of the hacking period, we had a working prototype and software. Both of these factors were able to integrate properly. The AI assistant, Sierra, can accurately recognize faces as well as detect settings in the real world. Although there were challenges along the way, the immense effort we put in paid off.
## What we learned
* How to work with a variety of Google Cloud-based tools and how to overcome potential challenges they pose to beginner users.
* How to connect a smartphone to a laptop with a remote connection to create more opportunities for practical designs and demonstrations.
How to connect a smartphone to a laptop with a remote connection to create more opportunities for practical designs and demonstrations.
How to create docker containers to deploy google cloud-based flask applications to host our dashboard.
How to develop Firebase Cloud Functions to implement cron jobs. We tried to developed a cron job that would send alerts to the user.
## What's next for Saight
### Optimizing the Response Time
Currently, the hardware limitations of our computers create a large delay in the assistant's response times. By improving the efficiency of the models used, we can improve the user experience in fast-paced environments.
### Testing Various Materials for the Mount
The physical prototype of the mount was mainly a proof-of-concept for the idea. In the future, we can conduct research and testing on various materials to find out which ones are most preferred by users. Factors such as density, cost and durability will all play a role in this decision. | ## Inspiration
We were inspired by all the people who go along their days thinking that no one can actually relate to what they are experiencing. The Covid-19 pandemic has taken a mental toll on many of us and has kept us feeling isolated. We wanted to make an easy to use web-app which keeps people connected and allows users to share their experiences with other users that can relate to them.
## What it does
Alone Together connects two matching people based on mental health issues they have in common. When you create an account you are prompted with a list of the general mental health categories that most fall under. Once your account is created you are sent to the home screen and entered into a pool of individuals looking for someone to talk to. When Alone Together has found someone with matching mental health issues you are connected to that person and forwarded to a chat room. In this chat room there is video-chat and text-chat. There is also an icebreaker question box that you can shuffle through to find a question to ask the person you are talking to.
## How we built it
Alone Together is built with React as frontend, a backend in Golang (using Gorilla for websockets), WebRTC for video and text chat, and Google Firebase for authentication and database. The video chat is built from scratch using WebRTC and signaling with the Golang backend.
## Challenges we ran into
This is our first remote Hackathon and it is also the first ever Hackathon for one of our teammates (Alex Stathis)! Working as a team virtually was definitely a challenge that we were ready to face. We had to communicate a lot more than we normally would to make sure that we stayed consistent with our work and that there was no overlap.
As for the technical challenges, we decided to use WebRTC for our video chat feature. The documentation for WebRTC was not the easiest to understand, since it is still relatively new and obscure. This also means that it is very hard to find resources on it. Despite all this, we were able to implement the video chat feature! It works, we just ran out of time to host it on a cloud server with SSL, meaning the video is not sent on localhost (no encryption). Google App Engine also doesn't allow websockets in standard mode, and also doesn't allow `go.mod` on `flex` mode, which was inconvenient and we didn't have time to rewrite parts of our webapp.
## Accomplishments that we're proud of
We are very proud for bringing our idea to life and working as a team to make this happen! WebRTC was not easy to implement, but hard work pays off.
## What we learned
We learned that whether we work virtually together or physically together we can create anything we want as long as we stay curious and collaborative!
## What's next for Alone Together
In the future, we would like to allow our users to add other users as friends. This would mean in addition of meeting new people with the same mental health issues as them, they could build stronger connections with people that they have already talked to.
We would also allow users to have the option to add moderation with AI. This would offer a more "supervised" experience to the user, meaning that if our AI detects any dangerous change of behavior we would provide the user with tools to help them or (with the authorization of the user) we would give the user's phone number to appropriate authorities to contact them. | winning |
## Inspiration
In today’s day and age, there are countless datasets available containing valuable information about any given location. This includes analytics based on urban infrastructures (dangerous intersections), traffic, and many more. Using these datasets and recent data analytics techniques, a modernized approach can be taken to support insurance companies with ideas to calculate effective and accurate premiums for their clients. So, we created Surely Insured, a platform that leverages this data and supports the car insurance industry. With the help and support from administrations and businesses, our platform can help many insurance companies by providing a modernized approach to make better decisions for pricing car insurance premiums.
## What it does
Surely Insured provides car insurance companies with a data-driven edge on calculating premiums for their clients.
Given a location, Surely Insured provides a whole suite of information that the insurance company can use to make better decisions on insurance premium pricing. More specifically, it provides possible factors or reasons for why your client's insurance premium should be higher or lower.
Moreover, Surely Insured serves three main purposes:
* Create a modernized approach to present traffic incidents and severity scores
* Provide analytics to help create effective insurance premiums
* Use the Google Maps Platform Geocoding API, Google Maps Platform Maps JavaScript API, and various Geotab Ignition datasets to extract valuable data for the analytics.
## How we built it
* We built the web app using React as the front-end framework and Flask as the back-end framework.
* We used the Google Maps Platform Maps Javascript API to dynamically display the map.
* We used the Google Maps Platform Geocoding API to get the latitude and longitude given the inputted address.
* We used three different Geotab Ignition datasets (HazardousDrivingAreas, IdlingAreas, ServiceCenterMetrics) to calculate metrics (with Pandas) based on the customer's location.
## Challenges we ran into
* Integrating the Google Maps Platform JavaScript API and Google Maps Platform Geocoding API with the front-end was a challenge.
* There were a lot of features to incorporate in this project, given the time constraints. However, we were able to accomplish the primary purpose of our project, which was to provide car insurance companies an effective method to calculate premiums for their clients.
* Not being able to communicate face to face meant we had to rely on digital apps, which made it difficult to brainstorm concepts and ideas. This was exceptionally challenging when we had to work together to discuss potential changes or help debug issues.
* Brainstorming a way to combine multiple API prizes in an ambitious manner was quite a creative exercise and our idea had gone through multiple iterations until it was refined.
## Accomplishments that we're proud of
We're proud that our implementation of the Google Maps Platform APIs works as we intended. We're also proud of having the front-end and back-end working simultaneously and the overall accomplishment of successfully incorporating multiple features into one platform.
## What we learned
* We learned how to use the Google Maps Platform Map JavaScript API and Geocoding API.
* Some of us improved our understanding of how to use Git for large team projects.
## What's next for Surely Insured
* We want to integrate other data sets to Surely Insured. For example, in addition to hazardous driving areas, we could also use weather patterns to assess whether insurance premiums should be high or low. \* Another possible feature is to give the user a quantitative price quote based on location in addition to traditional factors such as age and gender. | ## Inspiration
One of the biggest problems during this COVID-19 pandemic and these awful times in general is that thousands of people are filing for property and casualty insurance. As a result, insurance companies are receiving an influx of insurance claims, causing longer processing times. These delays not only hurt the company, but also negatively impact the people who filed the claims, as the payout could be essential.
We wanted to tackle these problems with our website, Smooth Claiminal. Our platform uses natural language algorithms to speed up the insurance claiming process. With the help and support from governments and businesses, our platform can save many lives during the current pandemic crisis, while easing the burdens on the employees working at insurance companies or banks.
## What it does
Smooth Claiminal serves three main purposes:
* Provides an analytics dashboard for insurance companies
* Uses AI to extract insights from long insurance claims
* Secures data from the claim using blockchain
The analytics dashboard provides insurance companies with information about the previously processed claims, as well as the overall company performance. The upload tab allows for a simplified claim submittal process, as they can be submitted digitally as a PDF or DOCX file.
Once the claim is submitted, our algorithm first scans the text for typos using the Bing Spell Check API by Microsoft Azure. Then, it intelligently summarizes the claim by creating a subset that only contains the most important and relevant information. The text is also passed through a natural language processing algorithm powered by Google Cloud. Our algorithm then parses and refines the information to extract insights such as names, dates, addresses, quotes, etc., and predict the type of insurance claim being processed (i.e. home, health, auto, dental).
Internally, the claim is also assigned a sentiment score, ranging from 0 (very unhappy) to 1 (very happy). The sentimental analysis is powered by GCP, and allows insurance companies to prioritize claims accordingly.
Finally, the claim submissions are stored in a blockchain database built with IPFS and OrbitDB. Our peer to peer network is fast, efficient, and maximizes data integrity through distribution. We also guarantee reliability, as it will remain functional even if the central server crashes.
## How we built it
* Website built with HTML, CSS, and JS for front end, with a Python and Flask back end
* Blockchain database built with IPFS and OrbitDB
* NLP algorithm built with Google Cloud's NL API, Microsoft Azure's Spell Check API, Gensim, and our own Python algorithms
## Challenges we ran into
* Setting up the front end was tough! We had lots of errors from misplaced files and missing dependencies, and resolving these took a lot more time than expected
* Our original BigchainDB was too resource-intensive and didn't work on Windows, so we had to scrap the idea and switch to OrbitDB, which was completely new to all of us
* Not being able to communicate face to face meant we had to rely on digital channels - this was exceptionally challenging when we had to work together to debug any issues
## Accomplishments that we're proud of
* Getting it to work! Most, if not all the technologies were new to us, so we're extremely proud and grateful to have a working NLP algorithm which accurately extracts insights and a working blockchain database. Oh yeah, and all in 36 hours!
* Finishing everything on time! Building our hack and filming the video remotely were daunting tasks, but we were able to work efficiently through everybody's combined efforts
## What we learned
* For some of us, it was our first time using Python as a back end language, so we learned a lot about how it can be used to handle API requests and leverage AI tools
* We explored a new APIs, frameworks, and technologies (like GCP, Azure, and OrbitDB)
## What's next for Smooth Claiminal
* We'd love to expand the number of classifiers for insurance claims, and perhaps increase the accuracy by training a new model with more data
* We also hope to improve the accuracy of the claim summarization and insights extraction
* Adding OCR so we can extract text from images of claims as well
* Expanding this application to more than just insurance claims! We see a diverse use case for Smooth Claiminal, especially for any industry where long applications are still the norm! We're also hoping to build a consumer version of this application, which could help to simplify long documents like terms and conditions, or privacy policies. | ## Inspiration
Currently the insurance claims process is quite labour intensive. A person has to investigate the car to approve or deny a claim, and so we aim to make the alleviate this cumbersome process smooth and easy for the policy holders.
## What it does
Quick Quote is a proof-of-concept tool for visually evaluating images of auto accidents and classifying the level of damage and estimated insurance payout.
## How we built it
The frontend is built with just static HTML, CSS and Javascript. We used Materialize css to achieve some of our UI mocks created in Figma. Conveniently we have also created our own "state machine" to make our web-app more responsive.
## Challenges we ran into
>
> I've never done any machine learning before, let alone trying to create a model for a hackthon project. I definitely took a quite a bit of time to understand some of the concepts in this field. *-Jerry*
>
>
>
## Accomplishments that we're proud of
>
> This is my 9th hackathon and I'm honestly quite proud that I'm still learning something new at every hackathon that I've attended thus far. *-Jerry*
>
>
>
## What we learned
>
> Attempting to do a challenge with very little description of what the challenge actually is asking for is like a toddler a man stranded on an island. *-Jerry*
>
>
>
## What's next for Quick Quote
Things that are on our roadmap to improve Quick Quote:
* Apply google analytics to track user's movement and collect feedbacks to enhance our UI.
* Enhance our neural network model to enrich our knowledge base.
* Train our data with more evalution to give more depth
* Includes ads (mostly auto companies ads). | partial |
## Inspiration
This year's theme was nostalgia, and in an urban environment like Toronto, I often find myself missing the greenspace I grew up with.
## What it does
I Need To Touch Grass allows users to quickly and easily find various natural areas near them, as well as pictures and directions.
## How I built it
I used the Google Maps API to generate a list of nearby natural areas based on user input, pandas to sort and visualize the data, and Django to create a user interface.
## Challenges I ran into
My teammate was unfortunately in the hospital, so I had to do it myself, which was difficult. I didn't accomplish everything I wanted to, but I'm proud of what I did accomplish.
## Accomplishments that I'm proud of
This was my first time using an API, and it was also my first time doing Python full-stack development! I'm proud of myself for learning Django on the job.
## What I learned
Building a web app seems like it would be easy, but it isn't!
## What's next for I Need To Touch Grass
Hopefully finishing all the aspects of Django I didn't get to finish. | ## Inspiration
Because of the current quarantine, many people are discovering new passions and hobbies. We wanted to make an app that would help beginner gardeners to arrange a virtual garden.
## What it does
Gardener lets the user arrange plants on a grid of soil. When the user searches for plants, they can also see helpful information about it.
## How we built it
We used the Django stack, so a python backend and standard html5, css3 and es6 frontend. We implemented the fabric.js library to generate images with interactive properties.
## Challenges we ran into
We were searching for an api that contained the growth time of plants and how much water they require, but we couldn't find one so we couldn't implement our idea for scheduled reminders. We were against web-scraping because it would be difficult to maintain over a long period of time.
## Accomplishments that we're proud of
We are proud that we were able to keep the UI simple and intuitive to use.
## What we learned
We learned that imagining an idea is straightforward compared to finding the data resources to realize that idea. Although realizing the idea may have been difficult, the sheer amount of information we took in and learned is amazing. As individuals, it's difficult to learn based off tutorials on Youtube and blogs, but once you're thrown into the thick of it, you begin to understand the program in a way you never did before.
## What's next for Gardener
Ideally we'll want to package it via docker and then run on a serverless service such as google cloud. Scaling up would be nice after we incorporate the front end with the backend of the api. | ## Inspiration
With COVID-19 forcing many public spaces and recreational facilities to close, people have been spending time outdoors more than ever. It can be boring, though, to visit the same places in your neighbourhood all the time. We created Explore MyCity to generate trails and paths for London, Ontario locals to explore areas of their city they may not have visited otherwise. Using machine learning, we wanted to creatively improve people’s lives.
## Benefits to Community
There are many benefits to this application to the London community. Firstly, this web app encourages people to explore London and can result in accessing city resources and visiting small businesses. It also motivates the community to be physically active and improve their physical and mental health.
## What it does
The user visits the web page and starts the application by picking their criteria for what kind of path they would like to walk on. The two criteria are 1) types of attractions, and 2) distance of the desired path. From the types of attractions, users can select whether they would like to visit trails, parks, public art, and/or trees. From the distance of their desired path, users can pick between ranges of 1-3, 3-5, 5-7, and 7-10 kilometres. Once users have specified their criteria, they click the Submit button and the application displays a trail using a GoogleMaps API with the calculated trail based on the criteria. The trail will be close in length to the input number of kilometres.
Users can also report a maintenance issue they notice on a path by using the dropdown menu on the home page to report an issue. These buttons lead to Service London’s page where issues are reported.
## How we built it
The program uses data from opendata.london.ca for the types of attractions and their addresses or coordinates and use them as .csv files. A python file reads the .csv files, parses each line for the coordinates or address of each attraction for each file, and stores it in a list.
The front-end of the web app was made using HTML pages. To connect the front and back-ends of the web app, we created a Flask web framework. We also connected the GoogleMaps API through Flask.
To get user input, we requested data through Flask and stored them in variables, which were then used as inputs to a python function. When the app loads, the user’s current location is retrieved through the browser using geolocation. Using these inputs, the python file checks which criteria the user selected and calls the appropriate functions. These functions calculate the distance between the user’s location and the nearest attraction; if the distance is within the distance input given, the attraction is added as a stop on the user’s path until no more attractions can be added.
This list of addresses and coordinates is given to the API, which displays the GoogleMaps route to users.
## Challenges we ran into
A challenge we ran into was creating the flask web framework; our team had never done this before so it took some time to learn how to implement it properly. We also ran into challenges with pulling python variables into Javascript. Using the API to display information was also a challenge because we were unfamiliar with the APIs and had to spend more time learning about them.
## Accomplishments that we're proud of
An accomplishment we’re proud of is implementing the GoogleMaps API and GeocodingAPI to create a user-friendly display like that of GoogleMaps. This brought our app to another level in terms of display and was an exciting feature to include. We were also proud of the large amounts of data parsing we did on the government’s data and how we were able to use it so well in combination with the two APIs mentioned above. A big accomplishment was also getting the Flask web framework to work properly, as it was a new skill and was a challenge to complete.
## What we learned
In this hack, we learned how to successfully create a Flask web framework, implement APIs, link python files between each other, and use GitHub correctly. We learned that time management should be a larger priority when it comes to timed hackathons and that ideas should be chosen earlier, even if the idea chosen is not the best. Lastly, we learned that collaboration is very important between team members and between mentors and volunteers.
## What's next for Explore MyCity
Explore MyCity’s next steps are to grow its features and expand its reach to other cities in Ontario and Canada.
Some features that we would add include:
* An option to include recreational (ie. reaching a tennis court, soccer field, etc.) and errand-related layovers; this would encourage users to take a walk and reach the desired target
* Compiling a database of paths generated by the program and keeping a count of how many users have gone on each of these paths. The municipality can know which paths are most used and which attractions are most visited and can allocate more resources to those areas.
* An interactive, social media-like feature that gives users a profile; users can take and upload pictures of the paths they walk on, share these with other local users, add their friends and family on the web app, etc. | losing |
## Inspiration
One of our team members' grandfathers went blind after slipping and hitting his spinal cord, going from a completely independent individual to reliant on others for everything. The lack of options was upsetting, how could a man who was so independent be so severely limited by a small accident. There is current technology out there for blind individuals to navigate their home, however, there is no such technology that allows blind AND frail individuals to do so. With an increasing aging population, Elderlyf is here to be that technology. We hope to help our team member's grandfather and others like him regain his independence by making a tool that is affordable, efficient, and liberating.
## What it does
Ask your Alexa to take you to a room in the house, and Elderlyf will automatically detect which room you're currently in, mapping out a path from your current room to your target room. With vibration disks strategically located underneath the hand rests, Elderlyf gives you haptic feedback to let you know when objects are in your way and in which direction you should turn. With an intelligent turning system, Elderlyf gently helps with turning corners and avoiding obstacles.
## How I built it
With a Jetson Nano and RealSense Cameras, front view obstacles are detected and a map of the possible routes are generated. SLAM localization was also achieved using those technologies. An Alexa and AWS Speech to Text API was used to activate the mapping and navigation algorithms. By using two servo motors that could independently apply a gentle brake to the wheels to aid users when turning and avoiding obstacles. Piezoelectric vibrating disks were also used to provide haptic feedback in which direction to turn and when obstacles are close.
## Challenges I ran into
Mounting the turning assistance system was a HUGE challenge as the setup needed to be extremely stable. We ended up laser-cutting mounting pieces to fix this problem.
## Accomplishments that we're proud of
We're proud of creating a project that is both software and hardware intensive and yet somehow managing to get it finished up and working.
## What I learned
Learned that the RealSense camera really doesn't like working on the Jetson Nano.
## What's next for Elderlyf
Hoping to incorporate a microphone to the walker so that you can ask Alexa to take you to various rooms even though the Alexa may be out of range. | ## Inspiration
In the United States, every 11 seconds, a senior is treated in the emergency room for a fall. Every 19 minutes, an older adult dies from a fall, directly or indirectly. Deteriorating balance is one of the direct causes of falling in seniors. This epidemic will only increase, as the senior population will double by 2060. While we can’t prevent the effects of aging, we can slow down this process of deterioration. Our mission is to create a solution to senior falls with Smart Soles, a shoe sole insert wearable and companion mobile app that aims to improve senior health by tracking balance, tracking number of steps walked, and recommending senior-specific exercises to improve balance and overall mobility.
## What it does
Smart Soles enables seniors to improve their balance and stability by interpreting user data to generate personalized health reports and recommend senior-specific exercises. In addition, academic research has indicated that seniors are recommended to walk 7,000 to 10,000 steps/day. We aim to offer seniors an intuitive and more discrete form of tracking their steps through Smart Soles.
## How we built it
The general design of Smart Soles consists of a shoe sole that has Force Sensing Resistors (FSRs) embedded on it. These FSRs will be monitored by a microcontroller and take pressure readings to take balance and mobility metrics. This data is sent to the user’s smartphone, via a web app to Google App Engine and then to our computer for processing. Afterwards, the output data is used to generate a report whether the user has a good or bad balance.
## Challenges we ran into
**Bluetooth Connectivity**
Despite hours spent on attempting to connect the Arduino Uno and our mobile application directly via Bluetooth, we were unable to maintain a **steady connection**, even though we can transmit the data between the devices. We believe this is due to our hardware, since our HC05 module uses Bluetooth 2.0 which is quite outdated and is not compatible with iOS devices. The problem may also be that the module itself is faulty. To work around this, we can upload the data to the Google Cloud, send it to a local machine for processing, and then send it to the user’s mobile app. We would attempt to rectify this problem by upgrading our hardware to be Bluetooth 4.0 (BLE) compatible.
**Step Counting**
We intended to use a three-axis accelerometer to count the user’s steps as they wore the sole. However, due to the final form factor of the sole and its inability to fit inside a shoe, we were unable to implement this feature.
**Exercise Repository**
Due to a significant time crunch, we were unable to implement this feature. We intended to create a database of exercise videos to recommend to the user. These recommendations would also be based on the balance score of the user.
## Accomplishments that we’re proud of
We accomplished a 65% success rate with our Recurrent Neural Network model and this was our very first time using machine learning! We also successfully put together a preliminary functioning prototype that can capture the pressure distribution.
## What we learned
This hackathon was all new experience to us. We learned about:
* FSR data and signal processing
* Data transmission between devices via Bluetooth
* Machine learning
* Google App Engine
## What's next for Smart Soles
* Bluetooth 4.0 connection to smartphones
* More data points to train our machine learning model
* Quantitative balance score system | # Summary
Echo is an intelligent, environment-aware smart cane that acts as assistive tech for the visually or mentally impaired.
---
## Overview
Over 5 million Americans are living with Alzheimer's. In fact, 1 in 10 people of age 65 and older has Alzheimer's or dementia. Often, those afflicted will have trouble remembering names from faces and recalling memories.
**Echo does exactly that!** Echo is a piece of assistive technology that helps the owner keep track of people he/she meets and provide a way for the owner to stay safe by letting them contact the authorities if they feel like they're in danger.
Using cameras, microphones, and state of the art facial recognition, natural language processing, and speech to text software, Echo is able recognize familiar and new faces allowing patients to confidently meet new people and learn more about the world around them.
When Echo hears an introduction being made, it uses its camera to continuously train itself to recognize the person. Then, if it sees the person again it'll notify its owner that the acquaintance is there. Echo also has a button that, when pressed, will contact the authorities- this way, if the owner is in danger, help is one tap away.
## Frameworks and APIs
* Remembering Faces
+ OpenCV Facial Detection
+ OpenCV Facial Recognition
* Analyzing Speech
+ Google Cloud Speech-To-Text
+ Google Cloud Natural Language Processing
* IoT Communications
+ gstreamer for making TCP video and audio streams
+ SMTP for email capabilities (to contact authorities)
## Challenges
There are many moving parts to Echo. We had to integrate an interface between Natural Language Processing and Facial Recognition. Furthermore, we had to manage a TCP stream between the Raspberry Pi, which interacts with our ML backend on a computer. Ensuring that all the parts seamlessly work involved hours of debugging and unit testing. Furthermore, we had to fine tune parameters such as stream quality to ensure that the Facial Recognition worked but we did not experience high latency, and synchronize the audio and video TCP streams from the Pi.
We wanted to make sure that the form factor of our hack could be experience just by looking at it. On our cane, we have a Raspberry Pi, a camera, and a button. The button is a distress signal, which will alert the selected contacts in the event of an emergency. The camera is part of the TCP stream that is used for facial recognition and training. The stream server and recognition backend are managed by separate Python scripts on either end of the stack. This results in a stable connection between the smart cane and the backend system.
## Echo: The Hacking Process
Echo attempts to solve a simple problem: individuals with Alzheimer's often forget faces easily and need assistance in order to help them socially and functionally in the real world. We rely on the fact that by using AI/ML, we can train a model to help the individual in a way that other solutions cannot. By integrating this with technology like Natural Language Processing, we can create natural interfaces to an important problem.
Echo's form factor shows that its usability in the real world is viable. Furthermore, since we are relying heavily on wireless technologies, it is reasonable to say that it is successful as an Internet of Things (IoT) device.
## Empowering the impaired
Echo empowers the impaired to become more independent and engage in their daily routines. This smart cane acts both as a helpful accessory that can catalyze social interaction and also a watchdog to quickly call help in an emergency. | partial |
## Inspiration
We were heavily focused on the machine learning aspect and realized that we lacked any datasets which could be used to train a model. So we tried to figure out what kind of activity which might impact insurance rates that we could also collect data for right from the equipment which we had.
## What it does
Insurity takes a video feed from a person driving and evaluates it for risky behavior.
## How we built it
We used Node.js, Express, and Amazon's Rekognition API to evaluate facial expressions and personal behaviors.
## Challenges we ran into
This was our third idea. We had to abandon two major other ideas because the data did not seem to exist for the purposes of machine learning. | ## Inspiration
Sign language is already difficult to learn; adding on the difficulty of learning movements from static online pictures makes it next to impossible to do without help. We came up with an elegant robotic solution to remedy this problem.
## What it does
Handy Signbot is a tool that translates voice to sign language, displayed using a set of prosthetic arms. It is a multipurpose sign language device including uses such as: a teaching model for new students, a voice to sign translator for live events, or simply a communication device between voice and sign.
## How we built it
**Physical**: The hand is built from 3D printed parts and is controlled by several servos and pulleys. Those are in turn controlled by Arduinos, housing all the calculations that allow for finger control and semi-spherical XYZ movement in the arm. The entire setup is enclosed and protected by a wooden frame.
**Software**: The bulk of the movement control is written in NodeJS, using the Johnny-Five library for servo control. Voice to text is process using the Nuance API, and text to sign is created with our own database of sign movements.
## Challenges we ran into
The Nuance library was not something we have worked with before, and took plenty of trial and error before we could eventually implement it. Other difficulties included successfully developing a database, and learning to recycle movements to create more with higher efficiency.
## Accomplishments that we're proud of
From calculating inverse trigonometry to processing audio, several areas had to work together for anything to work at all. We are proud that we were able successfully combine so many different parts together for one big project.
## What we learned
We learned about the importance of teamwork and friendship :)
## What's next for Handy Signbot
-Creating a smaller scale model that is more realistic for a home environment, and significantly reducing cost at the same time.
-Reimplement the LeapMotion to train the model for an increased vocabulary, and different accents (did you know you can have an accent in sign language too?). | ## Inspiration
We are inspired by how Machine Learning can streamline a lot of our lives and minimize possible errors which occurs. In the healthcare and financial field, one of the issues which happens the most in the Insurance field is how to best evaluate a quote for the consumer. Therefore, upon seeing the challenge online during the team-formation period, we decided to work on it and devise an algorithm and data model for each consumers, along with a simple app for consumers to use on the front end.
## What it does
Upon starting the app, the user can check to see different plans offered by the company. It is listed in a ScrollView Table and customers can hence have a simple idea of what kind of deals/packages there are. Then, the user can proceed to the "Information" page, and fill out their personal information to request a quotation from the system, where the user data is transmitted to our server and the predictions are being made there. Then, the app is returned with a suitable plan for the user, along with other data graphs to illustrate the general demographics of the participants of the program.
## How we built it
The app is built using React-Native, which is cross-platform compatible for iOS, Android and WebDev. While for the model, we used r and python to train it. We also used Kibana to perform data visualization and elasticsearch as the server.
## Challenges we ran into
It is hard to come up with more filters in further perfecting our model with the sample data set from observing the patterns within the data set.
## Accomplishments that we're proud of
Improving the accuracy of the model by two times the original that we started off with by applying different filters and devising different algorithms.
## What we learned
We are now more proficient in terms of training models, developing React Native applications, and using Machine Learning in solving daily life problems by spotting out data patterns and utilizing them to come up with algorithms for the data set.
## What's next for ViHack
Further fine-tuning of the recognition model to improve upon the percentage of correct predictions of our currently-trained model . | winning |
## Presentation + Award
See the presentation and awards ceremony here: <https://www.youtube.com/watch?v=jd8-WVqPKKo&t=351s&ab_channel=JoshuaQin>
## Inspiration
Back when we first came to the Yale campus, we were stunned by the architecture and the public works of art. One monument in particular stood out to us - the *Lipstick (Ascending) on Caterpillar Tracks* in the Morse College courtyard, for its oddity and its prominence. We learned from fellow students about the background and history behind the sculpture, as well as more personal experiences on how students used and interacted with the sculpture over time.
One of the great joys of traveling to new places is to learn about the community from locals, information which is often not recorded anywhere else. From monuments to parks to buildings, there are always interesting fixtures in a community with stories behind them that would otherwise go untold. We wanted to create a platform for people to easily discover and share those stories with one another.
## What it does
Our app allows anybody to point their phone camera at an interesting object, snap a picture of it, and learn more about the story behind it. Users also have the ability to browse interesting fixtures in the area around them, add new fixtures and stories by themselves, or modify and add to existing stories with their own information and experiences.
In addition to user-generated content, we also wrote scripts that scraped Wikipedia for geographic location, names, and descriptions of interesting monuments from around the New Haven community. The data we scraped was used both for testing purposes and to serve as initial data for the app, to encourage early adoption.
## How we built it
We used a combination of GPS location data and Google Cloud's image comparison tools to take any image snapped of a fixture and identify in our database what the object is. Our app is able to identify any fixture by first considering all the known fixtures within a fixed radius around the user, and then considering the similarity between known images of those fixtures and the image sent in by the user. Once we have identified the object, we provide a description of the object to the user. Our app also provides endpoints for members of the community to contribute their knowledge by modifying descriptions.
Our client application is a PWA written in React, which allows us to quickly deploy a lightweight and mobile-friendly app on as many devices as possible. Our server is written in Flask and Python, and we use Redis for our data store.
We used GitHub for source control and collaboration and organized our project by breaking it into three layers and providing each their separate repository in a GitHub organization. We used GitHub projects and issues to keep track of our to-dos and assign roles to different members of the team.
## Challenges we ran into
The first challenge that we ran into is that Google Cloud's image comparison tools were designed to recognize products rather than arbitrary images, which still worked well for our purposes but required us to implement workarounds. Because products couldn't be tagged by geographic data and could only be tagged under product categories, we were unable to optimize our image recognition to a specific geographic area, which could pose challenges to scaling. One workaround that we discussed was to implement several regions with overlapping fixtures, so that the image comparisons could be limited to any given user's immediate surroundings.
This was also the first time that many of us had used Flask before, and we had a difficult time choosing an appropriate architecture and structure. As a result, the integration between the frontend, middleware, and AI engine has not been completely finished, although each component is fully functional on its own. In addition, our team faced various technical difficulties throughout the duration of the hackathon.
## Accomplishments that we're proud of
We're proud of completing a fully functional PWA frontend, for effectively scraping 220+ locations from Wikipedia to populate our initial set of data, and for successfully implementing the Google Cloud's image comparison tools to meet our requirements, despite its limitations.
## What we learned
Many of the tools that we worked on in this hackathon were new to the members working on them. We learned a lot about Google Cloud's image recognition tools, progressive web applications, and Flask with Python-based web development.
## What's next for LOCA
We believe that our project is both unique and useful. Our next steps are to finish the integration between our three layers, add authentication and user roles, and implement a Wikipedia-style edit history record in order to keep track of changes over time. We would also want to add features to the app that would reward members of the community for their contributions, to encourage active participants. | ## Inspiration
The memory palace, also known as the method of loci, is a technique used to memorize large amounts of information, such as long grocery lists or vocabulary words. First, think of a familiar place in your life. Second, imagine the sequence of objects from the list along a path leading around your chosen location. Lastly, take a walk along your path and recall the information that you associated with your surroundings. It's quite simple, but extraordinarily effective. We've seen tons of requests on Internet forums for a program that can generate a simulator to make it easier to "build" the palace, so we decided to develop an app that satisfies this demand — and for our own practicality, too.
## What it does
Our webapp begins with a list provided by the user. We extract the individual words from the list and generate random images of these words from Flickr, a photo-sharing website. Then, we insert these images into a Google Streetview map that the user can walk through. The page displays the Google Streetview with the images. When walking near a new item from his/her list, a short melody (another mnemonic trick) is played based on the word. As an optional feature of the program, the user can take the experience to a whole new level through Google Cardboard by accessing the website on a smart device.
## How we built it
We started by searching for two APIs: one that allows for 3D interaction with an environment, and one that can find image URLs off the web based on Strings. For the first, we used Google Streetview, and for the second, we used a Flickr API. We used the Team Maps Street Overlay Demo as a jumping off point for inserting images into street view.
Used JavaScript, HTML, CSS
## Challenges we ran into
All of us are very new to JavaScript. It was a struggle to get different parts of the app to interact with each other asynchronously.
## Accomplishments that we're proud of
Building a functional web app with no prior experience
Creating melodies based on Strings
Virtual reality rendering using Google Cardboard
Website design
## What we learned
JavaScript, HTML, CSS
## What's next for Souvenir
Mobile app
More accurate image search
Integrating jingles | ## Inspiration
As college students, we didn't know anything, so we thought about how we can change that. One way was by being smarter about the way we take care of our unused items. We all felt that our unused items could be used in better ways through sharing with other students on campus. All of us shared our items on campus with our friends but we felt that there could be better ways to do this. However, we were truly inspired after one of our team members, and close friend, Harish, an Ecological Biology major, informed us about the sheer magnitude of trash and pollution in the oceans and the surrounding environments. Also, as the National Ocean Science Bowl Champion, Harish truly was able to educate the rest of the team on how areas such as the Great Pacific Garbage Patch affect the wildlife and oceanic ecosystems, and the effects we face on a daily basis from this. With our passions for technology, we wanted to work on an impactful project that caters to a true need for sharing that many of us have while focusing on maintaining sustainability.
## What it does
The application essentially works to allow users to list various products that they want to share with the community and allows users to request items. If one user sees a request they want to provide a tool for or an offer they find appealing, they’ll start a chat with the user through the app to request the tool. Furthermore, the app sorts and filters by location to make it convenient for users. Also, by allowing for community building through the chat messaging, we want to use
## How we built it
We first, focused on wireframing and coming up with ideas. We utilized brainstorming sessions to come up with unique ideas and then split our team based on our different skill sets. Our front-end team worked on coming up with wireframes and creating designs using Figma. Our backend team worked on a whiteboard, coming up with the system design of our application server, and together the front-end and back-end teams worked on coming up with the schemas for the database.
We utilized the MERN technical stack in order to build this. Our front-end uses ReactJS in order to build the web app, our back-end utilizes ExpressJS and NodeJS, while our database utilizes MongoDB.
We also took plenty of advice and notes, not only from mentors throughout the competition, but also our fellow hackers. We really went around trying to ask for others’ advice on our web app and our final product to truly flush out the best product that we could. We had a customer-centric mindset and approach throughout the full creation process, and we really wanted to look and make sure that what we are building has a true need and is truly wanted by the people. Taking advice from these various sources helped us frame our product and come up with features.
## Challenges we ran into
Integration challenges were some of the toughest for us. Making sure that the backend and frontend can communicate well was really tough, so what we did to minimize the difficulties. We designed the schemas for our databases and worked well with each other to make sure that we were all on the same page for our schemas. Thus, working together really helped to make sure that we were making sure to be truly efficient.
## Accomplishments that we're proud of
We’re really proud of our user interface of the product. We spent quite a lot of time working on the design (through Figma) before creating it in React, so we really wanted to make sure that the product that we are showing is visually appealing.
Furthermore, our backend is also something we are extremely proud of. Our backend system has many unconventional design choices (like for example passing common ids throughout the systems) in order to avoid more costly backend operations. Overall, latency and cost and ease of use for our frontend team was a big consideration when designing the backend system
## What we learned
We learned new technical skills and new soft skills. Overall in our technical skills, our team became much stronger with using the MERN frameworks. Our front-end team learned so many new skills and components through React and our back-end team learned so much about Express. Overall, we also learned quite a lot about working as a team and integrating the front end with the back-end, improving our software engineering skills
The soft skills that we learned about are how we should be presenting a product idea and product implementation. We worked quite a lot on our video and our final presentation to the judges and after speaking with hackers and mentors alike, we were able to use the collective wisdom that we gained in order to really feel that we created a video that shows truly our interest in designing important products with true social impact. Overall, we felt that we were able to convey our passion for building social impact and sustainability products.
## What's next for SustainaSwap
We’re looking to deploy the app in local communities as we’re at the point of deployment currently. We know there exists a clear demand for this in college towns, so we’ll first be starting off at our local campus of Philadelphia. Also, after speaking with many Harvard and MIT students on campus, we feel that Cambridge will also benefit, so we will shortly launch in the Boston/Cambridge area.
We will be looking to expand to other college towns and use this to help to work on the scalability of the product. We ideally, also want to push for the ideas of sustainability, so we would want to potentially use the platform (if it grows large enough) to host fundraisers and fundraising activities to give back in order to fight climate change.
We essentially want to expand city by city, community by community, because this app also focuses quite a lot on community and we want to build a community-centric platform. We want this platform to just build tight-knit communities within cities that can connect people with their neighbors while also promoting sustainability. | winning |
## Inspiration
Bubble tea is no longer a choice between a milk tea or fruit tea. Thousands of combinations exist, from the type of tea, toppings and the type of milk. Overwhelmed by the sheer amount of choices we have for bubble tea in Toronto, we felt inspired to create an application that could simplify our search for our bubble tea of choice.
## What it does
It helps the user find bubble tea shops based on geolocation and allows to view menus before you head over to the shop. It also allows store owners to partner with the application and allow their customers to place mobile orders.
## How we built it
Initial concepts were generated using Adobe Illustrator and later was implemented into the form of the application. It was built using Node.js for the back end and React for the front end. Google Firebase was used for handling the database and cloud functions. Google Maps API was used to generate a map with markers of bubble tea shops near the user. Material UI was used to stylize and create components for the application.
## Challenges we ran into
One of our initial challenge was connecting Google Firebase to React, and collecting information from queries. The majority of our issues that we ran into were stylistic problems that arose from trying to convert the concept images to a satisfactory application.
## Accomplishments that we're proud of
For the back end, we learned how to use Google Firebase to store our data and retrieve data from the database. We were also able to reinforce our knowledge of Node.js, React.js, and Material UI.
## What we learned
We learned how to store, utilize, and manipulate data within a database for the use in an application. We also learned how to read and utilize APIs such as the Google Maps API.
## What's next for SipMore
First, we would like develop fully functional iOS and Android apps as well as complete our current web application. Next, we would like to partner with bubble tea shops throughout Toronto and possibly expand into the Greater Toronto Area (GTA). | # FNAF VR: Study or Get Scared! 🎮📚👻
## 🎉 Inspiration
I LOVE *Five Nights at Freddy's* (FNAF)! 😍 But... sometimes I *really* don’t feel like studying 😅. So why not mash them together? 🎯 Now, with *FNAF VR*, you can play and study at the same time! Studying has never been this thrilling—answer questions or get spooked! 😱
## 😎 What it Does
Step into a spooky FNAF world where you’ll have to answer questions to stay safe! 🧐 If you get it right (and fast ⏰), you win! 🎉 But… if time runs out or you answer wrong… get ready for a jumpscare that’ll give you chills! 👾💥
## 🛠 How We Built It
This awesome (and scary 👀) mashup came together with:
* **Unity** for building the FNAF atmosphere 🎮
* **C#** to keep the gameplay smooth ⚙️
* **Meta Quest 3** for full VR immersion 👓
* **Gemini** to generate all kinds of fun and tricky questions! 💡
## 😬 Challenges We Ran Into
Getting the spooky lighting just right! 💡🕯️ We wanted it to be creepy enough to give you goosebumps but still clear enough to see the questions. Balancing horror with learning = not easy! 😅
## 🎉 Accomplishments We’re Proud Of
We made our first-ever VR horror game!! 🎉🤩 We’re super proud of mixing FNAF thrills with a fun, educational twist. Learning has never been so spooky and exciting! 👻📚
## 🚀 What’s Next for FNAF VR
We’ve got BIG plans! 🚀 Here’s what’s coming:
* More topics to learn from! 📖🎓
* Adjustable difficulty levels for even scarier (or easier) fun! 🎯
* Tons more questions to keep you on your toes! 🧠
* AI that makes the questions even smarter and more personalized! 🤖✨
So get ready to *study or scream* with *FNAF VR*—because learning should be as fun (and terrifying) as a jumpscare! 😱🎉📚 | ## Inspiration
I like web design, I like 90's web design, and I like 90's tech. So it all came together very naturally.
## What it does
nineties.tech is a love letter to the silly, chunky, and experimental technology of the 90s. There's a Brian Eno quote about how we end up cherishing the annoyances of "outdated" tech: *Whatever you now find weird, ugly, uncomfortable and nasty about a new medium will surely become its signature.* I think this attitude persists today, and making a website in 90s web design style helped me put myself in the shoes of web designers from 30 years ago (albeit, with flexbox!)
## How we built it
Built with Sveltekit, pure CSS and HTML, deployed with Cloudflare, domain name from get.tech.
## Challenges we ran into
First time using Cloudflare. I repeatedly tried to deploy a non-working branch and was close to tears. Then I exited out to the Deployments page and realized that the fix I'd thrown into the config file actually worked.
## Accomplishments that we're proud of
Grinded out this website in the span of a few hours; came up with a cool domain name; first time deploying a website through Cloudflare; first time using Svelte.
## What we learned
My friend Ivan helped me through the process of starting off with Svelte and serving sites through Cloudflare. This will be used for further nefarious and well-intentioned purposes in the future.
## What's next for nineties.tech
User submissions? Longer, better-written out entries? Branch the site out into several different pages instead of putting everything into one page? Adding a classic 90's style navigation sidebar? Many ideas... | losing |
## Inspiration
1 in 2 Canadians will personally experience a mental health issue by age 40, with minority communities at a greater risk. As the mental health epidemic surges and support at its capacity, we sought to build something to connect trained volunteer companions with people in distress in several ways for convenience.
## What it does
Vulnerable individuals are able to call or text any available trained volunteers during a crisis. If needed, they are also able to schedule an in-person meet-up for additional assistance. A 24/7 chatbot is also available to assist through appropriate conversation. You are able to do this anonymously, anywhere, on any device to increase accessibility and comfort.
## How I built it
Using Figma, we designed the front end and exported the frame into Reacts using Acovode for back end development.
## Challenges I ran into
Setting up the firebase to connect to the front end react app.
## Accomplishments that I'm proud of
Proud of the final look of the app/site with its clean, minimalistic design.
## What I learned
The need for mental health accessibility is essential but unmet still with all the recent efforts. Using Figma, firebase and trying out many open-source platforms to build apps.
## What's next for HearMeOut
We hope to increase chatbot’s support and teach it to diagnose mental disorders using publicly accessible data. We also hope to develop a modeled approach with specific guidelines and rules in a variety of languages. | ## Inspiration
Every year hundreds of thousands of preventable deaths occur due to the lack of first aid knowledge in our societies. Many lives could be saved if the right people are in the right places at the right times. We aim towards connecting people by giving them the opportunity to help each other in times of medical need.
## What it does
It is a mobile application that is aimed towards connecting members of our society together in times of urgent medical need. Users can sign up as respondents which will allow them to be notified when people within a 300 meter radius are having a medical emergency. This can help users receive first aid prior to the arrival of an ambulance or healthcare professional greatly increasing their chances of survival. This application fills the gap between making the 911 call and having the ambulance arrive.
## How we built it
The app is Android native and relies heavily on the Google Cloud Platform. User registration and authentication is done through the use of Fireauth. Additionally, user data, locations, help requests and responses are all communicated through the Firebase Realtime Database. Lastly, the Firebase ML Kit was also used to provide text recognition for the app's registration page. Users could take a picture of their ID and their information can be retracted.
## Challenges we ran into
There were numerous challenges in terms of handling the flow of data through the Firebase Realtime Database and providing the correct data to authorized users.
## Accomplishments that we're proud of
We were able to build a functioning prototype! Additionally we were able to track and update user locations in a MapFragment and ended up doing/implementing things that we had never done before. | ## Inspiration
Our inspiration comes from many of our own experiences with dealing with mental health and self-care, as well as from those around us. We know what it's like to lose track of self-care, especially in our current environment, and wanted to create a digital companion that could help us in our journey of understanding our thoughts and feelings. We were inspired to create an easily accessible space where users could feel safe in confiding in their mood and check-in to see how they're feeling, but also receive encouraging messages throughout the day.
## What it does
Carepanion allows users an easily accessible space to check-in on their own wellbeing and gently brings awareness to self-care activities using encouraging push notifications. With Carepanion, users are able to check-in with their personal companion and log their wellbeing and self-care for the day, such as their mood, water and medication consumption, amount of exercise and amount of sleep. Users are also able to view their activity for each day and visualize the different states of their wellbeing during different periods of time. Because it is especially easy for people to neglect their own basic needs when going through a difficult time, Carepanion sends periodic notifications to the user with messages of encouragement and assurance as well as gentle reminders for the user to take care of themselves and to check-in.
## How we built it
We built our project through the collective use of Figma, React Native, Expo and Git. We first used Figma to prototype and wireframe our application. We then developed our project in Javascript using React Native and the Expo platform. For version control we used Git and Github.
## Challenges we ran into
Some challenges we ran into included transferring our React knowledge into React Native knowledge, as well as handling package managers with Node.js. With most of our team having working knowledge of React.js but being completely new to React Native, we found that while some of the features of React were easily interchangeable with React Native, some features were not, and we had a tricky time figuring out which ones did and didn't. One example of this is passing props; we spent a lot of time researching ways to pass props in React Native. We also had difficult time in resolving the package files in our application using Node.js, as our team members all used different versions of Node. This meant that some packages were not compatible with certain versions of Node, and some members had difficulty installing specific packages in the application. Luckily, we figured out that if we all upgraded our versions, we were able to successfully install everything. Ultimately, we were able to overcome our challenges and learn a lot from the experience.
## Accomplishments that we're proud of
Our team is proud of the fact that we were able to produce an application from ground up, from the design process to a working prototype. We are excited that we got to learn a new style of development, as most of us were new to mobile development. We are also proud that we were able to pick up a new framework, React Native & Expo, and create an application from it, despite not having previous experience.
## What we learned
Most of our team was new to React Native, mobile development, as well as UI/UX design. We wanted to challenge ourselves by creating a functioning mobile app from beginning to end, starting with the UI/UX design and finishing with a full-fledged application. During this process, we learned a lot about the design and development process, as well as our capabilities in creating an application within a short time frame.
We began by learning how to use Figma to develop design prototypes that would later help us in determining the overall look and feel of our app, as well as the different screens the user would experience and the components that they would have to interact with. We learned about UX, and how to design a flow that would give the user the smoothest experience. Then, we learned how basics of React Native, and integrated our knowledge of React into the learning process. We were able to pick it up quickly, and use the framework in conjunction with Expo (a platform for creating mobile apps) to create a working prototype of our idea.
## What's next for Carepanion
While we were nearing the end of work on this project during the allotted hackathon time, we thought of several ways we could expand and add to Carepanion that we did not have enough time to get to. In the future, we plan on continuing to develop the UI and functionality, ideas include customizable check-in and calendar options, expanding the bank of messages and notifications, personalizing the messages further, and allowing for customization of the colours of the app for a more visually pleasing and calming experience for users. | winning |
## Inspiration
Our project is driven by a clear purpose: to make a real, positive difference in society using technology, especially by fixing how the government works. We're excited about using statistical and reinforcement learning to tackle big issues like the tax gap and to build tools that agencies like the IRS and FDA can use. We're at a key moment for AI and learning technologies. We believe these technologies can hugely improve government efficiency, helping it better serve the community in today's fast-moving world.
## What it does
Our project brings to life a unique system for automating and improving policy-making through AI. It starts by gathering preferences from people or AI on what matters most for societal well-being. Then, it designs a game-like scenario where these preferences guide the creation of policies, aiming to achieve the best outcomes for society. This continuous loop of feedback and improvement allows for experimenting with policies in a safe, simulated environment, making it easier to see what works and what doesn't before implementing these policies in the real world.
## How we built it
We built our system by experimenting with various AI models and hosting solutions. Initially, we tried GPT-3.5 Turbo, Groq, and Together.AI, but decided on self-hosting for optimal performance. We started with Ollama, moved to Mystic, and finally settled on VLLM with RunPod, utilizing tensor parallelism and automatic weight quantization for efficiency.
## Challenges we ran into
Scaling our backend was challenging due to the need for batching inputs and managing resources efficiently. We faced difficulties in finding the right balance between speed and quality, and in deploying models that met our requirements.
## Accomplishments that we're proud of
We're proud of deploying a system capable of running thousands of agents with efficient resource management, particularly our use of VLLM on RunPod with advanced computational strategies, which allowed us to achieve our goals.
## What we learned
We learned a lot about model optimization, the importance of the right hosting environment, and the balance between model size and performance. The experience has been invaluable in understanding how to scale AI systems effectively.
## What's next for Gov.AI
Next, we aim to scale up to 100,000 to 1M agents by refining our token-level encoding scheme, further speeding up processing by an estimated 10x. This expansion will allow for broader experimentation with policies and more nuanced governance decisions, leveraging the full potential of AI to modernize and improve governmental efficiency and responsiveness. Our journey continues as we explore new technologies and methodologies to enhance our system's capabilities, driving forward the mission of Gov.Ai for societal betterment. | We got too tired of watching out government taking commands from special interest groups and corrupt corporations and decided to do something about it. Our platform enables the citizens of the United States, especially our generation, to have our government actually act upon the decisions of its constitutions.
We are dedicated to this project no matter where it takes us.
The program was built as a webpage. We spent most of our time learning about the problem and how to legally and correctly approach it. We also talked to and learned from as many mentors as possible. Unfortunately, due to the magnitude of the project, we were unable to complete any coding aspect but rather have several incomplete parts.
The challenges associated with this project consisted of oscillating levels of functionality for some of the blockchain aspects of the project.
Both of our computers suffered from wifi problems so we were largely unable to access APIs and finish our website, that being said our idea largely evolved and is now a project that we will certainly continue after this Hackathon.
We are planning on finishing and releasing the project within a year. | ## Inspiration
Love is in the air. PennApps is not just about coding, it’s also about having fun hacking! Meeting new friends! Great food! PING PONG <3!
## What it does
When you navigate to any browser it will remind you about how great PennApps was! | losing |
## Inspiration
Transforming 2D images to 3D affects fields that are worth hundreds of BILLIONS of dollars. 3D environments are significant due to several applications and here are some reasons why this conversion is crucial:
Enhanced Visualization and Immersion:
Depth Perception: 3D models provide a clearer understanding of depth and spatial relationships between objects, something that's not easily captured in 2D.
Interactivity: Users can view 3D models from any angle, providing a more comprehensive perspective and interactive experience.
Medical Imaging:
Diagnosis: 3D reconstruction from 2D medical scans, like MRI or CT, allows doctors to view and analyze anomalies in the body more precisely.
Surgery Planning: Surgeons can plan interventions better by visualizing the exact morphology and position of organs, tumors, or vessels in 3D.
Entertainment and Media:
Video Games: Modern games rely on 3D environments and characters for realistic and immersive experiences.
Movies: 3D modeling and animation have become staples in film production, especially in CGI-intensive movies.
However converting 2D to 3D is extremely difficult. There is a steep learning curve, a powerful amount of software needed, and a high cost involved. In this project, we seeked to use the emerging use Gaussian splatting technology to make this process much easier.
## What it does
Leveraging the breakthrough with Gaussian splatting technology, GaussiScape is a web tool that transforms simple 2D imagery into immersive 3D landscapes. With applications spanning virtual/augmented reality, education, and medical imaging we're not just creating a tool—we're pioneering a 3D digital revolution.
GaussiScape takes a collection of images of objects or environments and converts them into a virtual 3D environment, maintaining visuals, shape, and quality. Say goodbye to extreme learning curves, insane costs, and ridiculous softwares.
## How we built it
Frontend: React, JavaScript, Vanilla HTML/CSS
Backend: Flask, Python, Gaussian Splatting, Embeddings, Node.js
## Challenges we ran into
With Gaussian Splatting being such a new technology, we ran into many errors while building our model. Documentation was unclear, not many people had built stuff before on it so there was a lot of trial and error
## Accomplishments that we're proud of
Making a very impressive UI and finishing the project even though we were working with a new technology in unfamiliar territory
## What we learned
We learned to be alot more patient with the process and understand that some functionalities didn’t work with the model simply because it was so new so, we could always find a fix if we worked towards it later down the line
## What's next for GaussiScape
We want to implement these 3D environments into specific fields. Bettering environments in the metaverse, making VR more real, the options are limitless. | ## Inspiration
We discussed on how time consuming it took to write up cover letters for each individual company/organization we applied to. One of us thought of the idea for an AI to auto generate a cover letter. How much time would that save us?
## What it does
The program asks the user to input general information found on cover letters. This includes their contact information, the businesses' name, and so fourth. The program also asks for a job description of the company which they are applying to. They simply need to copy and paste. An AI will proceed to generate a cover letter. This AI is trained based on some given job descriptions and cover letters provided before hand.
## How we built it
We used the React for frontend with Express JS backend, as well as co:here API for machine learning.
## Challenges we ran into
One of the challenging issues was how the API can only take a certain number of words so it made it difficult to train it under a small amount of data. The limit was 2048 word tokens. That jeopardized the quality of cover letters the API produced.
Another issue we ran into was setting up the backend for React as the sample API call for co:here does not execute on React with the standard API implementation. This has cost us a significant amount of time loss trying to get the API working. We had to contact the co:here team for their documentation for React.
## Accomplishments that we're proud of
We have not worked with machine learning API's for so it was a great experience both learning and working with one.
We practiced our website building skills.
Together it was our first Hackathon. Working as a team together was a great experience.
And finally, we are proud having a completed project.
## What we learned
If we organized our ideas and solutions before we actually implemented them, we would have saved a lot of time and energy. Our over all project would be more finer done and would have been better developed.
Preparation is important. We both did not prepare a project idea before coming into the Hackathon so we took some time braining storming ideas.
## What's next for Cover Letter AI
Using the same, perhaps another API to take in more data. Another API that could be used is to summarize the job descriptions given, and also identify the most frequent words of each job description.
Getting a larger data set of cover letters and job descriptions would make the API more accurate. | ## Inspiration
Our inspiration comes from the idea that the **Metaverse is inevitable** and will impact **every aspect** of society.
The Metaverse has recently gained lots of traction with **tech giants** like Google, Facebook, and Microsoft investing into it.
Furthermore, the pandemic has **shifted our real-world experiences to an online environment**. During lockdown, people were confined to their bedrooms, and we were inspired to find a way to basically have **access to an infinite space** while in a finite amount of space.
## What it does
* Our project utilizes **non-Euclidean geometry** to provide a new medium for exploring and consuming content
* Non-Euclidean geometry allows us to render rooms that would otherwise not be possible in the real world
* Dynamically generates personalized content, and supports **infinite content traversal** in a 3D context
* Users can use their space effectively (they're essentially "scrolling infinitely in 3D space")
* Offers new frontier for navigating online environments
+ Has **applicability in endless fields** (business, gaming, VR "experiences")
+ Changing the landscape of working from home
+ Adaptable to a VR space
## How we built it
We built our project using Unity. Some assets were used from the Echo3D Api. We used C# to write the game. jsfxr was used for the game sound effects, and the Storyblocks library was used for the soundscape. On top of all that, this project would not have been possible without lots of moral support, timbits, and caffeine. 😊
## Challenges we ran into
* Summarizing the concept in a relatively simple way
* Figuring out why our Echo3D API calls were failing (it turned out that we had to edit some of the security settings)
* Implementing the game. Our "Killer Tetris" game went through a few iterations and getting the blocks to move and generate took some trouble. Cutting back on how many details we add into the game (however, it did give us lots of ideas for future game jams)
* Having a spinning arrow in our presentation
* Getting the phone gif to loop
## Accomplishments that we're proud of
* Having an awesome working demo 😎
* How swiftly our team organized ourselves and work efficiently to complete the project in the given time frame 🕙
* Utilizing each of our strengths in a collaborative way 💪
* Figuring out the game logic 🕹️
* Our cute game character, Al 🥺
* Cole and Natalie's first in-person hackathon 🥳
## What we learned
### Mathias
* Learning how to use the Echo3D API
* The value of teamwork and friendship 🤝
* Games working with grids
### Cole
* Using screen-to-gif
* Hacking google slides animations
* Dealing with unwieldly gifs
* Ways to cheat grids
### Natalie
* Learning how to use the Echo3D API
* Editing gifs in photoshop
* Hacking google slides animations
* Exposure to Unity is used to render 3D environments, how assets and textures are edited in Blender, what goes into sound design for video games
## What's next for genee
* Supporting shopping
+ Trying on clothes on a 3D avatar of yourself
* Advertising rooms
+ E.g. as your switching between rooms, there could be a "Lululemon room" in which there would be clothes you can try / general advertising for their products
* Custom-built rooms by users
* Application to education / labs
+ Instead of doing chemistry labs in-class where accidents can occur and students can get injured, a lab could run in a virtual environment. This would have a much lower risk and cost.
…the possibility are endless | losing |
## Inspiration
Our app idea brewed from a common shared stressor of networking challenges. Recognizing the lack of available mentorship and struggle to form connections effortlessly, we envisioned a platform that seamlessly paired mentors and students to foster meaningful connections.
## What it does
mocha mentor is a web application that seamlessly pairs students and mentors based on their LinkedIn profiles. It analyzes user LinkedIn profiles, utilizes our dynamic backend structure and Machine Learning algorithm for accurate matching, and then as a result pairs a mentor and student together.
## How we built it
mocha mentor leverages a robust tech stack to enhance the mentor-student connection. MongoDB stores and manages profiles, while an Express.js server is ran on the backend. This server also executes Python scripts which employ pandas for data manipulation, scikit-learn for our ML cosine similarity-based matching algorithm, and reaches into the LinkedIn API for profile extraction. Our frontend was entirely built with React.js.
## Challenges we ran into
The hackathon's constrained timeframe led us to prioritize essential features. Additionally, other challenges we ran into were handling asynchronous events, errors integrating the backend and frontend, working with limited documentation, and running Python scripts efficiently in JavaScript.
## Accomplishments that we're proud of
We are proud of developing a complex technical project that had a diverse tech stack. Our backend was well designed and saved a lot of time when integrating with the frontend. With this year's theme of "Unlocking the Future with AI", we wanted to go beyond using a GPT backend, therefore, we utilized machine learning to develop our matching algorithm that gave accurate matches.
## What we learned
* The importance of good teamwork!
* How to integrate Python scripts in our Express server
* More about AI/ML and Cosine similarities
## What's next for mocha mentor
* Conduct outreach and incorporate community feedback
* Further develop UI
* Expand by adding additional features
* Improve efficiency in algorithms | ## Inspiration
Relationships between mentees and mentors are very important for career success. People want to connect with others in a professional manner to give and receive career advice. While many professional mentoring relationships form naturally, it can be particularly difficult for people in minority groups, such as women and people of color, to find mentors who can relate to their personal challenges and offer genuine advice. This website can provide a platform for those people to find mentors that can help them in their professional career.
## What it does
This web application is a platform that connects mentors and mentees online.
## How we built it
Our team used a MongoDB Atlas database in the backend for users. In addition, the team used jQuery (JavaScript) and Flask (Python) to increase the functionality of the site.
## Challenges we ran into
There were many challenges that we ran into. Some of the biggest ones include authenticating the MongoDB server and connecting jQuery to Python.
## Accomplishments that I'm proud of
We are proud of our ability to create many different aspects of the project in parallel. In addition, we are proud of setting up a cloud database, organizing a multi-page frontend, designing a searching algorithm, and much of the stitching completed in Flask.
## What we learned
We learned a lot about Python, JavaScript, MongoDB, and GET/POST requests.
## What's next for Mentors In Tech
More mentors and advanced searching could further optimize our platform. | ## Inspiration
Everyone in this team has previously been to post-secondary and noticed that their large group of friends have been slowly dwindling since graduation, especially after COVID. It's already well known that once you leave school it's a lot harder to make friends, so we got this idea to make FriendFinder to match you with people with similar hobbies in the same neighbourhood as you.
## What it does
**Find friends!**
When making an account on FriendFinder, you will be asked to input your hobbies, whether you prefer chatting or hanging out, whether you enjoy outdoor activities or not, and your neighbourhood. It then gives other users a relative score based on your profile, with more matching hobbies and preferences having a higher score. Now when ever you log in, the front page will show you a list of people near you with the highest score, allowing you to send them friend requests to start a chat.
## How we built it
**With friends!**
We used HTML, CSS, and Javascript for the frontend and Firebase and Firestore for the backend.
## Challenges we ran into
**Our friends...**
Just kidding. One of the biggest challenges we faced was the short amount of time (24 hours) of this hackathon. Being first year students, we made a project of similar scale in school but over 4 months! Another challenge was that none of us knew how to implement a real time chat app into our project. At first we wanted to learn a new language React and make the chat app beautiful, but due to time constraints, we researched a simpler way to do it just to give it base functionality.
## Accomplishments that we're proud of
**Our friendship survived!**
After the initial scramble to figure out what we were doing, we managed to get a minimum viable product in 24 hours. We are really proud that we incorporated our knowledge from school and learned something new and integrated it together without any major issues.
## What we learned
**Make good friends**
The most important thing we learned is that team work is one of the most important things needed for a good development team. Being able to communicate with your team and dividing work up by each team member's strengths is what made it possible to finish this project within the strict time limit. The hackathon was a really fun experience and we're really glad that we could form a team together.
## What's next for FriendFinder
**More features to find more friends better**
* beautify the app
* add friend / pending friend requests feature
* security/encryption of messages
* report user function
* more detailed hobby selection list for better matching
* update user's profile / hobby selection list at any time
* let users add photos
* group chat function
* rewrite sections of code to become more efficient | partial |
## Inspiration
We all had our own contributions to the creation of our idea; An educational game seemed to suit all of our interests best, allowing us to explore cybersecurity and ethical issues in the future of AI while marvelling at the innovative new-comings of machine learning. In addition, most of us could learn a new skill: game development in Unity. All of it came together as we were able to think more creatively than we would have if we hadn't made a story-based, educational project, rather than hyper focusing on technical aspects of the project. We were more inclined to have a better balance of creativity with technicality than to be
## What it does
The game takes place in a sci-fi, data filled world, representing the datasets and machine learning models that contribute to the creation of an AI model. The main character, a cute little piece of data, is tasked with "fixing" the world it is in, by playing minigames that solve the issues with the data.
* The first minigame is meant to represent cleaning data, looking for "bad" data to destroy, and "completing" the incomplete data. This is a timed mini game, with the goal of destroying 10 data and completing 10 data within a minute, chasing after the enemies to fix them.
* The second minigame is meant to represent data privacy and avoiding the use of sensitive information in training AI model. This is done in a ChatGPT themed space invaders style.
* The last minigame (incomplete) is meant to teach other considerations that AI developers must keep in mind with regards to ethics. The main character is taken into a dinosaur runner style game, where it must collect the hearts that represent the ethics concerns that are taken into consideration, symbolizing these moral values are kept in mind when building the AI. This part of the final product is not fully finished, so would need further developing to fully serve its purpose.
After these three minigames are completed, the AI model is ready to be trained and developed, and the main character has saved this doomed world, allowing it to contribute to the innovation that the future of AI holds.
## How we built it
Each person on the team took on a task. We broke them up as such:
* Minigame teleportation system, main map, and gameflow
* Asset/Graphic Design, main menu
* Minigame 1
* Minigame 2
* Minigame 3 (?) (for whoever finished their part)
## Challenges we ran into
As most of us were not familiar with Unity, a lot was learned as we went along, and many times from mistakes. Some challenges we ran into were:
* Collaboration on a Unity Project with more than 3 people is complicated, so we had to use a git repository for only assets. We each worked on a different minigame/aspect of the game, and brought all of the scenes together on one computer at the end to complete the final product.
* Half of our team had little to no experience with game development in Unity, so much of their time was spent learning, and things moved a little slower as they got used to the structure and workflow, constantly debugging
* We started the project confident we could make it aesthetically pleasing and fully complete, especially with a team of 4 people. But, we only had 3 team members present on the second QHacks day due to unforseen circumstances, making the development process lengthier and more hectic for us.
## Accomplishments that we're proud of
* We made something we like! We came to QHacks not knowing what to expect, and we ended it feeling accomplished. For our first Hackathon, we feel pride in the game we made, especially considering how much of it we learned on the spot and have now added to our skillset. We learned a lot and produced some impressive logic within our minigames despite being new to Unity. The fact that we have working games after spending ages debugging, wondering if it would ever work, is a huge accomplishment.
* We think the graphics in our game are quite visually appealing, sleek and simple. This gives them their charm, and they make the game look put together even if the game is not fully finished.
## What we learned
* Setting priorities within tasks is imperative when on a time crunch. We knew we wanted good graphics to add appeal to the game when our minigames would start off simple, but also knew when to switch gears from asset design to coding.
* Not everything will be perfect. It is okay to leave things to fix later if they are not crucial to the functioning of a program, and it is also okay if there isn't time to get it done eventually. The point of a hackathon is to do what you can, to search your mind at its greatest depths and produce creative ideas, not a full stack fully functioning application.
## What's next for AI Safety Squad
We had always planned to add multiple minigames to place greater emphasis on more aspects of ethics and cybersecurity concerns of AI, so we will definitely expand the amount of tasks the main character has to go through to make the AI a good, valid model.
We would also like to add more complexity to the whole game, both to expand our own knowledge of Unity further, but also to increase the game's quality and refine it to a more finished product. We would do this in terms of graphics by adding animations to make things more visually pleasing, and also on the game logic side by making more interesting levels that require more time and effort.
Lastly, we would like to solidify the story of the game and present more information about the backend of AI to players to make the game even more educational. We would like to make it as useful as possible to those who may not be well versed in the future of AI in relation to cybersecurity and privacy. | ## Inspiration
As teammates, we're doing off-season internships, and one thing we agreed on is that it's **sooooo** tough to both break the ice and find engaging activities during team meetings.
And what we got out of that was......**27 hours of planning**, \*\*96 different ideas from ChatGPT (*yeah, even this failed*), and one, incredibly fun all-nighter.
Inspired by Pictogram, Hangman, and even tools like Figma and Excalidraw, we knew something fun and interactive that could be a go-to for “water-cooler” moments would be awesome to try out during a hackathon. We also saw the need for this in our school clubs, so we decided to build a game that brings people together with a fun and competitive edge!
## What it does
Skribbl.ai is a competitive drawing game where two players compete to replicate an image given through a prompt, all on a shared virtual whiteboard.
Elevated with real-time video, voice, and chat, players can communicate and collaborate while racing against time to impress the AI judge, which scores the drawings based on accuracy.
## How we built it
We used several key technologies:
* **100ms** for real-time video and voice features. **tribute to [Nexus](https://devpost.com/software/nexus-27zakp)**
* **ChromaDB** to handle data storage for user interactions.
* **tldraw** and **tldraw sync** for real-time collaborative white-boarding primitives.
* **React** and **TypeScript** to power the frontend.
* **NextAuth** for user authentication and session management.
Despite starting at 9 pm on the Saturday before the hackathon's end, we managed to pivot from our original idea (voice-powered music production) and complete this project in record time.
## Challenges we ran into
* Our original idea of voice-powered music production wasn't compatible with the sponsor *Hume's* technology, forcing us to pivot.
* The tight deadline, constant pivoting, and **beyond** late start added additional pressure, but we powered through to deliver a fully functional app by the end of the hackathon.
* The Metreon WiFi, especially when building a network-heavy application, lead to many hotspots and remote work.
## Accomplishments that we're proud of
* We’re incredibly proud of how quickly we pivoted and built a polished app with video, voice, chat, and whiteboard integration in a matter of hours. Finishing the project under such time constraints felt like a huge accomplishment. Yeah, we may not have the crazy large feature set, be we do the one thing we planned to do, really well–at least, we think.
## What we learned
* We learned how to adapt quickly when things don’t go as planned, and we gained valuable experience integrating real-time video and collaboration features with technologies like **100ms**, **ChromaDB**, and **tldraw**.
* We also experience in perseverance and pushing through idea droughts. Since we're working, adjusting "back" to the hackathon mindset definitely takes time.
## What's next for Skribbl.ai
We’re super stoked to continue improving Skribbl.ai after CalHacks. We surprisingly—especially given our execution, see potential for the app to be used in virtual team-building exercises, school clubs, and social hangouts. Stuff like:
* **Multiplayer modes**: Expand to support larger groups and team-based drawing challenges.
* **Advanced AI judging**: Improve the AI to evaluate drawings based on creativity, style, and time taken, not just accuracy.
* **Custom game modes**: Allow users to create custom challenges, themes, and rules for personalized gameplay.
* **Leaderboard and achievements**: Introduce a ranking system, badges, and awards for top players.
* **Mobile app**: Develop a mobile-friendly version to make the game accessible across different devices.
* **Interactive spectators**: Let spectators participate in the game through voting or live commenting during matches.
* **Real-time drawing hints**: Implement features where players can give or receive subtle hints during gameplay without breaking the challenge.
* **Custom avatars and themes**: Offer players options to personalize their in-game experience with unique avatars, themes, and board designs.
All this stuff seems super exciting to build, and we're glad to have a baseline to expand off of.
Well, that's it for skribbl.ai, thanks for reading!
**Note for GoDaddy:** The promo-code we tried to apply `MLHCAL24` was not working on the website. We tried the second best thing, in Vercel. ; ) | ## Inspiration
Our game stems from the current global pandemic we are grappling with and the importance of getting vaccinated. As many of our loved ones are getting sick, we believe it is important to stress the effectiveness of vaccines and staying protected from Covid in a fun and engaging game.
## What it does
An avatar runs through a school terrain while trying to avoid obstacles and falling Covid viruses. The player wins the game by collecting vaccines and accumulating points, successfully dodging Covid, and delivering the vaccines to the hospital.
Try out our game by following the link to github!
## How we built it
After brainstorming our game, we split the game components into 4 parts for each team member to work on. Emily created the educational terrain using various assets, Matt created the character and its movements, Veronica created the falling Covid virus spikes, and Ivy created the vaccines and point counter. After each of the components were made, we brought it all together, added music, and our game was completed.
## Challenges we ran into
As all our team members had never used Unity before, there was a big learning curve and we faced some difficulties while navigating the new platform.
As every team member worked on a different scene on our Unity project, we faced some tricky merge conflicts at the end when we were bringing our project together.
## Accomplishments that we're proud of
We're proud of creating a fun and educational game that teaches the importance of getting vaccinated and avoiding Covid.
## What we learned
For this project, it was all our first time using the Unity platform to create a game. We learned a lot about programming in C# and the game development process. Additionally, we learned a lot about git management through debugging and resolving merge conflicts.
## What's next for CovidRun
We want to especially educate the youth on the importance of vaccination, so we plan on introducing the game into k-12 schools and releasing the game on steam. We would like to add more levels and potentially have an infinite level that is procedurally generated. | losing |
# Catch! (Around the World)
## Our Inspiration
Catch has to be one of our most favourite childhood games. Something about just throwing and receiving a ball does wonders for your serotonin. Since all of our team members have relatives throughout the entire world, we thought it'd be nice to play catch with those relatives that we haven't seen due to distance. Furthermore, we're all learning to social distance (physically!) during this pandemic that we're in, so who says we can't we play a little game while social distancing?
## What it does
Our application uses AR and Unity to allow you to play catch with another person from somewhere else in the globe! You can tap a button which allows you to throw a ball (or a random object) off into space, and then the person you send the ball/object to will be able to catch it and throw it back. We also allow users to chat with one another using our web-based chatting application so they can have some commentary going on while they are playing catch.
## How we built it
For the AR functionality of the application, we used **Unity** with **ARFoundations** and **ARKit/ARCore**. To record the user sending the ball/object to another user, we used a **Firebase Real-time Database** back-end that allowed users to create and join games/sessions and communicated when a ball was "thrown". We also utilized **EchoAR** to create/instantiate different 3D objects that users can choose to throw. Furthermore for the chat application, we developed it using **Python Flask**, **HTML** and **Socket.io** in order to create bi-directional communication between the web-user and server.
## Challenges we ran into
Initially we had a separate idea for what we wanted to do in this hackathon. After a couple of hours of planning and developing, we realized that our goal is far too complex and it was too difficult to complete in the given time-frame. As such, our biggest challenge had to do with figuring out a project that was doable within the time of this hackathon.
This also ties into another challenge we ran into was with initially creating the application and the learning portion of the hackathon. We did not have experience with some of the technologies we were using, so we had to overcome the inevitable learning curve.
There was also some difficulty learning how to use the EchoAR api with Unity since it had a specific method of generating the AR objects. However we were able to use the tool without investigating too far into the code.
## Accomplishments
* Working Unity application with AR
* Use of EchoAR and integrating with our application
* Learning how to use Firebase
* Creating a working chat application between multiple users | ## Inspiration
Many of us had class sessions in which the teacher pulled out whiteboards or chalkboards and used them as a tool for teaching. These made classes very interactive and engaging. With the switch to virtual teaching, class interactivity has been harder. Usually a teacher just shares their screen and talks, and students can ask questions in the chat. We wanted to build something to bring back this childhood memory for students now and help classes be more engaging and encourage more students to attend, especially in the younger grades.
## What it does
Our application creates an environment where teachers can engage students through the use of virtual whiteboards. There will be two available views, the teacher’s view and the student’s view. Each view will have a canvas that the corresponding user can draw on. The difference between the views is that the teacher’s view contains a list of all the students’ canvases while the students can only view the teacher’s canvas in addition to their own.
An example use case for our application would be in a math class where the teacher can put a math problem on their canvas and students could show their work and solution on their own canvas. The teacher can then verify that the students are reaching the solution properly and can help students if they see that they are struggling.
Students can follow along and when they want the teacher’s attention, click on the I’m Done button to notify the teacher. Teachers can see their boards and mark up anything they would want to. Teachers can also put students in groups and those students can share a whiteboard together to collaborate.
## How we built it
* **Backend:** We used Socket.IO to handle the real-time update of the whiteboard. We also have a Firebase database to store the user accounts and details.
* **Frontend:** We used React to create the application and Socket.IO to connect it to the backend.
* **DevOps:** The server is hosted on Google App Engine and the frontend website is hosted on Firebase and redirected to Domain.com.
## Challenges we ran into
Understanding and planning an architecture for the application. We went back and forth about if we needed a database or could handle all the information through Socket.IO. Displaying multiple canvases while maintaining the functionality was also an issue we faced.
## Accomplishments that we're proud of
We successfully were able to display multiple canvases while maintaining the drawing functionality. This was also the first time we used Socket.IO and were successfully able to use it in our project.
## What we learned
This was the first time we used Socket.IO to handle realtime database connections. We also learned how to create mouse strokes on a canvas in React.
## What's next for Lecturely
This product can be useful even past digital schooling as it can save schools money as they would not have to purchase supplies. Thus it could benefit from building out more features.
Currently, Lecturely doesn’t support audio but it would be on our roadmap. Thus, classes would still need to have another software also running to handle the audio communication. | ## Inspiration
Our team really considered the theme of **Connectivity**, and what it feels like to be connected. That got us to thinking about games we used to be able to play that involved contact such as Tag, Assassin, etc. We decided to see if we could create an **upgraded** spin on these games that would be timelessly fun, yet could also adhere to modern social-distancing guidelines.
## What it does
CameraShy is a free-for-all game, where the objective of the player is to travel within the designated geo-field, looking for other players, yet hiding from them as well. When they find a player, their goal is to snap a picture of them within the app, which acts as a "tagging" mechanism. The image is then compared against images of the players' faces, and if it is a match then the player who took the image gains a point, and the unsuspecting victim is eliminated from the competition. The last player standing, wins. Players themselves can create an arena and customize the location, size, game length, and player limit, sending a unique code to their friends to join.
## How we built it
CameraShy is separated into two main portions - the application itself, and the backend database.
### **Application**
We used both the Swift language, and SwiftUI language in building the application frontend. This includes all UI and UX. The application handles the creation of games, joining of games, taking of pictures, location handling, notification receiving, and any other data being sent to it or that needs to be sent to the backend. To authenticate users and ensure privacy, we utilized Apple's *Sign in With Apple* , which anonymizes the users' information, only giving us an email, which may be masked by Apple based on the User's choice.
### **Server**
We used MongoDB for our database with Node as our backend language. With it, we centralized our ongoing games, sent updates on player locations, arena location, arena boundary, time left, players list, and much more. When a user creates an account, their image is stored on the database with a unique identifier. During a game, when an image of a player is uploaded it is quickly put through Azure's Facial Recognition API, using the previously uploaded player images as reference to identify who was in the shot, if anyone was. We are proud to say that this also works with mask wearers. Finally, the server sends notifications to devices based on if they won/lost/left the arena and forfeited the game.
## Challenges we ran into
Taking on a decently sized project like this, we were bound to run into challenges (especially with 3/4 of us being first-time Hackers!). Here are a few of the challenges we ran into:
### 1. HTTPS Confirmation
We had issues with our database which set us a few hours back, but we found a way around it all pitched in (frontend devs as well) to figure out a solution as to why our database would not register with an HTTPS certificate.
### 2. Different Swift Languages
While both Swift and SwiftUI are unique languages written by Apple, for Apple devices, they are very different in nature. Swift relies on Storyboarding and is mostly imperative, whereas SwiftUI utilizes a different approach, and is declarative. With one front-end developer utilizing Swift, and the other SwiftUI, it was difficult to merge Views and connect features properly, but together we learnt a bit of the others' language in the process.
### 3. Facial Recognition with Masks
As anyone with a device that utilizes Facial Identification might know, Facial Recognition with a mask on can be difficult. We underwent numerous tests to figure out if it was even possible to utilize facial recognition with a mask, and figured out workarounds in order to do so properly.
## Accomplishments that we're proud of
One accomplishments we're proud of is being able to utilize multiple endpoints and APIs together seamlessly. At the beginning we were wary of dealing with so much data (geographical location, player counts, time, notification IDs, apple unique identifiers, images, facial recognition, and more!), but looking back from where we are now, we are glad we took the risk, as our product is so much better as as a result.
Another noteworthy accomplishment is our fluid transitions between SwiftUI and Swift. As previously mentioned, this was not a simple task, and we're very happy with how the product turned out.
## What we learned
As we overcame our challenges and embarked on our first Hackathon, the most important thing we learnt was that working as a team on a project does not necessarily mean each person has their own role. In many cases, we had to work together to help each other out, thinking of ideas for areas that were not our expertise. As a result, we were able to learn new tools and ways of doing things, as well as dabble in different coding languages.
## What's next for CameraShy - The World is Your Playground
Our next steps for CameraShy is to embrace user and game customizability. We would like to create a user-oriented settings view that allows them to clear their data off our servers themselves, reset their accounts, and more.
In terms of game customizability, what we have now is just the beginning. We have a long list of potential features including geographic neutral zones and bigger game arenas. Most importantly for us, however, is to continue fine-tuning what we've built so far before we go ahead and implement something new. | partial |
## Summary
Our AI-integrated website is a service that runs in a user’s background and sends a notification for the user to consider a break if their emotions reach over a certain threshold for an amount of time. We do this by utilizing OpenCV and Mediapipe to detect faces and capture image data which is then sent off to Hume’s streaming API every 60 frames for processing. Their AI then sends back emotional data which we then use to gauge a user’s “negative” emotion levels. Our service also offers a report generation system if a user would like to receive comprehensive reports on their emotional levels over the past day or week.
## Stack
Python, Reflex, HumeAI, CockroachDB, OpenCV
## Target Audience
Our goal is to help workers who spend long hours at their computers or even students who have to spend long hours on their computers doing schoolwork or other activities. As computer science students who spend long hours on computers ourselves, we understand how sometimes students can spend endless hours on their work with no break, increasingly growing more agitated or frustrated as things don’t go as planned.
## Mission
As Computer Science students, we certainly understand the pressure and difficulties working within a stressful environment for long hours. Our primary objective is to help people maintain their mental health through similar situations by suggesting breaks when they clearly need them. By promoting healthy work habits we aim to improve our client's efficiency, enabling them to succeed in an environment of their choice. We hope our tool will help many prevent burnout from endless grinding on their work and also help maintain their long-term mental health.
## Challenges
Using new tools such as Reflex served as quite a difficulty as we were lacking on a lot of documentation and had to consult the Reflex staff. Furthermore, due to unfortunate difficulties on Reflex's end with Docker images, our project is unable to be hosted in production and our video streaming is severely laggy.
## What We Learned
Throughout our time on the project, we were able to experiment with technologies both familiar and new to us. We expanded our skills in computer vision and full-stack development, and discovered a new framework to establish both a frontend and backend in python with Reflex.
## Privacy
We do not collect data on users for profitable purposes but only to assist in providing analysis for users to better understand their health.
## Future Plans
We plan to expand support to mobile apps for portable usage of our service and also plan to implement more features such as optimized health letters for physicians. | ## Inspiration
Have you ever walked up to a recycling can and wondered if you can recycle your trash. With Trash MIT, we take a picture of your item and run it through our database to check if it's recyclable.
## What it does
Trash MIT identifies what an object is using a webcam and checks it against our list of items. If it is unsure of what the item is, Trash MIT asks for user input. Over time it will collect data on what is and isn't recyclable.
Trash MIT has 2 purposes: (1) Collecting data on what people think is and isn't recyclable (2) telling people what is and isn't recyclable.
Trash MIT could easily be implemented at restaurant trash cans where there is a small known set of trash frequently thrown away. Trash MIT makes recycling fun and interactive encouraging recycling.
## How we built it
Google's cloud vision API identifies types of objects. Based on our list of recyclable objects, we then tell the user if the object is recyclable.
## Challenges we ran into
We searched around online looking for a comprehensive list of recyclable items and were unable to find one. We then realized we were going to have to create our data set ourselves.
We tried using barcodes; however, it is still hard to go from identifying an object to whether it's recyclable or not.
## Accomplishments that we're proud of
It runs!
## What we learned
How to use API's, google cloud and OpenCV.
