Spaces:
Running
on
Zero

Running
on
Zero
suggested patching
#1
by
multimodalart
HF staff
- opened
- .dockerignore +1 -2
- README.md +3 -3
- app.py +40 -204
- omni_zero.py +15 -152
- predict.py +12 -19
.dockerignore
CHANGED
|
@@ -1,2 +1 @@
|
|
| 1 |
-
models
|
| 2 |
-
venv
|
|
|
|
| 1 |
+
models
|
|
|
README.md
CHANGED
|
@@ -15,13 +15,13 @@ license: gpl-3.0
|
|
| 15 |
# Omni-Zero-Couples: A diffusion pipeline for zero-shot stylized couples portrait creation.
|
| 16 |
|
| 17 |
## Use Omni-Zero in HuggingFace Spaces ZeroGPU [https://huggingface.co/spaces/okaris/omni-zero-couples](https://huggingface.co/spaces/okaris/omni-zero-couples)
|
| 18 |
-

|
| 21 |
-

|
| 27 |
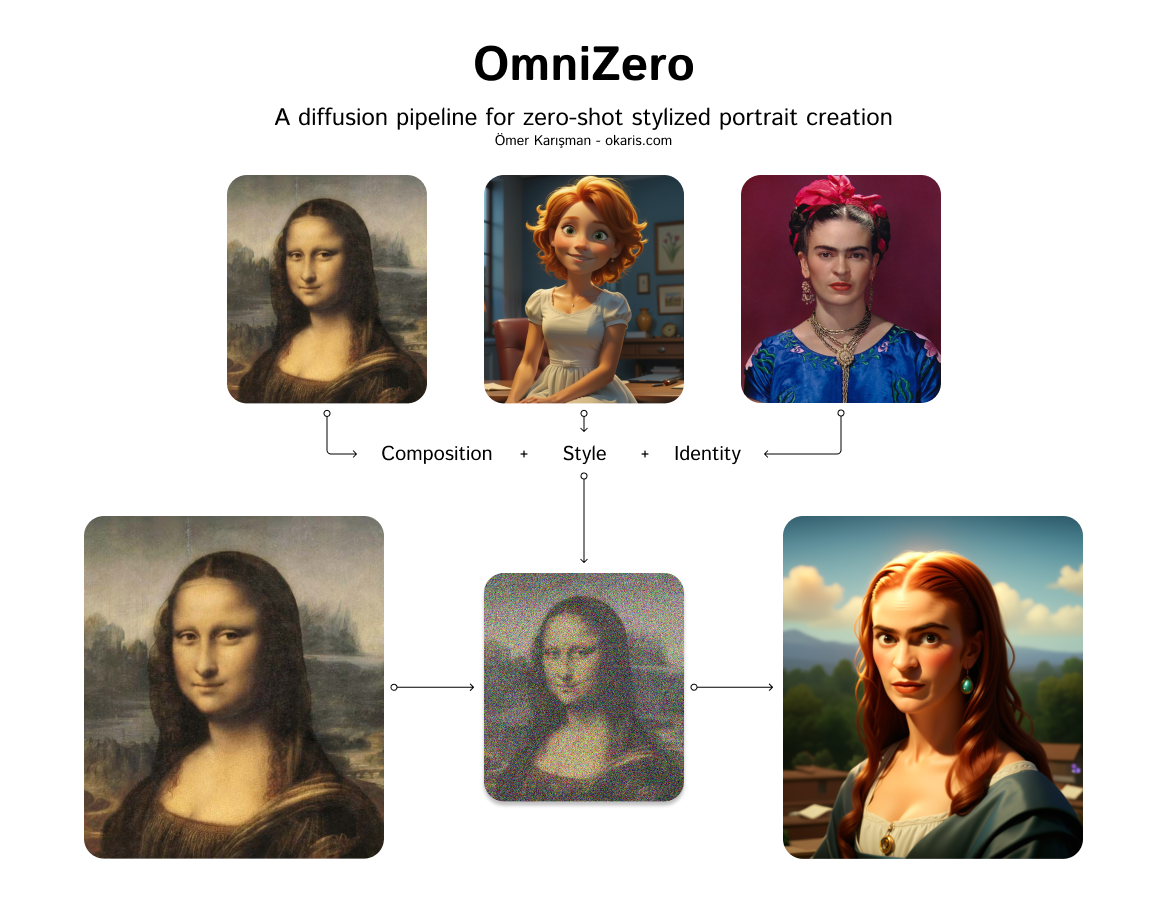
|
|
|
|
| 15 |
# Omni-Zero-Couples: A diffusion pipeline for zero-shot stylized couples portrait creation.
|
| 16 |
|
| 17 |
## Use Omni-Zero in HuggingFace Spaces ZeroGPU [https://huggingface.co/spaces/okaris/omni-zero-couples](https://huggingface.co/spaces/okaris/omni-zero-couples)
|
| 18 |
+

|
| 19 |
|
| 20 |
## Run on Replicate [https://replicate.com/okaris/omni-zero-couples](https://replicate.com/okaris/omni-zero-couples)
|
| 21 |
+

|
| 22 |
|
| 23 |
### Multiple Identities and Styles
|
| 24 |
+

|
| 25 |
|
| 26 |
### Single Identity and Style [https://github.com/okaris/omni-zero](https://github.com/okaris/omni-zero)
|
| 27 |

|
app.py
CHANGED
|
@@ -1,8 +1,6 @@
|
|
| 1 |
-
import os
|
| 2 |
-
|
| 3 |
import gradio as gr
|
| 4 |
import spaces
|
| 5 |
-
|
| 6 |
os.environ["HF_HUB_ENABLE_HF_TRANSFER"] = "1"
|
| 7 |
|
| 8 |
import torch
|
|
@@ -11,78 +9,14 @@ import torch
|
|
| 11 |
torch.jit.script = lambda f: f
|
| 12 |
####
|
| 13 |
|
| 14 |
-
import
|
| 15 |
-
import numpy as np
|
| 16 |
-
import PIL
|
| 17 |
-
from controlnet_aux import ZoeDetector
|
| 18 |
-
from diffusers import DPMSolverMultistepScheduler
|
| 19 |
-
from diffusers.image_processor import IPAdapterMaskProcessor
|
| 20 |
-
from diffusers.models import ControlNetModel
|
| 21 |
-
from huggingface_hub import snapshot_download
|
| 22 |
-
from insightface.app import FaceAnalysis
|
| 23 |
-
from pipeline import OmniZeroPipeline
|
| 24 |
-
from transformers import CLIPVisionModelWithProjection
|
| 25 |
-
from utils import align_images, draw_kps, load_and_resize_image
|
| 26 |
-
|
| 27 |
-
|
| 28 |
-
def patch_onnx_runtime(
|
| 29 |
-
inter_op_num_threads: int = 16,
|
| 30 |
-
intra_op_num_threads: int = 16,
|
| 31 |
-
omp_num_threads: int = 16,
|
| 32 |
-
):
|
| 33 |
-
import os
|
| 34 |
-
|
| 35 |
-
import onnxruntime as ort
|
| 36 |
-
|
| 37 |
-
os.environ["OMP_NUM_THREADS"] = str(omp_num_threads)
|
| 38 |
-
|
| 39 |
-
_default_session_options = ort.capi._pybind_state.get_default_session_options()
|
| 40 |
-
|
| 41 |
-
def get_default_session_options_new():
|
| 42 |
-
_default_session_options.inter_op_num_threads = inter_op_num_threads
|
| 43 |
-
_default_session_options.intra_op_num_threads = intra_op_num_threads
|
| 44 |
-
return _default_session_options
|
| 45 |
-
|
| 46 |
-
ort.capi._pybind_state.get_default_session_options = get_default_session_options_new
|
| 47 |
-
|
| 48 |
-
|
| 49 |
-
base_model = "frankjoshua/albedobaseXL_v13"
|
| 50 |
-
|
| 51 |
-
patch_onnx_runtime()
|
| 52 |
|
| 53 |
-
|
| 54 |
-
|
| 55 |
-
|
|
|
|
| 56 |
|
| 57 |
-
|
| 58 |
-
|
| 59 |
-
ip_adapter_plus_image_encoder = CLIPVisionModelWithProjection.from_pretrained(
|
| 60 |
-
"h94/IP-Adapter",
|
| 61 |
-
subfolder="models/image_encoder",
|
| 62 |
-
torch_dtype=dtype,
|
| 63 |
-
).to("cuda")
|
| 64 |
-
|
| 65 |
-
zoedepthnet_path = "okaris/zoe-depth-controlnet-xl"
|
| 66 |
-
zoedepthnet = ControlNetModel.from_pretrained(zoedepthnet_path,torch_dtype=dtype).to("cuda")
|
| 67 |
-
|
| 68 |
-
identitiynet_path = "okaris/face-controlnet-xl"
|
| 69 |
-
identitynet = ControlNetModel.from_pretrained(identitiynet_path, torch_dtype=dtype).to("cuda")
|
| 70 |
-
|
| 71 |
-
zoe_depth_detector = ZoeDetector.from_pretrained("lllyasviel/Annotators").to("cuda")
|
| 72 |
-
ip_adapter_mask_processor = IPAdapterMaskProcessor()
|
| 73 |
-
|
| 74 |
-
pipeline = OmniZeroPipeline.from_pretrained(
