|
--- |
|
language: |
|
- en |
|
license: apache-2.0 |
|
library_name: transformers |
|
tags: |
|
- mergekit |
|
- merge |
|
base_model: |
|
- sometimesanotion/Qwen2.5-14B-Vimarckoso-v3 |
|
- sometimesanotion/Lamarck-14B-v0.3 |
|
- sometimesanotion/Qwenvergence-14B-v3-Prose |
|
- Krystalan/DRT-o1-14B |
|
- underwoods/medius-erebus-magnum-14b |
|
- sometimesanotion/Abliterate-Qwenvergence |
|
- huihui-ai/Qwen2.5-14B-Instruct-abliterated-v2 |
|
metrics: |
|
- accuracy |
|
pipeline_tag: text-generation |
|
new_version: sometimesanotion/Lamarck-14B-v0.7 |
|
--- |
|
 |
|
--- |
|
|
|
> [!TIP] **Update:** Lamarck has, for the moment, taken the [#1 average score](https://shorturl.at/STz7B) on the [Open LLM Leaderboard](https://huggingface.co/spaces/open-llm-leaderboard/open_llm_leaderboard) for text-generation assistant language models under 32 billion parameters. This validates the complex merge techniques which combine the strengths of other finetunes in the community into one model. |
|
|
|
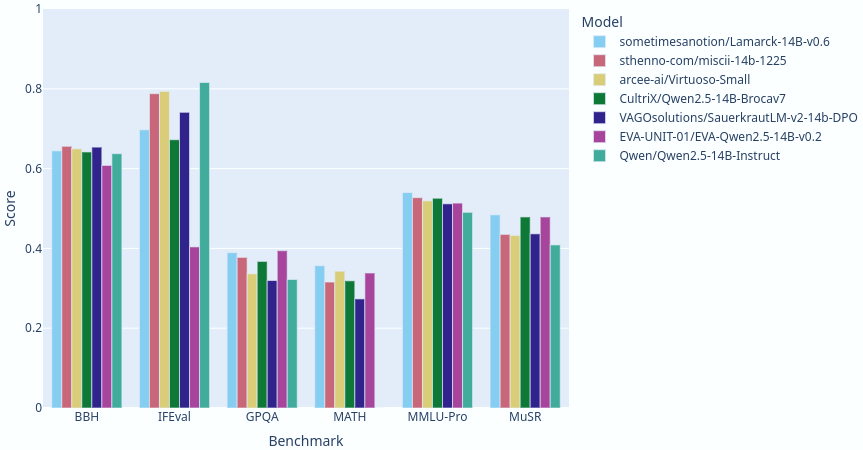
Lamarck 14B v0.6: A generalist merge focused on multi-step reasoning, prose, and multi-language ability. It is based on components that have punched above their weight in the 14 billion parameter class. Here you can see a comparison between Lamarck and other top-performing merges and finetunes: |
|
|
|
 |
|
|
|
A notable contribution to the middle to upper layers of Lamarck v0.6 comes from [Krystalan/DRT-o1-14B](https://huggingface.co/Krystalan/DRT-o1-14B). It has a fascinating research paper: [DRT-o1: Optimized Deep Reasoning Translation via Long Chain-of-Thought](https://huggingface.co/papers/2412.17498). |
|
|
|
Lamarck 0.6 uses a custom toolchain to create the merges which target specific layers: |
|
|
|
- **Extracted LoRA adapters from special-purpose merges** |
|
- **Separate branches for breadcrumbs and DELLA merges** |
|
- **Highly targeted weight/density gradients for every 2-4 layers** |
|
- **Finalization through SLERP merges recombining the separate branches** |
|
|
|
This approach selectively merges the strongest aspects of its ancestors. Lamarck v0.6 is my most complex merge to date. The LoRA extractions alone pushed my hardware enough to be the building's sole source of heat for several winter days! By comparison, the SLERP merge below which finalized it was a simple step. |
|
|
|
```yaml |
|
--- |
|
name: lamarck-14b-v0.6-005-model_stock |
|
merge_method: model_stock |
|
base_model: sometimesanotion/Qwenvergence-14B-Base-v2 |
|
tokenizer_source: sometimesanotion/Abliterate-Qwenvergence |
|
dtype: float32 |
|
out_dtype: bfloat16 |
|
parameters: |
|
int8_mask: true |
|
normalize: true |
|
rescale: false |
|
models: |
|
- model: arcee-ai/Virtuoso-Small-qv64 |
|
- model: Krystalan/DRT-o1-14B-qv128 |
|
- model: sometimesanotion/Qwen2.5-14B-Vimarckoso-v3-qv64 |
|
