
url
stringlengths 58
61
| repository_url
stringclasses 1
value | labels_url
stringlengths 72
75
| comments_url
stringlengths 67
70
| events_url
stringlengths 65
68
| html_url
stringlengths 46
51
| id
int64 600M
2.05B
| node_id
stringlengths 18
32
| number
int64 2
6.51k
| title
stringlengths 1
290
| user
dict | labels
listlengths 0
4
| state
stringclasses 2
values | locked
bool 1
class | assignee
dict | assignees
listlengths 0
4
| milestone
dict | comments
sequencelengths 0
30
| created_at
unknown | updated_at
unknown | closed_at
unknown | author_association
stringclasses 3
values | active_lock_reason
float64 | draft
float64 0
1
⌀ | pull_request
dict | body
stringlengths 0
228k
⌀ | reactions
dict | timeline_url
stringlengths 67
70
| performed_via_github_app
float64 | state_reason
stringclasses 3
values | is_pull_request
bool 2
classes |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
https://api.github.com/repos/huggingface/datasets/issues/3346 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3346/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3346/comments | https://api.github.com/repos/huggingface/datasets/issues/3346/events | https://github.com/huggingface/datasets/issues/3346 | 1,067,632,365 | I_kwDODunzps4_osbt | 3,346 | Failed to convert `string` with pyarrow for QED since 1.15.0 | {
"avatar_url": "https://avatars.githubusercontent.com/u/4812544?v=4",
"events_url": "https://api.github.com/users/tianjianjiang/events{/privacy}",
"followers_url": "https://api.github.com/users/tianjianjiang/followers",
"following_url": "https://api.github.com/users/tianjianjiang/following{/other_user}",
"gists_url": "https://api.github.com/users/tianjianjiang/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/tianjianjiang",
"id": 4812544,
"login": "tianjianjiang",
"node_id": "MDQ6VXNlcjQ4MTI1NDQ=",
"organizations_url": "https://api.github.com/users/tianjianjiang/orgs",
"received_events_url": "https://api.github.com/users/tianjianjiang/received_events",
"repos_url": "https://api.github.com/users/tianjianjiang/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/tianjianjiang/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/tianjianjiang/subscriptions",
"type": "User",
"url": "https://api.github.com/users/tianjianjiang"
} | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko"
} | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko"
}
] | null | [
"Scratch that, probably the old and incompatible usage of dataset builder from promptsource.",
"Actually, re-opening this issue cause the error persists\r\n\r\n```python\r\n>>> load_dataset(\"qed\")\r\nDownloading and preparing dataset qed/qed (download: 13.43 MiB, generated: 9.70 MiB, post-processed: Unknown size, total: 23.14 MiB) to /home/victor_huggingface_co/.cache/huggingface/datasets/qed/qed/1.0.0/47d8b6f033393aa520a8402d4baf2d6bdc1b2fbde3dc156e595d2ef34caf7d75...\r\n100%|███████████████████████████████████████████████████████████████████████| 2/2 [00:00<00:00, 2228.64it/s]\r\nTraceback (most recent call last): \r\n File \"<stdin>\", line 1, in <module>\r\n File \"/home/victor_huggingface_co/miniconda3/envs/promptsource/lib/python3.7/site-packages/datasets/load.py\", line 1669, in load_dataset\r\n use_auth_token=use_auth_token,\r\n File \"/home/victor_huggingface_co/miniconda3/envs/promptsource/lib/python3.7/site-packages/datasets/builder.py\", line 594, in download_and_prepare\r\n dl_manager=dl_manager, verify_infos=verify_infos, **download_and_prepare_kwargs\r\n File \"/home/victor_huggingface_co/miniconda3/envs/promptsource/lib/python3.7/site-packages/datasets/builder.py\", line 681, in _download_and_prepare\r\n self._prepare_split(split_generator, **prepare_split_kwargs)\r\n File \"/home/victor_huggingface_co/miniconda3/envs/promptsource/lib/python3.7/site-packages/datasets/builder.py\", line 1083, in _prepare_split\r\n num_examples, num_bytes = writer.finalize()\r\n File \"/home/victor_huggingface_co/miniconda3/envs/promptsource/lib/python3.7/site-packages/datasets/arrow_writer.py\", line 468, in finalize\r\n self.write_examples_on_file()\r\n File \"/home/victor_huggingface_co/miniconda3/envs/promptsource/lib/python3.7/site-packages/datasets/arrow_writer.py\", line 339, in write_examples_on_file\r\n pa_array = pa.array(typed_sequence)\r\n File \"pyarrow/array.pxi\", line 229, in pyarrow.lib.array\r\n File \"pyarrow/array.pxi\", line 110, in pyarrow.lib._handle_arrow_array_protocol\r\n File \"/home/victor_huggingface_co/miniconda3/envs/promptsource/lib/python3.7/site-packages/datasets/arrow_writer.py\", line 125, in __arrow_array__\r\n out = pa.array(cast_to_python_objects(self.data, only_1d_for_numpy=True), type=type)\r\n File \"pyarrow/array.pxi\", line 315, in pyarrow.lib.array\r\n File \"pyarrow/array.pxi\", line 39, in pyarrow.lib._sequence_to_array\r\n File \"pyarrow/error.pxi\", line 143, in pyarrow.lib.pyarrow_internal_check_status\r\n File \"pyarrow/error.pxi\", line 99, in pyarrow.lib.check_status\r\npyarrow.lib.ArrowInvalid: Could not convert 'in' with type str: tried to convert to boolean\r\n```\r\n\r\nEnvironment (datasets and pyarrow):\r\n\r\n```bash\r\n(promptsource) victor_huggingface_co@victor-dev:~/promptsource$ datasets-cli env\r\n\r\nCopy-and-paste the text below in your GitHub issue.\r\n\r\n- `datasets` version: 1.16.1\r\n- Platform: Linux-5.0.0-1020-gcp-x86_64-with-debian-buster-sid\r\n- Python version: 3.7.11\r\n- PyArrow version: 6.0.1\r\n```\r\n```bash\r\n(promptsource) victor_huggingface_co@victor-dev:~/promptsource$ pip show pyarrow\r\nName: pyarrow\r\nVersion: 6.0.1\r\nSummary: Python library for Apache Arrow\r\nHome-page: https://arrow.apache.org/\r\nAuthor: \r\nAuthor-email: \r\nLicense: Apache License, Version 2.0\r\nLocation: /home/victor_huggingface_co/miniconda3/envs/promptsource/lib/python3.7/site-packages\r\nRequires: numpy\r\nRequired-by: streamlit, datasets\r\n```"
] | "2021-11-30T20:11:42Z" | "2021-12-14T14:39:05Z" | "2021-12-14T14:39:05Z" | CONTRIBUTOR | null | null | null | ## Describe the bug
Loading QED was fine until 1.15.0.
related: bigscience-workshop/promptsource#659, bigscience-workshop/promptsource#670
Not sure where the root cause is, but here are some candidates:
- #3158
- #3120
- #3196
- #2891
## Steps to reproduce the bug
```python
load_dataset("qed")
```
## Expected results
Loading completed.
## Actual results
```shell
ArrowInvalid: Could not convert in with type str: tried to convert to boolean
Traceback:
File "/Users/s0s0cr3/Library/Python/3.9/lib/python/site-packages/streamlit/script_runner.py", line 354, in _run_script
exec(code, module.__dict__)
File "/Users/s0s0cr3/Documents/GitHub/promptsource/promptsource/app.py", line 260, in <module>
dataset = get_dataset(dataset_key, str(conf_option.name) if conf_option else None)
File "/Users/s0s0cr3/Library/Python/3.9/lib/python/site-packages/streamlit/caching.py", line 543, in wrapped_func
return get_or_create_cached_value()
File "/Users/s0s0cr3/Library/Python/3.9/lib/python/site-packages/streamlit/caching.py", line 527, in get_or_create_cached_value
return_value = func(*args, **kwargs)
File "/Users/s0s0cr3/Documents/GitHub/promptsource/promptsource/utils.py", line 49, in get_dataset
builder_instance.download_and_prepare()
File "/Users/s0s0cr3/Library/Python/3.9/lib/python/site-packages/datasets/builder.py", line 607, in download_and_prepare
self._download_and_prepare(
File "/Users/s0s0cr3/Library/Python/3.9/lib/python/site-packages/datasets/builder.py", line 697, in _download_and_prepare
self._prepare_split(split_generator, **prepare_split_kwargs)
File "/Users/s0s0cr3/Library/Python/3.9/lib/python/site-packages/datasets/builder.py", line 1106, in _prepare_split
num_examples, num_bytes = writer.finalize()
File "/Users/s0s0cr3/Library/Python/3.9/lib/python/site-packages/datasets/arrow_writer.py", line 456, in finalize
self.write_examples_on_file()
File "/Users/s0s0cr3/Library/Python/3.9/lib/python/site-packages/datasets/arrow_writer.py", line 325, in write_examples_on_file
pa_array = pa.array(typed_sequence)
File "pyarrow/array.pxi", line 222, in pyarrow.lib.array
File "pyarrow/array.pxi", line 110, in pyarrow.lib._handle_arrow_array_protocol
File "/Users/s0s0cr3/Library/Python/3.9/lib/python/site-packages/datasets/arrow_writer.py", line 121, in __arrow_array__
out = pa.array(cast_to_python_objects(self.data, only_1d_for_numpy=True), type=type)
File "pyarrow/array.pxi", line 305, in pyarrow.lib.array
File "pyarrow/array.pxi", line 39, in pyarrow.lib._sequence_to_array
File "pyarrow/error.pxi", line 122, in pyarrow.lib.pyarrow_internal_check_status
File "pyarrow/error.pxi", line 84, in pyarrow.lib.check_status
```
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.15.0, 1.16.1
- Platform: macOS 1.15.7 or above
- Python version: 3.7.12 and 3.9
- PyArrow version: 3.0.0, 5.0.0, 6.0.1
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3346/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3346/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/1408 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1408/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1408/comments | https://api.github.com/repos/huggingface/datasets/issues/1408/events | https://github.com/huggingface/datasets/pull/1408 | 760,590,589 | MDExOlB1bGxSZXF1ZXN0NTM1Mzk3MTAw | 1,408 | adding fake-news-english | {
"avatar_url": "https://avatars.githubusercontent.com/u/15351802?v=4",
"events_url": "https://api.github.com/users/MisbahKhan789/events{/privacy}",
"followers_url": "https://api.github.com/users/MisbahKhan789/followers",
"following_url": "https://api.github.com/users/MisbahKhan789/following{/other_user}",
"gists_url": "https://api.github.com/users/MisbahKhan789/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/MisbahKhan789",
"id": 15351802,
"login": "MisbahKhan789",
"node_id": "MDQ6VXNlcjE1MzUxODAy",
"organizations_url": "https://api.github.com/users/MisbahKhan789/orgs",
"received_events_url": "https://api.github.com/users/MisbahKhan789/received_events",
"repos_url": "https://api.github.com/users/MisbahKhan789/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/MisbahKhan789/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/MisbahKhan789/subscriptions",
"type": "User",
"url": "https://api.github.com/users/MisbahKhan789"
} | [] | closed | false | null | [] | null | [
"also don't forget to format your code using `make style` to fix the CI"
] | "2020-12-09T19:02:07Z" | "2020-12-13T00:49:19Z" | "2020-12-13T00:49:19Z" | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/1408.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1408",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/1408.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1408"
} | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1408/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1408/timeline | null | null | true |
|
https://api.github.com/repos/huggingface/datasets/issues/6136 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6136/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6136/comments | https://api.github.com/repos/huggingface/datasets/issues/6136/events | https://github.com/huggingface/datasets/issues/6136 | 1,844,887,866 | I_kwDODunzps5t9sE6 | 6,136 | CI check_code_quality error: E721 Do not compare types, use `isinstance()` | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
} | [
{
"color": "d4c5f9",
"default": false,
"description": "Maintenance tasks",
"id": 4296013012,
"name": "maintenance",
"node_id": "LA_kwDODunzps8AAAABAA_01A",
"url": "https://api.github.com/repos/huggingface/datasets/labels/maintenance"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
} | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
}
] | null | [] | "2023-08-10T10:19:50Z" | "2023-08-10T11:22:58Z" | "2023-08-10T11:22:58Z" | MEMBER | null | null | null | After latest release of `ruff` (https://pypi.org/project/ruff/0.0.284/), we get the following CI error:
```
src/datasets/utils/py_utils.py:689:12: E721 Do not compare types, use `isinstance()`
``` | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6136/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6136/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/1491 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1491/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1491/comments | https://api.github.com/repos/huggingface/datasets/issues/1491/events | https://github.com/huggingface/datasets/pull/1491 | 762,920,920 | MDExOlB1bGxSZXF1ZXN0NTM3NDIxMTc3 | 1,491 | added opus GNOME data | {
"avatar_url": "https://avatars.githubusercontent.com/u/22396042?v=4",
"events_url": "https://api.github.com/users/rkc007/events{/privacy}",
"followers_url": "https://api.github.com/users/rkc007/followers",
"following_url": "https://api.github.com/users/rkc007/following{/other_user}",
"gists_url": "https://api.github.com/users/rkc007/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/rkc007",
"id": 22396042,
"login": "rkc007",
"node_id": "MDQ6VXNlcjIyMzk2MDQy",
"organizations_url": "https://api.github.com/users/rkc007/orgs",
"received_events_url": "https://api.github.com/users/rkc007/received_events",
"repos_url": "https://api.github.com/users/rkc007/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/rkc007/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/rkc007/subscriptions",
"type": "User",
"url": "https://api.github.com/users/rkc007"
} | [] | closed | false | null | [] | null | [
"merging since the Ci is fixed on master"
] | "2020-12-11T21:21:51Z" | "2020-12-17T14:20:23Z" | "2020-12-17T14:20:23Z" | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/1491.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1491",
"merged_at": "2020-12-17T14:20:23Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1491.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1491"
} | Dataset : http://opus.nlpl.eu/GNOME.php | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1491/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1491/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/707 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/707/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/707/comments | https://api.github.com/repos/huggingface/datasets/issues/707/events | https://github.com/huggingface/datasets/issues/707 | 713,954,666 | MDU6SXNzdWU3MTM5NTQ2NjY= | 707 | Requirements should specify pyarrow<1 | {
"avatar_url": "https://avatars.githubusercontent.com/u/918541?v=4",
"events_url": "https://api.github.com/users/mathcass/events{/privacy}",
"followers_url": "https://api.github.com/users/mathcass/followers",
"following_url": "https://api.github.com/users/mathcass/following{/other_user}",
"gists_url": "https://api.github.com/users/mathcass/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mathcass",
"id": 918541,
"login": "mathcass",
"node_id": "MDQ6VXNlcjkxODU0MQ==",
"organizations_url": "https://api.github.com/users/mathcass/orgs",
"received_events_url": "https://api.github.com/users/mathcass/received_events",
"repos_url": "https://api.github.com/users/mathcass/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mathcass/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mathcass/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mathcass"
} | [] | closed | false | null | [] | null | [
"Hello @mathcass I would want to work on this issue. May I do the same? ",
"@punitaojha, certainly. Feel free to work on this. Let me know if you need any help or clarity.",
"Hello @mathcass \r\n1. I did fork the repository and clone the same on my local system. \r\n\r\n2. Then learnt about how we can publish our package on pypi.org. Also, found some instructions on same in setup.py documentation.\r\n\r\n3. Then I Perplexity document link that you shared above. I created a colab link from there keep both tensorflow and pytorch means a mixed option and tried to run it in colab but I encountered no errors at a point where you mentioned. Can you help me to figure out the issue. \r\n\r\n4.Here is the link of the colab file with my saved responses. \r\nhttps://colab.research.google.com/drive/1hfYz8Ira39FnREbxgwa_goZWpOojp2NH?usp=sharing",
"Also, please share some links which made you conclude that pyarrow < 1 would help. ",
"Access granted for the colab link. ",
"Thanks for looking at this @punitaojha and thanks for sharing the notebook. \r\n\r\nI just tried to reproduce this on my own (based on the environment where I had this issue) and I can't reproduce it somehow. If I run into this again, I'll include some steps to reproduce it. I'll close this as invalid. \r\n\r\nThanks again. ",
"I am sorry for hijacking this closed issue, but I believe I was able to reproduce this very issue. Strangely enough, it also turned out that running `pip install \"pyarrow<1\" --upgrade` did indeed fix the issue (PyArrow was installed in version `0.14.1` in my case).\r\n\r\nPlease see the Colab below:\r\n\r\nhttps://colab.research.google.com/drive/15QQS3xWjlKW2aK0J74eEcRFuhXUddUST\r\n\r\nThanks!"
] | "2020-10-02T23:39:39Z" | "2020-12-04T08:22:39Z" | "2020-10-04T20:50:28Z" | NONE | null | null | null | I was looking at the docs on [Perplexity](https://huggingface.co/transformers/perplexity.html) via GPT2. When you load datasets and try to load Wikitext, you get the error,
```
module 'pyarrow' has no attribute 'PyExtensionType'
```
I traced it back to datasets having installed PyArrow 1.0.1 but there's not pinning in the setup file.
https://github.com/huggingface/datasets/blob/e86a2a8f869b91654e782c9133d810bb82783200/setup.py#L68
Downgrading by installing `pip install "pyarrow<1"` resolved the issue. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/707/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/707/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/1395 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1395/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1395/comments | https://api.github.com/repos/huggingface/datasets/issues/1395/events | https://github.com/huggingface/datasets/pull/1395 | 760,448,255 | MDExOlB1bGxSZXF1ZXN0NTM1Mjc4MTQ2 | 1,395 | Add WikiSource Dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/1183441?v=4",
"events_url": "https://api.github.com/users/abhishekkrthakur/events{/privacy}",
"followers_url": "https://api.github.com/users/abhishekkrthakur/followers",
"following_url": "https://api.github.com/users/abhishekkrthakur/following{/other_user}",
"gists_url": "https://api.github.com/users/abhishekkrthakur/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/abhishekkrthakur",
"id": 1183441,
"login": "abhishekkrthakur",
"node_id": "MDQ6VXNlcjExODM0NDE=",
"organizations_url": "https://api.github.com/users/abhishekkrthakur/orgs",
"received_events_url": "https://api.github.com/users/abhishekkrthakur/received_events",
"repos_url": "https://api.github.com/users/abhishekkrthakur/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/abhishekkrthakur/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/abhishekkrthakur/subscriptions",
"type": "User",
"url": "https://api.github.com/users/abhishekkrthakur"
} | [] | closed | false | null | [] | null | [
"@lhoestq fixed :) "
] | "2020-12-09T15:52:06Z" | "2020-12-14T10:24:14Z" | "2020-12-14T10:24:13Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/1395.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1395",
"merged_at": "2020-12-14T10:24:13Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1395.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1395"
} | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1395/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1395/timeline | null | null | true |
|
https://api.github.com/repos/huggingface/datasets/issues/3725 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3725/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3725/comments | https://api.github.com/repos/huggingface/datasets/issues/3725/events | https://github.com/huggingface/datasets/pull/3725 | 1,138,835,625 | PR_kwDODunzps4y3bOG | 3,725 | Pin pandas to avoid bug in streaming mode | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
} | [] | closed | false | null | [] | null | [] | "2022-02-15T15:21:00Z" | "2022-02-15T15:52:38Z" | "2022-02-15T15:52:37Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/3725.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3725",
"merged_at": "2022-02-15T15:52:37Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3725.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3725"
} | Temporarily pin pandas version to avoid bug in streaming mode (patching no longer works).
Related to #3724. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3725/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3725/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4405 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4405/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4405/comments | https://api.github.com/repos/huggingface/datasets/issues/4405/events | https://github.com/huggingface/datasets/issues/4405 | 1,248,574,087 | I_kwDODunzps5Ka7qH | 4,405 | [TypeError: Couldn't cast array of type] Cannot process dataset in v2.2.2 | {
"avatar_url": "https://avatars.githubusercontent.com/u/39762734?v=4",
"events_url": "https://api.github.com/users/jiangwangyi/events{/privacy}",
"followers_url": "https://api.github.com/users/jiangwangyi/followers",
"following_url": "https://api.github.com/users/jiangwangyi/following{/other_user}",
"gists_url": "https://api.github.com/users/jiangwangyi/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/jiangwangyi",
"id": 39762734,
"login": "jiangwangyi",
"node_id": "MDQ6VXNlcjM5NzYyNzM0",
"organizations_url": "https://api.github.com/users/jiangwangyi/orgs",
"received_events_url": "https://api.github.com/users/jiangwangyi/received_events",
"repos_url": "https://api.github.com/users/jiangwangyi/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/jiangwangyi/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jiangwangyi/subscriptions",
"type": "User",
"url": "https://api.github.com/users/jiangwangyi"
} | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | [] | null | [
"And if the problem is that the way I am to construct the {Entity Type: list of spans} makes entity types without any spans hard to handle, is there a better way to meet the demand? Although I have verified that to make entity types without any spans to behave like `entity_chunk[label] = [[\"\"]]` can perform normally, I still wonder if there is a more elegant way?"
] | "2022-05-25T18:56:43Z" | "2022-06-07T14:27:20Z" | "2022-06-07T14:27:20Z" | NONE | null | null | null | ## Describe the bug
I am trying to process the [conll2012_ontonotesv5](https://huggingface.co/datasets/conll2012_ontonotesv5) dataset in `datasets` v2.2.2 and am running into a type error when casting the features.
## Steps to reproduce the bug
```python
import os
from typing import (
List,
Dict,
)
from collections import (
defaultdict,
)
from dataclasses import (
dataclass,
)
from datasets import (
load_dataset,
)
@dataclass
class ConllConverter:
path: str
name: str
cache_dir: str
def __post_init__(
self,
):
self.dataset = load_dataset(
path=self.path,
name=self.name,
cache_dir=self.cache_dir,
)
def convert(
self,
):
class_label = self.dataset["train"].features["sentences"][0]["named_entities"].feature
# label_set = list(set([
# label.split("-")[1] if label != "O" else label for label in class_label.names
# ]))
def prepare_chunk(token, entity):
assert len(token) == len(entity)
# Sequence length
length = len(token)
# Variable used
entity_chunk = defaultdict(list)
idx = flag = 0
# While loop
while idx < length:
if entity[idx] == "O":
flag += 1
idx += 1
else:
iob_tp, lab_tp = entity[idx].split("-")
assert iob_tp == "B"
idx += 1
while idx < length and entity[idx].startswith("I-"):
idx += 1
entity_chunk[lab_tp].append(token[flag: idx])
flag = idx
entity_chunk = dict(entity_chunk)
# for label in label_set:
# if label != "O" and label not in entity_chunk.keys():
# entity_chunk[label] = None
return entity_chunk
def prepare_features(
batch: Dict[str, List],
) -> Dict[str, List]:
sentence = [
sent for doc_sent in batch["sentences"] for sent in doc_sent
]
feature = {
"sentence": list(),
}
for sent in sentence:
token = sent["words"]
entity = class_label.int2str(sent["named_entities"])
entity_chunk = prepare_chunk(token, entity)
sent_feat = {
"token": token,
"entity": entity,
"entity_chunk": entity_chunk,
}
feature["sentence"].append(sent_feat)
return feature
column_names = self.dataset.column_names["train"]
dataset = self.dataset.map(
function=prepare_features,
with_indices=False,
batched=True,
batch_size=3,
remove_columns=column_names,
num_proc=1,
)
dataset.save_to_disk(
dataset_dict_path=os.path.join("data", self.path, self.name)
)
if __name__ == "__main__":
converter = ConllConverter(
path="conll2012_ontonotesv5",
name="english_v4",
cache_dir="cache",
)
converter.convert()
```
## Expected results
I want to use the dataset to perform NER task and to change the label list into a {Entity Type: list of spans} format.
## Actual results
<details>
<summary>Traceback</summary>
```python
Traceback (most recent call last): | 0/81 [00:00<?, ?ba/s]
File "/home2/jiangwangyi/miniconda3/lib/python3.9/site-packages/multiprocess/pool.py", line 125, in worker
result = (True, func(*args, **kwds))
File "/home2/jiangwangyi/miniconda3/lib/python3.9/site-packages/datasets/arrow_dataset.py", line 532, in wrapper
out: Union["Dataset", "DatasetDict"] = func(self, *args, **kwargs)
File "/home2/jiangwangyi/miniconda3/lib/python3.9/site-packages/datasets/arrow_dataset.py", line 499, in wrapper
out: Union["Dataset", "DatasetDict"] = func(self, *args, **kwargs)
File "/home2/jiangwangyi/miniconda3/lib/python3.9/site-packages/datasets/fingerprint.py", line 458, in wrapper
out = func(self, *args, **kwargs)
File "/home2/jiangwangyi/miniconda3/lib/python3.9/site-packages/datasets/arrow_dataset.py", line 2751, in _map_single
writer.write_batch(batch)
File "/home2/jiangwangyi/miniconda3/lib/python3.9/site-packages/datasets/arrow_writer.py", line 503, in write_batch
arrays.append(pa.array(typed_sequence))
File "pyarrow/array.pxi", line 230, in pyarrow.lib.array
File "pyarrow/array.pxi", line 110, in pyarrow.lib._handle_arrow_array_protocol
File "/home2/jiangwangyi/miniconda3/lib/python3.9/site-packages/datasets/arrow_writer.py", line 198, in __arrow_array__
out = cast_array_to_feature(out, type, allow_number_to_str=not self.trying_type)
File "/home2/jiangwangyi/miniconda3/lib/python3.9/site-packages/datasets/table.py", line 1675, in wrapper
return func(array, *args, **kwargs)
File "/home2/jiangwangyi/miniconda3/lib/python3.9/site-packages/datasets/table.py", line 1793, in cast_array_to_feature
arrays = [_c(array.field(name), subfeature) for name, subfeature in feature.items()]
File "/home2/jiangwangyi/miniconda3/lib/python3.9/site-packages/datasets/table.py", line 1793, in <listcomp>
arrays = [_c(array.field(name), subfeature) for name, subfeature in feature.items()]
File "/home2/jiangwangyi/miniconda3/lib/python3.9/site-packages/datasets/table.py", line 1675, in wrapper
return func(array, *args, **kwargs)
File "/home2/jiangwangyi/miniconda3/lib/python3.9/site-packages/datasets/table.py", line 1844, in cast_array_to_feature
raise TypeError(f"Couldn't cast array of type\n{array.type}\nto\n{feature}")
TypeError: Couldn't cast array of type
struct<CARDINAL: list<item: list<item: string>>, DATE: list<item: list<item: string>>, EVENT: list<item: list<item: string>>, FAC: list<item: list<item: string>>, GPE: list<item: list<item: string>>, LANGUAGE: list<item: list<item: string>>, LAW: list<item: list<item: string>>, LOC: list<item: list<item: string>>, MONEY: list<item: list<item: string>>, NORP: list<item: list<item: string>>, ORDINAL: list<item: list<item: string>>, ORG: list<item: list<item: string>>, PERCENT: list<item: list<item: string>>, PERSON: list<item: list<item: string>>, QUANTITY: list<item: list<item: string>>, TIME: list<item: list<item: string>>, WORK_OF_ART: list<item: list<item: string>>>
to
{'CARDINAL': Sequence(feature=Sequence(feature=Value(dtype='string', id=None), length=-1, id=None), length=-1, id=None), 'DATE': Sequence(feature=Sequence(feature=Value(dtype='string', id=None), length=-1, id=None), length=-1, id=None), 'EVENT': Sequence(feature=Sequence(feature=Value(dtype='string', id=None), length=-1, id=None), length=-1, id=None), 'FAC': Sequence(feature=Sequence(feature=Value(dtype='string', id=None), length=-1, id=None), length=-1, id=None), 'GPE': Sequence(feature=Sequence(feature=Value(dtype='string', id=None), length=-1, id=None), length=-1, id=None), 'LAW': Sequence(feature=Sequence(feature=Value(dtype='string', id=None), length=-1, id=None), length=-1, id=None), 'LOC': Sequence(feature=Sequence(feature=Value(dtype='string', id=None), length=-1, id=None), length=-1, id=None), 'MONEY': Sequence(feature=Sequence(feature=Value(dtype='string', id=None), length=-1, id=None), length=-1, id=None), 'NORP': Sequence(feature=Sequence(feature=Value(dtype='string', id=None), length=-1, id=None), length=-1, id=None), 'ORDINAL': Sequence(feature=Sequence(feature=Value(dtype='string', id=None), length=-1, id=None), length=-1, id=None), 'ORG': Sequence(feature=Sequence(feature=Value(dtype='string', id=None), length=-1, id=None), length=-1, id=None), 'PERCENT': Sequence(feature=Sequence(feature=Value(dtype='string', id=None), length=-1, id=None), length=-1, id=None), 'PERSON': Sequence(feature=Sequence(feature=Value(dtype='string', id=None), length=-1, id=None), length=-1, id=None), 'PRODUCT': Sequence(feature=Sequence(feature=Value(dtype='string', id=None), length=-1, id=None), length=-1, id=None), 'QUANTITY': Sequence(feature=Sequence(feature=Value(dtype='string', id=None), length=-1, id=None), length=-1, id=None), 'TIME': Sequence(feature=Sequence(feature=Value(dtype='string', id=None), length=-1, id=None), length=-1, id=None), 'WORK_OF_ART': Sequence(feature=Sequence(feature=Value(dtype='string', id=None), length=-1, id=None), length=-1, id=None)}
"""
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "/home2/jiangwangyi/workspace/work/Entity/dataconverter.py", line 110, in <module>
converter.convert()
File "/home2/jiangwangyi/workspace/work/Entity/dataconverter.py", line 91, in convert
dataset = self.dataset.map(
File "/home2/jiangwangyi/miniconda3/lib/python3.9/site-packages/datasets/dataset_dict.py", line 770, in map
{
File "/home2/jiangwangyi/miniconda3/lib/python3.9/site-packages/datasets/dataset_dict.py", line 771, in <dictcomp>
k: dataset.map(
File "/home2/jiangwangyi/miniconda3/lib/python3.9/site-packages/datasets/arrow_dataset.py", line 2459, in map
transformed_shards[index] = async_result.get()
File "/home2/jiangwangyi/miniconda3/lib/python3.9/site-packages/multiprocess/pool.py", line 771, in get
raise self._value
TypeError: Couldn't cast array of type
struct<CARDINAL: list<item: list<item: string>>, DATE: list<item: list<item: string>>, EVENT: list<item: list<item: string>>, FAC: list<item: list<item: string>>, GPE: list<item: list<item: string>>, LANGUAGE: list<item: list<item: string>>, LAW: list<item: list<item: string>>, LOC: list<item: list<item: string>>, MONEY: list<item: list<item: string>>, NORP: list<item: list<item: string>>, ORDINAL: list<item: list<item: string>>, ORG: list<item: list<item: string>>, PERCENT: list<item: list<item: string>>, PERSON: list<item: list<item: string>>, QUANTITY: list<item: list<item: string>>, TIME: list<item: list<item: string>>, WORK_OF_ART: list<item: list<item: string>>>
to
{'CARDINAL': Sequence(feature=Sequence(feature=Value(dtype='string', id=None), length=-1, id=None), length=-1, id=None), 'DATE': Sequence(feature=Sequence(feature=Value(dtype='string', id=None), length=-1, id=None), length=-1, id=None), 'EVENT': Sequence(feature=Sequence(feature=Value(dtype='string', id=None), length=-1, id=None), length=-1, id=None), 'FAC': Sequence(feature=Sequence(feature=Value(dtype='string', id=None), length=-1, id=None), length=-1, id=None), 'GPE': Sequence(feature=Sequence(feature=Value(dtype='string', id=None), length=-1, id=None), length=-1, id=None), 'LAW': Sequence(feature=Sequence(feature=Value(dtype='string', id=None), length=-1, id=None), length=-1, id=None), 'LOC': Sequence(feature=Sequence(feature=Value(dtype='string', id=None), length=-1, id=None), length=-1, id=None), 'MONEY': Sequence(feature=Sequence(feature=Value(dtype='string', id=None), length=-1, id=None), length=-1, id=None), 'NORP': Sequence(feature=Sequence(feature=Value(dtype='string', id=None), length=-1, id=None), length=-1, id=None), 'ORDINAL': Sequence(feature=Sequence(feature=Value(dtype='string', id=None), length=-1, id=None), length=-1, id=None), 'ORG': Sequence(feature=Sequence(feature=Value(dtype='string', id=None), length=-1, id=None), length=-1, id=None), 'PERCENT': Sequence(feature=Sequence(feature=Value(dtype='string', id=None), length=-1, id=None), length=-1, id=None), 'PERSON': Sequence(feature=Sequence(feature=Value(dtype='string', id=None), length=-1, id=None), length=-1, id=None), 'PRODUCT': Sequence(feature=Sequence(feature=Value(dtype='string', id=None), length=-1, id=None), length=-1, id=None), 'QUANTITY': Sequence(feature=Sequence(feature=Value(dtype='string', id=None), length=-1, id=None), length=-1, id=None), 'TIME': Sequence(feature=Sequence(feature=Value(dtype='string', id=None), length=-1, id=None), length=-1, id=None), 'WORK_OF_ART': Sequence(feature=Sequence(feature=Value(dtype='string', id=None), length=-1, id=None), length=-1, id=None)}
```
</details>
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 2.2.2
- Platform: Ubuntu 18.04
- Python version: 3.9.7
- PyArrow version: 7.0.0
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4405/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4405/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/3952 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3952/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3952/comments | https://api.github.com/repos/huggingface/datasets/issues/3952/events | https://github.com/huggingface/datasets/issues/3952 | 1,171,895,531 | I_kwDODunzps5F2bTr | 3,952 | Checksum error for glue sst2, stsb, rte etc datasets | {
"avatar_url": "https://avatars.githubusercontent.com/u/22090962?v=4",
"events_url": "https://api.github.com/users/ravindra-ut/events{/privacy}",
"followers_url": "https://api.github.com/users/ravindra-ut/followers",
"following_url": "https://api.github.com/users/ravindra-ut/following{/other_user}",
"gists_url": "https://api.github.com/users/ravindra-ut/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/ravindra-ut",
"id": 22090962,
"login": "ravindra-ut",
"node_id": "MDQ6VXNlcjIyMDkwOTYy",
"organizations_url": "https://api.github.com/users/ravindra-ut/orgs",
"received_events_url": "https://api.github.com/users/ravindra-ut/received_events",
"repos_url": "https://api.github.com/users/ravindra-ut/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/ravindra-ut/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ravindra-ut/subscriptions",
"type": "User",
"url": "https://api.github.com/users/ravindra-ut"
} | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | [] | null | [
"Hi, @ravindra-ut.\r\n\r\nI'm sorry but I can't reproduce your problem:\r\n```python\r\nIn [1]: from datasets import load_dataset\r\n\r\nIn [2]: ds = load_dataset(\"glue\", \"sst2\")\r\nDownloading builder script: 28.8kB [00:00, 11.6MB/s] \r\nDownloading metadata: 28.7kB [00:00, 12.9MB/s] \r\nDownloading and preparing dataset glue/sst2 (download: 7.09 MiB, generated: 4.81 MiB, post-processed: Unknown size, total: 11.90 MiB) to .../.cache/huggingface/datasets/glue/sst2/1.0.0/dacbe3125aa31d7f70367a07a8a9e72a5a0bfeb5fc42e75c9db75b96da6053ad...\r\nDownloading data: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 7.44M/7.44M [00:01<00:00, 5.82MB/s]\r\nDataset glue downloaded and prepared to .../.cache/huggingface/datasets/glue/sst2/1.0.0/dacbe3125aa31d7f70367a07a8a9e72a5a0bfeb5fc42e75c9db75b96da6053ad. Subsequent calls will reuse this data. \r\n100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 3/3 [00:00<00:00, 895.96it/s]\r\n\r\nIn [3]: ds\r\nOut[2]: \r\nDatasetDict({\r\n train: Dataset({\r\n features: ['sentence', 'label', 'idx'],\r\n num_rows: 67349\r\n })\r\n validation: Dataset({\r\n features: ['sentence', 'label', 'idx'],\r\n num_rows: 872\r\n })\r\n test: Dataset({\r\n features: ['sentence', 'label', 'idx'],\r\n num_rows: 1821\r\n })\r\n})\r\n``` \r\n\r\nMoreover, I see in your traceback that your error was for an URL at https://firebasestorage.googleapis.com\r\nHowever, the URLs were updated on Sep 16, 2020 (`datasets` version 1.0.2) to https://dl.fbaipublicfiles.com: https://github.com/huggingface/datasets/commit/2f03041a21c03abaececb911760c3fe4f420c229\r\n\r\nCould you please try to update `datasets`\r\n```shell\r\npip install -U datasets\r\n```\r\nand then force redownload\r\n```python\r\nds = load_dataset(\"glue\", \"sst2\", download_mode=\"force_redownload\")\r\n```\r\nto update the cache?\r\n\r\nPlease, feel free to reopen this issue if the problem persists."
] | "2022-03-17T03:45:47Z" | "2022-03-17T07:10:15Z" | "2022-03-17T07:10:14Z" | NONE | null | null | null | ## Describe the bug
Checksum error for glue sst2, stsb, rte etc datasets
## Steps to reproduce the bug
```python
>>> nlp.load_dataset('glue', 'sst2')
Downloading and preparing dataset glue/sst2 (download: 7.09 MiB, generated: 4.81 MiB, post-processed: Unknown sizetotal: 11.90 MiB) to
Downloading: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 73.0/73.0 [00:00<00:00, 18.2kB/s]
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/Library/Python/3.8/lib/python/site-packages/nlp/load.py", line 548, in load_dataset
builder_instance.download_and_prepare(
File "/Library/Python/3.8/lib/python/site-packages/nlp/builder.py", line 462, in download_and_prepare
self._download_and_prepare(
File "/Library/Python/3.8/lib/python/site-packages/nlp/builder.py", line 521, in _download_and_prepare
verify_checksums(
File "/Library/Python/3.8/lib/python/site-packages/nlp/utils/info_utils.py", line 38, in verify_checksums
raise NonMatchingChecksumError(error_msg + str(bad_urls))
nlp.utils.info_utils.NonMatchingChecksumError: Checksums didn't match for dataset source files:
['https://firebasestorage.googleapis.com/v0/b/mtl-sentence-representations.appspot.com/o/data%2FSST-2.zip?alt=media&token=aabc5f6b-e466-44a2-b9b4-cf6337f84ac8']
```
## Expected results
dataset load should succeed without checksum error.
## Actual results
```
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/Library/Python/3.8/lib/python/site-packages/nlp/load.py", line 548, in load_dataset
builder_instance.download_and_prepare(
File "/Library/Python/3.8/lib/python/site-packages/nlp/builder.py", line 462, in download_and_prepare
self._download_and_prepare(
File "/Library/Python/3.8/lib/python/site-packages/nlp/builder.py", line 521, in _download_and_prepare
verify_checksums(
File "/Library/Python/3.8/lib/python/site-packages/nlp/utils/info_utils.py", line 38, in verify_checksums
raise NonMatchingChecksumError(error_msg + str(bad_urls))
nlp.utils.info_utils.NonMatchingChecksumError: Checksums didn't match for dataset source files:
['https://firebasestorage.googleapis.com/v0/b/mtl-sentence-representations.appspot.com/o/data%2FSST-2.zip?alt=media&token=aabc5f6b-e466-44a2-b9b4-cf6337f84ac8']
```
## Environment info
- `datasets` version: '1.18.3'
- Platform: Mac OS
- Python version: Python 3.8.9
- PyArrow version: '7.0.0'
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3952/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3952/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5815 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5815/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5815/comments | https://api.github.com/repos/huggingface/datasets/issues/5815/events | https://github.com/huggingface/datasets/issues/5815 | 1,693,701,743 | I_kwDODunzps5k89Zv | 5,815 | Easy way to create a Kaggle dataset from a Huggingface dataset? | {
"avatar_url": "https://avatars.githubusercontent.com/u/5355286?v=4",
"events_url": "https://api.github.com/users/hrbigelow/events{/privacy}",
"followers_url": "https://api.github.com/users/hrbigelow/followers",
"following_url": "https://api.github.com/users/hrbigelow/following{/other_user}",
"gists_url": "https://api.github.com/users/hrbigelow/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/hrbigelow",
"id": 5355286,
"login": "hrbigelow",
"node_id": "MDQ6VXNlcjUzNTUyODY=",
"organizations_url": "https://api.github.com/users/hrbigelow/orgs",
"received_events_url": "https://api.github.com/users/hrbigelow/received_events",
"repos_url": "https://api.github.com/users/hrbigelow/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/hrbigelow/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/hrbigelow/subscriptions",
"type": "User",
"url": "https://api.github.com/users/hrbigelow"
} | [] | open | false | null | [] | null | [
"Hi @hrbigelow , I'm no expert for such a question so I'll ping @lhoestq from the `datasets` library (also this issue could be moved there if someone with permission can do it :) )",
"Hi ! Many datasets are made of several files, and how they are parsed often requires a python script. Because of that, datasets like wmt14 are not available as a single file on HF. Though you can create this file using `datasets`:\r\n\r\n```python\r\nfrom datasets import load_dataset\r\n\r\nds = load_dataset(\"wmt14\", \"de-en\", split=\"train\")\r\n\r\nds.to_json(\"wmt14-train.json\")\r\n# OR to parquet, which is compressed:\r\n# ds.to_parquet(\"wmt14-train.parquet\")\r\n```\r\n\r\nWe are also working on providing parquet exports for all datasets, but wmt14 is not supported yet (we're rolling it out for datasets <1GB first). They're usually available in the `refs/convert/parquet` branch (empty for wmt14):\r\n\r\n<img width=\"267\" alt=\"image\" src=\"https://user-images.githubusercontent.com/42851186/235878909-7339f5a4-be19-4ada-85d8-8a50d23acf35.png\">\r\n",
"also cc @nateraw for visibility on this (and cc @osanseviero too)",
"I've requested support for creating a Kaggle dataset from an imported HF dataset repo on their \"forum\" here: https://www.kaggle.com/discussions/product-feedback/427142 (upvotes appreciated 🙂)"
] | "2023-05-02T21:43:33Z" | "2023-07-26T16:13:31Z" | null | NONE | null | null | null | I'm not sure whether this is more appropriately addressed with HuggingFace or Kaggle. I would like to somehow directly create a Kaggle dataset from a HuggingFace Dataset.
While Kaggle does provide the option to create a dataset from a URI, that URI must point to a single file. For example:
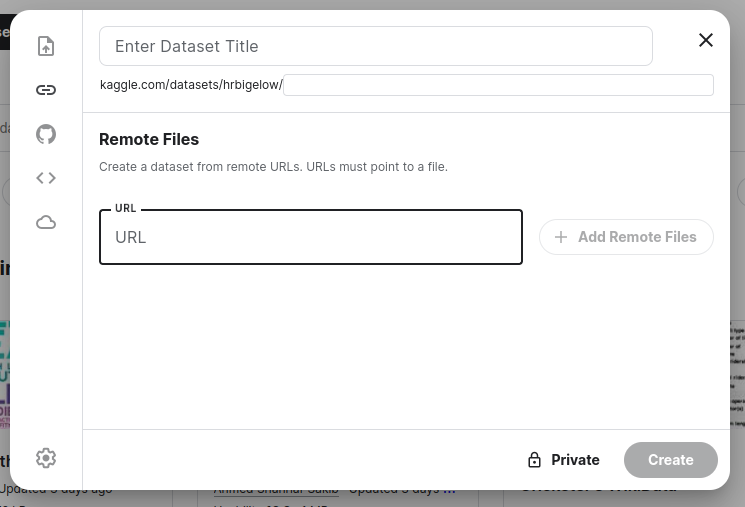
Is there some mechanism from huggingface to represent a dataset (such as that from `load_dataset('wmt14', 'de-en', split='train')` as a single file? Or, some other way to get that into a Kaggle dataset so that I can use the huggingface `datasets` module to process and consume it inside of a Kaggle notebook?
Thanks in advance!
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5815/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5815/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/2115 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2115/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2115/comments | https://api.github.com/repos/huggingface/datasets/issues/2115/events | https://github.com/huggingface/datasets/issues/2115 | 841,283,974 | MDU6SXNzdWU4NDEyODM5NzQ= | 2,115 | The datasets.map() implementation modifies the datatype of os.environ object | {
"avatar_url": "https://avatars.githubusercontent.com/u/19983848?v=4",
"events_url": "https://api.github.com/users/leleamol/events{/privacy}",
"followers_url": "https://api.github.com/users/leleamol/followers",
"following_url": "https://api.github.com/users/leleamol/following{/other_user}",
"gists_url": "https://api.github.com/users/leleamol/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/leleamol",
"id": 19983848,
"login": "leleamol",
"node_id": "MDQ6VXNlcjE5OTgzODQ4",
"organizations_url": "https://api.github.com/users/leleamol/orgs",
"received_events_url": "https://api.github.com/users/leleamol/received_events",
"repos_url": "https://api.github.com/users/leleamol/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/leleamol/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/leleamol/subscriptions",
"type": "User",
"url": "https://api.github.com/users/leleamol"
} | [] | closed | false | null | [] | null | [] | "2021-03-25T20:29:19Z" | "2021-03-26T15:13:52Z" | "2021-03-26T15:13:52Z" | NONE | null | null | null | In our testing, we noticed that the datasets.map() implementation is modifying the datatype of python os.environ object from '_Environ' to 'dict'.