Working in teams
## What's next for trash MIT
We have so many ideas!
### Trash MIT is missing hardware.
We would like to build a unit that could be attached to trash cans in urban areas. The unit would have a screen behind the trash to eliminate noise (during HackMIT we held a piece of paper behind items to stop the Google API from identifying items in the background).
Instead of using 'y' and 'n' to take in user input, we would place sensors on the trash can. That way we can collect data based on what people are already throwing away. We can use this data for two purposes. Reporting back to recycling authorities on whether people are actually recycling correctly and to improve our data.
### Developing the classification
We could also expand from single-stream recycling. Currently, we only identify recycling or non-recycling. We could expand so we can identify different types of recycling.
We could expand to use Machine Learning to help with the identification.
We could also contact local government for information on recycling laws in different areas.
We could improve the interface with more color to encourage more recycling. | ## Inspiration
University gets students really busy and really stressed, especially during midterms and exams. We would normally want to talk to someone about how we feel and how our mood is, but due to the pandemic, therapists have often been closed or fully online. Since people will be seeking therapy online anyway, swapping a real therapist with a chatbot trained in giving advice and guidance isn't a very big leap for the person receiving therapy, and it could even save them money. Further, since all the conversations could be recorded if the user chooses, they could track their thoughts and goals, and have the bot respond to them. This is the idea that drove us to build Companion!
## What it does
Companion is a full-stack web application that allows users to be able to record their mood and describe their day and how they feel to promote mindfulness and track their goals, like a diary. There is also a companion, an open-ended chatbot, which the user can talk to about their feelings, problems, goals, etc. With realtime text-to-speech functionality, the user can speak out loud to the bot if they feel it is more natural to do so. If the user finds a companion conversation helpful, enlightening or otherwise valuable, they can choose to attach it to their last diary entry.
## How we built it
We leveraged many technologies such as React.js, Python, Flask, Node.js, Express.js, Mongodb, OpenAI, and AssemblyAI. The chatbot was built using Python and Flask. The backend, which coordinates both the chatbot and a MongoDB database, was built using Node and Express. Speech-to-text functionality was added using the AssemblyAI live transcription API, and the chatbot machine learning models and trained data was built using OpenAI.
## Challenges we ran into
Some of the challenges we ran into were being able to connect between the front-end, back-end and database. We would accidentally mix up what data we were sending or supposed to send in each HTTP call, resulting in a few invalid database queries and confusing errors. Developing the backend API was a bit of a challenge, as we didn't have a lot of experience with user authentication. Developing the API while working on the frontend also slowed things down, as the frontend person would have to wait for the end-points to be devised. Also, since some APIs were relatively new, working with incomplete docs was sometimes difficult, but fortunately there was assistance on Discord if we needed it.
## Accomplishments that we're proud of
We're proud of the ideas we've brought to the table, as well the features we managed to add to our prototype. The chatbot AI, able to help people reflect mindfully, is really the novel idea of our app.
## What we learned
We learned how to work with different APIs and create various API end-points. We also learned how to work and communicate as a team. Another thing we learned is how important the planning stage is, as it can really help with speeding up our coding time when everything is nice and set up with everyone understanding everything.
## What's next for Companion
The next steps for Companion are:
* Ability to book appointments with a live therapists if the user needs it. Perhaps the chatbot can be swapped out for a real therapist for an upfront or pay-as-you-go fee.
* Machine learning model that adapts to what the user has written in their diary that day, that works better to give people sound advice, and that is trained on individual users rather than on one dataset for all users.
## Sample account
If you can't register your own account for some reason, here is a sample one to log into:
Email: [[email protected]](mailto:[email protected])
Password: password | losing |
## Inspiration I volunteering with Women in Computer Science
## What it does It is a website that connects minority groups in tech
## How I built it With Wix
## Challenges I ran into Finding new bundle features to use on the website to engage different groups
## Accomplishments that I'm proud of It is visually appealing
## What I learned Diversity is different for everyone, but we should all strive to educate people
## What's next for Connectwork
I hope to incorporate this mission in my school and my future career | ## Inspiration
Helping students to organise their school work at home to aid online education
## What it does
A portal wherein student can keep track of his/her/their school works and connect with classmates and school teachers and administrators.
## How we built it
Using web development technologies
## Challenges we ran into
Making the hack in a small amount of time
## Accomplishments that we're proud of
Built an Ed-Tech Hack quickly
## What we learned
Learned web development
## What's next for Eduboard
Add more features and host it online | ## Inspiration
Queriamos hacer una pagina interactiva la cual llamara la atencion de las personas jovenes de esta manera logrando mantenerlos durante mucho tiempo siendo leales a la familia de marcas Qualtias
## What it does
Lo que hace es
## How we built it
## Challenges we ran into
Al no tener un experiencia previa con el diseño de paginas web encontramos problemas al momento de querer imaginar el como se veria nuestra pagina.
## Accomplishments that we're proud of
Nos sentimos orgullosos de haber logrado un diseño con el cual nos senitmos orgullosos y logramos implementar las ideas que teniamos en mente.
## What we learned
Aprendimos mucho sobre diseño de paginas y de como implmentar diferentes tipos de infraestructuras y de como conectarlas.
## What's next for QualtiaPlay
Seguiremos tratando de mejorar nuestra idea para futuros proyectos y de mayor eficiencia | losing |
## Inspiration
I wanted to make something that let me explore everything you need to do at a hackathon.
## What it does
Currently, the web app stores and encrypts passwords onto a database hosted by cockroachDB with the "sign up" form. The web app also allows you to retrieve and decrypt your password with the "fetch" form.
## How we built it
I used python to build the server side components and flask to connect the server to the web app. I stored the user-data using the cockroachDB API. I used html, jinja2, and bootstrap to make the front-end look pretty.
## Challenges we ran into
Originally, I was going to use the @sign API and further continue my project, but the @platform uses Dart. I do not use Dart and I did not plan on doing so within the submission period. I then had to descale my project to something more achievable, which is what I have now.
## Accomplishments that we're proud of
I made something when I had little idea of what I was doing.
## What we learned
I learned a lot of the basic elements of creating a web app (front-end + back-end) and using databases (cockroachdb).
## What's next for Password Manager
Fulling fleshing out the entire web app. | # 🎉 CoffeeStarter: Your Personal Networking Agent 🚀
Names: Sutharsika Kumar, Aarav Jindal, Tanush Changani & Pranjay Kumar
Welcome to **CoffeeStarter**, a cutting-edge tool designed to revolutionize personal networking by connecting you with alumni from your school's network effortlessly. Perfect for hackathons and beyond, CoffeeStarter blends advanced technology with user-friendly features to help you build meaningful professional relationships.
---
## 🌟 Inspiration
In a world where connections matter more than ever, we envisioned a tool that bridges the gap between ambition and opportunity. **CoffeeStarter** was born out of the desire to empower individuals to effortlessly connect with alumni within their school's network, fostering meaningful relationships that propel careers forward.
---
## 🛠️ What It Does
CoffeeStarter leverages the power of a fine-tuned **LLaMA** model to craft **personalized emails** tailored to each alumnus in your school's network. Here's how it transforms your networking experience:
* **📧 Personalized Outreach:** Generates authentic, customized emails using your resume to highlight relevant experiences and interests.
* **🔍 Smart Alumnus Matching:** Identifies and connects you with alumni that align with your professional preferences and career goals.
* **🔗 Seamless Integration:** Utilizes your existing data to ensure every interaction feels genuine and impactful.
---
## 🏗️ How We Built It
Our robust technology stack ensures reliability and scalability:
* **🗄️ Database:** Powered by **SQLite** for flexible and efficient data management.
* **🐍 Machine Learning:** Developed using **Python** to handle complex ML tasks with precision.
* **⚙️ Fine-Tuning:** Employed **Tune** for meticulous model fine-tuning, ensuring optimal performance and personalization.
---
## ⚔️ Challenges We Faced
Building CoffeeStarter wasn't without its hurdles:
* **🔒 SQLite Integration:** Navigating the complexities of SQLite required innovative solutions.
* **🚧 Firewall Obstacles:** Overcoming persistent firewall issues to maintain seamless connectivity.
* **📉 Model Overfitting:** Balancing the model to avoid overfitting while ensuring high personalization.
* **🌐 Diverse Dataset Creation:** Ensuring a rich and varied dataset to support effective networking outcomes.
* **API Integration:** Working with various API's to get as diverse a dataset and functionality as possible.
---
## 🏆 Accomplishments We're Proud Of
* **🌈 Diverse Dataset Development:** Successfully created a comprehensive and diverse dataset that enhances the accuracy and effectiveness of our networking tool.
* Authentic messages that reflect user writing styles which contributes to personalization.
---
## 📚 What We Learned
The journey taught us invaluable lessons:
* **🤝 The Complexity of Networking:** Understanding that building meaningful connections is inherently challenging.
* **🔍 Model Fine-Tuning Nuances:** Mastering the delicate balance between personalization and generalization in our models.
* **💬 Authenticity in Automation:** Ensuring our automated emails resonate as authentic and genuine, without echoing our training data.
---
## 🔮 What's Next for CoffeeStarter
We're just getting started! Future developments include:
* **🔗 Enhanced Integrations:** Expanding data integrations to provide even more personalized networking experiences and actionable recommendations for enhancing networking effectiveness.
* **🧠 Advanced Fine-Tuned Models:** Developing additional models tailored to specific networking needs and industries.
* **🤖 Smart Choosing Algorithms:** Implementing intelligent algorithms to optimize alumnus matching and connection strategies.
---
## 📂 Submission Details for PennApps XXV
### 📝 Prompt
You are specializing in professional communication, tasked with composing a networking-focused cold email from an input `{student, alumni, professional}`, name `{your_name}`. Given the data from the receiver `{student, alumni, professional}`, your mission is to land a coffee chat. Make the networking text `{email, message}` personalized to the receiver’s work experience, preferences, and interests provided by the data. The text must sound authentic and human. Keep the text `{email, message}` short, 100 to 200 words is ideal.
### 📄 Version Including Resume
You are specializing in professional communication, tasked with composing a networking-focused cold email from an input `{student, alumni, professional}`, name `{your_name}`. The student's resume is provided as an upload `{resume_upload}`. Given the data from the receiver `{student, alumni, professional}`, your mission is to land a coffee chat. Use the information from the given resume of the sender and their interests from `{website_survey}` and information of the receiver to make this message personalized to the intersection of both parties. Talk specifically about experiences that `{student, alumni, professional}` would find interesting about the receiver `{student, alumni, professional}`. Compare the resume and other input `{information}` to find commonalities and make a positive impression. Make the networking text `{email, message}` personalized to the receiver’s work experience, preferences, and interests provided by the data. The text must sound authentic and human. Keep the text `{email, message}` short, 100 to 200 words is ideal. Once completed with the email, create a **1 - 10 score** with **1** being a very generic email and **10** being a very personalized email. Write this score at the bottom of the email.
## 🧑💻 Technologies Used
* **Frameworks & Libraries:**
+ **Python:** For backend development and machine learning tasks.
+ **SQLite:** As our primary database for managing user data.
+ **Tune:** Utilized for fine-tuning our LLaMA3 model.
* **External/Open Source Resources:**
+ **LLaMA Model:** Leveraged for generating personalized emails.
+ **Various Python Libraries:** Including Pandas for data processing and model training. | # About Our Project
## Inspiration:
Since forming our group, we identified early that the majority of our team's strengths were in back-end development. David told us about his interest in cybersecurity and shared some interesting resources regarding it, from there we had an idea, we just had to figure out what we could practically do with limited man-hours. From there, we settled on biometrics as our identification type and 2-type encryption.
## What it does:
We have an application. When launched you are prompted to choose a file you would like to encrypt. After choosing your file, you must scan your face to lock the file, we call it a 'passface'. From there, your passface is encoded using base64 encryption (so it cannot be used maliciously) and stored. Your file is then encrypted using Fernet encryption (which is very hard to crack without its unique and randomly generated key) and stored in a '.encrypted' file. When you would like to unlock and retrieve your file, reopen the application and browse for the encrypted file locked with your image. After scanning your face, the encoded passface is decoded and compared to your passface attempt. After matching your biometric data to that which is locking the file, your file is decoded and re-assembled to its original file type (.txt, .png, .pptx, .py, etc).
## How we built it:
We started by assigning each member to learn one of the concepts we were going to implement, after that, we divided into two groups to begin writing our two main modules, encoding/decoding and biometric retrieval/comparison. After constructing multiple working and easy-to-implement functions in our modules, we worked together on stitching it all together and debugging it (so many bugs!). We finished our project with a little bit of front-end work, making the GUI more user-friendly, comprehensive error messages etc.
## Challenges we ran into:
We thought the biggest challenge we would face would be the scanning and comparison of faces, none of us had any experience with image scanning through code and we honestly had no idea how to even start to think about doing it. But after asking our good friend ChatGPT, we got pointed in the direction of some useful APIs, and after reading ALOT of documentation, we successfully got our system up and running. The hardest challenge for us was figuring out the best and most secure ways we could reasonably store an encrypted file locally. To overcome this we had to throw alot of ideas at the chalkboard (we sat around a chalkboard for an hour) to come up with useable ideas. We settled on using separate encryption/decryption for the stored files and faces to keep a degree of separation for security, and changing the file to .encrypted so that it is not as easily openable (other than in a text file) and because it looks cool. Implementing all of this and making it work perfectly and consistently proved to be our biggest challenge and time-sink of the weekend.
## Accomplishments that we're proud of:
* getting a working face scanner and comparer, which means we successfully implemented biometric security into our coding project, which we celebrated.
* being able to encrypt and then decrypt any file type was awesome, as this is much harder than simple text and image files.
## What we learned:
We learned alot about the division of labour throughout our project. In hour 1 we struggled to effectively distribute tasks which often resulted in two people effectively doing the same thing, but separately which is a big waste of time. As we progressed, we got much more effective in picking tasks, allocating small tasks to individual people, and creating small teams to tackle a tough function or a debug marathon. We also learned the value of reading documentation; when using cv2 to scan faces we struggled with navigating its functions and implementation through brute force, but after assigning one person to dig their teeth into documentation, our group got a better understanding and we were able to get a function up and running with much less resistance. | partial |
## Inspiration
We all come from coding backgrounds, where typing speed is a valued asset. Normal typing tests, such as 10fastfingers or monkeytype are great, but we thought they were a little boring and not motivating enough.
## What it does
Complete words based on the level of difficulty.
## How we built it
The programming language we went with was Python. We used two APIs in order to generate the random words and sentences for our game.
## Challenges we ran into
When we originally tried to implement the APIs with C++ we would encounter syntax issues. We assumed this was due to minimal knowledge on implementing APIs with that specific language. However we found it easier to use Python which had modules that made the process of calling APIs much easier.
## Accomplishments that we're proud of
Utilizing APIs in Python.
## What we learned
Although APIs are universal among most common programming languages the difficulty to implement it into code varies.
## What's next for TypeHub
Providing visual graphics to make the game more appealing to a general audience. | ## Flagtrip: travel in multiplayer
Vacation planning, especially with friends, is unnecessarily complex. Travel is usually a social experience, but most software nowadays only focuses on individual and personal plans.
However, Flagtrip offers a real-time collaborative solution, allowing friends to easily pin down new places, find local recommendations ranging from food to housing, and even book Airbnb stays, flights, and Ubers.
Organizing a vacation no longer has to be a logistical nightmare! Welcome to Flagtrip: a flagship collaborative adventure-planning experience.
## Interface
Users of Flagtrip create accounts on our service and plan their vacations in centralized "Trip" rooms. These rooms exist in unlisted URLs, and if a User wants to invite a new friend to the Trip, they can add the new friend's email to the Trip, after which a SendGrid operation will send that user an invitation to the Trip. Users can dynamically add and remove location markers on a Google Maps interface specific to the Trip, and flight data, Uber ride estimates, hotels, points-of-interest, and restaurants are displayed conveniently on the map. When the vacation plans are finalized, SendGrid creates an email report of the itinerary and sends it to all participants.
## Challenges and Accomplishments
* Integration of Google Maps and Flight data
* Real-time collaboration with many-to-many user/trip mapping
* Uber/transportation solutions with path traversal calculations
* Enumerating database schema for different aspects of vacation travel (logistics to food, location recommendations, etc.)
* Fast, synchronized communication between a Javascript-heavy front end and Ruby on Rails backend
More pictures are available here: <http://imgur.com/a/flCWF> | ## Inspiration
Our team was inspired by the AllHealth track presented at the opening ceremony and the challenge of enhancing patient care in the least intrusive way possible. We considered the technologies people use daily and landed on typing, something everyone does across devices—whether sending texts, searching online, or writing documents. Research shows that analyzing typing patterns, like the rate of typos, can help predict mental health risk factors, cognitive decline, and other health conditions like Parkinsons. Links to some of the studies that inspired our project can be found at the end.
## What it does
CognitiveKeyboard is an alternative Android keyboard that updates a user’s typing statistics every 30 seconds. It tracks details like backspaces, special characters, typing speed, and pauses between keystrokes — without storing actual text. This approach eliminates privacy concerns about tracking what is typed. Using this data, along with demographic information (e.g., age, gender, known health conditions), we create data visualizations for researchers to analyze. They can filter participants, cluster users by typing patterns, and apply labels based on their research. These labels are fed back into our machine learning model to improve prediction accuracy.
## How we built it
We developed the keyboard and typing tracker in Android Studio, using Java and JDK, built on top of an open-source keyboard library. For the database, we used MongoDB Atlas, creating collections for user demographics, user clusters, and daily typing samples. Python APIs manage interactions between our backend and database, handling tasks like adding users, submitting samples, and retrieving data. The web interface for data visualization and researcher access was created using Python, while the Android app’s frontend was built with Java. We hosted everything on Linode.
## Challenges we ran into
One of our biggest challenges was choosing how to track typing statistics efficiently and privately. While using an alternate keyboard is unconventional, it offers the most secure and efficient method. Privacy was a key concern — this approach allowed us to analyze keystroke types without storing sensitive data like passwords. Alternative solutions either consumed too much battery or required excessive permissions, such as accessibility access to screen content.
Another challenge was identifying which typing statistics were most relevant for our analysis. We eventually focused on typing speed, keystroke intervals, typing accuracy (measured by backspaces), character variability, and special character usage. Managing this six-dimensional data presented visualization challenges, which we addressed by offering flexible filters and visualizing data in 2D or 3D, depending on the researchers’ preferences.
## Accomplishments that we're proud of
We’re proud of our commitment to patient privacy. Instead of storing sensitive data and encrypting it, we found a way to collect meaningful statistics without recording typed text. Our data visualizations are another key achievement—they simplify clustering and offer customization, making the research process more intuitive. Finally, we’re proud of staying sane and focused through the 36-hour marathon, creating something that has real potential to enhance patient care and identify early health risks.
## What we learned
As a group coming from a wide range of experience and backgrounds, through our collaboration we also had a wide range of takeaways.
**Taha:**
Throughout this project, I explored effective project management, particularly in a fast-paced environment. I learned how to delegate tasks, prioritize my own milestones, and quickly adapt when things didn’t go as planned. Working as a team under pressure and sleep deprivation taught me the importance of clear communication, supporting each other’s strengths, and maintaining focus. I also realized that persistence in debugging always pays off—it was worth sticking with a problem, no matter how long it took, because solving it in the end was rewarding. On the technical side, I gained valuable experience writing code in Java for Android applications.
**Shaurya:**
I worked on creating a machine learning model, developing data visualizations, and building a Python frontend for researchers. One major takeaway from this process was the importance of seeing the debugging process through from start to finish. I also learned how to manage our time across different tasks and the value of taking breaks to prevent burnout. This balance was key to maintaining productivity over the course of the project.
**Maggie:**
As a first-time hacker, I learned a lot from my teammates, especially about deploying a real-world project, managing time, and dividing responsibilities within the team. I appreciated the support we gave each other, especially during moments of exhaustion. On the technical side, I gained hands-on experience creating APIs to connect our backend with the database, which was completely new to me. Observing how my teammates handled their tasks also provided me with valuable second-hand learning experiences.
**Andrew:**
This was my first hackathon and my first time working in a team-based development environment, so I focused on learning from my teammates. I gained a lot from watching them work in different areas, particularly around creating visualizations and learning how to communicate effectively through the API. I also learned how to make API calls and how tools like MongoDB and Flask communicate. I familiarized myself with basic python packages like pandas, streamlit, numpy, and matplot.
## What's next for CognitiveKeyboard
Our next steps involve expanding the platform support. Since most typing happens on mobile, especially messaging, we prioritized mobile statistics for this hackathon. An iOS implementation was impractical within the timeframe due to App Store delays and cost barriers, but it’s on our roadmap. We also plan to support browser and desktop statistical analysis. Another future goal is to detect users at urgent risk, possibly through sentiment analysis or flagging risk-indicating keywords. Finally, we aim to develop an interface for healthcare providers, like our interface for researchers, to monitor patients at risk, catching potential issues early. Beyond these plans, there are numerous other directions for future expansion.
## Sources
<https://www.nature.com/articles/s41598-019-50002-9>
<https://www.nature.com/articles/s41598-023-28990-6?fromPaywallRec=false>
<https://www.nature.com/articles/s41598-018-25999-0>
<https://biomedeng.jmir.org/2022/2/e41003>
<https://www.nature.com/articles/s41598-023-28990-6?fromPaywallRec=false>
<https://ieeexplore.ieee.org/document/10340393>
<https://academic.oup.com/jamia/article-abstract/27/7/1007/5848291?redirectedFrom=fulltext> | losing |
## Inspiration
One of our team members was in the evacuation warning zone for the raging California fires in the Bay Area just a few weeks ago. Part of their family's preparation for this disaster included the tiresome, tedious, time-sensitive process of listing every item in their house for insurance claims in the event that it's burned down. This process took upwards of 15 hours between 3 people working on it and even then many items were missed an unaccounted for. Claim Cart is here to help!
## What it does
Problems Solved
(1) Families often have many belongings they don’t account for. It’s time intensive and inconvenient to coordinate, maintain, and update extensive lists of household items. Listing mundane, forgotten items can potentially add thousands of dollars to their insurance.
(2) Insurance companies have private master lists of the most commonly used items and what the cheapest viable replacements are. Families are losing out on thousands of dollars because their claims don’t state the actual brand or price of their items. For example, if a family listed “toaster”, they would get $5 (the cheapest alternative), but if they listed “stainless steel - high end toaster: $35” they might get $30 instead.
Claim Cart has two main value propositions: time and money. It is significantly faster to take a picture of your items than manually entering every object in. It’s also more efficient for members to collaborate on making a family master list.
## Challenges I ran into
Our team was split between 3 different time zones, so communication and coordination was a challenge!
## Accomplishments that I'm proud of
For three of our members, PennApps was their first hackathon. It was a great experience building our first hack!
## What's next for Claim Cart
In the future, we will make Claim Cart available to people on all platforms. | ## Inspiration
Two of our teammates have personal experiences with wildfires: one who has lived all her life in California, and one who was exposed to a fire in his uncle's backyard in the same state. We found the recent wildfires especially troubling and thus decided to focus our efforts on doing what we could with technology.
## What it does
CacheTheHeat uses different computer vision algorithms to classify fires from cameras/videos, in particular, those mounted on households for surveillance purposes. It calculates the relative size and rate-of-growth of the fire in order to alert nearby residents if said wildfire may potentially pose a threat. It hosts a database with multiple video sources in order for warnings to be far-reaching and effective.
## How we built it
This software detects the sizes of possible wildfires and the rate at which those fires are growing using Computer Vision/OpenCV. The web-application gives a pre-emptive warning (phone alerts) to nearby individuals using Twilio. It has a MongoDB Stitch database of both surveillance-type videos (as in campgrounds, drones, etc.) and neighborhood cameras that can be continually added to, depending on which neighbors/individuals sign the agreement form using DocuSign. We hope this will help creatively deal with wildfires possibly in the future.
## Challenges we ran into
Among the difficulties we faced, we had the most trouble with understanding the applications of multiple relevant DocuSign solutions for use within our project as per our individual specifications. For example, our team wasn't sure how we could use something like the text tab to enhance our features within our client's agreement.
One other thing we were not fond of was that DocuSign logged us out of the sandbox every few minutes, which was sometimes a pain. Moreover, the development environment sometimes seemed a bit cluttered at a glance, which we discouraged the use of their API.
There was a bug in Google Chrome where Authorize.Net (DocuSign's affiliate) could not process payments due to browser-specific misbehavior. This was brought to the attention of DocuSign staff.
One more thing that was also unfortunate was that DocuSign's GitHub examples included certain required fields for initializing, however, the description of these fields would be differ between code examples and documentation. For example, "ACCOUNT\_ID" might be a synonym for "USERNAME" (not exactly, but same idea).
## Why we love DocuSign
Apart from the fact that the mentorship team was amazing and super-helpful, our team noted a few things about their API. Helpful documentation existed on GitHub with up-to-date code examples clearly outlining the dependencies required as well as offering helpful comments. Most importantly, DocuSign contains everything from A-Z for all enterprise signature/contractual document processing needs. We hope to continue hacking with DocuSign in the future.
## Accomplishments that we're proud of
We are very happy to have experimented with the power of enterprise solutions in making a difference while hacking for resilience. Wildfires, among the most devastating of natural disasters in the US, have had a huge impact on residents of states such as California. Our team has been working hard to leverage existing residential video footage systems for high-risk wildfire neighborhoods.
## What we learned
Our team members learned concepts of various technical and fundamental utility. To list a few such concepts, we include MongoDB, Flask, Django, OpenCV, DocuSign, Fire safety.
## What's next for CacheTheHeat.com
Cache the Heat is excited to commercialize this solution with the support of Wharton Risk Center if possible. | ## Inspiration
Traveling can often be stressful, with countless variables to consider such as budget, destinations, activities, and personal interests. We aimed to create an app that simplifies travel planning, making it more enjoyable and personalized. Marco.ai was inspired by the need for a comprehensive travel companion that not only provides an engaging way to 'match' with various trip components but also offers real-time, personalized recommendations based on your location, ensuring users can make the most out of their trips.
## What it does
Marco.AI uses your geolocation on a trip to find food and activities that might be of interest to you. In comparison to competitors like Expedia and Google Search, Marco.AI isinputted with personalized data and your present location and provides live data based on your past preferences and adventures! After each experience, we ask for a 1-10 rating and use an initial survey to store a profile with your preferences.
## How we built it
To build Marco.ai, we integrated You.com, Groq Llama3 8b, and GPT-4o APIs. For the backend, we utilized python to handle user data, travel plans, and interactions with third-party APIs in a JSON format. For each experience, our model generates keywords relating to a 1-10 rating of the experience. Ex: a 10/10 for beach would have keywords like "ocean, calm, relaxing." For the mobile app frontend, we chose React Native to connect to our model output and present an easy to use interface. Python's standard libraries for handling JSON data were employed to parse and save AI-generated recommendations. Additionally, we implemented functionalities to dynamically update user ratings and preferences, ensuring the app remains relevant and personalized.
## Challenges we ran into
As first-time hackers, we definitely ran into a few obstacles. Combining multiple APIs and learning how they work took a while to figure out and implement into our model. We started off by using mindsDB and trying to utilize a RAG model with You.com. However we realized that for our purpose, we didn't need to use a largescale model management and platform and decided to move towards using prompt engineering. Engineering our prompts for GPT-40 was a back and forth process of learning how to properly utilize the AI to give us our output in a formatted way, making it easier to parse.
The most challenging aspect for our team was frontend design. This was our first experience with app development, and the learning curve was steep. We are happy that we are able to provide a functional prototype that can already be used by people while they plan a trip!
## What's next for marco.ai
In the future we hope to bring this model to life with payment integration and a feature to be able to swipe through and save different elements of your trip: hotel, flights, food based on your interests and budgets then pay at the end. Additionally, we aspire to transform Marco.ai into a social platform where users can share their past vacation experiences, likes, dislikes, and recommendations, creating a vibrant community of travel enthusiasts! Marco aims to pioneer a social app focused on encompassing travel experiences, filling a gap that has yet to be explored in the social media landscape. | winning |
## Inspiration
The issue of waste management is something that many people view as trivial yet is one of the fundamental factors that will decide the liveability of the world. Yet even in Canada, a developed country, only 9% of plastics are recycled, meaning that the equivalent of 24 CN towers of recyclable plastic enters our landfills each year. In developing nations, this is an even more serious issue that can have profound impacts on quality of life.
## What it does
Detritus AI is a smart garbage can that is able to detect and categorize waste into the respective containers and transmit essential information that allows for the optimization of garbage routes. DetritusAI tracks the quantity of waste that is in each container and communicates with the client-side applications used by garbage truck drivers to determine how full each container is. Based on the capacity of each garbage can and its location, DetritusAI calculates the optimal route for garbage trucks to collect garbage while minimizing distance and time, even taking into account traffic.
## How we built it
When users place an object near the garbage can, a time of flight sensor detects the object and triggers an image classification algorithm that identifies the category of the waste. A message is sent via Solace, which instructs the garbage can to open the appropriate lid.
Within the garbage cans, the time of flight sensors continuously determines the capacity of the bin and communicates that information via Solace to the client-side application.
Using the Google Directions API, the optimal route for garbage collection is determined by factoring in traffic, distance, and the capacity of each bin. An optimal route is displayed on the dashboard, along with turn by turn directions.
## Challenges I ran into
An issue we had was that we wanted to display a visual representation of the optimal route; however, we did not have enough time to figure out how to visually display the directions of the optimal route that we calculated.
## Accomplishments that I'm proud of
We're proud of how we were able to integrate the hardware, classification algorithm, and the dashboard into a seamless solution for waste management -- especially given the tight time constraint.
## What I learned
Communication between different components often takes more time than one might imagine. Thankfully, Solace is a very powerful tool that has resolved this issue.
## What's next for DetritusAI
1. Visually display the optimized route on the dashboard for the user
2. Add a compost category because the environment is cool.
3. Incorporate a social aspect that encourages people to recycle such as incentives or leaderboards | ## Inspiration:
Our journey began with a simple, yet profound realization: sorting waste is confusing! We were motivated by the challenge many face in distinguishing recyclables from garbage, and we saw an opportunity to leverage technology to make a real environmental impact. We aimed to simplify recycling, making it accessible and accurate for everyone.
## What it does:
EcoSort uses a trained ML model to identify and classify waste. Users present an item to their device's webcam, take a photo, and our website instantly advises whether it is recyclable or garbage. It's user-friendly, efficient, and encourages responsible waste disposal.
## How we built it:
We used Teachable Machine to train our ML model, feeding it diverse data and tweaking values to ensure accuracy. Integrating the model with a webcam interface was critical, and we achieved this through careful coding and design, using web development technologies to create a seamless user experience.
## Challenges we ran into:
* The most significant challenge was developing a UI that was not only functional but also intuitive and visually appealing. Balancing these aspects took several iterations.
* Another challenge we faced, was the integration of our ML model with our UI.
* Ensuring our ML model accurately recognized a wide range of waste items was another hurdle, requiring extensive testing and data refinement.
## Accomplishments that we're proud of:
What makes us stand out, is the flexibility of our project. We recognize that each region has its own set of waste disposal guidelines. To address this, we made our project such that the user can select their region to get the most accurate results. We're proud of creating a tool that simplifies waste sorting and encourages eco-friendly practices. The potential impact of our tool in promoting environmentally responsible behaviour is something we find particularly rewarding.
## What we learned:
This project enhanced our skills in ML, UI/UX design, and web development. On a deeper level, we learned about the complexities of waste management and the potential of technology to drive sustainable change.
## What's next for EcoSort:
* We plan to expand our database to accommodate different types of waste and adapt to varied recycling policies across regions. This will make EcoSort a more universally applicable tool, further aiding our mission to streamline recycling for everyone.
* We are also in the process of hosting the EcoSort website as our immediate next step. At the moment, EcoSort works perfectly fine locally. However, in regards to hosting the site, we have started to deploy it but are unfortunately running into some hosting errors.
* Our [site](https://stella-gu.github.io/EcoSort/) is currently working | ## Inspiration
Waste Management: Despite having bins with specific labels, people often put waste into wrong bins which lead to unnecessary plastic/recyclables in landfills.
## What it does
Uses Raspberry Pi, Google vision API and our custom classifier to categorize waste and automatically sorts and puts them into right sections (Garbage, Organic, Recycle). The data collected is stored in Firebase, and showed with respective category and item label(type of waste) on a web app/console. The web app is capable of providing advanced statistics such as % recycling/compost/garbage, your carbon emissions as well as statistics on which specific items you throw out the most (water bottles, bag of chips, etc.). The classifier is capable of being modified to suit the garbage laws of different places (eg. separate recycling bins for paper and plastic).
## How We built it
Raspberry pi is triggered using a distance sensor to take the photo of the inserted waste item, which is identified using Google Vision API. Once the item is identified, our classifier determines whether the item belongs in recycling, compost bin or garbage. The inbuilt hardware drops the waste item into the correct section.
## Challenges We ran into
Combining IoT and AI was tough. Never used Firebase. Separation of concerns was a difficult task. Deciding the mechanics and design of the bin (we are not mechanical engineers :D).
## Accomplishments that We're proud of
Combining the entire project. Staying up for 24+ hours.
## What We learned
Different technologies: Firebase, IoT, Google Cloud Platform, Hardware design, Decision making, React, Prototyping, Hardware
## What's next for smartBin
Improving the efficiency. Build out of better materials (3D printing, stronger servos). Improve mechanical movement. Add touch screen support to modify various parameters of the device. | partial |
## Inspiration
We were inspired to create a caffeine tracker because it's a tool that's directly relevant to our lives – we are both avid coffee drinkers, and wanted a better way to keep tabs on our caffeine intake. This project allowed us to merge our love for coffee with a desire to learn about web app development.
## What it does
Caffe-in-me is a web application designed to help users monitor and manage their caffeine intake effectively. It allows users to input their coffee consumption, including the type and time of each coffee drink they've had during the day. The application then provides a visual representation of their caffeine level throughout the day through an interactive graph.
## How we built it
We chose to use Reflex as our framework, which allowed us to create a responsive and interactive caffeine tracker. With Reflex, we were able to develop the project in a way that was both intuitive and efficient.
## Accomplishments that we're proud of
We had to familiarize myself with the intricacies of Reflex and the development process for web applications. This project has given us invaluable hands-on experience in building web applications, and we are proud of what we've accomplished.
## What we learned and challenges
One of the major challenges I faced was getting to grips with all the different components involved in web app development. From setting up a development environment to handling user interactions, there was a lot to learn.
## What's next for Caffe-in-me
To provide users with more valuable insights, we want to integrate machine learning algorithms that can predict caffeine effects on an individual's energy levels, sleep patterns, and overall well-being based on their caffeine intake. | ## Inspiration
We were inspired to create HaBits because we wanted to make health tracking both engaging and personalized. With so many fitness and health apps available, we noticed a gap in how they engage users with their data and motivate healthy habits in a way that fosters community. By integrating data from the iOS Health app, we wanted to give users an easy way to monitor their progress across key health categories—like sleep, meditation, and steps—in a visually intuitive and competitive way. Our goal is to make health tracking more social, personal, and fun, helping users improve their habits while connecting with their friends and competing on a leaderboard. We believe that building good habits becomes easier when you can track your progress and share the journey with others.
## What it does
HaBits is a personalized health tracker that syncs with the iOS Health app to monitor users' sleep, meditation, and steps. It visualizes this data using progress circles, giving users an easy way to understand their daily goals and how well they are doing. Additionally, the app features a leaderboard where users can compare their progress with friends, fostering healthy competition and community support. We are also developing a feature where users can scan pictures of their food, and our machine learning model will estimate calorie intake based on the food’s appearance. This will allow users to track their calorie consumption relative to their BMI, ensuring they're meeting their nutritional needs.
## How we built it
We built HaBits using React Native, TypeScript, and Expo to create a cross-platform mobile app that works seamlessly on both iOS and Android devices. We integrated Apple HealthKit to gather users' health data, including their sleep, meditation, and steps. For real-time updates and leaderboard functionality, we used Firebase, allowing users to stay connected with their friends and track their progress live. The food scanning feature, which is under development, uses a machine learning model to detect calorie intake based on photos of food. We designed the app with a focus on user experience, leveraging tools like Figma for prototyping, ensuring a sleek and intuitive interface.
## Challenges we ran into
One of the main challenges we encountered was connecting to the iOS Health app and accurately retrieving health data. Ensuring that we could securely access users' sleep, meditation, and step data while respecting their privacy and permissions required careful navigation of the Apple HealthKit API. We also had to handle potential data syncing issues and ensure the app functions smoothly across different devices.
## Accomplishments that we're proud of
We’re proud of successfully creating a social aspect with our leaderboard feature, which encourages users to stay motivated. We're also excited about our plans for the food scanning feature, which demonstrates how AI can play a role in helping users monitor their nutrition with minimal effort. Another accomplishment was our design; we received great feedback on how intuitive and visually appealing the app is.
## What we learned
Building HaBits was a valuable learning experience, especially since it was our first time working with React Native and Expo. We quickly adapted to these new technologies and learned how to build a mobile app that could seamlessly function across both iOS and Android platforms. The experience also taught us how to work efficiently as a team, coordinating between frontend, backend, and machine learning tasks to bring all the components together smoothly. Collaborating on complex features like integrating HealthKit data and Firebase for real-time updates required strong communication and problem-solving. Overall, we learned the importance of flexibility and teamwork when tackling unfamiliar technologies and how to combine our skills to create a cohesive product.
## What's next for HaBits
Next, we plan to expand the app’s functionality by integrating more health categories, such as hydration and stress levels, for a more holistic health tracking experience. We are also focused on improving the food scanning feature by enhancing the accuracy of calorie detection and expanding it to recognize portion sizes. Additionally, we plan to introduce features like personalized challenges and wellness tips based on the user’s data, making the app a more comprehensive health assistant. Finally, we’re looking to implement more social features, like group challenges and wellness goals, to further engage users in improving their health together. | ## Inspiration
Ordering delivery and eating out is a major aspect of our social lives. But when healthy eating and dieting comes into play it interferes with our ability to eat out and hangout with friends. With a wave of fitness hitting our generation as a storm we have to preserve our social relationships while allowing these health conscious people to feel at peace with their dieting plans. With NutroPNG, we enable these differences to be settled once in for all by allowing health freaks to keep up with their diet plans while still making restaurant eating possible.
## What it does
The user has the option to take a picture or upload their own picture using our the front end of our web application. With this input the backend detects the foods in the photo and labels them through AI image processing using Google Vision API. Finally with CalorieNinja API, these labels are sent to a remote database where we match up the labels to generate the nutritional contents of the food and we display these contents to our users in an interactive manner.
## How we built it
Frontend: Vue.js, tailwindCSS
Backend: Python Flask, Google Vision API, CalorieNinja API
## Challenges we ran into
As we are many first-year students, learning while developing a product within 24h is a big challenge.
## Accomplishments that we're proud of
We are proud to implement AI in a capacity to assist people in their daily lives. And to hopefully allow this idea to improve peoples relationships and social lives while still maintaining their goals.
## What we learned
As most of our team are first-year students with minimal experience, we've leveraged our strengths to collaborate together. As well, we learned to use the Google Vision API with cameras, and we are now able to do even more.
## What's next for McHacks
* Calculate sum of calories, etc.
* Use image processing to estimate serving sizes
* Implement technology into prevalent nutrition trackers, i.e Lifesum, MyPlate, etc.
* Collaborate with local restaurant businesses | losing |
## Inspiration
Lecture halls aren't the greatest way to meet new friends, and it shows.
Loneliness is a huge issue in universities; in 2017, 63.1% of nearly 48,000 college students indicated that they had felt “very lonely” in the previous 12 months [1]. College students often struggle to make friends outside of dorms or clubs, and while juggling all the pressure of classes and extracurriculars, it can be hard find friends - particularly because there isn't a great way to do so. At the same time, studies show that people tend to underestimate the mental benefits brought by conversing with strangers [2].
Fifteen aims to leverage the unexplored potential of with-stranger conversations to improve the well-being of students and reduce loneliness on college campuses. We aspire to bring college students closer in an enjoyable, adventurous way and cultivate a tighter-knit student community.
Fifteen won't just be for college students, either. Fifteen can be a tool to help build community everywhere. You might have heard of the six degrees of separation; everyone in the world is connected through no more than six connections. Through Fifteen, we hope to bring this number down to five.
## What it does
Fifteen is a platform that connects university students and encourages them to meet up with another random student for fifteen minutes every day. We use our algorithm to pair up our users to a stranger they'll get along with, and then the magic starts. They first chat with each other online anonymously, in a low-pressure, low-commitment environment, and then decide if they want to spend fifteen minutes together in real life.
## How we built it
* Dynamic website built off HTML, CSS, JavaScript, Python, Flask, Node.js, and Socket.io
* Custom design (all images are hand drawn and color-blind friendly)
* Functional chat feature built with NodeJS Express framework embedded into the website
* NetworkX and Geopandas backend processing for matching algorithm
* Google Firebase database for user profiles
* Google BigQuery for GIS data along with Cloud GPUs for processing
* Matplotlib and imagemagick for creating visuals
* Researched Meyer-Briggs personality tests to create entry survey
## Challenges we ran into
* Dream bigger — we started with a big idea to address the college student mental health issue, spending a lot of time doing user research and brainstorming the most effective and realistic solution.
* Algorithm & Visualization/database —figure out how to diagram and deliver this to our user, computation times were resource consuming and difficult as the dataset got larger
* Web development — Integrating multiple languages together, specifically with Flask and NodeJS; Making our website response and mobile-friendly
* User survey — challenging to balance between the comprehensiveness, length, and style during user survey design.
* Design — a lot of factors are put into considerations to increase Fifteen’s accessibility, user-friendliness, and desire to use our product
* repl.it — a coding collaboration platform that is always broken.
## Accomplishments that we're proud of
\*Human-centered design process - our product design iterates through cycles supported by substantial user research, which includes but is not limited to an anonymous chat function, color-blind friendly color palette, optimization of user flow, fifteen-minute meetup time and visualization of data
\*Interdisciplinary project —with diverse backgrounds, we capitalize on our engineering skill, design knowledge, and social science research methodologies to build Fifteen
## What's next for Fifteen
\*Expanding target audience - the elderly, middle-aged workers, etc.
More functions - give users the ability to choose between exploration mode and similarity mode (more flexibility in who they match with)
\*More incentives - find sponsorships to provide things like free meals to incentivize users to meet offline
Chatbot AI - suggest conversation topics and fun things to do to help reduce planning anxiety
References
[1] <https://www.acha.org/documents/ncha/NCHA-II_FALL_2017_REFERENCE_GROUP_EXECUTIVE_SUMMARY.pdf>
[2] <https://psycnet.apa.org/record/2014-28833-001> | ## Inspiration
As our world becomes more digitalized and interactions become a more permanent, our team noticed a rise in online anxiety stemming from an innate fear of being judged or making a mistake. In Elizabeth Armstrong's book *Paying for the Party* , Armstrong mentions the negative impacts of being unique at a school where it pays to not stand out. This exact sentiment can now be seen online, except now, everything can be traced back to an identity indefinitely. Our thoughts, questions, and personal lives are constantly be ridiculed and monitored for mistakes. Even after a decade of growth, we will still be tainted with the person we were years before. Contrary to this social fear, many of us started off a childhood with a confidence and naivety of social norms allowing us to simply make friends based on interests. Everyday was made for show-and-tell and asking questions. Through this platform, we seek to develop a web app that allows us to reminisce about the days when making friends was as easy as turning to stranger on the playground and asking to play.
## What it does
Our web app is designed to make befriending strangers with shared interests easier and making mistakes less permanent. When opening the app, users will be given a pseudo name and will be able to choose their interests based on a word cloud. Afterwards, the user can then follow one of three paths. The first would be a friend matching path where the user will receive eight different people who share common interests with them. In these profiles, each person's face would be blurred and the only thing shared would be interests and age. The user can select up to two people to message per day. The second path allows for learning. Once a user selects a topic they'd like to learn more about, they will then be matched to someone who is volunteering to share information. The third consists of a random match in the system for anyone who is feeling spontaneous. This was inspired by Google's "I'm feeling lucky" button. Once messaging begins, the both people will have the ability to reveal their identity at any point, which would resolve the blurred image on their profile for the user they are unlocking it for.
The overall objective is to create a space for users to share without their identity being attached.
## How we built it
Our team built this by taking time to learn UI design in Figma and then began to implement the frontend through html and css. We then attempted to build the back-end using python through Flask. We then hosted the web app on Azure as our server.
## Challenges we ran into
Our team is made up of 100% beginners with extremely limited coding experience, so finding the starting point for web app development was the biggest challenge we ran into. In addition, we ran into a significant amount of software downloading issues which we worked with a mentor to resolve for several hours. Due to these issues, we never fully implement the program.
## Accomplishments that we're proud of
Our team is extremely proud of the progress we have made thus far on the project. Coming in, most of us had very limited skills so being able to have learned Figma and launch a website in 36 hours feels incredible. Through this process, all of us were able to learn something new whether that be a software, language, or simply the process of website design and execution. As a group coming from four different schools from different parts of the world, we are also proud of the general enthusiasm, friendship, and team skills we built through this journey.
## What we learned
Coming in as beginner programmers, our team learned a lot about the process of creating and designing a web app from start to finish. Through talking to mentors, we were able to learn more about the different softwares, frameworks, and languages many applications use as well as the flow of going from frontend to backend. In terms of technical skills, we picked up Figma and html and css through this project.
## What's next for Playground
In the future, we hope to continue designing the frontend of Playground and then implementing the backend through python since we never got to the point of completion. As a web app, we hope to be able to later implement better matching algorithms and expanding into communities for different "playground." | ## Inspiration
It took us a while to think of an idea for this project- after a long day of zoom school, we sat down on Friday with very little motivation to do work. As we pushed through this lack of drive our friends in the other room would offer little encouragements to keep us going and we started to realize just how powerful those comments are. For all people working online, and university students in particular, the struggle to balance life on and off the screen is difficult. We often find ourselves forgetting to do daily tasks like drink enough water or even just take a small break, and, when we do, there is very often negativity towards the idea of rest. This is where You're Doing Great comes in.
## What it does
Our web application is focused on helping students and online workers alike stay motivated throughout the day while making the time and space to care for their physical and mental health. Users are able to select different kinds of activities that they want to be reminded about (e.g. drinking water, eating food, movement, etc.) and they can also input messages that they find personally motivational. Then, throughout the day (at their own predetermined intervals) they will receive random positive messages, either through text or call, that will inspire and encourage. There is also an additional feature where users can send messages to friends so that they can share warmth and support because we are all going through it together. Lastly, we understand that sometimes positivity and understanding aren't enough for what someone is going through and so we have a list of further resources available on our site.
## How we built it
We built it using:
* AWS
+ DynamoDB
+ Lambda
+ Cognito
+ APIGateway
+ Amplify
* React
+ Redux
+ React-Dom
+ MaterialUI
* serverless
* Twilio
* Domain.com
* Netlify
## Challenges we ran into
Centring divs should not be so difficult :(
Transferring the name servers from domain.com to Netlify
Serverless deploying with dependencies
## Accomplishments that we're proud of
Our logo!
It works :)
## What we learned
We learned how to host a domain and we improved our front-end html/css skills
## What's next for You're Doing Great
We could always implement more reminder features and we could refine our friends feature so that people can only include selected individuals. Additionally, we could add a chatbot functionality so that users could do a little check in when they get a message. | losing |
## Inspiration
As young college students who want to make sustainable life choices but are too bogged down by schoolwork to find time to do so, we were looking for a simple service that could "green-ify" our eating choices. Because nearly 1/3 of greenhouse gas emissions come from food production, eating sustainably has never been more important. So, we built SustainaBite!
## What it does
SustainaBite gives your typical calorie-counting meal tracker a unique twist: it breaks down each of your meal into environmental impact and gives your meal an overall "sustainability score"! The higher your scores, the more points you accrue, letting you earn badges and even redeem free food at sustainable restaurants. Best of all, the social media aspect of our app lets you and your friends cheer each other on in your sustainability goals, and even meet new people in your area with similar food preferences using AI models. For example, if you love Mexican food, we'll match you up with someone with similar tastes--first date's on SustainaBite! This is the perfect way to reach your sustainability goals while connecting with other users on a shared interest everyone enjoys: food!
## How we built it
We built the front-end with React, Next.js. We built the back-end with Convex and Flask. We also worked with OpenAI's API to compare users' food preferences.
Specifically for Convex, we were impressed by its broad, yet powerful utility. We needed a framework that could update databases in real-time while immediately updating our website's front-end. Especially since our website acts as a social media channel, the ability to balance multiple users' requests with Convex was extremely useful. We definitely plan on using Convex in our future full-stack projects.
## Challenges we ran into
Technical challenges: connecting our back-end with OpenAI's API, designing the UI of multiple tabs while coding "sustainability score" algorithms
Ethical challenges: how do we objectively "score" a meal, how do we prevent users from gaming the score system
Task allocation: Learning each others' strengths to effectively allocate tasks while also finding time for sleep and TreeHacks events.
## Accomplishments that we're proud of
We're proud of how we focused on impact and design first, then building the technical components from that. We designed our app together as a team, bouncing ideas off each other, then played to our strengths in the building process. We also didn't cut any corners when designing our scoring algorithms: we researched different methods of sustainability measures, how various factors could affect the environmental impact of certain foods, etc.
## What we learned
Full-stack programming is hard. Since each of us had different technical strengths, we split up our work into various tasks. However, connecting them all together took a lot of debugging and installations, but it was worth the effort in the end, and we all came away with a better understanding of full-stack frameworks.
## What's next for SustainaBite
Building a user base. We'll start with our friends and ask them to sign up. We'll ask our college's local Mexican joint to do a test partnership, and try various incentive programs to see which would maximize our users' increases in sustainability. We hope to expand so that many sustainable restaurants partner with us, and we can begin a two-way exchange in which we help sustainable restaurants attract customers and we help people who want to eat sustainably to find sustainable restaurants.
## Prizes we are entering:
**Sustainability Grand Prize:** Our project is focused on sustainable eating, an aspect of sustainability that can be overlooked but has a heavy impact on the environment. With our website, every single one of us can become more aware of the impact of each of our meals and make easy, small changes to increase sustainable eating habits.
**Best Use of Convex:** Our project used Convex for the back-end, allowing us to update our database of user posts in real-time while updates our website's front-end. Our use of Convex allowed the social media aspect of our website to function much more smoothly and balance multiple users' requests simultaneously.
**Best Natural Language Hack by Mem:** We used OpenAI to take in user food preferences and give users recommendations for related sustainable restaurants, as well as match users with other users with similar food preferences.
**Best Hack to Connect With Others Through Food any Otsuka VALUENEX:** Our project not only encourages sustainable eating, but also brings users together around sustainable eating. Our AI model matches users based on food preferences and allows them to enjoy a sustainable meal together on us, helping people connect through their love of food.
**Best Startup by YCombinator:** Our project has real value in the market, as we provide a unique, simple way to combine food tracking and sustainability, combined with a social media aspect to help build a community of users, and an opportunity for sustainable restaurants to sponsor our website to grow their own business and message of sustainability.
**Best Use of OpenAI Models:** We used OpenAI to take in user food preferences and give users recommendations and match users with similar food preferences. This use of OpenAI adds an aspect of community and connection to our project, allowing users to come together around food, especially sustainable food.
**Most Ethically Engaged Hack by Stanford Center for Ethics & Society (Our Ethical Considerations):**
Our team of hackers took the time to consider the ethics of our app, SustainaBite. The app's focus on sustainability and its potential impact on users' consumption habits could have significant implications, so it's important to approach this with care.
One ethical consideration that our team grappled with was how to accurately report the sustainability of consuming a certain number of portions of food without deterring users from eating more food. Our team had to recognize that a negative or overly restrictive message about the greater carbon emissions associated with a larger quantity of food could lead to unhealthy eating habits for a user.
Another ethical consideration that our team addressed was making high-quality information available to users without providing so much data that it was difficult for a user to interpret. Sustainability-related data can be complex and difficult to understand, which can lead to confusion or misinformation. By using data about the sustainability of various foods from a study published in the Proceedings of the National Academy of Sciences and simplifying the information into categories, our team ensured that users could easily interpret the data and make informed decisions.
In order to avoid ethical issues with our technology in the future, our team has action plans for the following areas:
Data privacy: As SustainaBite requires users to input personal information such as dietary preferences, there is a risk that this data could be compromised or misused. To address this issue, SustainaBite should ensure that users are informed about how their data is being collected, stored, and used.
Discrimination: There is a risk that SustainaBite's AI models could perpetuate bias or discrimination based on factors such as race, gender, or socio-economic status. To mitigate this risk, SustainaBite should take steps to ensure that its algorithms are transparent and auditable, and that it has a diverse and inclusive team working on its development.
Health and safety: While SustainaBite is designed to encourage healthy eating habits, there is a risk that users could become too focused on their sustainability score and ignore other important factors such as nutritional value and food safety. To address this, SustainaBite could in the future also provide users with clear guidelines on healthy eating habits and safe food handling practices.
Environmental impact: SustainaBite's sustainability score is based on a range of environmental factors, such as carbon footprint and water usage using the best available data for users. However, there is a risk that this could oversimplify complex issues and fail to capture the full environmental impact of different foods. To address this, SustainaBite should work with experts in the sustainability to develop a robust and evidence-based sustainability scoring system.
Disparities: There is a risk that some users may have less access to sustainable food options or be unable to afford meals at sustainable restaurants. To address this, SustainaBite will work to promote equity and inclusivity in its platform, and consider offering alternative rewards for users who may not have the means to redeem free food at sustainable restaurants. We want all users to have access to sustainable foods.
Overall, it's essential for SustainaBite to prioritize ethical considerations throughout the development and deployment of its technology. By taking a thoughtful and inclusive approach, SustainaBite can maximize its potential to promote sustainable eating habits and foster positive social connections among users. | ## Inspiration
Don't get us wrong, there's many great things about our country, the West, and principles that guide our lives. But we set out on this project because we noticed an unfairness in the world. We noticed that things that bring Goodness in the world, the actions that so many of us undertake on a daily basis, often go under-rewarded, far more than they ought to be.
Our project today aimed to bring awareness to those littler actions, to bring notice and measure to the way people live their lives and encourage people to do better. We wanted to build an app that quantifies every individual's contributions to our planet and encourages them to do more. Goodness crosses this hurdle, also solving the long-standing issue of finding it hard to wrap our heads around how we, the individual, might be contributing to the big issues such as climate change and global warming. We wanted to provide an app that brings forward this information directly to the user.
## What it does
We built a one-stop platform for users to measure their impact on the big issues such as environmental impact. Users answer simple questions about their own lifestyle to begin, or simply link their known social media accounts. We traverse this information and make predictions about their lifestyle, giving a score on users' environmental impact. We don't do this unashamedly - most of us live in heavy, metropolitan municipalities, totally dependent on the brutally hyper-efficient, human-focused, modern service industry. Most users of our app are net beneficiaries of the resources our planet provides. First we make people aware of this by giving people a score relating to their carbon footprint. Then, we offer suggestions and progression paths to turn those beneficiaries into contributors.
## How we built it
We divided the project into clear-cut subsections to work on. We identified a strong front-end GUI component, which we chose to build with ReactJS. The back-end would require an sqlite3 database supported by a RESTful API written in GoLang. We used these tools to research data from appropriate environmental services, including a in-depth study conducted by the University of California, Berkeley, and generated database values for our product.
## Challenges we ran into
We were ideally seeking to integrate the product with the Facebook API with features for parsing post history data to instantly obtain values on lifestyle data.
## Accomplishments that we're proud of
Functioning product that works as a website on both desktop and mobile. Dynamic values that are personalised to each user answering questions on themselves. Informed data on one's environmental impact in a persistent state that can be revisited and improved upon.
## What we learned
Personally furthered our individual expertise in these languages. Explored unique APIs such as OpenBank. Examined a range of approaches to try and obtain and handle unique data, such as one's lifestyle patterns.
## What's next for Goodness
We want to introduce a 'curated feed' aspect to improve on our suggestions. Ideally, if this were a true startup project, we'd hire dedicated individuals to feed through media and suggest it to our users so that they can always find more inspiration on how to bring more goodness into their lives. Alternatively, we've considered introducing a machine-learning algorithm to curate media data to similar effect. | ## Inspiration 🌱
Climate change is affecting every region on earth. The changes are widespread, rapid, and intensifying. The UN states that we are at a pivotal moment and the urgency to protect our Earth is at an all-time high. We wanted to harness the power of social media for a greater purpose: promoting sustainability and environmental consciousness.
## What it does 🌎
Inspired by BeReal, the most popular app in 2022, BeGreen is your go-to platform for celebrating and sharing acts of sustainability. Everytime you make a sustainable choice, snap a photo, upload it, and you’ll be rewarded with Green points based on how impactful your act was! Compete with your friends to see who can rack up the most Green points by performing more acts of sustainability and even claim prizes once you have enough points 😍.
## How we built it 🧑💻
We used React with Javascript to create the app, coupled with firebase for the backend. We also used Microsoft Azure for computer vision and OpenAI for assessing the environmental impact of the sustainable act in a photo.
## Challenges we ran into 🥊
One of our biggest obstacles was settling on an idea as there were so many great challenges for us to be inspired from.
## Accomplishments that we're proud of 🏆
We are really happy to have worked so well as a team. Despite encountering various technological challenges, each team member embraced unfamiliar technologies with enthusiasm and determination. We were able to overcome obstacles by adapting and collaborating as a team and we’re all leaving uOttahack with new capabilities.
## What we learned 💚
Everyone was able to work with new technologies that they’ve never touched before while watching our idea come to life. For all of us, it was our first time developing a progressive web app. For some of us, it was our first time working with OpenAI, firebase, and working with routers in react.
## What's next for BeGreen ✨
It would be amazing to collaborate with brands to give more rewards as an incentive to make more sustainable choices. We’d also love to implement a streak feature, where you can get bonus points for posting multiple days in a row! | losing |
## Inspiration
HealthCord is online Personal Health Record web application that you can use to maintain, manage and keep track of information from your medical history, doctor visits, tests, ailments and procedures. You can also document your life outside the doctor's office and your health priorities, such as tracking your food intake, exercise, and blood pressure. Analyse and provides you with the summary of your health.
## What it does
One can consult dieticians, fitness trainers to plan your diet and workout routine.
It also has a patient portal that allows users to access online appointment scheduling, and bill pay.
## How we built it
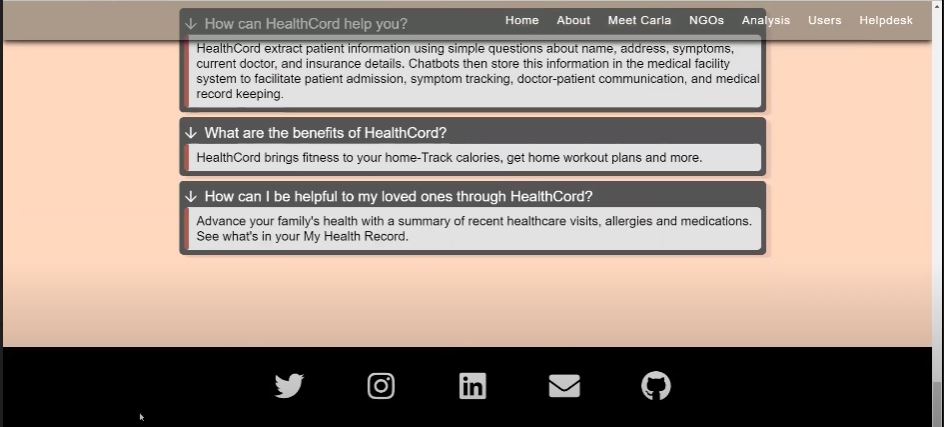
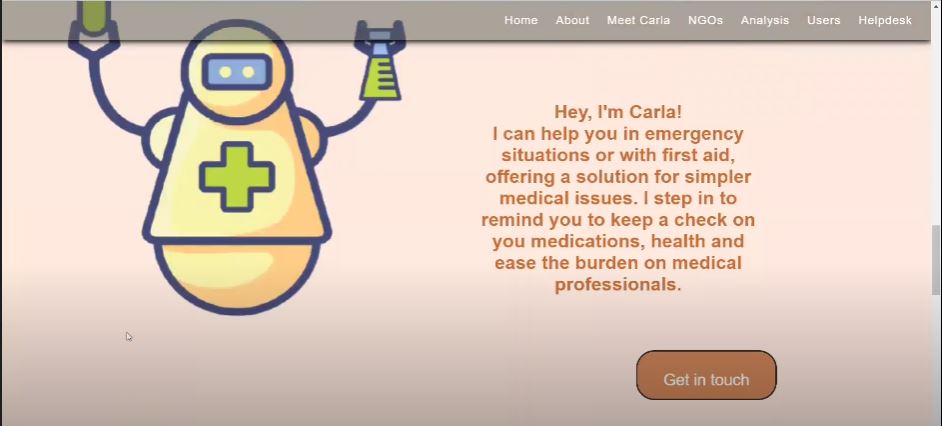

## Challenges we ran into
I took a lot of time configuring and refactoring the project HealthCord. Moreover, I was also looking at the security side, which is a very important thing to be kept in mind for these types of projects.
## Accomplishments that we're proud of
I explored so many things within 48 hours. It was a tad difficult for me to work in a virtual setting but I am proud of finishing the project on time which seemed like a tough task initially but happily was also able to add most of the concepts that I envisioned for the app during ideation. Lastly, I think the impact our project could have is a significant accomplishment. Especially, trailing the current scenario of COVID19, this could really be a product that people find useful!
This project was especially an achievement for us because this time the experience was very different than what we have while building typical hackathon projects, which also includes heavy brainstorming, extensive research, and yes, hitting the final pin on the board.
## What I learned
A lot of things, both summed up in technical & non-technical sides. Also not to mention, I enhanced our googling and Stackoverflow searching skill during the hackathon :)
## What's next for HealthCord
As previously mentioned, HealthCord is one of the most technically sound projects I have made till now, and I would love to keep it open-sourced indefinitely so that anyone can contribute to the project since I am aiming to expand the wings of our project beyond the hackathon. Apart from fine-tuning the project, I am also planning to integrate new user-intuitive features such as refined User/Patient access, easy checkout option for hospitals, adding more such IoT-based inter-device support for maximizing our audience interaction. Apart from these, a lot of code needs to be refactored which does include CSS improvements for desktop preview as I couldn't hit so much under limited time. Overall, I hope that one day this project can be widely used among the medical community to redefine the existing & remove the backlogs. | ## Inspiration
I wrote my college application essays on Boston Dynamics. When I saw Spot, I was a little kid again with a bright mind and an innocent smile. However, I didn't know what I wanted to build exactly, until I noticed the infinite supply of QR Codes around me!
## What it does
Spot utilizes a graph search algorithm to find a QR code in its environment. On detection, Spot gallops the entire distance (depth-perception) to the target. If Spot overcommited and got too close to the target, it flees the scene as a dog usually would!
## How we built it
I used Merklebot's abstraction and frameworks to run my code on Spot. I utilized a depth-perception algorithm that estimates how far an object is in the environment. The robot would search for the QR code, and once it found it, it would dash at the qr code. If it lost the target, it would commence search again. Search is based on DFS for simplicty. However, it can easily be changed to a more sophisticated algorithm, such as A\*, for instance.
## Challenges we ran into
It is a difficult task to get the search to work. Additionally, it's very tedious to get live data from the robot for analytics and debugging. Managing Spot necessitated high-quality code, so the robot doesn't damage anything, which was a strenuous task.
## Accomplishments that we're proud of
I actually worked with Spot and did something!!!!!
## What we learned
Murphy's Law exists for a reason. I should be better at estimating the breadth of projects.
## What's next for Untitled
Add a particle filtering sampling algorithm that listens on the microphone, and can detect where targets might be based on a sound they exhibit. This can be incorporated in an A\* algorithm as its heuristic. Play hide-and-seek! | ## Inspiration
We've all had to fill out paperwork going to a new doctor before: it's a pain, and it's information we've already written down for other doctors a million times before. Our health information ends up all over the place, not only making it difficult for us, but making it difficult for researchers to find participants for studies.
## What it does
HealthConnect stores your medical history on your phone, and enables you to send it to a doctor just by scanning a one-time-use QR code. It's completely end-to-end encrypted, and your information is encrypted when it's stored on your phone.
We provide an API for researchers to request a study of people with specific medical traits, such as a family history of cancer. Researchers upload their existing data analysis code written using PyTorch, and we automatically modify it to provide *differential privacy* -- in other words, we guarantee mathematically that our user's privacy will not be violated by any research conducted. It's completely automatic, saving researchers time and money.
## How we built it
### Architecture
We used a scalable microservice architecture to build our application: small connectors interface between the mobile app and doctors and researchers, and a dedicated executor runs machine learning code.
### Doctor Connector
The Doctor Connector enables seamless end-to-end encrypted transmission of data between users and medical providers. It receives a public key from a provider, and then allows the mobile app to upload data that's been encrypted with that key. After the data's been uploaded, the doctor's software can download it, decrypt it, and save it locally.
### ML Connector
The ML Connector is the star of the show: it manages what research studies are currently running, and processes new data as people join research studies. It uses a two-step hashing algorithm to verify that users are legitimate participants in a study (i.e. they have not modified their app to try and join every study), and collects the information of participants who are eligible to participate in the study. And, it does this without ever writing their data to disk, adding an extra layer of security.
### ML Executor
The ML Executor augments a researcher's Python analysis program to provide differential privacy guarantees, runs it, and returns the result to the researcher.
### Mobile App
The Mobile App interfaces with both connectors to share data, and provides secure, encrypted storage of users' health information.
### Languages Used
Our backend services are written in Python, and we used React Native to build our mobile app.
## Challenges we ran into
It was difficult to get each of our services working together since we were a distributed team.
## Accomplishments that we're proud of
We're proud of getting everything to work in concert together, and we're proud of the privacy and security guarantees we were able to provide in such a limited amount of time.
## What we learned
* Flask
* Python
## What's next for HealthConnect
We'd like to expand the HealthConnect platform so those beyond academic researchers, such as for-profit companies, could identify and compensate participants in medical studies.
Test | losing |
## Inspiration
While caught in the the excitement of coming up with project ideas, we found ourselves forgetting to follow up on action items brought up in the discussion. We felt that it would come in handy to have our own virtual meeting assistant to keep track of our ideas. We moved on to integrate features like automating the process of creating JIRA issues and providing a full transcript for participants to view in retrospect.
## What it does
*Minutes Made* acts as your own personal team assistant during meetings. It takes meeting minutes, creates transcripts, finds key tags and features and automates the process of creating Jira tickets for you.
It works in multiple spoken languages, and uses voice biometrics to identify key speakers.
For security, the data is encrypted locally - and since it is serverless, no sensitive data is exposed.
## How we built it
Minutes Made leverages Azure Cognitive Services for to translate between languages, identify speakers from voice patterns, and convert speech to text. It then uses custom natural language processing to parse out key issues. Interactions with slack and Jira are done through STDLIB.
## Challenges we ran into
We originally used Python libraries to manually perform the natural language processing, but found they didn't quite meet our demands with accuracy and latency. We found that Azure Cognitive services worked better. However, we did end up developing our own natural language processing algorithms to handle some of the functionality as well (e.g. creating Jira issues) since Azure didn't have everything we wanted.
As the speech conversion is done in real-time, it was necessary for our solution to be extremely performant. We needed an efficient way to store and fetch the chat transcripts. This was a difficult demand to meet, but we managed to rectify our issue with a Redis caching layer to fetch the chat transcripts quickly and persist to disk between sessions.
## Accomplishments that we're proud of
This was the first time that we all worked together, and we're glad that we were able to get a solution that actually worked and that we would actually use in real life. We became proficient with technology that we've never seen before and used it to build a nice product and an experience we're all grateful for.
## What we learned
This was a great learning experience for understanding cloud biometrics, and speech recognition technologies. We familiarised ourselves with STDLIB, and working with Jira and Slack APIs. Basically, we learned a lot about the technology we used and a lot about each other ❤️!
## What's next for Minutes Made
Next we plan to add more integrations to translate more languages and creating Github issues, Salesforce tickets, etc. We could also improve the natural language processing to handle more functions and edge cases. As we're using fairly new tech, there's a lot of room for improvement in the future. | ## Inspiration
To any financial institution, the most valuable asset to increase revenue, remain competitive and drive innovation, is aggregated **market** and **client** **data**. However, a lot of data and information is left behind due to lack of *structure*.
So we asked ourselves, *what is a source of unstructured data in the financial industry that would provide novel client insight and color to market research*?. We chose to focus on phone call audio between a salesperson and client on an investment banking level. This source of unstructured data is more often then not, completely gone after a call is ended, leaving valuable information completely underutilized.
## What it does
**Structerall** is a web application that translates phone call recordings to structured data for client querying, portfolio switching/management and novel client insight. **Structerall** displays text dialogue transcription from a phone call and sentiment analysis specific to each trade idea proposed in the call.
Instead of loosing valuable client information, **Structerall** will aggregate this data, allowing the institution to leverage this underutilized data.
## How we built it
We worked with RevSpeech to transcribe call audio to text dialogue. From here, we connected to Microsoft Azure to conduct sentiment analysis on the trade ideas discussed, and displayed this analysis on our web app, deployed on Azure.
## Challenges we ran into
We had some trouble deploying our application on Azure. This was definitely a slow point for getting a minimum viable product on the table. Another challenge we faced was learning the domain to fit our product to, and what format/structure of data may be useful to our proposed end users.
## Accomplishments that we're proud of
We created a proof of concept solution to an issue that occurs across a multitude of domains; structuring call audio for data aggregation.
## What we learned
We learnt a lot about deploying web apps, server configurations, natural language processing and how to effectively delegate tasks among a team with diverse skill sets.
## What's next for Structurall
We also developed some machine learning algorithms/predictive analytics to model credit ratings of financial instruments. We built out a neural network to predict credit ratings of financial instruments and clustering techniques to map credit ratings independent of s\_and\_p and moodys. We unfortunately were not able to showcase this model but look forward to investigating this idea in the future. | ## Inspiration
I got the inspiration from the Mirum challenge, which was to be able to recognize emotion in speech and text.
## What it does
It records speech from people for a set time, separating individual transcripts based on small pauses in between each person talking. It then transcribes this to a JSON string using the Google Speech API and passes this string into the IBM Watson Tone Analyzer API to analyze the emotion in each snippet.
## How I built it
I had to connect to the Google Cloud SDK and Watson Developer Cloud first, and learn some python that was necessary to get them working. I then wrote one script file, recording audio with pyaudio and using the APIs for the other two to get JSON data back.
## Challenges I ran into
I had trouble making a GUI, so I abandoned trying to make it. I didn't have enough practice with making GUIs in Python before this hackathon, and the use of the APIs were time-consuming already. Another challenge I ran into was getting the google-cloud-sdk to work on my laptop, as it seemed that there were conflicting files or missing files at times.
## Accomplishments that I'm proud of
I'm proud that I got the google-cloud-sdk set up and got the Speech API to work, as well as get an API which I had never heard of to work, the IBM Watson one.
## What I learned
To keep trying to get control of APIs, but ask for help from others who might've set theirs up already. I also learned to manage my time more effectively. This is my second hackathon, and I got a lot more work done than I did last time.
## What's next for Emotional Talks
I want to add a GUI that will make it easy for viewers to analyze their conversations, and perhaps also use some future Speech APIs to better process the speech part. This could potentially be sold to businesses for use in customer care calls. | winning |
## Inspiration
Our inspiration stemmed from the desire to create a platform where individuals could engage in meaningful debates, sharpening their communication skills while exploring diverse topics tailored towards their interests while also having fun.
## What it does
Debate Me offers a dynamic space for users to participate in debates tailored to their interests. It employs AI-generated topics, provides real-time feedback, and fosters a competitive environment through leaderboards. Debate Me fosters interactive learning experiences, encouraging users to articulate their perspectives and engage in compelling discussions. Its accessibility ensures that anyone, from seasoned debaters to beginners, can participate and grow. By customizing debate modes and offering personalized feedback, Debate Me adapts to individual learning styles, making the journey of skill refinement both engaging and effective.
## How we built it
We began with preliminary designs on Figma, defining the app's theme and layout. Front-end development followed, complemented by the establishment of the PostgreSQL database and API endpoints for the back-end. Integration with the GPT API enabled functionalities like generating debate feedback and topics.
## Challenges we ran into
Coordinating between separate front-end and back-end teams presented integration challenges. Crafting effective prompts for GPT and ensuring consistent output, particularly for debate judgment, proved demanding. Building a robust API took longer than anticipated due to our team's limited experience in web development and APIs.
## Accomplishments that we're proud of
We successfully deployed a feature-rich demo encompassing individual debates, feedback mechanisms, and leveling up. Achieving these milestones within the hackathon timeframe validated our dedication and teamwork.
## What we learned
Navigating the complexities of web development and APIs enhanced our technical proficiency. Collaborating across teams underscored the importance of seamless integration and communication in project development.
## What's next for Debate Me
Our vision includes implementing a multiplayer mode, enabling users to engage in head-to-head debates facilitated by GPT. This expansion aims to elevate Debate Me into a more immersive and competitive platform for honing communication and persuasion skills. GPT may add relevant content to augment these aspects further. | ## Inspiration
We believe that most LLMs are too agreeable, which is nice but not incredibly conducive to all use cases. That's where ArguMentor steps in - our application actively debates with you over your ideas to highlight flaws and weaknesses in your argument.
## What it does
Our application provides users with agents that can portray different scenarios, enabling users to find a customized scenario for their situation.
## How we built it
We fine-tuned our LLM to reflect more critical thinking with an Anthropic dataset using Together.ai. Additionally, we created a second model that was fine-tuned using Monster API. We also iterated on prompts to develop useful and generalizable AI agents for educational purposes, including simulated audience members for a panel discussion. Our front-end was modeled off of a Convex template and our backend is also powered by Convex.
## Challenges we ran into
This was our first hackathon, and we were relatively new to full-stack development, so we're proud of the progress and product we created. Some challenges we faced included: model fine-tuning and dataset formatting, multi-agent LLM tuning and prompt engineering, and integrating the front end with LLM API calls.
## Accomplishments that we're proud of
We are proud by the emergent multi-agent conversations our system is capable of. Particularly, different agents are capable of responding to one another as if they were scholars debating a research topic. Additionally, we are proud of using LLM's in an unconventional light, guiding them to be less agreeable and more honest in helping users strengthen their logic and prepare for challenging situations.
## What we learned
We learned a great deal: front-end development, fine-tuning and prompt-engineering for LLM's, multi-agent LLM interactions, and full-stack development.
## What's next for ArguMentor
We will continue iterating upon our models for better robustness and generalizability. We have many exciting ideas in education and sustainability applications related to this project! | # Nexus, **Empowering Voices, Creating Connections**.
## Inspiration
The inspiration for our project, Nexus, comes from our experience as individuals with unique interests and challenges. Often, it isn't easy to meet others with these interests or who can relate to our challenges through traditional social media platforms.
With Nexus, people can effortlessly meet and converse with others who share these common interests and challenges, creating a vibrant community of like-minded individuals.
Our aim is to foster meaningful connections and empower our users to explore, engage, and grow together in a space that truly understands and values their uniqueness.
## What it Does
In Nexus, we empower our users to tailor their conversational experience. You have the flexibility to choose how you want to connect with others. Whether you prefer one-on-one interactions for more intimate conversations or want to participate in group discussions, our application Nexus has got you covered.
We allow users to either get matched with a single person, fostering deeper connections, or join one of the many voice chats to speak in a group setting, promoting diverse discussions and the opportunity to engage with a broader community. With Nexus, the power to connect is in your hands, and the choice is yours to make.
## How we built it
We built our application using a multitude of services/frameworks/tool:
* React.js for the core client frontend
* TypeScript for robust typing and abstraction support
* Tailwind for a utility-first CSS framework
* DaisyUI for animations and UI components
* 100ms live for real-time audio communication
* Clerk for a seamless and drop-in OAuth provider
* React-icons for drop-in pixel perfect icons
* Vite for simplified building and fast dev server
* Convex for vector search over our database
* React-router for client-side navigation
* Convex for real-time server and end-to-end type safety
* 100ms for real-time audio infrastructure and client SDK
* MLH for our free .tech domain
## Challenges We Ran Into
* Navigating new services and needing to read **a lot** of documentation -- since this was the first time any of us had used Convex and 100ms, it took a lot of research and heads-down coding to get Nexus working.
* Being **awake** to work as a team -- since this hackathon is both **in-person** and **through the weekend**, we had many sleepless nights to ensure we can successfully produce Nexus.
* Working with **very** poor internet throughout the duration of the hackathon, we estimate it cost us multiple hours of development time.
## Accomplishments that we're proud of
* Finishing our project and getting it working! We were honestly surprised at our progress this weekend and are super proud of our end product Nexus.
* Learning a ton of new technologies we would have never come across without Cal Hacks.
* Being able to code for at times 12-16 hours straight and still be having fun!
* Integrating 100ms well enough to experience bullet-proof audio communication.
## What we learned
* Tools are tools for a reason! Embrace them, learn from them, and utilize them to make your applications better.
* Sometimes, more sleep is better -- as humans, sleep can sometimes be the basis for our mental ability!
* How to work together on a team project with many commits and iterate fast on our moving parts.
## What's next for Nexus
* Make Nexus rooms only open at a cadence, ideally twice each day, formalizing the "meeting" aspect for users.
* Allow users to favorite or persist their favorite matches to possibly re-connect in the future.
* Create more options for users within rooms to interact with not just their own audio and voice but other users as well.
* Establishing a more sophisticated and bullet-proof matchmaking service and algorithm.
## 🚀 Contributors 🚀
| | | | |
| --- | --- | --- | --- |
| [Jeff Huang](https://github.com/solderq35) | [Derek Williams](https://github.com/derek-williams00) | [Tom Nyuma](https://github.com/Nyumat) | [Sankalp Patil](https://github.com/Sankalpsp21) | | losing |
## [Visit studynotes](https://www.studynotes.space)
## Motivation
With the recent shift to remote learning, students around the world are faced with a common problem: without friends and faculty around, it becomes hard to find the motivation to study. **studynotes** is a web app that helps to promote a social aspect to studying whilst acting as an easy collaboration tool for sharing notes. Our goal is to create a social network for studying, where users are able to collaborate with others, share their notes, and view what their friends have been up to.
## About
There are three components to this app: the website, the API, and the desktop client.
**Web Client:** Our main app is a web app where users can create an account, view other users' activity, and view your friends' notes. It's written in **JavaScript** using **React** and deployed on **AWS** using **Amplify**. We decided to use a simplistic design for the web page to reduce the barriers that users will face and ease user onboarding. It is through this web client that users will be able to follow and interact with each other, establishing an encouraging atmosphere for learning.
**Desktop Client:** Using the desktop client, users are able to select their notes folder on their computer and automatically have their notes synced to our servers. This is a **Python** application with native-level support for Windows, macOS, and Linux. While running in the background, the client monitors the chosen directory, automatically detecting file changes and sending updates to our API. All the user has to do is save their files locally and their work will be automatically synced with our servers.
**API:** This is the central point of the entire stack. It connects everything together - the desktop client, the **MongoDB** database, and the web client. It's written in **Python** using **Flask** and **PyMODM** using a model-controller architecture and is deployed on **AWS ECS** as a **Docker** container for scalability. The service is backed by a load balancer and will automatically scale up and down depending on traffic. This is a fully fledged API complete with login and user authentication, CORS configurations, and a secure HTTPS connection.
## Challenges we ran into
One of the major issues we ran into was with CORS. Because we implemented our own login system, passing cookies over remote servers was a big pain and we spent a lot of time troubleshooting cross-origin policies.
We also ran into a couple of challenges with optimizing queries to MongoDB and preventing re-renders on the React side. Since we had a lot of data to work with, processing and retrieving data took up to eight seconds at first, which made the service completely unusable. To get around this, we implemented a caching laying on the API which greatly reduced the number of database queries, helping us get the load time to just over one second.
## Accomplishments that we're proud of
Firstly, we are extremely proud of our final product! It is especially fulfilling to have created a functioning application that is fully-deployed and not dependent on hard-coded data of any sort. We are also proud of how we picked up on many new skills over the course of this project, from working with low-level OS APIs for the client to learning how to use MongoDB. Most importantly though, we're proud of how well we worked together as a team, especially since this was our first times working together virtually rather than in-person. It's a weekend we'll remember for sure!
## What we learned
* How to build APIs using Python and Flask, with user authentication
* How to use functional components and hooks in React
* How to use Docker
* How to deploy an application for scalability
## What's next for studynotes
In the future, we hope to see our idea implemented by online learning and collaboration companies and turn it into a widely-used social media platform for students and workers across the world to share, collaborate, and better manage their work. Additional features include collaborative editing directly on the platform, direct uploads, more support for different file types, a chatting functionality, and group folders to organize notes for a particular subject or course. We also hope to integrate the app with existing platforms such as Google Drive and OneDrive and support additional files formats such as Word and LaTeX. | ## Inspiration
As music lovers, we often search music pieces online for a variety of purposes; however, one may not always remember the piece name despite being able to hum the tune or fundamental chord of a song. This inspired us to create Me♪o (pronounced “melo” in melody), a web app that acts as a search engine specifically for musical pieces.
## What it does
Melo is a music search engine designed to help musicians find the musical pieces that they are looking for. Songs can be searched in a traditional manner by name, artist, categories, etc.; however, a feature unique to Melo is that songs can be searched by a subset of notes that appear in them. In other words, users can enter notes in both staff and numbered musical notation to find songs in which the group of notes appear.
## How we built it
We created our project with React and had two main pages (different routes). The first page (Home) contains the title and a search box which receives the data from the user and returns the musical pieces that have matching results. To get this info, we needed a database. Originally, we planned to use CockroachDB, but ended up using a JSON file as our backend since we were running out of time. The second page is a user guide to our webapp with a link to our GitHub repository, if the users choose to view the source code.
