

license: apache-2.0
language:
- vi
- en
- zh
base_model:
- Qwen/Qwen2-VL-2B-Instruct
library_name: transformers
tags:
- erax
- multimodal
- erax-vl-2B
- insurance
- ocr
- vietnamese
- bcg
pipeline_tag: visual-question-answering
widget:
- src: images/photo-1-16505057982762025719470.webp
example_title: Test 1
- src: images/vt-don-thuoc-f0-7417.jpeg
example_title: Test 2

EraX-VL-2B-V1.5
Introduction 🎉
Hot on the heels of the popular EraX-VL-7B-V1.0 model, we proudly present EraX-VL-2B-V1.5. This enhanced multimodal model offers robust OCR and VQA capabilities across diverse languages 🌍, with a significant advantage in processing Vietnamese 🇻🇳. The EraX-VL-2B model stands out for its precise recognition capabilities across a range of documents 📝, including medical forms 🩺, invoices 🧾, bills of sale 💳, quotes 📄, and medical records 💊. This functionality is expected to be highly beneficial for hospitals 🏥, clinics 💉, insurance companies 🛡️, and other similar applications 📋. Built on the solid foundation of the Qwen/Qwen2-VL-2B-Instruct[1], which we found to be of high quality and fluent in Vietnamese, EraX-VL-2B has been fine-tuned to enhance its performance. We plan to continue improving and releasing new versions for free, along with sharing performance benchmarks in the near future.
One standing-out feature of EraX-VL-2B-V1.5 is the capability to do multi-turn Q&A with reasonable reasoning capability at its small size of only +2 billions parameters.
NOTA BENE:
- EraX-VL-2B-V1.5 is NOT a typical OCR-only tool likes Tesseract but is a Multimodal LLM-based model. To use it effectively, you may have to twist your prompt carefully depending on your tasks.
- This model was NOT finetuned with medical (X-ray) dataset or car accidences (yet). Stay tune for updated version coming up sometime 2025.
EraX-VL-2B-V1.5 is a young and tiny member of our EraX's LànhGPT collection of LLM models.
- Developed by:
- Nguyễn Anh Nguyên ([email protected])
- Nguyễn Hồ Nam (BCG)
- Phạm Huỳnh Nhật ([email protected])
- Phạm Đình Thục ([email protected])
- Funded by: Bamboo Capital Group and EraX
- Model type: Multimodal Transformer with over 2B parameters
- Languages (NLP): Primarily Vietnamese with multilingual capabilities
- License: Apache 2.0
- Fine-tuned from: Qwen/Qwen2-VL-2B-Instruct
- Prompt examples: Some popular prompt examples.
Benchmarks 📊
🏆 LeaderBoard
| Models | Open-Source | VI-MTVQA |
|---|---|---|
| EraX-VL-7B-V1.5 🥇 | ✅ | 47.2 |
| Qwen2-VL 72B 🥈 | ✘ | 41.6 |
| ViGPT-VL 🥉 | ✘ | 39.1 |
| EraX-VL-2B-V1.5 | ✅ | 38.2 |
| EraX-VL-7B-V1 | ✅ | 37.6 |
| Vintern-1B-V2 | ✅ | 37.4 |
| Qwen2-VL 7B | ✅ | 30.0 |
| Claude3 Opus | ✘ | 29.1 |
| GPT-4o mini | ✘ | 29.1 |
| GPT-4V | ✘ | 28.9 |
| Gemini Ultra | ✘ | 28.6 |
| InternVL2 76B | ✅ | 26.9 |
| QwenVL Max | ✘ | 23.5 |
| Claude3 Sonnet | ✘ | 20.8 |
| QwenVL Plus | ✘ | 18.1 |
| MiniCPM-V2.5 | ✅ | 15.3 |
The test code for evaluating models in the paper can be found in: EraX-JS-Company/EraX-MTVQA-Benchmark
API trial 🎉
Please contact [email protected] for API access inquiry.
Examples 🧩
1. OCR - Optical Character Recognition for Multi-Images
Example 01: Citizen identification card

