OmniGen
OmniGen is an image generation model. Unlike existing text-to-image models, OmniGen is a single model designed to handle a variety of tasks (e.g., text-to-image, image editing, controllable generation). It has the following features:
- Minimalist model architecture, consisting of only a VAE and a transformer module, for joint modeling of text and images.
- Support for multimodal inputs. It can process any text-image mixed data as instructions for image generation, rather than relying solely on text.
For more information, please refer to the paper. This guide will walk you through using OmniGen for various tasks and use cases.
Load model checkpoints
Model weights may be stored in separate subfolders on the Hub or locally, in which case, you should use the from_pretrained() method.
import torch
from diffusers import OmniGenPipeline
pipe = OmniGenPipeline.from_pretrained("Shitao/OmniGen-v1-diffusers", torch_dtype=torch.bfloat16)Text-to-image
For text-to-image, pass a text prompt. By default, OmniGen generates a 1024x1024 image.
You can try setting the height and width parameters to generate images with different size.
import torch
from diffusers import OmniGenPipeline
pipe = OmniGenPipeline.from_pretrained(
"Shitao/OmniGen-v1-diffusers",
torch_dtype=torch.bfloat16
)
pipe.to("cuda")
prompt = "Realistic photo. A young woman sits on a sofa, holding a book and facing the camera. She wears delicate silver hoop earrings adorned with tiny, sparkling diamonds that catch the light, with her long chestnut hair cascading over her shoulders. Her eyes are focused and gentle, framed by long, dark lashes. She is dressed in a cozy cream sweater, which complements her warm, inviting smile. Behind her, there is a table with a cup of water in a sleek, minimalist blue mug. The background is a serene indoor setting with soft natural light filtering through a window, adorned with tasteful art and flowers, creating a cozy and peaceful ambiance. 4K, HD."
image = pipe(
prompt=prompt,
height=1024,
width=1024,
guidance_scale=3,
generator=torch.Generator(device="cpu").manual_seed(111),
).images[0]
image.save("output.png")
Image edit
OmniGen supports multimodal inputs.
When the input includes an image, you need to add a placeholder <img><|image_1|></img> in the text prompt to represent the image.
It is recommended to enable use_input_image_size_as_output to keep the edited image the same size as the original image.
import torch
from diffusers import OmniGenPipeline
from diffusers.utils import load_image
pipe = OmniGenPipeline.from_pretrained(
"Shitao/OmniGen-v1-diffusers",
torch_dtype=torch.bfloat16
)
pipe.to("cuda")
prompt="<img><|image_1|></img> Remove the woman's earrings. Replace the mug with a clear glass filled with sparkling iced cola."
input_images=[load_image("https://raw.githubusercontent.com/VectorSpaceLab/OmniGen/main/imgs/docs_img/t2i_woman_with_book.png")]
image = pipe(
prompt=prompt,
input_images=input_images,
guidance_scale=2,
img_guidance_scale=1.6,
use_input_image_size_as_output=True,
generator=torch.Generator(device="cpu").manual_seed(222)
).images[0]
image.save("output.png") 
OmniGen has some interesting features, such as visual reasoning, as shown in the example below.
prompt="If the woman is thirsty, what should she take? Find it in the image and highlight it in blue. <img><|image_1|></img>"
input_images=[load_image("https://raw.githubusercontent.com/VectorSpaceLab/OmniGen/main/imgs/docs_img/edit.png")]
image = pipe(
prompt=prompt,
input_images=input_images,
guidance_scale=2,
img_guidance_scale=1.6,
use_input_image_size_as_output=True,
generator=torch.Generator(device="cpu").manual_seed(0)
).images[0]
image.save("output.png")
Controllable generation
OmniGen can handle several classic computer vision tasks. As shown below, OmniGen can detect human skeletons in input images, which can be used as control conditions to generate new images.
