|
--- |
|
base_model: |
|
- sometimesanotion/Lamarck-14B-v0.6 |
|
- deepseek-ai/DeepSeek-R1-Distill-Qwen-14B |
|
- sometimesanotion/Lamarck-14B-v0.3 |
|
- sometimesanotion/Qwenvergence-14B-v9 |
|
- sometimesanotion/Qwenvergence-14B-v3-Prose |
|
- arcee-ai/Virtuoso-Small |
|
library_name: transformers |
|
tags: |
|
- mergekit |
|
- merge |
|
license: apache-2.0 |
|
language: |
|
- en |
|
pipeline_tag: text-generation |
|
metrics: |
|
- accuracy |
|
--- |
|
 |
|
--- |
|
|
|
> [!TIP] This version of the model has [broken the 41.0 average](https://shorturl.at/jUqEk) maximum for 14B parameter models, and as of this writing, ranks #8 among models under 70B parameters on the Open LLM Leaderboard. Given the respectable performance in the 32B range, I think Lamarck deserves his shades. A little layer analysis in the 14B range goes a long, long way. |
|
|
|
Lamarck 14B v0.7: A generalist merge with emphasis on multi-step reasoning, prose, and multi-language ability. The 14B parameter model class has a lot of strong performers, and Lamarck strives to be well-rounded and solid: 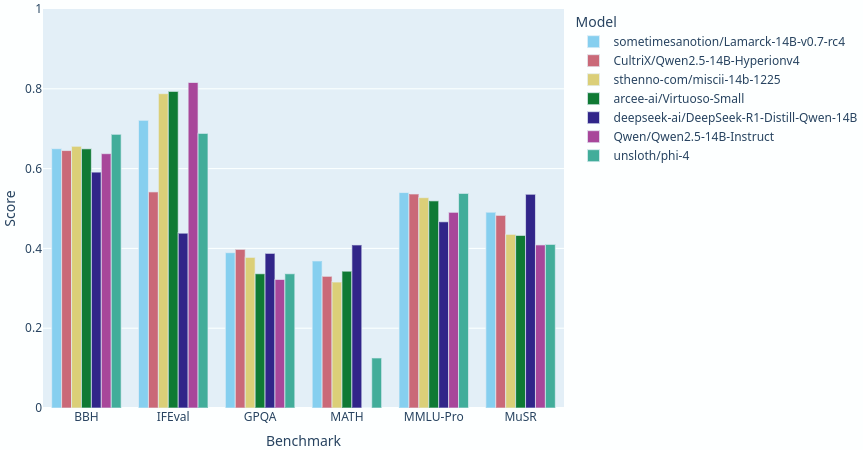 |
|
|
|
Lamarck is produced by a custom toolchain to automate a complex sequences of LoRAs and various layer-targeting merges: |
|
|
|
- **Extracted LoRA adapters from special-purpose merges** |
|
- **Custom base models and model_stocks of original models with LoRAs from from [huihui-ai/Qwen2.5-14B-Instruct-abliterated-v2](https://huggingface.co/huihui-ai/Qwen2.5-14B-Instruct-abliterated-v2) to minimize IFEVAL loss often seen in model_stock merges** |
|
- **Separate branches for aggressive breadcrumbs and conservative DELLA merges** |
|
- **Highly targeted weight/density gradients for every 2-4 layers, at each stage** |
|
- **Finalization through SLERP+TIES merges recombining the the breadcrumbs and DELLA branches to taste** |
|
|
|
Lamarck's performance comes from an ancestry that goes back through careful merges to select finetuning work, upcycled and combined. Through intermediate merges, [arcee-ai/Virtuoso-Small](https://huggingface.co/arcee-ai/Virtuoso-Small) [sthenno-com/miscii-14b-1225](https://huggingface.co/sthenno-com/miscii-14b-1225) and [VAGOsolutions/SauerkrautLM-v2-14b-DPO](https://huggingface.co/VAGOsolutions/SauerkrautLM-v2-14b-DPO) are emphasized in early layers for extra BBH; later layers add synergistic influence from [deepseek-ai/DeepSeek-R1-Distill-Qwen-14B](https://huggingface.co/deepseek-ai/DeepSeek-R1-Distill-Qwen-14B), [Krystalan/DRT-o1-14B](https://huggingface.co/Krystalan/DRT-o1-14B), [EVA-UNIT-01/EVA-Qwen2.5-14B-v0.2](https://huggingface.co/EVA-UNIT-01/EVA-Qwen2.5-14B-v0.2), and [CultriX/Qwen2.5-14B-Wernicke](https://huggingface.co/CultriX/Qwen2.5-14B-Wernicke). |
|
|
|
More subjectively, its prose and translation abilities are boosted by repeated re-emphasis of [Krystalan/DRT-o1-14B](https://huggingface.co/Krystalan/DRT-o1-14B) and [underwoods/medius-erebus-magnum-14b](https://huggingface.co/underwoods/medius-erebus-magnum-14b). Other models found in [sometimesanotion/Qwenvergence-14B-v3-Prose](https://huggingface/sometimesanotion/Qwenvergence-14B-v3-Prose) have their impact on prose quality - and surprising synergy of reasoning. |
|
|
|
Kudos to @arcee-ai, @deepseek-ai, @Krystalan, @underwoods, @VAGOSolutions, @CultriX, @sthenno-com, and @rombodawg whose models had the most influence. [Vimarckoso v3](https://huggingface.co/sometimesanotion/Qwen2.5-14B-Vimarckoso-v3) has the model card which documents its extended lineage. |