Front View

Back View
Source: Google Support
{
"Số thẻ":"037094012351"
"Họ và tên":"TRỊNH QUANG DUY"
"Ngày sinh":"04/09/1994"
"Giới tính":"Nam"
"Quốc tịch":"Việt Nam"
"Quê quán / Place of origin":"Tân Thành, Kim Sơn, Ninh Bình"
"Nơi thường trú / Place of residence":"Xóm 6 Tân Thành, Kim Sơn, Ninh Bình"
"Có giá trị đến":"04/09/2034"
"Đặc điểm nhân dạng / Personal identification":"seo chấm c:1cm trên đuôi mắt trái"
"Cục trưởng cục cảnh sát quản lý hành chính về trật tự xã hội":"Nguyễn Quốc Hùng"
"Ngày cấp":"10/12/2022"
}
Example 01: Identity Card

Front View

Back View
Source: Internet
{
"Số":"272737384"
"Họ tên":"PHẠM NHẬT TRƯỜNG"
"Sinh ngày":"08-08-2000"
"Nguyên quán":"Tiền Giang"
"Nơi ĐKHK thường trú":"393, Tân Xuân, Bảo Bình, Cẩm Mỹ, Đồng Nai"
"Dân tộc":"Kinh"
"Tôn giáo":"Không"
"Đặc điểm nhận dạng":"Nốt ruồi c.3,5cm trên sau cánh mũi phải."
"Ngày cấp":"30 tháng 01 năm 2018"
"Giám đốc CA":"T.BÌNH ĐỊNH"
}
Example 02: Driver's License

Front View

Back View
Source: Báo Pháp luật
{
"No.":"400116012313"
"Fullname":"NGUYỄN VĂN DŨNG"
"Date_of_birth":"08/06/1979"
"Nationality":"VIỆT NAM"
"Address":"X. Quỳnh Hầu, H. Quỳnh Lưu, T. Nghệ An
Nghệ An, ngày/date 23 tháng/month 04 năm/year 2022"
"Hang_Class":"FC"
"Expires":"23/04/2027"
"Place_of_issue":"Nghệ An"
"Date_of_issue":"ngày/date 23 tháng/month 04 năm/year 2022"
"Signer":"Trần Anh Tuấn"
"Các loại xe được phép":"Ô tô hạng C kéo rơmoóc, đầu kéo kéo sơmi rơmoóc và xe hạng B1, B2, C, FB2 (Motor vehicle of class C with a trailer, semi-trailer truck and vehicles of classes B1, B2, C, FB2)"
"Mã số":""
}
Example 03: Vehicle Registration Certificate
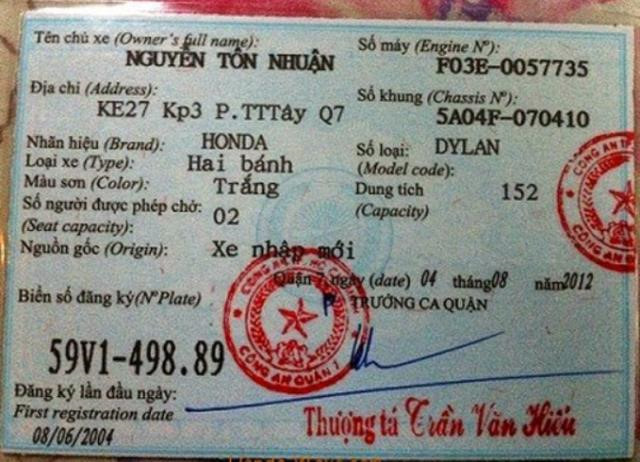
Source: Báo Vietnamnet
{
"Tên chủ xe":"NGUYỄN TÔN NHUẬN"
"Địa chỉ":"KE27 Kp3 P.TTTây Q7"
"Nhãn hiệu":"HONDA"
"Số loại":"DYLAN"
"Màu sơn":"Trắng"
"Số người được phép chở":"02"
"Nguồn gốc":"Xe nhập mới"
"Biển số đăng ký":"59V1-498.89"
"Đăng ký lần đầu ngày":"08/06/2004"
"Số máy":"F03E-0057735"
"Số khung":"5A04F-070410"
"Dung tích":"152"
"Quản lý":"TRƯỞNG CA QUẬN"
"Thượng tá":"Trần Văn Hiểu"
}
Example 04: Birth Certificate