|
| 75 |
-
base_model,
|
| 76 |
-
controlnet=[identitynet, identitynet, zoedepthnet],
|
| 77 |
-
torch_dtype=dtype,
|
| 78 |
-
image_encoder=ip_adapter_plus_image_encoder,
|
| 79 |
-
).to("cuda")
|
| 80 |
-
|
| 81 |
-
config = pipeline.scheduler.config
|
| 82 |
-
config["timestep_spacing"] = "trailing"
|
| 83 |
-
pipeline.scheduler = DPMSolverMultistepScheduler.from_config(config, use_karras_sigmas=True, algorithm_type="sde-dpmsolver++", final_sigmas_type="zero")
|
| 84 |
-
|
| 85 |
-
pipeline.load_ip_adapter(["okaris/ip-adapter-instantid", "okaris/ip-adapter-instantid", "h94/IP-Adapter"], subfolder=[None, None, "sdxl_models"], weight_name=["ip-adapter-instantid.bin", "ip-adapter-instantid.bin", "ip-adapter-plus_sdxl_vit-h.safetensors"])
|
| 86 |
|
| 87 |
@spaces.GPU()
|
| 88 |
def generate(
|
|
@@ -106,121 +40,26 @@ def generate(
|
|
| 106 |
mask_guidance_end=1.0,
|
| 107 |
progress=gr.Progress(track_tqdm=True)
|
| 108 |
):
|
| 109 |
-
|
| 110 |
-
|
| 111 |
-
if base_image is not None:
|
| 112 |
-
base_image = load_and_resize_image(base_image, resolution, resolution)
|
| 113 |
-
|
| 114 |
-
if depth_image is None:
|
| 115 |
-
depth_image = zoe_depth_detector(base_image, detect_resolution=resolution, image_resolution=resolution)
|
| 116 |
-
else:
|
| 117 |
-
depth_image = load_and_resize_image(depth_image, resolution, resolution)
|
| 118 |
-
|
| 119 |
-
base_image, depth_image = align_images(base_image, depth_image)
|
| 120 |
-
|
| 121 |
-
if style_image is not None:
|
| 122 |
-
style_image = load_and_resize_image(style_image, resolution, resolution)
|
| 123 |
-
else:
|
| 124 |
-
style_image = base_image
|
| 125 |
-
# raise ValueError("You must provide a style image")
|
| 126 |
-
|
| 127 |
-
if identity_image_1 is not None:
|
| 128 |
-
identity_image_1 = load_and_resize_image(identity_image_1, resolution, resolution)
|
| 129 |
-
else:
|
| 130 |
-
raise ValueError("You must provide an identity image")
|
| 131 |
-
|
| 132 |
-
if identity_image_2 is not None:
|
| 133 |
-
identity_image_2 = load_and_resize_image(identity_image_2, resolution, resolution)
|
| 134 |
-
else:
|
| 135 |
-
raise ValueError("You must provide an identity image 2")
|
| 136 |
-
|
| 137 |
-
height, width = base_image.size
|
| 138 |
-
|
| 139 |
-
face_info_1 = face_analysis.get(cv2.cvtColor(np.array(identity_image_1), cv2.COLOR_RGB2BGR))
|
| 140 |
-
for i, face in enumerate(face_info_1):
|
| 141 |
-
print(f"Face 1 -{i}: Age: {face['age']}, Gender: {face['gender']}")
|
| 142 |
-
face_info_1 = sorted(face_info_1, key=lambda x:(x['bbox'][2]-x['bbox'][0])*x['bbox'][3]-x['bbox'][1])[-1] # only use the maximum face
|
| 143 |
-
face_emb_1 = torch.tensor(face_info_1['embedding']).to("cuda", dtype=dtype)
|
| 144 |
-
|
| 145 |
-
face_info_2 = face_analysis.get(cv2.cvtColor(np.array(identity_image_2), cv2.COLOR_RGB2BGR))
|
| 146 |
-
for i, face in enumerate(face_info_2):
|
| 147 |
-
print(f"Face 2 -{i}: Age: {face['age']}, Gender: {face['gender']}")
|
| 148 |
-
face_info_2 = sorted(face_info_2, key=lambda x:(x['bbox'][2]-x['bbox'][0])*x['bbox'][3]-x['bbox'][1])[-1] # only use the maximum face
|
| 149 |
-
face_emb_2 = torch.tensor(face_info_2['embedding']).to("cuda", dtype=dtype)
|
| 150 |
-
|
| 151 |
-
zero = np.zeros((width, height, 3), dtype=np.uint8)
|
| 152 |
-
# face_kps_identity_image_1 = draw_kps(zero, face_info_1['kps'])
|
| 153 |
-
# face_kps_identity_image_2 = draw_kps(zero, face_info_2['kps'])
|
| 154 |
-
|
| 155 |
-
face_info_img2img = face_analysis.get(cv2.cvtColor(np.array(base_image), cv2.COLOR_RGB2BGR))
|
| 156 |
-
faces_info_img2img = sorted(face_info_img2img, key=lambda x:(x['bbox'][2]-x['bbox'][0])*x['bbox'][3]-x['bbox'][1])
|
| 157 |
-
face_info_a = faces_info_img2img[-1]
|
| 158 |
-
face_info_b = faces_info_img2img[-2]
|
| 159 |
-
# face_emb_a = torch.tensor(face_info_a['embedding']).to("cuda", dtype=dtype)
|
| 160 |
-
# face_emb_b = torch.tensor(face_info_b['embedding']).to("cuda", dtype=dtype)
|
| 161 |
-
face_kps_identity_image_a = draw_kps(zero, face_info_a['kps'])
|
| 162 |
-
