|
--- |
|
license: bigscience-openrail-m |
|
widget: |
|
- text: >- |
|
Native API functions such as <mask>, may be directed invoked via system |
|
calls/syscalls, but these features are also often exposed to user-mode |
|
applications via interfaces and libraries.. |
|
example_title: Native API functions |
|
- text: >- |
|
One way of explicitly assigning the PPID of a new process is via the <mask> |
|
API call, which supports a parameter that defines the PPID to use. |
|
example_title: Assigning the PPID of a new process |
|
- text: >- |
|
Enable Safe DLL Search Mode to force search for system DLLs in directories |
|
with greater restrictions (e.g. %<mask>%) to be used before local directory |
|
DLLs (e.g. a user's home directory) |
|
example_title: Enable Safe DLL Search Mode |
|
- text: >- |
|
GuLoader is a file downloader that has been used since at least December |
|
2019 to distribute a variety of <mask>, including NETWIRE, Agent Tesla, |
|
NanoCore, and FormBook. |
|
example_title: GuLoader is a file downloader |
|
language: |
|
- en |
|
tags: |
|
- cybersecurity |
|
- cyber threat intellignece |
|
--- |
|
# SecureBERT: A Domain-Specific Language Model for Cybersecurity |
|
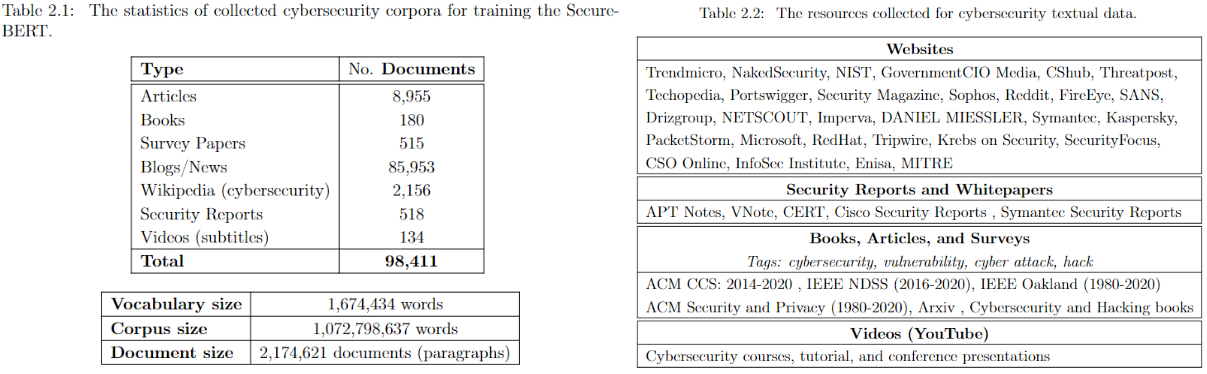
SecureBERT is a domain-specific language model based on RoBERTa which is trained on a huge amount of cybersecurity data and fine-tuned/tweaked to understand/represent cybersecurity textual data. |
|
|
|
|
|
[SecureBERT](https://link.springer.com/chapter/10.1007/978-3-031-25538-0_3) is a domain-specific language model to represent cybersecurity textual data which is trained on a large amount of in-domain text crawled from online resources. ***See the presentation on [YouTube](https://www.youtube.com/watch?v=G8WzvThGG8c&t=8s)*** |
|
|
|
See details at [GitHub Repo](https://github.com/ehsanaghaei/SecureBERT/blob/main/README.md) |
|
|
|
|
|
 |
|
|
|
## SecureBERT can be used as the base model for any downstream task including text classification, NER, Seq-to-Seq, QA, etc. |
|
* SecureBERT has demonstrated significantly higher performance in predicting masked words within the text when compared to existing models like RoBERTa (base and large), SciBERT, and SecBERT. |
|
* SecureBERT has also demonstrated promising performance in preserving general English language understanding (representation). |
|
|
|
|
|
|
|
# How to use SecureBERT |
|
SecureBERT has been uploaded to [Huggingface](https://huggingface.co/ehsanaghaei/SecureBERT) framework. You may use the code below |
|
|
|
```python |
|
from transformers import RobertaTokenizer, RobertaModel |
|
import torch |
|
|
|
tokenizer = RobertaTokenizer.from_pretrained("ehsanaghaei/SecureBERT") |
|
model = RobertaModel.from_pretrained("ehsanaghaei/SecureBERT") |
|
|
|
inputs = tokenizer("This is SecureBERT!", return_tensors="pt") |
|
outputs = model(**inputs) |
|
|
|
last_hidden_states = outputs.last_hidden_state |
|
|
|
## Fill Mask |
|
SecureBERT has been trained on MLM. Use the code below to predict the masked word within the given sentences: |
|
|
|
```python |
|
#!pip install transformers |
|
#!pip install torch |
|
#!pip install tokenizers |
|
|
|
import torch |
|
import transformers |
|
from transformers import RobertaTokenizer, RobertaTokenizerFast |
|
|
|
tokenizer = RobertaTokenizerFast.from_pretrained("ehsanaghaei/SecureBERT") |
|
model = transformers.RobertaForMaskedLM.from_pretrained("ehsanaghaei/SecureBERT") |
|
|
|
def predict_mask(sent, tokenizer, model, topk =10, print_results = True): |
|
token_ids = tokenizer.encode(sent, return_tensors='pt') |
|
masked_position = (token_ids.squeeze() == tokenizer.mask_token_id).nonzero() |
|
masked_pos = [mask.item() for mask in masked_position] |
|
words = [] |
|
with torch.no_grad(): |
|
output = model(token_ids) |
|
|
|
last_hidden_state = output[0].squeeze() |
|
|
|
list_of_list = [] |
|
for index, mask_index in enumerate(masked_pos): |
|
mask_hidden_state = last_hidden_state[mask_index] |
|
idx = torch.topk(mask_hidden_state, k=topk, dim=0)[1] |
|
words = [tokenizer.decode(i.item()).strip() for i in idx] |
|
words = [w.replace(' ','') for w in words] |
|
list_of_list.append(words) |
|
if print_results: |
|
print("Mask ", "Predictions : ", words) |
|
|
|
best_guess = "" |
|
for j in list_of_list: |
|
best_guess = best_guess + "," + j[0] |
|
|
|
return words |
|
|
|
|
|
while True: |
|
sent = input("Text here: \t") |
|
print("SecureBERT: ") |
|
predict_mask(sent, tokenizer, model) |
|
|
|
print("===========================\n") |
|
``` |
|
# Reference |
|
@inproceedings{aghaei2023securebert, |
|
title={SecureBERT: A Domain-Specific Language Model for Cybersecurity}, |
|
author={Aghaei, Ehsan and Niu, Xi and Shadid, Waseem and Al-Shaer, Ehab}, |
|
booktitle={Security and Privacy in Communication Networks: |
|
18th EAI International Conference, SecureComm 2022, Virtual Event, |
|
October 2022, |
|
Proceedings}, |
|
pages={39--56}, |
|
year={2023}, |
|
organization={Springer} } |
