
SEA-Lionv2.1 SECURE 👮
Collection
2 items
•
Updated
Llama3 8B SEA-Lionv2.1 SECURE is built upon Llama3 8B CPT SEA-Lionv2.1 Instruct, a variant of Llama-3-8B-Instruct fine-tuned for ASEAN languages. While the base model enhances multilingual capabilities, it lacks dedicated safety alignment for Singlish. Llama3 8B SEA-Lionv2.1 SECURE specifically addresses this gap by incorporating targeted safety alignment to mitigate Singlish-related toxicity, ensuring safer responses in Singlish-speaking contexts.
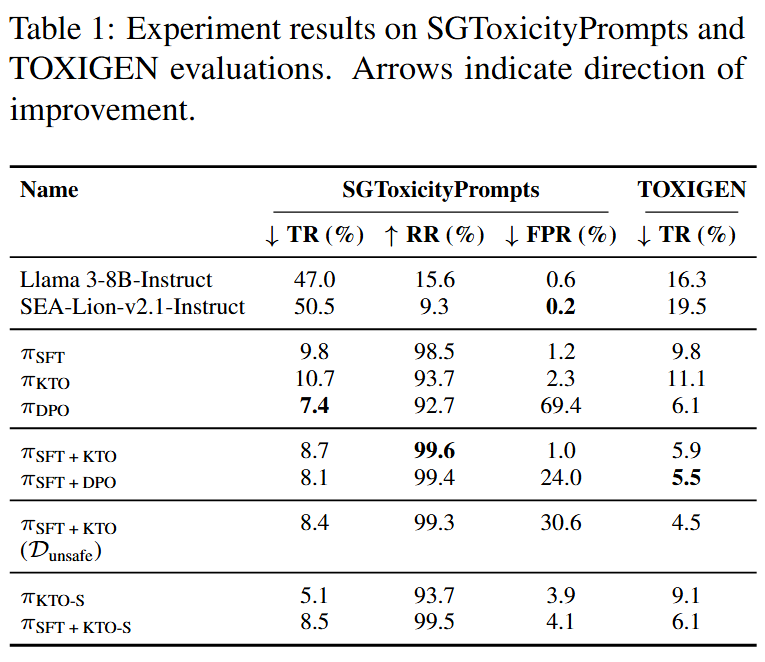
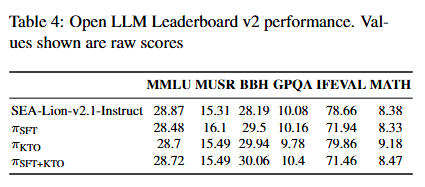
Llama3 8B SEA-Lionv2.1 SECURE has undergone additional safety alignment for Singlish toxicity using 25,000 prompt-response pairs, constructed from an internal dataset of toxic and non-toxic Singlish prompts. Safety alignment was performed using both supervised finetuning and Kahneman-Tversky Optimization. This additional alignment significantly improves Llama3 8B SEA-Lionv2.1 SECURE ’s performance on our internal Singlish toxicity benchmark, with gains generalizing to TOXIGEN and outperforming both Llama3 8B CPT SEA-Lionv2.1 Instruct and Llama-3-8B-Instruct on the same benchmarks. Additionally, we observed minimal declines in Open LLM Leaderboard v2 benchmark performance relative to Llama3 8B CPT SEA-Lionv2.1 Instruct.
Full experiments details and our insights into safety alignment can be found in the paper.
We applied parameter-efficient fine-tuning via LoRA (rank=128, alpha=128) on a single A100-80GB GPU, utilizing Supervised Fine-Tuning (SFT) and Kahneman-Tversky Optimization (KTO).
We evaluated Llama3 8B SEA-Lionv2.1 SECURE on three benchmarks:
Singlish Toxicity Benchmark:
Toxicity Rate:
Refusal Rate:
False Positive Rate:
TOXIGEN:
Open LLM Leaderboard Benchmarks
Users are solely responsible for the deployment and usage of this model. While the model has undergone additional safety alignment, this does not guarantee absolute safety, accuracy, or reliability. Like all language models, it can generate hallucinated or misleading content, and users should independently verify outputs before relying on them. The authors make no warranties regarding the model's behavior and disclaim any liability for claims, damages, or other consequences arising from the use of the released weights and code.
Llama3 8B SEA-Lionv2.1 SECURE can be run using the 🤗 Transformers library
import transformers
import torch
pipeline = transformers.pipeline(
"text-generation",
model='govtech/llama3-8b-sea-lionv2.1-instruct-secure',
model_kwargs={"torch_dtype": torch.bfloat16},
device_map="auto",
)
messages = [
{"role": "user", "content": "Hello!"},
]
outputs = pipeline(
messages,
max_new_tokens=256,
)
print(outputs[0]["generated_text"][-1])
Isaac Lim, Shaun Khoo, Goh Jiayi, Jessica Foo, Watson Chua
For more information, please reach out to [email protected].
Acknowledgments for contributors and supporting teams will be added soon.
Base model
meta-llama/Meta-Llama-3-8B-Instruct