
XLS-R
Collection
First release checkpoints for XLS-R, a large-scale model for cross-lingual speech representation learning based on wav2vec 2.0.
•
16 items
•
Updated
•
3
Facebook's Wav2Vec2 XLS-R fine-tuned for Speech Translation.

This is a SpeechEncoderDecoderModel model.
The encoder was warm-started from the facebook/wav2vec2-xls-r-1b checkpoint and
the decoder from the facebook/mbart-large-50 checkpoint.
Consequently, the encoder-decoder model was fine-tuned on 15 en -> {lang} translation pairs of the Covost2 dataset.
The model can translate from spoken en (Engish) to the following written languages {lang}:
en -> {de, tr, fa, sv-SE, mn, zh-CN, cy, ca, sl, et, id, ar, ta, lv, ja}
For more information, please refer to Section 5.1.1 of the official XLS-R paper.
The model can be tested on this space. You can select the target language, record some audio in English, and then sit back and see how well the checkpoint can translate the input.
As this a standard sequence to sequence transformer model, you can use the generate method to generate the
transcripts by passing the speech features to the model.
You can use the model directly via the ASR pipeline. By default, the checkpoint will
translate spoken English to written German. To change the written target language,
you need to pass the correct forced_bos_token_id to generate(...) to condition
the decoder on the correct target language.
To select the correct forced_bos_token_id given your choosen language id, please make use
of the following mapping:
MAPPING = {
"de": 250003,
"tr": 250023,
"fa": 250029,
"sv": 250042,
"mn": 250037,
"zh": 250025,
"cy": 250007,
"ca": 250005,
"sl": 250052,
"et": 250006,
"id": 250032,
"ar": 250001,
"ta": 250044,
"lv": 250017,
"ja": 250012,
}
As an example, if you would like to translate to Swedish, you can do the following:
from datasets import load_dataset
from transformers import pipeline
# select correct `forced_bos_token_id`
forced_bos_token_id = MAPPING["sv"]
# replace following lines to load an audio file of your choice
librispeech_en = load_dataset("patrickvonplaten/librispeech_asr_dummy", "clean", split="validation")
audio_file = librispeech_en[0]["file"]
asr = pipeline("automatic-speech-recognition", model="facebook/wav2vec2-xls-r-1b-en-to-15", feature_extractor="facebook/wav2vec2-xls-r-1b-en-to-15")
translation = asr(audio_file, forced_bos_token_id=forced_bos_token_id)
or step-by-step as follows:
import torch
from transformers import Speech2Text2Processor, SpeechEncoderDecoderModel
from datasets import load_dataset
model = SpeechEncoderDecoderModel.from_pretrained("facebook/wav2vec2-xls-r-1b-en-to-15")
processor = Speech2Text2Processor.from_pretrained("facebook/wav2vec2-xls-r-1b-en-to-15")
ds = load_dataset("patrickvonplaten/librispeech_asr_dummy", "clean", split="validation")
# select correct `forced_bos_token_id`
forced_bos_token_id = MAPPING["sv"]
inputs = processor(ds[0]["audio"]["array"], sampling_rate=ds[0]["audio"]["array"]["sampling_rate"], return_tensors="pt")
generated_ids = model.generate(input_ids=inputs["input_features"], attention_mask=inputs["attention_mask"], forced_bos_token_id=forced_bos_token)
transcription = processor.batch_decode(generated_ids)
en -> {lang}
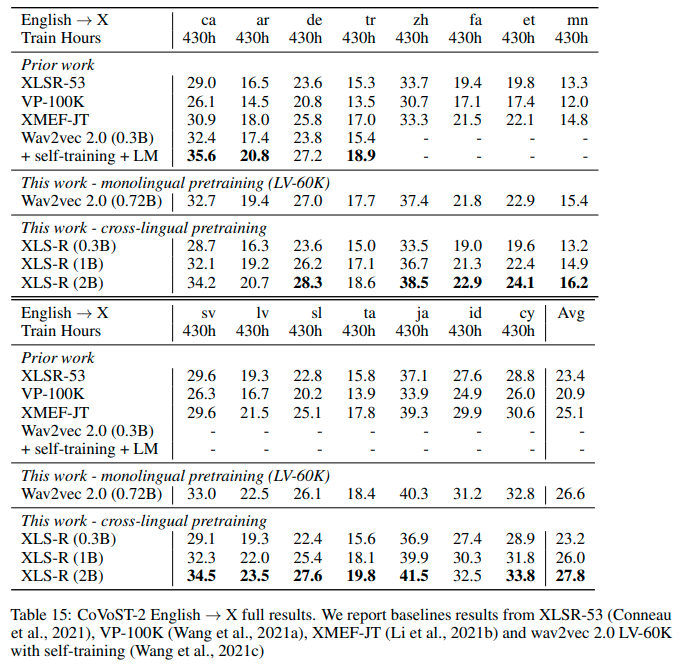
See the row of XLS-R (1B) for the performance on Covost2 for this model.
{lang} -> en Speech Translation