## Challenges we ran into
* Getting CockroachDB to work with React (this took a significant amount of our time)
* Getting the backend to deploy (JSON file)
* Miscommunication between teammates
* Waking up + working while sleep deprived
* We had too much fun :D
## Accomplishments that we're proud of
* Coded a full web app
* Used a server for backend
* Deployed the app
* We did ittt
## What we learned
We learned how to do API calls with React’s fetch functions. We learned to retrieve JSON data and convert it to readable and quantifiable results.
## What's next for Me♪o
* Incorporate a SQL database
* Convert sounds into notes and search database for similar songs/musical pieces
* Improve UI
* Personalized output based on user data (i.e. location)
* Add additional features: filters, sharing | ## Inspiration
In large lectures, students often have difficulty making friends and forming study groups due to the social anxieties attached to reaching out for help. Collaboration reinforces and heightens learning, so we sought to encourage students to work together and learn from each other.
## What it does
StudyDate is a personalized learning platform that assesses a user's current knowledge on a certain subject, and personalizes the lessons to cover their weaknesses. StudyDate also utilizes Facebook's Graph API to connect users with Facebook friends whose knowledge complement each other to promote mentorship and enhanced learning.
Moreover, StudyDate recommends and connects individuals together based on academic interests and past experience. Users can either study courses of interest online, share notes, chat with others online, or opt to meet in-person with others nearby.
## How we built it
We built our front-end in React.js and used node.js for RESTful requests to the database, Then, we integrated our web application with Facebook's API for authentication and Graph API.
## Challenges we ran into
We ran into challenges in persisting the state of Facebook authentication, and utilizing Facebook's Graph API to extract and recommend Facebook friends by matching with saved user data to discover friends with complementing knowledge. We also ran into challenges setting up the back-end infrastructure on Google Cloud.
## Accomplishments that we're proud of
We are proud of having built a functional, dynamic website that incorporates various aspects of profile and course information.
## What we learned
We learned a lot about implementing various functionalities of React.js such as page navigation and chat messages.
Completing this project also taught us about certain limitations, especially those dealing with using graphics. We also learned how to implement a login flow with Facebook API to store/pull user information from a database.
## What's next for StudyDate
We'd like to perform a Graph Representation of every user's knowledge base within a certain course subject and use a Machine Learning algorithm to better personalize lessons, as well as to better recommend Facebook friends or new friends in order to help users find friends/mentors who are experienced in same course. We also see StudyDate as a mobile application in the future with a dating app-like interface that allows users to select other students they are interested in working with. | losing |
SmartArm is our submission to UofTHacks 2018.
SmartArm uses Microsoft Cognitive Services, namely the Computer Vision API and Text to Speech API. We designed and rapid prototyped a prosthetic hand model, and embedded a Raspberry PI modular camera on to it. There are servo motors attached to each digit of the hand, powered by an Arduino Uno. The camera feeds image frames to the Analyze.py script, in which objects in the frame are recognzied against Microsoft's pretrained model. Based on the shape of the object, the arduino issues the optimal grasp to hold the identified object.
The SmartArm is a revolutionary step in prosthetics. Because it is completley 3D printed apart form the circuitry, it is meant to be a more cost-friendly and efficient method for amputees and those with congenital defects to gain access to fully functional prosthetics. | ## Inspiration
We were fascinated by the tech of the LeapMotion, and wanted to find a real-world example for the technology, that could positively help the disabled
## What it does
Our system is designed to be a portable sign language translator. Our wearable device has a leap motion device embedded into with a raspberry pi. Every new sign language input is compared to a machine learning model for gesture classification. The word or letter that is returned by the classification model is then output as spoken words, through our Text-to-Speech engine.
## How we built it
There were four main sub tasks in our build.
1) Hardware: We attempted to use a wearable with the raspberry pi and the leap motion device. A wristband was created to house the leap motion device. Furthermore, a button input and RGB led were soldered as hardware inputs.
2) Text-to-Speech: We made use of Google's TTS api in python to make sure we had comprehensible language, and smooth output
3) Leap Motion: We created a python project to collect relevant data from the leap motion device and store it as needed
4) Azure Machine Learning: We created a machine learning model based on training data we generated by outputting leap motion data to a .csv file. With the generated model, we created our own web api service in order to pass in input leap motion data to classify any gesture.
## Challenges we ran into
We ran into two main challenges:
1) Hardware Compatibility: We assumed that because we could write python could on Windows for the leap motion device, we could also port that code over to a Linux based system, such as a raspberry pi, with ease. As we prepared to port our code over, we found out that there is no supported hardware drivers for arm devices. In order to prepare something for demonstration, we used an Arduino for portable hardware inputs but the leap motion device had to stay plugged into a laptop.
2) Machine Learning Training: A lot of the gestures in the american sign language alphabet are very similar, therefore our classification model ended up returning a lot of false responses. We believe that with more training data and a more reliable data source for gestures, we could produce a more reliable classification model.
## Accomplishments that we are proud of
Although our machine learning model was not very accurate, we are still proud that we were able to produce speech output from gesture control. We also managed to work really well as a team; splitting up tasks, design, problem solving, and team atmosphere.
## What we learned
We learned more about machine learning and got a better idea of how to code in python.
## What's next for Gesture.io
Up next, we would look at finding compatible portable hardware to interact with the leap motion device and continue to train our classification model. | ## Inspiration
In online documentaries, we saw visually impaired individuals and their vision consisted of small apertures. We wanted to develop a product that would act as a remedy for this issue.
## What it does
When a button is pressed, a picture is taken of the user's current view. This picture is then analyzed using OCR (Optical Character Recognition) and the text is extracted from the image. The text is then converted to speech for the user to listen to.
## How we built it
We used a push button connected to the GPIO pins on the Qualcomm DragonBoard 410c. The input is taken from the button and initiates a python script that connects to the Azure Computer Vision API. The resulting text is sent to the Azure Speech API.
## Challenges we ran into
Coming up with an idea that we were all interested in, incorporated a good amount of hardware, and met the themes of the makeathon was extremely difficult. We attempted to use Speech Diarization initially but realized the technology is not refined enough for our idea. We then modified our idea and wanted to use a hotkey detection model but had a lot of difficulty configuring it. In the end, we decided to use a pushbutton instead for simplicity in favour of both the user and us, the developers.
## Accomplishments that we're proud of
This is our very first Makeathon and we were proud of accomplishing the challenge of developing a hardware project (using components we were completely unfamiliar with) within 24 hours. We also ended up with a fully function project.
## What we learned
We learned how to operate and program a DragonBoard, as well as connect various APIs together.
## What's next for Aperture
We want to implement hot-key detection instead of the push button to eliminate the need of tactile input altogether. | partial |
# 🎉 CoffeeStarter: Your Personal Networking Agent 🚀
Names: Sutharsika Kumar, Aarav Jindal, Tanush Changani & Pranjay Kumar
Welcome to **CoffeeStarter**, a cutting-edge tool designed to revolutionize personal networking by connecting you with alumni from your school's network effortlessly. Perfect for hackathons and beyond, CoffeeStarter blends advanced technology with user-friendly features to help you build meaningful professional relationships.
---
## 🌟 Inspiration
In a world where connections matter more than ever, we envisioned a tool that bridges the gap between ambition and opportunity. **CoffeeStarter** was born out of the desire to empower individuals to effortlessly connect with alumni within their school's network, fostering meaningful relationships that propel careers forward.
---
## 🛠️ What It Does
CoffeeStarter leverages the power of a fine-tuned **LLaMA** model to craft **personalized emails** tailored to each alumnus in your school's network. Here's how it transforms your networking experience:
* **📧 Personalized Outreach:** Generates authentic, customized emails using your resume to highlight relevant experiences and interests.
* **🔍 Smart Alumnus Matching:** Identifies and connects you with alumni that align with your professional preferences and career goals.
* **🔗 Seamless Integration:** Utilizes your existing data to ensure every interaction feels genuine and impactful.
---
## 🏗️ How We Built It
Our robust technology stack ensures reliability and scalability:
* **🗄️ Database:** Powered by **SQLite** for flexible and efficient data management.
* **🐍 Machine Learning:** Developed using **Python** to handle complex ML tasks with precision.
* **⚙️ Fine-Tuning:** Employed **Tune** for meticulous model fine-tuning, ensuring optimal performance and personalization.
---
## ⚔️ Challenges We Faced
Building CoffeeStarter wasn't without its hurdles:
* **🔒 SQLite Integration:** Navigating the complexities of SQLite required innovative solutions.
* **🚧 Firewall Obstacles:** Overcoming persistent firewall issues to maintain seamless connectivity.
* **📉 Model Overfitting:** Balancing the model to avoid overfitting while ensuring high personalization.
* **🌐 Diverse Dataset Creation:** Ensuring a rich and varied dataset to support effective networking outcomes.
* **API Integration:** Working with various API's to get as diverse a dataset and functionality as possible.
---
## 🏆 Accomplishments We're Proud Of
* **🌈 Diverse Dataset Development:** Successfully created a comprehensive and diverse dataset that enhances the accuracy and effectiveness of our networking tool.
* Authentic messages that reflect user writing styles which contributes to personalization.
---
## 📚 What We Learned
The journey taught us invaluable lessons:
* **🤝 The Complexity of Networking:** Understanding that building meaningful connections is inherently challenging.
* **🔍 Model Fine-Tuning Nuances:** Mastering the delicate balance between personalization and generalization in our models.
* **💬 Authenticity in Automation:** Ensuring our automated emails resonate as authentic and genuine, without echoing our training data.
---
## 🔮 What's Next for CoffeeStarter
We're just getting started! Future developments include:
* **🔗 Enhanced Integrations:** Expanding data integrations to provide even more personalized networking experiences and actionable recommendations for enhancing networking effectiveness.
* **🧠 Advanced Fine-Tuned Models:** Developing additional models tailored to specific networking needs and industries.
* **🤖 Smart Choosing Algorithms:** Implementing intelligent algorithms to optimize alumnus matching and connection strategies.
---
## 📂 Submission Details for PennApps XXV
### 📝 Prompt
You are specializing in professional communication, tasked with composing a networking-focused cold email from an input `{student, alumni, professional}`, name `{your_name}`. Given the data from the receiver `{student, alumni, professional}`, your mission is to land a coffee chat. Make the networking text `{email, message}` personalized to the receiver’s work experience, preferences, and interests provided by the data. The text must sound authentic and human. Keep the text `{email, message}` short, 100 to 200 words is ideal.
### 📄 Version Including Resume
You are specializing in professional communication, tasked with composing a networking-focused cold email from an input `{student, alumni, professional}`, name `{your_name}`. The student's resume is provided as an upload `{resume_upload}`. Given the data from the receiver `{student, alumni, professional}`, your mission is to land a coffee chat. Use the information from the given resume of the sender and their interests from `{website_survey}` and information of the receiver to make this message personalized to the intersection of both parties. Talk specifically about experiences that `{student, alumni, professional}` would find interesting about the receiver `{student, alumni, professional}`. Compare the resume and other input `{information}` to find commonalities and make a positive impression. Make the networking text `{email, message}` personalized to the receiver’s work experience, preferences, and interests provided by the data. The text must sound authentic and human. Keep the text `{email, message}` short, 100 to 200 words is ideal. Once completed with the email, create a **1 - 10 score** with **1** being a very generic email and **10** being a very personalized email. Write this score at the bottom of the email.
## 🧑💻 Technologies Used
* **Frameworks & Libraries:**
+ **Python:** For backend development and machine learning tasks.
+ **SQLite:** As our primary database for managing user data.
+ **Tune:** Utilized for fine-tuning our LLaMA3 model.
* **External/Open Source Resources:**
+ **LLaMA Model:** Leveraged for generating personalized emails.
+ **Various Python Libraries:** Including Pandas for data processing and model training. | ## Inspiration
Social interaction with peers is harder than ever in our world today where everything is online. We wanted to create a setting that will mimic organic encounters the same way as if they would occur in real life -- in the very same places that you’re familiar with.
## What it does
Traverse a map of your familiar environment with an avatar, and experience random encounters like you would in real life! A Zoom call will initiate when two people bump into each other.
## Use Cases
Many students entering their first year at university have noted the difficulty in finding new friends because few people stick around after zoom classes, and with cameras off, it’s hard to even put a name to the face. And it's not just first years too - everybody is feeling the [impact](https://www.mcgill.ca/newsroom/channels/news/social-isolation-causing-psychological-distress-among-university-students-324910).
Our solution helps students meet potential new friends and reunite with old ones in a one-on-one setting in an environment reminiscent of the actual school campus.
Another place where organic communication is vital is in the workplace. [Studies](https://pyrus.com/en/blog/how-spontaneity-can-boost-productivity) have shown that random spontaneous meetings between co-workers can help to inspire new ideas and facilitate connections. With indefinite work from home, this simply doesn't happen anymore. Again, Bump fills this gap of organic conversation between co-workers by creating random happenstances for interaction - you can find out which of your co-workers also likes to hang out in the (virtual) coffee room!
## How we built it
Webapp built with Vue.js for the main structure, firebase backend
Video conferencing integrated with Zoom Web SDK. Original artwork was created with Illustrator and Procreate.
## Major Challenges
Major challenges included implementing the character-map interaction and implementing the queueing process for meetups based on which area of the map each person’s character was in across all instances of the Bump client. In the prototype, queueing is achieved by writing the user id of the waiting client in documents located at area-specific paths in the database and continuously polling for a partner, and dequeuing once that partner is found. This will be replaced with a more elegant implementation down the line.
## What's next for bump
* Auto-map generation: give our app the functionality to create a map with zones just by uploading a map or floor plan (using OCR and image recognition technologies)
* Porting it over to mobile: change arrow key input to touch for apps
* Schedule mode: automatically move your avatar around on the map, following your course schedule. This makes it more likely to bump into classmates in the gap between classes.
## Notes
This demo is a sample of BUMP for a single community - UBC. In the future, we plan on adding the ability for users to be part of multiple communities. Since our login authentication uses email addresses, these communities can be kept secure by only allowing @ubc.ca emails into the UBC community, for example. This ensures that you aren’t just meeting random strangers on the Internet - rather, you’re meeting the same people you would have met in person if COVID wasn’t around. | ## Inspiration
This year, all the members in our team entered the first year of post-secondary and attended our various orientation event. We all realized that during orientation, we talked to many people but really only carried on a couple of friendships or acquaintances. As such, we decided to make an app so that people could quickly find others in their vicinity who share their common interests rather than talking to every single person in the room until they find someone who's a good match.
## What it does
Linkr is an app which shows the people in your area and sorts them by how much they have in common with you. When first installing the app, Linkr asks a series of questions to determine your personality and interests. Based on this, it will find matches for you, no matter where you go. The app uses geolocation of the users to determine how close other users are to you. Based on this and using AI to determine how much they have in common with you, you will get a sorted list of people with the person who has the most in common with you being at the top.
## How we built it
We planned to use Cohere to analyze the similarities between the preferences of different people, using Django for the backend and React Native for the front end. Additionally, we believe that music is a great indicator of personality. As such, we looked into using Spotipy to collect data on people's Spotify history and profiles.
With Cohere, we made use of the get\_embedded function, allowing us to relate preferences and interests to a numerical value, which we then could mathematically compare to others using the numpy module. Additionally, we used Cohere to generate a brief summary of users' Spotify data, as otherwise, there is quite a bit of information, some which may not be as relevant.
In the end, we ended up using React Native with Expo Go to develop the mobile app. We also used Appwrite as a database and authentication service.
## Challenges we ran into
Indecisiveness: We spent a lot of time choosing between and experimenting on two different projects. We were also indecisive about the stack we wanted to use (we started with wanting to use C++ but it took us time to realize that this would not actually be feasible) .
Combining different components: While we were successful in developing the different parts of the project individually, we had a difficult time combining the different technologies together.
## Accomplishments that we're proud of
We are proud of our perseverance. Working on this project was not easy, and we were met with many challenges. Especially considering how our indecisiveness cost us a large part of our time, we believe that we did well and completed a fairly large portion of the final product.
## What we learned
Incorporating different API's together.
Working with a completely new technology (all of us were new to mobile app dev).
Cohere's excellent functionalities.
## What's next for Linkr
Allowing more user customizability and ability to communicate with other matches.
Precise finding of other matches | partial |
## Inspiration
We all read <https://www.reddit.com/r/wallstreetbets/> and trade stocks, so last year we made the prized YoloOnFannieMae which recommends stocks based on the subreddit. This year, we wanted to utilize our award-winning API and actually build a project that buys the recommended stocks on a simulated trading environment!
## What it does
It prompts the user to create a Investopedia account (to do simulated stock trading). Then it presents users with 4 faces representing our 4 developers and based on whichever developer you click, it will buy a random amount of a random stock that is returned from our best YoloOnFannieMae API, so effectively you are buying stocks recommended from /r/wallstreetbets.
## How I built it
With lots of coconut water, smash64 (kindly provided by stdlib) sheer willpower. Also a lil bit of python and javascript
## Challenges I ran into
InvestopediaAPI uses dashes, so importing it in python 2.7 was broken :(
## Accomplishments that I'm proud of
Having this awesome top notch site that we can proudly share! <https://hughbets-ui.herokuapp.com/>
## What I learned
Python, Javascript, HTML, CSS
## What's next for HughBets
Project that buys REAL stocks instead of simulated one! | ## Inspiration
Our project was inspired by the movie recommendation system algorithms used by companies like Netflix to recommend content to their users. Following along on this, our project uses a similar algorithm to recommend investment options to individuals based on their profiles.
## What Finvest Advisor does
This app suggests investment options for users based on the information they have provided about their own unique profiles. Using machine learning algorithms, we harness the data of previous customers to make the best recommendations that we can.
## How it works
We built our web app to work together with a machine-learning model that we designed. Using the cosine similarity algorithm, we compare how similar the user's profile is compared to other individuals already in our database. Then, based on this, our model is able to recommend investments that would be ideal for the user, given the parameters they have entered
## Our biggest challenge
Acquiring the data to get this project functional was nearly impossible, given that individuals' financial information is very well protected and banks would (for obvious reasons) not allow us to work with any real data that they would have had. Constructing our database was challenging, but we overcame it by constructing our own data that was modelled to be similar to real-world statistics.
## Going forward...
We hope to further improve the accuracy of our model by testing different kinds of algorithms with different kinds of data. Not to mention, we would also look forward to possibly pitching our project to larger financial firms, such as local banks, and getting their help to improve upon our model even more. With access to real-world data, we could make our model even more accurate, and give more specific recommendations. | ## Inspiration
We came to this Treehacks wanting to contribute our efforts towards health care. After checking out and working with some of the fascinating technologies we had available to us, we realized that the Magic Leap AR device would be perfect for developing a hack to help the visually impaired.
## What it does
Sibylline uses Magic Leap AR to create a 3D model of the nearby world. It calculates the user distance from nearby objects and provides haptic feedback through a specifically designed headband. As a person gets closer to an object, the buzzing intensity increases in the direction of the object. Maneuverability options also include helping somebody walk in a straight line, by signaling deviations in their path.
## How we built it
Magic Leap creates a 3D triangle mesh of the nearby world. We used the Unity video game engine to interface with the model. Raycasts are sent in 6 different directions relative to the way the user is facing and calculate the distance towards the nearest object. These Raycasts correspond to 6 actuators that are attached to a headband and connected via an Arduino. These actuators buzz with higher intensity as the user gets closer to a nearby object.
## Challenges we ran into
For our initial prototype, the haptic buzzers would either be completely off or completely on. While this did allow the user to detect when an obstacle was vaguely near them in a certain direction, they had no way of knowing how far away it was. To solve this, we adjusted the actuators to modulate their intensity.
Additionally, raycasts were initially bound to the orientation of the head, meaning the user wouldn't detect obstacles in front of them if they were slouched or looking down. We had to take this into consideration when modifying our raycast vectors.
## Accomplishments that we're proud of
We're proud of the system we've built. It uses a complicated stream of data which must be carefully routed through several applications, and the final result is an intensely interesting product to use. We've been able to build off of this system to craft a few interesting and useful quality of life features, and there's still plenty of room for more.
Additionally, we're proud of the extraordinary amount of potential our idea still has. We've accomplished more than just building a hack with a single use case, we've built an entirely new system that can be iterated upon and refined to improve the base functionality and add new capabilities.
## What we learned
We jumped into a lot of new technologies and new skillsets while making this hack. Some of our team members used Arduino microcontrollers for the first time, while one of us learned how to solder. We all had to work hard to figure out how to interface with the Magic Leap, and we learned more about how meshing works in the Unity editor as well.
Lastly, though we cannot hope to fully understand the experience of vision impairment or blindness, we've cultivated a bit more empathy for some of the challenges such individuals face.
## What's next for Sybilline
With industry support, we could significantly expand functionality of Sybilline to apply a number of other vision related tasks. For example, with AI computer vision, Sybilline could tell the user what are objects in front of them.
We would be able to create a chunk-based loading system for multiple "zones" throughout the world, so the device isn't limited to a certain area. We would also want to prioritize the meshing for faster-moving objects, like people in a hallway or cars in an intersection.
With more advanced hardware, we could explore other sensory modalities as our primary method of feedback, like using directional pressure rather than buzzing. In a fully focused, specifically designed final product, we would like to have more camera angles to get more meshing data with, and an additional suite of sensors to cover other immediate concerns for the user. | losing |
## Inspiration
Answer: Our increasingly complex lives demand more than just a reminder tool; they need an understanding partner. We witnessed the strain of juggling health, work, academic responsibilities, and social lives. This inspired the creation of Edith – a comprehensive, intuitive, and health-conscious planner.
## What it does
Answer: Edith is an intelligent calendar that not only plans your day but also considers your health, stress levels, and preferences. Through integration with multiple APIs, it suggests Spotify playlists for stress, plans academic tasks, offers horoscope-based guidance, allows conversational planning, and even suggests activities based on the weather. It's a complete, holistic approach to daily planning.
## How we built it
Answer: Edith is a product of diverse API integrations. By harnessing the power of Terra API for health metrics, Spotify API for mood music, Canvas/Blackboard for academic commitments, Horoscope for celestial insights, OpenAI for chat-based planning, and Weather APIs, we developed a cohesive, user-friendly application. Our team utilized agile development, ensuring regular iterations and refinements based on user feedback.
## Challenges we ran into
Answer: Combining multiple API integrations seamlessly was our primary challenge. Ensuring real-time updates while maintaining the app's speed and responsiveness required optimized backend solutions. Also, refining Edith's AI to offer genuinely useful, not overwhelming, suggestions was a careful balancing act.
## Accomplishments that we're proud of
Answer: We are immensely proud of Edith's ability to "understand" individual users. Its adaptive learning and predictive capabilities set it apart from conventional planners. Our beta testing showed a significant reduction in users' reported stress levels and an increase in their daily productivity.
## What we learned
Answer: We learned the importance of user-centric design. By conducting surveys and continuous feedback loops, we understood the real needs of our audience. Technically, we also grasped the nuances of integrating diverse APIs to work harmoniously within a singular platform.
## What's next for Edith
Answer: We envision expanding Edith's capabilities with more integrations, like fitness trackers and meal planning tools. We're also looking into developing a community feature, allowing users to share tips, strategies, and success stories, fostering a supportive Edith community. | # We'd love if you read through this in its entirety, but we suggest reading "What it does" if you're limited on time
## The Boring Stuff (Intro)
* Christina Zhao - 1st-time hacker - aka "Is cucumber a fruit"
* Peng Lu - 2nd-time hacker - aka "Why is this not working!!" x 30
* Matthew Yang - ML specialist - aka "What is an API"
## What it does
It's a cross-platform app that can promote mental health and healthier eating habits!
* Log when you eat healthy food.
* Feed your "munch buddies" and level them up!
* Learn about the different types of nutrients, what they do, and which foods contain them.
Since we are not very experienced at full-stack development, we just wanted to have fun and learn some new things. However, we feel that our project idea really ended up being a perfect fit for a few challenges, including the Otsuka Valuenex challenge!
Specifically,
>
> Many of us underestimate how important eating and mental health are to our overall wellness.
>
>
>
That's why we we made this app! After doing some research on the compounding relationship between eating, mental health, and wellness, we were quite shocked by the overwhelming amount of evidence and studies detailing the negative consequences..
>
> We will be judging for the best **mental wellness solution** that incorporates **food in a digital manner.** Projects will be judged on their ability to make **proactive stress management solutions to users.**
>
>
>
Our app has a two-pronged approach—it addresses mental wellness through both healthy eating, and through having fun and stress relief! Additionally, not only is eating healthy a great method of proactive stress management, but another key aspect of being proactive is making your de-stressing activites part of your daily routine. I think this app would really do a great job of that!
Additionally, we also focused really hard on accessibility and ease-of-use. Whether you're on android, iphone, or a computer, it only takes a few seconds to track your healthy eating and play with some cute animals ;)
## How we built it
The front-end is react-native, and the back-end is FastAPI (Python). Aside from our individual talents, I think we did a really great job of working together. We employed pair-programming strategies to great success, since each of us has our own individual strengths and weaknesses.
## Challenges we ran into
Most of us have minimal experience with full-stack development. If you look at my LinkedIn (this is Matt), all of my CS knowledge is concentrated in machine learning!
There were so many random errors with just setting up the back-end server and learning how to make API endpoints, as well as writing boilerplate JS from scratch.
But that's what made this project so fun. We all tried to learn something we're not that great at, and luckily we were able to get past the initial bumps.
## Accomplishments that we're proud of
As I'm typing this in the final hour, in retrospect, it really is an awesome experience getting to pull an all-nighter hacking. It makes us wish that we attended more hackathons during college.
Above all, it was awesome that we got to create something meaningful (at least, to us).
## What we learned
We all learned a lot about full-stack development (React Native + FastAPI). Getting to finish the project for once has also taught us that we shouldn't give up so easily at hackathons :)
I also learned that the power of midnight doordash credits is akin to magic.
## What's next for Munch Buddies!
We have so many cool ideas that we just didn't have the technical chops to implement in time
* customizing your munch buddies!
* advanced data analysis on your food history (data science is my specialty)
* exporting your munch buddies and stats!
However, I'd also like to emphasize that any further work on the app should be done WITHOUT losing sight of the original goal. Munch buddies is supposed to be a fun way to promote healthy eating and wellbeing. Some other apps have gone down the path of too much gamification / social features, which can lead to negativity and toxic competitiveness.
## Final Remark
One of our favorite parts about making this project, is that we all feel that it is something that we would (and will) actually use in our day-to-day! | ## Inspiration
Our biggest inspiration came from our grandparents, who often felt lonely and struggled to find help. Specifically, one of us have a grandpa with dementia. He lives alone and finds it hard to receive help since most of his relatives live far away and he has reduced motor skills. Knowing this, we were determined to create a product -- and a friend -- that would be able to help the elderly with their health while also being fun to be around! Ted makes this dream a reality, transforming lives and promoting better welfare.
## What it does
Ted is able to...
* be a little cutie pie
* chat with speaker, reactive movements based on conversation (waves at you when greeting, idle bobbing)
* read heart rate, determine health levels, provide help accordingly
* Drives towards a person in need through using the RC car, utilizing object detection and speech recognition
* dance to Michael Jackson
## How we built it
* popsicle sticks, cardboards, tons of hot glue etc.
* sacrifice of my fingers
* Play.HT and Claude 3.5 Sonnet
* YOLOv8
* AssemblyAI
* Selenium
* Arudino, servos, and many sound sensors to determine direction of speaker
## Challenges we ran into
Some challenges we ran into during development was making sure every part was secure. With limited materials, we found that materials would often shift or move out of place after a few test runs, which was frustrating to keep fixing. However, instead of trying the same techniques again, we persevered by trying new methods of appliances, which eventually led a successful solution!
Having 2 speech-to-text models open at the same time showed some issue (and I still didn't fix it yet...). Creating reactive movements was difficult too but achieved it through the use of keywords and a long list of preset moves.
## Accomplishments that we're proud of
* Fluid head and arm movements of Ted
* Very pretty design on the car, poster board
* Very snappy response times with realistic voice
## What we learned
* power of friendship
* don't be afraid to try new things!
## What's next for Ted
* integrating more features to enhance Ted's ability to aid peoples' needs --> ex. ability to measure blood pressure | partial |
# Inspiration
Many cities in the United States are still severely behind on implementing infrastructure improvements to meet ADA (Americans with Disabilities Act) accessibility standards. Though 1 in 7 people in the US have a mobility-related disability, research has found that 65% of curb ramps and 48% of sidewalks are not accessible, and only 13% of state and local governments have transition plans for implementing improvements (Eisenberg et al, 2020). To make urban living accessible to all, cities need to upgrade their public infrastructure, starting with identifying areas that need the most improvement according to ADA guidelines. However, having city dispatchers travel and view every single area of a city is time consuming, expensive, and tedious. We aimed to utilize available data from Google Maps to streamline and automate the analysis of city areas for their compliance with ADA guidelines.
# What AcceCity does
AcceCity provides a machine learning-powered mapping platform that enables cities, urban planners, neighborhood associations, disability activists, and more to identify key areas to prioritize investment in. AcceCity identifies both problematic and up-to-standards spots and provides an interactive, dynamic map that enables on-demand regional mapping of accessibility concerns and improvements and street views of sites.
### Interactive dynamic map
AcceCity implements an interactive map, with city and satellite views, that enables on-demand mapping of accessibility concerns and improvements. Users can specify what regions they want to analyze, and a street view enables viewing of specific spots.
### Detailed accessibility concerns
AcceCity calculuates scores for each concern based on ADA standards in four categories: general accessibility, walkability, mobility, and parking. Examples of the features we used for each of these categories include the detection of ramps in front of raised entrances, the presence of sidewalks along roads, crosswalk markings at street intersections, and the number of handicap-reserved parking spots in parking lots. In addition, suggestions for possible solutions or improvements are provided for each concern.
### Accessibility scores
AcceCity auto-generates metrics for areas by computing regional scores (based on the scan area selected by the user) by category (general accessibility, walkability, mobility, and parking) in addition to an overall composite score.
# How we built it
### Frontend
We built the frontend using React with TailwindCSS for styling. The interactive dynamic map was implemented using the Google Maps API, and all map and site data are updated in real-time from Firebase using listeners.
New scan data are also instantly saved to the cloud for future reuse.
### Machine learning backend
First, we used the Google Maps API to send images of the street view to the backend. We looked for handicapped parking, sidewalks, disability ramps, and crosswalks and used computer vision, by custom-fitting a zero shot learning model called CLIP from OpenAI, to automatically detect those objects from the images. We tested the model using labeled data from Scale Rapid API.
After running this endpoint on all images in a region of interest, users can calculate a metric that represents the accessibility of that area to people with disabilities. We call that metric the ADA score, which can be good, average, or poor. (Regions with a poor ADA score should be specifically targeted by city planners to increase its accessibility.) We calculated this ADA score based on features such as the number of detected ramps, handicapped parking spaces, crosswalks, and sidewalks from the google maps image analysis discussed previously, in addition to using the number of accidents per year recorded in that area. We trained a proof of concept model using mage.ai, which provides an intuitive and high-level way to train custom models.
## Challenges we ran into
* Applying ML to diverse urban images, especially since it’s so “in the wild”
* Lack of general ML models for accessibility prediction
* Developing methods for calculating representative / accurate metrics
* Running ML model on laptops: very computationally expensive
## Accomplishments that we're proud of
* We developed the first framework that connects Google Maps images with computer vision models to analyze the cities we live in.
* We developed the first computer vision framework/model aimed to detect objects specific for people with disabilities
* We integrated the Google Maps API with a responsive frontend that allows users to view their areas of interest and enter street view to see the results of the model.
## What we learned
* We learned how to integrate the Google Maps API for different purposes.
* We learned how to customize the OpenAI zero shot learning for specific tasks.
* How to use Scale Rapid API to label images
* How to use Mage.ai to quickly and efficiently train classification models.
## What's next for AcceCity
* Integrating more external data (open city data): public buildings, city zoning, locations of social services, etc.
* Training the machine learning models with more data collected in tandem with city officials.
## Ethical considerations
As we develop technology made to enable and equalize the playing field for all people, it is important for us to benchmark our efforts against sustainable and ethical products. Accecity was developed with several ethical considerations in mind to address a potentially murky future at the intersection of everyday life (especially within our civilian infrastructure) and digital technology.
A primary lens we used to assist in our data collection and model training efforts was ensuring that we collected data points from a spectrum of different fields. We attempted to incorporate demographic, socioeconomic, and geopolitical diversity when developing our models to detect violations of the ADA. This is key, as studies have shown that ADA violations disproportionately affect socioeconomically disadvantaged groups, especially among Black and brown minorities.
By incorporating a diverse spectrum of information into our analysis, our outputs can also better serve the city and urban planners seeking to create more equitable access to cities for persons with disabilities and improve general walkability metrics.
At its core, AcceCity is meant to help urban planners design better cities. However, given the nature of our technology, it casts a wide, automatic net over certain regions. The voice of the end population is never heard, as all of our suggestion points are generated via Google Maps. In future iterations of our product, we would focus on implementing features that allow everyday civilians affected by ADA violations and lack of walkability to suggest changes to their cities or report concerns. People would have more trust in our product if they believe and see that it is truly creating a better city and neighborhood around them.
As we develop a technology that might revolutionize how cities approach urban planning and infrastructure budget, it is also important to consider how bad actors might aim to abuse our platform. The first and primary red flag is from the stance of someone who might abuse disability and reserved parking and actively seeks out those reserved spaces, when they have not applied for a disability placard, excluding those who need those spaces the most. Additionally, malicious actors might use the platform to scrape data on cities and general urban accessibility features and sell that data to firms that would want these kinds of metrics, which is why we firmly commit to securing our and never selling our data to third parties.
One final consideration for our product is its end goal: to help cities become more accessible for all. Once we achieve this goal, even on an individual concern by concern basis we should come back to cities and urban planners with information on the status of their improvements and more details on other places that they can attempt to create more equitable infrastructure. | ## Inspiration
One of our teammate’s grandfathers suffers from diabetic retinopathy, which causes severe vision loss.
Looking on a broader scale, over 2.2 billion people suffer from near or distant vision impairment worldwide. After examining the issue closer, it can be confirmed that the issue disproportionately affects people over the age of 50 years old. We wanted to create a solution that would help them navigate the complex world independently.
## What it does
### Object Identification:
Utilizes advanced computer vision to identify and describe objects in the user's surroundings, providing real-time audio feedback.
### Facial Recognition:
It employs machine learning for facial recognition, enabling users to recognize and remember familiar faces, and fostering a deeper connection with their environment.
### Interactive Question Answering:
Acts as an on-demand information resource, allowing users to ask questions and receive accurate answers, covering a wide range of topics.
### Voice Commands:
Features a user-friendly voice command system accessible to all, facilitating seamless interaction with the AI assistant: Sierra.
## How we built it
* Python
* OpenCV
* GCP & Firebase
* Google Maps API, Google Pyttsx3, Google’s VERTEX AI Toolkit (removed later due to inefficiency)
## Challenges we ran into
* Slow response times with Google Products, resulting in some replacements of services (e.g. Pyttsx3 was replaced by a faster, offline nlp model from Vosk)
* Due to the hardware capabilities of our low-end laptops, there is some amount of lag and slowness in the software with average response times of 7-8 seconds.
* Due to strict security measures and product design, we faced a lack of flexibility in working with the Maps API. After working together with each other and viewing some tutorials, we learned how to integrate Google Maps into the dashboard
## Accomplishments that we're proud of
We are proud that by the end of the hacking period, we had a working prototype and software. Both of these factors were able to integrate properly. The AI assistant, Sierra, can accurately recognize faces as well as detect settings in the real world. Although there were challenges along the way, the immense effort we put in paid off.
## What we learned
* How to work with a variety of Google Cloud-based tools and how to overcome potential challenges they pose to beginner users.
* How to connect a smartphone to a laptop with a remote connection to create more opportunities for practical designs and demonstrations.
How to connect a smartphone to a laptop with a remote connection to create more opportunities for practical designs and demonstrations.
How to create docker containers to deploy google cloud-based flask applications to host our dashboard.
How to develop Firebase Cloud Functions to implement cron jobs. We tried to developed a cron job that would send alerts to the user.
## What's next for Saight
### Optimizing the Response Time
Currently, the hardware limitations of our computers create a large delay in the assistant's response times. By improving the efficiency of the models used, we can improve the user experience in fast-paced environments.
### Testing Various Materials for the Mount
The physical prototype of the mount was mainly a proof-of-concept for the idea. In the future, we can conduct research and testing on various materials to find out which ones are most preferred by users. Factors such as density, cost and durability will all play a role in this decision. | ## Inspiration
Food is tastier when it's in season. It's also better for the environment, so we decided to promote seasonal foods to have a positive impact on both our taste buds and the planet!
## What it does
When you navigate to a recipe webpage, you can use our chrome extension to view which recipe ingredients are in season, and which ones are not, based on the current month. You also get an overall rating on the "in-season-ness" of the recipe, and you can hover over the produce to view the months when they will be the freshest.
## How we built it
The UI of the extension is built using vanilla JavaScript, HTML and CSS. The backend is written in python as a flask app, and is hosted on Heroku for it to be widely accessible.
## Challenges we ran into
We had trouble writing the logic to determine which produce appears in the ingredient list of the recipes.
We also had a really tough time uploading our backend server to Heroku. This was because we were running into CORS issues since we wanted our extension to be able to make a request from any domain. The fix was quite simple, but it still took a while for us to understand what was going on!
## Accomplishments that we're proud of
Pretty UI and nice animations.
Compatibility with most recipe sites.
We finished the project in time.
First hackathon for 3 out of 4 of our team members!
## What we learned
How to make a chrome extension.
How to build an API.
What CORS is.
Basic frontend development skills.
Onions have a season!
## What's next for Well Seasoned
Support locations outside of Canada.
Functionality to suggest recipes based on the season. | winning |
## Inspiration
With a prior interest in crypto and defi, we were attracted to Uniswap V3's simple yet brilliant automated market maker. The white papers were tantalizing and we had several eureka moments when pouring over them. However, we realized that the concepts were beyond the reach of most casual users who would be interested in using Uniswap. Consequently, we decided to build an algorithm that allowed Uniswap users to take a more hands-on and less theoretical approach, while mitigating risk, to understanding the nuances of the marketplace so they would be better suited to make decisions that aligned with their financial goals.
## What it does
This project is intended to help new Uniswap users understand the novel processes that the financial protocol (Uniswap) operates upon, specifically with regards to its automated market maker. Taking an input of a hypothetical liquidity mining position in a liquidity pool of the user's choice, our predictive model uses past transactions within that liquidity pool to project the performance of the specified liquidity mining position over time - thus allowing Uniswap users to make better informed decisions regarding which liquidity pools and what currencies and what quantities to invest in.
## How we built it
We divided the complete task into four main subproblems: the simulation model and rest of the backend, an intuitive UI with a frontend that emulated Uniswap's, the graphic design, and - most importantly - successfully integrating these three elements together. Each of these tasks took the entirety of the contest window to complete to a degree we were satisfied with given the time constraints.
## Challenges we ran into and accomplishments we're proud of
Connecting all the different libraries, frameworks, and languages we used was by far the biggest and most frequent challenge we faced. This included running Python and NumPy through AWS, calling AWS with React and Node.js, making GraphQL queries to Uniswap V3's API, among many other tasks. Of course, re-implementing many of the key features Uniswap runs on to better our simulation was another major hurdle and took several hours of debugging. We had to return to the drawing board countless times to ensure we were correctly emulating the automated market maker as closely as possible. Another difficult task was making our UI as easy to use as possible for users. Notably, this meant correcting the inputs since there are many constraints for what position a user may actually take in a liquidity pool. Ultimately, in spite of the many technical hurdles, we are proud of what we have accomplished and believe our product is ready to be released pending a few final touches.
## What we learned
Every aspect of this project introduced us to new concepts, or new implementations of concepts we had picked up previously. While we had dealt with similar subtasks in the past, this was our first time building something of this scope from the ground-up. | ## What it does
Think "virtual vision stick on steroids"! It is a wearable device that AUDIBLY provides visually impaired people with information on the objects in front of them as well as their proximity.
## How we built it
We used computer vision from Python and OpenCV to recognize objects such as "chair" and "person" and then we used an Arduino to interface with an ultrasonic sensor to receive distance data in REAL TIME. On top of that, the sensor was mounted on a servo motor, connected to a joystick so the user can control where the sensor scans in their field of vision.
## Challenges we ran into
The biggest challenge we ran into was integrating the ultrasonic sensor data from the Arduino with the OpenCV live object detection data. This is because we had to grab data from the Arduino (the code is in C++) and use it in our OpenCV program (written in Python). We solved this by using PySerial and calling our friends Phoebe Simon Ryan and Olivia from the Anti Anti Masker Mask project for help!
## Accomplishments that we're proud of
Using hardware and computer vision for the first time!
## What we learned
How to interface with hardware, work as a team, and be flexible (we changed our idea and mechanisms like 5 times).
## What's next for All Eyez On Me
Refine our design so it's more STYLISH :D | ## Inspiration
Our inspiration for this project was the technological and communication gap between healthcare professionals and patients, restricted access to both one’s own health data and physicians, misdiagnosis due to lack of historical information, as well as rising demand in distance-healthcare due to the lack of physicians in rural areas and increasing patient medical home practices. Time is of the essence in the field of medicine, and we hope to save time, energy, money and empower self-care for both healthcare professionals and patients by automating standard vitals measurement, providing simple data visualization and communication channel.
## What it does
What eVital does is that it gets up-to-date daily data about our vitals from wearable technology and mobile health and sends that data to our family doctors, practitioners or caregivers so that they can monitor our health. eVital also allows for seamless communication and monitoring by allowing doctors to assign tasks and prescriptions and to monitor these through the app.
## How we built it
We built the app on iOS using data from the health kit API which leverages data from apple watch and the health app. The languages and technologies that we used to create this are MongoDB Atlas, React Native, Node.js, Azure, Tensor Flow, and Python (for a bit of Machine Learning).
## Challenges we ran into
The challenges we ran into are the following:
1) We had difficulty narrowing down the scope of our idea due to constraints like data-privacy laws, and the vast possibilities of the healthcare field.
2) Deploying using Azure
3) Having to use Vanilla React Native installation
## Accomplishments that we're proud of
We are very proud of the fact that we were able to bring our vision to life, even though in hindsight the scope of our project is very large. We are really happy with how much work we were able to complete given the scope and the time that we have. We are also proud that our idea is not only cool but it actually solves a real-life problem that we can work on in the long-term.
## What we learned
We learned how to manage time (or how to do it better next time). We learned a lot about the health care industry and what are the missing gaps in terms of pain points and possible technological intervention. We learned how to improve our cross-functional teamwork, since we are a team of 1 Designer, 1 Product Manager, 1 Back-End developer, 1 Front-End developer, and 1 Machine Learning Specialist.
## What's next for eVital
Our next steps are the following:
1) We want to be able to implement real-time updates for both doctors and patients.
2) We want to be able to integrate machine learning into the app for automated medical alerts.
3) Add more data visualization and data analytics.
4) Adding a functional log-in
5) Adding functionality for different user types aside from doctors and patients. (caregivers, parents etc)
6) We want to put push notifications for patients' tasks for better monitoring. | winning |
## Inspiration
I got this idea because of the current hurricane Milton causing devastation across Florida.
The inspiration behind *Autonomous AI Society* stems from the need for faster, more efficient, and autonomous systems that can make critical decisions during disaster situations. With multiple sponsors like Fetch.ai, Groq, Deepgram, Hyperbolic, and Vapi providing powerful tools, I envisioned an intelligent system of AI agents capable of handling a disaster response chain—from analyzing distress calls to dispatching drones and contacting rescue teams. The goal was to build an AI-driven solution that can streamline emergency responses, save lives, and minimize risks.
## What it does
*Autonomous AI Society* is a fully autonomous multi-agent system that performs disaster response tasks in the following workflow:
1. **Distress Call Analysis**: The system first analyzes distress calls using Deepgram for speech-to-text and Hume AI to score distress levels. Based on the analysis, the agent identifies the most urgent calls and the city.
2. **Drone Dispatch**: The distress analyzer agent communicates with the drone agent (built using Fetch.ai) to dispatch drones to specific locations, assisting with flood and rescue operations.
3. **Human Detection**: Drones capture aerial images, which are analyzed by the human detection agent using Hyperbolic's LLaMA Vision model to detect humans in distress. The agent provides a description and coordinates.
4. **Priority-Based Action**: The drone results are displayed on a dashboard, ranked based on priority using Groq. Higher priority areas receive faster dispatches, and this is determined dynamically.
5. **Rescue Call**: The final agent, built using Vapi, places an emergency call to the rescue team. It uses instructions generated by Hyperbolic’s text model to give precise directions based on the detected individuals and their location.
## How I built it
The system consists of five agents, all built using **Fetch.ai**’s framework, allowing them to interact autonomously and make real-time decisions:
* **Request-sender agent** sends the initial requests.
* **Distress analyzer agent** uses **Hume AI** to analyze calls and **Groq** to generate dramatic messages.
* **Drone agent** dispatches drones to designated areas based on the distress score.
* **Human detection agent** uses **Hyperbolic’s LLaMA Vision** to process images and detect humans in danger.
* **Call rescue agent** sends audio instructions using **Deepgram**’s TTS and **Vapi** for automated phone calls.
## Challenges I ran into
* **Simulating a drone movement on florida map**: The lat\_lon\_to\_pixel function converts latitude and longitude coordinates to pixel positions on the screen. The drone starts at the center of Florida.
Its movement is calculated using trigonometry. The angle to the target city is calculated using math.atan2.
The drone moves towards the target using sin and cos functions.This allows placing cities and the drone accurately on the map.
* **Callibrating the map to right coordinates**: I had manually experiment with increasing and decreasing the coordinates to fit them at right spots on the florida map.
* **Coordinating AI agents**: Getting agents to communicate effectively while working autonomously was a challenge.
* **Handling dynamic priorities**: Ensuring real-time analysis and updating the priority of drone dispatch based on Groq's risk assessment was tricky.
* **Integration of multiple APIs**: Each sponsor's tools had specific nuances, and integrating all of them smoothly, especially with Fetch.ai, required careful handling.
## Accomplishments that I am proud of
* Successfully built an end-to-end autonomous system where AI agents can make intelligent decisions during a disaster, from distress call analysis to rescue actions.
* Integrated cutting-edge technologies like **Fetch.ai**, **Groq**, **Hyperbolic**, **Deepgram**, and **Vapi** in a single project to create a highly functional and real-time response system.
## What I learned
* **AI for disaster response**: Building systems that leverage multimodal AI agents can significantly improve response times and decision-making in life-critical scenarios.
* **Cross-platform integration**: We learned how to seamlessly integrate various tools, from vision AI to TTS to drone dispatch, using **Fetch.ai** and sponsor technologies.
* **Working with real-time data**: Developing an autonomous system that processes data in real-time provided insights into handling complex workflows.
## What's next for Autonomous AI Society
* **Scaling to more disasters**: Expanding the system to handle other types of natural disasters like wildfires or earthquakes.
* **Edge deployment**: Enabling drones and agents to run on the edge to reduce response times further.
* **Improved human detection**: Enhancing human detection with more precise models to handle low-light or difficult visual conditions.
* **Expanded rescue communication**: Integrating real-time communication with the victims themselves using Deepgram’s speech technology. | ## Inspiration
We all look forward to being home. The familiarity of snuggling up in our comfortable beds and the feeling of our own shower pressure is what we desire - even after a luxurious vacation. But when faced with the cold and dark of an empty house, the word "home" almost doesn't fit. Haven aims to make the event of opening the front door a pleasurable one. We hope to redefine the meaning of "welcome home" by personalizing and enhancing the experience.
While there are numerous smart home technologies developed in the real world, we aim to create a new culture along with new technologies. The consumer doesn't value taking the complicated steps to set up a smart home, and in addition are heavily worried about security and privacy. Though we can't get people to trust us, we rely on people trusting each other to create the smart home norm.
## What it does
Haven is not just an app or a function. It is a platform. Haven uses machine learning and image processing to recognize faces that are registered in the household. It then adjusts features in the house such as unlocking the door, adjusting lighting, heat, and anything else the user might want to create the most welcoming experience. It leaves behind the days of coming home to a lonely, stark house after a long tiring day. The API allows easy user registration and security, and the broad scope of our technology allows more and more functions to be added in the future, creating the most personalized experience possible.
We added a functions library similar to the smartphone's app store. This allows a public run development platform made for the public. With simpler steps. come more users, with more users, comes more trust, and with more trust, comes the popularization of smart homes.
## How we built it
Haven was built using Python and Flask for the face recognition and API respectively. It is hosted using Amazon AWS and utilises libraries including OpenCV for image processing and OpenFace for face recognition.
The hardware was powered a QualComm DragonBoard, which utilized a USB camera to take continuous images, which were processed by cv and sent to our server. This server powered our face recognition, utilizing OpenFace neural networks that we trained from many pictures of our own face. Tagged by an ID, the board receives the necessary permissions to trigger all of its actions. The homeowner's face can then turn on a light, or open the door.
Then, on the front end, we wire-framed our user story on paper before proceeding to create graphics on Adobe Illustrator and screens on Sketch. They were then imported into Principle to create the guiding animations and finally to create the user-centred software platform and to our smart technology.
## Challenges we ran into
Since no one on our team had any experience with machine learning and neural networks, we had to learn a lot very quickly in order to implement face recognition. Learning to use these complex algorithms were difficult, completely understanding them would have needed a Phd.
Hosting our application on AWS turned out to be difficult because setting up OpenFace without Docker had a lot of set-up and required a lot of storage; requiring us to attempt to set-up our servers multiple times.
On the hardware side of things, we found that we struggled the most with performing the necessary functions with the QualComm Dragonboard. Documentation was sparse and as a result we struggled quite a bit with necessary permissions and dealing with dependencies.
## Accomplishments that we're proud of
Although we are nowhere close to being experts on this subject, it was definitely super cool to see how image processing, even given a slightly limited set of data, could be so helpful and accurate in building our solution. Hosting this type of computation over the web was certainly not easy either, and we're happy about how well that turned out, as well as how seamless the integrations became as a result of AWS.
On the user experience front, we feel accomplished about the seamless animated interactions integrated into the front-end of our software platform. The custom illustrations, transitions, and user profiles allow an easy visual understanding of the Haven technology.
## What we learned
For some of our team members, it was our first hackathons. Learning to work as a very key subunit to a bigger team in a development setting was a new experience, especially seeing pieces fit together in the end. Some of us have never worked with Git.
By utilising neural networks and machine learning without having prior knowledge, we learned a lot about how neural networks and machine learning works. We've always joked about these "buzzwords", but when it comes to working with it, it certainly isn't easy and will always remind us how much there is to learn still.
## What's next for Haven
In order to truly give each individual their own home welcoming, we hope that there will be growth in potential functions that Haven can execute. Though we are providing the technology, security, and platform. Our vision is for the functions to be written by our users, for our users, just like skill on the Amazon Alexa, or apps for iOS to wholeheartedly capture customization and popularization of the smart home. | We really like raccoons, so we decided to make a Discord bot that would help us live our dreams of becoming a raccoon. | partial |
## Virality Pro: 95% reduced content production costs, 2.5x rate of going viral, 4 high ticket clients
We’re already helping companies go viral on instagram & TikTok, slash the need for large ad spend, and propel unparalleled growth at a 20x lower price.
## The problem: growing a company is **HARD and EXPENSIVE**
Here are the current ways companies grow reliably:
1. **Facebook ads / Google Ads**: Expensive Paid Ads
Producing ads often cost $2K - $10K+
Customer acquisition cost on Facebook can be as much as $100+, with clicks being as high as $10 on google ads
Simply untenable for lower-ticket products
2. **Organic Social Media**: Slow growth
Takes a long time and can be unreliable; some brands just cannot grow
Content production, posting, and effective social media management is expensive
Low engagement rates even at 100K+ followers, and hard to stay consistent
## Solution: Going viral with Virality Pro, Complete Done-For-You Viral Marketing
Brands and startups need the potential for explosive growth without needing to spend $5K+ on marketing agencies, $20K+ on ad spend, and getting a headache hiring and managing middle management.
We take care of everything so that you just give us your company name and product, and we manage everything from there.
The solution: **viral social media content at scale**.
Using our AI-assisted system, we can produce content following the form of proven viral videos at scale for brands to enable **consistent** posting with **rapid** growth.
## Other brands: Spends $5K to produce an ad, $20K on ad spend.
They have extremely thin margins with unprofitable growth.
## With Virality Pro: $30-50 per video, 0 ad spend, produced reliably for fast viral growth
Professional marketers and marketing agencies cost hundreds of thousands of dollars per year.
With Virality Pro, we can churn out **400% more content for 5 times less.**
This content can easily get 100,000+ views on tik tok and instagram for under $1000, while the same level of engagement would cost 20x more traditionally.
## Startups, Profitable Companies, and Brands use Virality Pro to grow
Our viral videos drive growth for early to medium-sized startups and companies, providing them a lifeline to expand rapidly.
## 4 clients use Virality Pro and are working with us for growth
1. **Minute Land** is looking to use Virality Pro to consistently produce ads, scaling to **$400K+** through viral videos off $0 in ad spend
2. **Ivy Roots Consulting** is looking to use Virality Pro to scale their college consulting business in a way that is profitable **without the need for VC money**. Instead of $100 CAC through paid ads, the costs with Virality Pro are close to 0 at scale.
3. **Manifold** is looking to use Virality Pro to go viral on social media over and over again to promote their new products without needing to hire a marketing department
4. **Yoodli** is looking to use Virality Pro to manage rapid social media growth on TikTok/Instagram without the need to expend limited funding for hiring middle managers and content producers to take on headache-inducing media projects
## Our team: Founders with multiple exits, Stanford CS+Math, University of Cambridge engineers
Our team consists of the best of the best, including Stanford CS/Math experts with Jane Street experience, founders with multiple large-scale exits multiple times, Singaporean top engineers making hundreds of thousands of dollars through past ventures, and a Cambridge student selected as the top dozen computer scientists in the entire UK.
## Business Model
Our pricing system charges $1900 per month for our base plan (5 videos per week), with our highest value plan being $9500 per month (8 videos per day).
With our projected goal of 100 customers within the next 6 months, we can make $400K in MRR with the average client paying $4K per month.
## How our system works
Our technology is split into two sectors: semi-automated production and fully-automated production.
Currently, our main offer is semi-automated production, with the fully-automated content creation sequence still in production.
## Semi-Automated AI-Powered Production Technology
We utilize a series of templates built around prompt engineering and fine-tuning models to create a large variety of content for companies around a single format.
We then scale the number of templates currently available to be able to produce hundreds and thousands of videos for a single brand off of many dozens of formats, each with the potential to go viral (having gone viral in the past).
## Creating the scripts and audios
Our template system uses AI to produce the scripts and the on-screen text, which is then fed into a database system. Here, a marketing expert verifies these scripts and adjusts them to improve its viral nature. For each template, a series of seperate audios are given as options and scripts are built around it.
## Sourcing Footage
For each client, we source a large database of footage found through filmed clips, AI-generated video, motion-graphic images, and taking large videos on youtube and using software to break them down into small clips, each representing a shot.
## Text to Speech
We use realistic-sounding AI voices and default AI voices to power the audio. This has proven to work in the past and can be produced consistently at scale.
## Stitching it all together
Using our system, we then compile the footage, text script, and audio into one streamlined sequence, after which it can be reviewed and posted onto social media.
## All done within 5 to 15 minutes per video
Instead of taking hours, we can get it done in **5 to 15 minutes**, which we are continuing to shave down.
## Fully Automated System
Our fully automated system is a work in progress that removes the need for human interaction and fully automates the video production, text creation, and other components, stitched together without the need for anyone to be involved in the process.
## Building the Fully Automated AI System
Our project was built employing Reflex for web development, OpenAI for language model integration, and DALL-E for image generation. Utilizing Prompt Engineering alongside FFmpeg, we synthesized relevant images to enhance our business narrative.
## Challenges Faced
Challenges encountered included slow Wi-Fi, the steep learning curve with Prompt Engineering and adapting to Reflex, diverging from conventional frameworks like React or Next.js for web application development.
## Future of Virality Pro
We are continuing to innovate our fully-automated production system and create further templates for our semi-automated systems. We hope that we can reduce the costs of production on our backend and increase the growth.
## Projections
We project to scale to 100 clients in 6 months to produce $400K in Monthly Recurring Revenue, and within a year, scale to 500 clients for $1.5M in MRR. | ## Inspiration
The COVID-19 pandemic has changed the way we go about everyday errands and trips. Along with needing to plan around wait times, distance, and reviews for a location we may want to visit, we now also need to consider how many other people will be there and whether its even a safe establishment to visit. *Planwise helps us plan our trips better.*
## What it does
Planwise searches for the places around you that you want to visit and calculates a PlanScore that weighs the Google **reviews**, current **attendance** vs usual attendance, **visits**, and **wait times** so that locations that are rated highly, have few people currently visit them compared to their usual weekly attendance, and have low waiting times are rated highly. A location's PlanScore **changes by the hour** to give users the most up-to-date information about whether they should visit an establishment. Furthermore, PlanWise also **flags** common types of places that are prone to promoting the spread of COVID-19, but still allows users to search for them in case they need to visit them for **essential work**.
## How we built it
We built Planwise as a web app with Python, Flask, and HTML/CSS. We used the Google Places and Populartimes APIs to get and rank places.
## Challenges we ran into
The hardest challenges weren't technical - they had more to do with our *algorithm* and considering the factors of the pandemic. Should we penalize an essential grocery store for being busy? Should we even display results for gyms in counties which have enforced shutdowns on them? Calculating the PlanScore was tough because a lot of places didn't have some of the information needed. We also spent some time considering which factors to weigh more heavily in the score.
## Accomplishments that we are proud of
We're proud of being able to make an application that has actual use in our daily lives. Planwise makes our lives not just easier but **safer**.
## What we learned
We learned a lot about location data and what features are relevant when ranking search results.
## What's next for Planwise
We plan to further develop the web application and start a mobile version soon! We would like to further **localize** advisory flags on search results depending on the county. For example, if a county has strict lockdown, then Planwise should flag more types of places than the average county. | ## Inspiration 💡
Online personal branding is a daunting science for many beginner content creators. Thankfully, existing media trends tell us how to make simple videos go viral.
## What it does 🧑💻
The user simply uploads a raw video and selects existing videos as inspiration. Then the app outputs an AI-edited video infused with viral video formats.
## How we built it 🛠️
Front: NextJS, TailwindCSS
Back: AWS Lambda, Docker
Dev: Vercel
## Challenges we ran into ⚠️
* Fetching video data (title, caption, video, etc.) from Instagram Business API
* Operating AWS Lambda functions across several local machines
* Integrating multiple ML model layers for video processing (Hugging Face, OpenAI Whisper)
## Accomplishments that we're proud of 🏆
* Learning and integrating an extremely complex tech stack in 24 hours
* Extracting sound/visual effects from Instagram videos
* Implementing AI video editing with raw user clips
## What we learned 📚
Our biggest lesson was choosing too many open ended and ambitious MVP features. We should've relied way less on AI processing.
## What's next for Editly 💭
We want to provide a wider range of editing options for video format infusion. This can include plot points, color effects, and more.
We also want to allow users to share inspiration boards via a community tab. Users would be able to create boards that contain video and/or creators that inspired individual video edits. | winning |
## Inspiration
The inspiration for this project came from my passion for decentralized technology.
One particular niche of decentralization
I am particularly fond of is NFT's and how they
can become a great income stream for artists.
With the theme of the hackathon being
exploration and showing a picture of a rocket
ship, it is no surprise that the idea of space
came to mind. Looking into space photography, I
found the [r/astrophotography](https://www.reddit.com/r/astrophotography/)
subreddit that has a community of 2.6 million members.
There, beautiful shots of space can be found,
but they also require expensive equipment and
precise editing. My idea for Astronofty is to
turn these photographs into NFT's for the users
to be able to sell as unique tokens on the
platform while using Estuary as decentralized
storage platform for the photos.
## What It Does
You can mint/create NFT's of your
astrophotography to sell to other users.
## How I Built It
* Frontend: React
* Transaction Pipeline: Solidity/MetaMask
* Photo Storage: Estuary
## Challenges I Ran Into
I wanted to be able to upload as many images as you want to a single NFT so figuring that out logistically, structurally and synchronously in React was a challenge.
## Accomplishments That We're Proud Of
Deploying a fully functional all-in-one NFT marketplace.
## What I Learned
I learned about using Solidity mappings and
structs to store data on the blockchain and all
the frontend/contract integrations needed to
make an NFT marketplace work.
## What's Next for Astronofty
A mechanism to keep track of highly sought after photographers. | ## Inspiration
There are 1.1 billion people without Official Identity (ID). Without this proof of identity, they can't get access to basic financial and medical services, and often face many human rights offences, due the lack of accountability.
The concept of a Digital Identity is extremely powerful.
In Estonia, for example, everyone has a digital identity, a solution was developed in tight cooperation between the public and private sector organizations.
Digital identities are also the foundation of our future, enabling:
* P2P Lending
* Fractional Home Ownership
* Selling Energy Back to the Grid
* Fan Sharing Revenue
* Monetizing data
* bringing the unbanked, banked.
## What it does
Our project starts by getting the user to take a photo of themselves. Through the use of Node JS and AWS Rekognize, we do facial recognition in order to allow the user to log in or create their own digital identity. Through the use of both S3 and Firebase, that information is passed to both our dash board and our blockchain network!
It is stored on the Ethereum blockchain, enabling one source of truth that corrupt governments nor hackers can edit.
From there, users can get access to a bank account.
## How we built it
Front End: | HTML | CSS | JS
APIs: AWS Rekognize | AWS S3 | Firebase
Back End: Node JS | mvn
Crypto: Ethereum
## Challenges we ran into
Connecting the front end to the back end!!!! We had many different databases and components. As well theres a lot of accessing issues for APIs which makes it incredibly hard to do things on the client side.
## Accomplishments that we're proud of
Building an application that can better the lives people!!
## What we learned
Blockchain, facial verification using AWS, databases
## What's next for CredID
Expand on our idea. | ## 🧠 Inspiration
Non-fungible tokens (NFTs) are digital blockchain-linked assets that are completely unique and not interchangeable with any other asset. The market for NFTs has tripled in 2020, with the total value of transactions increasing by 299% year on year to more than $250m\*. Because they are unique and impossible to replicate, they can bridge the gap between the virtual and the physical assets, it is possible to tokenize art and prove ownership with the use of NFTs.
Our team wanted to design a platform to bring the value of social responsibility into this newly blooming industry, and increase the accessibility and knowledge about NFTs. Our platform enables artists to securely register and list their art on the Hedera network and sell them where 10% of every transaction goes to a charitable organization, specifically tied to a UN Sustainable development goal. We also wanted to add a social aspect to gamify the donation process.
We also wanted to use a blockchain technology with lower gas fees and more reliability to increase our user base.
## 🤖 What it does
Every user who joins with us has an account on the Hedera network created for them. They can list their art assets on the hedera network for an amount of their choosing valued in HBAR. Other users can see the marketplace and purchase ownership of the art. This can be which can be transferred to another wallet and into any form of cryptocurrency. Users can filter art by the UN SDG goal they are most passionate about or by charitable organization. Additionally, we list our top contributors to charities in our leaderboard which can be shared on social media to promote activity on our platform. Since we are using blockchain, every transaction is recorded and immutable, so users can trust that their donations are going to the right place.
## 🛠 How we built it
We used Sketch to design our application, a JS, HTML, and CSS frontend, and an Express.js backend.
We used the Hedera Hashgraph blockchain tokenization service, file service, account creation service, and transfer of assets functionality.
## ⚙️ Challenges we ran into
Time restraints caused difficulties connecting our express JS backend to our frontend. We are all new to developing with blockchain, and for some of us it is our first time learning about many of the core concepts related to the technology.
## 🏆 Accomplishments that we're proud of
We are proud of the amount we accomplished within the time that we had. Developing with Hedera for the first time was difficult but we were able to see our transactions live on the test net which was very rewarding and shows the potential for our application when it is complete.
## 💁♀️What we learned
Mainly what was new to us was the fundamentals of blockchain and how to develop on the hedera blockchain. Express.js was also fairly new to us.
## ☀️What's next for Cryptble
Enabling KYC using a KYC provider, connecting our backend, improving our UI/UX, achieving compliance, contacting charities and organizations to join our platform.
## 🧑🤝🧑 Team Members
Pegah#0002
SAk#9408
daimoths#3947
Sharif#9380
* according to a new study released by NonFungible.com | winning |
## Inspiration
During events, we usually take some of our time to go through all the parking floors to find a parking spot. Not knowing where is the available spot, waste a lot of time specially for big city and important events.
We wanted to solve parking traffic that is caused by people circling in parking, to find a spot.
## What it does
Our platform brings real time data about parking spots for a event/parking so people can find empty spot's easier. Reducing the time spent looking for spots, and reducing the amount of fuel consumption, we provide solution to parking management problems. Our platform helps both parking managers and drivers.
## How we built it
Solace is the backbone of our platform. Using their event driven architecture, we can send information to multiple subscribers, in real time. We use their javascript (node.js) sdk for our client side communication and their python sdk for broker and handling events in backend. Messages sent to subscribers are guaranteed messages and they get queued, to make sure all of our available subscribers, get all the events.
Our Arduino, is using sonar distance detector which can detect if there is a vehicle parked in a parking spot. It also can connect to wifi and communicate with our broker.
We use nextjs for fullstack web app. We use typescript for our web app platform.
Our broker is a flask python app and it can handle APIs.
## Challenges we ran into
The first challenge was that we implemented the pub sub wrong, and then we learned how direct messages work and we fix it. Then again we found out that we haven't implemented the correct solution, so we went and ask question from mentors, and they told us about queues and we had to change everything to implement them. After that we saw our app is not being able to send information to multiple users, so we had to search on how to create temp queues and keep all of the users in sync with the data available. Also acknowledging messages to remove them from queue, was one of the thing that we didn't know and made us do a lot of research to fix.
Also we never used a sonar ultra sonic sensor before, and none of us is good at electrical part so it was very challenging for us.
We have 3-4 different apps (such as Arduino, broker, frontend, backend) that are sending messages together, and making sure all of them are secure, and with the correct architecture was a challenging technical task.
Also using Solace sdk, because it was the first time we were using it, and we never had experience with pub sub and event driven apps before. Understanding how it works and how we should plan our platform and which of their sdk we should use was also a challenging task for us.
Publishing app and using .tech domain as well!
## Accomplishments that we're proud of
Seeing that our Arduino signals reflects on multiple users browser in real time was a very proud moment. We planned all of the project and we could achieve the MVP we had in mind. We didn't know about any of pub sub architecture, but we could learn and use it with both python and javascript. Also, we went for more advanced sdk and being able to implement the ideal architecture and making it work, which although took a lot of time, but was a very rewarding achievement.
## What we learned
Using what are pub sub are and how they work and how to implement them was the most interesting skills we learn during this hackathon. We went through nearly all of solace document and tried to understand what is best for our app. Also a thank you for mentors for guiding us for the platform architecture.
Arduino and electrical part, because all of us are software engineers, and we had to go and learn basic and useful topics on how to do the board.
## What's next for Flow Park
Using Flow Park for some small parkings help us to see if our app can be useful for drivers and parking managers.
We need to use parking spots data to come up with solutions on how to fix the traffic in large parking during big events. | ## 💡Inspiration
The inspiration for ErgoAI came from firsthand experiences working part-time jobs in warehouses, factories, and supermarkets. Musculoskeletal Disorder (MSDs) injuries lead to significant insurance costs, amounting to $180 billion globally and $90 billion in the US alone. Traditional ergonomic assessments are often outdated, n operator-dependent, and unreliable. Conventional methods are reactive, identifying issues only after injuries occur, rather than preventing them. Existing processes are resource-intensive and rely heavily on human operators, causing inconsistencies. Additionally, there is a lack of awareness about how AI can effectively improve ergonomic assessments.
We saw the impact that repetitive physical tasks and poor posture can have on workers, leading to injuries that jeopardize both their health and livelihood. The REBA test, popularly used in industry, is easily automated - and that's what we did with our proprietary computer vision and artificial intelligence software.
## 👁️What it does
ErgoAI leverages advanced computer vision technology to analyze employees’ posture in real-time. We have 2 models, one where employers can send previously recorded videos and it runs real-time analysis. Next, we have a realtime mode that analyzes videos in realtime using realtime data processing from SingleStore to our advantage. In both models, we analyze the posture and compare to industry standard to the REBA scale and identify what the employee needs help on, what they could use assistance in, and what is an important issue to address. To further support injury prevention, ErgoAI generates AI-driven, personalized recommendations aimed at helping workers adjust their movements and improve their ergonomics.
## 📊How we built it
ErgoAI was built using SingleStore to handle real-time data processing and video streaming capabilities. The backbone of the system is a seamless integration of real-time video feeds with our posture analysis algorithm. The frontend is solely using Nextjs and the Tailwind CSS framework. The real magic is the backend, all conducted in a python backend communicating using FastAPI to the frontend. Our python script is using various libraries like OpenCV, Numpy, YOLOv5, and real-time Gemini contextualizations to provide an overall and complete analysis.
## ⛰️Challenges we ran into
With only 2 developers on the team, everything was a time crunch. Caleb worked mostly on backend and Arjun on frontend, but everything needed to be done quick in order for the project to get done in time.
```
- One challenge we ran into was getting our computer vision script to replicate the actual REBA test. There are tons of factors that go into the test, and every calculation had to be done with precision and quickly.
```
## 🏆Accomplishments that we're proud of
We’re proud of the way we navigated the complexities of integrating real-time video streaming with our posture analysis tool, especially given the challenges with SingleStore. The smooth collaboration between our design and development teams played a key role in bringing this project to life. By efficiently working together and iterating on feedback — communicating about what is possible and not especially within these 72 hours— we were able to transform a concept into a functional and innovative solution that has the potential to make a real impact on workplace safety.
## 😸What we learned
From a technical standpoint, we gained a deeper understanding of handling real-time data streams and integrating them with AI-based analytics. We also honed our skills in optimizing backend architecture for faster processing and better front-end responsiveness. On the softer side, we learned the importance of clear communication between cross-functional teams and how early collaboration between designers and developers can streamline the development process and lead to better outcomes. Adapting to challenges and refining our problem-solving approach were key takeaways that will inform how we handle future projects.
## 🤷What's next for ErgoAI
Our vision for ErgoAI is to make it a long-term solution that continues to evolve with the needs of the modern workplace. We plan to expand its capabilities by integrating more advanced AI models that can not only detect posture issues but also predict potential injuries before they occur. We also aim to incorporate machine learning algorithms that will enable the system to learn from past data and provide even more accurate and personalized recommendations. Additionally, we’re exploring partnerships with ergonomic experts and wellness programs to create a comprehensive ecosystem that promotes a culture of safety and well-being for employees worldwide. Our goal is to transform ErgoAI into a proactive tool that doesn’t just react to problems but actively prevents them, ultimately reducing workplace injuries and improving productivity. | ## Inspiration
We wanted to explore what GCP has to offer more in a practical sense, while trying to save money as poor students
## What it does
The app tracks you, and using Google Map's API, calculates a geofence that notifies the restaurants you are within vicinity to, and lets you load coupons that are valid.
## How we built it
React-native, Google Maps for pulling the location, python for the webscraper (*<https://www.retailmenot.ca/>*), Node.js for the backend, MongoDB to store authentication, location and coupons
## Challenges we ran into
React-Native was fairly new, linking a python script to a Node backend, connecting Node.js to react-native
## What we learned
New exposure APIs and gained experience on linking tools together
## What's next for Scrappy.io
Improvements to the web scraper, potentially expanding beyond restaurants. | losing |
## Inspiration
With elections right around the corner, many young adults are voting for the first time, and may not be equipped with knowledge of the law and current domestic events. We believe that this is a major problem with our nation, and we seek to use open source government data to provide day to day citizens with access to knowledge on legislative activities and current affairs in our nation.
## What it does
OpenLegislation aims to bridge the knowledge gap by providing easy access to legislative information. By leveraging open-source government data, we empower citizens to make informed decisions about the issues that matter most to them. This approach not only enhances civic engagement but also promotes a more educated and participatory democracy Our platform allows users to input an issue they are interested in, and then uses cosine analysis to fetch the most relevant bills currently in Congress related to that issue.
## How we built it
We built this application with a tech stack of MongoDB, ExpressJS, ReactJS, and OpenAI. DataBricks' Llama Index was used to get embeddings for the title of our bill. We used a Vector Search using Atlas's Vector Search and Mongoose for accurate semantic results when searching for a bill. Additionally, Cloudflare's AI Gateway was used to track calls to GPT-4o for insightful analysis of each bill.
## Challenges we ran into
At first, we tried to use OpenAI's embeddings for each bill's title. However, this brought a lot of issues for our scraper as while the embeddings were really good, they took up a lot of storage and were heavily rate limited. This was not feasible at all. To solve this challenge, we pivoted to a smaller model that uses a pre trained transformer to provide embeddings processed locally instead of through an API call. Although the semantic search was slightly worse, we were able to get satisfactory results for our MVP and be able to expand on different, higher-quality models in the future.
## Accomplishments that we're proud of
We are proud that we have used open source software technology and data to empower the people with transparency and knowledge of what is going on in our government and our nation. We have used the most advanced technology that Cloudflare and Databricks provides and leveraged it for the good of the people. On top of that, we are proud of our technical acheivement of our semantic search, giving the people the bills they want to see.
## What we learned
During the development of this project, we learned more of how vector embeddings work and are used to provide the best search results. We learned more of Cloudflare and OpenAI's tools in this development and will definitely be using them on future projects. Most importantly, we learned the value of open source data and technology and the impact it can have on our society.
## What's next for OpenLegislation
For future progress of OpenLegislation, we plan to expand to local states! Constituents can know directly what is going on in their state on top of their country with this addition and actually be able to receive updates on what officials they elected are actually proposing. In addition, we would expand our technology by using more advanced embeddings for more tailored searches. Finally, we would implore more data anlysis methods with help from Cloudflare and DataBricks' Open-Source technologies to help make this important data more available and transparant for the good of society. | ## Inspiration
There is a lack of awareness surrounding decisions that are made on a day-to-day basis in Ontario's parliament by our provincial representatives; decisions which can affect hundreds of thousands of Ontarians.
We believe that the backbone of a strong democracy is open and frequent communication between constituents and their representatives.
The greatest roadblock to citizen's becoming more involved in politics and being heard is simple... Time. It takes too much time to research current issues, figure out who one's local representative is, and writing them a compelling letter/email.
That's where SiMPPlify comes in. Our solution will lower that barrier to political participation by collecting and making sense of parliamentary data and opinions in one place and simplifying the process of petitioning your MPP.
## What it does
SiMPPlify geolocates the user to provide them information on their MPP. It also allows one to research issues and quickly generate a draft email, which one can send from the website to the MPP. The goal is to be able to do this in five minutes! Never have the barriers to participating in a democracy been lower.
## How we built it
siMPPlify is a web app that uses cheerio to scrape the Legislative Assembly of Ontario's website to gain information on the latest bills. It uses the Represent Civic Information API as well as Google Maps API to figure out who the user's MPP is. Then based on the user's choices, it helps populate an email, which the user can further edit, before submitting (using nodemailer).
## Challenges we ran into
Webscraping was difficult due to the fact that the website being scraped did not have consistent formatting/coding standards. This led to copious amounts of regex and dealing with edge cases where one web page was not similar to others and could not be scraped the same way.
We felt a bit short on time near the end and had to cut down on some of the nice-to-have features of the app.
## Accomplishments that we're proud of
We are very proud of each learning some new frameworks and technologies (e.g. Bootstrap, how to web scrape, async/await) over the course of this project. It was a blast working with and learning from each other.
## What we learned
Having a UI/UX designer is immeasurably helpful for distributed front-end development.
## What's next for siMPPlify
We would love to further refine the product, and cover not only provincial bills, but federal ones as well. Local municipal issues would be another area of expansion.
We would like to roll out additional functionality such as:
* Search for bills
* See how many others supported/opposed the bill
* A news feed of the latest stories on a particular bill
* Using ML and classification to categorize the bills and tag them for easier identification | We got too tired of watching out government taking commands from special interest groups and corrupt corporations and decided to do something about it. Our platform enables the citizens of the United States, especially our generation, to have our government actually act upon the decisions of its constitutions.
We are dedicated to this project no matter where it takes us.
The program was built as a webpage. We spent most of our time learning about the problem and how to legally and correctly approach it. We also talked to and learned from as many mentors as possible. Unfortunately, due to the magnitude of the project, we were unable to complete any coding aspect but rather have several incomplete parts.
The challenges associated with this project consisted of oscillating levels of functionality for some of the blockchain aspects of the project.
Both of our computers suffered from wifi problems so we were largely unable to access APIs and finish our website, that being said our idea largely evolved and is now a project that we will certainly continue after this Hackathon.
We are planning on finishing and releasing the project within a year. | winning |
# [Try it out!](https://ipfe.elguindi.xyz)
## Inspiration
Intrigued by the ability to access a large amount of data on the distributed network, we set out to classify files by similarity for interesting exploration. While there were powerful search tools like Google to access information on the web, we were unsure how to explore all of the data available on the distributed network.
## What it does
This project visualizes the vast quantities of data stored on the InterPlanetary File System using an intuitive 3D graph. Connected nodes are nearby and have similar content and all nodes are colour-coded based on their file type, with larger nodes representing larger files. Hovering over a node gives more information about the file and clicking on the node downloads the file.
Nodes can be dragged with the cursor and the view of the graph can be zoomed in or out with the scroll wheel.
## How we built it
We built this application using 3 important technologies: Golang, Python, and Three.js (JavaScript). Behind the scenes we used the powerful technologies of Estuary in order to interface and get files from the IPFS and Co:here's Embed platform in order to quantify the similarity of two files.
Our pipeline consists of fetching the headers of around 2000 files on the IPFS, embedding the texts into vectors, performing a reduction in vector space dimension with principal component analysis, classifying texts based on k nearest neighbors, and visualizing the resulting neighbors as a 3D graph.
## Challenges we ran into
* The data in the IPFS was too large to download and process so we embedded the files based only on their metadata.
* Co:here's embed model was unable to process more than 500 lines in one request.
* Data retrieval from IPFS was slower than centralized systems.
* Determining the best way to summarize the multi-dimensional data into 3-dimensional data.
* We were unable to fine-tune the Co:here command model.
## Accomplishments that we're proud of
* Reverse engineering the Estuary API to be able to access all files hosted on the IPFS through the miners with multiple scripts in Go using parallel processing.
* Performance with concurrence while fetching and formatting the file headers from the network.
* The handling of large data in an efficient pipeline.
* The use of Co:here embeddings in order to generate 3D vectors with minimal information loss with principal component analysis.
* The efficient and intuitive representation of the collected data which was categorized with k nearest neighbors.
## What we learned
This hackathon has served as an opportunity to learn uncountable things, but I would like to highlight a couple. To begin, we were able to learn about useful and important technologies that facilitated us to make the project possible, including the Estuary and Co:here APIs, and we improved in our abilities to code in Python, Golang, and Javascript. Furthermore, the presentations hosted by various sponsors were a nice opportunity to be able to talk with and meet successful individuals in the field of technology and get their advice on the future of technology, and how to improve ourselves as members of a team and technically.
## What's next for IPFE: InterPlanetary File Explorer
Since we were unable to process all of the file content during the vector embedding process due to file space and time feasibility limitations, IPFE can be improved by using the file content to influence the vector embedding of the files for a more accurate graph. Additionally, we were only able to scratch the surface of the number of files on the IPFS. This project can be scaled up to many more files, where individual "InterPlanetary Cluster" could consist of similar files and make up a whole "galaxy" of files that can be visually inspected and explored. | ## Inspiration
We always want to create a resume that will impress employers. The problem is fitting your resume to their expectations. How well or far off are you from the goalpost? We came up with the idea of ResumeReviser because it could help people looking or not looking for employment gauge how well their resumes meet those expectations.
## What it does
ResumeReviser is a Flask-based web application that allows users to upload their resumes in PDF format, enter a job listing, and receive feedback on the match percentage between the resume and the specified job listing. The application uses natural language processing techniques, specifically cosine similarity, to analyze the textual content of the resume and job listing, providing users with a percentage indicating how well their resume aligns with the specified job requirements.
## How we built it
We used Flask as our framework and SQLite3 as our database. We used multiple libraries to read our PDF files and then interpret the words on them. We then handled the comparison and assessed the job listing description and the resume to determine if they fit the role they were trying to apply for.
## Challenges we ran into
Most of the team had previously worked with Flask or SQL in a full-stack project. We also were working with limited time as we arrived late Friday evening. With the project, we found great difficulty maintaining data between user sessions. We had to figure out how to properly use the SQL database to avoid losing the comparison between job listings and user-uploaded resumes.
## Accomplishments that we're proud of
We integrated other technologies, such as Bootstrap, to improve the user experience further and create a pleasing general user interface. We successfully developed and researched the algorithms necessary to match the important keywords to their job descriptions.
## What we learned
We learned how to collaborate with multiple new technologies and the problems of doing so. How to set up the necessary virtual environment, set up schema, and access an SQL database. Consequently, it also taught us how to deal with user files and maintain their concurrency through sessions. We experimented with Bootstrap features on the front end to create a pleasing interface.
## What's next for ResumeReview
Improved user interface design.
Advanced analysis features or suggestions based on the resume and job listing.
Error handling and validation improvements.
Security enhancements. | ## Inspiration
Both chronic pain disorders and opioid misuse are on the rise, and the two are even more related than you might think -- over 60% of people who misused prescription opioids did so for the purpose of pain relief. Despite the adoption of PDMPs (Prescription Drug Monitoring Programs) in 49 states, the US still faces a growing public health crisis -- opioid misuse was responsible for more deaths than cars and guns combined in the last year -- and lacks the high-resolution data needed to implement new solutions.