This causes following function calls to fail as follows:
`
x = os.environ.get("TEST_ENV_VARIABLE_AFTER_dataset_map", default=None)
TypeError: get() takes no keyword arguments
`
It looks like the following line in datasets.map implementation introduced this functionality.
https://github.com/huggingface/datasets/blob/0cb1ac06acb0df44a1cf4128d03a01865faa2504/src/datasets/arrow_dataset.py#L1421
Here is the test script to reproduce this error.
```
from datasets import load_dataset
from transformers import AutoTokenizer
import os
def test_train():
model_checkpoint = "distilgpt2"
datasets = load_dataset('wikitext', 'wikitext-2-raw-v1')
tokenizer = AutoTokenizer.from_pretrained(model_checkpoint, use_fast=True)
tokenizer.pad_token = tokenizer.eos_token
def tokenize_function(examples):
y = tokenizer(examples['text'], truncation=True, max_length=64)
return y
x = os.environ.get("TEST_ENV_VARIABLE_BEFORE_dataset_map", default=None)
print(f"Testing environment variable: TEST_ENV_VARIABLE_BEFORE_dataset_map {x}")
print(f"Data type of os.environ before datasets.map = {os.environ.__class__.__name__}")
datasets.map(tokenize_function, batched=True, num_proc=2, remove_columns=["text"])
print(f"Data type of os.environ after datasets.map = {os.environ.__class__.__name__}")
x = os.environ.get("TEST_ENV_VARIABLE_AFTER_dataset_map", default=None)
print(f"Testing environment variable: TEST_ENV_VARIABLE_AFTER_dataset_map {x}")
if __name__ == "__main__":
test_train()
```
| {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2115/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2115/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/652 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/652/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/652/comments | https://api.github.com/repos/huggingface/datasets/issues/652/events | https://github.com/huggingface/datasets/pull/652 | 705,390,850 | MDExOlB1bGxSZXF1ZXN0NDkwMTI3MjIx | 652 | handle connection error in download_prepared_from_hf_gcs | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq"
} | [] | closed | false | null | [] | null | [] | "2020-09-21T08:21:11Z" | "2020-09-21T08:28:43Z" | "2020-09-21T08:28:42Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/652.diff",
"html_url": "https://github.com/huggingface/datasets/pull/652",
"merged_at": "2020-09-21T08:28:42Z",
"patch_url": "https://github.com/huggingface/datasets/pull/652.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/652"
} | Fix #647 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/652/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/652/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5087 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5087/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5087/comments | https://api.github.com/repos/huggingface/datasets/issues/5087/events | https://github.com/huggingface/datasets/pull/5087 | 1,400,487,967 | PR_kwDODunzps5AW-N9 | 5,087 | Fix filter with empty indices | {
"avatar_url": "https://avatars.githubusercontent.com/u/23029765?v=4",
"events_url": "https://api.github.com/users/Mouhanedg56/events{/privacy}",
"followers_url": "https://api.github.com/users/Mouhanedg56/followers",
"following_url": "https://api.github.com/users/Mouhanedg56/following{/other_user}",
"gists_url": "https://api.github.com/users/Mouhanedg56/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/Mouhanedg56",
"id": 23029765,
"login": "Mouhanedg56",
"node_id": "MDQ6VXNlcjIzMDI5NzY1",
"organizations_url": "https://api.github.com/users/Mouhanedg56/orgs",
"received_events_url": "https://api.github.com/users/Mouhanedg56/received_events",
"repos_url": "https://api.github.com/users/Mouhanedg56/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/Mouhanedg56/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Mouhanedg56/subscriptions",
"type": "User",
"url": "https://api.github.com/users/Mouhanedg56"
} | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._"
] | "2022-10-07T01:07:00Z" | "2022-10-07T18:43:03Z" | "2022-10-07T18:40:26Z" | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/5087.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5087",
"merged_at": "2022-10-07T18:40:26Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5087.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5087"
} | Fix #5085 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5087/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5087/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3735 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3735/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3735/comments | https://api.github.com/repos/huggingface/datasets/issues/3735/events | https://github.com/huggingface/datasets/issues/3735 | 1,140,087,891 | I_kwDODunzps5D9FxT | 3,735 | Performance of `datasets` at scale | {
"avatar_url": "https://avatars.githubusercontent.com/u/8264887?v=4",
"events_url": "https://api.github.com/users/lvwerra/events{/privacy}",
"followers_url": "https://api.github.com/users/lvwerra/followers",
"following_url": "https://api.github.com/users/lvwerra/following{/other_user}",
"gists_url": "https://api.github.com/users/lvwerra/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lvwerra",
"id": 8264887,
"login": "lvwerra",
"node_id": "MDQ6VXNlcjgyNjQ4ODc=",
"organizations_url": "https://api.github.com/users/lvwerra/orgs",
"received_events_url": "https://api.github.com/users/lvwerra/received_events",
"repos_url": "https://api.github.com/users/lvwerra/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lvwerra/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lvwerra/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lvwerra"
} | [] | open | false | null | [] | null | [
"> using command line git-lfs - [...] 300MB/s!\r\n\r\nwhich server location did you upload from?",
"From GCP region `us-central1-a`.",
"The most surprising part to me is the saving time. Wondering if it could be due to compression (`ParquetWriter` uses SNAPPY compression by default; it can be turned off with `to_parquet(..., compression=None)`). ",
"+1 to what @mariosasko mentioned. Also, @lvwerra did you parallelize `to_parquet` using similar approach in #2747? (we used multiprocessing at the shard level). I'm working on a similar PR to add multi_proc in `to_parquet` which might give you further speed up. \r\nStas benchmarked his approach and mine in this [gist](https://gist.github.com/stas00/dc1597a1e245c5915cfeefa0eee6902c) for `lama` dataset when we were working on adding multi_proc support for `to_json`.",
"@mariosasko I did not turn it off but I can try the next time - I have to run the pipeline again, anyway. \r\n\r\n@bhavitvyamalik Yes, I also sharded the dataset and used multiprocessing to save each shard. I'll have a closer look at your approach, too."
] | "2022-02-16T14:23:32Z" | "2022-03-15T09:15:29Z" | null | MEMBER | null | null | null | # Performance of `datasets` at 1TB scale
## What is this?
During the processing of a large dataset I monitored the performance of the `datasets` library to see if there are any bottlenecks. The insights of this analysis could guide the decision making to improve the performance of the library.
## Dataset
The dataset is a 1.1TB extract from GitHub with 120M code files and is stored as 5000 `.json.gz` files. The goal of the preprocessing is to remove duplicates and filter files based on their stats. While the calculating of the hashes for deduplication and stats for filtering can be parallelized the filtering itself is run with a single process. After processing the files are pushed to the hub.
## Machine
The experiment was run on a `m1` machine on GCP with 96 CPU cores and 1.3TB RAM.
## Performance breakdown
- Loading the data **3.5h** (_30sec_ from cache)
- **1h57min** single core loading (not sure what is going on here, corresponds to second progress bar)
- **1h10min** multi core json reading
- **20min** remaining time before and after the two main processes mentioned above
- Process the data **2h** (_20min_ from cache)
- **20min** Getting reading for processing
- **40min** Hashing and files stats (96 workers)
- **58min** Deduplication filtering (single worker)
- Save parquet files **5h**
- Saving 1000 parquet files (16 workers)
- Push to hub **37min**
- **34min** git add
- **3min** git push (several hours with `Repository.git_push()`)
## Conclusion
It appears that loading and saving the data is the main bottleneck at that scale (**8.5h**) whereas processing (**2h**) and pushing the data to the hub (**0.5h**) is relatively fast. To optimize the performance at this scale it would make sense to consider such an end-to-end example and target the bottlenecks which seem to be loading from and saving to disk. The processing itself seems to run relatively fast.
## Notes
- map operation on a 1TB dataset with 96 workers requires >1TB RAM
- map operation does not maintain 100% CPU utilization with 96 workers
- sometimes when the script crashes all the data files have a corresponding `*.lock` file in the data folder (or multiple e.g. `*.lock.lock` when it happened a several times). This causes the cache **not** to be triggered (which is significant at that scale) - i guess because there are new data files
- parallelizing `to_parquet` decreased the saving time from 17h to 5h, however adding more workers at this point had almost no effect. not sure if this is:
a) a bug in my parallelization logic,
b) i/o limit to load data form disk to memory or
c) i/o limit to write from memory to disk.
- Using `Repository.git_push()` was much slower than using command line `git-lfs` - 10-20MB/s vs. 300MB/s! The `Dataset.push_to_hub()` function is even slower as it only uploads one file at a time with only a few MB/s, whereas `Repository.git_push()` pushes files in parallel (each at a similar speed).
cc @lhoestq @julien-c @LysandreJik @SBrandeis
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 4,
"heart": 12,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 16,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3735/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3735/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/4019 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4019/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4019/comments | https://api.github.com/repos/huggingface/datasets/issues/4019/events | https://github.com/huggingface/datasets/pull/4019 | 1,180,628,293 | PR_kwDODunzps41AlFk | 4,019 | Make yelp_polarity streamable | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq"
} | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"The CI is failing because of the incomplete dataset card - this is unrelated to the goal of this PR so we can ignore it"
] | "2022-03-25T10:42:51Z" | "2022-03-25T15:02:19Z" | "2022-03-25T14:57:16Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/4019.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4019",
"merged_at": "2022-03-25T14:57:15Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4019.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4019"
} | It was using `dl_manager.download_and_extract` on a TAR archive, which is not supported in streaming mode. I replaced this by `dl_manager.iter_archive` | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4019/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4019/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5315 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5315/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5315/comments | https://api.github.com/repos/huggingface/datasets/issues/5315/events | https://github.com/huggingface/datasets/issues/5315 | 1,470,026,797 | I_kwDODunzps5XntQt | 5,315 | Adding new splits to a dataset script with existing old splits info in metadata's `dataset_info` fails | {
"avatar_url": "https://avatars.githubusercontent.com/u/16348744?v=4",
"events_url": "https://api.github.com/users/polinaeterna/events{/privacy}",
"followers_url": "https://api.github.com/users/polinaeterna/followers",
"following_url": "https://api.github.com/users/polinaeterna/following{/other_user}",
"gists_url": "https://api.github.com/users/polinaeterna/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/polinaeterna",
"id": 16348744,
"login": "polinaeterna",
"node_id": "MDQ6VXNlcjE2MzQ4NzQ0",
"organizations_url": "https://api.github.com/users/polinaeterna/orgs",
"received_events_url": "https://api.github.com/users/polinaeterna/received_events",
"repos_url": "https://api.github.com/users/polinaeterna/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/polinaeterna/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/polinaeterna/subscriptions",
"type": "User",
"url": "https://api.github.com/users/polinaeterna"
} | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | open | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/16348744?v=4",
"events_url": "https://api.github.com/users/polinaeterna/events{/privacy}",
"followers_url": "https://api.github.com/users/polinaeterna/followers",
"following_url": "https://api.github.com/users/polinaeterna/following{/other_user}",
"gists_url": "https://api.github.com/users/polinaeterna/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/polinaeterna",
"id": 16348744,
"login": "polinaeterna",
"node_id": "MDQ6VXNlcjE2MzQ4NzQ0",
"organizations_url": "https://api.github.com/users/polinaeterna/orgs",
"received_events_url": "https://api.github.com/users/polinaeterna/received_events",
"repos_url": "https://api.github.com/users/polinaeterna/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/polinaeterna/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/polinaeterna/subscriptions",
"type": "User",
"url": "https://api.github.com/users/polinaeterna"
} | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/16348744?v=4",
"events_url": "https://api.github.com/users/polinaeterna/events{/privacy}",
"followers_url": "https://api.github.com/users/polinaeterna/followers",
"following_url": "https://api.github.com/users/polinaeterna/following{/other_user}",
"gists_url": "https://api.github.com/users/polinaeterna/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/polinaeterna",
"id": 16348744,
"login": "polinaeterna",
"node_id": "MDQ6VXNlcjE2MzQ4NzQ0",
"organizations_url": "https://api.github.com/users/polinaeterna/orgs",
"received_events_url": "https://api.github.com/users/polinaeterna/received_events",
"repos_url": "https://api.github.com/users/polinaeterna/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/polinaeterna/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/polinaeterna/subscriptions",
"type": "User",
"url": "https://api.github.com/users/polinaeterna"
}
] | null | [
"EDIT:\r\nI think in this case, the metadata files (either README or JSON) should not be read (i.e. `self.info.splits` should be None).\r\n\r\nOne idea: \r\n- I think ideally we should set this behavior when we pass `--save_info` to the CLI `test`\r\n- However, currently, the builder is unaware of this: `save_info` arg is not passed to it",
"> I think in this case\r\n\r\n@albertvillanova You mean in cases when the script was changed? \r\n\r\nI suggest that we:\r\n* add a check on the slice (like 'split_name[n%]) kind of format here: https://github.com/huggingface/datasets/blob/main/src/datasets/splits.py#L523 to catch things like this. \r\n* Error here happens before splits verification, but in `_prepare_split`, and `_prepare_split` doesn't perform any verification and don't know about it. so we can pass this parameter and take splits from `split_generator`, not from `split.info` in case when `verify_infos` is False\r\n* we can check if split **names** from split_generators and self.info.splits are the same **before** preparing splits (if `verify_info=True`) so that we don't spend time on generating unwanted data. \r\n* provide some user-friendly warnings about `ignore_verifications` parameter so that users know that if something is not matching they can ignore it\r\n\r\nI started it here: https://github.com/huggingface/datasets/pull/5327/files\r\n\r\nWhat do you think @albertvillanova ?",
"I edited my previous comment:\r\n- First I proposed setting `self.info.splits` to None when `ignore_verifications=True`\r\n - I thought it was the easiest implementation because `ignore_verifications` is passed to `DatasetBuilder.download_and_prepare`\r\n - However, afterwards, I realized this might not be a good idea for this use case:\r\n - A user wants to optimize the loading of the dataset, and passes `ignore_verifications=False` to avoid all the verifications\r\n - In this case, we want `self.info.splits` to be read from metadata file\r\n- Then, I thought that it might be better to set `self.info.splits` to None when we pass `--save_info` to the CLI test: if we are going to save the info to the metadata file, it makes no sense to read the info from the metadata file\r\n - This implementation is not so easy because the Builder knows nothing about `--save_info`\r\n\r\nI agree with you there are 2 things to be addressed here:\r\n- One is what I have just commented: `self.info.splits` should be None in this case\r\n- The other, a validation should be implemented when calling `make_file_instructions` and/or `SplitDict.__getitem__`, so that when passing \"training\" to it, we get a more descriptive error other than `TypeError: expected str, bytes or os.PathLike object, not NoneType` "
] | "2022-11-30T18:02:15Z" | "2022-12-02T07:02:53Z" | null | CONTRIBUTOR | null | null | null | ### Describe the bug
If you first create a custom dataset with a specific set of splits, generate metadata with `datasets-cli test ... --save_info`, then change your script to include more splits, it fails.
That's what happened in https://huggingface.co/datasets/mrdbourke/food_vision_199_classes/discussions/2#6385fd1269634850f8ddff48.
### Steps to reproduce the bug
1. create a dataset with a custom split that returns, for example, only `"train"` split in `_splits_generators'`. specifically, if really want to reproduce, copy `https://huggingface.co/datasets/mrdbourke/food_vision_199_classes/blob/main/food_vision_199_classes.py
2. run `datasets-cli test dataset_script.py --save_info --all_configs` - this would generate metadata yaml in `README.md` that would contain info about splits, for example, like this:
```
splits:
- name: train
num_bytes: 2973286
num_examples: 19747
```
3. make changes to your script so that it returns another set of splits, for example, `"train"` and `"test"` (uncomment [these lines](https://huggingface.co/datasets/mrdbourke/food_vision_199_classes/blob/main/food_vision_199_classes.py#L271))
4. run `load_dataset` and get the following error:
```python
Traceback (most recent call last):
File "/home/daniel/code/pytorch/env/bin/datasets-cli", line 8, in <module>
sys.exit(main())
File "/home/daniel/code/pytorch/env/lib/python3.8/site-packages/datasets/commands/datasets_cli.py", line 39, in main
service.run()
File "/home/daniel/code/pytorch/env/lib/python3.8/site-packages/datasets/commands/test.py", line 141, in run
builder.download_and_prepare(
File "/home/daniel/code/pytorch/env/lib/python3.8/site-packages/datasets/builder.py", line 822, in download_and_prepare
self._download_and_prepare(
File "/home/daniel/code/pytorch/env/lib/python3.8/site-packages/datasets/builder.py", line 1555, in _download_and_prepare
super()._download_and_prepare(
File "/home/daniel/code/pytorch/env/lib/python3.8/site-packages/datasets/builder.py", line 913, in _download_and_prepare
self._prepare_split(split_generator, **prepare_split_kwargs)
File "/home/daniel/code/pytorch/env/lib/python3.8/site-packages/datasets/builder.py", line 1356, in _prepare_split
split_info = self.info.splits[split_generator.name]
File "/home/daniel/code/pytorch/env/lib/python3.8/site-packages/datasets/splits.py", line 525, in __getitem__
instructions = make_file_instructions(
File "/home/daniel/code/pytorch/env/lib/python3.8/site-packages/datasets/arrow_reader.py", line 111, in make_file_instructions
name2filenames = {
File "/home/daniel/code/pytorch/env/lib/python3.8/site-packages/datasets/arrow_reader.py", line 112, in <dictcomp>
info.name: filenames_for_dataset_split(
File "/home/daniel/code/pytorch/env/lib/python3.8/site-packages/datasets/naming.py", line 78, in filenames_for_dataset_split
prefix = filename_prefix_for_split(dataset_name, split)
File "/home/daniel/code/pytorch/env/lib/python3.8/site-packages/datasets/naming.py", line 57, in filename_prefix_for_split
if os.path.basename(name) != name:
File "/home/daniel/code/pytorch/env/lib/python3.8/posixpath.py", line 143, in basename
p = os.fspath(p)
TypeError: expected str, bytes or os.PathLike object, not NoneType
```
5. bonus: try to regenerate metadata in `README.md` with `datasets-cli` as in step 2 and get the same error.
This is because `dataset.info.splits` contains only `"train"` split so when we are doing `self.info.splits[split_generator.name]` it tries to infer smth like `info.splits['train[50%]']` and that's not the case and it fails.
### Expected behavior
to be discussed?
This can be solved by removing splits information from metadata file first. But I wonder if there is a better way.
### Environment info
- Datasets version: 2.7.1
- Python version: 3.8.13 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5315/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5315/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/695 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/695/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/695/comments | https://api.github.com/repos/huggingface/datasets/issues/695/events | https://github.com/huggingface/datasets/pull/695 | 712,843,949 | MDExOlB1bGxSZXF1ZXN0NDk2MjU5NTM0 | 695 | Update XNLI download link | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq"
} | [] | closed | false | null | [] | null | [] | "2020-10-01T13:27:22Z" | "2020-10-01T14:01:15Z" | "2020-10-01T14:01:14Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/695.diff",
"html_url": "https://github.com/huggingface/datasets/pull/695",
"merged_at": "2020-10-01T14:01:14Z",
"patch_url": "https://github.com/huggingface/datasets/pull/695.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/695"
} | The old link isn't working anymore. I updated it with the new official link.
Fix #690 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/695/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/695/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4820 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4820/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4820/comments | https://api.github.com/repos/huggingface/datasets/issues/4820/events | https://github.com/huggingface/datasets/issues/4820 | 1,335,117,132 | I_kwDODunzps5PlEVM | 4,820 | Terminating: fork() called from a process already using GNU OpenMP, this is unsafe. | {
"avatar_url": "https://avatars.githubusercontent.com/u/37379131?v=4",
"events_url": "https://api.github.com/users/talhaanwarch/events{/privacy}",
"followers_url": "https://api.github.com/users/talhaanwarch/followers",
"following_url": "https://api.github.com/users/talhaanwarch/following{/other_user}",
"gists_url": "https://api.github.com/users/talhaanwarch/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/talhaanwarch",
"id": 37379131,
"login": "talhaanwarch",
"node_id": "MDQ6VXNlcjM3Mzc5MTMx",
"organizations_url": "https://api.github.com/users/talhaanwarch/orgs",
"received_events_url": "https://api.github.com/users/talhaanwarch/received_events",
"repos_url": "https://api.github.com/users/talhaanwarch/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/talhaanwarch/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/talhaanwarch/subscriptions",
"type": "User",
"url": "https://api.github.com/users/talhaanwarch"
} | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | [] | null | [
"Fixed by installing either resampy<3 or resampy>=4"
] | "2022-08-10T19:42:33Z" | "2022-08-10T19:53:10Z" | "2022-08-10T19:53:10Z" | NONE | null | null | null | Hi, when i try to run prepare_dataset function in [fine tuning ASR tutorial 4](https://colab.research.google.com/github/patrickvonplaten/notebooks/blob/master/Fine_tuning_Wav2Vec2_for_English_ASR.ipynb) , i got this error.
I got this error
Terminating: fork() called from a process already using GNU OpenMP, this is unsafe.
There is no other logs available, so i have no clue what is the cause of it.
```
def prepare_dataset(batch):
audio = batch["path"]
# batched output is "un-batched"
batch["input_values"] = processor(audio["array"], sampling_rate=audio["sampling_rate"]).input_values[0]
batch["input_length"] = len(batch["input_values"])
with processor.as_target_processor():
batch["labels"] = processor(batch["text"]).input_ids
return batch
data = data.map(prepare_dataset, remove_columns=data.column_names["train"],
num_proc=4)
```
Specify the actual results or traceback.
There is no traceback except
`Terminating: fork() called from a process already using GNU OpenMP, this is unsafe.`
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 2.4.0
- Platform: Linux-5.15.0-43-generic-x86_64-with-glibc2.29
- Python version: 3.8.10
- PyArrow version: 9.0.0
- Pandas version: 1.4.3
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4820/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4820/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/710 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/710/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/710/comments | https://api.github.com/repos/huggingface/datasets/issues/710/events | https://github.com/huggingface/datasets/pull/710 | 714,186,999 | MDExOlB1bGxSZXF1ZXN0NDk3MzQ1NjQ0 | 710 | fix README typos/ consistency | {
"avatar_url": "https://avatars.githubusercontent.com/u/7703961?v=4",
"events_url": "https://api.github.com/users/discdiver/events{/privacy}",
"followers_url": "https://api.github.com/users/discdiver/followers",
"following_url": "https://api.github.com/users/discdiver/following{/other_user}",
"gists_url": "https://api.github.com/users/discdiver/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/discdiver",
"id": 7703961,
"login": "discdiver",
"node_id": "MDQ6VXNlcjc3MDM5NjE=",
"organizations_url": "https://api.github.com/users/discdiver/orgs",
"received_events_url": "https://api.github.com/users/discdiver/received_events",
"repos_url": "https://api.github.com/users/discdiver/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/discdiver/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/discdiver/subscriptions",
"type": "User",
"url": "https://api.github.com/users/discdiver"
} | [] | closed | false | null | [] | null | [] | "2020-10-03T22:20:56Z" | "2020-10-17T09:52:45Z" | "2020-10-17T09:52:45Z" | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/710.diff",
"html_url": "https://github.com/huggingface/datasets/pull/710",
"merged_at": "2020-10-17T09:52:45Z",
"patch_url": "https://github.com/huggingface/datasets/pull/710.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/710"
} | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/710/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/710/timeline | null | null | true |
|
https://api.github.com/repos/huggingface/datasets/issues/1529 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1529/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1529/comments | https://api.github.com/repos/huggingface/datasets/issues/1529/events | https://github.com/huggingface/datasets/pull/1529 | 764,748,410 | MDExOlB1bGxSZXF1ZXN0NTM4NjY4MjU4 | 1,529 | Ro sent | {
"avatar_url": "https://avatars.githubusercontent.com/u/2815308?v=4",
"events_url": "https://api.github.com/users/iliemihai/events{/privacy}",
"followers_url": "https://api.github.com/users/iliemihai/followers",
"following_url": "https://api.github.com/users/iliemihai/following{/other_user}",
"gists_url": "https://api.github.com/users/iliemihai/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/iliemihai",
"id": 2815308,
"login": "iliemihai",
"node_id": "MDQ6VXNlcjI4MTUzMDg=",
"organizations_url": "https://api.github.com/users/iliemihai/orgs",
"received_events_url": "https://api.github.com/users/iliemihai/received_events",
"repos_url": "https://api.github.com/users/iliemihai/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/iliemihai/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/iliemihai/subscriptions",
"type": "User",
"url": "https://api.github.com/users/iliemihai"
} | [] | closed | false | null | [] | null | [
"Hi @iliemihai, it looks like this PR holds changes from your previous PR #1493 .\r\nWould you mind removing them from the branch please ?",
"@SBrandeis I am sorry. Yes I will remove them. Thank you :D ",
"Hi @lhoestq @SBrandeis @iliemihai\r\n\r\nIs this still in progress or can I take over this one?\r\n\r\nThanks,\r\nGunjan",
"Hi,\r\nWhile trying to add this dataset, I found some potential issues. \r\nThe homepage mentioned is : https://github.com/katakonst/sentiment-analysis-tensorflow/tree/master/datasets/ro/, where the dataset is different from the URLs: https://raw.githubusercontent.com/dumitrescustefan/Romanian-Transformers/examples/examples/sentiment_analysis/ro/train.csv. It is unclear which dataset is \"correct\". I checked the total examples (train+test) in both places and they do not match.",
"We should use the data from dumitrescustefan and set the homepage to his repo IMO, since he's first author of the paper of the dataset.",
"Hi @lhoestq,\r\n\r\nCool, I'll get working on it.\r\n\r\nThanks",
"Hi @lhoestq, \r\n\r\nThis PR can be closed.",
"Closing in favor of #2011 \r\nThanks again for adding it !"
] | "2020-12-13T01:55:02Z" | "2021-03-19T10:32:43Z" | "2021-03-19T10:32:42Z" | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/1529.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1529",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/1529.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1529"
} | Movies reviews dataset for Romanian language. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1529/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1529/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/1264 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1264/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1264/comments | https://api.github.com/repos/huggingface/datasets/issues/1264/events | https://github.com/huggingface/datasets/pull/1264 | 758,686,474 | MDExOlB1bGxSZXF1ZXN0NTMzODE4MDM2 | 1,264 | enriched webnlg dataset rebase | {
"avatar_url": "https://avatars.githubusercontent.com/u/26709476?v=4",
"events_url": "https://api.github.com/users/TevenLeScao/events{/privacy}",
"followers_url": "https://api.github.com/users/TevenLeScao/followers",
"following_url": "https://api.github.com/users/TevenLeScao/following{/other_user}",
"gists_url": "https://api.github.com/users/TevenLeScao/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/TevenLeScao",
"id": 26709476,
"login": "TevenLeScao",
"node_id": "MDQ6VXNlcjI2NzA5NDc2",
"organizations_url": "https://api.github.com/users/TevenLeScao/orgs",
"received_events_url": "https://api.github.com/users/TevenLeScao/received_events",
"repos_url": "https://api.github.com/users/TevenLeScao/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/TevenLeScao/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/TevenLeScao/subscriptions",
"type": "User",
"url": "https://api.github.com/users/TevenLeScao"
} | [] | closed | false | null | [] | null | [
"I've removed the `en` within `de` and reciprocally; but I don't think I will be able to thin it more than this. (Edit: ignore the close, I missclicked !)"
] | "2020-12-07T17:05:45Z" | "2020-12-09T17:00:29Z" | "2020-12-09T17:00:27Z" | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/1264.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1264",
"merged_at": "2020-12-09T17:00:27Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1264.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1264"
} | Rebase of #1206 ! | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1264/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1264/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/2309 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2309/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2309/comments | https://api.github.com/repos/huggingface/datasets/issues/2309/events | https://github.com/huggingface/datasets/pull/2309 | 874,644,990 | MDExOlB1bGxSZXF1ZXN0NjI5MTU4NjQx | 2,309 | Fix conda release | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq"
} | [] | closed | false | null | [] | null | [] | "2021-05-03T14:52:59Z" | "2021-05-03T16:01:17Z" | "2021-05-03T16:01:17Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/2309.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2309",
"merged_at": "2021-05-03T16:01:17Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2309.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2309"
} | There were a few issues with conda releases (they've been failing for a while now).
To fix this I had to:
- add the --single-version-externally-managed tag to the build stage (suggestion from [here](https://stackoverflow.com/a/64825075))
- set the python version of the conda build stage to 3.8 since 3.9 isn't supported
- sync the evrsion requirement of `huggingface_hub`
With these changes I'm working on uploading all missing versions until 1.6.2 to conda
EDIT: I managed to build and upload all missing versions until 1.6.2 to conda :) | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2309/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2309/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/6000 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6000/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6000/comments | https://api.github.com/repos/huggingface/datasets/issues/6000/events | https://github.com/huggingface/datasets/pull/6000 | 1,782,456,878 | PR_kwDODunzps5UU_FB | 6,000 | Pin `joblib` to avoid `joblibspark` test failures | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko"
} | [] | closed | false | null | [] | null | [
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006722 / 0.011353 (-0.004631) | 0.004425 / 0.011008 (-0.006583) | 0.100850 / 0.038508 (0.062341) | 0.040816 / 0.023109 (0.017707) | 0.348823 / 0.275898 (0.072925) | 0.446285 / 0.323480 (0.122805) | 0.005738 / 0.007986 (-0.002247) | 0.003517 / 0.004328 (-0.000811) | 0.078824 / 0.004250 (0.074574) | 0.064695 / 0.037052 (0.027643) | 0.389894 / 0.258489 (0.131405) | 0.416107 / 0.293841 (0.122266) | 0.028850 / 0.128546 (-0.099696) | 0.009011 / 0.075646 (-0.066635) | 0.323117 / 0.419271 (-0.096154) | 0.049162 / 0.043533 (0.005629) | 0.340144 / 0.255139 (0.085005) | 0.382072 / 0.283200 (0.098872) | 0.023160 / 0.141683 (-0.118523) | 1.549218 / 1.452155 (0.097063) | 1.581266 / 1.492716 (0.088550) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.293360 / 0.018006 (0.275353) | 0.602189 / 0.000490 (0.601700) | 0.004608 / 0.000200 (0.004408) | 0.000082 / 0.000054 (0.000028) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.028144 / 0.037411 (-0.009267) | 0.107088 / 0.014526 (0.092562) | 0.112188 / 0.176557 (-0.064369) | 0.174669 / 0.737135 (-0.562466) | 0.116359 / 0.296338 (-0.179980) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.422911 / 0.215209 (0.207702) | 4.231524 / 2.077655 (2.153869) | 1.906711 / 1.504120 (0.402591) | 1.706841 / 1.541195 (0.165646) | 1.792066 / 1.468490 (0.323576) | 0.559221 / 4.584777 (-4.025556) | 3.434280 / 3.745712 (-0.311433) | 1.918714 / 5.269862 (-3.351148) | 1.073070 / 4.565676 (-3.492606) | 0.067891 / 0.424275 (-0.356384) | 0.011927 / 0.007607 (0.004320) | 0.530843 / 0.226044 (0.304799) | 5.309213 / 2.268929 (3.040285) | 2.439246 / 55.444624 (-53.005378) | 2.101245 / 6.876477 (-4.775231) | 2.177436 / 2.142072 (0.035363) | 0.672150 / 4.805227 (-4.133077) | 0.137571 / 6.500664 (-6.363093) | 0.068343 / 0.075469 (-0.007126) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.265262 / 1.841788 (-0.576525) | 14.988021 / 8.074308 (6.913713) | 13.611677 / 10.191392 (3.420285) | 0.171389 / 0.680424 (-0.509035) | 0.017681 / 0.534201 (-0.516520) | 0.377542 / 0.579283 (-0.201741) | 0.399475 / 0.434364 (-0.034889) | 0.469553 / 0.540337 (-0.070785) | 0.561888 / 1.386936 (-0.825048) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006782 / 0.011353 (-0.004571) | 0.004412 / 0.011008 (-0.006597) | 0.078594 / 0.038508 (0.040086) | 0.039930 / 0.023109 (0.016820) | 0.371879 / 0.275898 (0.095981) | 0.444910 / 0.323480 (0.121430) | 0.005707 / 0.007986 (-0.002279) | 0.003901 / 0.004328 (-0.000427) | 0.080125 / 0.004250 (0.075875) | 0.063977 / 0.037052 (0.026925) | 0.382781 / 0.258489 (0.124292) | 0.441791 / 0.293841 (0.147950) | 0.030428 / 0.128546 (-0.098118) | 0.009008 / 0.075646 (-0.066638) | 0.084447 / 0.419271 (-0.334824) | 0.044432 / 0.043533 (0.000899) | 0.365686 / 0.255139 (0.110547) | 0.394312 / 0.283200 (0.111113) | 0.024508 / 0.141683 (-0.117175) | 1.577020 / 1.452155 (0.124865) | 1.630259 / 1.492716 (0.137543) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.307960 / 0.018006 (0.289953) | 0.591473 / 0.000490 (0.590983) | 0.008098 / 0.000200 (0.007898) | 0.000110 / 0.000054 (0.000056) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.029567 / 0.037411 (-0.007845) | 0.112773 / 0.014526 (0.098247) | 0.117362 / 0.176557 (-0.059194) | 0.174293 / 0.737135 (-0.562843) | 0.123156 / 0.296338 (-0.173182) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.457475 / 0.215209 (0.242266) | 4.599067 / 2.077655 (2.521412) | 2.262638 / 1.504120 (0.758518) | 2.124943 / 1.541195 (0.583748) | 2.339912 / 1.468490 (0.871422) | 0.566264 / 4.584777 (-4.018513) | 3.489261 / 3.745712 (-0.256451) | 1.925151 / 5.269862 (-3.344711) | 1.099389 / 4.565676 (-3.466287) | 0.068232 / 0.424275 (-0.356043) | 0.011660 / 0.007607 (0.004052) | 0.571227 / 0.226044 (0.345183) | 5.702059 / 2.268929 (3.433130) | 2.837701 / 55.444624 (-52.606924) | 2.605468 / 6.876477 (-4.271008) | 2.818396 / 2.142072 (0.676323) | 0.681856 / 4.805227 (-4.123371) | 0.141401 / 6.500664 (-6.359263) | 0.069728 / 0.075469 (-0.005741) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.354935 / 1.841788 (-0.486853) | 15.437404 / 8.074308 (7.363095) | 15.415193 / 10.191392 (5.223801) | 0.153459 / 0.680424 (-0.526964) | 0.017190 / 0.534201 (-0.517011) | 0.367256 / 0.579283 (-0.212027) | 0.392709 / 0.434364 (-0.041655) | 0.426125 / 0.540337 (-0.114213) | 0.522612 / 1.386936 (-0.864324) |\n\n</details>\n</details>\n\n\n",
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.009183 / 0.011353 (-0.002170) | 0.005232 / 0.011008 (-0.005776) | 0.120349 / 0.038508 (0.081841) | 0.044715 / 0.023109 (0.021606) | 0.361519 / 0.275898 (0.085621) | 0.463702 / 0.323480 (0.140223) | 0.005842 / 0.007986 (-0.002144) | 0.004041 / 0.004328 (-0.000288) | 0.096953 / 0.004250 (0.092703) | 0.070593 / 0.037052 (0.033540) | 0.409790 / 0.258489 (0.151301) | 0.477452 / 0.293841 (0.183611) | 0.045827 / 0.128546 (-0.082719) | 0.014038 / 0.075646 (-0.061608) | 0.421317 / 0.419271 (0.002045) | 0.065276 / 0.043533 (0.021743) | 0.360074 / 0.255139 (0.104935) | 0.409147 / 0.283200 (0.125947) | 0.032444 / 0.141683 (-0.109238) | 1.739257 / 1.452155 (0.287102) | 1.831408 / 1.492716 (0.338692) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.274852 / 0.018006 (0.256846) | 0.596320 / 0.000490 (0.595830) | 0.006399 / 0.000200 (0.006199) | 0.000133 / 0.000054 (0.000079) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.031400 / 0.037411 (-0.006012) | 0.127052 / 0.014526 (0.112526) | 0.134269 / 0.176557 (-0.042288) | 0.225998 / 0.737135 (-0.511137) | 0.150019 / 0.296338 (-0.146319) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.654202 / 0.215209 (0.438993) | 6.216735 / 2.077655 (4.139081) | 2.440214 / 1.504120 (0.936094) | 2.150575 / 1.541195 (0.609380) | 2.124790 / 1.468490 (0.656300) | 0.923514 / 4.584777 (-3.661263) | 5.556924 / 3.745712 (1.811212) | 2.843886 / 5.269862 (-2.425975) | 1.834232 / 4.565676 (-2.731444) | 0.111735 / 0.424275 (-0.312540) | 0.014823 / 0.007607 (0.007216) | 0.820503 / 0.226044 (0.594459) | 7.887737 / 2.268929 (5.618809) | 3.120307 / 55.444624 (-52.324317) | 2.405856 / 6.876477 (-4.470621) | 2.411239 / 2.142072 (0.269167) | 1.071283 / 4.805227 (-3.733944) | 0.227738 / 6.500664 (-6.272926) | 0.073516 / 0.075469 (-0.001953) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.531806 / 1.841788 (-0.309982) | 18.547661 / 8.074308 (10.473353) | 21.083922 / 10.191392 (10.892530) | 0.241706 / 0.680424 (-0.438718) | 0.034169 / 0.534201 (-0.500032) | 0.497514 / 0.579283 (-0.081769) | 0.599801 / 0.434364 (0.165437) | 0.576465 / 0.540337 (0.036127) | 0.673509 / 1.386936 (-0.713427) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.007558 / 0.011353 (-0.003795) | 0.005001 / 0.011008 (-0.006008) | 0.093809 / 0.038508 (0.055301) | 0.039792 / 0.023109 (0.016683) | 0.456869 / 0.275898 (0.180971) | 0.493370 / 0.323480 (0.169891) | 0.005561 / 0.007986 (-0.002424) | 0.003982 / 0.004328 (-0.000346) | 0.085421 / 0.004250 (0.081170) | 0.059817 / 0.037052 (0.022765) | 0.468040 / 0.258489 (0.209550) | 0.514853 / 0.293841 (0.221012) | 0.044267 / 0.128546 (-0.084279) | 0.012674 / 0.075646 (-0.062972) | 0.098324 / 0.419271 (-0.320948) | 0.056604 / 0.043533 (0.013071) | 0.432200 / 0.255139 (0.177061) | 0.459812 / 0.283200 (0.176612) | 0.033872 / 0.141683 (-0.107811) | 1.618576 / 1.452155 (0.166421) | 1.676562 / 1.492716 (0.183846) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.230625 / 0.018006 (0.212619) | 0.600558 / 0.000490 (0.600068) | 0.003419 / 0.000200 (0.003219) | 0.000113 / 0.000054 (0.000059) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.026916 / 0.037411 (-0.010496) | 0.103003 / 0.014526 (0.088478) | 0.117078 / 0.176557 (-0.059478) | 0.169359 / 0.737135 (-0.567776) | 0.120305 / 0.296338 (-0.176034) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.616877 / 0.215209 (0.401668) | 6.157232 / 2.077655 (4.079577) | 2.869219 / 1.504120 (1.365099) | 2.381410 / 1.541195 (0.840216) | 2.417357 / 1.468490 (0.948867) | 0.914947 / 4.584777 (-3.669830) | 5.718526 / 3.745712 (1.972814) | 2.757253 / 5.269862 (-2.512609) | 1.794122 / 4.565676 (-2.771554) | 0.108423 / 0.424275 (-0.315852) | 0.013378 / 0.007607 (0.005771) | 0.831067 / 0.226044 (0.605023) | 8.478946 / 2.268929 (6.210018) | 3.685937 / 55.444624 (-51.758687) | 2.867472 / 6.876477 (-4.009005) | 2.895975 / 2.142072 (0.753903) | 1.137547 / 4.805227 (-3.667681) | 0.213891 / 6.500664 (-6.286773) | 0.075825 / 0.075469 (0.000356) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.621193 / 1.841788 (-0.220594) | 17.322110 / 8.074308 (9.247802) | 21.804016 / 10.191392 (11.612624) | 0.243692 / 0.680424 (-0.436732) | 0.030331 / 0.534201 (-0.503870) | 0.492186 / 0.579283 (-0.087097) | 0.632583 / 0.434364 (0.198219) | 0.576265 / 0.540337 (0.035927) | 0.713165 / 1.386936 (-0.673771) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008916 / 0.011353 (-0.002437) | 0.004737 / 0.011008 (-0.006271) | 0.134271 / 0.038508 (0.095763) | 0.054472 / 0.023109 (0.031363) | 0.380942 / 0.275898 (0.105044) | 0.474138 / 0.323480 (0.150658) | 0.007917 / 0.007986 (-0.000068) | 0.003748 / 0.004328 (-0.000580) | 0.092765 / 0.004250 (0.088515) | 0.077873 / 0.037052 (0.040821) | 0.397533 / 0.258489 (0.139043) | 0.454737 / 0.293841 (0.160896) | 0.039901 / 0.128546 (-0.088645) | 0.010188 / 0.075646 (-0.065458) | 0.447312 / 0.419271 (0.028040) | 0.068684 / 0.043533 (0.025151) | 0.371554 / 0.255139 (0.116415) | 0.459655 / 0.283200 (0.176455) | 0.027157 / 0.141683 (-0.114526) | 1.874643 / 1.452155 (0.422488) | 2.014800 / 1.492716 (0.522083) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.227079 / 0.018006 (0.209073) | 0.483241 / 0.000490 (0.482751) | 0.012404 / 0.000200 (0.012204) | 0.000409 / 0.000054 (0.000354) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.033135 / 0.037411 (-0.004277) | 0.137782 / 0.014526 (0.123257) | 0.142951 / 0.176557 (-0.033605) | 0.209825 / 0.737135 (-0.527311) | 0.152438 / 0.296338 (-0.143900) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.513066 / 0.215209 (0.297857) | 5.122776 / 2.077655 (3.045121) | 2.399270 / 1.504120 (0.895150) | 2.180143 / 1.541195 (0.638949) | 2.286395 / 1.468490 (0.817905) | 0.641866 / 4.584777 (-3.942911) | 4.694922 / 3.745712 (0.949210) | 2.543390 / 5.269862 (-2.726472) | 1.398592 / 4.565676 (-3.167084) | 0.088662 / 0.424275 (-0.335613) | 0.015854 / 0.007607 (0.008247) | 0.688891 / 0.226044 (0.462847) | 6.370148 / 2.268929 (4.101220) | 2.949974 / 55.444624 (-52.494650) | 2.538049 / 6.876477 (-4.338428) | 2.699380 / 2.142072 (0.557308) | 0.792670 / 4.805227 (-4.012557) | 0.169126 / 6.500664 (-6.331538) | 0.078511 / 0.075469 (0.003042) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.609119 / 1.841788 (-0.232669) | 18.785069 / 8.074308 (10.710761) | 16.670783 / 10.191392 (6.479391) | 0.213081 / 0.680424 (-0.467343) | 0.023904 / 0.534201 (-0.510296) | 0.567720 / 0.579283 (-0.011564) | 0.505806 / 0.434364 (0.071442) | 0.649466 / 0.540337 (0.109129) | 0.773174 / 1.386936 (-0.613762) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008036 / 0.011353 (-0.003317) | 0.004808 / 0.011008 (-0.006201) | 0.094316 / 0.038508 (0.055808) | 0.056174 / 0.023109 (0.033065) | 0.481618 / 0.275898 (0.205720) | 0.565300 / 0.323480 (0.241820) | 0.006339 / 0.007986 (-0.001646) | 0.003950 / 0.004328 (-0.000379) | 0.093389 / 0.004250 (0.089139) | 0.076163 / 0.037052 (0.039111) | 0.489013 / 0.258489 (0.230524) | 0.565451 / 0.293841 (0.271611) | 0.039392 / 0.128546 (-0.089155) | 0.010553 / 0.075646 (-0.065093) | 0.101406 / 0.419271 (-0.317865) | 0.062355 / 0.043533 (0.018822) | 0.470461 / 0.255139 (0.215322) | 0.502574 / 0.283200 (0.219375) | 0.030196 / 0.141683 (-0.111486) | 1.893926 / 1.452155 (0.441771) | 1.958902 / 1.492716 (0.466185) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.198074 / 0.018006 (0.180068) | 0.476828 / 0.000490 (0.476338) | 0.003457 / 0.000200 (0.003257) | 0.000105 / 0.000054 (0.000051) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.037576 / 0.037411 (0.000165) | 0.146663 / 0.014526 (0.132138) | 0.152969 / 0.176557 (-0.023588) | 0.218683 / 0.737135 (-0.518452) | 0.161552 / 0.296338 (-0.134786) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.525988 / 0.215209 (0.310779) | 5.234673 / 2.077655 (3.157018) | 2.571668 / 1.504120 (1.067548) | 2.339760 / 1.541195 (0.798565) | 2.422886 / 1.468490 (0.954395) | 0.651537 / 4.584777 (-3.933240) | 4.811148 / 3.745712 (1.065436) | 4.451165 / 5.269862 (-0.818697) | 2.016283 / 4.565676 (-2.549394) | 0.096393 / 0.424275 (-0.327882) | 0.015222 / 0.007607 (0.007615) | 0.739132 / 0.226044 (0.513087) | 6.813327 / 2.268929 (4.544399) | 3.169018 / 55.444624 (-52.275606) | 2.783120 / 6.876477 (-4.093356) | 2.918979 / 2.142072 (0.776907) | 0.797476 / 4.805227 (-4.007751) | 0.171038 / 6.500664 (-6.329626) | 0.079878 / 0.075469 (0.004409) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.595082 / 1.841788 (-0.246705) | 19.685844 / 8.074308 (11.611536) | 17.518989 / 10.191392 (7.327597) | 0.220015 / 0.680424 (-0.460409) | 0.026351 / 0.534201 (-0.507850) | 0.578977 / 0.579283 (-0.000306) | 0.549564 / 0.434364 (0.115200) | 0.667564 / 0.540337 (0.127227) | 0.802121 / 1.386936 (-0.584815) |\n\n</details>\n</details>\n\n\n"
] | "2023-06-30T12:36:54Z" | "2023-06-30T13:17:05Z" | "2023-06-30T13:08:27Z" | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/6000.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6000",
"merged_at": "2023-06-30T13:08:27Z",
"patch_url": "https://github.com/huggingface/datasets/pull/6000.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/6000"
} | `joblibspark` doesn't support the latest `joblib` release.