face_kps_identity_image_b = draw_kps(zero, face_info_b['kps'])
|
| 163 |
-
|
| 164 |
-
general_mask = PIL.Image.fromarray(np.ones((width, height, 3), dtype=np.uint8))
|
| 165 |
-
|
| 166 |
-
control_mask_1 = zero.copy()
|
| 167 |
-
x1, y1, x2, y2 = face_info_a["bbox"]
|
| 168 |
-
x1, y1, x2, y2 = int(x1), int(y1), int(x2), int(y2)
|
| 169 |
-
control_mask_1[y1:y2, x1:x2] = 255
|
| 170 |
-
control_mask_1 = PIL.Image.fromarray(control_mask_1.astype(np.uint8))
|
| 171 |
-
|
| 172 |
-
control_mask_2 = zero.copy()
|
| 173 |
-
x1, y1, x2, y2 = face_info_b["bbox"]
|
| 174 |
-
x1, y1, x2, y2 = int(x1), int(y1), int(x2), int(y2)
|
| 175 |
-
control_mask_2[y1:y2, x1:x2] = 255
|
| 176 |
-
control_mask_2 = PIL.Image.fromarray(control_mask_2.astype(np.uint8))
|
| 177 |
-
|
| 178 |
-
controlnet_masks = [control_mask_1, control_mask_2, general_mask]
|
| 179 |
-
ip_adapter_images = [face_emb_1, face_emb_2, style_image, ]
|
| 180 |
-
|
| 181 |
-
masks = ip_adapter_mask_processor.preprocess([control_mask_1, control_mask_2, general_mask], height=height, width=width)
|
| 182 |
-
ip_adapter_masks = [mask.unsqueeze(0) for mask in masks]
|
| 183 |
-
|
| 184 |
-
inpaint_mask = torch.logical_or(torch.tensor(np.array(control_mask_1)), torch.tensor(np.array(control_mask_2))).float()
|
| 185 |
-
inpaint_mask = PIL.Image.fromarray((inpaint_mask.numpy() * 255).astype(np.uint8)).convert("RGB")
|
| 186 |
-
|
| 187 |
-
new_ip_adapter_masks = []
|
| 188 |
-
for ip_img, mask in zip(ip_adapter_images, controlnet_masks):
|
| 189 |
-
if isinstance(ip_img, list):
|
| 190 |
-
num_images = len(ip_img)
|
| 191 |
-
mask = mask.repeat(1, num_images, 1, 1)
|
| 192 |
-
|
| 193 |
-
new_ip_adapter_masks.append(mask)
|
| 194 |
-
|
| 195 |
-
generator = torch.Generator(device="cpu").manual_seed(seed)
|
| 196 |
-
|
| 197 |
-
pipeline.set_ip_adapter_scale([identity_image_strength_1, identity_image_strength_2,
|
| 198 |
-
{
|
| 199 |
-
"down": { "block_2": [0.0, 0.0] }, #Composition
|
| 200 |
-
"up": { "block_0": [0.0, style_image_strength, 0.0] } #Style
|
| 201 |
-
}
|
| 202 |
-
])
|
| 203 |
-
|
| 204 |
-
images = pipeline(
|
| 205 |
prompt=prompt,
|
| 206 |
-
negative_prompt=negative_prompt,
|
| 207 |
guidance_scale=guidance_scale,
|
| 208 |
-
|
| 209 |
-
|
| 210 |
-
|
| 211 |
-
|
| 212 |
-
|
| 213 |
-
|
| 214 |
-
|
| 215 |
-
|
| 216 |
-
|
| 217 |
-
|
| 218 |
-
|
| 219 |
-
|
| 220 |
-
|
| 221 |
-
|
| 222 |
-
|
| 223 |
-
).images
|
| 224 |
|
| 225 |
return images
|
| 226 |
|
|
@@ -246,24 +85,24 @@ with gr.Blocks() as demo:
|
|
| 246 |
base_image = gr.Image(label="Base Image")
|
| 247 |
with gr.Row():
|
| 248 |
base_image_strength = gr.Slider(label="Strength",step=0.01, minimum=0.0, maximum=1.0, value=1.0)
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 249 |
with gr.Column(min_width=140):
|
| 250 |
with gr.Row():
|
| 251 |
identity_image = gr.Image(label="Identity Image")
|
| 252 |
with gr.Row():
|
| 253 |
-
identity_image_strength = gr.Slider(label="
|
| 254 |
with gr.Column(min_width=140):
|
| 255 |
with gr.Row():
|
| 256 |
identity_image_2 = gr.Image(label="Identity Image 2")
|
| 257 |
with gr.Row():
|
| 258 |
-
identity_image_strength_2 = gr.Slider(label="
|
| 259 |
-
with gr.Accordion("Advanced options", open=False):
|
| 260 |
-
with gr.Row():
|
| 261 |
-
with gr.Column():
|
| 262 |
-
style_image = gr.Image(label="Style Image")
|
| 263 |
-
style_image_strength = gr.Slider(label="Style Strength",step=0.01, minimum=0.0, maximum=1.0, value=1.0)
|
| 264 |
-
with gr.Column():
|
| 265 |
-
depth_image = gr.Image(label="Depth Image")
|
| 266 |
-
depth_image_strength = gr.Slider(label="Depth Strength",step=0.01, minimum=0.0, maximum=1.0, value=0.5)
|
| 267 |
with gr.Row():
|
| 268 |
seed = gr.Slider(label="Seed",step=1, minimum=0, maximum=10000000, value=42)
|
| 269 |
number_of_images = gr.Slider(label="Number of Outputs",step=1, minimum=1, maximum=4, value=1)
|
|
@@ -282,12 +121,12 @@ with gr.Blocks() as demo:
|
|
| 282 |
submit = gr.Button("Generate")
|
| 283 |
|
| 284 |
submit.click(generate, inputs=[
|
|
|
|
| 285 |
base_image,
|
| 286 |
-
style_image
|
| 287 |