While we were initially motivated to build Medley as an effort to address this problem, we quickly encountered another (and more personal) motivation. As one of our members has a chronic pain condition (albeit not one that requires opioids), we quickly realized that there is also a need for a medication and symptom tracking device on the patient side -- oftentimes giving patients access to their own health data and medication frequency data can enable them to better guide their own care.
## What it does
Medley interacts with users on the basis of a personal RFID card, just like your TreeHacks badge. To talk to Medley, the user presses its button and will then be prompted to scan their ID card. Medley is then able to answer a number of requests, such as to dispense the user’s medication or contact their care provider. If the user has exceeded their recommended dosage for the current period, Medley will suggest a number of other treatment options added by the care provider or the patient themselves (for instance, using a TENS unit to alleviate migraine pain) and ask the patient to record their pain symptoms and intensity.
## How we built it
This project required a combination of mechanical design, manufacturing, electronics, on-board programming, and integration with cloud services/our user website. Medley is built on a Raspberry Pi, with the raspiaudio mic and speaker system, and integrates an RFID card reader and motor drive system which makes use of Hall sensors to accurately actuate the device. On the software side, Medley uses Python to make calls to the Houndify API for audio and text, then makes calls to our Microsoft Azure SQL server. Our website uses the data to generate patient and doctor dashboards.
## Challenges we ran into
Medley was an extremely technically challenging project, and one of the biggest challenges our team faced was the lack of documentation associated with entering uncharted territory. Some of our integrations had to be twisted a bit out of shape to fit together, and many tragic hours spent just trying to figure out the correct audio stream encoding.
Of course, it wouldn’t be a hackathon project without overscoping and then panic as the deadline draws nearer, but because our project uses mechanical design, electronics, on-board code, and a cloud database/website, narrowing our scope was a challenge in itself.
## Accomplishments that we're proud of
Getting the whole thing into a workable state by the deadline was a major accomplishment -- the first moment we finally integrated everything together was a massive relief.
## What we learned
Among many things:
The complexity and difficulty of implementing mechanical systems
How to adjust mechatronics design parameters
Usage of Azure SQL and WordPress for dynamic user pages
Use of the Houndify API and custom commands
Raspberry Pi audio streams
## What's next for Medley
One feature we would have liked more time to implement is better database reporting and analytics. We envision Medley’s database as a patient- and doctor-usable extension of the existing state PDMPs, and would be able to leverage patterns in the data to flag abnormal behavior. Currently, a care provider might be overwhelmed by the amount of data potentially available, but adding a model to detect trends and unusual events would assist with this problem. | partial |
## Inspiration
Today’s technological advances have resulted in many consumers having to increasingly rely on Web-based banking and financial systems. Consumers often overlooked as we make this transition include the visually impaired and/or the less tech-savvy populations (e.g. elderly). It is critical that we guarantee that systems give equal and complete access to everyone, and none are disregarded. Some may point out that paper billing is an option, but on top of not being eco-friendly, paper billing is not an ideal way of getting the latest information about your records on the go.
We combine the convenience and efficiency of mobile/web applications with the ease of paper billing. **One button is all you need in a clean, user-friendly interface.**
## What *Bank Yeller* Does
Our application allows the user to voice chat with an AI (created using Dasha AI) to get their latest bank account information and be able to pay their bills vocally.
Users can ask about their latest transactions to find out how much they spent at each location, and they can ask about their latest bank statements to find out when and how much is due, as well as have the option to pay them off!
## How We Built *Bank Yeller*
* We used existing Dasha AI repositories as inspiration and guides to create our own personalized AI that was geared to our particular use case.
* We created and deployed an SQL Database to Google Cloud Platform to mimic a bank’s database and demonstrate how this would work in everyday life.
* We used Javascript to set up our Dasha.AI interactions as well as connect to our SQL Database and run queries.
* We used Figma to construct prototypes of the web and mobile based apps.
## Challenges We Ran Into
Using Dasha AI had its own learning curve, but the Dasha AI team was amazing and provided us with numerous resources and support throughout the creation of our project! (Special shoutout to Arthur Grishkevich and Andrey Turtsev at Dasha AI for putting up with Joud’s endless questions.)
Having not had much experience with async functions, we also struggled with dealing with them and figuring out how to use them when performing queries. We ended up watching several YouTube videos to understand the concepts and help us approach our problem. We were exposed to several new platforms this weekend, each with its own challenges, which only pushed us to work harder and learn more.
## Accomplishments We're Proud of
One of the accomplishments that we are proud of is the implementation of our Dasha AI accessing and verifying information from our SQL Database stored in Google Cloud. We are also proud that we were able to divide our time well this weekend to give us time to create a project we really care about and enjoyed creating as well as time to meet new people and learn about some very cool concepts! In our past hackathon we created an application to support local businesses in London, and we are proud to continue in this path of improving lives through the targeting of (often) overlooked populations.
## What We Learned
Each of us had skills that the other had not used before, so we were able to teach each other new concepts and new ways of approaching ideas! The Hack Western workshops also proved to be excellent learning resources.
## What's Next for *Bank Yeller*
Expanding! Having it available as a phone application where users can press anywhere on the screen (shown in Figma mockups) to launch Dasha. There, they will be able to perform all the aforementioned actions, and possibly some additional features! Taking visual impairments into note, we would add clear, large captions that indicate what is being said.
* for instructions on how to run Bank Yeller, please check out our README file :)) | ## Inspiration and What it does
We often go out with a lot of amazing friends for trips, restaurants, tourism, weekend expedition and what not. Every encounter has an associated messenger groupchat. We want a way to split money which is better than to discuss on the groupchat, ask people their public key/usernames and pay on a different platform. We've integrated them so that we can do transactions and chat at a single place.
We (our team) believe that **"The Future of money is Digital Currency "** (-Bill Gates), and so, we've integrated payment with Algorand's AlgoCoins with the chat. To make the process as simple as possible without being less robust, we extract payment information out of text as well as voice messages.
## How I built it
We used Google Cloud NLP and IBM Watson Natural Language Understanding apis to extract the relevant information. Voice messages are first converted to text using Rev.ai speech-to-text. We complete the payment using the blockchain set up with Algorand API. All scripts and database will be hosted on the AWS server
## Challenges I ran into
It turned out to be unexpectedly hard to accurately find out the payer and payee. Dealing with the blockchain part was a great learning experience.
## Accomplishments that I'm proud of
that we were able to make it work in less than 24 hours
## What I learned
A lot of different APIs
## What's next for Mess-Blockchain-enger
Different kinds of currencies, more messaging platforms | ## Inspiration
It’s Friday afternoon, and as you return from your final class of the day cutting through the trailing winds of the Bay, you suddenly remember the Saturday trek you had planned with your friends. Equipment-less and desperate you race down to a nearby sports store and fish out $$$, not realising that the kid living two floors above you has the same equipment collecting dust. While this hypothetical may be based on real-life events, we see thousands of students and people alike impulsively spending money on goods that would eventually end up in their storage lockers. This cycle of buy-store-collect dust inspired us to develop Lendit this product aims to stagnate the growing waste economy and generate passive income for the users on the platform.
## What it does
A peer-to-peer lending and borrowing platform that allows users to generate passive income from the goods and garments collecting dust in the garage.
## How we built it
Our Smart Lockers are built with RaspberryPi3 (64bit, 1GB RAM, ARM-64) microcontrollers and are connected to our app through interfacing with Google's Firebase. The locker also uses Facial Recognition powered by OpenCV and object detection with Google's Cloud Vision API.
For our App, we've used Flutter/ Dart and interfaced with Firebase. To ensure *trust* - which is core to borrowing and lending, we've experimented with Ripple's API to create an Escrow system.
## Challenges we ran into
We learned that building a hardware hack can be quite challenging and can leave you with a few bald patches on your head. With no hardware equipment, half our team spent the first few hours running around the hotel and even the streets to arrange stepper motors and Micro-HDMI wires. In fact, we even borrowed another team's 3-D print to build the latch for our locker!
On the Flutter/ Dart side, we were sceptical about how the interfacing with Firebase and Raspberry Pi would work. Our App Developer previously worked with only Web Apps with SQL databases. However, NoSQL works a little differently and doesn't have a robust referential system. Therefore writing Queries for our Read Operations was tricky.
With the core tech of the project relying heavily on the Google Cloud Platform, we had to resolve to unconventional methods to utilize its capabilities with an internet that played Russian roulette.
## Accomplishments that we're proud of
The project has various hardware and software components like raspberry pi, Flutter, XRP Ledger Escrow, and Firebase, which all have their own independent frameworks. Integrating all of them together and making an end-to-end automated system for the users, is the biggest accomplishment we are proud of.
## What's next for LendIt
We believe that LendIt can be more than just a hackathon project. Over the course of the hackathon, we discussed the idea with friends and fellow participants and gained a pretty good Proof of Concept giving us the confidence that we can do a city-wide launch of the project in the near future. In order to see these ambitions come to life, we would have to improve our Object Detection and Facial Recognition models. From cardboard, we would like to see our lockers carved in metal at every corner of this city. As we continue to grow our skills as programmers we believe our product Lendit will grow with it. We would be honoured if we can contribute in any way to reduce the growing waste economy. | partial |
## Inspiration
We took inspiration from our experience of how education can be hard. Studies conducted by EdX show that classes that teach quantitative subjects like Mathematics and Physics tend to receive lower ratings from students in terms of engagement and educational capacity than their qualitative counterparts. Of all advanced placement tests, AP Physics 1 receives on average the lowest scores year after year, according to College Board statistics. The fact is, across the board, many qualitative subjects are just more difficult to teach, a fact that is compounded by the isolation that came with remote working, as a result of the COVID-19 pandemic. So, we would like to find a way to promote learning in a fun way.
In keeping with the theme of Ctrl + Alt + Create, we took inspiration from another educational game from the history of computing. In 1991, Microsoft released a programming language and environment called QBASIC to teach first time programmers how to code. One of the demo programs they released with this development environment was a game called Gorillas, an artillery game where two players can guess the velocity and angle in order to try to hit their opponents. We decided to re-imagine this iconic little program from the 90s into a modern networked webgame, designed to teach students kinematics and projectile motion.
## What it does
The goal of our project was to create an educational entertainment game that allows students to better engage in qualitative subjects. We wanted to provide a tool for instructors for both in-classroom and remote education and provide a way to make education more accessible for students attending remotely. Specifically, we focused on introductory high school physics, one of the most challenging subjects to tackle. Similar to Kahoot, teachers can setup a classroom or lobby for students to join in from their devices. Students can join in either as individuals, or as a team. Once a competition begins, students use virtual tape measures to find distances in their surroundings, determining how far their opponent is and the size of obstacles that they need to overcome. Based on these parameters, they can then try out an appropriate angle and calculate an initial velocity to fire their projectiles. Although there is no timer, students are incentivized to work quickly in order to fire off their projectiles before their opponents. Students have a limited number of shots as well, incentivizing them to double-check their work wisely.
## How we built it
We built this web app using HTML, CSS, and Javascript. Our team split up into a Graphics Team and Logics Team. The Logics Team implemented the Kinematics and the game components of this modern recreation of QBASIC Gorillas. The Graphics Team created designs and programmed animations to represent the game logic as well as rendering the final imagery. The two teams came together to make sure everything worked well together.
## Challenges we ran into
We ran into many challenges which include time constraints and our lack of knowledge about certain concepts. We later realized we should have spent more time on planning and designing the game before splitting into teams because it caused problems in miscommunication between the teams about certain elements of the game. Due to time constraints, we did not have time to implement a multiplayer version of the game.
## Accomplishments that we're proud of
The game logically works in single player game. We are proud that we were able to logically implement the entire game, as well as having all the necessary graphics to show its functionality.
## What we learned
We learned the intricacies of game design and game development. Most of us have usually worked with more information-based websites and software technologies. We learned how to make a webapp game from scratch. We also improved our HTML/CSS/Javascript knowledge and our concepts of MVC.
## What's next for Gorillamatics
First we would like to add networking to this game to better meet the goals of increasing connectivity in the classroom as well as sparking a love for Physics in a fun way. We would also like to have better graphics. For the long term, we are planning on adding different obstacles to make different kinematics problems. | ## Inspiration
In a world in which we all have the ability to put on a VR headset and see places we've never seen, search for questions in the back of our mind on Google and see knowledge we have never seen before, and send and receive photos we've never seen before, we wanted to provide a way for the visually impaired to also see as they have never seen before. We take for granted our ability to move around freely in the world. This inspired us to enable others more freedom to do the same. We called it "GuideCam" because like a guide dog, or application is meant to be a companion and a guide to the visually impaired.
## What it does
Guide cam provides an easy to use interface for the visually impaired to ask questions, either through a braille keyboard on their iPhone, or through speaking out loud into a microphone. They can ask questions like "Is there a bottle in front of me?", "How far away is it?", and "Notify me if there is a bottle in front of me" and our application will talk back to them and answer their questions, or notify them when certain objects appear in front of them.
## How we built it
We have python scripts running that continuously take webcam pictures from a laptop every 2 seconds and put this into a bucket. Upon user input like "Is there a bottle in front of me?" either from Braille keyboard input on the iPhone, or through speech (which is processed into text using Google's Speech API), we take the last picture uploaded to the bucket use Google's Vision API to determine if there is a bottle in the picture. Distance calculation is done using the following formula: distance = ( (known width of standard object) x (focal length of camera) ) / (width in pixels of object in picture).
## Challenges we ran into
Trying to find a way to get the iPhone and a separate laptop to communicate was difficult, as well as getting all the separate parts of this working together. We also had to change our ideas on what this app should do many times based on constraints.
## Accomplishments that we're proud of
We are proud that we were able to learn to use Google's ML APIs, and that we were able to get both keyboard Braille and voice input from the user working, as well as both providing image detection AND image distance (for our demo object). We are also proud that we were able to come up with an idea that can help people, and that we were able to work on a project that is important to us because we know that it will help people.
## What we learned
We learned to use Google's ML APIs, how to create iPhone applications, how to get an iPhone and laptop to communicate information, and how to collaborate on a big project and split up the work.
## What's next for GuideCam
We intend to improve the Braille keyboard to include a backspace, as well as making it so there is simultaneous pressing of keys to record 1 letter. | ## Inspiration
We found that even there are so many resources to learn to code, but all of them fall into one of two categories: they are either in a generic course and grade structure, or are oversimplified to fit a high-level mould. We thought the ideal learning environment would be an interactive experience where players have to learn to code, not for a grade or score, but to progress an already interactive game. The code the students learn is actual Python script, but it guided with the help of an interactive tutorial.
## What it does
This code models a "dinosaur game" structure where players have to jump over obstacles. However, as the player experiences more and more difficult obstacles through the level progression, they are encouraged to automate the character behavior with the use of Python commands. Players can code the behavior for the given level, telling the player to "jump when the obstacles is 10 pixels away" with workable Python script. The game covers the basic concepts behind integers, loops, and boolean statements.
## How we built it
We began with a Pygame template and created a game akin to the "Dinosaur game" of Google Chrome. We then integrated a text editor that allows quick and dirty compilation of Python code into the visually appealing format of the game. Furthermore, we implemented a file structure for all educators to customize their own programming lessons and custom functions to target specific concepts, such as for loops and while loops.
## Challenges we ran into
We had most trouble with troubleshooting an idea that is both educational and fun. Finding that halfway point pushed both our creativity and technical abilities. While there were some ideas that had heavily utilizing AI and VR, we knew that we could not code that up in 36 hours. The idea we settled on still challenged us, but was something we thought was accomplishable. We also had difficulty with the graphics side of the project as that is something that we do not actively focus on learning through standard CS courses in school.
## Accomplishments that we're proud of
We were most proud of the code incorporation feature. We had many different approaches for incorporating the user input into the game, that finding one that worked proved to be very difficult. We considered making pre-written code snippets that the game would compare to the user input or creating a pseudocode system that could interpret the user's intentions. The idea we settled upon, the most graceful, was a method through which the user input is directly input into the character behavior instantiation, meaning that the user code is directly what is running the character--no proxies or comparison strings. We are proud of the cleanliness and truthfulness this hold with our mission statement--giving the user the most hand-ons and accurate coding experience.
## What we learned
We learned so much about game design and the implementation of computer science skills we learned in the classroom. We also learned a lot about education, through both introspection into ourselves as well as some research articles we found about how best to teach concepts and drill practice.
## What's next for The Code Runner
The next steps for Code Runner would be adding more concepts covered through the game functionality. We were hoping to cover while-loops and other Python elements that we thought were crucial building blocks for anyone working with code. We were also hoping to add some gravity features where obstacles can jump with realistic believability. | partial |
*At the beginning of this competition, we were in quite a pickle
But then we stumbled upon an idea that was quite the pinnacle
of green technology, that costs hardly a dime, or even a nickel,
solving the problematical,
with the mathematical,
all with only your own vehicle,
introducing: **Greenicle***
## Inspiration
74% of Canadians commute to work in a vehicle daily, according to the [National Household Survey](https://www12.statcan.gc.ca/nhs-enm/2011/as-sa/99-012-x/99-012-x2011003_1-eng.cfm). Driving is indeed a part of our daily routine, yet we hardly realize how this common activity impacts the environment around us; in fact, [a typical vehicle emits about 4.6 metric tons of CO2 per year](https://www.epa.gov/greenvehicles/greenhouse-gas-emissions-typical-passenger-vehicle). We believe that raising awareness is a key to reducing these harmful emissions, as most people are hardly aware of their individual impact - thus, we created *Greenicle*, a web application that allows users to you view car activity and reflect on their environmental impact while providing options to contribute to the community.
## What it does

What initially started as an idea of "AirBnB for cars", which then lead to "Tinder for Cars", *Greenicle* is a simple to use, dashboard-style web application that leverages the [*Smartcar* API](https://www.smartcar.com/) to provide users with real-time data on their emissions and overall vehicle stats. Users connect their vehicles to *smartcar*, which then allows Greenicle to personalize the users dashboard with their unique information. The application features two main sections that give users stats and insights on their driving: an information section, featuring basic vehicle data such as make/model and its estimated retail value , and a summary statistics section which displays things such as visited locations, distance travelled, and environmental impact.
Greenicle provides three measures of environmental impact for the user: total CO2 emissions, their equivalent in lightbulb hours, and the number of trees that would need to be planted in order to offset the effect of these emissions. Alongside each statistic is a community average, which allows the user to gauge how much they contribute to our global carbon footprint. Moreover, Greenicle includes a link which allows users to plant a tree, so that they may immediately act to offset the impact of their emissions. Ultimately, Greenicle leverages the IOT we have regarding the vehicles we drive to make a positive impact on the world we live in, guiding us to be more responsible citizens and towards a more sustainable future.
## How we built it
We created a clean UI with the use of React.JS, and powered our backend with Python and data storage with an Azure CosmosDB. We retrieve information from Azure Cognitive Services Bing Search API and an API built with Flask, however most of the data is gathered with the help of the Smartcar API, which also handles the log in. We also researched our own vehicle statistics to compute and estimate some data, including the retail value and community averages. All this was done on machines powered by Intel.
## Challenges we ran into
As with any piece of software, we were not short of challenges to overcome. Some of the biggest challenges included finding accurate information to base our calculations off of and deploying our application to Azure.
We quickly learned that determining our calculations would not be easy, as established car-sales services and other websites do not make their methods of calculation obvious, and webscraping data posed a lot of issues, thus we ended up having to manually estimate a car price after analyzing some of the data we were able to find on the internet.
We also had trouble deploying our web app to Azure. This was mainly because Azure has limited capabilities when it comes to hosting Python code, which we used for our back-end (it tends to prefer languages such as C# or Node.JS). We spent a great deal of time looking over documentation to properly deploy our app, but in the end were unable to follow through with this plan due to time constraints. Due to this, we were unable to deploy two planned micro-services (built as Logic Apps on Azure): one to track location in order to provide pinpoints on our map, and the other to track odometer data to provide further insights to the user about their trends.
## Accomplishments that we're proud of
We have built a full-stack application - integrating multiple languages, APIs, and frameworks - that is ready to be demoed and has the potential to be fleshed out into a truly fantastic application. Not to mention, we each learned a lot about working with various external resources and integrating different ideas, solutions, and approaches to ultimately create a beautiful, functional, and impactful piece of software.
## What we learned
Working on Greenify gave us the opportunity to learn many new technologies, like Azure Application Services (including building Logic Applications and hosting web applications on the App Services), CosmosDB, Flask for Python, and the Smartcar API. We also learned how to work with noSQL databases and how to integrate React web applications with a Python-based back-end. Having used GitHub as source code management, we also learned about best-practices for API key storage, including encryption, setting and accessing environment variables, and the Azure Key Vault. Overall, we have spent the weekend learning lots about the entire app development process, and working as a team to create a product we are all proud of.
## What's next for Greenicle
We have many exciting things in plan for the continued development of Greenicle. The first thing on our to-do list is to deploy Greenicle onto the Microsoft Azure Cloud so that we can begin providing our service to users all over the globe! This will also allow us to deploy and run our microservices, so that we can provide even more insights to users. We also plan to implement improvements to our data calculations, including the accuracy of the resale price tool and emissions calculation.
Further along in the future, we envision creating a community through Greenicle with the help of local trends and share features, as well as gamifying our application through "Green Incentives", both of which will further encourage users to interact with Greenify and, most importantly, incentivize them to take green initiatives that will help lead us all toward a more sustainable future!
### Our Weekend by the Numbers
Commits: 90
Pull Requests: 10
Redbulls Consumed: ????
Hours of Sleep: ~21 hours total (for all 4 of us, combined)
Junk Food Eaten: too much
Free Stuff Received: more than we can count
Stickers Stuck on Laptops: ~20
***A big thanks to the organizers of U of T Hacks VI for providing us with such a great opportunity!***
>
*"I still believe that there is a future in Tinder for Cars" - Volodymyr Klymenko* | ## Inspiration
The other day when we were taking the train to get from New Jersey to New York City we started to talk about how much energy we are saving by taking the train rather than driving, and slowly we realized that a lot of people always default to driving as their only mode of transit. We realized that because of this there is a significant amount of CO2 emissions entering our atmosphere. We already have many map apps and websites out there, but none of them take eco-friendliness into account, EcoMaps on the other hand does.
## What it does
EcoMaps allows users to input an origin and destination and then gives them the most eco-friendly way to get from their origin to destination. It uses Google Maps API in order to get the directions for the 4 different ways of travel (walking, biking, public transportation, and driving). From those 4 ways of travel it then chooses what would be the most convenient and most eco friendly way to get from point A to point B. Additionally it tells users how to get to their destination. If the best form of transportation is not driving, EcoMaps tells the user how much carbon emissions they are saving, but if driving is the best form of transportation it will tell them approximately how much carbon emissions they are putting out into our atmosphere. Our website also gives users a random fun fact about going green!
## How we built it
We started this project by importing the Google Maps API into javascript and learning the basics of how the basics worked such as getting a map on screen and going to certain positions. After this, Dan was able to encode the API’s direction function by converting the text strings entered by users into latitude and longitude coordinates through a built-in function. Once the directions started working, Dan built another function which extracted the time it takes to go from one place to another based on all 4 of our different transportation options: walking, biking, driving, and using public transit. Dan then used all of the times and availability of certain methods to determine the optimal method which users should use to help reduce emissions. Obviously, walking or biking is always the optimal option for this, however, the algorithm took into account that many trips are far too long to walk or bike. In other words, it combines both logic and sustainability of our environment. While Dan worked on the backend Rumi created the user interface using Figma and then used HTML and CSS to create a website design based off of the Figma design. Once this was all done, Dan worked on ensuring that the integration of his code and Rumi’s front end display integrated properly.
## Challenges we ran into
One problem we ran into during our project was the fact that Javascript is a single-threaded language. This means that it can only process one thing at a time, which especially came into play when getting data on 4 different trips varying by travel method. This caused the problem of the code skipping certain functions as opposed to waiting and then proceeding. In order to solve this, we learned about the asynchronous option which Javascript allows for in order to await for certain functions to finish before progressing forward in the code. This process of learning included both a quick Stack Overflow question as well as some quick google scans.
Another problem that we faced was dealing with different screen sizes for our website. Throughout our testing, we were solely using devices of the same monitor size, so once we switched to testing on a larger screen all of the proportions were off. At first, we were very confused as to why this was the case, but we soon realized that it was due to our CSS being specific to only our initial screen size. We then had to go through all of our HTML and CSS and adjust the properties so that it was based on percentages of whichever screen size the user had. Although it was a painstaking process, it was worth it in our end product!
## Accomplishments that we're proud of
We are proud of coming up with a website that gives users the most eco-friendly way to travel. This will push individuals to be more conscious of their travel and what form of transportation they end up taking. This is also our second ever hackathon and we are happily surprised by the fact that we were able to make a functioning product in such a short time. EcoMaps also functions in real time meaning that it updates according to variables such as traffic, stations closing, and transit lines closing. This makes EcoMaps more useful in the real world as we all function in real time as well.
## What we learned
Throughout the creation of EcoMaps we learned a host of new skills and information. We learned just how much traveling via car actually pollutes the environment around us, and just how convenient other forms of transportation can be. On the more technical side, we learned how to use Figma to create a website design and then how to create a website with HTML, CSS, and JavaScript based on this framework. We also learned how to implement Google Maps API in our software, and just how useful it can be. Most importantly we learned how to effectively combine our expertise in frontend and backend to create our now functional website, EcoMaps!
## What's next for EcoMaps
In the future we hope to make the app take weather into account and how that may impact the different travel options that are available. Turning EcoMaps into an app that is supported by mobile devices is a major future goal of ours, as most people primarily use their phones to navigate. | # muse4muse
**Control a Sphero ball with your mind.**
Muse will measure your brain waves.
Depending on the magnitude of the wave, the color of the Sphero will change color!
Alpha -> Green,
Beta -> Blue,
Delta -> Red,
Theta ->Yellow,
Gamma ->White
When the player keeps calm, increasing the Alpha wave, the Sphero ball will move forward.
When the player blinks his/her eyes, the ball will rotate clockwise.
The goal of the player is to control his/her mind and make the Sphero ball through the maze.
Come find Jenny&Youn and try it out!
---
This is an iOS app built with Objective-C, Sphero SDK, and Muse SDK.
Challenges we had:
-This is our first time using Objective-C as well as the two SDK's.
-Originally we made this game super hard and had to adjust the level.
-Because we didn't get any sleep, it was hard to control our own minds to test the game! but we did it! :D
Interesting fact:
* Muse can bring more information than the 5 types of brainwaves. However we decided not to use them because we felt those were irrelevant to our project. | partial |
## Inspiration
We see technology progressing rapidly in cool fields like virtual reality, social media and artificial intelligence but often neglect those who really need tech to make a difference in their lives.
SignFree aims to bridge the gap between the impaired and the general public by making it easier for everyone to communicate.
## What it does
SignFree is a smart glove that is able to detect movements and gestures to translate sign language into speech or text.
## How we built it
SignFree was built using a glove with embedded sensors to track finger patterns. The project relies on an Arduino board with a small logic circuit to detect which fingers are activated for each sign. This information is relayed over to a database and is collected by a script that converts this information into human speech.
## Challenges we ran into
Coming up with the logic behind sensing different finger patterns was difficult and took some planning
The speech API used on the web server was tricky to implement as well
## Accomplishments that we are proud of
We feel our hack has real world potential and this is something we aimed to accomplish at this hackathon.
## What we learned
Basic phrases in sign language. We used a bunch of new API's to get things working.
## What's next for SignFree
More hackathons. More hardware. More fun | ## What Does "Catiator" Mean?
**Cat·i·a·tor** (*noun*): Cat + Gladiator! In other words, a cat wearing a gladiator helmet 🐱
## What It Does
*Catiator* is an educational VR game that lets players battle gladiator cats by learning and practicing American Sign Language. Using finger tracking, players gesture corresponding letters on the kittens to fight them. In order to survive waves of fierce but cuddly warriors, players need to leverage quick memory recall. If too many catiators reach the player, it's game over (and way too hard to focus with so many chonky cats around)!
## Inspiration
There are approximately 36 million hard of hearing and deaf individuals live in the United States, and many of them use American Sign Language (ASL). By learning ASL, you'd be able to communicate with 17% more of the US population. For each person who is hard of hearing or deaf, there are many loved ones who hope to have the means to communicate effectively with them.
### *"Signs are to eyes as words are to ears."*
As avid typing game enthusiasts who have greatly improved typing speeds ([TypeRacer](https://play.typeracer.com/), [Typing of the Dead](https://store.steampowered.com/agecheck/app/246580/)), we wondered if we could create a similar game to improve the level of understanding of common ASL terms by the general populace. Through our Roman Vaporwave cat-gladiator-themed game, we hope to instill a low barrier and fun alternative to learning American Sign Language.
## Features
**1. Multi-mode gameplay.**
Learn the ASL alphabet in bite sized Duolingo-style lessons before moving on to "play mode" to play the game! Our in-app training allows you to reinforce your learning, and practice your newly-learned skills.
**2. Customized and more intuitive learning.**
Using the debug mode, users can define their own signs in Catiator to practice and quiz on. Like Quizlet flash cards, creating your own gestures allows you to customize your learning within the game. In addition to this, being able to see a 3D model of the sign you're trying to learn gives you a much better picture on how to replicate it compared to a 2D image of the sign.
## How We Built It
* **VR**: Oculus Quest, Unity3D, C#
* **3D Modeling & Animation**: Autodesk Maya, Adobe Photoshop, Unity3D
* **UX & UI**: Figma, Unity2D, Unity3D
* **Graphic Design**: Adobe Photoshop, Procreate
## Challenges We Ran Into
**1. Limitations in gesture recognition.** Similar gestures that involve crossing fingers (ASL letters M vs. N) were limited by Oculus' finger tracking system in differential recognition. Accuracy in finger tracking will continue to improve, and we're excited to see the capabilities that could bring to our game.
**2. Differences in hardware.** Three out of four of our team members either own a PC with a graphics card or an Oculus headset. Since both are necessary to debug live in Unity, the differences in hardware made it difficult for us to initially get set up by downloading the necessary packages and get our software versions in sync.
**3. Lack of face tracking.** ASL requires signers to make facial expressions while signing which we unfortunately cannot track with current hardware. The Tobii headset, as well as Valve's next VR headset both plan to include eye tracking so with the increased focus on facial tracking in future VR headsets we would better be able to judge signs from users.
## Accomplishments We're Proud Of
We're very proud of successfully integrating multiple artistic visions into one project. From Ryan's idea of including chonky cats to Mitchell's idea of a learning game to Nancy's vaporwave aesthetics to Jieying's concept art, we're so proud to see our game come together both aesthetically and conceptually. Also super proud of all the ASL we learned as a team in order to survive in *Catiator*, and for being a proud member of OhYay's table1.
## What We Learned
Each member of the team utilized challenging technology, and as a result learned a lot about Unity during the last 36 hours! We learned how to design, train and test a hand recognition system in Unity and build 3D models and UI elements in VR.
This project really helped us have a better understanding of many of the capabilities within Oculus, and in utilizing hand tracking to interpret gestures to use in an educational setting. We learned so much through this project and from each other, and had a really great time working as a team!
## Next Steps
* Create more lessons for users
* Fix keyboard issues so users can define gestures without debug/using the editor
* Multi-hand gesture support
* Additional mini games for users to practice ASL
## Install Instructions
To download, use password "Treehacks" on <https://trisol.itch.io/catiators>, because this is an Oculus Quest application you must sideload the APK using Sidequest or the Oculus Developer App.
## Project Credits/Citations
* Thinker Statue model: [Source](https://poly.google.com/u/1/view/fEyCnpGMZrt)
* ASL Facts: [ASL Benefits of Communication](https://smackhappy.com/2020/04/asl-benefits-communication/)
* Music: [Cassette Tape by Blue Moon](https://youtu.be/9lO_31BP7xY) |
[RESPECOGNIZE by Diamond Ortiz](https://www.youtube.com/watch?v=3lnEIXrmxNw) |
[Spirit of Fire by Jesse Gallagher](https://www.youtube.com/watch?v=rDtZwdYmZpo) |
* SFX: [Jingle Lose](https://freesound.org/people/LittleRobotSoundFactory/sounds/270334/) |
[Tada2 by jobro](https://freesound.org/people/jobro/sounds/60444/) |
[Correct by Eponn](https://freesound.org/people/Eponn/sounds/421002/) |
[Cat Screaming by InspectorJ](https://freesound.org/people/InspectorJ/sounds/415209/) |
[Cat2 by Noise Collector](https://freesound.org/people/NoiseCollector/sounds/4914/) | ## Inspiration
The ability to easily communicate with others is something that most of take for granted in our everyday life. However, for the millions of hearing impaired and deaf people all around the world, communicating their wants and needs is a battle they have to go through every day. The desire to make the world a more accessible place by bringing ASL to the general public in a fun and engaging manner was the motivation behind our app.
## What it does
Our app is essentially an education platform for ASL that is designed to also be fun and engaging. We provide lessons for basic ASL such as the alphabet, with plans to introduce more lessons in the future. What differentiates our app and makes it engaging, is that users can practice their ASL skills right in the app, with any new letter or word they learn, the app uses their webcam along with AI to instantly tell users when they are making the correct sign. The app also has a skills game that puts what they learnt to the test, in a time trial, that allows users to earn score for every signed letter/word. There is also a leaderboard so that users can compete globally and with friends.
## How we built it
Our app is a React app that we built with different libraries such as MUI, React Icons, Router, React-Webcam, and most importantly Fingerpose along with TensorflowJS for all our AI capabilities to recognize sign language gestures in the browser.
## Challenges we ran into
Our main struggle within this app was implementing Tensorflowjs as none of us have experience with this library prior to this event. Recognizing gestures in the browser in real time initially came with a lot of lag that led to a bad user experience, and so it took a lot of configuring and debugging in order to get a much more seamless experience.
## Accomplishments that we're proud of
As a team we were initially building another application with a similar theme that involved hardware components and we had to pivot quite late due to some unforseen complications, and so we're proud of being able to turn around with such a short amount of time and make a good product that we would be proud to show anyone. We're also proud of building a project that also has a real world usage to it that we all feel strongly about and that we think really does require a solution for.
## What we learned
Through this experience we all learned more about React as a framework, in addition to real time AI with Tensorflowjs.
## What's next for Battle Sign Language
Battle Sign Language has many more features that we would look to provide in the future, we currently have limited lessons, and our gestures are limited to the alphabet, so in the future we would increase our app to include more complex ASL such as words or sentences. We would also look forward to adding multiplayer games so that people can have fun learning and competing with friends simultaneously. | winning |
## Inspiration
## What it does
PhyloForest helps researchers and educators by improving how we see phylogenetic trees. Strong, useful data visualization is key to new discoveries and patterns. Thanks to our product, users have a greater ability to perceive depth of trees by communicating widths rather than lengths. The length between proteins is based on actual lengths scaled to size.
## How we built it
We used EggNOG to get phylogenetic trees in Newick format, then parsed them using a recursive algorithm to get the differences between the protein group in question. We connected names to IDs using the EBI (European Bioinformatics Institute) database, then took the lengths between the proteins and scaled them to size for our Unity environment. After we put together all this information, we went through an extensive integration process with Unity. We used EBI APIs for Taxon information, EggNOG gave us NCBI (National Center for Biotechnology Information) identities and structure. We could not use local NCBI lookup (as eggNOG does) due to the limitations of Virtual Reality headsets, so we used the EBI taxon lookup API instead to make the tree interactive and accurately reflect the taxon information of each species in question. Lastly, we added UI components to make the app easy to use for both educators and researchers.
## Challenges we ran into
Parsing the EggNOG Newick tree was our first challenge because there was limited documentation and data sets were very large. Therefore, it was difficult to debug results, especially with the Unity interface. We also had difficulty finding a database that could connect NCBI IDs to taxon information with our VR headset. We also had to implement a binary tree structure from scratch in C#. Lastly, we had difficulty scaling the orthologs horizontally in VR, in a way that would preserve the true relationships between the species.
## Accomplishments that we're proud of
The user experience is very clean and immersive, allowing anyone to visualize these orthologous groups. Furthermore, we think this occupies a unique space that intersects the fields of VR and genetics. Our features, such as depth and linearized length, would not be as cleanly implemented in a 2-dimensional model.
## What we learned
We learned how to parse Newick trees, how to display a binary tree with branches dependent on certain lengths, and how to create a model that relates large amounts of data on base pair differences in DNA sequences to something that highlights these differences in an innovative way.
## What's next for PhyloForest
Making the UI more intuitive so that anyone would feel comfortable using it. We would also like to display more information when you click on each ortholog in a group. We want to expand the amount of proteins people can select, and we would like to manipulate proteins by dragging branches to better identify patterns between orthologs. | ## Inspiration
The inspiration behind LeafHack stems from a shared passion for sustainability and a desire to empower individuals to take control of their food sources. Witnessing the rising grocery costs and the environmental impact of conventional agriculture, we were motivated to create a solution that not only addresses these issues but also lowers the barriers to home gardening, making it accessible to everyone.
## What it does
Our team introduces "LeafHack" an application that leverages computer vision to detect the health of vegetables and plants. The application provides real-time feedback on plant health, allowing homeowners to intervene promptly and nurture a thriving garden. Additionally, the images uploaded can be stored within a database custom to the user. Beyond disease detection, LeafHack is designed to be a user-friendly companion, offering personalized tips and fostering a community of like-minded individuals passionate about sustainable living
## How we built it
LeafHack was built using a combination of cutting-edge technologies. The core of our solution lies in the custom computer vision algorithm, ResNet9, that analyzes images of plants to identify diseases accurately. We utilized machine learning to train the model on an extensive dataset of plant diseases, ensuring robust and reliable detection. The database and backend were built using Django and Sqlite. The user interface was developed with a focus on simplicity and accessibility, utilizing next.js, making it easy for users with varying levels of gardening expertise
## Challenges we ran into
We encountered several challenges that tested our skills and determination. Fine-tuning the machine learning model to achieve high accuracy in disease detection posed a significant hurdle as there was a huge time constraint. Additionally, integrating the backend and front end required careful consideration. The image upload was a major hurdle as there were multiple issues with downloading and opening the image to predict with. Overcoming these challenges involved collaboration, creative problem-solving, and continuous iteration to refine our solution.
## Accomplishments that we're proud of
We are proud to have created a solution that not only addresses the immediate concerns of rising grocery costs and environmental impact but also significantly reduces the barriers to home gardening. Achieving a high level of accuracy in disease detection, creating an intuitive user interface, and fostering a sense of community around sustainable living are accomplishments that resonate deeply with our mission.
## What we learned
Throughout the development of LeafHack, we learned the importance of interdisciplinary collaboration. Bringing together our skills, we learned and expanded our knowledge in computer vision, machine learning, and user experience design to create a holistic solution. We also gained insights into the challenges individuals face when starting their gardens, shaping our approach towards inclusivity and education in the gardening process.
## What's next for LeafHack
We plan to expand LeafHack's capabilities by incorporating more plant species and diseases into our database. Collaborating with agricultural experts and organizations, we aim to enhance the application's recommendations for personalized gardening care. | ## Introduction
Sleep is important, and we all know it. There are many existing products on the market that can assist in your sleep with diverse capabilities and form factors, but they all come at a compromise - smartwatch sleep tracking is bulky and uncomfortable, smart rings serve only as passive trackers, and smart mattresses are exorbitantly expensive.
This is where Silent Night comes in. Our pillow dynamically adjusts to you throughout the night and uses non-intrusive tracking technologies to silently and accurately assess the quality of your sleep.
## What does it do?
The Silent Night pillow comes with three force sensors to track your sleep posture. Based on this information, it adjusts the height of different sections of the pillow with servo motors to enhance your comfort. The pillow also comes equipped with temperature, humidity, and light sensors so that it's aware of any environmental disruptions throughout the night.
Airway collapse (and therein snoring) often occurs when lying down face-up, so we built the servo interaction to suggest the user to sleep on their sides more often. With a built-in microphone, it detects when you are snoring and will change the shape of the pillow to suggest a better-supported sleeping position.
Finally, in the morning, Silent Night provides you with a summary of your sleep quality, giving you insights into your health and full control over your personal data.
## How we built it
The UI was built on Figma and then with HTML, CSS, and Javascript. On the hardware side, we used an ESP32 WROOM 32 module for obtaining sensor data and sending the packaged data as a JSON to a web server. The coding was done in Arduino, taking input from a DHT11 temperature humidity sensor, an electret microphone sensor, three force sensing resistors, and a photoresistor, all wired on a breadboard.
## Challenges we ran into
On the hardware side, we encountered several challenges:
* After connecting to WiFi, we received no data, which was resolved by moving all input pins from ADC2 to ADC1 because all of ADC2 gets used by WiFi.
* The force sensors were not reading workable data until we learned about voltage division and used that resistance information to convert it to workable data.
* Setting up the WiFi network was problematic as we couldn't use eduroam; we ended up using a personal hotspot and configured it to connect to the ESP32.
* We received DMT input as NaN, which was resolved by setting up a catch clause to output previous results if caught.
We also navigated the learning curve of how to code all those sensors in Arduino, send data from the ESP32 to a webserver through WiFi, and package the data in JSON.
On the UI side, converting a complex UI dashboard and integrating it with chart.js was quite difficult. Although we tried to make it work for our live demo, we had to use a backup version of our dashboard instead.
## Accomplishments that we're proud of
We managed to create a fully functional prototype of our idea in 24 hrs, including a hardware and software component. By committing to our idea early on and playing to our strengths, we were able to contribute the most where it mattered, resulting in a project that we are all really proud of.
## What we learned
We gained hands-on experience in integrating various sensors with an ESP32 module, coding in Arduino, and overcoming the challenges of wireless communication and data handling between hardware components and a web server.
## What's next for Silent Night
We'd like to implement an AI-based system that activates the panels only when the user's snoring sound is detected. Along with this, we'd like to reduce the amount of electronics in the pillow and swap it out with inflatable air packets to increase comfort and remove worries of electromagnetic radiation near the head.
### Sources
[https://www.nhlbi.nih.gov/health/sleep-deprivation#:~:text=According%20to%20the%20Centers%20for,at%20least%20once%20a%20month](https://www.nhlbi.nih.gov/health/sleep-deprivation#:%7E:text=According%20to%20the%20Centers%20for,at%20least%20once%20a%20month). | winning |
## Overview
People today are as connected as they've ever been, but there are still obstacles in communication, particularly for people who are deaf/mute and can not communicate by speaking. Our app allows bi-directional communication between people who use sign language and those who speak.
You can use your device's camera to talk using ASL, and our app will convert it to text for the other person to view. Conversely, you can also use your microphone to record your audio which is converted into text for the other person to read.
## How we built it
We used **OpenCV** and **Tensorflow** to build the Sign to Text functionality, using over 2500 frames to train our model. For the Text to Sign functionality, we used **AssemblyAI** to convert audio files to transcripts. Both of these functions are written in **Python**, and our backend server uses **Flask** to make them accessible to the frontend.
For the frontend, we used **React** (JS) and MaterialUI to create a visual and accessible way for users to communicate.
## Challenges we ran into
* We had to re-train our models multiple times to get them to work well enough.
* We switched from running our applications entirely on Jupyter (using Anvil) to a React App last-minute
## Accomplishments that we're proud of
* Using so many tools, languages and frameworks at once, and making them work together :D
* submitting on time (I hope? 😬)
## What's next for SignTube
* Add more signs!
* Use AssemblyAI's real-time API for more streamlined communication
* Incorporate account functionality + storage of videos | ## Inspiration
We wanted to create a webapp that will help people learn American Sign Language.
## What it does
SignLingo starts by giving the user a phrase to sign. Using the user's webcam, gets the input and decides if the user signed the phrase correctly. If the user signed it correctly, goes on to the next phrase. If the user signed the phrase incorrectly, displays the correct signing video of the word.
## How we built it
We started by downloading and preprocessing a word to ASL video dataset.
We used OpenCV to process the frames from the images and compare the user's input video's frames to the actual signing of the word. We used mediapipe to detect the hand movements and tkinter to build the front-end.
## Challenges we ran into
We definitely had a lot of challenges, from downloading compatible packages, incorporating models, and creating a working front-end to display our model.
## Accomplishments that we're proud of
We are so proud that we actually managed to build and submit something. We couldn't build what we had in mind when we started, but we have a working demo which can serve as the first step towards the goal of this project. We had times where we thought we weren't going to be able to submit anything at all, but we pushed through and now are proud that we didn't give up and have a working template.
## What we learned
While working on our project, we learned a lot of things, ranging from ASL grammar to how to incorporate different models to fit our needs.
## What's next for SignLingo
Right now, SignLingo is far away from what we imagined, so the next step would definitely be to take it to the level we first imagined. This will include making our model be able to detect more phrases to a greater accuracy, and improving the design. | ## Inspiration
With the interests and passions to learn sign language, we unfortunately found that resources for American Sign Language (ASL) were fairly limited and restricted. So, we made a "Google Translate" for ASL.
Of course, anyone can communicate without ASLTranslate by simply pulling out a phone or a piece of paper and writing down the words instead, but the aim of ASLTranslate is to foster the learning process of ASL to go beyond communication and generate deeper interpersonal connections. ASLTranslate's mission is to make learning ASL an enriching and accessible experience for everyone, because we are dedicated to providing a bridge between spoken language and sign language, fostering inclusivity, understanding, and connection.
## What it does
ASTranslation lets users type in words or sentences and to translate into ASL that is demonstrated by a video (gratefully from SigningSavvy). Additionally, there is a mini quiz page, where the user can test their vocabulary on commonly used signs. This provides the user with a tool to practice, familiarize, and increase exposure to sign language, important factors in learning any language.
## How we built it
We leveraged the fast development times of Flask and BeautifulSoup4 on the backend to retrieve the essential data required for crafting the output video. With the dynamic capabilities of React and JavaScript on the front end, we designed and developed an interactive and responsive user interface. Leveraging FFMpeg (available as a library in Python), we seamlessly stitched together the extracted videos, resulting in a cohesive and engaging final output to stream back to the user. We utilized MongoDB in order to perform file storing in order to cache words, trading network transfers in exchange for CPU cycles.
## Challenges we ran into
To ensure smooth teamwork, we needed consistent access to sample data for our individual project tasks. Connecting the frontend to the backend for testing had its challenges – data availability wasn't always the same on every machine. So, each developer had to set up both frontend and backend dependencies to access the required data for development and testing.Additionally, dealing with the backend's computational demands was tricky. We tried using a cloud server, but the resources we allocated were not enough. This led to different experiences in processing data on the backend for each team member.
## Accomplishments that we're proud of
For many of us, this project was the first time coding in a team environment. Furthermore, many of us were also working with full-stack development with React for the first time, and we are very content with our successfully completed the project. We overcame obstacles collaboratively despite being our first time working on a team project and we can’t be more proud of our team members who all worked very hard!
## What we learned
Throughout the building of the project, we learned a lot of meaningful lessons. Ranging from new tech-stacks, teamwork, the importance of sign language, and everything in between and combined. ASLTranslation has been a journey full of learning in hopes of learning journeys for others. All of our teammates had a wonderful time together and it has been an unforgettable experience that will become an important foundation for all of our future careers and life.
## What's next for ASLTranslate
We will add more user-interactive features such as sign language practice, where we build a program to detect the hand-motion to test the accuracy of the sign language.
To further expand, we will create an app-version of ASLTranslate and have it available to as many people as possible, through the website, mobile and more!
Additionally, as English and ASL does not always directly translate, ensuring grammatical accuracy would be highly beneficial. Currently, we prioritize generating user-friendly outputs over achieving perfect grammatical precision. We have considered the potential of employing artificial intelligence for this task, a avenue we are open to exploring further. | winning |
## Inspiration
So many people around the world, including those dear to us, suffer from mental health issues such as depression. Here in Berkeley, for example, the resources put aside to combat these problems are constrained. Journaling is one method commonly employed to fight mental issues; it evokes mindfulness and provides greater sense of confidence and self-identity.
## What it does
SmartJournal is a place for people to write entries into an online journal. These entries are then routed to and monitored by a therapist, who can see the journals of multiple people under their care. The entries are analyzed via Natural Language Processing and data analytics to give the therapist better information with which they can help their patient, such as an evolving sentiment and scans for problematic language. The therapist in turn monitors these journals with the help of these statistics and can give feedback to their patients.
## How we built it
We built the web application using the Flask web framework, with Firebase acting as our backend. Additionally, we utilized Microsoft Azure for sentiment analysis and Key Phrase Extraction. We linked everything together using HTML, CSS, and Native Javascript.
## Challenges we ran into
We struggled with vectorizing lots of Tweets to figure out key phrases linked with depression, and it was very hard to test as every time we did so we would have to wait another 40 minutes. However, it ended up working out finally in the end!
## Accomplishments that we're proud of
We managed to navigate through Microsoft Azure and implement Firebase correctly. It was really cool building a live application over the course of this hackathon and we are happy that we were able to tie everything together at the end, even if at times it seemed very difficult
## What we learned
We learned a lot about Natural Language Processing, both naively doing analysis and utilizing other resources. Additionally, we gained a lot of web development experience from trial and error.
## What's next for SmartJournal
We aim to provide better analysis on the actual journal entires to further aid the therapist in their treatments, and moreover to potentially actually launch the web application as we feel that it could be really useful for a lot of people in our community. | ## Inspiration
(<http://televisedrevolution.com/wp-content/uploads/2015/08/mr_robot.jpg>)
If you watch Mr. Robot, then you know that the main character, Elliot, deals with some pretty serious mental health issues. One of his therapeutic techniques is to write his thoughts on a private journal. They're great... they get your feelings out, and acts as a point of reference to look back to in the future.
We took the best parts of what makes a diary/journal great, and made it just a little bit better - with Indico. In short, we help track your mental health similar to how FitBit tracks your physical health. By writing journal entries on our app, we automagically parse through the journal entries, record your emotional state at that point in time, and keep an archive of the post to aggregate a clear mental profile.
## What it does
This is a FitBit for your brain. As you record entries about your live in the private journal, the app anonymously sends the data to Indico and parses for personality, emotional state, keywords, and overall sentiment. It requires 0 effort on the user's part, and over time, we can generate an accurate picture of your overall mental state.
The posts automatically embeds the strongest emotional state from each post so you can easily find / read posts that evoke a certain feeling (joy, sadness, anger, fear, surprise). We also have a analytics dashboard that further analyzes the person's longterm emotional state.
We believe being cognizant of one self's own mental health is much harder, and just as important as their physical health. A long term view of their emotional state can help the user detect sudden changes in the baseline, or seek out help & support long before the situation becomes dire.
## How we built it
The backend is built on a simple Express server on top of Node.js. We chose React and Redux for the client, due to its strong unidirectional data flow capabilities, as well as the component based architecture (we're big fans of css-modules). Additionally, the strong suite of redux middlewares such as sagas (for side-effects), ImmutableJS, and reselect, helped us scaffold out a solid, stable application in just one day.
## Challenges we ran into
Functional programming is hard. It doesn't have any of the magic that two-way data-binding frameworks come with, such as MeteorJS or AngularJS. Of course, we made the decision to use React/Redux being aware of this. When you're hacking away - code can become messy. Functional programming can at least prevent some common mistakes that often make a hackathon project completely unusable post-hackathon.
Another challenge was the persistance layer for our application. Originally, we wanted to use MongoDB - due to our familiarity with the process of setup. However, to speed things up, we decided to use Firebase. In hindsight, it may have cause us more trouble - since none of us ever used Firebase before. However, learning is always part of the process and we're very glad to have learned even the prototyping basics of Firebase.
## Accomplishments that we're proud of
* Fully Persistant Data with Firebase
* A REAL, WORKING app (not a mockup, or just the UI build), we were able to have CRUD fully working, as well as the logic for processing the various data charts in analytics.
* A sweet UI with some snazzy animations
* Being able to do all this while having a TON of fun.
## What we learned
* Indico is actually really cool and easy to use (not just trying to win points here). Albeit it's not always 100% accurate, but building something like this without Indico would be extremely difficult, and similar apis I've tried is not close to being as easy to integrate.
* React, Redux, Node. A few members of the team learned the expansive stack in just a few days. They're not experts by any means, but they definitely were able to grasp concepts very fast due to the fact that we didn't stop pushing code to Github.
## What's next for Reflect: Journal + Indico to track your Mental Health
Our goal is to make the backend algorithms a bit more rigorous, add a simple authentication algorithm, and to launch this app, consumer facing. We think there's a lot of potential in this app, and there's very little (actually, no one that we could find) competition in this space. | ## Inspiration
We wanted to create a convenient, modernized journaling application with methods and components that are backed by science. Our spin on the readily available journal logging application is our take on the idea of awareness itself. What does it mean to be aware? What form or shape can mental health awareness come in? These were the key questions that we were curious about exploring, and we wanted to integrate this idea of awareness into our application. The “awareness” approach of the journal functions by providing users with the tools to track and analyze their moods and thoughts, as well as allowing them to engage with the visualizations of the journal entries to foster meaningful reflections.
## What it does
Our product provides a user-friendly platform for logging and recording journal entries and incorporates natural language processing (NLP) to conduct sentiment analysis. Users will be able to see generated insights from their journal entries, such as how their sentiments have changed over time.
## How we built it
Our front-end is powered by the ReactJS library, while our backend is powered by ExpressJS. Our sentiment analyzer was integrated with our NodeJS backend, which is also connected to a MySQL database.
## Challenges we ran into
Creating this app idea under such a short period of time proved to be more challenge than we anticipated. Our product was meant to comprise of more features that helped the journaling aspect of the app as well as the mood tracking aspect of the app. We had planned on showcasing an aggregation of the user's mood over different time periods, for instance, daily, weekly, monthly, etc. And on top of that, we had initially planned on deploying our web app on a remote hosting server but due to the time constraint, we had decided to reduce our proof-of-concept to the most essential cores features for our idea.
## Accomplishments that we're proud of
Designing and building such an amazing web app has been a wonderful experience. To think that we created a web app that could potentially be used by individuals all over the world and could help them keep track of their mental health has been such a proud moment. It really embraces the essence of a hackathon in its entirety. And this accomplishment has been a moment that our team can proud of. The animation video is an added bonus, visual presentations have a way of captivating an audience.
## What we learned
By going through the whole cycle of app development, we learned how one single part does not comprise the whole. What we mean is that designing an app is more than just coding it, the real work starts in showcasing the idea to others. In addition to that, we learned the importance of a clear roadmap for approaching issues (for example, coming up with an idea) and that complicated problems do not require complicated solutions, for instance, our app in simplicity allows for users to engage in a journal activity and to keep track of their moods over time. And most importantly, we learned how the simplest of ideas can be the most useful if they are thought right.
## What's next for Mood for Thought
Making a mobile app could have been better, given that it would align with our goals of making journaling as easy as possible. Users could also retain a degree of functionality offline. This could have also enabled a notification feature that would encourage healthy habits.
More sophisticated machine learning would have the potential to greatly improve the functionality of our app. Right now, simply determining either positive/negative sentiment could be a bit vague.
Adding recommendations on good journaling practices could have been an excellent addition to the project. These recommendations could be based on further sentiment analysis via NLP. | winning |
## What it does
flarg.io is an Augmented Reality platform that allows you to play games and physical activities with your friends from across the world. The relative positions of each person will be recorded and displayed on a single augmented reality plane, so that you can interact with your friends as if they were in your own backyard.
The primary application is a capture the flag game, where your group will be split into two teams. Each team's goal is to capture the opposing flag and bring it back to the home-base. Tagging opposing players in non-safe-zones would put them on temporary time out, forcing them go back to their own home-base. May the best team win!
## What's next for flarg.io
Capture the flag is just the first of our suite of possible mini-games. Building off of the AR framework that we have built, the team foresees making other games like "floor is lava" and "sharks and minnows" with the same technology. | ## Inspiration
We got together a team passionate about social impact, and all the ideas we had kept going back to loneliness and isolation. We have all been in high pressure environments where mental health was not prioritized and we wanted to find a supportive and unobtrusive solution. After sharing some personal stories and observing our skillsets, the idea for Remy was born. **How can we create an AR buddy to be there for you?**
## What it does
**Remy** is an app that contains an AR buddy who serves as a mental health companion. Through information accessed from "Apple Health" and "Google Calendar," Remy is able to help you stay on top of your schedule. He gives you suggestions on when to eat, when to sleep, and personally recommends articles on mental health hygiene. All this data is aggregated into a report that can then be sent to medical professionals. Personally, our favorite feature is his suggestions on when to go on walks and your ability to meet other Remy owners.
## How we built it
We built an iOS application in Swift with ARKit and SceneKit with Apple Health data integration. Our 3D models were created from Mixima.
## Challenges we ran into
We did not want Remy to promote codependency in its users, so we specifically set time aside to think about how we could specifically create a feature that focused on socialization.
We've never worked with AR before, so this was an entirely new set of skills to learn. His biggest challenge was learning how to position AR models in a given scene.
## Accomplishments that we're proud of
We have a functioning app of an AR buddy that we have grown heavily attached to. We feel that we have created a virtual avatar that many people really can fall for.
## What we learned
Aside from this being many of the team's first times work on AR, the main learning point was about all the data that we gathered on the suicide epidemic for adolescents. Suicide rates have increased by 56% in the last 10 years, and this will only continue to get worse. We need change.
## What's next for Remy
While our team has set out for Remy to be used in a college setting, we envision many other relevant use cases where Remy will be able to better support one's mental health wellness.
Remy can be used as a tool by therapists to get better insights on sleep patterns and outdoor activity done by their clients, and this data can be used to further improve the client's recovery process. Clients who use Remy can send their activity logs to their therapists before sessions with a simple click of a button.
To top it off, we envisage the Remy application being a resource hub for users to improve their overall wellness. Through providing valuable sleep hygiene tips and even lifestyle advice, Remy will be the one-stop, holistic companion for users experiencing mental health difficulties to turn to as they take their steps towards recovery. | ## Inspiration
We wanted to build the most portable and accessible device for augmented reality.
## What it does
This application uses location services to detect where you are located and if you are in proximity to one of the landmark features based on a predefined set of coordinates. Then a 3d notification message appears with the name and information of the location.
## How we built it
We built on a stack with Objective-C, OpenGL, NodeJS, MongoDB, and Express using XCode. We also did the 3d modelling in Blender to create floating structures.
## Challenges we ran into
Math is hard. Real real hard. Dealing with 3D space, there were a lot of natural challenges dealing with calculations of matrices and quaternions. It was also difficult to calibrate for the scaling between the camera feed calculated in arbitrary units and the real world.
## Accomplishments that we're proud of
We created a functional 3-D augmented reality viewer complete with parallax effects and nifty animations. We think that's pretty cool.
## What we learned
We really honed our skills in developing within the 3-D space.
## What's next for Tour Aug
Possible uses could include location-based advertising and the inclusion of animated 3d characters. | winning |
## 🌟 Inspiration
The increasing demand for therapists puts us in long queues and financial burden. If only there was an alternative that was cheap, convenient and proactive in promoting good mental health. The rise of AI has opened so many gateways to produce life-changing technology in countless industries. BeHappy was created to promote positivity and introspection using the power of generative AI.
## 🧠 What it does
BeHappy is similar to a mental therapist in the way that it helps people who are suffering from poor mental health. However, BeHappy takes it to another level by proactively seeking out individuals who may be prone to mental health issues. At a random time everyday, BeHappy sends out a notification to it's user with a specialized prompt that forces them to think and write about events going on in their lives. Whether good or bad, BeHappy uses NLP to analyze the mood of the response and uses generative AI to create a counselling response based on the different things elaborated by the user. BeHappy focusses on validation, praise, and checkups which are key factors to consider when counselling an individual.
## 🔧 How we built it
BeHappy is a mobile app that is compatible for both iOS and Android built mainly using a MERN stack. The front-end is built using React Native and Native Base. The backend features a database using MongoDB and it is tied altogether using Express and Node. The AI portion uses the Eden AI api which uses the Google-trained model.
## 🪨 Challenges we ran into
As two individuals who have had zero experience in developing mobile applications, it was definitely a long winding road trying to develop this application. Prior experience in full-stack development definitely helped us tremendously but some of the exclusive mobile development concepts put a dent in our productivity. It was a fun and gruesome endeavour trying to tie everything together and create such a high impact app with an intuitive user experience
## 🏅 Accomplishments that we're proud of
We are very proud to have completed development on a mobile application, something that we went in to without having any experience in. We wanted to try something new and our goal seemed to fit a mobile application best, so it only made since to proceed down this road. We really enjoyed utilizing the power of AI and made it into a product that aims to promote good mental health.
## 📚 What we learned
As aforementioned, we learned a lot of mobile development, namely how it differs with that of web development. We also learned a lot about how to package incredibly powerful tools like generative AI and NLP in a product that can easily be used by anyone.
## 🏃 What's next for BeHappy
At it's core, BeHappy is in a state we hopped it to be and that is being able to help individuals when they need and additionally go out of its way to promote positive introspection and good mental health. However, there are so many features that we wish to bring to BeHappy to improve user experience. Some of these include, being able to track the notable events that the user shares and summarize it altogether in a end-of-week summary. We hope that this feature reminds user's and allows them to focus on the positive things that occured. | ## Inspiration
In today's world, the mental health crisis is on the rise, and finding a therapist has become increasingly difficult due to factors like the economy, accessibility, and finding the right fit. We believe everyone should have the opportunity to overcome their mental health challenges and have meaningful companions to rely on. Through the EVI (Empathic Voice Interface) model on Vercel, individuals are provided a safe space to express themselves without fear. Our mission is to empower people to openly share their thoughts and navigate through their mental health challenges, all for free, with just a click.
## What it does
Our project is a comprehensive mental health support system that includes our AI-powered therapy bot, user authentication, and personalized user profiles. By training Hume.ai's Empathic Voice Interface (EVI) with in-context learning and integrating the model into Vercel, we enable users to have meaningful conversations with the AI and work through their mental health challenges, getting advice, companionship, and more. Additionally, users can sign up or log in to create a profile that includes their personal information and emergency contacts, and our system ensures that all interactions are securely managed within the platform.
## How we built it
We gathered real-life therapist conversations. From there, we integrated a GPT 4-mini Hume AI model, training it with various real-world examples of therapist conversations with patients, understanding how they are feeling based on their tone and the way they are talking (sentiment analysis) and being able to provide them with the necessary advice they are looking for. We also altered the temperature to give them more specific responses to their particular questions but also allowed them to express themselves openly. For the front end, we first attempted to use React Native and Javascript before finally deciding to do HTML/CSS and Javascript to create a responsive and user-friendly website. After that, we needed database integration for the user authentication in which we attempted to use MongoDB, but we decided to utilize API localStorage. This setup allowed us to keep the front end lightweight while efficiently managing data from the backend database.
## Challenges we ran into
We encountered significant challenges connecting the front and back end, particularly establishing smooth communication between the two, which was more difficult than anticipated. While inputting our Hume AI into an HTML file, the HTML file was not able to capture the voice feature of Hume AI. To fix this, we deployed the model into a vercel app and implemented a link to the app in the HTML file. On the front-end side, we struggled with setting up a database for user authentication. Initially, we used MongoDB, but after facing connection issues, we had to explore alternative database solutions such as the API localStorage.
## What we learned & Accomplishments that we're proud of
During this project, we gained hands-on experience tackling the mental health crisis and integrating AI tools into existing systems. We learned the importance of adaptability, especially when transitioning from MongoDB to other database solutions for user authentication. Additionally, we improved our skills in debugging, API development, and managing the interaction between the front end and back end.
We’re proud of our resilience in the face of technical hurdles, git overwrites, and our ability to pivot when necessary. Despite these challenges, we successfully delivered a working solution, which is a major accomplishment for our team.
## What's next for Deeper Connections
In the future, to enhance the AI model's functionality, we can implement a system to flag trigger words during conversations with users. This feature would integrate with the emergency contact information from the "My Connections" page, adding an extra layer of protection as we tackle mental health crises. | ## Inspiration
When travelling in a new place, it is often the case that one doesn't have an adequate amount of mobile data to search for information they need.
## What it does
Mr.Worldwide allows the user to send queries and receive responses regarding the weather, directions, news and translations in the form of sms and therefore without the need of any data.
## How I built it
A natural language understanding model was built and trained with the use of Rasa nlu. This model has been trained to work as best possible with many variations of query styles to act as a chatbot. The queries are sent up to a server by sms with the twill API. A response is then sent back the same way to function as a chatbot.
## Challenges I ran into
Implementing the Twilio API was a lot more time consuming than we assumed it would be. This was due to the fact that a virtual environment had to be set up and our connection to the server originally was not directly connecting.
Another challenge was providing the NLU model with adequate information to train on.
## Accomplishments that I'm proud of
We are proud that our end result works as we intended it to.
## What I learned
A lot about NLU models and implementing API's.
## What's next for Mr.Worldwide
Potentially expanding the the scope of what services/information it can provide to the user. | losing |
## Inspiration
It’'s pretty common that you will come back from a grocery trip, put away all the food you bought in your fridge and pantry, and forget about it. Even if you read the expiration date while buying a carton of milk, chances are that a decent portion of your food will expire. After that you’ll throw away food that used to be perfectly good. But, that’s only how much food you and I are wasting. What about everything that Walmart or Costco trashes on a day to day basis?
Each year, 119 billion pounds of food is wasted in the United States alone. That equates to 130 billion meals and more than $408 billion in food thrown away each year.
About 30 percent of food in American grocery stores is thrown away. US retail stores generate about 16 billion pounds of food waste every year.
But, if there was a solution that could ensure that no food would be needlessly wasted, that would change the world.
## What it does
PantryPuzzle will scan in images of food items as well as extract its expiration date, and add it to an inventory of items that users can manage. When food nears expiration, it will notify users to incentivize action to be taken. The app will take actions to take with any particular food item, like recipes that use the items in a user’s pantry according to their preference. Additionally, users can choose to donate food items, after which they can share their location to food pantries and delivery drivers.
## How we built it
We built it with a React frontend and a Python flask backend. We stored food entries in a database using Firebase. For the food image recognition and expiration date extraction, we used a tuned version of Google Vision API’s object detection and optical character recognition (OCR) respectively. For the recipe recommendation feature, we used OpenAI’s GPT-3 DaVinci large language model. For tracking user location for the donation feature, we used Nominatim open street map.
## Challenges we ran into
React to properly display
Storing multiple values into database at once (food item, exp date)
How to display all firebase elements (doing proof of concept with console.log)
Donated food being displayed before even clicking the button (fixed by using function for onclick here)
Getting location of the user to be accessed and stored, not just longtitude/latitude
Needing to log day that a food was gotten
Deleting an item when expired.
Syncing my stash w/ donations. Don’t wanna list if not wanting to donate anymore)
How to delete the food from the Firebase (but weird bc of weird doc ID)
Predicting when non-labeled foods expire. (using OpenAI)
## Accomplishments that we're proud of
* We were able to get a good computer vision algorithm that is able to detect the type of food and a very accurate expiry date.
* Integrating the API that helps us figure out our location from the latitudes and longitudes.
* Used a scalable database like firebase, and completed all features that we originally wanted to achieve regarding generative AI, computer vision and efficient CRUD operations.
## What we learned
We learnt how big of a problem the food waste disposal was, and were surprised to know that so much food was being thrown away.
## What's next for PantryPuzzle
We want to add user authentication, so every user in every home and grocery has access to their personal pantry, and also maintains their access to the global donations list to search for food items others don't want.
We integrate this app with the Internet of Things (IoT) so refrigerators can come built in with this product to detect food and their expiry date.
We also want to add a feature where if the expiry date is not visible, the app can predict what the likely expiration date could be using computer vision (texture and color of food) and generative AI. | ## Inspiration
As college students more accustomed to having meals prepared by someone else than doing so ourselves, we are not the best at keeping track of ingredients’ expiration dates. As a consequence, money is wasted and food waste is produced, thereby discounting the financially advantageous aspect of cooking and increasing the amount of food that is wasted. With this problem in mind, we built an iOS app that easily allows anyone to record and track expiration dates for groceries.
## What it does
The app, iPerish, allows users to either take a photo of a receipt or load a pre-saved picture of the receipt from their photo library. The app uses Tesseract OCR to identify and parse through the text scanned from the receipt, generating an estimated expiration date for each food item listed. It then sorts the items by their expiration dates and displays the items with their corresponding expiration dates in a tabular view, such that the user can easily keep track of food that needs to be consumed soon. Once the user has consumed or disposed of the food, they could then remove the corresponding item from the list. Furthermore, as the expiration date for an item approaches, the text is highlighted in red.
## How we built it
We used Swift, Xcode, and the Tesseract OCR API. To generate expiration dates for grocery items, we made a local database with standard expiration dates for common grocery goods.
## Challenges we ran into
We found out that one of our initial ideas had already been implemented by one of CalHacks' sponsors. After discovering this, we had to scrap the idea and restart our ideation stage.
Choosing the right API for OCR on an iOS app also required time. We tried many available APIs, including the Microsoft Cognitive Services and Google Computer Vision APIs, but they do not have iOS support (the former has a third-party SDK that unfortunately does not work, at least for OCR). We eventually decided to use Tesseract for our app.
Our team met at Cubstart; this hackathon *is* our first hackathon ever! So, while we had some challenges setting things up initially, this made the process all the more rewarding!
## Accomplishments that we're proud of
We successfully managed to learn the Tesseract OCR API and made a final, beautiful product - iPerish. Our app has a very intuitive, user-friendly UI and an elegant app icon and launch screen. We have a functional MVP, and we are proud that our idea has been successfully implemented. On top of that, we have a promising market in no small part due to the ubiquitous functionality of our app.
## What we learned
During the hackathon, we learned both hard and soft skills. We learned how to incorporate the Tesseract API and make an iOS mobile app. We also learned team building skills such as cooperating, communicating, and dividing labor to efficiently use each and every team member's assets and skill sets.
## What's next for iPerish
Machine learning can optimize iPerish greatly. For instance, it can be used to expand our current database of common expiration dates by extrapolating expiration dates for similar products (e.g. milk-based items). Machine learning can also serve to increase the accuracy of the estimates by learning the nuances in shelf life of similarly-worded products. Additionally, ML can help users identify their most frequently bought products using data from scanned receipts. The app could recommend future grocery items to users, streamlining their grocery list planning experience.
Aside from machine learning, another useful update would be a notification feature that alerts users about items that will expire soon, so that they can consume the items in question before the expiration date. | We wanted to revolutionize the IOS navigation system, so when integrated into our life it would become a simple easy to use app.We created a way for the navigation system to give an ease of mind to as many people as possible.For example three people trying to meet up. When looking for a place to meet, this app would pin point a location,such as a cafe shop, that is the same distance apart from each person.It also than allows you to track and see the estimated time of arrival for their friend or family.
We used Swift to handle the IOS portion of the app and also Parse.
With every successful test trial that we conducted we became extremely proud. Many issues came ahead, but we were able to dodge pass them and continue ahead.
MeetUp has the possibility of improvements and expansion. MeetUp can be used by virtually anyone, and with a touch of a button they will be on their way to meet up. | winning |
[Play the game.](https://victorzshi.github.io/threeway-freeway/)
[Check out the GitHub repo.](https://github.com/victorzshi/threeway-freeway)
## Inspiration
The Nintendo Switch, crazy cooperation in general.
## What it does
Threeway Freeway pits three friends (or strangers!) in a constantly changing feat of peril, in which rules and roles change by the beat. The goal is to survive as long as possible and maybe lose your minds in the process.
## How we built it
We used the Godot game engine.
## Challenges we ran into
Originally planned as an online multiplayer web game, we quickly realized programming the networking was way out of our scope and time constraints. Accordingly, we downsized to a local multiplayer game played on the keyboard.
## Accomplishments that we're proud of
This was our group's first time developing any project with the Godot engine. We not only finished the game but learned a lot about this engine. This knowledge will surely prove useful in the future.
## What we learned
We learned GDScript, scenes, tree node structures, physics, and many other things Godot.
## What's next for Threeway Freeway
We will have a lot of fun playing it and showing it to friends and family. We encourage you to play as well. In the future, we may port or extend the base game. | ## Inspiration
It took us a while to think of an idea for this project- after a long day of zoom school, we sat down on Friday with very little motivation to do work. As we pushed through this lack of drive our friends in the other room would offer little encouragements to keep us going and we started to realize just how powerful those comments are. For all people working online, and university students in particular, the struggle to balance life on and off the screen is difficult. We often find ourselves forgetting to do daily tasks like drink enough water or even just take a small break, and, when we do, there is very often negativity towards the idea of rest. This is where You're Doing Great comes in.
## What it does
Our web application is focused on helping students and online workers alike stay motivated throughout the day while making the time and space to care for their physical and mental health. Users are able to select different kinds of activities that they want to be reminded about (e.g. drinking water, eating food, movement, etc.) and they can also input messages that they find personally motivational. Then, throughout the day (at their own predetermined intervals) they will receive random positive messages, either through text or call, that will inspire and encourage. There is also an additional feature where users can send messages to friends so that they can share warmth and support because we are all going through it together. Lastly, we understand that sometimes positivity and understanding aren't enough for what someone is going through and so we have a list of further resources available on our site.
## How we built it
We built it using:
* AWS
+ DynamoDB
+ Lambda
+ Cognito
+ APIGateway
+ Amplify
* React
+ Redux
+ React-Dom
+ MaterialUI
* serverless
* Twilio
* Domain.com
* Netlify
## Challenges we ran into
Centring divs should not be so difficult :(
Transferring the name servers from domain.com to Netlify
Serverless deploying with dependencies
## Accomplishments that we're proud of
Our logo!
It works :)
## What we learned
We learned how to host a domain and we improved our front-end html/css skills
## What's next for You're Doing Great
We could always implement more reminder features and we could refine our friends feature so that people can only include selected individuals. Additionally, we could add a chatbot functionality so that users could do a little check in when they get a message. | ## Inspiration
At work, we use a tele-presence robot call the BEAM. It is a very cool piece of technology that works to enable more personal remote meetings between people, and increase the amount of "presence" a person may have remotely. However, upon checking the cost of such technology, the 2.5k USD to 15k+ USD price tag per unit is very discouraging for adoption by everyone other than the largest of corporations. We as a team decided to leverage the ease-of-use for modern cloud servers, the power low cost IoT hardware, and powerful embedded code and iOS application through Swift, to tackle this challenge.
## What it does
Aura is a telepresence system that incorporates both hardware and software. The exception, is that the hardware and software are now separated, and any drive train can pair with any aura app holder to enable the use of the aura system. We aim to provide telepresence at a low cost, increased convenience, and flexibility. It allows multi-party video calling, and incorporates overlay UI to control the drive train.
## How we built it
Using Swift for iOS, Arduino for the ESP32, and NodeRED for the web application service, plus Watson IoT Platform and Twilio Video API.
## Challenges we ran into
One does not simply run into challenges, when working with the awesomeness that is aura.
## What's next for Aura
Add bluetooth support for local pairing, avoid extra complexity of IoT. Better UI with more time, and develop different sizes of drive trains that support life-sized telepresence, like the beam, with iPads and other tablets. | partial |
Currently, about 600,000 people in the United States have some form of hearing impairment. Through personal experiences, we understand the guidance necessary to communicate with a person through ASL. Our software eliminates this and promotes a more connected community - one with a lower barrier entry for sign language users.
Our web-based project detects signs using the live feed from the camera and features like autocorrect and autocomplete reduce the communication time so that the focus is more on communication rather than the modes. Furthermore, the Learn feature enables users to explore and improve their sign language skills in a fun and engaging way. Because of limited time and computing power, we chose to train an ML model on ASL, one of the most popular sign languages - but the extrapolation to other sign languages is easily achievable.
With an extrapolated model, this could be a huge step towards bridging the chasm between the worlds of sign and spoken languages. | ## Inspiration
In today's world, technology has made it possible for people from various backgrounds and cultures to interact and understand each other through various cross-cultural and cross-linguistic platforms. Spoken language is a much smaller barrier than it was a few decades ago. But there still remains a community amongst us with whom a majority of us can't communicate face-to-face due to our lack of knowledge of their mode of communication. What makes their language different from any other is that their speech isn't spoken, it is shown.
This is particularly pronounced in the education domain for students and educators in this domain can feel isolated in mixed learning environments and this project hopes that through it, they are able to better communicate and integrate with the world around them.
## What it does
Our contribution is Talk To The Hand — a web application that helps hearing impaired people share their message with the world, even if they don't have the physical or financial access to an interpreter. Sign language speakers open the application and sign into their computer’s camera. Talk To The Hand uses computer vision and machine learning to interpret their message, transmit the content to their audience via voice assistant, and create a written transcript for visual confirmation of the translation. After the user is done speaking, Talk To The Hand gives the opportunity to share the written transcript of their talk through email, text message, or link.
We imagine that this tool will be especially helpful and powerful in public speaking settings — not unlike presenting at a Hackathon! Talk To The Hand dramatically increases the ability of deaf and hard of hearing people to speak to a broad audience.
## How we built it
We have two components to the application, the first being the machine learning model that recognizes hand gestures and predicts the corresponding meaning and second being the web application that provides the user with an intuitive interface to perform the task of interpreting the signs and speaking them out with multiple language support for speech.
We built the model by training deep neural nets on a Kaggle dataset - Sign Language MNIST for hand gesture recognition (<https://www.kaggle.com/datamunge/sign-language-mnist>). Once we set up the inference mechanism to get the prediction from the model for the hand gesture given as an image, we used the prediction and converted it to speech in English using the Houndify text-to-speech API. We then set up the web application through which the user can interact using images of hand gestures and the interpretation of the gesture is both displayed as text and spoken out in their language of choice.
## Challenges we ran into
One of the biggest hurdles we faced as a team was the development of our hosting platform. Despite the lack of experience in the domain, we wanted to make our application more accessible and intuitive for our users. After exploring some of the more basic web development technologies such as HTML, CSS and Javascript, we shifted to nuanced web/mobile app development to make our application implementable in various domains with ease. We faced obstacles during the transfer of data from the frontend to the backend and vice versa for our images and speech responses from API calls. In the process, we managed to set up a web based application.
## Accomplishments that we're proud of
First and foremost, we are proud of having thought of and built the first iteration of an application that will allow for people dependent on sign language to cross any barriers to communication that may come their way. We are hopeful about the impact it will have on this community and are looking forward to carrying to the next phase. We are thrilled about developing a model that can predict the letter corresponding to the Sign Language and integrating it with Text-to-Speech API and deploying a functional web application even though our team is inexperienced with web development. Overall, we relish the experience for having pushed ourselves beyond what we thought was possible and working on something that we believe will change the world.
## What we learned
One of the biggest takeaways for our team as a whole is going through the entire development life cycle fo a product starting from ideation to building the minimum viable product. We were exposed to more applications of Computer Vision through this project.
## What's next for Talk to the Hand
Today’s version of Talk To The Hand is a very minimal representation created in 36 hours in order to show proof of concept. Next steps would include in-depth sign education and refined experience based on user testing and feedback. We believe Talk To The Hand could make a powerful impact in public speaking and presentation settings for the deaf and hard of hearing, especially in countries and communities where physical and financial access to interpreters proves difficult. Imagine a neighborhood activist sharing an impassioned speech before a protest, a middle school class president giving his inaugural address, or a young hacker pitching to her panel of judges. | ## Inspiration
Imagine living in a foreign country. Think about it. How would you feel if you lived in an area where the language, customs, and culture weren't native to you? You'd probably go through each day with reluctance and uncertainty. You'd want to say what's appropriate, not something that would be viewed as ignorant. You'd feel frustrated when you want to state your opinion but couldn't make yourself understood. You'd feel isolated when everyone was laughing at a joke, and you didn't understand the punch line.
Deaf and hard of hearing people often feel this way when they're surrounded by hearing people.
But the issue has more than just cultural and social implications. There's a critical shortage of accredited translators. The demand for Sign Language Interpreters is expected to rise 46% from 2012 to 2020 according to the Bureau of Statistics. There are currently five Canadian post-secondary programs that educate interpreters and each of these programs only graduate 6-13 people a year. Some of these programs operate on a cohort systems, meaning that classes only graduate every 2-3 years.
The shortage of accredited translators means that basic democratic right, such as representing yourself in court, seeing your doctor, and finding employment are being obstructed for a disabled and often misunderstood minority.
Signatio is committed to remove such obstructions because we believe that everyone deserves to have their voice heard.
## What it Does
We use machine learning and computer vision to gamify and break down the barriers of learning American Sign Language.Our web application encourages users to become more proficient in American Sign Language. Users improve their skills by completing modules and unlocking levels that increase gradually in difficulty.
We've included one level and three modules in our minimum viable product. Our first level seeks to teach users the ASL alphabet:
* An initial module to guide the user through the entire ASL alphabet
* A second module generates a randomized multiple choice test to help users associate the English and ASL alphabet
* Our third and final module tests our user's mastery of the alphabet by making them sign a letter without any aid
## How I Built It
We used Flask and Bootstrap to build our easy to use and interactive educational platform. Furthermore, we created a multi-class image classification model which we trained. This image classification model is utilized to recognize ASL alphabets by using the webcam and comparing to ensure the symbol matches the trained data of the model. We also have a random generator which randomly selects an ASL alphabet and has the user select which one the symbol/gesture matches. This randomly selects alphabet by utilizing a random library to randomly select a letter from list of alphabets. Once it selects, it removes the selected alphabet from the list and randomly selects two other letters and adds in multiple choice question for user to select correct corresponding alphabet given symbol. For our last module, it just randomly selects an alphabet and asks for user to show the symbol for that alphabet without any guide/aid in terms of what the hand gesture appears to be. The first module works on same idea except it also shows an image of alphabet to guide users in showing how the gesture for the alphabet appears.