See https://github.com/huggingface/datasets/actions/runs/5401870932/jobs/9812337078 for the errors | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6000/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6000/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3570 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3570/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3570/comments | https://api.github.com/repos/huggingface/datasets/issues/3570/events | https://github.com/huggingface/datasets/pull/3570 | 1,100,480,791 | PR_kwDODunzps4w3Xez | 3,570 | Add the KMWP dataset (extension of #3564) | {
"avatar_url": "https://avatars.githubusercontent.com/u/42150335?v=4",
"events_url": "https://api.github.com/users/sooftware/events{/privacy}",
"followers_url": "https://api.github.com/users/sooftware/followers",
"following_url": "https://api.github.com/users/sooftware/following{/other_user}",
"gists_url": "https://api.github.com/users/sooftware/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/sooftware",
"id": 42150335,
"login": "sooftware",
"node_id": "MDQ6VXNlcjQyMTUwMzM1",
"organizations_url": "https://api.github.com/users/sooftware/orgs",
"received_events_url": "https://api.github.com/users/sooftware/received_events",
"repos_url": "https://api.github.com/users/sooftware/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/sooftware/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sooftware/subscriptions",
"type": "User",
"url": "https://api.github.com/users/sooftware"
} | [
{
"color": "0e8a16",
"default": false,
"description": "Contribution to a dataset script",
"id": 4564477500,
"name": "dataset contribution",
"node_id": "LA_kwDODunzps8AAAABEBBmPA",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20contribution"
}
] | closed | false | null | [] | null | [
"Sorry, I'm late to check! I'll send it to you soon!",
"Thanks for your contribution, @sooftware. Are you still interested in adding this dataset?\r\n\r\nWe are removing the dataset scripts from this GitHub repo and moving them to the Hugging Face Hub: https://huggingface.co/datasets\r\n\r\nWe would suggest you create this dataset there, under this organization namespace: https://huggingface.co/tunib\r\n\r\nPlease, feel free to tell us if you need some help.",
"Close this PR. Thanks!"
] | "2022-01-12T15:33:08Z" | "2022-10-01T06:43:16Z" | "2022-10-01T06:43:16Z" | NONE | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/3570.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3570",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/3570.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3570"
} | New pull request of #3564 (Add the KMWP dataset) | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3570/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3570/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4902 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4902/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4902/comments | https://api.github.com/repos/huggingface/datasets/issues/4902/events | https://github.com/huggingface/datasets/issues/4902 | 1,352,469,196 | I_kwDODunzps5QnQrM | 4,902 | Name the default config `default` | {
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"events_url": "https://api.github.com/users/severo/events{/privacy}",
"followers_url": "https://api.github.com/users/severo/followers",
"following_url": "https://api.github.com/users/severo/following{/other_user}",
"gists_url": "https://api.github.com/users/severo/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/severo",
"id": 1676121,
"login": "severo",
"node_id": "MDQ6VXNlcjE2NzYxMjE=",
"organizations_url": "https://api.github.com/users/severo/orgs",
"received_events_url": "https://api.github.com/users/severo/received_events",
"repos_url": "https://api.github.com/users/severo/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/severo/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/severo/subscriptions",
"type": "User",
"url": "https://api.github.com/users/severo"
} | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
},
{
"color": "d876e3",
"default": true,
"description": "Further information is requested",
"id": 1935892912,
"name": "question",
"node_id": "MDU6TGFiZWwxOTM1ODkyOTEy",
"url": "https://api.github.com/repos/huggingface/datasets/labels/question"
}
] | closed | false | null | [] | null | [
"Addressed in #5331."
] | "2022-08-26T16:16:22Z" | "2023-07-24T21:15:31Z" | "2023-07-24T21:15:31Z" | CONTRIBUTOR | null | null | null | Currently, if a dataset has no configuration, a default configuration is created from the dataset name.
For example, for a dataset loaded from the hub repository, such as https://huggingface.co/datasets/user/dataset (repo id is `user/dataset`), the default configuration will be `user--dataset`.
It might be easier to handle to set it to `default`, or another reserved word. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 1,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4902/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4902/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/1081 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1081/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1081/comments | https://api.github.com/repos/huggingface/datasets/issues/1081/events | https://github.com/huggingface/datasets/pull/1081 | 756,672,527 | MDExOlB1bGxSZXF1ZXN0NTMyMTg0ODc4 | 1,081 | Add Knowledge-Enhanced Language Model Pre-training (KELM) | {
"avatar_url": "https://avatars.githubusercontent.com/u/9353833?v=4",
"events_url": "https://api.github.com/users/joeddav/events{/privacy}",
"followers_url": "https://api.github.com/users/joeddav/followers",
"following_url": "https://api.github.com/users/joeddav/following{/other_user}",
"gists_url": "https://api.github.com/users/joeddav/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/joeddav",
"id": 9353833,
"login": "joeddav",
"node_id": "MDQ6VXNlcjkzNTM4MzM=",
"organizations_url": "https://api.github.com/users/joeddav/orgs",
"received_events_url": "https://api.github.com/users/joeddav/received_events",
"repos_url": "https://api.github.com/users/joeddav/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/joeddav/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/joeddav/subscriptions",
"type": "User",
"url": "https://api.github.com/users/joeddav"
} | [] | closed | false | null | [] | null | [] | "2020-12-03T23:30:09Z" | "2020-12-04T16:36:28Z" | "2020-12-04T16:36:28Z" | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/1081.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1081",
"merged_at": "2020-12-04T16:36:28Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1081.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1081"
} | Adds the KELM dataset.
- Webpage/repo: https://github.com/google-research-datasets/KELM-corpus
- Paper: https://arxiv.org/pdf/2010.12688.pdf | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1081/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1081/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/502 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/502/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/502/comments | https://api.github.com/repos/huggingface/datasets/issues/502/events | https://github.com/huggingface/datasets/pull/502 | 678,546,070 | MDExOlB1bGxSZXF1ZXN0NDY3NDc1MDg0 | 502 | Fix tokenizers caching | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq"
} | [] | closed | false | null | [] | null | [
"This should fix #501 and also the issue you sent me on slack @sgugger ."
] | "2020-08-13T15:53:37Z" | "2020-08-19T13:37:19Z" | "2020-08-19T13:37:18Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/502.diff",
"html_url": "https://github.com/huggingface/datasets/pull/502",
"merged_at": "2020-08-19T13:37:17Z",
"patch_url": "https://github.com/huggingface/datasets/pull/502.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/502"
} | I've found some cases where the caching didn't work properly for tokenizers:
1. if a tokenizer has a regex pattern, then the caching would be inconsistent across sessions
2. if a tokenizer has a cache attribute that changes after some calls, the the caching would not work after cache updates
3. if a tokenizer is used inside a function, the caching of this function would result in the same cache file for different tokenizers
4. if `unique_no_split_tokens`'s attribute is not the same across sessions (after loading a tokenizer) then the caching could be inconsistent
To fix that, this is what I did:
1. register a specific `save_regex` function for pickle that makes regex dumps deterministic
2. ignore cache attribute of some tokenizers before dumping
3. enable recursive dump by default for all dumps
4. make `unique_no_split_tokens` deterministic in https://github.com/huggingface/transformers/pull/6461
I also added tests to make sure that tokenizers hashing works as expected.
In the future we should find a way to test if hashing also works across session (maybe using two CI jobs ? or by hardcoding a tokenizer's hash ?) | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/502/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/502/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/2935 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2935/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2935/comments | https://api.github.com/repos/huggingface/datasets/issues/2935/events | https://github.com/huggingface/datasets/pull/2935 | 999,518,469 | PR_kwDODunzps4r5j8B | 2,935 | Add Jigsaw unintended Bias | {
"avatar_url": "https://avatars.githubusercontent.com/u/494951?v=4",
"events_url": "https://api.github.com/users/Iwontbecreative/events{/privacy}",
"followers_url": "https://api.github.com/users/Iwontbecreative/followers",
"following_url": "https://api.github.com/users/Iwontbecreative/following{/other_user}",
"gists_url": "https://api.github.com/users/Iwontbecreative/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/Iwontbecreative",
"id": 494951,
"login": "Iwontbecreative",
"node_id": "MDQ6VXNlcjQ5NDk1MQ==",
"organizations_url": "https://api.github.com/users/Iwontbecreative/orgs",
"received_events_url": "https://api.github.com/users/Iwontbecreative/received_events",
"repos_url": "https://api.github.com/users/Iwontbecreative/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/Iwontbecreative/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Iwontbecreative/subscriptions",
"type": "User",
"url": "https://api.github.com/users/Iwontbecreative"
} | [] | closed | false | null | [] | null | [
"Note that the tests seem to fail because of a bug in an Exception at the moment, see: https://github.com/huggingface/datasets/pull/2936 for the fix",
"@lhoestq implemented your changes, I think this might be ready for another look.",
"Thanks @lhoestq, implemented the changes, let me know if anything else pops up."
] | "2021-09-17T16:12:31Z" | "2021-09-24T10:41:52Z" | "2021-09-24T10:41:52Z" | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/2935.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2935",
"merged_at": "2021-09-24T10:41:52Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2935.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2935"
} | Hi,
Here's a first attempt at this dataset. Would be great if it could be merged relatively quickly as it is needed for Bigscience-related stuff.
This requires manual download, and I had some trouble generating dummy_data in this setting, so welcoming feedback there. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2935/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2935/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3050 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3050/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3050/comments | https://api.github.com/repos/huggingface/datasets/issues/3050/events | https://github.com/huggingface/datasets/pull/3050 | 1,021,772,622 | PR_kwDODunzps4s-anK | 3,050 | Fix streaming: catch Timeout error | {
"avatar_url": "https://avatars.githubusercontent.com/u/715491?v=4",
"events_url": "https://api.github.com/users/borisdayma/events{/privacy}",
"followers_url": "https://api.github.com/users/borisdayma/followers",
"following_url": "https://api.github.com/users/borisdayma/following{/other_user}",
"gists_url": "https://api.github.com/users/borisdayma/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/borisdayma",
"id": 715491,
"login": "borisdayma",
"node_id": "MDQ6VXNlcjcxNTQ5MQ==",
"organizations_url": "https://api.github.com/users/borisdayma/orgs",
"received_events_url": "https://api.github.com/users/borisdayma/received_events",
"repos_url": "https://api.github.com/users/borisdayma/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/borisdayma/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/borisdayma/subscriptions",
"type": "User",
"url": "https://api.github.com/users/borisdayma"
} | [] | closed | false | null | [] | null | [
"I'm running a large test.\r\nLet's see if I get any error within a few days.",
"This time it stopped after 8h but correctly raised `ConnectionError: Server Disconnected`.\r\n\r\nTraceback:\r\n```\r\nTraceback (most recent call last): \r\n File \"/home/koush/dalle-mini/dev/seq2seq/run_seq2seq_flax.py\", line 1027, in <module> \r\n main() \r\n File \"/home/koush/dalle-mini/dev/seq2seq/run_seq2seq_flax.py\", line 991, in main \r\n for batch in tqdm( \r\n File \"/home/koush/.pyenv/versions/dev/lib/python3.9/site-packages/tqdm/std.py\", line 1180, in __iter__ \r\n for obj in iterable: \r\n File \"/home/koush/dalle-mini/dev/seq2seq/run_seq2seq_flax.py\", line 376, in data_loader_streaming\r\n for item in dataset:\r\n File \"/home/koush/datasets/src/datasets/iterable_dataset.py\", line 341, in __iter__\r\n for key, example in self._iter():\r\n File \"/home/koush/datasets/src/datasets/iterable_dataset.py\", line 338, in _iter\r\n yield from ex_iterable\r\n File \"/home/koush/datasets/src/datasets/iterable_dataset.py\", line 179, in __iter__\r\n key_examples_list = [(key, example)] + [\r\n File \"/home/koush/datasets/src/datasets/iterable_dataset.py\", line 179, in <listcomp>\r\n key_examples_list = [(key, example)] + [\r\n File \"/home/koush/datasets/src/datasets/iterable_dataset.py\", line 176, in __iter__\r\n for key, example in iterator:\r\n File \"/home/koush/datasets/src/datasets/iterable_dataset.py\", line 225, in __iter__\r\n for x in self.ex_iterable:\r\n File \"/home/koush/datasets/src/datasets/iterable_dataset.py\", line 99, in __iter__\r\n for key, example in self.generate_examples_fn(**kwargs_with_shuffled_shards):\r\n File \"/home/koush/datasets/src/datasets/iterable_dataset.py\", line 287, in wrapper\r\n for key, table in generate_tables_fn(**kwargs):\r\n File \"/home/koush/datasets/src/datasets/packaged_modules/json/json.py\", line 107, in _generate_tables\r\n batch = f.read(self.config.chunksize)\r\n File \"/home/koush/datasets/src/datasets/utils/streaming_download_manager.py\", line 136, in read_with_retries\r\n raise ConnectionError(\"Server Disconnected\")\r\nConnectionError: Server Disconnected\r\n```\r\n\r\nRight before this error, the warnings were correctly raised:\r\n\r\n```\r\n10/10/2021 06:02:26 - WARNING - datasets.utils.streaming_download_manager - Got disconnected from remote data host. Retrying in 1sec [1/3]\r\n10/10/2021 06:02:27 - WARNING - datasets.utils.streaming_download_manager - Got disconnected from remote data host. Retrying in 1sec [2/3] \r\n10/10/2021 06:02:28 - WARNING - datasets.utils.streaming_download_manager - Got disconnected from remote data host. Retrying in 1sec [3/3\r\n```\r\n\r\nI'm going to see what happens if I change the max retries to 20 and the interval to 5.",
"Also maybe we can raise the Server Disconnected error with more info about what kind of error caused it (client error, time out, etc.)",
"I have 2 runs:\r\n* [run 1](https://wandb.ai/dalle-mini/dalle-mini/runs/1nj161cl?workspace=user-borisd13) with [this data](https://huggingface.co/datasets/dalle-mini/encoded) that I will remove soon because I now use the 2nd one\r\n* [run 2](https://wandb.ai/dalle-mini/dalle-mini/runs/he9rrc3q?workspace=user-borisd13) with [this data](https://huggingface.co/datasets/dalle-mini/encoded-vqgan_imagenet_f16_16384)\r\n* `load_dataset(dataset_repo, data_files={'train':'data/train/*.jsonl', 'validation':'data/valid/*.jsonl'}, streaming=True)`\r\n\r\nThey have now been running by a bit more than a day for one run and 15h for the other.\r\n\r\nThe error logs are not shown in wandb because the script use `pylogging` (not sure why, I should change it) but basically so far with the new settings I had one timeout in each with successful reconnect afterwards.\r\n\r\nSo I think it's a good idea to have:\r\n* `STREAMING_READ_RETRY_INTERVAL = 5` since before my runs would get 3 errors in a row (with the default 1 second pause)\r\n* `STREAMING_READ_MAX_RETRIES` should also be increased. Since this type of error does not happen a lot, I would still have a large number (at least 10) because a stopped training run may be a big issue if checkpointing/restart is not well implemented which is not always trivial",
"I agree ! Feel free to open a PR to increase both values"
] | "2021-10-09T18:19:20Z" | "2021-10-12T15:28:18Z" | "2021-10-11T09:35:38Z" | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/3050.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3050",
"merged_at": "2021-10-11T09:35:38Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3050.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3050"
} | Catches Timeout error during streaming.
fix #3049 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3050/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3050/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/708 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/708/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/708/comments | https://api.github.com/repos/huggingface/datasets/issues/708/events | https://github.com/huggingface/datasets/issues/708 | 714,020,953 | MDU6SXNzdWU3MTQwMjA5NTM= | 708 | Datasets performance slow? - 6.4x slower than in memory dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/38154?v=4",
"events_url": "https://api.github.com/users/eugeneware/events{/privacy}",
"followers_url": "https://api.github.com/users/eugeneware/followers",
"following_url": "https://api.github.com/users/eugeneware/following{/other_user}",
"gists_url": "https://api.github.com/users/eugeneware/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/eugeneware",
"id": 38154,
"login": "eugeneware",
"node_id": "MDQ6VXNlcjM4MTU0",
"organizations_url": "https://api.github.com/users/eugeneware/orgs",
"received_events_url": "https://api.github.com/users/eugeneware/received_events",
"repos_url": "https://api.github.com/users/eugeneware/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/eugeneware/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/eugeneware/subscriptions",
"type": "User",
"url": "https://api.github.com/users/eugeneware"
} | [] | closed | false | null | [] | null | [
"Facing a similar issue here. My model using SQuAD dataset takes about 1h to process with in memory data and more than 2h with datasets directly.",
"And if you use in-memory-data with datasets with `load_dataset(..., keep_in_memory=True)`?",
"Thanks for the tip @thomwolf ! I did not see that flag in the docs. I'll try with that.",
"We should add it indeed and also maybe a specific section with all the tips for maximal speed. What do you think @lhoestq @SBrandeis @yjernite ?",
"By default the datasets loaded with `load_dataset` live on disk.\r\nIt's possible to load them in memory by using some transforms like `.map(..., keep_in_memory=True)`.\r\n\r\nSmall correction to @thomwolf 's comment above: currently we don't have the `keep_in_memory` parameter for `load_dataset` AFAIK but it would be nice to add it indeed :)",
"Yes indeed we should add it!",
"Great! Thanks a lot.\r\n\r\nI did a test using `map(..., keep_in_memory=True)` and also a test using in-memory only data.\r\n\r\n```python\r\nfeatures = dataset.map(tokenize, batched=True, remove_columns=dataset['train'].column_names)\r\nfeatures.set_format(type='torch', columns=['input_ids', 'token_type_ids', 'attention_mask'])\r\n\r\nfeatures_in_memory = dataset.map(tokenize, batched=True, keep_in_memory=True, remove_columns=dataset['train'].column_names)\r\nfeatures_in_memory.set_format(type='torch', columns=['input_ids', 'token_type_ids', 'attention_mask'])\r\n\r\nin_memory = [features['train'][i] for i in range(len(features['train']))]\r\n```\r\n\r\nFor using the features without any tweak, I got **1min17s** for copying the entire DataLoader to CUDA:\r\n\r\n```\r\n%%time\r\n\r\nfor i, batch in enumerate(DataLoader(features['train'], batch_size=16, num_workers=4)):\r\n batch['input_ids'].to(device)\r\n```\r\n\r\nFor using the features mapped with `keep_in_memory=True`, I also got **1min17s** for copying the entire DataLoader to CUDA:\r\n\r\n```\r\n%%time\r\n\r\nfor i, batch in enumerate(DataLoader(features_in_memory['train'], batch_size=16, num_workers=4)):\r\n batch['input_ids'].to(device)\r\n```\r\n\r\nAnd for the case using every element in memory, converted from the original dataset, I got **12.5s**:\r\n\r\n```\r\n%%time\r\n\r\nfor i, batch in enumerate(DataLoader(in_memory, batch_size=16, num_workers=4)):\r\n batch['input_ids'].to(device)\r\n```\r\n\r\nTaking a closer look in my SQuAD code, using a profiler, I see a lot of calls to `posix read` api. It seems that it is really reliying on disk, which results in a very high train time.",
"I am having the same issue here. When loading from memory I can get the GPU up to 70% util but when loading after mapping I can only get 40%.\r\n\r\nIn disk:\r\n```\r\nbook_corpus = load_dataset('bookcorpus', 'plain_text', cache_dir='/home/ad/Desktop/bookcorpus', split='train[:20%]')\r\nbook_corpus = book_corpus.map(encode, batched=True, num_proc=20, load_from_cache_file=True, batch_size=2500)\r\nbook_corpus.set_format(type='torch', columns=['text', \"input_ids\", \"attention_mask\", \"token_type_ids\"])\r\n\r\ntraining_args = TrainingArguments(\r\n output_dir=\"./mobile_bert_big\",\r\n overwrite_output_dir=True,\r\n num_train_epochs=1,\r\n per_device_train_batch_size=32,\r\n per_device_eval_batch_size=16,\r\n save_steps=50,\r\n save_total_limit=2,\r\n logging_first_step=True,\r\n warmup_steps=100,\r\n logging_steps=50,\r\n eval_steps=100,\r\n no_cuda=False,\r\n gradient_accumulation_steps=16,\r\n fp16=True)\r\n\r\ntrainer = Trainer(\r\n model=model,\r\n args=training_args,\r\n data_collator=data_collator,\r\n train_dataset=book_corpus,\r\n tokenizer=tokenizer)\r\n```\r\n\r\nIn disk I can only get 0,17 it/s:\r\n`[ 13/28907 01:03 < 46:03:27, 0.17 it/s, Epoch 0.00/1] `\r\n\r\nIf I load it with torch.utils.data.Dataset()\r\n```\r\nclass BCorpusDataset(torch.utils.data.Dataset):\r\n def __init__(self, encodings):\r\n self.encodings = encodings\r\n\r\n def __getitem__(self, idx):\r\n item = [torch.tensor(val[idx]) for key, val in self.encodings.items()][0]\r\n return item\r\n\r\n def __len__(self):\r\n length = [len(val) for key, val in self.encodings.items()][0]\r\n return length\r\n\r\n**book_corpus = book_corpus.select([i for i in range(16*2000)])** # filtering to not have 20% of BC in memory...\r\nbook_corpus = book_corpus(book_corpus)\r\n```\r\nI can get:\r\n` [ 5/62 00:09 < 03:03, 0.31 it/s, Epoch 0.06/1]`\r\n\r\nBut obviously I can not get BookCorpus in memory xD\r\n\r\nEDIT: it is something weird. If i load in disk 1% of bookcorpus:\r\n```\r\nbook_corpus = load_dataset('bookcorpus', 'plain_text', cache_dir='/home/ad/Desktop/bookcorpus', split='train[:1%]')\r\n```\r\n\r\nI can get 0.28 it/s, (the same that in memory) but if I load 20% of bookcorpus:\r\n```\r\nbook_corpus = load_dataset('bookcorpus', 'plain_text', cache_dir='/home/ad/Desktop/bookcorpus', split='train[:20%]')\r\n```\r\nI get again 0.17 it/s. \r\n\r\nI am missing something? I think it is something related to size, and not disk or in-memory.",
"There is a way to increase the batches read from memory? or multiprocessed it? I think that one of two or it is reading with just 1 core o it is reading very small chunks from disk and left my GPU at 0 between batches",
"My fault! I had not seen the `dataloader_num_workers` in `TrainingArguments` ! Now I can parallelize and go fast! Sorry, and thanks."
] | "2020-10-03T06:44:07Z" | "2021-02-12T14:13:28Z" | "2021-02-12T14:13:28Z" | NONE | null | null | null | I've been very excited about this amazing datasets project. However, I've noticed that the performance can be substantially slower than using an in-memory dataset.
Now, this is expected I guess, due to memory mapping data using arrow files, and you don't get anything for free. But I was surprised at how much slower.
For example, in the `yelp_polarity` dataset (560000 datapoints, or 17500 batches of 32), it was taking me 3:31 to just get process the data and get it on the GPU (no model involved). Whereas, the equivalent in-memory dataset would finish in just 0:33.
Is this expected? Given that one of the goals of this project is also accelerate dataset processing, this seems a bit slower than I would expect. I understand the advantages of being able to work on datasets that exceed memory, and that's very exciting to me, but thought I'd open this issue to discuss.
For reference I'm running a AMD Ryzen Threadripper 1900X 8-Core Processor CPU, with 128 GB of RAM and an NVME SSD Samsung 960 EVO. I'm running with an RTX Titan 24GB GPU.
I can see with `iotop` that the dataset gets quickly loaded into the system read buffers, and thus doesn't incur any additional IO reads. Thus in theory, all the data *should* be in RAM, but in my benchmark code below it's still 6.4 times slower.
What am I doing wrong? And is there a way to force the datasets to completely load into memory instead of being memory mapped in cases where you want maximum performance?
At 3:31 for 17500 batches, that's 12ms per batch. Does this 12ms just become insignificant as a proportion of forward and backward passes in practice, and thus it's not worth worrying about this in practice?
In any case, here's my code `benchmark.py`. If you run it with an argument of `memory` it will copy the data into memory before executing the same test.
``` py
import sys
from datasets import load_dataset
from transformers import DataCollatorWithPadding, BertTokenizerFast
from torch.utils.data import DataLoader
from tqdm import tqdm
if __name__ == '__main__':
tokenizer = BertTokenizerFast.from_pretrained('bert-base-cased')
collate_fn = DataCollatorWithPadding(tokenizer, padding=True)
ds = load_dataset('yelp_polarity')
def do_tokenize(x):
return tokenizer(x['text'], truncation=True)
ds = ds.map(do_tokenize, batched=True)
ds.set_format('torch', ['input_ids', 'token_type_ids', 'attention_mask'])
if len(sys.argv) == 2 and sys.argv[1] == 'memory':
# copy to memory - probably a faster way to do this - but demonstrates the point
# approximately 530 batches per second - 17500 batches in 0:33
print('using memory')
_ds = [data for data in tqdm(ds['train'])]
else:
# approximately 83 batches per second - 17500 batches in 3:31
print('using datasets')
_ds = ds['train']
dl = DataLoader(_ds, shuffle=True, collate_fn=collate_fn, batch_size=32, num_workers=4)
for data in tqdm(dl):
for k, v in data.items():
data[k] = v.to('cuda')
```
For reference, my conda environment is [here](https://gist.github.com/05b6101518ff70ed42a858b302a0405d)
Once again, I'm very excited about this library, and how easy it is to load datasets, and to do so without worrying about system memory constraints.
Thanks for all your great work.
| {
"+1": 4,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 4,
"url": "https://api.github.com/repos/huggingface/datasets/issues/708/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/708/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5014 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5014/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5014/comments | https://api.github.com/repos/huggingface/datasets/issues/5014/events | https://github.com/huggingface/datasets/issues/5014 | 1,383,422,639 | I_kwDODunzps5SdVqv | 5,014 | I need to read the custom dataset in conll format | {
"avatar_url": "https://avatars.githubusercontent.com/u/39985245?v=4",
"events_url": "https://api.github.com/users/shell-nlp/events{/privacy}",
"followers_url": "https://api.github.com/users/shell-nlp/followers",
"following_url": "https://api.github.com/users/shell-nlp/following{/other_user}",
"gists_url": "https://api.github.com/users/shell-nlp/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/shell-nlp",
"id": 39985245,
"login": "shell-nlp",
"node_id": "MDQ6VXNlcjM5OTg1MjQ1",
"organizations_url": "https://api.github.com/users/shell-nlp/orgs",
"received_events_url": "https://api.github.com/users/shell-nlp/received_events",
"repos_url": "https://api.github.com/users/shell-nlp/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/shell-nlp/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/shell-nlp/subscriptions",
"type": "User",
"url": "https://api.github.com/users/shell-nlp"
} | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | open | false | null | [] | null | [
"Hi! We don't currently have a builder for parsing custom `conll` datasets, but I guess we could add one as a packaged module (similarly to what [TFDS](https://github.com/tensorflow/datasets/blob/master/tensorflow_datasets/core/dataset_builders/conll/conll_dataset_builder.py) did). @lhoestq @albertvillanova WDYT?\r\n\r\nIn the meantime, you can use `Dataset.from_generator` to create a dataset as follows:\r\n```python\r\nfrom datasets import Dataset\r\n\r\n# 2009 version\r\nINPUT_COLUMNS = \"ID FORM LEMMA PLEMMA POS PPOS FEAT PFEAT HEAD PHEAD DEPREL PDEPREL\".split()\r\n\r\ndef read_conll(file):\r\n example = {col: [] for col in INPUT_COLUMNS}\r\n idx = 0\r\n with open(file) as f:\r\n for line in f:\r\n if line.startswith(\"-DOCSTART-\") or line == \"\\n\" or not line:\r\n if example[next(iter(example))]:\r\n yield idx, example\r\n idx += 1\r\n example = {col: [] for col in INPUT_COLUMNS}\r\n else:\r\n row_cols = line.split()\r\n for i, col in enumerate(example):\r\n example[col] = row_cols[i].rstrip()\r\n\r\n# (optional) pass custom features with `features=Features(...)`\r\ndset = Dataset.from_generator(read_conll, gen_kwargs={\"file\": \"path/to/conll/file\"}) \r\n``` ",
"I think we could add a dedicated builder if you think this format is general enough.",
"\r\n\r\n\r\n> I think we could add a dedicated builder if you think this format is general enough.\r\n\r\nI think its functions are incomplete. It should have to_ Conll and from_ There are two methods of conll."
] | "2022-09-23T07:49:42Z" | "2022-11-02T11:57:15Z" | null | NONE | null | null | null | I need to read the custom dataset in conll format
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5014/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5014/timeline | null | reopened | false |
https://api.github.com/repos/huggingface/datasets/issues/6457 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6457/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6457/comments | https://api.github.com/repos/huggingface/datasets/issues/6457/events | https://github.com/huggingface/datasets/issues/6457 | 2,015,650,563 | I_kwDODunzps54JGMD | 6,457 | `TypeError`: huggingface_hub.hf_file_system.HfFileSystem.find() got multiple values for keyword argument 'maxdepth' | {
"avatar_url": "https://avatars.githubusercontent.com/u/79070834?v=4",
"events_url": "https://api.github.com/users/wasertech/events{/privacy}",
"followers_url": "https://api.github.com/users/wasertech/followers",
"following_url": "https://api.github.com/users/wasertech/following{/other_user}",
"gists_url": "https://api.github.com/users/wasertech/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/wasertech",
"id": 79070834,
"login": "wasertech",
"node_id": "MDQ6VXNlcjc5MDcwODM0",
"organizations_url": "https://api.github.com/users/wasertech/orgs",
"received_events_url": "https://api.github.com/users/wasertech/received_events",
"repos_url": "https://api.github.com/users/wasertech/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/wasertech/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/wasertech/subscriptions",
"type": "User",
"url": "https://api.github.com/users/wasertech"
} | [] | closed | false | null | [] | null | [
"Updating `fsspec>=2023.10.0` did solve the issue.",
"May be it should be pinned somewhere?",
"> Maybe this should go in datasets directly... anyways you can easily fix this error by updating datasets>=2.15.1.dev0.\r\n\r\n@lhoestq @mariosasko for what I understand this is a bug fixed in `datasets` already, right? No need to do anything in `huggingface_hub`?",
"I've opened a PR with a fix in `huggingface_hub`: https://github.com/huggingface/huggingface_hub/pull/1875",
"Thanks! PR is merged and will be shipped in next release of `huggingface_hub`."
] | "2023-11-29T01:57:36Z" | "2023-11-29T15:39:03Z" | "2023-11-29T02:02:38Z" | NONE | null | null | null | ### Describe the bug
Please see https://github.com/huggingface/huggingface_hub/issues/1872
### Steps to reproduce the bug
Please see https://github.com/huggingface/huggingface_hub/issues/1872
### Expected behavior
Please see https://github.com/huggingface/huggingface_hub/issues/1872
### Environment info
Please see https://github.com/huggingface/huggingface_hub/issues/1872 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6457/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6457/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5356 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5356/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5356/comments | https://api.github.com/repos/huggingface/datasets/issues/5356/events | https://github.com/huggingface/datasets/pull/5356 | 1,494,961,609 | PR_kwDODunzps5FW-c9 | 5,356 | Clean filesystem and logging docstrings | {
"avatar_url": "https://avatars.githubusercontent.com/u/59462357?v=4",
"events_url": "https://api.github.com/users/stevhliu/events{/privacy}",
"followers_url": "https://api.github.com/users/stevhliu/followers",
"following_url": "https://api.github.com/users/stevhliu/following{/other_user}",
"gists_url": "https://api.github.com/users/stevhliu/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/stevhliu",
"id": 59462357,
"login": "stevhliu",
"node_id": "MDQ6VXNlcjU5NDYyMzU3",
"organizations_url": "https://api.github.com/users/stevhliu/orgs",
"received_events_url": "https://api.github.com/users/stevhliu/received_events",
"repos_url": "https://api.github.com/users/stevhliu/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/stevhliu/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/stevhliu/subscriptions",
"type": "User",
"url": "https://api.github.com/users/stevhliu"
} | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._"
] | "2022-12-13T18:54:09Z" | "2022-12-14T17:25:58Z" | "2022-12-14T17:22:16Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/5356.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5356",
"merged_at": "2022-12-14T17:22:16Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5356.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5356"
} | This PR cleans the `Filesystems` and `Logging` docstrings. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5356/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5356/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3057 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3057/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3057/comments | https://api.github.com/repos/huggingface/datasets/issues/3057/events | https://github.com/huggingface/datasets/issues/3057 | 1,022,508,315 | I_kwDODunzps488j0b | 3,057 | Error in per class precision computation | {
"avatar_url": "https://avatars.githubusercontent.com/u/38906722?v=4",
"events_url": "https://api.github.com/users/tidhamecha2/events{/privacy}",
"followers_url": "https://api.github.com/users/tidhamecha2/followers",
"following_url": "https://api.github.com/users/tidhamecha2/following{/other_user}",
"gists_url": "https://api.github.com/users/tidhamecha2/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/tidhamecha2",
"id": 38906722,
"login": "tidhamecha2",
"node_id": "MDQ6VXNlcjM4OTA2NzIy",
"organizations_url": "https://api.github.com/users/tidhamecha2/orgs",
"received_events_url": "https://api.github.com/users/tidhamecha2/received_events",
"repos_url": "https://api.github.com/users/tidhamecha2/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/tidhamecha2/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/tidhamecha2/subscriptions",
"type": "User",
"url": "https://api.github.com/users/tidhamecha2"
} | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | [] | null | [
"Hi @tidhamecha2, thanks for reporting.\r\n\r\nIndeed, we fixed this issue just one week ago: #3008\r\n\r\nThe fix will be included in our next version release.\r\n\r\nIn the meantime, you can incorporate the fix by installing `datasets` from the master branch:\r\n```\r\npip install -U git+ssh://[email protected]/huggingface/datasets.git@master#egg=datasest\r\n```\r\nor\r\n```\r\npip install -U git+https://github.com/huggingface/datasets.git@master#egg=datasets\r\n```"
] | "2021-10-11T10:05:19Z" | "2021-10-11T10:17:44Z" | "2021-10-11T10:16:16Z" | NONE | null | null | null | ## Describe the bug
When trying to get the per class precision values by providing `average=None`, following error is thrown `ValueError: can only convert an array of size 1 to a Python scalar`
## Steps to reproduce the bug
```python
from datasets import load_dataset, load_metric
precision_metric = load_metric("precision")
predictions = [0, 2, 1, 0, 0, 1]
references = [0, 1, 2, 0, 1, 2]
results = precision_metric.compute(predictions=predictions, references=references, average=None)
```
## Expected results
` {'precision': array([0.66666667, 0. , 0. ])}`
as per https://github.com/huggingface/datasets/blob/master/metrics/precision/precision.py
## Actual results
```
output = self._compute(predictions=predictions, references=references, **kwargs)
File "~/.cache/huggingface/modules/datasets_modules/metrics/precision/94709a71c6fe37171ef49d3466fec24dee9a79846c9f176dff66a649e9811690/precision.py", line 110, in _compute
sample_weight=sample_weight,
ValueError: can only convert an array of size 1 to a Python scalar
```
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.12.1
- Platform: linux
- Python version: 3.6.9
- PyArrow version: 5.0.0
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3057/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3057/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/6500 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6500/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6500/comments | https://api.github.com/repos/huggingface/datasets/issues/6500/events | https://github.com/huggingface/datasets/pull/6500 | 2,043,258,633 | PR_kwDODunzps5iFc6e | 6,500 | Enable setting config as default when push_to_hub | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
} | [] | closed | false | null | [] | null | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_6500). All of your documentation changes will be reflected on that endpoint. The docs are available until 30 days after the last update.",
"This is ready for review @huggingface/datasets. ",
"Also what if the config is being overwritten and it was the default config and the user doesn't pass `set_default` ?\r\nI'd expect the config to keep being the default one but lmk what you think",
"How can you unset a config as the default one? In the case you mentioned, I would expect the config not being the default one.",
"Maybe by passing `set_default=False` ? (set_default can be None by default)",
"I think that way we are unnecessarily complicating the logic of `push_to_hub` and as I told you, I would expect the contrary: the result of calling `push_to_hub` with a determined set of arguments should always be the same, independently of previous calls and the current state of the config on the Hub. Push to hub should be somehow stateless in that sense, and IMO the user expects that the push overwrites previous config if already present on the Hub. I find very confusing making it to partially update the config on the Hub.",
"That makes sense, having it stateless is simpler and no need to do something too fancy indeed",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.005329 / 0.011353 (-0.006024) | 0.002998 / 0.011008 (-0.008010) | 0.063756 / 0.038508 (0.025248) | 0.051713 / 0.023109 (0.028603) | 0.248135 / 0.275898 (-0.027763) | 0.269136 / 0.323480 (-0.054344) | 0.002970 / 0.007986 (-0.005015) | 0.002566 / 0.004328 (-0.001763) | 0.048110 / 0.004250 (0.043859) | 0.038415 / 0.037052 (0.001363) | 0.254012 / 0.258489 (-0.004477) | 0.281915 / 0.293841 (-0.011926) | 0.027503 / 0.128546 (-0.101043) | 0.010370 / 0.075646 (-0.065276) | 0.208965 / 0.419271 (-0.210306) | 0.035508 / 0.043533 (-0.008024) | 0.249116 / 0.255139 (-0.006023) | 0.266350 / 0.283200 (-0.016850) | 0.018440 / 0.141683 (-0.123243) | 1.101089 / 1.452155 (-0.351066) | 1.164870 / 1.492716 (-0.327847) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.090909 / 0.018006 (0.072903) | 0.298041 / 0.000490 (0.297551) | 0.000211 / 0.000200 (0.000012) | 0.000051 / 0.000054 (-0.000004) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.018137 / 0.037411 (-0.019275) | 0.059574 / 0.014526 (0.045048) | 0.071754 / 0.176557 (-0.104803) | 0.117980 / 0.737135 (-0.619155) | 0.072903 / 0.296338 (-0.223435) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.282844 / 0.215209 (0.067635) | 2.740916 / 2.077655 (0.663261) | 1.444546 / 1.504120 (-0.059574) | 1.321904 / 1.541195 (-0.219291) | 1.356957 / 1.468490 (-0.111533) | 0.568389 / 4.584777 (-4.016388) | 2.354042 / 3.745712 (-1.391671) | 2.719427 / 5.269862 (-2.550435) | 1.719616 / 4.565676 (-2.846061) | 0.062537 / 0.424275 (-0.361738) | 0.004915 / 0.007607 (-0.002692) | 0.334716 / 0.226044 (0.108672) | 3.299499 / 2.268929 (1.030571) | 1.814629 / 55.444624 (-53.629996) | 1.515245 / 6.876477 (-5.361232) | 1.553085 / 2.142072 (-0.588987) | 0.643859 / 4.805227 (-4.161368) | 0.116650 / 6.500664 (-6.384014) | 0.041432 / 0.075469 (-0.034037) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.948227 / 1.841788 (-0.893561) | 11.331103 / 8.074308 (3.256795) | 10.209658 / 10.191392 (0.018266) | 0.126721 / 0.680424 (-0.553703) | 0.013638 / 0.534201 (-0.520563) | 0.282540 / 0.579283 (-0.296743) | 0.262635 / 0.434364 (-0.171729) | 0.335357 / 0.540337 (-0.204981) | 0.441798 / 1.386936 (-0.945138) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.005200 / 0.011353 (-0.006153) | 0.003012 / 0.011008 (-0.007996) | 0.047571 / 0.038508 (0.009063) | 0.055069 / 0.023109 (0.031959) | 0.271150 / 0.275898 (-0.004748) | 0.294957 / 0.323480 (-0.028523) | 0.003922 / 0.007986 (-0.004064) | 0.002627 / 0.004328 (-0.001702) | 0.047777 / 0.004250 (0.043527) | 0.039507 / 0.037052 (0.002454) | 0.276314 / 0.258489 (0.017825) | 0.300436 / 0.293841 (0.006595) | 0.028951 / 0.128546 (-0.099595) | 0.010583 / 0.075646 (-0.065063) | 0.056535 / 0.419271 (-0.362737) | 0.032654 / 0.043533 (-0.010879) | 0.272945 / 0.255139 (0.017806) | 0.291909 / 0.283200 (0.008709) | 0.017545 / 0.141683 (-0.124138) | 1.195897 / 1.452155 (-0.256258) | 1.171855 / 1.492716 (-0.320861) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.091919 / 0.018006 (0.073913) | 0.299297 / 0.000490 (0.298807) | 0.000225 / 0.000200 (0.000025) | 0.000051 / 0.000054 (-0.000003) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.022271 / 0.037411 (-0.015140) | 0.068903 / 0.014526 (0.054377) | 0.083767 / 0.176557 (-0.092790) | 0.120239 / 0.737135 (-0.616896) | 0.083448 / 0.296338 (-0.212891) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.295353 / 0.215209 (0.080144) | 2.911452 / 2.077655 (0.833798) | 1.577941 / 1.504120 (0.073821) | 1.454514 / 1.541195 (-0.086681) | 1.459575 / 1.468490 (-0.008915) | 0.572475 / 4.584777 (-4.012302) | 2.443634 / 3.745712 (-1.302078) | 2.801171 / 5.269862 (-2.468691) | 1.724214 / 4.565676 (-2.841462) | 0.063539 / 0.424275 (-0.360736) | 0.004939 / 0.007607 (-0.002668) | 0.347705 / 0.226044 (0.121660) | 3.489591 / 2.268929 (1.220663) | 1.944952 / 55.444624 (-53.499672) | 1.652810 / 6.876477 (-5.223667) | 1.656361 / 2.142072 (-0.485712) | 0.647052 / 4.805227 (-4.158176) | 0.117286 / 6.500664 (-6.383379) | 0.040979 / 0.075469 (-0.034490) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.971761 / 1.841788 (-0.870027) | 11.770547 / 8.074308 (3.696239) | 10.402502 / 10.191392 (0.211110) | 0.128280 / 0.680424 (-0.552144) | 0.015160 / 0.534201 (-0.519041) | 0.286706 / 0.579283 (-0.292578) | 0.274539 / 0.434364 (-0.159825) | 0.324591 / 0.540337 (-0.215747) | 0.573846 / 1.386936 (-0.813090) |\n\n</details>\n</details>\n\n\n"
] | "2023-12-15T09:17:41Z" | "2023-12-18T11:56:11Z" | "2023-12-18T11:50:03Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/6500.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6500",
"merged_at": "2023-12-18T11:50:03Z",
"patch_url": "https://github.com/huggingface/datasets/pull/6500.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/6500"
} | Fix #6497. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 1,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6500/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6500/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5857 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5857/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5857/comments | https://api.github.com/repos/huggingface/datasets/issues/5857/events | https://github.com/huggingface/datasets/issues/5857 | 1,709,326,622 | I_kwDODunzps5l4kEe | 5,857 | Adding chemistry dataset/models in huggingface | {
"avatar_url": "https://avatars.githubusercontent.com/u/16902896?v=4",
"events_url": "https://api.github.com/users/knc6/events{/privacy}",
"followers_url": "https://api.github.com/users/knc6/followers",
"following_url": "https://api.github.com/users/knc6/following{/other_user}",
"gists_url": "https://api.github.com/users/knc6/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/knc6",
"id": 16902896,
"login": "knc6",
"node_id": "MDQ6VXNlcjE2OTAyODk2",
"organizations_url": "https://api.github.com/users/knc6/orgs",
"received_events_url": "https://api.github.com/users/knc6/received_events",
"repos_url": "https://api.github.com/users/knc6/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/knc6/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/knc6/subscriptions",
"type": "User",
"url": "https://api.github.com/users/knc6"
} | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | closed | false | null | [] | null | [
"Hi! \r\n\r\nThis would be a nice addition to the Hub! You can find the existing chemistry datasets/models on the Hub (using the `chemistry` tag) [here](https://huggingface.co/search/full-text?q=chemistry&type=model&type=dataset).\r\n\r\nFeel free to ping us here on the Hub if you need help adding the datasets.\r\n"
] | "2023-05-15T05:09:49Z" | "2023-07-21T13:45:40Z" | "2023-07-21T13:45:40Z" | NONE | null | null | null | ### Feature request
Huggingface is really amazing platform for open science.
In addition to computer vision, video and NLP, would it be of interest to add chemistry/materials science dataset/models in Huggingface? Or, if its already done, can you provide some pointers.
We have been working on a comprehensive benchmark on this topic: [JARVIS-Leaderboard](https://pages.nist.gov/jarvis_leaderboard/) and I am wondering if we could contribute/integrate this project as a part of huggingface.
### Motivation
Similar to the main stream AI field, there is need of large scale benchmarks/models/infrastructure for chemistry/materials data.
