
language:
- en
license: apache-2.0
library_name: transformers
tags:
- mergekit
- merge
base_model:
- sometimesanotion/Qwen2.5-14B-Vimarckoso-v3
- sometimesanotion/Lamarck-14B-v0.3
- sometimesanotion/Qwenvergence-14B-v3-Prose
- Krystalan/DRT-o1-14B
- underwoods/medius-erebus-magnum-14b
- sometimesanotion/Abliterate-Qwenvergence
- huihui-ai/Qwen2.5-14B-Instruct-abliterated-v2
metrics:
- accuracy
pipeline_tag: text-generation

Update: Lamarck has, for the moment, taken the #1 average score for 14 billion parameter models. Counting all the way up to 32 billion parameters, it's #7. This validates the complex merge techniques which captured the complementary strengths of other work in this community. Humor me, I'm giving our guy his meme shades!
Lamarck 14B v0.6: A generalist merge focused on multi-step reasoning, prose, multi-language ability, and code. It is based on components that have punched above their weight in the 14 billion parameter class. Here you can see a comparison between Lamarck and other top-performing merges and finetunes:
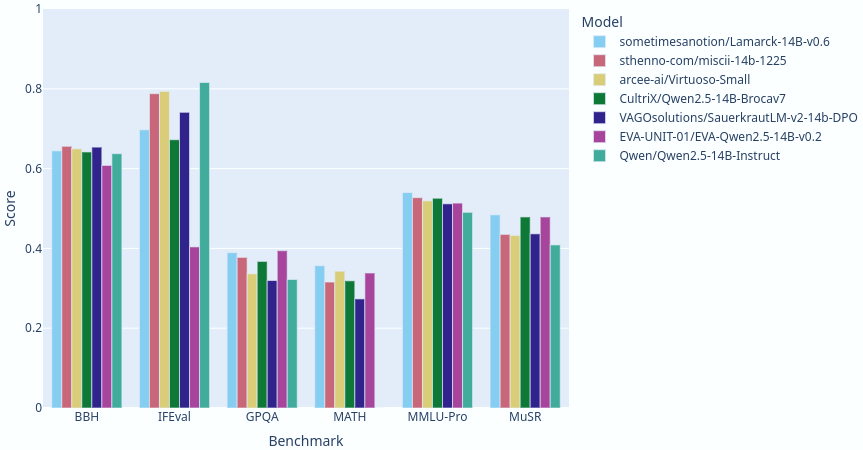
Previous releases were based on a SLERP merge of model_stock->della branches focused on reasoning and prose. The prose branch got surprisingly good at reasoning, and the reasoning branch became a strong generalist in its own right. Some of you have already downloaded it as sometimesanotion/Qwen2.5-14B-Vimarckoso-v3.
Lamarck 0.6 aims to build upon Vimarckoso v3's all-around strengths by using breadcrumbs and DELLA merges, with highly targeted weight/density gradients for every four layers and special andling for the first and final two layers. This approach selectively merges the strongest aspects of its ancestors.
The strengths Lamarck has combined from its immediate ancestors are in turn derived from select finetunes and merges. Kudoes to @arcee-ai, @CultriX, @sthenno-com, @Krystalan, @underwoods, @VAGOSolutions, and @rombodawg whose models had the most influence, as Vimarckoso v3's model card will show.
Merge Details
This model was made in two branches: a della_linear merge, and a sequence of model_stock and then breadcrumbs SLERP-merged below.
Models Merged
Top influences: The model_stock, breadcrumbs, and della_linear all use the following models:
- sometimesanotion/Qwen2.5-14B-Vimarckoso-v3 - As of this writing, Vimarckoso v3 has the #1 average score on open-llm-leaderboard/open_llm_leaderboard for any model under 32 billion parameters. This appears to be because of synergy between its component models.
- sometimesanotion/Lamarck-14B-v0.3 - With heavy influence from VAGOsolutions/SauerkrautLM-v2-14b-DPO, this is a leader in technical answers.
- sometimesanotion/Qwenvergence-14B-v3-Prose - a model_stock merge of multiple prose-oriented models which posts surprisingly high MATH, GPQA, and MUSR scores, with contributions from EVA-UNIT-01/EVA-Qwen2.5-14B-v0.2 and sthenno-com/miscii-14b-1028 apparent.
- Krystalan/DRT-o1-14B - A particularly interesting model which applies extra reasoning to language translation. Check out their fascinating research paper at arxiv.org/abs/2412.17498.
- underwoods/medius-erebus-magnum-14b - The leading contributor to prose quality, as it's finetuned on datasets behind the well-recognized Magnum series.
- sometimesanotion/Abliterate-Qwenvergence - A custom version of huihui-ai/Qwen2.5-14B-Instruct-abliterated-v2
Configuration
This model was made with two branches, diverged and recombined. The first branch was a Vimarckoso v3-based della_linear merge, and the second, a sequence of model_stock and then breadcrumbs+LoRA. The LoRAs required minor adjustments to most component models for intercompatibility. The breadcrumbs and della merges required many small slices, with highly focused layer-specific gradients, to effectively combine the models. This was my most complex merge to date. Suffice it to say, the SLERP merge below which finalized it was one of the simpler steps.
name: Lamarck-14B-v0.6-rc4
merge_method: slerp
base_model: sometimesanotion/lamarck-14b-converge-della-linear
tokenizer_source: base
dtype: float32
out_dtype: bfloat16
parameters:
int8_mask: true
normalize: true
rescale: false
parameters:
t:
- value: 0.30
slices:
- sources:
- model: sometimesanotion/lamarck-14b-converge-della-linear
layer_range: [ 0, 8 ]
- model: sometimesanotion/lamarck-14b-converge-breadcrumbs
layer_range: [ 0, 8 ]
- sources:
- model: sometimesanotion/lamarck-14b-converge-della-linear
layer_range: [ 8, 16 ]
- model: sometimesanotion/lamarck-14b-converge-breadcrumbs
layer_range: [ 8, 16 ]
- sources:
- model: sometimesanotion/lamarck-14b-converge-della-linear
layer_range: [ 16, 24 ]
- model: sometimesanotion/lamarck-14b-converge-breadcrumbs
layer_range: [ 16, 24 ]
- sources:
- model: sometimesanotion/lamarck-14b-converge-della-linear
layer_range: [ 24, 32 ]
- model: sometimesanotion/lamarck-14b-converge-breadcrumbs
layer_range: [ 24, 32 ]
- sources:
- model: sometimesanotion/lamarck-14b-converge-della-linear
layer_range: [ 32, 40 ]
- model: sometimesanotion/lamarck-14b-converge-breadcrumbs
layer_range: [ 32, 40 ]
- sources:
- model: sometimesanotion/lamarck-14b-converge-della-linear
layer_range: [ 40, 48 ]
- model: sometimesanotion/lamarck-14b-converge-breadcrumbs
layer_range: [ 40, 48 ]