identity_image,
|
| 288 |
identity_image_2,
|
| 289 |
seed,
|
| 290 |
-
prompt,
|
| 291 |
negative_prompt,
|
| 292 |
guidance_scale,
|
| 293 |
number_of_images,
|
|
@@ -296,8 +135,6 @@ with gr.Blocks() as demo:
|
|
| 296 |
style_image_strength,
|
| 297 |
identity_image_strength,
|
| 298 |
identity_image_strength_2,
|
| 299 |
-
depth_image,
|
| 300 |
-
depth_image_strength,
|
| 301 |
mask_guidance_start,
|
| 302 |
mask_guidance_end,
|
| 303 |
],
|
|
@@ -307,15 +144,14 @@ with gr.Blocks() as demo:
|
|
| 307 |
gr.Examples(
|
| 308 |
examples=[
|
| 309 |
[
|
|
|
|
| 310 |
"https://cdn-prod.styleof.com/inferences/cm1ho5cjl14nh14jec6phg2h8/i6k59e7gpsr45ufc7l8kun0g-medium.jpeg",
|
| 311 |
"https://cdn-prod.styleof.com/inferences/cm1ho5cjl14nh14jec6phg2h8/i6k59e7gpsr45ufc7l8kun0g-medium.jpeg",
|
| 312 |
"https://cdn-prod.styleof.com/inferences/cm1hp4lea14oz14jeoghnex7g/dlgc5xwo0qzey7qaixy45i1o-medium.jpeg",
|
| 313 |
-
"https://cdn-prod.styleof.com/inferences/cm1ho69ha14np14jesnusqiep/mp3aaktzqz20ujco5i3bi5s1-medium.jpeg"
|
| 314 |
-
42,
|
| 315 |
-
"Cinematic still photo of a couple. emotional, harmonious, vignette, 4k epic detailed, shot on kodak, 35mm photo, sharp focus, high budget, cinemascope, moody, epic, gorgeous, film grain, grainy",
|
| 316 |
]
|
| 317 |
],
|
| 318 |
-
inputs=[base_image, style_image, identity_image, identity_image_2
|
| 319 |
outputs=[out],
|
| 320 |
fn=generate,
|
| 321 |
cache_examples="lazy",
|
|
|
|
|
|
|
|
|
|
| 1 |
import gradio as gr
|
| 2 |
import spaces
|
| 3 |
+
import os
|
| 4 |
os.environ["HF_HUB_ENABLE_HF_TRANSFER"] = "1"
|
| 5 |
|
| 6 |
import torch
|
|
|
|
| 9 |
torch.jit.script = lambda f: f
|
| 10 |
####
|
| 11 |
|
| 12 |
+
from omni_zero import OmniZeroCouple
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 13 |
|
| 14 |
+
omni_zero = OmniZeroCouple(
|
| 15 |
+
base_model="frankjoshua/albedobaseXL_v13",
|
| 16 |
+
device="cuda",
|
| 17 |
+
)
|
| 18 |
|
| 19 |
+
omni_zero.generate = spaces.GPU(omni_zero.generate)
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 20 |
|
| 21 |
@spaces.GPU()
|
| 22 |
def generate(
|
|
|
|
| 40 |
mask_guidance_end=1.0,
|
| 41 |
progress=gr.Progress(track_tqdm=True)
|
| 42 |
):
|
| 43 |
+
images = omni_zero.generate(
|
| 44 |
+
seed=seed,
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 45 |
prompt=prompt,
|
| 46 |
+
negative_prompt=negative_prompt,
|
| 47 |
guidance_scale=guidance_scale,
|
| 48 |
+
number_of_images=number_of_images,
|
| 49 |
+
number_of_steps=number_of_steps,
|
| 50 |
+
base_image=base_image,
|
| 51 |
+
base_image_strength=base_image_strength,
|
| 52 |
+
style_image=style_image,
|
| 53 |
+
style_image_strength=style_image_strength,
|
| 54 |
+
identity_image_1=identity_image_1,
|
| 55 |
+
identity_image_strength_1=identity_image_strength_1,
|
| 56 |
+
identity_image_2=identity_image_2,
|
| 57 |
+
identity_image_strength_2=identity_image_strength_2,
|
| 58 |
+
depth_image=depth_image,
|
| 59 |
+
depth_image_strength=depth_image_strength,
|
| 60 |
+
mask_guidance_start=mask_guidance_start,
|
| 61 |
+
mask_guidance_end=mask_guidance_end,
|
| 62 |
+
)
|
|
|
|
| 63 |
|
| 64 |
return images
|
| 65 |
|
|
|
|
| 85 |
base_image = gr.Image(label="Base Image")
|
| 86 |
with gr.Row():
|
| 87 |
base_image_strength = gr.Slider(label="Strength",step=0.01, minimum=0.0, maximum=1.0, value=1.0)
|
| 88 |
+
#with gr.Row():
|
| 89 |
+
with gr.Column(min_width=140):
|
| 90 |
+
with gr.Row():
|
| 91 |
+
style_image = gr.Image(label="Style Image")
|
| 92 |
+
with gr.Row():
|
| 93 |
+
style_image_strength = gr.Slider(label="Strength",step=0.01, minimum=0.0, maximum=1.0, value=1.0)
|
| 94 |
+
with gr.Row():
|
| 95 |
with gr.Column(min_width=140):
|
| 96 |
with gr.Row():
|
| 97 |
identity_image = gr.Image(label="Identity Image")
|
| 98 |
with gr.Row():
|
| 99 |
+
identity_image_strength = gr.Slider(label="Strenght",step=0.01, minimum=0.0, maximum=1.0, value=1.0)
|
| 100 |
with gr.Column(min_width=140):
|
| 101 |
with gr.Row():
|
| 102 |
identity_image_2 = gr.Image(label="Identity Image 2")
|
| 103 |
with gr.Row():
|
| 104 |
+