### Your contribution
We can start adding datasets as our [benchmarks](https://github.com/usnistgov/jarvis_leaderboard/tree/main/jarvis_leaderboard/benchmarks) should be easily convertible to the dataset format. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5857/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5857/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/4234 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4234/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4234/comments | https://api.github.com/repos/huggingface/datasets/issues/4234/events | https://github.com/huggingface/datasets/pull/4234 | 1,216,818,846 | PR_kwDODunzps422Mwn | 4,234 | Autoeval config | {
"avatar_url": "https://avatars.githubusercontent.com/u/3278583?v=4",
"events_url": "https://api.github.com/users/nazneenrajani/events{/privacy}",
"followers_url": "https://api.github.com/users/nazneenrajani/followers",
"following_url": "https://api.github.com/users/nazneenrajani/following{/other_user}",
"gists_url": "https://api.github.com/users/nazneenrajani/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/nazneenrajani",
"id": 3278583,
"login": "nazneenrajani",
"node_id": "MDQ6VXNlcjMyNzg1ODM=",
"organizations_url": "https://api.github.com/users/nazneenrajani/orgs",
"received_events_url": "https://api.github.com/users/nazneenrajani/received_events",
"repos_url": "https://api.github.com/users/nazneenrajani/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/nazneenrajani/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/nazneenrajani/subscriptions",
"type": "User",
"url": "https://api.github.com/users/nazneenrajani"
} | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"Related to: https://github.com/huggingface/autonlp-backend/issues/414 and https://github.com/huggingface/autonlp-backend/issues/424",
"The tests are failing due to the changed metadata:\r\n\r\n```\r\ngot an unexpected keyword argument 'train-eval-index'\r\n```\r\n\r\nI think you can fix this by updating the `DatasetMetadata` class and implementing an appropriate `validate_train_eval_index()` function\r\n\r\n@lhoestq we are working with an arbitrary set of tags for `autoeval config`. See https://github.com/huggingface/autonlp-backend/issues/414\r\nI need to add a validator function though for the tests to pass. Our set is not well-defined as in the rest https://github.com/huggingface/datasets/tree/master/src/datasets/utils/resources. What's a workaround for this?",
"On the question of validating the `train-eval-index` metadata, I think the simplest approach would be to validate that the required fields exist and not worry about their values (which are open-ended).\r\n\r\nFor me, the required fields include:\r\n\r\n* `config`\r\n* `task`\r\n* `task_id`\r\n* `splits` (train / validation / eval)\r\n* `col_mapping`\r\n* `metrics` (checking that each one has `type`, `name`) \r\n\r\nHere I'm using the spec defined in https://github.com/huggingface/autonlp-backend/issues/414 as a guide.\r\n\r\nWDYT @lhoestq ?",
"Makes sense ! Currently the metadata type validator doesn't support subfields - let me open a PR to add it",
"I ended up improving the metadata validation in this PR x)\r\n\r\nIn particular:\r\n- I added support YAML keys with dashes instead of underscores for `train-eval-index`\r\n- I added `train-eval-index` validation with `validate_train_eval_index`. It does nothing fancy, it just checks that it is a list if it exists in the YAML, but feel free to improve it if you want\r\n\r\nLet me know if it sounds good to you ! I think we can improve `validate_train_eval_index` in another PR",
"Come on windows... I didn't do anything advanced...\r\n\r\nAnyway, will try to fix this when I get back home x)",
"> Come on windows... I didn't do anything advanced...\r\n> \r\n> Anyway, will try to fix this when I get back home x)\r\n\r\nHehe, thanks!",
"Thanks, @lhoestq this is great! ",
"Did I just fix it for windows and now it fails on linux ? xD",
"> Did I just fix it for windows and now it fails on linux ? xD\r\n\r\nLooks like the Heisenberg uncertainty principle is at play here - you cannot simultaneously have unit tests passing in both Linux and Windows 😅 ",
"The worst is that the tests pass locally both on my windows and my linux x)",
"Ok fixed it, the issue came from python 3.6 that doesn't return the right `__origin__` for Dict and List types",
"> Alright thanks for adding the first Autoeval config ! :D\r\n\r\nWoohoo! Thank you so much 🤗 ",
"This is cool!"
] | "2022-04-27T05:32:10Z" | "2022-05-06T13:20:31Z" | "2022-05-05T18:20:58Z" | NONE | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/4234.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4234",
"merged_at": "2022-05-05T18:20:58Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4234.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4234"
} | Added autoeval config to imdb as pilot | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4234/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4234/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4790 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4790/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4790/comments | https://api.github.com/repos/huggingface/datasets/issues/4790/events | https://github.com/huggingface/datasets/issues/4790 | 1,328,546,904 | I_kwDODunzps5PMARY | 4,790 | Issue with fine classes in trec dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
} | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
} | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
}
] | null | [] | "2022-08-04T12:28:51Z" | "2022-08-22T16:14:16Z" | "2022-08-22T16:14:16Z" | MEMBER | null | null | null | ## Describe the bug
According to their paper, the TREC dataset contains 2 kinds of classes:
- 6 coarse classes: TREC-6
- 50 fine classes: TREC-50
However, our implementation only has 47 (instead of 50) fine classes. The reason for this is that we only considered the last segment of the label, which is repeated for several coarse classes:
- We have one `desc` fine label instead of 2:
- `DESC:desc`
- `HUM:desc`
- We have one `other` fine label instead of 3:
- `ENTY:other`
- `LOC:other`
- `NUM:other`
From their paper:
> We define a two-layered taxonomy, which represents a natural semantic classification for typical answers in the TREC task. The hierarchy contains 6 coarse classes and 50 fine classes,
> Each coarse class contains a non-overlapping set of fine classes.
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4790/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4790/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/6263 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6263/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6263/comments | https://api.github.com/repos/huggingface/datasets/issues/6263/events | https://github.com/huggingface/datasets/issues/6263 | 1,914,951,043 | I_kwDODunzps5yI9WD | 6,263 | CI is broken: ImportError: cannot import name 'context' from 'tensorflow.python' | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
} | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
} | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
}
] | null | [] | "2023-09-27T08:12:05Z" | "2023-09-27T08:36:40Z" | "2023-09-27T08:36:40Z" | MEMBER | null | null | null | Python 3.10 CI is broken for `test_py310`.
See: https://github.com/huggingface/datasets/actions/runs/6322990957/job/17169678812?pr=6262
```
FAILED tests/test_py_utils.py::TempSeedTest::test_tensorflow - ImportError: cannot import name 'context' from 'tensorflow.python' (/opt/hostedtoolcache/Python/3.10.13/x64/lib/python3.10/site-packages/tensorflow/python/__init__.py)
```
```
_________________________ TempSeedTest.test_tensorflow _________________________
[gw1] linux -- Python 3.10.13 /opt/hostedtoolcache/Python/3.10.13/x64/bin/python
self = <tests.test_py_utils.TempSeedTest testMethod=test_tensorflow>
@require_tf
def test_tensorflow(self):
import tensorflow as tf
from tensorflow.keras import layers
model = layers.Dense(2)
def gen_random_output():
x = tf.random.uniform((1, 3))
return model(x).numpy()
> with temp_seed(42, set_tensorflow=True):
tests/test_py_utils.py:155:
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
/opt/hostedtoolcache/Python/3.10.13/x64/lib/python3.10/contextlib.py:135: in __enter__
return next(self.gen)
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
seed = 42, set_pytorch = False, set_tensorflow = True
@contextmanager
def temp_seed(seed: int, set_pytorch=False, set_tensorflow=False):
"""Temporarily set the random seed. This works for python numpy, pytorch and tensorflow."""
np_state = np.random.get_state()
np.random.seed(seed)
if set_pytorch and config.TORCH_AVAILABLE:
import torch
torch_state = torch.random.get_rng_state()
torch.random.manual_seed(seed)
if torch.cuda.is_available():
torch_cuda_states = torch.cuda.get_rng_state_all()
torch.cuda.manual_seed_all(seed)
if set_tensorflow and config.TF_AVAILABLE:
import tensorflow as tf
> from tensorflow.python import context as tfpycontext
E ImportError: cannot import name 'context' from 'tensorflow.python' (/opt/hostedtoolcache/Python/3.10.13/x64/lib/python3.10/site-packages/tensorflow/python/__init__.py)
/opt/hostedtoolcache/Python/3.10.13/x64/lib/python3.10/site-packages/datasets/utils/py_utils.py:257: ImportError
``` | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6263/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6263/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/162 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/162/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/162/comments | https://api.github.com/repos/huggingface/datasets/issues/162/events | https://github.com/huggingface/datasets/pull/162 | 620,513,554 | MDExOlB1bGxSZXF1ZXN0NDE5NzQ4Mzky | 162 | fix prev files hash in map | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq"
} | [] | closed | false | null | [] | null | [
"Awesome! ",
"Hi, yes, this seems to fix #160 -- I cloned the branch locally and verified",
"Perfect then :)"
] | "2020-05-18T21:20:51Z" | "2020-05-18T21:36:21Z" | "2020-05-18T21:36:20Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/162.diff",
"html_url": "https://github.com/huggingface/datasets/pull/162",
"merged_at": "2020-05-18T21:36:20Z",
"patch_url": "https://github.com/huggingface/datasets/pull/162.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/162"
} | Fix the `.map` issue in #160.
This makes sure it takes the previous files when computing the hash. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/162/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/162/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/2280 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2280/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2280/comments | https://api.github.com/repos/huggingface/datasets/issues/2280/events | https://github.com/huggingface/datasets/pull/2280 | 870,780,431 | MDExOlB1bGxSZXF1ZXN0NjI1OTE2Mzcy | 2,280 | Fixed typo seperate->separate | {
"avatar_url": "https://avatars.githubusercontent.com/u/32505743?v=4",
"events_url": "https://api.github.com/users/laksh9950/events{/privacy}",
"followers_url": "https://api.github.com/users/laksh9950/followers",
"following_url": "https://api.github.com/users/laksh9950/following{/other_user}",
"gists_url": "https://api.github.com/users/laksh9950/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/laksh9950",
"id": 32505743,
"login": "laksh9950",
"node_id": "MDQ6VXNlcjMyNTA1NzQz",
"organizations_url": "https://api.github.com/users/laksh9950/orgs",
"received_events_url": "https://api.github.com/users/laksh9950/received_events",
"repos_url": "https://api.github.com/users/laksh9950/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/laksh9950/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/laksh9950/subscriptions",
"type": "User",
"url": "https://api.github.com/users/laksh9950"
} | [] | closed | false | null | [] | null | [
"Hi ! Thanks for the fix :)\r\nThe CI fail isn't related to your PR. I opened a PR #2286 to fix the CI.\r\nWe'll wait for #2286 to be merged to master first if you don't mind",
"The PR has been merged ! Feel free to merge master into your branch to fix the CI"
] | "2021-04-29T08:55:46Z" | "2021-04-29T16:41:22Z" | "2021-04-29T16:41:16Z" | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/2280.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2280",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/2280.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2280"
} | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2280/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2280/timeline | null | null | true |
|
https://api.github.com/repos/huggingface/datasets/issues/3705 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3705/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3705/comments | https://api.github.com/repos/huggingface/datasets/issues/3705/events | https://github.com/huggingface/datasets/pull/3705 | 1,132,053,226 | PR_kwDODunzps4yfhyj | 3,705 | Raise informative error when loading a save_to_disk dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
} | [] | closed | false | null | [] | null | [] | "2022-02-11T08:21:03Z" | "2022-02-11T22:56:40Z" | "2022-02-11T22:56:39Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/3705.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3705",
"merged_at": "2022-02-11T22:56:39Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3705.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3705"
} | People recurrently report error when trying to load a dataset (using `load_dataset`) that was previously saved using `save_to_disk`.
This PR raises an informative error message telling them they should use `load_from_disk` instead.
Close #3700. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3705/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3705/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/2900 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2900/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2900/comments | https://api.github.com/repos/huggingface/datasets/issues/2900/events | https://github.com/huggingface/datasets/pull/2900 | 994,922,580 | MDExOlB1bGxSZXF1ZXN0NzMyNzczNDkw | 2,900 | Fix null sequence encoding | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq"
} | [] | closed | false | null | [] | null | [] | "2021-09-13T13:55:08Z" | "2021-09-13T14:17:43Z" | "2021-09-13T14:17:42Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/2900.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2900",
"merged_at": "2021-09-13T14:17:42Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2900.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2900"
} | The Sequence feature encoding was failing when a `None` sequence was used in a dataset.
Fix https://github.com/huggingface/datasets/issues/2892 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2900/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2900/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/1116 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1116/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1116/comments | https://api.github.com/repos/huggingface/datasets/issues/1116/events | https://github.com/huggingface/datasets/pull/1116 | 757,133,502 | MDExOlB1bGxSZXF1ZXN0NTMyNTYwNDk4 | 1,116 | add dbpedia_14 dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/29229602?v=4",
"events_url": "https://api.github.com/users/hfawaz/events{/privacy}",
"followers_url": "https://api.github.com/users/hfawaz/followers",
"following_url": "https://api.github.com/users/hfawaz/following{/other_user}",
"gists_url": "https://api.github.com/users/hfawaz/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/hfawaz",
"id": 29229602,
"login": "hfawaz",
"node_id": "MDQ6VXNlcjI5MjI5NjAy",
"organizations_url": "https://api.github.com/users/hfawaz/orgs",
"received_events_url": "https://api.github.com/users/hfawaz/received_events",
"repos_url": "https://api.github.com/users/hfawaz/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/hfawaz/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/hfawaz/subscriptions",
"type": "User",
"url": "https://api.github.com/users/hfawaz"
} | [] | closed | false | null | [] | null | [
"Thanks for the review. \r\nCheers!",
"Hi @hfawaz, this week we are doing the 🤗 `datasets` sprint (see some details [here](https://discuss.huggingface.co/t/open-to-the-community-one-week-team-effort-to-reach-v2-0-of-hf-datasets-library/2176)).\r\n\r\nNothing more to do on your side but it means that if you register on the thread I linked above, you can have some goodies for the present dataset that you have already added (and a special goodie if you want to spend more time and add 2 other datasets as well).\r\n\r\nIf you want to join, just tell me (or post on the thread on the HuggingFace forum: https://discuss.huggingface.co/t/open-to-the-community-one-week-team-effort-to-reach-v2-0-of-hf-datasets-library/2176)",
"Hello @thomwolf \r\nThanks for the feedback and for this invitation, indeed I would be glad to join you guys (you can add me). \r\nI will see if I have the time to implement a couple of datasets. \r\nCheers! ",
"@hfawaz invited you to the slack with your uha email.\r\n\r\nCheck your spam folder if you can't find the invitation :)",
"Oh thanks, but can you invite me on my gmail: [email protected] \r\nUHA is my old organization, I haven't had the time to update my online profiles yet.\r\nThank you "
] | "2020-12-04T14:13:59Z" | "2020-12-07T10:06:54Z" | "2020-12-05T15:36:23Z" | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/1116.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1116",
"merged_at": "2020-12-05T15:36:23Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1116.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1116"
} | This dataset corresponds to the DBpedia dataset requested in https://github.com/huggingface/datasets/issues/353. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1116/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1116/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/1517 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1517/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1517/comments | https://api.github.com/repos/huggingface/datasets/issues/1517/events | https://github.com/huggingface/datasets/pull/1517 | 764,045,214 | MDExOlB1bGxSZXF1ZXN0NTM4MzAyNDM1 | 1,517 | Kd conv smangrul | {
"avatar_url": "https://avatars.githubusercontent.com/u/13534540?v=4",
"events_url": "https://api.github.com/users/pacman100/events{/privacy}",
"followers_url": "https://api.github.com/users/pacman100/followers",
"following_url": "https://api.github.com/users/pacman100/following{/other_user}",
"gists_url": "https://api.github.com/users/pacman100/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/pacman100",
"id": 13534540,
"login": "pacman100",
"node_id": "MDQ6VXNlcjEzNTM0NTQw",
"organizations_url": "https://api.github.com/users/pacman100/orgs",
"received_events_url": "https://api.github.com/users/pacman100/received_events",
"repos_url": "https://api.github.com/users/pacman100/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/pacman100/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/pacman100/subscriptions",
"type": "User",
"url": "https://api.github.com/users/pacman100"
} | [] | closed | false | null | [] | null | [
"Hii please follow me",
"merging since the CI is fixed on master"
] | "2020-12-12T16:51:30Z" | "2020-12-16T14:56:14Z" | "2020-12-16T14:56:14Z" | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/1517.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1517",
"merged_at": "2020-12-16T14:56:14Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1517.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1517"
} | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1517/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1517/timeline | null | null | true |
|
https://api.github.com/repos/huggingface/datasets/issues/2107 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2107/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2107/comments | https://api.github.com/repos/huggingface/datasets/issues/2107/events | https://github.com/huggingface/datasets/pull/2107 | 839,495,825 | MDExOlB1bGxSZXF1ZXN0NTk5NTAxODE5 | 2,107 | Metadata validation | {
"avatar_url": "https://avatars.githubusercontent.com/u/17948980?v=4",
"events_url": "https://api.github.com/users/theo-m/events{/privacy}",
"followers_url": "https://api.github.com/users/theo-m/followers",
"following_url": "https://api.github.com/users/theo-m/following{/other_user}",
"gists_url": "https://api.github.com/users/theo-m/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/theo-m",
"id": 17948980,
"login": "theo-m",
"node_id": "MDQ6VXNlcjE3OTQ4OTgw",
"organizations_url": "https://api.github.com/users/theo-m/orgs",
"received_events_url": "https://api.github.com/users/theo-m/received_events",
"repos_url": "https://api.github.com/users/theo-m/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/theo-m/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/theo-m/subscriptions",
"type": "User",
"url": "https://api.github.com/users/theo-m"
} | [] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/33657802?v=4",
"events_url": "https://api.github.com/users/SBrandeis/events{/privacy}",
"followers_url": "https://api.github.com/users/SBrandeis/followers",
"following_url": "https://api.github.com/users/SBrandeis/following{/other_user}",
"gists_url": "https://api.github.com/users/SBrandeis/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/SBrandeis",
"id": 33657802,
"login": "SBrandeis",
"node_id": "MDQ6VXNlcjMzNjU3ODAy",
"organizations_url": "https://api.github.com/users/SBrandeis/orgs",
"received_events_url": "https://api.github.com/users/SBrandeis/received_events",
"repos_url": "https://api.github.com/users/SBrandeis/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/SBrandeis/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/SBrandeis/subscriptions",
"type": "User",
"url": "https://api.github.com/users/SBrandeis"
} | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/33657802?v=4",
"events_url": "https://api.github.com/users/SBrandeis/events{/privacy}",
"followers_url": "https://api.github.com/users/SBrandeis/followers",
"following_url": "https://api.github.com/users/SBrandeis/following{/other_user}",
"gists_url": "https://api.github.com/users/SBrandeis/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/SBrandeis",
"id": 33657802,
"login": "SBrandeis",
"node_id": "MDQ6VXNlcjMzNjU3ODAy",
"organizations_url": "https://api.github.com/users/SBrandeis/orgs",
"received_events_url": "https://api.github.com/users/SBrandeis/received_events",
"repos_url": "https://api.github.com/users/SBrandeis/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/SBrandeis/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/SBrandeis/subscriptions",
"type": "User",
"url": "https://api.github.com/users/SBrandeis"
}
] | null | [
"> Also I was wondering this is really needed to have `utils.metadata` as a submodule of `datasets` ? This is only used by the CI so I'm not sure we should have this in the actual `datasets` package.\r\n\r\nI'm unclear on the suggestion, would you rather have a root-level `./metadata.py` file? I think it's well where it is, if anything we could move it out of utils and into `datasets` as it could be used by e.g. `DatasetDict` so that users can pull the metadata easily rather than have to reparse the readme.\r\n",
"Ok that makes sense if we want to have functions that parse the metadata for users",
"Hi @theo-m @lhoestq \r\n\r\nThis seems very interesting. Should I add the descriptions to the PR on `datasets-tagging`? Alternatively, I can also create a google-sheet/markdown table :)\r\n\r\nSorry for the delay in responding.\r\n\r\nThanks,\r\nGunjan",
"> Hi @theo-m @lhoestq\r\n> \r\n> This seems very interesting. Should I add the descriptions to the PR on `datasets-tagging`? Alternatively, I can also create a google-sheet/markdown table :)\r\n> \r\n> Sorry for the delay in responding.\r\n> \r\n> Thanks,\r\n> Gunjan\r\n\r\nHi @gchhablani, yes I think at the moment the best solution is for you to write in `datasets-tagging`, as the PR will allow us to discuss and review, even though the work will be ported to this repo in the end. \r\nOr we wait for this to be merged and you reopen the PR here, your call :)",
"cc @abhi1thakur "
] | "2021-03-24T08:52:41Z" | "2021-04-26T08:27:14Z" | "2021-04-26T08:27:13Z" | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/2107.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2107",
"merged_at": "2021-04-26T08:27:13Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2107.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2107"
} | - `pydantic` metadata schema with dedicated validators against our taxonomy
- ci script to validate new changes against this schema and start a vertuous loop
- soft validation on tasks ids since we expect the taxonomy to undergo some changes in the near future
for reference with the current validation we have ~365~ 378 datasets with invalid metadata! full error report [_here_.](https://gist.github.com/theo-m/61b3c0c47fc6121d08d3174bd4c2a26b) | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2107/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2107/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/118 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/118/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/118/comments | https://api.github.com/repos/huggingface/datasets/issues/118/events | https://github.com/huggingface/datasets/issues/118 | 618,643,088 | MDU6SXNzdWU2MTg2NDMwODg= | 118 | ❓ How to apply a map to all subsets ? | {
"avatar_url": "https://avatars.githubusercontent.com/u/43774355?v=4",
"events_url": "https://api.github.com/users/astariul/events{/privacy}",
"followers_url": "https://api.github.com/users/astariul/followers",
"following_url": "https://api.github.com/users/astariul/following{/other_user}",
"gists_url": "https://api.github.com/users/astariul/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/astariul",
"id": 43774355,
"login": "astariul",
"node_id": "MDQ6VXNlcjQzNzc0MzU1",
"organizations_url": "https://api.github.com/users/astariul/orgs",
"received_events_url": "https://api.github.com/users/astariul/received_events",
"repos_url": "https://api.github.com/users/astariul/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/astariul/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/astariul/subscriptions",
"type": "User",
"url": "https://api.github.com/users/astariul"
} | [] | closed | false | null | [] | null | [
"That's the way!"
] | "2020-05-15T01:58:52Z" | "2020-05-15T07:05:49Z" | "2020-05-15T07:04:25Z" | NONE | null | null | null | I'm working with CNN/DM dataset, where I have 3 subsets : `train`, `test`, `validation`.
Should I apply my map function on the subsets one by one ?
```python
import nlp
cnn_dm = nlp.load_dataset('cnn_dailymail')
for corpus in ['train', 'test', 'validation']:
cnn_dm[corpus] = cnn_dm[corpus].map(my_func)
```
Or is there a better way to do this ? | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/118/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/118/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/1609 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1609/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1609/comments | https://api.github.com/repos/huggingface/datasets/issues/1609/events | https://github.com/huggingface/datasets/issues/1609 | 771,421,881 | MDU6SXNzdWU3NzE0MjE4ODE= | 1,609 | Not able to use 'jigsaw_toxicity_pred' dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/7424133?v=4",
"events_url": "https://api.github.com/users/jassimran/events{/privacy}",
"followers_url": "https://api.github.com/users/jassimran/followers",
"following_url": "https://api.github.com/users/jassimran/following{/other_user}",
"gists_url": "https://api.github.com/users/jassimran/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/jassimran",
"id": 7424133,
"login": "jassimran",
"node_id": "MDQ6VXNlcjc0MjQxMzM=",
"organizations_url": "https://api.github.com/users/jassimran/orgs",
"received_events_url": "https://api.github.com/users/jassimran/received_events",
"repos_url": "https://api.github.com/users/jassimran/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/jassimran/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jassimran/subscriptions",
"type": "User",
"url": "https://api.github.com/users/jassimran"
} | [] | closed | false | null | [] | null | [
"Hi @jassimran,\r\nThe `jigsaw_toxicity_pred` dataset has not been released yet, it will be available with version 2 of `datasets`, coming soon.\r\nYou can still access it by installing the master (unreleased) version of datasets directly :\r\n`pip install git+https://github.com/huggingface/datasets.git@master`\r\nPlease let me know if this helps",
"Thanks.That works for now."
] | "2020-12-19T17:35:48Z" | "2020-12-22T16:42:24Z" | "2020-12-22T16:42:23Z" | NONE | null | null | null | When trying to use jigsaw_toxicity_pred dataset, like this in a [colab](https://colab.research.google.com/drive/1LwO2A5M2X5dvhkAFYE4D2CUT3WUdWnkn?usp=sharing):
```
from datasets import list_datasets, list_metrics, load_dataset, load_metric
ds = load_dataset("jigsaw_toxicity_pred")
```
I see below error:
> FileNotFoundError: Couldn't find file at https://raw.githubusercontent.com/huggingface/datasets/1.1.3/datasets/jigsaw_toxicity_pred/jigsaw_toxicity_pred.py
During handling of the above exception, another exception occurred:
FileNotFoundError Traceback (most recent call last)
FileNotFoundError: Couldn't find file at https://s3.amazonaws.com/datasets.huggingface.co/datasets/datasets/jigsaw_toxicity_pred/jigsaw_toxicity_pred.py
During handling of the above exception, another exception occurred:
FileNotFoundError Traceback (most recent call last)
/usr/local/lib/python3.6/dist-packages/datasets/load.py in prepare_module(path, script_version, download_config, download_mode, dataset, force_local_path, **download_kwargs)
280 raise FileNotFoundError(
281 "Couldn't find file locally at {}, or remotely at {} or {}".format(
--> 282 combined_path, github_file_path, file_path
283 )
284 )
FileNotFoundError: Couldn't find file locally at jigsaw_toxicity_pred/jigsaw_toxicity_pred.py, or remotely at https://raw.githubusercontent.com/huggingface/datasets/1.1.3/datasets/jigsaw_toxicity_pred/jigsaw_toxicity_pred.py or https://s3.amazonaws.com/datasets.huggingface.co/datasets/datasets/jigsaw_toxicity_pred/jigsaw_toxicity_pred.py | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1609/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1609/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/3527 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3527/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3527/comments | https://api.github.com/repos/huggingface/datasets/issues/3527/events | https://github.com/huggingface/datasets/pull/3527 | 1,093,840,707 | PR_kwDODunzps4wiN1w | 3,527 | Update README.md | {
"avatar_url": "https://avatars.githubusercontent.com/u/90473723?v=4",
"events_url": "https://api.github.com/users/meg-huggingface/events{/privacy}",
"followers_url": "https://api.github.com/users/meg-huggingface/followers",
"following_url": "https://api.github.com/users/meg-huggingface/following{/other_user}",
"gists_url": "https://api.github.com/users/meg-huggingface/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/meg-huggingface",
"id": 90473723,
"login": "meg-huggingface",
"node_id": "MDQ6VXNlcjkwNDczNzIz",
"organizations_url": "https://api.github.com/users/meg-huggingface/orgs",
"received_events_url": "https://api.github.com/users/meg-huggingface/received_events",
"repos_url": "https://api.github.com/users/meg-huggingface/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/meg-huggingface/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/meg-huggingface/subscriptions",
"type": "User",
"url": "https://api.github.com/users/meg-huggingface"
} | [] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/90473723?v=4",
"events_url": "https://api.github.com/users/meg-huggingface/events{/privacy}",
"followers_url": "https://api.github.com/users/meg-huggingface/followers",
"following_url": "https://api.github.com/users/meg-huggingface/following{/other_user}",
"gists_url": "https://api.github.com/users/meg-huggingface/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/meg-huggingface",
"id": 90473723,
"login": "meg-huggingface",
"node_id": "MDQ6VXNlcjkwNDczNzIz",
"organizations_url": "https://api.github.com/users/meg-huggingface/orgs",
"received_events_url": "https://api.github.com/users/meg-huggingface/received_events",
"repos_url": "https://api.github.com/users/meg-huggingface/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/meg-huggingface/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/meg-huggingface/subscriptions",
"type": "User",
"url": "https://api.github.com/users/meg-huggingface"
} | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/90473723?v=4",
"events_url": "https://api.github.com/users/meg-huggingface/events{/privacy}",
"followers_url": "https://api.github.com/users/meg-huggingface/followers",
"following_url": "https://api.github.com/users/meg-huggingface/following{/other_user}",
"gists_url": "https://api.github.com/users/meg-huggingface/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/meg-huggingface",
"id": 90473723,
"login": "meg-huggingface",
"node_id": "MDQ6VXNlcjkwNDczNzIz",
"organizations_url": "https://api.github.com/users/meg-huggingface/orgs",
"received_events_url": "https://api.github.com/users/meg-huggingface/received_events",
"repos_url": "https://api.github.com/users/meg-huggingface/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/meg-huggingface/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/meg-huggingface/subscriptions",
"type": "User",
"url": "https://api.github.com/users/meg-huggingface"
}
] | null | [] | "2022-01-04T23:39:41Z" | "2022-01-05T00:23:50Z" | "2022-01-05T00:23:50Z" | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/3527.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3527",
"merged_at": "2022-01-05T00:23:50Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3527.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3527"
} | Adding licensing information. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3527/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3527/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4998 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4998/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4998/comments | https://api.github.com/repos/huggingface/datasets/issues/4998/events | https://github.com/huggingface/datasets/pull/4998 | 1,379,466,717 | PR_kwDODunzps4_Ryp3 | 4,998 | Don't add a tag on the Hub on release | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq"
} | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._"
] | "2022-09-20T13:54:57Z" | "2022-09-20T14:11:46Z" | "2022-09-20T14:08:54Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/4998.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4998",
"merged_at": "2022-09-20T14:08:54Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4998.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4998"
} | Datasets with no namespace on the Hub have tags to redirect to the version of datasets where they come from.
I’m about to remove them all because I think it looks bad/unexpected in the UI and it’s not actually useful
Therefore I'm also disabling tagging.
Note that the CI job will be completely removed in https://github.com/huggingface/datasets/pull/4974 anyway | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4998/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4998/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4/comments | https://api.github.com/repos/huggingface/datasets/issues/4/events | https://github.com/huggingface/datasets/issues/4 | 600,185,417 | MDU6SXNzdWU2MDAxODU0MTc= | 4 | [Feature] Keep the list of labels of a dataset as metadata | {
"avatar_url": "https://avatars.githubusercontent.com/u/959590?v=4",
"events_url": "https://api.github.com/users/jplu/events{/privacy}",
"followers_url": "https://api.github.com/users/jplu/followers",
"following_url": "https://api.github.com/users/jplu/following{/other_user}",
"gists_url": "https://api.github.com/users/jplu/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/jplu",
"id": 959590,
"login": "jplu",
"node_id": "MDQ6VXNlcjk1OTU5MA==",
"organizations_url": "https://api.github.com/users/jplu/orgs",
"received_events_url": "https://api.github.com/users/jplu/received_events",
"repos_url": "https://api.github.com/users/jplu/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/jplu/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jplu/subscriptions",
"type": "User",
"url": "https://api.github.com/users/jplu"
} | [] | closed | false | null | [] | null | [
"Yes! I see mostly two options for this:\r\n- a `Feature` approach like currently (but we might deprecate features)\r\n- wrapping in a smart way the Dictionary arrays of Arrow: https://arrow.apache.org/docs/python/data.html?highlight=dictionary%20encode#dictionary-arrays",
"I would have a preference for the second bullet point.",
"This should be accessible now as a feature in dataset.info.features (and even have the mapping methods).",
"Perfect! Well done!!",
"Hi,\r\nI hope we could get a better documentation.\r\nIt took me more than 1 hour to found this way to get the label information.",
"Yes we are working on the doc right now, should be in the next release quite soon."
] | "2020-04-15T10:17:10Z" | "2020-07-08T16:59:46Z" | "2020-05-04T06:11:57Z" | CONTRIBUTOR | null | null | null | It would be useful to keep the list of the labels of a dataset as metadata. Either directly in the `DatasetInfo` or in the Arrow metadata. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/6379 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6379/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6379/comments | https://api.github.com/repos/huggingface/datasets/issues/6379/events | https://github.com/huggingface/datasets/pull/6379 | 1,974,638,850 | PR_kwDODunzps5edDZL | 6,379 | Avoid redundant warning when encoding NumPy array as `Image` | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko"
} | [] | closed | false | null | [] | null | [
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008649 / 0.011353 (-0.002704) | 0.005754 / 0.011008 (-0.005254) | 0.101992 / 0.038508 (0.063484) | 0.084932 / 0.023109 (0.061823) | 0.393928 / 0.275898 (0.118030) | 0.414059 / 0.323480 (0.090579) | 0.006564 / 0.007986 (-0.001422) | 0.004746 / 0.004328 (0.000418) | 0.078624 / 0.004250 (0.074373) | 0.060465 / 0.037052 (0.023412) | 0.420767 / 0.258489 (0.162278) | 0.497797 / 0.293841 (0.203956) | 0.047031 / 0.128546 (-0.081516) | 0.014316 / 0.075646 (-0.061330) | 0.340347 / 0.419271 (-0.078925) | 0.067126 / 0.043533 (0.023593) | 0.390806 / 0.255139 (0.135667) | 0.413711 / 0.283200 (0.130512) | 0.037838 / 0.141683 (-0.103845) | 1.713547 / 1.452155 (0.261393) | 1.825591 / 1.492716 (0.332874) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.316357 / 0.018006 (0.298350) | 0.594279 / 0.000490 (0.593789) | 0.013659 / 0.000200 (0.013459) | 0.000547 / 0.000054 (0.000492) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.031310 / 0.037411 (-0.006101) | 0.090410 / 0.014526 (0.075884) | 0.114620 / 0.176557 (-0.061936) | 0.183036 / 0.737135 (-0.554099) | 0.112700 / 0.296338 (-0.183638) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.582424 / 0.215209 (0.367215) | 5.670424 / 2.077655 (3.592769) | 2.444326 / 1.504120 (0.940206) | 2.108555 / 1.541195 (0.567360) | 2.091594 / 1.468490 (0.623104) | 0.839067 / 4.584777 (-3.745710) | 5.280942 / 3.745712 (1.535230) | 4.611059 / 5.269862 (-0.658803) | 2.911145 / 4.565676 (-1.654531) | 0.091929 / 0.424275 (-0.332346) | 0.008774 / 0.007607 (0.001167) | 0.657948 / 0.226044 (0.431904) | 6.816300 / 2.268929 (4.547371) | 3.232260 / 55.444624 (-52.212364) | 2.479626 / 6.876477 (-4.396851) | 2.497886 / 2.142072 (0.355813) | 0.959160 / 4.805227 (-3.846068) | 0.222306 / 6.500664 (-6.278358) | 0.072962 / 0.075469 (-0.002507) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.580415 / 1.841788 (-0.261372) | 23.689597 / 8.074308 (15.615289) | 20.430709 / 10.191392 (10.239317) | 0.237891 / 0.680424 (-0.442533) | 0.028194 / 0.534201 (-0.506007) | 0.464915 / 0.579283 (-0.114368) | 0.611512 / 0.434364 (0.177148) | 0.556564 / 0.540337 (0.016227) | 0.811075 / 1.386936 (-0.575861) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008703 / 0.011353 (-0.002649) | 0.005030 / 0.011008 (-0.005978) | 0.079251 / 0.038508 (0.040743) | 0.079054 / 0.023109 (0.055945) | 0.440220 / 0.275898 (0.164322) | 0.479824 / 0.323480 (0.156344) | 0.006312 / 0.007986 (-0.001673) | 0.004506 / 0.004328 (0.000177) | 0.078454 / 0.004250 (0.074203) | 0.061041 / 0.037052 (0.023989) | 0.490104 / 0.258489 (0.231615) | 0.480925 / 0.293841 (0.187084) | 0.049601 / 0.128546 (-0.078945) | 0.013114 / 0.075646 (-0.062532) | 0.092576 / 0.419271 (-0.326696) | 0.059516 / 0.043533 (0.015983) | 0.433728 / 0.255139 (0.178589) | 0.490039 / 0.283200 (0.206839) | 0.035359 / 0.141683 (-0.106324) | 1.823618 / 1.452155 (0.371463) | 1.980894 / 1.492716 (0.488178) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.284679 / 0.018006 (0.266673) | 0.606623 / 0.000490 (0.606133) | 0.007531 / 0.000200 (0.007331) | 0.000109 / 0.000054 (0.000055) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.033261 / 0.037411 (-0.004150) | 0.102908 / 0.014526 (0.088382) | 0.123912 / 0.176557 (-0.052644) | 0.169893 / 0.737135 (-0.567242) | 0.115366 / 0.296338 (-0.180973) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.598239 / 0.215209 (0.383030) | 6.003464 / 2.077655 (3.925809) | 2.828483 / 1.504120 (1.324363) | 2.485996 / 1.541195 (0.944802) | 2.434986 / 1.468490 (0.966496) | 0.832718 / 4.584777 (-3.752058) | 5.327407 / 3.745712 (1.581694) | 4.732271 / 5.269862 (-0.537590) | 3.047555 / 4.565676 (-1.518121) | 0.103576 / 0.424275 (-0.320699) | 0.009795 / 0.007607 (0.002188) | 0.755443 / 0.226044 (0.529399) | 7.465857 / 2.268929 (5.196928) | 3.564923 / 55.444624 (-51.879701) | 2.740483 / 6.876477 (-4.135994) | 3.044993 / 2.142072 (0.902920) | 1.012925 / 4.805227 (-3.792302) | 0.207498 / 6.500664 (-6.293167) | 0.073361 / 0.075469 (-0.002108) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.704988 / 1.841788 (-0.136800) | 24.669992 / 8.074308 (16.595684) | 21.103096 / 10.191392 (10.911704) | 0.253759 / 0.680424 (-0.426665) | 0.040109 / 0.534201 (-0.494092) | 0.465646 / 0.579283 (-0.113637) | 0.619696 / 0.434364 (0.185332) | 0.552228 / 0.540337 (0.011890) | 0.794907 / 1.386936 (-0.592029) |\n\n</details>\n</details>\n\n\n",
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006347 / 0.011353 (-0.005006) | 0.003725 / 0.011008 (-0.007283) | 0.080233 / 0.038508 (0.041725) | 0.061013 / 0.023109 (0.037904) | 0.390046 / 0.275898 (0.114148) | 0.420526 / 0.323480 (0.097046) | 0.003579 / 0.007986 (-0.004407) | 0.002837 / 0.004328 (-0.001491) | 0.062929 / 0.004250 (0.058678) | 0.048781 / 0.037052 (0.011729) | 0.400722 / 0.258489 (0.142233) | 0.435022 / 0.293841 (0.141182) | 0.027560 / 0.128546 (-0.100986) | 0.007981 / 0.075646 (-0.067666) | 0.262838 / 0.419271 (-0.156433) | 0.045480 / 0.043533 (0.001947) | 0.394443 / 0.255139 (0.139304) | 0.413828 / 0.283200 (0.130628) | 0.023375 / 0.141683 (-0.118307) | 1.412865 / 1.452155 (-0.039290) | 1.495761 / 1.492716 (0.003044) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.224876 / 0.018006 (0.206870) | 0.424234 / 0.000490 (0.423745) | 0.007502 / 0.000200 (0.007302) | 0.000220 / 0.000054 (0.000166) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.024246 / 0.037411 (-0.013165) | 0.073982 / 0.014526 (0.059456) | 0.082704 / 0.176557 (-0.093852) | 0.143137 / 0.737135 (-0.593998) | 0.083398 / 0.296338 (-0.212941) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.400220 / 0.215209 (0.185010) | 3.973037 / 2.077655 (1.895382) | 2.025903 / 1.504120 (0.521783) | 1.912888 / 1.541195 (0.371693) | 1.999578 / 1.468490 (0.531088) | 0.499378 / 4.584777 (-4.085399) | 3.025715 / 3.745712 (-0.719997) | 2.992338 / 5.269862 (-2.277524) | 1.851155 / 4.565676 (-2.714522) | 0.057528 / 0.424275 (-0.366747) | 0.006802 / 0.007607 (-0.000805) | 0.469516 / 0.226044 (0.243471) | 4.675630 / 2.268929 (2.406702) | 2.472166 / 55.444624 (-52.972458) | 2.238052 / 6.876477 (-4.638424) | 2.288255 / 2.142072 (0.146183) | 0.584906 / 4.805227 (-4.220321) | 0.125902 / 6.500664 (-6.374762) | 0.060681 / 0.075469 (-0.014788) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.236383 / 1.841788 (-0.605404) | 17.554238 / 8.074308 (9.479930) | 13.749298 / 10.191392 (3.557906) | 0.144715 / 0.680424 (-0.535708) | 0.017449 / 0.534201 (-0.516752) | 0.334831 / 0.579283 (-0.244452) | 0.362660 / 0.434364 (-0.071704) | 0.385295 / 0.540337 (-0.155043) | 0.541173 / 1.386936 (-0.845763) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006118 / 0.011353 (-0.005235) | 0.003660 / 0.011008 (-0.007348) | 0.062373 / 0.038508 (0.023865) | 0.063404 / 0.023109 (0.040295) | 0.354149 / 0.275898 (0.078251) | 0.410324 / 0.323480 (0.086844) | 0.004826 / 0.007986 (-0.003160) | 0.002881 / 0.004328 (-0.001448) | 0.061631 / 0.004250 (0.057381) | 0.048052 / 0.037052 (0.010999) | 0.352905 / 0.258489 (0.094416) | 0.400096 / 0.293841 (0.106255) | 0.028472 / 0.128546 (-0.100075) | 0.008076 / 0.075646 (-0.067571) | 0.067910 / 0.419271 (-0.351362) | 0.040671 / 0.043533 (-0.002862) | 0.352131 / 0.255139 (0.096992) | 0.402140 / 0.283200 (0.118940) | 0.020065 / 0.141683 (-0.121618) | 1.456938 / 1.452155 (0.004783) | 1.506484 / 1.492716 (0.013767) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.222295 / 0.018006 (0.204288) | 0.416672 / 0.000490 (0.416183) | 0.003015 / 0.000200 (0.002815) | 0.000079 / 0.000054 (0.000025) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.026428 / 0.037411 (-0.010983) | 0.080072 / 0.014526 (0.065547) | 0.089992 / 0.176557 (-0.086564) | 0.141739 / 0.737135 (-0.595397) | 0.092281 / 0.296338 (-0.204058) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.417758 / 0.215209 (0.202549) | 4.175673 / 2.077655 (2.098018) | 2.262369 / 1.504120 (0.758249) | 2.100440 / 1.541195 (0.559246) | 2.075827 / 1.468490 (0.607337) | 0.505673 / 4.584777 (-4.079104) | 3.129020 / 3.745712 (-0.616692) | 2.843255 / 5.269862 (-2.426607) | 1.853288 / 4.565676 (-2.712389) | 0.058337 / 0.424275 (-0.365938) | 0.006461 / 0.007607 (-0.001147) | 0.491797 / 0.226044 (0.265753) | 4.933327 / 2.268929 (2.664399) | 2.675374 / 55.444624 (-52.769250) | 2.358103 / 6.876477 (-4.518374) | 2.540436 / 2.142072 (0.398363) | 0.591550 / 4.805227 (-4.213677) | 0.121572 / 6.500664 (-6.379092) | 0.057311 / 0.075469 (-0.018158) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.365368 / 1.841788 (-0.476419) | 17.763413 / 8.074308 (9.689105) | 14.368754 / 10.191392 (4.177362) | 0.132979 / 0.680424 (-0.547445) | 0.017957 / 0.534201 (-0.516244) | 0.334035 / 0.579283 (-0.245248) | 0.385349 / 0.434364 (-0.049015) | 0.392636 / 0.540337 (-0.147702) | 0.537957 / 1.386936 (-0.848979) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008053 / 0.011353 (-0.003300) | 0.004966 / 0.011008 (-0.006043) | 0.102219 / 0.038508 (0.063711) | 0.099319 / 0.023109 (0.076210) | 0.418458 / 0.275898 (0.142559) | 0.459344 / 0.323480 (0.135864) | 0.004756 / 0.007986 (-0.003229) | 0.003940 / 0.004328 (-0.000388) | 0.076824 / 0.004250 (0.072573) | 0.068090 / 0.037052 (0.031038) | 0.428689 / 0.258489 (0.170200) | 0.476153 / 0.293841 (0.182312) | 0.036927 / 0.128546 (-0.091619) | 0.010232 / 0.075646 (-0.065414) | 0.345126 / 0.419271 (-0.074145) | 0.063182 / 0.043533 (0.019649) | 0.416633 / 0.255139 (0.161494) | 0.437418 / 0.283200 (0.154218) | 0.028192 / 0.141683 (-0.113491) | 1.768869 / 1.452155 (0.316715) | 1.847022 / 1.492716 (0.354306) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.269997 / 0.018006 (0.251991) | 0.544246 / 0.000490 (0.543756) | 0.012940 / 0.000200 (0.012740) | 0.000754 / 0.000054 (0.000699) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.035570 / 0.037411 (-0.001842) | 0.104318 / 0.014526 (0.089792) | 0.115263 / 0.176557 (-0.061294) | 0.184693 / 0.737135 (-0.552442) | 0.116023 / 0.296338 (-0.180315) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.472361 / 0.215209 (0.257152) | 4.714327 / 2.077655 (2.636673) | 2.405434 / 1.504120 (0.901314) | 2.197871 / 1.541195 (0.656677) | 2.312901 / 1.468490 (0.844411) | 0.569736 / 4.584777 (-4.015041) | 4.600008 / 3.745712 (0.854296) | 4.127967 / 5.269862 (-1.141895) | 2.462232 / 4.565676 (-2.103445) | 0.067759 / 0.424275 (-0.356516) | 0.009277 / 0.007607 (0.001670) | 0.569658 / 0.226044 (0.343614) | 5.694050 / 2.268929 (3.425121) | 3.041495 / 55.444624 (-52.403129) | 2.688418 / 6.876477 (-4.188059) | 2.762175 / 2.142072 (0.620102) | 0.683250 / 4.805227 (-4.121977) | 0.158772 / 6.500664 (-6.341892) | 0.073364 / 0.075469 (-0.002105) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.627241 / 1.841788 (-0.214547) | 23.054465 / 8.074308 (14.980157) | 17.122451 / 10.191392 (6.931059) | 0.170272 / 0.680424 (-0.510152) | 0.021678 / 0.534201 (-0.512523) | 0.467301 / 0.579283 (-0.111982) | 0.509480 / 0.434364 (0.075116) | 0.555077 / 0.540337 (0.014740) | 0.816199 / 1.386936 (-0.570737) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008499 / 0.011353 (-0.002854) | 0.004724 / 0.011008 (-0.006284) | 0.077519 / 0.038508 (0.039011) | 0.103237 / 0.023109 (0.080127) | 0.447470 / 0.275898 (0.171572) | 0.484778 / 0.323480 (0.161298) | 0.006475 / 0.007986 (-0.001511) | 0.003946 / 0.004328 (-0.000383) | 0.075596 / 0.004250 (0.071346) | 0.069265 / 0.037052 (0.032213) | 0.454185 / 0.258489 (0.195696) | 0.491039 / 0.293841 (0.197198) | 0.038611 / 0.128546 (-0.089935) | 0.009889 / 0.075646 (-0.065758) | 0.084012 / 0.419271 (-0.335260) | 0.057265 / 0.043533 (0.013732) | 0.448622 / 0.255139 (0.193483) | 0.470961 / 0.283200 (0.187762) | 0.029220 / 0.141683 (-0.112463) | 1.773347 / 1.452155 (0.321192) | 1.872669 / 1.492716 (0.379953) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.272429 / 0.018006 (0.254423) | 0.569907 / 0.000490 (0.569418) | 0.013359 / 0.000200 (0.013159) | 0.000187 / 0.000054 (0.000133) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.038784 / 0.037411 (0.001373) | 0.114958 / 0.014526 (0.100432) | 0.132745 / 0.176557 (-0.043811) | 0.186283 / 0.737135 (-0.550852) | 0.126652 / 0.296338 (-0.169686) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.482753 / 0.215209 (0.267544) | 4.827287 / 2.077655 (2.749633) | 2.539959 / 1.504120 (1.035839) | 2.348483 / 1.541195 (0.807288) | 2.421739 / 1.468490 (0.953249) | 0.586064 / 4.584777 (-3.998713) | 4.579865 / 3.745712 (0.834152) | 3.950617 / 5.269862 (-1.319244) | 2.528447 / 4.565676 (-2.037229) | 0.070280 / 0.424275 (-0.353995) | 0.008801 / 0.007607 (0.001194) | 0.568857 / 0.226044 (0.342812) | 5.692739 / 2.268929 (3.423810) | 3.192045 / 55.444624 (-52.252579) | 2.768092 / 6.876477 (-4.108384) | 3.002934 / 2.142072 (0.860862) | 0.701887 / 4.805227 (-4.103340) | 0.155563 / 6.500664 (-6.345102) | 0.069397 / 0.075469 (-0.006072) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.607991 / 1.841788 (-0.233796) | 24.658060 / 8.074308 (16.583752) | 17.616229 / 10.191392 (7.424837) | 0.209730 / 0.680424 (-0.470693) | 0.024052 / 0.534201 (-0.510149) | 0.476648 / 0.579283 (-0.102635) | 0.534452 / 0.434364 (0.100089) | 0.567702 / 0.540337 (0.027365) | 0.772933 / 1.386936 (-0.614003) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.004684 / 0.011353 (-0.006669) | 0.002944 / 0.011008 (-0.008064) | 0.063065 / 0.038508 (0.024557) | 0.051627 / 0.023109 (0.028518) | 0.243485 / 0.275898 (-0.032413) | 0.275144 / 0.323480 (-0.048336) | 0.002934 / 0.007986 (-0.005052) | 0.002395 / 0.004328 (-0.001934) | 0.048579 / 0.004250 (0.044328) | 0.038940 / 0.037052 (0.001887) | 0.250244 / 0.258489 (-0.008245) | 0.287404 / 0.293841 (-0.006437) | 0.022958 / 0.128546 (-0.105588) | 0.007189 / 0.075646 (-0.068458) | 0.202483 / 0.419271 (-0.216788) | 0.035477 / 0.043533 (-0.008056) | 0.243793 / 0.255139 (-0.011346) | 0.265990 / 0.283200 (-0.017209) | 0.019675 / 0.141683 (-0.122008) | 1.119127 / 1.452155 (-0.333028) | 1.183230 / 1.492716 (-0.309486) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.097090 / 0.018006 (0.079084) | 0.305815 / 0.000490 (0.305325) | 0.000228 / 0.000200 (0.000028) | 0.000050 / 0.000054 (-0.000004) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.019233 / 0.037411 (-0.018178) | 0.061743 / 0.014526 (0.047217) | 0.077033 / 0.176557 (-0.099524) | 0.119786 / 0.737135 (-0.617349) | 0.074740 / 0.296338 (-0.221598) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.284361 / 0.215209 (0.069152) | 2.761501 / 2.077655 (0.683846) | 1.464980 / 1.504120 (-0.039140) | 1.348026 / 1.541195 (-0.193169) | 1.362690 / 1.468490 (-0.105800) | 0.392022 / 4.584777 (-4.192755) | 2.401330 / 3.745712 (-1.344382) | 2.618999 / 5.269862 (-2.650863) | 1.599526 / 4.565676 (-2.966150) | 0.045621 / 0.424275 (-0.378654) | 0.005153 / 0.007607 (-0.002454) | 0.337279 / 0.226044 (0.111234) | 3.330135 / 2.268929 (1.061206) | 1.803544 / 55.444624 (-53.641081) | 1.515545 / 6.876477 (-5.360932) | 1.561745 / 2.142072 (-0.580327) | 0.468735 / 4.805227 (-4.336492) | 0.098882 / 6.500664 (-6.401782) | 0.042923 / 0.075469 (-0.032546) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.961106 / 1.841788 (-0.880682) | 12.030489 / 8.074308 (3.956181) | 10.824166 / 10.191392 (0.632774) | 0.132135 / 0.680424 (-0.548289) | 0.015320 / 0.534201 (-0.518881) | 0.269691 / 0.579283 (-0.309592) | 0.270700 / 0.434364 (-0.163664) | 0.308317 / 0.540337 (-0.232020) | 0.397871 / 1.386936 (-0.989065) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.004859 / 0.011353 (-0.006494) | 0.003400 / 0.011008 (-0.007609) | 0.048095 / 0.038508 (0.009587) | 0.054885 / 0.023109 (0.031776) | 0.276976 / 0.275898 (0.001078) | 0.302298 / 0.323480 (-0.021182) | 0.004084 / 0.007986 (-0.003902) | 0.002647 / 0.004328 (-0.001681) | 0.048570 / 0.004250 (0.044319) | 0.040683 / 0.037052 (0.003631) | 0.279828 / 0.258489 (0.021339) | 0.306037 / 0.293841 (0.012196) | 0.024263 / 0.128546 (-0.104283) | 0.007336 / 0.075646 (-0.068310) | 0.053768 / 0.419271 (-0.365503) | 0.032284 / 0.043533 (-0.011248) | 0.276706 / 0.255139 (0.021567) | 0.294706 / 0.283200 (0.011506) | 0.018092 / 0.141683 (-0.123591) | 1.153430 / 1.452155 (-0.298725) | 1.208783 / 1.492716 (-0.283933) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.096946 / 0.018006 (0.078939) | 0.308118 / 0.000490 (0.307628) | 0.000234 / 0.000200 (0.000034) | 0.000053 / 0.000054 (-0.000001) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.021834 / 0.037411 (-0.015577) | 0.070934 / 0.014526 (0.056408) | 0.080310 / 0.176557 (-0.096247) | 0.123299 / 0.737135 (-0.613836) | 0.081591 / 0.296338 (-0.214748) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.302242 / 0.215209 (0.087033) | 2.934477 / 2.077655 (0.856822) | 1.623768 / 1.504120 (0.119648) | 1.493868 / 1.541195 (-0.047326) | 1.516553 / 1.468490 (0.048063) | 0.410319 / 4.584777 (-4.174458) | 2.471346 / 3.745712 (-1.274366) | 2.667371 / 5.269862 (-2.602491) | 1.625390 / 4.565676 (-2.940286) | 0.046465 / 0.424275 (-0.377810) | 0.004867 / 0.007607 (-0.002740) | 0.355516 / 0.226044 (0.129471) | 3.442294 / 2.268929 (1.173365) | 1.973859 / 55.444624 (-53.470765) | 1.682089 / 6.876477 (-5.194388) | 1.865253 / 2.142072 (-0.276819) | 0.475750 / 4.805227 (-4.329477) | 0.098298 / 6.500664 (-6.402366) | 0.041025 / 0.075469 (-0.034445) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.969864 / 1.841788 (-0.871924) | 12.437806 / 8.074308 (4.363498) | 10.461262 / 10.191392 (0.269870) | 0.131051 / 0.680424 (-0.549373) | 0.016232 / 0.534201 (-0.517969) | 0.273968 / 0.579283 (-0.305315) | 0.285369 / 0.434364 (-0.148995) | 0.309046 / 0.540337 (-0.231291) | 0.398776 / 1.386936 (-0.988160) |\n\n</details>\n</details>\n\n\n"
] | "2023-11-02T16:37:58Z" | "2023-11-06T17:53:27Z" | "2023-11-02T17:08:07Z" | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/6379.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6379",
"merged_at": "2023-11-02T17:08:07Z",
"patch_url": "https://github.com/huggingface/datasets/pull/6379.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/6379"
} | Avoid a redundant warning in `encode_np_array` by removing the identity check as NumPy `dtype`s can be equal without having identical `id`s.