## Challenges I Ran Into
* Embedding our webcam feed into the web app proved quite difficult, so instead we made separate application to feed data into our web app while simultaneously running a stream on our platform to both accurately mimic the UI off our modules and obtain accurate results
* Matching each letter to an image proved difficult to do but we found that matching the image to the file path name was the simplest
* Making sure duplicate options in our multiple choice was hard to do without iterating through every combination so we developed our own algorithm to do so
\*Routing our app was a challenge as we had to integrate our html buttons and a tags with our python back-end
## Accomplishments that I'm Proud of
Our entire team worked around the clock to solve what seemed like an impossible number of technical challenges. But what we're really proud of is that we used technology to try and make a real change. Discrimination in any
form closes the door to equal opportunity, a fundamental right of Canadian citizenship and democracy itself. Our team strongly believes that the culturally deaf, oral deaf, deafened, and hard of hearing have the right to fair an equitable treatment and to communicate both fully and freely. Making an effort to solve this issue was the biggest thing we accomplished.
## What I Learned
We were able to learn about numerous different technologies such as Flask, Bootstrap, and the general idea of image classification models as only one developer in our group had experience with these topics. The rest had little to no experience using web frameworks as most of our experience comes from plain Javascript, libraries such as React, or frameworks such as Spring. Image classification model is a form of machine learning which we always found extremely difficult to get into, but by having online GitHub repositories in which we could base our own model of it was quite simple. We were able to take a higher level approach and not need to actually understand the details of how the model actually works. Furthermore, due to being able to work with more experienced hackers, we were all able to experience and learn from our team members previous experience in how to actually tackle a problem first and how to focus on pitch before even getting into doing the implementation. They also were able to tone down any irrational hopes and expectations for the project before starting.As hackathons are such a short period of time that developers have little to no time to implement any features especially with the key trying to be innovative but also reliable so that you can demo project without any issues.
## What's Next for Signatio
There's a lot more work we plan to put into Signatio. We only managed to create one level and three modules. We had many more features and improvements we wanted to implement, here are some of them below:
\*Add a hangman module for level one
\*Implement video analysis as ASL has many gestures and movements that we currently aren't able to use since we only analyze static images
\*Add more level and module material (words, sentences, and topics)
\*Statistics page
\*Real time tutoring and playing with other users
* Add spaced repetition learning to the platform | partial |
## Inspiration
We were inspired because many sites are often attacked by password cracking distributed attacks. We wanted to provide a solution to help website owners surveille the overall risk level of incoming requests.
## What it does
The project is a solution for website owners to secure their site from malicious login attempts by checking with external API's and giving incoming requests a risk score based on the data. It also includes a registration and login system, as well as a dashboard to see the details of each request.
## How we built it
How it was built: The project was built using Django for the API to check for risk, NextJS for the registration, login system and dashboard, and a MYSQL database to store data.
## Challenges we ran into
Challenges faced: The biggest challenge was deploying the NextJS project onto AWS, which was not successful.
## What we learned
The team learned about the components that make up a dangerous incoming request and which API's to use to check them. | ## Problem Statement
Spoken language barriers do more than obstruct communication; they hinder the deep, emotional connections that bind us and limit opportunities in our increasingly global society. We've heard countless stories of individuals struggling to communicate with loved ones or feeling isolated in new environments due to language barriers: many grapple with a fear of judgment, making language acquisition incredibly difficult.
People should be able to learn languages in a way that feels supportive, engaging, and tailored to their unique needs. The power of speech in breaking down barriers and forging connections in everyday life cannot be overstated.
Our solution? Chime.
As a group of Stanford students who experienced the difficulties of language learning through our own or our loved one's experiences, we wanted to make language learning more accessible for those who need it the most.
## About Chime
Chime is an AI-driven conversational engine capable of adapting to individual learning styles and progress.
* Supports 56 languages
* Web & mobile app, with watchOS companion app
* Apple Watch “Chime-in” notifications for habit formation
* Integrates voice recognition, TTS, and AI LLMs
## Learning and takeaways
Embarking on this project, we delved into the complexities of language acquisition, cognitive psychology, and AI technology. Through a combination of voice recognition and multi-model machine learning systems, we've created personalized learning paths and subtle feedback mechanisms to encourage fun and explorative conversations. Informed by our personal experiences and user interviews, we also developed interactive real-world role-play situations where users can practice and broaden their vocabularies.
The journey of creating Chime has been challenging, yet incredible, and we can't wait to share this product with the people we've made it for! As we continue to grow and evolve Chime, our mission remains the same: to empower individuals to connect, communicate, and thrive in a multilingual world. | ## Inspiration
The vicarious experiences of friends, and some of our own, immediately made clear the potential benefit to public safety the City of London’s dataset provides. We felt inspired to use our skills to make more accessible, this data, to improve confidence for those travelling alone at night.
## What it does
By factoring in the location of street lights, and greater presence of traffic, safeWalk intuitively presents the safest options for reaching your destination within the City of London. Guiding people along routes where they will avoid unlit areas, and are likely to walk beside other well-meaning citizens, the application can instill confidence for travellers and positively impact public safety.
## How we built it
There were three main tasks in our build.
1) Frontend:
Chosen for its flexibility and API availability, we used ReactJS to create a mobile-to-desktop scaling UI. Making heavy use of the available customization and data presentation in the Google Maps API, we were able to achieve a cohesive colour theme, and clearly present ideal routes and streetlight density.
2) Backend:
We used Flask with Python to create a backend that we used as a proxy for connecting to the Google Maps Direction API and ranking the safety of each route. This was done because we had more experience as a team with Python and we believed the Data Processing would be easier with Python.
3) Data Processing:
After querying the appropriate dataset from London Open Data, we had to create an algorithm to determine the “safest” route based on streetlight density. This was done by partitioning each route into subsections, determining a suitable geofence for each subsection, and then storing each lights in the geofence. Then, we determine the total number of lights per km to calculate an approximate safety rating.
## Challenges we ran into:
1) Frontend/Backend Connection:
Connecting the frontend and backend of our project together via RESTful API was a challenge. It took some time because we had no experience with using CORS with a Flask API.
2) React Framework
None of the team members had experience in React, and only limited experience in JavaScript. Every feature implementation took a great deal of trial and error as we learned the framework, and developed the tools to tackle front-end development. Once concepts were learned however, it was very simple to refine.
3) Data Processing Algorithms
It took some time to develop an algorithm that could handle our edge cases appropriately. At first, we thought we could develop a graph with weighted edges to determine the safest path. Edge cases such as handling intersections properly and considering lights on either side of the road led us to dismissing the graph approach.
## Accomplishments that we are proud of
Throughout our experience at Hack Western, although we encountered challenges, through dedication and perseverance we made multiple accomplishments. As a whole, the team was proud of the technical skills developed when learning to deal with the React Framework, data analysis, and web development. In addition, the levels of teamwork, organization, and enjoyment/team spirit reached in order to complete the project in a timely manner were great achievements
From the perspective of the hack developed, and the limited knowledge of the React Framework, we were proud of the sleek UI design that we created. In addition, the overall system design lent itself well towards algorithm protection and process off-loading when utilizing a separate back-end and front-end.
Overall, although a challenging experience, the hackathon allowed the team to reach accomplishments of new heights.
## What we learned
For this project, we learned a lot more about React as a framework and how to leverage it to make a functional UI. Furthermore, we refined our web-based design skills by building both a frontend and backend while also use external APIs.
## What's next for safewalk.io
In the future, we would like to be able to add more safety factors to safewalk.io. We foresee factors such as:
Crime rate
Pedestrian Accident rate
Traffic density
Road type | losing |
## Inspiration
During the pandemic, we noticed that uncertainty surrounding COVID-19 had a negative effect on people's mental health. We wanted to create a project that could help people restore their lives to how they were before the pandemic. Inspired by the capabilities of other Discord bots, we looked to Discord, a virtual platform that many school clubs and classes had been using to adjust to online learning. This technology would be able to achieve our goals and reach the audience that needs it the most.
## What it does
Our Discord bot keeps server members organized and in check with their mental health. Commands allows users to:
* Quickly access a list of helplines
* Set timers and add new ones
* Check your personal schedule and add new events
* Log your mood
* Monitor your Discord usage and average recent mood
* See a motivational quote
* See cute pet photos
* Read jokes
* Read some good news
* See food pictures
* See memes
## How we built it
The bot was coded in Python. We used the following libraries:
* os
* discord
* dotenv
* random
* requests
* json
* BeautifulSoup
* time
* datetime
As well, we used the following APIs:
* Reddit API (<https://towardsdatascience.com/how-to-use-the-reddit-api-in-python-5e05ddfd1e5c>)
* Dog API (<https://dog.ceo/dog-api/>)
* Cat API (<https://thecatapi.com/>)
* ZenQuotes Premium (<https://premium.zenquotes.io/zenquotes-documentation/>)
We also used the following source for the list of hotlines:
* <https://www.cbc.ca/radio/opp/if-you-want-to-talk-to-someone-here-s-a-list-of-resources-that-might-help-1.4603730>
## Challenges we ran into
The Discord and Reddit APIs were very challenging to use at first because none of us had experience with them before. We had to spend hours reading the documentation and experimenting with it before we could use them effectively in our project.
As well, we had issues using time in functions like timer and schedule. This also took a while for us to get used to.
## Accomplishments that we're proud of
We’re proud that we were able to create a functional Discord bot with various features in just over a day. We’re also glad we were able to divide tasks and communicate well to efficiently complete our project.
## What we learned
We learned the basics of creating a Discord bot and working with APIs.
## What's next for Positivity Bot
We hope to implement more commands and improve the functionality and user-friendliness of our current ones, as well as improve the structure of our code. | ## Inspiration
In 2021, the [United Nations](https://www.un.org/press/en/2021/sc14445.doc.htm) said that climate change is the biggest threat to our world as we know it. We as people have the power to shape the world and try to fight this. Toronto is a city with vibrant culture, traditions, and people. The city is a hub for eco-friendly businesses, and initiatives. We must all work together to try to restore the world to how it was before pollution immensely increased the speed of climate change. That is what inspired us to create ShopGreen.
## What it does
ShopGreen provides an easy-to-use directory to green businesses within the City of Toronto! Simply pick from our categories and type a location to be given a list of businesses you can shop at and know you are supporting ethical practices.
## How we built it
In our webpage, we used React for the frontend and Flask for the backend. In terms of data processing, we used Python to extract the CSV dataset, and perform computations on it. From there, we created a MySQL server with the Google Cloud API to store the data in an efficient and easy-to-manage way.
## Challenges we ran into
There were a number of challenges we ran into throughout the creation of our project. This was our first time using many of our developer tools in this way, and we had to learn these in a very short time span. Neither of us had really used React for any of our projects, so we had to spend a lot of time learning how it works. Similarly, it was a challenge to connect the React frontend to the Flask backend. We had some challenges with the ports but were able to resolve them through consulting mentors and reading documentation.
## Accomplishments that we're proud of
We are most proud of the growth we've experienced over the past 36 hours. When we began this project, neither of us really understood what we were doing, yet we've now learned an entirely new framework and figured out how to attach endpoints to a different back-end framework. We learned how to use the Google Cloud API, and spent an entire weekend learning.
## What we learned
This hackathon was very learning intense for all of our group members. None of us knew how to use React prior to this Hackathon. A lot of our time was spent browsing the documentation and watching beginner videos on how to use the framework. After we learned the basics of how it works, we figured out how to tie it to Flask for the back-end. Our team already had a bit of experience working with Flask, but never alongside a front-end framework. We also learned how to remotely connect to a VM with the Google Cloud API, and how to use their Cloud SQL service.
## What's next for ShopGreen
We would absolutely like to continue building upon this project in the future. After UofTHacks, we plan to add the features we did not have time to add this weekend. We plan to implement geocoding to find a list of a certain number of businesses near you, and to have the output formatted in a user-friendly way. | ## Inspiration
Hungry college students
## What it does
RecipeBoy returns a list of recipes based on the ingredients you give him.
You can also send him your recommended recipes and get a list of recommendations!
## How we built it
Using Cisco Spark's API, Javascript, Node.js, and Food2Food API.
## Challenges we ran into
Phew, a lot.
We had to learn how to use Cisco Sparks' API, what Webhooks were and how to communicate with our RecipeBoy.
Free API's were hard to find and a lot of our time was spent looking for a suitable one.
## Accomplishments that we're proud of
Finishing...
And having successfully worked with new technology!
## What we learned
We learned a lot about Cisco Spark's API and how to use Node.js. Our team's Javascript skills were a bit rusty but this was a great refresher.
## What's next for RecipeBoy
RecipeBoy is looking for a buddy and RestaurantBoy just moved in next door!
We'd love to make a Cisco Spark bot for making restaurant recommendations and reservations. | losing |
## Inspiration
Our inspiration came from the desire to address the issue of food waste and to help those in need. We decided to create an online platform that connects people with surplus food to those who need to address the problem of food insecurity and food waste, which is a significant environmental and economic problem. We also hoped to highlight the importance of community-based solutions, where individuals and organizations can come together to make a positive impact. We believed in the power of technology and how it can be used to create innovative solutions to social issues.
## What it does
Users can create posts about their surplus perishable food (along with expiration date+time) and other users can find those posts to contact the poster and come pick up the food. We thought about it as analogous to Facebook Marketplace but focused on surplus food.
## How we built it
We used React + Vite for the frontend and Express + Node.js for the backend. For infrastructure, we used Cloudflare Pages for the frontend and Microsoft Azure App Service for backend.
## Security Practices
#### Strict repository access permissions
(Some of these were lifted temporarily to quickly make changes while working with the tight deadline in a hackathon environment):
* Pull Request with at least 1 review required for merging to the main branch so that one of our team members' machines getting compromised doesn't affect our service.
* Reviews on pull requests must be after the latest commit is pushed to the branch to avoid making malicious changes after a review
* Status checks (build + successful deployment) must pass before merging to the main branch to avoid erroneous commits in the main branch
* PR branches must be up to date with the main branch to merge to make sure there are no incompatibilities with the latest commit causing issues in the main branch
* All conversations on the PR must be marked as resolved to make sure any concerns (including security) concerns someone may have expressed have been dealt with before merging
* Admins of the repository are not allowed to bypass any of these rules to avoid accidental downtime or malicious commits due to the admin's machine being compromised
#### Infrastructure
* Use Cloudflare's CDN (able to mitigate the largest DDoS attacks in the world) to deploy our static files for the frontend
* Set up SPF, DMARC and DKIM records on our domain so that someone spoofing our domain in emails doesn't work
* Use Microsoft Azure's App Service for CI/CD to have a standard automated procedure for deployments and avoid mistakes as well as avoid the responsibility of having to keep up with OS security updates since Microsoft would do that regularly for us
* We worked on using DNSSEC for our domain to avoid DNS-related attacks but domain.com (the hackathon sponsor) requires contacting their support to enable it. For my other projects, I implement it by adding a DS record on the registrar's end using the nameserver-provided credentials
* Set up logging on Microsoft Azure
#### Other
* Use environment variables to avoid disclosing any secret credentials
* Signed up with Github dependabot alerts to receive updates about any security vulnerabilities in our dependencies
* We were in the process of implementing an Authentication service using an open-source service called Supabase to let users sign in using multiple OAuth methods and implement 2FA with TOTP (instead of SMS)
* For all the password fields required for our database and Azure service, we used Bitwarden password generator to generate 20-character random passwords as well as used 2FA with TOTP to login to all services that support it
* Used SSL for all communication between our resources
## Challenges we ran into
* Getting the Google Maps API to work
* Weird errors deploying on Azure
* Spending too much time trying to make CockroachDB work. It seemed to require certificates for connection even for testing. It seemed like their docs for using sequalize with their DB were not updated since this requirement was put into place.
## Accomplishments that we're proud of
Winning the security award by CSE!
## What we learned
We learned to not underestimate the amount of work required and do better planning next time.
Meanwhile, maybe go to fewer activities though they are super fun and engaging! Don't take us wrong as we did not regret doing them! XD
## What's next for Food Share
Food Share is built within a limited time. Some implementations that couldn't be included in time:
* Location of available food on the interactive map
* More filters for the search for available food
* Accounts and authentication method
* Implement Microsoft Azure live chat called Azure Web PubSub
* Cleaner UI | Team channel #43
Team discord users - Sarim Zia #0673,
Elly #2476,
(ASK),
rusticolus #4817,
Names -
Vamiq,
Elly,
Sarim,
Shahbaaz
## Inspiration
When brainstorming an idea, we concentrated on problems that affected a large population and that mattered to us. Topics such as homelessness, food waste and a clean environment came up while in discussion. FULLER was able to incorporate all our ideas and ended up being a multifaceted solution that was able to help support the community.
## What it does
FULLER connects charities and shelters to local restaurants with uneaten food and unused groceries. As food prices begin to increase along with homelessness and unemployment we decided to create FULLER. Our website serves as a communication platform between both parties. A scheduled pick-up time is inputted by restaurants and charities are able to easily access a listing of restaurants with available food or groceries for contactless pick-up later in the week.
## How we built it
We used React.js to create our website, coding in HTML, CSS, JS, mongodb, bcrypt, node.js, mern, express.js . We also used a backend database.
## Challenges we ran into
A challenge that we ran into was communication of the how the code was organized. This led to setbacks as we had to fix up the code which sometimes required us to rewrite lines.
## Accomplishments that we're proud of
We are proud that we were able to finish the website. Half our team had no prior experience with HTML, CSS or React, despite this, we were able to create a fair outline of our website. We are also proud that we were able to come up with a viable solution to help out our community that is potentially implementable.
## What we learned
We learned that when collaborating on a project it is important to communicate, more specifically on how the code is organized. As previously mentioned we had trouble editing and running the code which caused major setbacks.
In addition to this, two team members were able to learn HTML, CSS, and JS over the weekend.
## What's next for us
We would want to create more pages in the website to have it fully functional as well as clean up the Front-end of our project. Moreover, we would also like to look into how to implement the project to help out those in need in our community. | ## Inspiration
Partially inspired by the Smart Cities track, we wanted our app to have the direct utility of ordering food, while still being fun to interact with. We aimed to combine convenience with entertainment, making the experience more enjoyable than your typical drive-through order.
## What it does
You interact using only your voice. The app automatically detects when you start and stop talking, uses AI to transcribe what you say, figures out the food items (with modifications) you want to order, and adds them to your current order. It even handles details like size and flavor preferences. The AI then generates text-to-speech audio, which is played back to confirm your order in a humorous, engaging way. There is absolutely zero set-up or management necessary, as the program will completely ignore all background noises and conversation. Even then, it will still take your order with staggering precision.
## How we built it
The frontend of the app is built with React and TypeScript, while the backend uses Flask and Python. We containerized the app using Docker and deployed it using Defang. The design of the menu is also done in Canva with a dash of Harvard colors.
## Challenges we ran into
One major challenge was getting the different parts of the app—frontend, backend, and AI—to communicate effectively. From media file conversions to AI prompt engineering, we worked through each of the problems together. We struggled particularly with maintaining smooth communication once the app was deployed. Additionally, fine-tuning the AI to accurately extract order information from voice inputs while keeping the interaction natural was a big hurdle.
## Accomplishments that we're proud of
We're proud of building a fully functioning product that successfully integrates all the features we envisioned. We also managed to deploy the app, which was a huge achievement given the complexity of the project. Completing our initial feature set within the hackathon timeframe was a key success for us. Trying to work with Python data type was difficult to manage, and we were proud to navigate around that. We are also extremely proud to meet a bunch of new people and tackle new challenges that we were not previously comfortable with.
## What we learned
We honed our skills in React, TypeScript, Flask, and Python, especially in how to make these technologies work together. We also learned how to containerize and deploy applications using Docker and Docker Compose, as well as how to use Defang for cloud deployment.
## What's next for Harvard Burger
Moving forward, we want to add a business-facing interface, where restaurant staff would be able to view and fulfill customer orders. There will also be individual kiosk devices to handle order inputs. These features would allow *Harvard Burger* to move from a demo to a fully functional app that restaurants could actually use. Lastly, we can sell the product by designing marketing strategies for fast food chains. | partial |
## Inspiration
In a world where people often skim and hate reading long documents. We wanted to solve the problem of people signing the documents, business contracts, etc in a hurry. We want to create an error proof and efficient process of contract signing.
## What it does
Our product summarizes the content of documents into a few key lines which will give an overview to the user about the contract. This allows the reader to understand the summary and main points behind the text. Then using DocuSign's API, the user can share the contract to be signed by the recipient. The recipient of contract will also get the summarized text through the API of DocuSign through his email. After that the recipient will sign the contract and the sender will receive notifications on when this is done. DocuSign's main purpose is signing, but our team was able to utilize it's other features such as end to end notification on where the document is on this signing process.
## How I built it
Frontend - HTML, CSS, Bootstrap
Backend - Django Web Development Framework, DocuSign API, Python. Our highly efficient backend was written in Python with 90%+ accuracy in summarizing the main points of a document. We used machine learning and a ranking scheme to create this.
## Challenges I ran into
1. Integrating the API and text summarizer to our website.
2. Some problems with libraries while uploading the project to heroku platform for hosting the website.
3. Dividing the work in team members. We were all new and met at Hack MIT.
## Accomplishments that I'm proud of
1. Completing the project and using DocuSign API Successfully. The process is very smooth and can be used for a legal secretary.
2. Building something with real use and has an impact.
## What I learned
1. Using DocuSign API and learning the cool features behind it.
2. Working with new people in a short span of time, the DocuSign mentors help us a ton!
3. Don't give up, try until the goal is reached.
## What's next for Sign-Off
1. Sentimental analysis that will be transferred as subject (like Urgent, Not-Urgent, etc.)
2. Partnership with DocuSign or an agreement to turn Sign-Off into a startup. We ready to ship this into the real world and want to visit the DocuSign HQ and talk merger!
3. Using neural network methods like LSTM, CNN, etc for text summarization. Our algorithm is 90% efficient but we want to improve this even further!
4. Blockchain technology for vast network. | ## Inspiration
With the excitement of blockchain and the ever growing concerns regarding privacy, we wanted to disrupt one of the largest technology standards yet: Email. Email accounts are mostly centralized and contain highly valuable data, making one small breach, or corrupt act can serious jeopardize millions of people. The solution, lies with the blockchain. Providing encryption and anonymity, with no chance of anyone but you reading your email.
Our technology is named after Soteria, the goddess of safety and salvation, deliverance, and preservation from harm, which we believe perfectly represents our goals and aspirations with this project.
## What it does
First off, is the blockchain and message protocol. Similar to PGP protocol it offers \_ security \_, and \_ anonymity \_, while also **ensuring that messages can never be lost**. On top of that, we built a messenger application loaded with security features, such as our facial recognition access option. The only way to communicate with others is by sharing your 'address' with each other through a convenient QRCode system. This prevents anyone from obtaining a way to contact you without your **full discretion**, goodbye spam/scam email.
## How we built it
First, we built the block chain with a simple Python Flask API interface. The overall protocol is simple and can be built upon by many applications. Next, and all the remained was making an application to take advantage of the block chain. To do so, we built a React-Native mobile messenger app, with quick testing though Expo. The app features key and address generation, which then can be shared through QR codes so we implemented a scan and be scanned flow for engaging in communications, a fully consensual agreement, so that not anyone can message anyone. We then added an extra layer of security by harnessing Microsoft Azures Face API cognitive services with facial recognition. So every time the user opens the app they must scan their face for access, ensuring only the owner can view his messages, if they so desire.
## Challenges we ran into
Our biggest challenge came from the encryption/decryption process that we had to integrate into our mobile application. Since our platform was react native, running testing instances through Expo, we ran into many specific libraries which were not yet supported by the combination of Expo and React. Learning about cryptography and standard practices also played a major role and challenge as total security is hard to find.
## Accomplishments that we're proud of
We are really proud of our blockchain for its simplicity, while taking on a huge challenge. We also really like all the features we managed to pack into our app. None of us had too much React experience but we think we managed to accomplish a lot given the time. We also all came out as good friends still, which is a big plus when we all really like to be right :)
## What we learned
Some of us learned our appreciation for React Native, while some learned the opposite. On top of that we learned so much about security, and cryptography, and furthered our beliefs in the power of decentralization.
## What's next for The Soteria Network
Once we have our main application built we plan to start working on the tokens and distribution. With a bit more work and adoption we will find ourselves in a very possible position to pursue an ICO. This would then enable us to further develop and enhance our protocol and messaging app. We see lots of potential in our creation and believe privacy and consensual communication is an essential factor in our ever increasingly social networking world. | ## Inspiration
The project was inspired by looking at the challenges that artists face when dealing with traditional record labels and distributors. Artists often have to give up ownership of their music, lose creative control, and receive only a small fraction of the revenue generated from streams. Record labels and intermediaries take the bulk of the earnings, leaving the artists with limited financial security. Being a music producer and a DJ myself, I really wanted to make a product with potential to shake up this entire industry for the better. The music artists spend a lot of time creating high quality music and they deserve to be paid for it much more than they are right now.
## What it does
Blockify lets artists harness the power of smart contracts by attaching them to their music while uploading it and automating the process of royalty payments which is currently a very time consuming process. Our primary goal is to remove the record labels and distributors from the industry since they they take a majority of the revenue which the artists generate from their streams for the hard work which they do. By using a decentralized network to manage royalties and payments, there won't be any disputes regarding missed or delayed payments, and artists will have a clear understanding of how much money they are making from their streams since they will be dealing with the streaming services directly. This would allow artists to have full ownership over their work and receive a fair compensation from streams which is currently far from the reality.
## How we built it
BlockChain: We used the Sui blockchain for its scalability and low transaction costs. Smart contracts were written in Move, the programming language of Sui, to automate royalty distribution.
Spotify API: We integrated Spotify's API to track streams in real time and trigger royalty payments.
Wallet Integration: Sui wallets were integrated to enable direct payments to artists, with real-time updates on royalties as songs are streamed.
Frontend: A user-friendly web interface was built using React to allow artists to connect their wallets, and track their earnings. The frontend interacts with the smart contracts via the Sui SDK.
## Challenges we ran into
The most difficult challenge we faced was the Smart Contract Development using the Move language. Unlike commonly known language like Ethereum, Move is relatively new and specifically designed to handle asset management. Another challenge was trying to connect the smart wallets in the application and transferring money to the artist whenever a song was streamed, but thankfully the mentors from the Sui team were really helpful and guided us in the right path.
## Accomplishments that we're proud of
This was our first time working with blockchain, and me and my teammate were really proud of what we were able to achieve over the two days. We worked on creating smart contracts and even though getting started was the hardest part but we were able to complete it and learnt some great stuff along the way. My teammate had previously worked with React but I had zero experience with JavaScript, since I mostly work with other languages, but we did the entire project in Node and React and I was able to learn a lot of the concepts in such a less time which I am very proud of myself for.
## What we learned
We learned a lot about Blockchain technology and how can we use it to apply it to the real-world problems. One of the most significant lessons we learned was how smart contracts can be used to automate complex processes like royalty payments. We saw how blockchain provides an immutable and auditable record of every transaction, ensuring that every stream, payment, and contract interaction is permanently recorded and visible to all parties involved. Learning more and more about this technology everyday just makes me realize how much potential it holds and is certainly one aspect of technology which would rule the future. It is already being used in so many aspects of life and we are still discovering the surface.
## What's next for Blockify
We plan to add more features, such as NFTs for exclusive content or fan engagement, allowing artists to create new revenue streams beyond streaming. There have been some real-life examples of artists selling NFT's to their fans and earning millions from it, so we would like to tap into that industry as well. Our next step would be to collaborate with other streaming services like Apple Music and eliminate record labels to the best of our abilities. | partial |
## Inspiration
Music has become a crucial part of people's lives, and they want customized playlists to fit their mood and surroundings. This is especially true for drivers who use music entertain themselves on their journey and to stay alert.
Based off of personal experience and feedback from our peers, we realized that many drivers are dissatisfied with the repetitive selection of songs on the radio and also on the regular Spotify playlists. That's why we were inspired to create something that could tackle this problem in a creative manner.
## What It Does
Music Map curates customized playlists based on factors such as time of day, weather, driving speed, and locale, creating a set of songs that fit the drive perfectly. The songs are selected from a variety of pre-existing Spotify playlists that match the users tastes and weighted based on the driving conditions to create a unique experience each time. This allows Music Map to introduce new music to the user while staying true to their own tastes.
## How we built it
HTML/CSS, Node.js, Esri, Spotify, Google Maps APIs
## Challenges we ran into
Spotify API was challenging to work with, especially authentication.
Overlaying our own UI over the map was also a challenge.
## Accomplishments that we're proud of
Learning a lot and having something to show for it
The clean and aesthetic UI
## What we learned
For the majority of the team, this was our first Hackathon and we learned how to work together well and distribute the workload under time pressure, playing to each of our strengths. We also learned a lot about the various APIs and how to fit different pieces of code together.
## What's next for Music Map
We will be incorporating more factors into the curation of the playlists and gathering more data on the users' preferences. | ## Inspiration
Music is a universal language, and we recognized Spotify wrapped to be one of the most anticipated times of the year. Realizing that people have an interest in learning about their own music taste, we created ***verses*** to not only allow people to quiz themselves on their musical interests, but also quiz their friends to see who knows them best.
## What it does
A quiz that challenges you to answer questions about your Spotify listening habits, allowing you to share with friends and have them guess your top songs/artists by answering questions. Creates a leaderboard of your friends who have taken the quiz, ranking them by the scores they obtained on your quiz.
## How we built it
We built the project using react.js, HTML, and CSS. We used the Spotify API to get data on the user's listening history, top songs, and top artists as well as enable the user to log into ***verses*** with their Spotify. JSON was used for user data persistence and Figma was used as the primary UX/UI design tool.
## Challenges we ran into
Implementing the Spotify API was a challenge as we had no previous experience with it. We had to seek out mentors for help in order to get it working. Designing user-friendly UI was also a challenge.
## Accomplishments that we're proud of
We took a while to get the backend working so only had a limited amount of time to work on the frontend, but managed to get it very close to our original Figma prototype.
## What we learned
We learned more about implementing APIs and making mobile-friendly applications.
## What's next for verses
So far, we have implemented ***verses*** with Spotify API. In the future, we hope to link it to more musical platforms such as Apple Music. We also hope to create a leaderboard for players' friends to see which one of their friends can answer the most questions about their music taste correctly. | ## Inspiration
Our idea was inspired by our group's shared interest in musical composition, as well as our interests in AI models and their capabilites. The concept that inspired our project was: "*What if life had a soundtrack?*"
## What it does
AutOST generates and produces a constant stream of original live music designed to automatically adjust to and accompany any real-life scenario.
## How we built it
We built our project in python, using the Mido library to send note signals directly to FL studio, allowing us to play constant audio without a need to export to a file. The whole program is linked up to a live video feed that uses Groq AI's computer vision api to determine the mood of an image and adjust the audio accordingly.
## Challenges we ran into
The main challenge we faced in this project is the struggle that came with making the generated music not only sound coherent and good, but also have the capability to adjust according to parameters. Turns out that generating music mathematically is more difficult than it seems.
## Accomplishments that we're proud of
We're proud of the fact that our program's music sounds somewhat decent, and also that we were able to brainstorm a concept that (to our knowlege) has not really seen much experimentation.
## What we learned
We learned that music generation is much harder than we initially thought, and that AIs aren't all that great at understanding human emotions.
## What's next for AutOST
If we continue work on this project post-hackathon, the next steps would be to expand its capabilities for recieving input, allowing it to do all sorts of amazing things such as creating a dynamic soundtrack for video games, or integrating with smart headphones to create tailored background music that would allow users to feel as though they are living inside a movie. | partial |
# 🤖🖌️ [VizArt Computer Vision Drawing Platform](https://vizart.tech)
Create and share your artwork with the world using VizArt - a simple yet powerful air drawing platform.
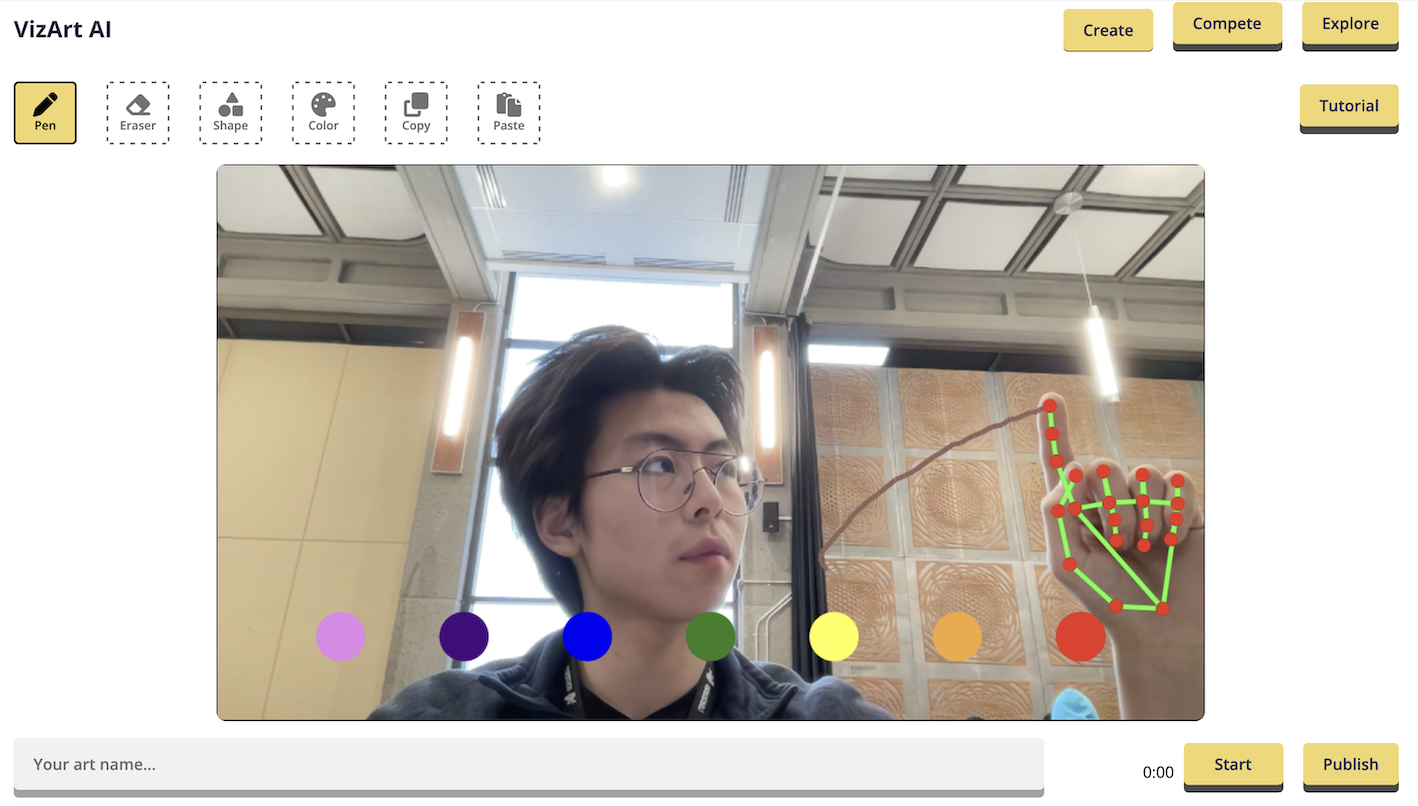
## 💫 Inspiration
>
> "Art is the signature of civilizations." - Beverly Sills
>
>
>
Art is a gateway to creative expression. With [VizArt](https://vizart.tech/create), we are pushing the boundaries of what's possible with computer vision and enabling a new level of artistic expression. ***We envision a world where people can interact with both the physical and digital realms in creative ways.***
We started by pushing the limits of what's possible with customizable deep learning, streaming media, and AR technologies. With VizArt, you can draw in art, interact with the real world digitally, and share your creations with your friends!
>
> "Art is the reflection of life, and life is the reflection of art." - Unknow
>
>
>
Air writing is made possible with hand gestures, such as a pen gesture to draw and an eraser gesture to erase lines. With VizArt, you can turn your ideas into reality by sketching in the air.
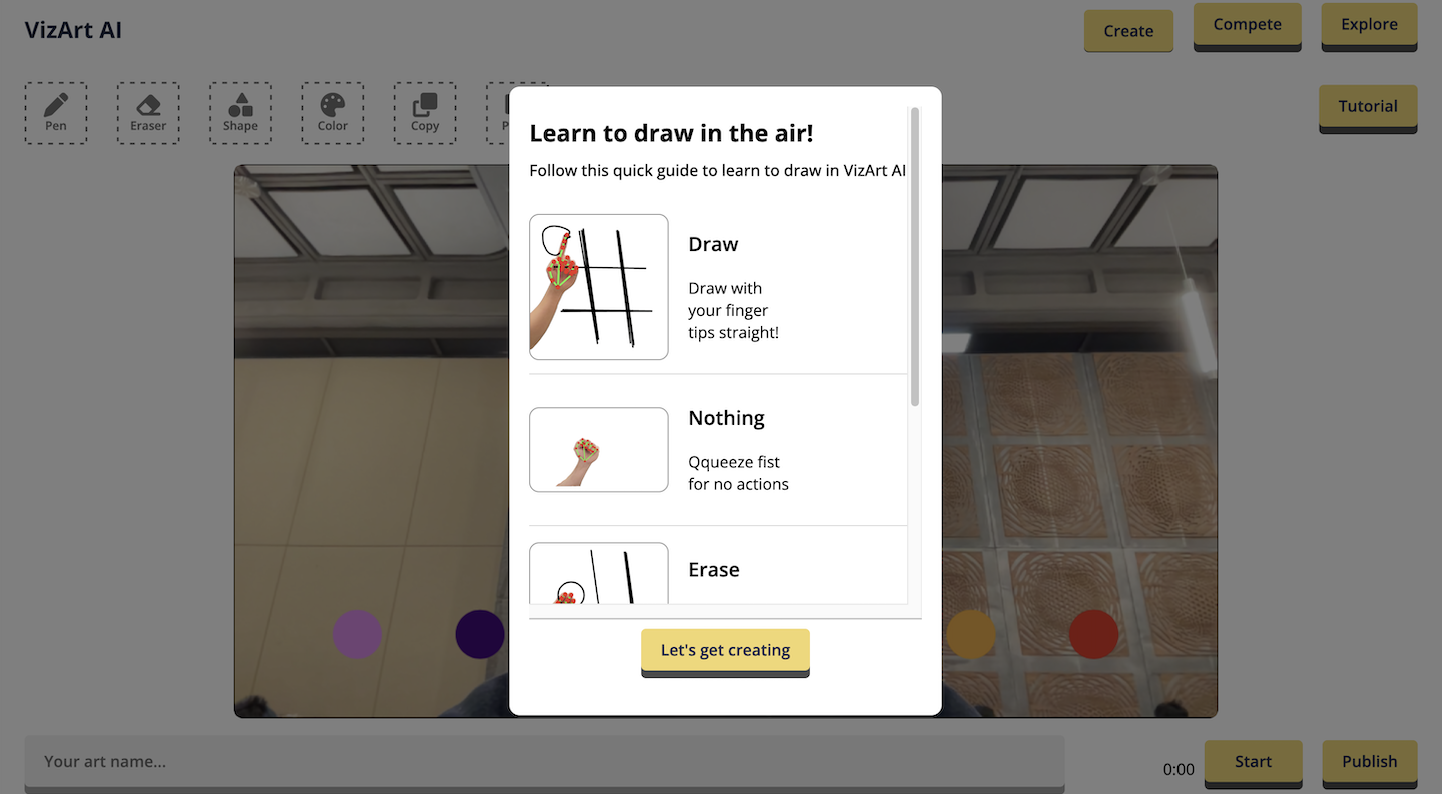
Our computer vision algorithm enables you to interact with the world using a color picker gesture and a snipping tool to manipulate real-world objects.
>
> "Art is not what you see, but what you make others see." - Claude Monet
>
>
>
The features I listed above are great! But what's the point of creating something if you can't share it with the world? That's why we've built a platform for you to showcase your art. You'll be able to record and share your drawings with friends.
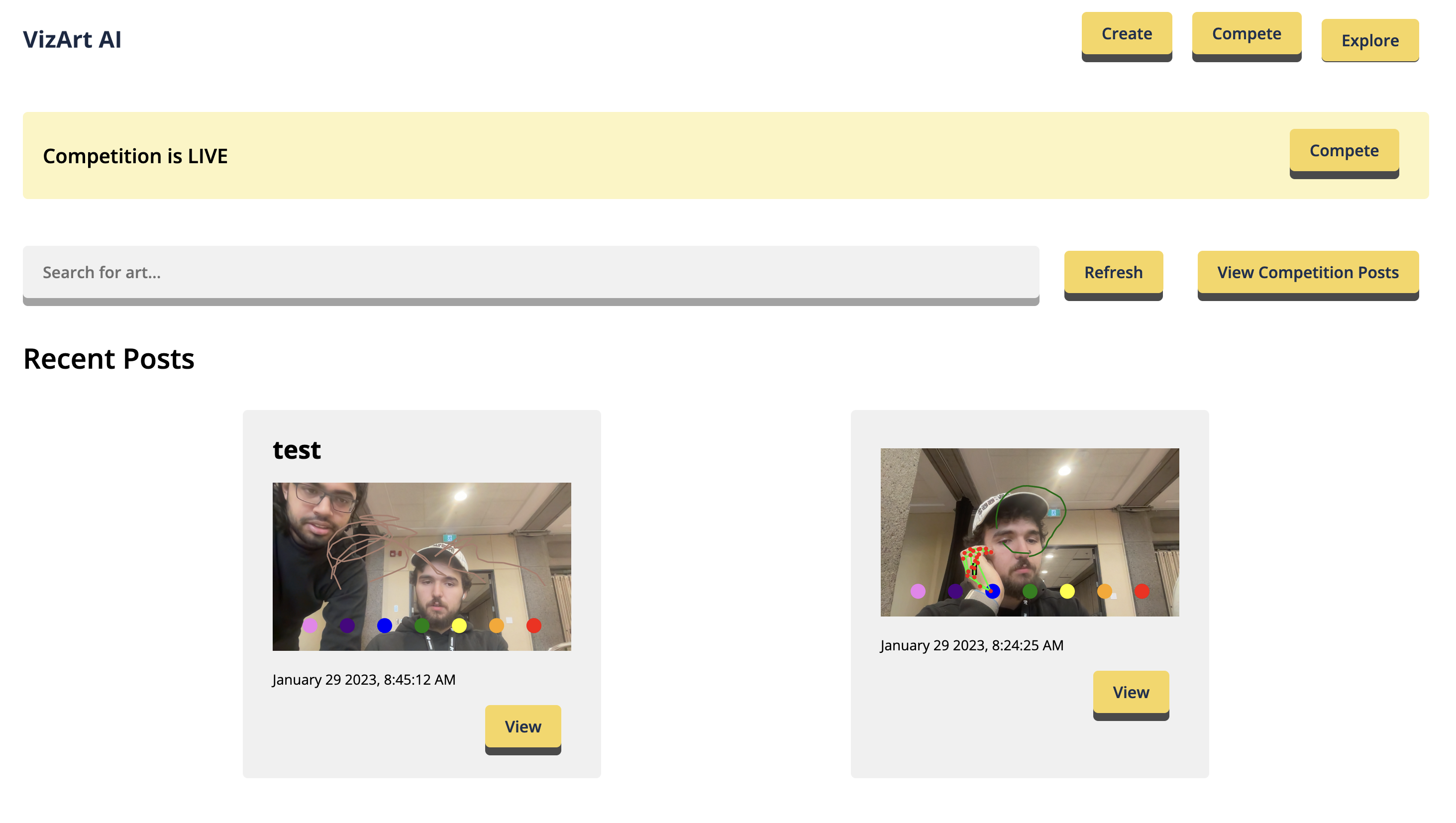
I hope you will enjoy using VizArt and share it with your friends. Remember: Make good gifts, Make good art.
# ❤️ Use Cases
### Drawing Competition/Game
VizArt can be used to host a fun and interactive drawing competition or game. Players can challenge each other to create the best masterpiece, using the computer vision features such as the color picker and eraser.
### Whiteboard Replacement
VizArt is a great alternative to traditional whiteboards. It can be used in classrooms and offices to present ideas, collaborate with others, and make annotations. Its computer vision features make drawing and erasing easier.
### People with Disabilities
VizArt enables people with disabilities to express their creativity. Its computer vision capabilities facilitate drawing, erasing, and annotating without the need for physical tools or contact.
### Strategy Games
VizArt can be used to create and play strategy games with friends. Players can draw their own boards and pieces, and then use the computer vision features to move them around the board. This allows for a more interactive and engaging experience than traditional board games.
### Remote Collaboration
With VizArt, teams can collaborate remotely and in real-time. The platform is equipped with features such as the color picker, eraser, and snipping tool, making it easy to interact with the environment. It also has a sharing platform where users can record and share their drawings with anyone. This makes VizArt a great tool for remote collaboration and creativity.
# 👋 Gestures Tutorial
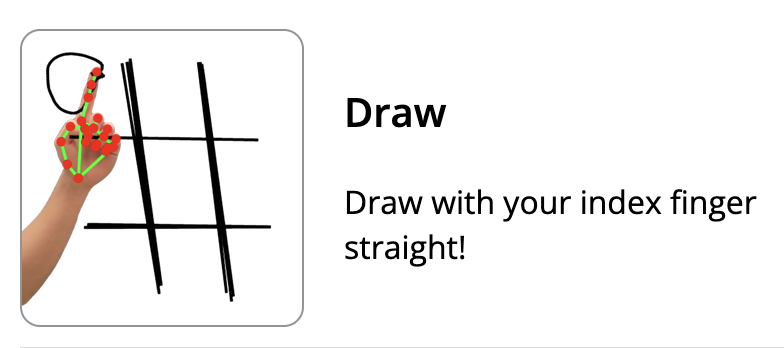

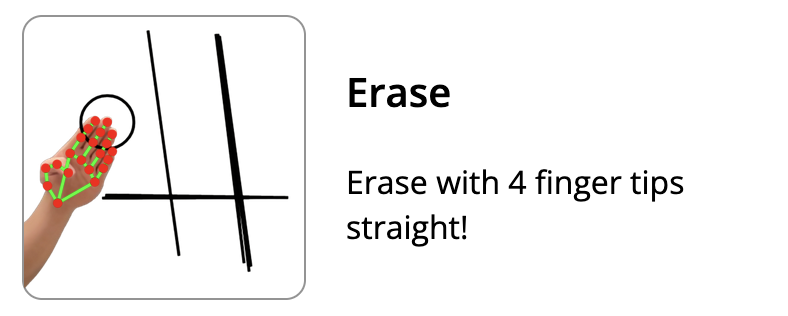

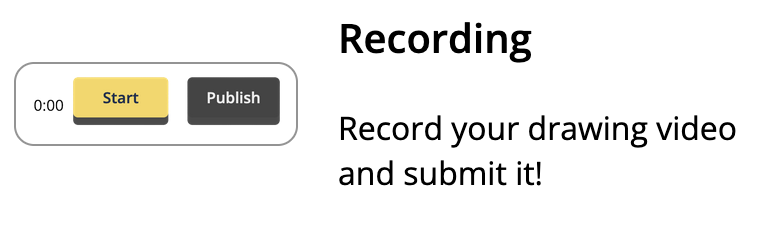
# ⚒️ Engineering
Ah, this is where even more fun begins!
## Stack
### Frontend
We designed the frontend with Figma and after a few iterations, we had an initial design to begin working with. The frontend was made with React and Typescript and styled with Sass.
### Backend
We wrote the backend in Flask. To implement uploading videos along with their thumbnails we simply use a filesystem database.
## Computer Vision AI
We use MediaPipe to grab the coordinates of the joints and upload images. WIth the coordinates, we plot with CanvasRenderingContext2D on the canvas, where we use algorithms and vector calculations to determinate the gesture. Then, for image generation, we use the DeepAI open source library.
# Experimentation
We were using generative AI to generate images, however we ran out of time.
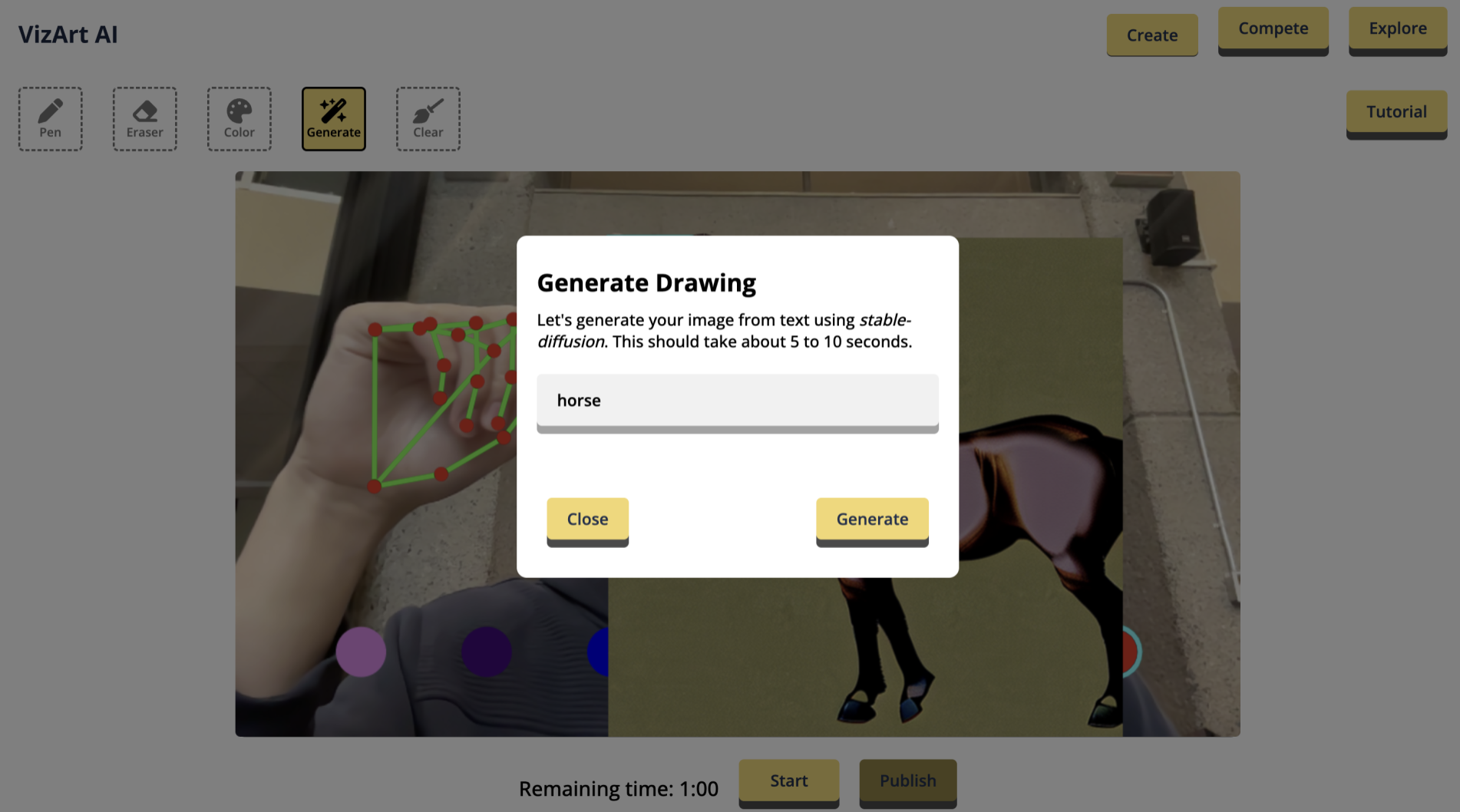
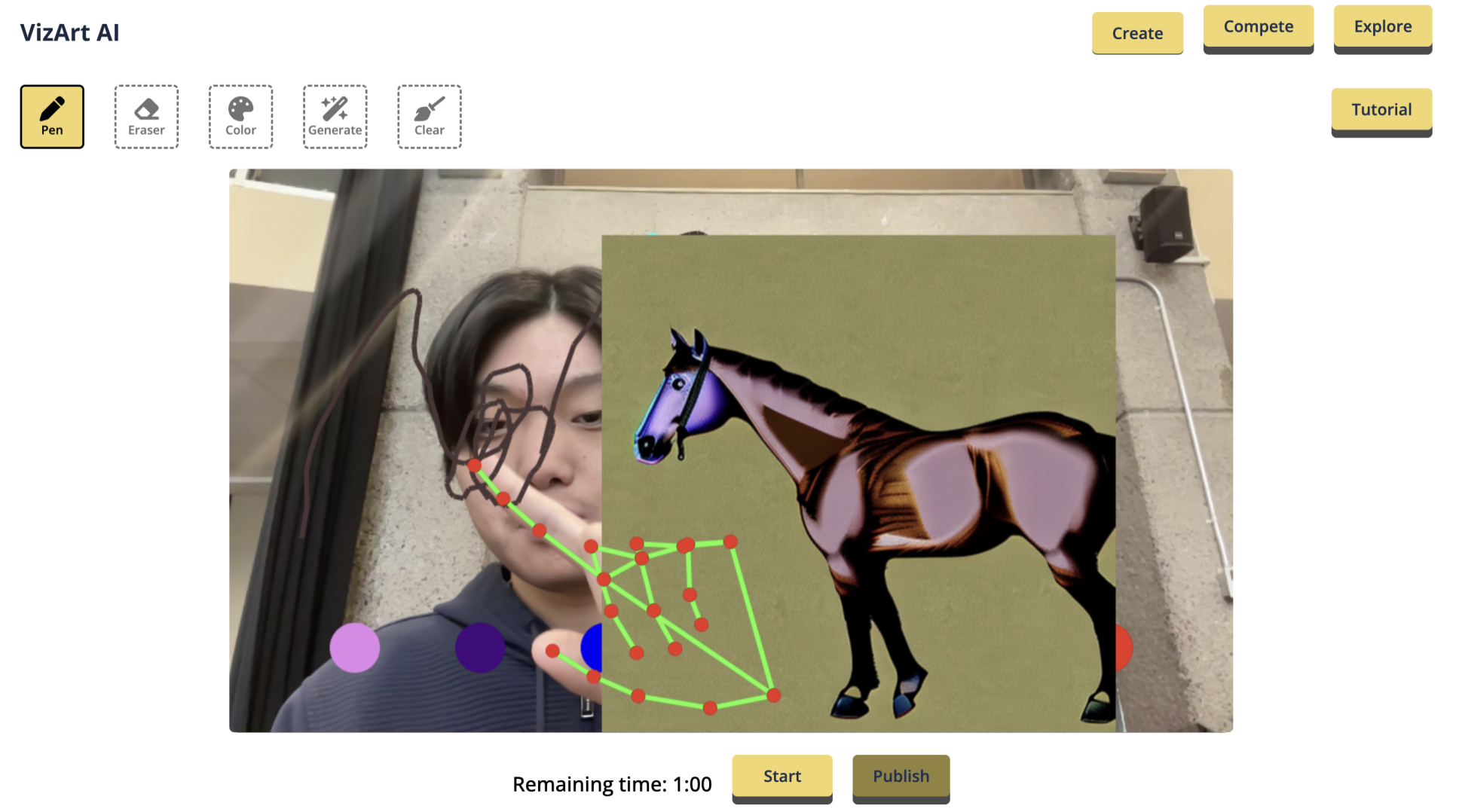
# 👨💻 Team (”The Sprint Team”)
@Sheheryar Pavaz
@Anton Otaner
@Jingxiang Mo
@Tommy He | ## Inspiration
**Machine learning** is a powerful tool for automating tasks that are not scalable at the human level. However, when deciding on things that can critically affect people's lives, it is important that our models do not learn biases. [Check out this article about Amazon's automated recruiting tool which learned bias against women.](https://www.reuters.com/article/us-amazon-com-jobs-automation-insight/amazon-scraps-secret-ai-recruiting-tool-that-showed-bias-against-women-idUSKCN1MK08G?fbclid=IwAR2OXqoIGr4chOrU-P33z1uwdhAY2kBYUEyaiLPNQhDBVfE7O-GEE5FFnJM) However, to completely reject the usefulness of machine learning algorithms to help us automate tasks is extreme. **Fairness** is becoming one of the most popular research topics in machine learning in recent years, and we decided to apply these recent results to build an automated recruiting tool which enforces fairness.
## Problem
Suppose we want to learn a machine learning algorithm that automatically determines whether job candidates should advance to the interview stage using factors such as GPA, school, and work experience, and that we have data from which past candidates received interviews. However, what if in the past, women were less likely to receive an interview than men, all other factors being equal, and certain predictors are correlated with the candidate's gender? Despite having biased data, we do not want our machine learning algorithm to learn these biases. This is where the concept of **fairness** comes in.
Promoting fairness has been studied in other contexts such as predicting which individuals get credit loans, crime recidivism, and healthcare management. Here, we focus on gender diversity in recruiting.
## What is fairness?
There are numerous possible metrics for fairness in the machine learning literature. In this setting, we consider fairness to be measured by the average difference in false positive rate and true positive rate (**average odds difference**) for unprivileged and privileged groups (in this case, women and men, respectively). High values for this metric indicates that the model is statistically more likely to wrongly reject promising candidates from the underprivileged group.
## What our app does
**jobFAIR** is a web application that helps human resources personnel keep track of and visualize job candidate information and provide interview recommendations by training a machine learning algorithm on past interview data. There is a side-by-side comparison between training the model before and after applying a *reweighing algorithm* as a preprocessing step to enforce fairness.
### Reweighing Algorithm
If the data is unbiased, we would think that the probability of being accepted and the probability of being a woman would be independent (so the product of the two probabilities). By carefully choosing weights for each example, we can de-bias the data without having to change any of the labels. We determine the actual probability of being a woman and being accepted, then set the weight (for the woman + accepted category) as expected/actual probability. In other words, if the actual data has a much smaller probability than expected, examples from this category are given a higher weight (>1). Otherwise, they are given a lower weight. This formula is applied for the other 3 out of 4 combinations of gender x acceptance. Then the reweighed sample is used for training.
## How we built it
We trained two classifiers on the same bank of resumes, one with fairness constraints and the other without. We used IBM's [AIF360](https://github.com/IBM/AIF360) library to train the fair classifier. Both classifiers use the **sklearn** Python library for machine learning models. We run a Python **Django** server on an AWS EC2 instance. The machine learning model is loaded into the server from the filesystem on prediction time, classified, and then the results are sent via a callback to the frontend, which displays the metrics for an unfair and a fair classifier.
## Challenges we ran into
Training and choosing models with appropriate fairness constraints. After reading relevant literature and experimenting, we chose the reweighing algorithm ([Kamiran and Calders 2012](https://core.ac.uk/download/pdf/81728147.pdf?fbclid=IwAR3P1SFgtml7w0VNQWRf_MK3BVk8WyjOqiZBdgmScO8FjXkRkP9w1RFArfw)) for fairness, logistic regression for the classifier, and average odds difference for the fairness metric.
## Accomplishments that we're proud of
We are proud that we saw tangible differences in the fairness metrics of the unmodified classifier and the fair one, while retaining the same level of prediction accuracy. We also found a specific example of when the unmodified classifier would reject a highly qualified female candidate, whereas the fair classifier accepts her.
## What we learned
Machine learning can be made socially aware; applying fairness constraints helps mitigate discrimination and promote diversity in important contexts.
## What's next for jobFAIR
Hopefully we can make the machine learning more transparent to those without a technical background, such as showing which features are the most important for prediction. There is also room to incorporate more fairness algorithms and metrics. | ## Inspiration
With the emergence of AI generation technology such as style-gan, mid-journey, and DALL-E, our team decided to focus on a project that would explore the possibilities of such technology in a cool and interactive way. Meet DrawBot, an AI-powered image generation robot that draws whatever masterpiece you have in mind onto physical paper. (This is also our team’s first hardware hack!)
## What it does
Whenever you have a masterpiece in mind but don’t have the artistic talent for it, simply narrate your idea into our frontend app and we’ll create your artwork for you! This feat was accomplished by utilizing AssemblyAI for speech-to-text input, Stable Diffusion for image generation, and a gantry system to bring your ideas to life.
## How we built it
*Getting User Input:* Speech-to-Text with AssemblyAI, Web App with Express.js
DrawBot first creates a transcription of speech input using AssemblyAI’s real-time speech-to-text API. Our web app allows the user to record their desired image prompt, then automatically uploads and transcribes their speech using AssemblyAI. It then sends the final formatted image prompt to be used with Stable Diffusion, along with important keywords to ensure that the generated image would work well with the rest of our pipeline.
*Generating Custom Image:* AI Image Generation with Stable Diffusion
After receiving the prompt from the user, a customized masterpiece is generated using the AI image generation tool Stable Diffusion.
*Processing User Input:* Cortex Image Processing
After generating the image via Stable Diffusion, it is sent to our Raspberry Pi cortex for processing. The image is then resized into the proper format, cleaned, and processed using the Canny Edge Detection algorithm. Then, after translating the bitmap image into a vector format, the cortex interprets the Bezier Curves into physical coordinates to be drawn on paper.
*Drawing Final Result:* Gantry System
* Data is sent to the Raspberry Pi, the central control system of the gantry system
* Implement an HBOT belt system, this allows for accurate control of the gantry head in 2-space while keeping both stepper motors stationary
* A third motor is used for the activation of a drawing utensil, only drawing lines where it needs to
*Gantry with HBOT layout:*
* To bring the artwork to life, we created an HBOT gantry system to move and manipulate a marker over a whiteboard
* By efficiently utilizing our pulleys and motors, we were able to manipulate the gantry anywhere in 2D space using just 2 stepper motors
* The HBOT layout utilizes fewer stepper motors and keeps them all stationary, which reduces the weight of the system, thereby increasing efficiency
* Various joints, structural components, and pulley systems were modeled with Fusion 360 and 3D printed in the University of Waterloo’s Rapid Prototyping Centre
Laser cutting:
* Due to limited time for 3D printing, we utilized AutoCAD to design and create .dwg designs for the main assembly of our gantry system
* Our team learned AutoCAD to complete this project, having zero previous experience with the tool
Fusion360 & 3D printing:
* Various aspects of our hack were 3D printed: joints, gantry blocks, marker arm, etc.
## Challenges we ran into
When creating our gantry design, we overestimated the torque our stepper motors could produce. This means that while our design can successfully move in 2D space, the movement is inaccurate, and the assembly tends to get stuck at specific points. Alternatively, this could be interpreted as too much friction rather than weak motors.
We had trouble sourcing materials for this project and used wooden dowels as pseudo pulleys. Unfortunately, these dowels cause significant friction and create too much resistance for our motors to handle.
## Accomplishments that we're proud of
* Hack the North 2022 was the first hardware hack and in-person hack for all of our team members. With new experiences comes new challenges, and we are proud to see how our team came together to create an awesome robot
* Controlling motors using software on a Raspberry Pi
* Successfully using AutoCAD to laser cut the main chassis of our gantry with no prior experience
* Building an awesome web app
## What we learned
* The importance of preparation can't be stressed enough. The acquisition of hardware should've been done beforehand. This also includes 3D modeling and printing all necessary parts
* How SVGs work and the mathematics behind Bezier Curves and Canny Edge Detection
* How to utilize AutoCAD for laser cutting
* Fusion360
* Express.js
* Using AssemblyAI’s APIs
## What's next for DrawBot
Our principal next step is to complete our vision by bringing everything together, iterating on our existing design, and adding new features. In the future, we hope to support multiple colors and drawing styles to create a fully-fledged masterpiece. In addition, we hope to work on larger pieces of paper to create impressive artwork on a larger scale. | winning |
## Inspiration
We originally wanted to build a large robot that could move on it's own until we realized that we could do the same thing but with multiple smaller bots, which could also make tasks more efficient with the same amount of resources.
## What it does
It moves around and finds trash and marks them on a map. It also stores images for later use.
## How we built it
We used an arduino and two servos for each bot, with cardboard for wheels and rubber bands around for additional traction. The bots are primarily held together by duct tape. The large of the three bots has an additional front wheel for stabilizing the phone on it.
## Challenges we ran into
When we got ahold of the arduinos we realized that none of them had wifi shields, none of the servos were continuous, and we were missing staple tools. It took a lot of creative approaches and scrapping ideas before we found the best way to approach the problems.
## Accomplishments that we're proud of
With limited resources, we managed to build several functioning robots.
## What we learned
There is no such thing as too much duct tape if you are using duct tape as your primary building material in the first place.
## What's next for kero23
We originally planned to autodriving and image recognition, as well as using imaging to keep track the location of the other bots for improved coordination. Overall, we aim to reduce the amount of manual interactions from the user. | ## intelliTrash
**Inspiration and What it does**
intelliTrash is an automated waste machine which uses vision AI to be able to determine, and sort trash into either recycling, compost, or garbage. This idea was hatched when a teammate found out that a family friend had been disposing of used diapers in recycling, after mistaking a symbol on a recycling poster for a diaper. Another teammate then suggested we use Google's Vision API to be able to detect and categorize certain types of trash. Eventually we came to the conclusion that incorporating automated parts, vision AI, and IoT would allow us to bring our project to life!
**How we built it**
For the hardware component of our hack, we used various GPIO pins on the Raspberry Pi to read out to the push button, and two servos, while using the built in attachment for the Pi Cam. We also built a physical system out of wood, which allows intelliTrash to be automated, and deliver the trash into it's designated bin. After the Pi Cam takes an image, and we used Google Cloud's Vision API to identify what the waste is and where it belongs. Afterwards, our program will rotate the servo motors. Each specific type of rubbish corresponds to a specific angle which the motors turn to. This allows the system to "sort" the trash into Recycling, Compost or Garbage.
**Challenges we ran into**
We learned quite a few things on this journey. Initially, our team struggled trying to connect the Pi to the "UofT" network, as it is considered a hidden network- meaning the Pi doesn't seem to like it. Instead, we ended up using a team member's personal LTE network to hotspot the Pi.
We also had initially planned a conveyor system to sort the trash, as opposed to the "rotating" system we have now. We learned that the servos would not be able to support the weight of trash put onto a conveyor. Our team then ventured out, and bought two DC motors. After working for a while, we realized that the DC motors were also incredibly weak. We then needed to change the system in a way, which does not conflict with the physical capabilities of of the servo motors- which is how our "rotating" system was born!
**Accomplishments that we are proud of**
Our team feels incredibly accomplished for being able to work together through these constraints, and be able to create a project which we are all incredibly passionate about in such a limited timeframe. We are also proud that we were all able to come from such different backgrounds and use that as a motive to create a project which encompasses all of our strengths, but also taught us how to work around our weaknesses!
**What's next for intelliTrash**
Next we want to be able to identify the type of plastics to be able to sort it into even more categories such as Plastics, Mixed Paper, Coffee Cups and more. Additionally we would like to use the city location to adhere to their waste rules. | ## Inspiration
We as a team shared the same interest in knowing more about Machine Learning and its applications. upon looking at the challenges available, we were immediately drawn to the innovation factory and their challenges, and thought of potential projects revolving around that category. We started brainstorming, and went through over a dozen design ideas as to how to implement a solution related to smart cities. By looking at the different information received from the camera data, we landed on the idea of requiring the raw footage itself and using it to look for what we would call a distress signal, in case anyone felt unsafe in their current area.
## What it does
We have set up a signal that if done in front of the camera, a machine learning algorithm would be able to detect the signal and notify authorities that maybe they should check out this location, for the possibility of catching a potentially suspicious suspect or even being present to keep civilians safe.
## How we built it
First, we collected data off the innovation factory API, and inspected the code carefully to get to know what each part does. After putting pieces together, we were able to extract a video footage of the nearest camera to us. A member of our team ventured off in search of the camera itself to collect different kinds of poses to later be used in training our machine learning module. Eventually, due to compiling issues, we had to scrap the training algorithm we made and went for a similarly pre-trained algorithm to accomplish the basics of our project.
## Challenges we ran into
Using the Innovation Factory API, the fact that the cameras are located very far away, the machine learning algorithms unfortunately being an older version and would not compile with our code, and finally the frame rate on the playback of the footage when running the algorithm through it.
## Accomplishments that we are proud of
Ari: Being able to go above and beyond what I learned in school to create a cool project
Donya: Getting to know the basics of how machine learning works
Alok: How to deal with unexpected challenges and look at it as a positive change
Sudhanshu: The interesting scenario of posing in front of a camera while being directed by people recording me from a mile away.
## What I learned
Machine learning basics, Postman, working on different ways to maximize playback time on the footage, and many more major and/or minor things we were able to accomplish this hackathon all with either none or incomplete information.
## What's next for Smart City SOS
hopefully working with innovation factory to grow our project as well as inspiring individuals with similar passion or desire to create a change. | losing |
## Inspiration
Wanted to combine passion for Canadian wildlife, biological research and conservational efforts to make a tool that can help researchers and nature enthusiasts alike!
## What it does
Provides platform for nature enthusiasts to aid in conservational efforts using just their smartphone camera. Natural.ly provides a series of machine-learning libraries to assist users in identifying the animals before their eyes. Users use their smartphone to snap pictures of wildlife they spot; findings are then automatically identified and catalogued, or if necessary overriden by the user for a further increase in collection accuracy. Spotted animals can be catalogued by users which contribute to the overall collection of local habitat knowledge generated by the app.
## How we built it
Developed a series of custom AI training models using Clarifai's API to form calculated predictions of the photographed animal. We used Android's XML layout to form intuitive frontends, seamless Maps API integration to add a geographical basis to spottings, and finally a way to save your contributions on a Firebase server.
## Challenges we ran into
Interacting with Clarifai's Java API was helpful yet challenging due to our team needing an asynchronous workaround. Handling Android permissions was also a challenge due to the ever-increasing prompts given to the user.
## Accomplishments that we're proud of
* Successfully implementing machine-learning to identify animals
* Learned about the value of asynchronous vs. synchronous methods
* Happy to contribute to conserving Canadian wildlife
## What we learned
Learned the value of taking time to write down team goals, planning/allocating workloads and not being afraid to ask for help from coding experts
## What's next for Natural.ly
There's never too big a training model! | ## Inspiration
As tech enthusiasts, we constantly faced the dilemma: ***What to wear?*** and ***Do I look on point?*** These questions resonate with many teenagers who, influenced by celebrities and peers with sharp fashion senses, may struggle with self-doubt. Moreover, staying trendy doesn't come cheap, and scouring for the best deals on the latest fashion is a challenge in itself.
And buying isn't simple - **would it look good on me?** is always a question we have.
That's where SnapShop comes in—an intelligent assistant designed to address your fashion queries.
Our personal experiences, like attending hackathons unprepared for the weather or dress code, highlighted the need for a solution. We recall a time at Calhacks where our lack of preparation led us to seek warmth sleeping near a bathroom (and getting woken up by the security)! SnapShop aims to prevent such fashion faux pas by providing weather-appropriate and event-specific style advice, ensuring you feel confident and appropriately dressed for any occasion, while keeping the bills bearable.
## What it does
#### Click an image to Shop:
SnapShop recognizes all the fashion items in the image and tells you what YOU need to buy, to get exactly the same look at the best deals.
Basicaly, image -> best shopping links
[demo link]
#### Ask a query
Say you don't know much about the outfit style you want to go with, for an event
You can ask questions like ***"I'm going to Mumbai, India for a wedding. It's a Gujarati family. I don't want to overdress. What should I wear?"***
And voila, shopwise will generate a list of ethnic wear you should consider buying.
... or **"There's a tech meetup in San Fransisco. The meetup is about AI, I don't know if I should wear formal. I'm going next week. "**\_ (Sent in November)
SnapShop recognises that San Fransisco will be really cold, and that techies usually wear plain t-shirts.
So, it recommends **semi-formal**- buying plain t-shirts and a zip-up jacket, and a pant.

Another prompt:
I'm going to mumbai in the summer, what should I wear?

#### TRY IT ON ME
Users can also try clothes on themselves!
(... Update: Disabled, too costly to run/test)
#### Explore page
On the explore page, users can easily find good deals found by other users.
## How we built it
Here's the tech stack we used:
* OpenAI's new **Vision**
* **ShopWise \* API** that we built for scraping the web to get the best prices for products
* **Flutter** for the Mobile app
* **FastAPI** for python backend
* **Redis**, hosted on Redis Cloud (As DB)
* A Cloudflare Worker as a proxy for Verbwire API
* **VerbWire** to store images on blockchain
* **Firebase** for user authentication

With this infrastructure, we still manage to get really fast response times - evern with image and web scraping, we can get perfect response in less than 30 seconds.
## Challenges we ran into
It was really difficult to implement the Vision part effectively, and get the output data in a certain format so that we can properly parse it (Since the vision API doesn't support function calls)
And ofcourse, the indexing and web search part was especially complex. Getting it to work was very, very challenging, as finding the best deals from all over the internet is a very difficult task.
## Accomplishments that we're proud of
We are really proud of making something that we would actually use in our daily lives. Finding the best deals and being fashionable is a real problem that both of us face. Also, the fact that we completed the entire thing, and got it to work, while making it look good and usable is quite the feat.
## What we learned
We learnt a lot from SnapShop. A very important thing that we realised was time management and it's importance in hackathons. Also, we realised that we didn't take pricing into consideration, and after building the try it on me feature, we realised that it was wayyy too expensive to run for us.
## What's next for SnapShop
In the future, we want to make snapshop into a full consumer product. Because we really believe in the idea, we think that monetizing the app wouldn't be that big of a challenge. | ## Inspiration
Diseases in monoculture farms can spread easily and significantly impact food security and farmers' lives. We aim to create a solution that uses computer vision for the early detection and mitigation of these diseases.
## What it does
Our project is a proof-of-concept for detecting plant diseases using leaf images. We have a raspberry pi with a camera that takes an image of the plant, processes it, and sends an image to our API, which uses a neural network to detect signs of disease in that image. Our end goal is to incorporate this technology onto a drone-based system that can automatically detect crop diseases and alert farmers of potential outbreaks.
## How we built it
The first layer of our implementation is a raspberry pi that connects to a camera to capture leaf images. The second layer is our neural network, which the raspberry pi accesses through an API deployed on Digital Ocean.
## Challenges we ran into
The first hurdle in our journey was training the neural network for disease detection. We overcame this with FastAI and using transfer learning to build our network on top of ResNet, a complicated and performant CNN. The second part of our challenge was interfacing our software with our hardware, which ranged from creating and deploying APIs to figuring out specific Arduino wirings.
## Accomplishments that we're proud of
We're proud of creating a working POC of a complicated idea that has the potential to make an actual impact on people's lives.
## What we learned
We learned about a lot of aspects of building and deploying technology, ranging from MLOps to electronics. Specifically, we explored Computer Vision, Backend Development, Deployment, and Microcontrollers (and all the things that come between).
## What's next for Plant Disease Analysis
The next stage is to incorporate our technology with drones to automate the process of image capture and processing. We aim to create a technology that can help farmers prevent disease outbreaks and push the world into a more sustainable direction. | partial |
## Inspiration
Rock
## What it does
RoCK
## How we built it
RocK
## Challenges we ran into
rOcK
## Accomplishments that we're proud of
RoCk
## What we learned
rOck
## What's next for Vivian
rocks | ## Inspiration
deez nuts
## What it does
deez nuts
## How we built it
deez nuts
## Challenges we ran into
deez nuts
## Accomplishments that we're proud of
deez nuts
## What we learned
deez nuts
## What's next for deez nuts
deez nuts | ## Inspiration
A deep and unreasonable love of xylophones
## What it does
An air xylophone right in your browser!
Play such classic songs as twinkle twinkle little star, ba ba rainbow sheep and the alphabet song or come up with the next club banger in free play.
We also added an air guitar mode where you can play any classic 4 chord song such as Wonderwall
## How we built it
We built a static website using React which utilised Posenet from TensorflowJS to track the users hand positions and translate these to specific xylophone keys.
We then extended this by creating Xylophone Hero, a fun game that lets you play your favourite tunes without requiring any physical instruments.
## Challenges we ran into
Fine tuning the machine learning model to provide a good balance of speed and accuracy
## Accomplishments that we're proud of
I can get 100% on Never Gonna Give You Up on XylophoneHero (I've practised since the video)
## What we learned
We learnt about fine tuning neural nets to achieve maximum performance for real time rendering in the browser.
## What's next for XylophoneHero
We would like to:
* Add further instruments including a ~~guitar~~ and drum set in both freeplay and hero modes
* Allow for dynamic tuning of Posenet based on individual hardware configurations
* Add new and exciting songs to Xylophone
* Add a multiplayer jam mode | losing |
## Inspiration
There is a big problem with the way we find friends. Before the age of the internet, location was a big constraint for meeting new friends, but now we are more globally connected than ever, yet our friends still seem to be local. By do we depend on this serendipitous approach? Just think about it, imagine all the people out there that could be your "optimal" friend, your best friend. And in the rare occasion that you think you have found "the one", think about the chances, slim to none. A prime example is my hackathon partner. I am from the UK, he is from South Africa. We are great friends now, but what were our chances of meeting before? Very low. Social media plays a good role in keeping up to date with current friends, but how do you make new ones?
## What it does
Diversify solves this problem by connecting you with new people that share similar interests but have extremely different stories. Simply sign up for an account, complete a rigorous yet simple form by answering questions about your interests etc, similar to Myers-Briggs tests. Our matching algorithm then matches you up with the most compatible users. You can then see all your common interests, and introduce yourself to them, starting a conversation that could possibly change your life.
But that is not all, not only do we strive for diversity, but also inclusivity. Diversify offers custom text to speech for visually impaired users, where they can simply double click on text elements to hear the audible format.
## How we built it
The app was built with Flask, MongoDB and html/css.
## Challenges we ran into
The main challenge we ran into was the team. As we were a team of 2, we had to balance more to cover a larger amount of work. We successfully managed this though, and finished the app.
## Accomplishments that we're proud of
Accomplishments that I'm proud of As a team, we knew coordination would be a challenge as we are an international team from 2 different continents and hence, 2 different time zones. We stepped up to the challenge and made it work, by delegating each person with tasks of equal work, we managed to lower the workload all while keeping good communication.
## What we learned
What I learned This was also our first time as a team using Figma, and we quickly adapted to it and learned in a short time period. We also improved our understanding of Docker. Only one person in the team had any experience with using Docker and AWS, but we all made it a priority to learn.
## What's next for Diversify
We look to add more accessibility features and expand the user base so more people can find their optimal friends! | ## Inspiration
Everyone in this team has previously been to post-secondary and noticed that their large group of friends have been slowly dwindling since graduation, especially after COVID. It's already well known that once you leave school it's a lot harder to make friends, so we got this idea to make FriendFinder to match you with people with similar hobbies in the same neighbourhood as you.
## What it does
**Find friends!**
When making an account on FriendFinder, you will be asked to input your hobbies, whether you prefer chatting or hanging out, whether you enjoy outdoor activities or not, and your neighbourhood. It then gives other users a relative score based on your profile, with more matching hobbies and preferences having a higher score. Now when ever you log in, the front page will show you a list of people near you with the highest score, allowing you to send them friend requests to start a chat.
## How we built it
**With friends!**
We used HTML, CSS, and Javascript for the frontend and Firebase and Firestore for the backend.
## Challenges we ran into
**Our friends...**
Just kidding. One of the biggest challenges we faced was the short amount of time (24 hours) of this hackathon. Being first year students, we made a project of similar scale in school but over 4 months! Another challenge was that none of us knew how to implement a real time chat app into our project. At first we wanted to learn a new language React and make the chat app beautiful, but due to time constraints, we researched a simpler way to do it just to give it base functionality.
## Accomplishments that we're proud of
**Our friendship survived!**
After the initial scramble to figure out what we were doing, we managed to get a minimum viable product in 24 hours. We are really proud that we incorporated our knowledge from school and learned something new and integrated it together without any major issues.
## What we learned
**Make good friends**
The most important thing we learned is that team work is one of the most important things needed for a good development team. Being able to communicate with your team and dividing work up by each team member's strengths is what made it possible to finish this project within the strict time limit. The hackathon was a really fun experience and we're really glad that we could form a team together.
## What's next for FriendFinder
**More features to find more friends better**
* beautify the app
* add friend / pending friend requests feature
* security/encryption of messages
* report user function
* more detailed hobby selection list for better matching
* update user's profile / hobby selection list at any time
* let users add photos
* group chat function
* rewrite sections of code to become more efficient | ## Inspiration
Imagine a world where your best friend is standing in front of you, but you can't see them. Or you go to read a menu, but you are not able to because the restaurant does not have specialized brail menus. For millions of visually impaired people around the world, those are not hypotheticals, they are facts of life.
Hollywood has largely solved this problem in entertainment. Audio descriptions allow the blind or visually impaired to follow the plot of movies easily. With Sight, we are trying to bring the power of audio description to everyday life.
## What it does
Sight is an app that allows the visually impaired to recognize their friends, get an idea of their surroundings, and have written text read aloud. The app also uses voice recognition to listen for speech commands to identify objects, people or to read text.
## How we built it
The front-end is a native iOS app written in Swift and Objective-C with XCode. We use Apple's native vision and speech API's to give the user intuitive control over the app.
---
The back-end service is written in Go and is served with NGrok.
---
We repurposed the Facebook tagging algorithm to recognize a user's friends. When the Sight app sees a face, it is automatically uploaded to the back-end service. The back-end then "posts" the picture to the user's Facebook privately. If any faces show up in the photo, Facebook's tagging algorithm suggests possibilities for who out of the user's friend group they might be. We scrape this data from Facebook to match names with faces in the original picture. If and when Sight recognizes a person as one of the user's friends, that friend's name is read aloud.
---
We make use of the Google Vision API in three ways:
* To run sentiment analysis on people's faces, to get an idea of whether they are happy, sad, surprised etc.
* To run Optical Character Recognition on text in the real world which is then read aloud to the user.
* For label detection, to indentify objects and surroundings in the real world which the user can then query about.
## Challenges we ran into
There were a plethora of challenges we experienced over the course of the hackathon.
1. Each member of the team wrote their portion of the back-end service a language they were comfortable in. However when we came together, we decided that combining services written in different languages would be overly complicated, so we decided to rewrite the entire back-end in Go.
2. When we rewrote portions of the back-end in Go, this gave us a massive performance boost. However, this turned out to be both a curse and a blessing. Because of the limitation of how quickly we are able to upload images to Facebook, we had to add a workaround to ensure that we do not check for tag suggestions before the photo has been uploaded.