identity_image_strength_2 = gr.Slider(label="Strenght",step=0.01, minimum=0.0, maximum=1.0, value=1.0)
|
| 105 |
+
with gr.Accordion("Advanced options", open=False):
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 106 |
with gr.Row():
|
| 107 |
seed = gr.Slider(label="Seed",step=1, minimum=0, maximum=10000000, value=42)
|
| 108 |
number_of_images = gr.Slider(label="Number of Outputs",step=1, minimum=1, maximum=4, value=1)
|
|
|
|
| 121 |
submit = gr.Button("Generate")
|
| 122 |
|
| 123 |
submit.click(generate, inputs=[
|
| 124 |
+
prompt,
|
| 125 |
base_image,
|
| 126 |
+
style_image,
|
| 127 |
identity_image,
|
| 128 |
identity_image_2,
|
| 129 |
seed,
|
|
|
|
| 130 |
negative_prompt,
|
| 131 |
guidance_scale,
|
| 132 |
number_of_images,
|
|
|
|
| 135 |
style_image_strength,
|
| 136 |
identity_image_strength,
|
| 137 |
identity_image_strength_2,
|
|
|
|
|
|
|
| 138 |
mask_guidance_start,
|
| 139 |
mask_guidance_end,
|
| 140 |
],
|
|
|
|
| 144 |
gr.Examples(
|
| 145 |
examples=[
|
| 146 |
[
|
| 147 |
+
"Cinematic still photo of a couple. emotional, harmonious, vignette, 4k epic detailed, shot on kodak, 35mm photo, sharp focus, high budget, cinemascope, moody, epic, gorgeous, film grain, grainy",
|
| 148 |
"https://cdn-prod.styleof.com/inferences/cm1ho5cjl14nh14jec6phg2h8/i6k59e7gpsr45ufc7l8kun0g-medium.jpeg",
|
| 149 |
"https://cdn-prod.styleof.com/inferences/cm1ho5cjl14nh14jec6phg2h8/i6k59e7gpsr45ufc7l8kun0g-medium.jpeg",
|
| 150 |
"https://cdn-prod.styleof.com/inferences/cm1hp4lea14oz14jeoghnex7g/dlgc5xwo0qzey7qaixy45i1o-medium.jpeg",
|
| 151 |
+
"https://cdn-prod.styleof.com/inferences/cm1ho69ha14np14jesnusqiep/mp3aaktzqz20ujco5i3bi5s1-medium.jpeg"
|
|
|
|
|
|
|
| 152 |
]
|
| 153 |
],
|
| 154 |
+
inputs=[prompt, base_image, style_image, identity_image, identity_image_2],
|
| 155 |
outputs=[out],
|
| 156 |
fn=generate,
|
| 157 |
cache_examples="lazy",
|
omni_zero.py
CHANGED
|
@@ -1,164 +1,31 @@
|
|
| 1 |
import os
|
| 2 |
-
|
| 3 |
os.environ["HF_HUB_ENABLE_HF_TRANSFER"] = "1"
|
| 4 |
|
| 5 |
import sys
|
| 6 |
-
|
| 7 |
sys.path.insert(0, './diffusers/src')
|
| 8 |
|
| 9 |
-
import cv2
|
| 10 |
-
import numpy as np
|
| 11 |
-
import PIL
|
| 12 |
import torch
|
| 13 |
-
|
|
|
|
|
|
|
| 14 |
from diffusers import DPMSolverMultistepScheduler
|
| 15 |
-
from diffusers.image_processor import IPAdapterMaskProcessor
|
| 16 |
from diffusers.models import ControlNetModel
|
| 17 |
-
from
|
| 18 |
-
from insightface.app import FaceAnalysis
|
| 19 |
-
from pipeline import OmniZeroPipeline
|
| 20 |
-
from transformers import CLIPVisionModelWithProjection
|
| 21 |
-
from utils import align_images, draw_kps, load_and_resize_image
|
| 22 |
-
import random
|
| 23 |
-
|
| 24 |
-
class OmniZeroSingle():
|
| 25 |
-
def __init__(self,
|
| 26 |
-
base_model="stabilityai/stable-diffusion-xl-base-1.0",
|
| 27 |
-
device="cuda",
|
| 28 |
-
):
|
| 29 |
-
snapshot_download("okaris/antelopev2", local_dir="./models/antelopev2")
|
| 30 |
-
self.face_analysis = FaceAnalysis(name='antelopev2', root='./', providers=['CUDAExecutionProvider', 'CPUExecutionProvider'])
|
| 31 |
-
self.face_analysis.prepare(ctx_id=0, det_size=(640, 640))
|
| 32 |
-
|
| 33 |
-
dtype = torch.float16
|
| 34 |
-
|
| 35 |
-
ip_adapter_plus_image_encoder = CLIPVisionModelWithProjection.from_pretrained(
|
| 36 |
-
"h94/IP-Adapter",
|
| 37 |
-
subfolder="models/image_encoder",
|
| 38 |
-
torch_dtype=dtype,
|
| 39 |
-
).to(device)
|
| 40 |
-
|
| 41 |
-
zoedepthnet_path = "okaris/zoe-depth-controlnet-xl"
|
| 42 |
-
zoedepthnet = ControlNetModel.from_pretrained(zoedepthnet_path,torch_dtype=dtype).to(device)
|
| 43 |
-
|
| 44 |
-
identitiynet_path = "okaris/face-controlnet-xl"
|
| 45 |
-
identitynet = ControlNetModel.from_pretrained(identitiynet_path, torch_dtype=dtype).to(device)
|
| 46 |
-
|
| 47 |
-
self.zoe_depth_detector = ZoeDetector.from_pretrained("lllyasviel/Annotators").to(device)
|
| 48 |
-
|
| 49 |
-
self.pipeline = OmniZeroPipeline.from_pretrained(
|
| 50 |
-
base_model,
|
| 51 |
-
controlnet=[identitynet, zoedepthnet],
|
| 52 |
-
torch_dtype=dtype,
|