Additionally, fix "unreachable" checks in `encode_np_array`. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6379/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6379/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/823 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/823/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/823/comments | https://api.github.com/repos/huggingface/datasets/issues/823/events | https://github.com/huggingface/datasets/issues/823 | 739,815,763 | MDU6SXNzdWU3Mzk4MTU3NjM= | 823 | how processing in batch works in datasets | {
"avatar_url": "https://avatars.githubusercontent.com/u/73364383?v=4",
"events_url": "https://api.github.com/users/rabeehkarimimahabadi/events{/privacy}",
"followers_url": "https://api.github.com/users/rabeehkarimimahabadi/followers",
"following_url": "https://api.github.com/users/rabeehkarimimahabadi/following{/other_user}",
"gists_url": "https://api.github.com/users/rabeehkarimimahabadi/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/rabeehkarimimahabadi",
"id": 73364383,
"login": "rabeehkarimimahabadi",
"node_id": "MDQ6VXNlcjczMzY0Mzgz",
"organizations_url": "https://api.github.com/users/rabeehkarimimahabadi/orgs",
"received_events_url": "https://api.github.com/users/rabeehkarimimahabadi/received_events",
"repos_url": "https://api.github.com/users/rabeehkarimimahabadi/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/rabeehkarimimahabadi/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/rabeehkarimimahabadi/subscriptions",
"type": "User",
"url": "https://api.github.com/users/rabeehkarimimahabadi"
} | [
{
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset",
"id": 2067376369,
"name": "dataset request",
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request"
}
] | closed | false | null | [] | null | [
"Hi I don’t think this is a request for a dataset like you labeled it.\r\n\r\nI also think this would be better suited for the forum at https://discuss.huggingface.co. we try to keep the issue for the repo for bug reports and new features/dataset requests and have usage questions discussed on the forum. Thanks.",
"Hi Thomas,\nwhat I do not get from documentation is that why when you set batched=True,\nthis is processed in batch, while data is not divided to batched\nbeforehand, basically this is a question on the documentation and I do not\nget the batched=True, but sure, if you think this is more appropriate in\nforum I will post it there.\nthanks\nBest\nRabeeh\n\nOn Tue, Nov 10, 2020 at 12:21 PM Thomas Wolf <[email protected]>\nwrote:\n\n> Hi I don’t think this is a request for a dataset like you labeled it.\n>\n> I also think this would be better suited for the forum at\n> https://discuss.huggingface.co. we try to keep the issue for the repo for\n> bug reports and new features/dataset requests and have usage questions\n> discussed on the forum. Thanks.\n>\n> —\n> You are receiving this because you authored the thread.\n> Reply to this email directly, view it on GitHub\n> <https://github.com/huggingface/datasets/issues/823#issuecomment-724639476>,\n> or unsubscribe\n> <https://github.com/notifications/unsubscribe-auth/ARPXHH4FIPFHVVUHANAE4F3SPEO2JANCNFSM4TQQVEXQ>\n> .\n>\n",
"Yes the forum is perfect for that. You can post in the `datasets` section.\r\nThanks a lot!"
] | "2020-11-10T11:11:17Z" | "2020-11-10T13:11:10Z" | "2020-11-10T13:11:09Z" | NONE | null | null | null | Hi,
I need to process my datasets before it is passed to dataloader in batch,
here is my codes
```
class AbstractTask(ABC):
task_name: str = NotImplemented
preprocessor: Callable = NotImplemented
split_to_data_split: Mapping[str, str] = NotImplemented
tokenizer: Callable = NotImplemented
max_source_length: str = NotImplemented
max_target_length: str = NotImplemented
# TODO: should not be a task item, but cannot see other ways.
tpu_num_cores: int = None
# The arguments set are for all tasks and needs to be kept common.
def __init__(self, config):
self.max_source_length = config['max_source_length']
self.max_target_length = config['max_target_length']
self.tokenizer = config['tokenizer']
self.tpu_num_cores = config['tpu_num_cores']
def _encode(self, batch) -> Dict[str, torch.Tensor]:
batch_encoding = self.tokenizer.prepare_seq2seq_batch(
[x["src_texts"] for x in batch],
tgt_texts=[x["tgt_texts"] for x in batch],
max_length=self.max_source_length,
max_target_length=self.max_target_length,
padding="max_length" if self.tpu_num_cores is not None else "longest", # TPU hack
return_tensors="pt"
)
return batch_encoding.data
def data_split(self, split):
return self.split_to_data_split[split]
def get_dataset(self, split, n_obs=None):
split = self.data_split(split)
if n_obs is not None:
split = split+"[:{}]".format(n_obs)
dataset = load_dataset(self.task_name, split=split)
dataset = dataset.map(self.preprocessor, remove_columns=dataset.column_names)
dataset = dataset.map(lambda batch: self._encode(batch), batched=True)
dataset.set_format(type="torch", columns=['input_ids', 'token_type_ids', 'attention_mask', 'label'])
return dataset
```
I call it like
`AutoTask.get(task, train_dataset_config).get_dataset(split="train", n_obs=data_args.n_train)
`
This gives the following error, to me because the data inside the dataset = dataset.map(lambda batch: self._encode(batch), batched=True) is not processed in batch, could you tell me how I can process dataset in batch inside my function? thanks
File "finetune_multitask_trainer.py", line 192, in main
if training_args.do_train else None
File "finetune_multitask_trainer.py", line 191, in <dictcomp>
split="train", n_obs=data_args.n_train) for task in data_args.task}
File "/remote/idiap.svm/user.active/rkarimi/dev/internship/seq2seq/tasks.py", line 56, in get_dataset
dataset = dataset.map(lambda batch: self._encode(batch), batched=True)
File "/idiap/user/rkarimi/libs/anaconda3/envs/internship/lib/python3.7/site-packages/datasets/arrow_dataset.py", line 1236, in map
update_data = does_function_return_dict(test_inputs, test_indices)
File "/idiap/user/rkarimi/libs/anaconda3/envs/internship/lib/python3.7/site-packages/datasets/arrow_dataset.py", line 1207, in does_function_return_dict
function(*fn_args, indices, **fn_kwargs) if with_indices else function(*fn_args, **fn_kwargs)
File "/remote/idiap.svm/user.active/rkarimi/dev/internship/seq2seq/tasks.py", line 56, in <lambda>
dataset = dataset.map(lambda batch: self._encode(batch), batched=True)
File "/remote/idiap.svm/user.active/rkarimi/dev/internship/seq2seq/tasks.py", line 37, in _encode
[x["src_texts"] for x in batch],
File "/remote/idiap.svm/user.active/rkarimi/dev/internship/seq2seq/tasks.py", line 37, in <listcomp>
[x["src_texts"] for x in batch],
TypeError: string indices must be integers
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/823/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/823/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/4180 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4180/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4180/comments | https://api.github.com/repos/huggingface/datasets/issues/4180/events | https://github.com/huggingface/datasets/issues/4180 | 1,208,042,320 | I_kwDODunzps5IAUNQ | 4,180 | Add some iteration method on a dataset column (specific for inference) | {
"avatar_url": "https://avatars.githubusercontent.com/u/204321?v=4",
"events_url": "https://api.github.com/users/Narsil/events{/privacy}",
"followers_url": "https://api.github.com/users/Narsil/followers",
"following_url": "https://api.github.com/users/Narsil/following{/other_user}",
"gists_url": "https://api.github.com/users/Narsil/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/Narsil",
"id": 204321,
"login": "Narsil",
"node_id": "MDQ6VXNlcjIwNDMyMQ==",
"organizations_url": "https://api.github.com/users/Narsil/orgs",
"received_events_url": "https://api.github.com/users/Narsil/received_events",
"repos_url": "https://api.github.com/users/Narsil/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/Narsil/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Narsil/subscriptions",
"type": "User",
"url": "https://api.github.com/users/Narsil"
} | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | open | false | null | [] | null | [
"Thanks for the suggestion ! I agree it would be nice to have something directly in `datasets` to do something as simple as that\r\n\r\ncc @albertvillanova @mariosasko @polinaeterna What do you think if we have something similar to pandas `Series` that wouldn't bring everything in memory when doing `dataset[\"audio\"]` ? Currently it returns a list with all the decoded audio data in memory.\r\n\r\nIt would be a breaking change though, since `isinstance(dataset[\"audio\"], list)` wouldn't work anymore, but we could implement a `Sequence` so that `dataset[\"audio\"][0]` still works and only loads one item in memory.\r\n\r\nYour alternative suggestion with `iterate` is also sensible, though maybe less satisfactory in terms of experience IMO",
"I agree that current behavior (decoding all audio file sin the dataset when accessing `dataset[\"audio\"]`) is not useful, IMHO. Indeed in our docs, we are constantly warning our collaborators not to do that.\r\n\r\nTherefore I upvote for a \"useful\" behavior of `dataset[\"audio\"]`. I don't think the breaking change is important in this case, as I guess no many people use it with its current behavior. Therefore, for me it seems reasonable to return a generator (instead of an in-memeory list) for \"special\" features, like Audio/Image.\r\n\r\n@lhoestq on the other hand I don't understand your proposal about Pandas-like... ",
"I recall I had the same idea while working on the `Image` feature, so I agree implementing something similar to `pd.Series` that lazily brings elements in memory would be beneficial.",
"@lhoestq @mariosasko Could you please give a link to that new feature of `pandas.Series`? As far as I remember since I worked with pandas for more than 6 years, there was no lazy in-memory feature; it was everything in-memory; that was the reason why other frameworks were created, like Vaex or Dask, e.g. ",
"Yea pandas doesn't do lazy loading. I was referring to pandas.Series to say that they have a dedicated class to represent a column ;)"
] | "2022-04-19T09:15:45Z" | "2022-04-21T10:30:58Z" | null | CONTRIBUTOR | null | null | null | **Is your feature request related to a problem? Please describe.**
A clear and concise description of what the problem is.
Currently, `dataset["audio"]` will load EVERY element in the dataset in RAM, which can be quite big for an audio dataset.
Having an iterator (or sequence) type of object, would make inference with `transformers` 's `pipeline` easier to use and not so memory hungry.
**Describe the solution you'd like**
A clear and concise description of what you want to happen.
For a non breaking change:
```python
for audio in dataset.iterate("audio"):
# {"array": np.array(...), "sampling_rate":...}
```
For a breaking change solution (not necessary), changing the type of `dataset["audio"]` to a sequence type so that
```python
pipe = pipeline(model="...")
for out in pipe(dataset["audio"]):
# {"text":....}
```
could work
**Describe alternatives you've considered**
A clear and concise description of any alternative solutions or features you've considered.
```python
def iterate(dataset, key):
for item in dataset:
yield dataset[key]
for out in pipeline(iterate(dataset, "audio")):
# {"array": ...}
```
This works but requires the helper function which feels slightly clunky.
**Additional context**
Add any other context about the feature request here.
The context is actually to showcase better integration between `pipeline` and `datasets` in the Quicktour demo: https://github.com/huggingface/transformers/pull/16723/files
@lhoestq
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4180/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4180/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5923 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5923/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5923/comments | https://api.github.com/repos/huggingface/datasets/issues/5923/events | https://github.com/huggingface/datasets/issues/5923 | 1,737,436,227 | I_kwDODunzps5njyxD | 5,923 | Cannot import datasets - ValueError: pyarrow.lib.IpcWriteOptions size changed, may indicate binary incompatibility | {
"avatar_url": "https://avatars.githubusercontent.com/u/71412682?v=4",
"events_url": "https://api.github.com/users/ehuangc/events{/privacy}",
"followers_url": "https://api.github.com/users/ehuangc/followers",
"following_url": "https://api.github.com/users/ehuangc/following{/other_user}",
"gists_url": "https://api.github.com/users/ehuangc/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/ehuangc",
"id": 71412682,
"login": "ehuangc",
"node_id": "MDQ6VXNlcjcxNDEyNjgy",
"organizations_url": "https://api.github.com/users/ehuangc/orgs",
"received_events_url": "https://api.github.com/users/ehuangc/received_events",
"repos_url": "https://api.github.com/users/ehuangc/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/ehuangc/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ehuangc/subscriptions",
"type": "User",
"url": "https://api.github.com/users/ehuangc"
} | [] | open | false | null | [] | null | [
"Based on https://github.com/rapidsai/cudf/issues/10187, this probably means your `pyarrow` installation is not compatible with `datasets`.\r\n\r\nCan you please execute the following commands in the terminal and paste the output here?\r\n```\r\nconda list | grep arrow\r\n``` \r\n```\r\npython -c \"import pyarrow; print(pyarrow.__file__)\"\r\n```\r\n\r\n\r\n",
"> Based on [rapidsai/cudf#10187](https://github.com/rapidsai/cudf/issues/10187), this probably means your `pyarrow` installation is not compatible with `datasets`.\r\n> \r\n> Can you please execute the following commands in the terminal and paste the output here?\r\n> \r\n> ```\r\n> conda list | grep arrow\r\n> ```\r\n> \r\n> ```\r\n> python -c \"import pyarrow; print(pyarrow.__file__)\"\r\n> ```\r\n\r\n\r\nHere is the output to the first command:\r\n```\r\narrow-cpp 11.0.0 py39h7f74497_0 \r\npyarrow 12.0.0 pypi_0 pypi\r\n```\r\nand the second:\r\n```\r\n/Users/edward/opt/anaconda3/envs/cs235/lib/python3.9/site-packages/pyarrow/__init__.py\r\n```\r\nThanks!\r\n\r\n\r\n\r\n",
"after installing pytesseract 0.3.10, I got the above error. FYI ",
"RuntimeError: Failed to import transformers.trainer because of the following error (look up to see its traceback):\r\npyarrow.lib.IpcWriteOptions size changed, may indicate binary incompatibility. Expected 88 from C header, got 72 from PyObject",
"I got the same error, pyarrow 12.0.0 released May/2023 (https://pypi.org/project/pyarrow/) is not compatible, running `pip install pyarrow==11.0.0` to force install the previous version solved the problem.\r\n\r\nDo we need to update dependencies? ",
"Please note that our CI properly passes all tests with `pyarrow-12.0.0`, for Python 3.7 and Python 3.10, for Ubuntu and Windows: see for example https://github.com/huggingface/datasets/actions/runs/5157324334/jobs/9289582291",
"For conda with python3.8.16 this solved my problem! thanks!\r\n\r\n> I got the same error, pyarrow 12.0.0 released May/2023 (https://pypi.org/project/pyarrow/) is not compatible, running `pip install pyarrow==11.0.0` to force install the previous version solved the problem.\r\n> \r\n> Do we need to update dependencies? I can work on that if no one else is working on it.\r\n\r\n",
"Thanks for replying. I am not sure about those environments but it seems like pyarrow-12.0.0 does not work for conda with python 3.8.16. \r\n\r\n> Please note that our CI properly passes all tests with `pyarrow-12.0.0`, for Python 3.7 and Python 3.10, for Ubuntu and Windows: see for example https://github.com/huggingface/datasets/actions/runs/5157324334/jobs/9289582291\r\n\r\n",
"Got the same error with:\r\n\r\n```\r\narrow-cpp 11.0.0 py310h7516544_0 \r\npyarrow 12.0.0 pypi_0 pypi\r\n\r\npython 3.10.11 h7a1cb2a_2 \r\n\r\ndatasets 2.13.0 pyhd8ed1ab_0 conda-forge\r\n```",
"> I got the same error, pyarrow 12.0.0 released May/2023 (https://pypi.org/project/pyarrow/) is not compatible, running `pip install pyarrow==11.0.0` to force install the previous version solved the problem.\r\n> \r\n> Do we need to update dependencies?\r\n\r\nThis solved the issue for me as well.",
"> I got the same error, pyarrow 12.0.0 released May/2023 (https://pypi.org/project/pyarrow/) is not compatible, running `pip install pyarrow==11.0.0` to force install the previous version solved the problem.\r\n> \r\n> Do we need to update dependencies?\r\n\r\nSolved it for me also",
"> 基于 [rapidsai/cudf#10187](https://github.com/rapidsai/cudf/issues/10187),这可能意味着您的安装与 不兼容。`pyarrow``datasets`\r\n> \r\n> 您能否在终端中执行以下命令并将输出粘贴到此处?\r\n> \r\n> ```\r\n> conda list | grep arrow\r\n> ```\r\n> \r\n> ```\r\n> python -c \"import pyarrow; print(pyarrow.__file__)\"\r\n> ```\r\n\r\narrow-cpp 11.0.0 py310h7516544_0 \r\npyarrow 12.0.1 pypi_0 pypi\r\n\r\n/root/miniconda3/lib/python3.10/site-packages/pyarrow/__init__.py",
"Got the same problem with\r\n\r\narrow-cpp 11.0.0 py310h1fc3239_0 \r\npyarrow 12.0.1 pypi_0 pypi\r\n\r\nminiforge3/envs/mlp/lib/python3.10/site-packages/pyarrow/__init__.py\r\n\r\nReverting back to pyarrow 11 solved the problem.\r\n",
"Solved with `pip install pyarrow==11.0.0`",
"I got different. Solved with\r\npip install pyarrow==12.0.1\r\npip install cchardet\r\n\r\nenv:\r\nPython 3.9.16\r\ntransformers 4.32.1",
"> I got the same error, pyarrow 12.0.0 released May/2023 (https://pypi.org/project/pyarrow/) is not compatible, running `pip install pyarrow==11.0.0` to force install the previous version solved the problem.\r\n> \r\n> Do we need to update dependencies?\r\n\r\nThis works for me as well",
"> I got different. Solved with pip install pyarrow==12.0.1 pip install cchardet\r\n> \r\n> env: Python 3.9.16 transformers 4.32.1\r\n\r\nI guess it also depends on the Python version. I got Python 3.11.5 and pyarrow==12.0.0. \r\nIt works! ",
"Hi, if this helps anyone, pip install pyarrow==11.0.0 did not work for me (I'm using Colab) but this worked: \r\n!pip install --extra-index-url=https://pypi.nvidia.com cudf-cu11"
] | "2023-06-02T04:16:32Z" | "2023-12-13T15:53:52Z" | null | NONE | null | null | null | ### Describe the bug
When trying to import datasets, I get a pyarrow ValueError:
Traceback (most recent call last):
File "/Users/edward/test/test.py", line 1, in <module>
import datasets
File "/Users/edward/opt/anaconda3/envs/cs235/lib/python3.9/site-packages/datasets/__init__.py", line 43, in <module>
from .arrow_dataset import Dataset
File "/Users/edward/opt/anaconda3/envs/cs235/lib/python3.9/site-packages/datasets/arrow_dataset.py", line 65, in <module>
from .arrow_reader import ArrowReader
File "/Users/edward/opt/anaconda3/envs/cs235/lib/python3.9/site-packages/datasets/arrow_reader.py", line 28, in <module>
import pyarrow.parquet as pq
File "/Users/edward/opt/anaconda3/envs/cs235/lib/python3.9/site-packages/pyarrow/parquet/__init__.py", line 20, in <module>
from .core import *
File "/Users/edward/opt/anaconda3/envs/cs235/lib/python3.9/site-packages/pyarrow/parquet/core.py", line 45, in <module>
from pyarrow.fs import (LocalFileSystem, FileSystem, FileType,
File "/Users/edward/opt/anaconda3/envs/cs235/lib/python3.9/site-packages/pyarrow/fs.py", line 49, in <module>
from pyarrow._gcsfs import GcsFileSystem # noqa
File "pyarrow/_gcsfs.pyx", line 1, in init pyarrow._gcsfs
ValueError: pyarrow.lib.IpcWriteOptions size changed, may indicate binary incompatibility. Expected 88 from C header, got 72 from PyObject
### Steps to reproduce the bug
`import datasets`
### Expected behavior
Successful import
### Environment info
Conda environment, MacOS
python 3.9.12
datasets 2.12.0
| {
"+1": 2,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 2,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5923/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5923/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/3190 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3190/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3190/comments | https://api.github.com/repos/huggingface/datasets/issues/3190/events | https://github.com/huggingface/datasets/issues/3190 | 1,041,153,631 | I_kwDODunzps4-Dr5f | 3,190 | combination of shuffle and filter results in a bug | {
"avatar_url": "https://avatars.githubusercontent.com/u/6278280?v=4",
"events_url": "https://api.github.com/users/rabeehk/events{/privacy}",
"followers_url": "https://api.github.com/users/rabeehk/followers",
"following_url": "https://api.github.com/users/rabeehk/following{/other_user}",
"gists_url": "https://api.github.com/users/rabeehk/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/rabeehk",
"id": 6278280,
"login": "rabeehk",
"node_id": "MDQ6VXNlcjYyNzgyODA=",
"organizations_url": "https://api.github.com/users/rabeehk/orgs",
"received_events_url": "https://api.github.com/users/rabeehk/received_events",
"repos_url": "https://api.github.com/users/rabeehk/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/rabeehk/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/rabeehk/subscriptions",
"type": "User",
"url": "https://api.github.com/users/rabeehk"
} | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | [] | null | [
"I cannot reproduce this on master and pyarrow==4.0.1.\r\n",
"Hi ! There was a regression in `datasets` 1.12 that introduced this bug. It has been fixed in #3019 in 1.13\r\n\r\nCan you try to update `datasets` and try again ?",
"Thanks a lot, fixes with 1.13"
] | "2021-11-01T13:07:29Z" | "2021-11-02T10:50:49Z" | "2021-11-02T10:50:49Z" | CONTRIBUTOR | null | null | null | ## Describe the bug
Hi,
I would like to shuffle a dataset, then filter it based on each existing label. however, the combination of `filter`, `shuffle` seems to results in a bug. In the minimal example below, as you see in the filtered results, the filtered labels are not unique, meaning filter has not worked. Any suggestions as a temporary fix is appreciated @lhoestq.
Thanks.
Best regards
Rabeeh
## Steps to reproduce the bug
```python
import numpy as np
import datasets
datasets = datasets.load_dataset('super_glue', 'rte', script_version="master")
shuffled_data = datasets["train"].shuffle(seed=42)
for label in range(2):
print("label ", label)
data = shuffled_data.filter(lambda example: int(example['label']) == label)
print("length ", len(data), np.unique(data['label']))
```
## Expected results
Filtering per label, should only return the data with that specific label.
## Actual results
As you can see, filtered data per label, has still two labels of [0, 1]
```
label 0
length 1249 [0 1]
label 1
length 1241 [0 1]
```
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.12.1
- Platform: linux
- Python version: 3.7.11
- PyArrow version: 5.0.0
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3190/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3190/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/814 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/814/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/814/comments | https://api.github.com/repos/huggingface/datasets/issues/814/events | https://github.com/huggingface/datasets/issues/814 | 738,500,443 | MDU6SXNzdWU3Mzg1MDA0NDM= | 814 | Joining multiple datasets | {
"avatar_url": "https://avatars.githubusercontent.com/u/73364383?v=4",
"events_url": "https://api.github.com/users/rabeehkarimimahabadi/events{/privacy}",
"followers_url": "https://api.github.com/users/rabeehkarimimahabadi/followers",
"following_url": "https://api.github.com/users/rabeehkarimimahabadi/following{/other_user}",
"gists_url": "https://api.github.com/users/rabeehkarimimahabadi/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/rabeehkarimimahabadi",
"id": 73364383,
"login": "rabeehkarimimahabadi",
"node_id": "MDQ6VXNlcjczMzY0Mzgz",
"organizations_url": "https://api.github.com/users/rabeehkarimimahabadi/orgs",
"received_events_url": "https://api.github.com/users/rabeehkarimimahabadi/received_events",
"repos_url": "https://api.github.com/users/rabeehkarimimahabadi/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/rabeehkarimimahabadi/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/rabeehkarimimahabadi/subscriptions",
"type": "User",
"url": "https://api.github.com/users/rabeehkarimimahabadi"
} | [
{
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset",
"id": 2067376369,
"name": "dataset request",
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request"
}
] | closed | false | null | [] | null | [
"found a solution here https://discuss.pytorch.org/t/train-simultaneously-on-two-datasets/649/35, closed for now, thanks "
] | "2020-11-08T16:19:30Z" | "2020-11-08T19:38:48Z" | "2020-11-08T19:38:48Z" | NONE | null | null | null | Hi
I have multiple iterative datasets from your library with different size and I want to join them in a way that each datasets is sampled equally, so smaller datasets more, larger one less, could you tell me how to implement this in pytorch? thanks | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/814/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/814/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/1608 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1608/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1608/comments | https://api.github.com/repos/huggingface/datasets/issues/1608/events | https://github.com/huggingface/datasets/pull/1608 | 771,329,434 | MDExOlB1bGxSZXF1ZXN0NTQyODkyMTQ4 | 1,608 | adding ted_talks_iwslt | {
"avatar_url": "https://avatars.githubusercontent.com/u/9033954?v=4",
"events_url": "https://api.github.com/users/skyprince999/events{/privacy}",
"followers_url": "https://api.github.com/users/skyprince999/followers",
"following_url": "https://api.github.com/users/skyprince999/following{/other_user}",
"gists_url": "https://api.github.com/users/skyprince999/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/skyprince999",
"id": 9033954,
"login": "skyprince999",
"node_id": "MDQ6VXNlcjkwMzM5NTQ=",
"organizations_url": "https://api.github.com/users/skyprince999/orgs",
"received_events_url": "https://api.github.com/users/skyprince999/received_events",
"repos_url": "https://api.github.com/users/skyprince999/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/skyprince999/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/skyprince999/subscriptions",
"type": "User",
"url": "https://api.github.com/users/skyprince999"
} | [] | closed | false | null | [] | null | [
"Closing this with reference to the new approach #1676 "
] | "2020-12-19T07:36:41Z" | "2021-01-02T15:44:12Z" | "2021-01-02T15:44:11Z" | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/1608.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1608",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/1608.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1608"
} | UPDATE2: (2nd Jan) Wrote a long writeup on the slack channel. I don't think this approach is correct. Basically this created language pairs (109*108)
Running the `pytest `went for more than 40+ hours and it was still running!
So working on a different approach, such that the number of configs = number of languages. Will make a new pull request with that.
UPDATE: This requires manual download dataset
This is a draft version | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1608/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1608/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5217 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5217/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5217/comments | https://api.github.com/repos/huggingface/datasets/issues/5217/events | https://github.com/huggingface/datasets/pull/5217 | 1,441,252,740 | PR_kwDODunzps5CetXs | 5,217 | Reword E2E training and inference tips in the vision guides | {
"avatar_url": "https://avatars.githubusercontent.com/u/22957388?v=4",
"events_url": "https://api.github.com/users/sayakpaul/events{/privacy}",
"followers_url": "https://api.github.com/users/sayakpaul/followers",
"following_url": "https://api.github.com/users/sayakpaul/following{/other_user}",
"gists_url": "https://api.github.com/users/sayakpaul/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/sayakpaul",
"id": 22957388,
"login": "sayakpaul",
"node_id": "MDQ6VXNlcjIyOTU3Mzg4",
"organizations_url": "https://api.github.com/users/sayakpaul/orgs",
"received_events_url": "https://api.github.com/users/sayakpaul/received_events",
"repos_url": "https://api.github.com/users/sayakpaul/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/sayakpaul/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sayakpaul/subscriptions",
"type": "User",
"url": "https://api.github.com/users/sayakpaul"
} | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._"
] | "2022-11-09T02:40:01Z" | "2022-11-10T01:38:09Z" | "2022-11-10T01:36:09Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/5217.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5217",
"merged_at": "2022-11-10T01:36:08Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5217.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5217"
} | Reference: https://github.com/huggingface/datasets/pull/5188#discussion_r1012148730 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5217/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5217/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5575 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5575/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5575/comments | https://api.github.com/repos/huggingface/datasets/issues/5575/events | https://github.com/huggingface/datasets/issues/5575 | 1,598,396,552 | I_kwDODunzps5fRZiI | 5,575 | Metadata for each column | {
"avatar_url": "https://avatars.githubusercontent.com/u/11356471?v=4",
"events_url": "https://api.github.com/users/parsa-ra/events{/privacy}",
"followers_url": "https://api.github.com/users/parsa-ra/followers",
"following_url": "https://api.github.com/users/parsa-ra/following{/other_user}",
"gists_url": "https://api.github.com/users/parsa-ra/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/parsa-ra",
"id": 11356471,
"login": "parsa-ra",
"node_id": "MDQ6VXNlcjExMzU2NDcx",
"organizations_url": "https://api.github.com/users/parsa-ra/orgs",
"received_events_url": "https://api.github.com/users/parsa-ra/received_events",
"repos_url": "https://api.github.com/users/parsa-ra/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/parsa-ra/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/parsa-ra/subscriptions",
"type": "User",
"url": "https://api.github.com/users/parsa-ra"
} | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | open | false | null | [] | {
"closed_at": null,
"closed_issues": 0,
"created_at": "2023-02-13T16:22:42Z",
"creator": {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko"
},
"description": "Next major release",
"due_on": null,
"html_url": "https://github.com/huggingface/datasets/milestone/10",
"id": 9038583,
"labels_url": "https://api.github.com/repos/huggingface/datasets/milestones/10/labels",
"node_id": "MI_kwDODunzps4Aier3",
"number": 10,
"open_issues": 4,
"state": "open",
"title": "3.0",
"updated_at": "2023-09-22T14:07:52Z",
"url": "https://api.github.com/repos/huggingface/datasets/milestones/10"
} | [
"Hi! Indeed it would be useful to support this. PyArrow natively supports schema-level and column-level metadata, so implementing this should be straightforward. The API I have in mind would work as follows:\r\n```python\r\ncol_feature = Value(\"string\", metadata=\"Some column-level metadata\")\r\n\r\nfeatures = Features({\"col\": col_feature}, metadata=\"Some schema-level metadata\")\r\n```\r\n\r\nWDYT?",
"Sorry for the late reply, \r\nYes, I think this is the most straight-forward approach with the things that we already have.\r\n\r\n",
"@mariosasko Let me know how I can help.",
"Hi, is this feature to be implemented in the near future? It would be really nice if that would be the case! "
] | "2023-02-24T10:53:44Z" | "2023-12-04T20:28:03Z" | null | NONE | null | null | null | ### Feature request
Being able to put some metadata for each column as a string or any other type.
### Motivation
I will bring the motivation by an example, lets say we are experimenting with embedding produced by some image encoder network, and we want to iterate through a couple of preprocessing and see which one works better in our downstream task, here as workaround right now what I do is the compute the hash of the preprocessing that the images went through as part of the new columns name, it would be nice to attach some kinda meta data in these scenarios to the each columns. metadata
### Your contribution
Maybe we could map another relational like database as the metadata? | {
"+1": 3,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 3,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5575/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5575/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/4834 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4834/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4834/comments | https://api.github.com/repos/huggingface/datasets/issues/4834/events | https://github.com/huggingface/datasets/pull/4834 | 1,336,993,511 | PR_kwDODunzps49FJOu | 4,834 | Fix documentation card of recipe_nlg dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
} | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._"
] | "2022-08-12T09:49:39Z" | "2022-08-12T11:28:18Z" | "2022-08-12T11:13:40Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/4834.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4834",
"merged_at": "2022-08-12T11:13:40Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4834.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4834"
} | Fix documentation card of recipe_nlg dataset | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4834/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4834/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3142 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3142/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3142/comments | https://api.github.com/repos/huggingface/datasets/issues/3142/events | https://github.com/huggingface/datasets/issues/3142 | 1,033,566,034 | I_kwDODunzps49mvdS | 3,142 | Provide a way to write a streamed dataset to the disk | {
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"events_url": "https://api.github.com/users/severo/events{/privacy}",
"followers_url": "https://api.github.com/users/severo/followers",
"following_url": "https://api.github.com/users/severo/following{/other_user}",
"gists_url": "https://api.github.com/users/severo/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/severo",
"id": 1676121,
"login": "severo",
"node_id": "MDQ6VXNlcjE2NzYxMjE=",
"organizations_url": "https://api.github.com/users/severo/orgs",
"received_events_url": "https://api.github.com/users/severo/received_events",
"repos_url": "https://api.github.com/users/severo/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/severo/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/severo/subscriptions",
"type": "User",
"url": "https://api.github.com/users/severo"
} | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
},
{
"color": "E5583E",
"default": false,
"description": "Related to the dataset viewer on huggingface.co",
"id": 3470211881,
"name": "dataset-viewer",
"node_id": "LA_kwDODunzps7O1zsp",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset-viewer"
}
] | open | false | null | [] | null | [
"Yes, I agree this feature is much needed. We could do something similar to what TF does (https://www.tensorflow.org/api_docs/python/tf/data/Dataset#cache). \r\n\r\nIdeally, if the entire streamed dataset is consumed/cached, the generated cache should be reusable for the Arrow dataset."
] | "2021-10-22T13:09:53Z" | "2021-10-29T11:14:39Z" | null | CONTRIBUTOR | null | null | null | **Is your feature request related to a problem? Please describe.**
The streaming mode allows to get the 100 first rows of a dataset very quickly. But it does not cache the answer, so a posterior call to get the same 100 rows will send a request to the server again and again.
**Describe the solution you'd like**
Provide a way to write the streamed rows of a dataset on the disk, and to load from it later.