Source: https://congchung247.com.vn
{
"name": "NGUYỄN NAM PHƯƠNG",
"gender": "Nữ",
"date_of_birth": "08/6/2011",
"place_of_birth": "Bệnh viện Việt - Pháp Hà Nội",
"nationality": "Việt Nam",
"father_name": "Nguyễn Ninh Hồng Quang",
"father_dob": "1980",
"father_address": "309 nhà E2 Bạch Khoa - Hai Bà Trưng - Hà Nội",
"mother_name": "Phạm Thùy Trang",
"mother_dob": "1984",
"mother_address": "309 nhà E2 Bạch Khoa - Hai Bà Trưng - Hà Nội",
"registration_place": "UBND phường Bạch Khoa - Quận Hai Bà Trưng - Hà Nội",
"registration_date": "05/8/2011",
"registration_ralation": "cha",
"notes": None,
"certified_by": "Nguyễn Thị Kim Hoa"
}
Quickstart 🎮
Install the necessary packages:
python -m pip install git+https://github.com/huggingface/transformers accelerate
python -m pip install qwen-vl-utils
pip install flash-attn --no-build-isolation
Then you can use EraX-VL-2B-V1.5 like this:
import os
import base64
import json
import cv2
import numpy as np
import matplotlib.pyplot as plt
import torch
from transformers import Qwen2VLForConditionalGeneration, AutoTokenizer, AutoProcessor
from qwen_vl_utils import process_vision_info
model_path = "erax/EraX-VL-2B-V1.5"
model = Qwen2VLForConditionalGeneration.from_pretrained(
model_path,
torch_dtype=torch.bfloat16,
attn_implementation="eager", # replace with "flash_attention_2" if your GPU is Ampere architecture
device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained(model_path)
# processor = AutoProcessor.from_pretrained(model_path)
min_pixels = 256 * 28 * 28
max_pixels = 1280 * 28 * 28
processor = AutoProcessor.from_pretrained(
model_path,
min_pixels=min_pixels,
max_pixels=max_pixels,
)
image_path ="image.jpg"
with open(image_path, "rb") as f:
encoded_image = base64.b64encode(f.read())
decoded_image_text = encoded_image.decode('utf-8')
base64_data = f"data:image;base64,{decoded_image_text}"
messages = [
{
"role": "user",
"content": [
{
"type": "image",
"image": base64_data,
},
{
"type": "text",
"text": "Trích xuất thông tin nội dung từ hình ảnh được cung cấp."
},
],
}
]
# Prepare prompt
tokenized_text = processor.apply_chat_template(
messages, tokenize=False, add_generation_prompt=True
)
image_inputs, video_inputs = process_vision_info(messages)
inputs = processor(
text=[ tokenized_text],
images=image_inputs,
videos=video_inputs,
padding=True,
return_tensors="pt",
)
inputs = inputs.to("cuda")
# Generation configs
generation_config = model.generation_config
generation_config.do_sample = True
generation_config.temperature = 1.0
generation_config.top_k = 1
generation_config.top_p = 0.9
generation_config.min_p = 0.1
generation_config.best_of = 5
generation_config.max_new_tokens = 2048
generation_config.repetition_penalty = 1.06
# Inference
generated_ids = model.generate(**inputs, generation_config=generation_config)
generated_ids_trimmed = [
out_ids[len(in_ids) :] for in_ids, out_ids in zip(inputs.input_ids, generated_ids)
]
output_text = processor.batch_decode(
generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False
)
print(output_text[0])
References 📑
[1] Qwen team. Qwen2-VL. 2024.
[2] Bai, Jinze, et al. "Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond." arXiv preprint arXiv:2308.12966 (2023).
[4] Yang, An, et al. "Qwen2 technical report." arXiv preprint arXiv:2407.10671 (2024).
[5] Chen, Zhe, et al. "Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks." Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2024.
[6] Chen, Zhe, et al. "How far are we to gpt-4v? closing the gap to commercial multimodal models with open-source suites." arXiv preprint arXiv:2404.16821 (2024).
[7] Tran, Chi, and Huong Le Thanh. "LaVy: Vietnamese Multimodal Large Language Model." arXiv preprint arXiv:2404.07922 (2024).
Contact 🤝
- For correspondence regarding this work or inquiry for API trial, please contact Nguyễn Anh Nguyên at [email protected].
- Follow us on EraX Github