3. When the Optical Character Recognition service was prototyped in Python on Google App Engine, it became mysteriously rate-limited by the Google Vision API. Re-generating API keys proved to no avail, and ultimately we overcame this by rewriting the service in Go.
## Accomplishments that we're proud of
Each member of the team came to this hackathon with a very disjoint set of skills and ideas, so we are really glad about how well we were able to build an elegant and put together app.
Facebook does not have an official algorithm for letting apps use their facial recognition service, so we are proud of the workaround we figured out that allowed us to use Facebook's powerful facial recognition software.
We are also proud of how fast the Go back-end runs, but more than anything, we are proud of building a really awesome app.
## What we learned
Najm taught himself Go over the course of the weekend, which he had no experience with before coming to YHack.
Nathaniel and Liang learned about the Google Vision API, and how to use it for OCR, facial detection, and facial emotion analysis.
Zak learned about building a native iOS app that communicates with a data-rich APIs.
We also learned about making clever use of Facebook's API to make use of their powerful facial recognition service.
Over the course of the weekend, we encountered more problems and bugs than we'd probably like to admit. Most of all we learned a ton of valuable problem-solving skills while we worked together to overcome these challenges.
## What's next for Sight
If Facebook ever decides to add an API that allows facial recognition, we think that would allow for even more powerful friend recognition functionality in our app.
Ultimately, we plan to host the back-end on Google App Engine. | losing |
## Inspiration
In 2010, when Haiti was rocked by an earthquake that killed over 150,000 people, aid workers manned SMS help lines where victims could reach out for help. Even with the international humanitarian effort, there was not enough manpower to effectively handle the volume of communication. We set out to fix that.
## What it does
EmergAlert takes the place of a humanitarian volunteer at the phone lines, automating basic contact. It allows victims to request help, tell their location, place calls and messages to other people, and inform aid workers about their situation.
## How we built it
We used Mix.NLU to create a Natural Language Understanding model that categorizes and interprets text messages, paired with the Smooch API to handle SMS and Slack contact. We use FHIR to search for an individual's medical history to give more accurate advice.
## Challenges we ran into
Mentoring first time hackers was both a challenge and a joy.
## Accomplishments that we're proud of
Coming to Canada.
## What we learned
Project management is integral to a good hacking experience, as is realistic goal-setting.
## What's next for EmergAlert
Bringing more depth to the NLU responses and available actions would improve the app's helpfulness in disaster situations, and is a good next step for our group. | ## Inspiration
Imagine: A major earthquake hits. Thousands call 911 simultaneously. In the call center, a handful of operators face an impossible task. Every line is ringing. Every second counts. There aren't enough people to answer every call.
This isn't just hypothetical. It's a real risk in today's emergency services. A startling **82% of emergency call centers are understaffed**, pushed to their limits by non-stop demands. During crises, when seconds mean lives, staffing shortages threaten our ability to mitigate emergencies.
## What it does
DispatchAI reimagines emergency response with an empathetic AI-powered system. It leverages advanced technologies to enhance the 911 call experience, providing intelligent, emotion-aware assistance to both callers and dispatchers.
Emergency calls are aggregated onto a single platform, and filtered based on severity. Critical details such as location, time of emergency, and caller's emotions are collected from the live call. These details are leveraged to recommend actions, such as dispatching an ambulance to a scene.
Our **human-in-the-loop-system** enforces control of human operators is always put at the forefront. Dispatchers make the final say on all recommended actions, ensuring that no AI system stands alone.
## How we built it
We developed a comprehensive systems architecture design to visualize the communication flow across different softwares.

We developed DispatchAI using a comprehensive tech stack:
### Frontend:
* Next.js with React for a responsive and dynamic user interface
* TailwindCSS and Shadcn for efficient, customizable styling
* Framer Motion for smooth animations
* Leaflet for interactive maps
### Backend:
* Python for server-side logic
* Twilio for handling calls
* Hume and Hume's EVI for emotion detection and understanding
* Retell for implementing a voice agent
* Google Maps geocoding API and Street View for location services
* Custom-finetuned Mistral model using our proprietary 911 call dataset
* Intel Dev Cloud for model fine-tuning and improved inference
## Challenges we ran into
* Curated a diverse 911 call dataset
* Integrating multiple APIs and services seamlessly
* Fine-tuning the Mistral model to understand and respond appropriately to emergency situations
* Balancing empathy and efficiency in AI responses
## Accomplishments that we're proud of
* Successfully fine-tuned Mistral model for emergency response scenarios
* Developed a custom 911 call dataset for training
* Integrated emotion detection to provide more empathetic responses
## Intel Dev Cloud Hackathon Submission
### Use of Intel Hardware
We fully utilized the Intel Tiber Developer Cloud for our project development and demonstration:
* Leveraged IDC Jupyter Notebooks throughout the development process
* Conducted a live demonstration to the judges directly on the Intel Developer Cloud platform
### Intel AI Tools/Libraries
We extensively integrated Intel's AI tools, particularly IPEX, to optimize our project:
* Utilized Intel® Extension for PyTorch (IPEX) for model optimization
* Achieved a remarkable reduction in inference time from 2 minutes 53 seconds to less than 10 seconds
* This represents a 80% decrease in processing time, showcasing the power of Intel's AI tools
### Innovation
Our project breaks new ground in emergency response technology:
* Developed the first empathetic, AI-powered dispatcher agent
* Designed to support first responders during resource-constrained situations
* Introduces a novel approach to handling emergency calls with AI assistance
### Technical Complexity
* Implemented a fine-tuned Mistral LLM for specialized emergency response with Intel Dev Cloud
* Created a complex backend system integrating Twilio, Hume, Retell, and OpenAI
* Developed real-time call processing capabilities
* Built an interactive operator dashboard for data summarization and oversight
### Design and User Experience
Our design focuses on operational efficiency and user-friendliness:
* Crafted a clean, intuitive UI tailored for experienced operators
* Prioritized comprehensive data visibility for quick decision-making
* Enabled immediate response capabilities for critical situations
* Interactive Operator Map
### Impact
DispatchAI addresses a critical need in emergency services:
* Targets the 82% of understaffed call centers
* Aims to reduce wait times in critical situations (e.g., Oakland's 1+ minute 911 wait times)
* Potential to save lives by ensuring every emergency call is answered promptly
### Bonus Points
* Open-sourced our fine-tuned LLM on HuggingFace with a complete model card
(<https://huggingface.co/spikecodes/ai-911-operator>)
+ And published the training dataset: <https://huggingface.co/datasets/spikecodes/911-call-transcripts>
* Submitted to the Powered By Intel LLM leaderboard (<https://huggingface.co/spaces/open-llm-leaderboard/open_llm_leaderboard>)
* Promoted the project on Twitter (X) using #HackwithIntel
(<https://x.com/spikecodes/status/1804826856354725941>)
## What we learned
* How to integrate multiple technologies to create a cohesive, functional system
* The potential of AI to augment and improve critical public services
## What's next for Dispatch AI
* Expand the training dataset with more diverse emergency scenarios
* Collaborate with local emergency services for real-world testing and feedback
* Explore future integration | ## Inspiration
The increasing frequency and severity of natural disasters such as wildfires, floods, and hurricanes have created a pressing need for reliable, real-time information. Families, NGOs, emergency first responders, and government agencies often struggle to access trustworthy updates quickly, leading to delays in response and aid. Inspired by the need to streamline and verify information during crises, we developed Disasteraid.ai to provide concise, accurate, and timely updates.
## What it does
Disasteraid.ai is an AI-powered platform consolidating trustworthy live updates about ongoing crises and packages them into summarized info-bites. Users can ask specific questions about crises like the New Mexico Wildfires and Floods to gain detailed insights. The platform also features an interactive map with pin drops indicating the precise coordinates of events, enhancing situational awareness for families, NGOs, emergency first responders, and government agencies.
## How we built it
1. Data Collection: We queried You.com to gather URLs and data on the latest developments concerning specific crises.
2. Information Extraction: We extracted critical information from these sources and combined it with data gathered through Retrieval-Augmented Generation (RAG).
3. AI Processing: The compiled information was input into Anthropic AI's Claude 3.5 model.
4. Output Generation: The AI model produced concise summaries and answers to user queries, alongside generating pin drops on the map to indicate event locations.
## Challenges we ran into
1. Data Verification: Ensuring the accuracy and trustworthiness of the data collected from multiple sources was a significant challenge.
2. Real-Time Processing: Developing a system capable of processing and summarizing information in real-time requires sophisticated algorithms and infrastructure.
3. User Interface: Creating an intuitive and user-friendly interface that allows users to easily access and interpret information presented by the platform.
## Accomplishments that we're proud of
1. Accurate Summarization: Successfully integrating AI to produce reliable and concise summaries of complex crisis situations.
2. Interactive Mapping: Developing a dynamic map feature that provides real-time location data, enhancing the usability and utility of the platform.
3. Broad Utility: Creating a versatile tool that serves diverse user groups, from families seeking safety information to emergency responders coordinating relief efforts.
## What we learned
1. Importance of Reliable Data: The critical need for accurate, real-time data in disaster management and the complexities involved in verifying information from various sources.
2. AI Capabilities: The potential and limitations of AI in processing and summarizing vast amounts of information quickly and accurately.
3. User Needs: Insights into the specific needs of different user groups during a crisis, allowing us to tailor our platform to better serve these needs.
## What's next for DisasterAid.ai
1. Enhanced Data Sources: Expanding our data sources to include more real-time feeds and integrating social media analytics for even faster updates.
2. Advanced AI Models: Continuously improving our AI models to enhance the accuracy and depth of our summaries and responses.
3. User Feedback Integration: Implementing feedback loops to gather user input and refine the platform's functionality and user interface.
4. Partnerships: Building partnerships with more emergency services and NGOs to broaden the reach and impact of Disasteraid.ai.
5. Scalability: Scaling our infrastructure to handle larger volumes of data and more simultaneous users during large-scale crises. | winning |
## Inspiration
The inspiration for this came from grandparents that were forced to try lots of different types of hearing aids. The hearing aids all came from the same three manufacturers, which had a monopoly on all the options and pricing. The profit made on these hearing aids is almost scandalous since the price of manufacture has steadily decreased, similar to the current market of graphing calculators as well. The goal with this project is to create a cheap pair of AR glasses for displaying text on a see through display to allow for less isolating communication at the dinner table with friends. As peoples sense of hearing degrades faster than their eyesight it can cause issues with communication in the elderly as well as with their loved ones. When it is difficult to understand each other it can facilitate a breakdown in communication and understanding. Sometimes insurance is too expensive to be able to pay for pricey hearing aids and this project costs much less than low priced hearing aids with an estimated BOM cost of under 200 dollars.
## What it does
Currently it uses a speech to text API with a microphone array as the input. This applies de noising algorithms which help with improving the speech to text performance. This then sends the text over bluetooth to the ESP32 with an OLED based display mounted with a battery and boost converter onto a pair of cheap magnifying glasses for inspection work. This brings the display closer to your face and allows for the text to be easily read, while also allowing for easy prototyping and integration.
## How we built it
We built it using a 3D printer to print the brackets which we mounted to the magnifying glasses. We then used a soldering iron to press threaded inserts into the brackets. This was used with M2, M3, M4 screws and zipties to mount the different PCBs and display to the repurposed magnifying glasses. We used an arduino library with the ESP32 to talk via bluetooth to our phone initially and then to the microphone array, as well as display text on the screen. The proof of concept initially was using googles speech to text on an android phone with a bluetooth serial terminal to send the text to the screen. Once this was successful the next step was plumbing the microphone array into the speech to text software, sending the output to the screen on the ESP32.
## Challenges we ran into
The main issues we had were related to the transparent OLED, initially to use SPI mode all of the jumper pads had to be scratched off of the back of the driver board. When scratching them off the driver board was damaged and trying to use I2C mode was unsuccessful. Luckily we brought multiple displays and used another one to at least demonstrate the proof of concept even even though it is more difficult to see out of the glasses with it. Another challenge we ran into was using mozilla deepspeech to do the inference on one of our laptops. We spent multiple hours trying to install CUDA to use a GPU accelerated speech to text model that never worked properly due to driver issues with Debian. We were able to run the model and infer using the CPU pipeline but it was not very fast and unfortunately the microphone inputs to the Debian laptop also did not work due to driver issues. This made interfacing to the microphone board more difficult than initially thought.
## Accomplishments that we're proud of
We are proud that we managed to build a successful hardware project with multiple different issues that had to be overcome. It was enjoyable to work with real hardware and test out different parts of the original idea in different hardware concepts and ideas. Getting the display to work properly with the ESP32 was a slight challenge and seeing it display text for the first time was awesome. When the model started inferring properly it was also super exciting. Seeing the brackets come together, printed properly with mounting for all of our boards was a good feeling as well. Wearing the display for the first time while it was working was awesome.
## What we learned
We learned about how to interface with the ESP32 and used a buffer to display text on the screen as well as generate multiple lines of text and scrolling animations. We also learned a decent amount about battery voltage regulation, with one battery powering the ESP32 as well as the display on the front of the AR glasses. Learning the basics of how natural language processing works and how to implement it properly in a project was super interesting and valuable for future projects.
## What's next for Dialog
Our next goals will be designing a custom PCBA for the natural language processing. Using a Xilinx FPGA with the recently released Vitis software package to convert the deepspeech model to infer locally using the FPGA. The FPGA can be used to drive the display, perform the digital signal processing on the audio streams from the microphone array as well as perform natural language processing. The nice advantage to using a custom PCBA is that the board can be lower power when not doing the inference and signal processing. It will also be cheaper to manufacture due to the fact that the product can be higher volume. Since hearing aid manufacturers have gotten lazy due to their continued monopoly it is an industry ripe for change with a huge market capitalization. | ## Inspiration
Many visually impaired people have difficulties on a day-to-day basis reading text and other items, and other comparable technologies and software are either expensive or bulky and impractical to use. We sought to create a cheap, light and reliable system for text reading.
## What it does
A wearable that reads aloud text to its user through a mobile app. It was made for the visually impaired who have trouble reading text that doesn't have a braille translation.
## How we built it
We used an ESP-32 Cam, mounted in a 3d printed enclosure atop a hat. The camera hosts a WiFi Local Access Point, to which the user's smartphone is connected to. The smartphone processes the image with an OCR, and sends the resulting text to a text-to-speech API, which is played to the user.
## Challenges we ran into
* We forgot to bring a charger and HDMI cable for our raspberry PI and were unable to rely on its processing power.
* We tried to run ML models on the ESP32-CAM but we were only able to small and simple models due to the hardware limitations.
* We were unable to send images over Bluetooth LE because of the low data transfer limit and we were unable to connect the ESP32-CAM so we opted to create a soft access point on the esp32 so other devices could connect to it to retrieve images.
* Getting a 3D profile of the hat (we borrowed **stole** from xero) was challenging because we couldn't measure the spherical shape of the hat.
* We had a lot of trouble retrieving images on our React Native app, making us switch to React. After a lot of trial and error, we finally got the ESP32-CAM to stream images on a ReactJS website, but we didn't have enough time to combine the text recognition with it.
## Accomplishments that we're proud of
* 3d Printed Shroud
* Building a website and implemented Machine Learning model
* Streaming ESP32-CAM to our website
## What we learned
* Always allow more overhead when possible to allow for changes while creating your project
* Create a schedule to predict what you will have time for and when it should be done by
+ ML training is very time-consuming and it is very likely that you will have bugs to work out
+ Start with a smaller project and work up towards a larger and more complete one
* New things our team members have experienced: React (JS & Native), ESP32-CAM, Tesseract (js & py), NodeJS, 3d modeling/printing under a time constraint, getting free food
## What's next for Assisted Reader
* Fix issues / merge the ESP32-CAM with the ML models
* Better form factor (smaller battery, case, lower power usage)
* Use automatic spelling correction to ensure Text-to-Speech always reads proper English words
* More ML training for an improved OCR model
* Translation to other languages for a larger customer base
* Cleaner and more modern User Interface
* Add support for Bluetooth and connecting to other Wifi networks | ## Inspiration
We wanted to create a device that ease the life of people who have disabilities and with AR becoming mainstream it would only be proper to create it.
## What it does
Our AR Headset converts speech to text and then displays it realtime on the monitor to allow the user to read what the other person is telling them making it easier for the first user as he longer has to read lips to communicate with other people
## How we built it
We used IBM Watson API in order to convert speech to text
## Challenges we ran into
We have attempted to setup our system using the Microsoft's Cortana and the available API but after struggling to get the libraries ti work we had to resort to using an alternative method
## Accomplishments that we're proud of
Being able to use the IBM Watson and unity to create a working prototype using the Kinect as the Web Camera and the Oculus rift as the headset thus creating an AR headset
## What we learned
## What's next for Hear Again
We want to make the UI better, improve the speed to text recognition and transfer our project over to the Microsoft Holo Lens for the most nonintrusive experience. | losing |
## Inspiration
Everybody knows how annoying it can be to develop web applications. But this sentiment is certainly true for those who have minimal to no working experience with web development. We were inspired by the power of Cohere LLM's to transform natural language into many different forms and in our case, to generate websites. With this, we are able to quickly turn a users idea into a website which they can download and edit on the spot.
## What it does
SiteSynth turns natural language input into a clean formatted and stylized website.
## How we built it
SiteSynth is powered by Django in the back end and HTML/CSS/JS in the front end. In the back end, we use the Cohere generate API to generate the HTML and CSS code.
## Challenges we ran into
Some challenges that we ran into were with the throttled API and perfecting the prompt. One of the most important parts of an NLP project is the input prompt to the LLM. We spent a lot of time perfecting the prompt of the input in order to ensure that the output is HTML code and ONLY HTML code. Also, the throttled speed of API calls slowed down our development and leads to a slow running app. However, despite these hardships, we have ended up with a project that we are quite proud of.
## Accomplishments that we're proud of
The project as a whole was a huge accomplishment which we are very happy with, but there are some parts which we appreciate more than others. In particular, we think the design of the main page is very clean. Likewise, the backend, while messy, does the job very well and we are proud of that.
## What we learned
This project was very insightful for learning about new cutting edge technologies. While we have worked with Django before, this was our first time working with the Cohere API (or any LLM API for that matter) and the importance of verbose and specific prompts was certainly highlighted. We also learned how difficult it can be to create a full-fledged application in a day in a half.
## What's next for SiteSynth
For the future, there are many ways in which we can improve SiteSynth. In particular, we know that images are integral to web development and as such we would like to properly integrate images. Likewise, with a proper API key, we could speed up the app tremendously. Finally, by also supporting dynamic templates, we can make the websites truly unique and desired. | ## Inspiration
After learning about NLP and Cohere, we were inspired to explore the capabilities it had and decided to use it for a more medical oriented field. We realized that people prefer the internet to tediously needing to call somebody and wait in long hold times so we designed an alternative to the 811 hotline. We believed that this would not only help those with speech impediments but also aid the health industry with what they want to hire their future employees for.
## What it does
We designed a web application on which the user inputs how they are feeling (as a string), which is then sent onto our web server which contains the Cohere python application, from which we ask for specific data (The most probable illness thought by the NLP model and the percentage certainty it has) to be brought back to the web application as an output.
## How we built it
We built this website itself using HTML, CSS and Javascript. We then imported 100 training examples regarding symptoms for the natural language processing model to learn from, which we then exported as Python code, which was then deployed as a Flask microframework upon DigitalOcean’s Cloud Service Platform so that we could connect it to our website. This sucessfully helped connect our frontend and backend.
## Challenges we ran into
We ran into many challenges as we were all very inexperienced with Flask, Cohere's NLP models, professional web development and Wix (which we tried very hard to work with for the first half of the hackathon). This was because 3 of us were first and second years and half of our team hadn't been to a hackathon before. It was a very stressful 24 hours in which we worked very hard. We were also limited by Cohere's free limit of 100 training examples thus forcing our NLP model to not be as accurate as we wanted it to be.
## Accomplishments that we're proud of
We're very proud of the immense progress we made after giving up upon hosting our website on Wix. Despite losing more than a third of our time, we still managed to not only create a nice web app, we succesfully used Cohere's NLP model, and most notably, we were able to connect our Frontend and Backend using a Flask microframework and a cloud based server. These were all things outside of our confortzone and provided us with many learning opportunities.
## What we learned
We learned a tremendous amount during this hackathon. We became more skilled in flexbox to create a more professional website, we learned how to use flask to connect our python application data with our website domain.
## What's next for TXT811
We believe that the next step is to work on our web development skills to create an even more professional website and train our NLP model to be more accurate in its diagnosis, as well as expand upon what it can diagnose so that it can reach a wider audience of patients. Although we don't believe that it can 100% aid in professional diagnosis as that would be a dangerous concept to imply, it's definetly a very efficient software to point out warning signs to push the general public to reach out before their symptoms could get worse. | ## Inspiration
Nowadays, we have been using **all** sorts of development tools for web development, from the simplest of HTML, to all sorts of high-level libraries, such as Bootstrap and React. However, what if we turned back time, and relived the *nostalgic*, good old times of programming in the 60s? A world where the programming language BASIC was prevalent. A world where coding on paper and on **office memo pads** were so popular. It is time, for you all to re-experience the programming of the **past**.
## What it does
It's a programming language compiler and runtime for the BASIC programming language. It allows users to write interactive programs for the web with the simple syntax and features of the BASIC language. Users can read our sample the BASIC code to understand what's happening, and write their own programs to deploy on the web. We're transforming code from paper to the internet.
## How we built it
The major part of the code is written in TypeScript, which includes the parser, compiler, and runtime, designed by us from scratch. After we parse and resolve the code, we generate an intermediate representation. This abstract syntax tree is parsed by the runtime library, which generates HTML code.
Using GitHub actions and GitHub Pages, we are able to implement a CI/CD pipeline to deploy the webpage, which is **entirely** written in BASIC! We also have GitHub Dependabot scanning for npm vulnerabilities.
We use Webpack to bundle code into one HTML file for easy deployment.
## Challenges we ran into
Creating a compiler from scratch within the 36-hour time frame was no easy feat, as most of us did not have prior experience in compiler concepts or building a compiler. Constructing and deciding on the syntactical features was quite confusing since BASIC was such a foreign language to all of us. Parsing the string took us the longest time due to the tedious procedure in processing strings and tokens, as well as understanding recursive descent parsing. Last but **definitely not least**, building the runtime library and constructing code samples caused us issues as minor errors can be difficult to detect.
## Accomplishments that we're proud of
We are very proud to have successfully "summoned" the **nostalgic** old times of programming and deployed all the syntactical features that we desired to create interactive features using just the BASIC language. We are delighted to come up with this innovative idea to fit with the theme **nostalgia**, and to retell the tales of programming.
## What we learned
We learned the basics of making a compiler and what is actually happening underneath the hood while compiling our code, through the *painstaking* process of writing compiler code and manually writing code samples as if we were the compiler.
## What's next for BASIC Web
This project can be integrated with a lot of modern features that is popular today. One of future directions can be to merge this project with generative AI, where we can feed the AI models with some of the syntactical features of the BASIC language and it will output code that is translated from the modern programming languages. Moreover, this can be a revamp of Bootstrap and React in creating interactive and eye-catching web pages. | losing |
## Inspiration
We created AR World to make AR more accessible for everyone. Through the mobile app, any static image in the real world is instantly replaced by a video. Through the web app, users can upload any image and video pair to be replaced in real-time. The end result is a world where movie posters turn into trailers, textbook diagrams become tutorial videos, and newspapers/paintings come to life straight out of Harry Potter. These are just a few of the endless possibilities in how AR World can improve and transform the way we learn, entertain, and share information.
## What it Does
AR World is an Android app that recognizes images seen through the phone's camera and seamlessly replaces images with its corresponding video using AR Core. It also includes a React web app that allows users to upload their own image and video pairs. This allows businesses like publishers, news companies, or museums to create content for its customers. Individual users may also upload their own images and videos to customize their experience with the app.
## How We Built It
We built the mobile app using Android Studio, with Sceneform and AR Core on the backend to recognize images and map them to the corresponding videos. In the first pass, we recognized certain static images and replaced them with the appropriate videos. Then, we built a web page and API to accept more photo-video pairs that can be identified by the cameras of users. Thus, we needed AWS S3 to store these photos and videos, MediaConvert to convert them from MP4 format to a streamable DASH-ISO format, and CloudFront to serve the video streaming requests. Also, MongoDB was required to store a map from the image to the corresponding video link on S3.
## Challenges We Ran Into
There were several challenging aspects to our project. To start, streaming resources from AWS, GCP or some cloud storage provider onto a device on demand proved to be a hurdle.
* Getting the video to stay anchored in the real-world
* Recognizing a static image
* Automating the conversion from user-uploaded mp4 to a streamable format
* Dynamically updating the image-video pairing database
## Accomplishments That We're Proud Of
I think it's an accomplishment to have a fully functional app that can effectively recognize images within a certain set and replace it with the desired video from end to end (where the back-end, front-end, and infrastructure is complete).
## What We Learned
I think we learned that there are a lot of unexpected issues when connecting different resources, and it takes a lot of patience and debugging to work through them. None of us had worked with Kotlin or AR before!
## What's Next for AR World
For AR World, the next big step would be to create organizations in which people can be enrolled. This would help assign a group of picture-video pairs that pertain to a group (e.g. a group on a museum tour, to see more information about artifacts in the museum).
Another big step would be to give the full VR experience to the customer. With headsets like Google Cardboard, we can help people explore different parts of their environments simultaneously. | ## What is 'Titans'?
VR gaming shouldn't just be a lonely, single-player experience. We believe that we can elevate the VR experience by integrating multiplayer interactions.
We imagined a mixed VR/AR experience where a single VR player's playing field can be manipulated by 'Titans' -- AR players who can plan out the VR world by placing specially designed tiles-- blocking the VR player from reaching the goal tile.
## How we built it
We had three streams of development/design to complete our project: the design, the VR experience, and the AR experience.
For design, we used Adobe Illustrator and Blender to create the assets that were used in this project. We had to be careful that our tile designs were recognizable by both human and AR standards, as the tiles would be used by the AR players to lay our the environment the VR players would be placed in. Additionally, we pursued a low-poly art style with our 3D models, in order to reduce design time in building intricate models and to complement the retro/pixel-style of our eventual AR environment tiles.
For building the VR side of the project, we selected to build a Unity VR application targeting Windows and Mac with the Oculus Rift. One of our most notable achievements here is a custom terrain tessellation and generation engine that mimics several environmental biomes represented in our game as well as integrating a multiplayer service powered by Google Cloud Platform.
The AR side of the project uses Google's ARCore and Google Cloud Anchors API to seamlessly stream anchors (the tiles used in our game) to other devices playing in the same area.
## Challenges we ran into
Hardware issues were one of the biggest time-drains in this project. Setting up all the programs-- Unity and its libraries, blender, etc...-- took up the initial hours following the brainstorming session. The biggest challenge was our Alienware MLH laptop resetting overnight. This was a frustrating moment for our team, as we were in the middle of testing our AR features such as testing the compatibility of our environment tiles.
## Accomplishments that we're proud of
We're proud of the consistent effort and style that went into the game design, from the physical environment tiles to the 3D models, we tried our best to create a pleasant-to-look at game style. Our game world generation is something we're also quite proud of. The fact that we were able to develop an immersive world that we can explore via VR is quite surreal. Additionally, we were able to accomplish some form of AR experience where the phone recognizes the environment tiles.
## What we learned
All of our teammates learned something new: multiplayer in unity, ARCore, Blender, etc... Most importantly we learned the various technical and planning challenges involved in AR/VR game development
## What's next for Titans AR/VR
We hope to eventually connect the AR portion and VR portion of the project together the way we envisioned: where AR players can manipulate the virutal world of the VR player. | ## TLDR
Duolingo is one of our favorite apps of all time for learning. For DeerHacks, we wanted to bring the amazing learning experience from Duolingo even more interactive by bringing it to life in VR, making it more accessible by offering it for free for all, and making it more personalized by offering courses beyond languages so everyone can find a topic they enjoy.
Welcome to the future of learning with Boolingo, let's make learning a thrill again!
## Inspiration 🌟
We were inspired by the monotonous grind of traditional learning methods that often leave students disengaged and uninterested. We wanted to transform learning into an exhilarating adventure, making it as thrilling as gaming. Imagine diving into the depths of mathematics, exploring the vast universe of science, or embarking on quests through historical times—all while having the time of your life. That's the spark that ignited BooLingo! 🚀
## What it does 🎮
BooLingo redefines the learning experience by merging education with the immersive world of virtual reality (VR). It’s not just a game; it’s a journey through knowledge. Players can explore different subjects like Math, Science, Programming, and even Deer Facts, all while facing challenges, solving puzzles, and unlocking levels in a VR landscape. BooLingo makes learning not just interactive, but utterly captivating! 🌈
## How we built it 🛠️
We leveraged the power of Unity and C# to craft an enchanting VR world, filled with rich, interactive elements that engage learners like never before. By integrating the XR Plug-in Management for Oculus support, we ensured that BooLingo delivers a seamless and accessible experience on the Meta Quest 2, making educational adventures available to everyone, everywhere. The journey from concept to reality has been nothing short of a magical hackathon ride! ✨
## Challenges we ran into 🚧
Embarking on this adventure wasn’t without its trials. From debugging intricate VR mechanics to ensuring educational content was both accurate and engaging, every step presented a new learning curve. Balancing educational value with entertainment, especially in a VR environment, pushed us to our creative limits. Yet, each challenge only fueled our passion further, driving us to innovate and iterate relentlessly. 💪
## Accomplishments that we're proud of 🏆
Seeing BooLingo come to life has been our greatest achievement. We're incredibly proud of creating an educational platform that’s not only effective but also enormously fun. Watching players genuinely excited to learn, laughing, and learning simultaneously, has been profoundly rewarding. We've turned the daunting into the delightful, and that’s a victory we’ll cherish forever. 🌟
## What we learned 📚
This journey taught us the incredible power of merging education with technology. We learned that when you make learning fun, the potential for engagement and retention skyrockets. The challenges of VR development also taught us a great deal about patience, perseverance, and the importance of a user-centric design approach. BooLingo has been a profound learning experience in itself, teaching us that the sky's the limit when passion meets innovation. 🛸
## What's next for BooLingo 🚀
The adventure is just beginning! We envision BooLingo expanding its universe to include more subjects, languages, and historical epochs, creating a limitless educational playground. We’re also exploring social features, allowing learners to team up or compete in knowledge quests. Our dream is to see BooLingo in classrooms and homes worldwide, making learning an adventure that everyone looks forward to. Join us on this exhilarating journey to make education thrillingly unforgettable! Let's change the world, one quest at a time. 🌍💫 | partial |
## Inspiration
We all felt that it is quite a difficult decision to make about choosing your career in your grade 12 year. There's not enough guidance provided to students to completely clarify which program or career choice is best for them and so students often try to search on websites like reddit or even private message strangers on social media in hopes of getting helpful feedback. From this, we decided to create our web app, UniBot, which is solely dedicated to senior high school students. Through these websites, students can wish to live chat with alumni or current uni students or even registered profs and receive the best feedback possible. Not everyone gets the chance to attend university fairs or open houses, so this application could replace that missed opportunity while still providing beneficial feedback. After all, it's your future career we are talking about!
## What it does
What our web app, UniBot, does is that it allows clients (high school students) and to sign up and browse through the website. Inside, the student can choose the university they are interested in and filter further by choosing their program of interest. Once they have chosen their university and program, they will be able to see a list of alumni, profs or current university students in the specific program at the chosen university and get a chance to have a live one on one or a group chat with them. This way, students can receive the best feedback as possible!
## How we built it
We built this web application using HTML/CSS/Bootstrap for front end designing and layout of the widgets and JavaScript to make the application interactive. To route between different pages, we used the Flask framework in the backend. Essentially, there's two sides to this application: one one end, high school students sign up and login into the website and request for a live chat when available and on the other side, current university students or alumni can log in and accept the requests sent by students and commence the chat! To store the username data, we used SQLite3.
## Challenges we ran into
We ran into many challenges. For example this was our first time using Jquery so we had to read some documentation to debug the code. Furthermore, one small challenge we ran into was sharing code with one another. We decided not to use any version control system so at one point it became slightly difficult to merge our code together, but in the end we were successfully able to do it.
## Accomplishments that we're proud of
The largest accomplishment for us is to be able to create an app which has the potential to help thousands of future students in clarifying their goals and set them on the correct pathway! Aside from that, this was a great learning opportunity and we were able to gain a good deal of full stack development knowledge, and that itself is something we are proud of.
## What we learned
The most important non-technical skill we learned was perseverance because we came across many challenges during this project and it taught us to never give up. In terms of technical skills, we learned a lot about the Flask framework and the SQLite3 database. Furthermore, we also learned about backend development because going into the hackathon most of us only had previous experience coding in HTML and CSS.
## What's next for UniBot
We are planning on expanding the database to include more universities and programs. We also want to further increase traffic on the website and increase the number of feedback students from certain programs provide. In the future, we would like to expand who is able to mentor secondary school students to professors. This would allow students to receive professional advice from those who have been in their respective fields for decades. Lastly, we want to develop an in-built networking tool on our website such as voice and video chat options. We look forward to further working on this project! | ## Being a university student during the pandemic is very difficult. Not being able to connect with peers, run study sessions with friends and experience university life can be challenging and demotivating. With no present implementation of a specific data base that allows students to meet people in their classes and be automatically put into group chats, we were inspired to create our own.
## Our app allows students to easily setup a personalized profile (school specific) to connect with fellow classmates, be automatically put into class group chats via schedule upload and be able to browse clubs and events specific to their school. This app is a great way for students to connect with others and stay on track of activities happening in their school community.
## We built this app using an open-source mobile application framework called React Native and a real-time, cloud hosted database called Firebase. We outlined the GUI with the app using flow diagrams and implemented an application design that could be used by students via mobile. To target a wide range of users, we made sure to implement an app that could be used on android and IOS.
## Being new to this form of mobile development, we faced many challenges creating this app. The first challenge we faced was using GitHub. Although being familiar to the platform, we were unsure how to use git commands to work on the project simultaneously. However, we were quick to learn the required commands to collaborate and deliver the app on GitHub. Another challenge we faced was nested navigation within the software. Since our project highly relied on a real-time database, we also encountered difficulties with implementing the data base framework into our implementation.
## An accomplishment we are proud of is learning a plethora of different frameworks and how to implement them. We are also proud of being able to learn, design and code a project that can potentially help current and future university students across Ontario enhance their university lifestyles.
## We learned many things implementing this project. Through this project we learned about version control and collaborative coding through Git Hub commands. Using Firebase, we learned how to handle changing data and multiple authentications. We were also able to learn how to use JavaScript fundamentals as a library to build GUI via React Native. Overall, we were able to learn how to create an android and IOS application from scratch.
## What's next for USL- University Student Life!
We hope to further our expertise with the various platforms used creating this project and be able to create a fully functioning version. We hope to be able to help students across the province through this application. | ## Inspiration
My recent job application experience with a small company opened my eyes to the hiring challenges faced by recruiters. After taking time to thoughtfully evaluate each candidate, they explained how even a single bad hire wastes significant resources for small teams. This made me realize the need for a better system that saves time and reduces stress for both applicants and hiring teams. That sparked the idea for CareerChain.
## What it does
CareerChain allows job seekers and recruiters to create verified profiles on our blockchain-based platform.
For applicants, we use a microtransaction system similar to rental deposits or airport carts. A small fee is required to submit each application, refunded when checking status later. This adds friction against mass spam applications, ensuring only serious, passionate candidates apply.
For recruiters, our AI prescreens applicants, filtering out unqualified candidates. This reduces time wasted on low-quality applications, allowing teams to focus on best fits. Verified profiles also prevent fraud.
By addressing inefficiencies for both sides, CareerChain streamlines hiring through emerging technologies.
## How I built it
I built CareerChain using:
* XRP Ledger for blockchain transactions and smart contracts
* Node.js and Express for the backend REST API
* Next.js framework for the frontend
## Challenges we ran into
Implementing blockchain was challenging as it was my first time building on the technology. Learning the XRP Ledger and wiring up the components took significant learning and troubleshooting.
## Accomplishments that I'm proud of
I'm proud to have gained hands-on blockchain experience and built a working prototype leveraging these cutting-edge technologies.
## What I learned
I learned so much about blockchain capabilities and got exposure to innovative tools from sponsors. The hacking experience really expanded my skills.
## What's next for CareerChain
Enhancing fraud detection, improving the microtransaction UX, and exploring integrations like background checks to further optimize hiring efficiency. | losing |
## Inspiration
We are inspired by how Machine Learning can streamline a lot of our lives and minimize possible errors which occurs. In the healthcare and financial field, one of the issues which happens the most in the Insurance field is how to best evaluate a quote for the consumer. Therefore, upon seeing the challenge online during the team-formation period, we decided to work on it and devise an algorithm and data model for each consumers, along with a simple app for consumers to use on the front end.
## What it does
Upon starting the app, the user can check to see different plans offered by the company. It is listed in a ScrollView Table and customers can hence have a simple idea of what kind of deals/packages there are. Then, the user can proceed to the "Information" page, and fill out their personal information to request a quotation from the system, where the user data is transmitted to our server and the predictions are being made there. Then, the app is returned with a suitable plan for the user, along with other data graphs to illustrate the general demographics of the participants of the program.
## How we built it
The app is built using React-Native, which is cross-platform compatible for iOS, Android and WebDev. While for the model, we used r and python to train it. We also used Kibana to perform data visualization and elasticsearch as the server.
## Challenges we ran into
It is hard to come up with more filters in further perfecting our model with the sample data set from observing the patterns within the data set.
## Accomplishments that we're proud of
Improving the accuracy of the model by two times the original that we started off with by applying different filters and devising different algorithms.
## What we learned
We are now more proficient in terms of training models, developing React Native applications, and using Machine Learning in solving daily life problems by spotting out data patterns and utilizing them to come up with algorithms for the data set.
## What's next for ViHack
Further fine-tuning of the recognition model to improve upon the percentage of correct predictions of our currently-trained model . | ## Inspiration **💪🏼**
Health insurance, everyone needs it, no one wants to pay for it. As soon-will-be adults, health insurance has been a growing concern. Since a simple ambulance ride easily costs up to thousands of dollars, not having health insurance is a terrible decision in the US. But how much are you supposed to pay for it? Insurance companies publish their rates, but just having formulas doesn't tell me anything about if they are ripping me off, especially for young adults having never paid for health insurance.
## What it does? **🔍**
Thus, to prevent being ripped off on health insurance after leaving our parents' household. We have developed Health Insurance 4 Dummies. A website utilizing a machine learning model that determines a fair estimate for the annual costs of health insurance, based on user inputs of their personal information. It also uses a LMM to provide detailed information on the composition of the cost.
## How we built it **👷🏼♀️**
The front-end is built using convex-react, creating an UI that takes inputs from the user. The backend is built using python-flask, which communicates with remote services, InterSystems and Together.AI. The ML model for predicting the cost is built on InterSystems using the H2O, trained on a dataset consist of individual's information and their annual rate for health insurance. The explanation of costs is created using Together.AI's Llama-2 model.
## Challenges we ran into **🔨**
Full-stack development is tedious, especially when the functions require remote resources. Finding good datasets to train the model. Authentication in connecting and accessing the trained model on InterSystem using their IRIS connection driver. Choosing the right model to use from Together.AI.
## Accomplishments that we're proud of **⭐**
Trained and accessed ML model on a remote database open possibility for massive datasets, integrating LMMs to provide automated information.
## What we learned **📖**
Full-Stack Development skills, ML model training and utilizing. Accessing remote services using APIs, TLS authentication.
## What's next for Health Insurance 4 Dummys **🔮**
Gather larger datasets to make more parameters available and give more accurate predictions. | ## Inspiration
We wanted to any easy to get to know your friends without worrying about every detail!
## What it does
HobbyTree allows you to organize and share memories with your friends.
## How we built it
We built it from scratch using java.
## Challenges we ran into
We wanted to utilize cohere's language processing api but faced difficulty getting text data to be processed by the ai.
## Accomplishments that we're proud of
Proud that we met on the same day, and build a product together.
## What we learned
To align better to understand each others skills
## What's next for Hobby Tree
Launch baby! | partial |
## Inspiration
The Housing market is currently booming, yet there are many in our society who are homeless, near homeless and are in desperate need of financial assistance for housing. This issue is exacerbated for people from minority backgrounds and ethnicities, who have been discriminated against for generations with various types of biased housing policies and access to finance.
..
## What it does
FairhouseCoin addresses these issues by using anonymization and blockchain technology to bring a fairer, more equitable and more efficient housing market to all.
Using Fairhousecoin, an investor can buy into a mortgage instruments which combines houses from the most expensive and least expensive areas into a single instrument, thus amortizing the risk and making the scheme profitable. This then reduces the burden on potential homebuyers who can then use fairhousecoin tokens to apply for mortgages.
## uniswap video
<https://www.youtube.com/watch?v=R7ZeQBucBik>
## How we built it
FairHouseCoin (FHC) is an ERC20 token which can be traded for Eth on Uniswap. This allows multiple people to have joint possession of a property fractional income sharing. The FHC Eth trading pair was setup on Uniswap, the housing and mortgage data was taken from datasets published by the Fed and Zillow and stored on cockroachdb. The frontend allows ap applicant to apply for a mortgage and transforms this application into an anonymized FHC mortgage.
## Challenges we ran into
Synchronization and integration. Uniswap was new to all of us and we are all located remote to each other,
## Accomplishments that we're proud of
Working prototype on a new technology
## What we learned
There is an absolutely ridiculous amount of bias in the housing industry both at the private and at the policy level
## What's next for FairHouse
Address issues of accessibility to housing markets by introducing mainstream or stablecoin swap pairs | ## Inspiration
As software engineering and computer science students we ended up having spent a lot of time looking at a screen. Inevitably we strain our eyes from the long hours. To combat this we decided to create an AI companion that helps manage your health as you spend time in front of a screen.
## What it does
Study Doctor helps you keep on track towards having healthier screen time habits by embracing the Pomodoro method as a way to help manage your time more efficiently without burning yourself out. While you are collecting more screen time hours it keeps tabs on important data points that you as the user can check out later to see where you may be lacking.
## How we built it
* CustomTkinter (Tkinter) as the Interface
* OpenCV (Mediapipe & dlib)
## Challenges we ran into
The toughest challenge we faced as a team was being able to correctly detect certain features of the face.
## Accomplishments that we're proud of
We're proud that we as a team were able to create a functional and presentable proof-of-concept. We were able to implement all the core functionalities that we envisioned at the beginning of DeltaHacks X. We wanted users to have someone be there for them to track their screen time habits and push them in the right direction towards better habits
## What we learned
We learned how to work as a team, how to plan and execute a project within a tight deadline, and how to be adaptable. We preserved through our challenges and because of that, it led to a functional proof-of-concept that solves a real-world problem.
## What's next for Study Doctor
hopefully he gets a full time job! (He's an unpaid intern) ヾ(≧▽≦\*)o | #### PLEASE WATCH THE DEMO VIDEO IN THE HEADING OF THIS DEVPOST
## Auxilium Inspiration
In many low income areas around the world, people are forced to rely on unaccredited institutions for loans because their jobs do not provide them with a formal/stable source of income. This issue is primarily prominent in India where workers like rickshaw drivers and food-stop owners have to rely on unregulated loans to sustain and grow their businesses. These unregulated loans may come with unfavourable conditions that can harm the borrowers.
Auxilium aims to create value for the grey financial system in 3 key ways:
1. Help borrowers build credit history to make them eligible for loans from accredited institutions
2. Serve as a mediator between lenders and borrowers to avoid bounty hunting
3. Provide charitable microloans that directly improve people’s quality of life
In order to actualize on these goals we envision a network of low cost ATMs designed specifically for loan management. To keep deployment costs low, we intend to use cheap telecommunications infrastructure, like text messaging and phone calls as a user interface. Lenders use our web application to extend credit to individuals through a regulated interest schedule. In the case of loan default, lenders can negotiate with Auxilium for reasonable insurance instead of head hunting individual borrowers. Transactions for borrowers and lenders will be recorded on the Stellar blockchain as an immutable credit history that could eventually be used to prove creditworthiness for home mortgages or other large payments. Since many of the users we intend to reach may not have a government issued ID, we intend to use facial recognition software to validate identities.
The scope of our hackathon project was:
1. A hardware ATM that enables that is interfaced with our server.
2. A blockchain schema on the Stellar Network that provides a publicly visible and immutable record that can be used to evaluate creditworthiness. *(Stellar)*
3. A facial recognition based registration process that doesn’t allow for fraudulent duplicate account creation. *(AWS Rekognition)*
4. A server that retains user information and coordinates Twilio, ATMs and the Stellar blockchain
## Auxilium Tech Stack
**Hardware** *(Raspberry Pi 3, IR Break-Beam Sensor, Servo Motor, 3D Printer, Laser Cutter)* : We created a miniature ATM to satisfy a pivotal need in this project. First we used the 3D printer and laser cutter to create the housing for the ATM. We added a slot to allow for coin deposit and one for coin withdrawal. The coin deposit mechanism was created by using the break-beam sensor to implement counting functionality. The coin withdrawal mechanism was created using the servo motor and custom cut parts from the laser cutter. This information is collected via python scripts which are running on a node server which is running on the Raspberry Pi 3.
**Blockchain** *(Stellar)* : Stellar serves as an immutable transaction ledger that can be used by financial institutions to evaluate creditworthiness of borrowers. Every time a transaction occurs on our network, it is pushed to the Stellar ledger. Our web-view populates the transactions for users from the ledger and is meant to serve as a portal for lenders to extend credit to borrowers on our platform.
**Web View** *(React.js)* : The web-view allows the user and financial institutions to view the registered transaction history of users. They can toggle the settings to view a feed of live transactions or view their own. It also allows users to create accounts and displays statistics about Auxilium.
**AWS** *(Amazon Rekognition, S3 Bucket)*: We used Amazon Rekognition to bolster authentication for our web platform. We upload the user image into the bucket and use the AI library to compare this image to all other users. Since improving credit history is a critical motivating factor for people to repay loans, we want to ensure that no individual can reset their credit scores by creating an alternate identity.
**Backend** *(Node.js, Express.js, MongoDB)* : The backend of our service acts as a liaison between all the other services. It interacts with the Stellar network in order to populate the web view with the transaction history. It also relays vital information between the ATM and Twilio, such as withdraw limit and number of coins deposited.
**Twilio**: Twilio is a pivotal part of our application and the means which we use to securely communicate with the client. Upon receiving a text message or phone call from the user, the Twilio flow verifies the user identify by hitting authentication endpoints in the back-end. From there we allow the user to conduct many operations over the phone such as withdrawing and depositing money at the ATM. Attached above is a screenshot of the Twilio flow diagram. | losing |
This code allows the user to take photos of animals, and the app determines whether the photos are pleasing enough for people to see the cuteness of the animals. | ## Inspiration
We were interested in developing a solution to automate the analysis of microscopic material images.
## What it does
Our program utilizes image recognition and image processing tools such as edge detection, gradient analysis, gaussian/median/average filters, morphologies, image blending etc. to determine specific shapes of a microscopic image and apply binary thresholds for analysis. In addition, the program has the ability to differentiate between light and dark materials under poor lighting conditions, as well as calculate the average surface areas of grains and the percentage of dark grains.
## How we built it
We used Python algorithms incorporated with OpenCV tools in the PyCharm developing environment.
## Challenges we ran into
Contouring for images was extremely difficult considering there were many limitations and cleaning/calibrating data and threshold values. The time constraints also impacted us, as we would have liked to be able to develop a more accurate algorithm for our image analysis software.
## Accomplishments that we're proud of
Making a breakthrough in iterative masking of the images to achieve an error percentage consistently below 0.5%. We're also incredibly proud of the fact that we were able to complete the majority of the challenge tasks as well as develop a user-friendly interface.
## What we learned
We became better equipped with Python and the opensource materials available to all of us. We also learned valuable computer vision skills through practical applications as well as a developed a better understanding of data processing algorithms.
## What's next for Material Arts 2000
We're looking to further refine our algorithms so that it will be of more practical use in the future. Potentially looking to expand from the specific field of microscopic materials to develop a more widely applicable algorithm. | ## Inspiration
## What it does
You can point your phone's camera at a checkers board and it will show you all of the legal moves and mark the best one.
## How we built it
We used Android studio to develop an Android app that streams camera captures to a python server that handles
## Challenges we ran into
Detection of the orientation of the checkers board and the location of the pieces.
## Accomplishments that we're proud of
We used markers to provide us easy to detect reference points which we used to infer the orientation of the board.
## What we learned
* Android Camera API
* Computer Vision never works as robust as you think it will.
## What's next for Augmented Checkers
* Better graphics and UI
* Other games | winning |
## Overview
AOFS is an automatic sanitization robot that navigates around spaces, detecting doorknobs using a custom trained machine-learning algorithm and sanitizing them using antibacterial agent.
## Inspiration
It is known that in hospitals and other public areas, infections spread via our hands. Door handles, in particular, are one such place where germs accumulate. Cleaning such areas is extremely important, but hospitals are often at a short of staff and the sanitization may not be done as often as should be. We therefore wanted to create a robot that would automate this, which both frees up healthcare staff to do more important tasks and ensures that public spaces remain clean.
## What it does
AOFS travels along walls in public spaces, monitoring the walls. When a door handle is detected, the robot stops automatically sprays it with antibacterial agent to sanitize it.
## How we built it
The body of the robot came from a broken roomba. Using two ultrasonic sensors for movement and a mounted web-cam for detection, it navigates along walls and scans for doors. Our doorknob-detecting computer vision algorithm is trained via transfer learning on the [YOLO network](https://pjreddie.com/darknet/yolo/) (one of the state of the art real-time object detection algorithms) using custom collected and labelled data: using the pre-trained weights for the network, we froze all 256 layers except the last three, which we re-trained on our data using a Google Cloud server. The trained algorithm runs on a Qualcomm Dragonboard 410c which then relays information to the arduino.
## Challenges we ran into
Gathering and especially labelling our data was definitely the most painstaking part of the project, as all doorknobs in our dataset of over 3000 pictures had to be boxed by hand. Training the network then also took a significant amount of time. Some issues also occured as the serial interface is not native to the qualcomm dragonboard.
## Accomplishments that we're proud of
We managed to implement all hardware elements such as pump, nozzle and electrical components, as well as an algorithm that navigated using wall-following. Also, we managed to train an artificial neural network with our own custom made dataset, in less than 24h!
## What we learned
Hacking existing hardware for a new purpose, creating a custom dataset and training a machine learning algorithm.
## What's next for AOFS
Increasing our training dataset to incorporate more varied images of doorknobs and training the network on more data for a longer period of time. Using computer vision to incorporate mapping of spaces as well as simple detection, in order to navigate more intelligently. | ## Motivation
Our motivation was a grand piano that has sat in our project lab at SFU for the past 2 years. The piano was Richard Kwok's grandfathers friend and was being converted into a piano scroll playing piano. We had an excessive amount of piano scrolls that were acting as door stops and we wanted to hear these songs from the early 20th century. We decided to pursue a method to digitally convert the piano scrolls into a digital copy of the song.
The system scrolls through the entire piano scroll and uses openCV to convert the scroll markings to individual notes. The array of notes are converted in near real time to an MIDI file that can be played once complete.
## Technology
The scrolling through the piano scroll utilized a DC motor control by arduino via an H-Bridge that was wrapped around a Microsoft water bottle. While the notes were recorded using openCV via a Raspberry Pi 3, which was programmed in python. The result was a matrix representing each frame of notes from the Raspberry Pi camera. This array was exported to an MIDI file that could then be played.
## Challenges we ran into
The openCV required a calibration method to assure accurate image recognition.
The external environment lighting conditions added extra complexity in the image recognition process.
The lack of musical background in the members and the necessity to decrypt the piano scroll for the appropriate note keys was an additional challenge.
The image recognition of the notes had to be dynamic for different orientations due to variable camera positions.
## Accomplishments that we're proud of
The device works and plays back the digitized music.
The design process was very fluid with minimal set backs.
The back-end processes were very well-designed with minimal fluids.
Richard won best use of a sponsor technology in a technical pickup line.
## What we learned
We learned how piano scrolls where designed and how they were written based off desired tempo of the musician.
Beginner musical knowledge relating to notes, keys and pitches. We learned about using OpenCV for image processing, and honed our Python skills while scripting the controller for our hack.
As we chose to do a hardware hack, we also learned about the applied use of circuit design, h-bridges (L293D chip), power management, autoCAD tools and rapid prototyping, friction reduction through bearings, and the importance of sheave alignment in belt-drive-like systems. We also were exposed to a variety of sensors for encoding, including laser emitters, infrared pickups, and light sensors, as well as PWM and GPIO control via an embedded system.
The environment allowed us to network with and get lots of feedback from sponsors - many were interested to hear about our piano project and wanted to weigh in with advice.
## What's next for Piano Men
Live playback of the system | ## Inspiration
The failure of a certain project using Leap Motion API motivated us to learn it and use it successfully this time.
## What it does
Our hack records a motion password desired by the user. Then, when the user wishes to open the safe, they repeat the hand motion that is then analyzed and compared to the set password. If it passes the analysis check, the safe unlocks.
## How we built it
We built a cardboard model of our safe and motion input devices using Leap Motion and Arduino technology. To create the lock, we utilized Arduino stepper motors.
## Challenges we ran into
Learning the Leap Motion API and debugging was the toughest challenge to our group. Hot glue dangers and complications also impeded our progress.
## Accomplishments that we're proud of
All of our hardware and software worked to some degree of success. However, we recognize that there is room for improvement and if given the chance to develop this further, we would take it.
## What we learned
Leap Motion API is more difficult than expected and communicating with python programs and Arduino programs is simpler than expected.
## What's next for Toaster Secure
-Wireless Connections
-Sturdier Building Materials
-User-friendly interface | partial |
## Inspiration
People think of education simply as the encoding of knowledge, but most people don't realize that the hard part about learning is the recall. Our focus was to use Augmented Reality to enhance recall by mapping concepts and knowledge onto spatial objects on a path–a popular recalling technique called the Method of Loci. This idea, inspired from the Mind Palace technique in the tv show Sherlock, helps enhance association of knowledge using paths that we are familiar with - for instance, those we walk as we go through our daily routine.
## What it does
LociAR is an iOS App that helps users improve recall by enabling them to create virtual "mind palaces" based on routes they are familiar with. This is done through Augmented Reality - the user can create nodes corresponding to spatial objects on the path they choose to travel by, such as trees, lampposts, etc. Each node can store a title (visible through the camera), and a more detailed description that appears if the node is selected. The user can also store and load different paths, with each corresponding to any particular category.
## How we built it
We used ARKit along with the SceneKit framework to build the iOS App. Since none of us were familiar with Swift, we first learned the basics of iOS App Development and then created a flowchart for all the functions in the project. We each implemented various functions, such as focusing on the persistence of AR Sessions, creation of nodes, detection of nodes, etc.
## Challenges we ran into
There wasn't much detailed information about the technicalities of using ARKit with Xcode and as such, initial research was laborious. Moreover, AR technology is still very much in development and the tracking and placement aren't as refined as we would have liked it to be. Certain other specific challenges included AR persistence to save and load paths.
## Accomplishments that we're proud of
In less than 36 hours, we managed to familiarize ourselves with the workings of Xcode, ARKit, and Swift and created a working app that accomplished the task we set out to do.
## What we learned
We learnt the basics of a relatively new field of computer science and how it could be used to aid education and recollection capabilities. Moreover, we learnt the importance of time management and allocating specific tasks within a group.
## What's next for LociAR
Introducing additional forms of spatial representations and mapping colours to spatial objects | ## Inspiration
We get the inspiration from the idea provided by Stanley Black&Decker, which is to show users how would the product like in real place and in real size using AR technic. We choose to solve this problem because we also encounter same problem in our daily life. When we are browsing website for buying furnitures or other space-taking product, the first wonders that we come up with is always these two: How much room would it take and would it suit the overall arrangement.
## What it does
It provides customer with 3D models of products which they might be interested in and enable the customers to place, arrange (move and rotate) and interact with these models in their exact size in reality space to help they make decision on whether to buy it or not.
## How we built it
We use iOS AR kit.
## Challenges we ran into
Plane detection; How to open and close the drawer; how to build 3D model by ourselves from nothing
## Accomplishments that we're proud of
We are able to open and close drawer
## What we learned
How to make AR animation
## What's next for Y.Cabinet
We want to enable the change of size and color of a series/set of products directly in AR view, without the need to go back to choose. We also want to make the products look more realistic by finding a way to add light and shadow to it. | # Relive and Relearn
*Step foot into a **living photo album** – a window into your memories of your time spent in Paris.*
## Inspiration
Did you know that 70% of people worldwide are interested in learning a foreign language? However, the most effective learning method, immersion and practice, is often challenging for those hesitant to speak with locals or unable to find the right environment. We sought out to try and solve this problem by – even for experiences you yourself may not have lived; While practicing your language skills and getting personalized feedback, enjoy the ability to interact and immerse yourself in a new world!
## What it does
Vitre allows you to interact with a photo album containing someone else’s memories of their life! We allow you to communicate and interact with characters around you in those memories as if they were your own. At the end, we provide tailored feedback and an AI backed DELF (Diplôme d'Études en Langue Française) assessment to quantify your French capabilities. Finally, it allows for the user to make learning languages fun and effective; where users are encouraged to learn through nostalgia.
## How we built it
We built all of it on Unity, using C#. We leveraged external API’s to make the project happen.
When the user starts speaking, we used ChatGPT’s Whisper API to transform speech into text.
Then, we fed that text into co:here, with custom prompts so that it could role play and respond in character.
Meanwhile, we are checking the responses by using co:here rerank to check on the progress of the conversation, so we knew when to move on from the memory.
We store all of the conversation so that we can later use co:here classify to give the player feedback on their grammar, and give them a level on their french.
Then, using Eleven Labs, we converted co:here’s text to speech and played it for the player to simulate a real conversation.
## Challenges we ran into
VR IS TOUGH – but incredibly rewarding! None of our team knew how to use Unity VR and the learning curve sure was steep. C# was also a tricky language to get our heads around but we pulled through! Given that our game is multilingual, we ran into challenges when it came to using LLMs but we were able to use and prompt engineering to generate suitable responses in our target language.
## Accomplishments that we're proud of
Figuring out how to build and deploy on Oculus Quest 2 from Unity
Getting over that steep VR learning curve – our first time ever developing in three dimensions
Designing a pipeline between several APIs to achieve desired functionality
Developing functional environments and UI for VR
## What we learned
* 👾 An unfathomable amount of **Unity & C#** game development fundamentals – from nothing!
* 🧠 Implementing and working with **Cohere** models – rerank, chat & classify
* ☎️ C# HTTP requests in a **Unity VR** environment
* 🗣️ **OpenAI Whisper** for multilingual speech-to-text, and **ElevenLabs** for text-to-speech
* 🇫🇷🇨🇦 A lot of **French**. Our accents got noticeably better over the hours of testing.
## What's next for Vitre
* More language support
* More scenes for the existing language
* Real time grammar correction
* Pronunciation ranking and rating
* Change memories to different voices
## Credits
We took inspiration from the indie game “Before Your Eyes”, we are big fans! | partial |
## What it does
flarg.io is an Augmented Reality platform that allows you to play games and physical activities with your friends from across the world. The relative positions of each person will be recorded and displayed on a single augmented reality plane, so that you can interact with your friends as if they were in your own backyard.
The primary application is a capture the flag game, where your group will be split into two teams. Each team's goal is to capture the opposing flag and bring it back to the home-base. Tagging opposing players in non-safe-zones would put them on temporary time out, forcing them go back to their own home-base. May the best team win!
## What's next for flarg.io
Capture the flag is just the first of our suite of possible mini-games. Building off of the AR framework that we have built, the team foresees making other games like "floor is lava" and "sharks and minnows" with the same technology. | Demo: <https://youtu.be/cTh3Q6a2OIM?t=2401>
## Inspiration
Fun Mobile AR Experiences such as Pokemon Go
## What it does
First, a single player hides a virtual penguin somewhere in the room. Then, the app creates hundreds of obstacles for the other players in AR. The player that finds the penguin first wins!
## How we built it
We used AWS and Node JS to create a server to handle realtime communication between all players. We also used Socket IO so that we could easily broadcast information to all players.
## Challenges we ran into
For the majority of the hackathon, we were aiming to use Apple's Multipeer Connectivity framework for realtime peer-to-peer communication. Although we wrote significant code using this framework, we had to switch to Socket IO due to connectivity issues.
Furthermore, shared AR experiences is a very new field with a lot of technical challenges, and it was very exciting to work through bugs in ensuring that all users have see similar obstacles throughout the room.
## Accomplishments that we're proud of
For two of us, it was our very first iOS application. We had never used Swift before, and we had a lot of fun learning to use xCode. For the entire team, we had never worked with AR or Apple's AR-Kit before.
We are proud we were able to make a fun and easy to use AR experience. We also were happy we were able to use Retro styling in our application
## What we learned
-Creating shared AR experiences is challenging but fun
-How to work with iOS's Multipeer framework
-How to use AR Kit
## What's next for ScavengAR
* Look out for an app store release soon! | ## Inspiration
Last year, we wanted to build Augmented Reality between two people that can be played around the world. We wanted to make fantasy game that would not be seen normally today, like Pokemon. With technology like Microsoft Kinect, we can interact with User actions and animation at same time.
## What it does
The game is a 2 player gesture-based fighting game. Two users are using two Kinects backed by a Firebase backend to read all the data. The players are attempting to use these gestures to inflict damage on one another until a player wins. When a player gets hit, the phone vibrates in their pocket to give them feedback.
## How I built it
We started out with generic game view where you can see yourself on the Kinect screen of the computer. We formatted that we can recognize the gestures on the screen and add graphics. We also integrated IOS device to the game so users can get real time feed back and provide additional functionality to the game itself.
## Challenges I ran into
We had challenges on wireless networking as we are trying to have two computers get data from other other. Rendering effects using graphics and recognizing gestures took time.
## Accomplishments that I'm proud of
We are proud that we integrated Kinect, ios, and window application in one game. We were able to make a working game out of our love for fantasy gaming.
## What I learned
We learning a lot about C# and the Kinect's capabilities. Although it did not completely worked, we also learned a lot about networking and how to read/write bytes between two computers. We also learned about Firebase-iOS-Visual Studio integration.
## What's next for 4D-MOn
We plan to add more items and more custom appearances to enhance the user experience. We could potentially use the phone to add more effects too. | winning |
## Inspiration
I'm taking EECS 16A this semester and one thing that always bothers me is the homework submission. I have to combine everything into one PDF to submit, but this includes handwritten, typed, and code components. I usually had to use online PDF combiners to submit everything, but this meant that I had to export multiple PDFs, which was a hassle. So, I decided that for Cal Hacks, I would solve this problem using Google Apps Script.
## What it does
This add-on creates a sidebar that allows you to upload a PDF and displays it as a series of pages. These pages are all images, which can be then copied and pasted into the document. PDFs need to be uploaded one at a time, and any previous display is erased before a new PDF is shown.
## How I built it
I used Google Apps Script, which is something I am not too familiar with, but thankfully the documentation has some good examples. The sidebar is written in HTML, and unfortunately the online editor doesn’t have many functionalities, so the css and js scripts are also inside the same file. I used PDF.js, and created a separate canvas that would hold each PDF page to be displayed. This allows the user to copy each image individually and paste it into their document.
## Challenges I ran into
The one big challenge I had was actually to figure out how to publish it to the public. Most of the code is relatively simple and templated, so I was able to make a working prototype fairly quickly. However, figuring out how to allow other people to use this script took a long time. Because scripts are specific to each Google account, I can’t share the project. Anyways, at the moment, I have it pending for review in the Google Workspace Marketplace, and once it finishes the review process, other people will be able to use it.
## Accomplishments that I’m proud of
I’m proud of being able to come up with a working prototype in a day. I have worked on projects in the past, but they usually were at a more casual pace, where making it spanned several weeks or months. This being my first hackathon, I think I did pretty well in coming up with a good idea and making it in this short of a time frame.
## What I learned
I learned a lot about how to work with Google Apps Script as well as some different aspects of HTML/JS that I hadn’t known about before. It was really interesting to see that it didn’t take that much code to throw together an add-on, and it was fun to work a little on the front end.
## What's next for PDFs in Google Docs
At the moment, it is a somewhat rudimentary prototype. The design is very plain and, while it gets the job done, it is still a little cumbersome because you have to copy each individual page of the PDF. The next steps would probably be to allow for the drag and drop mechanic of pages, as well as a button to insert the whole PDF as a series of images into a certain spot in the document. I believe these are feasible and I already have a couple ideas to implement these features. | ## Inspiration
The inspiration came after we participated to the Cloud Platform on board conference in Montreal
## What it does
The web app takes an image that a user uploads to the site and converts it to Google Forms. It is saved in the Google Drive
## How we built it
We used Node,js, Google Cloud Platform with the help if the Vision API, AppScript API
## Challenges we ran into
We had a lot of problems connecting the AppScript mainly because we didn't know all the settings to include for authentification when sending the request.
## Accomplishments that we're proud of
We build an app that works with a nice UI
## What we learned
Google Cloud Platform is a great platform.
## What's next for GFormers
The sky is the limit | ## Inspiration
The other day, I heard my mom, a math tutor, tell her students "I wish you were here so I could give you some chocolate prizes!" We wanted to bring this incentive program back, even among COVID, so that students can have a more engaging learning experience.
## What it does
The student will complete a math worksheet and use the Raspberry Pi to take a picture of their completed work. The program then sends it to Google Cloud Vision API to extract equations. Our algorithms will then automatically mark the worksheet, annotate the jpg with Pure Image, and upload it to our website. The student then gains money based on the score that they received. For example, if they received a 80% on the worksheet, they will get 80 cents. Once the student has earned enough money, they can choose to buy a chocolate, where the program will check to ensure they have enough funds, and if so, will dispense it for them.
## How we built it
We used a Raspberry Pi to take pictures of worksheets, Google Cloud Vision API to extract text, and Pure Image to annotate the worksheet. The dispenser uses the Raspberry Pi and Lego to dispense the Mars Bars.
## Challenges we ran into
We ran into the problem that if the writing in the image was crooked, it would not detect the numbers on the same line. To fix this, we opted for line paper instead of blank paper which helped us to write straight.
## Accomplishments that we're proud of
We are proud of getting the Raspberry Pi and motor working as this was the first time using one. We are also proud of the gear ratio where we connected small gears to big gears ensuring high torque to enable us to move candy. We also had a lot of fun building the lego.
## What we learned
We learned how to use the Raspberry Pi, the Pi camera, and the stepper motor. We also learned how to integrate backend functions with Google Cloud Vision API
## What's next for Sugar Marker
We are hoping to build an app to allow students to take pictures, view their work, and purchase candy all from their phone. | losing |
## Inspiration
Our team wanted to make a smart power bar device to tackle the challenge of phantom power consumption. Phantom power is the power consumed by devices when they are plugged in and idle, accounting for approximately 10% of a home’s power consumption. [1] The best solution for this so far has been for users to unplug their devices after use. However, this method is extremely inconvenient for the consumer as there can be innumerable household devices that require being unplugged, such as charging devices for phones, laptops, vacuums, as well as TV’s, monitors, and kitchen appliances. [2] We wanted to make a device that optimized convenience for the user while increasing electrical savings and reducing energy consumption.
## What It Does
The device monitors power consumption and based on continual readings automatically shuts off power to idle devices. In addition to reducing phantom power consumption, the smart power bar monitors real-time energy consumption and provides graphical analytics to the user through MongoDB. The user is sent weekly power consumption update-emails, and notifications whenever the power is shut off to the smart power bar. It also has built-in safety features, to automatically cut power when devices draw a dangerous amount of current, or a manual emergency shut off button should the user determine their power consumption is too high.
## How We Built It
We developed a device using an alternating current sensor wired in series with the hot terminal of a power cable. The sensor converts AC current readings into 5V logic that can be read by an Arduino to measure both effective current and voltage. In addition, a relay is also wired in series with the hot terminal, which can be controlled by the Arduino’s 5V logic. This allows for both the automatic and manual control of the circuit, to automatically control power consumption based on predefined thresholds, or to turn on or off the circuit if the user believes the power consumption to be too high. In addition to the product’s controls, the Arduino microcontroller is connected to the Qualcomm 410C DragonBoard, where we used Python to push data sensor data to MongoDB, which updates trends in real-time for the user to see. In addition, we also send the user email updates through Python with the time-stamps based on when the power bar is shut off. This adds an extended layer of user engagement and notification to ensure they are aware of the system’s status at critical events.
## Challenges We Ran Into
One of our major struggles was with operating and connecting the DragonBoard, such as setting up connection and recognition of the monitor to be able to program and install packages on the DragonBoard. In addition, connecting to the shell was difficult, as well as any interfacing in general with peripherals was difficult and not necessarily straightforward, though we did find solutions to all of our problems.
We struggled with establishing a two-way connection between the Arduino and the DragonBoard, due to the Arduino microntrontroller shield that was supplied with the kit. Due to unknown hardware or communication problems between the Arduino shield and DragonBoard, the DragonBoard would continually shut off, making troubleshooting and integration between the hardware and software impossible.
Another challenge was tuning and compensating for error in the AC sensor module, as due to lack of access to a multimeter or an oscilloscope for most of our build, it was difficult to pinpoint exactly what the characteristic of the AC current sinusoids we were measuring. For context, we measured the current draw of 2-prong devices such as our phone and laptop chargers. Therefore, a further complication to accurately measure the AC current draws of our devices would have been to cut open our charging cables, which was out of the question considering they are our important personal devices.
## Accomplishments That We Are Proud Of
We are particularly proud of our ability to have found and successfully used sensors to quantify power consumption in our electrical devices. Coming into the competition as a team of mostly strangers, we cycled through different ideas ahead of the Makeathon that we would like to pursue, and 1 of them happened to be how to reduce wasteful power consumption in consumer homes. Finally meeting on the day of, we realized we wanted to pursue the idea, but unfortunately had none of the necessary equipment, such as AC current sensors, available. With some resourcefulness and quick-calling to stores in Toronto, we were luckily able to find components at the local electronics stores, such as Creatron and the Home Hardware, to find the components we needed to make the project we wanted.
In a short period of time, we were able to leverage the use of MongoDB to create an HMI for the user, and also read values from the microcontroller into the database and trend the values.
In addition, we were proud of our research into understanding the operation of the AC current sensor modules and then applying the theory behind AC to DC current and voltage conversion to approximate sensor readings to calculate apparent power generation. In theory the physics are very straightforward, however in practice, troubleshooting and accounting for noise and error in the sensor readings can be confusing!
## What's Next for SmartBar
We would build a more precise and accurate analytics system with an extended and extensible user interface for practical everyday use. This could include real-time cost projections for user billing cycles and power use on top of raw consumption data. As well, this also includes developing our system with more accurate and higher resolution sensors to ensure our readings are as accurate as possible. This would include extended research and development using more sophisticated testing equipment such as power supplies and oscilloscopes to accurately measure and record AC current draw. Not to mention, developing a standardized suite of sensors to offer consumers, to account for different types of appliances that require different size sensors, ranging from washing machines and dryers, to ovens and kettles and other smaller electronic or kitchen devices. Furthermore, we would use additional testing to characterize maximum and minimum thresholds for different types of devices, or more simply stated recording when the devices were actually being useful as opposed to idle, to prompt the user with recommendations for when their devices could be automatically shut off to save power. That would make the device truly customizable for different consumer needs, for different devices.
## Sources
[1] <https://www.hydroone.com/saving-money-and-energy/residential/tips-and-tools/phantom-power>
[2] <http://www.hydroquebec.com/residential/energy-wise/electronics/phantom-power.html> | ## Inspiration
We wanted to create a proof-of-concept for a potentially useful device that could be used commercially and at a large scale. We ultimately designed to focus on the agricultural industry as we feel that there's a lot of innovation possible in this space.
## What it does
The PowerPlant uses sensors to detect whether a plant is receiving enough water. If it's not, then it sends a signal to water the plant. While our proof of concept doesn't actually receive the signal to pour water (we quite like having working laptops), it would be extremely easy to enable this feature.
All data detected by the sensor is sent to a webserver, where users can view the current and historical data from the sensors. The user is also told whether the plant is currently being automatically watered.
## How I built it
The hardware is built on an Arduino 101, with dampness detectors being used to detect the state of the soil. We run custom scripts on the Arduino to display basic info on an LCD screen. Data is sent to the websever via a program called Gobetwino, and our JavaScript frontend reads this data and displays it to the user.
## Challenges I ran into
After choosing our hardware, we discovered that MLH didn't have an adapter to connect it to a network. This meant we had to work around this issue by writing text files directly to the server using Gobetwino. This was an imperfect solution that caused some other problems, but it worked well enough to make a demoable product.
We also had quite a lot of problems with Chart.js. There's some undocumented quirks to it that we had to deal with - for example, data isn't plotted on the chart unless a label for it is set.
## Accomplishments that I'm proud of
For most of us, this was the first time we'd ever created a hardware hack (and competed in a hackathon in general), so managing to create something demoable is amazing. One of our team members even managed to learn the basics of web development from scratch.
## What I learned
As a team we learned a lot this weekend - everything from how to make hardware communicate with software, the basics of developing with Arduino and how to use the Charts.js library. Two of our team member's first language isn't English, so managing to achieve this is incredible.
## What's next for PowerPlant
We think that the technology used in this prototype could have great real world applications. It's almost certainly possible to build a more stable self-contained unit that could be used commercially. | ## Inspiration
We love the playing the game and were disappointed in the way that there wasnt a nice web implementation of the game that we could play with each other remotely. So we fixed that.
## What it does
Allows between 5 and 10 players to play Avalon over the web app.
## How we built it
We made extensive use of Meteor and forked a popular game called [Spyfall](https://github.com/evanbrumley/spyfall) to build it out. This game had a very basic subset of rules that were applicable to Avalon. Because of this we added a lot of the functionality we needed on top of Spyfall to make the Avalon game mechanics work.
## Challenges we ran into
Building realtime systems is hard. Moreover, using a framework like Meteor that makes a lot of things easy by black boxing them is also difficult by the same token. So a lot of the time we struggled with making things work that happened to not be able to work within the context of the framework we were using. We also ended up starting the project over again multiple times since we realized that we were going down a path in which it was impossible to build that application.
## Accomplishments that we're proud of
It works. Its crisp. Its clean. Its responsive. Its synchronized across clients.
## What we learned
Meteor is magic. We learned how to use a lot of the more magical client synchronization features to deal with race conditions and the difficulties of making a realtime application.
## What's next for Avalon
Fill out the different roles, add a chat client, integrate with a video chat feature. | winning |
## Inspiration
Since the pandemic, millions of people worldwide have turned to online alternatives to replace public fitness facilities and other physical activities. At-home exercises have become widely acknowledged, but the problem is that there is no way of telling whether people are doing the exercises accurately and whether they notice potentially physically damaging bad habits they may have developed. Even now, those habits may continuously affect and damage their bodies if left unnoticed. That is why we created **Yudo**.
## What it does
Yudo is an exercise web app that uses **TensorFlow AI**, a custom-developed exercise detection algorithm, and **pose detection** to help users improve their form while doing various exercises.
Once you open the web app, select your desired workout and Yudo will provide a quick exercise demo video. The closer your form matches the demo, the higher your accuracy score will be. After completing an exercise, Yudo will provide feedback generated via **ChatGPT** to help users identify and correct the discrepancies in their form.
## How we built it
We first developed the connection between **TensorFlow** and streaming Livestream Video via **BlazePose** and **JSON**. We used the video's data and sent it to TensorFlow, which returned back a JSON object of the different nodes and coordinates which we used to draw the nodes onto a 2D canvas that updates every single frame and projected this on top of the video element. The continuous flow of JSON data from Tensorflow helped create a series of data sets of what different planks forms would look like. We used our own created data sets, took the relative positions of the relevant nodes, and then created mathematical formulas which matched that of the data sets.
After a discussion with Sean, a MLH member, we decided to integrate OpenAI into our project by having it provide feedback based on how well your plank form is. We did so by utilizing the **ExpressJS** back-end to handle requests for the AI-response endpoint. In the process, we also used **Nodaemon**, a process for continuously restarting servers on code change, to help with our development. We also used **Axios** to send data back and forth between the front end and backend
The front end was designed using **Figma** and **Procreate** to create a framework that we could base our **React** components on. Since it was our first time using React and Tensorflow, it took a lot of trial and error to get CSS and HTML elements to work with our React components.
## Challenges we ran into
* Learning and implementing TensorFlow AI and React for the first time during the hackathon
* Creating a mathematical algorithm that accurately measures the form of a user while performing a specific exercise
* Making visual elements appear and move smoothly on a live video feed
## Accomplishments that we're proud of
* This is our 2nd hackathon (except Darryl)
* Efficient and even work distribution between all team members
* Creation of our own data set to accurately model a specific exercise
* A visually aesthetic, mathematically accurate and working application!
## What we learned
* How to use TensorFlow AI and React
* Practical applications of mathematics in computer science algorithms
## What's next for Yudo
* Implementation of more exercises
* Faster and more accurate live video feed and accuracy score calculations
* Provide live feedback during the duration of the exercise
* Integrate a database for users to save their accuracy scores and track their progress | ## Inspiration
We wanted to get better at sports, but we don't have that much time to perfect our moves.
## What it does
Compares your athletic abilities to other users by building skeletons of both people and showing you where you can improve.
Uses ML to compare your form to a professional's form.
# Tells you improvements.
## How I built it
We used OpenPose to train a dataset we found online and added our own members to train for certain skills. Backend was made in python which takes the skeletons and compares them to our database of trained models to see how you preform. The skeleton for both videos are combined side by side in a video and sent to our react frontend.
## Challenges I ran into
Having multiple libraries out of date and having to compare skeletons.
## Accomplishments that I'm proud of
## What I learned
## What's next for trainYou | ## Inspiration
In today's fast-paced world, highly driven individuals often overwork themselves without regard for how it impacts their health, only experiencing the consequences *when it is too late*. **AtlasAI** aims to bring attention to these health issues at an early stage, such that our users are empowered to live their best lives in a way that does not negatively impact their health.
## What it does
We realized that there exists a gap between today's abundance of wearable health data and meaningful, individualized solutions which users can implement. For example, many smart watches today are saturated with metrics such as *sleep scores* and *heart rate variability*, many of which actually mean nothing to their users in practice. Therefore, **AtlasAI** aims to bridge this gap to finally **empower** our users to use this health data to enhance the quality of their lives.
Using our users' individual health data, **AtlasAI** is able to:
* suggest event rescheduling
* provide *targeted*, *actionable* feedback
* recommend Spotify playlists depending on user mood
## How we built it
Our frontend was built with `NextJS`, with styling from `Tailwind` and `MaterialUI`.
Our backend was built with `Convex`, which integrates technologies from `TerraAPI`, `TogetherAI` and `SpotifyAPI`.
We used a two-phase approach to fine-tune our model. First, we utilized TogetherAI's base models to generate test data (a list of rescheduled JSON event objects for the day). Then, we picked logically sound examples to fine-tune our model.
## Challenges we ran into
In the beginning, our progress was extremely slow as **AtlasAI** integrates so many new technologies. We only had prior experience with `NextJS`, `Tailwind` and `MaterialUI`, which essentially meant that we had to learn how to create our entire backend from scratch.
**AtlasAI** also went through many integrations throughout this weekend as we strove to provide the best recommendations for our users. This involved long hours spent in fine-tuning our `TogetherAI` models and testing out features until we were satisfied with our product.
## Accomplishments that we're proud of
We are extremely proud that we managed to integrate so many new technologies into **AtlasAI** over the course of three short days.
## What we learned
In the development realm, we successfully mastered the integration of several valuable third-party applications such as Convex and TogetherAI. This expertise significantly accelerated our ability to construct lightweight prototypes that accurately embody our vision. Furthermore, we honed our collaborative skills through engaging in sprint cycles and employing agile methodologies, which collectively enhanced our efficiency and expedited our workflow.
## What's next for AtlasAI
Research indicates that health data can reveal critical insights into health symptoms like depression and anxiety. Our goal is to delve deeper into leveraging this data to furnish enhanced health insights as proactive measures against potential health ailments. Additionally, we aim to refine lifestyle recommendations for the user's calendar to foster better recuperation. | winning |
### [GitHub](https://github.com/rylandonohoe/DevMate)
## Inspiration
As software interns these past few summers, we have continually encountered challenges learning the tools, procedures, and commands specific to the company at which we were working. Navigating proprietary commands and facing undocumented bugs have always made for a steep learning curve. The company wiki that is available is often disorganized, scattered, and sometimes deprecated. A more organized and updated company wiki system would not only accelerate our onboarding process but also allow employees alike to work more efficiently and autonomously.
## Build
To combat these hurdles, we set out to develop DevMate, an AI-powered assistant that integrates a finely-tuned chatbot with project board management. The chatbot is uniquely trained on a comprehensive set of resources: from wikis and code repositories to academic papers and project board issues. It creates embeddings, and uses caching and memory to store conversation history and optimize our requests. Our current proof of concept is specific to the IMAGE Project at McGill University’s Shared Reality Lab. This chatbot assistant can be applied to any organization’s documentation to provide their developers with a helpful aid in learning and navigating company software. It efficiently answers questions, provides direction, and offers interactive troubleshooting and debugging assistance.
Following a conversation with DevMate, if a user reports that they have solved their issue, DevMate parses through the company’s project board to see if other people have reported similar problems and, if so, it posts an automated comment summarizing the solution that was reached. If a user is not able to solve their problem with DevMate, they have the option to create a new issue on the project board automatically.