**Describe alternatives you've considered**
Provide a third mode: `lazy`, which would use the local cache for the data that have already been fetched previously, and use streaming to get the rest of the requested data.
| {
"+1": 2,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 2,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3142/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3142/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/3769 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3769/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3769/comments | https://api.github.com/repos/huggingface/datasets/issues/3769/events | https://github.com/huggingface/datasets/issues/3769 | 1,146,258,023 | I_kwDODunzps5EUoJn | 3,769 | `dataset = dataset.map()` causes faiss index lost | {
"avatar_url": "https://avatars.githubusercontent.com/u/13076552?v=4",
"events_url": "https://api.github.com/users/Oaklight/events{/privacy}",
"followers_url": "https://api.github.com/users/Oaklight/followers",
"following_url": "https://api.github.com/users/Oaklight/following{/other_user}",
"gists_url": "https://api.github.com/users/Oaklight/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/Oaklight",
"id": 13076552,
"login": "Oaklight",
"node_id": "MDQ6VXNlcjEzMDc2NTUy",
"organizations_url": "https://api.github.com/users/Oaklight/orgs",
"received_events_url": "https://api.github.com/users/Oaklight/received_events",
"repos_url": "https://api.github.com/users/Oaklight/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/Oaklight/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Oaklight/subscriptions",
"type": "User",
"url": "https://api.github.com/users/Oaklight"
} | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | open | false | null | [] | null | [
"Hi ! Indeed `map` is dropping the index right now, because one can create a dataset with more or fewer rows using `map` (and therefore the index might not be relevant anymore)\r\n\r\nI guess we could check the resulting dataset length, and if the user hasn't changed the dataset size we could keep the index, what do you think ?",
"doing `.add_column(\"x\",x_data)` also removes the index. the new column might be irrelevant to the index so I don't think it should drop. \r\n\r\nMinimal example\r\n\r\n```python\r\nfrom datasets import load_dataset\r\nimport numpy as np\r\n\r\ndata=load_dataset(\"ceyda/cats_vs_dogs_sample\") #just a test dataset\r\ndata=data[\"train\"]\r\nembd_data=data.map(lambda x: {\"emb\":np.random.uniform(-1,0,50).astype(np.float32)})\r\nembd_data.add_faiss_index(column=\"emb\")\r\nprint(embd_data.list_indexes())\r\nembd_data=embd_data.add_column(\"x\",[0]*data.num_rows)\r\nprint(embd_data.list_indexes())\r\n```",
"I agree `add_column` shouldn't drop the index indeed ! Is it something you'd like to contribute ? I think it's just a matter of copying the `self._indexes` dictionary to the output dataset"
] | "2022-02-21T21:59:23Z" | "2022-06-27T14:56:29Z" | null | NONE | null | null | null | ## Describe the bug
assigning the resulted dataset to original dataset causes lost of the faiss index
## Steps to reproduce the bug
`my_dataset` is a regular loaded dataset. It's a part of a customed dataset structure
```python
self.dataset.add_faiss_index('embeddings')
self.dataset.list_indexes()
# ['embeddings']
dataset2 = my_dataset.map(
lambda x: self._get_nearest_examples_batch(x['text']), batch=True
)
# the unexpected result:
dataset2.list_indexes()
# []
self.dataset.list_indexes()
# ['embeddings']
```
in case something wrong with my `_get_nearest_examples_batch()`, it's like this
```python
def _get_nearest_examples_batch(self, examples, k=5):
queries = embed(examples)
scores_batch, retrievals_batch = self.dataset.get_nearest_examples_batch(self.faiss_column, queries, k)
return {
'neighbors': [batch['text'] for batch in retrievals_batch],
'scores': scores_batch
}
```
## Expected results
`map` shouldn't drop the indexes, in another word, indexes should be carried to the generated dataset
## Actual results
map drops the indexes
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.18.3
- Platform: Ubuntu 20.04.3 LTS
- Python version: 3.8.12
- PyArrow version: 7.0.0
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3769/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3769/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5307 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5307/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5307/comments | https://api.github.com/repos/huggingface/datasets/issues/5307/events | https://github.com/huggingface/datasets/pull/5307 | 1,466,477,427 | PR_kwDODunzps5Dzj8r | 5,307 | Use correct dataset type in `from_generator` docs | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko"
} | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._"
] | "2022-11-28T13:59:10Z" | "2022-11-28T15:30:37Z" | "2022-11-28T15:27:26Z" | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/5307.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5307",
"merged_at": "2022-11-28T15:27:26Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5307.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5307"
} | Use the correct dataset type in the `from_generator` docs (example with sharding). | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5307/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5307/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/301 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/301/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/301/comments | https://api.github.com/repos/huggingface/datasets/issues/301/events | https://github.com/huggingface/datasets/issues/301 | 643,763,525 | MDU6SXNzdWU2NDM3NjM1MjU= | 301 | Setting cache_dir gives error on wikipedia download | {
"avatar_url": "https://avatars.githubusercontent.com/u/33862536?v=4",
"events_url": "https://api.github.com/users/hallvagi/events{/privacy}",
"followers_url": "https://api.github.com/users/hallvagi/followers",
"following_url": "https://api.github.com/users/hallvagi/following{/other_user}",
"gists_url": "https://api.github.com/users/hallvagi/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/hallvagi",
"id": 33862536,
"login": "hallvagi",
"node_id": "MDQ6VXNlcjMzODYyNTM2",
"organizations_url": "https://api.github.com/users/hallvagi/orgs",
"received_events_url": "https://api.github.com/users/hallvagi/received_events",
"repos_url": "https://api.github.com/users/hallvagi/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/hallvagi/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/hallvagi/subscriptions",
"type": "User",
"url": "https://api.github.com/users/hallvagi"
} | [] | closed | false | null | [] | null | [
"Whoops didn't mean to close this one.\r\nI did some changes, could you try to run it from the master branch ?",
"Now it works, thanks!"
] | "2020-06-23T11:31:44Z" | "2020-06-24T07:05:07Z" | "2020-06-24T07:05:07Z" | NONE | null | null | null | First of all thank you for a super handy library! I'd like to download large files to a specific drive so I set `cache_dir=my_path`. This works fine with e.g. imdb and squad. But on wikipedia I get an error:
```
nlp.load_dataset('wikipedia', '20200501.de', split = 'train', cache_dir=my_path)
```
```
OSError Traceback (most recent call last)
<ipython-input-2-23551344d7bc> in <module>
1 import nlp
----> 2 nlp.load_dataset('wikipedia', '20200501.de', split = 'train', cache_dir=path)
~/anaconda3/envs/fastai2/lib/python3.7/site-packages/nlp/load.py in load_dataset(path, name, version, data_dir, data_files, split, cache_dir, download_config, download_mode, ignore_verifications, save_infos, **config_kwargs)
522 download_mode=download_mode,
523 ignore_verifications=ignore_verifications,
--> 524 save_infos=save_infos,
525 )
526
~/anaconda3/envs/fastai2/lib/python3.7/site-packages/nlp/builder.py in download_and_prepare(self, download_config, download_mode, ignore_verifications, save_infos, try_from_hf_gcs, dl_manager, **download_and_prepare_kwargs)
385 with utils.temporary_assignment(self, "_cache_dir", tmp_data_dir):
386 reader = ArrowReader(self._cache_dir, self.info)
--> 387 reader.download_from_hf_gcs(self._cache_dir, self._relative_data_dir(with_version=True))
388 downloaded_info = DatasetInfo.from_directory(self._cache_dir)
389 self.info.update(downloaded_info)
~/anaconda3/envs/fastai2/lib/python3.7/site-packages/nlp/arrow_reader.py in download_from_hf_gcs(self, cache_dir, relative_data_dir)
231 remote_dataset_info = os.path.join(remote_cache_dir, "dataset_info.json")
232 downloaded_dataset_info = cached_path(remote_dataset_info)
--> 233 os.rename(downloaded_dataset_info, os.path.join(cache_dir, "dataset_info.json"))
234 if self._info is not None:
235 self._info.update(self._info.from_directory(cache_dir))
OSError: [Errno 18] Invalid cross-device link: '/home/local/NTU/nn/.cache/huggingface/datasets/025fa4fd4f04aaafc9e939260fbc8f0bb190ce14c61310c8ae1ddd1dcb31f88c.9637f367b6711a79ca478be55fe6989b8aea4941b7ef7adc67b89ff403020947' -> '/data/nn/nlp/wikipedia/20200501.de/1.0.0.incomplete/dataset_info.json'
``` | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/301/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/301/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/476 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/476/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/476/comments | https://api.github.com/repos/huggingface/datasets/issues/476/events | https://github.com/huggingface/datasets/pull/476 | 672,991,854 | MDExOlB1bGxSZXF1ZXN0NDYyOTMyMTgx | 476 | CheckList | {
"avatar_url": "https://avatars.githubusercontent.com/u/698010?v=4",
"events_url": "https://api.github.com/users/marcotcr/events{/privacy}",
"followers_url": "https://api.github.com/users/marcotcr/followers",
"following_url": "https://api.github.com/users/marcotcr/following{/other_user}",
"gists_url": "https://api.github.com/users/marcotcr/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/marcotcr",
"id": 698010,
"login": "marcotcr",
"node_id": "MDQ6VXNlcjY5ODAxMA==",
"organizations_url": "https://api.github.com/users/marcotcr/orgs",
"received_events_url": "https://api.github.com/users/marcotcr/received_events",
"repos_url": "https://api.github.com/users/marcotcr/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/marcotcr/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/marcotcr/subscriptions",
"type": "User",
"url": "https://api.github.com/users/marcotcr"
} | [
{
"color": "0e8a16",
"default": false,
"description": "Contribution to a dataset script",
"id": 4564477500,
"name": "dataset contribution",
"node_id": "LA_kwDODunzps8AAAABEBBmPA",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20contribution"
}
] | closed | false | null | [] | null | [
"> Also, a little out of my depth there, but would there be a way to have the default pip install checklist command not require mysql and mariadb to be installed? Feels like that might be a source of confusion for users.\r\n\r\nI removed the pattern dependency, mysql is not a requirement anymore. I'm not sure where mariadb is coming from. ",
"Thanks for your contribution, @marcotcr. Are you still interested in adding this dataset?\r\n\r\nWe are removing the dataset scripts from this GitHub repo and moving them to the Hugging Face Hub: https://huggingface.co/datasets\r\n\r\nWe would suggest you create this dataset there. Please, feel free to tell us if you need some help."
] | "2020-08-04T18:32:05Z" | "2022-10-03T09:43:37Z" | "2022-10-03T09:43:37Z" | NONE | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/476.diff",
"html_url": "https://github.com/huggingface/datasets/pull/476",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/476.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/476"
} | Sorry for the large pull request.
- Added checklists as datasets. I can't run `test_load_real_dataset` (see #474), but I can load the datasets successfully as shown in the example notebook
- Added a checklist wrapper | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 1,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/476/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/476/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/2248 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2248/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2248/comments | https://api.github.com/repos/huggingface/datasets/issues/2248/events | https://github.com/huggingface/datasets/pull/2248 | 864,853,447 | MDExOlB1bGxSZXF1ZXN0NjIxMDEyNzg5 | 2,248 | Implement Dataset to JSON | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
} | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | closed | false | null | [] | {
"closed_at": "2021-05-31T16:20:53Z",
"closed_issues": 3,
"created_at": "2021-04-09T13:16:31Z",
"creator": {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
},
"description": "Next minor release",
"due_on": "2021-05-14T07:00:00Z",
"html_url": "https://github.com/huggingface/datasets/milestone/3",
"id": 6644287,
"labels_url": "https://api.github.com/repos/huggingface/datasets/milestones/3/labels",
"node_id": "MDk6TWlsZXN0b25lNjY0NDI4Nw==",
"number": 3,
"open_issues": 0,
"state": "closed",
"title": "1.7",
"updated_at": "2021-05-31T16:20:53Z",
"url": "https://api.github.com/repos/huggingface/datasets/milestones/3"
} | [] | "2021-04-22T11:46:51Z" | "2021-04-27T15:29:21Z" | "2021-04-27T15:29:20Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/2248.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2248",
"merged_at": "2021-04-27T15:29:20Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2248.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2248"
} | Implement `Dataset.to_json`. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2248/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2248/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3670 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3670/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3670/comments | https://api.github.com/repos/huggingface/datasets/issues/3670/events | https://github.com/huggingface/datasets/pull/3670 | 1,122,439,827 | PR_kwDODunzps4x_kBx | 3,670 | feat: 🎸 generate info if dataset_infos.json does not exist | {
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"events_url": "https://api.github.com/users/severo/events{/privacy}",
"followers_url": "https://api.github.com/users/severo/followers",
"following_url": "https://api.github.com/users/severo/following{/other_user}",
"gists_url": "https://api.github.com/users/severo/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/severo",
"id": 1676121,
"login": "severo",
"node_id": "MDQ6VXNlcjE2NzYxMjE=",
"organizations_url": "https://api.github.com/users/severo/orgs",
"received_events_url": "https://api.github.com/users/severo/received_events",
"repos_url": "https://api.github.com/users/severo/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/severo/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/severo/subscriptions",
"type": "User",
"url": "https://api.github.com/users/severo"
} | [] | closed | false | null | [] | null | [
"It's a first attempt at solving https://github.com/huggingface/datasets/issues/3013.",
"I only kept these ones:\r\n```\r\n path: str,\r\n data_files: Optional[Union[Dict, List, str]] = None,\r\n download_config: Optional[DownloadConfig] = None,\r\n download_mode: Optional[GenerateMode] = None,\r\n revision: Optional[Union[str, Version]] = None,\r\n use_auth_token: Optional[Union[bool, str]] = None,\r\n **config_kwargs,\r\n```\r\n\r\nLet me know if it's better for you now !\r\n\r\n(note that there's no breaking change since the ones that are removed can be passed as config_kwargs if you really want)",
"(https://github.com/huggingface/datasets/pull/3670/commits/5636911880ea4306c27c7f5825fa3f9427ccc2b6 and https://github.com/huggingface/datasets/pull/3670/commits/07c3f0800dd34dfebb9674ad46c67a907b08ded8 -> I has forgotten to update black in my venv)"
] | "2022-02-02T22:11:56Z" | "2022-02-21T15:57:11Z" | "2022-02-21T15:57:10Z" | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/3670.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3670",
"merged_at": "2022-02-21T15:57:10Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3670.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3670"
} | in get_dataset_infos(). Also: add the `use_auth_token` parameter, and create get_dataset_config_info()
✅ Closes: #3013 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3670/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3670/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/2825 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2825/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2825/comments | https://api.github.com/repos/huggingface/datasets/issues/2825/events | https://github.com/huggingface/datasets/issues/2825 | 976,584,926 | MDU6SXNzdWU5NzY1ODQ5MjY= | 2,825 | The datasets.map function does not load cached dataset after moving python script | {
"avatar_url": "https://avatars.githubusercontent.com/u/35392624?v=4",
"events_url": "https://api.github.com/users/hobbitlzy/events{/privacy}",
"followers_url": "https://api.github.com/users/hobbitlzy/followers",
"following_url": "https://api.github.com/users/hobbitlzy/following{/other_user}",
"gists_url": "https://api.github.com/users/hobbitlzy/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/hobbitlzy",
"id": 35392624,
"login": "hobbitlzy",
"node_id": "MDQ6VXNlcjM1MzkyNjI0",
"organizations_url": "https://api.github.com/users/hobbitlzy/orgs",
"received_events_url": "https://api.github.com/users/hobbitlzy/received_events",
"repos_url": "https://api.github.com/users/hobbitlzy/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/hobbitlzy/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/hobbitlzy/subscriptions",
"type": "User",
"url": "https://api.github.com/users/hobbitlzy"
} | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq"
} | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq"
}
] | null | [
"This also happened to me on COLAB.\r\nDetails:\r\nI ran the `run_mlm.py` in two different notebooks. \r\nIn the first notebook, I do tokenization since I can get 4 CPU cores without any GPUs, and save the cache into a folder which I copy to drive.\r\nIn the second notebook, I copy the cache folder from drive and re-run the run_mlm.py script (this time I uncomment the trainer code which happens after the tokenization)\r\n\r\nNote: I didn't change anything in the arguments, not even the preprocessing_num_workers\r\n ",
"Thanks for reporting ! This is indeed a bug, I'm looking into it",
"#2854 fixed the issue :)\r\n\r\nWe'll do a new release of `datasets` soon to make the fix available.\r\nIn the meantime, feel free to try it out by installing `datasets` from source\r\n\r\nIf you have other issues or any question, feel free to re-open the issue :)"
] | "2021-08-23T03:23:37Z" | "2021-08-31T13:14:41Z" | "2021-08-31T13:13:36Z" | NONE | null | null | null | ## Describe the bug
The datasets.map function caches the processed data to a certain directory. When the map function is called another time with totally the same parameters, the cached data are supposed to be reloaded instead of re-processing. However, it doesn't reuse cached data sometimes. I use the common data processing in different tasks, the datasets are processed again, the only difference is that I run them in different files.
## Steps to reproduce the bug
Just run the following codes in different .py files.
```python
if __name__ == '__main__':
from datasets import load_dataset
from transformers import AutoTokenizer
raw_datasets = load_dataset("wikitext", "wikitext-2-raw-v1")
tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")
def tokenize_function(examples):
return tokenizer(examples["text"], padding="max_length", truncation=True)
tokenized_datasets = raw_datasets.map(tokenize_function, batched=True)
```
## Expected results
The map function should reload data in the second or any later runs.
## Actual results
The processing happens in each run.
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.8.0
- Platform: linux
- Python version: 3.7.6
- PyArrow version: 3.0.0
This is the first time I report a bug. If there is any problem or confusing description, please let me know 😄.
| {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2825/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2825/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5942 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5942/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5942/comments | https://api.github.com/repos/huggingface/datasets/issues/5942/events | https://github.com/huggingface/datasets/pull/5942 | 1,752,021,681 | PR_kwDODunzps5Su-V4 | 5,942 | Pass datasets-cli additional args as kwargs to DatasetBuilder in `run_beam.py` | {
"avatar_url": "https://avatars.githubusercontent.com/u/84066822?v=4",
"events_url": "https://api.github.com/users/graelo/events{/privacy}",
"followers_url": "https://api.github.com/users/graelo/followers",
"following_url": "https://api.github.com/users/graelo/following{/other_user}",
"gists_url": "https://api.github.com/users/graelo/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/graelo",
"id": 84066822,
"login": "graelo",
"node_id": "MDQ6VXNlcjg0MDY2ODIy",
"organizations_url": "https://api.github.com/users/graelo/orgs",
"received_events_url": "https://api.github.com/users/graelo/received_events",
"repos_url": "https://api.github.com/users/graelo/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/graelo/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/graelo/subscriptions",
"type": "User",
"url": "https://api.github.com/users/graelo"
} | [] | open | false | null | [] | null | [] | "2023-06-12T06:50:50Z" | "2023-06-30T09:15:00Z" | null | NONE | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/5942.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5942",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/5942.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5942"
} | Hi,
Following this <https://discuss.huggingface.co/t/how-to-preprocess-a-wikipedia-dataset-using-dataflowrunner/41991/3>, here is a simple PR to pass any additional args to datasets-cli as kwargs in the DatasetBuilder in `run_beam.py`.
I also took the liberty to add missing setup steps to the `beam.mdx` docs in order to help everyone.
@lhoestq | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5942/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5942/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/6479 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6479/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6479/comments | https://api.github.com/repos/huggingface/datasets/issues/6479/events | https://github.com/huggingface/datasets/pull/6479 | 2,029,040,121 | PR_kwDODunzps5hVLom | 6,479 | More robust preupload retry mechanism | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko"
} | [] | closed | false | null | [] | null | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_6479). All of your documentation changes will be reflected on that endpoint. The docs are available until 30 days after the last update.",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.005669 / 0.011353 (-0.005683) | 0.003684 / 0.011008 (-0.007324) | 0.063477 / 0.038508 (0.024969) | 0.068760 / 0.023109 (0.045651) | 0.252741 / 0.275898 (-0.023157) | 0.286499 / 0.323480 (-0.036981) | 0.003311 / 0.007986 (-0.004674) | 0.003487 / 0.004328 (-0.000842) | 0.049636 / 0.004250 (0.045385) | 0.040983 / 0.037052 (0.003931) | 0.262230 / 0.258489 (0.003740) | 0.292131 / 0.293841 (-0.001710) | 0.028231 / 0.128546 (-0.100315) | 0.010912 / 0.075646 (-0.064734) | 0.211248 / 0.419271 (-0.208023) | 0.036679 / 0.043533 (-0.006854) | 0.258139 / 0.255139 (0.003000) | 0.277568 / 0.283200 (-0.005631) | 0.019576 / 0.141683 (-0.122107) | 1.102588 / 1.452155 (-0.349567) | 1.178587 / 1.492716 (-0.314130) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.098968 / 0.018006 (0.080962) | 0.298777 / 0.000490 (0.298287) | 0.000220 / 0.000200 (0.000020) | 0.000043 / 0.000054 (-0.000012) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.020408 / 0.037411 (-0.017003) | 0.062832 / 0.014526 (0.048306) | 0.076047 / 0.176557 (-0.100509) | 0.125209 / 0.737135 (-0.611926) | 0.079098 / 0.296338 (-0.217240) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.285603 / 0.215209 (0.070394) | 2.811530 / 2.077655 (0.733875) | 1.481012 / 1.504120 (-0.023108) | 1.362740 / 1.541195 (-0.178455) | 1.448999 / 1.468490 (-0.019491) | 0.557740 / 4.584777 (-4.027037) | 2.391377 / 3.745712 (-1.354335) | 2.973181 / 5.269862 (-2.296681) | 1.837147 / 4.565676 (-2.728530) | 0.064445 / 0.424275 (-0.359831) | 0.004992 / 0.007607 (-0.002615) | 0.339207 / 0.226044 (0.113162) | 3.378508 / 2.268929 (1.109580) | 1.843969 / 55.444624 (-53.600655) | 1.597794 / 6.876477 (-5.278682) | 1.657665 / 2.142072 (-0.484407) | 0.654267 / 4.805227 (-4.150961) | 0.120408 / 6.500664 (-6.380256) | 0.045298 / 0.075469 (-0.030171) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.949030 / 1.841788 (-0.892758) | 12.922161 / 8.074308 (4.847852) | 11.115660 / 10.191392 (0.924268) | 0.130556 / 0.680424 (-0.549868) | 0.016278 / 0.534201 (-0.517923) | 0.288137 / 0.579283 (-0.291146) | 0.265978 / 0.434364 (-0.168386) | 0.331491 / 0.540337 (-0.208847) | 0.437782 / 1.386936 (-0.949154) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.005342 / 0.011353 (-0.006010) | 0.003636 / 0.011008 (-0.007373) | 0.049527 / 0.038508 (0.011019) | 0.054856 / 0.023109 (0.031746) | 0.271922 / 0.275898 (-0.003976) | 0.295654 / 0.323480 (-0.027826) | 0.004023 / 0.007986 (-0.003963) | 0.002814 / 0.004328 (-0.001515) | 0.048963 / 0.004250 (0.044712) | 0.039936 / 0.037052 (0.002884) | 0.274336 / 0.258489 (0.015847) | 0.310100 / 0.293841 (0.016259) | 0.030006 / 0.128546 (-0.098540) | 0.010750 / 0.075646 (-0.064896) | 0.057989 / 0.419271 (-0.361283) | 0.033692 / 0.043533 (-0.009841) | 0.274084 / 0.255139 (0.018945) | 0.289428 / 0.283200 (0.006229) | 0.018739 / 0.141683 (-0.122944) | 1.126224 / 1.452155 (-0.325931) | 1.171595 / 1.492716 (-0.321121) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.093983 / 0.018006 (0.075977) | 0.298516 / 0.000490 (0.298026) | 0.000221 / 0.000200 (0.000022) | 0.000053 / 0.000054 (-0.000001) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.022498 / 0.037411 (-0.014914) | 0.071909 / 0.014526 (0.057383) | 0.083940 / 0.176557 (-0.092617) | 0.121059 / 0.737135 (-0.616076) | 0.084141 / 0.296338 (-0.212198) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.301792 / 0.215209 (0.086583) | 2.971971 / 2.077655 (0.894317) | 1.618718 / 1.504120 (0.114598) | 1.495816 / 1.541195 (-0.045379) | 1.546709 / 1.468490 (0.078219) | 0.571448 / 4.584777 (-4.013329) | 2.459182 / 3.745712 (-1.286531) | 2.937584 / 5.269862 (-2.332278) | 1.804670 / 4.565676 (-2.761007) | 0.062264 / 0.424275 (-0.362011) | 0.004915 / 0.007607 (-0.002692) | 0.355054 / 0.226044 (0.129009) | 3.490468 / 2.268929 (1.221539) | 1.978948 / 55.444624 (-53.465677) | 1.701020 / 6.876477 (-5.175457) | 1.744684 / 2.142072 (-0.397388) | 0.635880 / 4.805227 (-4.169347) | 0.115933 / 6.500664 (-6.384732) | 0.042646 / 0.075469 (-0.032823) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.999486 / 1.841788 (-0.842302) | 13.373854 / 8.074308 (5.299546) | 10.959784 / 10.191392 (0.768392) | 0.131032 / 0.680424 (-0.549392) | 0.015059 / 0.534201 (-0.519142) | 0.289892 / 0.579283 (-0.289391) | 0.279383 / 0.434364 (-0.154981) | 0.337670 / 0.540337 (-0.202668) | 0.597102 / 1.386936 (-0.789834) |\n\n</details>\n</details>\n\n\n"
] | "2023-12-06T17:19:38Z" | "2023-12-06T19:47:29Z" | "2023-12-06T19:41:06Z" | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/6479.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6479",
"merged_at": "2023-12-06T19:41:06Z",
"patch_url": "https://github.com/huggingface/datasets/pull/6479.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/6479"
} | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6479/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6479/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/349 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/349/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/349/comments | https://api.github.com/repos/huggingface/datasets/issues/349/events | https://github.com/huggingface/datasets/pull/349 | 652,231,571 | MDExOlB1bGxSZXF1ZXN0NDQ1MzQwMTQ1 | 349 | Hyperpartisan news detection | {
"avatar_url": "https://avatars.githubusercontent.com/u/13795113?v=4",
"events_url": "https://api.github.com/users/ghomasHudson/events{/privacy}",
"followers_url": "https://api.github.com/users/ghomasHudson/followers",
"following_url": "https://api.github.com/users/ghomasHudson/following{/other_user}",
"gists_url": "https://api.github.com/users/ghomasHudson/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/ghomasHudson",
"id": 13795113,
"login": "ghomasHudson",
"node_id": "MDQ6VXNlcjEzNzk1MTEz",
"organizations_url": "https://api.github.com/users/ghomasHudson/orgs",
"received_events_url": "https://api.github.com/users/ghomasHudson/received_events",
"repos_url": "https://api.github.com/users/ghomasHudson/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/ghomasHudson/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ghomasHudson/subscriptions",
"type": "User",
"url": "https://api.github.com/users/ghomasHudson"
} | [] | closed | false | null | [] | null | [
"Thank you so much for working on this! This is awesome!\r\n\r\nHow much would it help you if we would remove the manual request?\r\n\r\nWe are naturally interested in getting some broad idea of how many people and who are using our dataset. But if you consider hosting the dataset yourself, I would rather remove this small barrier on our side (so that we then still get the download count from your library).",
"This is an interesting aspect indeed!\r\nDo you want to send me an email (see my homepage) and I'll invite you on our slack channel to talk about that?\r\n@ghomasHudson wanna reach out to me as well? I tried to find your email to invite you without success."
] | "2020-07-07T11:06:37Z" | "2020-07-07T20:47:27Z" | "2020-07-07T14:57:11Z" | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/349.diff",
"html_url": "https://github.com/huggingface/datasets/pull/349",
"merged_at": "2020-07-07T14:57:11Z",
"patch_url": "https://github.com/huggingface/datasets/pull/349.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/349"
} | Adding the hyperpartisan news detection dataset from PAN. This contains news article text, labelled with whether they're hyper-partisan and why kinds of biases they display.
Implementation notes:
- As with many PAN tasks, the data is hosted on [Zenodo](https://zenodo.org/record/1489920) and must be requested before use. I've used the manual download stuff for this, although the dataset is provided under a Creative Commons Attribution 4.0 International License, so we could host a version if we wanted to?
- The 'bias' attribute doesn't exist for the 'byarticle' configuration. I've added an empty string to the class labels to deal with this. Is there a more standard value for empty data?
- Should we always subclass `nlp.BuilderConfig`?
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/349/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/349/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/2146 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2146/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2146/comments | https://api.github.com/repos/huggingface/datasets/issues/2146/events | https://github.com/huggingface/datasets/issues/2146 | 844,673,244 | MDU6SXNzdWU4NDQ2NzMyNDQ= | 2,146 | Dataset file size on disk is very large with 3D Array | {
"avatar_url": "https://avatars.githubusercontent.com/u/22685854?v=4",
"events_url": "https://api.github.com/users/jblemoine/events{/privacy}",
"followers_url": "https://api.github.com/users/jblemoine/followers",
"following_url": "https://api.github.com/users/jblemoine/following{/other_user}",
"gists_url": "https://api.github.com/users/jblemoine/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/jblemoine",
"id": 22685854,
"login": "jblemoine",
"node_id": "MDQ6VXNlcjIyNjg1ODU0",
"organizations_url": "https://api.github.com/users/jblemoine/orgs",
"received_events_url": "https://api.github.com/users/jblemoine/received_events",
"repos_url": "https://api.github.com/users/jblemoine/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/jblemoine/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jblemoine/subscriptions",
"type": "User",
"url": "https://api.github.com/users/jblemoine"
} | [] | open | false | null | [] | null | [
"Hi ! In the arrow file we store all the integers as uint8.\r\nSo your arrow file should weigh around `height x width x n_channels x n_images` bytes.\r\n\r\nWhat feature type do your TFDS dataset have ?\r\n\r\nIf it uses a `tfds.features.Image` type, then what is stored is the encoded data (as png or jpg for example). Since these encodings are made for compression, the resulting tfrecord is smaller that the arrow file.\r\n\r\nWe are working on adding a similar feature in `datasets`: the ability to store the encoded data instead of the raw integers for images, but also for audio data. This way, arrow files will have similar sizes as tfrecords for images.",
"Thanks for the prompt response. You're right about the encoding, I have the `tfds.features.Image` feature type you mentioned.\r\nHowever, as described in the `dataset_info.json`, my dataset is made of 1479 (224x224x3) images. 1479 x 224 x 224 x 3 = 222630912 bytes which is far from the actual size 520803408 bytes. \r\n\r\nAnyway I look forward to the Image feature type in `datasets`. ",
"@lhoestq I changed the data structure so I have a 2D Array feature type instead of a 3D Array by grouping the two last dimensions ( a 224x672 2D Array instead of a 224x224x3 3D Array). The file size is now 223973964 bytes, nearly half the previous size! Which is around of what I would expect.\r\nI found similar behavior in existing `datasets` collection, when comparing black and white vs color image, for example MNIST vs CIFAR. ",
"Interesting !\r\nThis may be because of the offsets that are stored with the array data.\r\n\r\nCurrently the offsets are stored even if the `shape` of the arrays is fixed. This was needed because of some issues with pyarrow a few months ago. I think these issues have been addressed now, so we can probably try to remove them to make the file lighter.\r\n\r\nIdeally in your case the floats data should be 220 MB for both Array2D and Array3D",
"Yeah for sure, can you be a bit more specific about where the offset is stored in the code base ? And any reference to pyarrow issues if you have some. I would be very interested in contributing to `datasets` by trying to fix this issue. ",
"Pyarrow has two types of lists: variable length lists and fixed size lists.\r\nCurrently we store the ArrayXD data as variable length lists. They take more disk space because they must store both actual data and offsets.\r\nIn the `datasets` code this is done here:\r\n\r\nhttps://github.com/huggingface/nlp/blob/dbac87c8a083f806467f5afc4ec9b401a7e4c15c/src/datasets/features.py#L346-L352\r\n\r\nTo use a fixed length list, one should use the `list_size` argument of `pyarrow.list_()`.\r\nI believe this would work directly modulo some changes in the numpy conversion here:\r\n\r\nhttps://github.com/huggingface/nlp/blob/dbac87c8a083f806467f5afc4ec9b401a7e4c15c/src/datasets/features.py#L381-L395"
] | "2021-03-30T14:46:09Z" | "2021-04-16T13:07:02Z" | null | NONE | null | null | null | Hi,
I have created my own dataset using the provided dataset loading script. It is an image dataset where images are stored as 3D Array with dtype=uint8.
The actual size on disk is surprisingly large. It takes 520 MB. Here is some info from `dataset_info.json`.
`{
"description": "",
"citation": "",
"homepage": "",
"license": "",
"features": {
"image": {
"shape": [224, 224, 3],
"dtype": "uint8",
"id": null,
"_type": "Array3D",
}
},
"post_processed": null,
"supervised_keys": null,
"builder_name": "shot_type_image_dataset",
"config_name": "default",
"version": {
"version_str": "0.0.0",
"description": null,
"major": 0,
"minor": 0,
"patch": 0,
},
"splits": {
"train": {
"name": "train",
"num_bytes": 520803408,
"num_examples": 1479,
"dataset_name": "shot_type_image_dataset",
}
},
"download_checksums": {
"": {
"num_bytes": 16940447118,
"checksum": "5854035705efe08b0ed8f3cf3da7b4d29cba9055c2d2d702c79785350d72ee03",
}
},
"download_size": 16940447118,
"post_processing_size": null,
"dataset_size": 520803408,
"size_in_bytes": 17461250526,
}`
I have created the same dataset with tensorflow_dataset and it takes only 125MB on disk.
I am wondering, is it normal behavior ? I understand `Datasets` uses Arrow for serialization wheres tf uses TF Records.
This might be a problem for large dataset.
Thanks for your help.
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2146/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2146/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/644 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/644/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/644/comments | https://api.github.com/repos/huggingface/datasets/issues/644/events | https://github.com/huggingface/datasets/pull/644 | 704,534,501 | MDExOlB1bGxSZXF1ZXN0NDg5NDQzMTk1 | 644 | Better windows support | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq"
} | [] | closed | false | null | [] | null | [
"This PR is ready :)\r\nIt brings official support for windows.\r\n\r\nSome tests `AWSDatasetTest` are failing.\r\nThis is because I had to fix a few datasets that were not compatible with windows.\r\nThese test will pass once they got merged on master :)"
] | "2020-09-18T17:17:36Z" | "2020-09-25T14:02:30Z" | "2020-09-25T14:02:28Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/644.diff",
"html_url": "https://github.com/huggingface/datasets/pull/644",
"merged_at": "2020-09-25T14:02:28Z",
"patch_url": "https://github.com/huggingface/datasets/pull/644.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/644"
} | There are a few differences in the behavior of python and pyarrow on windows.
For example there are restrictions when accessing/deleting files that are open
Fix #590 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/644/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/644/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3398 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3398/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3398/comments | https://api.github.com/repos/huggingface/datasets/issues/3398/events | https://github.com/huggingface/datasets/issues/3398 | 1,073,590,384 | I_kwDODunzps4__bBw | 3,398 | Add URL field to Wikimedia dataset instances: wikipedia,... | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
} | [
{
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset",
"id": 2067376369,
"name": "dataset request",
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request"
}
] | closed | false | null | [] | null | [
"@geohci, I think the field \"url\" does not appear in the Wikimedia dumps. Therefore I guess we should generate it, using the \"title\" field and making some transformation of it (replacing spaces with underscores) and prepending the domain (created using the language)?",
"Indeed:\r\n\r\n> To re-distribute text on Wikipedia in any form, provide credit to the authors either by including a) a [hyperlink](https://en.wikipedia.org/wiki/Hyperlink) (where possible) or [URL](https://en.wikipedia.org/wiki/URL) to the page or pages you are re-using, b) a hyperlink (where possible) or URL to an alternative, stable online copy which is freely accessible, which conforms with the license, and which provides credit to the authors in a manner equivalent to the credit given on this website, or c) a list of all authors. (Any list of authors may be filtered to exclude very small or irrelevant contributions.) This applies to text developed by the Wikipedia community. Text from external sources may attach additional attribution requirements to the work, which should be indicated on an article's face or on its talk page. For example, a page may have a banner or other notation indicating that some or all of its content was originally published somewhere else. Where such notations are visible in the page itself, they should generally be preserved by re-users.\r\n\r\nsource: https://en.wikipedia.org/wiki/Wikipedia:Copyrights\r\n\r\nI guess it's fine to add the URL field - it can be constructed easily from the title page IIRC.",
"yep, sorry forgot that that wasn't already in the dumps. specifically `f\"https://{language}.wikipedia.org/wiki/{title.replace(' ', '_')}` should do it",
"Thanks @geohci.\r\n\r\nI had already been looking for information about the conversion from title to URL and I found that apart from replacing blanks with underscores, some other special character must also be percent-encoded (e.g. `\"` to `%22`): https://meta.wikimedia.org/wiki/Help:URL\r\n\r\nTherefore, I have finally used `urllib.parse.quote` function. This additionally percent-encodes non-ASCII characters, but Wikimedia docs say these are equivalent:\r\n> For the other characters either the code or the character can be used in internal and external links, they are equivalent. The system does a conversion when needed.\r\n> [[%C3%80_propos_de_M%C3%A9ta]]\r\n> is rendered as [À_propos_de_Méta](https://meta.wikimedia.org/wiki/%C3%80_propos_de_M%C3%A9ta), almost like [À propos de Méta](https://meta.wikimedia.org/wiki/%C3%80_propos_de_M%C3%A9ta), which leads to this page on Meta with in the address bar the URL\r\n> [http://meta.wikipedia.org/wiki/%C3%80_propos_de_M%C3%A9ta](https://meta.wikipedia.org/wiki/%C3%80_propos_de_M%C3%A9ta)\r\n> while [http://meta.wikipedia.org/wiki/À_propos_de_Méta](https://meta.wikipedia.org/wiki/%C3%80_propos_de_M%C3%A9ta) leads to the same. ",
"Closed by:\r\n- #3789 "
] | "2021-12-07T17:17:27Z" | "2022-03-22T16:53:27Z" | "2022-03-22T16:53:27Z" | MEMBER | null | null | null | As reported by @geohci, in order to host pre-processed data in the Hub, we should add the full URL to data instances (new field "url"), so that we conform to proper attribution from license requirement. See, e.g.: https://fair-trec.github.io/docs/Fair_Ranking_2021_Participant_Instructions.pdf#subsection.3.2
This should be done for all pre-processed datasets under "wikimedia" org in the Hub: https://huggingface.co/wikimedia
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3398/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3398/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/1113 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1113/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1113/comments | https://api.github.com/repos/huggingface/datasets/issues/1113/events | https://github.com/huggingface/datasets/pull/1113 | 757,115,557 | MDExOlB1bGxSZXF1ZXN0NTMyNTQ1Mzg2 | 1,113 | add qed | {
"avatar_url": "https://avatars.githubusercontent.com/u/27137566?v=4",
"events_url": "https://api.github.com/users/patil-suraj/events{/privacy}",
"followers_url": "https://api.github.com/users/patil-suraj/followers",
"following_url": "https://api.github.com/users/patil-suraj/following{/other_user}",
"gists_url": "https://api.github.com/users/patil-suraj/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/patil-suraj",
"id": 27137566,
"login": "patil-suraj",
"node_id": "MDQ6VXNlcjI3MTM3NTY2",
"organizations_url": "https://api.github.com/users/patil-suraj/orgs",
"received_events_url": "https://api.github.com/users/patil-suraj/received_events",
"repos_url": "https://api.github.com/users/patil-suraj/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/patil-suraj/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patil-suraj/subscriptions",
"type": "User",
"url": "https://api.github.com/users/patil-suraj"
} | [] | closed | false | null | [] | null | [] | "2020-12-04T13:47:57Z" | "2020-12-05T15:46:21Z" | "2020-12-05T15:41:57Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/1113.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1113",
"merged_at": "2020-12-05T15:41:57Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1113.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1113"
} | adding QED: Dataset for Explanations in Question Answering
https://github.com/google-research-datasets/QED
https://arxiv.org/abs/2009.06354 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1113/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1113/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/2179 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2179/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2179/comments | https://api.github.com/repos/huggingface/datasets/issues/2179/events | https://github.com/huggingface/datasets/issues/2179 | 852,237,957 | MDU6SXNzdWU4NTIyMzc5NTc= | 2,179 | Load small datasets in-memory instead of using memory map | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq"
} | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
},
{
"color": "c5def5",
"default": false,
"description": "Generic discussion on the library",
"id": 2067400324,
"name": "generic discussion",
"node_id": "MDU6TGFiZWwyMDY3NDAwMzI0",
"url": "https://api.github.com/repos/huggingface/datasets/labels/generic%20discussion"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
} | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
}
] | null | [] | "2021-04-07T09:58:16Z" | "2021-04-20T10:04:04Z" | "2021-04-20T10:04:03Z" | MEMBER | null | null | null | Currently all datasets are loaded using memory mapping by default in `load_dataset`.
However this might not be necessary for small datasets. If a dataset is small enough, then it can be loaded in-memory and:
- its memory footprint would be small so it's ok
- in-memory computations/queries would be faster
- the caching on-disk would be disabled, making computations even faster (no I/O bound because of the disk)
- but running the same computation a second time would recompute everything since there would be no cached results on-disk. But this is probably fine since computations would be fast anyway + users should be able to provide a cache filename if needed.
Therefore, maybe the default behavior of `load_dataset` should be to load small datasets in-memory and big datasets using memory mapping. | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2179/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2179/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/1873 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1873/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1873/comments | https://api.github.com/repos/huggingface/datasets/issues/1873/events | https://github.com/huggingface/datasets/pull/1873 | 807,750,745 | MDExOlB1bGxSZXF1ZXN0NTcyOTM4MTYy | 1,873 | add iapp_wiki_qa_squad | {
"avatar_url": "https://avatars.githubusercontent.com/u/15519308?v=4",
"events_url": "https://api.github.com/users/cstorm125/events{/privacy}",
"followers_url": "https://api.github.com/users/cstorm125/followers",
"following_url": "https://api.github.com/users/cstorm125/following{/other_user}",
"gists_url": "https://api.github.com/users/cstorm125/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/cstorm125",
"id": 15519308,
"login": "cstorm125",
"node_id": "MDQ6VXNlcjE1NTE5MzA4",
"organizations_url": "https://api.github.com/users/cstorm125/orgs",
"received_events_url": "https://api.github.com/users/cstorm125/received_events",
"repos_url": "https://api.github.com/users/cstorm125/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/cstorm125/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/cstorm125/subscriptions",
"type": "User",
"url": "https://api.github.com/users/cstorm125"
} | [] | closed | false | null | [] | null | [] | "2021-02-13T13:34:27Z" | "2021-02-16T14:21:58Z" | "2021-02-16T14:21:58Z" | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/1873.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1873",
"merged_at": "2021-02-16T14:21:58Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1873.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1873"
} | `iapp_wiki_qa_squad` is an extractive question answering dataset from Thai Wikipedia articles.
It is adapted from [the original iapp-wiki-qa-dataset](https://github.com/iapp-technology/iapp-wiki-qa-dataset)
to [SQuAD](https://rajpurkar.github.io/SQuAD-explorer/) format, resulting in
5761/742/739 questions from 1529/191/192 articles. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1873/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1873/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/2930 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2930/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2930/comments | https://api.github.com/repos/huggingface/datasets/issues/2930/events | https://github.com/huggingface/datasets/issues/2930 | 998,154,311 | I_kwDODunzps47fqBH | 2,930 | Mutable columns argument breaks set_format | {
"avatar_url": "https://avatars.githubusercontent.com/u/12866554?v=4",
"events_url": "https://api.github.com/users/Rocketknight1/events{/privacy}",
"followers_url": "https://api.github.com/users/Rocketknight1/followers",
"following_url": "https://api.github.com/users/Rocketknight1/following{/other_user}",
"gists_url": "https://api.github.com/users/Rocketknight1/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/Rocketknight1",
"id": 12866554,
"login": "Rocketknight1",
"node_id": "MDQ6VXNlcjEyODY2NTU0",
"organizations_url": "https://api.github.com/users/Rocketknight1/orgs",
"received_events_url": "https://api.github.com/users/Rocketknight1/received_events",
"repos_url": "https://api.github.com/users/Rocketknight1/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/Rocketknight1/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Rocketknight1/subscriptions",
"type": "User",
"url": "https://api.github.com/users/Rocketknight1"
} | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/12866554?v=4",
"events_url": "https://api.github.com/users/Rocketknight1/events{/privacy}",
"followers_url": "https://api.github.com/users/Rocketknight1/followers",
"following_url": "https://api.github.com/users/Rocketknight1/following{/other_user}",
"gists_url": "https://api.github.com/users/Rocketknight1/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/Rocketknight1",
"id": 12866554,
"login": "Rocketknight1",
"node_id": "MDQ6VXNlcjEyODY2NTU0",
"organizations_url": "https://api.github.com/users/Rocketknight1/orgs",
"received_events_url": "https://api.github.com/users/Rocketknight1/received_events",
"repos_url": "https://api.github.com/users/Rocketknight1/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/Rocketknight1/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Rocketknight1/subscriptions",
"type": "User",
"url": "https://api.github.com/users/Rocketknight1"
} | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/12866554?v=4",
"events_url": "https://api.github.com/users/Rocketknight1/events{/privacy}",
"followers_url": "https://api.github.com/users/Rocketknight1/followers",
"following_url": "https://api.github.com/users/Rocketknight1/following{/other_user}",
"gists_url": "https://api.github.com/users/Rocketknight1/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/Rocketknight1",
"id": 12866554,
"login": "Rocketknight1",
"node_id": "MDQ6VXNlcjEyODY2NTU0",
"organizations_url": "https://api.github.com/users/Rocketknight1/orgs",
"received_events_url": "https://api.github.com/users/Rocketknight1/received_events",
"repos_url": "https://api.github.com/users/Rocketknight1/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/Rocketknight1/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Rocketknight1/subscriptions",
"type": "User",
"url": "https://api.github.com/users/Rocketknight1"
},
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq"
}
] | null | [
"Pushed a fix to my branch #2731 "
] | "2021-09-16T12:27:22Z" | "2021-09-16T13:50:53Z" | "2021-09-16T13:50:53Z" | MEMBER | null | null | null | ## Describe the bug
If you pass a mutable list to the `columns` argument of `set_format` and then change the list afterwards, the returned columns also change.