- model: sometimesanotion/Qwenvergence-14B-v3-Prose-qv256 |
|
- model: sometimesanotion/Abliterate-Qwenvergence |
|
--- |
|
name: lamarck-14b-converge-breadcrumbs |
|
merge_method: breadcrumbs |
|
base_model: sometimesanotion/lamarck-14b-v0.6-005-model_stock |
|
tokenizer_source: base |
|
dtype: bfloat16 |
|
out_dtype: bfloat16 |
|
parameters: |
|
int8_mask: true |
|
normalize: true |
|
rescale: false |
|
density: 0.95 |
|
weight: 1.00 |
|
gamma: 0.018 |
|
# Here there be dragons! |
|
--- |
|
name: lamarck-14b-converge-della-linear |
|
merge_method: della_linear |
|
base_model: sometimesanotion/Qwen2.5-14B-Vimarckoso-v3 |
|
tokenizer_source: base |
|
dtype: float32 |
|
out_dtype: bfloat16 |
|
parameters: |
|
int8_mask: true |
|
normalize: true |
|
rescale: false |
|
density: 0.95 |
|
weight: 1.00 |
|
epsilon: 0.018 |
|
lambda: 1.20 |
|
smoothing_factor: 0.07 |
|
# Yep, dragons. |
|
--- |
|
name: Lamarck-14B-v0.6-rc4 |
|
merge_method: slerp |
|
base_model: sometimesanotion/lamarck-14b-converge-della-linear |
|
tokenizer_source: base |
|
dtype: float32 |
|
out_dtype: bfloat16 |
|
parameters: |
|
int8_mask: true |
|
normalize: true |
|
rescale: false |
|
parameters: |
|
t: |
|
- value: 0.30 |
|
# Not so dragon-ish. |
|
slices: |
|
- sources: |
|
- model: sometimesanotion/lamarck-14b-converge-della-linear |
|
layer_range: [ 0, 8 ] |
|
- model: sometimesanotion/lamarck-14b-converge-breadcrumbs |
|
layer_range: [ 0, 8 ] |
|
- sources: |
|
- model: sometimesanotion/lamarck-14b-converge-della-linear |
|
layer_range: [ 8, 16 ] |
|
- model: sometimesanotion/lamarck-14b-converge-breadcrumbs |
|
layer_range: [ 8, 16 ] |
|
- sources: |
|
- model: sometimesanotion/lamarck-14b-converge-della-linear |
|
layer_range: [ 16, 24 ] |
|
- model: sometimesanotion/lamarck-14b-converge-breadcrumbs |
|
layer_range: [ 16, 24 ] |
|
- sources: |
|
- model: sometimesanotion/lamarck-14b-converge-della-linear |
|
layer_range: [ 24, 32 ] |
|
- model: sometimesanotion/lamarck-14b-converge-breadcrumbs |
|
layer_range: [ 24, 32 ] |
|
- sources: |
|
- model: sometimesanotion/lamarck-14b-converge-della-linear |
|
layer_range: [ 32, 40 ] |
|
- model: sometimesanotion/lamarck-14b-converge-breadcrumbs |
|
layer_range: [ 32, 40 ] |
|
- sources: |
|
- model: sometimesanotion/lamarck-14b-converge-della-linear |
|
layer_range: [ 40, 48 ] |
|
- model: sometimesanotion/lamarck-14b-converge-breadcrumbs |
|
layer_range: [ 40, 48 ] |
|
|
|
``` |
|
|
|
Lamarck's performance comes from an ancestry that goes back through careful merges to select finetuning work, upcycled and combined. Kudoes to @arcee-ai, @CultriX, @sthenno-com, @Krystalan, @underwoods, @VAGOSolutions, and @rombodawg whose models had the most influence. [Vimarckoso v3](https://huggingface.co/sometimesanotion/Qwen2.5-14B-Vimarckoso-v3) has the model card which documents its extended lineage. |