import torch
from diffusers import OmniGenPipeline
from diffusers.utils import load_image
pipe = OmniGenPipeline.from_pretrained(
"Shitao/OmniGen-v1-diffusers",
torch_dtype=torch.bfloat16
)
pipe.to("cuda")
prompt="Detect the skeleton of human in this image: <img><|image_1|></img>"
input_images=[load_image("https://raw.githubusercontent.com/VectorSpaceLab/OmniGen/main/imgs/docs_img/edit.png")]
image1 = pipe(
prompt=prompt,
input_images=input_images,
guidance_scale=2,
img_guidance_scale=1.6,
use_input_image_size_as_output=True,
generator=torch.Generator(device="cpu").manual_seed(333)
).images[0]
image1.save("image1.png")
prompt="Generate a new photo using the following picture and text as conditions: <img><|image_1|></img>\n A young boy is sitting on a sofa in the library, holding a book. His hair is neatly combed, and a faint smile plays on his lips, with a few freckles scattered across his cheeks. The library is quiet, with rows of shelves filled with books stretching out behind him."
input_images=[load_image("https://raw.githubusercontent.com/VectorSpaceLab/OmniGen/main/imgs/docs_img/skeletal.png")]
image2 = pipe(
prompt=prompt,
input_images=input_images,
guidance_scale=2,
img_guidance_scale=1.6,
use_input_image_size_as_output=True,
generator=torch.Generator(device="cpu").manual_seed(333)
).images[0]
image2.save("image2.png") 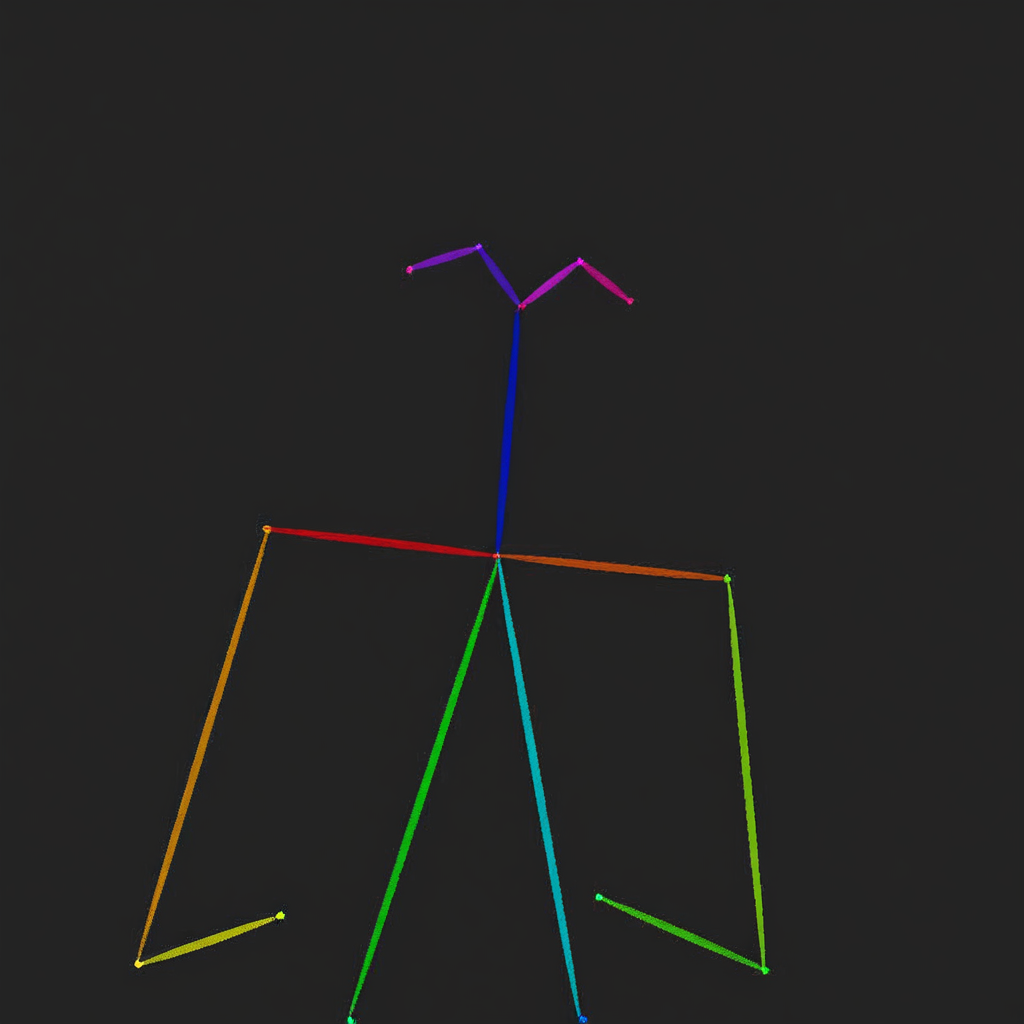

OmniGen can also directly use relevant information from input images to generate new images.