| 53 |
-
image_encoder=ip_adapter_plus_image_encoder,
|
| 54 |
-
).to(device)
|
| 55 |
-
|
| 56 |
-
config = self.pipeline.scheduler.config
|
| 57 |
-
config["timestep_spacing"] = "trailing"
|
| 58 |
-
self.pipeline.scheduler = DPMSolverMultistepScheduler.from_config(config, use_karras_sigmas=True, algorithm_type="sde-dpmsolver++", final_sigmas_type="zero")
|
| 59 |
-
|
| 60 |
-
self.pipeline.load_ip_adapter(["okaris/ip-adapter-instantid", "h94/IP-Adapter", "h94/IP-Adapter"], subfolder=[None, "sdxl_models", "sdxl_models"], weight_name=["ip-adapter-instantid.bin", "ip-adapter-plus_sdxl_vit-h.safetensors", "ip-adapter-plus_sdxl_vit-h.safetensors"])
|
| 61 |
-
|
| 62 |
-
def get_largest_face_embedding_and_kps(self, image, target_image=None):
|
| 63 |
-
face_info = self.face_analysis.get(cv2.cvtColor(np.array(image), cv2.COLOR_RGB2BGR))
|
| 64 |
-
if len(face_info) == 0:
|
| 65 |
-
return None, None
|
| 66 |
-
largest_face = sorted(face_info, key=lambda x: x['bbox'][2] * x['bbox'][3], reverse=True)[0]
|
| 67 |
-
face_embedding = torch.tensor(largest_face['embedding']).to("cuda")
|
| 68 |
-
if target_image is None:
|
| 69 |
-
target_image = image
|
| 70 |
-
zeros = np.zeros((target_image.size[1], target_image.size[0], 3), dtype=np.uint8)
|
| 71 |
-
face_kps_image = draw_kps(zeros, largest_face['kps'])
|
| 72 |
-
return face_embedding, face_kps_image
|
| 73 |
-
|
| 74 |
-
def generate(self,
|
| 75 |
-
seed=42,
|
| 76 |
-
prompt="A person",
|
| 77 |
-
negative_prompt="blurry, out of focus",
|
| 78 |
-
guidance_scale=3.0,
|
| 79 |
-
number_of_images=1,
|
| 80 |
-
number_of_steps=10,
|
| 81 |
-
base_image=None,
|
| 82 |
-
base_image_strength=0.15,
|
| 83 |
-
composition_image=None,
|
| 84 |
-
composition_image_strength=1.0,
|
| 85 |
-
style_image=None,
|
| 86 |
-
style_image_strength=1.0,
|
| 87 |
-
identity_image=None,
|
| 88 |
-
identity_image_strength=1.0,
|
| 89 |
-
depth_image=None,
|
| 90 |
-
depth_image_strength=0.5,
|
| 91 |
-
):
|
| 92 |
-
resolution = 1024
|
| 93 |
-
|
| 94 |
-
if base_image is not None:
|
| 95 |
-
base_image = load_and_resize_image(base_image, resolution, resolution)
|
| 96 |
-
else:
|
| 97 |
-
if composition_image is not None:
|
| 98 |
-
base_image = load_and_resize_image(composition_image, resolution, resolution)
|
| 99 |
-
else:
|
| 100 |
-
raise ValueError("You must provide a base image or a composition image")
|
| 101 |
-
|
| 102 |
-
if depth_image is None:
|
| 103 |
-
depth_image = self.zoe_depth_detector(base_image, detect_resolution=resolution, image_resolution=resolution)
|
| 104 |
-
else:
|
| 105 |
-
depth_image = load_and_resize_image(depth_image, resolution, resolution)
|
| 106 |
-
|
| 107 |
-
base_image, depth_image = align_images(base_image, depth_image)
|
| 108 |
-
|
| 109 |
-
if composition_image is not None:
|
| 110 |
-
composition_image = load_and_resize_image(composition_image, resolution, resolution)
|
| 111 |
-
else:
|
| 112 |
-
composition_image = base_image
|
| 113 |
|
| 114 |
-
|
| 115 |
-
style_image = load_and_resize_image(style_image, resolution, resolution)
|
| 116 |
-
else:
|
| 117 |
-
raise ValueError("You must provide a style image")
|
| 118 |
-
|
| 119 |
-
if identity_image is not None:
|
| 120 |
-
identity_image = load_and_resize_image(identity_image, resolution, resolution)
|
| 121 |
-
else:
|
| 122 |
-
raise ValueError("You must provide an identity image")
|
| 123 |
-
|
| 124 |
-
face_embedding_identity_image, target_kps = self.get_largest_face_embedding_and_kps(identity_image, base_image)
|
| 125 |
-
if face_embedding_identity_image is None:
|
| 126 |
-
raise ValueError("No face found in the identity image, the image might be cropped too tightly or the face is too small")
|
| 127 |
-
|
| 128 |
-
face_embedding_base_image, face_kps_base_image = self.get_largest_face_embedding_and_kps(base_image)
|
| 129 |
-
if face_embedding_base_image is not None:
|
| 130 |
-
target_kps = face_kps_base_image
|
| 131 |
|
| 132 |
-
|
| 133 |
-
|
| 134 |
-
|
| 135 |
-
|
| 136 |
-
},
|
| 137 |
-
{
|
| 138 |
-
"down": { "block_2": [0.0, composition_image_strength] },
|