## Challenges
This project naturally integrated many different softwares and tools for it to come fully together. One of the largest parts of our project was figuring out how to train a LLM with the unique data of IMAGE. We experimented with several different LLMs and corresponding APIs for our chatbot, including GPT, DaVinci, Google, and Llama. We ran into many issues with the limitations of our computers and the constraints of available free APIs. While most of the models were very slow or had limitations on requests per minute, we ended up choosing GPT 3.5 for its superior performance. | ## Inspiration
We were inspired by the theme of exploration to better explore our communities and the events and new people that we can reach out to.
## What it does
Our web app uses a map where users can drop markers with information about events, sports games, parties, bar nights etc. The goal here is to inform users of nearby events and allow them to connect with others by posting their own events as well.
## How we built it
We built our project in javascript. We utilized the leaflet library for the map, and used express for the backend.
## Challenges we ran into
Leaflet was a library that we had never seen before and it took a long time to get used to using it. Furthermore, integrating it within our project was no easy task.
## Accomplishments that we're proud of
We're proud of creating an interesting project that we're actually passionate about and have plans on continuing work on it in the future. We believe we did a great job creating a complex and unique web app.
## What we learned
We learned a lot, especially about integrating multiple different parts of the project to create the final product. This was not an easy process, but we learned a lot of transferrable knowledge through this process.
## What's next for GoHere
We have plans to add a couple more features to GoHere that we didn't have the time to add within the hackathon. We wish to have a user verification system for making and removing posts along as adding a chat feature. | ## Inspiration
it's really fucking cool that big LLMs (ChatGPT) are able to figure out on their own how to use various tools to accomplish tasks.
for example, see Toolformer: Language Models Can Teach Themselves to Use Tools (<https://arxiv.org/abs/2302.04761>)
this enables a new paradigm self-assembling software: machines controlling machines.
what if we could harness this to make our own lives better -- a lil LLM that works for you?
## What it does
i made an AI assistant (SMS) using GPT-3 that's able to access various online services (calendar, email, google maps) to do things on your behalf.
it's just like talking to your friend and asking them to help you out.
## How we built it
a lot of prompt engineering + few shot prompting.
## What's next for jarbls
shopping, logistics, research, etc -- possibilities are endless
* more integrations !!!
the capabilities explode exponentially with the number of integrations added
* long term memory
come by and i can give you a demo | losing |
## Inspiration
Living in the big city, we're often conflicted between the desire to get more involved in our communities, with the effort to minimize the bombardment of information we encounter on a daily basis. NoteThisBoard aims to bring the user closer to a happy medium by allowing them to maximize their insights in a glance. This application enables the user to take a photo of a noticeboard filled with posters, and, after specifying their preferences, select the events that are predicted to be of highest relevance to them.
## What it does
Our application uses computer vision and natural language processing to filter any notice board information in delivering pertinent and relevant information to our users based on selected preferences. This mobile application lets users to first choose different categories that they are interested in knowing about and can then either take or upload photos which are processed using Google Cloud APIs. The labels generated from the APIs are compared with chosen user preferences to display only applicable postings.
## How we built it
The the mobile application is made in a React Native environment with a Firebase backend. The first screen collects the categories specified by the user and are written to Firebase once the user advances. Then, they are prompted to either upload or capture a photo of a notice board. The photo is processed using the Google Cloud Vision Text Detection to obtain blocks of text to be further labelled appropriately with the Google Natural Language Processing API. The categories this returns are compared to user preferences, and matches are returned to the user.
## Challenges we ran into
One of the earlier challenges encountered was a proper parsing of the fullTextAnnotation retrieved from Google Vision. We found that two posters who's text were aligned, despite being contrasting colours, were mistaken as being part of the same paragraph. The json object had many subfields which from the terminal took a while to make sense of in order to parse it properly.
We further encountered troubles retrieving data back from Firebase as we switch from the first to second screens in React Native, finding the proper method of first making the comparison of categories to labels prior to the final component being rendered. Finally, some discrepancies in loading these Google APIs in a React Native environment, as opposed to Python, limited access to certain technologies, such as ImageAnnotation.
## Accomplishments that we're proud of
We feel accomplished in having been able to use RESTful APIs with React Native for the first time. We kept energy high and incorporated two levels of intelligent processing of data, in addition to smoothly integrating the various environments, yielding a smooth experience for the user.
## What we learned
We were at most familiar with ReactJS- all other technologies were new experiences for us. Most notably were the opportunities to learn about how to use Google Cloud APIs and what it entails to develop a RESTful API. Integrating Firebase with React Native exposed the nuances between them as we passed user data between them. Non-relational database design was also a shift in perspective, and finally, deploying the app with a custom domain name taught us more about DNS protocols.
## What's next for notethisboard
Included in the fullTextAnnotation object returned by the Google Vision API were bounding boxes at various levels of granularity. The natural next step for us would be to enhance the performance and user experience of our application by annotating the images for the user manually, utilizing other Google Cloud API services to obtain background colour, enabling us to further distinguish posters on the notice board to return more reliable results. The app can also be extended to identifying logos and timings within a poster, again catering to the filters selected by the user. On another front, this app could be extended to preference-based information detection from a broader source of visual input. | # F.A.C.E. (FACE Analytics with Comp-vision Engineering)
## Idea
Using computer vision to provide business analytics on customers in brick and mortar stores
## Features
* number of customers over time period
* general customer demographics, such as age, and gender
* ability to see quantity of returning customers
* dashboard to view all of this information
* support for multiple cameras
## Technology
* Python script recording its camera, doing vision analysis, and then sending stats to node.js back-end
* express.js web-app providing communication between python scripts, mongodb, and dashboard.
* dashboard is built using bootstrap and jQuery | ## Inspiration
Selin's journey was the spark that ignited the creation of our platform. Originally diving into the world of chemistry, she believed it was her calling. However, as time unfolded, she realized it wasn't the path that resonated with her true passions. This realization, while enlightening, also brought with it a wave of confusion and stress. The weight of expectations, both self-imposed and from the university, pressed down on her, urging her to find a new direction swiftly. Yet, the vast expanse of potential careers felt overwhelming, leaving her adrift in a sea of options, not knowing which shore to swim towards. Selin's story isn't unique. It's a narrative that echoes across university halls, with countless students grappling with the same feelings of uncertainty and pressure. Recognizing this widespread challenge became the cornerstone of our mission: to illuminate the myriad of career paths available and guide students towards their true calling.
## What it does
Our platform is an AI-powered career mapping tool designed for students navigating the tech landscape. Utilizing advanced machine learning algorithms combined with psychology-driven techniques, it offers a dynamic and data-driven representation of potential career paths. Each job node within the map is informed by LLM and RAG methodologies, providing a comprehensive view based on real user trajectories and data. Beyond mere visualization, the platform breaks down tasks into detailed timelines, ensuring clarity at every step. By integrating insights from both AI and psychology algorithms, we aim to provide students with a clear, strategic blueprint for their ideal tech career.
## How we built it
We integrated advanced machine learning algorithms with psychology-driven techniques. The platform's backbone is built on LLM and RAG methodologies, informed by real user trajectories. We also incorporated various APIs, like the Hume AI API, to enhance user experience and data collection.
## Challenges we ran into
Embarking on this journey, we were rookies in the arena of hackathons, stepping into uncharted territory with a blend of enthusiasm and trepidation. The path was riddled with unexpected hurdles, the most formidable being a persistent bug in the RAG model from MindsDB. Hours that could have been spent refining and enhancing were instead consumed in troubleshooting this elusive issue. As if the technical challenges weren't daunting enough, the spirit of the hackathon was challenged as friends, one after another, decided to step away despite having amazing ideas. The weight of their absence, combined with the mounting pressure of having to reconstruct a new model (the bug turned out to be withing MindDB's RAG handler which we had no control over) in a race against time, was palpable. With the clock ticking, sleep became a luxury we could scarcely afford, operating on a mere three hours. Yet, in the face of these adversities, it was our shared vision and unwavering determination that became our beacon, guiding us through the darkest hours and reminding us of the potential impact of our creation. The true essence of our challenge wasn't just in navigating technical glitches or decreasing excitement in the event; it was about resilience, adaptability, and the relentless pursuit of innovation.
## Accomplishments that we're proud of
Successfully integrating the Hume AI API to translate user opinions into actionable data was a significant win and as well as connecting it into a spreadsheet for further analysis. Despite the hurdles and it being our inaugural hackathon, our team's perseverance saw us through to the end.
## What we learned
We gained a lot of insignts into the nature of LLM models and the intricacies of the RAG model. The experience also taught us the importance of adaptability and persistence in the face of unforeseen challenges.
## What's next for Orna
Our immediate goal is to finalize the MVP, refining the suggestion system. With these enhancements, we aim to secure seed investment to propel Orna to new heights. | winning |
## Inspiration
I love learning random, useless facts, so why not make a game out of it?!
## What it does
Series of games and challenges like tic-tac-toe, hangman and rock-paper-scissors, with the end result of "earning a fun fact". One does not simply learn a new fun fact... you earn it.
## How I built it
Repl.it IDE
Domain.com
## Challenges I ran into
1. Making each games function
2. Launching an actual website for the first time
3. Making the frontend aesthetic
## Accomplishments that I'm proud of
I worked alone so I'm quite proud I could still finish a project although I couldn't find teammates.
## What I learned
Learning to pivot!! When I ran into a wall, easily adapted to new approaches.
## What's next for EAFF (Earn a Fun Fact)
Would be nice to add more games/levels. | ## Inspiration
Winter Quarter is a rough quarter for every student at Stanford. Skies are gray, and rain drops every day. Even if we feel blue, there might not be someone that we could talk to. Duck Syndrom is real.
We first wanted to concentrate on Mental Health. However, because it might be a little dangerous if people who need help from professionals to rely on the bot, we thought it would be better to concentrate on increasing the positivity of the teenagers and college students. We thought if there is some software or technology that enables us to talk anytime we want to, that would be really helpful while going through mental crisis. If we could save the happiest moments of people's life and pull them up when they need it using the software, that would also help. We thought the best medium to do this is to use a bot.
## What it does
The ListenerBot is targeted for teenagers and college students, who would have a lot of different types of emotional crises and want to talk to somebody. The bot automatically replies to the user's input message. When the user inputs a positive message, the bot automatically saves it into its database. If the user types good memory, the bot will pick one of the positive messages in the database and return it to the user.
## How we built it
We used javascript, Ngrok, Firebase, Levenshtein Algorithm, and Machine Learning to build a listenerbot. We started from the starter chatbot pack, where we started to add the features that we wanted.
## Challenges we ran into
Working in a completely different framework and having to learn new languages and tools were the biggest challenge we faced. Especially because we had so many things to choose from, we were not sure which would help us reach the goal the most.
## Accomplishments that we're proud of
Implementing Levenshtein Algorithm, which we learned through reading journals, to generate the response was amazing. Making the Firebase work well with javascript, and pulling out the responses when needed was awesome.
## What we learned
It was our first hackathon!! Only two of the three members in our team had a working knowledge of development. However, we learned how to use javascript, nodeJS, and API calls to make the thing that we wanted to make. We have improved a lot as a hacker.
## What's next for ListenerBot
We hope to implement some machine learning techniques so that the bot can learn from the user's input. Feedback from a lot of users would be Also, in addition to the current integration with Facebook Messenger, we would love to see this bot in Skype or different medium. | ## Inspiration
The inspiration for the project was our desire to make studying and learning more efficient and accessible for students and educators. Utilizing advancements in technology, like the increased availability and lower cost of text embeddings, to make the process of finding answers within educational materials more seamless and convenient.
## What it does
Wise Up is a website that takes many different types of file format, as well as plain text, and separates the information into "pages". Using text embeddings, it can then quickly search through all the pages in a text and figure out which ones are most likely to contain the answer to a question that the user sends. It can also recursively summarize the file at different levels of compression.
## How we built it
With blood, sweat and tears! We used many tools offered to us throughout the challenge to simplify our life. We used Javascript, HTML and CSS for the website, and used it to communicate to a Flask backend that can run our python scripts involving API calls and such. We have API calls to openAI text embeddings, to cohere's xlarge model, to GPT-3's API, OpenAI's Whisper Speech-to-Text model, and several modules for getting an mp4 from a youtube link, a text from a pdf, and so on.
## Challenges we ran into
We had problems getting the backend on Flask to run on a Ubuntu server, and later had to instead run it on a Windows machine. Moreover, getting the backend to communicate effectively with the frontend in real time was a real challenge. Extracting text and page data from files and links ended up taking more time than expected, and finally, since the latency of sending information back and forth from the front end to the backend would lead to a worse user experience, we attempted to implement some features of our semantic search algorithm in the frontend, which led to a lot of difficulties in transferring code from Python to Javascript.
## Accomplishments that we're proud of
Since OpenAI's text embeddings are very good and very new, and we use GPT-3.5 based on extracted information to formulate the answer, we believe we likely equal the state of the art in the task of quickly analyzing text and answer complex questions on it, and the ease of use for many different file formats makes us proud that this project and website can be useful for so many people so often. To understand a textbook and answer questions about its content, or to find specific information without knowing any relevant keywords, this product is simply incredibly good, and costs pennies to run. Moreover, we have added an identification system (users signing up with a username and password) to ensure that a specific account is capped at a certain usage of the API, which is at our own costs (pennies, but we wish to avoid it becoming many dollars without our awareness of it.
## What we learned
As time goes on, not only do LLMs get better, but new methods are developed to use them more efficiently and for greater results. Web development is quite unintuitive for beginners, especially when different programming languages need to interact. One tool that has saved us a few different times is using json for data transfer, and aws services to store Mbs of data very cheaply. Another thing we learned is that, unfortunately, as time goes on, LLMs get bigger and so sometimes much, much slower; api calls to GPT3 and to Whisper are often slow, taking minutes for 1000+ page textbooks.
## What's next for Wise Up
What's next for Wise Up is to make our product faster and more user-friendly. A feature we could add is to summarize text with a fine-tuned model rather than zero-shot learning with GPT-3. Additionally, a next step is to explore partnerships with educational institutions and companies to bring Wise Up to a wider audience and help even more students and educators in their learning journey, or attempt for the website to go viral on social media by advertising its usefulness. Moreover, adding a financial component to the account system could let our users cover the low costs of the APIs, aws and CPU running Whisper. | losing |
## Inspiration
We wanted to do something fun and exciting, nothing too serious. Slang is a vital component to thrive in today's society. Ever seen Travis Scott go like, "My dawg would prolly do it for a Louis belt", even most menials are not familiar with this slang. Therefore, we are leveraging the power of today's modern platform called "Urban Dictionary" to educate people about today's ways. Showing how today's music is changing with the slang thrown in.
## What it does
You choose your desired song it will print out the lyrics for you and then it will even sing it for you in a robotic voice. It will then look up the urban dictionary meaning of the slang and replace with the original and then it will attempt to sing it.
## How I built it
We utilized Python's Flask framework as well as numerous Python Natural Language Processing libraries. We created the Front end with a Bootstrap Framework. Utilizing Kaggle Datasets and Zdict API's
## Challenges I ran into
Redirecting challenges with Flask were frequent and the excessive API calls made the program super slow.
## Accomplishments that I'm proud of
The excellent UI design along with the amazing outcomes that can be produced from the translation of slang
## What I learned
A lot of things we learned
## What's next for SlangSlack
We are going to transform the way today's menials keep up with growing trends in slang. | ## Inspiration
We all deal with nostalgia. Sometimes we miss our loved ones or places we visited and look back at our pictures. But what if we could revolutionize the way memories are shown? What if we said you can relive your memories and mean it literally?
## What it does
retro.act takes in a user prompt such as "I want uplifting 80s music" and will then use sentiment analysis and Cohere's chat feature to find potential songs out of which the user picks one. Then the user chooses from famous dance videos (such as by Michael Jackson). Finally, we will either let the user choose an image from their past or let our model match images based on the mood of the music and implant the dance moves and music into the image/s.
## How we built it
We used Cohere classify for sentiment analysis and to filter out songs whose mood doesn't match the user's current state. Then we use Cohere's chat and RAG based on the database of filtered songs to identify songs based on the user prompt. We match images to music by first generating a caption of the images using the Azure computer vision API doing a semantic search using KNN and Cohere embeddings and then use Cohere rerank to smooth out the final choices. Finally we make the image come to life by generating a skeleton of the dance moves using OpenCV and Mediapipe and then using a pretrained model to transfer the skeleton to the image.
## Challenges we ran into
This was the most technical project any of us have ever done and we had to overcome huge learning curves. A lot of us were not familiar with some of Cohere's features such as re rank, RAG and embeddings. In addition, generating the skeleton turned out to be very difficult. Apart from simply generating a skeleton using the standard Mediapipe landmarks, we realized we had to customize which landmarks we are connecting to make it a suitable input for the pertained model. Lastly, understanding and being able to use the model was a huge challenge. We had to deal with issues such as dependency errors, lacking a GPU, fixing import statements, deprecated packages.
## Accomplishments that we're proud of
We are incredibly proud of being able to get a very ambitious project done. While it was already difficult to get a skeleton of the dance moves, manipulating the coordinates to fit our pre trained model's specifications was very challenging. Lastly, the amount of experimentation and determination to find a working model that could successfully take in a skeleton and output an "alive" image.
## What we learned
We learned about using media pipe and manipulating a graph of coordinates depending on the output we need, We also learned how to use pre trained weights and run models from open source code. Lastly, we learned about various new Cohere features such as RAG and re rank.
## What's next for retro.act
Expand our database of songs and dance videos to allow for more user options, and get a more accurate algorithm for indexing to classify iterate over/classify the data from the db. We also hope to make the skeleton's motions more smooth for more realistic images. Lastly, this is very ambitious, but we hope to make our own model to transfer skeletons to images instead of using a pretrained one. | ## Inspiration
When travelling in a new place, it is often the case that one doesn't have an adequate amount of mobile data to search for information they need.
## What it does
Mr.Worldwide allows the user to send queries and receive responses regarding the weather, directions, news and translations in the form of sms and therefore without the need of any data.
## How I built it
A natural language understanding model was built and trained with the use of Rasa nlu. This model has been trained to work as best possible with many variations of query styles to act as a chatbot. The queries are sent up to a server by sms with the twill API. A response is then sent back the same way to function as a chatbot.
## Challenges I ran into
Implementing the Twilio API was a lot more time consuming than we assumed it would be. This was due to the fact that a virtual environment had to be set up and our connection to the server originally was not directly connecting.
Another challenge was providing the NLU model with adequate information to train on.
## Accomplishments that I'm proud of
We are proud that our end result works as we intended it to.
## What I learned
A lot about NLU models and implementing API's.
## What's next for Mr.Worldwide
Potentially expanding the the scope of what services/information it can provide to the user. | winning |
# Accel - Placed in Intel Track (to be updated by organizers)
Your empathetic chemistry tutor
[**GitHub »**](https://github.com/DavidSMazur/AI-Berkeley-Hackathon)
[Alex Talreja](https://www.linkedin.com/in/alexander-talreja)
·
[Cindy Yang](https://www.linkedin.com/in/2023cyang/)
·
[David Mazur](https://www.linkedin.com/in/davidsmazur/)
·
[Selina Sun](https://www.linkedin.com/in/selina-sun-550301227/)
## About The Project
Traditional study methods and automated tutoring systems often focus solely on providing answers. This approach neglects the emotional and cognitive processes that are crucial for effective learning. Students are left feeling overwhelmed, anxious, and disconnected from the material.
Accel is designed to address these challenges by offering a unique blend of advanced AI technology and emotional intelligence. Here's how Accel transforms the study experience:
* **Concept Breakdown**: Accel deconstructs complex chemistry topics into easy-to-understand segments, ensuring that students grasp foundational concepts thoroughly.
* **Emotional Intelligence**: Using cutting-edge vocal emotion recognition technology, Accel detects frustration, confusion, or boredom, tailoring its responses to match the student’s emotional state, offering encouragement and hints instead of immediate answers.
* **Adaptive Learning**: With Quiz Mode, students receive feedback on their progress, highlighting their strengths and areas for improvement, fostering a sense of accomplishment.
### Built With
[](https://nextjs.org/)
[](https://reactjs.org/)
[](https://tailwindcss.com/)
[](https://flask.palletsprojects.com/en/3.0.x/)
[](https://aws.amazon.com/bedrock/?gclid=CjwKCAjw7NmzBhBLEiwAxrHQ-R43KC_xeXdqadUZrt7upH8LYrZMbCOi-j7Hn7RHxfyKg1tJdlt2FBoCr_IQAvD_BwE&trk=0eaabb80-ee46-4e73-94ae-368ffb759b62&sc_channel=ps&ef_id=CjwKCAjw7NmzBhBLEiwAxrHQ-R43KC_xeXdqadUZrt7upH8LYrZMbCOi-j7Hn7RHxfyKg1tJdlt2FBoCr_IQAvD_BwE:G:s&s_kwcid=AL!4422!3!692006004688!p!!g!!amazon%20bedrock!21048268554!159639952935)
[](https://www.langchain.com/)
[](https://www.intel.com/content/www/us/en/developer/topic-technology/artificial-intelligence/overview.html)
[](https://beta.hume.ai/)
## Technologies
Technical jargon time 🙂↕️
### Intel AI
To build the core capabilities of Accel, we used both Intel Gaudi and the Intel AI PC. Intel Gaudi allowed us to distill a model ("selinas/Accel3") by fine-tuning with synthetic data we generated from Llama 70B model to 3B, allowing us to successfully run our app on the Intel AI PC. The prospect of distributing AI apps with local compute to deliver a cleaner and more secure user experience was very exciting, and we also enjoyed thinking about the distributed systems implications of NPUs.
### Amazon Bedrock
To further enhance the capabilities of Accel, we utilized Amazon Bedrock to integrate Retrieval-Augmented Generation (RAG) and AI agents. This integration allows the chatbot to provide more accurate, contextually relevant, and detailed responses, ensuring a comprehensive learning experience for students.
When a student asks a question, the RAG mechanism first retrieves relevant information from a vast database of chemistry resources. It then uses this retrieved information to generate detailed and accurate responses. This ensures that the answers are not only contextually relevant but also backed by reliable sources.
Additionally, we utilized agents to service the chat and quiz features of Accel. Accel dynamically routes queries to the appropriate agent, which work in coordination to deliver a seamless and multi-faceted tutoring experience. When a student queries, the relevant agent is activated to provide a specialized response.
### Hume EVI
The goal of Accel is to not only provides accurate academic support but also understands and responds to the emotional states of students, fostering a more supportive and effective learning environment.
Hume's EVI model was utilized for real-time speech to text (and emotion) conversion. The model begins listening when the user clicks the microphone input button, updating the input bar with what the model has heard so far. When the user turns their microphone off, this text is automatically sent as a message to Accel, along with the top 5 emotions picked up by EVI. Accel uses these cues to generate an appropriate response using our fine-tuned LLM.
Additionally, the users' current mood gauge is displayed on the frontend for a deeper awareness of their own study tendencies.
## Contact
Alex Talreja (LLM agents, Amazon Bedrock, RAG) - [[email protected]](mailto:[email protected])
Cindy Yang (frontend, design, systems integration) - [[email protected]](mailto:[email protected])
David Mazur (model distillation, model integration into web app) - [[email protected]](mailto:[email protected])
Selina Sun (synthetic data generation, scalable data for training, distribution through HuggingFace) - [[email protected]](mailto:[email protected]) | ## Inspiration
In many of our own lectures, professors ask students to indicate if they are following along (e.g., hand raising, and thumbs up/down reactions, one professor even said clap if you’re confused). We asked around, and students, including ourselves, often opt out of these reactions in-class to prevent looking like, in front of the whole class, that we’re the only ones not understanding the material. In turn, professors do not get an accurate overview of students’ understanding, harming both the professor and students. We want to make learning more productive through convenient and instantaneous feedback. We know people need what we’re making because we want to use this ourselves and have heard professors eager to gain student feedback during the lectures multiple times.
## What it does
We are creating software that allows professors to gain real-time feedback on the pace and clarity of their lectures.
During lectures, students can anonymously indicate they are confused, speed of the lecture, and ask and upvote questions at any point. The feedback is instantaneously communicated to the professor anonymously.
On the professor’s side, as more students click on the confused button, a small circle floating on the professor’s screen will turn red to alert the professor to re-explain a concept in real-time. If no one is confused, the circle remains green.
If the professor wants more information, he/she can hover over the circle to expand the window. The window includes student data on preferred lecture speed, percent of people confused, and top student questions. Professors can clear the question bank when they click on the clear button. Confusion and speed reactions will be cleared every 30 seconds automatically.
## How we built it
We used ElectronJS to build a cross-platform desktop client for both the professor and the student. In ElectronJS, we used HTML, CSS, and JavaScript to build a frontend as well as asynchronous techniques (using the electron ipcRenderer) to communicate between different processes. By leveraging special functions in ElectronJS, we’re able to produce a frameless, non-resizable, yet draggable floating window (that remains present even in a fullscreen) that perfectly achieves the behavior we intend for the floating indicator.
We used Firebase as a backend, leveraging the Firestore NoSQL database as a way to communicate the students’ engagement and feedback on the material, anonymously, with the professor. Implementation of snapshot listeners on both the student and professor clients allows for real-time feedback and achieves our value proposition of seamless feedback.
## Challenges we ran into
While designing the interface for the professor, we really wanted to be certain to make it as simple as possible while still providing essential information about student sentiment. As such, we found it challenging to design a UI that fulfilled these requirements without disrupting the professor’s lecture. Ultimately, we created a small, circular floating icon that can be moved throughout the screen. The icon changes color depending on students' reported confusion and lecture speed.
Another design challenge that we faced was whether or not to incorporate a “speed up” request button for the students. We felt conflicted that this button may be rarely used, but if it were used it would offer a lot of benefits. Ultimately we decided to incorporate this feature because the increase in UI complexity was minimal compared to the benefit it provided. This is because if a lecture is going too slow, it can actually increase student confusion because the points may seem disconnected.
## Accomplishments that we're proud of
We’re proud of narrowing down our scope to create a solution that solves a specific problem in the University track. VibeCheck effectively solves the problem that professors cannot gauge student understanding in lectures.
## What we learned
We learned how to work as a team, and bounce ideas off each other. For design, wireframes, and pitch deck, we brushed up on Figma and learned how to use some of their new features.
In order to build our software, we learned how to use HTML, CSS, and JavaScript in a lightweight and scalable way as we built VibeCheck. We also learned how to use ElectronJS to realize the value proposition (e.g., seamless, non-disruptive, immediate feedback) we’ve envisioned. We also learned how to integrate Firebase with ElectronJS (given that this integration is not officially supported), learned how to use the NoSQL database structure of FireStore, and use its real-time database features to achieve real-time feedback (another one of our value propositions) between the student and the professor.
Coming from a background of iOS app development with Swift, our developer really enjoyed learning how to use web-dev languages and platforms to create VibeCheck.
## What's next for VibeCheck
The next feature we want to implement is to allow professors to monitor the progress of the class and potentially reach out to students who, based on the statistics tracked by our platform, indicate they struggled with the class material (whose identity is hidden from the professor unless they otherwise consent). Additionally, this data can be played back during lecture recordings so that viewers can identify parts of the lecture requiring careful attention.
\*Github repo is not runnable because Google Cloud credentials are removed. | ## Inspiration
COVID revolutionized the way we communicate and work by normalizing remoteness. **It also created a massive emotional drought -** we weren't made to empathize with each other through screens. As video conferencing turns into the new normal, marketers and managers continue to struggle with remote communication's lack of nuance and engagement, and those with sensory impairments likely have it even worse.
Given our team's experience with AI/ML, we wanted to leverage data to bridge this gap. Beginning with the idea to use computer vision to help sensory impaired users detect emotion, we generalized our use-case to emotional analytics and real-time emotion identification for video conferencing in general.
## What it does
In MVP form, empath.ly is a video conferencing web application with integrated emotional analytics and real-time emotion identification. During a video call, we analyze the emotions of each user sixty times a second through their camera feed.
After the call, a dashboard is available which displays emotional data and data-derived insights such as the most common emotions throughout the call, changes in emotions over time, and notable contrasts or sudden changes in emotion
**Update as of 7.15am: We've also implemented an accessibility feature which colors the screen based on the emotions detected, to aid people with learning disabilities/emotion recognition difficulties.**
**Update as of 7.36am: We've implemented another accessibility feature which uses text-to-speech to report emotions to users with visual impairments.**
## How we built it
Our backend is powered by Tensorflow, Keras and OpenCV. We use an ML model to detect the emotions of each user, sixty times a second. Each detection is stored in an array, and these are collectively stored in an array of arrays to be displayed later on the analytics dashboard. On the frontend, we built the video conferencing app using React and Agora SDK, and imported the ML model using Tensorflow.JS.
## Challenges we ran into
Initially, we attempted to train our own facial recognition model on 10-13k datapoints from Kaggle - the maximum load our laptops could handle. However, the results weren't too accurate, and we ran into issues integrating this with the frontend later on. The model's still available on our repository, and with access to a PC, we're confident we would have been able to use it.
## Accomplishments that we're proud of
We overcame our ML roadblock and managed to produce a fully-functioning, well-designed web app with a solid business case for B2B data analytics and B2C accessibility.
And our two last minute accessibility add-ons!
## What we learned
It's okay - and, in fact, in the spirit of hacking - to innovate and leverage on pre-existing builds. After our initial ML model failed, we found and utilized a pretrained model which proved to be more accurate and effective.
Inspiring users' trust and choosing a target market receptive to AI-based analytics is also important - that's why our go-to-market will focus on tech companies that rely on remote work and are staffed by younger employees.
## What's next for empath.ly
From short-term to long-term stretch goals:
* We want to add on AssemblyAI's NLP model to deliver better insights. For example, the dashboard could highlight times when a certain sentiment in speech triggered a visual emotional reaction from the audience.
* We want to port this to mobile and enable camera feed functionality, so those with visual impairments or other difficulties recognizing emotions can rely on our live detection for in-person interactions.
* We want to apply our project to the metaverse by allowing users' avatars to emote based on emotions detected from the user. | partial |
## Inspiration
We decided to create Roadie with a profound purpose rooted in our team's diverse background encompassing music, computer science, business, operations planning, and a shared love of indie rock. Our collective mission was clear: to craft a service to democratize and empower independent "indie" musicians.
In the world of indie music, these immensely talented artists face a unique and daunting challenge – they must wear multiple hats. To pursue their passion and share their art with the world, a musician must not only excel in their craft but also play the roles of accountant, merchandise salesman, and tour planner. The weight of these responsibilities can become an overwhelming burden, detracting from what matters most – their music. Our heartfelt desire is to alleviate this burden, allowing artists to center their focus on their craft and get their show on the road.
In the ever-changing music industry, technology has transformed indie music. Social media and streaming have opened doors for indie artists. Today, a microphone and a computer can launch a music career. While online platforms offer global exposure, streaming and royalties alone are not enough for indie artists to in terms of income. Live performances are now crucial for indie musicians' financial survival.
Our goal is simple: to simplify the arduous process of touring for independent musicians by eliminating the need for intermediaries such as tour managers and booking agents. By doing so, we aim to enhance artists' financial sustainability, bolstering their bottom line and ultimately enabling them to continue doing what they love most: creating music that resonates with audiences far and wide. At its core, Roadie is driven by a profound love for music and the passionate artists who create it.
## What it does
Roadie offers a comprehensive suite of services to indie artists, including:
* Tour Routing / Optimization: Finding the most cost-effective travel options for artists. Venue
* Matching: Matching artists with venues that align with their Spotify profiles.
* Data-Driven Insights: Utilizing data analytics to optimize tour planning for cost-efficiency and time optimization.
With Roadie, artists can easily plan their tour by entering a list of target cities. From this, we give them the most optimal tour route, considering time and money, optimizing their time, and improving their bottom line.
Roadie stands out as the first platform directly catering to indie artists in tour planning. Existing tour management software primarily targets tour managers and provides a different level of direct access and cost reduction for artists. We offer direct access and cost savings that were previously out of reach for artists, putting their tour planning needs front and center.
## How we built it
Html, Css, Python, Beautiful Soup, Pandas, Flask, Selenium, Javascript, Figma, Spotify APIi, GPT 3.5
Our mission was to solve the “Traveling Salesman Problem”, a transportation optimization problem, for artists, a task often marked by complexity. To accommodate the touring preferences of smaller indie artists, limiting the number of cities to a maximum of 10 is prudent. We implemented a swift brute-force search algorithm for this scenario, swiftly delivering optimal solutions. Should the need arise for more extensive tours, we ventured into the realm of heuristic and approximation algorithms, notably considering Christofides' Algorithm for transportation optimization.
Our choice to define edge weights based on flight prices was strategic, recognizing economics's pivotal role in an artist's touring decisions. We navigated the challenges of integrating flight price APIs, acknowledging the inherent complexity in handling such data.
Curating a comprehensive database of concert venues across the United States was an exhaustive task. Surprisingly, existing datasets fell short of our needs, compelling us to scour the web for a suitable source. Harnessing the tenacity of our team and power of Selenium,
, we scraped over 300 subpages to extract invaluable data, meticulously cataloging each venue's name, address, and capacity. The result was a meticulously sorted dataset, faithfully serving our vision of optimizing concert tours for artists.
## Challenges we ran into
We encountered several challenges during our project:
Working with Flight Price APIs
* Integrating and effectively utilizing flight price APIs presented difficulties in terms of data retrieval and processing.
Setting Up the Basic Web Page
* The initial setup of our web page, which involved taking in Spotify links and location data and implementing the necessary HTML, JavaScript, and CSS, proved to be a complex task.
Web Scraping Spotify Data:
* Scraping Spotify URLs to extract artist names and monthly listeners required specialized knowledge and skills in web scraping.
Scraping Venue Data
* Collecting data from 6000 venues, including addresses and names, through web scraping was a time-consuming and technically demanding process.
Learning JavaScript:
* We had to invest time and effort into learning JavaScript to build the algorithm needed for our project, which was a significant learning curve.
Optimization Problem:
* Determining the most efficient approach to solving our optimization problem posed a unique challenge, requiring careful planning and problem-solving.
Overcoming these challenges required dedication, teamwork, and a commitment to expanding our technical expertise.
Lack of GPT Credit
* We wrote functional code to integrate an AI Chatbot into our service to help streamline the functionality and help users. Unfortunately we ran out of GPT Credit and could not implement this into our project.
## Accomplishments that we're proud of
1. Innovative Data Solution
We are proud of our ability to devise a novel solution to obtain monthly data from Spotify users when it was not readily available through the API. This innovative approach has empowered us to provide more prosperous and more insightful recommendations to our users, enhancing their overall experience.
2. Front-End Development
Prior to this project, our team had no experience with front end web development. While it took hard work, we take pride in our platform's user-friendly, visually appealing, and responsive design, which has garnered positive feedback and improved user engagement.
3. Resourceful Problem Solving
When faced with challenges in obtaining data from flight APIs, we showcased our resourcefulness by finding effective workarounds. This adaptability and problem-solving mindset have enabled us to provide comprehensive travel information to our users, even when traditional data sources pose limitations.
4. Creative Ideation and Efficient Operations
Our ability to ideate and organize operations efficiently is another source of pride. We have cultivated a culture of innovation and creativity within our team, allowing us to continually refine our product and work quickly.
5. Collaborative Teamwork
Teamwork is at the core of our success. Our diverse and talented team members collaborate seamlessly to tackle complex challenges, share knowledge, and support one another. Our teamwork formed an environment where innovative ideas flourish and each team member's unique strengths contribute to our collective success.
## What we learned
Rapid Problem-Solving
* We honed our ability to quickly analyze and solve complex problems under time constraints, a crucial skill for agile development.
JavaScript Mastery
* We sharpened our JavaScript skills, enabling us to create dynamic and interactive web applications.
Web Scraping Proficiency
* We learned efficient web scraping techniques, facilitating data collection from online sources.
Flask Server Setup
* Setting up and managing Flask servers became second nature to us, ensuring stable and responsive web applications.
Operations Management
* We improved our operations management capabilities, enhancing efficiency and cost-effectiveness.
Music Industry Insights
* We delved into the music industry, gaining valuable background knowledge that informs our data-driven recommendations and artist-venue matching.
These newfound skills and knowledge empower our team to excel in future projects and contribute to our ongoing growth and success.
## What's next for Roadie
To further enhance the user experience for Roadie, we have several exciting next steps in the pipeline:
1. Leveraging Data-Driven Insights: Besides artists picking their tour locations, We are harnessing the power of data-driven insights from streaming services. To make informed decisions about which cities and artists should be included in their tours
2. Genre-Based Venue Matching: Currently, our venue matching is based on the size of the artists. We aim to use Spotify data to identify musical genres and match them with venues that best suit those genres. For instance, we can tailor our recommendations so that a small country artist with a predominantly male fan base is connected with intimate venues like a pub. This process involves a deep dive into historical booking data for each venue, allowing us to match our users' profiles with past artists who share similar characteristics.
3. Algorithm Refinement: Our commitment to improvement extends to further optimizing our algorithm. This means striving for lower prices and minimizing the time artists spend on the road. We're constantly fine-tuning our algorithms to provide the most efficient and cost-effective touring options.
4. Integrated Accommodation Options: We also aim to incorporate hotel and Airbnb options into our platform. This feature will assist artists in selecting their accommodations while on tour, ensuring they have a comfortable and convenient place to stay.
At Roadie, we're dedicated to elevating the touring experience for both artists and fans, and these upcoming enhancements reflect our ongoing commitment to achieving that goal. | ## Inspiration
We love Travel. We love the environment. And just like us, the majority of Gen Z is prioritizing travel and their love for the environment 90% of Gen Z members reported making changes in their daily lives to live more sustainably, and according to Fortune, 79% Of Gen Z and Millennials see leisure travel as an important budget priority.
This inspired us to build Sproute, to help people do what they already want to do while being as sustainable as possible.
## What it does
Sproute is an AI-powered travel planner that prioritizes sustainability and making eco-friendly travel choices. Simply add your destination and preferences, and Sproute will give you a detailed itinerary of activities to do once you're at your destination including location, description, cost. Sproute will also give you the most sustainable mode of transportation between your activities with the time it takes, cost, and emissions associated with it. Sproute also allows you to add the itinerary to your calendar by downloading an ics file.
## How we built it
On the frontend we used React with shadcn and React Router. We used Flask to handle our itinerary generation, leveraging Groq and langchain for detailed and sustainable activity suggestions. We spent a significant amount of time engineering our prompt to prioritize activities with minimal carbon footprints and to ensure transportation between activities is as eco-friendly as possible. We calculate the carbon footprint for each instance of traveling based on the structured output of our LLM. To ensure ease of development, we used Docker to package each of our services.
## Challenges we ran into
Our first iteration of the backend would take longer than a minute to fulfill a request. By utilizing groq's inferencing power and formulating a more concise yet still comprehensive prompt, we were able to reduce this latency by a factor of 10.
## Accomplishments that we're proud of
This is our first time working with some of these tools and we are proud in this limited time we were able to build a fully functioning MVP.
## What's next for Sproute
Our mission is to help people do what they already want to do while being as sustainable as possible using AI.
Sproute doesn't stop at trip planning, we envision a product that helps people improve and rewards them for being more sustainable, including envisioning a sproute credit card that rewards the user for making green purchases, helps with tracking all the metrics of sustainability using AI. | ## Inspiration
3-D Printing. It has been around for decades, yet the printing process is often too complex to navigate, labour intensive and time consuming. Although the technology exists, it is only used by those who are trained in the field because of the technical skills required to operate the machine. We want to change all that. We want to make 3-D printing simpler, faster, and accessible for everyone. By leveraging the power of IoT and Augmented Reality, we created a solution to bridge that gap.
## What it does
Printology revolutionizes the process of 3-D printing by allowing users to select, view and print files with a touch of a button. Printology is the first application that allows users to interact with 3-D files in augmented reality while simultaneously printing it wirelessly. This is groundbreaking because it allows children, students, healthcare educators and hobbyists to view, create and print effortlessly from the comfort of their mobile devices. For manufacturers and 3-D Farms, it can save millions of dollars because of the drastically increased productivity.
The product is composed of a hardware and a software component. Users can download the iOS app on their devices and browse a catalogue of .STL files. They can drag and view each of these items in augmented reality and print it to their 3-D printer directly from the app. Printology is compatible with all models of printers on the market because of the external Raspberry Pi that generates a custom profile for each unique 3-D printer. Combined, the two pieces allow users to print easily and wirelessly.
## How I built it
We built an application in XCode that uses Apple’s AR Kit and converts STL models to USDZ models, enabling the user to view 3-D printable models in augmented reality. This had never been done before, so we had to write our own bash script to convert these models. Then we stored these models in a local server using node.js. We integrated functions into the local servers which are called by our application in Swift.
In order to print directly from the app, we connected a Raspberry Pi running Octoprint (a web based software to initialize the 3-D printer). We also integrated functions into our local server using node.js to call functions and interact with Octoprint. Our end product is a multifunctional application capable of previewing 3-D printable models in augmented reality and printing them in real time.
## Challenges I ran into
We created something that had never been done before hence we did not have a lot of documentation to follow. Everything was built from scratch. In other words this project needed to be incredibly well planned and executed in order to achieve a successful end product. We faced many barriers and each time we pushed through. Here were some major issues we faced.
1. No one on our team had done iOS development before and we a lot through online resources and trial and error. Altogether we watched more than 12 hours of YouTube tutorials on Swift and XCode - It was quite a learning curve. Ultimately with insane persistence, a full all-nighter and the generous help of the Deltahacks mentors, we troubleshooted errors and found new ways of getting around problems.
2. No one on our team had experience in bash or node.js. We learned everything from the Google and our mentors. It was exhausting and sometimes downright frustrating. Learning the connection between our javascript server and our Swift UI was extremely difficult and we went through loads of troubleshooting for our networks and IP addresses.
## Accomplishments that I'm proud of and what I've Learned
We're most proud of learning the integration of multiple languages, APIs and devices into one synchronized system. It was the first time that this had been done before and most of the software was made in house. We learned command line functions and figured out how to centralize several applications to provide a solution. It was so rewarding to learn an entirely new language and create something valuable in 24 hours.
## What's next for Print.ology
We are working on a scan feature on the app that allows users to do a 3-D scan with their phone of any object and be able to produce a 3-D printable STL file from the photos. This has also never been accomplished before and it would allow for major advancements in rapid prototyping. We look forward to integrating machine learning techniques to analyze a 3-D model and generate settings that reduce the number of support structures needed. This would reduce the waste involved in 3-D printing. A future step would be to migrate our STL files o a cloud based service in which users can upload their 3-D models. | losing |
## Inspiration
We wanted to take it easier this hackathon and do a "fun" hack.
## What it does
The user can search for a song in the Spotify library, and Music in Motion will make a music video based off of the lyrics of the song.
## How we built it
Music in Motion first searches for the song in the Spotify library, then scrapes the internet for the lyrics to the song. It then takes main keywords from the lyrics and uses those to find relevant gifs for each line of the song. These gifs are put together in succession and synced with the lyrics of the song to create a music video.
## Challenges we ran into
Our initial plan to use .lrc files to sync lyrics with gifs was thrown out the window when we weren't able to secure a reliable source of .lrc files. However, we found other ways of getting lyric timings that were nearly the same quality.
## Accomplishments that we're proud of
Getting the lyrics/gifs to sync up with the music was very challenging. Although not always perfect, we're definitely proud of the quality of what we were able to accomplish.
It also looks nice. At least we think so.
## What we learned
APIs can be very unreliable. Documentation is important.
## What's next for Music In Motion
FInding a reliable way to get .lrc files or lyric timings for a given song. Also finding other, more reliable gif APIs, since Giphy didn't always have a gif for us. | 
## Inspiration
Getting engagement is hard. People only read about 20% of the text on the average page.

After viewing the percent of article content viewed it shows that most readers scroll to about the 50 percent mark, or the 1,000th pixel, in Slate stories (a news platform).
This is alarming. Suppose if a company is writing an article about an event that they have sponsored. Having negligible engagement is not valued within the goals of any company spending money on marketing purposes.
Rather, what if this article was brought into a one minute format which would bring about to a much better engagement rate as compared to long pieces of text.
## What it does ⚡️
nu:here, an online platform for people of all age levels to create and distribute customizable videos based on Wikipedia articles created via Artificial Intelligence 👀. With our platform, we allow users to customize many different video aspects within the platform and share it with the world.
**The process for the user:**
1. User searches for a Wikipedia article on our platform
2. The user can start our video generation platform by specifying the length of the video that is wanted
3. The user can specify the formality of the video depending on what the target audience is (For the classroom, for sharing information on TikTok & Instagram, etc.)
4. The user can specify what voice model they want to use for the audio, using IBM’s text-to-speech API, the possibilities are endless
5. The user can then specify what kind of background music they want playing in the video
6. Once this step for the user is done, we are able to generate a short version of the Wikipedia article via co:here, create audio for the video via Watson AI, and generate keywords to use while finding GIFs, videos, and images on Pexels and Tenor, and put them in a video format.
## How we built it ⚡️
We mashed up many cutting-edge services to help bring our project to life.
* Firebase Storage - Store Audio files From Watson in the Cloud ☁️
* Watson Text-to-Speech - Generate audio for the video 🎵
* Wikipedia API - Get all the information from Wikipedia ℹ️
* co:here Generate API - Generate summaries for Wikipedia articles. The generate API is also used to find the best visual elements for the video. 🤖
* GPT-3 - Help generate training data for co:here at scale 🤖
* Pexels API - Find images and videos to put into our generated video 🖼
* Remotion - React library to help us play and assist in generating a video 🎥
* Tailwind CSS - CSS Framework ⭐️
* React.js - Frontend Library ⚛️
* Node.js & Express.js - Frameworks 🔐
* Figma - Design 🎨
## Challenges we ran into ⚡️
### co:here
We were determined to use co:here in this project, but we ran into a few major obstacles.
First, every call to co:here’s `generate` API had to contain no more than 2048 tokens. Our goal was to summarise whole Wikipedia articles, which often contain far more than 2048 words. To get around this, we developed complex algorithms to summarize sections of articles, then summarize groups of summaries, and so on.
It was difficult to preserve accuracy during this process, because the models were not perfect. We tried to engineer prompts using few-shot learning methods to teach our model what a good summary was. We even used GPT3 to generate training examples at scale! However, we were always limited by the 2048-token limit. Training data uses up capacity that we need for input.
A strange consequence of few-shot learning is that the model would pick up on the contents and cause our training data to bleed into our summaries. For example, one of our training summaries was a paragraph about Waterloo. When we asked co:here to summarize an article about geological faults, it wrongly claimed that there was one in Waterloo.
We had a desire to fit our videos into a certain amount of viewing time. We tried to restrict the duration using a token limit, but co:here does not consider the limit when planning its summaries. It sometimes goes into too much detail and misses out on points from later on in the text.
## Accomplishments that we're proud of ⚡️
* We are proud of using the co:here platform
* We are proud that we will be able to start sharing this platform after this hackathon is over
* We are proud that people will be able to use this
* We are proud of overcoming our obstacles
* We were able to accomplish all functionalities
* Most of all we had **fun**!
## What we learned ⚡️
We learned so much throughout the course of the hackathon. Natural Language Processing is not a silver bullet. In order to get our models to do what we want, we have to think like them. We didn’t have much experience using NLP but now we will continue to explore more applications for it.
## What's next for nu:here ⚡️
Adding features for users to customize and share videos is top priority for us on the engineering side. At the same time, we must address the elephant in the room: accuracy. In our quest to make information accessible and digestible, we must try as hard as we can to guard our users from mis-summarizations. Better models and user feedback can help us get there.
**View Video Demo Here (if the Youtube Video does not work): [Demo](https://cdn.discordapp.com/attachments/1019611034971013171/1021027599285231716/2022-09-18_07-52-35_Trim.mp4)** | ## 💡 Inspiration
Manga are Japanese comics, considered to form a genre unique from other graphic novels. Similar to other comics, it lacks a musical component. However, their digital counterparts (such as sites like Webtoons) have innovated on their take on the traditional format with the addition of soundtracks, playing concurrently with the reader's progression through the comic. It can create an immersive experience for the reader building the emotion on screen. While Webtoon’s take on incorporating music is not mainstream, we believe there is potential in building on the concept and making it mainstream in online manga. Imagine how cool it would be to generate a soundtrack to the story unfolding. Who doesn't enjoy personalized music while reading?
## 💻 What it does
1. Users choose a manga chapter to read (in our prototype, we're using just one page).
2. Sentiment analysis is performed on the dialogue of the manga.
3. The resulting sentiment is used to determine what kind of music is fed into the song-generating model.
4. A new song will be created and played while the user reads the manga.
## 🔨 How we built it
* Started with brainstorming
* Planned and devised a plan for implementation
* Divided tasks
* Implemented the development of the project using the following tools
*Tech Stack* : Tensorflow, Google Cloud (Cloud Storage, Vertex AI), Node.js
Registered Domain name : **mangajam.tech**
## ❓Challenges we ran into
* None of us knew machine learning at the level that this project demanded of us.
* Timezone differences and the complexity of the project
## 🥇 Accomplishments that we're proud of
The teamwork of course!! We are a team of four coming from three different timezones, this was the first hackathon for one of us and the enthusiasm and coordination and support were definitely unique and spirited. This was a very ambitious project but we did our best to create a prototype proof of concept. We really enjoyed learning new technologies.
## 📖 What we learned
* Using TensorFlow for sound generation
* Planning and organization
* Time management
* Performing Sentiment analysis using Node.js
## 🚀 What's next for Magenta
Oh tons!! We have many things planned for Magenta in the future.
* Ideally, we would also do image recognition on the manga scenes to help determine sentiment, but it's hard to actualize because of varying art styles and genres.
* To add more sentiments
* To deploy the website so everyone can try it out
* To develop a collection of Manga along with the generated soundtrack | partial |
## Inspiration
We wanted to make an app that would be useful for university/college students. Cooking for yourself is one of the hardest things to get used to when coming to post-secondary school, and PantryPal is useful tool to aid students in learning how to cook.
## What it does
The user can input the food items they have in their pantry (and fridge), then PantryPal will generate a list of possible recipes that can be made with the food on hand. The use of Spoonacular.api allows you to access over 365,000 recipes and 86,000 food products
## How we built it
We developed PantryPal using Android Studio and Java.
## Challenges we ran into
The main challenge we faced was building the GUI for the app. None of our group was familiar with building apps in Android Studio so the learning curve was quite steep.
## Accomplishments that we're proud of
We are happy that we got a working product.
## What we learned
We learned a lot about Android Studio, but more importantly we learned about how rewarding perseverance and hard work is.
## What's next for Hackathon Project
Polishing up the GUI and improving app functionality, publishing the app on the Google Play Store. | ## Inspiration
The motivation for creating this application came from a lazy evening when we opened our refrigerator and took a thorough look. We realized that much of our groceries were expired. Two cans of milk were one week out of date, the chicken that we bought from Whole foods smelt really bad and the mushrooms looked like they were left untouched for months. It is not that we do not cook at home at all but still such sight made us shocked. We realized we cannot be the only one who waste food and the very next day we started thinking for the food!
## What it does
Our android application is able to scan barcode and list the food items along with their purchase date and expiry date. We know that we cannot get expiry date from just scanning barcodes but if we create a tie up with grocery stores and can access their inventory then by just scanning the 1-D barcode which is present in the bill, we can fetch all the important information. Once we have the data that we need then we notify the user prior to the expiry date. The user will also have an option to enter the dates manually.
Another novel idea is to generate a list of recipes based on the ingredients generated by Artificial Intelligence which will not only help the user to cook but also to make use of the foods that can otherwise be perished sitting idle inside the refrigerator.
## How we built it
The application we built is by using Android Studio, Kotlin and love.
## Challenges we ran into
Apart from tiring days and sleepless nights, we ran into series of small technical issues that we worked hard to solve.
## Accomplishments that we're proud of
We are proud of what we have achieved in this short span of time. We built something that we really put a thought into after several iterations and we hope someday it will be of real use to the world.
## What we learned
We all need to contribute something to the society and if the work is interesting we are ready to put 100% of our time and effort.
## What's next for For Food
the future is definitely bright for app as it can affect the life of millions. | ## Inspiration
The inspiration for our application stemmed from the desire to solve an issue we, our friends, and our families have experienced. We noticed that hospitals work individually to combat the issue of long patient wait times, and the Canadian government has spent over 100 million dollars to fix it in the past year alone. Introducing, a service that works with all hospitals—a collaborative approach to better the lives of all Canadian citizens.
## What it does
TimeToCare is a web-based application designed to mitigate the long wait times experienced in hospital ER settings. Our service tackles the root of the problem by directing patient streams to hospitals better-suited to accommodate them. This results in a smoothed out demand at each health care centre, less frequent patient-demand spikes, and thus faster time to be treated.
## How we built it
We built the components of our app with a few different languages and tools. They include HTML/CSS to build the framework of our website, Javascript for the general functionality of the website, and data from the Google Maps API.
## Challenges we ran into
Challenges in our project mostly arose from the learning curve of what was required to build our application.
## Accomplishments that we're proud of
We are very proud to have developed a website, we believe, could have an impact in the health field. We came to HackWestern with the hope of solving this problem and despite our relative inexperience with any of the APIs or new languages, we feel like we have accomplished something amazing.
## What we learned
Including the programs and tools we used to build TimeToCare, we also learned teamwork, the importance of clear communication and good design principles.
## What's next for TimeToCare
Our next step for TimeToCare would be to create a scalable build. Now that we have supported our theory of directing patients to hospitals based on wait times and distance, we would like to see it run using real-time data, in numerous locations. We could see the required data being pulled from a government website or provided by the hospitals directly to the app. | losing |
## Inspiration
Despite the advent of the information age, misinformation remains a big issue in today's day and age. Yet, mass media accessibility for newer language speakers, such as younger children or recent immigrants, remains lacking. We want these people to be able to do their own research on various news topics easily and reliably, without being limited by their understanding of the language.
## What it does
Our Chrome extension allows users to shorten and simplify and any article of text to a basic reading level. Additionally, if a user is not interested in reading the entire article, it comes with a tl;dr feature. Lastly, if a user finds the article interesting, our extension will find and link related articles that the user may wish to read later. We also include warnings to the user if the content of the article contains potentially sensitive topics, or comes from a source that is known to be unreliable.
Inside of the settings menu, users can choose a range of dates for the related articles which our extension finds. Additionally, users can also disable the extension from working on articles that feature explicit or political content, alongside being able to disable thumbnail images for related articles if they do not wish to view such content.
## How we built it
The front-end Chrome extension was developed in pure HTML, CSS and JavaScript. The CSS was done with the help of [Bootstrap](https://getbootstrap.com/), but still mostly written on our own. The front-end communicates with the back-end using REST API calls.
The back-end server was built using [Flask](https://flask.palletsprojects.com/en/2.0.x/), which is where we handled all of our web scraping and natural language processing.
We implemented text summaries using various NLP techniques (SMMRY, TF-IDF), which were then fed into the OpenAI API in order to generate a simplified version of the summary. Source reliability was determined using a combination of research data provided by [Ad Fontes Media](https://www.adfontesmedia.com/) and [Media Bias Check](https://mediabiasfactcheck.com/).
To save time (and spend less on API tokens), parsed articles are saved in a [MongoDB](https://www.mongodb.com/) database, which acts as a cache and saves considerable time by skipping all the NLP for previously processed news articles.
Finally, [GitHub Actions](https://github.com/features/actions) was used to automate our builds and deployments to [Heroku](https://www.heroku.com/), which hosted our server.
## Challenges we ran into
Heroku was having issues with API keys, causing very confusing errors which took a significant amount of time to debug.
In regards to web scraping, news websites have wildly different formatting which made extracting the article's main text difficult to generalize across different sites. This difficulty was compounded by the closure of many prevalent APIs in this field, such as Google News API which shut down in 2011.
We also faced challenges with tuning the prompts in our requests to OpenAI to generate the output we were expecting. A significant amount of work done in the Flask server is pre-processing the article's text, in order to feed OpenAI a more suitable prompt, while retaining the meaning.
## Accomplishments that we're proud of
This was everyone on our team's first time creating a Google Chrome extension, and we felt that we were successful at it. Additionally, we are happy that our first attempt at NLP was relatively successful, since none of us have had any prior experience with NLP.
Finally, we slept at a Hackathon for the first time, so that's pretty cool.
## What we learned
We gained knowledge of how to build a Chrome extension, as well as various natural language processing techniques.
## What's next for OpBop
Increasing the types of text that can be simplified, such as academic articles. Making summaries and simplifications more accurate to what a human would produce.
Improving the hit rate of the cache by web crawling and scraping new articles while idle.
## Love,
## FSq x ANMOL x BRIAN | ## Inspiration
Our mission is rooted in the **fight against fake news, misinformation, and disinformation,** which are increasingly pervasive threats in today’s digital world. As the saying goes, "the pen is mightier than the sword," which underscores the power of words and information. We aim to ensure that no one falls victim to digital deception.
While technology has contributed to the spread of misinformation, we believe it can also be a powerful ally in promoting the truth. By leveraging AI for good, we aim to combat falsehoods and uphold the integrity of information.
*Fun fact: Moodeng is a pygmy hippopotamus born on July 10, 2024, living in Khao Kheow Open Zoo, Thailand. She became a viral internet sensation during a busy political season in the US. Amid the flood of true and half-true information, Moodeng, symbolizing purity and honesty, stood as a beacon of clarity. Like Moodeng, our tool is here to cut through the noise and keep things transparent. So, Vote for Moodeng!*
## What it does
Social media platforms are now major sources of rapidly shared information. Our Chrome extension, MD FactFarm, simplifies fact-checking through AI-driven content analysis and verification. Initially focused on YouTube, our tool offers **real-time fact-checking** by scanning video content to **identify and flag misinformation** while providing reliable sources for users to verify accuracy.
## How we built it
* At the core of our system is a Large Language Model (LLM) that we trained and optimized to accurately understand and interpret various forms of misinformation, powering our fact-checking capabilities.
* We integrated an AI agent using Fetch.ai and built services and APIs to enable seamless communication with the agent.
* Our front-end, built with HTML, CSS, and JavaScript, was designed and deployed as a Chrome extension.
## Challenges we ran into
* One of the major challenges we encountered was ensuring that the AI could accurately differentiate between fact, opinion, and misleading content. Early on, the outputs were inconsistent, making it difficult to trust the results.
To achieve this, we had to rethink our approach to prompt engineering. We provided the AI with more detailed context and built a structured framework to clearly separate different types of content. Additionally, we implemented a formula for the AI to use to determine a confidence score for each output. These changes helped us generate more consistent and reliable results, enabling the AI to better recognize the subtle distinctions between fact, opinion, and misleading content.
* Another challenge was integrating multiple agent frameworks into a unified system that could operate seamlessly. Managing the intricacies of coordinating tasks and data flow between these diverse components contributed to a complex integration process.
## Accomplishments that we're proud of
* We successfully developed a Chrome extension that that provides real-time fact-checking for YouTube, empowering users to make informed decisions.
* We crafted prompts that effectively leverage the LLM's ability to detect misinformation.
* We successfully integrated Fetch.ai, utilizing agents that lay the foundation for scalability.
## What we learned
We learned the importance of defining the problem clearly and deciding on a minimum viable product (MVP) within a limited timeframe. Additionally, we focused on framing our work to align with the AI agent framework, which has been crucial in improving our approach to misinformation detection.
## What's next for MD FactFarm
Moving forward, we plan to expand our platform to include other social networks, such as Twitter and Facebook, where misinformation spreads rapidly. We aim to gather a wider range of information sources to ensure more comprehensive fact-checking and cover more diverse content. Moreover, we are working on enhancing our AI's fact-checking mechanics, utilizing more advanced techniques to improve accuracy. | Fake news or not? Make informed decisions with Insite, the summarizing and analyzing extension. Get the real Insite on things!
See right away if an article is perceived to be fake with the use of advanced APIs that analyze the article from beginning to end.
Download now @ <https://chrome.google.com/webstore/detail/insite/kalaoonpgfodfdoleffjbchodofdmgno?hl=en>
## Inspiration
We wanted to have a quick and simple way of determining if something was likely to be fake news or not. Many existing services take too long, and need you to copy and paste the url into a separate web page. Insite allows you to do this in the browser, without ever leaving the page.
## What it does
Key features:
* Fake news analysis in percentage
* Summarize long articles to a fraction of their size
* Helps people make informed decisions about what they're reading
## How we built it
Used a Python Flask backend that called the required APIs and dealt with required authentication for said APIs. The backend also parsed and returned the data from the APIs into a simple format so that the frontend could easily use it.
We made a chrome extension with a popup that would appear when you clicked on the icon. From there, we used jquery to simply call the Python backend, and displayed the data it returned.
## Challenges we ran into
As a result of a lack of foresight, we initially rushed into the project without enough planning. As a result, we began developing the Chrome extension as a tooltip that would appear when the mouse hovered above a valid link. This, however, proved to be extremely difficult given our inexperience with web extensions. We struggled to get the tooltip to appear in the first place. Once we were able to implement a dummy tooltip, we were unable to modify our extension to call the API's used in our project. This problem persisted, and thus, we decided to take a more streamlined approach that alleviates the need for a tooltip. Our team now realizes that we spent too much time trying to develop the tooltip functionality, which distracted us from the bigger picture. In the future, we will come together as a team periodically and discuss our progress to ensure that we stay on track throughout the hackathon.
## Accomplishments that we're proud of
We're proud that we pivoted away from trying to directly fix the problem, as the potential solutions that we tried to implement didn't work. Instead, a more simple and easier implementation was used, which completely avoided the issues that we had with the flood of server requests with the back end. Finding this simplicity was key to being able to deliver our project.
## What we learned
Never underestimate a task, no matter how easy it *seems*. If you are running into trouble, either pivot the idea, or try to simplify things, as making things more complex than they need to be is never good. Never spend more than 1 hour doing something if you aren't making progress.
Break down problems, and discuss constantly with team mates about any blocking challenges or issues.
## What's next for Insite
Performance improvements on the backend, as well as displaying more metrics to help people make an informed decision. | partial |
## Inspiration
As students around 16 years old, skin conditions such as acne make us even more self-conscious than we already are. Furthermore, one of our friends is currently suffering from eczema, so we decided to make an app relating to skin care. While brainstorming for ideas, we realized that the elderly are affected by more skin conditions than younger people. These skin diseases can easily transform into skin cancer if left unchecked.
## What it does
Ewmu is an app that can assist people with various skin conditions. It utilizes machine learning to provide an accurate evaluation of the skin condition of an individual. After analyzing the skin, Ewmu returns some topical creams or over-the-top-medication that can alleviate the users' symptoms.
## How we built it
We built Ewmu by splitting the project into 3 distinct parts. The first part involved developing and creating the Machine Learning backend model using Swift and the CoreML framework. This model was trained on datasets from Kaggle.com, which we procured over 16,000 images of various skin conditions ranging from atopic dermatitis to melanoma. 200 iterations were used to train the ML model, and it achieved over 99% training accuracy, and 62% validation accuracy and 54% testing accuracy.
The second part involved deploying the ML model on a flask backend which provided an API endpoint for the frontend to call from and send the image to. The flask backend fed the image data to the ML model which gave the classification and label for the image. The result was then taken to the frontend where it was displayed.
The frontend was built with React.JS and many libraries that created a dashboard for the user. In addition we used libraries to take a photo of the user and then encoded that image to a base64 string which was sent to the flask backend.
## Challenges we ran into
Some challenges we ran into were deploying the ML model to a flask backend because of the compatibility issue between Apple and other platforms. Another challenge we ran into was the states within React and trying to get a still image from the webcam, then mapping it over to a base64 encode, then finally sending it over to the backend flask server which then returned a classification.
## Accomplishments that we're proud of
* Skin condition classifier ML model
+ 99% training accuracy
+ 62% validation accuracy
+ 54% testing accuracy
We're really proud of creating that machine learning model since we are all first time hackers and haven't used any ML or AI software tools before, which marked a huge learning experience and milestone for all of us. This includes learning how to use Swift on the day of, and also cobbling together multiple platforms and applications: backend, ML model, frontend.
## What we learned
We learned that time management is all to crucial!! We're writing this within the last 5 minutes as we speak LMAO. From the technical side, we learned how to use React.js to build a working and nice UI/UX frontend, along with building a flask backend that could host our custom built ML model. The biggest thing we took away from this was being open to new ideas and learning all that we could under such a short time period!
* TIL uoft kids love: ~~uwu~~
## What's next for Ewmu
We're planning on allowing dermatologists to connect with their patients on the website. Patients will be able to send photos of their skin condition to doctors. | ## Inspiration
The general challenge of UottaHack 4 was to create a hack surrounding COVID-19. We got inspired by a COVID-19 restriction in the province of Quebec which requires stores to limit the number of people allowed in the store at once (depending on the store floor size). This results in many stores having to place an employee at the door of the shop to monitor the people entering/exiting, if they are wearing a mask and to make sure they disinfect their hands. Having an employee dedicated to monitoring the entrance can be a financial drain on a store and this is where our idea kicks in, dedicating the task of monitoring the door to the machine so the human resources could be best used elsewhere in the store.
## What it does
Our hack monitors the entrance of a store and does the following:
1. It counts how many people are currently in the store by monitoring the number of people that are entering/leaving the store.
2. Verifies that the person entering is wearing PPE ( a mask ). If no PPE was recognized, and a reminder to wear a mask is played from a speaker on the Raspberry Pi.
3. Verify that the person entering has used the sanitation station and displays a message thanking them for using it.
4. Display information to people entering such as. how many people are in the store and what is the store's max capacity, reminders to wear a mask, and thanks for using the sanitation station
5. Provides useful stats to the shop owner about the monitoring of the shop.
## How we built it
**Hardware:** The hack uses a Raspberry Pi and it PiCam to monitor the entrance.
**Monitoring backend:** The program starts by monitoring the floor in front of the door for movement this is done using OpenCV. Once movement is detected pictures are captured and stored. the movement is also analyzed to estimate if the person is leaving or entering the store. Following an event of someone entering/exiting, a secondary program analyses the collection of a picture taken and submits chooses one of them to be analyzed by google cloud vision API. The picture sent to the google API looks for three features: faces, object location (to identify people's bodies), and labels (to look for PPE). Using the info from the Vision API we can determine first if the person has PPE and if the difference in the number of people leaving and entering by comparing the number of faces to the body detected. if the is fewer faces than bodies then that means people have left, if there is the same amount then only people entered. Back on the first program, another point is being monitored which is the sanitation station. if there is an interaction(movement) with it then we know the person entering has used it.
**cloud backend:**
The front end and monitoring hardware need a unified API to broker communication between the services, as well as storage in the mongoDB data lake; This is where the cloud backend shines. Handling events triggered by the monitoring system, as well as user defined configurations from the front end, logging, and storage. All from a highly available containerized Kubernetes environment on GKE.
**cloud frontend:**
The frontend allows the administration to set the box parameters for where the objects will be in the store. If they are wearing a mask and sanitized their hands, a message will appear stating "Thank you for slowing the spread." However, if they are not wearing a mask or sanitized their hands, then a message will state "Please put on a mask." By doing so, those who are following protocols will be rewarded, and those who are not will be reminded to follow them.
## Challenges we ran into
On the monitoring side, we ran into problems because of the color of the pants. Having bright-colored pants registered as PPE to Google's Cloud Vision API (they looked to similar to reflective pants PPe's).
On the backend architecture side, developing event driven code was a challenge, as it was our first time working with such technologies.
## Accomplishments that we're proud of
The efficiency of our computer vision is something we are proud of as we initially started with processing each frame every 50 milliseconds, however, we optimized the computer vision code to only process a fraction of our camera feed, yet maintain the same accuracy. We went from 50 milliseconds to 10 milliseconds
## What we learned
**Charles:** I've learn how to use the google API
**Mingye:** I've furthered my knowledge about computer vision and learned about google's vision API
**Mershab:** I built and deployed my first Kubernetes cluster in the cloud. I also learned event driven architecture.
## What's next for Sanitation Station Companion
We hope to continue improving our object detection and later on, detect if customers in the store are at least six feet apart from the person next to them. We will also remind them to keep their distance throughout the store as well. Their is also the feature of having more then on point of entry(door) monitored at the same time. | View presentation at the following link: <https://youtu.be/Iw4qVYG9r40>
## Inspiration
During our brainstorming stage, we found that, interestingly, two-thirds (a majority, if I could say so myself) of our group took medication for health-related reasons, and as a result, had certain external medications that result in negative drug interactions. More often than not, one of us is unable to have certain other medications (e.g. Advil, Tylenol) and even certain foods.
Looking at a statistically wider scale, the use of prescription drugs is at an all-time high in the UK, with almost half of the adults on at least one drug and a quarter on at least three. In Canada, over half of Canadian adults aged 18 to 79 have used at least one prescription medication in the past month. The more the population relies on prescription drugs, the more interactions can pop up between over-the-counter medications and prescription medications. Enter Medisafe, a quick and portable tool to ensure safe interactions with any and all medication you take.
## What it does
Our mobile application scans barcodes of medication and outputs to the user what the medication is, and any negative interactions that follow it to ensure that users don't experience negative side effects of drug mixing.
## How we built it
Before we could return any details about drugs and interactions, we first needed to build a database that our API could access. This was done through java and stored in a CSV file for the API to access when requests were made. This API was then integrated with a python backend and flutter frontend to create our final product. When the user takes a picture, the image is sent to the API through a POST request, which then scans the barcode and sends the drug information back to the flutter mobile application.
## Challenges we ran into
The consistent challenge that we seemed to run into was the integration between our parts.
Another challenge that we ran into was one group member's laptop just imploded (and stopped working) halfway through the competition, Windows recovery did not pull through and the member had to grab a backup laptop and set up the entire thing for smooth coding.
## Accomplishments that we're proud of
During this hackathon, we felt that we *really* stepped out of our comfort zone, with the time crunch of only 24 hours no less. Approaching new things like flutter, android mobile app development, and rest API's was daunting, but we managed to preserver and create a project in the end.
Another accomplishment that we're proud of is using git fully throughout our hackathon experience. Although we ran into issues with merges and vanishing files, all problems were resolved in the end with efficient communication and problem-solving initiative.
## What we learned
Throughout the project, we gained valuable experience working with various skills such as Flask integration, Flutter, Kotlin, RESTful APIs, Dart, and Java web scraping. All these skills were something we've only seen or heard elsewhere, but learning and subsequently applying it was a new experience altogether. Additionally, throughout the project, we encountered various challenges, and each one taught us a new outlook on software development. Overall, it was a great learning experience for us and we are grateful for the opportunity to work with such a diverse set of technologies.
## What's next for Medisafe
Medisafe has all 3-dimensions to expand on, being the baby app that it is. Our main focus would be to integrate the features into the normal camera application or Google Lens. We realize that a standalone app for a seemingly minuscule function is disadvantageous, so having it as part of a bigger application would boost its usage. Additionally, we'd also like to have the possibility to take an image from the gallery instead of fresh from the camera. Lastly, we hope to be able to implement settings like a default drug to compare to, dosage dependency, etc. | partial |
## Inspiration
Most navigation problems in unfamiliar spaces resolve into three challenges: find the current location, find the way to a destination, and find and maintain orientation. When they visit unfamiliar spaces, they first need a sighted guide in order to learn and familiarize themselves with the spaces, rather than use landmarks to find location and orientation.
## What it does
HelpingEyes.tech leverages the power of MappedIn's advanced indoor navigation, offering a transformative app for the visually impaired. Volunteers connect via video calls to guide users seamlessly through indoor spaces, providing real-time assistance and fostering independence.
## How we built it
HelpingEyes.tech seamlessly integrates MappedIn's SDK with the power of React and Next.js. This dynamic combination enables us to deliver a user-centric indoor navigation experience for the visually impaired.
## Challenges we ran into
One of our primary challenges was achieving real-time location updates within MappedIn's indoor navigation. Ensuring accurate and timely positioning demanded intricate solutions to synchronize the user's movements seamlessly with the map. Additionally, incorporating a live camera feature posed complexities in integrating real-time video communication while maintaining system stability.
## Accomplishments that we're proud of
We take pride in seamlessly integrating live video chat into HelpingEyes.tech, providing real-time assistance through a user-friendly interface. Additionally, achieving optimal route planning by finding the shortest path on the map showcases our commitment to enhancing efficiency and accessibility.
## What we learned
Working with MappedIn enlightened us on the potential of advanced indoor mapping in accessibility solutions. The project deepened our understanding of incorporating third-party technologies and reinforced the importance of user-centered design in creating impactful applications.
## What's next for HelpingEyes.tech
Our future endeavors include implementing a robust authentication system to verify and onboard volunteers, ensuring a secure and trustworthy experience for users. Additionally, we plan to introduce a rating and review system, allowing users to provide feedback on volunteer assistance. | ## Inspiration
As UW engineering students, studying takes up the majority of our day (sadly). Especially during the exam season, finding a place to study in popular places like the library or student centre is impossible. However we quickly discovered that the UW Portal app lists free classrooms with no lectures going on for the rest of the day! We found that these rooms are completely silent, isolated from other students, and have no distractions. However, there was one issue: these classrooms are scattered across campus and the rooms can be difficult to find.
After learning about MappedIn, we knew it was the missing piece of the puzzle. MappedIn can create 3D designs of buildings across campus, allowing us to find to available empty classrooms easily. Combined with the UW Portal API, we were inspired to create a tool that drastically cuts down on finding open classrooms, and lets us get to studying faster!
## What it does
Users can navigate to <https://www.lockedin.study/> to see a 3D rendering of buildings that have available empty classrooms. They can select any of the available buildings to access, as well as a room number and the floor of the building that they are on. MappedIn will then create a straightforward path to the room, traversing floors if necessary.
## How we built it
We used React with TypeScript to build the front end of the project, using the MappedIn SDK to create navigation routes. We also using MappedIn's platform to create a complete indoor map of select buildings on campus. We integrated the UW Portal API to dynamically generate available study rooms in buildings. For the backend, we used Express.js to store basic info about user likes and study room availability.
## Challenges we ran into
Working with MappedIn's SDK and mapping editor was a new experience for all three of us. In particular, creating navigation routes spanning multiple floors was a challenge, but we were quickly able to figure out how to use MappedIn's React hooks and map objects.
## Accomplishments that we're proud of
We're proud of successfully implementing our map with the UI while keeping the interface accessible and clean. Working on solving a problem that all three members experience daily was very enjoyable since we got to solve a problem that directly influences our day-to-day life in university.
## What we learned
Building LockedIn inspired all three of us to go out of our comfort zones with new technologies and skills. We all came out of this with greatly improved frontend, backend, design, and mapping skills.
## What's next for LockedIn
In the future, we aim to implement geolocation to make the user experience even simpler by tracking their movements in real-time. Geolocation can also be used to detect if a classroom is in use. | ## Inspiration
Have you ever had to wait in long lines just to buy a few items from a store? Not wanted to interact with employees to get what you want? Now you can buy items quickly and hassle free through your phone, without interacting with any people whatsoever.
## What it does
CheckMeOut is an iOS application that allows users to buy an item that has been 'locked' in a store. For example, clothing that have the sensors attached to them or items that are physically locked behind glass. Users can scan a QR code or use ApplePay to quickly access the information about an item (price, description, etc.) and 'unlock' the item by paying for it. The user will not have to interact with any store clerks or wait in line to buy the item.
## How we built it
We used xcode to build the iOS application, and MS Azure to host our backend. We used an intel Edison board to help simulate our 'locking' of an item.
## Challenges I ran into
We're using many technologies that our team is unfamiliar with, namely Swift and Azure.
## What I learned
I've learned not underestimate things you don't know, to ask for help when you need it, and to just have a good time.
## What's next for CheckMeOut
Hope to see it more polished in the future. | losing |
Professor's Pet
## Demo
### Home Page

### Attendance Page

---
## Inspiration
According to [*The Journal*](https://thejournal.com/articles/2020/06/02/survey-teachers-feeling-stressed-anxious-overwhelmed-and-capable.aspx), **more than 94%** of the teachers have transitioned to remote teaching, but there has been a **lack of improvements** in tools to support remote teaching.
Dude to this lack of tools and technologies in the educational field, teachers have been struggling to cover the necessary amount of curriculum within a year and expressing frustrations faced by the harsh situation:
* ["I am feeling overwhelmed with vast amount of ideas and resources available."](https://ditchthattextbook.com/dear-teacher-overwhelmed-by-technology/)
* ["I don’t have much experience, and I’m learning things all over again,”](https://berkeleyhighjacket.com/2020/features/educators-feel-overwhelmed-by-the-increased-workload-of-distance-learning/)
* [“I didn’t grow up with computers. Back then, we had typewriters, maybe an electric typewriter, and now they no longer exist,”](https://berkeleyhighjacket.com/2020/features/educators-feel-overwhelmed-by-the-increased-workload-of-distance-learning/)
---
## What it does
The web app [Professor's Pet](https://github.com/lanpai/ProfessorsPet) is a tool that simplifies teacher’s tasks and reduces the overwhelming responsibilities of managing various remote learning platforms like Zoom and Google Classroom by integrating them into a single master platform. This will provide the teachers to have a single user-friendly website that not only prevents unnecessary hoppings around different websites but also allows them to execute daily tasks with automation and visualizations, such as attendance, announcements, and invitations to a meeting.
---
## How We built it
Our team integrated [Zoom API](https://marketplace.zoom.us/docs/api-reference/zoom-api) with OAuth and [Google Classroom API](https://developers.google.com/classroom). For the backend, we utilized node.js, express.js, Nginx on the Unix server. For the frontend, HTML, CSS, and JavaScript are used. | ## Inspiration
**As Computer Science is a learning-intensive discipline, students tend to aspire to their professors**. We were inspired to hack this weekend by our beloved professor Daniel Zingaro (UTM). Answering questions in Dan's classes often ends up being a difficult part of our lectures, as Dan is visually impaired. This means students are expected to yell to get his attention when they have a question, directly interrupting the lecture. Teachers Pet could completely change the way Dan teaches and interacts with his students.
## What it does
Teacher's Pet (TP) empowers students and professors by making it easier to ask and answer questions in class. Our model helps to streamline lectures by allowing professors to efficiently target and destroy difficult and confusing areas in curriculum. Our module consists of an app, a server, and a camera. A professor, teacher, or presenter may download the TP app, and receive a push notification in the form of a discrete vibration whenever a student raises their hand for a question. This eliminates students feeling anxious for keeping their hands up, or professors receiving bad ratings for inadvertently neglecting students while focusing on teaching.
## How we built it
We utilized an Azure cognitive backend and had to manually train our AI model with over 300 images from around UofTHacks. Imagine four sleep-deprived kids running around a hackathon asking participants to "put your hands up". The AI is wrapped in a python interface, and takes input from a camera module. The camera module is hooked up to a Qualcomm dragonboard 410c, which hosts our python program. Upon registering, you may pair your smartphone to your TP device through our app, and set TP up in your classroom within seconds. Upon detecting a raised hand, TP will send a simple vibration to the phone in your pocket, allowing you to quickly answer a student query.
## Challenges we ran into
We had some trouble accurately differentiating when a student was stretching vs. actually raising their hand, so we took a sum of AI-guess-accuracies over 10 frames (250ms). This improved our AI success rate exponentially.
Another challenge we faced was installing the proper OS and drivers onto our Dragonboard. We had to "Learn2Google" all over again (for hours and hours). Luckily, we managed to get our board up and running, and our project was up and running!
## Accomplishments that we're proud of
Gosh darn we stayed up for a helluva long time - longer than any of us had previously. We also drank an absolutely disgusting amount of coffee and red bull. In all seriousness, we all are proud of each others commitment to the team. Nobody went to sleep while someone else was working. Teammates went on snack and coffee runs in freezing weather at 3AM. Smit actually said a curse word. Everyone assisted on every aspect to some degree, and in the end, that fact likely contributed to our completion of TP. The biggest accomplishment that came from this was knowledge of various new APIs, and the gratification that came with building something to help our fellow students and professors.
## What we learned
Among the biggest lessons we took away was that **patience is key**. Over the weekend, we struggled to work with datasets as well as our hardware. Initially, we tried to perfect as much as possible and stressed over what we had left to accomplish in the timeframe of 36 hours. We soon understood, based on words of wisdom from our mentors, that \_ the first prototype of anything is never perfect \_. We made compromises, but made sure not to cut corners. We did what we had to do to build something we (and our peers) would love.
## What's next for Teachers Pet
We want to put this in our own classroom. This week, our team plans to sit with our faculty to discuss the benefits and feasibility of such a solution. | ## Inspiration
Currently the insurance claims process is quite labour intensive. A person has to investigate the car to approve or deny a claim, and so we aim to make the alleviate this cumbersome process smooth and easy for the policy holders.
## What it does
Quick Quote is a proof-of-concept tool for visually evaluating images of auto accidents and classifying the level of damage and estimated insurance payout.
## How we built it
The frontend is built with just static HTML, CSS and Javascript. We used Materialize css to achieve some of our UI mocks created in Figma. Conveniently we have also created our own "state machine" to make our web-app more responsive.
## Challenges we ran into
>
> I've never done any machine learning before, let alone trying to create a model for a hackthon project. I definitely took a quite a bit of time to understand some of the concepts in this field. *-Jerry*
>
>
>
## Accomplishments that we're proud of
>
> This is my 9th hackathon and I'm honestly quite proud that I'm still learning something new at every hackathon that I've attended thus far. *-Jerry*
>
>
>
## What we learned
>
> Attempting to do a challenge with very little description of what the challenge actually is asking for is like a toddler a man stranded on an island. *-Jerry*
>
>
>
## What's next for Quick Quote
Things that are on our roadmap to improve Quick Quote:
* Apply google analytics to track user's movement and collect feedbacks to enhance our UI.
* Enhance our neural network model to enrich our knowledge base.
* Train our data with more evalution to give more depth
* Includes ads (mostly auto companies ads). | losing |
## Inspiration
I suck at snake.
## What it does
I made something to help me be better at snake.
## How we built it
We enticed the snake with frozen mice until it played well.
## Challenges we ran into
Sometimes the snek wasn't hungry.
## Accomplishments that we're proud of
We are snek charmers.
## What we learned
Sneks are cool.