import torch
from diffusers import OmniGenPipeline
from diffusers.utils import load_image
pipe = OmniGenPipeline.from_pretrained(
"Shitao/OmniGen-v1-diffusers",
torch_dtype=torch.bfloat16
)
pipe.to("cuda")
prompt="Following the pose of this image <img><|image_1|></img>, generate a new photo: A young boy is sitting on a sofa in the library, holding a book. His hair is neatly combed, and a faint smile plays on his lips, with a few freckles scattered across his cheeks. The library is quiet, with rows of shelves filled with books stretching out behind him."
input_images=[load_image("https://raw.githubusercontent.com/VectorSpaceLab/OmniGen/main/imgs/docs_img/edit.png")]
image = pipe(
prompt=prompt,
input_images=input_images,
guidance_scale=2,
img_guidance_scale=1.6,
use_input_image_size_as_output=True,
generator=torch.Generator(device="cpu").manual_seed(0)
).images[0]
image.save("output.png")
ID and object preserving
OmniGen can generate multiple images based on the people and objects in the input image and supports inputting multiple images simultaneously. Additionally, OmniGen can extract desired objects from an image containing multiple objects based on instructions.
import torch
from diffusers import OmniGenPipeline
from diffusers.utils import load_image
pipe = OmniGenPipeline.from_pretrained(
"Shitao/OmniGen-v1-diffusers",
torch_dtype=torch.bfloat16
)
pipe.to("cuda")
prompt="A man and a woman are sitting at a classroom desk. The man is the man with yellow hair in <img><|image_1|></img>. The woman is the woman on the left of <img><|image_2|></img>"
input_image_1 = load_image("https://raw.githubusercontent.com/VectorSpaceLab/OmniGen/main/imgs/docs_img/3.png")
input_image_2 = load_image("https://raw.githubusercontent.com/VectorSpaceLab/OmniGen/main/imgs/docs_img/4.png")
input_images=[input_image_1, input_image_2]
image = pipe(
prompt=prompt,
input_images=input_images,
height=1024,
width=1024,
guidance_scale=2.5,
img_guidance_scale=1.6,
generator=torch.Generator(device="cpu").manual_seed(666)
).images[0]
image.save("output.png")


import torch
from diffusers import OmniGenPipeline
from diffusers.utils import load_image
pipe = OmniGenPipeline.from_pretrained(
"Shitao/OmniGen-v1-diffusers",
torch_dtype=torch.bfloat16
)
pipe.to("cuda")
prompt="A woman is walking down the street, wearing a white long-sleeve blouse with lace details on the sleeves, paired with a blue pleated skirt. The woman is <img><|image_1|></img>. The long-sleeve blouse and a pleated skirt are <img><|image_2|></img>."
input_image_1 = load_image("https://raw.githubusercontent.com/VectorSpaceLab/OmniGen/main/imgs/docs_img/emma.jpeg")
input_image_2 = load_image("https://raw.githubusercontent.com/VectorSpaceLab/OmniGen/main/imgs/docs_img/dress.jpg")
input_images=[input_image_1, input_image_2]
image = pipe(
prompt=prompt,
input_images=input_images,
height=1024,
width=1024,
guidance_scale=2.5,
img_guidance_scale=1.6,
generator=torch.Generator(device="cpu").manual_seed(666)
).images[0]
image.save("output.png")


Optimization when using multiple images
For text-to-image task, OmniGen requires minimal memory and time costs (9GB memory and 31s for a 1024x1024 image on A800 GPU). However, when using input images, the computational cost increases.
Here are some guidelines to help you reduce computational costs when using multiple images. The experiments are conducted on an A800 GPU with two input images.
Like other pipelines, you can reduce memory usage by offloading the model: pipe.enable_model_cpu_offload() or pipe.enable_sequential_cpu_offload() .
In OmniGen, you can also decrease computational overhead by reducing the max_input_image_size.
The memory consumption for different image sizes is shown in the table below:
| Method | Memory Usage |
|---|---|
| max_input_image_size=1024 | 40GB |
| max_input_image_size=512 | 17GB |
| max_input_image_size=256 | 14GB |