| 139 |
-
"up": { "block_0": [0.0, 0.0, 0.0] }
|
| 140 |
-
}
|
| 141 |
-
])
|
| 142 |
|
| 143 |
-
|
| 144 |
|
| 145 |
-
|
| 146 |
-
|
| 147 |
-
|
| 148 |
-
guidance_scale=guidance_scale,
|
| 149 |
-
ip_adapter_image=[face_embedding_identity_image, style_image, composition_image],
|
| 150 |
-
image=base_image,
|
| 151 |
-
control_image=[target_kps, depth_image],
|
| 152 |
-
controlnet_conditioning_scale=[identity_image_strength, depth_image_strength],
|
| 153 |
-
identity_control_indices=[(0,0)],
|
| 154 |
-
num_inference_steps=number_of_steps,
|
| 155 |
-
num_images_per_prompt=number_of_images,
|
| 156 |
-
strength=(1-base_image_strength),
|
| 157 |
-
generator=generator,
|
| 158 |
-
seed=seed,
|
| 159 |
-
).images
|
| 160 |
|
| 161 |
-
|
| 162 |
|
| 163 |
class OmniZeroCouple():
|
| 164 |
def __init__(self,
|
|
@@ -210,7 +77,7 @@ class OmniZeroCouple():
|
|
| 210 |
number_of_images=1,
|
| 211 |
number_of_steps=10,
|
| 212 |
base_image=None,
|
| 213 |
-
base_image_strength=0.
|
| 214 |
style_image=None,
|
| 215 |
style_image_strength=1.0,
|
| 216 |
identity_image_1=None,
|
|
@@ -223,9 +90,6 @@ class OmniZeroCouple():
|
|
| 223 |
mask_guidance_end=1.0,
|
| 224 |
):
|
| 225 |
|
| 226 |
-
if seed == -1:
|
| 227 |
-
seed = random.randint(0, 1000000)
|
| 228 |
-
|
| 229 |
resolution = 1024
|
| 230 |
|
| 231 |
if base_image is not None:
|
|
@@ -350,7 +214,6 @@ class OmniZeroCouple():
|
|
| 350 |
omp_num_threads: int = 16,
|
| 351 |
):
|
| 352 |
import os
|
| 353 |
-
|
| 354 |
import onnxruntime as ort
|
| 355 |
|
| 356 |
os.environ["OMP_NUM_THREADS"] = str(omp_num_threads)
|
|
|
|
| 1 |
import os
|
|
|
|
| 2 |
os.environ["HF_HUB_ENABLE_HF_TRANSFER"] = "1"
|
| 3 |
|
| 4 |
import sys
|
|
|
|
| 5 |
sys.path.insert(0, './diffusers/src')
|
| 6 |
|
|
|
|
|
|
|
|
|
|
| 7 |
import torch
|
| 8 |
+
import torch.nn as nn
|
| 9 |
+
|
| 10 |
+
from huggingface_hub import snapshot_download
|
| 11 |
from diffusers import DPMSolverMultistepScheduler
|
|
|
|
| 12 |
from diffusers.models import ControlNetModel
|
| 13 |
+
from diffusers.image_processor import IPAdapterMaskProcessor
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 14 |
|
| 15 |
+
from transformers import CLIPVisionModelWithProjection
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 16 |
|
| 17 |
+
from pipeline import OmniZeroPipeline
|
| 18 |
+
from insightface.app import FaceAnalysis
|
| 19 |
+
from controlnet_aux import ZoeDetector
|
| 20 |
+
from utils import draw_kps, load_and_resize_image, align_images
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 21 |
|
| 22 |
+
from pydantic import BaseModel, Field
|
| 23 |
|
| 24 |
+
import cv2
|
| 25 |
+
import numpy as np
|
| 26 |
+
from torchvision.transforms import functional as TVF
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 27 |
|
| 28 |
+
import PIL
|
| 29 |
|
| 30 |
class OmniZeroCouple():
|
| 31 |
def __init__(self,
|
|
|
|
| 77 |
number_of_images=1,
|
| 78 |
number_of_steps=10,
|
| 79 |
base_image=None,
|
| 80 |
+
base_image_strength=0.15,
|
| 81 |
style_image=None,
|
| 82 |
style_image_strength=1.0,
|
| 83 |
identity_image_1=None,
|
|
|
|
| 90 |
mask_guidance_end=1.0,
|
| 91 |
):
|
| 92 |
|
|
|
|
|
|
|
|
|
|
| 93 |
resolution = 1024
|
| 94 |
|
| 95 |
if base_image is not None:
|
|
|
|
| 214 |
omp_num_threads: int = 16,
|
| 215 |
):
|
| 216 |
import os
|
|
|
|
| 217 |
import onnxruntime as ort
|
| 218 |
|
| 219 |
os.environ["OMP_NUM_THREADS"] = str(omp_num_threads)
|
predict.py
CHANGED
|
@@ -4,7 +4,6 @@
|
|
| 4 |
from cog import BasePredictor, Input, Path
|
| 5 |
from typing import List
|
| 6 |
from omni_zero import OmniZeroCouple
|
| 7 |
-
from PIL import Image
|
| 8 |
|
| 9 |
class Predictor(BasePredictor):
|
| 10 |
def setup(self):
|
|
@@ -14,20 +13,20 @@ class Predictor(BasePredictor):
|
|
| 14 |
)
|
| 15 |
def predict(
|
| 16 |
self,
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 17 |
base_image: Path = Input(description="Base image for the model", default=None),
|
| 18 |
-
base_image_strength: float = Input(description="Base image strength for the model", default=0.