## What's next for sNNake
The snek will learn to play itself. | ## Inspiration
As certified pet owners, we understand that our pets are part of our family. Our companions deserve the best care and attention available. We envisioned the goal of simplifying and modernizing pet care, all in one convenient and elegant app. Our idea began with our longing for our pets. Being international students ourselves, we constantly miss our pets and wish to see them. We figured that a pet livestream would allow us to check in on our pals, and from then on pet boarding, and our many other services arose.
## What it does
Playground offers readily available and affordable pet care. Our services include:
Pet Grooming: Flexible grooming services with pet-friendly products.
Pet Walking: Real-time tracking of your pet as it is being walked by our friendly staff.
Pet Boarding: In-home and out-of-home live-streamed pet-sitting services.
Pet Pals™: Adoption services, meet-and-greet areas, and pet-friendly events.
PetU™: Top-tier training with positive reinforcement for all pets
Pet Protect™: Life insurance and lost pet recovery
Pet Supplies: Premium quality, chew-resistant, toys and training aids.
## How we built it
First, we carefully created our logo using Adobe Illustrator. After scratching several designs, we settled on a final product. Then, we designed the interface using Figma. We took our time to ensure an appealing design. We programmed the front end with Flutter in Visual Studio Code. Finally, we used the OpenAI API GPT3.5 to implement a personalized chat system to suggest potential services and products to our users.
## Challenges we ran into
We ran into several bugs when making the app, and used our debugging skills from previous CS work and eventually solved them. One of the bugs involved an image overflow when coding the front end. Our icons were too large for the containers we used, but with adjustments to the dimensions of the containers and some cropping, we managed to solve this issue.
## Accomplishments that we're proud of
We’re proud of our resilience when encountering bugs on Flutter. Despite not being as experienced with this language as we are with others, we were able to identify and solve the problems we faced. Furthermore, we’re proud of our effort to make our logo because we are not the best artists, but our time spent on the design paid off. We feel that our logo reflects the quality and niche of our app.
## What we learned
We learned that programming the front end is as important if not more important than the back end of an app. Without a user-friendly interface, no app could function seeing as customer retention would be minimal. Our approachable interface allows users of all levels of digital literacy to get the best care for their beloved pets.
## What's next for Playground
After polishing the app, we plan on launching it in Peru and gathering as much feedback as we can. Then we plan on working on implementing our users’ suggestions and fixing any issues that arise. After finishing the new and improved version of Playground, we plan on launching internationally and bringing the best care for all our pets. More importantly, 10% of our earnings will go to animal rescue organizations! | ## Inspiration
Queriamos hacer una pagina interactiva la cual llamara la atencion de las personas jovenes de esta manera logrando mantenerlos durante mucho tiempo siendo leales a la familia de marcas Qualtias
## What it does
Lo que hace es
## How we built it
## Challenges we ran into
Al no tener un experiencia previa con el diseño de paginas web encontramos problemas al momento de querer imaginar el como se veria nuestra pagina.
## Accomplishments that we're proud of
Nos sentimos orgullosos de haber logrado un diseño con el cual nos senitmos orgullosos y logramos implementar las ideas que teniamos en mente.
## What we learned
Aprendimos mucho sobre diseño de paginas y de como implmentar diferentes tipos de infraestructuras y de como conectarlas.
## What's next for QualtiaPlay
Seguiremos tratando de mejorar nuestra idea para futuros proyectos y de mayor eficiencia | losing |
## Inspiration:
The inspiration for RehabiliNation comes from a mixture of our love for gaming, and our personal experiences regarding researching and working with those who have physical and mental disabilities.
## What it does:
Provides an accessible gaming experience for people with physical disabilities and motivate those fighting through the struggles of physical rehabilitation. It can also be used to track the progress people make while going through their healing process.
## How we built it:
The motion control arm band collects data using the gyroscope module linked to the Arduino board. It sends back the data to the Arduino serial monitor in the form of angles. We then use a python script to read the data from the serial monitor. It interprets the data into keyboard input, this allows us to interface with multiple games. Currently, it is used to play our Pac-man game which is written in java.
## Challenges we ran into:
Our main challenges was determining how to utilize the gyroscope with the Arduino board and to trying to figure out how to receive and interpret the data with a python script. We also came across some issues with calibrating the motion sensors.
## Accomplishments that we're proud of
Throughout our creation process, we all managed to learn about new technologies and new skills and programming concepts. We may have been pushed into the pool, but it was quite a fun way to learn, and in the end we came out with a finished product capable of helping people in need.
## What we learned
We learned a great amount about the hardware product process, as well as the utilization of hardware in general. In general, it was a difficult but rewarding experience, and we thank U of T for providing us with this opportunity.
## What's next for RehabiliNation
RehabiliNation will continue to refine our products in the future, including the use of better materials and more responsive hardware pieces than what was shown in today's proof of concept. Hopefully our products will be implemented by physical rehabilitation centres to help brighten the rehab process. | ## 💡Inspiration
Gaming is often associated with sitting for long periods of time in front of a computer screen, which can have negative physical effects. In recent years, consoles such as the Kinect and Wii have been created to encourage physical fitness through games such as "Just Dance". However, these consoles are simply incompatible with many of the computer and arcade games that we love and cherish.
## ❓What it does
We came up with Motional at HackTheValley wanting to create a technological solution that pushes the boundaries of what we’re used to and what we can expect. Our product, Motional, delivers on that by introducing a new, cost-efficient, and platform-agnostic solution to universally interact with video games through motion capture, and reimagining the gaming experience.
Using state-of-the-art machine learning models, Motional can detect over 500 features on the human body (468 facial features, 21 hand features, and 33 body features) and use these features as control inputs to any video game.
Motional operates in 3 modes: using hand gestures, face gestures, or full-body gestures. We ship certain games out-of-the-box such as Flappy Bird and Snake, with predefined gesture-to-key mappings, so you can play the game directly with the click of a button. For many of these games, jumping in real-life (body gesture) /opening the mouth (face gesture) will be mapped to pressing the "space-bar"/"up" button.
However, the true power of Motional comes with customization. Every simple possible pose can be trained and clustered to provide a custom command. Motional will also play a role in creating a more inclusive gaming space for people with accessibility needs, who might not physically be able to operate a keyboard dexterously.
## 🤔 How we built it
First, a camera feed is taken through Python OpenCV. We then use Google's Mediapipe models to estimate the positions of the features of our subject. To learn a new gesture, we first take a capture of the gesture and store its feature coordinates generated by Mediapipe. Then, for future poses, we compute a similarity score using euclidean distances. If this score is below a certain threshold, we conclude that this gesture is the one we trained on. An annotated image is generated as an output through OpenCV. The actual keyboard presses are done using PyAutoGUI.
We used Tkinter to create a graphical user interface (GUI) where users can switch between different gesture modes, as well as select from our current offering of games. We used MongoDB as our database to keep track of scores and make a universal leaderboard.
## 👨🏫 Challenges we ran into
Our team didn't have much experience with any of the stack before, so it was a big learning curve. Two of us didn't have a lot of experience in Python. We ran into many dependencies issues, and package import errors, which took a lot of time to resolve. When we initially were trying to set up MongoDB, we also kept timing out for weird reasons. But the biggest challenge was probably trying to write code while running on 2 hours of sleep...
## 🏆 Accomplishments that we're proud of
We are very proud to have been able to execute our original idea from start to finish. We managed to actually play games through motion capture, both with our faces, our bodies, and our hands. We were able to store new gestures, and these gestures were detected with very high precision and low recall after careful hyperparameter tuning.
## 📝 What we learned
We learned a lot, both from a technical and non-technical perspective. From a technical perspective, we learned a lot about the tech stack (Python + MongoDB + working with Machine Learning models). From a non-technical perspective, we worked a lot working together as a team and divided up tasks!
## ⏩ What's next for Motional
We would like to implement a better GUI for our application and release it for a small subscription fee as we believe there is a market for people that would be willing to invest money into an application that will help them automate and speed up everyday tasks while providing the ability to play any game they want the way they would like. Furthermore, this could be an interesting niche market to help gamify muscle rehabilition, especially for children. | ## Inspiration
One of our friends is blind. She describes using her cane as a hassle, and explains that when she is often stressed about accidentally touching someone with her cane, doing two-handed tasks like carrying groceries or giving a friend a hug, and setting the cane down or leaning it against the wall when she sits down. So, we set out to build a device that would free up two hands, reduce her mobility related stresses, and remain as or more intuitive than the cane is.
## What it does
Our prototype employs an infrared distance sensor, which feeds into an Arduino Nano, and outputs as a haptic signal on your forearm via a servo motor. In this way, by pointing your wrist at various surfaces, you will be able to get an idea of how close or far they are, allowing you to intuitively navigate your physical environment.
## How we built it
We used an infrared distance sensor with an accurate range of 0.2m - 1.5m, an Arduino Nano, a servo motor to provide haptic feedback, and a 3D printer to build a case and wrist-mount for the components.
## Challenges we ran into
1. The Arduino Nano, due to budgetary constraints, was frankly sketchy and did not have the correct bootloader and drivers installed. Fixing this and getting the Arduino to integrate with our other components was a fairly big project of its own.
2. The mapping of the sensor was non-linear, so we had to figure out how to correctly assign the output of the sensor to a specific haptic feedback that felt intuitive. This was difficult, and primarily done through experimentation.
3. Finally, making the device compact, wearable, and comfortable was a big design challenge.
## Accomplishments that we're proud of
Our critical test and initial goal was having someone who is fully blindfolded navigate a small obstacle course using the device. After multiple iterations and experimentation with what haptic feedback was useful and intuitive, we were able to have a team-member navigate the obstacle course successfully without the use of his sight. Great success!
## What we learned
We learned about loading bootloaders onto different devices, different chipsets and custom drivers, mapping input to output in components non-linearly, 3D printing casing for components, and finally making this housing comfortably wearable.
## What's next for Mobile Optical Infrared Sensory Transmitter
Next up, we are hoping to swap out the external battery powering the device to either human-heat power or at least rechargeable batteries. We also want to switch the infrared sensor out for a LIDAR sensor which would give us greater range and accuracy. Additionally, we are hoping to make the device much more compact. Finally, we also want to increase the comfort of the wrist-mount of the device so that it can be used comfortably over longer periods of time. | partial |
Can you save a life?
## Inspiration
For the past several years heart disease has remained the second leading cause of death in Canada. Many know how to prevent it, but many don’t know how to deal with cardiac events that have the potential to end your life. What if you can change this?
## What it does
Can You Save Me simulates three different conversational actions showcasing cardiac events at some of their deadliest moments. It’s your job to make decisions to save the person in question from either a stroke, sudden cardiac arrest, or a heart attack. Can You Save Me puts emphasis on the symptomatic differences between men and women during specific cardiac events. Are you up for it?
## How we built it
We created the conversational action with Voiceflow. While the website was created with HTML, CSS, Javascript, and Bootstrap. Additionally, the backend of the website, which counts the number of simulated lives our users saved, uses Node.js and Google sheets.
## Challenges we ran into
There were several challenges our team ran into, however, we managed to overcome each of them. Initially, we used React.js but it deemed too complex and time consuming given our time-sensitive constraints. We switched over to Javascript, HTML, CSS, and Bootstrap instead for the frontend of the website.
## Accomplishments that we're proud of
Our team is proud of the fact that we were able to come together as complete strangers and produce a product that is educational and can empower people to save lives. We managed our time efficiently and divided our work fairly according to our strengths.
## What we learned
Our team learned many technical skills such as how to use React.js, Node.js, Voiceflow and how to deploy actions on Google Assistant. Due to the nature of this project, we completed extensive research on cardiovascular health using resources from Statstics Canada, the Standing Committee on Health, the University of Ottawa Heart Institute, The Heart & Stroke Foundation, American Journal of Cardiology, American Heart Association and Harvard Health.
## What's next for Can You Save Me
We're interested in adding more storylines and variables to enrich our users' experience and learning. We are considering adding a play again action to improve our Voice Assistant and encourage iterations. | **In times of disaster, there is an outpouring of desire to help from the public. We built a platform which connects people who want to help with people in need.**
## Inspiration
Natural disasters are an increasingly pertinent global issue which our team is quite concerned with. So when we encountered the IBM challenge relating to this topic, we took interest and further contemplated how we could create a phone application that would directly help with disaster relief.
## What it does
**Stronger Together** connects people in need of disaster relief with local community members willing to volunteer their time and/or resources. Such resources include but are not limited to shelter, water, medicine, clothing, and hygiene products. People in need may input their information and what they need, and volunteers may then use the app to find people in need of what they can provide. For example, someone whose home is affected by flooding due to Hurricane Florence in North Carolina can input their name, email, and phone number in a request to find shelter so that this need is discoverable by any volunteers able to offer shelter. Such a volunteer may then contact the person in need through call, text, or email to work out the logistics of getting to the volunteer’s home to receive shelter.
## How we built it
We used Android Studio to build the Android app. We deployed an Azure server to handle our backend(Python). We used Google Maps API on our app. We are currently working on using Twilio for communication and IBM watson API to prioritize help requests in a community.
## Challenges we ran into
Integrating the Google Maps API into our app proved to be a great challenge for us. We also realized that our original idea of including a blood donation as one of the resources would require some correspondence with an organization such as the Red Cross in order to ensure the donation would be legal. Thus, we decided to add a blood donation to our future aspirations for this project due to the time constraint of the hackathon.
## Accomplishments that we're proud of
We are happy with our design and with the simplicity of our app. We learned a great deal about writing the server side of an app and designing an Android app using Java (and Google Map’s API” during the past 24 hours. We had huge aspirations and eventually we created an app that can potentially save people’s lives.
## What we learned
We learned how to integrate Google Maps API into our app. We learn how to deploy a server with Microsoft Azure. We also learned how to use Figma to prototype designs.
## What's next for Stronger Together
We have high hopes for the future of this app. The goal is to add an AI based notification system which alerts people who live in a predicted disaster area. We aim to decrease the impact of the disaster by alerting volunteers and locals in advance. We also may include some more resources such as blood donations. | Check out our slides here: shorturl.at/fCLR4
## Inspiration
In a digital age increasingly dictated by streaming services’ editorial teams and algorithms, we want to bring the emotion back to the music discovery experience. Your playlists have become an echo chamber of your own past preferences and the short, chorus-led song mold artists now follow to maximize playlist performance, giving music streaming platforms much of the control over who succeeds in this industry and what types of music users can easily access. We want to democratize the process of finding unique, emotion-driven sound and bring your personal emotions back to the forefront of your listening experience.
## What It Does
Thus Maestro was born, a chat bot that integrates with virtually any messaging service and enables a user to send an emoji corresponding to how they’re feeling and receive a personalized new song recommendation through YouTube.
## How We Built It
To achieve this maximized integrability, we used Gupshup to build the Messenger chatbot and developed the back-end on a Python Flask-JSON localhost server exposed on Ngrok. The AI sentiment analysis is performed a public, large Kaggle dataset scraping tweets with emojis. Given the sentiment an emoji conveys, we then match it to a corresponding YouTube playlist, and scrape the playlist for a suitable song track.
## Challenges We Ran Into
The FB Messenger API was hard to access - we wasted some time initially trying to gain access to build on top of it & to integrate it with AWS. That’s when we switched over to GupShop.io. However, it was extremely clunky. It slowed us down massively and required a lot of duplicative work.
We also struggled to combine our front end and back end in one continuous integration pipeline. After receiving a tip from a mentor on what resources we could use to achieve this, it took massive efforts to integrate it all together.
## Accomplishments We're Proud Of
A working Messenger bot that can be used by anyone, at anytime! These are emoji-song recommendations that are actually GOOD :)
## What We Learned
Through our hack, we learned to perform sentiment analysis on not just text but emojis as well. We also learned how to integrate back-end and front-end -- especially with hosting a server and exposing it on a URL, as well as setting up a Messenger chatbot most smoothly.
## What's Next For Maestro
We're very excited to develop Maestro further, including building a feedback loop so that users can tell us if they like their song, adding personalization so that music recommendations are tailored to the user, and catering to more streaming platforms so users can listen on Spotify/Apple Music/Youtube/etc. We'd also like to port to other platforms so that we achieve integration with Whatsapp, SMS, Instagram DMs, and others, as well as build on human curators to better select music. | winning |
## Inspiration
Beautiful stationery and binders filled with clips, stickies, and colourful highlighting are things we miss from the past. Passing notes and memos and recognizing who it's from just from the style and handwriting, holding the sheet in your hand, and getting a little personalized note on your desk are becoming a thing of the past as the black and white of emails and messaging systems take over. Let's bring back the personality, color, and connection opportunities from memo pads in the office while taking full advantage of modern technology to make our lives easier. Best of both worlds!
## What it does
Memomi is a web application for offices to simplify organization in a busy environment while fostering small moments of connection and helping fill in the gaps on the way. Using powerful NLP technology, Memomi automatically links related memos together, suggests topical new memos to expand on missing info on, and allows you to send memos to other people in your office space.
## How we built it
We built Memomi using Figma for UI design and prototyping, React web apps for frontend development, Flask APIs for the backend logic, and Google Firebase for the database. Cohere's NLP API forms the backbone of our backend logic and is what powers Memomi's intelligent suggestions for tags, groupings, new memos, and links.
## Challenges we ran into
With such a dynamic backend with more complex data, we struggled to identify how best to organize and digitize the system. We also struggled a lot with the frontend because of the need to both edit and display data annotated at the exact needed positions based off our information. Connecting our existing backend features to the frontend was our main barrier to showing off our accomplishments.
## Accomplishments that we're proud of
We're very proud of the UI design and what we were able to implement in the frontend. We're also incredibly proud about how strong our backend is! We're able to generate and categorize meaningful tags, groupings, and links between documents and annotate text to display it.
## What we learned
We learned about different NLP topics, how to make less rigid databases, and learned a lot more about advanced react state management.
## What's next for Memomi
We would love to implement sharing memos in office spaces as well as authorization and more text editing features like markdown support. | ## Inspiration
With the ubiquitous and readily available ML/AI turnkey solutions, the major bottlenecks of data analytics lay in the consistency and validity of datasets.
**This project aims to enable a labeller to be consistent with both their fellow labellers and their past self while seeing the live class distribution of the dataset.**
## What it does
The UI allows a user to annotate datapoints from a predefined list of labels while seeing the distribution of labels this particular datapoint has been previously assigned by another annotator. The project also leverages AWS' BlazingText service to suggest labels of incoming datapoints from models that are being retrained and redeployed as it collects more labelled information. Furthermore, the user will also see the top N similar data-points (using Overlap Coefficient Similarity) and their corresponding labels.
In theory, this added information will motivate the annotator to remain consistent when labelling data points and also to be aware of the labels that other annotators have assigned to a datapoint.
## How we built it
The project utilises Google's Firestore realtime database with AWS Sagemaker to streamline the creation and deployment of text classification models.
For the front-end we used Express.js, Node.js and CanvasJS to create the dynamic graphs. For the backend we used Python, AWS Sagemaker, Google's Firestore and several NLP libraries such as SpaCy and Gensim. We leveraged the realtime functionality of Firestore to trigger functions (via listeners) in both the front-end and back-end. After K detected changes in the database, a new BlazingText model is trained, deployed and used for inference for the current unlabeled datapoints, with the pertinent changes being shown on the dashboard
## Challenges we ran into
The initial set-up of SageMaker was a major timesink, the constant permission errors when trying to create instances and assign roles were very frustrating. Additionally, our limited knowledge of front-end tools made the process of creating dynamic content challenging and time-consuming.
## Accomplishments that we're proud of
We actually got the ML models to be deployed and predict our unlabelled data in a pretty timely fashion using a fixed number of triggers from Firebase.
## What we learned
Clear and effective communication is super important when designing the architecture of technical projects. There were numerous times where two team members were vouching for the same structure but the lack of clarity lead to an apparent disparity.
We also realized Firebase is pretty cool.
## What's next for LabelLearn
Creating more interactive UI, optimizing the performance, have more sophisticated text similarity measures. | ## Inspiration
It took us a while to think of an idea for this project- after a long day of zoom school, we sat down on Friday with very little motivation to do work. As we pushed through this lack of drive our friends in the other room would offer little encouragements to keep us going and we started to realize just how powerful those comments are. For all people working online, and university students in particular, the struggle to balance life on and off the screen is difficult. We often find ourselves forgetting to do daily tasks like drink enough water or even just take a small break, and, when we do, there is very often negativity towards the idea of rest. This is where You're Doing Great comes in.
## What it does
Our web application is focused on helping students and online workers alike stay motivated throughout the day while making the time and space to care for their physical and mental health. Users are able to select different kinds of activities that they want to be reminded about (e.g. drinking water, eating food, movement, etc.) and they can also input messages that they find personally motivational. Then, throughout the day (at their own predetermined intervals) they will receive random positive messages, either through text or call, that will inspire and encourage. There is also an additional feature where users can send messages to friends so that they can share warmth and support because we are all going through it together. Lastly, we understand that sometimes positivity and understanding aren't enough for what someone is going through and so we have a list of further resources available on our site.
## How we built it
We built it using:
* AWS
+ DynamoDB
+ Lambda
+ Cognito
+ APIGateway
+ Amplify
* React
+ Redux
+ React-Dom
+ MaterialUI
* serverless
* Twilio
* Domain.com
* Netlify
## Challenges we ran into
Centring divs should not be so difficult :(
Transferring the name servers from domain.com to Netlify
Serverless deploying with dependencies
## Accomplishments that we're proud of
Our logo!
It works :)
## What we learned
We learned how to host a domain and we improved our front-end html/css skills
## What's next for You're Doing Great
We could always implement more reminder features and we could refine our friends feature so that people can only include selected individuals. Additionally, we could add a chatbot functionality so that users could do a little check in when they get a message. | winning |
## Inspiration
Deaf-mute people in the U.S constitute a non-underestimable 2,1% of the population (between 18 and 64 years). This may seem a low percentage but, what if I told you that it is 4 million people? Just like the whole population of Panama!
Concerned about this, we first decided to contribute our grain of sand by developing a nice hack to ease their day to day. After some brainstorming we started working in a messaging aplication which would allow deaf-mute people to comunicate at a distance using their own language: the American Sign Language (ASL).
After some work on the design we realized that we could split our system in various modules to cover a much wider variety of applications
## What it does and how we built it
So, what did we exactly do? We have implemented a set of modules dynamically programmed so that they can be piled up to perform a lot of functionalities. These modules are:
-**Voice to text:** Through Bing Speech API we have implemented a python class to record and get the text of a talking person. It communicates using HTTP posts. The content had to be binary audio.
-**Text to voice:** As before, with Bing Speech API, and Cognitive-Speech-TTS we have implemented a user-friendly python application to transform text into Cortana's Voice.
-**ASL Alphabet to text:** Through a (fully trained) deep neural network we have been able to transform images of signs made with our hands, to text in real time. For this, we had to create a dataset from scratch recording our own hands performing the signs. We also spent many hours training, but we got some good results, though!
Some technicalities: due to lack of time (DL training limitations!) we have only implemented up to 11 letters of the ASL alphabet. Also for better performance we have restricted our sign pictures to white background. Needless to say, with time, computer power and more data, this is totally upgradable to many ASL signs and not restricted background.
-**Text to ASL Alphabet:** To complement all the previous tools, we have developed a python GUI which displays a text translated to ASL Alphabet.
-**Text to Text:** We got to send text messages through AWS Databases with MySQL, thus allowing to comunicate at a distance between all this modules.
## Possibilities
-**Messaging:** The first application we thought of. By combining all the previous modules, we got deaf people do communicate with his natural language. From sign language to text, from text through internet to the other computer and from text to voice!
-**Learning:** From audio to text and from text to sign language modules will allow us to learn to spell all the words we can say! Furthermore, we can practice our skills by going all the way around and make the machine tell us what are we saying.
## Accomplishments that we're proud of
Getting all the different parts work together and actually perform well has been really satisfying.
## What we learned
This is the first time for us implementing a full project based on Machine Learning from scratch, and we are proud of the results we have got. Also we have never worked before with Microsoft API's so we have get to work with this new environment.
## What's next for Silent Voice
One idea that we had in mind from the begining was bringing everything to a more portable device such as a RaspberryPi or a Mobile phone. However, because of time limitations, we could not explore this path. It would be very useful to have our software in such devices and ease the day to day of deaf people (as was our first intention!).
Of course, we are conscious that the ASL is better spoken through words and not just as a concatenation of letters but because of its enormousness it was difficult for us embarking in such an adventure from scratch. A nice future work would be trying to implement a sort of a full ASL.
A funny way to explode our models would be implementing a Naruto ninja fight game, since they are based in hand signs too!
Thanks! | ## Inspiration
Just in the United States, 11 million people are deaf, of which half a million use ASL natively. For people who are deaf to communicate with those who are hearing, and therefore most likely not fluent in sign language, they’re constricted to slower methods of communication, such as writing. Similarly, for people who don’t know sign language to immediately be able to communicate comfortably with someone who is deaf, the only options are writing or lip-reading, which has been proven to only be 30-40% effective. By creating Gesture Genie, we aim to make the day to day lives of both the deaf and hearing communities significantly more tension-free.
## What it does
Two Way Sign Language Translator that can translate voice into visual sign language and can translate visual sign language into speech. We use computer vision algorithms to recognize the sign language gestures and translate into text.
## How we built it
Sign Gestures to Text
* We used OpenCV to to capture video from the user which we processed into
* We used Google MediaPipe API to detect all 21 joints in the user's hands
* Trained neural networks to detect and classify ASL gestures
<https://youtu.be/3gNQDp1nM_w>
Voice to Sign Language Gestures
* Voice to text translation
* Text to words/fingerspelling
* By web scraping online ASL dictionaries we can show videos for all ASL through gestures or fingerspelling
* Merging videos of individual sign language words/gestures
<https://youtu.be/mBUhU8b3gK0?si=eIEOiOFE0mahXCWI>
## Challenges we ran into
The biggest challenge that we faced was incorporating the backend into the React/node.js frontend. We use OpenCV for the backend, and we needed to ensure that the camera's output is shown on the front end. We were able to solve this problem by using iFrames in order to integrate the local backend into our combined webpage.
## Accomplishments that we're proud of
We are most proud of being able to recognize action-based sign language words rather than simply relying on fingerspelling to understand the sign language that we input. Additionally, we were able to integrate these videos from our backend into the front end seamlessly using Flask APIs and iFrames.
## What we learned
## What's next for Gesture Genie
Next, we hope to be able to incorporate more phrases/action based gestures, scaling our product to be able to work seamlessly in the day-to-day lives of those who are hard of hearing. We also aim to use more LLMs to better translate the text, recognizing voice and facial emotions as well. | ## Inspiration
We were inspired by the fact that **diversity in disability is often overlooked** - individuals who are hard-of-hearing or deaf and use **American Sign Language** do not have many tools that support them in learning their language. Because of the visual nature of ASL, it's difficult to translate between it and written languages, so many forms of language software, whether it is for education or translation, do not support ASL. We wanted to provide a way for ASL-speakers to be supported in learning and speaking their language.
Additionally, we were inspired by recent news stories about fake ASL interpreters - individuals who defrauded companies and even government agencies to be hired as ASL interpreters, only to be later revealed as frauds. Rather than accurately translate spoken English, they 'signed' random symbols that prevented the hard-of-hearing community from being able to access crucial information. We realized that it was too easy for individuals to claim their competence in ASL without actually being verified.
All of this inspired the idea of EasyASL - a web app that helps you learn ASL vocabulary, translate between spoken English and ASL, and get certified in ASL.
## What it does
EasyASL provides three key functionalities: learning, certifying, and translating.
**Learning:** We created an ASL library - individuals who are learning ASL can type in the vocabulary word they want to learn to see a series of images or a GIF demonstrating the motions required to sign the word. Current ASL dictionaries lack this dynamic ability, so our platform lowers the barriers in learning ASL, allowing more members from both the hard-of-hearing community and the general population to improve their skills.
**Certifying:** Individuals can get their mastery of ASL certified by taking a test on EasyASL. Once they start the test, a random word will appear on the screen and the individual must sign the word in ASL within 5 seconds. Their movements are captured by their webcam, and these images are run through OpenAI's API to check what they signed. If the user is able to sign a majority of the words correctly, they will be issued a unique certificate ID that can certify their mastery of ASL. This certificate can be verified by prospective employers, helping them choose trustworthy candidates.
**Translating:** EasyASL supports three forms of translation: translating from spoken English to text, translating from ASL to spoken English, and translating in both directions. EasyASL aims to make conversations between ASL-speakers and English-speakers more fluid and natural.
## How we built it
EasyASL was built primarily with **typescript and next.js**. We captured images using the user's webcam, then processed the images to reduce the file size while maintaining quality. Then, we ran the images through **Picsart's API** to filter background clutter for easier image recognition and host images in temporary storages. These were formatted to be accessible to **OpenAI's API**, which was trained to recognize the ASL signs and identify the word being signed. This was used in both our certification stream, where the user's ASL sign was compared against the prompt they were given, and in the translation stream, where ASL phrases were written as a transcript then read aloud in real time. We also used **Google's web speech API** in the translation stream, which converted English to written text. Finally, the education stream's dictionary was built using typescript and a directory of open-source web images.
## Challenges we ran into
We faced many challenges while working on EasyASL, but we were able to persist through them to come to our finished product. One of our biggest challenges was working with OpenAI's API: we only had a set number of tokens, which were used each time we ran the program, meaning we couldn't test the program too many times. Also, many of our team members were using TypeScript and Next.js for the first time - though there was a bit of a learning curve, we found that its similarities with JavaScript helped us adapt to the new language. Finally, we were originally converting our images to a UTF-8 string, but got strings that were over 500,000 characters long, making them difficult to store. We were able to find a workaround by keeping the images as URLs and passing these URLs directly into our functions instead.
## Accomplishments that we're proud of
We were very proud to be able to integrate APIs into our project. We learned how to use them in different languages, including TypeScript. By integrating various APIs, we were able to streamline processes, improve functionality, and deliver a more dynamic user experience. Additionally, we were able to see how tools like AI and text-to-speech could have real-world applications.
## What we learned
We learned a lot about using Git to work collaboratively and resolve conflicts like separate branches or merge conflicts. We also learned to use Next.js to expand what we could do beyond JavaScript and HTML/CSS. Finally, we learned to use APIs like Open AI API and Google Web Speech API.
## What's next for EasyASL
We'd like to continue developing EasyASL and potentially replacing the Open AI framework with a neural network model that we would train ourselves. Currently processing inputs via API has token limits reached quickly due to the character count of Base64 converted image. This results in a noticeable delay between image capture and model output. By implementing our own model, we hope to speed this process up to recreate natural language flow more readily. We'd also like to continue to improve the UI/UX experience by updating our web app interface. | losing |
## Inspiration
We want to have some fun and find out what we could get out of Computer Vision API from Microsoft.
## What it does
This is a web application that allows the user to upload an image, generates an intelligent poem from it and reads the poem out load with different chosen voices.
## How we built it
We used Python interface of Cognitive Service API from Microsoft and built a web application with django. We used a public open source tone generator to play different tones reading the poem to the users.
## Challenges we ran into
We learned django from scratch. It's not very easy to use. But we eventually made all the components connect together using Python.
## Accomplishments that we're proud of
It’s fun!
## What we learned
It's difficult to combine different components together.
## What's next for PIIC - Poetic and Intelligent Image Caption
We plan to make an independent project with different technology than Cognitive Services and published to the world. | # Links
Youtube: <https://youtu.be/VVfNrY3ot7Y>
Vimeo: <https://vimeo.com/506690155>
# Soundtrack
Emotions and music meet to give a unique listening experience where the songs change to match your mood in real time.
## Inspiration
The last few months haven't been easy for any of us. We're isolated and getting stuck in the same routines. We wanted to build something that would add some excitement and fun back to life, and help people's mental health along the way.
Music is something that universally brings people together and lifts us up, but it's imperfect. We listen to our same favourite songs and it can be hard to find something that fits your mood. You can spend minutes just trying to find a song to listen to.
What if we could simplify the process?
## What it does
Soundtrack changes the music to match people's mood in real time. It introduces them to new songs, automates the song selection process, brings some excitement to people's lives, all in a fun and interactive way.
Music has a powerful effect on our mood. We choose new songs to help steer the user towards being calm or happy, subtly helping their mental health in a relaxed and fun way that people will want to use.
We capture video from the user's webcam, feed it into a model that can predict emotions, generate an appropriate target tag, and use that target tag with Spotify's API to find and play music that fits.
If someone is happy, we play upbeat, "dance-y" music. If they're sad, we play soft instrumental music. If they're angry, we play heavy songs. If they're neutral, we don't change anything.
## How we did it
We used Python with OpenCV and Keras libraries as well as Spotify's API.
1. Authenticate with Spotify and connect to the user's account.
2. Read webcam.
3. Analyze the webcam footage with openCV and a Keras model to recognize the current emotion.
4. If the emotion lasts long enough, send Spotify's search API an appropriate query and add it to the user's queue.
5. Play the next song (with fade out/in).
6. Repeat 2-5.
For the web app component, we used Flask and tried to use Google Cloud Platform with mixed success. The app can be run locally but we're still working out some bugs with hosting it online.
## Challenges we ran into
We tried to host it in a web app and got it running locally with Flask, but had some problems connecting it with Google Cloud Platform.
Making calls to the Spotify API pauses the video. Reducing the calls to the API helped (faster fade in and out between songs).
We tried to recognize a hand gesture to skip a song, but ran into some trouble combining that with other parts of our project, and finding decent models.
## Accomplishments that we're proud of
* Making a fun app with new tools!
* Connecting different pieces in a unique way.
* We got to try out computer vision in a practical way.
## What we learned
How to use the OpenCV and Keras libraries, and how to use Spotify's API.
## What's next for Soundtrack
* Connecting it fully as a web app so that more people can use it
* Allowing for a wider range of emotions
* User customization
* Gesture support | ## Inspiration
We tried to figure out what kept us connected during the pandemic other then the non ending zoom meetings or the occasional time you spend in class together, and fundamentally this all came down to our ability to just speak and once we started thinking about it we couldn't stop
## What it does
We created a web app that displays a sentence that the user can read and using assembly ai’s real time word detection API we stream what the user is reading, while providing feedback on their correctness. Using a Profanity free comprehensive dictionary, we randomized which words are shown to the user to help make each sentence challenging in a different way.
## How we built it
In our design process, we started with the idea. After coming up with our idea we started our research to find the best way to implement the features we wanted to use and after realizing we had access to assembly ai, we knew it was a match made in heaven. Afterwards, we started designing basic functionalities and creating flowcharts to identify possible points of difficulty. After our design process, we started developing our project using html, css, NodeJS, JQuery and assembly ai.
## Challenges we ran into
We initially hoped to use python as our main language, however, learning Django while also finding ways to provide accurate feedback proved to be too difficult within the time frame which further lead us into building our project in JS. Furthermore, learning Node.js and assembly ai was also significantly difficult considering the time frame.
## Accomplishments that we're proud of
Having ran into countless problems with Django Web Kit and Python in the beginning, we decided to switch to a JavaScript base. Now, with only half the remaining time left, we were forced to be creative and work diligently to finish before the deadline. Ultimately, the end product was better than we could have hoped for, and incorporated many completely new concepts to us. It was this ability to problem solve and learn quickly that we are both very proud of ourselves for.
## What we learned
Along the way to finishing our project, some of (far from all) the things we learnt about were: web device interfaces for recording audio, networking and websockets to help communicate with external APIs, audio streams with machine learning, running javascript as a backend, using NodeJS modules, hosting client and server side platforms, and in general, user experience optimization as a whole.
## What's next for TSPeach
We hoped but were unable to include was the increasing of user feedback based on their pronunciations. We initially wanted to analyze and compare each user's pronunciation to a text-to-speech engine, however it was too hard to do in the time frame, so this would be another feature we would love to add. Optimizing our interface with Assembly AI would be our next major goal. Currently, the asynchronous approach to handling responses from Assembly AI uses a single async thread, however having multiple collaborating would be the ultimate goal. | winning |
## Inspiration
Blip emerged from a simple observation: in our fast-paced world, long-form content often goes unheard. Inspired by the success of short-form video platforms like Tiktok, we set out to revolutionize the audio space.
## What it does
Our vision is to create a platform where bite-sized audio clips could deliver maximum impact, allowing users to learn, stay informed, and be entertained in the snippets of time they have available throughout their day. Blip is precisely that. Blip offers a curated collection of short audio clips, personalized to each user's interests and schedule, ensuring they get the most relevant and engaging content whenever they have a few minutes to spare.
## How we built it
Building Blip was a journey that pushed our technical skills to new heights. We used a modern tech stack including TypeScript, NextJS, and TailwindCSS to create a responsive and intuitive user interface. The backend, powered by NextJS and enhanced with OpenAI and Cerebras APIs, presented unique challenges in processing and serving audio content efficiently. One of our proudest accomplishments was implementing an auto-play algorithm that allows users to listen to similar Blips, but also occasionally recommends more unique content.
## Challenges we ran into
The backend, powered by NextJS and enhanced with OpenAI and Cerebras APIs, presented unique challenges in processing and serving audio content efficiently. We had to make sure that no more audio clips than necessary were loaded at anytime to ensure browser speed optimality.
## Accomplishments that we're proud of
One of our proudest accomplishments was implementing an auto-play algorithm that allows users to listen to similar Blips, but also occasionally recommends more unique content. It allows users to listen to what they are comfortable with, yet also allows them to branch out.
## What we learned
Throughout the development process, we encountered and overcame numerous hurdles. Optimizing audio playback for seamless transitions between clips, ensuring UI-responsiveness, and efficiently utilizing sponsor APIs were just a few of the obstacles we faced. These challenges not only improved our problem-solving skills but also deepened our understanding of audio processing technologies and user experience design.
## What's next for Blip
The journey of creating Blip has been incredibly rewarding. We've learned the importance of user-centric design, found a new untapped market for entertainment, and harnessed the power of AI in enhancing content discovery and generation. Looking ahead, we're excited about the potential of Blip to transform how people consume audio content. Our roadmap includes expanding our content categories, scaling up our recommendation algorithm, and exploring partnerships with content creators and educators to bring even more diverse and engaging content to our platform.
Blip is more than just an app; it's a new way of thinking about audio content in the digital age. We're proud to have created a platform that makes learning and staying informed more accessible and enjoyable for everyone, regardless of their busy schedules. As we move forward, we're committed to continually improving and expanding Blip, always with our core mission in mind: to turn little moments into big ideas, one short-cast at a time. | ## Inspiration:
The inspiration for Kisan Mitra came from the realization that Indian farmers face a number of challenges in accessing information that can help them improve their productivity and incomes. These challenges include:
```
Limited reach of extension services
Lack of awareness of government schemes
Difficulty understanding complex information
Language barriers
```
Kisan Mitra is designed to address these challenges by providing farmers with timely and accurate information in a user-friendly and accessible manner.
## What it does :
Kisan Mitra is a chatbot that can answer farmers' questions on a wide range of topics, including:
```
Government schemes and eligibility criteria
Farming techniques and best practices
Crop selection and pest management
Irrigation and water management
Market prices and weather conditions
```
Kisan Mitra can also provide farmers with links to additional resources, such as government websites and agricultural research papers.
## How we built it:
Kisan Mitra is built using the PaLM API, which is a large language model from Google AI. PaLM is trained on a massive dataset of text and code, which allows it to generate text, translate languages, write different kinds of creative content, and answer your questions in an informative way.
Kisan Mitra is also integrated with a number of government databases and agricultural knowledge bases. This ensures that the information that Kisan Mitra provides is accurate and up-to-date.
## Challenges we ran into:
One of the biggest challenges we faced in developing Kisan Mitra was making it accessible to farmers of all levels of literacy and technical expertise. We wanted to create a chatbot that was easy to use and understand, even for farmers who have never used a smartphone before.
Another challenge was ensuring that Kisan Mitra could provide accurate and up-to-date information on a wide range of topics. We worked closely with government agencies and agricultural experts to develop a knowledge base that is comprehensive and reliable.
## Accomplishments that we're proud of:
We are proud of the fact that Kisan Mitra is a first-of-its-kind chatbot that is designed to address the specific needs of Indian farmers. We are also proud of the fact that Kisan Mitra is user-friendly and accessible to farmers of all levels of literacy and technical expertise.
## What we learned:
We learned a lot while developing Kisan Mitra. We learned about the challenges that Indian farmers face in accessing information, and we learned how to develop a chatbot that is both user-friendly and informative. We also learned about the importance of working closely with domain experts to ensure that the information that we provide is accurate and up-to-date.
## What's next for Kisan Mitra:
We are committed to continuing to develop and improve Kisan Mitra. We plan to add new features and functionality, and we plan to expand the knowledge base to cover more topics. We also plan to work with more government agencies and agricultural experts to ensure that Kisan Mitra is the best possible resource for Indian farmers.
We hope that Kisan Mitra will make a positive impact on the lives of Indian farmers by helping them to improve their productivity and incomes. | ## Inspiration
The inspiration behind Mentis emerged from a realization of the vast potential that a personalized learning AI platform holds in transforming education. We envisioned an AI-driven mentor capable of adapting to individual learning styles and needs, making education more accessible, engaging, and effective for everyone. The idea was to create an AI that could dynamically update its teaching content based on live user questions, ensuring that every learner could find a path that suits them best, regardless of their background or level of knowledge.
We wanted to build something that encompasses the intersection of: accessibility, interactivity and audiovisual.
## What it does
Mentis is an AI-powered educational platform that offers personalized learning experiences across a wide range of topics. It is able to generate and teach animated lesson plans with both visuals and audio, as it generates checkpoint questions for the user and listens to the questions of its users and dynamically adjusts the remainder of the teaching content and teaching methods to suit their individual learning preferences. Whether it's mathematics, science, or economics, Mentis provides tailored guidance, ensuring that users not only receive answers to their questions but also a deep understanding of the subject matter.
## How we built it
At its core, a fast API backend powers the intelligent processing and dynamic delivery of educational content, ensuring rapid response to user queries. This backend is complemented by our use of advanced Large Language Models (LLMs), which have been fine-tuned to understand a diverse range of educational topics and specialize in code generation for the best animation, enhancing the platform's ability to deliver tailored learning experiences.
We curated a custom dataset in order to leverage LLMs to the fullest and reduce errors in both script and code generation. Using our curated datasets, we were able to fine-tune models using MonsterAPI tailoring our LLMs and improve accuracy.. We implemented several API calls to ensure a smooth and dynamic operation of our platform, for general organization of the lesson plan, script generation, audio generation with ElevenLabs, and code generation for the manim library we utilize to create the animations on our front end in Bun and Next.js.
[Fine tuned open source model](https://huggingface.co/generaleoley/mixtral-8x7b-manim-lora/tree/main)
[Curated custom dataset](https://huggingface.co/datasets/generaleoley/manim-codegen)
## Challenges we ran into
Throughout the development of Mentis, we encountered significant challenges, particularly in setting up environments and installing various dependencies. These hurdles consumed a considerable amount of our time, persisting until the final stages of development.
Every stage of our application had issues we had to address: generating dynamic sections for our video scripts, ensuring that the code is able to execute the animation, integrating the text-to-speech component to generate audio for our educational content all introduced layers of complexity, requiring precise tuning and a lot of playing with to set up.
The number of API calls needed to fetch, update, and manage content dynamically, coupled with ensuring the seamless interaction between the user and our application, demanded a meticulous approach. We found ourselves in a constant battle to maintain efficiency and reliability, as we tried to keep our latency low for practicality and interactivity of our product.
## Accomplishments that we're proud of
Despite the setbacks, we are incredibly proud of:
* Technical Overcomes: Overcoming significant technical hurdles, learning from them and enhancing our problem-solving capabilities.
* Versatile System: Enabling our platform to cover a broad range of topics, making learning accessible to everyone.
* Adaptive Learning: Developing a system that can truly adapt to each user's unique learning style and needs.
* User-Friendly UI: Creating a user-friendly design and experience keeping our application as accessible as possible.
* API Management: Successfully managing numerous API calls, we smoothed the backend operation as much as possible for a seamless user experience.
* Fine tuned/Tailored Models: Going through the full process of data exploration & cleaning, model selection, and configuring the fine-tuned model.
## What we learned
Throughout the backend our biggest challenge and learning point was the setup, coordination and training of multiple AI agents and APIs.
For all of us, this was our first time fine-tuning a LLM and there were many things we learned through this process such as dataset selection, model selection, fine-tuning configuration. We gained an appreciation for all the great work that was being done by the many researchers. With careful tuning and prompting, we were able to greatly increase the efficiency and accuracy of the models.
We also learned a lot about coordinating multi-agent systems and how to efficiently have them run concurrently and together. We tested many architectures and ended up settling for one that would optimize first for accuracy then for speed. To accomplish this, we set up an asynchronous query system where multiple “frames” can be generated at once and allow us not to be blocked by cloud computation time.
## What's next for mentis.ai
Looking ahead, Mentis.ai has exciting plans for improvement and expansion:
**Reducing Latency:** We're committed to enhancing efficiency, aiming to minimize latency further and optimize performance across the platform.
**Innovative Features:** Given more time, we plan to integrate cutting-edge features, like using HeyGen API to create natural videos of personalized AI tutors, combining custom images, videos, and audio for a richer learning experience.
**Classroom Integration:** We're exploring opportunities to bring Mentis into classroom settings, testing its effectiveness in a real-world educational environment and tailoring its capabilities to support teachers and students alike. | winning |
## Inspiration
Inspired by personal experience of commonly getting separated in groups and knowing how inconvenient and sometimes dangerous it can be, we aimed to create an application that kept people together. We were inspired by how interlinked and connected we are today by our devices and sought to address social issues while using the advancements in decentralized compute and communication. We also wanted to build a user experience that is unique and can be built upon with further iterations and implementations.
## What it does
Huddle employs mesh networking capability to maintain a decentralized network among a small group of people, but can be scaled to many users. By having a mesh network of mobile devices, Huddle manages the proximity of its users. When a user is disconnected, Huddle notifies all of the devices on its network, thereby raising awareness, should someone lose their way.
The best use-case for Huddle is in remote areas where cell-phone signals are unreliable and managing a group can be cumbersome. In a hiking scenario, should a unlucky hiker choose the wrong path or be left behind, Huddle will reduce risks and keep the team together.
## How we built it
Huddle is an Android app built with the RightMesh API. With many cups of coffee, teamwork, brainstorming, help from mentors, team-building exercises, and hours in front of a screen, we produced our first Android app.
## Challenges we ran into
Like most hackathons, our first challenge was deciding on an idea to proceed with. We employed the use of various collaborative and brainstorming techniques, approached various mentors for their input, and eventually we decided on this scalable idea.
As mentioned, none of us developed an Android environment before, so we had a large learning curve to get our environment set-up, developing small applications, and eventually building the app you see today.
## Accomplishments that we're proud of
One of our goals was to be able to develop a completed product at the end. Nothing feels better than writing this paragraph after nearly 24 hours of non-stop hacking.
Once again, developing a rather complete Android app without any developer experience was a monumental achievement for us. Learning and stumbling as we go in a hackathon was a unique experience and we are really happy we attended this event, no matter how sleepy this post may seem.
## What we learned
One of the ideas that we gained through this process was organizing and running a rather tightly-knit developing cycle. We gained many skills in both user experience, learning how the Android environment works, and how we make ourselves and our product adaptable to change. Many design changes occured, and it was great to see that changes were still what we wanted and what we wanted to develop.
Aside from the desk experience, we also saw many ideas from other people, different ways of tackling similar problems, and we hope to build upon these ideas in the future.
## What's next for Huddle
We would like to build upon Huddle and explore different ways of using the mesh networking technology to bring people together in meaningful ways, such as social games, getting to know new people close by, and facilitating unique ways of tackling old problems without centralized internet and compute.
Also V2. | ## Inspiration
We thought it would be nice if, for example, while working in the Computer Science building, you could send out a little post asking for help from people around you.
Also, it would also enable greater interconnectivity between people at an event without needing to subscribe to anything.
## What it does
Users create posts that are then attached to their location, complete with a picture and a description. Other people can then view it two ways.
**1)** On a map, with markers indicating the location of the post that can be tapped on for more detail.
**2)** As a live feed, with the details of all the posts that are in your current location.
The posts don't last long, however, and only posts within a certain radius are visible to you.
## How we built it
Individual pages were built using HTML, CSS and JS, which would then interact with a server built using Node.js and Express.js. The database, which used cockroachDB, was hosted with Amazon Web Services. We used PHP to upload images onto a separate private server. Finally, the app was packaged using Apache Cordova to be runnable on the phone. Heroku allowed us to upload the Node.js portion on the cloud.
## Challenges we ran into
Setting up and using CockroachDB was difficult because we were unfamiliar with it. We were also not used to using so many technologies at once. | ## Inspiration:
*This project was inspired by the idea of growth mindset. We all live busy lives and face obstacles everyday but in the face of a difficult situation we can either rise to the occasion or let our obstacles win.*
## What it does
*Through the use of Google NLP, our app runs analysis on the users text input of how they are feeling and runs analysis on their text to determine if they are thinking positively or negatively. Then they are prompted to change the negative thought into a positive one.*
## How I built it
*We built the app using Swift code,Swift UI kit and designed the logo on adobe illustrator, We used APIs from the Google Cloud Platform such as NLP for text/sentiment analysis.*
## Challenges I ran into
*Having a starting point was difficult since neither one of us was experienced with coding Swift on XCOde. But with perseverance we were able to overcome this challenge and keep going. We also ran into difficulties with using APIs due to the version of Swift not matching. Then we did not have the time to build a server so we had to tweak our idea slightly.*
## Accomplishments that I'm proud of:
*-creating a fully functional iOS application on Swift for the first time
-using our creativity to come up with a social impact project
-combating each challenge that came our way*
## What I learned
*I learned expect the unexpected since not everything goes as planned. But with a courage you can accomplish anything. I also learned to prioritize.*
## What's next for Vent
*to improve search optimization
build traction for the app
have an optional Facebook login page in case users want to enter in their information
Build the website version of the app* | partial |
## What it does
Think "virtual vision stick on steroids"! It is a wearable device that AUDIBLY provides visually impaired people with information on the objects in front of them as well as their proximity.
## How we built it
We used computer vision from Python and OpenCV to recognize objects such as "chair" and "person" and then we used an Arduino to interface with an ultrasonic sensor to receive distance data in REAL TIME. On top of that, the sensor was mounted on a servo motor, connected to a joystick so the user can control where the sensor scans in their field of vision.
## Challenges we ran into
The biggest challenge we ran into was integrating the ultrasonic sensor data from the Arduino with the OpenCV live object detection data. This is because we had to grab data from the Arduino (the code is in C++) and use it in our OpenCV program (written in Python). We solved this by using PySerial and calling our friends Phoebe Simon Ryan and Olivia from the Anti Anti Masker Mask project for help!
## Accomplishments that we're proud of
Using hardware and computer vision for the first time!
## What we learned
How to interface with hardware, work as a team, and be flexible (we changed our idea and mechanisms like 5 times).
## What's next for All Eyez On Me
Refine our design so it's more STYLISH :D | ## Inspiration
We realized how visually-impaired people find it difficult to perceive the objects coming near to them, or when they are either out on road, or when they are inside a building. They encounter potholes and stairs and things get really hard for them. We decided to tackle the issue of accessibility to support the Government of Canada's initiative to make work and public places completely accessible!
## What it does
This is an IoT device which is designed to be something wearable or that can be attached to any visual aid being used. What it does is that it uses depth perception to perform obstacle detection, as well as integrates Google Assistant for outdoor navigation and all the other "smart activities" that the assistant can do. The assistant will provide voice directions (which can be geared towards using bluetooth devices easily) and the sensors will help in avoiding obstacles which helps in increasing self-awareness. Another beta-feature was to identify moving obstacles and play sounds so the person can recognize those moving objects (eg. barking sounds for a dog etc.)
## How we built it
Its a raspberry-pi based device and we integrated Google Cloud SDK to be able to use the vision API and the Assistant and all the other features offered by GCP. We have sensors for depth perception and buzzers to play alert sounds as well as camera and microphone.
## Challenges we ran into
It was hard for us to set up raspberry-pi, having had no background with it. We had to learn how to integrate cloud platforms with embedded systems and understand how micro controllers work, especially not being from the engineering background and 2 members being high school students. Also, multi-threading was a challenge for us in embedded architecture
## Accomplishments that we're proud of
After hours of grinding, we were able to get the raspberry-pi working, as well as implementing depth perception and location tracking using Google Assistant, as well as object recognition.
## What we learned
Working with hardware is tough, even though you could see what is happening, it was hard to interface software and hardware.
## What's next for i4Noi
We want to explore more ways where i4Noi can help make things more accessible for blind people. Since we already have Google Cloud integration, we could integrate our another feature where we play sounds of living obstacles so special care can be done, for example when a dog comes in front, we produce barking sounds to alert the person. We would also like to implement multi-threading for our two processes and make this device as wearable as possible, so it can make a difference to the lives of the people. | ## Inspiration
We thought about how visually impaired people have a very limited perception range, less 2m from their body at all times. To gather information about new environments they would need to physically explore the space which is impractically and time-consuming to do.
## What it does
The system consists of 2 cameras attached to a hat which the user wears. These cameras detect objects in the environment, acting as the user's visual guide. The user can ask "What's around?", and the system will respond with a description of the environment as seen by the 2 cameras. The user can ask "Where are the chairs?" and the system will respond with positions of chairs relative to the user.
## How we built it
This project uses YOLOv8 to run object detection using two cameras. We used a pipeline of python classes to detect objects, filter bounding boxes, translate boxes into 3d space and play spacial audio to the user. Additionally, we build the camera mounts and the box containing the Nividia Jetson, running all of our code.
## Challenges we ran into
The biggest challenge that we tackled during this hackathon was developing on the Nividia Jetson. Getting the permissions on the file systems and installing the correct dependencies is especially challenging, as we navigated with little documentation. We also spent considerable time planning out how to mount the cameras so they were stable for object detection and have no overlap.
## Accomplishments that we're proud of
Translating the object detection into spacial audio is something that we are specifically proud of, having to integrate multiple different complex sub-systems.
## What we learned
We once again learned how hard integration is, and how much there is to learn about linux! | winning |
## Inspiration
In a world where finance is extremely important, everyone needs access to **banking services**. Citizens within **third world countries** are no exception, but they lack the banking technology infrastructure that many of us in first world countries take for granted. Mobile Applications and Web Portals don't work 100% for these people, so we decided to make software that requires nothing more than a **cellular connection to send SMS messages** in order to operate. This resulted in our hack, **UBank**.
## What it does
**UBank** allows users to operate their bank accounts entirely through **text messaging**. Users can deposit money, transfer funds between accounts, transfer accounts to other users, and even purchases shares of stock via SMS. In addition to this text messaging capability, UBank also provides a web portal so that when our users gain access to a steady internet connection or PC, they can view their financial information on a more comprehensive level.
## How I built it
We set up a backend HTTP server in **Node.js** to receive and fulfill requests. **Twilio** with ngrok was used to send and receive the text messages through a webhook on the backend Node.js server and applicant data was stored in firebase. The frontend was primarily built with **HTML, CSS, and Javascript** and HTTP requests were sent to the Node.js backend to receive applicant information and display it on the browser. We utilized Mozilla's speech to text library to incorporate speech commands and chart.js to display client data with intuitive graphs.
## Challenges I ran into
* Some team members were new to Node.js, and therefore working with some of the server coding was a little complicated. However, we were able to leverage the experience of other group members which allowed all of us to learn and figure out everything in the end.
* Using Twilio was a challenge because no team members had previous experience with the technology. We had difficulties making it communicate with our backend Node.js server, but after a few hours of hard work we eventually figured it out.
## Accomplishments that I'm proud of
We are proud of making a **functioning**, **dynamic**, finished product. It feels great to design software that is adaptable and begging for the next steps of development. We're also super proud that we made an attempt at tackling a problem that is having severe negative effects on people all around the world, and we hope that someday our product can make it to those people.
## What I learned
This was our first using **Twillio** so we learned a lot about utilizing that software. Front-end team members also got to learn and practice their **HTML/CSS/JS** skills which were a great experience.
## What's next for UBank
* The next step for UBank probably would be implementing an authentication/anti-fraud system. Being a banking service, it's imperative that our customers' transactions are secure at all times, and we would be unable to launch without such a feature.
* We hope to continue the development of UBank and gain some beta users so that we can test our product and incorporate customer feedback in order to improve our software before making an attempt at launching the service. | ## Inspiration
More money, more problems.
Lacking an easy, accessible, and secure method of transferring money? Even more problems.
An interesting solution to this has been the rise of WeChat Pay, allowing for merchants to use QR codes and social media to make digital payments.
But where does this leave people without sufficient bandwidth? Without reliable, adequate Wi-Fi, technologies like WeChat Pay and Google Pay simply aren't options. People looking to make money transfers are forced to choose between bloated fees or dangerously long wait times.
As designers, programmers, and students, we tend to think about how we can design tech. But how do you design tech for that negative space? During our research, we found of the people that lack adequate bandwidth, 1.28 billion of them have access to mobile service. This ultimately led to our solution: **Money might not grow on trees, but Paypayas do.** 🍈
## What it does
Paypaya is an SMS chatbot application that allows users to perform simple and safe transfers using just text messages.
Users start by texting a toll free number. Doing so opens a digital wallet that is authenticated by their voice. From that point, users can easily transfer, deposit, withdraw, or view their balance.
Despite being built for low bandwidth regions, Paypaya also has huge market potential in high bandwidth areas as well. Whether you are a small business owner that can't afford a swipe machine or a charity trying to raise funds in a contactless way, the possibilities are endless.
Try it for yourself by texting +1-833-729-0967
## How we built it
We first set up our Flask application in a Docker container on Google Cloud Run to streamline cross OS development. We then set up our database using MongoDB Atlas. Within the app, we also integrated the Twilio and PayPal APIs to create a digital wallet and perform the application commands. After creating the primary functionality of the app, we implemented voice authentication by collecting voice clips from Twilio to be used in Microsoft Azure's Speaker Recognition API.
For our branding and slides, everything was made vector by vector on Figma.
## Challenges we ran into
Man. Where do we start. Although it was fun, working in a two person team meant that we were both wearing (too) many hats. In terms of technical problems, the PayPal API documentation was archaic, making it extremely difficult for us figure out how to call the necessary functions. It was also really difficult to convert the audio from Twilio to a byte-stream for the Azure API. Lastly, we had trouble keeping track of conversation state in the chatbot as we were limited by how the webhook was called by Twilio.
## Accomplishments that we're proud of
We're really proud of creating a fully functioning MVP! All of 6 of our moving parts came together to form a working proof of concept. All of our graphics (slides, logo, collages) are all made from scratch. :))
## What we learned
Anson - As a first time back end developer, I learned SO much about using APIs, webhooks, databases, and servers. I also learned that Jacky falls asleep super easily.
Jacky - I learned that Microsoft Azure and Twilio can be a pain to work with and that Google Cloud Run is a blessing and a half. I learned I don't have the energy to stay up 36 hours straight for a hackathon anymore 🙃
## What's next for Paypaya
More language options! English is far from the native tongue of the world. By expanding the languages available, Paypaya will be accessible to even more people. We would also love to do more with financial planning, providing a log of previous transactions for individuals to track their spending and income. There are also a lot of rough edges and edge cases in the program flow, so patching up those will be important in bringing this to market. | ## Inspiration
We want to revolutionize taxes to be simple, tax assistance to be instant and accessible, and forms completed in thirty minutes or less.
## What it does
TabbyTax compiles simple tax forms for submission to the IRS via Facebook Messenger. Optimized for first-time taxpayers, students, and those making under $30,000, TabbyTax uses powerful IBM image processing and Artificial Intelligence Natural Language Processing to understand and converse with users. Users can begin a conversation with TabbyTax by simply messaging the page, and TabbyTax will prompt the user for all necessary information to populate a simple case of the 1040 form, with additional support for life events, and tax forms common among college students and the low-income community.
## How we built it
## Challenges we ran into
Tying in the Watson API and the Natural Language Processing API... three hours down the drain RIP
## Accomplishments that we're proud of
Easy to interact with and professional UI courtesy of Facebook, conversational Tabby
## What we learned
## What's next for TabbyTax
Building out functions for slightly more complex tax cases including an expanded number of life events to increase the potential user base. | winning |
## Inspiration
With a prior interest in crypto and defi, we were attracted to Uniswap V3's simple yet brilliant automated market maker. The white papers were tantalizing and we had several eureka moments when pouring over them. However, we realized that the concepts were beyond the reach of most casual users who would be interested in using Uniswap. Consequently, we decided to build an algorithm that allowed Uniswap users to take a more hands-on and less theoretical approach, while mitigating risk, to understanding the nuances of the marketplace so they would be better suited to make decisions that aligned with their financial goals.
## What it does
This project is intended to help new Uniswap users understand the novel processes that the financial protocol (Uniswap) operates upon, specifically with regards to its automated market maker. Taking an input of a hypothetical liquidity mining position in a liquidity pool of the user's choice, our predictive model uses past transactions within that liquidity pool to project the performance of the specified liquidity mining position over time - thus allowing Uniswap users to make better informed decisions regarding which liquidity pools and what currencies and what quantities to invest in.
## How we built it
We divided the complete task into four main subproblems: the simulation model and rest of the backend, an intuitive UI with a frontend that emulated Uniswap's, the graphic design, and - most importantly - successfully integrating these three elements together. Each of these tasks took the entirety of the contest window to complete to a degree we were satisfied with given the time constraints.
## Challenges we ran into and accomplishments we're proud of
Connecting all the different libraries, frameworks, and languages we used was by far the biggest and most frequent challenge we faced. This included running Python and NumPy through AWS, calling AWS with React and Node.js, making GraphQL queries to Uniswap V3's API, among many other tasks. Of course, re-implementing many of the key features Uniswap runs on to better our simulation was another major hurdle and took several hours of debugging. We had to return to the drawing board countless times to ensure we were correctly emulating the automated market maker as closely as possible. Another difficult task was making our UI as easy to use as possible for users. Notably, this meant correcting the inputs since there are many constraints for what position a user may actually take in a liquidity pool. Ultimately, in spite of the many technical hurdles, we are proud of what we have accomplished and believe our product is ready to be released pending a few final touches.
## What we learned
Every aspect of this project introduced us to new concepts, or new implementations of concepts we had picked up previously. While we had dealt with similar subtasks in the past, this was our first time building something of this scope from the ground-up. | ## Inspiration
Uniswap creator, Hayden, mentioned during the CalHacks 8.0 kickoff that he felt some of the best features in Uniswap v3 were being under-utilized. We wanted to find out if there was something in this space we could work on.
While reading up about v3 and the v3 Oracle in particular, we experimented with the Uniswap interface for pooling. The advanced options for concentrated liquidity pooling are pretty impressive - but we felt there was more to be done to take advantage of the opportunities created by this difference between v2 and v3.
[This paper](https://arxiv.org/pdf/2106.12033.pdf) by Neuder et al. gave us some implementation-specific inspiration.
## What it does (and will do)
RainbowPool builds upon the existing Uniswap router to give LPs access to safe and cost-efficient implementations of strategic liquidity provision - like splitting liquidity provision over bins with different ranges and executing smart re-balancing.
The decentralized app we implemented this weekend allows liquidity providers to interface with our liquidity optimization smart contract. It is a web3.0 application that acts as a proof of concept for our product.
We plan on integrating Uniswap v3 Router to facilitate transactions across liquidity pools on the mainnet. Uniswap v3 Oracle will provide data for our optimization algorithms so that we can do things like automatically re-provision liquidity.
## How we built it
We used the existing [scaffold-eth](https://github.com/scaffold-eth/scaffold-eth) framework to facilitate rapid-prototyping and iteration of a user interface linked to a smart contract.
We deployed contracts on a local chain created using Hardhat.
## Challenges we ran into
When trying to integrate Uniswap v3 into our environment we ran into problems related to Solidity complier versioning. This (disappointingly) stopped us from interacting with the Uniswap Router and Liquidity Management functionality directly.
## What we learned
This hackathon was - for our team - an introduction to the dapp developement space. None of us had deployed chains locally or programmed in Solidity before this event.
## What's next for RainbowPool
Full integration with Uniswap v3 Router.
Leveraging Oracle v3 for data.
Implementation of liquidity provisioning algorithms in Solidity. | ## Inspiration
Our team members really enjoy going to museums. One of the problems that all of us encountered is that after admiring artwork at a museum, we take pictures of our favorite pieces to remember them but do not interact with them a second time. The photo is then lost in the camera roll. We forget the title of the art and do not remember the artist which makes it difficult to find information about the piece later.
Additionally, we are all users of GoodReads. After talking about our common issue, we decided that building a platform that is similar to GoodReads, but marketed for artwork, would be the perfect solution. This is how we came up with our idea for **ArtJournal+**
## What it does
The **ArtJournal+** mobile app provides a way for users to easily scan a piece of artwork. Using machine learning, relevant information about the artwork, such as the title, author, date of production, and context is displayed. The platform also functions as a social network, allowing users to connect with friends, search for trending art pieces, and post commentary on art pieces.
The website is a MVP of the future **ArtJournal+** platform. After a user sign's in, their artwork is displayed. The user can add pieces of art, comment on them, and then view these pieces in a rotating 3D gallery.
## How we built it
A machine learning component allows users to find information about a painting based on just a photograph. The integration of react-three-fibr creates the 3D gallery. We developed the app mock up in apphive.
## Challenges we ran into
The machine learning component was incredibly difficult to implement. We developed a majority of the code but were unable to fully implement it. This component would be further implemented in future generations.
## Accomplishments that we're proud of
Our 3D website represents the future of museum and artwork interaction. We are excited to approach museums from a new lens.
## What we learned
We learned immense website and app building skills, worked on ML implementation, and learned to work with 3D visualization.
## What's next for ArtJournal+
As ArtJournal+ moves forward, we will update the functionality of the app to allow for user consumption. We will also integrate the ML component with the app and website. | winning |
## Inspiration
The idea for VenTalk originated from an everyday stressor that everyone on our team could relate to; commuting alone to and from class during the school year. After a stressful work or school day, we want to let out all our feelings and thoughts, but do not want to alarm or disturb our loved ones. Releasing built-up emotional tension is a highly effective form of self-care, but many people stay quiet as not to become a burden on those around them. Over time, this takes a toll on one’s well being, so we decided to tackle this issue in a creative yet simple way.
## What it does
VenTalk allows users to either chat with another user or request urgent mental health assistance. Based on their choice, they input how they are feeling on a mental health scale, or some topics they want to discuss with their paired user. The app searches for keywords and similarities to match 2 users who are looking to have a similar conversation. VenTalk is completely anonymous and thus guilt-free, and chats are permanently deleted once both users have left the conversation. This allows users to get any stressors from their day off their chest and rejuvenate their bodies and minds, while still connecting with others.
## How we built it
We began with building a framework in React Native and using Figma to design a clean, user-friendly app layout. After this, we wrote an algorithm that could detect common words from the user inputs, and finally pair up two users in the queue to start messaging. Then we integrated, tested, and refined how the app worked.
## Challenges we ran into
One of the biggest challenges we faced was learning how to interact with APIs and cloud programs. We had a lot of issues getting a reliable response from the web API we wanted to use, and a lot of requests just returned CORS errors. After some determination and a lot of hard work we finally got the API working with Axios.
## Accomplishments that we're proud of
In addition to the original plan for just messaging, we added a Helpful Hotline page with emergency mental health resources, in case a user is seeking professional help. We believe that since this app will be used when people are not in their best state of minds, it's a good idea to have some resources available to them.
## What we learned
Something we got to learn more about was the impact of user interface on the mood of the user, and how different shades and colours are connotated with emotions. We also discovered that having team members from different schools and programs creates a unique, dynamic atmosphere and a great final result!
## What's next for VenTalk
There are many potential next steps for VenTalk. We are going to continue developing the app, making it compatible with iOS, and maybe even a webapp version. We also want to add more personal features, such as a personal locker of stuff that makes you happy (such as a playlist, a subreddit or a netflix series). | ## Inspiration
Given the increase in mental health awareness, we wanted to focus on therapy treatment tools in order to enhance the effectiveness of therapy. Therapists rely on hand-written notes and personal memory to progress emotionally with their clients, and there is no assistive digital tool for therapists to keep track of clients’ sentiment throughout a session. Therefore, we want to equip therapists with the ability to better analyze raw data, and track patient progress over time.
## Our Team
* Vanessa Seto, Systems Design Engineering at the University of Waterloo
* Daniel Wang, CS at the University of Toronto
* Quinnan Gill, Computer Engineering at the University of Pittsburgh
* Sanchit Batra, CS at the University of Buffalo
## What it does
Inkblot is a digital tool to give therapists a second opinion, by performing sentimental analysis on a patient throughout a therapy session. It keeps track of client progress as they attend more therapy sessions, and gives therapists useful data points that aren't usually captured in typical hand-written notes.
Some key features include the ability to scrub across the entire therapy session, allowing the therapist to read the transcript, and look at specific key words associated with certain emotions. Another key feature is the progress tab, that displays past therapy sessions with easy to interpret sentiment data visualizations, to allow therapists to see the overall ups and downs in a patient's visits.
## How we built it
We built the front end using Angular and hosted the web page locally. Given a complex data set, we wanted to present our application in a simple and user-friendly manner. We created a styling and branding template for the application and designed the UI from scratch.
For the back-end we hosted a REST API built using Flask on GCP in order to easily access API's offered by GCP.
Most notably, we took advantage of Google Vision API to perform sentiment analysis and used their speech to text API to transcribe a patient's therapy session.
## Challenges we ran into
* Integrated a chart library in Angular that met our project’s complex data needs
* Working with raw data
* Audio processing and conversions for session video clips
## Accomplishments that we're proud of
* Using GCP in its full effectiveness for our use case, including technologies like Google Cloud Storage, Google Compute VM, Google Cloud Firewall / LoadBalancer, as well as both Vision API and Speech-To-Text
* Implementing the entire front-end from scratch in Angular, with the integration of real-time data
* Great UI Design :)
## What's next for Inkblot
* Database integration: Keeping user data, keeping historical data, user profiles (login)
* Twilio Integration
* HIPAA Compliancy
* Investigate blockchain technology with the help of BlockStack
* Testing the product with professional therapists | ## 💡 Inspiration
We got inspiration from or back-end developer Minh. He mentioned that he was interested in the idea of an app that helped people record their positive progress and showcase their accomplishments there. This then led to our product/UX designer Jenny to think about what this app would target as a problem and what kind of solution would it offer. From our research, we came to the conclusion quantity over quality social media use resulted in people feeling less accomplished and more anxious. As a solution, we wanted to focus on an app that helps people stay focused on their own goals and accomplishments.
## ⚙ What it does
Our app is a journalling app that has the user enter 2 journal entries a day. One in the morning and one in the evening. During these journal entries, it would ask the user about their mood at the moment, generate am appropriate response based on their mood, and then ask questions that get the user to think about such as gratuity, their plans for the day, and what advice would they give themselves. Our questions follow many of the common journalling practices. The second journal entry then follows a similar format of mood and questions with a different set of questions to finish off the user's day. These help them reflect and look forward to the upcoming future. Our most powerful feature would be the AI that takes data such as emotions and keywords from answers and helps users generate journal summaries across weeks, months, and years. These summaries would then provide actionable steps the user could take to make self-improvements.
## 🔧 How we built it
### Product & UX
* Online research, user interviews, looked at stakeholders, competitors, infinity mapping, and user flows.
* Doing the research allowed our group to have a unified understanding for the app.
### 👩💻 Frontend
* Used React.JS to design the website
* Used Figma for prototyping the website
### 🔚 Backend
* Flask, CockroachDB, and Cohere for ChatAI function.
## 💪 Challenges we ran into
The challenge we ran into was the time limit. For this project, we invested most of our time in understanding the pinpoint in a very sensitive topic such as mental health and psychology. We truly want to identify and solve a meaningful challenge; we had to sacrifice some portions of the project such as front-end code implementation. Some team members were also working with the developers for the first time and it was a good learning experience for everyone to see how different roles come together and how we could improve for next time.
## 🙌 Accomplishments that we're proud of
Jenny, our team designer, did tons of research on problem space such as competitive analysis, research on similar products, and user interviews. We produced a high-fidelity prototype and were able to show the feasibility of the technology we built for this project. (Jenny: I am also very proud of everyone else who had the patience to listen to my views as a designer and be open-minded about what a final solution may look like. I think I'm very proud that we were able to build a good team together although the experience was relatively short over the weekend. I had personally never met the other two team members and the way we were able to have a vision together is something I think we should be proud of.)
## 📚 What we learned
We learned preparing some plans ahead of time next time would make it easier for developers and designers to get started. However, the experience of starting from nothing and making a full project over 2 and a half days was great for learning. We learned a lot about how we think and approach work not only as developers and designer, but as team members.
## 💭 What's next for budEjournal
Next, we would like to test out budEjournal on some real users and make adjustments based on our findings. We would also like to spend more time to build out the front-end. | winning |
# Liber Populus
## Vote like your life depends on it.
By many accounts, this upcoming 2020 election will be one of the most contentious to date. With a global pandemic,
economic crisis, racial unrest, two starkly different candidates, and a polarized nation, it is important that everyone who is able to partakes in the democratic process at the heart of the American story.
This is where **Liber Populus** comes in.
**Liber Populus** – Latin for *“free people”*
**Liber Populus** provides an assortment of tools and information to equip every voter with what they need to ensure they register and cast their ballot while avoiding obstacles such as voter suppression, ballot filing mistakes, and more! | +1 902 903 6416 (send 'cmd' to get started)
## Inspiration
We believe in the right of every individual to have access to information, regardless of price or censorship
## What it does
NoNet gives unfettered access to internets most popular service without an internet or data connection. It accomplishes this through sending SMS queries to a server which then processes the query and returns results that were previously only accessible to those with an uncensored internet connection. It works with Yelp, Google Search (headlines), Google Search (Articles/Websites), Wikipedia, and Google Translate.
some commands include:
* 'web: border wall' // returns top results from google
* 'url: [www.somesite.somearticle.com](http://www.somesite.somearticle.com)' // returns article content
* 'tr ru: Hello my russian friend!' // returns russian translation
* 'wiki: Berlin' // returns Wikipedia for Berlin
* 'cmd' // returns all commands available
The use cases are many:
* in many countries, everyone has a phone with sms, but data is prohibitively expensive so they have no internet access
* Countries like China have a censored internet, and this would give citizens the freedom to bybass that
* Authoritarian Countries turn of internet in times of mass unrest to keep disinformation
## How we built it
We integrated Twilio for SMS with a NodeJS server, hosted on Google App Engine, and using multiple API's
## Challenges we ran into
We faced challenges at every step of the way, from establishing two way messaging, to hosting the server, to parsing the correct information to fit sms format. We tackled the problems as a team and overcome them to produce a finished product
## Accomplishments that we're proud of:
"Weathering a Tsunami" - getting through all the challenges we faced and building a product that can truly help millions of people across the world
## What we learned
We learned how to face problems as well as new technologies
## What's next for NoNet
Potential Monetization Strategies would be to put ads in the start of queries (like translink bus stop messaging), or give premium call limits to registered numbers | ## Inspiration
We were inspired to create this by looking at the lack of resources for people to access information about their medications with just a prescription or report such as blood tests
## What it does
Takes image of prescriptions, blood tests, X rays or any medical records -> performs OCR or image recognization according to the record provided -> converts text to fetch more info from the web -> stores data -> predicts health
## How we built it
Using python and google and IBM's machine learning API's
## Challenges we ran into
Integrating the learning into our platform.
## Accomplishments that we're proud of
The web app
## What we learned
How to create a learning web platform
## What's next for MedPred
To make it a platform for long term health predictions | partial |
## Inspiration
We wanted to explore something in the area of safety, and thought about the possibility of being able to know when someone who has harmed or abused you has come within the vicinity.
## What it does
When an 'abuser' enters within a set radius of a 'victim', the abuser gets an alert telling them they have entered within the vicinity and need to leave. While the victim gets an alert telling them that the abuser has come within the vicinity as well, they also get the option of calling emergency services, with their location sent over in real time so the operator will have their location, as well as the other person's location, in real time. | ## Inspiration
“Am I safe?”
Maybe you know you’re way around maybe you are new to an area. For women finding the safest way to simply walk outside is something as common place as navigating to avoid traffic and WalkMeHome treats this reality as the obstacle and threat that it is.
Our team wanted to design a platform for women to mark where they have felt uncomfortable and a tool to navigate through the world with other women’s experiences taken into account. How would you advise a friend to get home? “This road is well lit, stay away from that bus stop...text me when you get there.” This familiar farewell is proof alone that we need something.
Through Esri’s platform we have the capabilities to collect and store live data, underlay existing crime statistics for an area, and even record users notes to arm ladies with invaluable local knowledge.
By collecting this data we can look out for each other, as well as notify lawmakers and business owners about potential problems. Yes, all women, and #metoo can have live data points of what women’s daily experience, and an undeniable conversation piece when comes to gaslighting. It's real what’s happening to us as women, and we're taking notes.
It is not enough to play damage control for rape culture, it's been time to tear it down. Our team sees this project having the potential to grow into a way to study women’s safety, and even be a social accountability system to have safety economically tied to local business and workplaces, not unlike glassdoor or yelp. “Lets go for drinks! This place has good food and a place other women recommend!” We are hoping social pressure of not having multiple reports of bad experiences will push business owners to “hold the public space” better and actively look out for predators. Maybe even require training for employees to notice when women are recipients of relentless unsolicited attention, or simply just having adjacent alleys better lit.
When it comes down to it, a world that is safer for women is safer for all folks of all genders, and we would hope that this project can act as a model for all people to get home safe.
## What it does
At the moment, we have the capability to find the user’s location and place a dot on it. This is a start! Esri is an incredibly powerful tool with LOTS of functionality. We met a bit of a learning curve figuring out terminology, choosing the appropriate features, and piecing it all together in time. This weekend three of the four team members fell terribly ill, which greatly slowed production, and the last dev hacking now knows survival Java. Even with the Great TreeHacks Plauge of 2019, with all the hours the Esri mentors risked spending with us (Thanks all!!), we have a good handle on moving forward.
## Looking Ahead
All four of us, as well as some friends and mentors who we pitched to along the way, are excited to stay in touch and continue development on this much needed service.
In our research we came across the "Free to Be" project in Australia, documenting street harassment and creating a report of harassment hot spots for lawmakers to consider. For six weeks last spring, the project's map service accepted submissions to then later be turned into a report along with testimonials. On receiving such an overwhelming response, they continued on to other major cities. With Esri's help we can turn the energy to report into a tool that can take down the need to.
## Notes on Intended Usage
We spent much energy talking about how to design an app that would give the needed safety data without stressing out or triggering our users. Hearing details of someone being seriously and violently hurt nearby when causally mapping a walk home could very negatively affect our user’s mental health.
With this discussion in mind we chose to have all reports weighted the same to not feel like a big deal, and to be a tool to record when and when the uncomfortable moments of a women's day are with a simple, causal, and anonymous check mark. We would want people to not feel bad about marking workplaces or restaurants, and for others to see that maybe those companies and establishments may have a problem, while still being a very serious and important tool. The scary stuff, although severely under-reported, we'll leave for now to Esri's crime layer from verified police data, and take this into account in our routing feature to come.
Thanks all!
-WalkMeHome Team | ## Inspiration
Recent mass shooting events are indicative of a rising, unfortunate trend in the United States. During a shooting, someone may be killed every 3 seconds on average, while it takes authorities an average of 10 minutes to arrive on a crime scene after a distress call. In addition, cameras and live closed circuit video monitoring are almost ubiquitous now, but are almost always used for post-crime analysis. Why not use them immediately? With the power of Google Cloud and other tools, we can use camera feed to immediately detect weapons real-time, identify a threat, send authorities a pinpointed location, and track the suspect - all in one fell swoop.
## What it does
At its core, our intelligent surveillance system takes in a live video feed and constantly watches for any sign of a gun or weapon. Once detected, the system immediately bounds the weapon, identifies the potential suspect with the weapon, and sends the authorities a snapshot of the scene and precise location information. In parallel, the suspect is matched against a database for any additional information that could be provided to the authorities.
## How we built it
The core of our project is distributed across the Google Cloud framework and AWS Rekognition. A camera (most commonly a CCTV) presents a live feed to a model, which is constantly looking for anything that looks like a gun using GCP's Vision API. Once detected, we bound the gun and nearby people and identify the shooter through a distance calculation. The backend captures all of this information and sends this to check against a cloud-hosted database of people. Then, our frontend pulls from the identified suspect in the database and presents all necessary information to authorities in a concise dashboard which employs the Maps API. As soon as a gun is drawn, the authorities see the location on a map, the gun holder's current scene, and if available, his background and physical characteristics. Then, AWS Rekognition uses face matching to run the threat against a database to present more detail.
## Challenges we ran into
There are some careful nuances to the idea that we had to account for in our project. For one, few models are pre-trained on weapons, so we experimented with training our own model in addition to using the Vision API. Additionally, identifying the weapon holder is a difficult task - sometimes the gun is not necessarily closest to the person holding it. This is offset by the fact that we send a scene snapshot to the authorities, and most gun attacks happen from a distance. Testing is also difficult, considering we do not have access to guns to hold in front of a camera.
## Accomplishments that we're proud of
A clever geometry-based algorithm to predict the person holding the gun. Minimized latency when running several processes at once. Clean integration with a database integrating in real-time.
## What we learned
It's easy to say we're shooting for MVP, but we need to be careful about managing expectations for what features should be part of the MVP and what features are extraneous.
## What's next for HawkCC
As with all machine learning based products, we would train a fresh model on our specific use case. Given the raw amount of CCTV footage out there, this is not a difficult task, but simply a time-consuming one. This would improve accuracy in 2 main respects - cleaner identification of weapons from a slightly top-down view, and better tracking of individuals within the frame. SMS alert integration is another feature that we could easily plug into the surveillance system as well, and further compound the reaction improvement time. | losing |