## Steps to reproduce the bug
```python
from datasets import load_dataset
dataset = load_dataset("glue", "cola")
column_list = ["idx", "label"]
dataset.set_format("python", columns=column_list)
column_list[1] = "foo" # Change the list after we call `set_format`
dataset['train'][:4].keys()
```
## Expected results
```python
dict_keys(['idx', 'label'])
```
## Actual results
```python
dict_keys(['idx'])
``` | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2930/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2930/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5456 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5456/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5456/comments | https://api.github.com/repos/huggingface/datasets/issues/5456/events | https://github.com/huggingface/datasets/pull/5456 | 1,553,905,148 | PR_kwDODunzps5IXq92 | 5,456 | feat: tqdm for `to_parquet` | {
"avatar_url": "https://avatars.githubusercontent.com/u/33707069?v=4",
"events_url": "https://api.github.com/users/zanussbaum/events{/privacy}",
"followers_url": "https://api.github.com/users/zanussbaum/followers",
"following_url": "https://api.github.com/users/zanussbaum/following{/other_user}",
"gists_url": "https://api.github.com/users/zanussbaum/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/zanussbaum",
"id": 33707069,
"login": "zanussbaum",
"node_id": "MDQ6VXNlcjMzNzA3MDY5",
"organizations_url": "https://api.github.com/users/zanussbaum/orgs",
"received_events_url": "https://api.github.com/users/zanussbaum/received_events",
"repos_url": "https://api.github.com/users/zanussbaum/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/zanussbaum/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/zanussbaum/subscriptions",
"type": "User",
"url": "https://api.github.com/users/zanussbaum"
} | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.012395 / 0.011353 (0.001042) | 0.006466 / 0.011008 (-0.004542) | 0.127605 / 0.038508 (0.089097) | 0.044929 / 0.023109 (0.021820) | 0.399856 / 0.275898 (0.123958) | 0.491341 / 0.323480 (0.167861) | 0.009193 / 0.007986 (0.001207) | 0.005419 / 0.004328 (0.001090) | 0.100577 / 0.004250 (0.096327) | 0.045338 / 0.037052 (0.008286) | 0.409970 / 0.258489 (0.151481) | 0.452941 / 0.293841 (0.159100) | 0.054350 / 0.128546 (-0.074197) | 0.019069 / 0.075646 (-0.056578) | 0.427036 / 0.419271 (0.007765) | 0.073616 / 0.043533 (0.030083) | 0.395384 / 0.255139 (0.140245) | 0.442381 / 0.283200 (0.159181) | 0.123185 / 0.141683 (-0.018498) | 1.797640 / 1.452155 (0.345485) | 1.888860 / 1.492716 (0.396143) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.211041 / 0.018006 (0.193035) | 0.539350 / 0.000490 (0.538860) | 0.001683 / 0.000200 (0.001483) | 0.000118 / 0.000054 (0.000064) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.031699 / 0.037411 (-0.005712) | 0.132696 / 0.014526 (0.118170) | 0.133710 / 0.176557 (-0.042846) | 0.190074 / 0.737135 (-0.547061) | 0.142919 / 0.296338 (-0.153420) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.643521 / 0.215209 (0.428312) | 6.137350 / 2.077655 (4.059695) | 2.463894 / 1.504120 (0.959774) | 2.120043 / 1.541195 (0.578848) | 2.121898 / 1.468490 (0.653408) | 1.287319 / 4.584777 (-3.297458) | 5.517864 / 3.745712 (1.772151) | 5.070820 / 5.269862 (-0.199042) | 2.948967 / 4.565676 (-1.616710) | 0.175861 / 0.424275 (-0.248415) | 0.015292 / 0.007607 (0.007685) | 0.843195 / 0.226044 (0.617150) | 7.884275 / 2.268929 (5.615347) | 3.182821 / 55.444624 (-52.261803) | 2.576093 / 6.876477 (-4.300384) | 2.537160 / 2.142072 (0.395088) | 1.510029 / 4.805227 (-3.295198) | 0.249404 / 6.500664 (-6.251260) | 0.080434 / 0.075469 (0.004965) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.618695 / 1.841788 (-0.223093) | 18.879207 / 8.074308 (10.804899) | 21.075272 / 10.191392 (10.883880) | 0.260781 / 0.680424 (-0.419643) | 0.046387 / 0.534201 (-0.487813) | 0.570709 / 0.579283 (-0.008574) | 0.619050 / 0.434364 (0.184686) | 0.642295 / 0.540337 (0.101958) | 0.780070 / 1.386936 (-0.606866) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.010418 / 0.011353 (-0.000935) | 0.006104 / 0.011008 (-0.004905) | 0.133609 / 0.038508 (0.095101) | 0.035101 / 0.023109 (0.011992) | 0.471931 / 0.275898 (0.196033) | 0.504498 / 0.323480 (0.181018) | 0.007388 / 0.007986 (-0.000598) | 0.004852 / 0.004328 (0.000523) | 0.094535 / 0.004250 (0.090284) | 0.056832 / 0.037052 (0.019779) | 0.470513 / 0.258489 (0.212024) | 0.531285 / 0.293841 (0.237444) | 0.058271 / 0.128546 (-0.070276) | 0.020523 / 0.075646 (-0.055123) | 0.437398 / 0.419271 (0.018126) | 0.065390 / 0.043533 (0.021857) | 0.503702 / 0.255139 (0.248563) | 0.515876 / 0.283200 (0.232677) | 0.118615 / 0.141683 (-0.023068) | 1.865380 / 1.452155 (0.413225) | 1.990316 / 1.492716 (0.497600) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.246772 / 0.018006 (0.228766) | 0.560607 / 0.000490 (0.560118) | 0.005675 / 0.000200 (0.005475) | 0.000142 / 0.000054 (0.000088) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.034692 / 0.037411 (-0.002719) | 0.174016 / 0.014526 (0.159490) | 0.179838 / 0.176557 (0.003282) | 0.217118 / 0.737135 (-0.520018) | 0.184811 / 0.296338 (-0.111527) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.675970 / 0.215209 (0.460760) | 6.787039 / 2.077655 (4.709384) | 2.932619 / 1.504120 (1.428499) | 2.545076 / 1.541195 (1.003882) | 2.566705 / 1.468490 (1.098215) | 1.287365 / 4.584777 (-3.297412) | 5.468441 / 3.745712 (1.722729) | 5.227726 / 5.269862 (-0.042136) | 2.868970 / 4.565676 (-1.696706) | 0.153535 / 0.424275 (-0.270740) | 0.020087 / 0.007607 (0.012480) | 0.860562 / 0.226044 (0.634518) | 8.656109 / 2.268929 (6.387180) | 3.749424 / 55.444624 (-51.695200) | 3.011337 / 6.876477 (-3.865139) | 3.119045 / 2.142072 (0.976973) | 1.562174 / 4.805227 (-3.243053) | 0.279161 / 6.500664 (-6.221504) | 0.084905 / 0.075469 (0.009436) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.638684 / 1.841788 (-0.203104) | 18.834760 / 8.074308 (10.760452) | 21.554310 / 10.191392 (11.362918) | 0.274518 / 0.680424 (-0.405906) | 0.030343 / 0.534201 (-0.503858) | 0.539094 / 0.579283 (-0.040189) | 0.627258 / 0.434364 (0.192895) | 0.624638 / 0.540337 (0.084301) | 0.742776 / 1.386936 (-0.644160) |\n\n</details>\n</details>\n\n\n"
] | "2023-01-23T22:05:38Z" | "2023-01-24T11:26:47Z" | "2023-01-24T11:17:12Z" | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/5456.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5456",
"merged_at": "2023-01-24T11:17:12Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5456.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5456"
} | As described in #5418
I noticed also that the `to_json` function supports multi-workers whereas `to_parquet`, is that not possible/not needed with Parquet or something that hasn't been implemented yet? | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5456/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5456/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3595 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3595/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3595/comments | https://api.github.com/repos/huggingface/datasets/issues/3595/events | https://github.com/huggingface/datasets/pull/3595 | 1,107,260,527 | PR_kwDODunzps4xOIxH | 3,595 | Add ImageNet toy datasets from fastai | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko"
} | [
{
"color": "0e8a16",
"default": false,
"description": "Contribution to a dataset script",
"id": 4564477500,
"name": "dataset contribution",
"node_id": "LA_kwDODunzps8AAAABEBBmPA",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20contribution"
}
] | closed | false | null | [] | null | [
"Thanks for your contribution, @mariosasko. Are you still interested in adding this dataset?\r\n\r\nWe are removing the dataset scripts from this GitHub repo and moving them to the Hugging Face Hub: https://huggingface.co/datasets\r\n\r\nWe would suggest you create this dataset there. Please, feel free to tell us if you need some help."
] | "2022-01-18T19:03:35Z" | "2023-09-24T09:39:07Z" | "2022-09-30T14:39:35Z" | CONTRIBUTOR | null | 1 | {
"diff_url": "https://github.com/huggingface/datasets/pull/3595.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3595",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/3595.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3595"
} | Adds the ImageNet toy datasets from FastAI: Imagenette, Imagewoof and Imagewang.
TODOs:
* [ ] add dummy data
* [ ] add dataset card
* [ ] generate `dataset_info.json` | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3595/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3595/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3904 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3904/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3904/comments | https://api.github.com/repos/huggingface/datasets/issues/3904/events | https://github.com/huggingface/datasets/issues/3904 | 1,167,730,095 | I_kwDODunzps5FmiWv | 3,904 | CONLL2003 Dataset not available | {
"avatar_url": "https://avatars.githubusercontent.com/u/4755430?v=4",
"events_url": "https://api.github.com/users/omarespejel/events{/privacy}",
"followers_url": "https://api.github.com/users/omarespejel/followers",
"following_url": "https://api.github.com/users/omarespejel/following{/other_user}",
"gists_url": "https://api.github.com/users/omarespejel/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/omarespejel",
"id": 4755430,
"login": "omarespejel",
"node_id": "MDQ6VXNlcjQ3NTU0MzA=",
"organizations_url": "https://api.github.com/users/omarespejel/orgs",
"received_events_url": "https://api.github.com/users/omarespejel/received_events",
"repos_url": "https://api.github.com/users/omarespejel/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/omarespejel/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/omarespejel/subscriptions",
"type": "User",
"url": "https://api.github.com/users/omarespejel"
} | [
{
"color": "2edb81",
"default": false,
"description": "A bug in a dataset script provided in the library",
"id": 2067388877,
"name": "dataset bug",
"node_id": "MDU6TGFiZWwyMDY3Mzg4ODc3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20bug"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
} | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
}
] | null | [
"Thanks for reporting, @omarespejel.\r\n\r\nI'm sorry but I can't reproduce the issue: the loading of the dataset works perfecto for me and I can reach the data URL: https://data.deepai.org/conll2003.zip\r\n\r\nMight it be due to a temporary problem in the data owner site (https://data.deepai.org/) that is fixed now?\r\nCould you please try loading the dataset again and tell if the problem persists?",
"@omarespejel I'm closing this issue. Feel free to reopen it if the problem persists.",
"getting same issue. Can't find any solution.",
"I am getting the same issue. I use google colab with CPU.\r\nThe code I used is exactly the same as described above.\r\n```\r\nfrom datasets import load_dataset\r\ndataset = load_dataset(\"conll2003\")\r\n```\r\n\r\nThe produced error:\r\n\r\n\r\nNote: This error is different from what was initially described in this thread. This is because I use CPU. When I use GPU I reproduce the same initial error of the thread.\r\n\r\nMoreover, I receive the following warning:\r\n```\r\nWARNING:urllib3.connection:Certificate did not match expected hostname: data.deepai.org. Certificate: {'subject': ((('commonName', '*.b-cdn.net'),),), 'issuer': ((('countryName', 'GB'),), (('stateOrProvinceName', 'Greater Manchester'),), (('localityName', 'Salford'),), (('organizationName', 'Sectigo Limited'),), (('commonName', 'Sectigo RSA Domain Validation Secure Server CA'),)), 'version': 3, 'serialNumber': 'DDED48B13E1EA03983E833AB2C35EF07', 'notBefore': 'Nov 7 00:00:00 2022 GMT', 'notAfter': 'Nov 11 23:59:59 2023 GMT', 'subjectAltName': (('DNS', '*.b-cdn.net'), ('DNS', 'b-cdn.net')), 'OCSP': ('http://ocsp.sectigo.com/',), 'caIssuers': ('http://crt.sectigo.com/SectigoRSADomainValidationSecureServerCA.crt',)}\r\nDownloading and preparing dataset conll2003/conll2003 to /root/.cache/huggingface/datasets/conll2003/conll2003/1.0.0/9a4d16a94f8674ba3466315300359b0acd891b68b6c8743ddf60b9c702adce98...\r\nWARNING:urllib3.connection:Certificate did not match expected hostname: data.deepai.org. Certificate: {'subject': ((('commonName', '*.b-cdn.net'),),), 'issuer': ((('countryName', 'GB'),), (('stateOrProvinceName', 'Greater Manchester'),), (('localityName', 'Salford'),), (('organizationName', 'Sectigo Limited'),), (('commonName', 'Sectigo RSA Domain Validation Secure Server CA'),)), 'version': 3, 'serialNumber': 'DDED48B13E1EA03983E833AB2C35EF07', 'notBefore': 'Nov 7 00:00:00 2022 GMT', 'notAfter': 'Nov 11 23:59:59 2023 GMT', 'subjectAltName': (('DNS', '*.b-cdn.net'), ('DNS', 'b-cdn.net')), 'OCSP': ('http://ocsp.sectigo.com/',), 'caIssuers': ('http://crt.sectigo.com/SectigoRSADomainValidationSecureServerCA.crt',)}\r\n```\r\n"
] | "2022-03-13T23:46:15Z" | "2023-06-28T18:08:16Z" | "2022-03-17T08:21:32Z" | NONE | null | null | null | ## Describe the bug
[CONLL2003](https://huggingface.co/datasets/conll2003) Dataset can no longer reach 'https://data.deepai.org/conll2003.zip'

## Steps to reproduce the bug
```python
from datasets import load_dataset
datasets = load_dataset("conll2003")
```
## Expected results
Download the conll2003 dataset.
## Actual results
Error: `ConnectionError: Couldn't reach https://data.deepai.org/conll2003.zip (error 502)`
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3904/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3904/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/6102 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6102/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6102/comments | https://api.github.com/repos/huggingface/datasets/issues/6102/events | https://github.com/huggingface/datasets/pull/6102 | 1,828,494,896 | PR_kwDODunzps5WwyGy | 6,102 | Release 2.14.2 | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
} | [] | closed | false | null | [] | null | [
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006517 / 0.011353 (-0.004836) | 0.004217 / 0.011008 (-0.006792) | 0.083162 / 0.038508 (0.044654) | 0.074476 / 0.023109 (0.051367) | 0.321193 / 0.275898 (0.045295) | 0.358348 / 0.323480 (0.034868) | 0.005531 / 0.007986 (-0.002455) | 0.003621 / 0.004328 (-0.000707) | 0.063819 / 0.004250 (0.059568) | 0.056524 / 0.037052 (0.019471) | 0.322145 / 0.258489 (0.063656) | 0.371415 / 0.293841 (0.077574) | 0.030612 / 0.128546 (-0.097934) | 0.008907 / 0.075646 (-0.066739) | 0.289451 / 0.419271 (-0.129821) | 0.051959 / 0.043533 (0.008426) | 0.317729 / 0.255139 (0.062590) | 0.339750 / 0.283200 (0.056550) | 0.022430 / 0.141683 (-0.119253) | 1.487661 / 1.452155 (0.035506) | 1.554916 / 1.492716 (0.062199) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.296673 / 0.018006 (0.278667) | 0.599183 / 0.000490 (0.598694) | 0.002524 / 0.000200 (0.002324) | 0.000076 / 0.000054 (0.000021) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.027898 / 0.037411 (-0.009514) | 0.080870 / 0.014526 (0.066344) | 0.094894 / 0.176557 (-0.081662) | 0.152350 / 0.737135 (-0.584785) | 0.095765 / 0.296338 (-0.200573) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.415442 / 0.215209 (0.200233) | 4.161155 / 2.077655 (2.083500) | 2.117061 / 1.504120 (0.612941) | 1.937846 / 1.541195 (0.396651) | 1.979635 / 1.468490 (0.511145) | 0.488381 / 4.584777 (-4.096396) | 3.509836 / 3.745712 (-0.235876) | 3.833074 / 5.269862 (-1.436788) | 2.307536 / 4.565676 (-2.258141) | 0.057059 / 0.424275 (-0.367216) | 0.007366 / 0.007607 (-0.000241) | 0.487752 / 0.226044 (0.261708) | 4.869406 / 2.268929 (2.600478) | 2.594775 / 55.444624 (-52.849849) | 2.191712 / 6.876477 (-4.684765) | 2.413220 / 2.142072 (0.271147) | 0.584513 / 4.805227 (-4.220714) | 0.132162 / 6.500664 (-6.368502) | 0.061059 / 0.075469 (-0.014410) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.245178 / 1.841788 (-0.596610) | 20.624563 / 8.074308 (12.550255) | 14.675545 / 10.191392 (4.484153) | 0.165838 / 0.680424 (-0.514586) | 0.018700 / 0.534201 (-0.515501) | 0.392475 / 0.579283 (-0.186808) | 0.399884 / 0.434364 (-0.034480) | 0.457478 / 0.540337 (-0.082859) | 0.624553 / 1.386936 (-0.762383) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006716 / 0.011353 (-0.004637) | 0.004308 / 0.011008 (-0.006700) | 0.064495 / 0.038508 (0.025987) | 0.083194 / 0.023109 (0.060085) | 0.371994 / 0.275898 (0.096096) | 0.433045 / 0.323480 (0.109566) | 0.005535 / 0.007986 (-0.002450) | 0.003469 / 0.004328 (-0.000859) | 0.064342 / 0.004250 (0.060092) | 0.059362 / 0.037052 (0.022309) | 0.393819 / 0.258489 (0.135330) | 0.442591 / 0.293841 (0.148750) | 0.031594 / 0.128546 (-0.096952) | 0.008943 / 0.075646 (-0.066703) | 0.070689 / 0.419271 (-0.348582) | 0.049219 / 0.043533 (0.005686) | 0.361568 / 0.255139 (0.106429) | 0.417085 / 0.283200 (0.133886) | 0.025112 / 0.141683 (-0.116571) | 1.497204 / 1.452155 (0.045049) | 1.552781 / 1.492716 (0.060064) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.325254 / 0.018006 (0.307248) | 0.528399 / 0.000490 (0.527909) | 0.007429 / 0.000200 (0.007229) | 0.000101 / 0.000054 (0.000047) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.029908 / 0.037411 (-0.007504) | 0.087114 / 0.014526 (0.072588) | 0.103366 / 0.176557 (-0.073191) | 0.155145 / 0.737135 (-0.581990) | 0.103458 / 0.296338 (-0.192880) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.409432 / 0.215209 (0.194223) | 4.093327 / 2.077655 (2.015673) | 2.154115 / 1.504120 (0.649995) | 1.953492 / 1.541195 (0.412297) | 2.021532 / 1.468490 (0.553042) | 0.478928 / 4.584777 (-4.105849) | 3.515287 / 3.745712 (-0.230426) | 4.976239 / 5.269862 (-0.293623) | 2.832803 / 4.565676 (-1.732873) | 0.057239 / 0.424275 (-0.367036) | 0.007718 / 0.007607 (0.000111) | 0.484102 / 0.226044 (0.258057) | 4.833020 / 2.268929 (2.564092) | 2.564550 / 55.444624 (-52.880074) | 2.268969 / 6.876477 (-4.607508) | 2.513308 / 2.142072 (0.371235) | 0.582822 / 4.805227 (-4.222406) | 0.133989 / 6.500664 (-6.366675) | 0.062078 / 0.075469 (-0.013391) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.393766 / 1.841788 (-0.448021) | 20.224546 / 8.074308 (12.150238) | 14.359438 / 10.191392 (4.168046) | 0.166358 / 0.680424 (-0.514066) | 0.018840 / 0.534201 (-0.515361) | 0.393206 / 0.579283 (-0.186077) | 0.404220 / 0.434364 (-0.030144) | 0.462346 / 0.540337 (-0.077992) | 0.603078 / 1.386936 (-0.783858) |\n\n</details>\n</details>\n\n\n",
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006835 / 0.011353 (-0.004518) | 0.004530 / 0.011008 (-0.006478) | 0.087506 / 0.038508 (0.048997) | 0.088289 / 0.023109 (0.065180) | 0.351575 / 0.275898 (0.075677) | 0.391873 / 0.323480 (0.068393) | 0.005627 / 0.007986 (-0.002359) | 0.003735 / 0.004328 (-0.000594) | 0.065747 / 0.004250 (0.061497) | 0.058779 / 0.037052 (0.021726) | 0.358076 / 0.258489 (0.099587) | 0.408466 / 0.293841 (0.114626) | 0.031369 / 0.128546 (-0.097178) | 0.008807 / 0.075646 (-0.066839) | 0.293253 / 0.419271 (-0.126019) | 0.052950 / 0.043533 (0.009417) | 0.350411 / 0.255139 (0.095272) | 0.384827 / 0.283200 (0.101627) | 0.026219 / 0.141683 (-0.115464) | 1.464290 / 1.452155 (0.012136) | 1.549688 / 1.492716 (0.056972) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.270354 / 0.018006 (0.252348) | 0.593436 / 0.000490 (0.592946) | 0.003872 / 0.000200 (0.003673) | 0.000091 / 0.000054 (0.000036) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.031625 / 0.037411 (-0.005787) | 0.092599 / 0.014526 (0.078073) | 0.104619 / 0.176557 (-0.071938) | 0.163183 / 0.737135 (-0.573952) | 0.103245 / 0.296338 (-0.193094) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.390213 / 0.215209 (0.175004) | 3.894519 / 2.077655 (1.816864) | 1.905739 / 1.504120 (0.401619) | 1.728873 / 1.541195 (0.187678) | 1.838692 / 1.468490 (0.370202) | 0.484730 / 4.584777 (-4.100047) | 3.706749 / 3.745712 (-0.038963) | 5.572311 / 5.269862 (0.302449) | 3.389949 / 4.565676 (-1.175727) | 0.057315 / 0.424275 (-0.366960) | 0.007475 / 0.007607 (-0.000132) | 0.464690 / 0.226044 (0.238645) | 4.622242 / 2.268929 (2.353314) | 2.380957 / 55.444624 (-53.063667) | 2.038225 / 6.876477 (-4.838251) | 2.358881 / 2.142072 (0.216809) | 0.606358 / 4.805227 (-4.198869) | 0.133584 / 6.500664 (-6.367080) | 0.061894 / 0.075469 (-0.013575) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.259575 / 1.841788 (-0.582213) | 20.915216 / 8.074308 (12.840908) | 14.971952 / 10.191392 (4.780560) | 0.160206 / 0.680424 (-0.520218) | 0.018675 / 0.534201 (-0.515526) | 0.396821 / 0.579283 (-0.182462) | 0.430982 / 0.434364 (-0.003382) | 0.452895 / 0.540337 (-0.087443) | 0.647869 / 1.386936 (-0.739067) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.007194 / 0.011353 (-0.004158) | 0.004340 / 0.011008 (-0.006669) | 0.065125 / 0.038508 (0.026617) | 0.096243 / 0.023109 (0.073134) | 0.374361 / 0.275898 (0.098463) | 0.411863 / 0.323480 (0.088383) | 0.005813 / 0.007986 (-0.002172) | 0.003615 / 0.004328 (-0.000713) | 0.064953 / 0.004250 (0.060703) | 0.063171 / 0.037052 (0.026119) | 0.376238 / 0.258489 (0.117749) | 0.415826 / 0.293841 (0.121985) | 0.031926 / 0.128546 (-0.096620) | 0.008821 / 0.075646 (-0.066825) | 0.072150 / 0.419271 (-0.347122) | 0.049484 / 0.043533 (0.005951) | 0.369691 / 0.255139 (0.114552) | 0.390669 / 0.283200 (0.107470) | 0.025732 / 0.141683 (-0.115950) | 1.493833 / 1.452155 (0.041679) | 1.601786 / 1.492716 (0.109070) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.284279 / 0.018006 (0.266272) | 0.585909 / 0.000490 (0.585419) | 0.000411 / 0.000200 (0.000211) | 0.000057 / 0.000054 (0.000002) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.033642 / 0.037411 (-0.003769) | 0.095328 / 0.014526 (0.080802) | 0.105810 / 0.176557 (-0.070746) | 0.159779 / 0.737135 (-0.577357) | 0.108938 / 0.296338 (-0.187400) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.408112 / 0.215209 (0.192902) | 4.067035 / 2.077655 (1.989380) | 2.114504 / 1.504120 (0.610384) | 1.944027 / 1.541195 (0.402832) | 2.066117 / 1.468490 (0.597627) | 0.486441 / 4.584777 (-4.098336) | 3.622659 / 3.745712 (-0.123053) | 3.399310 / 5.269862 (-1.870552) | 2.183151 / 4.565676 (-2.382525) | 0.057490 / 0.424275 (-0.366785) | 0.007955 / 0.007607 (0.000347) | 0.490221 / 0.226044 (0.264177) | 4.887301 / 2.268929 (2.618373) | 2.679806 / 55.444624 (-52.764819) | 2.258992 / 6.876477 (-4.617484) | 2.592493 / 2.142072 (0.450420) | 0.606515 / 4.805227 (-4.198712) | 0.135645 / 6.500664 (-6.365019) | 0.063956 / 0.075469 (-0.011513) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.331304 / 1.841788 (-0.510483) | 21.458611 / 8.074308 (13.384303) | 14.898964 / 10.191392 (4.707572) | 0.172110 / 0.680424 (-0.508314) | 0.018791 / 0.534201 (-0.515409) | 0.395944 / 0.579283 (-0.183339) | 0.424526 / 0.434364 (-0.009838) | 0.462517 / 0.540337 (-0.077821) | 0.610139 / 1.386936 (-0.776797) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.005957 / 0.011353 (-0.005396) | 0.003581 / 0.011008 (-0.007427) | 0.079624 / 0.038508 (0.041116) | 0.058004 / 0.023109 (0.034895) | 0.309345 / 0.275898 (0.033447) | 0.346653 / 0.323480 (0.023173) | 0.005420 / 0.007986 (-0.002566) | 0.002906 / 0.004328 (-0.001423) | 0.061970 / 0.004250 (0.057720) | 0.047627 / 0.037052 (0.010575) | 0.314096 / 0.258489 (0.055607) | 0.361368 / 0.293841 (0.067527) | 0.027211 / 0.128546 (-0.101335) | 0.007853 / 0.075646 (-0.067793) | 0.260202 / 0.419271 (-0.159070) | 0.045308 / 0.043533 (0.001775) | 0.312150 / 0.255139 (0.057011) | 0.341085 / 0.283200 (0.057886) | 0.021302 / 0.141683 (-0.120381) | 1.430315 / 1.452155 (-0.021840) | 1.608989 / 1.492716 (0.116273) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.185289 / 0.018006 (0.167283) | 0.423318 / 0.000490 (0.422828) | 0.005741 / 0.000200 (0.005541) | 0.000070 / 0.000054 (0.000015) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.023777 / 0.037411 (-0.013634) | 0.071937 / 0.014526 (0.057412) | 0.079406 / 0.176557 (-0.097151) | 0.143815 / 0.737135 (-0.593320) | 0.081648 / 0.296338 (-0.214690) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.431514 / 0.215209 (0.216305) | 4.314471 / 2.077655 (2.236817) | 2.305167 / 1.504120 (0.801047) | 2.137894 / 1.541195 (0.596699) | 2.161034 / 1.468490 (0.692544) | 0.511701 / 4.584777 (-4.073076) | 3.098213 / 3.745712 (-0.647499) | 4.086837 / 5.269862 (-1.183024) | 2.517184 / 4.565676 (-2.048492) | 0.058272 / 0.424275 (-0.366003) | 0.006415 / 0.007607 (-0.001192) | 0.504792 / 0.226044 (0.278747) | 5.046758 / 2.268929 (2.777829) | 2.752049 / 55.444624 (-52.692576) | 2.407707 / 6.876477 (-4.468770) | 2.532162 / 2.142072 (0.390090) | 0.597562 / 4.805227 (-4.207666) | 0.125935 / 6.500664 (-6.374729) | 0.060837 / 0.075469 (-0.014632) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.257048 / 1.841788 (-0.584740) | 17.877849 / 8.074308 (9.803541) | 13.904805 / 10.191392 (3.713413) | 0.131647 / 0.680424 (-0.548776) | 0.016975 / 0.534201 (-0.517226) | 0.329651 / 0.579283 (-0.249633) | 0.354358 / 0.434364 (-0.080006) | 0.377545 / 0.540337 (-0.162792) | 0.545593 / 1.386936 (-0.841343) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.005839 / 0.011353 (-0.005514) | 0.003580 / 0.011008 (-0.007428) | 0.062204 / 0.038508 (0.023696) | 0.057943 / 0.023109 (0.034834) | 0.400165 / 0.275898 (0.124267) | 0.427911 / 0.323480 (0.104431) | 0.004412 / 0.007986 (-0.003574) | 0.002794 / 0.004328 (-0.001534) | 0.062933 / 0.004250 (0.058683) | 0.046243 / 0.037052 (0.009191) | 0.413640 / 0.258489 (0.155151) | 0.418592 / 0.293841 (0.124751) | 0.027020 / 0.128546 (-0.101526) | 0.007927 / 0.075646 (-0.067720) | 0.067581 / 0.419271 (-0.351691) | 0.041927 / 0.043533 (-0.001606) | 0.381863 / 0.255139 (0.126724) | 0.415711 / 0.283200 (0.132511) | 0.019827 / 0.141683 (-0.121856) | 1.464049 / 1.452155 (0.011894) | 1.528387 / 1.492716 (0.035671) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.224999 / 0.018006 (0.206993) | 0.419167 / 0.000490 (0.418678) | 0.000363 / 0.000200 (0.000163) | 0.000054 / 0.000054 (-0.000001) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.024827 / 0.037411 (-0.012585) | 0.077134 / 0.014526 (0.062608) | 0.085142 / 0.176557 (-0.091414) | 0.137400 / 0.737135 (-0.599735) | 0.086434 / 0.296338 (-0.209905) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.452716 / 0.215209 (0.237507) | 4.530610 / 2.077655 (2.452955) | 2.467309 / 1.504120 (0.963189) | 2.300441 / 1.541195 (0.759246) | 2.323475 / 1.468490 (0.854985) | 0.501847 / 4.584777 (-4.082930) | 3.079432 / 3.745712 (-0.666280) | 2.793107 / 5.269862 (-2.476755) | 1.835010 / 4.565676 (-2.730666) | 0.057698 / 0.424275 (-0.366577) | 0.006756 / 0.007607 (-0.000851) | 0.529062 / 0.226044 (0.303017) | 5.287822 / 2.268929 (3.018894) | 2.908411 / 55.444624 (-52.536214) | 2.571627 / 6.876477 (-4.304850) | 2.691188 / 2.142072 (0.549116) | 0.592289 / 4.805227 (-4.212938) | 0.126091 / 6.500664 (-6.374573) | 0.062312 / 0.075469 (-0.013157) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.328854 / 1.841788 (-0.512933) | 18.185628 / 8.074308 (10.111320) | 13.858781 / 10.191392 (3.667389) | 0.142421 / 0.680424 (-0.538003) | 0.016535 / 0.534201 (-0.517666) | 0.330839 / 0.579283 (-0.248444) | 0.346559 / 0.434364 (-0.087805) | 0.389153 / 0.540337 (-0.151185) | 0.516897 / 1.386936 (-0.870039) |\n\n</details>\n</details>\n\n\n"
] | "2023-07-31T06:27:47Z" | "2023-07-31T06:48:09Z" | "2023-07-31T06:32:58Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/6102.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6102",
"merged_at": "2023-07-31T06:32:58Z",
"patch_url": "https://github.com/huggingface/datasets/pull/6102.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/6102"
} | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6102/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6102/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/314 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/314/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/314/comments | https://api.github.com/repos/huggingface/datasets/issues/314/events | https://github.com/huggingface/datasets/pull/314 | 645,461,174 | MDExOlB1bGxSZXF1ZXN0NDM5OTM4MTMw | 314 | Fixed singlular very minor spelling error | {
"avatar_url": "https://avatars.githubusercontent.com/u/40696362?v=4",
"events_url": "https://api.github.com/users/SchizoidBat/events{/privacy}",
"followers_url": "https://api.github.com/users/SchizoidBat/followers",
"following_url": "https://api.github.com/users/SchizoidBat/following{/other_user}",
"gists_url": "https://api.github.com/users/SchizoidBat/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/SchizoidBat",
"id": 40696362,
"login": "SchizoidBat",
"node_id": "MDQ6VXNlcjQwNjk2MzYy",
"organizations_url": "https://api.github.com/users/SchizoidBat/orgs",
"received_events_url": "https://api.github.com/users/SchizoidBat/received_events",
"repos_url": "https://api.github.com/users/SchizoidBat/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/SchizoidBat/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/SchizoidBat/subscriptions",
"type": "User",
"url": "https://api.github.com/users/SchizoidBat"
} | [] | closed | false | null | [] | null | [
"Thank you BatJeti! The storm-joker, aka the typo, finally got caught!"
] | "2020-06-25T10:45:59Z" | "2020-06-26T08:46:41Z" | "2020-06-25T12:43:59Z" | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/314.diff",
"html_url": "https://github.com/huggingface/datasets/pull/314",
"merged_at": "2020-06-25T12:43:59Z",
"patch_url": "https://github.com/huggingface/datasets/pull/314.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/314"
} | An instance of "independantly" was changed to "independently". That's all. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/314/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/314/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/146 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/146/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/146/comments | https://api.github.com/repos/huggingface/datasets/issues/146/events | https://github.com/huggingface/datasets/pull/146 | 619,564,653 | MDExOlB1bGxSZXF1ZXN0NDE5MDI5MjUx | 146 | Add BERTScore to metrics | {
"avatar_url": "https://avatars.githubusercontent.com/u/7753366?v=4",
"events_url": "https://api.github.com/users/felixgwu/events{/privacy}",
"followers_url": "https://api.github.com/users/felixgwu/followers",
"following_url": "https://api.github.com/users/felixgwu/following{/other_user}",
"gists_url": "https://api.github.com/users/felixgwu/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/felixgwu",
"id": 7753366,
"login": "felixgwu",
"node_id": "MDQ6VXNlcjc3NTMzNjY=",
"organizations_url": "https://api.github.com/users/felixgwu/orgs",
"received_events_url": "https://api.github.com/users/felixgwu/received_events",
"repos_url": "https://api.github.com/users/felixgwu/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/felixgwu/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/felixgwu/subscriptions",
"type": "User",
"url": "https://api.github.com/users/felixgwu"
} | [] | closed | false | null | [] | null | [] | "2020-05-16T22:09:39Z" | "2020-05-17T22:22:10Z" | "2020-05-17T22:22:09Z" | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/146.diff",
"html_url": "https://github.com/huggingface/datasets/pull/146",
"merged_at": "2020-05-17T22:22:09Z",
"patch_url": "https://github.com/huggingface/datasets/pull/146.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/146"
} | This PR adds [BERTScore](https://arxiv.org/abs/1904.09675) to metrics.
Here is an example of how to use it.
```sh
import nlp
bertscore = nlp.load_metric('metrics/bertscore') # or simply nlp.load_metric('bertscore') after this is added to huggingface's s3 bucket
predictions = ['example', 'fruit']
references = [['this is an example.', 'this is one example.'], ['apple']]
results = bertscore.compute(predictions, references, lang='en')
print(results)
``` | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 3,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 3,
"url": "https://api.github.com/repos/huggingface/datasets/issues/146/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/146/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/6375 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6375/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6375/comments | https://api.github.com/repos/huggingface/datasets/issues/6375/events | https://github.com/huggingface/datasets/pull/6375 | 1,973,877,879 | PR_kwDODunzps5eacao | 6,375 | Temporarily pin pyarrow < 14.0.0 | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
} | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008947 / 0.011353 (-0.002406) | 0.005602 / 0.011008 (-0.005406) | 0.111208 / 0.038508 (0.072700) | 0.082750 / 0.023109 (0.059641) | 0.453277 / 0.275898 (0.177379) | 0.480072 / 0.323480 (0.156592) | 0.005254 / 0.007986 (-0.002731) | 0.005421 / 0.004328 (0.001092) | 0.082899 / 0.004250 (0.078648) | 0.062859 / 0.037052 (0.025807) | 0.466703 / 0.258489 (0.208214) | 0.478241 / 0.293841 (0.184400) | 0.050754 / 0.128546 (-0.077792) | 0.017726 / 0.075646 (-0.057920) | 0.374830 / 0.419271 (-0.044442) | 0.068577 / 0.043533 (0.025044) | 0.453643 / 0.255139 (0.198504) | 0.453736 / 0.283200 (0.170537) | 0.037313 / 0.141683 (-0.104369) | 1.741215 / 1.452155 (0.289060) | 1.862247 / 1.492716 (0.369531) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.314174 / 0.018006 (0.296168) | 0.644439 / 0.000490 (0.643949) | 0.013914 / 0.000200 (0.013715) | 0.000478 / 0.000054 (0.000424) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.030462 / 0.037411 (-0.006949) | 0.096789 / 0.014526 (0.082263) | 0.109999 / 0.176557 (-0.066557) | 0.184610 / 0.737135 (-0.552525) | 0.113846 / 0.296338 (-0.182493) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.586508 / 0.215209 (0.371299) | 5.785138 / 2.077655 (3.707484) | 2.578512 / 1.504120 (1.074392) | 2.266981 / 1.541195 (0.725786) | 2.442463 / 1.468490 (0.973973) | 0.880973 / 4.584777 (-3.703804) | 5.410327 / 3.745712 (1.664615) | 4.976842 / 5.269862 (-0.293020) | 3.020535 / 4.565676 (-1.545142) | 0.089640 / 0.424275 (-0.334635) | 0.009126 / 0.007607 (0.001519) | 0.682364 / 0.226044 (0.456319) | 6.840507 / 2.268929 (4.571579) | 3.313314 / 55.444624 (-52.131310) | 2.815313 / 6.876477 (-4.061164) | 2.851787 / 2.142072 (0.709715) | 1.044916 / 4.805227 (-3.760312) | 0.218346 / 6.500664 (-6.282318) | 0.075655 / 0.075469 (0.000186) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.641767 / 1.841788 (-0.200020) | 24.618096 / 8.074308 (16.543788) | 21.557652 / 10.191392 (11.366260) | 0.211622 / 0.680424 (-0.468801) | 0.028775 / 0.534201 (-0.505426) | 0.480469 / 0.579283 (-0.098814) | 0.593311 / 0.434364 (0.158948) | 0.560620 / 0.540337 (0.020283) | 0.827026 / 1.386936 (-0.559910) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.009347 / 0.011353 (-0.002006) | 0.005184 / 0.011008 (-0.005824) | 0.078878 / 0.038508 (0.040370) | 0.083067 / 0.023109 (0.059957) | 0.446591 / 0.275898 (0.170693) | 0.512934 / 0.323480 (0.189454) | 0.006614 / 0.007986 (-0.001372) | 0.004477 / 0.004328 (0.000148) | 0.087403 / 0.004250 (0.083153) | 0.060710 / 0.037052 (0.023658) | 0.451811 / 0.258489 (0.193322) | 0.482031 / 0.293841 (0.188190) | 0.051685 / 0.128546 (-0.076862) | 0.013436 / 0.075646 (-0.062210) | 0.109012 / 0.419271 (-0.310259) | 0.059654 / 0.043533 (0.016121) | 0.439041 / 0.255139 (0.183902) | 0.481708 / 0.283200 (0.198508) | 0.037393 / 0.141683 (-0.104290) | 1.761704 / 1.452155 (0.309549) | 1.946711 / 1.492716 (0.453995) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.287981 / 0.018006 (0.269975) | 0.610219 / 0.000490 (0.609729) | 0.006733 / 0.000200 (0.006533) | 0.000128 / 0.000054 (0.000074) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.038999 / 0.037411 (0.001588) | 0.100613 / 0.014526 (0.086087) | 0.126445 / 0.176557 (-0.050111) | 0.187596 / 0.737135 (-0.549540) | 0.122130 / 0.296338 (-0.174208) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.647686 / 0.215209 (0.432477) | 6.176079 / 2.077655 (4.098424) | 2.800232 / 1.504120 (1.296112) | 2.434625 / 1.541195 (0.893430) | 2.460646 / 1.468490 (0.992155) | 0.923736 / 4.584777 (-3.661041) | 5.480197 / 3.745712 (1.734485) | 4.849250 / 5.269862 (-0.420612) | 3.031576 / 4.565676 (-1.534101) | 0.102525 / 0.424275 (-0.321750) | 0.008688 / 0.007607 (0.001081) | 0.766097 / 0.226044 (0.540052) | 7.626822 / 2.268929 (5.357893) | 3.719155 / 55.444624 (-51.725469) | 2.967121 / 6.876477 (-3.909356) | 3.182464 / 2.142072 (1.040392) | 1.018315 / 4.805227 (-3.786912) | 0.211300 / 6.500664 (-6.289364) | 0.083055 / 0.075469 (0.007586) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.731619 / 1.841788 (-0.110168) | 25.315978 / 8.074308 (17.241669) | 22.736306 / 10.191392 (12.544914) | 0.270330 / 0.680424 (-0.410094) | 0.034790 / 0.534201 (-0.499411) | 0.488675 / 0.579283 (-0.090608) | 0.603426 / 0.434364 (0.169062) | 0.572547 / 0.540337 (0.032210) | 0.825719 / 1.386936 (-0.561217) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008992 / 0.011353 (-0.002360) | 0.005086 / 0.011008 (-0.005923) | 0.107400 / 0.038508 (0.068892) | 0.091894 / 0.023109 (0.068785) | 0.382347 / 0.275898 (0.106449) | 0.446581 / 0.323480 (0.123101) | 0.005179 / 0.007986 (-0.002807) | 0.006356 / 0.004328 (0.002028) | 0.084979 / 0.004250 (0.080729) | 0.060647 / 0.037052 (0.023594) | 0.385940 / 0.258489 (0.127451) | 0.444817 / 0.293841 (0.150976) | 0.049484 / 0.128546 (-0.079062) | 0.014173 / 0.075646 (-0.061473) | 0.345704 / 0.419271 (-0.073567) | 0.068082 / 0.043533 (0.024550) | 0.377170 / 0.255139 (0.122031) | 0.411816 / 0.283200 (0.128616) | 0.043049 / 0.141683 (-0.098633) | 1.681499 / 1.452155 (0.229344) | 1.805428 / 1.492716 (0.312712) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.323170 / 0.018006 (0.305164) | 0.693845 / 0.000490 (0.693355) | 0.015499 / 0.000200 (0.015299) | 0.000603 / 0.000054 (0.000548) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.031629 / 0.037411 (-0.005783) | 0.093511 / 0.014526 (0.078985) | 0.112400 / 0.176557 (-0.064157) | 0.173731 / 0.737135 (-0.563405) | 0.116013 / 0.296338 (-0.180325) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.576724 / 0.215209 (0.361515) | 5.775055 / 2.077655 (3.697400) | 2.755869 / 1.504120 (1.251749) | 2.430253 / 1.541195 (0.889058) | 2.479629 / 1.468490 (1.011139) | 0.841472 / 4.584777 (-3.743305) | 5.120536 / 3.745712 (1.374824) | 4.813281 / 5.269862 (-0.456581) | 3.054617 / 4.565676 (-1.511059) | 0.091459 / 0.424275 (-0.332816) | 0.009072 / 0.007607 (0.001465) | 0.742674 / 0.226044 (0.516629) | 7.137861 / 2.268929 (4.868933) | 3.497568 / 55.444624 (-51.947056) | 2.814658 / 6.876477 (-4.061819) | 2.934415 / 2.142072 (0.792343) | 0.970855 / 4.805227 (-3.834372) | 0.213366 / 6.500664 (-6.287299) | 0.078763 / 0.075469 (0.003293) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.584716 / 1.841788 (-0.257072) | 24.098173 / 8.074308 (16.023865) | 20.746352 / 10.191392 (10.554960) | 0.215313 / 0.680424 (-0.465111) | 0.029538 / 0.534201 (-0.504663) | 0.448672 / 0.579283 (-0.130611) | 0.580023 / 0.434364 (0.145659) | 0.537867 / 0.540337 (-0.002471) | 0.804622 / 1.386936 (-0.582314) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008965 / 0.011353 (-0.002388) | 0.005544 / 0.011008 (-0.005464) | 0.076806 / 0.038508 (0.038298) | 0.085333 / 0.023109 (0.062224) | 0.509974 / 0.275898 (0.234076) | 0.511548 / 0.323480 (0.188068) | 0.007136 / 0.007986 (-0.000849) | 0.004491 / 0.004328 (0.000163) | 0.086687 / 0.004250 (0.082437) | 0.066539 / 0.037052 (0.029486) | 0.483663 / 0.258489 (0.225174) | 0.529480 / 0.293841 (0.235639) | 0.046296 / 0.128546 (-0.082250) | 0.014736 / 0.075646 (-0.060910) | 0.088261 / 0.419271 (-0.331010) | 0.056753 / 0.043533 (0.013220) | 0.511698 / 0.255139 (0.256559) | 0.497956 / 0.283200 (0.214756) | 0.034753 / 0.141683 (-0.106930) | 1.828354 / 1.452155 (0.376199) | 1.799211 / 1.492716 (0.306494) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.389652 / 0.018006 (0.371645) | 0.602522 / 0.000490 (0.602033) | 0.068363 / 0.000200 (0.068163) | 0.000493 / 0.000054 (0.000439) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.036431 / 0.037411 (-0.000980) | 0.102162 / 0.014526 (0.087636) | 0.122466 / 0.176557 (-0.054091) | 0.181001 / 0.737135 (-0.556134) | 0.125743 / 0.296338 (-0.170596) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.583847 / 0.215209 (0.368638) | 5.913008 / 2.077655 (3.835354) | 2.716088 / 1.504120 (1.211968) | 2.328631 / 1.541195 (0.787437) | 2.459953 / 1.468490 (0.991463) | 0.792829 / 4.584777 (-3.791948) | 5.183965 / 3.745712 (1.438253) | 4.508264 / 5.269862 (-0.761598) | 2.855444 / 4.565676 (-1.710232) | 0.090704 / 0.424275 (-0.333571) | 0.009303 / 0.007607 (0.001696) | 0.694303 / 0.226044 (0.468258) | 6.951876 / 2.268929 (4.682947) | 3.418244 / 55.444624 (-52.026381) | 2.799743 / 6.876477 (-4.076734) | 3.043657 / 2.142072 (0.901584) | 0.921537 / 4.805227 (-3.883691) | 0.191774 / 6.500664 (-6.308890) | 0.068602 / 0.075469 (-0.006867) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.624842 / 1.841788 (-0.216946) | 24.570622 / 8.074308 (16.496314) | 21.207566 / 10.191392 (11.016174) | 0.217734 / 0.680424 (-0.462689) | 0.033109 / 0.534201 (-0.501091) | 0.451651 / 0.579283 (-0.127632) | 0.590890 / 0.434364 (0.156526) | 0.546195 / 0.540337 (0.005858) | 0.730298 / 1.386936 (-0.656638) |\n\n</details>\n</details>\n\n\n"
] | "2023-11-02T09:48:58Z" | "2023-11-02T10:22:33Z" | "2023-11-02T10:11:19Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/6375.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6375",
"merged_at": "2023-11-02T10:11:19Z",
"patch_url": "https://github.com/huggingface/datasets/pull/6375.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/6375"
} | Temporarily pin `pyarrow` < 14.0.0 until permanent solution is found.