|
| 19 |
style_image: Path = Input(description="Style image for the model", default=None),
|
| 20 |
style_image_strength: float = Input(description="Style image strength for the model", default=1.0, ge=0.0, le=1.0),
|
| 21 |
identity_image_1: Path = Input(description="First identity image for the model", default=None),
|
| 22 |
identity_image_strength_1: float = Input(description="First identity image strength for the model", default=1.0, ge=0.0, le=1.0),
|
| 23 |
identity_image_2: Path = Input(description="Second identity image for the model", default=None),
|
| 24 |
identity_image_strength_2: float = Input(description="Second identity image strength for the model", default=1.0, ge=0.0, le=1.0),
|
| 25 |
-
seed: int = Input(description="Random seed for the model. Use -1 for random", default=-1),
|
| 26 |
-
prompt: str = Input(description="Prompt for the model", default="Cinematic still photo of a couple. emotional, harmonious, vignette, 4k epic detailed, shot on kodak, 35mm photo, sharp focus, high budget, cinemascope, moody, epic, gorgeous, film grain, grainy"),
|
| 27 |
-
negative_prompt: str = Input(description="Negative prompt for the model", default="anime, cartoon, graphic, (blur, blurry, bokeh), text, painting, crayon, graphite, abstract, glitch, deformed, mutated, ugly, disfigured"),
|
| 28 |
-
guidance_scale: float = Input(description="Guidance scale for the model", default=3.0, ge=0.0, le=14.0),
|
| 29 |
-
number_of_images: int = Input(description="Number of images to generate", default=1, ge=1, le=4),
|
| 30 |
-
number_of_steps: int = Input(description="Number of steps for the model", default=10, ge=1, le=50),
|
| 31 |
depth_image: Path = Input(description="Depth image for the model", default=None),
|
| 32 |
depth_image_strength: float = Input(description="Depth image strength for the model", default=0.2, ge=0.0, le=1.0),
|
| 33 |
mask_guidance_start: float = Input(description="Mask guidance start value", default=0.0, ge=0.0, le=1.0),
|
|
@@ -35,17 +34,11 @@ class Predictor(BasePredictor):
|
|
| 35 |
) -> List[Path]:
|
| 36 |
"""Run a single prediction on the model"""
|
| 37 |
|
| 38 |
-
base_image = Image.open(base_image) if base_image else None
|
| 39 |
-
style_image = Image.open(style_image) if style_image else None
|
| 40 |
-
identity_image_1 = Image.open(identity_image_1) if identity_image_1 else None
|
| 41 |
-
identity_image_2 = Image.open(identity_image_2) if identity_image_2 else None
|
| 42 |
-
depth_image = Image.open(depth_image) if depth_image else None
|
| 43 |
-
|
| 44 |
-
print("base_image", base_image)
|
| 45 |
-
print("style_image", style_image)
|
| 46 |
-
print("identity_image_1", identity_image_1)
|
| 47 |
-
print("identity_image_2", identity_image_2)
|
| 48 |
-
print("depth_image", depth_image)
|
| 49 |
|
| 50 |
images = self.omni_zero.generate(
|
| 51 |
seed=seed,
|
|
|
|
| 4 |
from cog import BasePredictor, Input, Path
|
| 5 |
from typing import List
|
| 6 |
from omni_zero import OmniZeroCouple
|
|
|
|
| 7 |
|
| 8 |
class Predictor(BasePredictor):
|
| 9 |
def setup(self):
|
|
|
|
| 13 |
)
|
| 14 |
def predict(
|
| 15 |
self,
|
| 16 |
+
seed: int = Input(description="Random seed for the model", default=42),
|
| 17 |
+
prompt: str = Input(description="Prompt for the model", default="Cinematic still photo of a couple. emotional, harmonious, vignette, 4k epic detailed, shot on kodak, 35mm photo, sharp focus, high budget, cinemascope, moody, epic, gorgeous, film grain, grainy"),
|
| 18 |
+
negative_prompt: str = Input(description="Negative prompt for the model", default="anime, cartoon, graphic, (blur, blurry, bokeh), text, painting, crayon, graphite, abstract, glitch, deformed, mutated, ugly, disfigured"),
|
| 19 |
+
guidance_scale: float = Input(description="Guidance scale for the model", default=3.0, ge=0.0, le=14.0),
|
| 20 |
+
number_of_images: int = Input(description="Number of images to generate", default=1, ge=1, le=4),
|
| 21 |
+
number_of_steps: int = Input(description="Number of steps for the model", default=10, ge=1, le=50),
|
| 22 |
base_image: Path = Input(description="Base image for the model", default=None),
|
| 23 |
+
base_image_strength: float = Input(description="Base image strength for the model", default=0.3, ge=0.0, le=1.0),
|
| 24 |
style_image: Path = Input(description="Style image for the model", default=None),
|
| 25 |
style_image_strength: float = Input(description="Style image strength for the model", default=1.0, ge=0.0, le=1.0),
|
| 26 |
identity_image_1: Path = Input(description="First identity image for the model", default=None),
|
| 27 |
identity_image_strength_1: float = Input(description="First identity image strength for the model", default=1.0, ge=0.0, le=1.0),
|
| 28 |
identity_image_2: Path = Input(description="Second identity image for the model", default=None),
|
| 29 |
identity_image_strength_2: float = Input(description="Second identity image strength for the model", default=1.0, ge=0.0, le=1.0),
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 30 |
depth_image: Path = Input(description="Depth image for the model", default=None),
|
| 31 |
depth_image_strength: float = Input(description="Depth image strength for the model", default=0.2, ge=0.0, le=1.0),
|
| 32 |
mask_guidance_start: float = Input(description="Mask guidance start value", default=0.0, ge=0.0, le=1.0),
|
|
|
|
| 34 |
) -> List[Path]:
|
| 35 |
"""Run a single prediction on the model"""
|
| 36 |
|
| 37 |
+
# base_image = Image.open(base_image) if base_image else None
|
| 38 |
+
# style_image = Image.open(style_image) if style_image else None
|
| 39 |
+
# identity_image_1 = Image.open(identity_image_1) if identity_image_1 else None
|
| 40 |
+
# identity_image_2 = Image.open(identity_image_2) if identity_image_2 else None
|
| 41 |
+
# depth_image = Image.open(depth_image) if depth_image else None
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 42 |
|
| 43 |
images = self.omni_zero.generate(
|
| 44 |
seed=seed,
|