Hot fix #6374. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6375/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6375/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4852 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4852/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4852/comments | https://api.github.com/repos/huggingface/datasets/issues/4852/events | https://github.com/huggingface/datasets/issues/4852 | 1,339,450,991 | I_kwDODunzps5P1mZv | 4,852 | Bug in multilingual_with_para config of exams dataset and checksums error | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
} | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
} | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
}
] | null | [
"Hi @albertvillanova. Unfortunately I still get this error. Is this because the merge has yet to be released? Is there a way to track the release?",
"Hi @thesofakillers, yes you are right: the fix will be available after next release (it was planned for today; Monday at the latest).\r\n\r\nIn the meantime, you can use the version of the `exams` on our main branch by passing `revision` to `load_dataset`:\r\n```python\r\nds = load_dataset(\"exams\", revision=\"main\")\r\n```"
] | "2022-08-15T20:14:52Z" | "2022-09-16T09:50:55Z" | "2022-08-16T06:29:07Z" | MEMBER | null | null | null | ## Describe the bug
There is a bug for "multilingual_with_para" config in exams dataset:
```python
ds = load_dataset("./datasets/exams", split="train")
```
raises:
```
KeyError: 'choices'
```
Moreover, there is a NonMatchingChecksumError:
```
NonMatchingChecksumError: Checksums didn't match for dataset source files:
['https://github.com/mhardalov/exams-qa/raw/main/data/exams/multilingual/with_paragraphs/train_with_para.jsonl.tar.gz', 'https://github.com/mhardalov/exams-qa/raw/main/data/exams/multilingual/with_paragraphs/dev_with_para.jsonl.tar.gz', 'https://github.com/mhardalov/exams-qa/raw/main/data/exams/multilingual/with_paragraphs/test_with_para.jsonl.tar.gz', 'https://github.com/mhardalov/exams-qa/raw/main/data/exams/cross-lingual/with_paragraphs/test_with_para.jsonl.tar.gz', 'https://github.com/mhardalov/exams-qa/raw/main/data/exams/cross-lingual/with_paragraphs/train_bg_with_para.jsonl.tar.gz', 'https://github.com/mhardalov/exams-qa/raw/main/data/exams/cross-lingual/with_paragraphs/dev_bg_with_para.jsonl.tar.gz', 'https://github.com/mhardalov/exams-qa/raw/main/data/exams/cross-lingual/with_paragraphs/train_hr_with_para.jsonl.tar.gz', 'https://github.com/mhardalov/exams-qa/raw/main/data/exams/cross-lingual/with_paragraphs/dev_hr_with_para.jsonl.tar.gz', 'https://github.com/mhardalov/exams-qa/raw/main/data/exams/cross-lingual/with_paragraphs/train_hu_with_para.jsonl.tar.gz', 'https://github.com/mhardalov/exams-qa/raw/main/data/exams/cross-lingual/with_paragraphs/dev_hu_with_para.jsonl.tar.gz', 'https://github.com/mhardalov/exams-qa/raw/main/data/exams/cross-lingual/with_paragraphs/train_it_with_para.jsonl.tar.gz', 'https://github.com/mhardalov/exams-qa/raw/main/data/exams/cross-lingual/with_paragraphs/dev_it_with_para.jsonl.tar.gz', 'https://github.com/mhardalov/exams-qa/raw/main/data/exams/cross-lingual/with_paragraphs/train_mk_with_para.jsonl.tar.gz', 'https://github.com/mhardalov/exams-qa/raw/main/data/exams/cross-lingual/with_paragraphs/dev_mk_with_para.jsonl.tar.gz', 'https://github.com/mhardalov/exams-qa/raw/main/data/exams/cross-lingual/with_paragraphs/train_pl_with_para.jsonl.tar.gz', 'https://github.com/mhardalov/exams-qa/raw/main/data/exams/cross-lingual/with_paragraphs/dev_pl_with_para.jsonl.tar.gz', 'https://github.com/mhardalov/exams-qa/raw/main/data/exams/cross-lingual/with_paragraphs/train_pt_with_para.jsonl.tar.gz', 'https://github.com/mhardalov/exams-qa/raw/main/data/exams/cross-lingual/with_paragraphs/dev_pt_with_para.jsonl.tar.gz', 'https://github.com/mhardalov/exams-qa/raw/main/data/exams/cross-lingual/with_paragraphs/train_sq_with_para.jsonl.tar.gz', 'https://github.com/mhardalov/exams-qa/raw/main/data/exams/cross-lingual/with_paragraphs/dev_sq_with_para.jsonl.tar.gz', 'https://github.com/mhardalov/exams-qa/raw/main/data/exams/cross-lingual/with_paragraphs/train_sr_with_para.jsonl.tar.gz', 'https://github.com/mhardalov/exams-qa/raw/main/data/exams/cross-lingual/with_paragraphs/dev_sr_with_para.jsonl.tar.gz', 'https://github.com/mhardalov/exams-qa/raw/main/data/exams/cross-lingual/with_paragraphs/train_tr_with_para.jsonl.tar.gz', 'https://github.com/mhardalov/exams-qa/raw/main/data/exams/cross-lingual/with_paragraphs/dev_tr_with_para.jsonl.tar.gz', 'https://github.com/mhardalov/exams-qa/raw/main/data/exams/cross-lingual/with_paragraphs/train_vi_with_para.jsonl.tar.gz', 'https://github.com/mhardalov/exams-qa/raw/main/data/exams/cross-lingual/with_paragraphs/dev_vi_with_para.jsonl.tar.gz']
```
CC: @thesofakillers | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 1,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4852/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4852/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5058 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5058/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5058/comments | https://api.github.com/repos/huggingface/datasets/issues/5058/events | https://github.com/huggingface/datasets/pull/5058 | 1,394,962,424 | PR_kwDODunzps5AEVWn | 5,058 | Mark CI tests as xfail when 502 error | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
} | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._"
] | "2022-10-03T15:53:55Z" | "2022-10-04T10:03:23Z" | "2022-10-04T10:01:23Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/5058.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5058",
"merged_at": "2022-10-04T10:01:23Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5058.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5058"
} | To make CI more robust, we could mark as xfail when the Hub raises a 502 error (besides 500 error):
- FAILED tests/test_upstream_hub.py::TestPushToHub::test_push_dataset_to_hub_skip_identical_files
- https://github.com/huggingface/datasets/actions/runs/3174626525/jobs/5171672431
```
> raise HTTPError(http_error_msg, response=self)
E requests.exceptions.HTTPError: 502 Server Error: Bad Gateway for url: https://hub-ci.huggingface.co/datasets/__DUMMY_TRANSFORMERS_USER__/test-16648055339047.git/info/lfs/objects/batch
```
- FAILED tests/test_upstream_hub.py::TestPushToHub::test_push_dataset_dict_to_hub_overwrite_files
- https://github.com/huggingface/datasets/actions/runs/3145587033/jobs/5113074889
```
> raise HTTPError(http_error_msg, response=self)
E requests.exceptions.HTTPError: 502 Server Error: Bad Gateway for url: https://hub-ci.huggingface.co/datasets/__DUMMY_TRANSFORMERS_USER__/test-16643866807322.git/info/lfs/objects/verify
```
Currently, we mark as xfail when 500 error:
- #4845 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5058/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5058/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4290 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4290/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4290/comments | https://api.github.com/repos/huggingface/datasets/issues/4290/events | https://github.com/huggingface/datasets/pull/4290 | 1,227,592,826 | PR_kwDODunzps43Zr08 | 4,290 | Update paper link in medmcqa dataset card | {
"avatar_url": "https://avatars.githubusercontent.com/u/17107749?v=4",
"events_url": "https://api.github.com/users/monk1337/events{/privacy}",
"followers_url": "https://api.github.com/users/monk1337/followers",
"following_url": "https://api.github.com/users/monk1337/following{/other_user}",
"gists_url": "https://api.github.com/users/monk1337/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/monk1337",
"id": 17107749,
"login": "monk1337",
"node_id": "MDQ6VXNlcjE3MTA3NzQ5",
"organizations_url": "https://api.github.com/users/monk1337/orgs",
"received_events_url": "https://api.github.com/users/monk1337/received_events",
"repos_url": "https://api.github.com/users/monk1337/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/monk1337/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/monk1337/subscriptions",
"type": "User",
"url": "https://api.github.com/users/monk1337"
} | [
{
"color": "0e8a16",
"default": false,
"description": "Contribution to a dataset script",
"id": 4564477500,
"name": "dataset contribution",
"node_id": "LA_kwDODunzps8AAAABEBBmPA",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20contribution"
}
] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"@albertvillanova Kindly check :)"
] | "2022-05-06T08:52:51Z" | "2022-09-30T11:51:28Z" | "2022-09-30T11:49:07Z" | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/4290.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4290",
"merged_at": "2022-09-30T11:49:07Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4290.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4290"
} | Updating readme in medmcqa dataset. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4290/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4290/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5064 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5064/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5064/comments | https://api.github.com/repos/huggingface/datasets/issues/5064/events | https://github.com/huggingface/datasets/pull/5064 | 1,395,978,143 | PR_kwDODunzps5AHsP0 | 5,064 | Align signature of create/delete_repo with latest hfh | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
} | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._"
] | "2022-10-04T09:54:53Z" | "2022-10-07T17:02:11Z" | "2022-10-07T16:59:30Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/5064.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5064",
"merged_at": "2022-10-07T16:59:30Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5064.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5064"
} | This PR aligns the signature of `create_repo`/`delete_repo` with the current one in hfh, by removing deprecated `name` and `organization`, and using `repo_id` instead.
Related to:
- #5063
CC: @lhoestq | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5064/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5064/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3817 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3817/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3817/comments | https://api.github.com/repos/huggingface/datasets/issues/3817/events | https://github.com/huggingface/datasets/pull/3817 | 1,158,592,335 | PR_kwDODunzps4z5pQ7 | 3,817 | Simplify Common Voice code | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq"
} | [] | closed | false | null | [] | null | [
"I think the script looks pretty clean and readable now! cool!\r\n"
] | "2022-03-03T16:01:21Z" | "2022-03-04T14:51:48Z" | "2022-03-04T12:39:23Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/3817.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3817",
"merged_at": "2022-03-04T12:39:23Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3817.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3817"
} | In #3736 we introduced one method to generate examples when streaming, that is different from the one when not streaming.
In this PR I propose a new implementation which is simpler: it only has one function, based on `iter_archive`. And you still have access to local audio files when loading the dataset in non-streaming mode.
cc @patrickvonplaten @polinaeterna @anton-l @albertvillanova since this will become the template for many audio datasets to come.
This change can also trivially be applied to the other audio datasets that already exist. Using this line, you can get access to local files in non-streaming mode:
```python
local_extracted_archive = dl_manager.extract(archive_path) if not dl_manager.is_streaming else None
``` | {
"+1": 2,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 2,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3817/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3817/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/376 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/376/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/376/comments | https://api.github.com/repos/huggingface/datasets/issues/376/events | https://github.com/huggingface/datasets/issues/376 | 655,047,826 | MDU6SXNzdWU2NTUwNDc4MjY= | 376 | to_pandas conversion doesn't always work | {
"avatar_url": "https://avatars.githubusercontent.com/u/7353373?v=4",
"events_url": "https://api.github.com/users/thomwolf/events{/privacy}",
"followers_url": "https://api.github.com/users/thomwolf/followers",
"following_url": "https://api.github.com/users/thomwolf/following{/other_user}",
"gists_url": "https://api.github.com/users/thomwolf/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/thomwolf",
"id": 7353373,
"login": "thomwolf",
"node_id": "MDQ6VXNlcjczNTMzNzM=",
"organizations_url": "https://api.github.com/users/thomwolf/orgs",
"received_events_url": "https://api.github.com/users/thomwolf/received_events",
"repos_url": "https://api.github.com/users/thomwolf/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/thomwolf/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/thomwolf/subscriptions",
"type": "User",
"url": "https://api.github.com/users/thomwolf"
} | [] | closed | false | null | [] | null | [
"**Edit**: other topic previously in this message moved to a new issue: https://github.com/huggingface/nlp/issues/387",
"Could you try to update pyarrow to >=0.17.0 ? It should fix the `to_pandas` bug\r\n\r\nAlso I'm not sure that structures like list<struct> are fully supported in the lib (none of the datasets use that).\r\nIt can cause issues when using dataset transforms like `filter` for example"
] | "2020-07-10T21:33:31Z" | "2022-10-04T18:05:39Z" | "2022-10-04T18:05:39Z" | MEMBER | null | null | null | For some complex nested types, the conversion from Arrow to python dict through pandas doesn't seem to be possible.
Here is an example using the official SQUAD v2 JSON file.
This example was found while investigating #373.
```python
>>> squad = load_dataset('json', data_files={nlp.Split.TRAIN: ["./train-v2.0.json"]}, download_mode=nlp.GenerateMode.FORCE_REDOWNLOAD, version="1.0.0", field='data')
>>> squad['train']
Dataset(schema: {'title': 'string', 'paragraphs': 'list<item: struct<qas: list<item: struct<question: string, id: string, answers: list<item: struct<text: string, answer_start: int64>>, is_impossible: bool, plausible_answers: list<item: struct<text: string, answer_start: int64>>>>, context: string>>'}, num_rows: 442)
>>> squad['train'][0]
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/Users/thomwolf/Documents/GitHub/datasets/src/nlp/arrow_dataset.py", line 589, in __getitem__
format_kwargs=self._format_kwargs,
File "/Users/thomwolf/Documents/GitHub/datasets/src/nlp/arrow_dataset.py", line 529, in _getitem
outputs = self._unnest(self._data.slice(key, 1).to_pandas().to_dict("list"))
File "pyarrow/array.pxi", line 559, in pyarrow.lib._PandasConvertible.to_pandas
File "pyarrow/table.pxi", line 1367, in pyarrow.lib.Table._to_pandas
File "/Users/thomwolf/miniconda2/envs/datasets/lib/python3.7/site-packages/pyarrow/pandas_compat.py", line 766, in table_to_blockmanager
blocks = _table_to_blocks(options, table, categories, ext_columns_dtypes)
File "/Users/thomwolf/miniconda2/envs/datasets/lib/python3.7/site-packages/pyarrow/pandas_compat.py", line 1101, in _table_to_blocks
list(extension_columns.keys()))
File "pyarrow/table.pxi", line 881, in pyarrow.lib.table_to_blocks
File "pyarrow/error.pxi", line 105, in pyarrow.lib.check_status
pyarrow.lib.ArrowNotImplementedError: Not implemented type for Arrow list to pandas: struct<qas: list<item: struct<question: string, id: string, answers: list<item: struct<text: string, answer_start: int64>>, is_impossible: bool, plausible_answers: list<item: struct<text: string, answer_start: int64>>>>, context: string>
```
cc @lhoestq would we have a way to detect this from the schema maybe?
Here is the schema for this pretty complex JSON:
```python
>>> squad['train'].schema
title: string
paragraphs: list<item: struct<qas: list<item: struct<question: string, id: string, answers: list<item: struct<text: string, answer_start: int64>>, is_impossible: bool, plausible_answers: list<item: struct<text: string, answer_start: int64>>>>, context: string>>
child 0, item: struct<qas: list<item: struct<question: string, id: string, answers: list<item: struct<text: string, answer_start: int64>>, is_impossible: bool, plausible_answers: list<item: struct<text: string, answer_start: int64>>>>, context: string>
child 0, qas: list<item: struct<question: string, id: string, answers: list<item: struct<text: string, answer_start: int64>>, is_impossible: bool, plausible_answers: list<item: struct<text: string, answer_start: int64>>>>
child 0, item: struct<question: string, id: string, answers: list<item: struct<text: string, answer_start: int64>>, is_impossible: bool, plausible_answers: list<item: struct<text: string, answer_start: int64>>>
child 0, question: string
child 1, id: string
child 2, answers: list<item: struct<text: string, answer_start: int64>>
child 0, item: struct<text: string, answer_start: int64>
child 0, text: string
child 1, answer_start: int64
child 3, is_impossible: bool
child 4, plausible_answers: list<item: struct<text: string, answer_start: int64>>
child 0, item: struct<text: string, answer_start: int64>
child 0, text: string
child 1, answer_start: int64
child 1, context: string
``` | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/376/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/376/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/1458 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1458/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1458/comments | https://api.github.com/repos/huggingface/datasets/issues/1458/events | https://github.com/huggingface/datasets/pull/1458 | 761,235,962 | MDExOlB1bGxSZXF1ZXN0NTM1OTMyMTA1 | 1,458 | Add id_nergrit_corpus | {
"avatar_url": "https://avatars.githubusercontent.com/u/7669893?v=4",
"events_url": "https://api.github.com/users/cahya-wirawan/events{/privacy}",
"followers_url": "https://api.github.com/users/cahya-wirawan/followers",
"following_url": "https://api.github.com/users/cahya-wirawan/following{/other_user}",
"gists_url": "https://api.github.com/users/cahya-wirawan/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/cahya-wirawan",
"id": 7669893,
"login": "cahya-wirawan",
"node_id": "MDQ6VXNlcjc2Njk4OTM=",
"organizations_url": "https://api.github.com/users/cahya-wirawan/orgs",
"received_events_url": "https://api.github.com/users/cahya-wirawan/received_events",
"repos_url": "https://api.github.com/users/cahya-wirawan/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/cahya-wirawan/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/cahya-wirawan/subscriptions",
"type": "User",
"url": "https://api.github.com/users/cahya-wirawan"
} | [] | closed | false | null | [] | null | [
"merging since the CI is fixed on master"
] | "2020-12-10T13:20:34Z" | "2020-12-17T10:45:15Z" | "2020-12-17T10:45:15Z" | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/1458.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1458",
"merged_at": "2020-12-17T10:45:15Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1458.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1458"
} | Nergrit Corpus is a dataset collection of Indonesian Named Entity Recognition, Statement Extraction, and Sentiment Analysis.
Recently my PR for id_nergrit_ner has been accepted and merged to the main branch. The id_nergrit_ner has only one dataset (NER), and this new PR renamed the dataset from id_nergrit_ner to id_nergrit_corpus and added 2 other remaining datasets (Statement Extraction, and Sentiment Analysis.) | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1458/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1458/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/1766 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1766/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1766/comments | https://api.github.com/repos/huggingface/datasets/issues/1766/events | https://github.com/huggingface/datasets/issues/1766 | 792,044,105 | MDU6SXNzdWU3OTIwNDQxMDU= | 1,766 | Issues when run two programs compute the same metrics | {
"avatar_url": "https://avatars.githubusercontent.com/u/8089862?v=4",
"events_url": "https://api.github.com/users/lamthuy/events{/privacy}",
"followers_url": "https://api.github.com/users/lamthuy/followers",
"following_url": "https://api.github.com/users/lamthuy/following{/other_user}",
"gists_url": "https://api.github.com/users/lamthuy/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lamthuy",
"id": 8089862,
"login": "lamthuy",
"node_id": "MDQ6VXNlcjgwODk4NjI=",
"organizations_url": "https://api.github.com/users/lamthuy/orgs",
"received_events_url": "https://api.github.com/users/lamthuy/received_events",
"repos_url": "https://api.github.com/users/lamthuy/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lamthuy/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lamthuy/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lamthuy"
} | [] | closed | false | null | [] | null | [
"Hi ! To avoid collisions you can specify a `experiment_id` when instantiating your metric using `load_metric`. It will replace \"default_experiment\" with the experiment id that you provide in the arrow filename. \r\n\r\nAlso when two `experiment_id` collide we're supposed to detect it using our locking mechanism. Not sure why it didn't work in your case. Could you share some code that reproduces the issue ? This would help us investigate.",
"Thank you for your response. I fixed the issue by set \"keep_in_memory=True\" when load_metric. \r\nI cannot share the entire source code but below is the wrapper I wrote:\r\n\r\n```python\r\nclass Evaluation:\r\n def __init__(self, metric='sacrebleu'):\r\n # self.metric = load_metric(metric, keep_in_memory=True)\r\n self.metric = load_metric(metric)\r\n\r\n def add(self, predictions, references):\r\n self.metric.add_batch(predictions=predictions, references=references)\r\n\r\n def compute(self):\r\n return self.metric.compute()['score']\r\n```\r\n\r\nThen call the given wrapper as follows:\r\n\r\n```python\r\neval = Evaluation(metric='sacrebleu')\r\nfor query, candidates, labels in tqdm(dataset):\r\n predictions = net.generate(query)\r\n references = [[s] for s in labels]\r\n eval.add(predictions, references)\r\n if n % 100 == 0:\r\n bleu += eval.compute()\r\n eval = Evaluation(metric='sacrebleu')"
] | "2021-01-22T14:22:55Z" | "2021-02-02T10:38:06Z" | "2021-02-02T10:38:06Z" | NONE | null | null | null | I got the following error when running two different programs that both compute sacreblue metrics. It seems that both read/and/write to the same location (.cache/huggingface/metrics/sacrebleu/default/default_experiment-1-0.arrow) where it caches the batches:
```
File "train_matching_min.py", line 160, in <module>ch_9_label
avg_loss = valid(epoch, args.batch, args.validation, args.with_label)
File "train_matching_min.py", line 93, in valid
bleu += eval.compute()
File "/u/tlhoang/projects/seal/match/models/eval.py", line 23, in compute
return self.metric.compute()['score']
File "/dccstor/know/anaconda3/lib/python3.7/site-packages/datasets/metric.py", line 387, in compute
self._finalize()
File "/dccstor/know/anaconda3/lib/python3.7/site-packages/datasets/metric.py", line 355, in _finalize
self.data = Dataset(**reader.read_files([{"filename": f} for f in file_paths]))
File "/dccstor/know/anaconda3/lib/python3.7/site-packages/datasets/arrow_reader.py", line 231, in read_files
pa_table = self._read_files(files)
File "/dccstor/know/anaconda3/lib/python3.7/site-packages/datasets/arrow_reader.py", line 170, in _read_files
pa_table: pa.Table = self._get_dataset_from_filename(f_dict)
File "/dccstor/know/anaconda3/lib/python3.7/site-packages/datasets/arrow_reader.py", line 299, in _get_dataset_from_filename
pa_table = f.read_all()
File "pyarrow/ipc.pxi", line 481, in pyarrow.lib.RecordBatchReader.read_all
File "pyarrow/error.pxi", line 84, in pyarrow.lib.check_status
pyarrow.lib.ArrowInvalid: Expected to read 1819307375 metadata bytes, but only read 454396
``` | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1766/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1766/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/1526 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1526/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1526/comments | https://api.github.com/repos/huggingface/datasets/issues/1526/events | https://github.com/huggingface/datasets/pull/1526 | 764,591,243 | MDExOlB1bGxSZXF1ZXN0NTM4NTgxNDg4 | 1,526 | added Hebrew thisworld corpus | {
"avatar_url": "https://avatars.githubusercontent.com/u/10088963?v=4",
"events_url": "https://api.github.com/users/imvladikon/events{/privacy}",
"followers_url": "https://api.github.com/users/imvladikon/followers",
"following_url": "https://api.github.com/users/imvladikon/following{/other_user}",
"gists_url": "https://api.github.com/users/imvladikon/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/imvladikon",
"id": 10088963,
"login": "imvladikon",
"node_id": "MDQ6VXNlcjEwMDg4OTYz",
"organizations_url": "https://api.github.com/users/imvladikon/orgs",
"received_events_url": "https://api.github.com/users/imvladikon/received_events",
"repos_url": "https://api.github.com/users/imvladikon/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/imvladikon/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/imvladikon/subscriptions",
"type": "User",
"url": "https://api.github.com/users/imvladikon"
} | [] | closed | false | null | [] | null | [
"merging since the CI is fixed on master"
] | "2020-12-12T23:42:52Z" | "2020-12-18T10:47:30Z" | "2020-12-18T10:47:30Z" | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/1526.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1526",
"merged_at": "2020-12-18T10:47:30Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1526.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1526"
} | added corpus from https://thisworld.online/ , https://github.com/thisworld1/thisworld.online | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1526/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1526/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5600 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5600/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5600/comments | https://api.github.com/repos/huggingface/datasets/issues/5600/events | https://github.com/huggingface/datasets/issues/5600 | 1,606,585,596 | I_kwDODunzps5fwoz8 | 5,600 | Dataloader getitem not working for DreamboothDatasets | {
"avatar_url": "https://avatars.githubusercontent.com/u/76955987?v=4",
"events_url": "https://api.github.com/users/salahiguiliz/events{/privacy}",
"followers_url": "https://api.github.com/users/salahiguiliz/followers",
"following_url": "https://api.github.com/users/salahiguiliz/following{/other_user}",
"gists_url": "https://api.github.com/users/salahiguiliz/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/salahiguiliz",
"id": 76955987,
"login": "salahiguiliz",
"node_id": "MDQ6VXNlcjc2OTU1OTg3",
"organizations_url": "https://api.github.com/users/salahiguiliz/orgs",
"received_events_url": "https://api.github.com/users/salahiguiliz/received_events",
"repos_url": "https://api.github.com/users/salahiguiliz/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/salahiguiliz/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/salahiguiliz/subscriptions",
"type": "User",
"url": "https://api.github.com/users/salahiguiliz"
} | [] | closed | false | null | [] | null | [
"Hi! \r\n\r\n> (see example of DreamboothDatasets)\r\n\r\n\r\nCould you please provide a link to it? If you are referring to the example in the `diffusers` repo, your issue is unrelated to `datasets` as that example uses `Dataset` from PyTorch to load data."
] | "2023-03-02T11:00:27Z" | "2023-03-13T17:59:35Z" | "2023-03-13T17:59:35Z" | NONE | null | null | null | ### Describe the bug
Dataloader getitem is not working as before (see example of [DreamboothDatasets](https://github.com/huggingface/peft/blob/main/examples/lora_dreambooth/train_dreambooth.py#L451C14-L529))
moving Datasets to 2.8.0 solved the issue.
### Steps to reproduce the bug
1- using DreamBoothDataset to load some images
2- error after loading when trying to visualise the images
### Expected behavior
I was expecting a numpy array of the image
### Environment info
- Platform: Linux-5.10.147+-x86_64-with-glibc2.29
- Python version: 3.8.10
- PyArrow version: 9.0.0
- Pandas version: 1.3.5 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5600/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5600/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/6469 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6469/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6469/comments | https://api.github.com/repos/huggingface/datasets/issues/6469/events | https://github.com/huggingface/datasets/pull/6469 | 2,023,695,839 | PR_kwDODunzps5hC6xf | 6,469 | Don't expand_info in HF glob | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq"
} | [] | closed | false | null | [] | null | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_6469). All of your documentation changes will be reflected on that endpoint.",
"Merging this one for now, but lmk if you had other optimizations in mind for the next version of `huggingface_hub`",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.004998 / 0.011353 (-0.006355) | 0.003523 / 0.011008 (-0.007486) | 0.064932 / 0.038508 (0.026424) | 0.050107 / 0.023109 (0.026998) | 0.253715 / 0.275898 (-0.022183) | 0.275364 / 0.323480 (-0.048116) | 0.003902 / 0.007986 (-0.004084) | 0.002716 / 0.004328 (-0.001612) | 0.048458 / 0.004250 (0.044208) | 0.037802 / 0.037052 (0.000750) | 0.262328 / 0.258489 (0.003839) | 0.285911 / 0.293841 (-0.007930) | 0.027112 / 0.128546 (-0.101435) | 0.010780 / 0.075646 (-0.064867) | 0.206447 / 0.419271 (-0.212824) | 0.035771 / 0.043533 (-0.007761) | 0.255031 / 0.255139 (-0.000108) | 0.270530 / 0.283200 (-0.012670) | 0.017152 / 0.141683 (-0.124530) | 1.094734 / 1.452155 (-0.357421) | 1.163480 / 1.492716 (-0.329237) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.092944 / 0.018006 (0.074938) | 0.301042 / 0.000490 (0.300553) | 0.000238 / 0.000200 (0.000038) | 0.000049 / 0.000054 (-0.000006) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.019090 / 0.037411 (-0.018321) | 0.061046 / 0.014526 (0.046520) | 0.073330 / 0.176557 (-0.103227) | 0.121124 / 0.737135 (-0.616012) | 0.080544 / 0.296338 (-0.215795) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.323866 / 0.215209 (0.108657) | 2.797727 / 2.077655 (0.720072) | 1.502994 / 1.504120 (-0.001126) | 1.376177 / 1.541195 (-0.165018) | 1.422741 / 1.468490 (-0.045749) | 0.562990 / 4.584777 (-4.021786) | 2.431781 / 3.745712 (-1.313931) | 2.783226 / 5.269862 (-2.486635) | 1.788055 / 4.565676 (-2.777621) | 0.064206 / 0.424275 (-0.360069) | 0.004989 / 0.007607 (-0.002618) | 0.338282 / 0.226044 (0.112237) | 3.356226 / 2.268929 (1.087297) | 1.855644 / 55.444624 (-53.588980) | 1.580876 / 6.876477 (-5.295601) | 1.617418 / 2.142072 (-0.524655) | 0.636816 / 4.805227 (-4.168411) | 0.117680 / 6.500664 (-6.382985) | 0.042560 / 0.075469 (-0.032909) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.956410 / 1.841788 (-0.885377) | 11.764886 / 8.074308 (3.690578) | 10.535801 / 10.191392 (0.344409) | 0.137797 / 0.680424 (-0.542627) | 0.014368 / 0.534201 (-0.519833) | 0.286213 / 0.579283 (-0.293070) | 0.267093 / 0.434364 (-0.167271) | 0.334802 / 0.540337 (-0.205535) | 0.441866 / 1.386936 (-0.945070) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.005348 / 0.011353 (-0.006005) | 0.003551 / 0.011008 (-0.007458) | 0.049226 / 0.038508 (0.010718) | 0.052072 / 0.023109 (0.028963) | 0.268025 / 0.275898 (-0.007873) | 0.289968 / 0.323480 (-0.033512) | 0.004034 / 0.007986 (-0.003952) | 0.002675 / 0.004328 (-0.001653) | 0.048099 / 0.004250 (0.043848) | 0.040141 / 0.037052 (0.003089) | 0.272974 / 0.258489 (0.014485) | 0.296097 / 0.293841 (0.002256) | 0.028972 / 0.128546 (-0.099575) | 0.010689 / 0.075646 (-0.064957) | 0.057853 / 0.419271 (-0.361418) | 0.032488 / 0.043533 (-0.011045) | 0.272018 / 0.255139 (0.016879) | 0.287179 / 0.283200 (0.003980) | 0.018446 / 0.141683 (-0.123237) | 1.140346 / 1.452155 (-0.311809) | 1.247743 / 1.492716 (-0.244974) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.091987 / 0.018006 (0.073980) | 0.300527 / 0.000490 (0.300037) | 0.000224 / 0.000200 (0.000024) | 0.000044 / 0.000054 (-0.000010) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.021390 / 0.037411 (-0.016021) | 0.068768 / 0.014526 (0.054242) | 0.080798 / 0.176557 (-0.095759) | 0.119081 / 0.737135 (-0.618054) | 0.082461 / 0.296338 (-0.213878) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.286631 / 0.215209 (0.071422) | 2.804633 / 2.077655 (0.726978) | 1.574122 / 1.504120 (0.070002) | 1.459994 / 1.541195 (-0.081201) | 1.499739 / 1.468490 (0.031249) | 0.579595 / 4.584777 (-4.005182) | 2.426407 / 3.745712 (-1.319306) | 2.917994 / 5.269862 (-2.351868) | 1.846439 / 4.565676 (-2.719238) | 0.063274 / 0.424275 (-0.361001) | 0.005028 / 0.007607 (-0.002579) | 0.341114 / 0.226044 (0.115070) | 3.402677 / 2.268929 (1.133748) | 1.940980 / 55.444624 (-53.503645) | 1.651902 / 6.876477 (-5.224575) | 1.677037 / 2.142072 (-0.465036) | 0.651576 / 4.805227 (-4.153651) | 0.116398 / 6.500664 (-6.384266) | 0.041060 / 0.075469 (-0.034409) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.973278 / 1.841788 (-0.868509) | 12.248332 / 8.074308 (4.174024) | 10.830627 / 10.191392 (0.639235) | 0.143146 / 0.680424 (-0.537278) | 0.016249 / 0.534201 (-0.517952) | 0.298563 / 0.579283 (-0.280720) | 0.278643 / 0.434364 (-0.155721) | 0.338206 / 0.540337 (-0.202132) | 0.589485 / 1.386936 (-0.797451) |\n\n</details>\n</details>\n\n\n"
] | "2023-12-04T12:00:37Z" | "2023-12-15T13:18:37Z" | "2023-12-15T13:12:30Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/6469.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6469",
"merged_at": "2023-12-15T13:12:30Z",
"patch_url": "https://github.com/huggingface/datasets/pull/6469.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/6469"
} | Finally fix https://github.com/huggingface/datasets/issues/5537 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6469/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6469/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/2908 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2908/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2908/comments | https://api.github.com/repos/huggingface/datasets/issues/2908/events | https://github.com/huggingface/datasets/pull/2908 | 995,970,612 | PR_kwDODunzps4rumwW | 2,908 | Update Zenodo metadata with creator names and affiliation | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
} | [] | closed | false | null | [] | null | [] | "2021-09-14T12:39:37Z" | "2021-09-14T14:29:25Z" | "2021-09-14T14:29:25Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/2908.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2908",
"merged_at": "2021-09-14T14:29:25Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2908.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2908"
} | This PR helps in prefilling author data when automatically generating the DOI after each release. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2908/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2908/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4636 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4636/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4636/comments | https://api.github.com/repos/huggingface/datasets/issues/4636/events | https://github.com/huggingface/datasets/issues/4636 | 1,294,547,836 | I_kwDODunzps5NKTt8 | 4,636 | Add info in docs about behavior of download_config.num_proc | {
"avatar_url": "https://avatars.githubusercontent.com/u/32437151?v=4",
"events_url": "https://api.github.com/users/nateraw/events{/privacy}",
"followers_url": "https://api.github.com/users/nateraw/followers",
"following_url": "https://api.github.com/users/nateraw/following{/other_user}",
"gists_url": "https://api.github.com/users/nateraw/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/nateraw",
"id": 32437151,
"login": "nateraw",
"node_id": "MDQ6VXNlcjMyNDM3MTUx",
"organizations_url": "https://api.github.com/users/nateraw/orgs",
"received_events_url": "https://api.github.com/users/nateraw/received_events",
"repos_url": "https://api.github.com/users/nateraw/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/nateraw/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/nateraw/subscriptions",
"type": "User",
"url": "https://api.github.com/users/nateraw"
} | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
} | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
}
] | null | [] | "2022-07-05T17:01:00Z" | "2022-07-28T10:40:32Z" | "2022-07-28T10:40:32Z" | CONTRIBUTOR | null | null | null | **Is your feature request related to a problem? Please describe.**
I went to override `download_config.num_proc` and was confused about what was happening under the hood. It would be nice to have the behavior documented a bit better so folks know what's happening when they use it.
**Describe the solution you'd like**
- Add note about how the default number of workers is 16. Related code:
https://github.com/huggingface/datasets/blob/7bcac0a6a0fc367cc068f184fa132b8de8dfa11d/src/datasets/download/download_manager.py#L299-L302
- Add note that if the number of workers is higher than the number of files to download, it won't use multiprocessing.
**Describe alternatives you've considered**
maybe it would also be nice to set `num_proc` = `num_files` when `num_proc` > `num_files`.
**Additional context**
...
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4636/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4636/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/4062 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4062/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4062/comments | https://api.github.com/repos/huggingface/datasets/issues/4062/events | https://github.com/huggingface/datasets/issues/4062 | 1,186,330,732 | I_kwDODunzps5Gtfhs | 4,062 | Loading mozilla-foundation/common_voice_7_0 dataset failed | {
"avatar_url": "https://avatars.githubusercontent.com/u/19529125?v=4",
"events_url": "https://api.github.com/users/aapot/events{/privacy}",
"followers_url": "https://api.github.com/users/aapot/followers",
"following_url": "https://api.github.com/users/aapot/following{/other_user}",
"gists_url": "https://api.github.com/users/aapot/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/aapot",
"id": 19529125,
"login": "aapot",
"node_id": "MDQ6VXNlcjE5NTI5MTI1",
"organizations_url": "https://api.github.com/users/aapot/orgs",
"received_events_url": "https://api.github.com/users/aapot/received_events",
"repos_url": "https://api.github.com/users/aapot/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/aapot/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/aapot/subscriptions",
"type": "User",
"url": "https://api.github.com/users/aapot"
} | [
{
"color": "2edb81",
"default": false,
"description": "A bug in a dataset script provided in the library",
"id": 2067388877,
"name": "dataset bug",
"node_id": "MDU6TGFiZWwyMDY3Mzg4ODc3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20bug"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
} | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
}
] | null | [
"Hi @aapot, thanks for reporting.\r\n\r\nWe are investigating the cause of this issue. We will keep you informed. ",
"When making HTTP request from code line:\r\n```\r\nresponse = requests.get(f\"{_API_URL}/bucket/dataset/{path}/{use_cdn}\", timeout=10.0).json()\r\n```\r\nit cannot be decoded to JSON because it raises a 404 Not Found error.\r\n\r\nThe request is fixed if removing the `/{use_cdn}` from the URL.\r\n\r\nMaybe there was a change in the Common Voice API?\r\n\r\nCC: @anton-l @patrickvonplaten @polinaeterna ",
"We have contacted by email the data owners of the Common Voice dataset.",
"Hotfix: https://huggingface.co/datasets/mozilla-foundation/common_voice_7_0/commit/17b237961e4f7f84a2a0aea645abe5428a9d568e",
"I have also made the hotfix for all the rest of Common Voice script versions: 8.0, 6.1, 6.0,..., 1.0",
"Hey, is there anything new?\r\nI could not load the dataset.",
"cc @lhoestq @polinaeterna ",
"Hi @ngoquanghuy99! The dataset should load fine if you go through the following steps:\r\n\r\n1. Go to https://huggingface.co/datasets/mozilla-foundation/common_voice_9_0 and click \"Access repository\" if you see a message about sharing your contact information with Mozilla Foundation at the top of the page. If you've already done that then skip to step 2.\r\n2. Run the command `huggingface-cli login` in your terminal or notebook to authenticate your machine.\r\n3. Load the dataset with `use_auth_token=True`:\r\n```python\r\nfrom datasets import load_dataset\r\n\r\ndataset = load_dataset(\"mozilla-foundation/common_voice_9_0\", \"ab\", use_auth_token=True)\r\n```",
"Thanks @anton-l \r\nI could load the dataset now, but in another way.\r\nThanks anyways!"
] | "2022-03-30T11:39:41Z" | "2022-06-21T07:36:23Z" | "2022-03-31T08:18:04Z" | NONE | null | null | null | ## Describe the bug
I wanted to load `mozilla-foundation/common_voice_7_0` dataset with `fi` language and `test` split from datasets on Colab/Kaggle notebook, but I am getting an error `JSONDecodeError: [Errno Expecting value] Not Found: 0` while loading it. The bug seems to affect other languages and splits too than just the `fi` and `test` split.
## Steps to reproduce the bug
```python
from datasets import load_dataset
dataset = load_dataset("mozilla-foundation/common_voice_7_0", "fi", split="test", use_auth_token="YOUR TOKEN")
```
## Expected results
load `mozilla-foundation/common_voice_7_0` dataset succesfully
## Actual results
```
JSONDecodeError Traceback (most recent call last)
/opt/conda/lib/python3.7/site-packages/requests/models.py in json(self, **kwargs)
909 try:
--> 910 return complexjson.loads(self.text, **kwargs)
911 except JSONDecodeError as e:
/opt/conda/lib/python3.7/site-packages/simplejson/__init__.py in loads(s, encoding, cls, object_hook, parse_float, parse_int, parse_constant, object_pairs_hook, use_decimal, **kw)
524 and not use_decimal and not kw):
--> 525 return _default_decoder.decode(s)
526 if cls is None:
/opt/conda/lib/python3.7/site-packages/simplejson/decoder.py in decode(self, s, _w, _PY3)
369 s = str(s, self.encoding)
--> 370 obj, end = self.raw_decode(s)
371 end = _w(s, end).end()
/opt/conda/lib/python3.7/site-packages/simplejson/decoder.py in raw_decode(self, s, idx, _w, _PY3)
399 idx += 3
--> 400 return self.scan_once(s, idx=_w(s, idx).end())
JSONDecodeError: Expecting value: line 1 column 1 (char 0)
During handling of the above exception, another exception occurred:
JSONDecodeError Traceback (most recent call last)
/tmp/ipykernel_358/370980805.py in <module>
1 # load Common Voice 7.0 dataset from Huggingface with Finnish "test" split
----> 2 test_dataset = load_dataset("mozilla-foundation/common_voice_7_0", "fi", split="test", use_auth_token=True)
/opt/conda/lib/python3.7/site-packages/datasets/load.py in load_dataset(path, name, data_dir, data_files, split, cache_dir, features, download_config, download_mode, ignore_verifications, keep_in_memory, save_infos, revision, use_auth_token, task, streaming, **config_kwargs)
1690 ignore_verifications=ignore_verifications,
1691 try_from_hf_gcs=try_from_hf_gcs,
-> 1692 use_auth_token=use_auth_token,
1693 )
1694
/opt/conda/lib/python3.7/site-packages/datasets/builder.py in download_and_prepare(self, download_config, download_mode, ignore_verifications, try_from_hf_gcs, dl_manager, base_path, use_auth_token, **download_and_prepare_kwargs)
604 if not downloaded_from_gcs:
605 self._download_and_prepare(
--> 606 dl_manager=dl_manager, verify_infos=verify_infos, **download_and_prepare_kwargs
607 )
608 # Sync info
/opt/conda/lib/python3.7/site-packages/datasets/builder.py in _download_and_prepare(self, dl_manager, verify_infos)
1102
1103 def _download_and_prepare(self, dl_manager, verify_infos):
-> 1104 super()._download_and_prepare(dl_manager, verify_infos, check_duplicate_keys=verify_infos)
1105
1106 def _get_examples_iterable_for_split(self, split_generator: SplitGenerator) -> ExamplesIterable:
/opt/conda/lib/python3.7/site-packages/datasets/builder.py in _download_and_prepare(self, dl_manager, verify_infos, **prepare_split_kwargs)
670 split_dict = SplitDict(dataset_name=self.name)
671 split_generators_kwargs = self._make_split_generators_kwargs(prepare_split_kwargs)
--> 672 split_generators = self._split_generators(dl_manager, **split_generators_kwargs)
673
674 # Checksums verification
~/.cache/huggingface/modules/datasets_modules/datasets/mozilla-foundation--common_voice_7_0/fe20cac47c166e25b1f096ab661832e3da7cf298ed4a91dcaa1343ad972d175b/common_voice_7_0.py in _split_generators(self, dl_manager)
151
152 self._log_download(self.config.name, bundle_version, hf_auth_token)
--> 153 archive = dl_manager.download(self._get_bundle_url(self.config.name, bundle_url_template))
154
155 if self.config.version < datasets.Version("5.0.0"):
~/.cache/huggingface/modules/datasets_modules/datasets/mozilla-foundation--common_voice_7_0/fe20cac47c166e25b1f096ab661832e3da7cf298ed4a91dcaa1343ad972d175b/common_voice_7_0.py in _get_bundle_url(self, locale, url_template)
130 path = urllib.parse.quote(path.encode("utf-8"), safe="~()*!.'")
131 use_cdn = self.config.size_bytes < 20 * 1024 * 1024 * 1024
--> 132 response = requests.get(f"{_API_URL}/bucket/dataset/{path}/{use_cdn}", timeout=10.0).json()
133 return response["url"]
134
/opt/conda/lib/python3.7/site-packages/requests/models.py in json(self, **kwargs)
915 raise RequestsJSONDecodeError(e.message)
916 else:
--> 917 raise RequestsJSONDecodeError(e.msg, e.doc, e.pos)
918
919 @property
JSONDecodeError: [Errno Expecting value] Not Found: 0
```
## Environment info
- `datasets` version: 2.0.0
- Platform: Linux-5.10.90+-x86_64-with-debian-bullseye-sid
- Python version: 3.7.12
- PyArrow version: 5.0.0
- Pandas version: 1.3.5
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4062/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4062/timeline | null | completed | false |